| 编辑推荐: |
本文主要介绍了GPU逻辑上的模块划分相关内容。希望对你的学习有帮助。
本文来自于微信公众号TrustZone ,由火龙果软件Linda编辑、推荐。 |
|
前言
上期我们介绍了一个基本的qq应该包含什么样的流水线,随着时代的发展,新的需求逐渐出现。我们就来看看如何从基本的图形流水线逐步扩充成现在的样子。
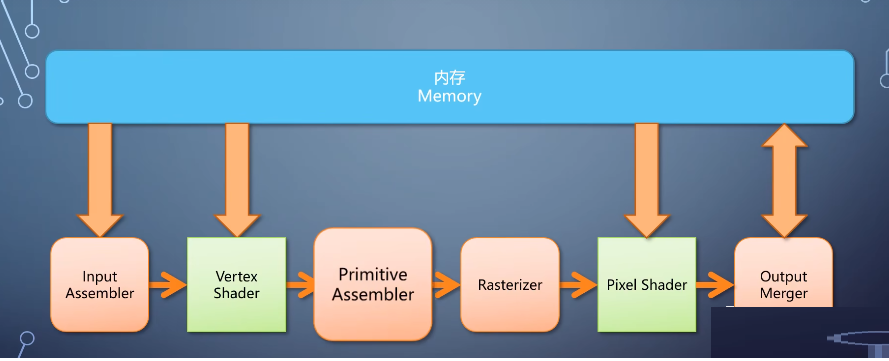
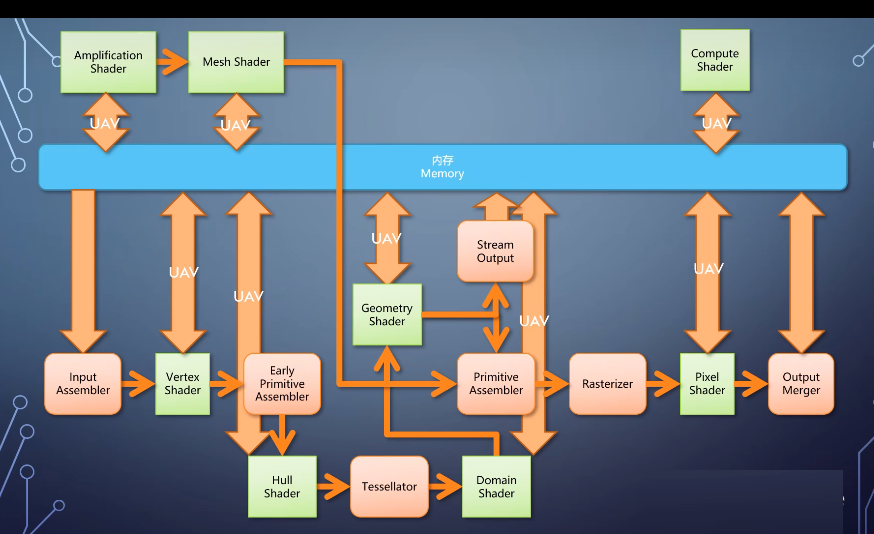
1-geometry shader
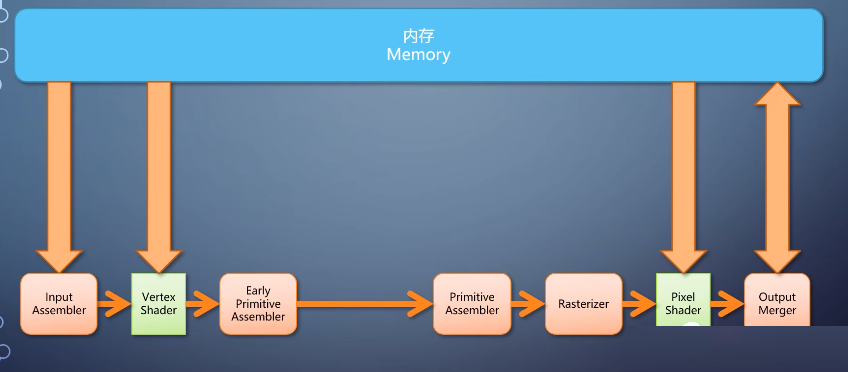
前面讲的vertex shader和pixel shader,都是单入单出结构,他们只接受一个输入单元。处理后输出一个,然而这样的流水线有个缺失的功能,如果我们要处理的单元不是顶点,也不是像素。
而是一个图元,那就做不了了。这个需求催生了一个新的shader,叫geometry shader,它相当于把primitive
Assembler给拆开了。
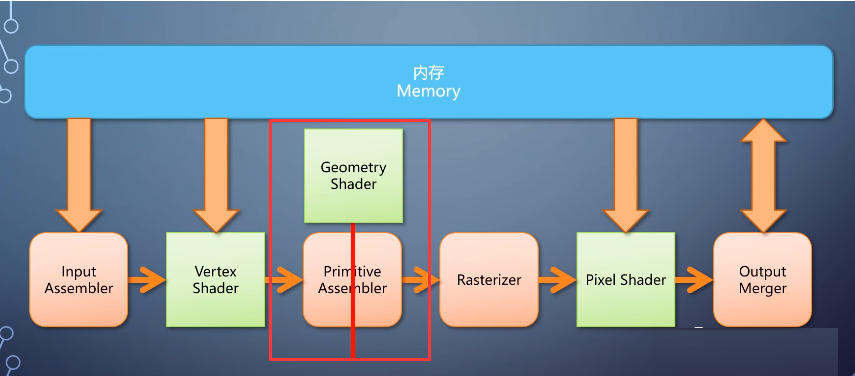
vertex shader输出处理后的顶点之后,整个primitive先被送入geometry shader,处理后往下做primitive
assembler的剩余事情。
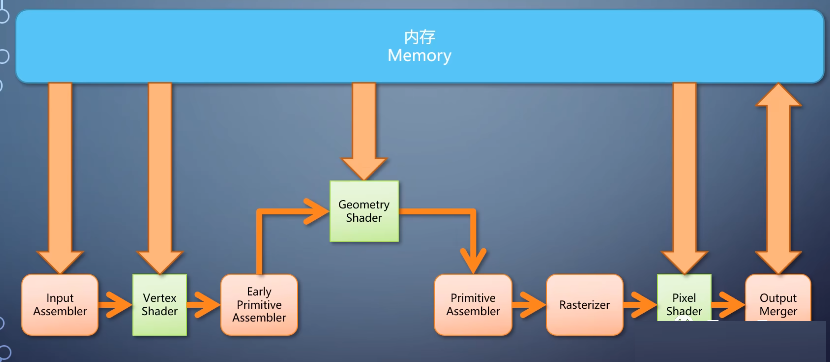
geometry shader和前两种shader的相比有个很大的特点是单入多出。
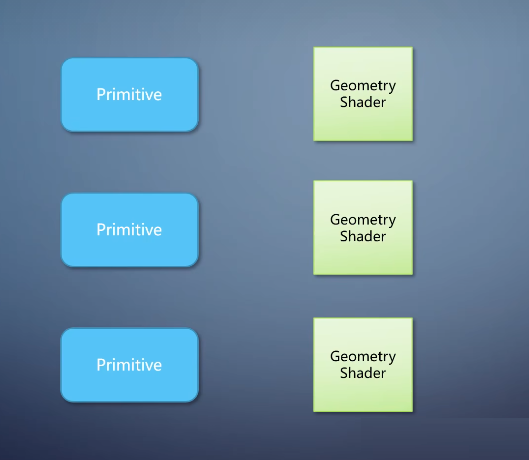
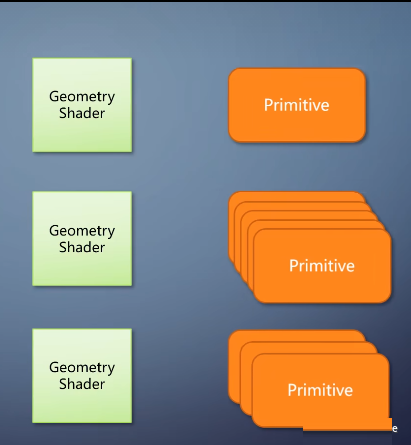
一个primitive进入geometry shader的可以输出多个primitive。因此我们可以把整个三角形移动位置,或者一个三角形切成多个。它的存在使得GPU可以做非均匀输出这样更加灵活多变的任务。
比如,第一个三角形输出一个三角形,第二个三角形输出五个,第三个三角形输出三个。
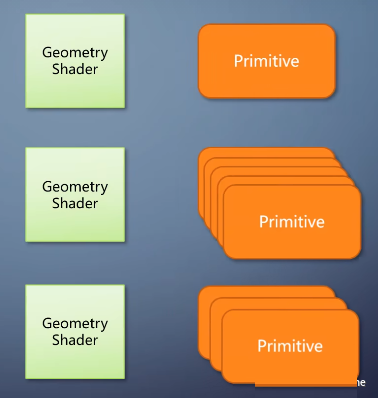
另一个不同之处在于,vertex shader和pixel shader都是必须的,如果你不指定,就无法串整条流水线。而geometry
shader是可选的,不指定就表示直接往后连。
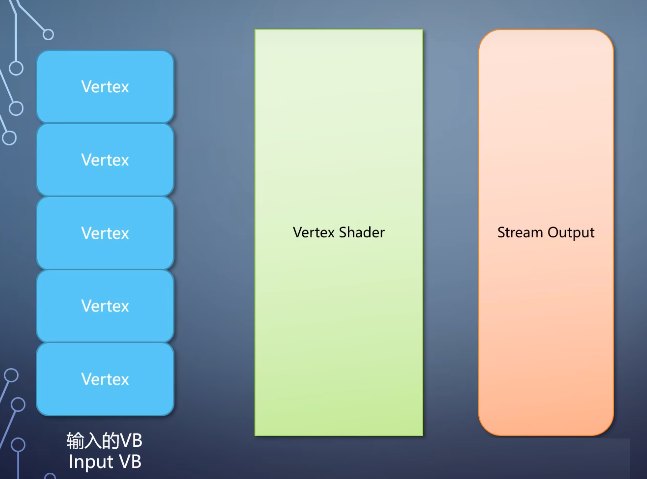
geometry shader输出的primitive不但可以进入primitive assembler完成整条线流水线。
也可以直接把数据输出到内存,这个过程称为stream output。当然你也可以不指定geometry
shader,从vertex shader直接输出,这就给了从流水线中间直接导出数据的能力。
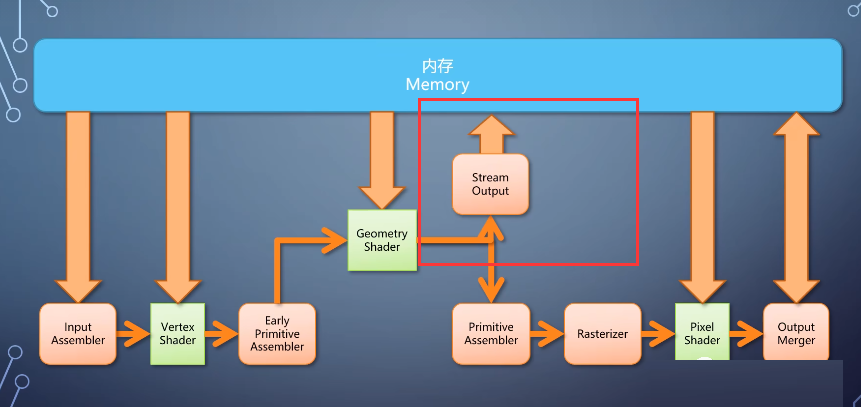
有时候我们把vertex buffer里的顶点处理一遍,存出去,之后反复多次使用,以减少重复计算。

但是这里有个问题,geometry shader看起来很灵活,可以做各种各样的事情。然而一用就发现性能奇低无比,正因为灵活,硬件无法做各种假设来优化性能。只能实现的非常保守。
尤其是把一个三角形切成多个的情况,本来是个算法固定的操作,但如果全面弄成可编程。硬件在执行之前甚至不知道你是要细分三角形,更没办法优化,随着三角形细分,这个需求逐步增加。
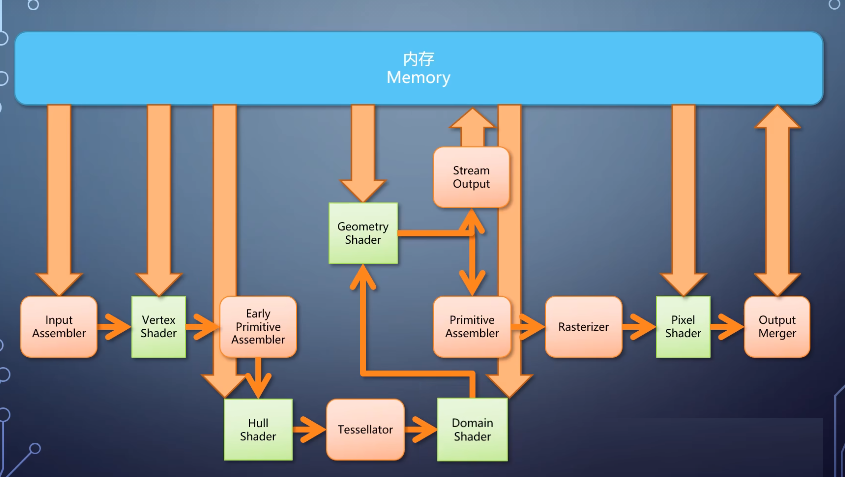
2-tessellation
gpu的流水线在vertex shader的之后,加入了专门的tessellation功能。它不是一个单元,而是三个,
• 首先有个可编程的hull shader,在里面可以指定每个图元需要如何被细分?比如内部分成多少个,每条边分成多少段,然后有一个固定流水线的tessellator。用固定的算法来执行细分,
• 紧接着是一个domain shader,根据细分的参数负责计算细分之后每个顶点的信息。这部分也是可选的,如果不启用就直接往下送。
这时候有人就想了,既然gpu有这样强大的计算能力,那不光可以图形渲染?还可以用作更加通用的并行计算,最早的做法是渲染一个覆盖屏幕的大三角形。在pixel
shader里面做通用并行计算,相当于每个pixel是一个线程。
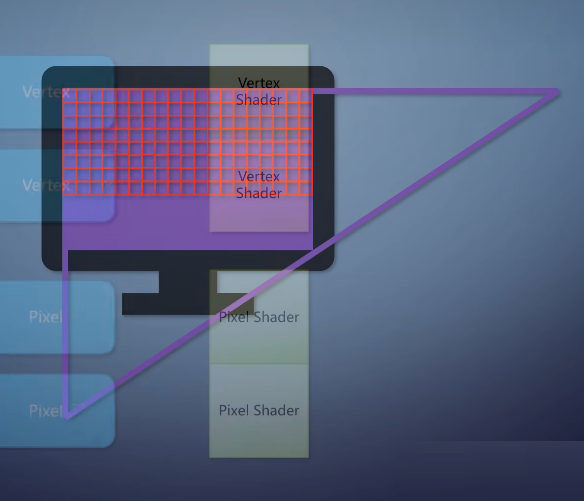
这样虽然能解决一些问题,但单入单出的限制仍然存在,并且仍然要让数据通过vertex shader、等整条流水线,
还是存在浪费,再加上这种方式使开发人员必须学习图形流水线。提高了门槛。
即便如此也仍然没有阻止2003年左右的探索者。这个发展起来的方向被称为gpgpu。
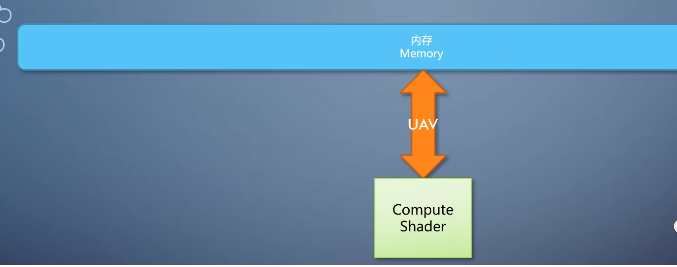
3-computer shader
用gpu做通用计算。这个需求进一步催生了有硬件支持的gpgpu。
可以多入多出。可以任意读取,可以任意写入,不再需要经过那些固定流水线的单元,利用gpu上的计算单元进行变形计算。这种shader叫做computer
shader,它独立于图形流水线单独存在,输入输出都是内存,限制,比图形流水线小。
整条计算流水线只有一步,使得开发难度和程序构成更接近传统,门槛低了很多。
至此gpu的流水线已经非常接近现在的能满足实时渲染和计算的各种求。
同时,gpu的流水线也变得非常复杂,还能更复杂点吗?能啊,在Rasterizer之前的部分Vertex
shader、hull shader、domain shader、geometry shader。他们存在的意义就是把几何数据该变化变化,该拆开拆开,最后送入Rasterizer。
但他们都无法脱离输入的几个数据,要渲染更复杂的物体,就得输入更复杂的数据。
要解决这个问题,就必须在少量甚至没有输入数据的情况下,让gpu自己生成大量复杂的数据。computer
shader的任意读写能做这件事情,但他不能接入Rasterizer,这个需求催生了amplification
shader和mesh shader。
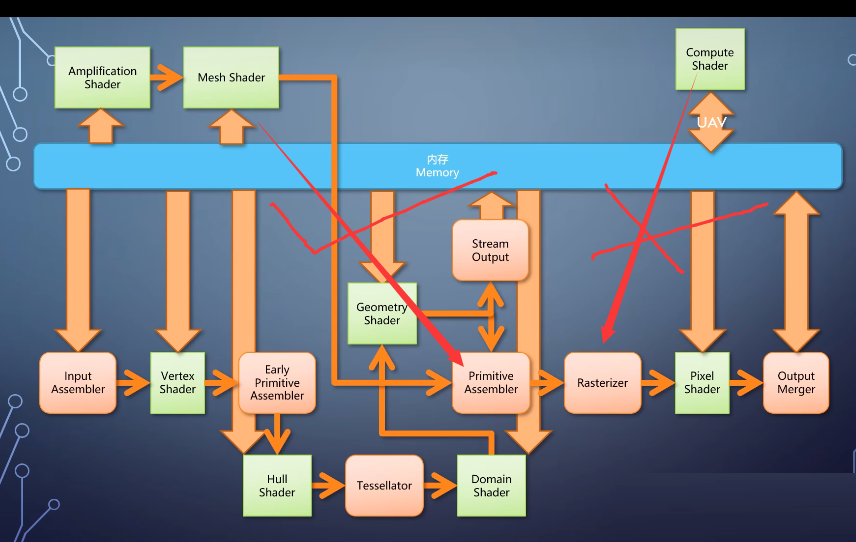
amplification shader负责指定执行多少次mesh shader,mesh shader负责产生几何体。这时候渲染的单元就不再是图元,而是一小块网格,称为mashlate。

当一个mashlate送到amplification shader,他可以决定这个mashlate是否需要进一步处理,如果要的话就往下送到mesh
shader。
产生带有丰富细节的一堆图元。虽然这两个shalder的就能取代原先那一堆,但支持的gpu和使用它的程序并不多,在现在的gqu里。他们能是和原先的流水线并存。
当然,需求的发展并没有停止,这些年来,游戏用了各种方法提高真实感的体验。
这些方法往往互相冲突,或者用了很多限制很大的hack,另一方面。光线跟踪这个古老但通用的技术一直没法很好的在GPU上应用,因为它不但计算量大。
4-光线跟踪
还跟基于光栅化的渲染方法有着完全不一样的流程,长期以来,研究人员一直在尝试如何用现有的gpu实现更高效的光线跟踪。这样的需求终于随着gpu提供光线跟踪的能力而得到了实质性的发展,这时候又出现了一条独立的流水线。包含了各种新类型的shalder。
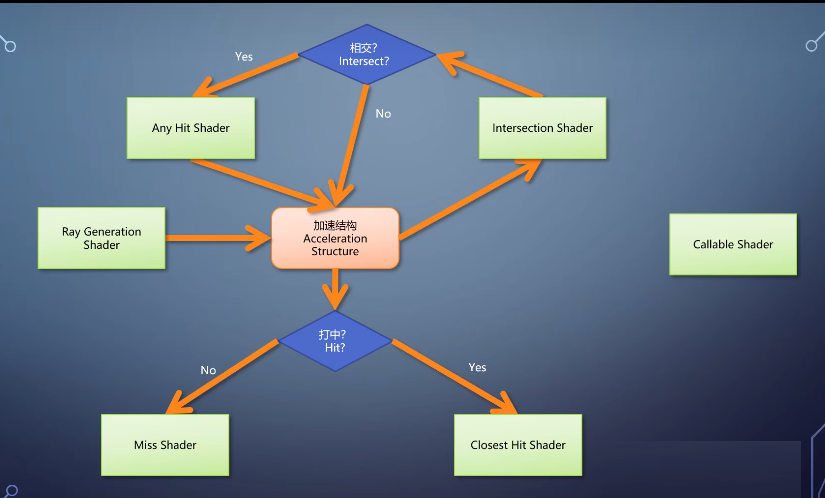
• ray generation shader:生成光线
• intersection shader:判定光线与物体是否相交
• any hit shader:在光线打到物体的时候,判定是否要继续往前走,
• closest hit shader:在光线打到物体的最近点计算颜色,
• miss shader:负责当光线没打到任何物体的时候计算颜色,
• 以及与它们配合使用的cllable shader,可以进行动态调用。
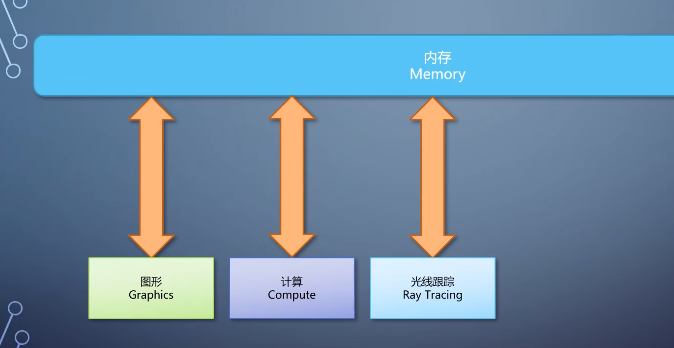
5-GPU逻辑模块组成
后面会有一期讲解硬件光线跟踪的细节。同样的思路也可以用在更多领域,比如,GPU加入了计算神经网络专用的tensor计算模块、视频编码,解码专用的模块等等都是独立的流水线。
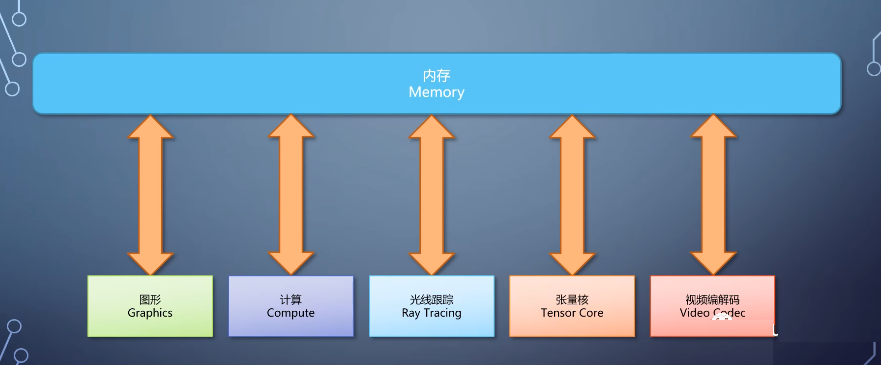
这里我们可以看到cpu和gpu的第二个大别,cpu的目的是一个通用模块,编程的时候一路往下写就是了。
GPU则分成多个模块,各有各的特点和用途,编程的时候就需要开发者对这些模块有比较明确的了解。在程序里安排如何使用它们。
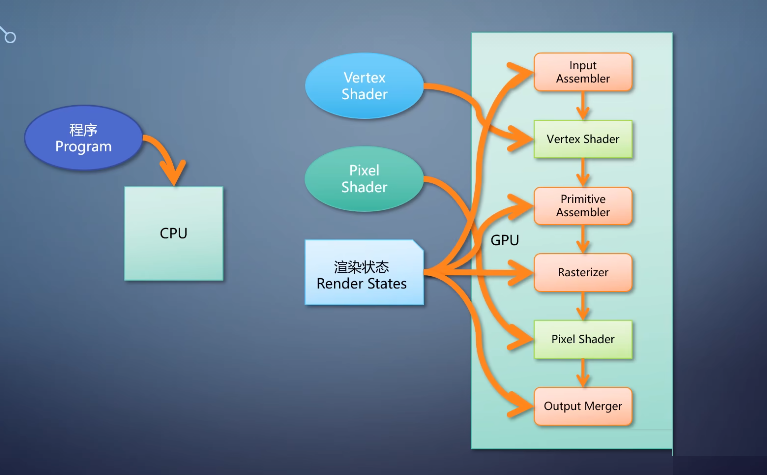
目前的gpu这些流水线之间不能互相调用,如果你要在图形流水线里用到计算流水线。就得先调用计算的,把结果写入textture或者buffer,再在图形流水线里面读取。
十多年前,我提出过配置是流水线的构想,不但有可编程单元,连线也是可编程的。这样就能根据需要组装流水线
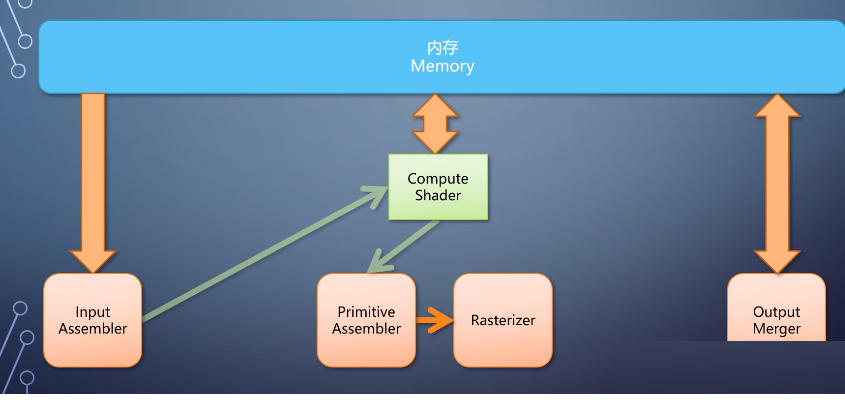
然后到了现在,也没有这样的GPU出现,不过现在图形流水线的各个单元。也有了任意输出的能力,部分解决了这个问题。
长期以来,在GPU上做开发的人分为两大阵营,一类基本只用GPU的图形流水线。典型的是游戏的图形的应用。
另一类基本只用GPU的计算流水线,典型的是机器学习的应用。由于后者在这几年非常火,从pc到手机到服务器都有覆盖,以至于有些自称作GPU芯片的公司。做的是所谓的gpgpu芯片,只有计算流水线的通用gpu。

正如我在上一期里说的,gpu的g是graphics,只拥有了图形流水线才能叫gpu。
只有在GPU上做通用计算才能叫gpgqu。
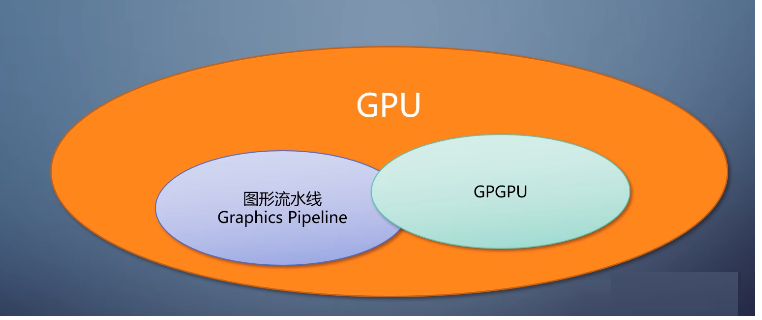
(注意这个依赖关系和先后的顺序)
只有计算能力,没有图形能力,就敢叫gqi只是在诈骗而已,没有图形能力的图形处理器这不自相矛盾吗?

更何况,即便在纯计算的情况下。一些固定流水线单元也可以好好利用,作为通用计算的补充,比如比如rasterizer可以作为高效的差值器。把一些数据线性扩散开来。
output merger里的alpha blending也可以用来作为高效的数据累加器。
这些都能进一步提高通用计算的性能。
至此在逻辑层面,我们看到了gpu是什么,现在的gpu应该包含哪些东西?但是如果按照这个模块划分,直接去实现gpu硬件会有两个巨大的问题。
• 第一shader种类那么多,如果一个程序只用到一部分,负载不平衡。其他算能力不就浪费了?
• 第二流水线已经这么复杂,如何在有限的成本内把它安排到硬件上。
还好,这两个问题都可以用同一个方法来解决。本期我们把GPU逻辑上的模块补齐了,建立了在现在的需求下。gpu应有的组成。 |







 订阅
订阅