| БрМЭЦМі: |
| БОЮФРДздCSDNЃЌЮФеТНщЩмСЫWeexЕФПЊЗЂРћЦїweex-toolkit,вдМАдѕбљЪЙгУЁЂЭъГЩЯюФПЕФДюНЈЕШЯрЙиФкШнЁЃ |
|
РћЦї
ЫзЛАЫЕЃЌгћвЊЩЦЦфЪТЃЌБиЯШРћЦфЦїЁЃЖдгкПЊЗЂWeexЃЌБОШЫВЂВЛЭЦМіТуБМЁЃЪЪКЯЕФЙЄОпЃЌФмШУФуЕФЙЄзїЪТАыЙІБЖЁЃ
ПьЫйГЂЯЪ
ЮвУЧдкФкЭјЛЗОГДюНЈСЫвЛИідкЯпАцЕФБрМЦїКЭдЄРРЙЄОпЃЌШчЙћФуЯЃЭћПьЫйГЂЯЪКЭЪдДэЃЌПЩвджБНгЗУЮЪhttp://weex.alibaba-inc.com/playgroundЃЌВЂАДШчЯТВйзїМДПЩЃК
зМБИПЊЗЂЛЗОГ
дкНјааБОЕиПЊЗЂжЎЧАЃЌФуашвЊзМБИвЛЬЈФмЫГРћЕФдЫааBashУќСюЕФЕчФдЃЌБШШчMac Book ProЁЃЖјЖдгкжгЧщгкWindowsЕФЭЌбЇРДЫЕЃЌWeexЕФвЛЯЕСаЙЄОпВЂУЛгаЖдWindowsЛЗОГзіЬиЪтЕФЪЪХфЃЌЫљвдПМТЧWindowsЩЯЕФПЊЗЂЬхбщЃЌЧПСвНЈвщЯТдивЛИіcmderРДдЫааИїжжУќСюЁЃ
ЫЕЭъСЫУќСюааЙЄОпЃЌМђЕЅЧПЕїЯТШэМўЛЗОГЃКNodejs >= 4.0ЁЃ
ПЊЗЂЕЅЖРвГУц
WeexЕФвЛИігХЪЦОЭЪЧФмПьЫйПЊЗЂВЂЩЯЯпвЛИіПЩвддЫаагкШ§ЖЫЕФвГУцЃЌЮЊДЫаЇТЪОЭКмживЊЁЃЫљвдЃЌБОШЫвЊЭЦМіWeexЕФПЊЗЂРћЦїweex-toolkitЁЃЫќПЩвдЭЈЙ§npmАВзАЕНФуБОЛњЕФШЋОжЛЗОГжаЃЈnpm
i weex-toolkit -gЃЉЃЌДгДЫФуЕФПЊЗЂЛЗОГЯТОЭЖрСЫвЛИіЩёЦцЕФУќСюweexЁЃ
ЪзЯШЃЌПЩвдгУЩёЦцЕФweexУќСюДДНЈвЛИіЪОР§ЮФМўЃК
ШЛКѓЫцБуБрМЕуЪВУДЃЌБШШчЃК
<template>
<div class="wxc-hellworld">
<text>Hello Weex</text>
</div>
</template> |
НєНгзХЃЌдйдЫааФЧИіЩёЦцЕФУќСюЃК
УЭЕиЛсГіЯжвЛИіЫЖДѓЕФЖўЮЌТыЃЌУцЖдетИіЖўЮЌТыПЩЧЇЭђВЛвЊуТШІЃЌЧыКЭЮввЛЦ№ЯТдиСэвЛИіЩёЦїWeex PlaygroundЁЃ
ЕБгУетИіЩёЦцЕФЩЈТыЙІФмЩЈУшетИіЖўЮЌТыЃЌОЭФмеЙЪОHello WeexЕФНчУцЁЃВЂЧвЃЌетИіЖўЮЌТыжЇГжLive
ReloadЁЃШЮКЮЖдhelloworld.weЕФИФЖЏЖМЛсСЂМДИќаТPlaygroundРяЫљеЙЪОЕФНчУцЁЃ
ДюНЈЭъећЙЄГЬ
ВЛЙ§ЃЌЖдгкЮвУЧетаЉПрБЦЕФЧАЖЫЙЅГЧЪІРДЫЕЃЌЯждкШЮКЮвЛИіЛюЖЏЖМУЛЗЈгУвЛИіМђЕЅвГУцРДИуЖЈСЫЃЌИќВЛгУЫЕИДдгЕФВњЦЗЁЃЫљвдЃЌвЛИіДѓЖјУРЕФЙЄГЬВХФмЬюВЙаФжаЕФвѕгАЁЃ
ШчЙћФуЪЧвЛЮЛАпТэЦНЬЈЕФДигЕепЃЌНЈвщФужБНгЗУЮЪАпТэЦНЬЈЕФАяжњЮФЕЕРДЭъГЩетМўЪТЧщЃКWeex for ZebraЁЃ
ЖјНгЯТРДЃЌЮвЯывЊЯъЯИВћЪіЕФЪЧВЛвРРЕЬиЖЈЦНЬЈЕФWeexЙЄГЬДюНЈЁЃ
НХЪжМм
AdamЃЌбЧЕБЃЌвЛЧажЎдДЁЃгУСЫЫќЃЌдйвВВЛгУЕЃаФЕквЛДЮЕФоЯоЮСЫЁЃ
КУСЫЃЌгВЙуЪБМфНсЪјЁЃШчЙћвЊДюНЈЙЄГЬЃЌНХЪжМмЪЧВЛПЩЛёШЁЕФЁЃетРяЭЦМівЛИіНазіadamЕФНХЪжМмЙЄОпЃЌВЛНіМђЕЅвзгУЃЌЛЙФмЧсЫЩЕФДДНЈФуздМКЯывЊЕФНХЪжМмЁЃЪзЯШЃЌЭЈЙ§tnpmАВзАЁЃ
ШЛКѓЃЌЬэМгWeexЕФНХЪжМмЃК
НєНгзХЃЌдкФГИіПеФПТМЯТЃЌдЫааadamЃЌВЂИљОнЬсЪОЭъГЩГѕЪМЛЏЁЃ
НХБО
етИіНХЪжМмЙЄГЬжаАќКЌСЫЛљБОЕФПЊЗЂУќСюЃЌЭЈЙ§npm iАВзАЭъвРРЕКѓЃЌОЭПЩвдгУетаЉНХБОРДНјааПЊЗЂСЫЃК
зЊЛЛsrcФПТМЯТЕФЫљга.weЮФМўЃЌВЂЪфГіЕНdistФПТМЯТ
МрЬ§.weЮФМўЕФИФЖЏЃЌВЂИќаТdistФПТМЯТЕФЯргІЮФМў
дЄРРH5АцвГУц
дкфЏРРЦїжаДђПЊЃКhttp://localhost:3000/index.html?page=dist/welcome.js
ЩњГЩЙЉPlaygorundЩЈУшЕФЖўЮЌТы
| npm run qr --
src/welcome.we |
ЦєЖЏЕїЪдЙЄОпЃЈЯТУцгаеТНкОпЬхСФетИіЪТЃЉ
гаСЫЩЯЪіетУДЖрРћЦїЃЌПЊЗЂWeexецЪЧЬЋЫЌСЫЃЁ
ФЅЕЖВЛЮѓПГВёЙЄ
гаСЫРћЦїКѓЃЌЯШВЛУІзХЩЯЪжЃЌвђЮЊФуЛЙвЊЯШбЇЛсдѕУДВйПиЫќЃЌШУЫќФмгыФуШЫЦїКЯвЛЁЃ
ЮФМўФПТМНсЙЙ
WeexФЌШЯЕФЮФМўНсЙЙЪЧвЊЧѓЫљгаЯрЙиЕФweЮФМўЖМдкЭЌвЛМЖФПТМЯТЃЌвдБуФмзМШЗЕФевЕНвРРЕЕФзщМўЃЌР§ШчЃК
bar.we
<template>
<div><text>bar</text></div>
</template> |
foo.we
<template>
<div><bar></bar></div>
</template> |
ЕБашвЊЬсШЁвЛаЉЙЋЙВзщМўЃЌетаЉЙЋЙВзщМўвЛАуДцЗХдквЛИіЙЋЙВФПТМЯТЃЈздНЈЕФФПТМЛђЭЈЙ§npmАВзАЕНnode_modulesФПТМЃЉЃЌЖјетбљЕФЮФМўНсЙЙЃЌвВЭљЭљГіЯждквЛаЉЭъећЕФЯюФПЙЄГЬжаЃЌЕБЭЈЙ§ЩЯЪіЕФНХЪжМмДюНЈКУЪОР§ЙЄГЬЪжЃЌПЩвдЭЈЙ§ЧАЖЫЯАЙпЕФrequireЗНЪНРДв§гУЗЧЯрЭЌФПТМЯТЕФweЮФМўЃЌР§ШчЃК
components/bar.we
<template>
<div><text>bar</text></div>
</template> |
foo.we
<template>
<div><bar></bar></div>
</template>
<script>
require('./components/bar')
</script> |
ЦфБГКѓЕФдРэЃЌЪЕМЪЩЯЪЧећИізЊЛЛКЭДђАќЙ§ГЬНшжњСЫwebpackвдМАweex-loaderЃЌЪЙЕУЦфжаЕФФЃПщЛЏЖЈвхзёбБъзМЕФThe
way of CommonJSЁЃ
в§гУБъзМJSЮФМў
гаСЫwebpackЕФжњСІЃЌдкweЮФМўжаЃЌвВФмЧсЫЩЪЙгУвЛИіЗћКЯCommonJSЙцЗЖЕФJSЮФМўЁЃР§ШчЃЌЭЈЙ§npmАВзАСЫвЕНчNo.1ЕФЙЄОпПтlodashЃК
foo.we
<template>
<div><text>{{foo + bar}}</text></div>
</template>
<script>
var _ = require('lodash')
module.exports = {
data: {
foo: 'foo',
bar: 'bar'
},
created: function() {
_.assign(this.data, {foo: 'the foo', bar: 'the
bar'})
}
}
</script> |
гУЩЯTomorrow's cssКЭES2015
ШчНёЧАЖЫЕФПЊЗЂЃЌвЛАуРыВЛПЊдЄДІРэЦїЃЌБШШчpostcssКЭbabelЁЃдкФЌШЯЕФweЮФМўжаЃЌМДЪЙгаwebpackЕФжњСІЃЌетРрдЄДІРэЦївВЪЧЖдЦфЮоФмЮЊСІЕФЁЃЮЊДЫЃЌЮвУЧашвЊВ№ЗжетИіweЮФМўЃЌШУЫќБфГЩБъзМЕФhtmlЁЂcssЛђjsЮФМўЁЃ
bar.we.html
<template>
<div><text class="hello">Hello
{{name}}</text></div>
</template> |
bar.we.css
.hello {
font-size: 40px;
color: #333;
} |
bar.we.js
module.exports
= {
template: require('./foo.we.html'),
style: require('./foo.we.css'),
data: {
name: 'Weex'
}
} |
ВЂЧвЃЌашвЊдкwebpack.config.jsжаМгШыМИИіФмНтЮіетаЉЬиЪтЮФМўЕФloaderЃК
loaders: [
{
test: /\.we\.js(\?[^?]+)?$/,
loaders: ['weex?type=script']
},
{
test: /\.we\.css(\?[^?]+)?$/,
loaders: ['weex?type=style']
},
{
test: /\.we\.html(\?[^?]+)?$/,
loaders: ['weex?type=tpl']
}
] |
жЎКѓЃЌШдШЛЪЙгУrequireЕФЗНЪНРДв§гУетИі'we'ЮФМўЃК
foo.we
<template>
<div><bar></bar></div>
</template>
<script>
require('./bar.we.js')
</script> |
ЕБЗжИюСЫweЮФМўКѓЃЌФуОЭПЩвдЗжБ№ЖдЦфжаЕФcssЛђjsЮФМўЪЙгУФуЯывЊЕФдЄДІРэЦїЁЃ
ВЛЙ§ашвЊЬиБ№ЬсабЕФЪЧЃЌФПЧАweex-loaderжЛжЇГжmodule.exports={...}ЕФФЃПщЪфГіЗНЪНЃЌЫљвдМДЪЙФудкjsЮФМўжагУСЫES6ЕФimportЃЌЕЋЧыЮ№ЪЙгУexportРДЕМГіФЃПщ
ДЌЕНЧХЭЗздШЛжБ
дкЪЕМЪНјааWeexПЊЗЂЪБЃЌВЛУтгіЕНвЛаЉСюШЫРЇЛѓЕФЮЪЬтЁЃСэЭтЃЌвВгаПЩФмаДЕФДњТыУЛФЧУДОЋеПЖјЪЙЕУЙЄГЬжЪСПЛђВњЦЗадФмДяВЛЕНдЄЦкЁЃБЪепзїЮЊjs-frameworkЕФжївЊПЊЗЂепжЎвЛЃЌЫфШЛвВУЛаДЙ§ЖрЩйВњЦЗДњТыЃЌЕЋЦОНшЖдjs-frameworkЕФЩюШыРэНтЃЌвдМАЖджкЖрвЕЮёЕБжаВлЕуЕФЦЪЮіЃЌОЁСПИјДѓМвГЪЯжвЛаЉПЊЗЂЩЯЕФЪЕМљЗНАИЁЃВЛЧѓзюМбЃЌЕЋЧѓзюЪЕгУЁЃЃЈзЂЃКвдЯТЙлЕуЃЌВЛЗжЯШКѓЃЉ
ЕїгУnativeЬсЙЉЕФФЃПщЗНЗЈ
WeexЕФДњТыБОЩэЪЧдЫаадкjsЕФruntimeЯТЕФЃЌЫљвдЮЊСЫКЭnativeНјааЭЈбЖЃЌОЭашвЊНшгЩhybridЕФЗНЪНЁЃЦфжаЃЌЖдгкnativeЬсЙЉЕФвЛЯЕСаФЃПщЗНЗЈЃЌОЭашвЊгУвЛжжЬиЪтЃЌЕЋжБЙлЕФЗНЪНРДЕїгУЁЃ
дБОЃЌWeexжаМЏГЩСЫвЛаЉдЄЖЈвхЕФAPIЃЌР§Шчthis.$sendMtopЁЃЕЋетаЉдЄЖЈвхAPIЕФЮЌЛЄГЩБОЙ§ИпЃЌвђДЫдкзюаТЩѕжСвдКѓЕФWeexАцБОжаЃЌЛсНЅНЅЗЯЦњетРрдЄЖЈвхЕФAPIЃЌЖјИФгУИќМгЭЈгУЕФЗНЪНЃК
var stream =
require('@weex-module/stream')
module.exports = {
ready: function() {
if (stream && stream.sendMtop) {
stream.sendMtop(params, callback)
} else {
console.error('stream.sendMtop is invalid')
}
}
} |
етРягждйДЮЧыГіСЫЭђФмЕФrequireЃЌВЛЙ§КЭЦеЭЈЕФrequireВЛЭЌЕФЪЧЃЌашвЊжИЖЈЬиЖЈЕФ@weex-moduleЧАзКЗНФме§ШЗЪЙгУЁЃ
ЩїгУЛђВЛгУвьВНКЏЪ§
ЮЊСЫНтЪЭвьВНКЏЪ§ЕФдкWeexжаЕФЮЃКІЃЌЪзЯШвЊРэНтдкWeexжаВњЩњЕФСНРрtaskЁЃвЛРрЃЌЪЧгЩWeexПижЦЕФjsКЭnativeНЛЛЅЪБВњЩњЕФtaskЃЈвдЯТМђГЦWeexЕФtaskЃЉЃЌБШШчвЛЯЕСавьВНЕїгУnativeФЃПщЗНЗЈЃЌЛђепЕуЛїЪТМўЕШЁЃвЛРрЃЌЪЧЯЕЭГдЩњЕФtaskЃЈвдЯТМђГЦдЩњЕФtaskЃЉЃЌБШШчsetTimeoutЃЌPromiseЁЃдкWeexЕФtaskжаИќаТЪ§ОнЪБЃЌWeexПЩвдздЖЏИќаТViewЁЃЖјдкдЩњЕФtaskжаЃЌвђЮЊWeexЩЅЪЇСЫПижЦШЈЃЌЫљвдЮоЗЈзіЕНздЖЏИќаТЁЃетОЭЕМжТЃЌдкдЩњЕФtaskжаВњЩњЕФdiffЃЌЛсжЭСєжБЕНЯТвЛДЮWeexЕФtaskВХЛсБЛДЅЗЂИќаТViewЁЃДгБэУцЩЯПДЃЌОЭЪЧдкетаЉдЩњЕФtaskжаИФБфЪ§ОнКѓЃЌВЂУЛгаМАЪБЗДгІЕНViewЩЯЁЃЮЊСЫЃЌБмУтетИіЮЪЬтЕФВњЩњЃЌФПЧАРДЫЕВЂВЛЭЦМіЪЙгУPromiseЁЃЖјЖдгкsetTimeoutРДЫЕЃЌПЩвдЪЙгУnativeЬсЙЉЕФtimer.setTimeoutЕФФЃПщЗНЗЈЁЃ
ЩњУќжмЦкЕФвЛЖўШ§
WeexЕБЧААцБОЩшМЦСЫзщМўЕФЩњУќжмЦкЃЌвдЯТЕФвЛеХЭМПЩвдБШНЯжБЙлЕФИцЫпДѓМвдкећИіЩњУќжмЦкРяЖМзіСЫаЉЪВУДЪТЧщЃК
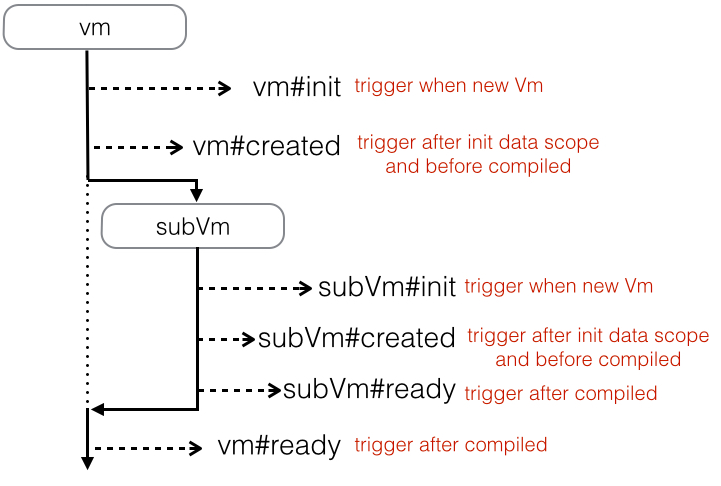
ФЧУДдкетаЉЩњУќжмЦкЕФHookРяЃЌПЩвдзіФФаЉЪТЧщФиЃК
дкinitжаПЩвдНјааЪ§ОнЧыЧѓЃЌБШШчmtopЁЃЕЋетИіЪБКђЩЯЯТЮФжаЛЙУЛгаdataЖдЯѓЃЌЭЌЪБвВВЛНЈвщдкжЎКѓЕФШЮКЮНзЖЮИФБфdataЕФЪ§ОнНсЙЙЁЃ
дкcreatedжаЃЌПЩвдЖдdataНјааВйзїСЫЃЌЧвДЫЪБИќаТЪ§ОнВЛЛсВњЩњЖргрЕФdiffЃЌЕЋЧаМЩвВВЛФмИќИФdataЕФЪ§ОнНсЙЙЁЃСэЭтЃЌПЩвдЭЈЙ§this.$onРДМрЬ§згзщМўЕФdispatchЁЃ
дкreadyжаЃЌДЫЪБзгзщМўвбОreadyЃЌПЩвдЛёШЁзгзщМўЕФVmЖдЯѓСЫЁЃЖјДЫЪБЃЌШчЙћИќаТЪ§ОнЃЌЛсВњЩњЖргрЕФdiffЁЃ
ЬиБ№ЬсабЃКетШ§ИіНзЖЮЃЌЖМЪЧВЛдЪаэИќИФdataЕФЪ§ОнНсЙЙЕФЁЃ
[Bug]ЩшжУбљЪНЕФФЌШЯжЕ
РДПДвЛИіЭЈЙ§ИФБфclassРДИФБфбљЪНЕФР§згЃК
<template>
<div>
<text class="{{className}}"
onclick="toggle">Hello Weex</text>
</div>
</template>
<style>
.normal {
font-size: 40px;
}
.hightlight {
font-size: 40px;
color: red;
}
</style>
<script>
module.exports = {
data: {
className: 'normal'
},
methods: {
toggle: function() {
if (this.className === 'normal') {
this.className = 'hightlight'
} else {
this.className = 'normal'
}
}
}
}
</script> |
ЩЯЪіР§згЃЌЭЈЙ§ЕуЛїРДЧаЛЛбљЪНУћЁЃЕЋЪЧФуЛсОЊЦцЕФЗЂЯжЃЌдкзюГѕвЛДЮЧаЛЛжЎКѓЃЌзжЬхЕФбеЩЋОЭвЛжБЪЧКьЩЋЕФСЫЁЃ
етЦфЪЕЪЧФПЧАWeexвЛИіbugЃЌЬжТлШчКЮаоИДЕФissueдкетРя#397ЁЃдвђОЭЪЧЃЌдкWeexжабљЪНБэбљЪНЕФЧаЛЛЃЌВЂВЛЛсЧхГ§дРДЕФбљЪНЁЃР§ШчЃЌЕБЧАбљЪНЪЧhighlightЃЌЦфжазжЬхбеЩЋЪЧredЃЌдкЧаЛЛЕНnormalЪБЃЌвђЮЊУЛгажИЖЈзжЬхбеЩЋЃЌНсЙћдРДЕФredбеЩЋОЭБЛБЃСєСЫЯТРДЖјВЂУЛгаЧхГ§ЕєЁЃЫљвдЃЌдкЩЯУцЕФР§згжаЮЊСЫБмПЊетИіbugЃЌашвЊЯдЪОЕФЩшжУзжЬхбеЩЋЃК
.normal {
font-size: 40px;
color: black;
} |
СэЭтЃЌЖдгкзюМбЪЕМљРДЫЕЃЌПЩвдЭЈЙ§зщКЯclassУћГЦЕФЗНЪНЃЌАбашвЊЧаЛЛЕФбљЪНЬсШЁГіРДЃК
<template>
<div>
<text class="common {{className}}"
onclick="toggle">Hello Weex</text>
</div>
</template>
<style>
.common {
font-size: 40px;
}
.normal {
color: black;
}
.hightlight {
color: red;
}
</style> |
дЊЫиЩЯЕФЪєадЖЈвх
WeexгЕгавЛЬзРрЫЦЧАЖЫПЊЗЂЯАЙпЕФDSLЃЌHTMLКЭCSSВПЗжвВЖМЛсзёбW3CЕФБъзМЁЃЦфжадЊЫиЩЯЕФЪєадЖЈвхЃЌЖдгкЗЧЧАЖЫЭЌбЇРДЫЕЛсгаКмЖрЮѓЧјЃЌетРяЮёБивЊЫЕУїЯТЁЃ
ЪєадУћБиаыШЋВПаЁаДЃЌПЩвдЪЙгУСЌНгЗћ-ЁЃ
ЪєаджЕЃЌОЁСПБЃжЄЪЧдЪМРраЭЃЌМДnumber/string/boolean/undefined/nullЁЃЖдЯѓРраЭЕФжЕвЛАугУгкДѓЪ§ОнСПЕФЪ§ОнАѓЖЈЁЃ
вЛаЉHTMLЮФеТРяЛсЭЦМідкЪєадЩЯгУdata-xxxЕФЗНЪНЃЌетРяВЂВЛашвЊЬивтМгdataЧАзКЃЌвђЮЊWeexЕФjsжаВЂУЛгаdatasetЕФAPIПЩЙЉЕїгУЁЃ
ИуЖЈзгзщМўЕФЪ§ОнАѓЖЈ
ГУШШДђЬњЃЌРДЫЕЯТзгзщМўЕФЪ§ОнАѓЖЈЁЃвђЮЊЪ§ОнАѓЖЈвВЪЧЭЈЙ§ЪєадРДЖЈвхЕФЃЌЫљвдЪзЯШвЊзёбЩЯвЛЖЮЫљЫЕЕФЙцдђЁЃ
АѓЖЈЪ§ОнЭЈЙ§ЪєадРДЖЈвхЃЌВЛНіашвЊдкЪЙгУЕФдЊЫиЩЯжИЖЈЪєадВЂАѓЖЈИИзщМўжаЕФЪ§ОнЃЌвВвЊдкзгзщМўЕФdataжажИЖЈЖдгІЕФМќЃЌВЂЧвдЊЫиЩЯЕФЪєадКЭзгзщМўжаЕФМќУћЕФЖдгІЙцдђЪЧЃКШчЙћЪєаджагаСЌНгЗћЃЌдђМќУћЮЊШЅЕєСЌНгЗћКѓЕФЭеЗхаДЗЈЃЌЗёдђШЋВПвдаЁаДУќУћЁЃ
ШчЙћНіНіашвЊИјзгзщМўДЋЕнЪ§ОнЃЌЖјЦфжаЕФЪ§ОнНсЙЙЖдИИзщМўЪЧЭИУїЕФЃЌФЧУДНЈвщжБНгЪЙгУвЛИіЪєадРДгГЩфЃЛШчЙћЃЌЪєадЪЧзгзщМўЕФвЛаЉЙІФмЃЈЧвЪ§СПаЁгкЕШгк5ИіЃЉЃЌдђПЩвдЖРСЂПЊРДЃЈЛљБОЩЯКЭAPIааЮЊЕФЩшМЦддђВюВЛЖрЃЉЃЌР§ШчЃК
<we-element
name="sub1">
<template>
<div><text>sub1</text></div>
</template>
<script>
module.exports = {
data: {
aMtopData: {}
}
}
</script>
</we-element>
<we-element name="sub2">
<template>
<div><text>sub2</text></div>
</template>
<script>
module.exports = {
data: {
option1: '',
option2: ''
}
}
</script>
</we-element>
<template>
<div>
<sub1
a-mtop-data="{{mtopdata}}"></sub1>
<sub2 option1="{{options.op1}}" options2="{{options.op2}}"></sub2>
</div>
</template>
<script>
module.exports = {
data: {
options: {
op1: 'op1',
op2: 'op2'
},
mtopdata: {}
},
created: function() {
var self = this
this.$sendMtop({...}, function(r) {
self.mtopdata = r.data
})
}
}
</script> |
БщРњГЄСаБэ
дкЮвУЧИїРрДѓаЭдЫгЊЛюЖЏЕФвГУцжаЃЌДѓМвЖдТЅВу/ПгЮЛетаЉДЪгІИУВЛФАЩњЁЃЖјетаЉУћДЪЕФНчУцЃЌЛљБОЖМвЊППбЛЗСаБэРДЭъГЩЁЃЖјбЛЗСаБэЕФадФмгжЪЧећИідЫгЊвГУцЕФЙиМќЁЃЫљвддкБщРњетбљЕФСаБэЛђепЪ§зщЕФЪБКђЃЌОЭашвЊвЛаЉММЧЩЁЃ
ЭЈГЃРДЫЕЃЌвђЮЊДцдкТЅВуЕФИХФюЃЌЖјТЅВуРягжЪЧЖрИіПгЮЛЃЌПгЮЛгжОГЃЪЧЫЋСаБІБДЃЌблГђзХетЕУгУИіШ§жибЛЗВХФмИуЖЈЁЃВЛЙ§ЪЕМЪЩЯЃЌЫЋСаБІБДПЩвдгХЛЏГЩВЛЪЙгУбЛЗЕФНсЙЙЁЃЕБШЛСЫЃЌЧАЖЫЕФЭЏбЅУЧвЛЖЈвЊЖдзХФуУЧЕФЗўЮёЖЫЭЏбЅБЃГжМсЖЈСЂГЁЃЌвЊЧѓЛёЕУЧхЮњЧве§ШЗЕФЪ§ОнНсЙЙЃЌШЗБЃЧАЖЫВЛашвЊЖдЪ§ОнНсЙЙзіЖўДЮДІРэЁЃ
ЭЈГЃЕФЪ§ОнНсЙЙКЭЖдгІЕФФЃАхвЛАуЪЧетбљЕФЃК
<template>
<div onclick="update">
<div
class="tabheader">
<div repeat="{{headers}}"
track-by="name" append="tree">
<text>{{name}}</text>
</div>
</div>
<div class="floor"
repeat="{{floor in floors}}" track-by="floorId">
<div class="items" repeat="{{items
in floor.items}}" track-by="lineId"
append="tree">
<text>{{items.list[0].name}}</text>
<text>{{items.list[1].name}}</text>
</div>
</div>
</div>
</template>
<style>
.tabheader {
flex-direction: row;
}
.items {
flex-direction: row;
}
</style>
<script>
module.exports = {
data: {
floors: [
{
floorId: 1,
name: 'f1',
items:[
{lineId: 1, list: [{itemId:1, name: 'i1'}, {itemId:2,
name: 'i2'}]},
{lineId: 2, list: [{itemId:3, name: 'i3'}, {itemId:4,
name: 'i4'}]}
]
}
]
},
computed: {
headers: function() {
return this.floors.map(function(v) {
return {name: v.name}
})
}
},
methods: {
update: function() {
this.floors[0].items.push(
{lineId: 3, list: [{itemId:5, name: 'i5'}, {itemId:6,
name: 'i6'}]},
{lineId: 4, list: [{itemId:7, name: 'i7'}, {itemId:8,
name: 'i8'}]}
)
this.floors.push({
floorId: 2,
name: 'f2',
items: [
{lineId: 5, list: [{itemId:9, name: 'i9'}, {itemId:10,
name: 'i10'}]},
{lineId: 6, list: [{itemId:11, name: 'i11'}, {itemId:12,
name: 'i12'}]}
]
})
}
}
}
</script> |
ЦфжаБШНЯГЃМћЕФЪ§ОнНсЙЙЮЪЬтЃЌБШШчitemsжЛЪЧвЛИівЛЮЌЪ§зщЁЃШчЙћФмдкЗўЮёЖЫОЭДІРэКУitemsЕФЖрЮЌЪ§зщЮЪЬтЃЌФЧУДЧАЖЫЕФаЇТЪЛсИпКмЖрЁЃ
дйзаЯИЦЪЮіЦфжаЕФФЃАхЃК
<div class="tabheader"
repeat="{{headers}}">
...
computed: {
headers: function() {
return this.floors.map(function(v) {
return {name: v.name}
})
}
} |
етРяАѓЖЈСЫвЛИіcomputedЬиадЕФЪ§ОнЁЃЕБФГРрЪ§ОнВЛЬЋЪЪКЯеЙЪОЕФЪБКђЃЌЭЦМіПЩвдгУcomputedЕФЗНЪНРДДяЕНЪ§ОндЄДІРэЕФФПЕФЃЌЖјВЛЪЧдкcreatedжаПдпъПдпъЕФЫувЛЗнаТЕФЪ§ОнНсЙЙГіРДЁЃ
...
<div
repeat="{{headers}}" track-by="name"
append="tree">
...
<div class="floor" repeat="{{floor
in floors}}" track-by="floorId">
<div class="items" repeat="{{items
in floor.items}}" track-by="lineId"> |
дкетШ§ИіrepeatжаЖМгУСЫtrack-byЁЃЫќЕФЬиЕуЪЧЃЌПЩвдМЧТМЪ§зщжаФГИіЯюЕФвЛИіжїМќЃЌВЂдкжЎКѓЕФИќаТжаИДгУетИіЬиЖЈЕФЯюЃЌЖјВЛЪЧжиЙЙећИіЪ§зщЁЃР§Шч
ТЅВу1діМгСНааПгЮЛ
this.floors[0].items.push(
{lineId: 3, list: [{itemId:5, name: 'i5'}, {itemId:6,
name: 'i6'}]},
{lineId: 4, list: [{itemId:7, name: 'i7'}, {itemId:8,
name: 'i8'}]}
) |
діМгвЛИіТЅВу
this.floors.push({
floorId: 2,
name: 'f2',
items: [
{lineId: 5, list: [{itemId:9, name: 'i9'}, {itemId:10,
name: 'i10'}]},
{lineId: 6, list: [{itemId:11, name: 'i11'}, {itemId:12,
name: 'i12'}]}
]
}) |
ШчЙћУЛгаЩшжУtrack-byЃЌФЧУДWeexЛсжиЙЙећИіЪ§зщЃЌЕМжТдЊЫиБЛЩОГ§КѓгжжиаТЬэМгЁЃЖјЬэМгСЫidзїЮЊtrack-byЕФжїМќКѓЃЌidЯрЭЌЕФдЊЫиЛсЭЈЙ§вЦЖЏЕФЗНЪНРДгХЛЏВйзїЁЃ
гХЛЏГЄСаБэ
ГЄСаБэЯраХДѓМвЖМзіЙ§ЁЃWeexжаЃЌЖдСаБэЕФгХЛЏвбОЗЧГЃНгНќдЩњЯЕЭГЕФСаБэСЫЃЌетИівЊЙщЙІгкЮвУЧЕФNativeЭХЖгЁЃЕЋМДЪЙгаСЫадФмВЛДэЕФСаБэЃЌЖдгкЪзЦСЕФфжШОЛЙЪЧгазЗЧѓЕФЁЃ
дкWeexжаЃЌвЊзіЮоОЁСаБэЦфЪЕЗЧГЃМђЕЅЃЌвђЮЊдкlistКЭscrollЕФдЊЫиЩЯЃЌвбОЪЕЯжСЫonloadmoreЪТМўЃЌетИіЪТМўЛсдкЙіЖЏДЅЕзЃЈЛђепРыЕзВПвЛЖЈЕФОрРыЃЉЪБДЅЗЂЃЌЫљвдетбљПДЦ№РДЃЌзіЮоОЁСаБэБфЕУЗЧГЃШнвзЁЃВЛЙ§ЃЌетбљЕФЮоОЁСаБэЬхбщОјЖдЫуВЛЩЯМЋжТЁЃетИіЪБКђЃЌПЩвдНшжњloadingетИізщМўЃЌВЂХфКЯonloadingЪТМўЃЌРДеЙЯжИќМгГіЩЋЕФЮоОЁСаБэЁЃ
<template>
<list>
<cell repeat="{{v in
items}}" track-by="id">
<text>{{v.name}}</text>
</cell>
<loading class="loading" onLoading="loadingHandler">
<text>{{loadingText}}</text>
</loading>
</list>
</template>
<script>
module.exports = {
data: {
index: 0,
size: 50,
count: 10,
loadingText: 'МгдиИќЖр...',
items: []
},
created: function() {
this.addPage()
},
methods: {
addPage: function() {
for (var i = 0; i < this.size; i++) {
var id = this.index * this.size + i
this.items.push({id: id, name: 'item-' + id})
}
this.index++
},
loadingHandler: function() {
if (this.index === this.count) {
this.loadingText = 'УЛгаИќЖрСЫ'
} else {
this.addPage()
}
}
}
}
</script> |
ЩшМЦгХауЕФWeexзщМў
дкWeexдЩњЙІФмдНРДдНЗсИЛЕФЧАЬсЯТЃЌПЊЗЂепПЩвдЩшМЦГіИїРрЗћКЯвЕЮёашЧѓЕФUIзщМўЃЌетаЉUIзщМўЛљБОПЩвдзёбБъзМЕФФЃПщЛЏПЊЗЂЃЌвбДяЕНИДгУКЭИпЖШЖЈжЦЕФФПЕФЁЃ
гУНХЪжМмРДГѕЪМЛЏWeexзщМўЕФВжПтдйКЯЪЪВЛЙ§СЫЁЃ
WeexЪЧвЛжжЪ§ОнЧ§ЖЏЕФЩшМЦПђМмЃЌзщМўВЂВЛЪЧЭЈЙ§APIРДБЉТЖааЮЊЃЌЖјЪЧЭЈЙ§Ъ§ОнАѓЖЈРДИјзщМўЩшжУааЮЊЁЃ
зщМўЕФЭЈаХЃЌПЩвдЭЈЙ§$dispath/$broadcastРДЭъГЩЃЌВЛЙ§етЕУИЖГівЛЕуЕуадФмЕФДњМлЁЃЖјдкИИзщМўФУЕНжБНгзгзщМўЕФЖдЯѓКѓЃЌЦфЪЕПЩвдЭЈЙ§$on/$emitРДМѕЩйадФмЕФПЊЯњЁЃ
ШчЙћзщМўашвЊИпЖШЖЈжЦUIЃЌПЩвдПМТЧЪЙгУcontent/slotБъЧЉЃЌОпЬхПЩвдВЮПМЯТwxc-marqueeЁЃ
НшгЩНХЪжМмГѕЪМЛЏWeexзщМўЙЄГЬЃЌПЩвдЧсЫЩЗЂВМЕНnpm/tnpmЃЌВЂЧвПЊЗЂепдкЭЈЙ§npm installАВзАКѓЃЌПЩвдЧсЫЩЕФвдrequireЗНЪНРДв§ШыетаЉзщМўЁЃ
ЕїЪдДњТыЃЈВщПДШежОЃЉ
WeexЮДРДЛсНгШыChrome Dev-toolsЃЌЩѕжСDebugger for IDEЃЌетаЉЖМПЩвдаЁаЁЦкД§ЯТЕФЁЃЖјЕБЯТПЩвдЭЈЙ§ЪфГіШежОЕФдЪМЗНЪНРДЕїЪдЁЃ
дкзюПЊЪМЕФРћЦївЛеТжаЃЌЮввбОШУДѓМвАВзАСЫweex-toolkitЃЌВЂгЕгаСЫweexУќСюЁЃФЧУДЯждквЊгУЫќРДПЊЦєЕїЪдЕФДѓУХЃК
ЛђепдкНХЪжМмЙЄГЬжадЫааЃК
етИіЪБКђЛсЪфГівЛЖЮБОЕиЕФipЕижЗЃЌдкфЏРРЦїРяЪфШыетИіЕижЗЃЌЛсеЙЪОвЛИіЖўЮЌТыЁЃгУЪжЬдdebugАќЛђPlaygroundЩЈТыжЎКѓЃЌОЭПЊЦєСЫЪфГіШежОФЃЪНЁЃ
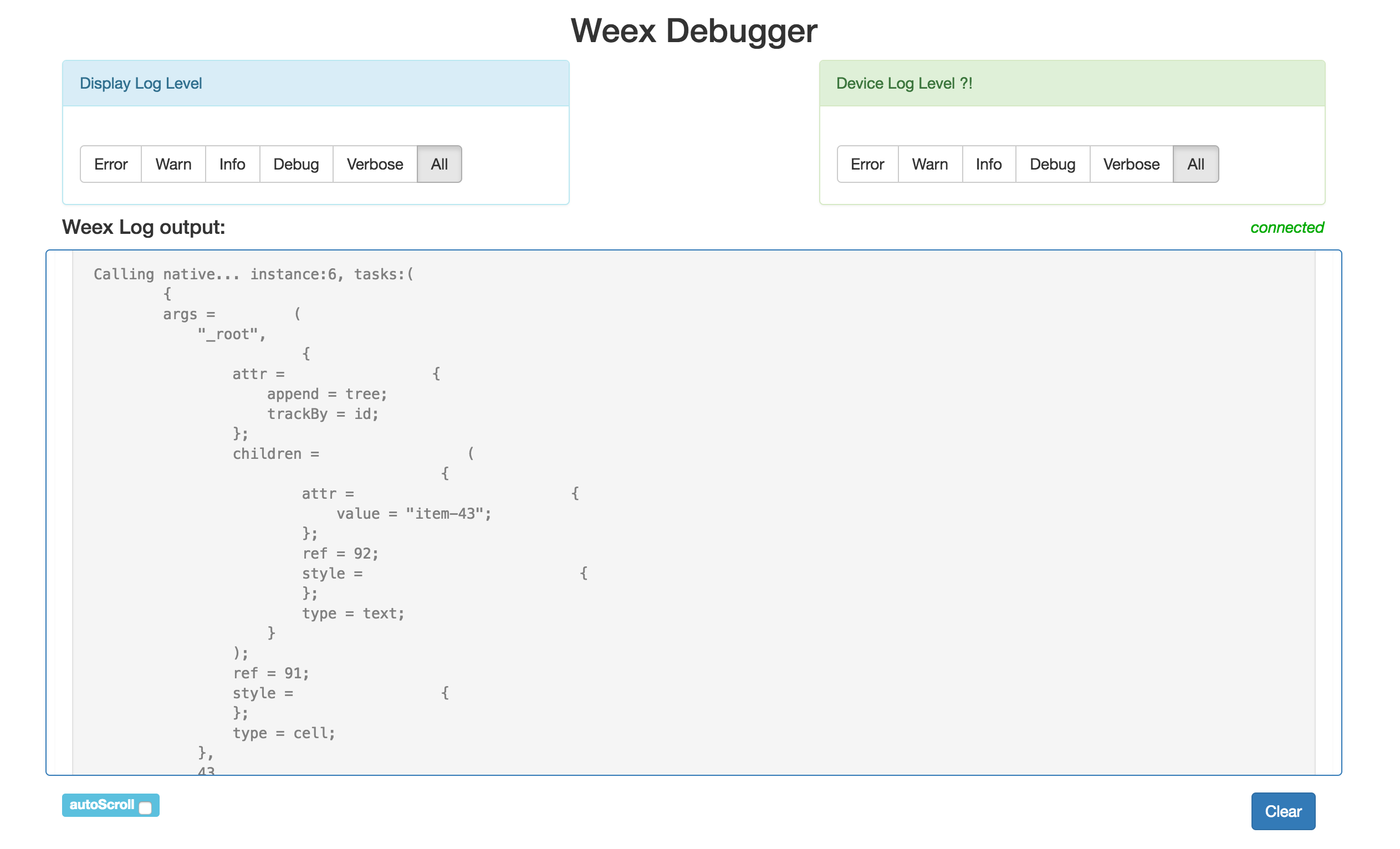
дкетИіНчУцжаЃЌФуПЩвдЭЈЙ§бЁдёЩшБИЕФШежОМЖБ№ЃЌвдМАеЙЪОЕФЪфГіМЖБ№РДевЕНФуЯывЊЕФШежОЁЃЭЌЪБдкДњТыжаЃЌПЩвдЭЈЙ§console.log/debug/info/warn/debugРДЪфГіЯргІМЖБ№ЕФШежОЁЃ
дкШежОdebugМЖБ№жаЃЌвд[js framework]ПЊЭЗЕФЃЌБуЪЧjs-frameworkЕФНтЮіВйзїЁЃдкШежОverboseМЖБ№жаЃЌвдCalling
JSКЭCalling NativeПЊЭЗЕФЃЌОЭЪЧjsКЭnativeЛЅЯрЭЈаХЕФВйзїЁЃ
|









