| 编辑推荐: |
本文对nlp中一个极为重要的模型——主题模型LDA(Latent
Dirichlet Allocation)从宏观理解与数学解释两个维度进行介绍,希望对您的学习有所帮助。
本文来自于知乎 ,由火龙果软件Alice编辑、推荐。 |
|
1、LDA的宏观理解
谈起LDA,自然需要引入pLSA。pLSA是用一个生成模型来建模文章的生成过程。假设有K个主题,M篇文章;对语料库中的任意文章d,假设该文章有N个词,则对于其中的每一个词,我们首先选择一个主题z,然后在当前主题的基础上生成一个词w。
生成主题z和词w的过程遵照一个确定的概率分布。设在文章d中生成主题z的概率为 [公式] ,在选定主题的条件下生成词w的概率为
[公式] ,则给定文章d,生成词w的概率可以写成:
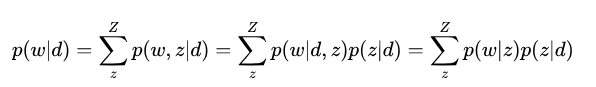
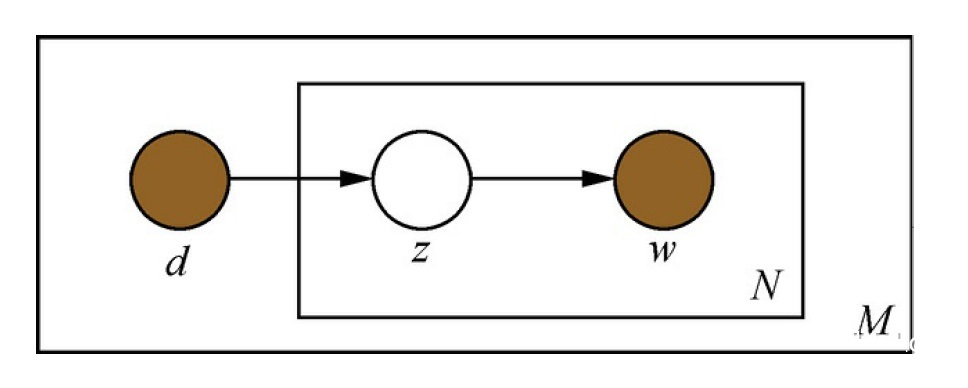
pLSA概率图模型
LDA可以看作是pLSA的贝叶斯版本,其文本生成过程与pLSA基本相同,不同的是为主题分布和词分布分别加了两个狄利克雷(Dirichlet)先验。为什么要加入狄利克雷先验呢?这就要从频率学派和贝叶斯学派的区别说起。pLSA采用的是频率派思想,将每篇文章对应的主题分布[公式]和每个主题对应的词分布[公式]看成确定的未知常数,并可以利用EM算法求解出来;
而LDA采用的是贝叶斯学派的思想,认为待估计的参数(主题分布和词分布)不再是一个固定的常数,而是服从一定分布的随机变量。这个分布符合一定的先验概率分布(即狄利克雷分布),并且在观察到样本信息之后,可以对先验分布进行修正,从而得到后验分布。LDA之所以选择狄利克雷分布作为先验分布,是因为它为多项式分布的共轭先验概率分布,后验概率依然服从狄利克雷分布,这样做可以为计算带来便利。——《百面机器学习》
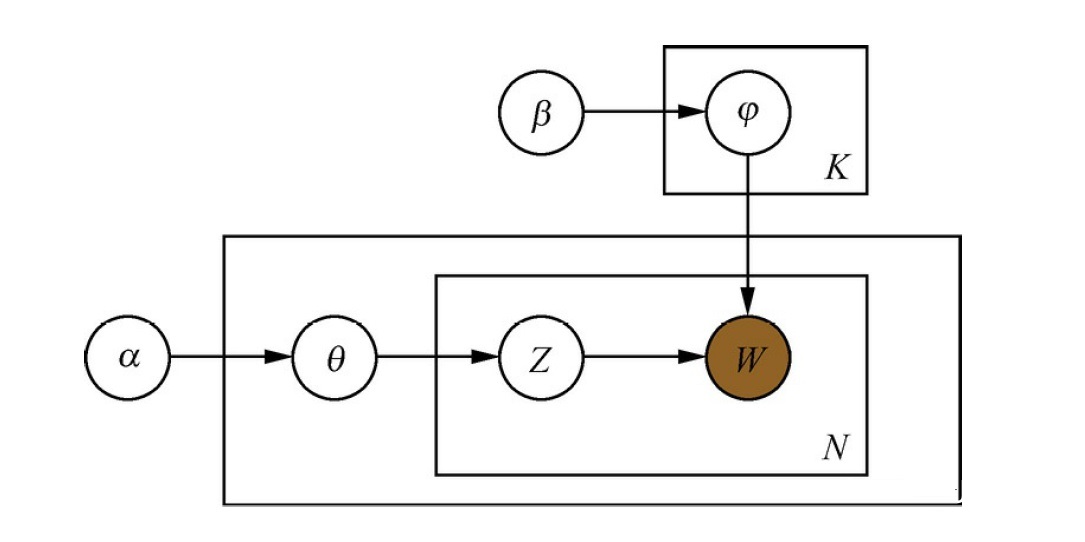
LDA概率图模型
在LDA概率图模型中,α,β分别为两个狄利克雷分布的超参数,为人工设定。
补充:pLSA虽然可以从概率的角度解释了主题模型,却都只能对训练样本中的文本进行主题识别,而对不在样本中的文本是无法识别其主题的。根本原因在于NMF与pLSA这类主题模型方法没有考虑主题概率分布的先验知识,比如文本中出现体育主题的概率肯定比哲学主题的概率要高,这点来源于我们的先验知识,但是无法告诉NMF主题模型。而LDA主题模型则考虑到了这一问题,目前来说,绝大多数的文本主题模型都是使用LDA以及其变体。
2、LDA的数学基础
2.1 概率基础
(1)二项分布与多项分布
二项分布: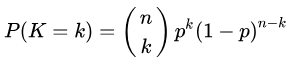
多项分布: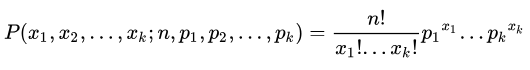
(2)Gamma函数
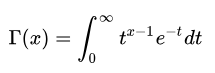
Gamma函数如有这样的性质: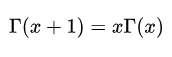
Gamma函数可以看成是阶乘在实数集上的延拓: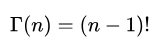
(3)Beta分布和Dirichlet分布
Beta分布的概率密度函数为:
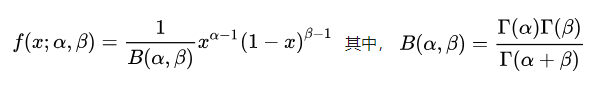
Dirichlet分布的概率密度函数为:
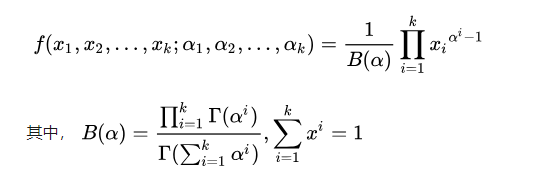
这说明,对于Beta分布的随机变量,其均值可以用 [公式] 来估计。
Dirichlet分布也有类似的结论,如果 [公式] , 同样可以证明:
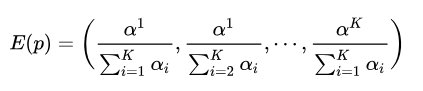
(4)共轭先验分布
在贝叶斯概率理论中,如果后验概率 [公式] 和先验概率 [公式] 满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭先验分布。
2.2 MCMC及Gibbs Sampling
(1)MCMC简介
MCMC采样法主要包括两个MC,即蒙特卡洛法(Monte Carlo)和马尔可夫链(Markov
Chain)。蒙特卡洛法是指基于采样的数值型近似求解方法,而马尔可夫链则用于进行采样。MCMC采样法基本思想是:针对待采样的目标分布,构造一个马尔可夫链,使得该马尔可夫链的平稳分布就是目标分布;然后,从任何一个初始状态出发,沿着马尔可夫链进行状态转移,最终得到的状态转移序列会收敛到目标分布,由此可以得到目标分布的一系列样本。在实际操作中,核心点是如何构造合适的马尔可夫链,即确定马尔可夫链的状态转移概率,这涉及一些马尔可夫链的相关知识点,如时齐性、细致平衡条件、可遍历性、平稳分布等。——《百面机器学习》
在现实应用中,我们很多时候很难精确求出精确的概率分布,常常采用近似推断方法。近似推断方法大致可分为两大类:第一类是采样(Sampling),
通过使用随机化方法完成近似;第二类是使用确定性近似完成近似推断,典型代表为变分推断(variational
inference)。在很多任务中,我们关心某些概率分布并非因为对这些概率分布本身感兴趣,而是要基于他们计算某些期望,并且还可能进一步基于这些期望做出决策。采样法正式基于这个思路。
蒙特卡洛法(Monte Carlo)是指基于采样的数值型近似求解方法,具体来说,假定我们的目标是计算函数f(x)在概率密度函数p(x)下的期望:
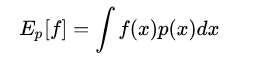
根据 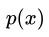 进行样本采样 进行样本采样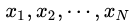 ,最终可计算f(x)在这些样本上的均值: ,最终可计算f(x)在这些样本上的均值:
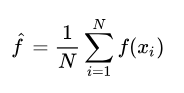
若概率密度函数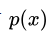 很复杂,则构造服从p分布的独立同分布样本也很困难。MCMC方法的关键在于通过构造“平稳分布为
的马尔可夫链”来产生样本:若马尔科夫链运行时间足够长,即收敛到平稳状态,则此时产出的样本X近似服从分布p。细致平衡条件为: 很复杂,则构造服从p分布的独立同分布样本也很困难。MCMC方法的关键在于通过构造“平稳分布为
的马尔可夫链”来产生样本:若马尔科夫链运行时间足够长,即收敛到平稳状态,则此时产出的样本X近似服从分布p。细致平衡条件为:
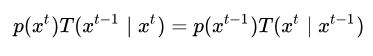
(2)Metropolis-Hastings算法采样过程:
对于目标分布 ,首先选择一个容易采样的参考条件分布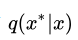 ,并令 ,并令
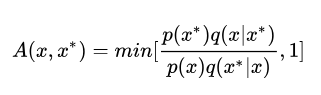
然后根据如下过程进行采样:
1)随机选一个初始样本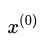 ; ;
2)For t = 1, 2, 3, … :
根据参考条件分布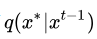 抽取一个样本 抽取一个样本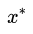 ; ;
根据均匀分布U(0,1)产生随机数 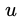 ; ;
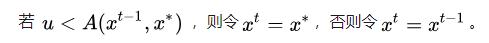
(3)Gibbs Sampling算法采样过程:
吉布斯采样法是Metropolis-Hastings算法 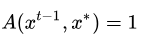 时的一个特例,其核心思想是每次只对样本的一个维度进行采样和更新。对于目标分布p(x),按如下过程进行采样: 时的一个特例,其核心思想是每次只对样本的一个维度进行采样和更新。对于目标分布p(x),按如下过程进行采样:
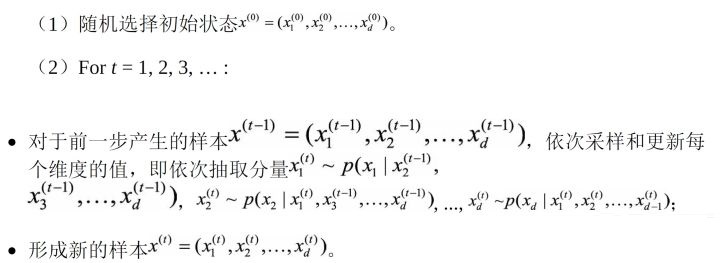
3、pLSA中的参数估计:
EM求解(1)通过极大似然估计建立目标函数:

(2)EM求解-E步:
确定后验概率:
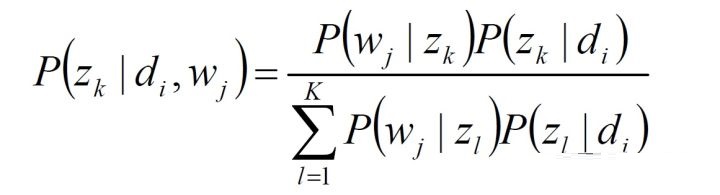
并带入新的期望目标函数中:
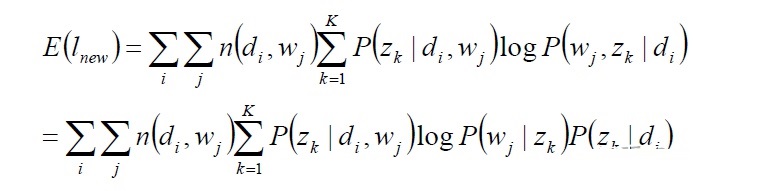
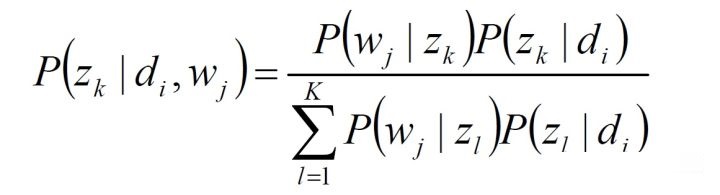
(3)EM求解-M步:
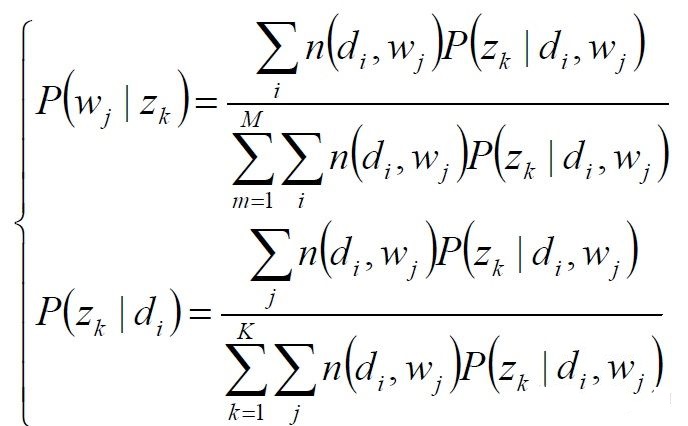
4、LDA中的参数估计:Gibbs Sampling
本节中通过Gibbs Sampling对进行参数估计,需要特别指出的是,Gibbs Sampling其实不是求解的过程,而是通过采样去求后验分布的期望,从而估计最终参数。
通过Gibbs Sampling对进行参数估计分为3个步骤:1)确定联合分布;2)求解后验概率Gibbs
updating rule;3)确立后验分布并求期望估计参数;
(1)确定联合分布:
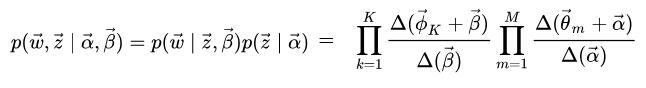
(2)根据(1)求出的联合分布可以求解Gibbs updating rule
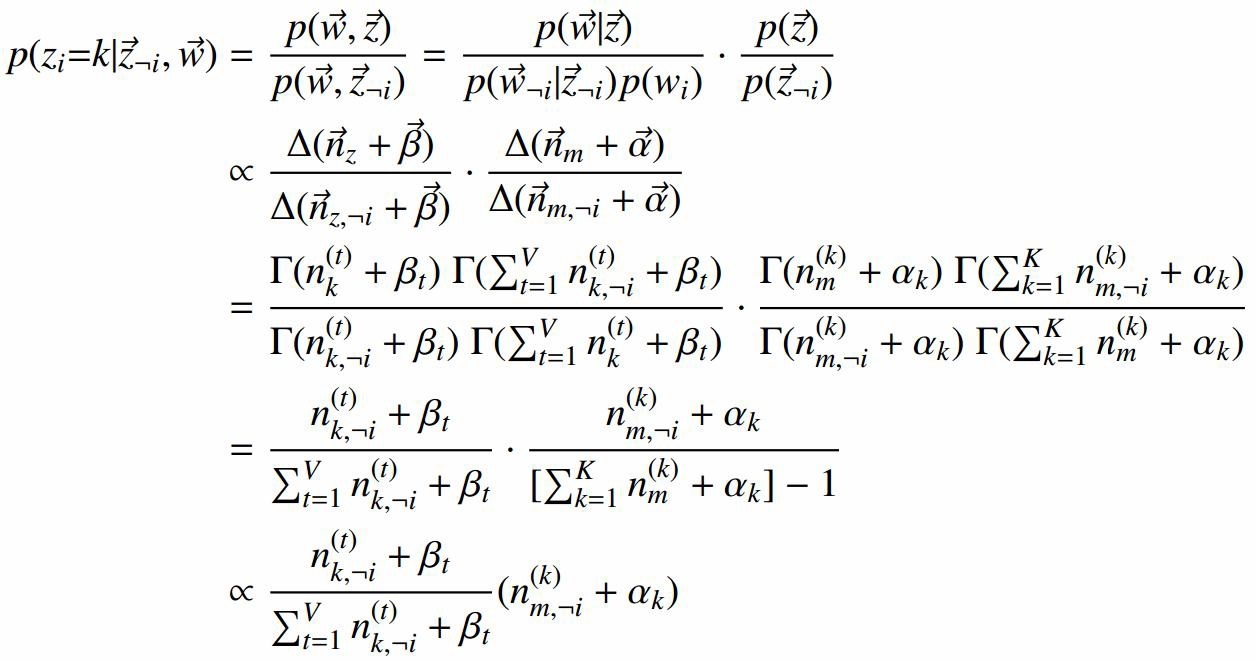
(3)确立后验分布并求期望估计参数:
每个文档上Topic的后验分布和每个Topic下的词的后验分布分别如下(据上文可知:其后验分布跟它们的先验分布一样,也都是Dirichlet
分布):
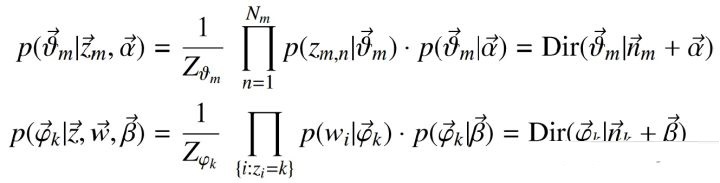
根据Dirichlet 分布参数估计:
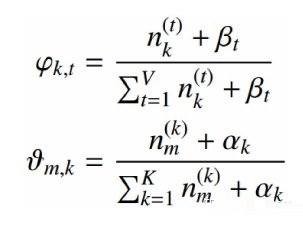
5、LDA的训练和预测过程:
(1)训练过程

(2)预测过程:LDA的各个主题的词分布 [公式] 已经确定:

6、LDA主题数目选择及评估标准
在LDA中,主题的个数K是一个预先指定的超参数。对于模型超参数的选择,实践中的做法一般是将全部数据集分成训练集、验证集、和测试集3部分,然后利用验证集对超参数进行选择。例如,在确定LDA的主题个数时,我们可以随机选取60%的文档组成训练集,另外20%的文档组成验证集,剩下20%的文档组成测试集。在训练时,尝试多组超参数的取值,并在验证集上检验哪一组超参数所对应的模型取得了最好的效果。最终,在验证集上效果最好的一组超参数和其对应的模型将被选定,并在测试集上进行测试。
为了衡量LDA模型在验证集和测试集上的效果,需要寻找一个合适的评估指标。一个常用的评估指标是困惑度(perplexity)。在文档集合D上,模型的困惑度被定义为:
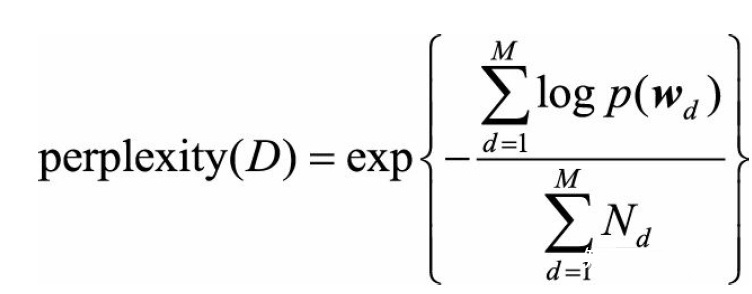
其中M为文档的总数, [公式] 为文档d中单词所组成的词袋向量,p([公式])为模型所预测的文档d的生成概率,
[公式] 为文档d中单词的总数。
|









