| 编辑推荐: |
本文主要介绍了从输入URL到Web页面呈现的全过程。 希望对您的学习有所帮助。
本文来自于博客园,由火龙果软件Linda编辑、推荐。 |
|
当用户在浏览器的地址栏中输入 URL 并点击回车后,页面是如何呈现的。
简单来说,当用户在浏览器的地址栏中输入 URL 并点击回车后,浏览器从服务端获取资源,然后将内容显示在页面上。这个过程经过了:浏览器缓存
-> DNS 域名解析 -> URL 编码 -> 使用 HTTP 或者使用 HTTPS
协议发送请求 ->
对于访问静态资源的 HTTP 请求:CDN -> CDN 回源到对象存储 OSS 或者源服务器
对于访问动态资源的 HTTP 请求:负载均衡器 Nginx -> 应用服务器【API 网关(Zuul、GateWay
等)-> 内部服务(微服务,Controller、Service、DAO)】-> 缓存系统(Redis、EhCache
等) -> 存储系统(MySQL、PostgreSQL、MongoDB 等)
为了减少响应时间,整个过程中的几乎每一个环节都会有缓存。
为了提高系统的可用性、性能,整个过程中的很多环节都需要部署多节点。
浏览器
当用户在浏览器的地址栏中输入 URL 并点击回车后,首先由浏览器进行处理。
浏览器缓存
当用户在浏览器的地址栏中输入 URL 并点击回车后,浏览器会查看自己是否缓存了该资源。
如果浏览器缓存了该资源,并且缓存未过期,那么直接从缓存中获取资源,不向服务端发送请求(命中强缓存)。
如果浏览器缓存了该资源,但是缓存已经过期了,那么浏览器向服务端发送条件请求。服务端会根据条件请求首部字段(If-Match、If-Modified-Since
等)来判断是否命中协商缓存。
如果命中了协商缓存,那么服务端会返回 304 状态码(Not Modified),而不返回浏览器请求的资源。告诉浏览器可以直接用浏览器缓存中的资源。
如果没有命中协商缓存,那么服务器返回浏览器请求的资源。
DNS 域名解析
当用户在浏览器的地址栏中输入 URL 并点击回车后,浏览器要判断 URL 中的是 IP 地址,还是域名。如果
URL 中的是域名,那么首先要做的就是域名解析。
域名解析的过程:首先是浏览器查看浏览器的缓存。如果浏览器中没有该域名的缓存,那么浏览器询问【本地
DNS 解析器】,【本地 DNS 解析器】首先查看本地 DNS 缓存。如果本地 DNS 缓存中没有该域名的缓存,那么【本地
DNS 解析器】请求【本地 DNS 服务器】进行域名解析。如果【本地 DNS 服务器】中没有该域名的缓存,那么【本地
DNS 服务器】向 DNS 系统中的其他远程 DNS 服务器发送查询请求。
如果域名解析失败,浏览器会展示一个报错页面,提示域名不存在。
如果域名解析成功,浏览器就获取到一个域名对应的 IP 地址。
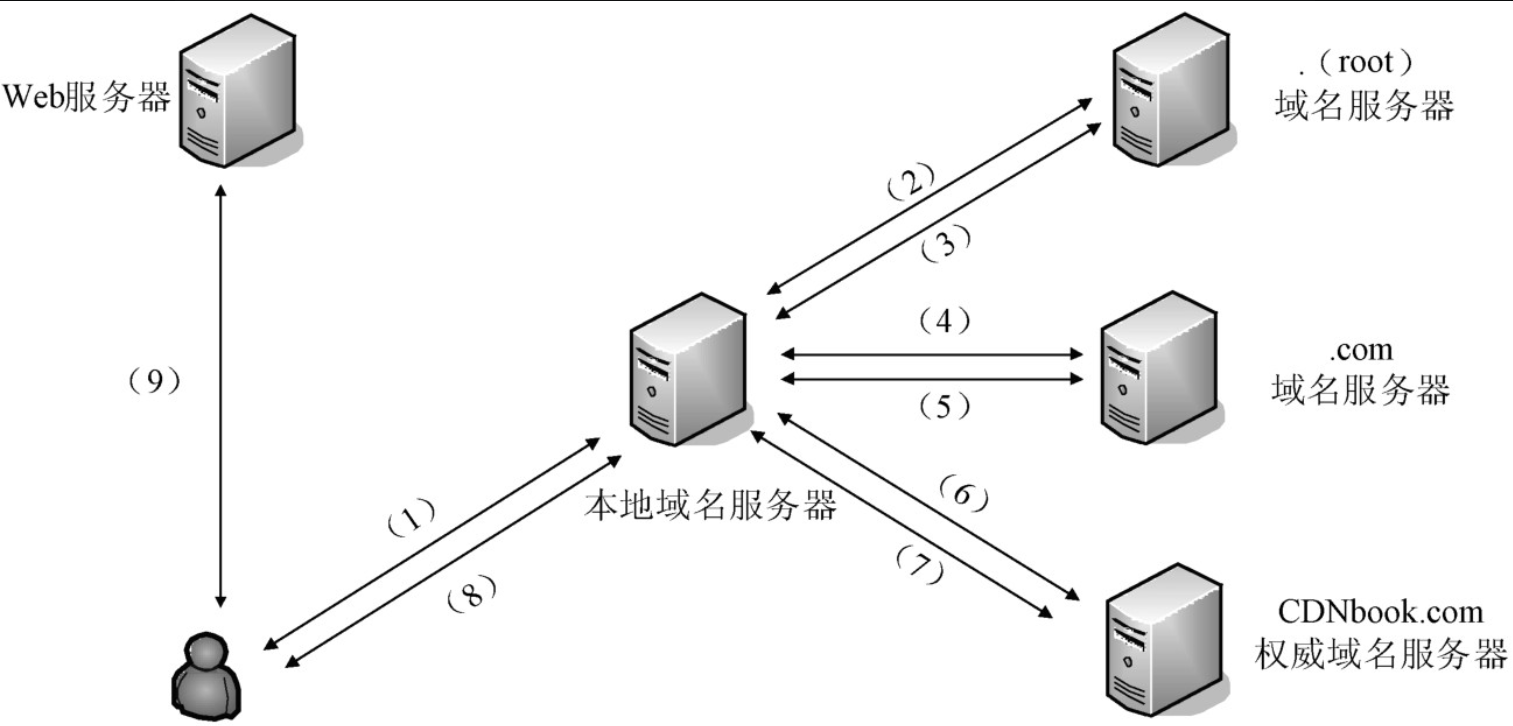
以【本地 DNS 解析器】请求【本地 DNS 服务器】进行 www.CDNbook.com 域名的解析为例:
(1)【本地 DNS 解析器】向【本地 DNS 服务器】发送域名解析请求。(8)【本地 DNS 解析器】收到来自【本地
DNS 服务器】的应答。
(2)【本地 DNS 服务器】向【根 DNS 服务器】发送域名解析请求,【根 DNS 服务器】返回
.com 顶级域的域名服务器列表(多条 NS 记录)。
(4)【本地 DNS 服务器】收到应答后,在 .com 顶级域的域名服务器列表中选择一个 IP 地址,向这个
IP 地址对应的 DNS 服务器发送域名解析请求,.com 顶级域的域名服务器返回 CDNbook.com
域的域名服务器列表。
(6)【本地 DNS 服务器】收到应答后,在 CDNbook.com 域的域名服务器列表中选择一个
IP 地址,向这个 IP 地址对应的 DNS 服务器发送域名解析请求,CDNbook.com 域的域名服务器返回
www.CDNbook.com 域的 A 记录列表(多个 IP 地址)。
(8)【本地 DNS 服务器】收到应答后,在 www.CDNbook.com 域的 A 记录列表中选择一个
IP 地址,将该 IP 地址返回给【本地 DNS 解析器】。
(9)浏览器获取到域名对应的 IP 地址,这个 IP 地址可能是 CDN 服务器的 IP 地址,也可能是源服务器的
IP 地址。无论是什么服务器的 IP 地址,浏览器都会向这个服务器发送请求,服务器将用户请求的内容返回给浏览器。
URL 编码
URL 编码也被称为百分号编码。
URL 编码的作用是:在 URL 中,使用 “安全的字符”(允许出现的字符、无歧义的字符) 替换
“不安全的字符”(不允许出现的字符、有歧义的字符)
将 “非 ASCII 字符” 编码为 “ASCII 字符”,便于在 URL 中传输非 ASCII
字符。(URL 中只能出现 ASCII 字符,不能出现非 ASCII 字符)
将 “空格” 编码为 “%20”,便于在 URL 中传输空格。(URL 中不能出现空格)
将 “没有表示特殊含义的保留字符” 进行 URL 编码。(URL 中多个查询参数之间用 &
符号分隔。如果参数值中包含了 & 字符,那么会对 URL 解析造成影响,因此需要对造成歧义的
& 符号进行编码)
URL 编码的规则:简单来说,如果需要对一个字符进行 URL 编码,首先需要判断该字符是否是 ASCII
字符:
如果一个字符是 ASCII 字符,那么对该字符进行 URL 编码,首先需要把该字符的 ASCII
的值表示为两个 16 进制的数字,然后在其前面放置转义字符 %,就得到了该字符的 URL 编码结果。
如果一个字符是非 ASCII 字符,那么对该字符进行 URL 编码,首先需要使用指定的字符编码方式(建议使用
UTF-8 字符编码),将 “非 ASCII 字符” 编码为字节序列(字节序列即二进制数据);然后对其字节序列进行
URL 编码。URL 编码 “二进制数据”,首先需要把 “二进制数据” 表示为 8 位组的序列,将每个
8 位组表示为两个 16 进制的数字,然后在其前面放置转义字符 %,就得到了 “二进制数据” 的 URL
编码结果。
HTTPS 通信
浏览器使用 HTTP 或者使用 HTTPS 协议和服务器通信。
使用 HTTPS 协议通信,通信的双方会先建立 TCP 连接,然后执行 TLS 握手,之后就可以在安全的通信环境里发送
HTTP 报文了。
TCP 握手 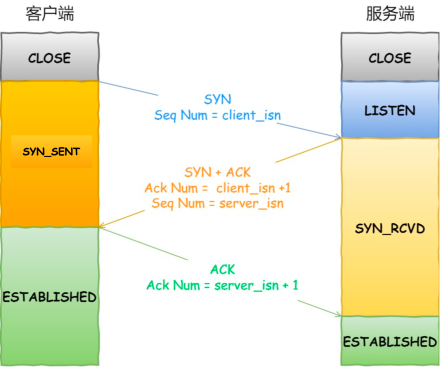
一开始,客户端和服务端都处于 close 状态。
先是服务端监听某个端口,此时服务端处于 listen 状态。
这个时候客户端就可以发送连接请求报文了。
第一次握手
客户端会主动发送连接请求报文,随机初始化序列号为 x,并把 SYN 标志位设置为 1,表示 SYN
报文。
客户端发送 SYN 报文后,客户端进入 syn_sent 状态。
第二次握手
服务端收到 SYN 报文后,服务端会发送 SYN-ACK 报文,用于对客户端发送的 SYN 报文进行应答。
服务端会随机初始化序列号为 y,确认序列号设置为 x + 1,并把 SYN 标志位、ACK 标志位设置为
1。
服务端发送 SYN-ACK 报文后,服务端进入 syn_receive 状态。
第三次握手
客户端收到 SYN-ACK 报文后,客户端会发送 ACK 报文,用于对服务端发送的报文进行应答。
客户端会将序列号设置为 x + 1,确认序列号设置为 y + 1,ACK 标志位设置为 1。
客户端发送 ACK 报文后,客户端处于 established 状态。
当服务端收到 ACK 报文后,服务端进入 established 状态。
此时 TCP 连接就建立完成了,客户端和服务端就可以相互发送数据了。
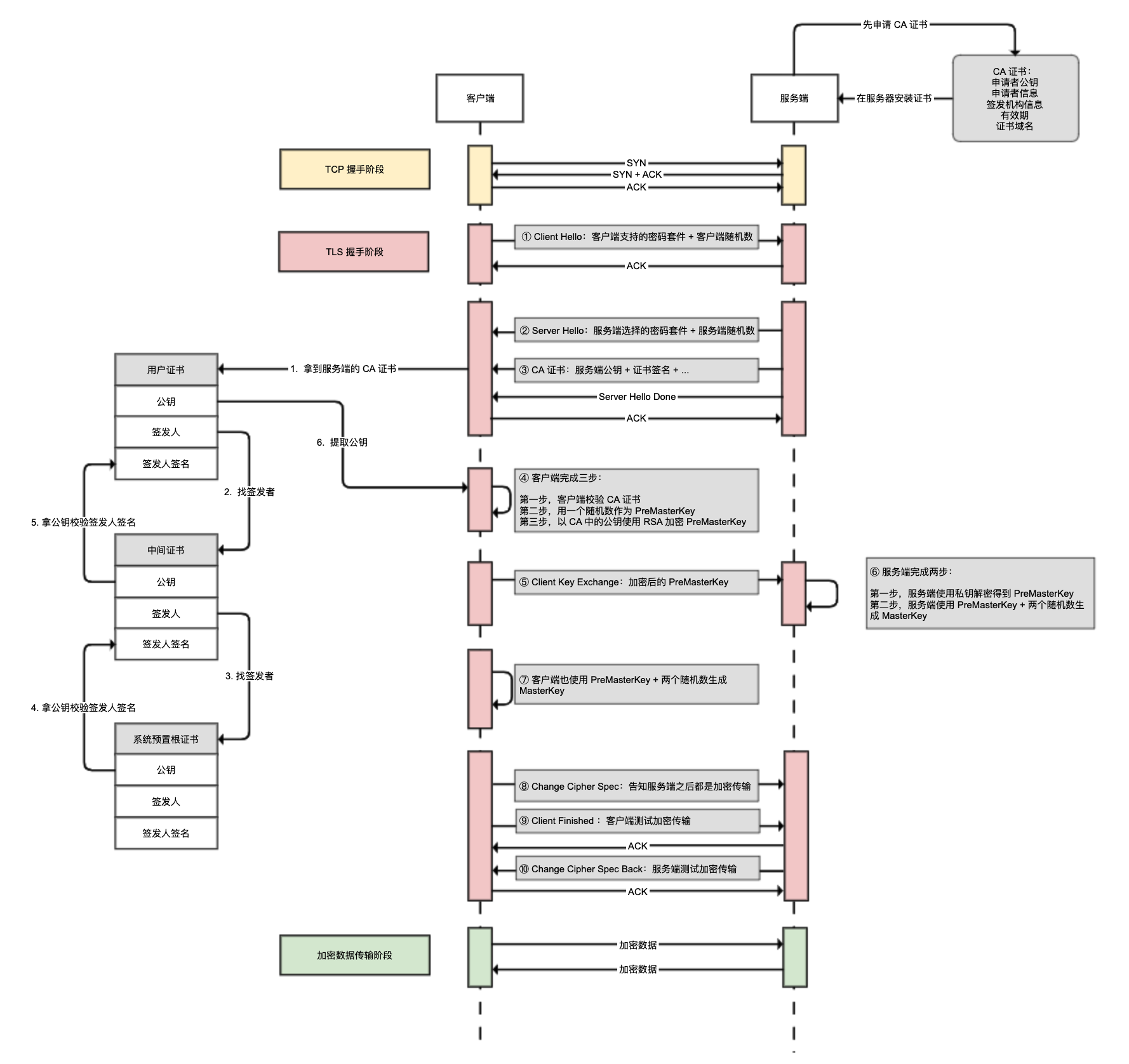
TLS 握手
TLS 握手过程的简要描述:通信的双方在 TLS 握手的过程中协商 TLS 的版本号、密码套件,交换随机数、数字证书和密钥参数,最终通信的双方协商得到会话密钥。("Hello"
消息交换随机数,"Key Exchange" 消息交换 "Pre Master
Secret")
浏览器给服务器发送 "Client Hello" 消息,服务器给浏览器发送 "Server
Hello" 消息。通信的双方协商 TLS 的版本号、密码套件,并交换随机数。
交换数字证书:服务器为了向浏览器证明自己的身份,服务器给浏览器发送 "server Certificate"
消息,以发送数字证书链,其中包含了两个证书。一个是 CA 机构颁发的数字证书,另一个是 CA 机构的数字证书。
服务器给浏览器发送 "Server Key Exchange" 消息,浏览器给服务器发送
"Client Key Exchange" 消息。通信的双方交换密钥参数(Client
Params 和 Server Params),然后通信的双方就用 ECDHE 算法算出 "Pre
Master Secret"。
通信的双方根据自己已知的参数(Client Random、Server Random 和 Pre Master
Secret)算出主密钥 "Master Secret",并使用主密钥拓展出更多的密钥(会话密钥),避免只用一个密钥带来的安全隐患。
浏览器给服务器发送 "Change Cipher Spec" 消息,服务器也给浏览器发送
"Change Cipher Spec" 消息。告诉对方:后续传输的都是对称密钥加密的密文。
浏览器给服务器发送 "Finished" 消息,服务器也给浏览器发送 "Finished"
消息。通信的双方把之前发送的数据做个摘要,再用对称密钥加密一下,让对方做个验证。
双方都验证成功,握手正式结束,之后就可以正常收发被加密的 HTTP 请求和响应了。 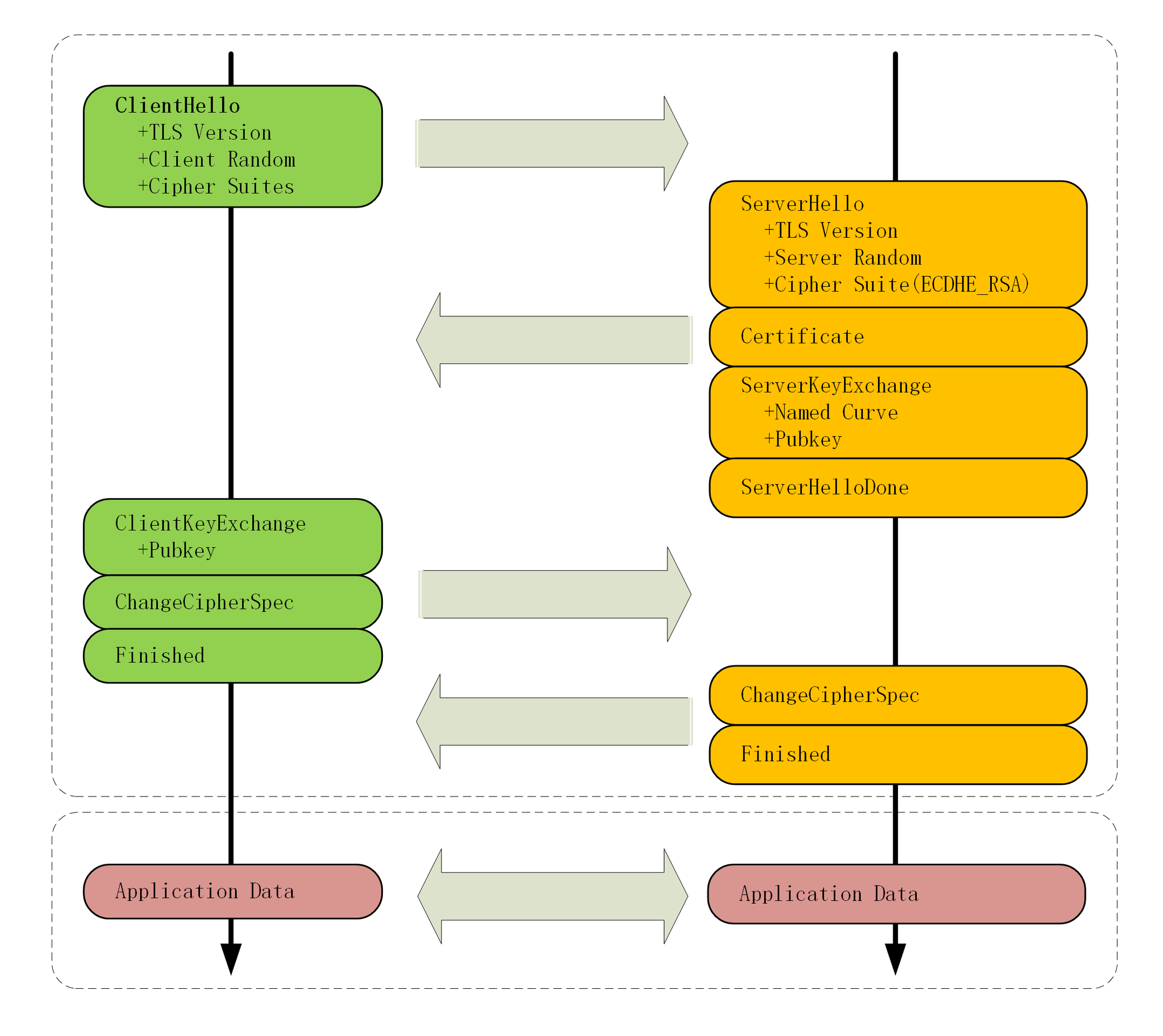
TCP / IP 模型的通信 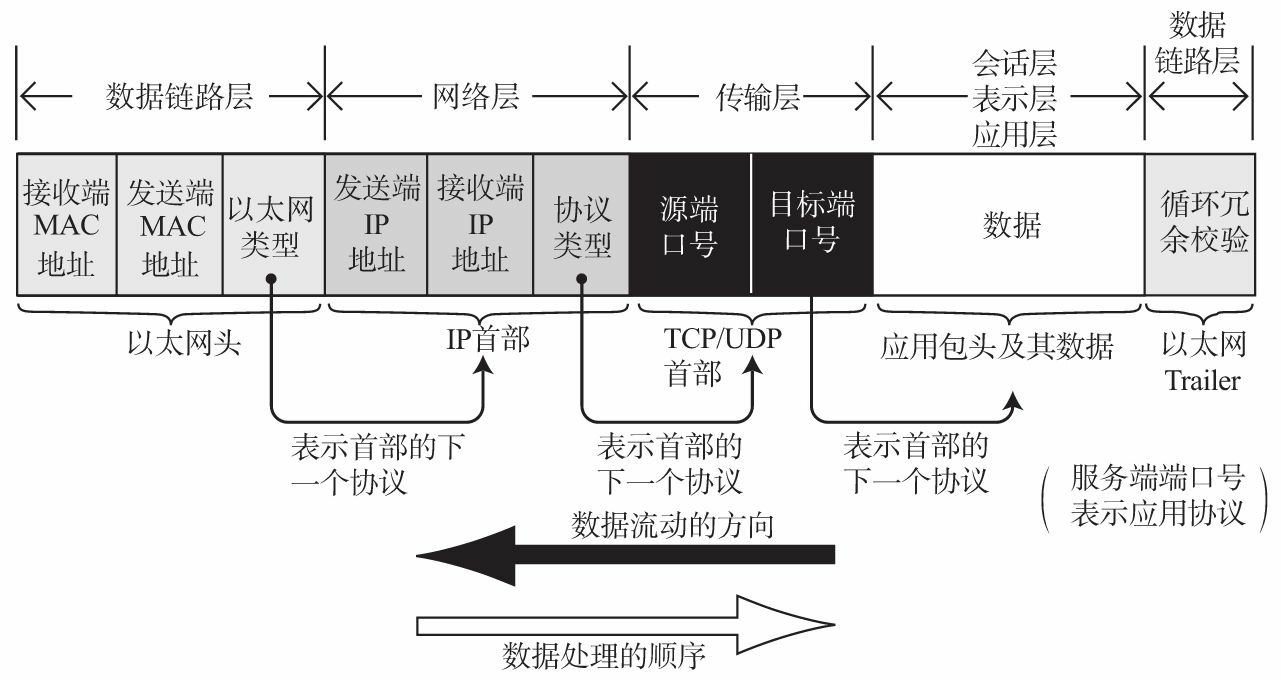
发送数据包
当用户在浏览器的地址栏中输入 URL 并点击回车后,首先由浏览器进行处理,这些处理相当于应用层功能。浏览器处理完成以后,浏览器依据
HTTP 规范构建报文,并将 HTTP 报文发送给传输层的 TCP。
TCP 模块的处理:TCP 根据浏览器的指示,负责建立连接、发送数据以及断开连接。TCP 在浏览器发送过来的数据前端再加上自己的
TCP 首部,随后将附加了 TCP 首部的包再发送给网络层的 IP。
IP 模块的处理:IP 将 TCP 传过来的 TCP 首部和 TCP 数据合起来当做自己的数据,并在
TCP 首部的前端再加上自己的 IP 首部。IP 包生成后,参考路由控制表决定接受此 IP 包的路由器
或 主机。随后,IP 包将被发送给连接这些路由器 或 主机网络接口的驱动程序,以实现真正的发送数据。
如果尚不知道接收端的物理地址(MAC 地址),可以利用 ARP(Address Resolution
Protocol) 通过 IP 地址查找物理地址(MAC地址)。
只要知道了对端的物理地址(MAC 地址),就可以将 MAC 地址和 IP 地址交给以太网的驱动程序,以实现真正的发送数据。
网络接口(以太网驱动) 的处理:以太网的驱动程序将 IP 传过来的 IP 首部和 IP 数据合起来当做自己的数据,并在
IP 首部的前端再加上自己的以太网首部。以太网数据包将通过物理层传输给接收端。
接收数据包
网络接口(以太网驱动) 的处理:主机收到以太网包以后,首先从以太网的包首部找到物理地址(MAC 地址)。主机根据物理地址(MAC
地址),判断是否为发给自己的包。
如果接收到的不是发给自己的包,那么主机丢弃数据。
如果接收到的恰好是发给自己的包,那么主机接收数据并查找以太网包首部中的类型域(类型域记录上一层的协议类型),从而确定将数据传给哪个处理程序。
如果上一层协议是 IP,那么就将数据传给处理 IP 的程序;
如果上一层协议是 ARP,那么就将数据传给处理 ARP 的程序;
如果以太网包首部的类型域包含了一个无法识别的协议类型,那么主机丢弃数据。
IP 模块的处理:IP 模块收到 IP 包首部及后面的数据部分以后,也做和以太网驱动类似的处理。
如果判断得出包首部中的 IP 地址与自己的 IP 地址匹配,那么就接收数据并查找 IP 包首部中的类型域(类型域记录上一层的协议类型),从而确定将数据传给哪个处理程序。
如果上一层协议是 TCP,那么就将数据传给处理 TCP 的程序;
如果上一层协议是 UDP,那么就将数据传给处理 UDP 的程序。
对于有路由器的情况下,接收端的 IP 地址往往不是自己的 IP 地址,此时需要借助路由控制表,在查找到应该送达的主机
或 路由器以后再转发数据。
TCP 模块的处理:TCP 模块收到 TCP 包首部及后面的数据部分以后,首先会计算一下校验和,判断数据是否被破坏。然后检查是否在按照序号接收数据。最后检查端口号,从而确定将数据传给哪个具体的应用程序。
TCP 模块接收数据完毕后,接收端给发送端发送一个 “确认(ACK)”。如果发送端没有收到这个确认信息,那么发送端会认为接收端没有接收到数据,然后发送端会一直反复发送。
数据被完整地接收以后,会传给由端口号识别的应用程序。
应用程序的处理:接收端应用程序会直接接收发送端发送的数据。服务器准备好发送端应用程序所需的数据以后,以同样的方式将数据发送到发送端应用程序。
服务端
当浏览器的请求到达服务端之后,请求首先经过 Linux 虚拟服务器 LVS,调度器将网络请求分发到
Nginx 上。
如果 Nginx 上缓存的有用户请求的内容,那么 Nginx 直接将用户请求的内容发送给浏览器。
如果 Nginx 上没有缓存用户请求的内容,那么 Nginx 访问应用服务器(Web 服务器,比如
Java 的 Tomcat / Netty / Jetty,Python 的 Django)获取资源,再将用户请求的内容返回给浏览器。Nginx
会根据缓存策略缓存从应用服务器获取到的资源,浏览器也会根据缓存策略缓存收到的内容。
Nginx 也可以直接访问缓存系统尝试获取资源(Varnish 缓存静态资源,Redis 缓存动态资源)。如果缓存系统中没有用户请求的内容,再访问应用服务器获取资源。
当 Nginx 的请求到达应用服务器之后,请求首先经过 API 网关。API 网关根据路由规则,将外部访问网关地址的流量路由到内部服务集群中正确的服务节点上。网关还可以根据需要作为流量过滤器来使用,提供某些额外的可选的功能,例如:
流量治理:流量控制、服务容错(限流、降级、熔断)
安全防护、访问控制:防刷控制、防爬虫、黑白名单、认证、授权、数据完整性校验、数据加密
监控:性能监控、日志监控
其他:协议适配转换、缓存
外部访问网关地址的流量被路由到内部服务集群中正确的服务节点上之后,服务节点会再访问缓存系统(比如 Redis、EhCache
等),存储系统(比如 MySQL、PostgreSQL、MongoDB 等)实现业务操作,获取资源。
服务节点将获取到的资源返回给 API 网关,API 网关将资源返回给 Nginx,Nginx 再将用户请求的内容返回给客户端,客户端依据
HTTP 规则解析报文,并将用户请求的内容显示在页面上。
| 






 订阅
订阅