| 编辑推荐: |
本文主重点介绍了无人驾驶算法首先定义极小值点,Canny 边缘检测,对障碍物判别以及相关实验结果。
本文来自于无人驾驶视界公众号,由火龙果软件Anna编辑、推荐。 |
|
O.1 引言
基于现实世界是一个三维空间,所以对计算机视觉的研究也应该是在三维空间中进行的。
在自动驾驶过程中的首要任务就是道路识别 [1] ,主要是图像特征法和模型匹配法来进行识别。 行驶过程中需要进行障碍物检测
[2] 和路标路牌识别等,此时车辆上的信息采集便可以运用单目视觉或者多目视觉。 相比之下,运用多目视觉更具优势,获取的图像信息可构建成三维空间,物体运动以及遮挡等问题对其影响较小。目前有很多智能小车的研究都是基于室内环境的研究,本文基于室外环境,采用双目摄像机模型
[3] ,考虑光照、路面材质等问题,采用分水岭算法 [4] 对智能车的区域进行定位,以及在行驶区域中采用多阈值
canny 算法来进行障碍物的检测,进而计算出障碍物大小位置等信息。
NO.2 分水岭算法
定义极小值点,本质上的意义就是定义道路和图像中其他区域的极小值点,使道路与图像中的其他区域划分开。
接着对极小值点的相邻像素按照等级进行逐级划分,等级是按照极小值点与相邻像素的距离划分的,而这里的距离是指两个像素点之间灰度值的差值。
从定义的极小值点开始逐步扩展形成集水盆。 从最小等级开始,对与集水盆相邻的像素点进行扩展。 如果当前要扩展的像素点只与一个集水盆相连,则把该点标记为相近集水盆的标记;如果当前要扩展的像素点
2个或多个集水盆相连,则把该点标记为分水线或者分水岭。 在进行扩展的过程中,只有当前等级的所有像素被划分完毕后,才能对下一个等级的像素进行划分。
NO.3 基于多阈值 canny 的障碍物检测
由于室外环境下,阴影、光照、雨水等天气原因都会对图像的拍摄造成影响,所以采用的是双目摄像头模型,可以有效地减轻外界因素对图像的干扰。
Canny 边缘检测 [5] 算法阈值的不同,会导致所获得的边缘信息不同,本文中利用 2 个不同的阈值将点分为
3 类:强边缘点、弱边缘点、弱纹理点;其中弱边缘点是利用阈值较小的算子检测,除去通过阈值较大的算子得到的强边缘点所剩下的点;剩余的其他像素点则为弱纹理点。
再根据各点特征分配匹配窗口大小,强边缘点主要是位于边界和视差不连续点,其支持窗口应该越小越好;而弱纹理点周围的梯度变化不明显,窗口应足够大,包含更多的图像信息进来;而弱边缘点特征介于强边缘点与弱纹理点之间,处于
2 个以上的弱纹理交界处,兼有边缘与弱纹理的特征,所以窗口介于两者之间。 在本文算法中,强边缘点分配的是
1 ×3 窗口,弱边缘点分配的是 5 ×5 窗口,弱纹理点分配的是 11 ×11 窗口。
分配好所有点的窗口大小后,则需要进行最关键的一步———立体匹配 [6] 。 本文采用的是SAD 来作为匹配测度函数,如式(1)。
算法中假设以右图为参考图,令为匹配测度,d 为滑动窗口位移量,Wr 为匹配窗口,Ir (x,y)和
Ii(x+d,y) 分别为左图和右图中匹配窗口中心像素的灰度值。
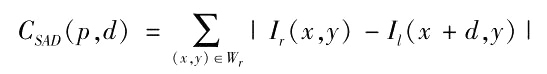
最后可得到一幅初始视差图,图像的灰度深浅即表示了前方物体离摄像机的远近。
NO.4 障碍物判别
在得到初始视差图后,需要进一步判别障碍物的远近及大小,所以这里引入 V-视差和 U-视差理论 [7]
。 V-视差图是在初始视差图的基础上,累加视差图像每一行上具有相同视差值 dv 的像素个数,以像素的个数作为像素坐标(dv,y)的灰度值,为
0 到 255。 V-视差图的高度与原图像是相同的,但是宽度只有 256 [8] 。 同理,U-视差图是累加视差图像每一列上具有相同视差值
du 的像素个数,高度为 256。
根据 V-视差图的原理,每一行中的视差值相同点的个数会被投影成一条直线,所以在 V-视差图中路面是一条斜线,障碍物是一条看似与斜线垂直的线段,可以通过该线段求出障碍物的高度
。 同理,可通过 U-视差图计算出障碍物的宽度。 根据初始视差图中包含的视差值,由式(2)可以计算出每个障碍物的距离,其中摄像机的焦距
f 和 2 个摄像机基线距离 b 均是固定并且是已知的。
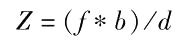
NO.5实验结果
5. 1 道路识别结果该算法
基于 VC 平台实现的,输入的图片是由摄像机所拍摄的普通道路图片,实验结果如图1
所示。

5. 2 障碍物检测结果
输入的原始图片是由双目摄像机所拍摄的左右图像(图 2)。

实验采用的是平行的摄像机模型,以右摄像机拍摄的图像为参考图像进行 Canny 边缘检测。 图 3为对参考图像进行不同阈值的边缘检测。

在求得每个点的最佳视差值之后,用该点的视差值来表示该点的像素值,形成图像的初始视差图,并且进行中值滤波后期处理,效果如图
4。

得到的初始视差图,利用 V-视差图和 U-视差图后根据图中信息计算障碍物的大小与位置。 输入 V-视差图和
U-视差图后,分别计算出了高度和宽度。 如图 5 所示。
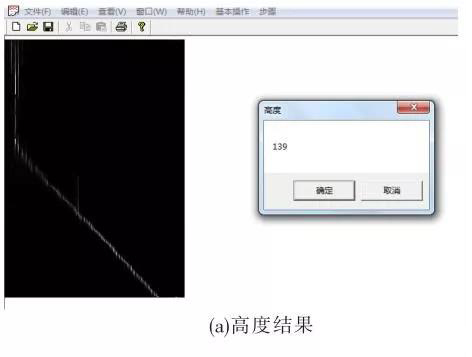
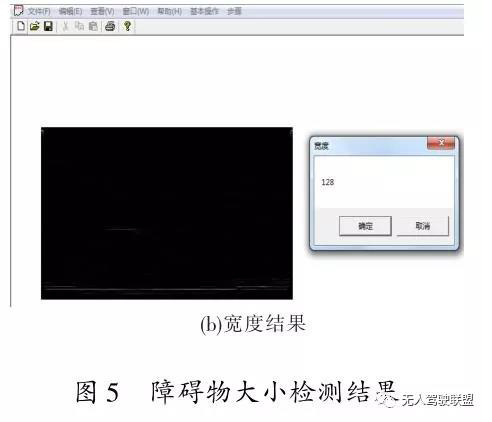
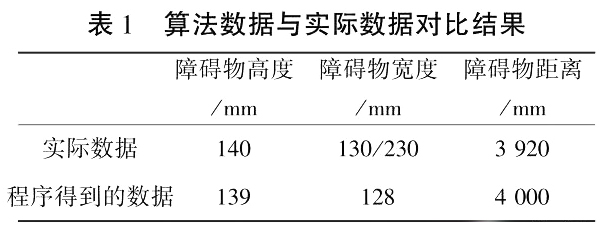
实验中摄像机的焦距 30 mm,摄像机之间的基线距离为 200 mm,即可计算出障碍物所在位置离摄像机的距离。
算法数据与实际数据对比结果如表 1 所示。
NO.6 总结
本论文中主要研究了基于双目视觉的自动驾驶,包括了道路识别算法、基于多阈值 Canny 的障碍物检测和判别。
算法的处理效果比较理想,运行处理速度在背景复杂的情况下偏慢。 研究了基于双目视觉的自动驾驶中障碍物识别问题。
该算法实验效果较好,但由于水平方向的信息较少使得障碍物的宽度检测结果存在一些误差。
|









