| 编辑推荐: |
本文主要介绍了利用孪生网络的匹配能力进行跟踪,希望对您的学习有所帮助。
本文来自于CSDN,由火龙果软件Alice编辑、推荐。 |
|
comment:利用孪生网络的匹配能力进行跟踪,这种思想不难想到。跟踪的很大的一个分支就是基于目标检测(匹配)的跟踪。在以后相当长的一段时间里,基于孪生网络的跟踪方案并解决长时间(long-term)问题一定是跟踪领域的热点。但相比于DCF及其衍生的CNN-DCF优秀的跟踪性能,Siamese还有相当长的路要走。一方面,基于匹配的跟踪何如引入时间场效应(temporal
smooth)?如何引入attention机制将是难点。此外,如果想成为一种普适性的方法,很显然网络不能太复杂太深,否则时效性不好,平衡精度与速度始终是跟踪领域两座大山。
1. 摘要 及 目的
我提出一个和之前顶级跟踪器都不一样的新型跟踪器,没有模型更新,没有遮挡检测,没有跟踪器级联和重检测,也没有几何匹配(就是啥也没有,完全依赖深度卷积强大的特征表达能力)。方法就是用学习到的匹配函数进行最佳块匹配策略。
以DCF为核心的方法征服整个跟踪领域的途中,偶然出现一篇最佳匹配实现跟踪确实让人眼前一亮,但是这也只是停留在最初步阶段,更多的是给研究者更多的选择。本文另外一个亮点应该在重识别上,在一个完整是视频中,如何解决目标确实后的重识别问题一直是研究的热点。
我原文是这样说的:We focus on learning the matching function
suited for application in trackers. Hence, our aim
is not to build a fully fledged tracker which might
need explicit occlusion detection, model updating,
tracker combination, forget mechanisms and other.
We rather focus on the matching function alone, similar
to the simplicity of the normalized cross-correlation
(NCC) tracker .In each frame, the tracker simply finds
the candidate patch that matches best to the initial
patch of the target in the first frame by the learned
matching function.
2. 方法 及 细节
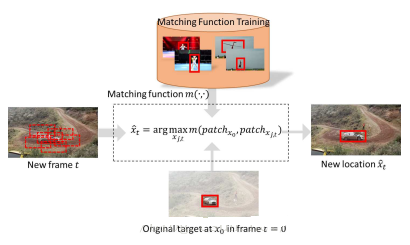
图1:预训练好的匹配函数,用于跟踪实例中的最佳快匹配跟踪
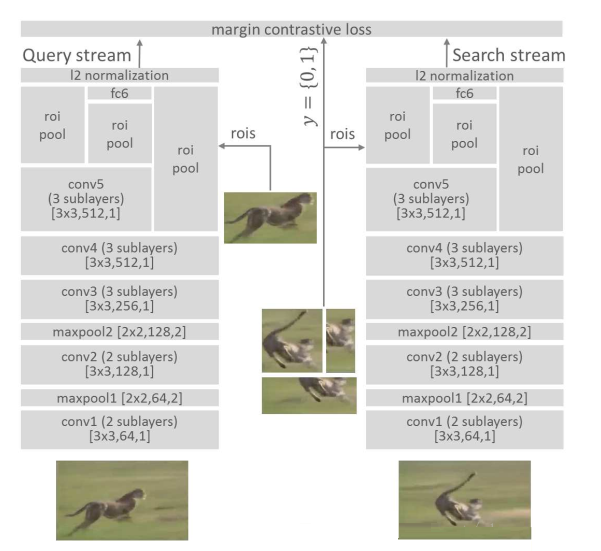
图2 The proposed Siamese invariance network to learn
the generic matching function for tracking. ‘conv’,
‘maxpool’, ‘roipool’ and ‘fc’ stand for convolution,
max pooling, region-of-interest pooling and fully
connected layers respectively. Numbers in square brackets
are kernel size, number of outputs and stride. The
fully connected layer has 4096 units. All conv layers
are followed by rectified linear units (ReLU)。(这里没有翻译,主要在于我提到的两个点。其一,ROI池化;其二,全连接层采用了大量的神经元)
损失函数用的还是hinge loss:
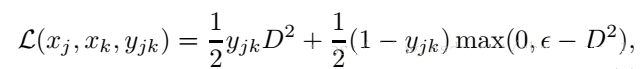
D是指两个特征表达的欧氏距离。 训练采用的还是老方法,一对图像以及他们的标签。
跟踪过程:
We propose a simple tracking strategy. As the only
reliable data we have for the target object is its
location at the first frame, at each frame we compare
the sampled candidate boxes with the target object
at the first frame. We pass all the candidate boxes
from the search stream of our network and pick the
candidate box that matches best to the original target:
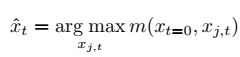
HighLight候选样本的采集策略:
We employ the radius sampling strategy. More specifically,
around the predicted location of the previous frame
we sample locations evenly on circles of different
radii。
为了避免候选样本的穷尽搜索问题,我提议采用半径采样策略。更确切地说,以前一帧预测中心为基准利用不同半径进行候选样本采样。We
use 10 radial and 10 angular divisions
和文献中不同的是,我将候选样本进行多尺度/多分辨率处理
Box Refinement 策略:我训练四个岭回归分类器,针对矩形框的圆心坐标、高度、宽度进行优化。这主要参考了前人的工作,通过回归进行矩形窗精修可以大大提高目标定位的准确度。
很奇怪.....我采用权重衰减为0.001;然而作为对别人孪生网络的精修,竟然采用了0.001的初始学习率。
3. 结论 及 反思
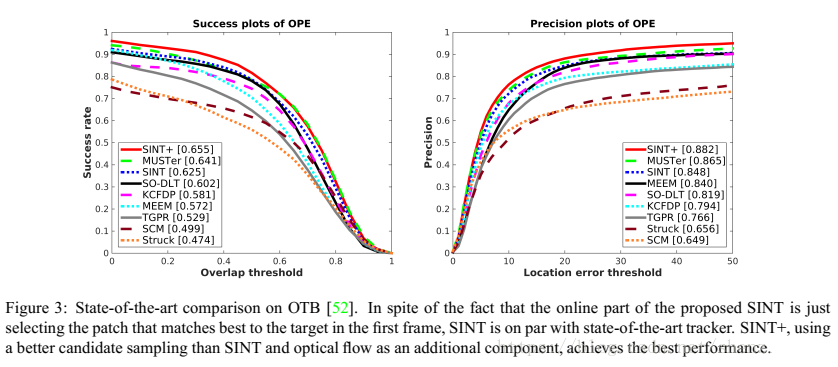
comment:这篇文章有毒...我竟然直接剔除了遮挡的视频,而且文章中大量的小tricks 和
处理只是给了别人的效果,却没有解释自己实验中的效益!
通过后续我补充提交的失败案例来看,果不其然,跟踪性能是真的差啊...

图4. 两例跟踪失败的情况。左边:基于最佳匹配原理很难处理空间相似性目标的干扰。因为搜索空间的等权重的,这里应该利用余弦窗函数加以约束,施加位移惩罚。
右边:最佳匹配跟踪无法解决遮挡问题,这主要还是因为模型更新没有做好。在我的文章中压根没有做模型更新。所以该方法应用非常有限。
|






