| 编辑推荐: |
本文将对如下几个问题进行展开介绍:分支切换、 嵌套的effect、 无限递归、
可调度性,希望对您的学习有所帮助。
本文来自于51CTO,由火龙果软件Linda编辑、推荐。 |
|
1、写在前面
上篇文章主要介绍了如何简易的实现一个响应系统,只是个简易的仍然存在很多未知的不可控的问题,比如副作用函数嵌套、如何避免无限递归以及多个副作用函数之间会产生什么影响?
本文将会解决以下几个问题:
分支切换
嵌套的effect
无限递归
可调度性
2、分支切换与cleanup
分支切换
在进行页面渲染时,我们需要避免副作用函数产生的遗留。为什么这么说呢?先看下面的代码片段,在副作用函数effect内部的箭头函数中有个三元表达式,根据state.flag的值去切换页面渲染的值,这是我们期待的分支切换。
const data =
{
name:"pingping",
age:18,
flag:true
};
const state = new Proxy(data,{
/* 其他代码省略 */
});
//副作用函数,effect执行渲染了页面
effect(()=>{
console.log("render");
document.body.innerHTML = state.flag ? state.name
: state.age;
})
|
flag的值为初始值true时,页面渲染的结果如图所示:

但是事实上,分支切换可能会产生遗留的副作用函数。上面代码片段,flag的初始值是true,此时会去响应式对象state中获取字段flag的值,此时effect函数会执行触发flag和name的读取操作,副作用函数会与响应数据之间建立联系。
flag初始值为true的时候,事实上的Map的key值只有flag和name与副作用函数建立了联系,也只会收集这两个响应式数据的依赖--副作用函数。
flag字段值修改为false时,会触发副作用函数effect重新执行,按道理name的值不会被读取,只会触发flag和age的读取操作,理想情况应该是依赖集合收集的是这两个字段所对应的副作用函数。
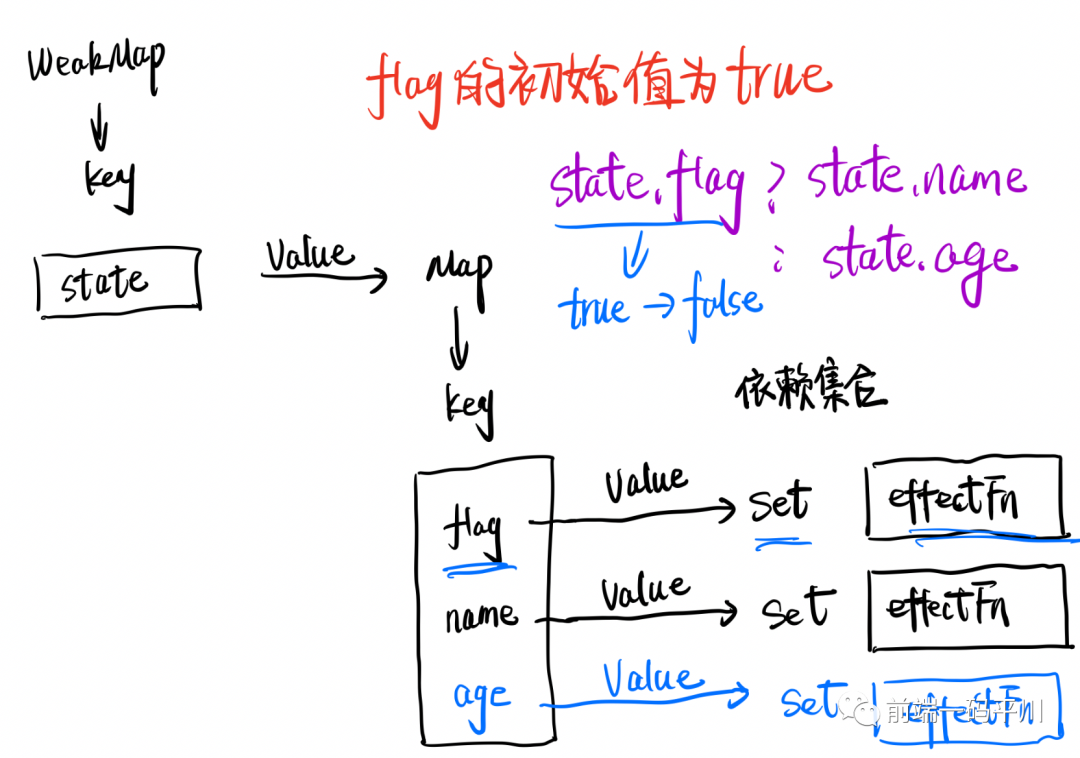
副作用函数与响应数据之间的关系
但是事实上,在上面代码中实现不了这种变化,在修改字段flag的值会触发副作用函数重新执行后,整个依赖关系会保持flag为true时的关系图,name字段所产生的副作用函数会遗留。
// 设置一个不存在的属性时
setTimeout(()=>{
state.flag = false;
},1000) |
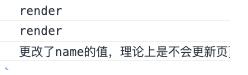
如上面代码,遗留的副作用函数会导致数据不必要的更新,之所以这样说,是因为flag的值改为false后,会触发更新导致副作用函数重新执行。此时应该不存在name的依赖关系,即不会读取name的值了,无论flag的值怎么变化都应该只是读取age的值而非name。
上面代码实际执行效果如下图所示,页面的渲染值没有改变,控制台打印显示:
// 设置一个不存在的属性时
setTimeout(()=>{
state.flag = false;
setTimeout(()=>{
console.log("更改了name的值,理论上是不会更新页面数据的...");
state.name = "onechuan"
})
},1000) |
即使我们在setTimeout中继续修改name的值,页面依然渲染的是name的初始值"pingping",控制台显示我们是修改了name的值的。
cleanup
那么,我们应该如何解决上面的副作用函数遗留问题呢?其实,我们只需要设置在每次副作用函数触发执行时,先把它从所有与之相关联的依赖集合中删除。当副作用函数执行完毕后,会重新建立联系,重新在依赖集合中收集副作用函数,但是之前遗留的副作用函数已经被清理。『打扫干净屋子,重新请客』。
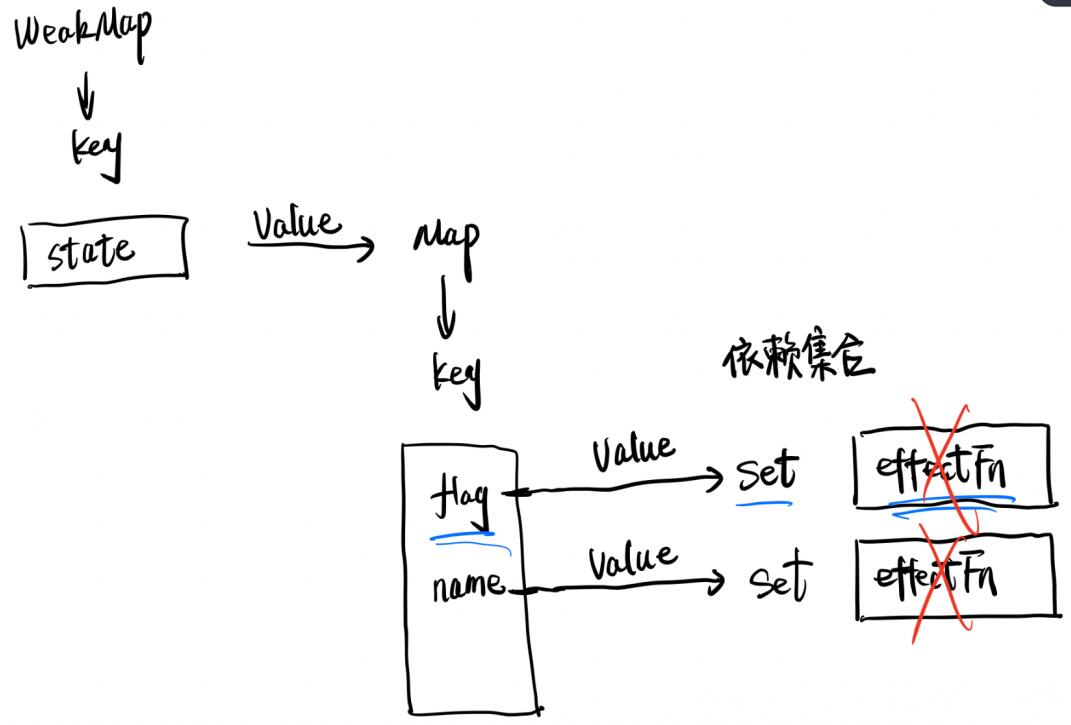
清除副作用函数与响应式数据之间的联系
我们应该如何实现上面的理论呢,得先确定哪些依赖集合中包含了遗留的副作用函数,我们需要重新设计副作用函数effect。
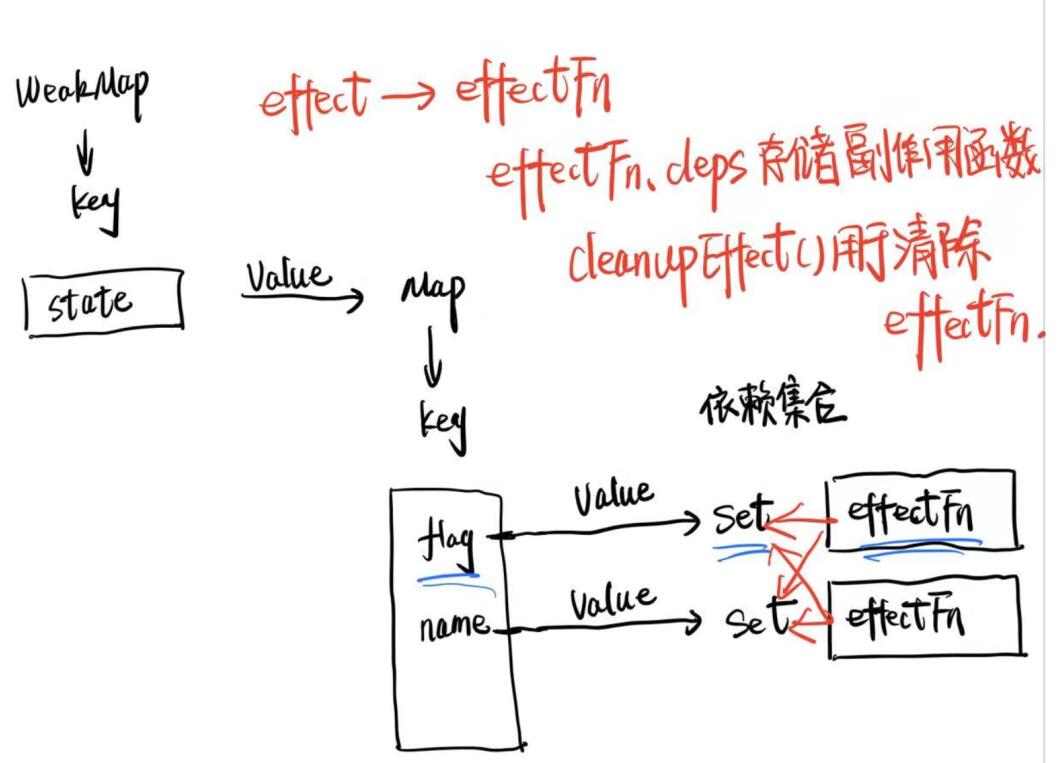
在effect函数内部定义一个effectFn函数,为其添加effectFn.deps数组,用于存储所有包含当前副作用函数的依赖集合。在每次执行副作用函数前,都需要根据effectFn.deps获取依赖集合,调用cleanupEffect函数完成清理遗留的副作用函数。
// 全局变量用于存储被注册的副作用函数
let activeEffect;
// effect用于注册副作用函数
function effect(fn){
const effectFn = ()=>{
// 调用函数完成清理遗留副作用函数
cleanupEffect(effectFn)
// 当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect = effectFn;
// 执行副作用函数
fn();
}
//deps是用于存储所有与该副作用函数相关联的依赖集合
effectFn.deps = [];
// 执行副作用函数effectFn
effectFn()
} |
cleanupEffect函数的设计实现如下代码段,其接收一个effectFn副作用函数作为参数,遍历收集依赖集合的effectFn.deps数组,将effectFn该函数从依赖集合中清除,最后重置effectFn.deps数组。
// 遗留的副作用函数的清除函数
function cleanupEffect(effectFn){
const { deps } = effectFn
// 遍历依赖集合数组
for(let i = 0; i < deps.length; i++){
//从依赖集合中删除
deps[i].delete(effectFn)
}
// 重置数组
deps.length = 0
} |
那么,effectFn.deps数组又是如何收集依赖集合的呢?首先将当前执行的副作用函数activeEffect添加到依赖集合deps中,此时deps存储的是与当前副作用函数存在联系的依赖集合,而后将其添加到activeEffect.deps数组中完成收集。
// 在get拦截函数中调用追踪取值函数的变化
function track(target, key){
// 没有activeEffect
if(!activeEffect) return
// 根据目标对象从桶中获得副作用函数
let depsMap = bucket.get(target);
// 判断是否存在,不存在则创建一个Map
if(!depsMap) bucket.set(target, depsMap = new
Map())
// 根据key从depsMap取的deps,存储着与key相关的副作用函数
let deps = depsMap.get(key);
// 判断key对应的副作用函数是否存在
if(!deps) depsMap.set(key, deps = new Set())
// 最后将激活的副作用函数添加到桶里
deps.add(activeEffect)
// deps是与当前副作用函数存在联系的依赖集合
activeEffect.deps.push(deps)
} |
注意:前面的代码片段在副作用函数触发时会执行清理操作,在执行后会进行收集effect,但是在执行过程中会导致无限循环执行(死循环)。
为什么会出现死循环呢?
这是因为在trigger函数中,会遍历存储着副作用函数Set集合effects。在副作用函数执行时,会调用cleanup执行清除操作,实际上就是从effects集合中找出当前执行的副作用函数进行清除。但是副作用函数的执行,会导致其重新被收集到effects集合中,这样就不断的清除和收集了。
在ECMA规范中:调用forEach对Set集合进行遍历时,如果一个值已经被访问过,那么该值被删除并重新添加到集合中,如果此时forEach遍历没有结束,该值就会重新被访问。
let effect =
() => {};
let s = new Set([effect])
s.forEach(item=>{
s.delete(effect);
s.add(effect)}
); // 这样就导致死循环了 |
那么我们应该如何打破循环呢?
很简单,只需要新构造一个Set集合进行遍历即可。即在trigger函数中修改语句即可:
// 在set拦截函数中调用trigger函数触发变化
function trigger(target, key){
// 根据target从桶中取的depMaps
const depMaps = bucket.get(target);
// 判断是否存在
if(!depMaps) return
// 根据key值取得对应的副作用函数
const effects = depMaps.get(key);
// 执行副作用函数
// effects && effects.forEach(fn=>fn())
const effectsToRun = new Set(effects);
effectsToRun.forEach(effectFn=>effectFn());
} |
此时就有:
修改age值前的页面

控制台打印结果:
3、嵌套的effect和effect栈
嵌套的effect
在实际开发中,我们不可避免会写出effect函数嵌套,即一个effect函数内部嵌套着另外一个effect函数。
effect(()=>{
effct(()=>{
/*...*/
})
}) |
如果我们的响应式系统不支持effect嵌套,那么会发生什么事情呢?
// 原始数据
const data = {
name:"pingping",
age:18,
flag:true
}
//代理对象
const state = new Proxy(data,{
/* 其他代码省略 */
});
//全局变量
let temp1, temp2;
//effectFn1嵌套effectFn2
effect(()=>{
console.log("执行effectFn1");
effect(()=>{
console.log("执行effectFn2");
//在effectFn2中读取state.name属性
temp2 = state.name;
})
//在effectFn1中读取state.age属性
temp1 = state.age;
})
setTimeout(()=>{
state.age = 19
},1000) |
在上面代码中,简单的写了一个effect嵌套的demo,effectFn1内部嵌套了effectFn2,那么effectFn1执行会导致effectFn2的执行。effectFn2中读取了state.name的值,而effectFn1中读取了state.age的值,且effectFn2的读取操作优先于effectFn1的读取操作。即:
state
|__ name
|__ effectFn1
|__ age
|__ effectFn2 |
在这种情况下,理论上修改state.name的值只会触发effectFn2的执行,而当修改state.age的值时,会触发effectFn1的执行且间接触发effectFn2函数的执行。
但是,事实上修改state.age的值输出的结果如下图所示,打印了三次,effectFn1只执行了一次,而effectFn2却执行了两次,修改时的并没有重新执行effectFn1函数。
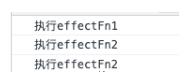
为什么会出现这种情况呢?
这是因为我们嵌套了多个effect函数,而activeEffect全局变量同一时刻只能存储一个通过effect函数注册的副作用函数。当effect发生嵌套时,内层effect产生的副作用函数会覆盖掉activeEffect的值,并且永远不能回到过去了。『真是个渣男』。
effect执行栈
那么应该如何解决这个问题呢?
想下js事件循环机制就知道,通过一个栈数据结构去存储当前执行的事件。同样的,我们也可以添加一个副作用函数执行栈effectStack,当前副作用函数执行时,将其压入栈中,在执行完毕后将其出栈,并让activeEffect指向栈顶的副作用函数,即最近执行的副作用函数。
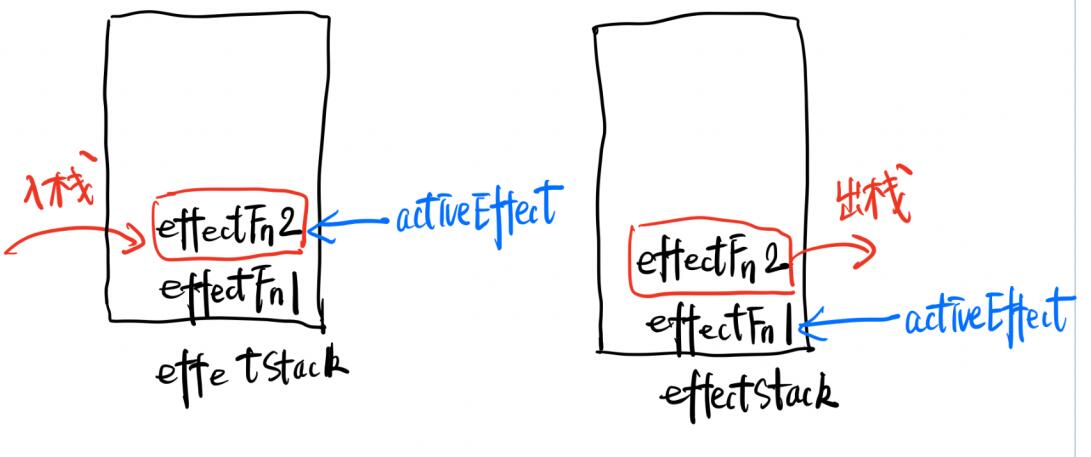
let effectStack
= [];
// effect用于注册副作用函数
function effect(fn){
const effectFn = ()=>{
// 调用函数完成清理遗留副作用函数
cleanupEffect(effectFn)
// 当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect = effectFn;
// 在副作用函数执行前压栈
effectStack.push(effectFn)
// 执行副作用函数
fn();
// 执行完毕后出栈
effectStack.pop()
activeEffect = effectStack[effectStack.length
- 1]
}
//deps是用于存储所有与该副作用函数相关联的依赖集合
effectFn.deps = [];
// 执行副作用函数effectFn
effectFn()
} |
在上面代码片段中,定义了一个effectStack数组去存储待执行的副作用函数,activeEffect始终指向当前执行的副作用函数。根据栈结构的先进后出原则,刚好外层effect先进存储在栈地,内层effect后进存储在栈顶,在内层执行完毕后出栈执行外层effect。这样,响应式数据只会收集直接读取当前值的副作用函数作为依赖,从而避免错乱。
这样控制打印:
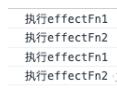
打印结果
4、避免无限递归循环
前面在存储当前执行的副作用函数的依赖集合时,可能会出现循环执行的情况,我们也添加了新Set集合进行解决。当我们在副作用函数中,对同一个字段的值进行无限递归循环,那么会出现什么情况?
// 原始数据
const data = {
name:"pingping",
age:18,
flag:true
}
//代理对象
const state = new Proxy(data,{
/* 其他代码省略 */
});
effect(()=>{
state.age++;
}) |
我们看到执行结果出现爆栈的情况,内存溢出:

内存溢出
我们可以看到state.age++;语句中,既有state.age的读取操作,又有设值操作,这样前一个副作用函数还没执行完毕,又重新开启了新的执行,这样就无限递归调用自己了。『我调用我自己,超越本我』
那么,我们应该如何避免栈溢出呢?
在前面的文章中知道,在对state.age的取值track和设值trigger操作都是在同一个副作用函数activeEffect中执行的。那么只需要在trigger中增加守卫条件:判断下触发trigger的副作用函数和当前正在执行的副作用函数是不是同一个,如果是同一个则不触发执行,否则执行。
// 在set拦截函数中调用trigger函数触发变化
function trigger(target, key){
// 根据target从桶中取的depMaps
const depMaps = bucket.get(target);
// 判断是否存在
if(!depMaps) return
// 根据key值取得对应的副作用函数
const effects = depMaps.get(key);
const effectsToRun = new Set();
// 执行副作用函数
effects && effects.forEach(effectFn=>{
if(effectFn !== activeEffect){
effectsToRun.add(effectFn)
}
})
effectsToRun.forEach(effectFn=>effectFn());
} |
在执行触发trigger时,对触发trigger的副作用函数和当前执行的副作用函数进行比较筛选,即可避免栈内存的溢出。
5、调度执行
先了解下可调度性对于意义,就是trigger触发副作用函数重新执行时,可以自定义决定副作用函数执行的时机、次数、及执行方式。
// 原始数据
const data = {
name:"pingping",
age:18,
flag:true
}
//代理对象
const state = new Proxy(data,{
/* 其他代码省略 */
});
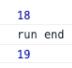
effect(()=>{
console.log(state.age);
});
state.age++;
console.log("run end"); |

执行结果
如果我们需要改变代码的执行顺序,得到不同的结果,那么需要提供给用户调度能力,即允许使用者自定义调度器。
// effect用于注册副作用函数
function effect(fn,options={}){
const effectFn = ()=>{
// 调用函数完成清理遗留副作用函数
cleanupEffect(effectFn)
// 当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect = effectFn;
// 在副作用函数执行前压栈
effectStack.push(effectFn)
// 执行副作用函数
fn();
// 执行完毕后出栈
effectStack.pop()
activeEffect = effectStack[effectStack.length
- 1]
}
// 将options挂载到effectFn函数上
effectFn.options = options
//deps是用于存储所有与该副作用函数相关联的依赖集合
effectFn.deps = [];
// 执行副作用函数effectFn
effectFn()
}
// 在set拦截函数中调用trigger函数触发变化
function trigger(target, key){
// 根据target从桶中取的depMaps
const depMaps = bucket.get(target);
// 判断是否存在
if(!depMaps) return
// 根据key值取得对应的副作用函数
const effects = depMaps.get(key);
const effectsToRun = new Set();
// 执行副作用函数
effects && effects.forEach(effectFn=>{
if(effectFn !== activeEffect){
effectsToRun.add(effectFn)
}
})
effectsToRun.forEach(effectFn=>{
// 如果副作用函数中存在调度器
if(effectFn.options.scheduler){
effectFn.options.scheduler(effectFn)
}else{
effectFn()
}
});
} |
在上面代码片段中,在trigger触发副作用函数执行时,会先判断该副作用函数中是否存在调度器:
存在调度器,直接执行调度器函数,并将当前副作用函数作为参数传递effectFn.options.scheduler(effectFn)。
不存在调度器,则直接执行副作用函数effectFn()。
effect(()=>{
console.log(state.age);
},{//options
scheduler(fn){//调度器
setTimeout(fn);
}
});
state.age++;
console.log("run end"); |
执行结果
这样,系统设计实现了控制副作用函数的执行顺序。除此之外,我们还可以添加实现控制副作用函数的执行次数,同样只需要修改调度器代码就行,这里就不赘述了。
6、写在最后
在本文中,主要解决的问题有:
分支切换导致遗留的副作用函数,可以添加一个集合收集依赖集合,在每次执行副作用函数前将其对应的联系清除,在执行后重新建立联系。
对于effect嵌套问题可以通过添加一个effectStack执行栈解决,外层副作用函数先入栈,内层后入栈,activeEffect永远指向当前要执行的副作用函数。
对于避免无限递归循环,可以在trigger触发副作用函数执行前进行判断,触发的副作用函数与当前执行的副作用函数是否相同。
对于响应系统的调度性,可以通过设置调度器去控制副作用函数执行的顺序、时机、次数等。 | 






 订阅
订阅