| 编辑推荐: |
本文主要介绍了机器学习算法:主成分分析,从二维视角下PCA的原理到数学推导以至于计算实例,希望对您的学习有所帮助。
本文来自于知乎,由火龙果软件Alice编辑、推荐。 |
|
引入
在对实际问题进行数据挖掘时,涉及到的特证数即数据维度往往是成百上千的,出于以下两个原因可能导致数据集质量不佳:
噪声特征:该特征并不能对我们建模产生正向作用,或者同关注的变量基本上是不相关的
特征之间可替代性:当两个特征包含几乎一模一样的信息时,其中一个特征往往是可以剔除的(比如温度和体感温度变量)
主成分分析Principal Component Analysis, PCA是最常用的降维方法之一,它可以尽可能提取众多维度中的有效信息,降低数据的复杂度。(当然这也会以损失一部分信息作为代码,机器学习本身就处处充满了trade-off的过程)
在主成分分析方法中,数据从原来的坐标系转换到新的坐标系,而组成新坐标系的坐标轴正是原有特征的线性组合。第一个新坐标轴选择的是原始数据中方差最大的方向(因为方差越大表示数据代表越多的信息),第二个新坐标轴选择的是和第一个坐标轴正交(组成坐标系的重要条件,且不会浪费信息)且具有最大方差的方向。该过程一直重复,重复次数即为原始数据中特征的数目。由于新坐标轴的方差逐渐递减,我们会发现大部分的方差都包含在最前面的几个坐标轴中,因此我们忽视余下的坐标轴(这就是以损失一部分信息为代价)即完成数据的降维。
二维视角下PCA的原理
以如下坐标空间中的大量数据点为例,如果我们需要作出一条尽可能覆盖所有点的直线,那么最合适的就是直线B
。该直线覆盖了数据的最大方差,即在单维度的情况下给出了数据最重要的信息。在选择了覆盖数据最大差异性的坐标轴之后,我们选择和第一条坐标轴正交的直线
C作为第二条坐标轴。
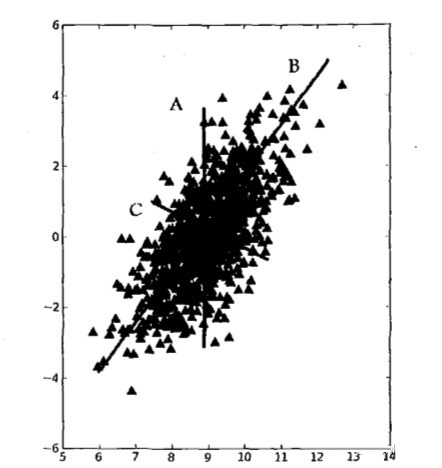
总而言之,我们将数据坐标轴旋转至数据角度上最重要的方向。
前面我们从数据方差的角度旋转坐标轴找出代表数据信息重要性依次递减的两条新坐标轴(如果原始数据有n个维度,我们就能找到重要性依次递减的n条坐标轴)。
接下来我们讲一下如果根据信息量进行降维。下图包含了三个类别,但是我们可以仅根据横坐标一个维度的信息即可完成效率较高的分类(在这个例子中,纵坐标即是代表数据信息量较少的噪声数据),例如x<4的样本可以完全归为一类。
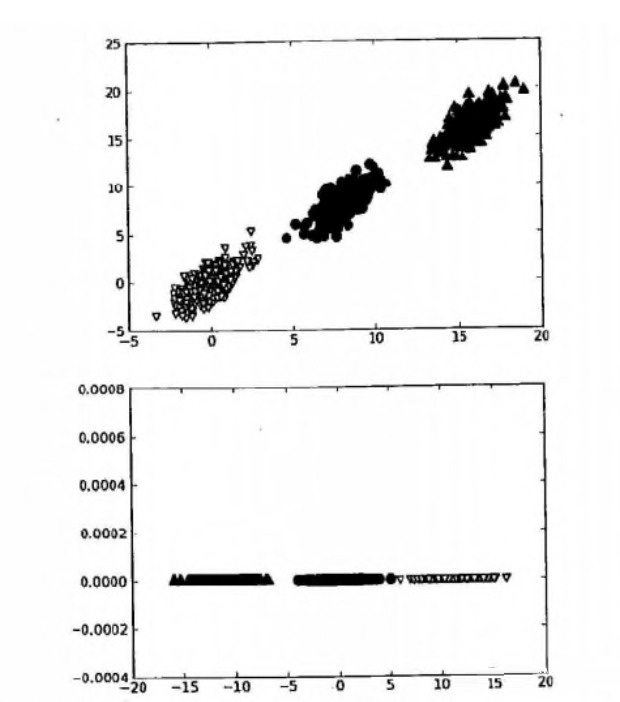
现在我们把视角放到n维数据中,我们先从数据方差最大的方向抽取出第一个主成分,第二个主成分则来自于数据差异性次大的方向,并且需要满足和第一个主成分正交的关系。一旦得到数据差异性递减的
n个主成分,我们就可以保留其中最大的前m 个主成分,从而将原始数据集投射到新的低维空间(即超平面,直线的高维推广)上,实现降维的目的。
数学推导
对于正交属性空间(高维坐标系)中的样本点,如果我们需要用一个超平面(直线的高维推广,相当于降维)对样本进行恰当的表达,可以从以下两个思路入手:
最近重构性:样本点到这个超平面的距离都足够近
最大可分性:样本点在这个超平面的投影尽可能分开
最近重构性表示降维后忽视的坐标轴带来的信息损失尽可能最少,最大可分性表示新的坐标系尽可能代表原来样本点更多的信息。这两者本质上是一致的。
基于最近重构性和最大可分性,我们可以得到主成分分析的两种等价推导:
1.最近重构性
假定数据样本进行了中心化,即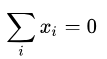 ,再假定原先的坐标 ,再假定原先的坐标 投影后得到的新坐标系为
投影后得到的新坐标系为 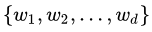 ,其中是标准正交向量(基向量的思想): ,其中是标准正交向量(基向量的思想):
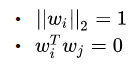

考虑一下整个训练集,原样本点xi 与基于投影重构的样本点之间的距离为:
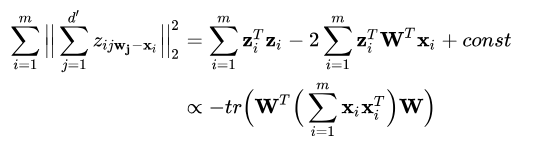
其中 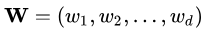 ,根据最近重构性的原理,我们应该最小化上式,有: ,根据最近重构性的原理,我们应该最小化上式,有:
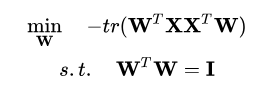
2.最大可分性
最大可分性要求所有样本点在新坐标系中投影尽可能分开,也就是投影后样本点的方差应尽可能最大化。
如下图所示,在二维空间降维到一维空间(即直线)同时使所有样本点尽可能分开,我们需要使原始数据集尽量投影在最长的直线上,也就是最大化投影点的方差。
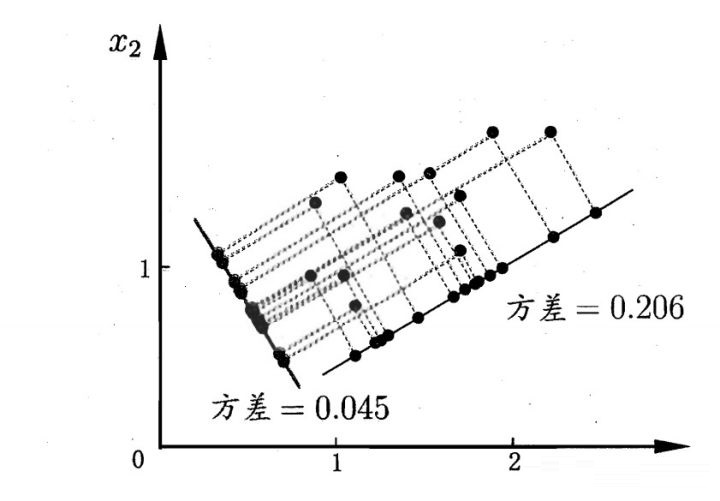
投影后样本点的方差为 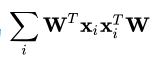 ,于是优化目标如下: ,于是优化目标如下:
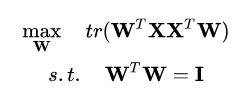
至此我们可以发现基于最近重构性和最大可分性的优化目标是等价的,使用拉格朗日乘子法可以得到:
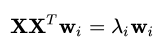
只需要对协方差矩阵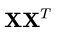 进行特征值分解,将求得的特征值排序:
进行特征值分解,将求得的特征值排序: 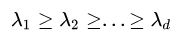 ,取前d'个特征值对应的特征向量构成 ,取前d'个特征值对应的特征向量构成
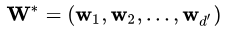 即是主成分分析的解。 即是主成分分析的解。
降维后的维数d'通常是根据实际情况选定,一方面可以选取不同维数对开销较小的分类器进行交叉验证来选取合适的d'
值,另一方面也可以从重构的角度设置一个重构阈值(衡量了新选择的维数表达了原始数据集的信息量),设置阈值为d'
,然后选择使下式成立的最小d'值:
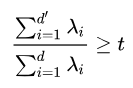
计算实例
我们在二维空间下构造一个假的数据集,让数据沿着 [公式] 度角分布,并且在与该方向垂直的方向上方差最小。
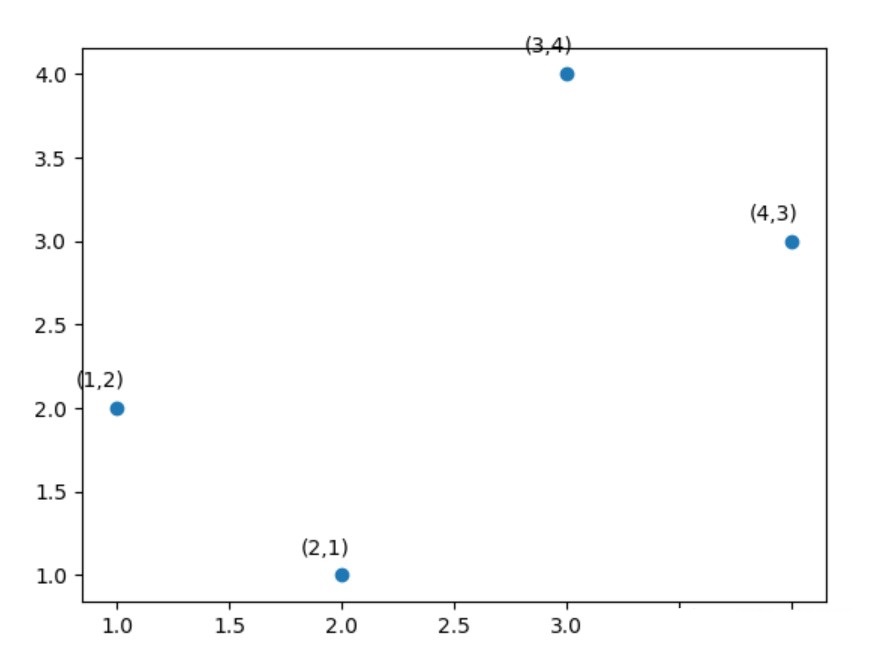
首先将上述数据集表示为一个矩阵X :
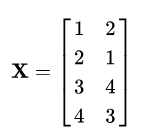
我们可以计算 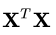 为:
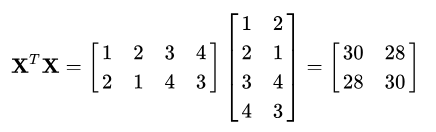
解析出对应的特征值为: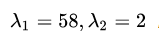 ,对应的单位特征矩阵向量为: ,对应的单位特征矩阵向量为:
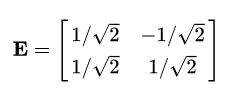
正交向量构成的任意矩阵都代表欧式空间下的一个坐标旋转,上面的这个矩阵可以看成是对原数据集施加一个45度的逆时针旋转,将原数据集X乘上E
,得到:
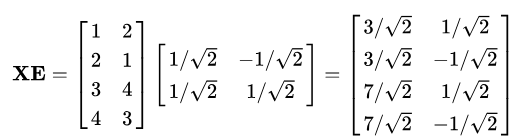
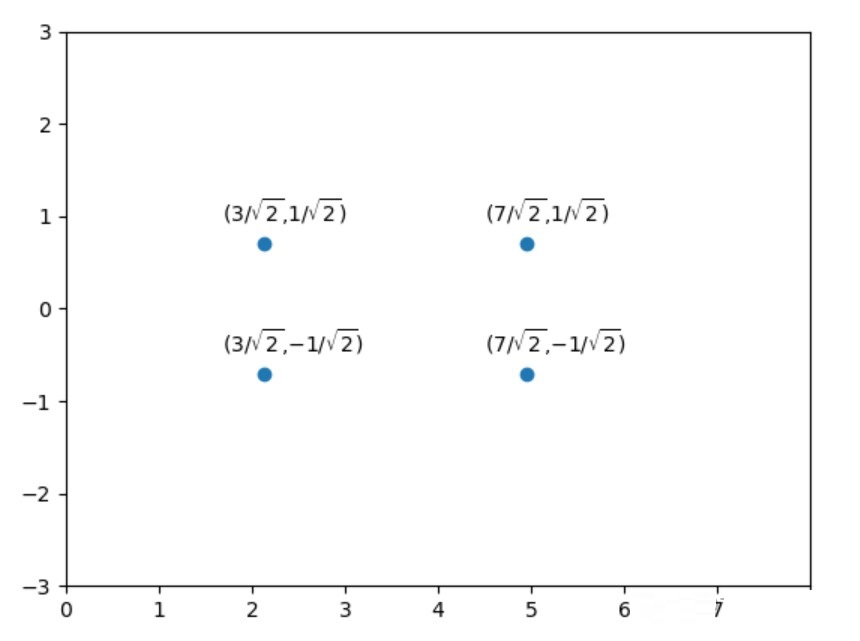
这意味着第一个数据点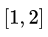 变换到 变换到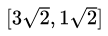 ,如下图所示: ,如下图所示:
Reference
[1] 机器学习实战
[2] Mining of Massive Datasets
[3] 机器学习 |









