| БрМЭЦМі: |
ЮЊЪВУДашвЊSpring ЪВУДЪЧSpringЖдгкетбљЕФЮЪЬтЃЌДѓВПЗжШЫЖМЪЧДІгквЛжжыќыќыЪыЪЕФзДЬЌЃЌЫЕЕФГіРДЃЌЕЋгжВЛЪЧЭъШЋЫЕЕФГіРДЃЌНёЬьЮвУЧОЭвдМмЙЙЩшМЦЕФНЧЖШГЂЪдНтПЊSpringЕФЩёУиУцЩДЁЃ
РДздгк51CTO ,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд
ЮЊЪВУДашвЊSpring ЪВУДЪЧSpring
ЖдгкетбљЕФЮЪЬтЃЌДѓВПЗжШЫЖМЪЧДІгквЛжжыќыќыЪыЪЕФзДЬЌЃЌЫЕЕФГіРДЃЌЕЋгжВЛЪЧЭъШЋЫЕЕФГіРДЃЌНёЬьЮвУЧОЭвдМмЙЙЩшМЦЕФНЧЖШГЂЪдНтПЊSpringЕФЩёУиУцЩДЁЃ
БОЦЊЮФеТвдгЩЧГШыЩюЕФЗНЪННјааНщЩмЃЌДѓМвВЛБиОЊЛХЃЌЮвПЩвдБЃжЄЃЌжЛвЊФуЛсБрГЬОЭФмПДЖЎЁЃ
БОЦЊЮФеТЛљгкSpring 5.2.8ЃЌдФЖСЪБГЄДѓИХашвЊ20Зжжг
АИР§
ЮвУЧЯШРДПДвЛИіАИР§ЃКгавЛИіаЁЛяЃЌгавЛСОМЊРћГЕЃЌ ЦНГЃОЭПЊМЊРћГЕЩЯАр
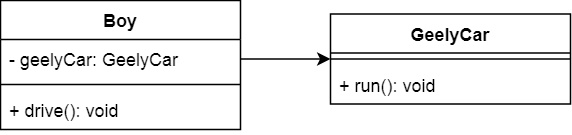
ДњТыЪЕЯжЃК
public?class?GeelyCar?{
public?void?run(){?
System.out.println("geely?running");
}?
}? |
public?class?Boy?{
//?вРРЕGeelyCar
private?final?GeelyCar?geelyCar?=?new?GeelyCar();
public?void?drive(){
geelyCar.run();
}
} |
гавЛЬьЃЌаЁЛязЌЧЎСЫЃЌгжТђСЫСОКьЦьЃЌЯыПЊаТГЕЁЃ
МђЕЅЃЌАбвРРЕЛЛГЩHongQiCar
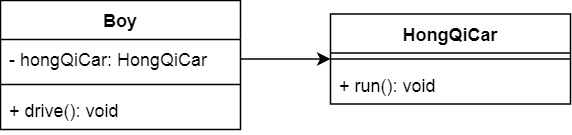
ДњТыЪЕЯжЃК
public?class?HongQiCar?{
public?void?run(){
System.out.println("hongqi?running");
}
}
|
public?class?Boy?{
//?аоИФвРРЕЮЊHongQiCar
private?final?HongQiCar?hongQiCar?=?new?HongQiCar();
public?void?drive(){
hongQiCar.run();
}
} |
аТГЕПЊФхСЫЃЌгжЯыЛЛЛиРЯГЕЃЌетЪБКђЃЌОЭЛсГіЯжвЛИіЮЪЬтЃКетИіДњТывЛжБдкИФРДИФШЅ
КмЯдШЛЃЌетИіАИР§ЮЅБГСЫЮвУЧЕФвРРЕЕЙжУддђ(DIP):ГЬађВЛгІвРРЕгкЪЕЯжЃЌЖјгІвРРЕгкГщЯѓ
гХЛЏКѓ
ЯждкЮвУЧЖдДњТыНјааШчЯТгХЛЏЃК
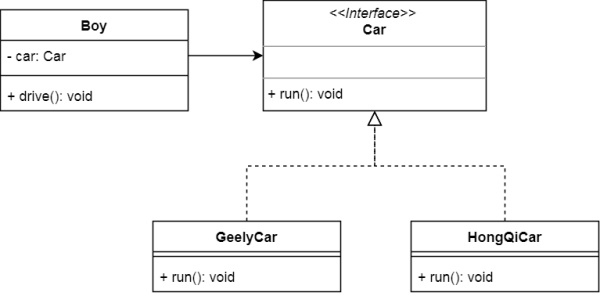
BoyвРРЕгкCarНгПкЃЌЖјжЎЧАЕФGeelyCarгыHongQiCarЮЊCarНгПкЪЕЯж
ДњТыЪЕЯжЃК
ЖЈвхГіCarНгПк
public?interface?Car?{
void?run();
} |
НЋжЎЧАЕФGeelyCarгыHongQiCarИФЮЊCarЕФЪЕЯжРр
public?class?GeelyCar?implements?Car?{
@Override
public?void?run(){
System.out.println("geely?running");
}
} |
HongQiCarЯрЭЌ
PersonДЫЪБвРРЕЕФЮЊCarНгПк
public?class?Boy?{
//?вРРЕгкНгПк?
private?final?Car?car;
???
public?Person(Car?car){
this.car?=?car;
}?
public?void?drive(){
car.run();
}
} |
ДЫЪБаЁЛяЯыЛЛЪВУДГЕПЊЃЌОЭДЋШыЪВУДВЮЪ§МДПЩЃЌДњТыВЛдйЗЂЩњБфЛЏЁЃ
ОжЯоад
вдЩЯАИР§ИФдьКѓПДЦ№РДШЗЪЕУЛгаЪВУДУЋВЁСЫЃЌЕЋЛЙЪЧДцдквЛЖЈЕФОжЯоадЃЌШчЙћДЫЪБдіМгаТЕФГЁОАЃК
гавЛЬьаЁЛяКШОЦСЫУЛЗЈПЊГЕЃЌашвЊевИіДњМнЁЃДњМнВЂВЛЙиаФЫћИјФФИіаЁЛяПЊГЕЃЌвВВЛЙиаФПЊЕФЪЧЪВУДГЕЃЌаЁЛяОЭЭЛШЛГЩСЫИіГщЯѓЃЌетЪБДњТыгжвЊНјааИФЖЏСЫЃЌДњМнвРРЕаЁЛяЕФДњТыПЩФмЛсГЄетИібљзгЃК
| private final Boy boy = new YoungBoy(new HongQiCar()); |
ЫцзХЯЕЭГЕФИДдгЖШдіМгЃЌетбљЕФЮЪЬтОЭЛсдНРДдНЖрЃЌдНРДдНФбвдЮЌЛЄЃЌФЧУДЮвУЧгІЕБШчКЮНтОіетИіЮЪЬтФи
ЫМПМ
ЪзЯШЃЌЮвУЧПЩвдПЯЖЈЃКЪЙгУвРРЕЕЙжУддђЪЧУЛгаЮЪЬтЕФЃЌЫќдквЛЖЈГЬЖШЩЯНтОіСЫЮвУЧЕФЮЪЬтЁЃ
ЮвУЧОѕЕУГіЮЪЬтЕФЕиЗНЪЧдкДЋШыВЮЪ§ЕФЙ§ГЬЃКГЬађашвЊЪВУДЮвУЧОЭДЋШыЪВУДЃЌвЛЕЋЯЕЭГжаГіЯжЖрживРРЕЕФРрЙиЯЕЃЌетИіДЋШыЕФВЮЪ§ОЭЛсБфЕУМЋЦфИДдгЁЃ
ЛђаэЮвУЧПЩвдАбЫМТЗЗДзЊвЛЯТЃКЮвУЧгаЪВУДЃЌГЬађОЭгУЪВУД!
ЕБЮвУЧжЛЪЕЯжHongQiCarКЭYoungBoyЪБЃЌДњМнОЭЪЙгУЕФЪЧПЊзХHongQiCarЕФYoungBoy!
ЕБЮвУЧжЛЪЕЯжGeelyCarКЭOldBoyЪБЃЌДњМнздШЛЖјШЛОЭИФБфГЩСЫПЊзХGeelyCarЕФOldBoy!
ЖјШчКЮЗДзЊЃЌОЭЪЧSpringЫљНтОіЕФвЛДѓФбЬтЁЃ
SpringНщЩм
SpringЪЧвЛИівЛеОЪНЧсСПМЖжиСПМЖЕФПЊЗЂПђМмЃЌФПЕФЪЧЮЊСЫНтОіЦѓвЕМЖгІгУПЊЗЂЕФИДдгадЃЌЫќЮЊПЊЗЂJavaгІгУГЬађЬсЙЉШЋУцЕФЛљДЁМмЙЙжЇГжЃЌШУJavaПЊЗЂепВЛдйашвЊЙиаФРргыРржЎМфЕФвРРЕЙиЯЕЃЌПЩвдзЈзЂЕФПЊЗЂгІгУГЬађ(crud)ЁЃ
SpringЮЊЦѓвЕМЖПЊЗЂЬсЙЉИјСЫЗсИЛЕФЙІФмЃЌЖјетаЉЙІФмЕФЕзВуЖМвРРЕгкЫќЕФСНИіКЫаФЬиад:вРРЕзЂШы(DI)КЭУцЯђЧаУцБрГЬ(AOP)ЁЃ
SpringЕФКЫаФИХФю
IoCШнЦї
IoCЕФШЋГЦЮЊInversion of ControlЃЌвтЮЊПижЦЗДзЊЃЌIoCвВБЛГЦЮЊвРРЕадзЂШы(DI)ЃЌетЪЧвЛИіЭЈЙ§вРРЕзЂШыЖдЯѓЕФЙ§ГЬЃКЖдЯѓНіЭЈЙ§ЙЙдьКЏЪ§ЁЂЙЄГЇЗНЗЈЃЌЛђепдкЖдЯѓЪЕР§ЛЏдкЦфЩЯЩшжУЕФЪєадРДЖЈвхЦфвРРЕЙиЯЕ(МДгыЫќУЧзщКЯЕФЦфЫћЖдЯѓ)ЃЌШЛКѓШнЦїдкДДНЈbeanЪБзЂШыетаЉашвЊЕФвРРЕЁЃетИіЙ§ГЬДгИљБОЩЯЫЕЪЧBeanБОЩэЭЈЙ§ЪЙгУжБНгЙЙНЈРрЛђжюШчЗўЮёЖЈЮЛФЃЪНЕФЛњжЦЃЌРДПижЦЦфвРРЕЙиЯЕЕФЪЕР§ЛЏЛђЮЛжУЕФФцЙ§ГЬ(вђДЫБЛГЦЮЊПижЦЗДзЊ)ЁЃ
вРРЕЕЙжУддђЪЧIoCЕФЩшМЦдРэЃЌвРРЕзЂШыЪЧIoCЕФЪЕЯжЗНЪНЁЃ
ШнЦї
дкSpringжаЃЌЮвУЧПЩвдЪЙгУXMLЁЂJavaзЂНтЛђJavaДњТыЕФЗНЪНРДБраДХфжУаХЯЂЃЌЖјЭЈЙ§ХфжУаХЯЂЃЌЛёШЁгаЙиЪЕР§ЛЏЁЂХфжУКЭзщзАЖдЯѓЕФЫЕУїЃЌНјааЪЕР§ЛЏЁЂХфжУКЭзщзАгІгУЖдЯѓЕФГЦЮЊШнЦїЁЃ
вЛАуЧщПіЯТЃЌЮвУЧжЛашвЊЬэМгМИИізЂНтЃЌетбљШнЦїНјааДДНЈКЭГѕЪМЛЏКѓЃЌЮвУЧОЭПЩвдЕУЕНвЛИіПЩХфжУЕФЃЌПЩжДааЕФЯЕЭГЛђгІгУГЬађЁЃ
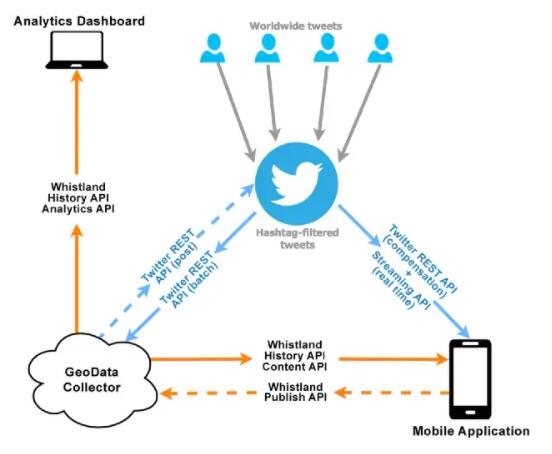
Bean
дкSpringжаЃЌгЩSpring IOCШнЦїНјааЪЕР§ЛЏЁЊ>зщзАЙмРэЁЊ>ЙЙГЩГЬађЙЧМмЕФЖдЯѓГЦЮЊBeanЁЃBeanОЭЪЧгІгУГЬађжажкЖрЖдЯѓжЎвЛЁЃ
вдЩЯШ§ЕуДЎЦ№РДОЭЪЧЃКSpringФкВПЪЧвЛИіЗХжУBeanЕФIoCШнЦїЃЌЭЈЙ§вРРЕзЂШыЕФЗНЪНДІРэBeanжЎМфЕФвРРЕЙиЯЕЁЃ
AOP
УцЯђЧаУцБрГЬ(Aspect-oriented Programming)ЃЌЪЧЯрЖдУцЯђЖдЯѓБрГЬ(OOP)ЕФвЛжжЙІФмВЙГф,OOPУцЯђЕФжївЊЖдЯѓЪЧРрЃЌЖјAOPдђЪЧЧаУцЁЃдкДІРэШежОЁЂАВШЋЙмРэЁЂЪТЮёЙмРэЕШЗНУцгаЗЧГЃживЊЕФзїгУЁЃAOPЪЧSpringПђМмживЊЕФзщМўЃЌЫфШЛIOCШнЦїУЛгавРРЕAOPЃЌЕЋЪЧAOPЬсЙЉСЫЗЧГЃЧПДѓЕФЙІФмЃЌгУРДЖдIOCзіВЙГфЁЃ
AOPПЩвдШУЮвУЧдкВЛаоИФдгаДњТыЕФЧщПіЯТЃЌЖдЮвУЧЕФвЕЮёЙІФмНјаадіЧПЃКНЋвЛЖЮЙІФмЧаШыЕНЮвУЧжИЖЈЕФЮЛжУЃЌШчдкЗНЗЈЕФЕїгУСДжЎМфДђгЁШежОЁЃ
SpringЕФгХЕу
1ЁЂSpringЭЈЙ§DIЁЂAOPРДМђЛЏЦѓвЕМЖJavaПЊЗЂ
2ЁЂSpringЕФЕЭЧжШыЪНЩшМЦЃЌШУДњТыЕФЮлШОМЋЕЭ
3ЁЂSpringЕФIoCШнЦїНЕЕЭСЫвЕЮёЖдЯѓжЎМфЕФИДдгадЃЌШУзщМўжЎМфЛЅЯрНтёю
4ЁЂSpringЕФAOPжЇГждЪаэНЋвЛаЉЭЈгУШЮЮёШчАВШЋЁЂЪТЮёЁЂШежОЕШНјааМЏжаЪНДІРэЃЌДгЖјЬсИпСЫИќКУЕФИДгУад
5ЁЂSpringЕФИпЖШПЊЗХадЃЌВЂВЛЧПжЦгІгУЭъШЋвРРЕгкSpringЃЌПЊЗЂепПЩздгЩбЁгУSpringПђМмЕФВПЗжЛђШЋВП
6ЁЂSpringЕФИпЖШРЉеЙадЃЌШУПЊЗЂепПЩвдЧсвзЕФШУздМКЕФПђМмдкSpringЩЯНјааМЏГЩ
7ЁЂSpringЕФЩњЬЌМЋЦфЭъећЃЌМЏГЩСЫИїжжгХауЕФПђМмЃЌШУПЊЗЂепПЩвдЧсвзЕФЪЙгУЫќУЧ
ЮвУЧПЩвдУЛгаJavaЃЌЕЋЪЧВЛФмУЛгаSpring~
гУSpringИФдьАИР§
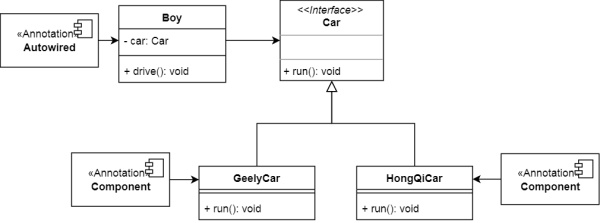
ЮвУЧЯждквбОШЯЪЖСЫЪВУДЪЧSpringЃЌЯждкОЭГЂЪдЪЙгУSpringЖдАИР§НјааИФдьвЛЯТ
дРДЕФНсЙЙУЛгаБфЛЏЃЌжЛашдкGeelyCarЛђHongQiCarЩЯдіМг@ComponentзЂНтЃЌBoyдкЪЙгУЪБМгЩЯ@AutowiredзЂНт
ДњТыбљЪНЃК
| @Componentpublic class GeelyCar implements Car { @Override public void run() { System. out .println( "geely car running" ); }} |
HongQiCarЯрЭЌ
дкSpringжаЃЌЕБРрБъЪЖСЫ@ComponentзЂНтКѓОЭБэЪОетЪЧвЛИіBeanЃЌПЩвдБЛIoCШнЦїЫљЙмРэ
| @Componentpublic class Boy { // ЪЙгУAutowiredзЂНтБэЪОcarашвЊНјаавРРЕзЂШы @Autowired private Car car; public void driver(){ car.run(); }} |
ЮвУЧжЎЧАЫљЫЕЕФЃКЮвУЧЪЕЯжЪВУДЃЌГЬађОЭЪЙгУЪВУДЃЌдкетРяОЭЕШЭЌгкЮвУЧдкФФИіРрЩЯБъЪЖСЫComponentзЂНтЃЌФФИіРрОЭЛсЪЧвЛИіBeanЃЌSpringОЭЛсЪЙгУЫќзЂШыBoyЕФЪєадCarжа
ЫљвдЕБЮвУЧИјGeelyCarБъЪЖComponentзЂНтЪБЃЌBoyПЊЕФГЕОЭЪЧGeelyCarЃЌЕБЮвУЧИјHongQiCarБъЪЖComponentзЂНтЪБЃЌBoyПЊЕФГЕОЭЪЧHongQiCar
ЕБШЛЃЌЮвУЧВЛПЩвддкGeelyCarКЭHongQiCarЩЯЭЌЪББъЪЖComponentзЂНтЃЌвђЮЊетбљSpringОЭВЛжЊЕРгУФФИіCarНјаазЂШыСЫЁЊЁЊSpringвВгабЁдёРЇФбжЂ(or вЛboyВЛФмПЊСЉГЕ)
ЪЙгУSpringЦєЖЏГЬађ
| // ИцЫпSpringДгФФИіАќЯТЩЈУшBeanЃЌВЛаДОЭЪЧЕБЧААќТЗОЖ@ComponentScan(basePackages = "com.my.spring.test.demo" ) public class Main { public static void main(String[] args) { // НЋMain(ХфжУаХЯЂ)ДЋШыЕНApplicationContext(IoCШнЦї)жа ApplicationContext context = new AnnotationConfigApplicationContext(Main.class); // Дг(IoCШнЦї)жаЛёШЁЕНЮвУЧЕФboy Boy boy = (Boy) context.getBean( "boy" ); // ПЊГЕ boy.driver(); }} |
етРяОЭПЩвдАбЮвУЧИеИеНщЩмSpringЕФжЊЪЖНјааНтЖССЫ
АбОпгаComponentScanзЂНт(ХфжУаХЯЂ)ЕФMainРрЃЌДЋИјAnnotationConfigApplicationContext(IoCШнЦї)НјааГѕЪМЛЏЃЌОЭЕШгкЃКIoCШнЦїЭЈЙ§ЛёШЁХфжУаХЯЂНјааЪЕР§ЛЏЁЂЙмРэКЭзщзАBeanЁЃ
ЖјШчКЮНјаавРРЕзЂШыдђЪЧдкIoCШнЦїФкВПЭъГЩЕФЃЌетвВЪЧБОЮФвЊЬжТлЕФжиЕу
ЫМПМ
ЮвУЧЭЈЙ§вЛИіИФдьАИР§ЭъећЕФШЯЪЖСЫSpringЕФЛљБОЙІФмЃЌвВЖджЎЧАЕФИХФюгаСЫвЛИіОпЯѓЛЏЕФЬхбщЃЌЖјЮвУЧЛЙВЂВЛжЊЕРSpringЕФвРРЕзЂШыетвЛФкВПЖЏзїЪЧШчКЮЭъГЩЕФЃЌЫљЮНжЊЦфШЛИќвЊжЊЦфЫљвдШЛЃЌНсКЯЮвУЧЕФЯжгажЊЪЖЃЌвдМАЖдSpringЕФРэНтЃЌДѓЕЈВТЯыЭЦВтвЛЯТАЩ(етЪЧКмживЊЕФФмСІХЖ)
ЦфЪЕВТВтОЭЪЧжИЃКШчЙћШУЮвУЧздМКЪЕЯжЃЌЮвУЧЛсШчКЮЪЕЯжетИіЙ§ГЬ
ЪзЯШЃЌЮвУЧвЊЧхГўЮвУЧашвЊзіЕФЪТЧщЪЧЪВУДЃКЩЈУшжИЖЈАќЯТУцЕФРрЃЌНјааЪЕР§ЛЏЃЌВЂИљОнвРРЕЙиЯЕзщКЯКУЁЃ
ВНжшЗжНтЃК
ЩЈУшжИЖЈАќЯТУцЕФРр -> ШчЙћетИіРрБъЪЖСЫComponentзЂНт(ЪЧИіBean) -> АбетИіРрЕФаХЯЂДцЦ№РД
НјааЪЕР§ЛЏ -> БщРњДцКУЕФРраХЯЂ -> ЭЈЙ§ЗДЩфАбетаЉРрНјааЪЕР§ЛЏ
ИљОнвРРЕЙиЯЕзщКЯ -> НтЮіРраХЯЂ -> ХаЖЯРржаЪЧЗёгаашвЊНјаавРРЕзЂШыЕФзжЖЮ -> ЖдзжЖЮНјаазЂШы
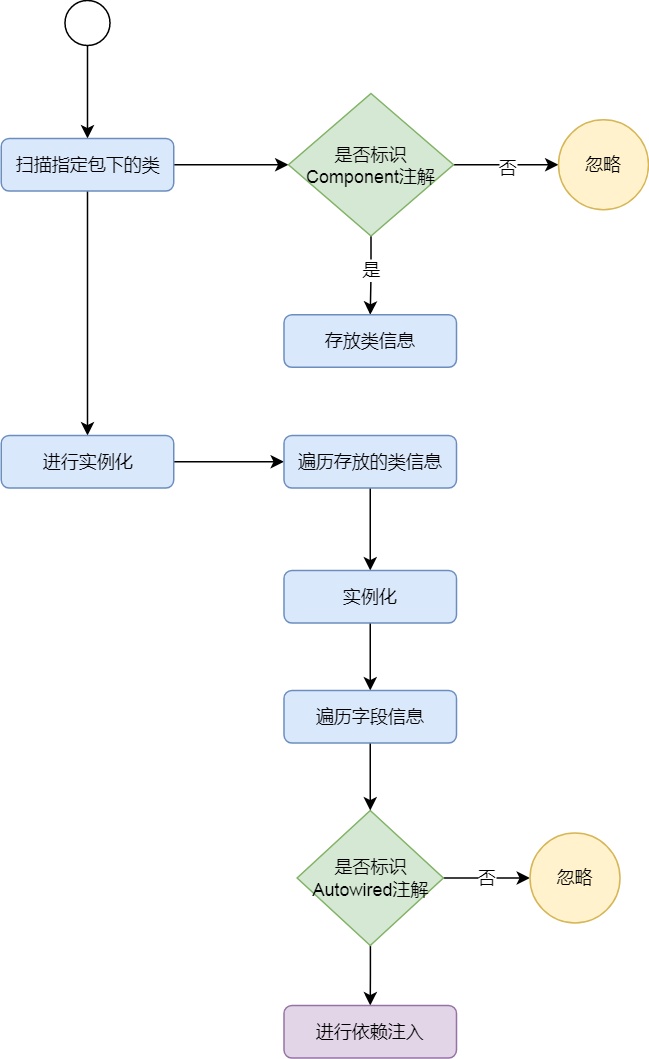
ЗНАИЪЕЯж
ЮвУЧЯждквбОгаСЫвЛИіПДЦ№РДЯёЪЧФЧУДвЛЛиЪТЕФНтОіЗНАИЃЌЯждкОЭГЂЪдАбетИіЗНАИЪЕЯжГіРД
ЖЈвхзЂНт
ЪзЯШЮвУЧашвЊЖЈвхГіашвЊгУЕНЕФзЂНтЃКComponentScan,Component,Autowired
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public?@interface?ComponentScan?{
String?basePackages()?default?"";
} |
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Component {
String value() default "";
} |
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public?@interface?Autowired?{
} |
ЩЈУшжИЖЈАќЯТУцЕФРр
ЩЈУшжИЖЈАќЯТЕФЫљгаРрЃЌЬ§Ц№РДКУЯёвЛЪБУўВЛзХЭЗФдЃЌЦфЪЕЫќЕШЭЌгкСэвЛИіЮЪЬтЃКШчКЮБщРњЮФМўФПТМ
ФЧУДДцЗХРраХЯЂгІИУгУЪВУДФиЮвУЧПДПДЩЯУцР§згжаgetBeanЕФЗНЗЈЃЌЪЧВЛЪЧЯёMapжаЕФЭЈЙ§keyЛёШЁvalueЖјMapжаЛЙгаКмЖрЪЕЯжЃЌЕЋЯпГЬАВШЋЕФШДжЛгавЛИіЃЌФЧОЭЪЧConcurrentHashMap(Б№ИњЮвЫЕHashTable)
ЖЈвхДцЗХРраХЯЂЕФmap
| private?final?Map<String,?Class<>>?classMap?=?new?ConcurrentHashMap<>(16); |
ОпЬхСїГЬЃЌЯТУцЭЌбљИНЩЯДњТыЪЕЯжЃК
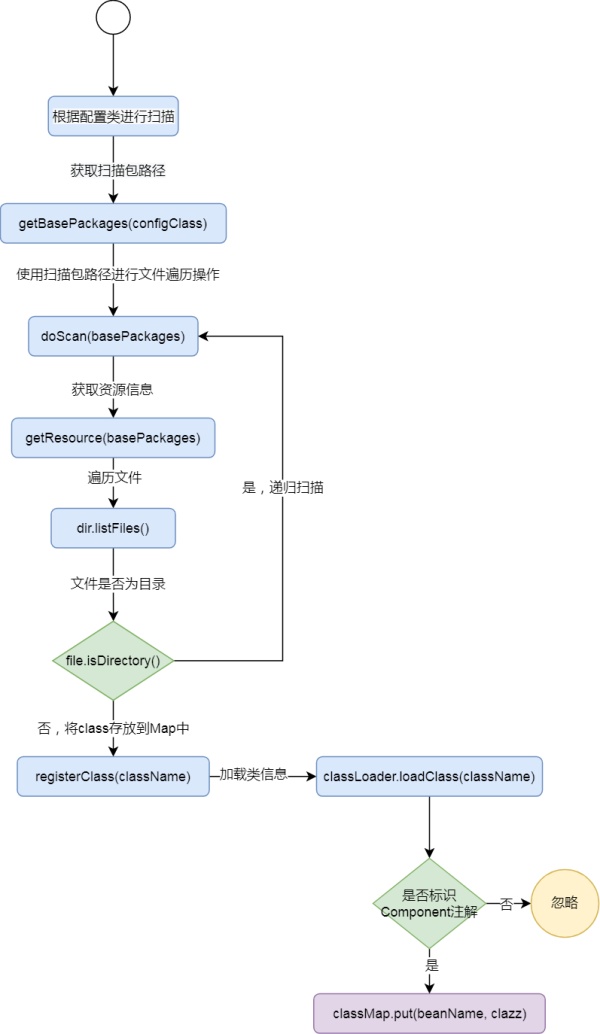
ДњТыЪЕЯжЃЌПЩвдгыСїГЬЭМНсКЯЙлПДЃК
ЩЈУшРраХЯЂ
private?void?scan(Class<>?configClass)?{
//?НтЮіХфжУРрЃЌЛёШЁЕНЩЈУшАќТЗОЖ
String?basePackages?=?this.getBasePackages(configClass);
//?ЪЙгУЩЈУшАќТЗОЖНјааЮФМўБщРњВйзї
this.doScan(basePackages);
} |
private?String?getBasePackages(Class<>?configClass)?{
//?ДгComponentScanзЂНтжаЛёШЁЩЈУшАќТЗОЖ
ComponentScan?componentScan?=?configClass.getAnnotation(ComponentScan.class); return?componentScan.basePackages();
}?
|
private?void?doScan(String?basePackages)?{
//?ЛёШЁзЪдДаХЯЂ?
URI?resource?=?this.getResource(basePackages);
File?dir?=?new?File(resource.getPath());
for?(File?file?:?dir.listFiles())?{
if?(file.isDirectory())?{//?ЕнЙщЩЈУш?
doScan(basePackages?+?"."?+?file.getName());?
}?
else?{?
//?com.my.spring.example?+?.?+?Boy.class?->?
com.my.spring.example.Boy?
String?className?=?basePackages?+?"."?
+?file.getName().replace(".class",?"");?
//?НЋclassДцЗХЕНclassMapжа?
this.registerClass(className);? }?
}?
}?
|
private?void?registerClass(String?className){
try?{
//?МгдиРраХЯЂ
Class<>?clazz?=?classLoader.loadClass(className);
//?ХаЖЯЪЧЗёБъЪЖComponentзЂНт
if(clazz.isAnnotationPresent(Component.class)){
//?ЩњГЩbeanName?com.my.spring.example.Boy?->?boy
String?beanName?=?this.generateBeanName(clazz);
//?car:?com.my.spring.example.Car
classMap.put(beanName,?clazz);
}?}?catch?(ClassNotFoundException?ignore)?{}
}?
|
ЪЕР§ЛЏ
ЯждквбОАбЫљгаЪЪКЯЕФРрЖМНтЮіКУСЫЃЌНгЯТРДОЭЪЧЪЕР§ЛЏЕФЙ§ГЬСЫ
ЖЈвхДцЗХBeanЕФMap
- private final Map<String, Object> beanMap = new ConcurrentHashMap<>(16);
ОпЬхСїГЬЃЌЯТУцЭЌбљИјГіДњТыЪЕЯжЃК
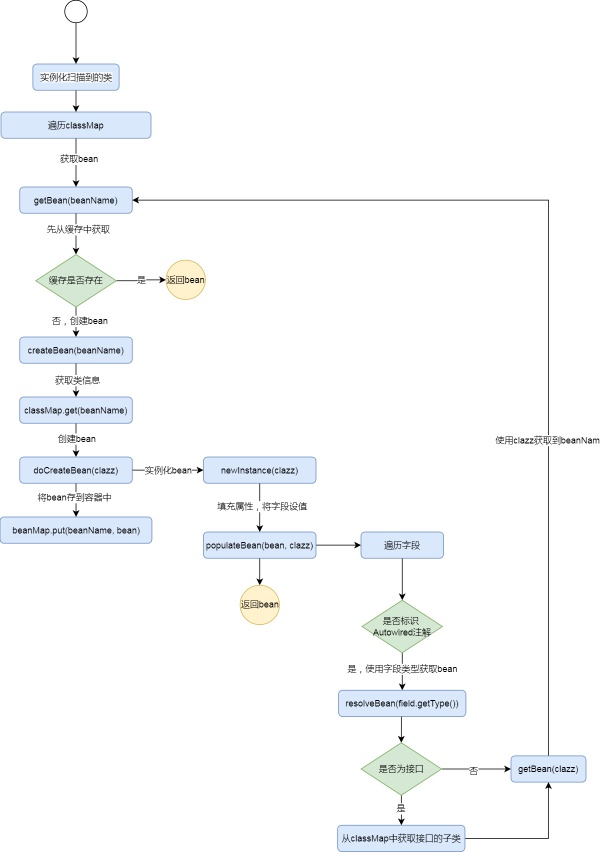
ДњТыЪЕЯжЃЌПЩвдгыСїГЬЭМНсКЯЙлПДЃК
БщРњclassMapНјааЪЕР§ЛЏBean
public?void?instantiateBean()?{
for?(String?beanName?:?classMap.keySet())?{
getBean(beanName);
}
} |
Object?bean?=?beanMap.get(beanName);
if(bean?!=?null){
return?bean;
}? return?this.createBean(beanName);
}
|
private?Object?createBean(String?beanName){
try?{
//?ДДНЈbean
Object?bean?=?this.doCreateBean(clazz);
//?НЋbeanДцЕНШнЦїжа
beanMap.put(beanName,?bean);
return?bean;
}?catch?(IllegalAccessException?e)?{
throw?new?RuntimeException(e);?}
}?
|
private?Object?doCreateBean(Class<>?clazz)?throws?IllegalAccessException?{??//?ЪЕР§ЛЏbean??Object?bean?=?this.newInstance(clazz);??//?ЬюГфзжЖЮЃЌНЋзжЖЮЩшжЕthis.populateBean(bean,?clazz);??return?bean;}?
|
private?void?populateBean(Object?bean,?Class<>?clazz)?
throws?IllegalAccessException?{?
//?НтЮіclassаХЯЂЃЌХаЖЯРржаЪЧЗёгаашвЊНјаавРРЕзЂШыЕФзжЖЮ?
final?Field[]?fields?=?clazz.getDeclaredFields();?
for?(Field?field?:?fields)?{????
Autowired?autowired?=?field.getAnnotation(Autowired.class);??
if(autowired?!=?null){??????//?ЛёШЁbean???
Object?value?=?this.resolveBean(field.getType());
field.setAccessible(true);?field.set(bean,?value);?
?
}??}}
|
?
private?Object?resolveBean(Class<>?clazz){
//?ЯШХаЖЯclazzЪЧЗёЮЊвЛИіНгПкЃЌЪЧдђХаЖЯclassMapжаЪЧЗёДцдкзгРр
if(clazz.isInterface()){
//?днЪБжЛжЇГжclassMapжЛгавЛИізгРрЕФЧщПі
?
for?(Map.Entry<String,?Class<>
entry?:?classMap.entrySet())?{?
if?(clazz.isAssignableFrom(entry.getValue()))?{?????
return?getBean(entry.getValue());??????}???}??
throw?new?RuntimeException("евВЛЕНПЩвдНјаавРРЕзЂШыЕФbean")?
}else?{????return?getBean(clazz);??}
|
зщКЯ
СНИіКЫаФЗНЗЈвбОаДКУСЫЃЌНгЯТАбЫќУЧзщКЯЦ№РДЃЌЮвАбЫќУЧЪЕЯждкздЖЈвхЕФApplicationContextРржаЃЌЙЙдьЗНЗЈШчЯТЃК
public?ApplicationContext(Class<>?configClass)?{?
//?1.ЩЈУшХфжУаХЯЂжажИЖЈАќЯТЕФРр?
this.scan(configClass);?
//?2.ЪЕР§ЛЏЩЈУшЕНЕФРр?
this.instantiateBean();?
}?
|
UMLРрЭМЃК
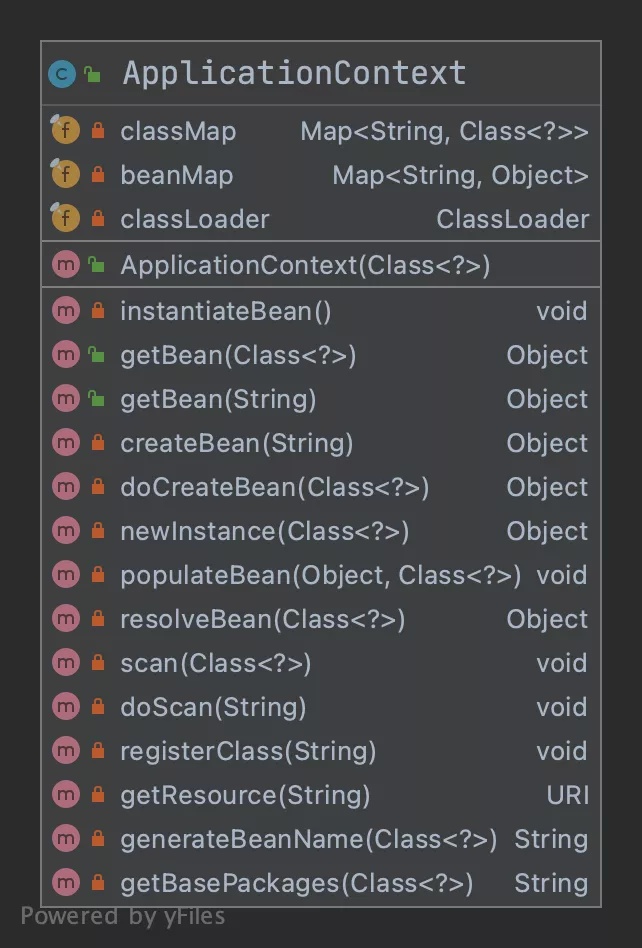
ВтЪд
ДњТыНсЙЙгыАИР§ЯрЭЌЃЌетРяеЙЪОвЛЯТЮвУЧздМКЕФSpringЪЧЗёПЩвде§ГЃдЫаа
дЫаае§ГЃЃЌжаЙњШЫВЛЦжаЙњШЫ
дДТыЛсдкЮФФЉИјГі
ЛиЙЫ
ЯждкЃЌЮвУЧвбОИљОнЩшЯыЕФЗНАИНјааСЫЪЕЯжЃЌдЫааЕФЧщПівВДяЕНСЫдЄЦкЕФаЇЙћЁЃЕЋШчЙћзаЯИбаОПвЛЯТЃЌдйНсКЯЮвУЧЦНГЃЪЙгУSpringЕФГЁОАЃЌОЭЛсЗЂЯжетвЛЗнДњТыЕФВЛЩйЮЪЬтЃК
1ЁЂЮоЗЈжЇГжЙЙдьЦїзЂШыЃЌЕБШЛвВУЛгажЇГжЗНЗЈзЂШыЃЌетЪЧЪєгкЙІФмЩЯЕФШБЪЇЁЃ
2ЁЂМгдиРраХЯЂЕФЮЪЬтЃЌМгдиРрЪБЮвУЧЪЙгУЕФЪЧclassLoader.loadClassЕФЗНЪНЃЌЫфШЛетБмУтСЫРрЕФГѕЪМЛЏ(ПЩЧЇЭђБ№гУClass.forNameЕФЗНЪН)ЃЌЕЋЛЙЪЧВЛПЩБмУтЕФАбРрдЊаХЯЂМгдиЕНСЫдЊПеМфжаЃЌЕБЮвУЧЩЈУшАќЯТгаВЛашвЊЕФРрЪБЃЌетОЭРЫЗбСЫЮвУЧЕФФкДцЁЃ
3ЁЂЮоЗЈНтОіbeanжЎМфЕФбЛЗвРРЕЃЌБШШчгавЛИіAЖдЯѓвРРЕСЫBЖдЯѓЃЌ BЖдЯѓгжвРРЕСЫAЖдЯѓЃЌетИіЪБКђЮвУЧдйРДПДПДДњТыТпМЃЌОЭЛсЗЂЯжДЫЪБЛсЯнШыЫРбЛЗЁЃ
4ЁЂРЉеЙадКмВюЃЌЮвУЧАбЫљгаЕФЙІФмЖМаДдквЛИіРрРяЃЌЕБЯывЊЭъЩЦЙІФм(БШШчвдЩЯ3ИіЮЪЬт)ЪБЃЌОЭашвЊЦЕЗБаоИФетИіРрЃЌетИіРрвВЛсБфЕУдНРДдНгЗжзЃЌБ№ЫЕЕќДњаТЙІФмЃЌЮЌЛЄЖМЛсСюШЫЭЗЬлЁЃ
гХЛЏЗНАИ
ЖдгкЧАШ§ИіЮЪЬтЖМРрЫЦгкЙІФмЩЯЕФЮЪЬтЃЌЙІФмТяЃЌИФвЛИФОЭКУСЫЁЃ
ЮвУЧашвЊзХжиЙизЂЕФЪЧЕкЫФИіЮЪЬтЃЌвЛПюПђМмЯывЊБфЕУгХауЃЌФЧУДЫќЕФЕќДњФмСІвЛЖЈвЊКУЃЌетбљЙІФмВХФмБфЕУЗсИЛЃЌЖјЕќДњФмСІЕФгАЯьвђЫигаКмЖрЃЌЦфжажЎвЛОЭЪЧЫќЕФРЉеЙадЁЃ
ФЧУДгІИУШчКЮЬсИпЮвУЧЕФЗНАИЕФРЉеЙадФиЃЌСљДѓЩшМЦддђИјСЫЮвУЧКмКУЕФжИЕМзїгУЁЃ
дкЗНАИжаЃЌApplicationContextзіСЫКмЖрЪТЧщЃЌ жївЊПЩвдЗжЮЊСНДѓПщ
1ЁЂЩЈУшжИЖЈАќЯТЕФРр
2ЁЂЪЕР§ЛЏBean
НшжњЕЅвЛжАд№ддђЕФЫМЯыЃКвЛИіРржЛзівЛжжЪТЃЌвЛИіЗНЗЈжЛзівЛМўЪТЁЃ
ЮвУЧАбЩЈУшжИЖЈАќЯТЕФРретМўЪТЕЅЖРЪЙгУвЛИіДІРэЦїНјааДІРэЃЌвђЮЊЩЈУшХфжУЪЧДгХфжУРрЖјРДЃЌФЧЮвУЧОЭНаЫћХфжУРрДІРэЦїЃКConfigurationCalssProcessor

ЪЕР§ЛЏBeanетМўЪТЧщвВЭЌбљШчДЫЃЌЪЕР§ЛЏBeanгжЗжЮЊСЫСНМўЪТЃКЪЕР§ЛЏКЭвРРЕзЂШы
ЪЕР§ЛЏBeanОЭЪЧЯрЕБгквЛИіЩњВњBeanЕФЙ§ГЬЃЌЮвУЧОЭАбетМўЪТЪЙгУвЛИіЙЄГЇРрНјааДІРэЃЌЫќОЭНазіЃКBeanFactoryЃЌМШШЛЪЧдкЩњВњBeanЃЌФЧОЭашвЊдСЯ(Class)ЃЌЫљвдЮвУЧАбclassMapКЭbeanMapЖМЖЈвхЕНетРя

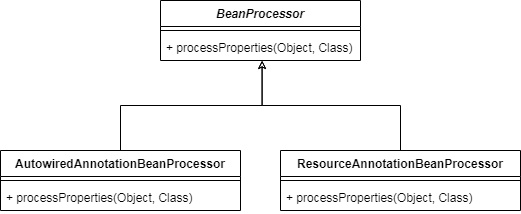
ЖјвРРЕзЂШыЕФЙ§ГЬЃЌЦфЪЕОЭЪЧдкДІРэAutowiredзЂНтЃЌФЧЫќОЭНазі: AutowiredAnnotationBeanProcessor

ЮвУЧЛЙдкжЊЕРЃЌдкSpringжаЃЌВЛНіНіжЛгаетжжЪЙгУЗНЪНЃЌЛЙгаxmlЃЌmvcЃЌSpringBootЕФЗНЪНЃЌЫљвдЮвУЧНЋApplicationContextНјааГщЯѓЃЌжЛЪЕЯжжїИЩСїГЬЃЌдРДЕФзЂНтЗНЪННЛгЩAnnotationApplicationContextЪЕЯжЁЃ
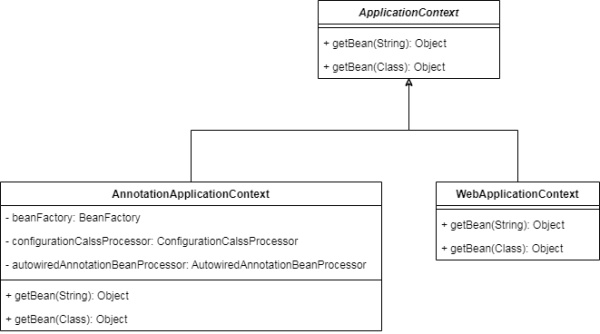
НшжњвРРЕЕЙжУддђЃКГЬађгІЕБвРРЕгкГщЯѓ
дкЮДРДЃЌРраХЯЂВЛНіНіПЩвдДгРраХЯЂРДЃЌвВПЩвдДгХфжУЮФМўЖјРДЃЌЫљвдЮвУЧНЋConfigurationCalssProcessorГщЯѓ
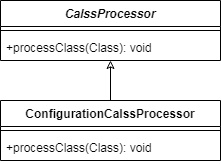
ЖјвРРЕзЂШыЕФЗНЪНВЛвЛЖЈЗЧЕУЪЧгУAutowriedзЂНтБъЪЖЃЌвВПЩвдЪЧБ№ЕФзЂНтБъЪЖЃЌБШШчResourceЃЌЫљвдЮвУЧНЋAutowiredAnnotationBeanProcessorГщЯѓ
BeanЕФРраЭвВПЩвдгаКмЖрЃЌПЩвдЪЧЕЅР§ЕФЃЌПЩвдЪЙЖрР§ЕФЃЌвВПЩвдЪЧИіЙЄГЇBeanЃЌЫљвдЮвУЧНЋBeanFactoryГщЯѓ
ЯждкЃЌЮвУЧНшжњСНДѓЩшМЦддђЖдЮвУЧЕФЗНАИНјааСЫгХЛЏЃЌЯрБШгкжЎЧАПЩЮНЪЧЁБЭбЬЅЛЛЙЧЁАЁЃ
SpringЕФЩшМЦ
дкЩЯвЛВНЃЌЮвУЧЪЕЯжСЫздМКЕФЗНАИЃЌВЂЛљгквЛаЉЩшЯыНјааСЫРЉеЙадгХЛЏЃЌЯждкЃЌЮвУЧОЭРДШЯЪЖвЛЯТЪЕМЪЩЯSpringЕФЩшМЦ
ФЧУДЃЌдкSpringжагжЪЧгЩФФаЉ"НЧЩЋ"ЙЙГЩЕФФи
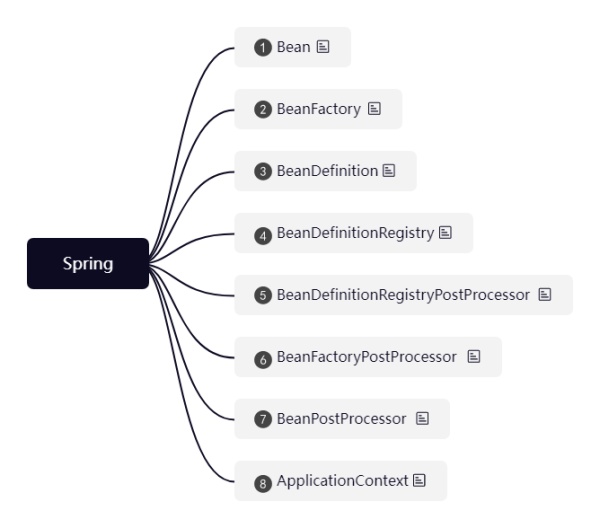
1ЁЂBean: SpringзїЮЊвЛИіIoCШнЦїЃЌзюживЊЕФЕБШЛЪЧBeanПЉ
2ЁЂBeanFactory: ЩњВњгыЙмРэBeanЕФЙЄГЇ
3ЁЂBeanDefinition: BeanЕФЖЈвхЃЌвВОЭЪЧЮвУЧЗНАИжаЕФClassЃЌSpringЖдЫќНјааСЫЗтзА
4ЁЂBeanDefinitionRegistry: РрЫЦгкBeanгыBeanFactoryЕФЙиЯЕЃЌBeanDefinitionRegistryгУгкЙмРэBeanDefinition
5ЁЂBeanDefinitionRegistryPostProcessor: гУгкдкНтЮіХфжУРрЪБЕФДІРэЦїЃЌРрЫЦгкЮвУЧЗНАИжаЕФClassProcessor
6ЁЂBeanFactoryPostProcessor: BeanDefinitionRegistryPostProcessorИИРрЃЌШУЮвУЧПЩвддйНтЮіХфжУРржЎКѓНјааКѓжУДІРэ
7ЁЂBeanPostProcessor: BeanЕФКѓжУДІРэЦїЃЌгУгкдкЩњВњBeanЕФЙ§ГЬжаНјаавЛаЉДІРэЃЌБШШчвРРЕзЂШыЃЌРрЫЦЮвУЧЕФAutowiredAnnotationBeanProcessor
8ЁЂApplicationContext: ШчЙћЫЕвдЩЯЕФНЧЩЋЖМЪЧдкЙЄГЇжаЩњВњBeanЕФЙЄШЫЃЌФЧУДApplicationContextОЭЪЧЮвУЧSpringЕФУХУцЃЌApplicationContextгыBeanFactoryЪЧвЛжжзщКЯЕФЙиЯЕЃЌЫљвдЫќЭъШЋРЉеЙСЫBeanFactoryЕФЙІФмЃЌВЂдкЦфЛљДЁЩЯЬэМгСЫИќЖрЬиЖЈгкЦѓвЕЕФЙІФмЃЌБШШчЮвУЧЪьжЊЕФApplicationListener(ЪТМўМрЬ§Цї)
вдЩЯЫЕЕФРрЫЦЦфЪЕгавЛаЉБОФЉЕЙжУСЫЃЌвђЮЊЪЕМЪЩЯгІИУЪЧЮвУЧЗНАИжаЕФЪЕЯжРрЫЦгкSpringжаЕФЪЕЯжЃЌетбљЫЕжЛЪЧЮЊСЫШУДѓМвИќКУЕФРэНт
ЮвУЧдкОРњСЫздМКЗНАИЕФЩшМЦгыгХЛЏКѓЃЌЖдетаЉНЧЩЋЦфЪЕЪЧЗЧГЃШнвзРэНтЕФ
НгЯТРДЃЌЮвУЧОЭвЛИівЛИіЕФЯъЯИСЫНтвЛЯТ
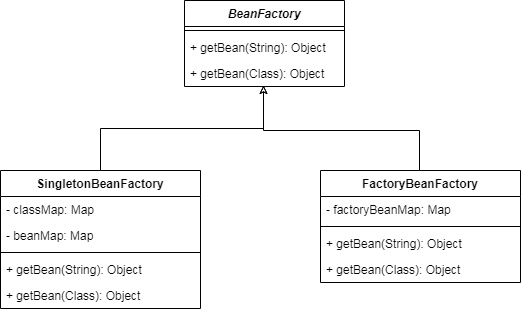
BeanFactory
BeanFactoryЪЧSpringжаЕФвЛИіЖЅМЖНгПкЃЌЫќЖЈвхСЫЛёШЁBeanЕФЗНЪНЃЌSpringжаЛЙгаСэвЛИіНгПкНаSingletonBeanRegistryЃЌЫќЖЈвхЕФЪЧВйзїЕЅР§BeanЕФЗНЪНЃЌетРяЮвНЋетСНИіЗХдквЛЦ№НјааНщЩмЃЌвђЮЊЫќУЧДѓЬхЯрЭЌЃЌSingletonBeanRegistryЕФзЂЪЭЩЯвВаДСЫПЩвдгыBeanFactoryНгПквЛЦ№ЪЕЯжЃЌЗНБуЭГвЛЙмРэЁЃ
BeanFactory
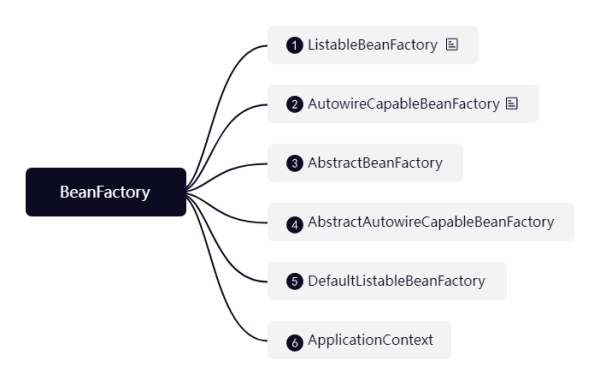
1ЁЂListableBeanFactoryЃКНгПкЃЌЖЈвхСЫЛёШЁBean/BeanDefinitionСаБэЯрЙиЕФЗНЗЈЃЌШчgetBeansOfType(Class type)
2ЁЂAutowireCapableBeanFactoryЃКНгПкЃЌЖЈвхСЫBeanЩњУќжмЦкЯрЙиЕФЗНЗЈЃЌШчДДНЈbean, вРРЕзЂШыЃЌГѕЪМЛЏ
3ЁЂAbstractBeanFactoryЃКГщЯѓРрЃЌЛљБОЩЯЪЕЯжСЫЫљгагаЙиBeanВйзїЕФЗНЗЈЃЌЖЈвхСЫBeanЩњУќжмЦкЯрЙиЕФГщЯѓЗНЗЈ
4ЁЂAbstractAutowireCapableBeanFactoryЃКГщЯѓРрЃЌМЬГаСЫAbstractBeanFactoryЃЌЪЕЯжСЫBeanЩњУќжмЦкЯрЙиЕФФкШнЃЌЫфШЛЪЧИіГщЯѓРрЃЌЕЋЫќУЛгаГщЯѓЗНЗЈ
5ЁЂDefaultListableBeanFactoryЃКМЬГагыЪЕЯжвдЩЯЫљгаРрКЭНгПкЃЌЪЧЮЊSpringжазюЕзВуЕФBeanFactory, здЩэЪЕЯжСЫListableBeanFactoryНгПк
6ЁЂApplicationContextЃКвВЪЧвЛИіНгПкЃЌЮвУЧЛсдкЯТУцгазЈУХЖдЫќЕФНщЩм
SingletonBeanRegistry
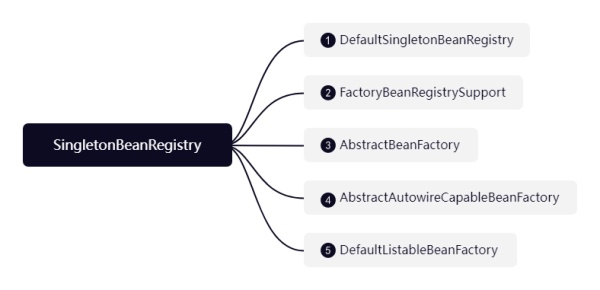
1ЁЂDefaultSingletonBeanRegistryЃК ЖЈвхСЫBeanЕФЛКДцГиЃЌРрЫЦгкЮвУЧЕФBeanMapЃЌЪЕЯжСЫгаЙиЕЅР§ЕФВйзїЃЌБШШчgetSingleton(УцЪдГЃЮЪЕФШ§МЖЛКДцОЭдкетРя)
2ЁЂFactoryBeanRegistrySupportЃКЬсЙЉСЫЖдFactoryBeanЕФжЇГжЃЌБШШчДгFactoryBeanжаЛёШЁBean
BeanDefinition
BeanDefinitionЦфЪЕвВЪЧИіНгПк(ЯыВЛЕНАЩ)ЃЌетРяЖЈвхСЫаэЖрКЭРраХЯЂЯрЙиЕФВйзїЗНЗЈЃЌЗНБудкЩњВњBeanЕФЪБКђжБНгЪЙгУЃЌБШШчgetBeanClassName
ЫќЕФДѓИХНсЙЙШчЯТ(етРяОйР§RootBeanDefinitionзгРр)ЃК

РяУцЕФИїжжЪєадЯыБиДѓМввВОјВЛФАЩњ
ЭЌбљЕФЃЌЫќвВгааэЖрЪЕЯжРрЃК
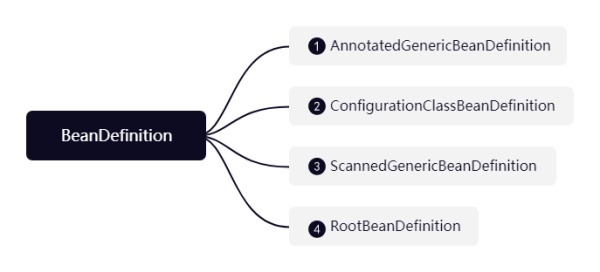
1ЁЂAnnotatedGenericBeanDefinitionЃКНтЮіХфжУРргыНтЮіImportзЂНтДјШыЕФРрЪБЃЌОЭЛсЪЙгУЫќНјааЗтзА
2ЁЂScannedGenericBeanDefinitionЃКЗтзАЭЈЙ§@ComponentScanЩЈУшАќЫљЕУЕНЕФРраХЯЂ
3ЁЂConfigurationClassBeanDefinitionЃКЗтзАЭЈЙ§@BeanзЂНтЫљЕУЕНЕФРраХЯЂ
4ЁЂRootBeanDefinitionЃКConfigurationClassBeanDefinitionИИРрЃЌвЛАудкSpringФкВПЪЙгУЃЌНЋЦфЫћЕФBeanDefitionзЊЛЏГЩИУРр
BeanDefinitionRegistry
ЖЈвхСЫгыBeanDefinitonЯрЙиЕФВйзїЃЌШчregisterBeanDefinitionЃЌgetBeanDefinitionЃЌдкBeanFactoryжаЃЌЪЕЯжРрОЭЪЧDefaultListableBeanFactory
BeanDefinitionRegistryPostProcessor
ВхЛАЃКНВЕНетРяЃЌгаУЛгаЗЂЯжSpringЕФУќУћМЋЦфЙцЗЖЃЌSpringЭХЖгдјбдSpringжаЕФРрУћЖМЪЧЗДИДЭЦЧУВХШЗШЯЕФЃЌецЪЧУћИБЦфЪЕбНЃЌЫљвдПДSpringдДТыецЕФЪЧвЛМўКмЪцЗўЕФЪТЧщЃЌПДПДРрУћЗНЗЈУћОЭФмВТГіЫќУЧЕФЙІФмСЫЁЃ
ИУНгПкжЛЖЈвхСЫвЛИіЙІФмЃКДІРэBeanDefinitonRegistryЃЌвВОЭЪЧНтЮіХфжУРржаЕФImportЁЂComponentЁЂComponentScanЕШзЂНтНјааЯргІЕФДІРэЃЌДІРэЭъБЯКѓНЋетаЉРрзЂВсГЩЖдгІЕФBeanDefinition
дкSpringФкВПжаЃЌжЛгавЛИіЪЕЯжЃКConfigurationClassPostProcessor
BeanFactoryPostProcessor
ЫљЮНBeanFactoryЕФКѓжУДІРэЦїЃЌЫќЖЈвхСЫдкНтЮіЭъХфжУРрКѓПЩвдЕїгУЕФДІРэТпМЃЌРрЫЦгквЛИіВхВлЃЌШчЙћЮвУЧЯыдкХфжУРрНтЮіЭъКѓзіЕуЪВУДЃЌОЭПЩвдЪЕЯжИУНгПкЁЃ
дкSpringФкВПжаЃЌЭЌбљжЛгаConfigurationClassPostProcessorЪЕЯжСЫЫќЃКгУгкзЈУХДІРэМгСЫConfigurationзЂНтЕФРр
етРяДЎГЁвЛИіаЁЮЪЬтЃЌШчжЊвдЯТДњТыЃК
@Configuraiton
public?class?MyConfiguration{
@Bean
public?Car?car(){
return?new?Car(wheel());
}
@Bean
public?Wheel?wheel(){
return?new?Wheel();
}?
}? |
ЮЪЃКWheelЖдЯѓдкSpringЦєЖЏЪБЃЌБЛnewСЫМИДЮЮЊЪВУД
BeanPostProcessor
НКўЗвыЃКBeanЕФКѓжУДІРэЦї
ИУКѓжУДІРэЦїЙсДЉСЫBeanЕФЩњУќжмЦкећИіЙ§ГЬЃЌдкBeanЕФДДНЈЙ§ГЬжаЃЌвЛЙВБЛЕїгУСЫ9ДЮЃЌжСгкФФ9ДЮЮвУЧЯТДЮдйРДЬНОПЃЌвдЯТНщЩмЫќЕФЪЕЯжРрвдМАзїгУ
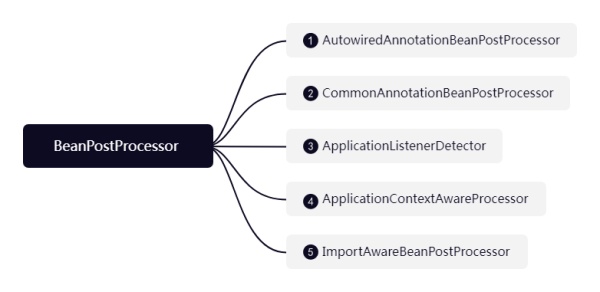
1ЁЂAutowiredAnnotationBeanPostProcessorЃКгУгкЭЦЖЯЙЙдьЦїНјааЪЕР§ЛЏЃЌвдМАДІРэAutowiredКЭValueзЂНт
2ЁЂCommonAnnotationBeanPostProcessorЃКДІРэJavaЙцЗЖжаЕФзЂНтЃЌШчResourceЁЂPostConstruct
3ЁЂApplicationListenerDetector: дкBeanЕФГѕЪМЛЏКѓЪЙгУЃЌНЋЪЕЯжСЫApplicationListenerНгПкЕФbeanЬэМгЕНЪТМўМрЬ§ЦїСаБэжа
4ЁЂApplicationContextAwareProcessorЃКгУгкЛиЕїЪЕЯжСЫAwareНгПкЕФBean
5ЁЂImportAwareBeanPostProcessor: гУгкЛиЕїЪЕЯжСЫImportAwareНгПкЕФBean
ApplicationContext
ApplicationContextзїЮЊSpringЕФКЫаФЃЌвдУХУцФЃЪНИєРыСЫBeanFactoryЃЌвдФЃАхЗНЗЈФЃЪНЖЈвхСЫSpringЦєЖЏСїГЬЕФЙЧМмЃЌгжвдВпТдФЃЪНЕїгУСЫИїЪНИїбљЕФProcessor......ЪЕдкЪЧДэзлИДдггжОЋУюОјТз!
ЫќЕФЪЕЯжРрШчЯТЃК
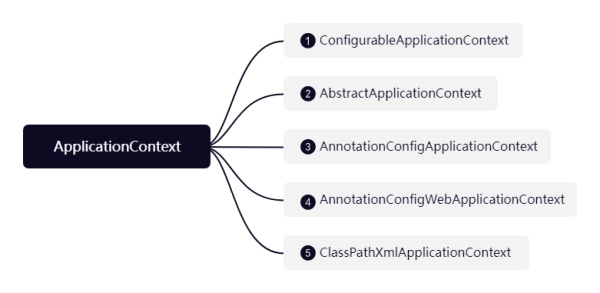
1ЁЂConfigurableApplicationContextЃКНгПкЃЌЖЈвхСЫХфжУгыЩњУќжмЦкЯрЙиВйзїЃЌШчrefresh
2ЁЂAbstractApplicationContext: ГщЯѓРрЃЌЪЕЯжСЫrefreshЗНЗЈЃЌrefreshЗНЗЈзїЮЊSpringКЫаФжаЕФКЫаФ,ПЩвдЫЕећИіSpringНддкrefreshжЎжаЃЌЫљгазгРрЖМЭЈЙ§refreshЗНЗЈЦєЖЏЃЌдкЕїгУИУЗНЗЈжЎКѓЃЌНЋЪЕР§ЛЏЫљгаЕЅР§
3ЁЂAnnotationConfigApplicationContext: дкЦєЖЏЪБЪЙгУЯрЙиЕФзЂНтЖСШЁЦїгыЩЈУшЦїЃЌЭљSpringШнЦїжазЂВсашвЊгУЕФДІРэЦїЃЌЖјКѓдкrefreshЗНЗЈдкБЛжїСїГЬЕїгУМДПЩ
4ЁЂAnnotationConfigWebApplicationContextЃКЪЕЯжloadBeanDefinitionsЗНЗЈЃЌвдЦкдкrefreshСїГЬжаБЛЕїгУЃЌДгЖјМгдиBeanDefintion
5ЁЂClassPathXmlApplicationContext: ЭЌЩЯ
ДгзгРрЕФЧщПіПЩвдПДГіЃЌзгРрЕФВЛЭЌжЎДІдкгкШчКЮМгдиBeanDefiniton, AnnotationConfigApplicationContextЪЧЭЈЙ§ХфжУРрДІРэЦї(ConfigurationClassPostProcessor)МгдиЕФЃЌЖјAnnotationConfigWebApplicationContextгыClassPathXmlApplicationContextдђЪЧЭЈЙ§здМКЪЕЯжloadBeanDefinitionsЗНЗЈЃЌЦфЫћСїГЬдђЭъШЋвЛжТ
SpringЕФСїГЬ
вдЩЯЃЌЮвУЧвбОЧхГўСЫSpringжаЕФжївЊНЧЩЋвдМАзїгУЃЌЯждкЮвУЧГЂЪдАбЫќУЧзщКЯЦ№РДЃЌЙЙНЈвЛИіSpringЕФЦєЖЏСїГЬ
ЭЌбљвдЮвУЧГЃгУЕФAnnotationConfigApplicationContextЮЊР§
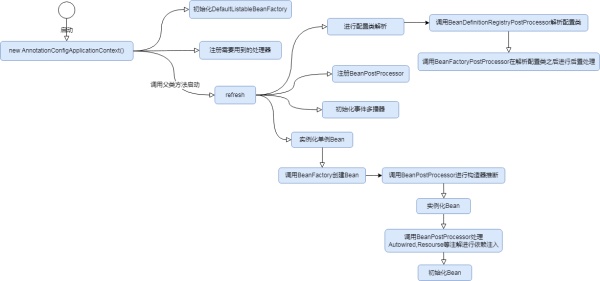
ЭМжажЛЛГіСЫSpringжаЕФВПЗжДѓИХСїГЬЃЌЯъЯИФкШнЮвУЧЛсдкКѓУцЕФеТНкеЙПЊ
аЁНс
ЫљЮНЭђЪТПЊЭЗФбЃЌБОЮФГѕждОЭЪЧФмШУДѓМввдгЩЧГШыЩюЕФЗНЪНШЯЪЖSpringЃЌГѕВННЈСЂSpringЕФШЯжЊЬхЯЕЃЌУїАзSpringЕФФкВПМмЙЙЃЌЖдSpringЕФШЯжЊВЛдйИЁгкБэУцЁЃ
ЯждкЭЗвбОПЊСЫЃЌЯраХКѓУцФкШнЕФбЇЯАвВНЋЫЎЕНЧўРДЁЃ
БОЦЊЮФеТМШНВЪЧSpringЕФМмЙЙЩшМЦЃЌвВЯЃЭћФмГЩЮЊЮвУЧвдКѓИДЯАSpringећЬхФкШнЪБЪЙгУЕФЪжВсЁЃ
зюКѓЃЌПДЭъЮФеТжЎКѓЃЌЯраХЖдвдЯТУцЪдГЃЮЪЕФЮЪЬтЛиД№Ц№РДвВЪЧЧсЖјвзОй
1ЁЂЪВУДЪЧBeanDefinition
2ЁЂBeanFactoryгыApplicationContextЕФЙиЯЕ
3ЁЂКѓжУДІРэЦїЕФЗжРргызїгУ
4ЁЂSpringЕФжївЊСїГЬЪЧдѕУДбљЕФ
|









