| 编辑推荐: |
本文主要介绍了特征描述子、特征提取层和决策层匹配的问题,希望对您的学习有所帮助。
本文来自于CSDN,由火龙果软件Alice编辑、推荐。 |
|
1. 摘要 及 目的
利用卷积神经网络在欧式空间下学习高效性能的描述子 descriptor。的方法在四个方面与众不同,1.我们提出了一种渐进的抽样策略,使网络能够在几次的时间内访问数十亿的训练样本。2.从局部匹配问题的基本概念派生而来,我们强调了描述符之间的相对距离。3.对中间特征图进行额外的监督。
4.将描述符的紧凑性考虑在内。就是采用L2距离对特征描述子进行度量。收获到了非常好的结果(同期也有相关的工作)。
引用的原文更能说明问题:
The proposed L2-Net is a CNN based model without
metric learning layers, and it outputs 128 dimensional
descriptors, which can be directly matched by L2 distance.
Comment:没有测度学习层,研究的是特征描述子、特征提取层和决策层匹配的问题。
损失函数中融合了三个误差:其一,特征描述子之间的误差;其二,控制描述子的稠密度和过拟合;其三,二外的监督控制中间的特征图。
2. 方法 及 细节
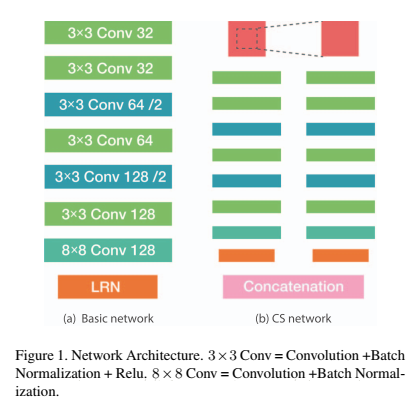
图1. 使用的网络结构。3x3 Cov = 卷积层 + 批正则化 + 整流函数。 8x8 Conv
= 卷积 + 批正则化。典型的全卷积结构,降采样通过跨步卷积实现(stride = 2)。每层卷积层后面都跟随批正则化。进行了小的修改,批正则化层的权重核
偏置没有更新,固定为1和0.在设计描述子过程中,标准化是很关键的一部,采用Local Response
Normalization 层作为输出层,产生单位描述子。L2-Net 将32x32的输入图像块转换成128维的特征向量。注意:右侧的网络架构是借鉴了前面的工作,也就是center-surround模型。这里不深入研究。
引用原文:Since normalization is an important step in
designing descriptors, we use a Local Response Normalization
layer (LRN) as the output layer to produce unit descriptors.
2.1 训练数据和与处理技巧
两个标准的测试集:Brown dataset 和 HPatches dataset。对于每一个图像块,进行去均值和对比度归一化。也就是我们平常所说的去除均值除以标准差。
For each patch, we remove the pixel mean calculated
across all the training patches, and then contrast
normalization is applied, i.e., subtracted by the
mean and divided by the standard deviation。
2.2 训练集进行渐进抽样
主要是因为在训练样本中,非匹配的图像对远远多于匹配的图像对,所有的非匹配对不可能完全遍历到,所以一个好的采样策略很重要。(其实是一种非常简单的采样策略)
引用原文:In local patch matching problem, the number
of potential non-matching (negative) patches is orders
of magnitude larger than the number of matching (positive)
patches. Due to the so large amount of negative pairs,
it is impossible to traverse all of them, therefore
a good sampling
strategy is very crucial.
2.3 损失函数设计(精华)
1. 特征之间的测度
2. 描述子的特征维度应该最大限度去相关 (谈到这个事似乎也没解释清楚)
3. 对中间的特征图也要施加约束 (其实可以用正则化来解释的)
2.3 训练参数
我们使用SGD从头开始训练网络,初始学习率为0.01,动量为0.9,权重衰减为0.0001。学习率每20个时期除以10,训练不超过50个时期。对于csl2网络的训练,我们使用训练良好的L2网络初始化两个塔。图1-(b)中左塔的参数是固定的,我们微调右塔直到收敛。我们让p1=p2=q/2=64,数据扩充(可选)是通过随机旋转(90、180、270度)和翻转来实现的。
3. 实验与结论
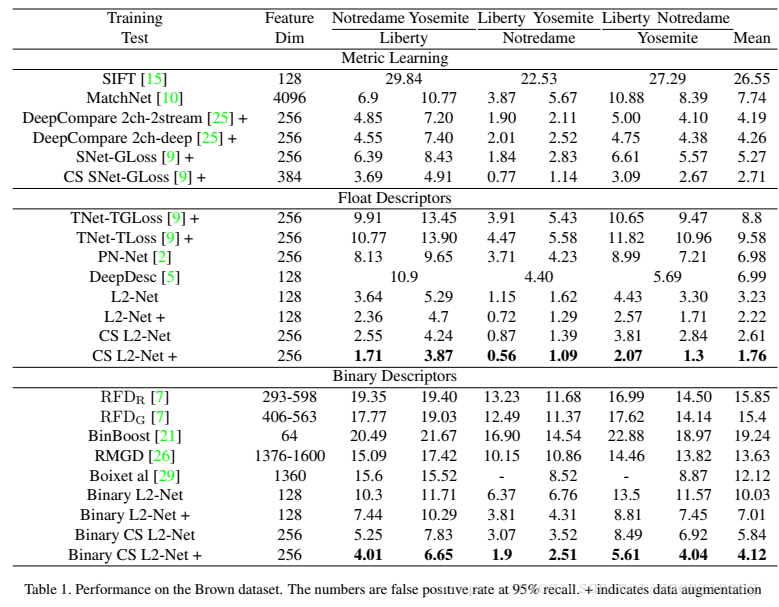
这张表有两个经验值得学习:
1. 数据增强的效果:确实数据增强可以提升模型的性能
2. 数据处理的效果:同等情况下描述子的浮点表达形式明显优于二值表达形式
3.关于结构的探讨:一般情况下不赞成使用池化效应。同时赞成使用不同深度的框架
现在纠结的是,同样使用的类似的、简单的网络结构,为什么可以得到如此好的结果??? 原因一定是出现在损失函数的构造上!!!
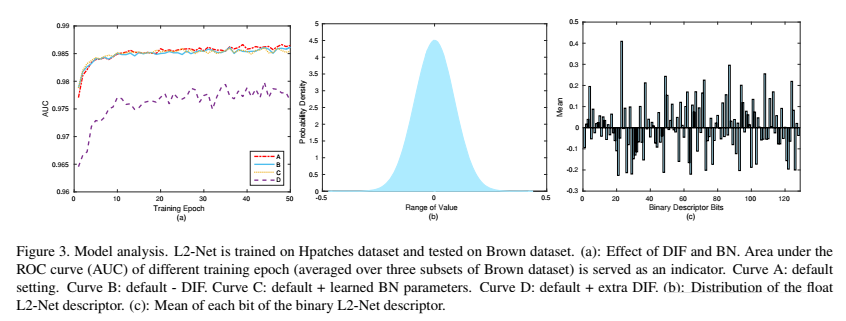
特征维度紧致的重要性。我们尝试在没有E2的情况下训练L2网络,但是网络不收敛。由于大量的训练样本被输入到网络中,网络更容易记忆训练数据而不是学习泛化。如果没有E2,则会发生强过拟合,并且输出描述符的维数高度相关。因此,紧性对渐进抽样策略至关重要。通过限制紧性,网络实际上倾向于提取包含更多信息的不相关特征
Comment:其实这是自己操控的试验训练过程。如果直接应用数据库,里面有大量相关性非常强的图像对,这就会造成网络去记忆训练数据,而不是泛化的去学习特征。因此,其实吧,提及到的特征紧密型之所以没有数理证明,是因为训练数据相对独立,这就暗含着特征维度间相对去相关。
L2距离的优势。还好还好 也就一般啦...
DIF的有效性,实验还没有重复出来....
批归一化的收益:这个应该是所有人都关心的,批归一化一般可以加快收敛速度这没的说,关键是BatchNorm对提高模型的准确度到底贡献几何?在我们的BN层中,权重α和偏差β固定为1和0,因为我们发现学习它们会使输出的特征映射(和描述符)分布不良。在这个实验中,除了两个BN层在DIF之前(因为DIF依赖于标准化特征)学习了所有BN层的加权和偏差参数。训练程序如图3-(a)中的曲线C所示。比较曲线A和C,可以发现更新α和偏差β导致性能略有下降。为了说明这一现象,假设a~N(μ1,σ1)和b~N(μ2,σ2)是两个服从高斯分布的随机变量。不难理解,分离它们的最简单方法是增加|μ1-μ2
|,而
减小|σ1 |和|σ2 |。因此,学习α和β会使提取的特征变得尖锐和非零分布,从而影响性能。解决这些问题的基础是我们希望不同面片的特征映射(和描述符)是独立的、同分布的。通过这种方式,网络被迫提取出具有高度区分性而非偏见的特征的设置方法是DIF前两个BN层没有进行学习,解释的原因是DIF依赖归一化特征,过多的使用BN层会破坏不同对图相间的独立同分布性质,又绕回去了,我们要的是泛化的判别能力,而不是记忆训练集的能力。
结论:在本文中,我们提出了一种新的数据驱动描述符,它可以在欧几里德空间中进行匹配,并且性能明显优于现有的数据驱动描述符。它的良好性能主要归功于一种新的渐进采样策略
以及一个包含三项的专用损失函数。通过逐步抽样,我们设法访问了数十亿个训练样本。通过回到匹配(NNS)的基本概念,我们深入研究了每个批次中的信息。通过要求紧凑,我们成功地处理了过度拟合。通过使用中间特征映射,进一步提高了性能。
|









