| 编辑推荐: |
本文主要介绍了什么是感知器以及如何使用TensorFlow库实现它. 希望对您的学习有所帮助。
本文来自人户智能学习网,由火龙果软件Alice编辑、推荐。 |
|
介绍
因为你知道感知器是创建深层神经网络的基本构件,因此,很明显,我们应该从感知器开始掌握深层学习的旅程,并学习如何使用TensorFlow来实现它来解决不同的问题。如果你对深度学习还不太熟悉,我建议你浏览一下这个深度学习教程系列的前一篇博客,以避免任何困惑。以下是本博客中关于感知器学习算法的主题:
感知器作为线性分类器使用TensorFlow库实现感知器声纳数据分类使用单层感知器分类问题类型
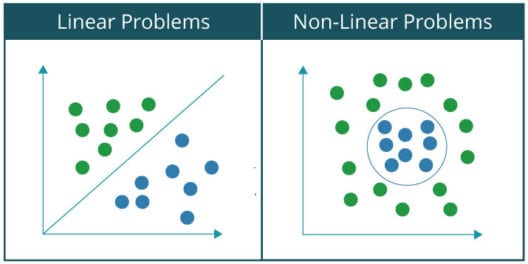
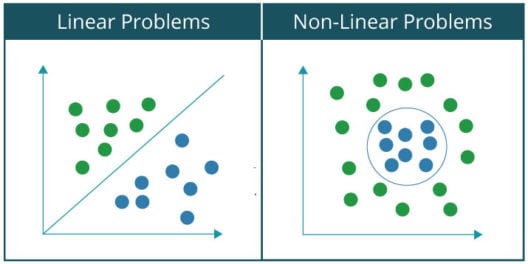
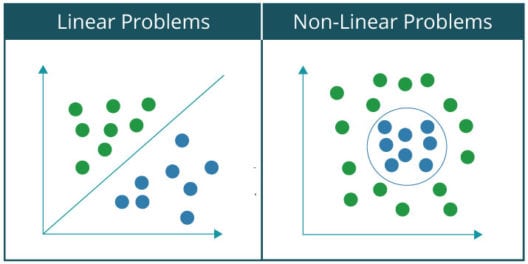
可以对各种分类问题进行分类可以用神经网络分为两大类:
线性可分问题非线性可分问题
基本上,如果你能用一条线把数据集分为两类或两类,那么一个问题就称为线性可分问题。例如,把猫和一群猫狗分开。相反,在一个非线性可分问题中,数据集包含多个类,需要非线性线将它们分离到各自的类中。例如,手写数字的分类。让我们通过绘制线性可分问题和非线性问题数据集的图形来直观地看到两者之间的区别:,因为大家都熟悉和Gates,我将用它作为一个例子来解释感知器如何作为线性分类器工作。
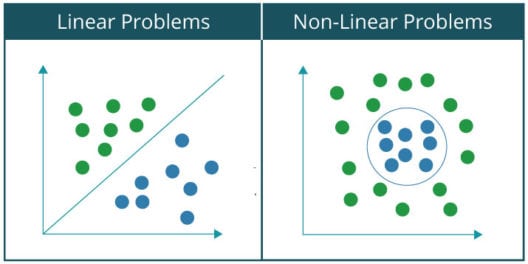
注意:当您着手处理更复杂的问题时,例如我在上一篇博客中简要介绍了图像识别技术,由于要捕获的数据中的关系变得高度非线性,因此需要一个由多个人工神经元组成的网络,称为人工神经网络。
感知器as和Gate ,如你所知,在所有其他情况下,如果输入都是1和0,Gate会产生1的输出。因此,感知器可以用作分隔符或决定线,将输入集和门分成两类:
类1:输出为0的输入位于决定线以下。
第2类:输出为1的输入,位于决定线或分隔符之上。下图显示了使用感知器对输入和门进行分类的上述想法:
到目前为止,您已经了解到线性感知器可用于将输入数据集分类为两类。但是,它实际上是如何对数据进行分类的呢?
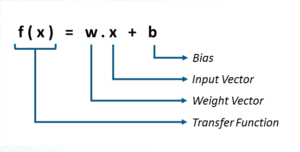
在数学上,可以将感知器表示为权重、输入和偏差(垂直偏移)的函数: 感知器接收到的每个输入都已根据其对获得最终输出的贡献量进行了加权。偏差允许我们移动决策线,以便它能够最好地分离输入分为两类。
理论够了,让我们看看这个博客上的第一个关于感知器学习算法的例子,在这里我将从头开始使用感知器实现和门。
感知器学习算法:实现和门1。导入所有必需的库
我将从导入所有必需的库开始。在这种情况下,我只需要导入一个库,即TensorFlow:
#导入所需库将tensorflow导入为tf2。
为输入和输出 定义矢量变量现在,我将为我的感知器 创建用于存储输入、输出和偏差的变量#输入1、输入2和偏置列车进站=[[1.,1.,1],[1,0,1],[0,1.,1],[0,0,1]]#输出列车开出=[[1.],[0],[0],[0]]
定义权重变量 现在,我需要定义权重变量并在开始时为其分配一些随机值。因为这里有三个输入(输入1、输入2和偏差),所以我需要为每个输入指定三个权重值。因此,我将为我们的权重定义一个形状为3×1的张量变量,它将用随机值初始化:
#使用random_normal()用随机值初始化的权重变量w=tf.Variable(tf.random_normal([3,1],seed=12))
注:在TensorFlow中,变量是处理随学习过程而更新的不断变化的神经网络权重的唯一方法。
在TensorFlow中定义输入和输出 的占位符,可以指定可以在运行时接受外部输入的占位符。所以,我将定义两个占位符–x表示输入,y表示输出。稍后,您将了解如何将输入馈送给占位符。
#输入和输出占位符x=tf.placeholder(tf.float32,[无,3])y=tf.placeholder(tf.float32,[无,1])5个。如前所述,计算输出和激活函数
,首先将感知器接收到的输入乘以相应的权重,然后将所有这些加权输入相加。然后,这个总和值被输入到activation以获得最终结果,如下图所示,后面跟着代码:
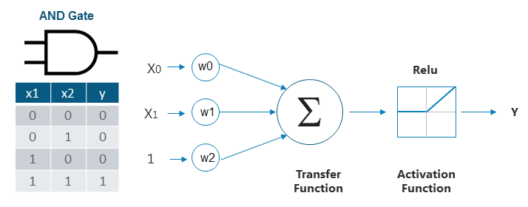
#计算输出输出=tf.nn.relu(tf.matmul(x,w))
注意:在这种情况下,我使用relu作为我的激活函数。其他重要的激活功能将被介绍,因为你继续在这个博客感知器神经网络。
计算成本或误差
现在,我需要计算误差值w.r.t感知器输出和期望输出。一般来说,这个误差被计算为均方误差,即感知器输出与期望输出之差的平方,如下所示:
#均方损失或误差损失=tf.减少和(tf.平方(输出-y))7号。
最小化错误 TensorFlow提供了优化器,可以缓慢地更改每个变量(权重和偏差),以便在连续迭代中最小化损失。最简单的优化器是梯度下降,我将在本例中使用它。
#使用学习率为0.01的GradientDescentOptimizer将损失最小化优化器=tf.train.gradientdescentominizer(0.01)列车=优化器。最小化(损失)8个。初始化调用tf.Variable时未初始化所有变量
变量。因此,我需要使用以下代码显式初始化TensorFlow程序中的所有变量: #初始化所有全局变量init=tf.global_variables_initializer()sess=tf.Session()sess.run(初始化)
在迭代中训练感知器现在,我需要训练感知器,即在连续迭代中更新权值和偏差值,以最小化误差或损失。在这里,我将在1000个时代训练我们的感知器。
#计算输入向量的输出和成本w.r.t运行(train,{x:train,y:train,out})cost=sess.run(丢失,feed_dict={x:train_in,y:train_out})打印('Epoch--',i,'--loss--',cost)上面代码中的
,您可以观察我是如何将train-in(和Gate的输入集)和train-out(和Gate的输出集)分别输入占位符x和y,使用feed-dict计算成本或误差。
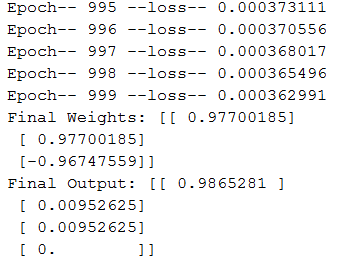
输出: 以下是我的感知器模型经过训练后获得的最终输出:
激活函数 如前所述,激活函数应用于感知器的输出,如下图所示:
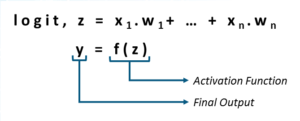
在前一示例中,我已经向您展示了如何使用带有relu激活函数的线性感知器对和门的输入集执行线性分类。但是,如果您希望执行的分类本质上是非线性的,该怎么办。在这种情况下,您将使用一个非线性激活函数。一些突出的非线性激活函数如下所示:
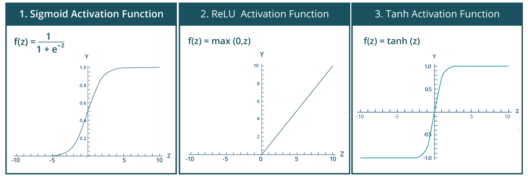
TensorFlow库提供了应用激活函数的内置函数。上述激活函数的内置函数w.r.t.如下所示:
tf.sigmoid(x,name=None)按x元素的顺序计算x元素的sigmoid,sigmoid按-y=1/(1
exp(-x))tf.nn.relu(features,name=None)按-max(features,0)tf.tanh(x,name=None)计算x元素
的双曲正切到目前为止,您已经了解了感知器的工作原理以及如何使用TensorFlow对其进行编程。所以,现在是时候前进并应用我们对感知器的理解来解决一个关于声纳数据分类的有趣的用例了。
声纳数据分类使用单层感知器
在这个用例中,我得到了一个声纳数据集,其中包含了通过反射声纳信号获得的关于208个模式的数据在不同的角度和条件下从金属圆筒(水雷)和岩石中取出。现在,如你所知,海军水雷是一种放置在水中的独立爆炸装置,用于损坏或摧毁水面舰艇或潜艇。因此,我们的目标是建立一个模型,根据我们的数据集来预测目标是水雷还是岩石。

现在,让我们来看看我们的声纳数据集:

整个基本程序与与门的基本程序相同,差异不大,为避免混淆,将对其进行讨论。让我向您介绍使用单层感知器对声纳数据集执行线性分类的所有步骤:
既然您对本用例中涉及的所有步骤都有了很好的了解,那么让我们继续使用TensorFlow对模型进行编程:
导入所有需要的库:
首先,我将从下面列出的所有需要的库开始:
matplotlib库:它提供了绘制图形的功能。tensorflow库:提供实现深度学习模型的功能;pandas、numpy和sklearn库:提供数据预处理功能。读取并预处理数据集:
在前面的示例中,我定义了输入和输出变量w.r.t.和Gate,并显式地为其分配了所需的值。但是,在像SONAR这样的实际用例中,我们将为您提供需要读取和预处理的原始数据集,以便您可以围绕它训练模型。
首先,我将使用read_CSV()函数读取CSV文件(输入数据集),然后,我将把特征列(自变量)和输出列(因变量)分别分离为X和y。输出列由字符串分类值“M”和“R”组成,分别表示Rock和Mine。因此,我将它们标记为0和1
w.r.t.“M”和“r”在将这些分类值转换为整数标签后,我将使用下一步讨论的一个“hot_encode()函数”应用一个热编码#读取声纳数据集df=pd.read_csv(“sonar.csv”)打印(len(df.columns))X=df[df.列[0:60].值y=df[df.列[60]]#对因变量进行编码,因为它有两个分类值编码器=标签编码器()编码器配合(y)y=编码器。变换(y)Y=一个热编码(Y)三。
一个热编码器的功能: 一个热编码器根据列中的标签数量添加额外的列。在本例中,我有两个标签0和1(用于Rock和Mine)。因此,将为每个分类值添加两个额外的列,如下图所示:
#应用一个热编码器的功能定义一个热编码(标签):núu labels=len(标签)n_unique_labels=len(np.unique(labels))one_hot_encode=np.zeros((n_labels,n_unique_labels))一个热编码[np.arange(n_labels),labels]=1返回一个热编码四。将数据集划分为训练和测试子集
在处理任何深度学习项目时,您需要将数据集划分为两部分,其中一部分用于训练深度学习模型,另一部分用于在模型经过训练后对其进行验证。因此,在这一步中,我还将数据集划分为两个子集:
训练子集:它用于训练模型测试子集:它用于验证我们训练的模型
我将使用sklearn库中的train_Test_split()函数来划分数据集:
#训练测试子集中的数据划分十、 Y=随机播放(X,Y,random_state=1)列车x,试验x,列车y,试验y=列车y分离(x,y,试验尺寸=0.20,随机状态=42)5个。在这里定义变量和占位符
,我将为以下实体定义变量: 学习率:权重调整的量。训练阶段:迭代成本历史的次数:在连续阶段中存储成本值的数组。
Weight:用于存储权重值的张量变量Bias:用于存储偏移值 的张量变量除了变量外,我还需要可以接受输入的占位符。因此,我将为我的输入创建占位符,并在稍后将数据集提供给它。
最后,我将调用global_variable_initializer()来初始化所有变量。
#定义所有变量以使用张量学习率=0.1训练阶段=1000成本历史=np.empty(shape=[1],dtype=float)n?dim=X.形状[1]n_类=2x=tf.placeholder(tf.float32,[无,n_dim])W=tf.Variable(tf.zeros([n_dim,n_class]))b=tf.Variable(tf.zeros([n_类])6。计算成本或误差
类似和门实现,我将计算成本或误差产生的模型。在这种情况下,我将使用交叉熵来计算误差,而不是均方误差。
y_u=tf.placeholder(tf.float32,[无,n_类])y=tf.nn.softmax(tf.matmul(x,W)
b)成本函数=tf.reduce_mean(-tf.reduce_sum((y_uxtf.log(y)),reduce_index=[1]))training_step=tf.train.GradientDescentOptimizer(学习率).minimize(成本函数)7号。现在,我将在连续的时间段内训练感知器模型
,我将在连续的时间段内训练我的模型。在每一个时期,成本都是计算出来的,然后,优化器根据这个成本修改权重和偏差变量,以使误差最小化。
#最小化每个时代的成本对于射程中的历元(训练历元):sess.run(训练步骤,feed
dict={x:train,y:train)cost=sess.run(cost_函数,feed_dict={x:train_x,y_u:train_y})成本历史=np.append(成本历史,成本)打印(“epoch:”,epoch,“-”,“cost:”,cost)8个。基于测试子集
的模型验证如前所述,基于测试子集计算训练模型的精度。因此,首先,我将把测试子集提供给我的模型并获得输出(标签)。
然后,我将从模型中获得的输出与实际或期望的输出进行比较,最后,将以正确预测占测试子集上总预测的百分比来计算精度。
#在测试子集上运行训练模型pred_y=sess.run(y,feed_dict={x:test_x})#计算正确的预测正确预测=tf.equal(tf.argmax(pred_y,1),tf.argmax(test_y,1))准确度=tf.reduce_mean(tf.cast(正确预测,tf.float32))打印(精度:&;amp;quot;,sess.run(精度))输出:
以下是训练完成后您将得到的输出:
如您所见,我们得到了83.34%的精度,足够下降。现在,让我们通过绘制一张成本与历次次数的关系图来观察如何在连续历次中降低成本或误差:
使用单层感知器 的声纳数据分类完整代码#导入所需的库将matplotlib.pyplot导入为plt将tensorflow导入为tf将numpy导入为np导入熊猫作为pd从sklearn.preprocessing导入LabelEncoder从sklearn.utils导入shuffle来自sklearn.model_selection
import train_test_split#定义一个热编码函数定义一个热编码(标签):núu labels=len(标签)n_unique_labels=len(np.unique(labels))one_hot_encode=np.zeros((n_labels,n_unique_labels))一个热编码[np.arange(n_labels),labels]=1返回一个热编码#读取声纳数据集df=pd.read_csv(&;amp;quot;sonar.csv&;amp;quot;)打印(len(df.columns))X=df[df.列[0:60].值y=df[df.列[60]]#编码包含分类值的因变量编码器=标签编码器()编码器配合(y)y=编码器。变换(y)Y=一个热编码(Y)#训练和测试中的数据转换十、
Y=随机播放(X,Y,random_state=1)列车x,试验x,列车y,试验y=列车y分离(x,y,试验尺寸=0.20,随机状态=42)#定义并初始化变量以使用张量学习率=0.1训练阶段=1000#存储每个历元中获得的成本的数组成本历史=np.empty(shape=[1],dtype=float)n?dim=X.形状[1]n_类=2x=tf.placeholder(tf.float32,[无,n_dim])W=tf.Variable(tf.zeros([n_dim,n_class]))b=tf.Variable(tf.zeros([n_类])#初始化所有变量。init=tf.global_variables_initializer()#定义成本函数y_u=tf.placeholder(tf.float32,[无,n_类])y=tf.nn.softmax(tf.matmul(x,W)
b)成本函数=tf.reduce_mean(-tf.reduce_sum((y_uxtf.log(y)),reduce_index=[1]))training_step=tf.train.GradientDescentOptimizer(学习率).minimize(成本函数)#初始化会话sess=tf.Session()sess.run(初始化)mse_history=[]#计算每个历元的成本对于射程中的历元(训练历元):sess.run(训练步骤,feed
dict={x:train,y:train)cost=sess.run(cost_函数,feed_dict={x:train_x,y_u:train_y})成本历史=np.append(成本历史,成本)打印(“epoch:”,epoch,“-”,“cost:”,cost)pred_y=sess.run(y,feed_dict={x:test_x})#计算精度正确预测=tf.equal(tf.argmax(pred_y,1),tf.argmax(test_y,1))准确度=tf.reduce_mean(tf.cast(正确预测,tf.float32))打印(精度:&;amp;quot;,sess.run(精度))plt.plot(范围(len(成本历史)),成本历史)plt.axis([0,培训阶段,0,np.max(成本历史)]节目表()
结论
在这个关于感知器学习算法的博客中,您了解了什么是感知器以及如何使用TensorFlow库实现它。您还了解了如何将感知器用作线性分类器,我演示了如何使用这个事实来实现感知器并使用感知器进行选通。最后,我向前迈出了一步,并应用感知器解决了一个实时用例,在这个用例中,我对声纳数据集进行分类,以检测岩石和矿井之间的差异。
|









