| БрМЭЦМі: |
| БОЮФРДздsegmentfaultЃЌЮФеТНщЩмСЫгУРДНјаазгНјГЬДДНЈЕФchild_processФЃПщЁЂРћгУforkЪЕЯжmaster-workerФЃаЭЕШЯрЙиФкШнЁЃ |
|
жкЫљжмжЊNodeЛљгкV8ЃЌЖјдкV8жаJavaScriptЪЧЕЅЯпГЬдЫааЕФЃЌетРяЕФЕЅЯпГЬВЛЪЧжИNodeЦєЖЏЕФЪБКђОЭжЛгавЛИіЯпГЬЃЌЖјЪЧЫЕдЫааJavaScriptДњТыЪЧдкЕЅЯпГЬЩЯЃЌNodeЛЙгаЦфЫћЯпГЬЃЌБШШчНјаавьВНIOВйзїЕФIOЯпГЬЁЃетжжЕЅЯпГЬФЃаЭДјРДЕФКУДІОЭЪЧЯЕЭГЕїЖШЙ§ГЬжаВЛЛсЦЕЗБНјааЩЯЯТЮФЧаЛЛЃЌЬсЩ§СЫЕЅКЫCPUЕФРћгУТЪЁЃ
ЕЋЪЧетжжзіЗЈгаИіШБЯнЃЌОЭЪЧЮвУЧЮоЗЈРћгУЗўЮёЦїCPUЖрКЫЕФадФмЃЌвЛИіNodeНјГЬжЛФмРћгУвЛИіCPUЁЃЖјЧвЕЅЯпГЬФЃЪНЯТвЛЕЉДњТыБРРЃОЭЪЧећИіГЬађБРРЃЁЃЭЈГЃНтОіЗНАИОЭЪЧЪЙгУNodeЕФclusterФЃПщЃЌЭЈЙ§master-workerФЃЪНЦєгУЖрИіНјГЬЪЕР§ЁЃЯТУцЮвУЧЯъЯИНВЪіЯТЃЌNodeШчКЮЪЙгУЖрНјГЬФЃаЭРћгУЖрКЫCPUЃЌвдМАздДјЕФclusterФЃПщОпЬхЕФЙЄзїдРэЁЃ
ШчКЮДДНЈзгНјГЬ
nodeЬсЙЉСЫchild_processФЃПщгУРДНјаазгНјГЬЕФДДНЈЃЌИУФЃПщвЛЙВгаЫФИіЗНЗЈгУРДДДНЈзгНјГЬЁЃ
const { spawn,
exec, execFile, fork } = require('child_process')
spawn(command[, args][, options])
exec(command[, options][, callback])
execFile(file[, args][, options][, callback])
fork(modulePath[, args][, options]) |
spawn
ЪзЯШШЯЪЖвЛЯТspawnЗНЗЈЃЌЯТУцЪЧNodeЮФЕЕЕФЙйЗНЪЕР§ЁЃ
const { spawn
} = require('child_process');
const child = spawn('ls', ['-lh', '/home']);
child.on('close', (code) => {
console.log(`згНјГЬЭЫГіТыЃК${code}`);
});
const { stdin, stdout, stderr } = child
stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
stderr.on('data', (data) => {
console.log(`stderr: ${data}`);
}); |
ЭЈЙ§spawnДДНЈЕФзгНјГЬЃЌМЬГаздEventEmitterЃЌЫљвдПЩвддкЩЯУцНјааЪТМўЃЈdiscountЃЌerrorЃЌcloseЃЌmessageЃЉЕФМрЬ§ЁЃЭЌЪБзгНјГЬОпгаШ§ИіЪфШыЪфГіСїЃКstdinЁЂstdoutЁЂstderrЃЌЭЈЙ§етШ§ИіСїЃЌПЩвдЪЕЪБЛёШЁзгНјГЬЕФЪфШыЪфГіКЭДэЮѓаХЯЂЁЃ
етИіЗНЗЈЕФзюжеЪЕЯжЛљгкlibuvЃЌетРяВЛдйеЙПЊЬжТлЃЌИааЫШЄПЩвдВщПДдДТыЁЃ
// ЕїгУlibuvЕФapiЃЌГѕЪМЛЏвЛИіНјГЬ
int err = uv_spawn(env->event_loop(), &wrap->process_,
&options); |
exec/execFile
жЎЫљвдАбетСНИіЗХЕНвЛЦ№ЃЌЪЧвђЮЊexecзюКѓЕїгУЕФОЭЪЧexecFileЗНЗЈЃЌдДТыдкетРя)ЁЃЮЈвЛЕФЧјБ№ЪЧЃЌexecжаЕїгУЕФnormalizeExecArgsЗНЗЈЛсНЋoptsЕФshellЪєадФЌШЯЩшжУЮЊtrueЁЃ
exports.exec
= function exec(/* command , options, callback
*/) {
const opts = normalizeExecArgs.apply(null, arguments);
return exports.execFile(opts.file, opts.options,
opts.callback);
};
function normalizeExecArgs(command, options,
callback) {
options = { ...options };
options.shell = typeof options.shell === 'string'
? options.shell : true;
return { options };
} |
дкexecFileжаЃЌзюжеЕїгУЕФЪЧspawnЗНЗЈЁЃ
exports.execFile
= function execFile(file /* , args, options, callback
*/) {
let args = [];
let callback;
let options;
var child = spawn(file, args, {
// ... some options
});
return child;
} |
execЛсНЋspawnЕФЪфШыЪфГіСїзЊЛЛГЩStringЃЌФЌШЯЪЙгУUTF-8ЕФБрТыЃЌШЛКѓДЋЕнИјЛиЕїКЏЪ§ЃЌЪЙгУЛиЕїЗНЪНдкnodeжаНЯЮЊЪьЯЄЃЌБШСїИќШнвзВйзїЃЌЫљвдЮвУЧФмЪЙгУexecЗНЗЈжДаавЛаЉshellУќСюЃЌШЛКѓдкЛиЕїжаЛёШЁЗЕЛижЕЁЃгаЕуашвЊзЂвтЃЌетРяЕФbufferЪЧгазюДѓЛКДцЧјЕФЃЌШчЙћГЌГіЛсжБНгБЛkillЕєЃЌПЩгУЭЈЙ§maxBufferЪєадНјааХфжУЃЈФЌШЯ:
200*1024ЃЉЁЃ
const { exec
} = require('child_process');
exec('ls -lh /home', (error, stdout, stderr) =>
{
console.log(`stdout: ${stdout}`);
console.log(`stderr: ${stderr}`);
}); |
fork
forkзюКѓвВЪЧЕїгУspawnРДДДНЈзгНјГЬЃЌЕЋЪЧforkЪЧspawnЕФвЛжжЬиЪтЧщПіЃЌгУгкбмЩњаТЕФ
Node.js НјГЬЃЌЛсВњЩњвЛИіаТЕФV8ЪЕР§ЃЌЫљвджДааforkЗНЗЈЪБашвЊжИЖЈвЛИіjsЮФМўЁЃ
exports.fork
= function fork(modulePath /* , args, options
*/) {
// ...
options.shell = false;
return spawn(options.execPath, args, options);
}; |
ЭЈЙ§forkДДНЈзгНјГЬжЎКѓЃЌИИзгНјГЬжБНгЛсДДНЈвЛИіIPCЃЈНјГЬМфЭЈаХЃЉЭЈЕРЃЌЗНБуИИзгНјГЬжБНгЭЈаХЃЌдкjsВуЪЙгУ
process.send(message) КЭ process.on('message', msg
=> {}) НјааЭЈаХЁЃЖјдкЕзВуЃЌЪЕЯжНјГЬМфЭЈаХЕФЗНЪНгаКмЖрЃЌNodeЕФНјГЬМфЭЈаХЛљгкlibuvЪЕЯжЃЌВЛЭЌВйзїЯЕЭГЪЕЯжЗНЪНВЛвЛжТЁЃдк*unixЯЕЭГжаВЩгУUnix
Domain SocketЗНЪНЪЕЯжЃЌWindowsжаЪЙгУУќУћЙмЕРЕФЗНЪНЪЕЯжЁЃ
ГЃМћНјГЬМфЭЈаХЗНЪНЃКЯћЯЂЖгСаЁЂЙВЯэФкДцЁЂpipeЁЂаХКХСПЁЂЬзНгзж
ЯТУцЪЧвЛИіИИзгНјГЬЭЈаХЕФЪЕР§ЁЃ
parent.js
const path =
require('path')
const { fork } = require('child_process'
)
const child = fork(path.join(__dirname, 'child.js'))
child.on('message', msg => {
console.log('message from child', msg)
});
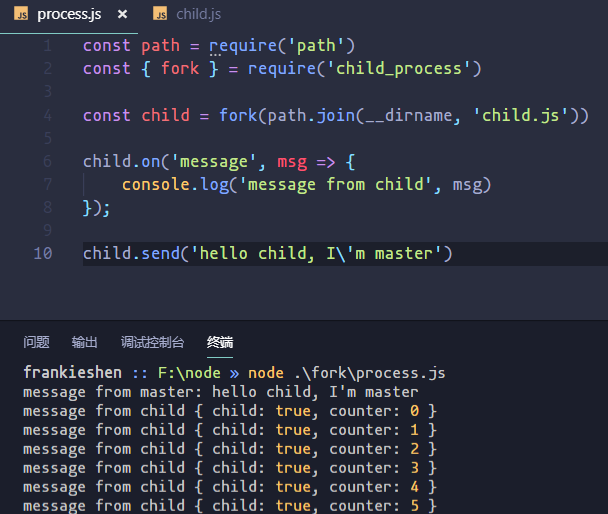
child.send('hello child, I\'m master') |
child.js
process.on('message',
msg => {
console.log('message from master:', msg)
});
let counter = 0
setInterval(() => {
process.send({
child: true,
counter: counter++
})
}, 1000); |
аЁНс
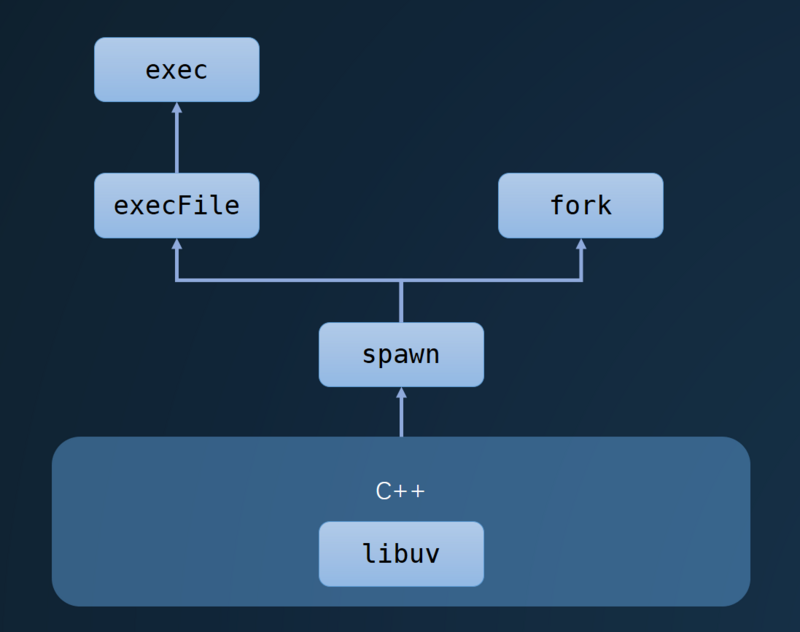
ЦфЪЕПЩвдПДЕНЃЌетаЉЗНЗЈЖМЪЧЖдspawnЗНЗЈЕФИДгУЃЌШЛКѓspawnЗНЗЈЕзВуЕїгУСЫlibuvНјааНјГЬЕФЙмРэЃЌОпЬхПЩвдПДЯТЭМЁЃ
РћгУforkЪЕЯжmaster-workerФЃаЭ
ЪзЯШРДПДПДЃЌШчЙћЮвУЧдкchild.jsжаЦєЖЏвЛИіhttpЗўЮёЛсЗЂЩњЪВУДЧщПіЁЃ
// master.js
const { fork } = require('child_process')
for (let i = 0; i < 2; i++) {
const child = fork('./child.js')
}
// child.js
const http = require('http')
http.createServer((req, res) => {
res.end('Hello World\n');
}).listen(8000) |
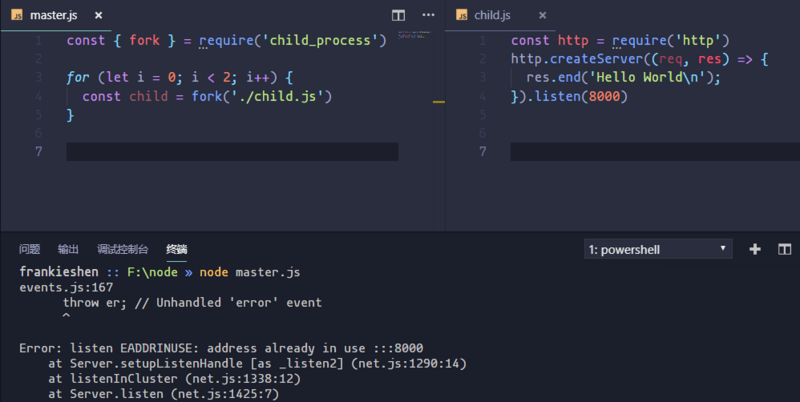
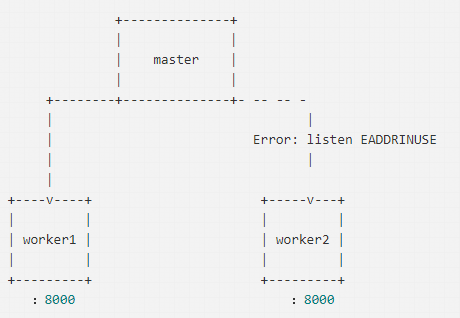
ЮвУЧforkСЫСНИізгНјГЬЃЌвђЮЊСНИізгНјГЬЭЌЪБЖдвЛИіЖЫПкНјааМрЬ§ЃЌNodeЛсжБНгХзГівЛИівьГЃЃЈError:
listen EADDRINUSEЃЉЃЌШчЩЯЭМЫљЪОЁЃФЧУДЮвУЧФмВЛФмЪЙгУДњРэФЃЪНЃЌЭЌЪБМрЬ§ЖрИіЖЫПкЃЌШУmasterНјГЬМрЬ§80ЖЫПкЪеЕНЧыЧѓЪБЃЌдйНЋЧыЧѓЗжЗЂИјВЛЭЌЗўЮёЃЌЖјЧвmasterНјГЬЛЙФмзіЪЪЕБЕФИКдиОљКтЁЃ
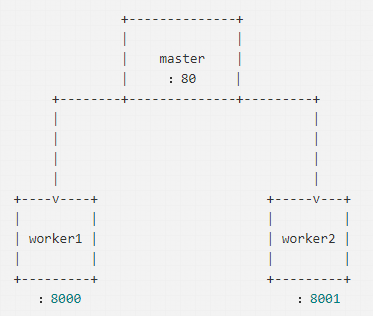
ЕЋЪЧетУДзігжЛсДјРДСэвЛИіЮЪЬтЃЌДњРэФЃЪНжаЪЎЗжЯћКФЮФМўУшЪіЗћЃЈlinuxЯЕЭГФЌШЯЕФзюДѓЮФМўУшЪіЗћЯожЦЪЧ1024ЃЉЃЌЮФМўУшЪіЗћдкwindowsЯЕЭГжаГЦЮЊОфБњЃЈhandleЃЉЃЌЯАЙпадЕФЮвУЧвВПЩвдГЦlinuxжаЕФЮФМўУшЪіЗћЮЊОфБњЁЃЕБгУЛЇНјааЗУЮЪЃЌЪзЯШСЌНгЕНmasterНјГЬЃЌЛсЯћКФвЛИіОфБњЃЌШЛКѓmasterНјГЬдйДњРэЕНworkerНјГЬгжЛсЯћКФЕєвЛИіОфБњЃЌЫљвдетжжзіЗЈЪЎЗжРЫЗбЯЕЭГзЪдДЁЃЮЊСЫНтОіетИіЮЪЬтЃЌNodeЕФНјГЬМфЭЈаХПЩвдЗЂЫЭОфБњЃЌНкЪЁЯЕЭГзЪдДЁЃ
ОфБњЪЧвЛжжЬиЪтЕФжЧФмжИеы ЁЃЕБвЛИігІгУГЬађвЊв§гУЦфЫћЯЕЭГЃЈШчЪ§ОнПтЁЂВйзїЯЕЭГЃЉЫљЙмРэЕФФкДцПщЛђЖдЯѓЪБЃЌОЭвЊЪЙгУОфБњЁЃ
ЮвУЧПЩвддкmasterНјГЬЦєЖЏвЛИіtcpЗўЮёЃЌШЛКѓЭЈЙ§IPCНЋЗўЮёЕФОфБњЗЂЫЭИјзгНјГЬЃЌзгНјГЬдйЖдЗўЮёЕФСЌНгЪТМўНјааМрЬ§ЃЌОпЬхДњТыШчЯТЃК
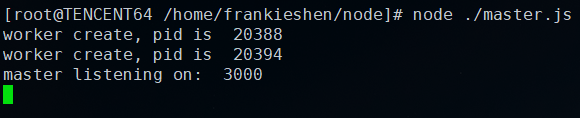
// master.js
var { fork } = require('child_process')
var server = require('net').createServer()
server.on('connection', function(socket) {
socket.end('handled by master') // ЯьгІРДздmaster
})
server.listen(3000, function() {
console.log('master listening on: ', 3000)
})
for (var i = 0; i < 2; i++) {
var child = fork('./child.js')
child.send('server', server) // ЗЂЫЭОфБњИјworker
console.log('worker create, pid is ', child.pid)
}
// child.js
process.on('message', function (msg, handler)
{
if (msg !== 'server') {
return
}
// ЛёШЁЕНОфБњКѓЃЌНјааЧыЧѓЕФМрЬ§
handler.on('connection', function(socket) {
socket.end('handled by worker, pid is ' + process.pid)
})
}) |
ЯТУцЮвУЧЭЈЙ§curlСЌајЧыЧѓ 5 ДЮЗўЮёЁЃ
for varible1
in {1..5}
do
curl "localhost:3000"
done |
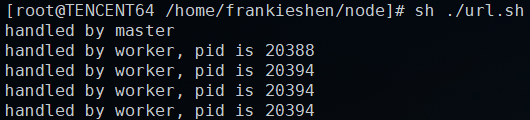
ПЩвдПДЕНЃЌЯьгІЧыЧѓЕФПЩвдЪЧИИНјГЬЃЌвВПЩвдЪЧВЛЭЌзгНјГЬЃЌЖрИіНјГЬЖдЭЌвЛИіЗўЮёЯьгІЕФСЌНгЪТМўМрЬ§ЃЌЫЯШЧРеМЃЌОЭгЩЫНјааЯьгІЁЃетРяОЭЛсГіЯжвЛИіLinuxЭјТчБрГЬжаКмГЃМћЕФЪТМўЃЌЕБЖрИіНјГЬЭЌЪБМрЬ§ЭјТчЕФСЌНгЪТМўЃЌЕБетИігааТЕФСЌНгЕНДяЪБЃЌетаЉНјГЬБЛЭЌЪБЛНабЃЌетБЛГЦЮЊЁАОЊШКЁБЁЃетбљЕМжТЕФЧщПіОЭЪЧЃЌвЛЕЉЪТМўЕНДяЃЌУПИіНјГЬЭЌЪБШЅЯьгІетвЛИіЪТМўЃЌЖјзюжежЛгавЛИіНјГЬФмДІРэЪТМўГЩЙІЃЌЦфЫћЕФНјГЬдкДІРэИУЪТМўЪЇАмКѓжиаТанУпЃЌдьГЩСЫЯЕЭГзЪдДЕФРЫЗбЁЃ
psЃКдкwindowsЯЕЭГЩЯЃЌгРдЖЖМЪЧзюКѓЖЈвхЕФзгНјГЬЧРеМЕНОфБњЃЌетПЩФмКЭlibuvЕФЪЕЯжЛњжЦгаЙиЃЌОпЬхдвђЭљгаДѓРаФмЙЛжИЕуЁЃ
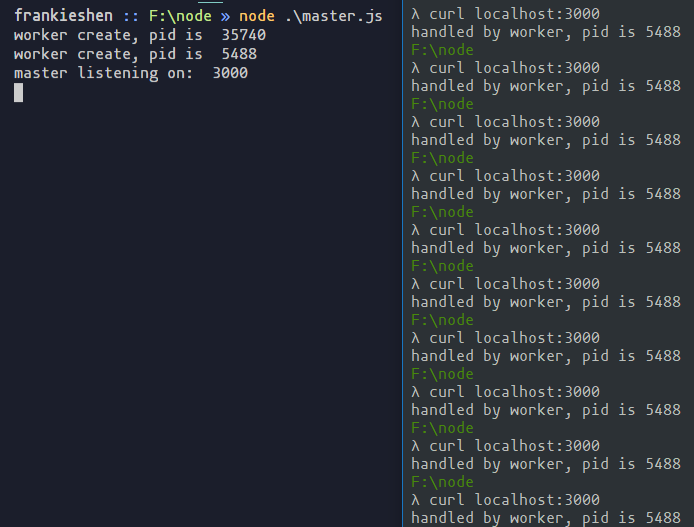
ГіЯжетбљЕФЮЪЬтПЯЖЈЪЧДѓМвЖМВЛдИвтЕФТяЃЌетИіЪБКђЮвУЧОЭЯыЦ№СЫnginxЕФКУСЫЃЌетРягаЦЊЮФеТНВНтСЫnginxЪЧШчКЮНтОіЁАОЊШКЁБЕФЃЌРћгУnginxЕФЗДЯђДњРэПЩвдгааЇЕиНтОіетИіЮЪЬтЃЌБЯОЙnginxБОРДОЭКмЩУГЄетжжЮЪЬтЁЃ
http {
upstream node {
server 127.0.0.1:8000;
server 127.0.0.1:8001;
server 127.0.0.1:8002;
server 127.0.0.1:8003;
keepalive 64;
}
server {
listen 80;
server_name shenfq.com;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://node; # етРявЊКЭзюЩЯУцupstreamКѓЕФгІгУУћвЛжТЃЌПЩвдздЖЈвх
}
}
} |
аЁНс
ШчЙћЮвУЧздМКгУNodeдЩњРДЪЕЯжвЛИіЖрНјГЬФЃаЭЃЌДцдкетбљЛђепФЧбљЕФЮЪЬтЃЌЫфШЛзюжеЮвУЧНшжњСЫnginxДяЕНСЫетИіФПЕФЃЌЕЋЪЧЪЙгУnginxЕФЛАЃЌЮвУЧашвЊСэЭтЮЌЛЄвЛЬзnginxЕФХфжУЃЌЖјЧвШчЙћгавЛИіNodeЗўЮёЙвСЫЃЌnginxВЂВЛжЊЕРЃЌЛЙЪЧЛсНЋЧыЧѓзЊЗЂЕНФЧИіЖЫПкЁЃ
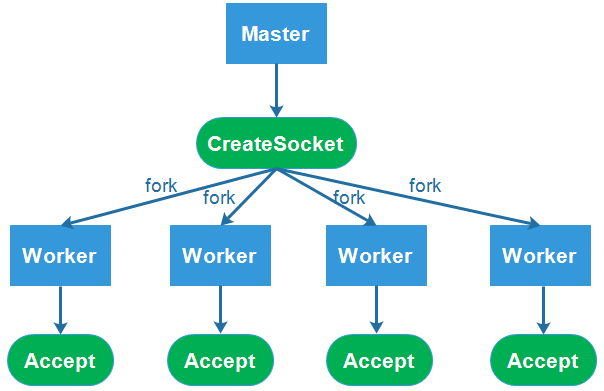
clusterФЃПщ
Г§СЫгУnginxзіЗДЯђДњРэЃЌnodeБОЩэвВЬсЙЉСЫвЛИіclusterФЃПщЃЌгУгкЖрКЫCPUЛЗОГЯТЖрНјГЬЕФИКдиОљКтЁЃclusterФЃПщДДНЈзгНјГЬБОжЪЩЯЪЧЭЈЙ§child_procee.forkЃЌРћгУИУФЃПщПЩвдКмШнвзЕФДДНЈЙВЯэЭЌвЛЖЫПкЕФзгНјГЬЗўЮёЦїЁЃ
ЩЯЪжжИФЯ
гаСЫетИіФЃПщЃЌФуЛсИаОѕЪЕЯжNodeЕФЕЅЛњМЏШКЪЧЖрУДШнвзЕФвЛМўЪТЧщЁЃЯТУцПДПДЙйЗНЪЕР§ЃЌЖЬЖЬЕФЪЎМИааДњТыОЭЪЕЯжСЫвЛИіЖрНјГЬЕФNodeЗўЮёЃЌЧвздДјИКдиОљКтЁЃ
const cluster
= require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) { // ХаЖЯЪЧЗёЮЊжїНјГЬ
console.log(`жїНјГЬ ${process.pid} е§дкдЫаа`);
// бмЩњЙЄзїНјГЬЁЃ
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal)
=> {
console.log(`ЙЄзїНјГЬ ${worker.process.pid} вбЭЫГі`);
});
} else { // згНјГЬНјааЗўЮёЦїДДНЈ
// ЙЄзїНјГЬПЩвдЙВЯэШЮКЮ TCP СЌНгЁЃ
// дкБОР§згжаЃЌЙВЯэЕФЪЧвЛИі HTTP ЗўЮёЦїЁЃ
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`ЙЄзїНјГЬ ${process.pid} вбЦєЖЏ`);
} |
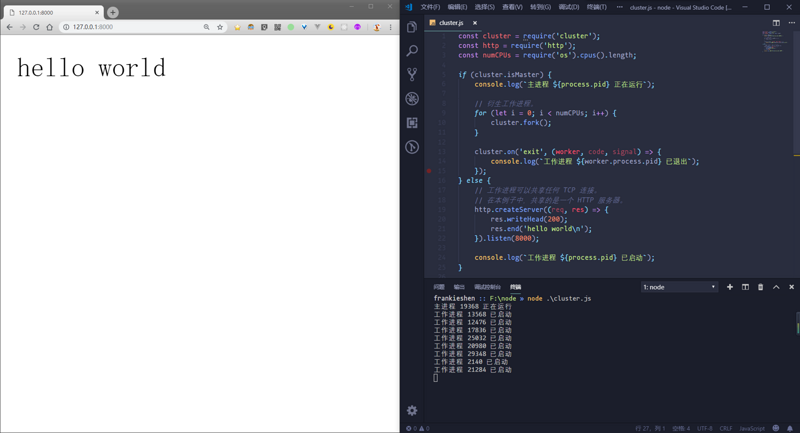
clusterФЃПщдДТыЗжЮі
ЪзЯШПДДњТыЃЌЭЈЙ§isMasterРДХаЖЯЪЧЗёЮЊжїНјГЬЃЌШчЙћЪЧжїНјГЬНјааforkВйзїЃЌзгНјГЬДДНЈЗўЮёЦїЁЃетРяclusterНјааforkВйзїЪБЃЌжДааЕФЪЧЕБЧАЮФМўЁЃcluster.forkзюжеЕїгУЕФchild_process.forkЃЌЧвЕквЛИіВЮЪ§ЮЊprocess.argv.slice(2)ЃЌдкforkзгНјГЬжЎКѓЃЌЛсЖдЦфinternalMessageЪТМўНјааМрЬ§ЃЌетИіКѓУцЛсЬсЕНЃЌОпЬхДњТыШчЯТЃК
const { fork
} = require('child_process');
cluster.fork = function(env) {
cluster.setupMaster();
const id = ++ids;
const workerProcess = createWorkerProcess(id,
env);
const worker = new Worker({
id: id,
process: workerProcess
});
// МрЬ§згНјГЬЕФЯћЯЂ
worker.process.on('internalMessage', internal(worker,
onmessage));
// ...
};
// ХфжУmasterНјГЬ
cluster.setupMaster = function(options) {
cluster.settings = {
args: process.argv.slice(2),
exec: process.argv[1],
execArgv: process.execArgv,
silent: false,
...cluster.settings,
...options
};
};
// ДДНЈзгНјГЬ
function createWorkerProcess(id, env) {
return fork(cluster.settings.exec, cluster.settings.args,
{
// some options
});
}
|
згНјГЬЖЫПкМрЬ§ЮЪЬт
етРяЛсгавЛИіЮЪЬтЃЌзгНјГЬШЋВПЖМдкМрЬ§ЭЌвЛИіЖЫПкЃЌЮвУЧжЎЧАвбОЪдбщЙ§ЃЌЗўЮёМрЬ§ЭЌвЛИіЖЫПкЛсГіЯжЖЫПкеМгУЕФЮЪЬтЃЌФЧУДclusterФЃПщШчКЮБЃжЄЖЫПкВЛГхЭЛЕФФиЃП
ВщдФдДТыЗЂЯжЃЌhttpФЃПщЕФcreateServerМЬГаздnetФЃПщЁЃ
| util.inherits(Server,
net.Server); |
ЖјдкnetФЃПщжаЃЌlistenЗНЗЈЛсЕїгУlistenInClusterЗНЗЈЃЌlistenInClusterХаЖЯЕБЧАЪЧЗёЮЊmasterНјГЬЁЃ
lib/net.js
Server.prototype.listen
= function(...args) {
// ...
if (typeof options.port === 'number' || typeof
options.port === 'string') {
// ШчЙћlistenЗНЗЈжЛДЋШыСЫЖЫПкКХЃЌзюКѓЛсзпЕНетРя
listenInCluster(this, null, options.port | 0,
4, backlog, undefined, options.exclusive);
return this;
}
// ...
};
function listenInCluster(server, address, port,
addressType, backlog, fd, exclusive, flags)
{
if (cluster === undefined) cluster = require('cluster');
if (cluster.isMaster) {
// ШчЙћЪЧжїНјГЬдђЦєЖЏвЛИіЗўЮё
// ЕЋЪЧжїНјГЬУЛгаЕїгУЙ§listenЗНЗЈЃЌЫљвдУЛгазпетРявЛВН
server._listen2(address, port, addressType,
backlog, fd, flags);
return;
}
const serverQuery = {
address: address,
port: port,
addressType: addressType,
fd: fd,
flags,
};
// згНјГЬЛёШЁжїНјГЬЗўЮёЕФОфБњ
cluster._getServer(server, serverQuery, listenOnMasterHandle);
function listenOnMasterHandle(err, handle) {
server._handle = handle; // жиаДhandleЃЌЖдlistenЗНЗЈНјааСЫhack
server._listen2(address, port, addressType,
backlog, fd, flags);
}
} |
ПДЩЯУцДњТыПЩвджЊЕРЃЌеце§ЦєЖЏЗўЮёЕФЗНЗЈЮЊserver._listen2ЁЃдк_listen2ЗНЗЈжаЃЌзюжеЕїгУЕФЪЧ_handleЯТЕФlistenЗНЗЈЁЃ
function setupListenHandle(address,
port, addressType, backlog, fd, flags) {
// ...
this._handle.onconnection = onconnection;
var err = this._handle.listen(backlog || 511);
// ...
}
Server.prototype._listen2 = setupListenHandle;
// legacy alias |
ФЧУДcluster._getServerЗНЗЈЕНЕззіСЫЪВУДФиЃП
ЫббАЫќЕФдДТыЃЌЪзЯШЯђmasterНјГЬЗЂЫЭСЫвЛИіЯћЯЂЃЌЯћЯЂРраЭЮЊqueryServerЁЃ
// child.js
cluster._getServer = function(obj, options, cb)
{
// ...
const message = {
act: 'queryServer',
index,
data: null,
...options
};
// ЗЂЫЭЯћЯЂЕНmasterНјГЬЃЌЯћЯЂРраЭЮЊ queryServer
send(message, (reply, handle) => {
rr(reply, indexesKey, cb); // Round-robin.
});
// ...
}; |
етРяЕФrrЗНЗЈЃЌЖдЧАУцЬсЕНЕФ_handle.listenНјааСЫhackЃЌЫљгазгНјГЬЕФlistenЦфЪЕЪЧВЛЦ№зїгУЕФЁЃ
function rr(message,
indexesKey, cb) {
if (message.errno)
return cb(message.errno, null);
var key = message.key;
function listen(backlog) { // listenЗНЗЈжБНгЗЕЛи0ЃЌВЛдйНјааЖЫПкМрЬ§
return 0;
}
function close() {
send({ act: 'close', key });
}
function getsockname(out) {
return 0;
}
const handle = { close, listen, ref: noop, unref:
noop };
handles.set(key, handle); // ИљОнkeyНЋЙЄзїНјГЬЕФ handle
НјааЛКДц
cb(0, handle);
}
// етРяЕФcbЛиЕїОЭЪЧЧАУц_getServerЗНЗЈДЋШыЕФЁЃ ВЮПМжЎЧАnetФЃПщЕФlistenЗНЗЈ
function listenOnMasterHandle(err, handle) {
server._handle = handle; // жиаДhandleЃЌЖдlistenЗНЗЈНјааСЫhack
// ИУЗНЗЈЕїгУКѓЃЌЛсЖдhandleАѓЖЈвЛИі onconnection ЗНЗЈЃЌзюКѓЛсНјааЕїгУ
server._listen2(address, port, addressType,
backlog, fd, flags);
} |
жїНјГЬгызгНјГЬЭЈаХ
ФЧУДЕНЕздкФФРяЖдЖЫПкНјааСЫМрЬ§ФиЃП
ЧАУцЬсЕНЙ§ЃЌforkзгНјГЬЕФЪБКђЃЌЖдзгНјГЬНјааСЫinternalMessageЪТМўЕФМрЬ§ЁЃ
| worker.process.on('internalMessage',
internal(worker, onmessage)); |
згНјГЬЯђmasterНјГЬЗЂЫЭЯћЯЂЃЌвЛАуЪЙгУprocess.sendЗНЗЈЃЌЛсБЛМрЬ§ЕФmessageЪТМўЫљНгЪеЁЃетРяЪЧвђЮЊЗЂЫЭЕФmessageжИЖЈСЫcmd:
'NODE_CLUSTER'ЃЌжЛвЊcmdзжЖЮвдNODE_ПЊЭЗЃЌетбљЯћЯЂОЭЛсШЯЮЊЪЧФкВПЭЈаХЃЌБЛinternalMessageЪТМўЫљНгЪеЁЃ
// child.js
function send(message, cb) {
return sendHelper(process, message, null, cb);
}
// utils.js
function sendHelper(proc, message, handle, cb)
{
if (!proc.connected)
return false;
// Mark message as internal. See INTERNAL_PREFIX
in lib/child_process.js
message = { cmd: 'NODE_CLUSTER', ...message,
seq };
if (typeof cb === 'function')
callbacks.set(seq, cb);
seq += 1;
return proc.send(message, handle);
} |
masterНјГЬНгЪеЕНЯћЯЂКѓЃЌИљОнactЕФРраЭПЊЪМжДааВЛЭЌЕФЗНЗЈЃЌетРяactЮЊqueryServerЁЃqueryServerЗНЗЈЛсЙЙдьвЛИіkeyЃЌШчЙћетИіkeyЃЈЙцдђжївЊЮЊЕижЗ+ЖЫПк+ЮФМўУшЪіЗћЃЉжЎЧАВЛДцдкЃЌдђЖдRoundRobinHandleЙЙдьКЏЪ§НјааСЫЪЕР§ЛЏЃЌRoundRobinHandleЙЙдьКЏЪ§жаЦєЖЏСЫвЛИіTCPЗўЮёЃЌВЂЖджЎЧАжИЖЈЕФЖЫПкНјааСЫМрЬ§ЁЃ
// master.js
const handles = new Map();
function onmessage(message, handle) {
const worker = this;
if (message.act === 'online')
online(worker);
else if (message.act === 'queryServer')
queryServer(worker, message);
// other act logic
}
function queryServer(worker, message) {
// ...
const key = `${message.address}:${message.port}:
${message.addressType}:`
+
`${message.fd}:${message.index}`;
var handle = handles.get(key);
// ШчЙћжЎЧАУЛгаЖдИУkeyНјааЪЕР§ЛЏЃЌдђНјааЪЕР§ЛЏ
if (handle === undefined) {
let address = message.address;
// const RoundRobinHandle = require('internal/cluster/round_robin_handle');
var constructor = RoundRobinHandle;
handle = new constructor(key,
address,
message.port,
message.addressType,
message.fd,
message.flags);
handles.set(key, handle);
}
// ...
}
// internal/cluster/round_robin_handle
function RoundRobinHandle(key, address, port,
addressType, fd, flags) {
this.server = net.createServer(assert.fail);
// етРяЦєЖЏвЛИіTCPЗўЮёЦї
this.server.listen({ port, host });
// TCPЗўЮёЦїЦєЖЏЪБЕФЪТМў
this.server.once('listening', () => {
this.handle = this.server._handle;
this.handle.onconnection = (err, handle) =>
this.distribute(err, handle);
});
// ...
} |
ПЩвдПДЕНTCPЗўЮёЦєЖЏКѓЃЌСЂТэЖдconnectionЪТМўНјааСЫМрЬ§ЃЌЛсЕїгУRoundRobinHandleЕФdistributeЗНЗЈЁЃ
// RoundRobinHandle
this.handle.onconnection = (err, handle) =>
this.distribute(err, handle);
// distribute ЖдЙЄзїНјГЬНјааЗжЗЂ
RoundRobinHandle.prototype.distribute = function(err,
handle) {
this.handles.push(handle); // ДцШыTCPЗўЮёЕФОфБњ
const worker = this.free.shift(); // ШЁГіЕквЛИіЙЄзїНјГЬ
if (worker)
this.handoff(worker); // ЧаЛЛЕНЙЄзїНјГЬ
};
RoundRobinHandle.prototype.handoff = function(worker)
{
const handle = this.handles.shift(); // ЛёШЁTCPЗўЮёОфБњ
if (handle === undefined) {
this.free.push(worker); // НЋИУЙЄзїНјГЬжиаТЗХШыЖгСажа
return;
}
const message = { act: 'newconn', key: this.key
};
// ЯђЙЄзїНјГЬЗЂЫЭвЛИіРраЭЮЊ newconn ЕФЯћЯЂвдМАTCPЗўЮёЕФОфБњ
sendHelper(worker.process, message, handle,
(reply) => {
if (reply.accepted)
handle.close();
else
this.distribute(0, handle); // ЙЄзїНјГЬВЛФме§ГЃдЫааЃЌЦєЖЏЯТвЛИі
this.handoff(worker);
});
}; |
дкзгНјГЬжавВгаЖдФкВПЯћЯЂНјааМрЬ§ЃЌдкcluster/child.jsжаЃЌгаИіcluster._setupWorkerЗНЗЈЃЌИУЗНЗЈЛсЖдФкВПЯћЯЂМрЬ§ЃЌИУЗНЗЈЕФдкlib/internal/bootstrap/node.jsжаЕїгУЃЌетИіЮФМўЪЧУПДЮЦєЖЏnodeУќСюКѓЃЌгЩC++ФЃПщЕїгУЕФЁЃ
СДНг
function startup()
{
// ...
startExecution();
}
function startExecution() {
// ...
prepareUserCodeExecution();
}
function prepareUserCodeExecution() {
if (process.argv[1] && process.env.NODE_UNIQUE_ID)
{
const cluster = NativeModule.require('cluster');
cluster._setupWorker();
delete process.env.NODE_UNIQUE_ID;
}
}
startup() |
ЯТУцПДПД_setupWorkerЗНЗЈзіСЫЪВУДЁЃ
cluster._setupWorker
= function() {
// ...
process.on('internalMessage', internal(worker,
onmessage));
function onmessage(message, handle) {
// ШчЙћactЮЊ newconn ЕїгУonconnectionЗНЗЈ
if (message.act === 'newconn')
onconnection(message, handle);
else if (message.act === 'disconnect')
_disconnect.call(worker, true);
}
};
function onconnection(message, handle) {
const key = message.key;
const server = handles.get(key);
const accepted = server !== undefined;
send({ ack: message.seq, accepted });
if (accepted)
server.onconnection(0, handle); // ЕїгУnetжаЕФonconnectionЗНЗЈ
} |
зюКѓзгНјГЬЛёШЁЕНПЭЛЇЖЫОфБњКѓЃЌЕїгУnetФЃПщЕФonconnectionЃЌЖдSocketНјааЪЕР§ЛЏЃЌКѓУцОЭгыЦфЫћhttpЧыЧѓЕФТпМвЛжТСЫЃЌВЛдйЯИНВЁЃ
жСДЫЃЌclusterФЃПщЕФТпМОЭзпЭЈСЫЁЃ
|









