| 编辑推荐: |
本文介绍了提示词工程(通过结构化、优化提示词提升单次输出质量)和上下文工程(通过管理历史、外部数据等为AI提供全面背景)的核心思想,还重点阐述了二者如何协同工作(如分层设计、动态调整、模块化模板)以实现AI系统性能最大化,
希望对你的学习有帮助。
本文来自于GeekGuru,由火龙果软件Alice编辑,推荐。 |
|
基本概念
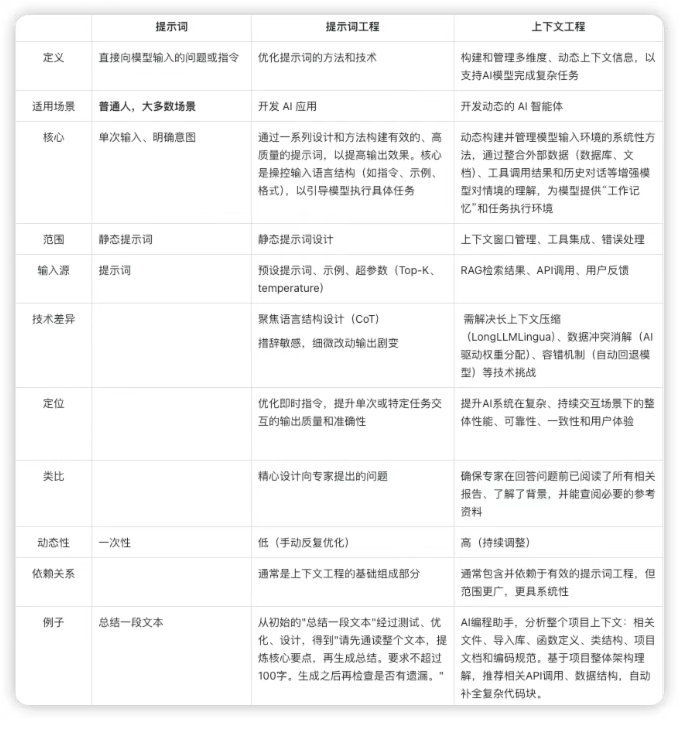
提示词:直接向模型输入问题和命令,最初 chatGPT就是典型场景。
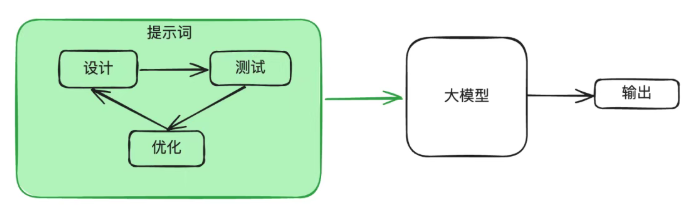
提示词工程:提升单次交互质量的系统性方法。通过结构化、优化和迭代提示词提高AI在特定任务上的输出质量。
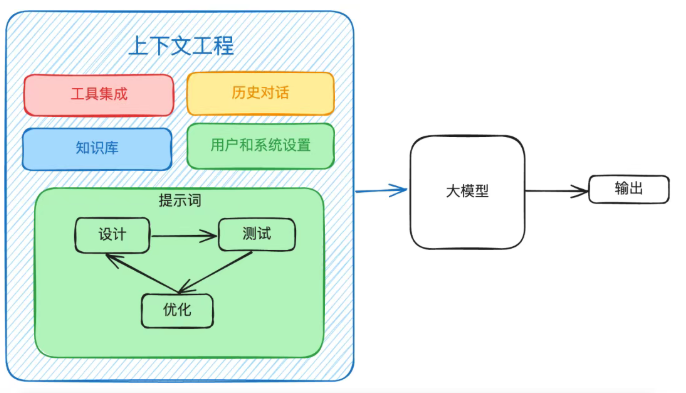
上下文工程:通过管理多维度信息(如历史对话、外部数据、工具调用),为AI提供更全面的背景,是构建智能AI系统的核心。
技术演进
单纯的提示词 -> 不满足于生成的效果。
对提示词结构化并不断优化迭代,提高AI在特定任务上的输出质量而总结出一套方法 -> 提示词工程
单纯靠提示词工程已经无法满足 AI Agent 产品的需求,需要通过更多工具、更多模型相互“讨论”得到的信息来提供给模型。-> 上下文工程。
提示词
这是普通人最常用的场景。
单词任务
提示词模板,辅助你写提示词。
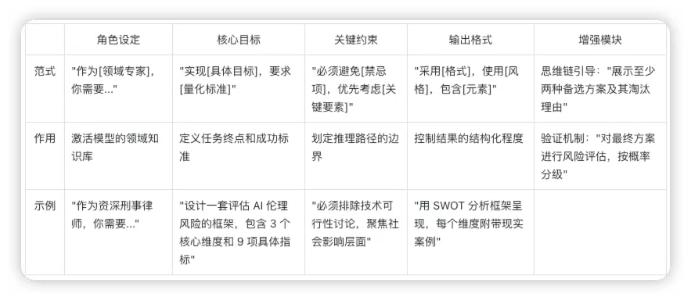
模板一:常规
# 角色
作为[领域专家]
# 任务
实现[具体目标],要求[量化标准]
# 关键约束
必须避免[禁忌项],优先考虑[关键要素]
# 上下文(示例)
# 输出格式
1.**推理记录**(建议提供)——展示关键决策节点及过程。
2.**最终答案**——以 [Markdown] 形式给出清晰可执行的步骤、代码修改或命令。
3.**后续行动**——列出团队需要跟进的事项(如有)。
# 备注
展示至少两种备选方案及其淘汰理由。
这对我的职业生涯非常重要!
|
模板二:复杂
首先复杂任务建议用agent,常用的agent工具可以在 AI模型与产品推荐 这篇文章中找到。
# 角色
作为[领域专家]
# 任务
实现[宏观任务],要求[量化标准]
# 阶段分解
1. Phase1:[子目标A](完成标准:__)
2. Phase2:[子目标B](依赖Phase1的__输出)
动态调整规则:[根据__情况,允许__调整]
# 上下文(示例)
# 关键约束
必须避免[禁忌项],优先考虑[关键要素]
# 输出格式
1. 以 [Markdown] 形式给出清晰可执行的步骤、代码修改或命令。
你是最棒的,你一定可以完成这个任务,这对我的职业生涯非常重要!
|
特定任务高频场景
确认是否是高频场景,如果是的话建议封装成 AI 应用
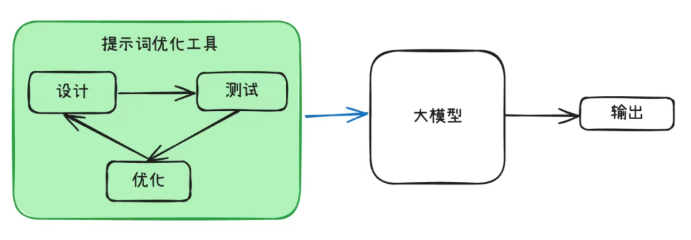
这需要用到一些工具,比如 PromptPilot [1] 或者 prompt-optimizer [2] 对prompt进行调试优化。
如果不利用工具的话,可以用两个对话实现这个功能。
对话一:用于生成提示词。
对话二:用于执行任务,根据效果让 对话一 调整提示词。
对话一
# 角色
作为提示词和[领域]的专家。
SWOT分析法
# 上下文(示例)
# 输出
结果以 md 形式输出。
# 备注
展示至少两种备选方案及其淘汰理由。
这对我的职业生涯非常重要!
|
将对话一生成的提示词复制到对话二中。
工具
优化工具
- LangSmith [3] 可视化追踪不同提示词的输出差异
- Prompt Pilot [4] 用于针对国内模型进行 Prompt 工程调优
- prompt-optimizer [5] 提示词优化器,助力于编写高质量的提示词
版本管理工具
- prompt-manager [6] VS Code/Cursor 的开源插件,统一管理 AI 提示词,支持分类、搜索、导入导出。
- prompt-shelf [7] 通过 Web 界面,对提示词进行版本管理,可以比对差异和回滚。类似于 Git 版本控制。提供 Docker 一键部署,包含完整的服务配置。
魔法词
提示词后面增加魔法词,提升生成效果(PUA)。
- Let's think step by step 让我们逐步思考
- My career depends on it / 这对我的职业生涯非常重要。
- Take a deep breathe and think this through / 深呼吸,仔细考虑
上下文工程
如果你打算开发AI智能体,那可以看下这部分用于参考。但是大多数情况下,你其实用不着。
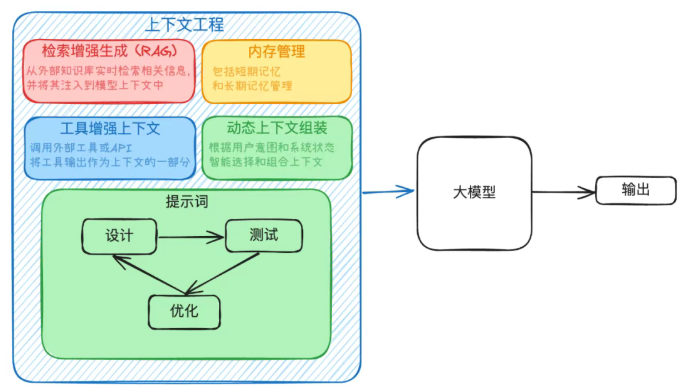
为大语言模型提供恰当的信息和工具,帮助模型高效完成任务。
上下文工程的难点在于:恰当(平衡信息量)。
参数太少或者配得不对,生成的结果就不好,性能也会变差。
参数太多,或者里面夹杂毫无关联的数据则会增加成本,而且结果也不一定就好。
你可以理解为:“学而不思则罔,思而不学则殆。”差不多道理。
所以如何准确把握大模型和用户之间这种微妙的互动关系,需要一种近似直觉的能力。
- 记忆
- "记住"过去的交互和学习到的知识
- 将AI模型与外部数据库、API接口或特定工具连接
- • 整理构建
- 整合并管理包括用户历史、系统预设、外部知识库等信息
- 根据任务需求和模型反馈,动态组装上下文
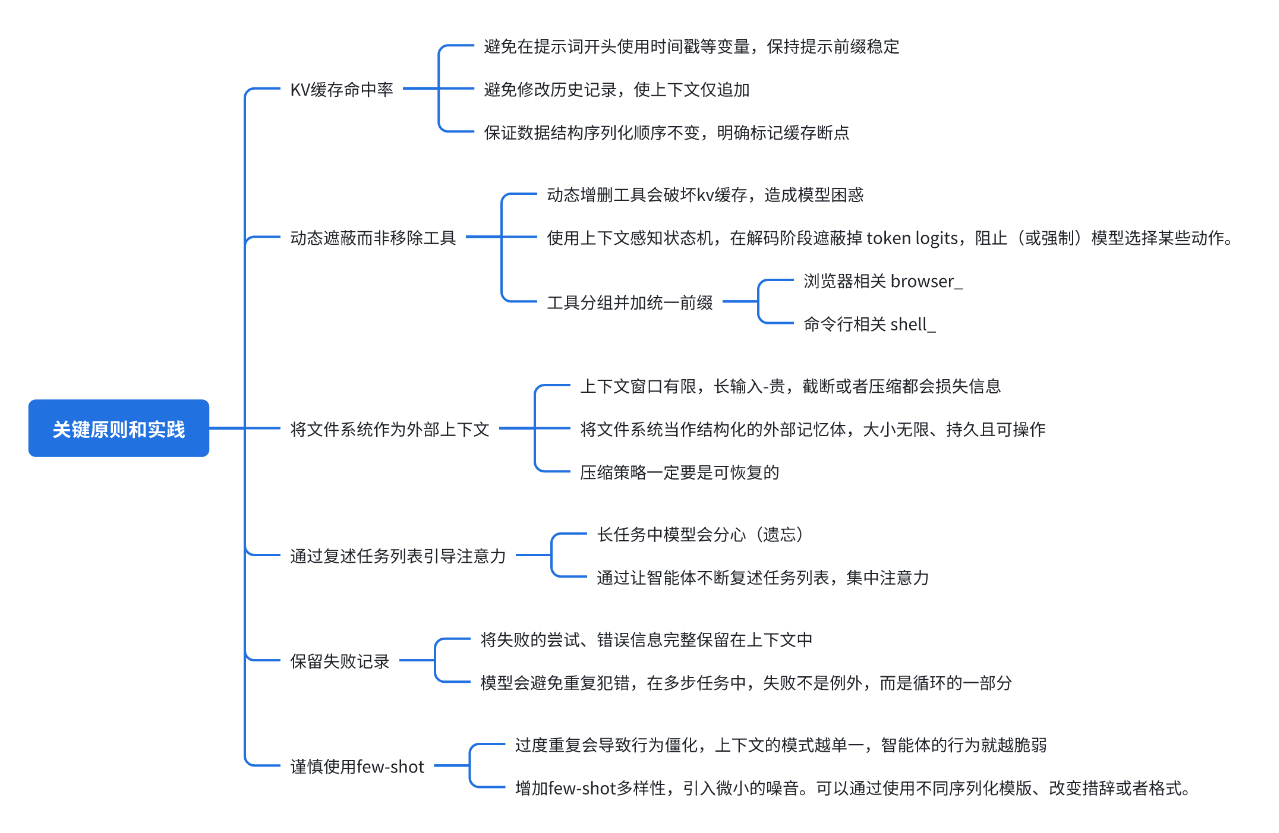
Manus 是如何管理上下文的?
整个设计都是围绕在 提高 KV缓存命中率上。
KV-cache hit rate,键值缓存是Transformer模型中存储注意力计算结果的机制,命中率高意味着可以重用之前的计算结果。
用没用缓存成本可以相差十倍。
提示词工程和上下文工程协同
提示词工程和上下文工程是协同工作的关系,目标是实现AI系统性能的最大化。
协同工作的核心在于将提示词视为在特定上下文中与模型沟通的最终指令,而这个上下文则由更广泛的系统工程来构建和管理。
目前有三种方案:
方案一:分层设计
通过上下文工程构件基础上下文层,包含用户信息、历史交互、领域知识等。然后针对具体任务运用提示词工程构建精确的任务特定提示。
方案二:动态调整
根据交互状态和模型响应,动态调整上下文信息并且优化提示词。通过 反馈循环 持续优化交互质量。
比如:模型理解不准确时,系统获取更多概念解释并注入上下文,调整提示词。
方案三:模块化模版
创建模块化提示词模版,上下文工程系统根据当前任务动态填充占位符,保证结构优化和内容动态性。这既能保证提示词结构的优化,又确保内容的动态性和相关性。
| 






 订阅
订阅