| 编辑推荐: |
本文主要介绍了我们应该怎样使用这种复杂的图谱呢?基于知识图谱的问答系统会给我们提供一个很好的使用方法/交互方式,希望对您的学习有所帮助。
本文来自于微信公众号,由火龙果软件Alice编辑、推荐。 |
|
为什么金融知识问答需要知识图谱?
举个例子
在搜索引擎里面输入问题“川普他老婆多高”
使用不同的搜索引擎搜索得到了不一样的效果:左边的直接给我们答案(这个是基于谷歌的知识图谱来做的),右边的结果虽然给出了一堆搜索结果,但我们可能看很久也找不到想要的结果。从搜索的效果来看,左右两边的差别非常大。
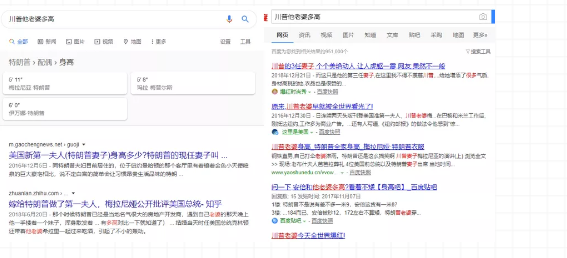
知识图谱发展后,可以帮助我们解决很多问题。知识图谱和智能问答在很多行业、领域可以带来很好的交互体验,为我们节省大量的时间。
知识图谱与问答系统的介绍
在经历过蒸汽时代、电气时代和信息时代之后,人类社会正处在迈进智能化时代的阶段中。近十年人工智能技术迅速发展,这也在在这次新冠疫情有所体现——智能测温、智能填表……他们都是人工智能的应用展现。
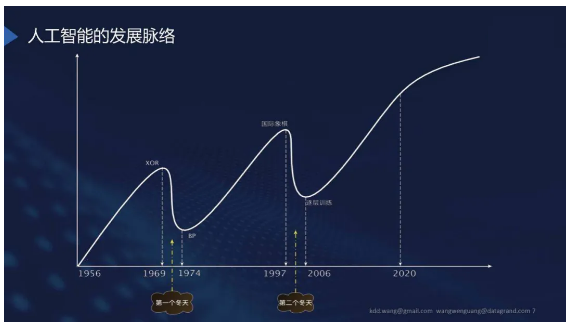
人工智能发展脉络
人工智能不是非常新的技术,早在1956年就有了概念,经历了70年代前后和2000年之前的两个人工智能冬天。这两个冬天的出现都是因为在取得巨大的发展后,人工智能遇到了发展的瓶颈。
2006年开始,以深度学习技术为基础开始了这一次人工智能的发展。从语音识别、图像和计算机视觉领域一直到现在的NLP和知识图谱领域,未来还会继续发展。
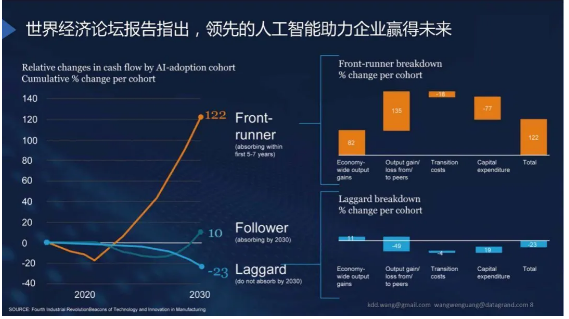
在目前的阶段,采用人工智能技术的企业可以赢得未来。如果没有采用人工智能技术可能会落后于整个世界的科技。下图是世界经济论坛报告中的一张图片,图片展示的是如果企业在2020年前后依然不采用人工智能技术,那么在未来可能会被整个社会淘汰/失去企业竞争力。采用人工智能技术的公司反而可以得到飞速的发展。
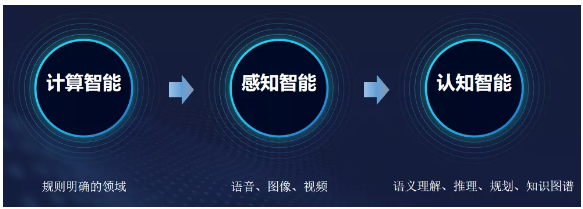
人工智能的三个发展阶段
人工智能首先是从计算智能开始发展的。在90年代的时候,国际象棋大师被IBM的深蓝所击败,这个阶段基本上被称为计算智能发展阶段。
在计算智能发展到一定阶段后,人工智能进入到了感知智能的发展阶段,这个阶段是让机器去感受外界或自然界。计算机视觉、语音识别、无人驾驶都被认为是感知智能的典型代表。虽然无人驾驶现在还没有达到真正实用的阶段,但是它在一些封闭的环境下已经可以使用了——这也是感知智能发展到非常高级阶段的表现。
人工智能的三个发展阶段
很多人工智能界大佬都认为,我们人类的人工智能技术应该要走向认知智能阶段。认知智能是以语义理解、推理、规划、知识图谱等技术综合来推进的。NLP和知识图谱被认为是实现认知智能的关键技术。
什么是知识图谱?
知识图谱(Knowledge Graph)旨在描述世界万物的知识、概念、实体、属性、事件及其之间的关系。可以将知识图谱简单理解为把知识连接在一起组成的网络,这些网络就是我们所谓的图谱。它以结点来代表实体、概念、事件,每一个结点都是一知识点,而边代表实体/概念之间的各种语义关系。
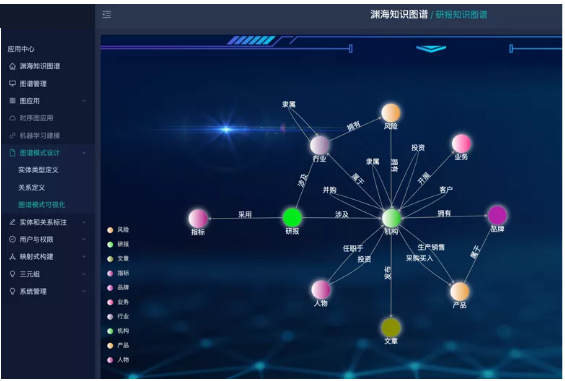
举一个直观的例子,这个例子也是我们CCKS评测里的一个图谱模式(Schema)。从金融研报中抽取能代表研报的金融知识点:如果说机构是常见的实体类型,那风险就是金融研报里面非常关心的点。风险点不是物理世界里存在的实体,但是它可以作为我们金融知识图谱里面的一个知识点的存在。(点击了解赛事:基于本体的金融知识图谱自动化构建技术评测)。
同样,业务、产品、品牌这些类型都可以作为知识点,而这些知识点之也存在某些联系(例如:机构开展业务、机构生产销售产品、采购产品),这些知识点连接成了一个网络,这样就可以非常直观的理解我们所谓的知识图谱。
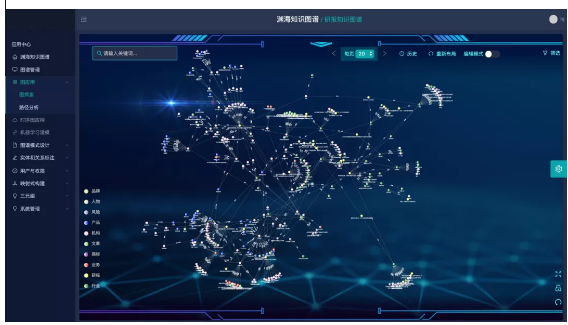
达观渊海知识图谱
上图是我们定义好知识图谱Schema后,从研报里抽取出来的一个构建好的图谱。虽然非常复杂,但它能将我们所关心的金融知识点关联起来。我们应该怎样使用这种复杂的图谱呢?基于知识图谱的问答系统会给我们提供一个很好的使用方法/交互方式,这也是我们要研究知识问答系统的一个原因。
达观数据渊海知识图谱
达观数据渊海知识图谱将整个知识图谱分为以下三部分:
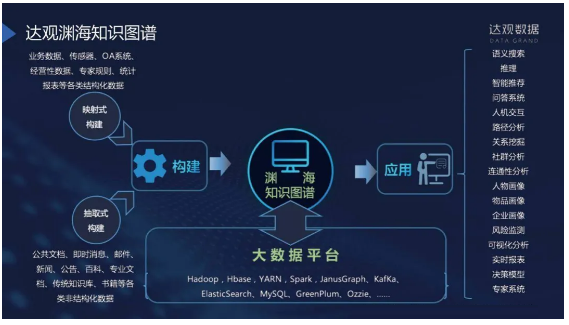
1.构建
抽取式构建:
知识图谱不是凭空产生的,我们刚才提到的研报知识图谱的内容来源是PDF、PPT、Word这样的非结构化文档,我们要从非结构化文档中把知识点抽取出来、建立联系。这个过程我们称之为抽取式构建,需要使用各种各样的NLP技术。
映射式构建:
我们在过去的时间里存有了大量的已经结构化的知识,这些知识点可能是人工整理的、用各种正则表达式抽取的、也可能是在其他系统中已经通过NLP技术抽取出来的结构化的数据。这些数据可能在Oracle、MySQL等数据库中,也可能在Excel、CSV的文件中,或者有可能在Hadoop、Hbase这样的大数据平台中。我们可以通过规则、映射等方法,用这些数据构建图谱。
存储
一般来说,我们会将构建好图谱需要存储在图数据库中。常见的图数据库有janusGraph、Neo4J……达观渊海知识图谱就是使用janusGraph存储。janusGraph的底层存储是Hbase和Hadoop这个平台,它可以支持百亿甚至千亿级的数据存储。
知识图谱平台如何使用?这会涉及到一些信息检索相关内容,我们使用ElasticSearch来做知识图谱的搜索功能。当然还有一些辅助的,比如使用Ozzie用来做一些任务调度。
3.应用
知识图谱有很多不同方向的应用。在银行的风控中会涉及到图计算、图挖掘,比如说去分类可以用来做反欺诈或者做营销,而我们今天讲的一个问答系统,也是知识图谱的应用之一,或者说它可以提供更好的语义搜索/检索。
什么是问答系统?
问答系统是信息检索系统的一种比较高级的形式,在我们输入问题后,系统会寻找关键词、并做筛选,给出我们想要的答案。它涉及到非常多、非常复杂的技术,是NLP、信息检索、知识推理等人工智能技术的综合应用。
最重要的是,它能够准确地理解我们输入的问题,然后给出直接的、简洁的、准确的答案。问答系统存在的形式多种多样,Siri、小度机器人、各种各样的语音助手都有问答系统。微信公众号有些也会存在一些自动化的对话机器人或者问答系统来帮助我们获取知识或资料。我们今天主要介绍通用技术在金融行业的应用。
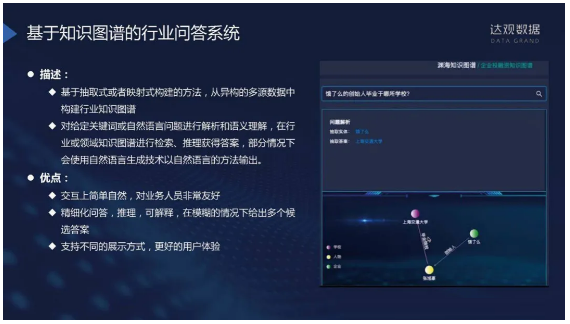
金融行业做知识图谱的问答系统有什么好处呢?我们前面提到的研报知识图谱,构建好研报知识图谱后可以有一些应用。当做证券分析或做投研时,我们需要了解某企业的研报,可能去一些金融终端搜索。也可以有其他的信息获取方式——比如语音输入,对话后把研报推送到微信或者邮箱中,方便我们收到想要的信息。

问答系统在还可以在客服、智能助理等领域应用。我们有些客户,他们就在构建金融业务知识库,来帮助他们的客户更好地去理解他们公司。比如说银行或者券商内部的一些知识,可以提升客户的满意度,不需要让客户等太久或者是回答不了客户的问题。
智能助理也是一样的,当我们把这些问答系统和语音识别和语音合组合成在一起,就可以实现专业领域里面的智能助理。智能助理有个非常好的应用,比如我们在开车的时候,想了解一些突发事件的内容或者我们要解决一些问题,刚好有个idea,就可以使用云识别连接到我们的问答系统,获取到相关的一些信息,这些信息可以帮助我们在路上任何时候都能够处理我们想要处理的问题。
基于知识图谱的金融问答系统的构建过程
如何去做这样的一个知识问答系统?下图是达观渊海智能问答引擎的总架构图,共分为四个大模块:预处理、问题理解、知识检索和答案生成。在每个大模块里面又有很多不同的算法和处理逻辑。当然这里面还是一个初步的分析,真实系统要远比这个复杂,还有很多各种细节上的处理。
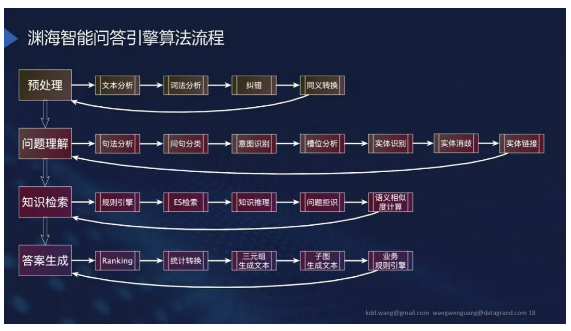
当然这一块已经是我们能够抽象出来的比较好的方法,也希望大家在这个之后可以有自己的一些理解和对整个问答系统或者问答相关功能的进一步的思考。
预处理
对于问答系统,首先我们会对搜集到的问句做一些预处理。预处理主要包括哪些内容呢?
1.文本分析
首先对问句做字符串的处理,比如标点处理、特殊字符处理、英文的全角字符和半角字符之间切换以及各种停用词的处理等。需要注意的是有时候处理图谱中的实体内容是会存在误处理。
以减号“-”为例,比如“战斗机F-22”。假设库里有一个F-22实体,如果我们把所有的减号都去掉,就可能对后续的识别产生非常大的负面作用。
2.词法分析
词法分析就是我们常说的分词和词性标注,它可以更好的帮助我们完成接下来的处理环节。词法分析是NLP里使用非常广泛、非常基础的内容,然而我们在实际使用时可能会有很多“坑”。
比如特斯拉的一款产品“Model 3”,通常在分词时会分成“Model”、“3”,这个结果是错误的。所以如何做好类似“Model
3”的分词,将它分成一个词,这就是我们在做分词时需要考虑的。在实际操作过程中,我们可以用图谱本身的内容来增强我们的分词效果。
3.纠错
纠错在以前的搜索引擎里面已经有非常多的应用。像百度或者谷歌这样的搜索引擎会利用很多历史query相关的分析来进行纠错处理。同样的,我们做问答系统也可以用历史query来纠错。但通常来说,对于企业内部的一些知识检索,其历史query量没有那么大。
那如何来进行纠错呢?我们可以利用图谱内容本身来进行纠错。这其中有两方面,一方面来增强我们的纠错效果;另外一方面避免我们做一些误判。
4.同义转换
同义转换跟实体消息或实体融合有一些技术上共通之处,在模型和算法上有很多可以共用的地方。在同义转换处理中,我们更多地会使用词表和领域词典的方式。
以上文提到的F-22为例,F-22有非常多的写法或者读法,比如我们可以称其为“战斗机”。那么在这个情况下,如果我们在专业领域已经收集好了领域词典/行业词表/领域词表,词表或词典的使用会对我们有非常大的帮助。
问题理解
对于一个问题在预处理完成之后,我们接下来要做的是真正地去理解这个问题。这其中会涉及到非常多的算法:
1.句法分析
句法分析是在词法分析之上,从句子的角度来对分词结果进行分析处理。它能帮我们识别中心词和关键词相关的内容。
存储句法分析得到的分析结果,后续用来做由多任务模型实现的三个相关分析——问句分类、意图识别和槽位分析。这三个分析过程会对问题进行不同角度分类。
2.问句分类
问句分类是对问题的类型进行分类,比如事实型、枚举型、关系型或者定义、原因等。枚举型的问句如:“有哪些”或者“有什么样子的”。事实型通常为描述一个事实,或者直接给出事实的结果。
3.意图识别
意图识别用于识别用户的目的,它往往会与一些属性关联在一起。举例:“要获取一个文档”或“要了解一个时间”。
4.槽位分析
槽位分析过程是把用户的问题理解后进行分解,并关联到图谱模式(Schema)。也可以简单理解为:根据Schema生成很多模板,并且将这个问题划分到其中一个模板上。
5.实体识别和实体链接、实体消歧
在完成上述分析之后,我们会进行实体识别和实体链接以及实体消歧。下文将会针对这几个难点为大家分享一些模型。
利用多任务实现问句分类、意图识别和槽位分析
问句分类、意图识别和槽位分析模型使用的是Bert + BiLSTM + CRF的联合模型。其中包含三个任务分别是:问句分类任务、意图分类任务、槽位标注任务。
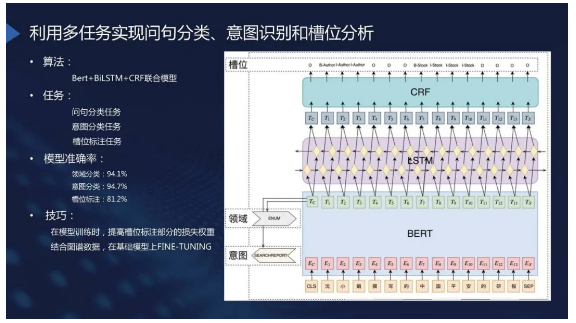
该模型所使用的算法如上图所表示:底层为Bert预训练模型,运用模型后会根据图谱数据进行FINE-TUNING。之后在上面连接三个不同的任务,其中一个任务是序列标注,目前常见的通过BiLSTM
+ CRF来连接序列标注相关的内容。
另外两个方法也是在Bert中经常用到的,利用Bert来做分类的算法。这其中两个分类任务,一个是“领域分类”或者说“问句分类”的任务;另外一个就是意图分类的任务。当然领域分类在针对不同的问答系统中基本上是通用的。而槽位分析和意图识别在一个具体的知识图谱中说对于不同的Schema或者图谱模式都会有不同的分类结果。所以针对不同的图谱,我们可能需要重新训练模型。
在我们自己进行的测试中,通常会有一个标准的测试集。针对测试集我们完成的三个任务都可以取得比较好的效果,最终评测能够达到80%以上。当然这其中存在一些训练上的技巧,由于是三个不同的任务我们的实践表明对于整个槽位标注变成我们的损失程度可能要更高一些。
对于金融研报的知识图谱,我们会进行问句分类(事实型、枚举型、是非型等),意图识别(查报告、查作者、查时间等),槽位分析(股票、人物、研报、行业等)。
举个例子
问句为“沈海兵写的关于中国平安的研报”
对中文问句分字后,将各自字的符编码、位置编码、片段编码相加,经自注意力机制处理,能够学习到上下文之间的依赖关系,位于句首的
CLS 则捕获到句子在字符级水平上充分交互后的特征。这是某只股票的研报,系统会将其分成类不同的类别,预测结果如下:
在问句分类上,它是属于枚举型,因为需要返回一系列的研报
在意图识别上,结果是查询报告,可能需要看这个报告的原文
在槽位分析上,涉及到人物类型以及股票类型,其对应的每个类型都有一个标注,比如陈海滨属于人物类型,中国平安是股票类型的一个实体。
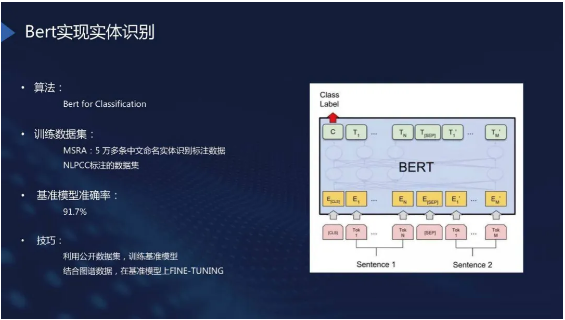
实体识别
实体识别是把问句里所有可能的实体识别出来。实体识别是一个常见任务,我们使用BERT实现,而且不使用序列标注,直接使用分类。通过在几个公开数据上测试,在刚才提及的研报图谱上,能达到
91% 的准确率,当然这个准确率是通过图谱数据在BERT基础上做 Finetuning 实现的。
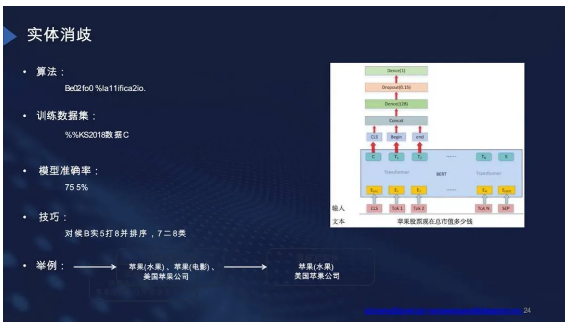
实体消歧
关于实体消歧,比较常见的方法是基于BERT再做一些处理。我们使用了
CCKS2018 数据集进行评测,准确率约为 75%。结合以上几点,系统可以很好地理解问题。
知识检索
在问题分析上,我们大量使用 BERT 模型,因为在很多领域,对 BERT 进行小的调整就能达到非常好的效果,可以说是简单粗暴。在业界里面还有很多好的SOTA模型,这些模型可以通过查阅相关论文了解。但在落地应用层面,这些模型需要更多语料来实现较好的效果,这往往是企业应用时所无法达到的,因为很多时候客户能够给语料很少,我们需要权衡如何用更少的预料来达到不错的效果。

在问题分析后,下一步是知识检索,即从知识图谱库里找出所需内容。鉴于知识图谱一般会非常大,我们会使用信息检索的相关技术。首先是基于业务专家所提供知识的规则引擎,专家知识会提供有效补充。
最主要方法的是基于ES检索,Elastic Search 是搜索引擎中最常用的开源系统,非常完善和强大。我们会把知识图谱的所有内容都进入
Elastic Search 做索引,当然我们会做一些调整,比如实体类型,关系和属性会有不同的索引类型、类别和方法。
对于知识图谱的问答而言,仅使用 Elastic Search 搜索引擎有可能不够。比如说,当查找两个实体之间可能存在的关系时,仅用检索可能无法发现这些关系,这时可能需要触发图分析、图计算、或是图神经网络相关的推理。
举个简单的例子,我们在疫情期间会遇到查找两个公司可能存在的关系的场景,那要如何查找呢?如果有了一个企业工商信息的图谱之后,我们可以询问问答系统:A公司和B公司什么关系?系统首先获取
A公司和B公司输入,然后通过问题分类确定查找关系类型,从而触发路径分析算法,去查找起点是 A公司终点是B公司的一些路径,结果可能是最短路径或多个路径。这些路径让我们能够理解
A 公司和 B 公司之间存在的关系,以上所需的知识推理相关算法和模型。
语义相似度计算
在知识检索和知识推理后,系统获取到可能需要的候选集。对于候选集还需做最后一步处理:语义相似度计算。我们会计算检索出的三元组或子图与原始问句的相似度,进一步剔除一些不合适的答案。语义相似度计算的结果也可以对答案的排序(Ranking)提供相应的依据。
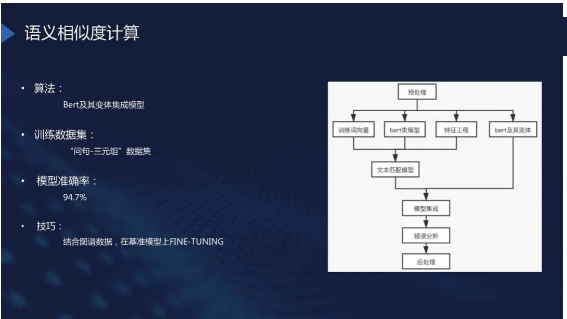
在Elastic Search中,会使用 ES检索语法,其中核心是基于语义相似度计算的模型。我们也会使用
BERT模型得到初始结果,然后利用 BERT 输出的向量来计算相似度,从而剔除一些不合理的结果。
在一个收集了大量公开问句和三元组的评测集上,我们用 BERT 和集成模型计算的向量,来计算结果的三元组和问句之间的语义相似度,然后把某个阈值以下的直接剔除,结果准确率能进一步提至升95%
左右。以上是语义相似度计算模型,目前还存在许多其它优秀模型,我们会继续探索。
答案生成
拿到了我们要的候选集后,我们需要进行相关处理,可以认为这就是答案生成,或被称为后处理。答案生成会涉及到以下几个问题:
1.Ranking
如果我们的答案是有多个的,我们需要对它进行排序,常用的是Ranking算法。
2.统计转换
有时我们需要做统计转换的工作,比如说我们搜索“川普有几个孩子”,这时需要返回的是“3”而不是列表,那么你可能就需要通过统计转换,或者通过相关规则、算法实现。
3.三元组生成文本和子图生成文本
我们可以利用NLG相关的算法来生成一句话来回答问题。基于NLG和知识谱结合的三元组生成文本目前做得还不是特别好,这也是当前研究的热门领域之一。
4.业务规则引擎
业务规则引擎可以帮助我们过滤或增强,它属于业务偏好内容,每一次具体应用使用方法都有不同,很多时候是属于dirty
work,就是我们把各种规则融合起来。
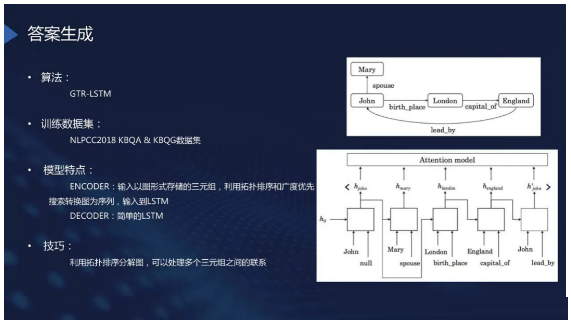
上图是其中的一种算法或者是数据集,但目前还处于探索阶段,使用效果不是特别好。可以使用NLPCC 2018
KBQA & KBQG的数据集进行训练。
举个例子,随写一个中国平安的研报,我们会给出结果,我们目前的方法是给出一个列表或可视化图表展示结果。如果在云助手或微信公众号中做问答,生成一句话或一段话效果会更好。我们需要使用三元组到TST的生成算法来实现。
举个例子
问句:沈小娟写的中国平安的研报有哪些
知识检索三元组结果:
1.沈小娟||撰写||一马当先,铸就典范
2.沈小娟||撰写||寿险转型深化,新业务价值率稳健增长
3.一马当先,铸就典范||分析||中国平安
寿险转型深化,新业务价值率稳健增长||分析||中国平安
答句:
沈小娟撰写的中国平安的研报有“一马当先,铸就典范”和“寿险转型深化,新业务价值率稳健增长”
金融知识问答系统
刚刚介绍的是整个问答系统,那么在金融行业,问答系统会如何应用呢?再给大家看个例子。
举个例子
问题是:生产口罩的上市公司有哪些?
这个问题在疫情期间非常热门,因为现在生产口罩利润非常高,这也说明相关公司值得投资。
左侧的搜索结果:在了解生产口罩的公司时,如果只用百度搜索,得到的结果并不直观,你需要大量时间去分析结果。但如果我们有效果很好的的知识图谱做知识问答,我们就能得到完全不同的结果。
右侧的搜索结果:将结果梳理成列表,还把主营产品名称都列出来。我们也可以连接金融数据库,把当前股价、市值、价格曲线展示出来,我们的结果就会非常的友好。
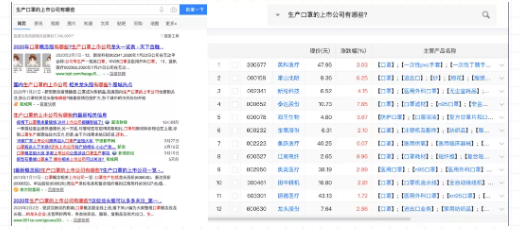
图左:搜索引擎搜索结果
图右:知识问答系统搜索结果
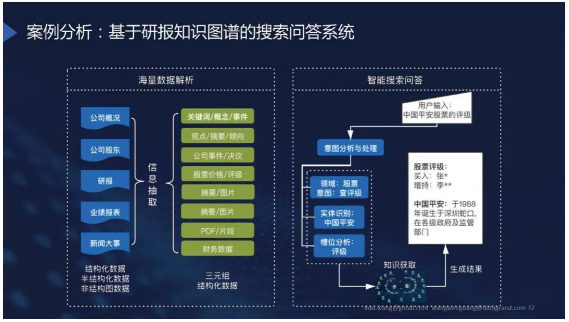
案例分析
这个项目包括两方面的内容:
一方面我们要通过研报构建知识图谱;
另一方面我们要提供友好的交互方式,帮助我们的投研人员、金融公司内部员工可以更好地使用。
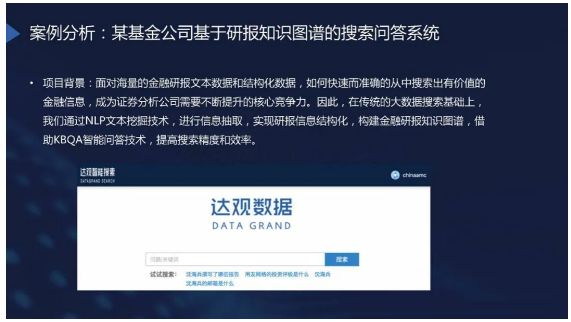
这其中会涉及到哪些内容?
左边是构建部分,技术领域属于信息收集或知识图谱构建。
右边是应用部分(智能搜索问答),它综合了基于知识图谱的问答系统和传统搜索。
如果搜索的内容不在构建好图谱中,就会触发普通搜索。
举几个例子
搜索人名时,如果他是某个研报的作者,那么我们会把对应的实体类展示出来,同时还可以展示他所写的研报。
搜索中国平安的评级时,搜索结果会从研报中抽取出来的增持、买入评级,这时可以在评级中可以看到对应的知识来源。
如果搜索问题不在构建好的图谱中,则会触发普通搜索的功能。
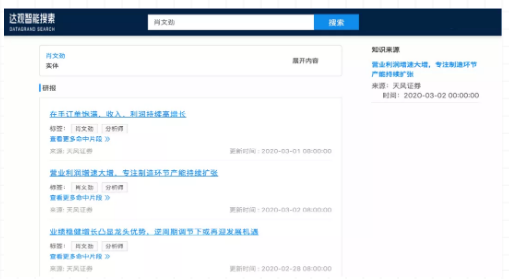
例1:搜索人名展示对应实体及所写研报
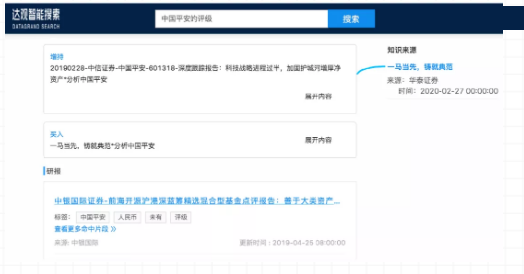
例2:搜索中国平安评级展示评级及对应知识来源
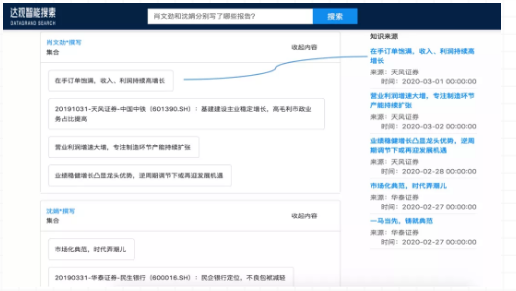
例3:普通搜索
这是一个更复杂的例子,就是我们可以搜不同的人写出来的一些例子,同样我们也会有各种各样的溯源,这个溯源在我们金融问答里面还是很重要的。下图就是一个例子,点击溯源它所获得的研究报告原文。

|









