| 编辑推荐: |
本文主要介绍了分布式计算框架MapReduce和spark的相关概念、原理等。希望能够帮助大家。
本文来自于博客园 ,由火龙果软件Linda编辑、推荐。 |
|
MapReduce
简介
概念
面向批处理的分布式计算框架
一种编程模型: MapReduce程序被分为Map(映射)和Reduce(化简)阶段
核心思想
分而治之, 并行计算
移动计算而非移动数据
特点
MapReduce有几个特点:
移动计算而不移动数据:分布式计算,计算跟着数据走,数据存放在哪就在哪里进行计算,极大的减少了IO的开销。
良好的扩展性:分布式计算框架拥有相当良好的扩展性,随着节点数量的增加,单个节点的计算量减小,整体的计算能力近乎线性的递增。
高容错性:计算任务失败,会自动恢复计算,拥有良好的容错性。
状态监控:提交任务之后,任务具体执行在哪个节点,具体执行到哪个阶段,在后台或者监控界面,我们都能实时的进行监控。
适合于海量数据的离线批处理:MapReduce在设计之初的目标就是面向离线批处理,特别是大吞吐量的离线处理场景,更适合于MapReduce。
降低了分布式编程的门槛:大部分操作MapReduce已经实现,我们仅仅需要在特定的部分编写我们自己的业务逻辑,极大的减少了工作量,同时也降低了编程的门槛。

MR原理
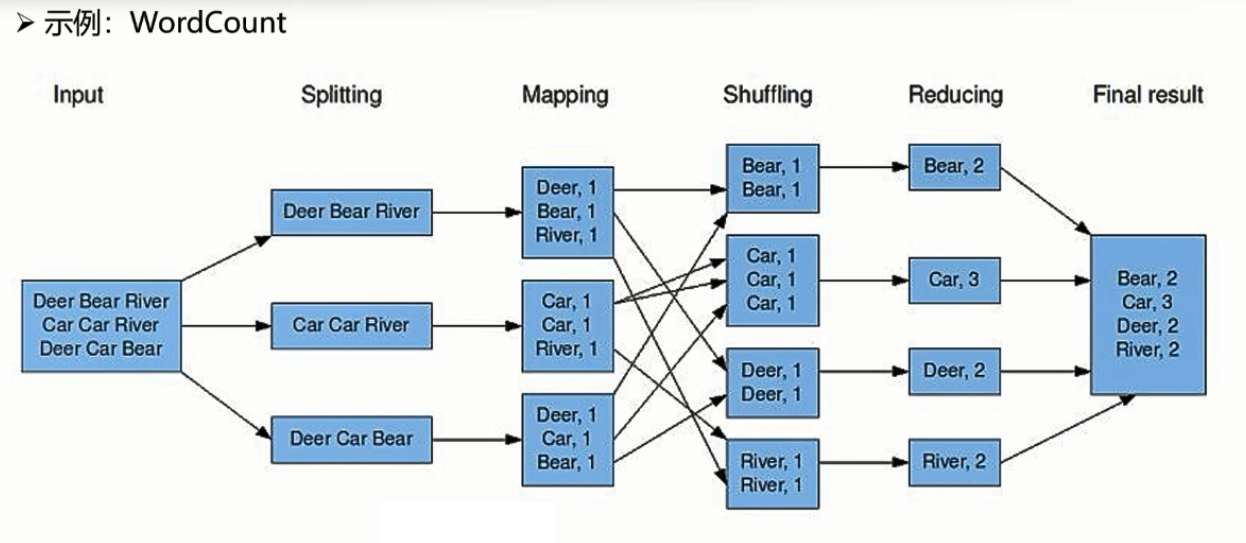
1. 作业(job):作业是客户端提交请求执行的一个单元,它包括数据、计算框架以及一些配置信息等。
2. 任务(task):是作业细分之后的细分工作单元,如MapReduce中的Map Task和Reduce
Task。
MapReduce划分为四个阶段,分别为:Split、Map、Shuffle、Reduce。
1. Split阶段,主要负责“分”,这个阶段会由MapReduce自动将一个大文件切分成多个小的split文件片段,split只是逻辑概念,仅包含如数据起始位置,长度,所在位置等描述信息。2.x当中默认的切分规则,一个split刚好为一个block大小128M。那么10TB的数据文件,此时就会划分为像图中一样多个小split片段,每一个split交由一个Map
Task处理。
2. Map阶段,会处理经过Split阶段切分好的数据片段,每一个split将对应一个Map的任务,也就说像图中所画Split切分为三个片段,分别对应着三个Map
Task任务。Map阶段需要开发人员自己按照业务做实现,并且当我们分析的数据是HDFS当中文本数据时,他会一行一行来进行读取,最终需要按照Key-Value形式输出。那在WordCount案例中,读到每行数据时我们按照文本的分隔符将文本切分为一个一个单词,最后以单词作为key、1作为value进行输出。这样输出之后,最终对于每一个单词我们只要将1做累加就可以得到结果。
3. Shuffle阶段,他会完成分区、排序、分组等操作,分区决定了Map任务交由哪个Reduce任务处理,Reduce任务决定了有多少个分区。先分析WordCount,默认Shuffle阶段会将Map阶段输出的Key-Value键值对按照单词的顺序做排序、分组,最终将相同的单词划分到一组,交给下个阶段Reduce来处理。
4. Reduce阶段,和Map一样都需要开发人员自己实现,它所处理的数据是Map输出之后经过Shuffle排好序、分好组的数据,那么在WordCount当中,Reduce任务每次处理的都是单词相同的一组数据,这段代码实现就很简单我只要对于这一组数据当中的Value进行累加,即可得到一个单词的数量,当Reduce所有任务执行完成即把每组单词数据处理完成之后,即可拿到最终的结果。


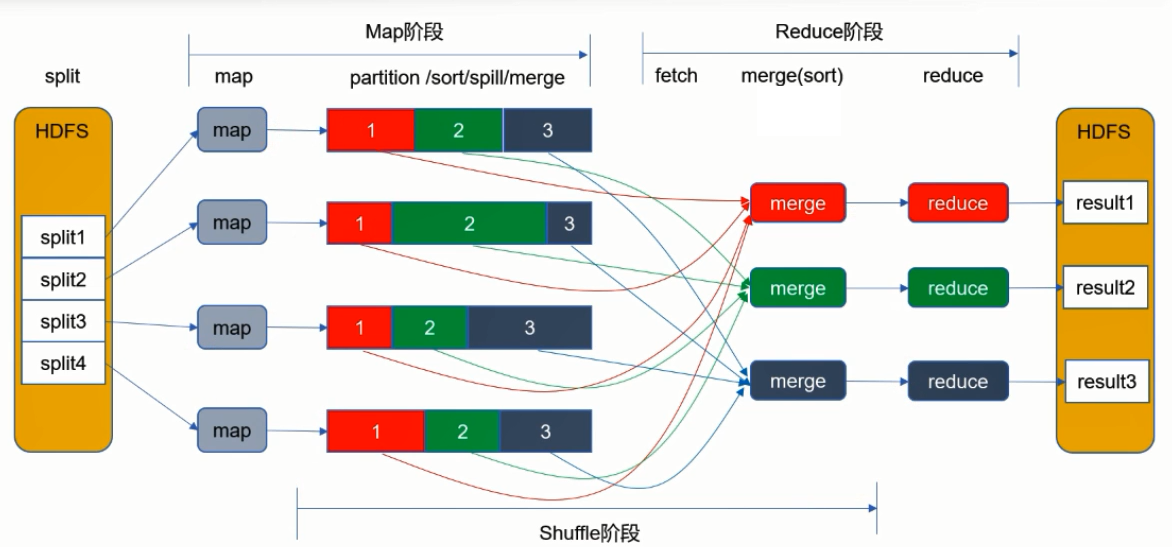
图中展示了Mapreduce的执行流程。首先数据要被Split切分,但是因为存储在HDFS上,所以数据已经被切分成了Block块,那接下来就会在每个Block块上分发一个Map作业进行中间结果的计算,计算结果保存为key-value的形式。此时shuffle阶段负责将Key值相同的数据分发到同一个Reduce节点上进行计算。Shuffle对Key值进行Hash取模,然后按照Reduce的个数形成对应的文件。Reduce节点会去Map节点去取自己的文件,取到之后进行合并。合并成大文件之后,在Reduce节点进行结果的汇总,最终结果保存到HDFS中。
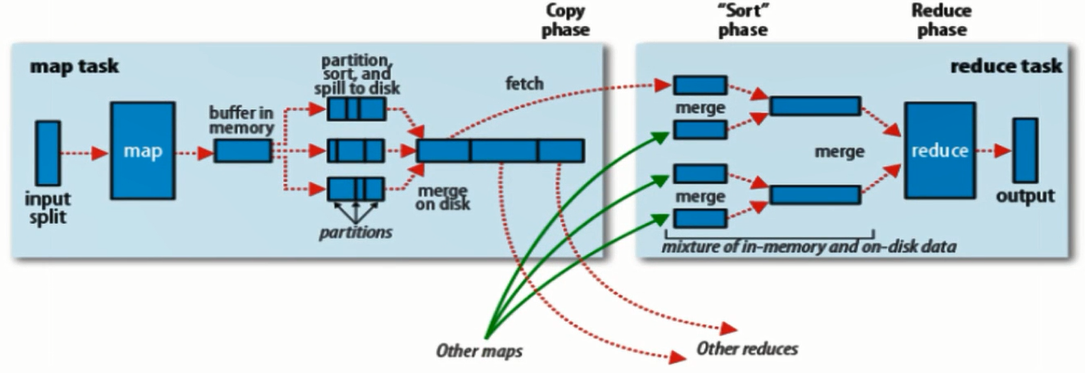
Shuffle详解
Shuffle连接了Map以及Reduce,它在Map以及Reduce两台服务器上都有执行。

作业运行管理
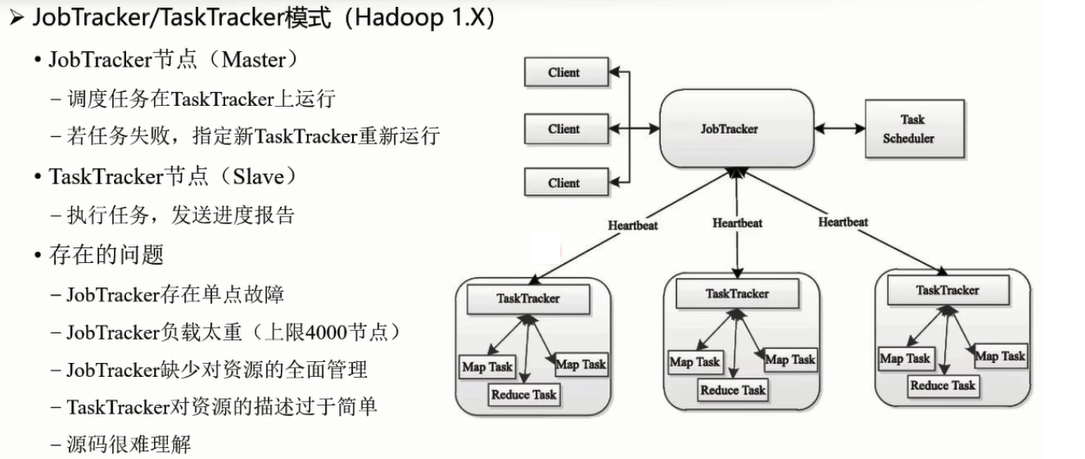
TaskTracker 和DataNode放在同一个节点: 移动计算


Spark
简介


原理
编程模型
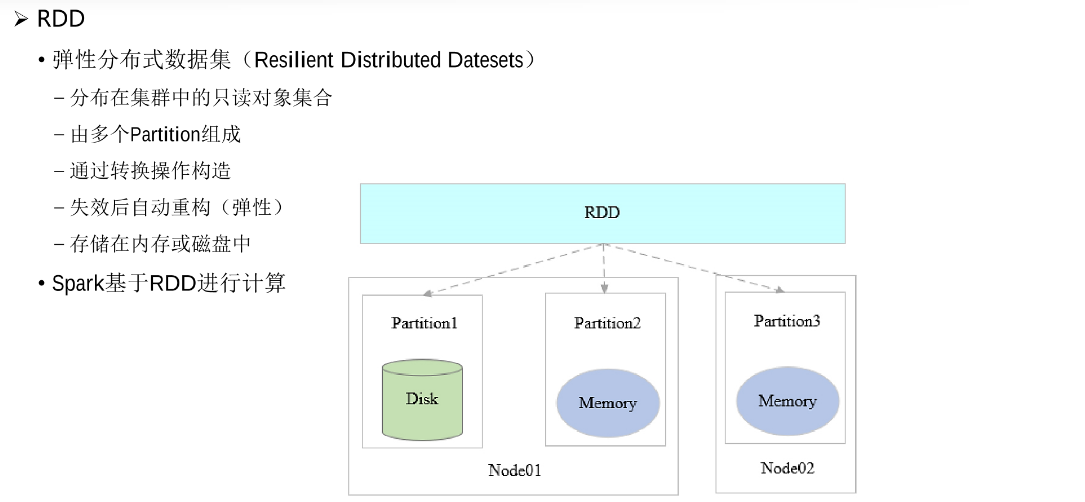
RDD(Resilient Distributed Datesets、弹性分布式数据集)是Spark特有的数据模型,Spark当中的计算都是通过操作RDD来完成的。DAG(有向无环图),RDD各项操作之间的相互依赖会被转成DAG,DAG划分不同的stage阶段,由不同的task任务运行。
RDD同时也是Spark的基本计算单元,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。对应用透明,开发人员只需要对于RDD进行操作即可不需要其他的处理。RDD的创建操作只能是基于稳定的数据集或者已有的RDD,整个Job任务在计算过程中如果出现错误,可以通过这一系列的转换、算子追述到之前的操作,自动重构从而保证计算的正确性。
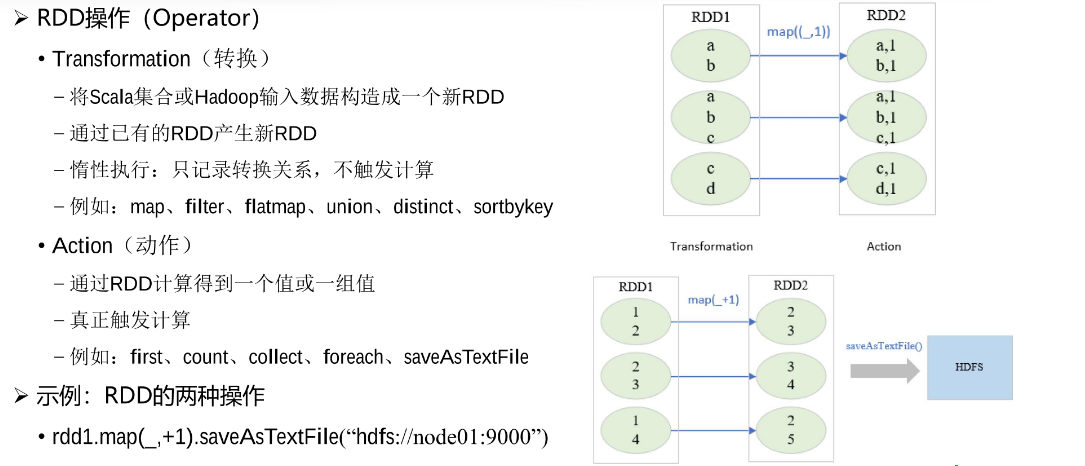

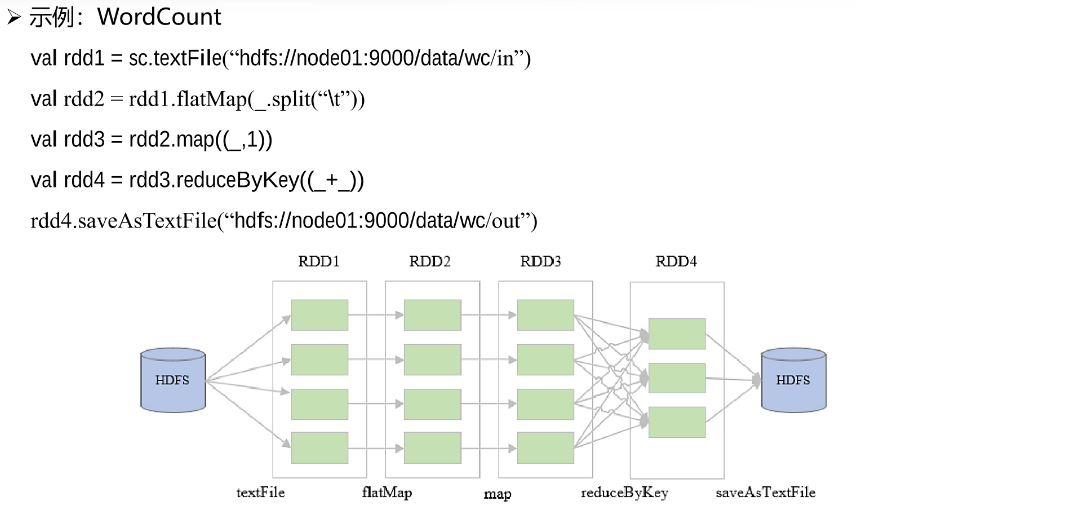
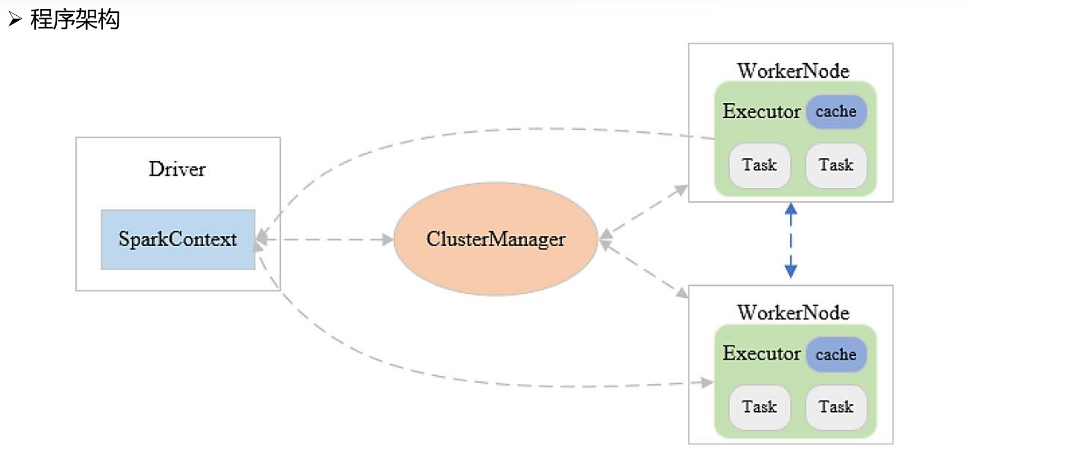
在程序运行的时候,首先会运行Driver,Driver相当于是整个任务的管理程序,负责对任务进行解析、分发、监控等。Driver中包含的SparkContext是Spark的运行环境。
Driver运行起来之后,会向ClusterManager主节点去申请资源,申请到的资源是在WorkerNode上封装好的Executor容器,容器包含了程序运行的CPU、内存等资源。
然后Driver会将Task分发到这些Executor中进行执行,执行过程中,会时刻监控这些Task的运行情况,并做实时的管理和调度。
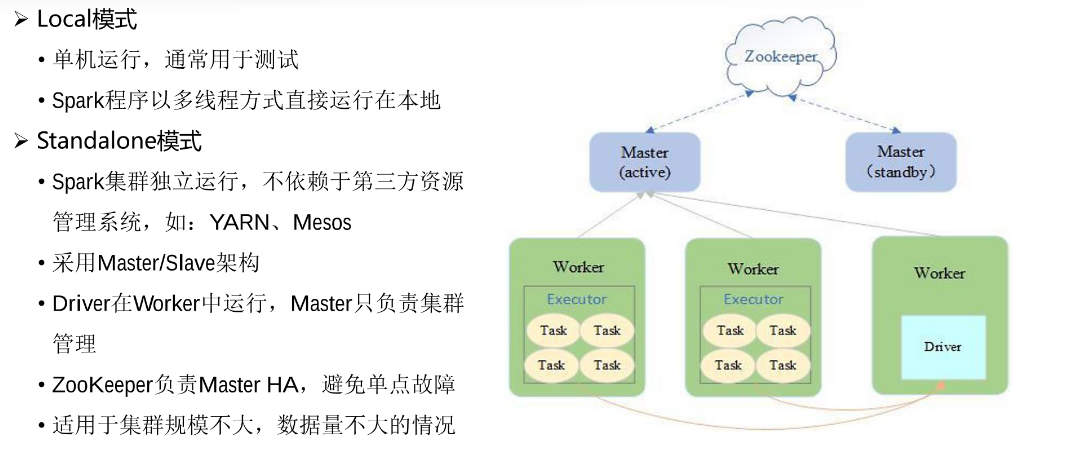
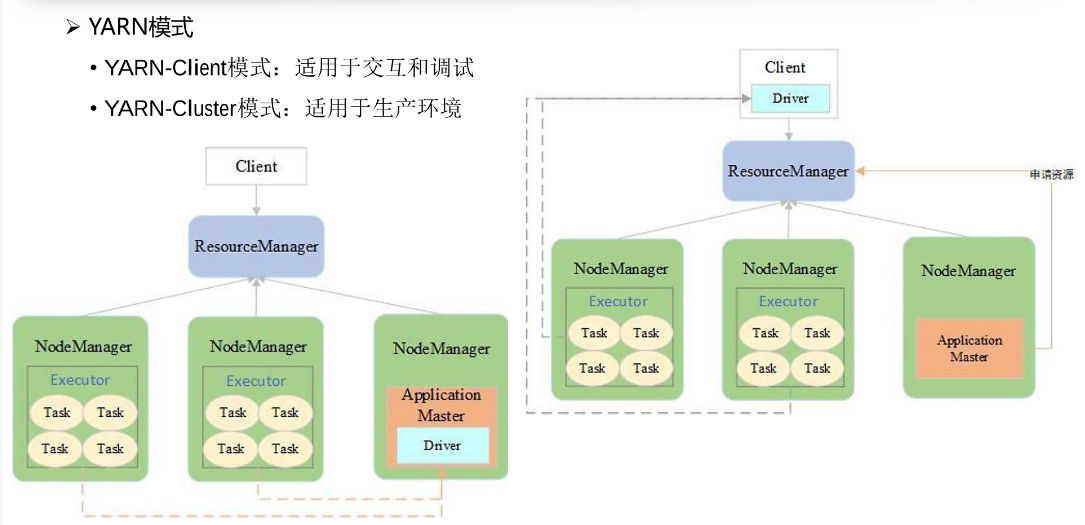
Yarn模式是比较常见的一种模式,Spark将任务提交到yarn上去运行。这种模式根据Driver的位置不同,又细分为Client和Cluster两种模式。
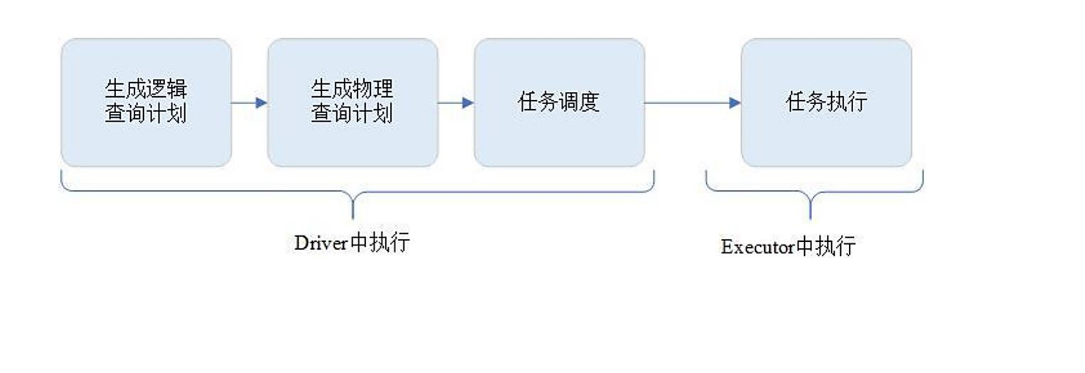
Executor拿到我们分发的这些个任务,开始任务的真正执行。
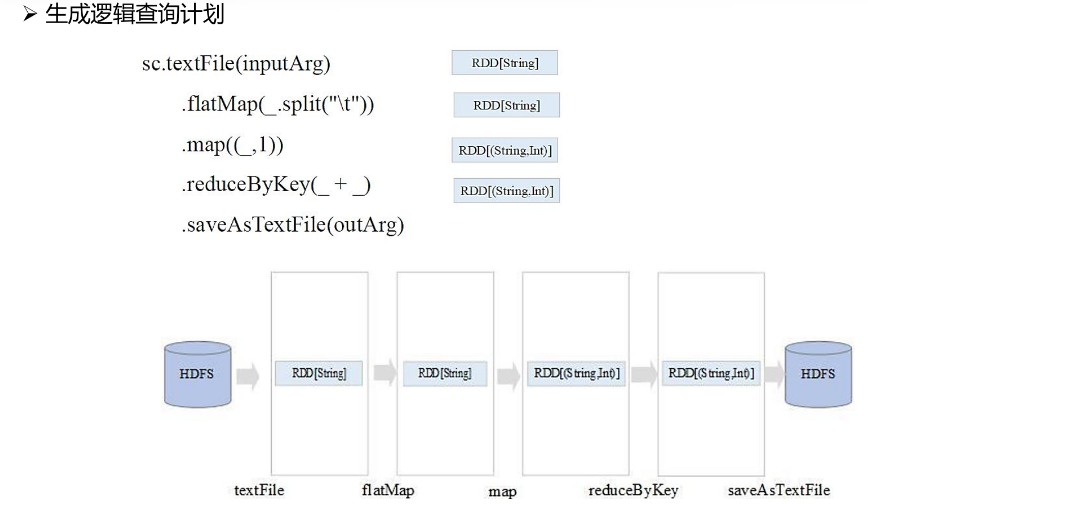
逻辑查询计划的生成基本上就是我们所写的计算逻辑,根据RDD之间的流程关系等,生成对应的逻辑查询计划。
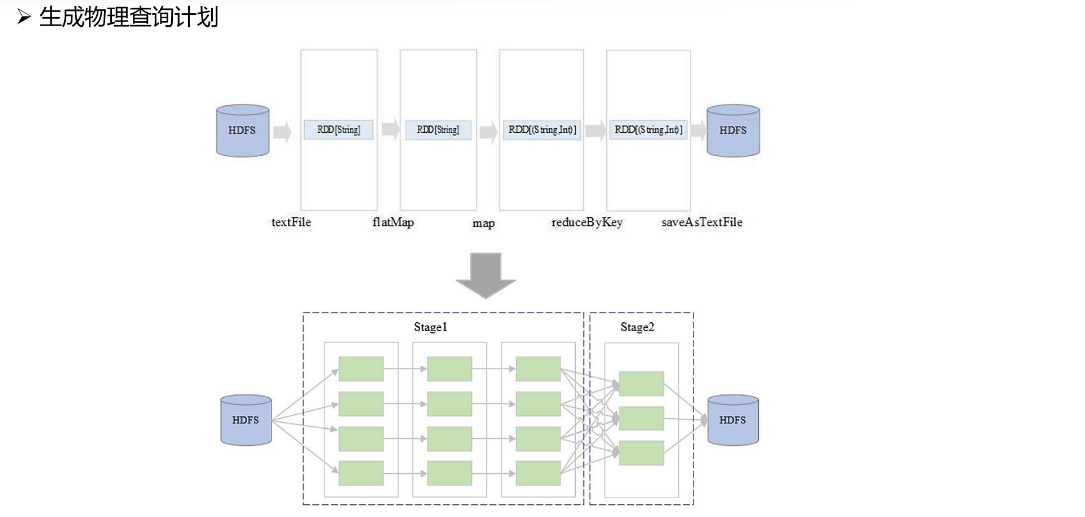
物理查询计划的生成,依赖于我们的逻辑查询计划。首先根据我们RDD的种类以及对应的宽窄依赖关系,生成多个Stage,每个Stage之间也会有对应的逻辑关系,如图所示。最后由我们的多个Stage,组成了我们最后的DAG。
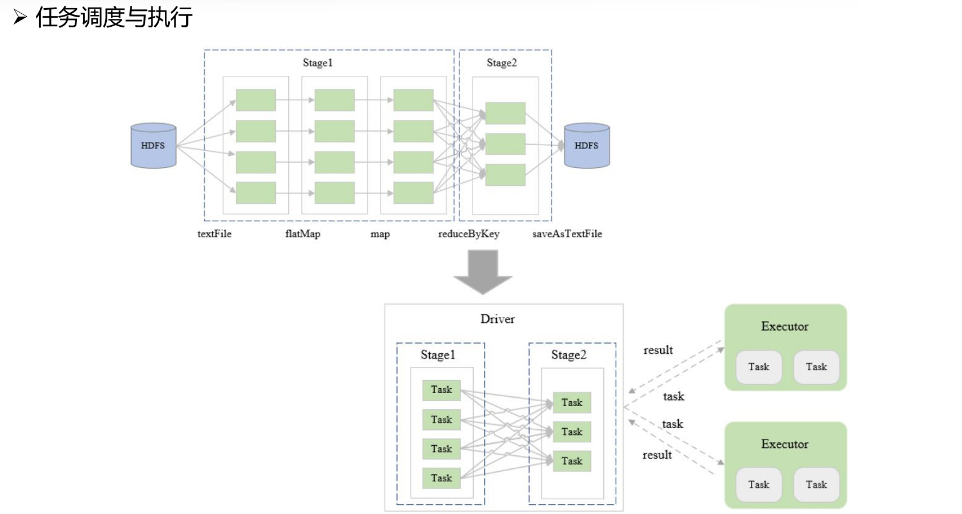
当拿到了多个Stage,提交给Driver来执行的时候,基本就是这个样子。以图为例,首先Stage1中全部是一些Transformation操作,而Stage1到Stage2之间出现了宽依赖关系,也就是出现了Action操作。这些个动作转换,就是要提交给Executor来执行的Task任务,所有Task任务的分配以及监控,都是由SparkContext来完成的。
DAG任务规划与调度

RDD操作中的一系列依赖关系,Spark后期会转换为DAG来进行表示。 |







 订阅
订阅