| 编辑推荐: |
文章主要通过案例介绍了TF-IDF算法,怎么获取一篇文章中所有词的词频,计算每一个词在文本中出现的次数,计算“逆文档频率”等等。
本文来自微信公众号简言,由火龙果软件Anna编辑、推荐。 |
|
TF,是“Term Frequency”(TF)的缩写。
IDF,是“Inverse Document Frequency”(逆文档频率)的缩写。
我觉得这个算法可用于帮助译者提取一篇待译文章中的“术语”,所以准备写一篇文章来简要介绍这个算法的实现方法。我将使用百度的分词技术来处理中文文本,用以计算中文词语的“TF-IDF”值。
第一步:引入百度的分词API,获取一篇文章中所有词的词频
在本公众号之前的文章中,我们已经介绍了如何引入百度的分词API,本文就不再介绍细节了。
首先启动本地开发环境XAMPP,将百度分词API下载到工作文件夹(下图的api文件夹中):
在“index.php”中输入百度分词API引入模板,并在指定位置填写基本信息:
<?php
require_once 'api/AipNlp.php';
// 你的 APPID AK SK
const APP_ID = '你的 App ID';
const API_KEY = '你的 Api Key';
const SECRET_KEY = '你的 Secret Key';
$client = new AipNlp(APP_ID, API_KEY, SECRET_KEY);
?> |
填入API信息,并测试是否能够成功分词:
index.php
<?php
require_once 'api/AipNlp.php';
// 你的 APPID AK SK
const APP_ID = '*****';
const API_KEY = '*****';
const SECRET_KEY = '*****';
$client = new AipNlp(APP_ID, API_KEY, SECRET_KEY);
$text = "今天我们要一起来学习TF-IDF算法。";
// 调用词法分析
$result = $client->lexer($text);
var_dump($result);
?>
|
在浏览器中运行代码:

代码运行成功,API成功引入,并顺利获得分词结果。
第二步:计算每一个词在文本中出现的次数
基于上一步的分析结果,我们可以将所有的词放到一个数组中存储,如下代码:
<?php
require_once 'api/AipNlp.php';
// 你的 APPID AK SK
const APP_ID = '*****';
const API_KEY = '*****';
const SECRET_KEY = '*****';
$client = new AipNlp(APP_ID, API_KEY, SECRET_KEY);
$text = "今天我们要一起来学习TF-IDF算法。";
// 调用词法分析
$result = $client->lexer($text);
//var_dump($result);
$items = $result["items"];
$words = array();
foreach($items as $word )
{
$words[] = $word["item"];
}
var_dump($words);
?>
|
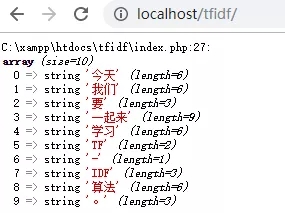
在上面的代码中,我们将所有的分词结果都放到了变量$words中,通过第27行代码查看$words中的内容,效果如下:
在PHP中有一个函数array_count_values(),可用于对数组中的所有值进行次数统计,如下代码:
index.php
<?php
require_once 'api/AipNlp.php';
// 你的 APPID AK SK
const APP_ID = '*****';
const API_KEY = '*****';
const SECRET_KEY = '*****';
$client = new AipNlp(APP_ID, API_KEY, SECRET_KEY);
$text = "今天我们要一起来学习TF-IDF算法。明天我们将一起学习术语提取。";
// 调用词法分析
$result = $client->lexer($text);
//var_dump($result);
$items = $result["items"];
$words = array();
foreach($items as $word )
{
$words[] = $word["item"];
}
var_dump(array_count_values($words));
?> |
运行效果如下:
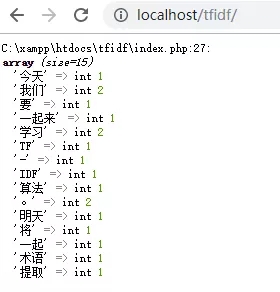
从上面的代码运行效果可以看出,在“今天我们要一起来学习TF-IDF算法。明天我们将一起学习术语提取。”这个句子中,“我们”、“学习”和“。”都各出现了2次。
根据阮一峰的文章,“考虑到文章有长短之分,为了便于不同文章的比较,进行'词频'标准化。”可使用下面的方式来计算词频:

或

我们先计算总词数:
<?php
require_once 'api/AipNlp.php';
// 你的 APPID AK SK
const APP_ID = '*****';
const API_KEY = '*****';
const SECRET_KEY = '*****';
$client = new AipNlp(APP_ID, API_KEY, SECRET_KEY);
$text = "今天我们要一起来学习TF-IDF算法。明天我们将一起学习术语提取。";
// 调用词法分析
$result = $client->lexer($text);
//var_dump($result);
$items = $result["items"];
$words = array();
foreach($items as $word )
{
$words[] = $word["item"];
}
$all_words = array_count_values($words);
$num_of_words = count($all_words);
echo $num_of_words;
?> |
这段代码运行后,浏览器中会显示:15。表明上面的这两句话中一共有15个词。(你可能会对这个结果有疑问,我们暂时先不考虑这里英文单词和标点符号带来的问题。)
有了文本的总词数和每个词在文本中出现的次数,我们就可以计算词频了。
第三步:计算“逆文档频率”
阮一峰在文章中给出的公式是:
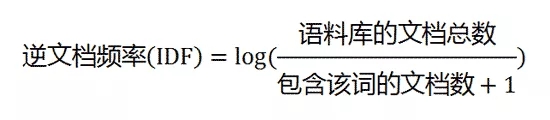
简单解释一下就是:
如果我们想知道“算法”这个词的逆文档频率,那么我们就得先有一个规模相当的语料库,这个语料库中有很多文档,有些文档里包含“算法”这个词,有些文档里不包含,那么我们就去计算包含“算法”这个词的文档总数,然后把“文档总数”和“包含该词的文档数”带入到上面的公式中,就可以了。
举个例子:
如果一个语料库中有1000篇文档,其中0篇文档中包含“算法”,那么逆文档频率就是:
log(1000/1)=3
(以上是我用计算器算出来的,不是心算的)
如果一个语料库中有1000篇文档,其中999篇文档中包含“算法”,那么逆文档频率就是:
log(1000/1000)=log1=0
如果一个语料库中有1000篇文档,其中1000篇文档中包含“算法”,那么逆文档频率就是:
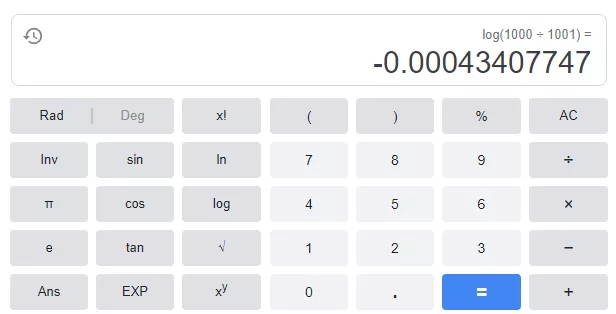
log(1000/1001)=
我们再画个图大家可能就更能直观理解“log”了:
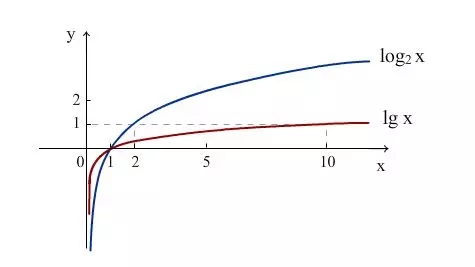
在上图的log函数中,如果x=1,那么函数值就是0
在我们上面的例子中,什么时候函数的值会接近于0呢?是当1000篇文章中每篇都包含“算法”这个词的时候,也就是说:
“如果一个词越常见,那么分母就越大,逆文档频率就越小,越接近于0。”
但是,当一个词并没有出现在语料库中时,我们又不能让分母变成0,所以在分母那里又加了一个“1”。
log函数在这里可用于衡量一个词在语料库中是否常见。
第四步:计算TF-IDF值
阮一峰的文章中讲到计算TF-IDF值的公式是:
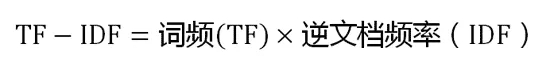
怎么理解这个公式呢?
以“算法”为例:
假如“算法”这个词在语料库的文章中,每篇文章中都有,那么它的IDF值就趋近于0。
既然IDF都等于0了,那么都不用考虑词频了,TF-IDF的值就是0了。
以“涛林韩”为例:
这个词我自己都没怎么见过,语料库中包含这个词的数据就更少了,所以IDF的值就会很大,如果在某篇待译的文本中出现次数多,两个数字一乘,那么最后算出来的TF-IDF值就会很大。
当我们把待译文本中所有词的TF-IDF值都算出来,按数量从高到低一排,最靠前的数字就是所谓的“关键词”了。(这个大家可能也会疑惑,我们暂时也不过多介绍。)
计算待译文本中每个词的词频很容易,在本文前面的几步中大家就能体会到基于百度分词几行代码就能搞定词频统计。
而逆文档频率就需要基于语料库去计算了,而且这个语料库的容量还不是什么小数目,互联网上的文章数目可是数以亿计的,所以像谷歌、百度这样的搜索引擎企业汇聚了大量的网络文章,他们来做这个事儿再合适不过了。
语料库的规模越大,逆文档频率就计算得越准确,TF-IDF的值就越有参考性。
但是,大家也能猜出这种算法的问题在哪里。我们平时做翻译,去看原文中的关键词时,可并不是光看“词频”的,而且有些词在某篇文章中是有特殊含义的,哪怕在互联网中有很多的文本都包含了这个词,但词义不一样,逆文档频率的计算结果就不一样。
话虽如此,TF-IDF算法本身产生的应用效果很强,所以很出名。 |









