вЛЁЂV8ЕФРЌЛјЛиЪеЛњжЦгыФкДцЯожЦ
NodeЪЙгУchromeЕФV8зїЮЊJSНХБОв§ЧцЃЌвђДЫNodeЕФФкДцЙмРэгыV8ЙиЯЕКмУмЧаЁЃ
1.V8ЕФФкДцЯожЦ
вђЮЊV8ЪЧЮЊфЏРРЦїЛЗОГЩшМЦЕФЃЌЫљвдФкДцЯожЦКмаЁЃЌдк64ЮЛЯЕЭГЯТдМЮЊ1.4 GBЃЌ32ЮЛЯЕЭГЯТдМЮЊ0.7
GBЁЃ
2.V8ЕФЖдЯѓЗжХф
дкV8жаЃЌЫљгаЕФJavaScriptЖдЯѓЖМЪЧЭЈЙ§ЖбРДНјааЗжХфЕФЁЃШчЙћвбЩъЧыЕФЖбПеЯаФкДцВЛЙЛЗжХфаТЕФЖдЯѓЃЌНЋМЬајЩъЧыЖбФкДцЃЌжБЕНЖбЕФДѓаЁГЌЙ§V8ЕФЯожЦЮЊжЙЁЃ
жСгкV8ЮЊКЮвЊЯожЦЖбЕФДѓаЁЃЌБэВудвђЮЊV8зюГѕЮЊфЏРРЦїЖјЩшМЦЃЌВЛЬЋПЩФмгіЕНгУДѓСПФкДцЕФГЁОАЁЃЖдгкЭјвГРДЫЕЃЌV8ЕФЯожЦжЕвбОДТДТгагрЁЃЩюВудвђЪЧV8ЕФРЌЛјЛиЪеЛњжЦЕФЯожЦЁЃАДЙйЗНЕФЫЕЗЈЃЌвд1.5
GBЕФРЌЛјЛиЪеЖбФкДцЮЊР§ЃЌV8зівЛДЮаЁЕФРЌЛјЛиЪеашвЊ50КСУывдЩЯЃЌзівЛДЮЗЧдіСПЪНЕФРЌЛјЛиЪеЩѕжСвЊ1УывдЩЯЁЃетЪЧРЌЛјЛиЪежав§Ц№JavaScriptЯпГЬднЭЃжДааЕФЪБМфЃЌдкетбљЕФЪБМфЛЈЯњЯТЃЌгІгУЕФадФмКЭЯьгІФмСІЖМЛсжБЯпЯТНЕЁЃетбљЕФЧщПіВЛНіНіКѓЖЫЗўЮёЮоЗЈНгЪмЃЌЧАЖЫфЏРРЦївВЮоЗЈНгЪмЁЃвђДЫЃЌдкЕБЪБЕФПМТЧЯТжБНгЯожЦЖбФкДцЪЧвЛИіКУЕФбЁдёЁЃЁБ
3.РЌЛјЛиЪеЛњжЦ
V8ЪЙгУЗжДњЪНЛиЪеЃК АбФкДцЗжЮЊаТЩњДњКЭРЯЩњДњЁЃ ЖдаТЩњДњЪЙгУИДжЦЫуЗЈЃЈФкДцвЛЗжЖўЃЌЗжЮЊFromКЭToЃЉЃЌЖдРЯЩњДњЪЙгУБъМЧЧхГ§КЭБъМЧећРэЫуЗЈЁЃ

дкФЌШЯЧщПіЯТЃЌV8ЕФЖдЯѓЗжХфжївЊМЏжадкFromПеМфжаЁЃЖдЯѓДгFromПеМфжаИДжЦЕНToПеМфЪБЃЌЛсМьВщЫќЕФФкДцЕижЗРДХаЖЯетИіЖдЯѓЪЧЗёвбООРњЙ§вЛДЮScavengeЛиЪеЁЃШчЙћвбООРњЙ§СЫЃЌЛсНЋИУЖдЯѓДгFromПеМфИДжЦЕНРЯЩњДњПеМфжаЃЌШчЙћУЛгаЃЌдђИДжЦЕНToПеМфжаЁЃСэвЛИіХаЖЯЬѕМўЪЧToПеМфЕФФкДцеМгУБШЁЃЕБвЊДгFromПеМфИДжЦвЛИіЖдЯѓЕНToПеМфЪБЃЌШчЙћToПеМфвбОЪЙгУСЫГЌЙ§25%ЃЌдђетИіЖдЯѓжБНгНњЩ§ЕНРЯЩњДњПеМфжаЁЃжЎКѓFromКЭToЕиЮЛЛЅЛЛЁЃ
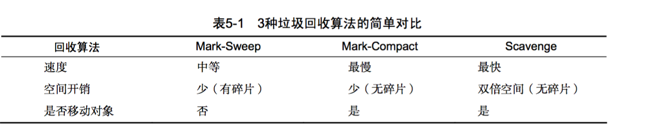
дкMark-SweepКЭMark-CompactжЎМфЃЌгЩгкMark-CompactашвЊвЦЖЏЖдЯѓЃЌЫљвдЫќЕФжДааЫйЖШВЛПЩФмКмПьЃЌЫљвддкШЁЩсЩЯЃЌV8жївЊЪЙгУMark-SweepЃЌдкПеМфВЛзувдЖдДгаТЩњДњжаНњЩ§Й§РДЕФЖдЯѓНјааЗжХфЪБВХЪЙгУMark-CompactЁЃ
діСПБъМЧ
ЮЊСЫБмУтГіЯжJavaScriptгІгУТпМгыРЌЛјЛиЪеЦїПДЕНЕФВЛвЛжТЕФЧщПіЃЌРЌЛјЛиЪеЕФ3жжЛљБОЫуЗЈЖМашвЊНЋгІгУТпМднЭЃЯТРДЃЌД§жДааЭъРЌЛјЛиЪеКѓдйЛжИДжДаагІгУТпМЃЌетжжааЮЊБЛГЦЮЊЁАШЋЭЃЖйЁБЃЈstop-the-worldЃЉЁЃ
дкV8ЕФЗжДњЪНРЌЛјЛиЪежаЃЌвЛДЮаЁРЌЛјЛиЪежЛЪеМЏаТЩњДњЃЌгЩгкаТЩњДњФЌШЯХфжУЕУНЯаЁЃЌЧвЦфжаДцЛюЖдЯѓЭЈГЃНЯЩйЃЌЫљвдМДБуЫќЪЧШЋЭЃЖйЕФгАЯьвВВЛДѓЁЃЕЋV8ЕФРЯЩњДњЭЈГЃХфжУЕУНЯДѓЃЌЧвДцЛюЖдЯѓНЯЖрЃЌШЋЖбРЌЛјЛиЪеЃЈfull
РЌЛјЛиЪеЃЉЕФБъМЧЁЂЧхРэЁЂећРэЕШЖЏзїдьГЩЕФЭЃЖйОЭЛсБШНЯПЩХТЃЌашвЊЩшЗЈИФЩЦЁЃ
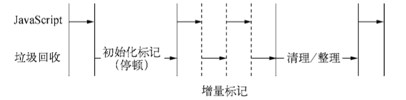
ЮЊСЫНЕЕЭШЋЖбРЌЛјЛиЪеДјРДЕФЭЃЖйЪБМфЃЌV8ЯШДгБъМЧНзЖЮШыЪжЃЌНЋдБОвЊвЛПкЦјЭЃЖйЭъГЩЕФЖЏзїИФЮЊдіСПБъМЧЃЈincremental
markingЃЉЃЌвВОЭЪЧВ№ЗжЮЊаэЖраЁЁАВННјЁБЃЌУПзіЭъвЛ
ЁАВННјЁБОЭШУJavaScriptгІгУТпМжДаавЛаЁЛсЖљЃЌРЌЛјЛиЪегыгІгУТпМНЛЬцжДаажБЕНБъМЧНзЖЮЭъГЩЁЃ
V8КѓајЛЙв§ШыСЫбгГйЧхРэЃЈlazy sweepingЃЉгыдіСПЪНећРэЃЈincremental
compactionЃЉЃЌШУЧхРэгыећРэЖЏзївВБфГЩдіСПЪНЕФЁЃЭЌЪБЛЙМЦЛЎв§ШыВЂааБъМЧгыВЂааЧхРэЃЌНјвЛВНРћгУЖрКЫадФмНЕЕЭУПДЮЭЃЖйЕФЪБМфЁЃ
4.ЖбЭтФкДц
NodeжаЕФФкДцЪЙгУВЂЗЧЖМЪЧЭЈЙ§V8НјааЗжХфЕФЁЃЮвУЧНЋФЧаЉВЛЪЧЭЈЙ§V8ЗжХфЕФФкДцГЦЮЊЖбЭтФкДцЁЃ
BufferЖдЯѓВЛЭЌгкЦфЫћЖдЯѓЃЌЫќВЛОЙ§V8ЕФФкДцЗжХфЛњжЦЃЌЫљвдвВВЛЛсгаЖбФкДцЕФДѓаЁЯожЦЁЃ
етвтЮЖзХРћгУЖбЭтФкДцПЩвдЭЛЦЦФкДцЯожЦЕФЮЪЬтЁЃ
ЮЊКЮBufferЖдЯѓВЂЗЧЭЈЙ§V8ЗжХфЃПетдкгкNodeВЂВЛЭЌгкфЏРРЦїЕФгІгУГЁОАЁЃдкфЏРРЦїжаЃЌJavaScriptжБНгДІРэзжЗћДЎМДПЩТњзуОјДѓЖрЪ§ЕФвЕЮёашЧѓЃЌЖјNodeдђашвЊДІРэЭјТчСїКЭЮФМўI/OСїЃЌВйзїзжЗћДЎдЖдЖВЛФмТњзуДЋЪфЕФадФмашЧѓЁЃ
ЖўЁЂФкДцаЙТЖ
ЭЈГЃдвђЃК
ЛКДц
ЖгСаЯћЗбВЛМАЪБ
зїгУгђЮДЪЭЗХ
1.ЩїгУФкДцзіЛКДц
БШШчunderscoreЕФmemorizeЗНЗЈЁЃ
ПЩвдРћгУНјГЬЭтЛКДцЃЌ БШШчRedisЛђепMemcached
2.ЖгСаЕФЮЪЬт
вЊМрПиЖгСаГЄЖШЃЌвЛЕЉЖбЛ§ЃЌвЊЭЈЙ§МрПиЯЕЭГЗЂГіОЏБЈ
СэвЛИіЗНАИЃК ИјвьВНЕїгУвЛИіГЌЪБЛњжЦЃЌДгЖјИјЖгСаЯћЗбЫйЖШвЛИіЯТЯоЁЃ
3.ОЭЪЧБеАќЕФЮЪЬтЁЃ
Ш§ЁЂДѓФкДцгІгУ
дкNodeжаЃЌВЛПЩБмУтЕиЛЙЪЧЛсДцдкВйзїДѓЮФМўЕФГЁОАЁЃгЩгкNodeЕФФкДцЯожЦЃЌВйзїДѓЮФМўвВашвЊаЁаФЃЌКУдкNodeЬсЙЉСЫstreamФЃПщгУгкДІРэДѓЮФМўЁЃ
streamФЃПщЪЧNodeЕФдЩњФЃПщЃЌжБНгв§гУМДПЩЁЃstreamМЬГаздEventEmitterЃЌОпБИЛљБОЕФздЖЈвхЪТМўЙІФмЃЌЭЌЪБГщЯѓГіБъзМЕФЪТМўКЭЗНЗЈЁЃЫќЗжПЩЖСКЭПЩаДСНжжЁЃNodeжаЕФДѓЖрЪ§ФЃПщЖМгаstreamЕФгІгУЃЌБШШчfsЕФcreateReadStream()КЭcreateWriteStream()ЗНЗЈПЩвдЗжБ№гУгкДДНЈЮФМўЕФПЩЖССїКЭПЩаДСїЃЌprocessФЃПщжаЕФstdinКЭstdoutдђЗжБ№ЪЧПЩЖССїКЭПЩаДСїЕФЪОР§ЁЃ
гЩгкV8ЕФФкДцЯожЦЃЌЮвУЧЮоЗЈЭЈЙ§fs.readFile()КЭfs.writeFile()жБНгНјааДѓЮФМўЕФВйзїЃЌЖјИФгУfs.createReadStream()КЭfs.createWriteStream()ЗНЗЈЭЈЙ§СїЕФЗНЪНЪЕЯжЖдДѓЮФМўЕФВйзїЁЃ
ЫФЁЂРэНтBuffer
1.ЛљБОгУЗЈ
гЩгкBufferЬЋЙ§ГЃМћЃЌNodeдкНјГЬЦєЖЏЪБОЭвбОМгдиСЫЫќЃЌВЂНЋЦфЗХдкШЋОжЖдЯѓЃЈglobalЃЉЩЯЁЃЫљвддкЪЙгУBufferЪБЃЌЮоаыЭЈЙ§require()МДПЩжБНгЪЙгУЁЃ
BufferЖдЯѓРрЫЦгкЪ§зщЃЌЫќЕФдЊЫиЮЊ16НјжЦЕФСНЮЛЪ§ЃЌМД0ЕН255ЕФЪ§жЕЁЃЪОР§ДњТыШчЯТЫљЪОЃК
| var
str = "ЩюШыЧГГіnode.js";
var buf = new Buffer(str, 'utf-8');
console.log(buf);
// => <Buffer e6 b7 b1 e5 85 a5 e6 b5
85 e5 87 ba 6e 6f 64 65 2e 6a 73>
|
гЩЩЯУцЕФЪОР§ПЩМћЃЌВЛЭЌБрТыЕФзжЗћДЎеМгУЕФдЊЫиИіЪ§ИїВЛЯрЭЌЃЌЩЯУцДњТыжаЕФжаЮФзждкUTF-8БрТыЯТеМгУ3ИідЊЫиЃЌзжФИКЭАыНЧБъЕуЗћКХеМгУ1ИідЊЫиЁЃ
BufferЪмArrayРраЭЕФгАЯьКмДѓЃЌПЩвдЗУЮЪlengthЪєадЕУЕНГЄЖШЃЌвВПЩвдЭЈЙ§ЯТБъЗУЮЪдЊЫиЃЌдкЙЙдьЖдЯѓЪБвВЪЎЗжЯрЫЦЃЌДњТыШчЯТЃК
|
var buf = new Buffer(100);
console.log(buf.length); // => 100
|
ЩЯЪіДњТыЗжХфСЫвЛИіГЄ100зжНкЕФBufferЖдЯѓЁЃПЩвдЭЈЙ§ЯТБъЗУЮЪИеГѕЪМЛЏЕФBufferЕФдЊЫиЃЌДњТыШчЯТЃК
етРяЛсЕУЕНвЛИіБШНЯЦцЙжЕФНсЙћЃЌЫќЕФдЊЫижЕЪЧвЛИі0ЕН255ЕФЫцЛњжЕЁЃ
жЕЕУзЂвтЕФЪЧЃЌШчЙћИјдЊЫиИГжЕВЛЪЧ0ЕН255ЕФећЪ§ЖјЪЧ
аЁЪ§ЪБЛсдѕбљФиЃПЪОР§ДњТыШчЯТЫљЪОЃК
| buf[20]
= -100;
console.log(buf[20]); // 156
buf[21] = 300;
console.log(buf[21]); // 44
buf[22] = 3.1415;
console.log(buf[22]); // 3
|
ИјдЊЫиЕФИГжЕШчЙћаЁгк0ЃЌОЭНЋИУжЕж№ДЮМг256ЃЌжБЕНЕУЕНвЛИі0ЕН255жЎМфЕФећЪ§ЁЃШчЙћЕУЕНЕФЪ§жЕДѓгк255ЃЌОЭж№ДЮМѕ256ЃЌжБЕНЕУЕН0~255ЧјМфФкЕФЪ§жЕЁЃШчЙћЪЧаЁЪ§ЃЌЩсЦњаЁЪ§ВПЗжЃЌжЛБЃСєећЪ§ВПЗжЁЃ
2.ФкДцЗжХф
BufferЖдЯѓЕФФкДцЗжХфВЛЪЧдкV8ЕФЖбФкДцжаЃЌЖјЪЧдкNodeЕФC++ВуУцЪЕЯжФкДцЕФЩъЧыЕФЁЃвђЮЊДІРэДѓСПЕФзжНкЪ§ОнВЛФмВЩгУашвЊвЛЕуФкДцОЭЯђВйзїЯЕЭГЩъЧывЛЕуФкДцЕФЗНЪНЃЌетПЩФмдьГЩДѓСПЕФФкДцЩъЧыЕФЯЕЭГЕїгУЃЌЖдВйзїЯЕЭГгавЛЖЈбЙСІЁЃЮЊДЫNodeдкФкДцЕФЪЙгУЩЯгІгУЕФЪЧдкC++ВуУцЩъЧыФкДцЁЂдкJavaScriptжаЗжХфФкДцЕФВпТдЁЃ
ЮЊСЫИпаЇЕиЪЙгУЩъЧыРДЕФФкДцЃЌNodeВЩгУСЫslabЗжХфЛњжЦЁЃslabЪЧвЛжжЖЏЬЌФкДцЙмРэЛњжЦЃЌзюдчЕЎЩњгкSunOSВйзїЯЕЭГЃЈSolarisЃЉжаЃЌФПЧАдквЛаЉ*nixВйзїЯЕЭГжагаЙуЗКЕФгІгУЃЌШчFreeBSDКЭLinuxЁЃ
МђЕЅЖјбдЃЌslabОЭЪЧвЛПщЩъЧыКУЕФЙЬЖЈДѓаЁЕФФкДцЧјгђЁЃslabОпгаШчЯТ3жжзДЬЌЁЃ
fullЃКЭъШЋЗжХфзДЬЌЁЃ
partialЃКВПЗжЗжХфзДЬЌЁЃ
emptyЃКУЛгаБЛЗжХфзДЬЌЁЃ
ЕБЮвУЧашвЊвЛИіBufferЖдЯѓЃЌПЩвдЭЈЙ§вдЯТЗНЪНЗжХфжИЖЈДѓаЁЕФBufferЖдЯѓЃК
new Buffer(size);
Nodeвд8 KBЮЊНчЯоРДЧјЗжBufferЪЧДѓЖдЯѓЛЙЪЧаЁЖдЯѓЃК
Buffer.poolSize = 8 * 1024;
етИі8 KBЕФжЕвВОЭЪЧУПИіslabЕФДѓаЁжЕЃЌдкJavaScriptВуУцЃЌвдЫќзїЮЊЕЅЮЛЕЅдЊНјааФкДцЕФЗжХфЁЃ
1.ЗжХфаЁЖдЯѓ
ШчЙћжИЖЈBufferЕФДѓаЁЩйгк8 KBЃЌNodeЛсАДееаЁЖдЯѓЕФЗНЪННјааЗжХфЁЃBufferЕФЗжХфЙ§ГЬжажївЊЪЙгУвЛИіОжВПБфСПpoolзїЮЊжаМфДІРэЖдЯѓЃЌДІгкЗжХфзДЬЌЕФslabЕЅдЊЖМжИЯђЫќЁЃвдЯТЪЧЗжХфвЛИіШЋаТЕФslabЕЅдЊЕФВйзїЃЌЫќЛсНЋаТЩъЧыЕФSlowBufferЖдЯѓжИЯђЫќЃК

дкЭМ6-2жаЃЌ slabДІгкemptyзДЬЌЁЃ
ЙЙдьаЁBufferЖдЯѓЪБЕФДњТыШчЯТЃК
new Buffer(1024);
етДЮЙЙдьНЋЛсШЅМьВщpoolЖдЯѓЃЌШчЙћpoolУЛгаБЛДДНЈЃЌНЋЛсДДНЈвЛИіаТЕФslabЕЅдЊжИЯђЫќЃК
| if
(!pool || pool.length - pool.used < this.length)
allocPool();
|
ЭЌЪБЕБЧАBufferЖдЯѓЕФparentЪєаджИЯђИУslabЃЌВЂМЧТМЯТЪЧДгетИіslabЕФФФИіЮЛжУЃЈoffsetЃЉПЊЪМЪЙгУЕФЃЌslabЖдЯѓздЩэвВМЧТМБЛЪЙгУСЫЖрЩйзжНкЃЌДњТыШчЯТЃК
| this.parent
= pool;
this.offset = pool.used;
pool.used += this.length;
if (pool.used & 7) pool.used = (pool.used
+ 8) & ~7; |

ЕБдйДЮДДНЈвЛИіBufferЖдЯѓЪБЃЌЙЙдьЙ§ГЬжаНЋЛсХаЖЯетИіslabЕФЪЃгрПеМфЪЧЗёзуЙЛЁЃШчЙћзуЙЛЃЌЪЙгУЪЃгрПеМфЃЌВЂИќаТslabЕФЗжХфзДЬЌЁЃ
2.ЗжХфДѓBufferЖдЯѓ
ШчЙћашвЊГЌЙ§8 KBЕФBufferЖдЯѓЃЌНЋЛсжБНгЗжХфвЛИіSlowBufferЖдЯѓзїЮЊslabЕЅдЊЃЌетИіslabЕЅдЊНЋЛсБЛетИіДѓBufferЖдЯѓЖРеМЁЃ
| //
Big buffer, just alloc one
this.parent = new SlowBuffer(this.length);
this.offset = 0; |
етРяЕФSlowBufferРрЪЧдкC++жаЖЈвхЕФЃЌЫфШЛв§гУbufferФЃПщПЩвдЗУЮЪЕНЫќЃЌЕЋЪЧВЛЭЦМіжБНгВйзїЫќЃЌЖјЪЧгУBufferЬцДњЁЃ
ЩЯУцЬсЕНЕФBufferЖдЯѓЖМЪЧJavaScriptВуУцЕФЃЌФмЙЛБЛV8ЕФРЌЛјЛиЪеБъМЧЛиЪеЁЃЕЋЪЧЦфФкВПЕФparentЪєаджИЯђЕФSlowBufferЖдЯѓШДРДздгкNodeздЩэC++жаЕФЖЈвхЃЌЪЧC++ВуУцЩЯЕФBufferЖдЯѓЃЌЫљгУФкДцВЛдкV8ЕФЖбжаЁЃ
3.BufferЕФзЊЛЛКЭЦДНг
зжЗћДЎКЭBufferжЎМфПЩвдЛЅЯрзЊЛЛЃЌжЛвЊЖЈвхБрТыРраЭМДПЩЁЃ
е§ШЗЕФЦДНгЗНЪНЪЧгУвЛИіЪ§зщРДДцДЂНгЪеЕНЕФЫљгаBufferЦЌЖЮВЂМЧТМЯТЫљгаЦЌЖЮЕФзмГЄЖШЃЌШЛКѓЕїгУBuffer.concat()ЗНЗЈЩњГЩвЛИіКЯВЂЕФBufferЖдЯѓЁЃ
4.BufferгыадФм
BufferдкЮФМўI/OКЭЭјТчI/OжадЫгУЙуЗКЃЌгШЦфдкЭјТчДЋЪфжаЃЌЫќЕФадФмОйзуЧсжиЁЃдкгІгУжаЃЌЮвУЧЭЈГЃЛсВйзїзжЗћДЎЃЌЕЋвЛЕЉдкЭјТчжаДЋЪфЃЌЖМашвЊзЊЛЛЮЊBufferЃЌвдНјааЖўНјжЦЪ§ОнДЋЪфЁЃдкWebгІгУжаЃЌзжЗћДЎзЊЛЛЕНBufferЪЧЪБЪБПЬПЬЗЂЩњЕФЃЌЬсИпзжЗћДЎЕНBufferЕФзЊЛЛаЇТЪЃЌПЩвдКмДѓГЬЖШЕиЬсИпЭјТчЭЬЭТТЪЁЃ
|









