| БрМЭЦМі: |
БОЮФгУ 7 еХЭМзмНсСЫ RocketMQ ЕФКЫаФжЊЪЖЃЌдкНВНтЪБСІЧѓОЋМђЁЂЭЈЫзвзЖЎЃЌЭЈЙ§ЭМНтРДИје§дкбЇЯА
RocketMQ ЕФаЁЛяАщДјРДАяжњЁЃRocketMQ ЪЧАЂРяАЭАЭЕФЗжВМЪНЯћЯЂжаМфМўЃЌдк
2012 ФъПЊдДЃЌдк 2017 ФъГЩЮЊ Apache ЖЅМЖЯюФПЁЃ
РДздгк51CTO ,гЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
1 МЏШКМмЙЙ
RocketMQ ЕФМЏШКМмЙЙШчЯТЭМЃК
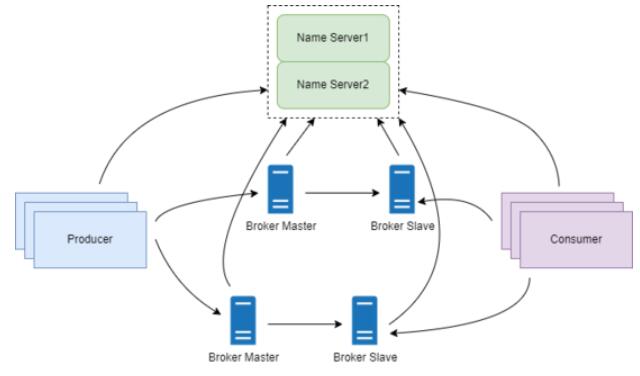
ДгЩЯЭМПЩвдПДЕНЃЌећИіМЏШКжагаЫФИіНЧЩЋЃК Name ServerМЏШКЁЂBrokerжїДгМЏШКЁЂProducerЁЂConsumerЁЃ
1.1 Name Server МЏШК
Name Server МЏШКВПЪ№ЃЌЕЋЪЧНкЕужЎМфВЂВЛЛсЭЌВНЪ§ОнЃЌвђЮЊУПИіНкЕуЖМЛсБЃДцЭъећЕФЪ§ОнЁЃвђДЫЕЅИіНкЕуЙвЕєЃЌВЂВЛЛсЖдМЏШКВњЩњгАЯьЁЃ
1.2 Broker
Broker ВЩгУжїДгМЏШКЃЌЪЕЯжЖрИББОДцДЂКЭИпПЩгУЁЃУПИі Broker НкЕуЖМвЊИњЫљгаЕФ Name
Server НкЕуНЈСЂГЄСЌНгЃЌЖЈвхзЂВс Topic ТЗгЩаХЯЂКЭЗЂЫЭаФЬјЁЃ
ИњЫљга Name Server НЈСЂСЌНгЃЌОЭВЛЛсвђЮЊЕЅИі Name Server ЙвСЫгАЯь Broker
ЪЙгУЁЃBroker жїДгФЃЪНжаЃЌ Slave НкЕужїЖЏДг Master НкЕуРШЁЯћЯЂЁЃ
1.3 Producer
Producer Ињ Name Server ЕФШЮвтвЛИіНкЕуНЈСЂГЄСЌНгЃЌЖЈЦкДг Name Server
РШЁ Topic ТЗгЩаХЯЂЁЃProducer ЪЧЗёВЩгУМЏШКЃЌШЁОігкЫќЫљдкЕФвЕЮёЯЕЭГЁЃ
1.4 Consumer
Consumer Ињ Name Server ЕФШЮвтвЛИіНкЕуНЈСЂГЄСЌНгЃЌЖЈЦкДг Name Server
РШЁ Topic ТЗгЩаХЯЂЁЃConsumer ЪЧЗёВЩгУМЏШКЃЌШЁОігкЫќЫљдкЕФвЕЮёЯЕЭГЁЃ
Producer КЭ Consumer жЛИњШЮвтвЛИі Name Server НкЕуНЈСЂСЌНгЃЌвђЮЊ
Broker ЛсЯђЫљга Name Server зЂВс Topic аХЯЂЃЌЫљвдУПИі Name Server
БЃДцЕФЪ§ОнЦфЪЕЪЧвЛжТЕФЁЃ
2 MessageQueue
Producer ЗЂЫЭЕФЯћЯЂЛсдк Broker ЕФ MessageQueue жаБЃДцЃЌШчЯТЭМЃК
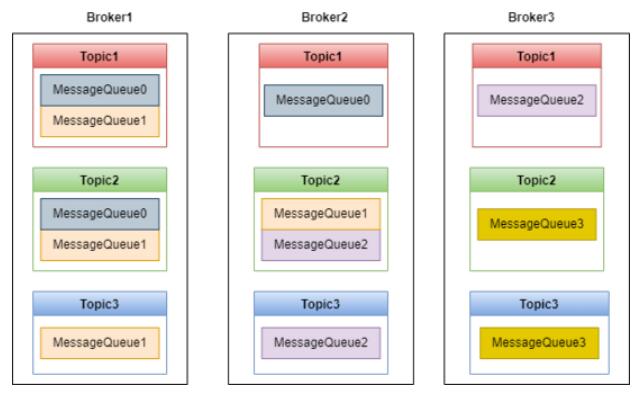
гаСЫ MessageQueue ЃЌTopic ОЭПЩвддк Broker жаЪЕЯжЗжВМЪНДцДЂЃЌШчЩЯЭМЃЌBroker
МЏШКжаБЃДцСЫ 4 ИіMessageQueueЃЌетаЉ MessageQueue БЃДцСЫ Topic1-Topic3
етШ§Иі Topic ЕФЯћЯЂЁЃ
MessageQueue РрЫЦгк Kafka жаЕФ PartitionЃЌгаСЫ MessageQueueЃЌProducer
ПЩвдВЂЗЂЕиЯђ Broker жаЗЂЫЭЯћЯЂЃЌConsumer вВПЩвдВЂЗЂЕиЯћЗбЯћЯЂЁЃ
ФЌШЯ Topic ПЩвдДДНЈЕФ MessageQueue Ъ§СПЪЧ 4ЃЌBroker ПЩвдДДНЈЕФ MessageQueue
Ъ§СПЪЧ 8, RocketMQ бЁдёЖўепжаЪ§СПаЁЕФЃЌвВОЭЪЧ 4ЁЃВЛЙ§етСНИіжЕЖМПЩвдХфжУЁЃ
3 Consumer
RocketMQЕФЯћЗбФЃЪНШчЯТЭМЃК
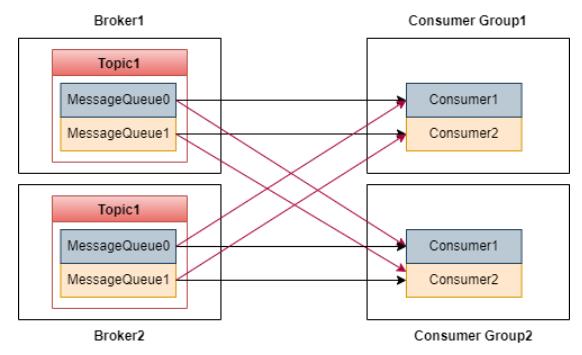
ЭМжаЃЌTopic1 ЕФЯћЯЂаДШыСЫСНИі MessageQueueЃЌСНИіЖгСаБЃДцдк Broker1 КЭ
Broker2 ЩЯЁЃ
RocketMQ ЭЈЙ§ Consumer Group ЪЕЯжЯћЯЂЙуВЅЁЃБШШчЩЯЭМжагаСНИіЯћЗбепзщЃЌУПИіЯћЗбепзщгаСНИіЯћЗбепЁЃ
вЛИіЯћЗбепПЩвдЯћЗбЖрИі MessageQueueЃЌЕЋЪЧЭЌвЛИі MessageQueue жЛФмБЛЭЌвЛИіЯћЗбепзщЕФвЛИіЯћЗбепЯћЗбЁЃБШШч
MessageQueue0 жЛФмБЛ Consumer Group1 жаЕФ Consumer1 ЯћЗбЃЌ
ВЛФмБЛ Consumer2 ЯћЗбЁЃ
4 Broker ИпПЩгУМЏШК
Broker МЏШКШчЯТЭМЃК
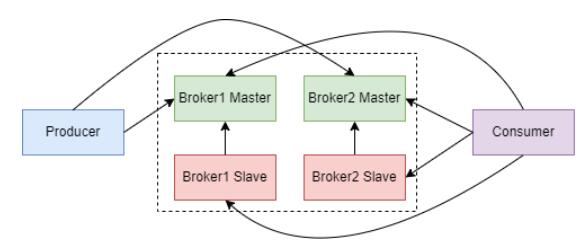
Broker ЭЈЙ§жїДгМЏШКРДЪЕЯжЯћЯЂИпПЩгУЁЃИњ Kafka ВЛЭЌЕФЪЧЃЌRocketMQ ВЂУЛга Master
НкЕубЁОйЙІФмЃЌЖјЪЧВЩгУЖр Master Жр Slave ЕФМЏШКМмЙЙЁЃProducer аДШыЯћЯЂЪБаДШы
Master НкЕуЃЌSlave НкЕужїЖЏДг Master НкЕуРШЁЪ§ОнРДБЃГжИњ Master НкЕуЕФЪ§ОнвЛжТЁЃ
Consumer ЯћЗбЯћЯЂЪБЃЌМШПЩвдДг Master НкЕуРШЁЪ§ОнЃЌвВПЩвдДг Slave НкЕуРШЁЪ§ОнЁЃ
ЕНЕзЪЧДг Master РШЁЛЙЪЧДг Slave РШЁШЁОігк Master НкЕуЕФИКдиКЭ Slave
ЕФЭЌВНЧщПі ЁЃШчЙћ Master ИКдиКмИпЃЌMaster ЛсЭЈжЊ Consumer Дг Slave
РШЁЯћЯЂЃЌЖјШчЙћ Slave ЭЌВНЯћЯЂНјЖШбгКѓЃЌдђ Master ЛсЭЈжЊ Consumer Дг Master
РШЁЪ§ОнЁЃзмжЎЃЌДг Master РШЁЛЙЪЧДг Slave РШЁгЩ Master РДОіЖЈЁЃ
ШчЙћ Master НкЕуЗЂЩњЙЪеЯЃЌRocketMQ ЛсЪЙгУЛљгк raft авщЕФ DLedger
ЫуЗЈРДНјаажїДгЧаЛЛЁЃ
Broker УПИє 30s Яђ Name Server ЗЂЫЭаФЬјЃЌName Server ШчЙћ 120s
УЛгаЪеЕНаФЬјЃЌОЭЛсХаЖЯ Broker хДЛњСЫЁЃ
5 ЯћЯЂДцДЂ
RocketMQ ЕФДцДЂЩшМЦЪЧЗЧГЃгаДДдьадЕФЁЃДцДЂЮФМўжївЊгаШ§ИіЃКCommitLogЁЂConsumeQueueЁЂIndexЁЃШчЯТЭМЃК
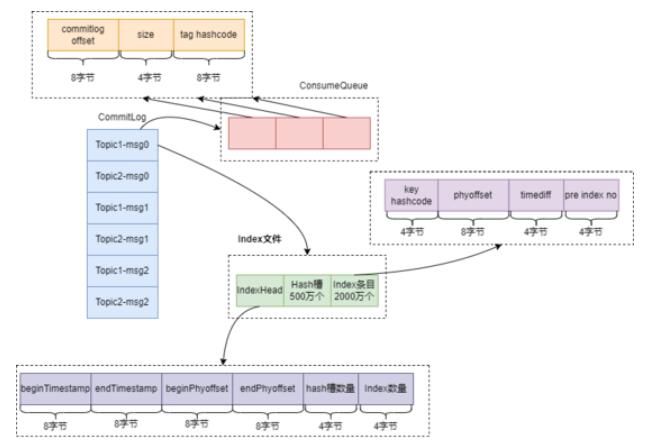
5.1 CommitLog
RocketMQ ЕФЯћЯЂБЃДцдк CommitLog жаЃЌCommitLog УПИіЮФМў 1G ДѓаЁЁЃгаШЄЕФЪЧЃЌЮФМўУћВЂВЛНа
CommitLogЃЌЖјЪЧгУЯћЯЂЕФЦЋвЦСПРДУќУћЁЃБШШчЕквЛИіЮФМўЮФМўУћЪЧ 0000000000000000000ЃЌЕкЖўИіЮФМўЮФМўУћЪЧ
00000000001073741824ЃЌвРДЮРрЭЦОЭПЩвдЕУЕНЫљгаЮФМўЕФЮФМўУћЁЃ
гаСЫЩЯУцЕФУќУћЙцдђЃЌИјЖЈвЛИіЯћЯЂЕФЦЋвЦСПЃЌОЭПЩвдИљОнЖўЗжВщевПьЫйевЕНЯћЯЂЫљдкЕФЮФМўЃЌВЂЧвгУЯћЯЂЦЋвЦСПМѕШЅЮФМўУћОЭПЩвдЕУЕНЯћЯЂдкЮФМўжаЕФЦЋвЦСПЁЃ
R oc ketMQ аД CommitLog ЪБВЩгУЫГађаДЃЌДѓДѓЬсИпСЫаДШыадФмЁЃ
5.2 ConsumeQueue
ШчЙћжБНгДг CommitLog жаМьЫї Topic жаЕФвЛЬѕЯћЯЂЃЌаЇТЪЛсКмЕЭЃЌвђЮЊашвЊДгЮФМўЕФЕквЛЬѕЯћЯЂПЊЪМвРДЮВщевЁЃв§ШыСЫ
ConsumeQueue зїЮЊ CommitLog ЕФЫїв§ЮФМўЃЌЛсШУМьЫїаЇТЪДѓдіЁЃ
ИеПЊЪМВЛРэНт ConsumeQueue КЭ MessageQueue ЕФЧјБ№ЃЌЭјЩЯВщСЫвЛаЉзЪСЯЗЂЯжЃЌУПИіConsumeQueueЖдгІвЛИіЩЯУцНщЩмЕФ
MessageQueueЃЌMessageQueue жЛЪЧвЛИіИХФюФЃаЭЁЃ
ConsumeQueue жаЕФдЊЫиФкШнШчЯТЃК
ЧА 8 ИізжНкМЧТМЯћЯЂдк CommitLog жаЕФЦЋвЦСПЁЃ
жаМф 4 ИізжНкМЧТМЯћЯЂЯћЯЂДѓаЁЁЃ
зюКѓ 8 ИізжНкМЧТМЯћЯЂжа tag ЕФ hashcodeЁЃ
етИі tag ЕФзїгУЗЧГЃживЊЃЌМйШчвЛИі Consumer ЖЉдФСЫ TopicAЃЌTag1 КЭ Tag2ЃЌФЧетИі
Consumer ЕФЖЉдФЙиЯЕШчЯТЭМЃК
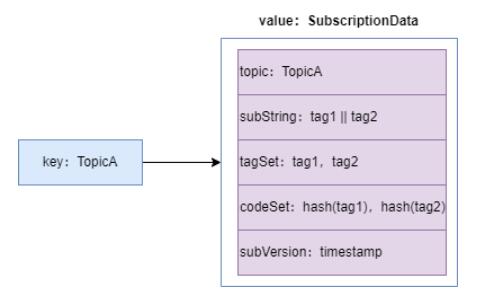
ПЩвдПДЕНЃЌетИіЖЉдФЙиЯЕЪЧвЛИі hash РраЭЕФНсЙЙЃЌkey ЪЧ Topic УћГЦЃЌvalue ЪЧвЛИі
SubscriptionData РраЭЕФЖдЯѓЃЌетИіЖдЯѓЗтзАСЫ tagЁЃ
РШЁЯћЯЂЪБЃЌЪзЯШДг Name Server ЛёШЁЖЉдФЙиЯЕЃЌЕУЕНЕБЧА Consumer ЫљгаЖЉдФ tag
ЕФ hashcode МЏКЯ codeSetЃЌШЛКѓДг ConsumerQueue ЛёШЁвЛЬѕМЧТМЃЌХаЖЯзюКѓ
8 ИізжНк tag hashcode ЪЧЗёдк codeSet жаЃЌвдОіЖЈЪЧЗёНЋИУЯћЯЂЗЂЫЭИјConsumerЁЃ
5.3 Index ЮФМў
RocketMQ жЇГжАДееЯћЯЂЕФЪєадВщевЯћЯЂЃЌЮЊСЫжЇГжетИіЙІФмЃЌRocketMQ в§ШыСЫ Index
Ыїв§ЮФМўЁЃIndex ЮФМўгаШ§ВПЗжзщГЩЃЌЮФМўЭЗ IndexHeadЁЂ500ЭђИі hash ВлКЭ 2000
ЭђИі Index ЬѕФПзщГЩЁЃ
5.3.1 IndexHead
змЙВга 6 ИідЊЫизщГЩЃЌЧАСНИідЊЫиБэЪОЕБЧАетИі Index ЮФМўжаЕквЛЬѕЯћЯЂКЭзюКѓвЛЬѕЯћЯЂЕФТфХЬЪБМфЃЌЕкШ§ЁЂЕкЫФСНИідЊЫиБэЪОЕБЧАетИі
Index ЮФМўжаЕквЛЬѕЯћЯЂКЭзюКѓвЛЬѕЯћЯЂдк CommitLog ЮФМўжаЕФЮяРэЦЋвЦСПЃЌЕкЮхИідЊЫиБэЪОЕБЧАетИі
Index ЮФМўжа hash ВлЕФЪ§СПЃЌЕкСљИідЊЫиБэЪОЕБЧАетИі Index ЮФМўжаЫїв§ЬѕФПЕФИіЪ§ЁЃ
ВщевЕФЪБКђГ§СЫДЋШы key ЛЙашвЊДЋШыЕквЛЬѕЯћЯЂКЭзюКѓвЛЬѕЯћЯЂЕФТфХЬЪБМфЃЌетЪЧвђЮЊ Index ЮФМўУћЪЧЪБМфДСУќУћЕФЃЌДЋШыТфХЬЪБМфПЩвдИќМгОЋШЗЕиЖЈЮЛ
Index ЮФМўЁЃ
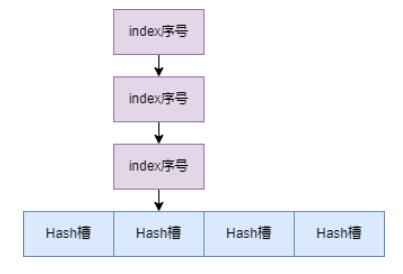
5.3.2 Hash Вл
ЪьЯЄ Java жа HashMap ЕФЭЌбЇгІИУЖМБШНЯЪьЯЄ Hash ВлетИіИХФюСЫЃЌЦфЪЕОЭЪЧ Hash
НсЙЙЕФЕзВуЪ§зщЁЃIndex ЮФМўжаЕФ Hash Влга 500 ЭђИіЪ§зщдЊЫиЃЌУПИідЊЫиЪЧ 4 ИізжНк
int РраЭдЊЫиЃЌБЃДцЕБЧАВлЯТзюаТЕФФЧИі index ЬѕФПЕФађКХЁЃ
етРя Hash ВлНтОі Hash ГхЭЛЕФЗНЪНЪЧСДБэЗЈЃЌШчЯТЭМЃК
5.3.3 Index ЬѕФП
УПИі Index ЬѕФПжаЃЌkey ЕФ hashcode еМ 4 ИізжНкЃЌphyoffset БэЪОЯћЯЂдк
CommitLog жаЕФЮяРэЦЋвЦСПеМ 8 ИізжНкЃЌtimediff БэЪОЯћЯЂЕФТфХЬЪБМфгы header
РяЕФ beginTimestamp ЕФВюжЕеМ 4 ИізжНкЃЌpre index no еМ 4 ИізжНкЁЃ
pre index no БЃДцЕФЪЧЕБЧАЕФ Hash ВлжаЧАвЛИі index ЬѕФПЕФађКХЃЌвЛАудк key
ЗЂЩњ Hash ГхЭЛЪБВХЛсгажЕЃЌЗёдђетИіжЕОЭЪЧ 0ЃЌБэЪОЕБЧАдЊЫиЪЧ Hash ВлжаЕквЛИідЊЫиЁЃ
In dex ЬѕФПжаБЃДц timediffЃЌЪЧЮЊСЫЗРжЙ key жиИДЁЃ Вщев key ЪБЃЌдк key
ЯрЭЌЕФЧщПіЯТЃЌ ШчЙћДЋШыЕФЪБМфЗЖЮЇИњ timediff ВЛТњзуЃЌдђЛсВщев pre index no
етИіЬѕФПЁЃ
5.3.4 БОНкзмНс
ЭЈЙ§ЩЯУцЕФЗжЮіЃЌЮвУЧПЩвдзмНсвЛИіЭЈЙ§ key дк Index ЮФМўжаВщевЯћЯЂЕФСїГЬЃЌШчЯТЃК
МЦЫу key ЕФ hashcodeЃЛ
ИљОн hashcode дк Hash ВлжаВщевЮЛжУ sЃЛ
МЦЫу Hash Влдк Index ЮФМўжаЮЛжУ 40+(s-1)*4ЃЛ
ЖСШЁетИіВлЕФжЕЃЌвВОЭЪЧIndexЬѕФПађКХ nЃЛ
МЦЫуИУ index ЬѕФПдк Index ЮФМўжаЕФЮЛжУЃЌЙЋЪНЃК40 + 500Эђ * 4 + (n-1)
* 20ЃЛ
ЖСШЁетИіЬѕФПЃЌБШНЯ key ЕФ hashcode КЭ index ЬѕФПжа hashcodeЪЧЗёЯрЭЌЃЌвдМА
key ДЋШыЕФЪБМфЗЖЮЇИњ Index ЬѕФПжаЕФ timediff ЪЧЗёЦЅХфЁЃШчЙћЬѕМўВЛЗћКЯЃЌдђВщев
pre index no етИіЬѕФПЃЌевЕНКѓЃЌДг CommitLog жаШЁГіЯћЯЂЁЃ
6 ЫЂХЬВпТд
Rocket MQ ВЩгУСщЛюЕФЫЂХЬВпТдЁЃ
6.1 вьВНЫЂХЬ
ЯћЯЂаДШы CommitLog ЪБЃЌВЂВЛЛсжБНгаДШыДХХЬЃЌЖјЪЧЯШаДШыPageCache ЛКДцжаЃЌШЛКѓгУКѓЬЈЯпГЬвьВНАбЯћЯЂЫЂШыДХХЬЁЃвьВНЫЂХЬВпТдОЭЪЧЯћЯЂаДШы
PageCache КѓСЂМДЗЕЛиГЩЙІЃЌетбљаДШыаЇТЪЗЧГЃИпЁЃШчЙћФмШнШЬЯћЯЂЖЊЪЇЃЌвьВНЫЂХЬЪЧзюКУЕФбЁдёЁЃ
6.2 ЭЌВНЫЂХЬ
МДЪЙЭЌВНЫЂХЬЃЌRocketMQ вВВЛЪЧУПЬѕЯћЯЂЖМвЊЫЂХЬЃЌЯпГЬНЋЯћЯЂаДШыФкДцКѓЃЌЛсЧыЧѓЫЂХЬЯпГЬНјааЫЂХЬЃЌЕЋЪЧЫЂХЬЯпГЬВЂВЛЛсжЛАбЕБЧАЧыЧѓЕФЯћЯЂЫЂХЬЃЌЖјЪЧЛсАбД§ЫЂХЬЕФЯћЯЂвЛЭЌЫЂХЬЁЃЭЌВНЫЂХЬВпТдБЃжЄСЫЯћЯЂЕФПЩППадЃЌЕЋЪЧвВНЕЕЭСЫЭЬЭТСПЃЌдіМгСЫбгГйЁЃ
7 змНс
БОЮФгУ 7 еХЭМзмНсСЫ RocketMQ ЕФКЫаФжЊЪЖЃЌЯЃЭћФмДјФуПьЫйШыУХЁЃ |









