| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЖрМЖЛКДцМмЙЙЕФЗжВуЩшМЦЃЌШчКЮЩшМЦЁЃ
РДздгкCSDNЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЖрМЖЛКДцМмЙЙЕФЗжВуЩшМЦ
ЧАбд
дкЛЅСЊЭјИпЫйЗЂеЙЕФНёЬьЃЌЛКДцММЪѕБЛЙуЗКЕигІгУЁЃЮоТлвЕФкЛЙЪЧвЕЭтЃЌжЛвЊЪЧЬсЕНадФмЮЪЬтЃЌДѓМвЖМЛсЭбПкЖјГіЁАгУЛКДцНтОіЁБЁЃ
етжжЫЕЗЈДјгаЦЌУцадЃЌЩѕжСЪЧвЛжЊАыНтЃЌЕЋЪЧзїЮЊзЈвЕШЫЪПЕФЮвУЧЃЌашвЊЖдЛКДцгаИќЩюЁЂИќЙуЕФСЫНтЁЃ
ЛКДцММЪѕДцдкгкгІгУГЁОАЕФЗНЗНУцУцЁЃДгфЏРРЦїЧыЧѓЃЌЕНЗДЯђДњРэЗўЮёЦїЃЌДгНјГЬФкЛКДцЕНЗжВМЪНЛКДцЁЃЦфжаЛКДцВпТдЃЌЫуЗЈвВЪЧВуГіВЛЧюЃЌНёЬьОЭДјДѓМвзпНјЛКДцЁЃ
е§ЮФ
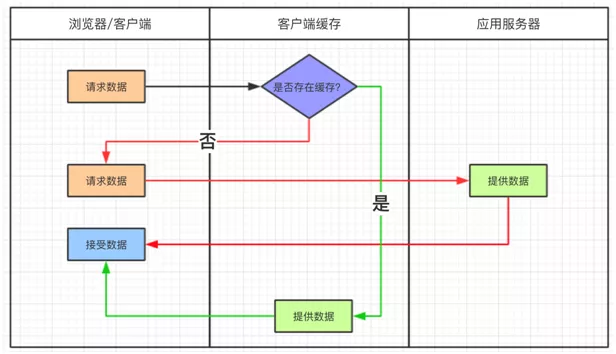
ЛКДцЖдгкУПИіПЊЗЂепРДЫЕЪЧЯрЕБЪьЯЄСЫЃЌЮЊСЫЬсИпГЬађЕФадФмЮвУЧЛсШЅМгЛКДцЃЌЕЋЪЧдкЪВУДЕиЗНМгЛКДцЃЌШчКЮМгЛКДцФиЃП
МйЩшвЛИіЭјеОЃЌашвЊЬсИпадФмЃЌЛКДцПЩвдЗХдкфЏРРЦїЃЌПЩвдЗХдкЗДЯђДњРэЗўЮёЦїЃЌЛЙПЩвдЗХдкгІгУГЬађНјГЬФкЃЌЭЌЪБПЩвдЗХдкЗжВМЪНЛКДцЯЕЭГжаЁЃ

ДггУЛЇЧыЧѓЪ§ОнЕНЪ§ОнЗЕЛиЃЌЪ§ОнОЙ§СЫфЏРРЦїЃЌCDNЃЌДњРэЗўЮёЦїЃЌгІгУЗўЮёЦїЃЌвдМАЪ§ОнПтИїИіЛЗНкЁЃУПИіЛЗНкЖМПЩвддЫгУЛКДцММЪѕЁЃ
ДгфЏРРЦї/ПЭЛЇЖЫПЊЪМЧыЧѓЪ§ОнЃЌЭЈЙ§ HTTP ХфКЯ CDN ЛёШЁЪ§ОнЕФБфИќЧщПіЃЌЕНДяДњРэЗўЮёЦїЃЈNginxЃЉПЩвдЭЈЙ§ЗДЯђДњРэЛёШЁОВЬЌзЪдДЁЃ
дйЭљЯТРДЕНгІгУЗўЮёЦїПЩвдЭЈЙ§НјГЬФкЃЈЖбФкЃЉЛКДцЃЌЗжВМЪНЛКДцЕШЕнНјЕФЗНЪНЛёШЁЪ§ОнЁЃШчЙћвдЩЯЫљгаЛКДцЖМУЛгаУќжаЪ§ОнЃЌВХЛсЛидДЕНЪ§ОнПтЁЃ
ЛКДцЕФЧыЧѓЫГађЪЧЃКгУЛЇЧыЧѓ Ёњ HTTP ЛКДц Ёњ CDN ЛКДц Ёњ ДњРэЗўЮёЦїЛКДц Ёњ НјГЬФкЛКДц
Ёњ ЗжВМЪНЛКДц Ёњ Ъ§ОнПтЁЃ
ПДРДдкММЪѕЕФМмЙЙУПИіЛЗНкЖМПЩвдМгШыЛКДцЃЌПДПДУПИіЛЗНкЪЧШчКЮгІгУЛКДцММЪѕЕФЁЃ
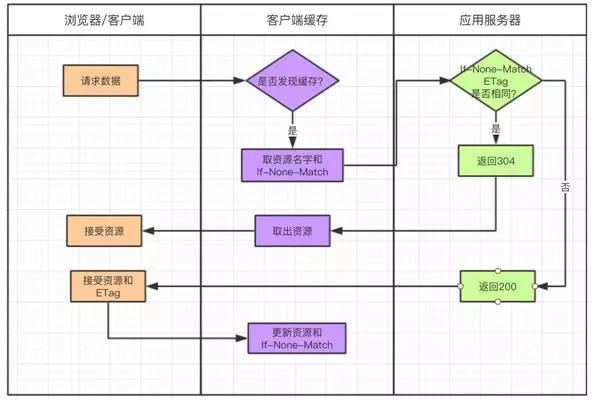
1. HTTPЛКДц
ЕБгУЛЇЭЈЙ§фЏРРЦїЧыЧѓЗўЮёЦїЕФЪБКђЃЌЛсЗЂЦ№ HTTP ЧыЧѓЃЌШчЙћЖдУПДЮ HTTP ЧыЧѓНјааЛКДцЃЌФЧУДПЩвдМѕЩйгІгУЗўЮёЦїЕФбЙСІЁЃ
ЕБЕквЛДЮЧыЧѓЕФЪБКђЃЌфЏРРЦїБОЕиЛКДцПтУЛгаЛКДцЪ§ОнЃЌЛсДгЗўЮёЦїШЁЪ§ОнЃЌВЂЧвЗХЕНфЏРРЦїЕФЛКДцПтжаЃЌЯТДЮдйНјааЧыЧѓЕФЪБКђЛсИљОнЛКДцЕФВпТдРДЖСШЁБОЕиЛђепЗўЮёЕФаХЯЂЁЃ
вЛАуаХЯЂЕФДЋЕнЭЈЙ§ HTTP ЧыЧѓЭЗ Header РДДЋЕнЁЃФПЧАБШНЯГЃМћЕФЛКДцЗНЪНгаСНжжЃЌЗжБ№ЪЧЃК
ЧПжЦЛКДц
ЖдБШЛКДц
1.1. ЧПжЦЛКДц
ЕБфЏРРЦїБОЕиЛКДцПтБЃДцСЫЛКДцаХЯЂЃЌдкЛКДцЪ§ОнЮДЪЇаЇЕФЧщПіЯТЃЌПЩвджБНгЪЙгУЛКДцЪ§ОнЁЃЗёдђОЭашвЊжиаТЛёШЁЪ§ОнЁЃ
етжжЛКДцЛњжЦПДЩЯШЅБШНЯжБНгЃЌФЧУДШчКЮХаЖЯЛКДцЪ§ОнЪЧЗёЪЇаЇФиЃПетРяашвЊЙизЂ HTTP Header
жаЕФСНИізжЖЮ Expires КЭ Cache-ControlЁЃ
Expires ЮЊЗўЮёЖЫЗЕЛиЕФЙ§ЦкЪБМфЃЌПЭЛЇЖЫЕквЛДЮЧыЧѓЗўЮёЦїЃЌЗўЮёЦїЛсЗЕЛизЪдДЕФЙ§ЦкЪБМфЁЃШчЙћПЭЛЇЖЫдйДЮЧыЧѓЗўЮёЦїЃЌЛсАбЧыЧѓЪБМфгыЙ§ЦкЪБМфзіБШНЯЁЃ
ШчЙћЧыЧѓЪБМфаЁгкЙ§ЦкЪБМфЃЌФЧУДЫЕУїЛКДцУЛгаЙ§ЦкЃЌдђПЩвджБНгЪЙгУБОЕиЛКДцПтЕФаХЯЂЁЃ
ЗДжЎЃЌЫЕУїЪ§ОнвбОЙ§ЦкЃЌБиаыДгЗўЮёЦїжиаТЛёШЁаХЯЂЃЌЛёШЁЭъБЯгжЛсИќаТзюаТЕФЙ§ЦкЪБМфЁЃ
етжжЗНЪНдк HTTP 1.0 гУЕФБШНЯЖрЃЌЕНСЫ HTTP 1.1 ЛсЪЙгУ Cache-Control
ЬцДњЁЃ
Cache-Control жагаИі max-age ЪєадЃЌЕЅЮЛЪЧУыЃЌгУРДБэЪОЛКДцФкШндкПЭЛЇЖЫЕФЙ§ЦкЪБМфЁЃ
Р§ШчЃКmax-age ЪЧ 60 УыЃЌЕБЧАЛКДцУЛгаЪ§ОнЃЌПЭЛЇЖЫЕквЛДЮЧыЧѓЭъКѓЃЌНЋЪ§ОнЗХШыБОЕиЛКДцЁЃ
ФЧУДдк 60 УывдФкПЭЛЇЖЫдйЗЂЫЭЧыЧѓЃЌЖМВЛЛсЧыЧѓгІгУЗўЮёЦїЃЌЖјЪЧДгБОЕиЛКДцжажБНгЗЕЛиЪ§ОнЁЃШчЙћСНДЮЧыЧѓЯрИєЪБМфГЌЙ§СЫ
60 УыЃЌФЧУДОЭашвЊЭЈЙ§ЗўЮёЦїЛёШЁЪ§ОнЁЃ
1.2. ЖдБШЛКДц
ашвЊЖдБШЧАКѓСНДЮЕФЛКДцБъжОРДХаЖЯЪЧЗёЪЙгУЛКДцЁЃфЏРРЦїЕквЛДЮЧыЧѓЪБЃЌЗўЮёЦїЛсНЋЛКДцБъЪЖгыЪ§ОнвЛЦ№ЗЕЛиЃЌфЏРРЦїНЋЖўепБИЗнжСБОЕиЛКДцПтжаЁЃфЏРРЦїдйДЮЧыЧѓЪБЃЌНЋБИЗнЕФЛКДцБъЪЖЗЂЫЭИјЗўЮёЦїЁЃ
ЗўЮёЦїИљОнЛКДцБъЪЖНјааХаЖЯЃЌШчЙћХаЖЯЪ§ОнУЛгаЗЂЩњБфЛЏЃЌАбХаЖЯГЩЙІЕФ 304 зДЬЌТыЗЂИјфЏРРЦїЁЃ
етЪБфЏРРЦїОЭПЩвдЪЙгУЛКДцЕФЪ§ОнРДЁЃЗўЮёЦїЗЕЛиЕФОЭжЛЪЧ HeaderЃЌВЛАќКЌ BodyЁЃ
ЯТУцНщЩмСНжжБъЪЖЙцдђЃК
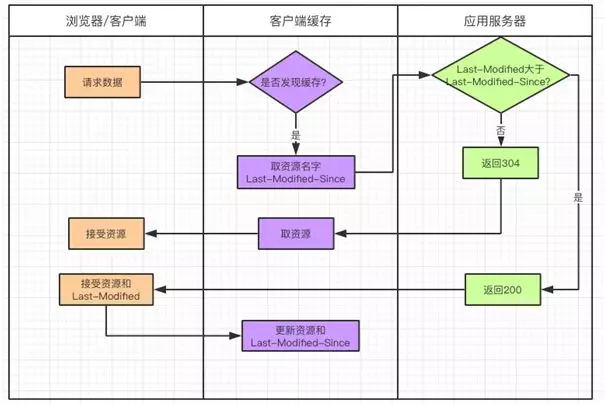
1.2.1. Last-Modified/If-Modified-Since Йцдђ
дкПЭЛЇЖЫЕквЛДЮЧыЧѓЕФЪБКђЃЌЗўЮёЦїЛсЗЕЛизЪдДзюКѓЕФаоИФЪБМфЃЌМЧзї Last-ModifiedЁЃПЭЛЇЖЫНЋетИізжЖЮСЌЭЌзЪдДЛКДцЦ№РДЁЃ
Last-Modified БЛБЃДцвдКѓЃЌдкЯТДЮЧыЧѓЪБЛсвд Last-Modified-Since
зжЖЮБЛЗЂЫЭЁЃ
ЕБПЭЛЇЖЫдйДЮЧыЧѓЗўЮёЦїЪБЃЌЛсАб Last-Modified СЌЭЌЧыЧѓЕФзЪдДвЛЦ№ЗЂИјЗўЮёЦїЃЌетЪБ Last-Modified
ЛсБЛУќУћЮЊ If-Modified-SinceЃЌДцЗХЕФФкШнЖМЪЧвЛбљЕФЁЃ
ЗўЮёЦїЪеЕНЧыЧѓЃЌЛсАб If-Modified-Since зжЖЮгыЗўЮёЦїЩЯБЃДцЕФ Last-Modified
зжЖЮзїБШНЯЃК
ШєЗўЮёЦїЩЯЕФ Last-Modified зюКѓаоИФЪБМфДѓгкЧыЧѓЕФ If-Modified-SinceЃЌЫЕУїзЪдДБЛИФЖЏЙ§ЃЌОЭЛсАбзЪдДЃЈАќРЈ
Header+BodyЃЉжиаТЗЕЛиИјфЏРРЦїЃЌЭЌЪБЗЕЛизДЬЌТы 200ЁЃ
ШєзЪдДЕФзюКѓаоИФЪБМфаЁгкЛђЕШгк If-Modified-SinceЃЌЫЕУїзЪдДУЛгаИФЖЏЙ§ЃЌжЛЛсЗЕЛи
HeaderЃЌВЂЧвЗЕЛизДЬЌТы 304ЁЃфЏРРЦїНгЪмЕНетИіЯћЯЂОЭПЩвдЪЙгУБОЕиЛКДцПтЕФЪ§ОнЁЃ
зЂвтЃКLast-Modified КЭ If-Modified-Since жИЕФЪЧЭЌвЛИіжЕЃЌжЛЪЧдкПЭЛЇЖЫКЭЗўЮёЦїЖЫЕФНаЗЈВЛЭЌЁЃ
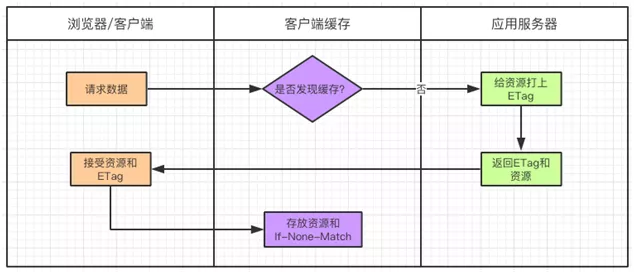
1.2.2. ETag / If-None-Match Йцдђ
ПЭЛЇЖЫЕквЛДЮЧыЧѓЕФЪБКђЃЌЗўЮёЦїЛсИјУПИізЪдДЩњГЩвЛИі ETag БъМЧЁЃетИі ETag ЪЧИљОнУПИізЪдДЩњГЩЕФЮЈвЛ
Hash ДЎЃЌзЪдДШчКЮЗЂЩњБфЛЏ ETag ЫцжЎИќИФЃЌжЎКѓНЋетИі ETag ЗЕЛиИјПЭЛЇЖЫЃЌПЭЛЇЖЫАбЧыЧѓЕФзЪдДКЭ
ETag ЖМЛКДцЕНБОЕиЁЃ
ETag БЛБЃДцвдКѓЃЌдкЯТДЮЧыЧѓЪБЛсЕБзї If-None-Match зжЖЮБЛЗЂЫЭГіШЅЁЃ
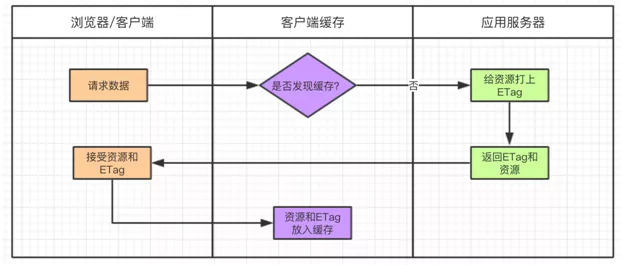
дкфЏРРЦїЕкЖўДЮЧыЧѓЗўЮёЦїЯрЭЌзЪдДЪБЃЌЛсАбзЪдДЖдгІЕФ ETag вЛВЂЗЂЫЭИјЗўЮёЦїЁЃдкЧыЧѓЪБ ETag
зЊЛЏГЩ If-None-MatchЃЌЕЋЦфФкШнВЛБфЁЃ
ЗўЮёЦїЪеЕНЧыЧѓКѓЃЌЛсАб If-None-Match гыЗўЮёЦїЩЯзЪдДЕФ ETag НјааБШНЯЃК
ШчЙћВЛвЛжТЃЌЫЕУїзЪдДБЛИФЖЏЙ§ЃЌдђЗЕЛизЪдДЃЈHeader+BodyЃЉЃЌЗЕЛизДЬЌТы 200ЁЃ
ШчЙћвЛжТЃЌЫЕУїзЪдДУЛгаБЛИФЙ§ЃЌдђЗЕЛи HeaderЃЌЗЕЛизДЬЌТы 304ЁЃфЏРРЦїНгЪмЕНетИіЯћЯЂОЭПЩвдЪЙгУБОЕиЛКДцПтЕФЪ§ОнЁЃ
зЂвтЃКETag КЭ If-None-Match жИЕФЪЧЭЌвЛИіжЕЃЌжЛЪЧдкПЭЛЇЖЫКЭЗўЮёЦїЖЫЕФНаЗЈВЛЭЌЁЃ
2. CDN ЛКДц
HTTP ЛКДцжївЊЪЧЖдОВЬЌЪ§ОнНјааЛКДцЃЌАбДгЗўЮёЦїФУЕНЕФЪ§ОнЛКДцЕНПЭЛЇЖЫ/фЏРРЦїЁЃ
ШчЙћдкПЭЛЇЖЫКЭЗўЮёЦїжЎМфдйМгЩЯвЛВу CDNЃЌПЩвдШУ CDN ЮЊгІгУЗўЮёЦїЬсЙЉЛКДцЃЌШчЙћдк CDN
ЩЯЛКДцЃЌОЭВЛгУдйЧыЧѓгІгУЗўЮёЦїСЫЁЃВЂЧв HTTP ЛКДцЬсЕНЕФСНжжВпТдЭЌбљПЩвддк CDN ЗўЮёЦїжДааЁЃ
CDN ЕФШЋГЦЪЧ Content Delivery NetworkЃЌМДФкШнЗжЗЂЭјТчЁЃ
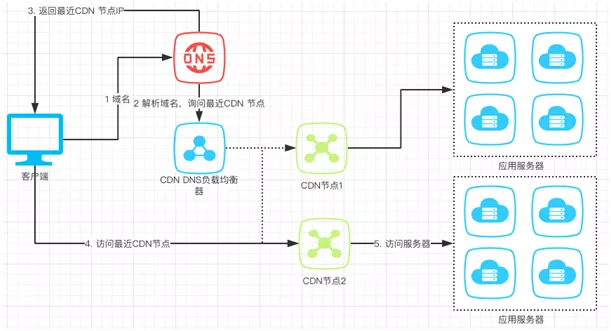
ШУЮвУЧРДПДПДЫќЪЧШчКЮЙЄзїЕФАЩЃК
ПЭЛЇЖЫЗЂЫЭ URL Иј DNS ЗўЮёЦїЁЃ
DNS ЭЈЙ§гђУћНтЮіЃЌАбЧыЧѓжИЯђ CDN ЭјТчжаЕФ DNS ИКдиОљКтЦїЁЃ
DNS ИКдиОљКтЦїНЋзюНќ CDN НкЕуЕФ IP ИцЫп DNSЃЌDNS ИцжЎПЭЛЇЖЫзюаТ CDN НкЕуЕФ
IPЁЃ
ПЭЛЇЖЫЧыЧѓзюНќЕФ CDN НкЕуЁЃ
CDN НкЕуДггІгУЗўЮёЦїЛёШЁзЪдДЗЕЛиИјПЭЛЇЖЫЃЌЭЌЪБНЋОВЬЌаХЯЂЛКДцЁЃзЂвтЃКПЭЛЇЖЫЯТДЮЛЅЖЏЕФЖдЯѓОЭЪЧ
CDN ЛКДцСЫЃЌCDN ПЩвдКЭгІгУЗўЮёЦїЭЌВНЛКДцаХЯЂЁЃ
CDN НгЪмПЭЛЇЖЫЕФЧыЧѓЃЌЫќОЭЪЧРыПЭЛЇЖЫзюНќЕФЗўЮёЦїЃЌЫќКѓУцЛсСДНгЖрЬЈЗўЮёЦїЃЌЦ№ЕНСЫЛКДцКЭИКдиОљКтЕФзїгУЁЃ
3. ИКдиОљКтЛКДц
ЫЕЭъПЭЛЇЖЫЃЈHTTPЃЉЛКДцКЭ CDN ЛКДцЃЌЮвУЧРыгІгУЗўЮёдНРДдННќСЫЃЌдкЕНДягІгУЗўЮёжЎЧАЃЌЧыЧѓЛЙвЊОЙ§ИКдиОљКтЦїЁЃ
ЫфЫЕЫќЕФжївЊЙЄзїЪЧЖдгІгУЗўЮёЦїНјааИКдиОљКтЃЌЕЋЪЧЫќвВПЩвдзїЛКДцЁЃПЩвдАбвЛаЉаоИФЦЕТЪВЛИпЕФЪ§ОнЛКДцдкетРяЃЌР§ШчЃКгУЛЇаХЯЂЃЌХфжУаХЯЂЁЃЭЈЙ§ЗўЮёЖЈЦкЫЂаТетИіЛКДцОЭааСЫЁЃ
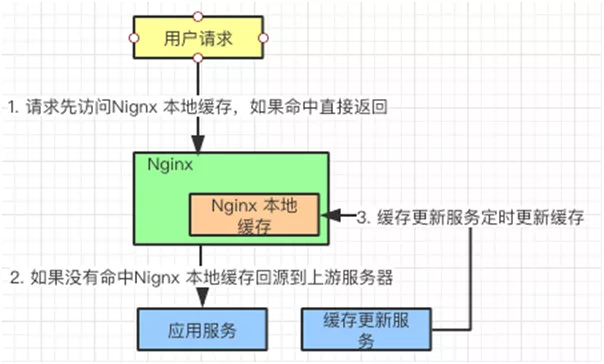
вд Nginx ЮЊР§ЃЌЮвУЧПДПДЫќЪЧШчКЮЙЄзїЕФЃК
гУЛЇЧыЧѓдкДяЕНгІгУЗўЮёЦїжЎЧАЃЌЛсЯШЗУЮЪ Nginx ИКдиОљКтЦїЃЌШчЙћЗЂЯжгаЛКДцаХЯЂЃЌжБНгЗЕЛиИјгУЛЇЁЃ
ШчЙћУЛгаЗЂЯжЛКДцаХЯЂЃЌNginx ЛидДЕНгІгУЗўЮёЦїЛёШЁаХЯЂЁЃ
СэЭтЃЌгавЛИіЛКДцИќаТЗўЮёЃЌЖЈЦкАбгІгУЗўЮёЦїжаЯрЖдЮШЖЈЕФаХЯЂИќаТЕН Nginx БОЕиЛКДцжаЁЃ
4. НјГЬФкЛКДц
ЭЈЙ§СЫПЭЛЇЖЫЃЌCDNЃЌИКдиОљКтЦїЃЌЮвУЧжегкРДЕНСЫгІгУЗўЮёЦїЁЃгІгУЗўЮёЦїЩЯВПЪ№зХвЛИіИігІгУЃЌетаЉгІгУвдНјГЬЕФЗНЪНдЫаазХЃЌФЧУДдкНјГЬжаЕФЛКДцЪЧдѕбљЕФФиЃП
НјГЬФкЛКДцгжНаЭаЙмЖбЛКДцЃЌвд Java ЮЊР§ЃЌетВПЗжЛКДцЗХдк JVM ЕФЭаЙмЖбЩЯУцЃЌЭЌЪБЛсЪмЕНЭаЙмЖбЛиЪеЫуЗЈЕФгАЯьЁЃ
гЩгкЦфдЫаадкФкДцжаЃЌЖдЪ§ОнЕФЯьгІЫйЖШКмПьЃЌЭЈГЃЮвУЧЛсАбШШЕуЪ§ОнЗХдкетРяЁЃ
дкНјГЬФкЛКДцУЛгаУќжаЕФЪБКђЃЌЮвУЧЛсШЅЫбЫїНјГЬЭтЕФЛКДцЛђепЗжВМЪНЛКДцЁЃетжжЛКДцЕФКУДІЪЧУЛгаађСаЛЏКЭЗДађСаЛЏЃЌЪЧзюПьЕФЛКДцЁЃШБЕуЪЧЛКДцЕФПеМфВЛФмЬЋДѓЃЌЖдРЌЛјЛиЪеЦїЕФадФмгагАЯьЁЃ
ФПЧАБШНЯСїааЕФЪЕЯжга EhcacheЁЂGuavaCacheЁЂCaffeineЁЃетаЉМмЙЙПЩвдКмЗНБуЕФАбвЛаЉШШЕуЪ§ОнЗХЕННјГЬФкЕФЛКДцжаЁЃ
етРяЮвУЧашвЊЙизЂМИИіЛКДцЕФЛиЪеВпТдЃЌОпЬхЕФЪЕЯжМмЙЙЕФЛиЪеВпТдЛсгаЫљВЛЭЌЃЌЕЋДѓжТЕФЫМТЗЖМЪЧвЛжТЕФЃК
FIFOЃЈFirst In First OutЃЉЃКЯШНјЯШГіЫуЗЈЃЌзюЯШЗХШыЛКДцЕФЪ§ОнзюЯШБЛвЦГ§ЁЃ
LRUЃЈLeast Recently UsedЃЉЃКзюНќзюЩйЪЙгУЫуЗЈЃЌАбзюОУУЛгаЪЙгУЙ§ЕФЪ§ОнвЦГ§ЛКДцЁЃ
LFUЃЈLeast Frequently UsedЃЉЃКзюВЛГЃгУЫуЗЈЃЌдквЛЖЮЪБМфФкЪЙгУЦЕТЪзюаЁЕФЪ§ОнБЛвЦГ§ЛКДцЁЃ
дкЗжВМЪНМмЙЙЕФНёЬьЃЌЖргІгУжаШчЙћВЩгУНјГЬФкЛКДцЛсДцдкЪ§ОнвЛжТадЕФЮЪЬтЁЃ
етРяЭЦМіСНИіЗНАИЃК
ЯћЯЂЖгСааоИФЗНАИ
Timer аоИФЗНАИ
4.1. ЯћЯЂЖгСааоИФЗНАИ
гІгУдкаоИФЭъздЩэЛКДцЪ§ОнКЭЪ§ОнПтЪ§ОнжЎКѓЃЌИјЯћЯЂЖгСаЗЂЫЭЪ§ОнБфЛЏЭЈжЊЃЌЦфЫћгІгУЖЉдФСЫЯћЯЂЭЈжЊЃЌдкЪеЕНЭЈжЊЕФЪБКђаоИФЛКДцЪ§ОнЁЃ
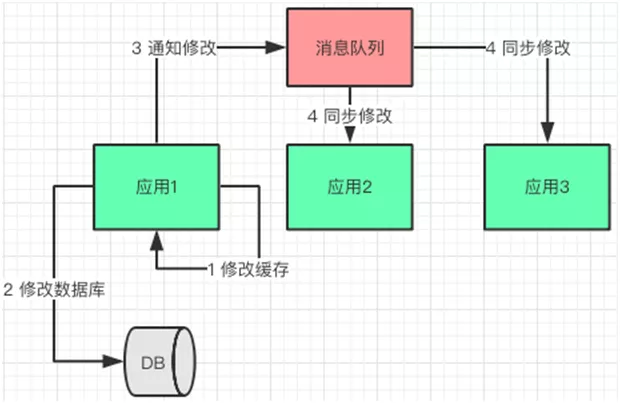
4.2. Timer аоИФЗНАИ
ЮЊСЫБмУтёюКЯЃЌНЕЕЭИДдгадЃЌЖдЁАЪЕЪБвЛжТадЁБВЛУєИаЕФЧщПіЯТЁЃУПИігІгУЖМЛсЦєЖЏвЛИі TimerЃЌЖЈЪБДгЪ§ОнПтРШЁзюаТЕФЪ§ОнЃЌИќаТЛКДцЁЃ
ВЛЙ§дкгаЕФгІгУИќаТЪ§ОнПтКѓЃЌЦфЫћНкЕуЭЈЙ§ Timer ЛёШЁЪ§ОнжЎМфЃЌЛсЖСЕНдрЪ§ОнЁЃетРяашвЊПижЦКУ
Timer ЕФЦЕТЪЃЌвдМАгІгУгыЖдЪЕЪБадвЊЧѓВЛИпЕФГЁОАЁЃ
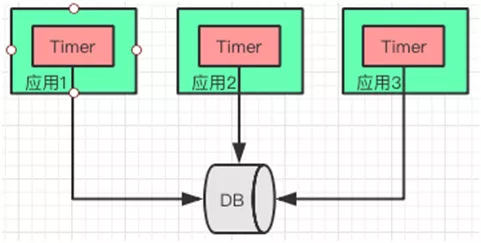
НјГЬФкЛКДцгаФФаЉЪЙгУГЁОАФиЃП
ГЁОАвЛЃКжЛЖСЪ§ОнЃЌПЩвдПМТЧдкНјГЬЦєЖЏЪБМгдиЕНФкДцЁЃЕБШЛЃЌАбЪ§ОнМгдиЕНРрЫЦ Redis етбљЕФНјГЬЭтЛКДцЗўЮёвВФмНтОіетРрЮЪЬтЁЃ
ГЁОАЖўЃКИпВЂЗЂЃЌПЩвдПМТЧЪЙгУНјГЬФкЛКДцЃЌР§ШчЃКУыЩБЁЃ
5. ЗжВМЪНЛКДц
ЫЕЭъНјГЬФкЛКДцЃЌздШЛОЭЙ§ЖШЕННјГЬЭтЛКДцСЫЁЃгыНјГЬФкЛКДцВЛЭЌЃЌНјГЬЭтЛКДцдкгІгУдЫааЕФНјГЬжЎЭтЃЌЫќгЕгаИќДѓЕФЛКДцШнСПЃЌВЂЧвПЩвдВПЪ№ЕНВЛЭЌЕФЮяРэНкЕуЃЌЭЈГЃЛсгУЗжВМЪНЛКДцЕФЗНЪНЪЕЯжЁЃ
ЗжВМЪНЛКДцЪЧгыгІгУЗжРыЕФЛКДцЗўЮёЃЌзюДѓЕФЬиЕуЪЧЃЌздЩэЪЧвЛИіЖРСЂЕФгІгУ/ЗўЮёЃЌгыБОЕигІгУИєРыЃЌЖрИігІгУПЩжБНгЙВЯэвЛИіЛђепЖрИіЛКДцгІгУ/ЗўЮёЁЃ
МШШЛЪЧЗжВМЪНЛКДцЃЌЛКДцЕФЪ§ОнЛсЗжВМЕНВЛЭЌЕФЛКДцНкЕуЩЯЃЌУПИіЛКДцНкЕуЛКДцЕФЪ§ОнДѓаЁЭЈГЃвВЪЧгаЯожЦЕФЁЃ
Ъ§ОнБЛЛКДцЕНВЛЭЌЕФНкЕуЃЌЮЊСЫФмЗНБуЕФЗУЮЪетаЉНкЕуЃЌашвЊв§ШыЛКДцДњРэЃЌРрЫЦ TwemproxyЁЃЫћЛсАяжњЧыЧѓевЕНЖдгІЕФЛКДцНкЕуЁЃ
ЭЌЪБШчЙћЛКДцНкЕудіМгСЫЃЌетИіДњРэвВЛсжЛФмЪЖБ№ВЂЧвАбаТЕФЛКДцЪ§ОнЗжЦЌЕНаТЕФНкЕуЃЌзіКсЯђЕФРЉеЙЁЃ
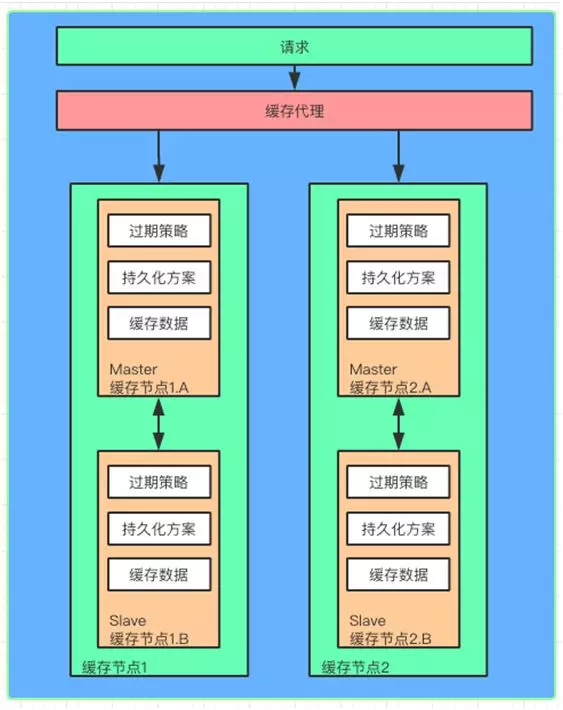
ЮЊСЫЬсИпЛКДцЕФПЩгУадЃЌЛсдкдгаЕФЛКДцНкЕуЩЯМгШы Master/Slave ЕФЩшМЦЁЃЕБЛКДцЪ§ОнаДШы
Master НкЕуЕФЪБКђЃЌЛсЭЌЪБЭЌВНвЛЗнЕН Slave НкЕуЁЃ
вЛЕЉ Master НкЕуЪЇаЇЃЌПЩвдЭЈЙ§ДњРэжБНгЧаЛЛЕН Slave НкЕуЃЌетЪБ Slave НкЕуОЭБфГЩСЫ
Master НкЕуЃЌБЃжЄЛКДцЕФе§ГЃЙЄзїЁЃ
УПИіЛКДцНкЕуЛЙЛсЬсЙЉЛКДцЙ§ЦкЕФЛњжЦЃЌВЂЧвЛсАбЛКДцФкШнЖЈЦквдПьееЕФЗНЪНБЃДцЕНЮФМўЩЯЃЌЗНБуЛКДцБРРЃжЎКѓЦєЖЏдЄШШМгдиЁЃ
5.1. ИпадФм
ЕБЛКДцзіГЩЗжВМЪНЕФЪБКђЃЌЪ§ОнЛсИљОнвЛЖЈЕФЙцТЩЗжХфЕНУПИіЛКДцгІгУ/ЗўЮёЩЯЁЃ
ШчЙћЮвУЧАбетаЉЛКДцгІгУ/ЗўЮёНазіЛКДцНкЕуЃЌУПИіНкЕувЛАуЖМПЩвдЛКДцвЛЖЈШнСПЕФЪ§ОнЃЌР§ШчЃКRedis
вЛИіНкЕуПЩвдЛКДц 2G ЕФЪ§ОнЁЃ
ШчЙћашвЊЛКДцЕФЪ§ОнСПБШНЯДѓОЭашвЊРЉеЙЖрИіЛКДцНкЕуРДЪЕЯжЃЌетУДЖрЕФЛКДцНкЕуЃЌПЭЛЇЖЫЕФЧыЧѓВЛжЊЕРЗУЮЪФФИіНкЕудѕУДАьЃПЛКДцЕФЪ§ОнгжШчКЮЗХЕНетаЉНкЕуЩЯЃП
ЛКДцДњРэЗўЮёвбОАяЮвУЧНтОіетаЉЮЪЬтСЫЃЌР§ШчЃКTwemproxy ВЛЕЋПЩвдАяжњЛКДцТЗгЩЃЌЭЌЪБПЩвдЙмРэЛКДцНкЕуЁЃ
етРягаНщЩмШ§жжЛКДцЪ§ОнЗжЦЌЕФЫуЗЈЃЌгаСЫетаЉЫуЗЈЛКДцДњРэОЭПЩвдЗНБуЕФевЕНЗжЦЌЕФЪ§ОнСЫЁЃ
5.1.1. ЙўЯЃЫуЗЈ
Hash БэЪЧзюГЃМћЕФЪ§ОнНсЙЙЃЌЪЕЯжЗНЪНЪЧЃЌЖдЪ§ОнМЧТМЕФЙиМќжЕНјаа HashЃЌШЛКѓдйЖдашвЊЗжЦЌЕФЛКДцНкЕуИіЪ§НјааШЁФЃЕУЕНЕФгрЪ§НјааЪ§ОнЗжХфЁЃ
Р§ШчЃКгаШ§ЬѕМЧТМЪ§ОнЗжБ№ЪЧ R1ЃЌR2ЃЌR3ЁЃЫћУЧЕФ ID ЗжБ№ЪЧ 01ЃЌ02ЃЌ03ЃЌМйЩшЖдетШ§ИіМЧТМЕФ
ID зїЮЊЙиМќжЕНјаа Hash ЫуЗЈжЎКѓЕФНсЙћвРОЩЪЧ 01ЃЌ02ЃЌ03ЁЃ
ЮвУЧЯыАбетШ§ЬѕЪ§ОнЗХЕНШ§ИіЛКДцНкЕужаЃЌПЩвдАбетИіНсЙћЗжБ№Жд 3 етИіЪ§зжШЁФЃЕУЕНгрЪ§ЃЌетИігрЪ§ОЭЪЧетШ§ЬѕМЧТМЗжБ№ЗХжУЕФЛКДцНкЕуЁЃ
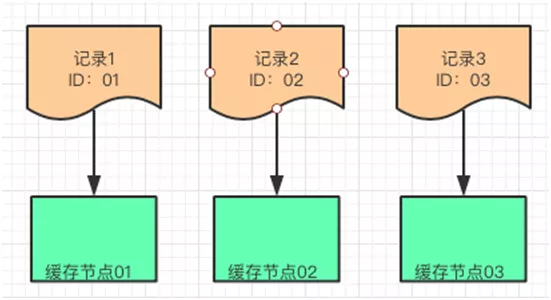
Hash ЫуЗЈЪЧФГжжГЬЖШЩЯЕФЦНОљЗХжУЃЌВпТдБШНЯМђЕЅЃЌШчЙћвЊдіМгЛКДцНкЕуЃЌЖдвбОДцдкЕФЪ§ОнЛсгаНЯДѓЕФБфЖЏЁЃ
5.1.2. вЛжТадЙўЯЃЫуЗЈ
вЛжТад Hash ЪЧНЋЪ§ОнАДееЬиеїжЕгГЩфЕНвЛИіЪзЮВЯрНгЕФ Hash ЛЗЩЯЃЌЭЌЪБвВНЋЛКДцНкЕугГЩфЕНетИіЛЗЩЯЁЃ
ШчЙћвЊЛКДцЪ§ОнЃЌЭЈЙ§Ъ§ОнЕФЙиМќжЕЃЈKeyЃЉдкЛЗЩЯевЕНздМКДцЗХЕФЮЛжУЁЃетаЉЪ§ОнАДеездЩэЕФ ID ШЁ
Hash жЎКѓЕУЕНЕФжЕАДееЫГађдкЛЗЩЯХХСаЁЃ
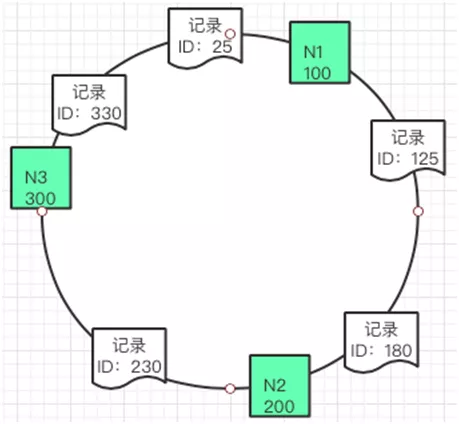
ШчЙћетИіЪБКђвЊВхШывЛЬѕаТЕФЪ§ОнЦф ID ЪЧ 115ЃЌФЧУДОЭгІИУВхШыЕНШчЯТЭМЕФЮЛжУЁЃ
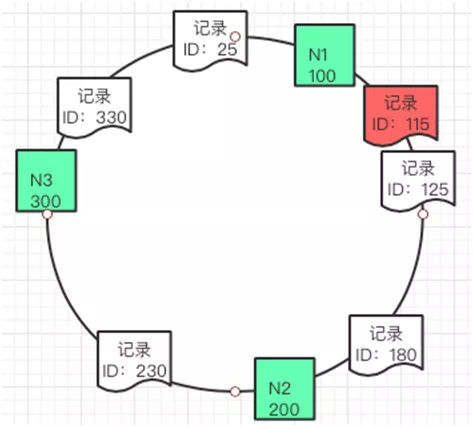
ЭЌРэШчЙћвЊдіМгвЛИіЛКДцНкЕу N4 150ЃЌвВПЩвдЗХЕНШчЯТЭМЕФЮЛжУЁЃ

етжжЫуЗЈЖдгкдіМгЛКДцЪ§ОнЃЌКЭЛКДцНкЕуЕФПЊЯњЯрЖдБШНЯаЁЁЃ
5.1.3. Range Based ЫуЗЈ
етжжЗНЪНЪЧАДееЙиМќжЕЃЈР§Шч IDЃЉНЋЪ§ОнЛЎЗжГЩВЛЭЌЕФЧјМфЃЌУПИіЛКДцНкЕуИКд№вЛИіЛђепЖрИіЧјМфЁЃИњвЛжТадЙўЯЃгаЕуЯёЁЃ
Р§ШчЃКДцдкШ§ИіЛКДцНкЕуЗжБ№ЪЧ N1ЃЌN2ЃЌN3ЁЃЫћУЧгУРДДцЗХЪ§ОнЕФЧјМфЗжБ№ЪЧЃЌN1(0, 100]ЃЌ
N2(100, 200]ЃЌ N3(300, 400]ЁЃ
ФЧУДЪ§ОнИљОнздМК ID зїЮЊЙиМќзжзі Hash вдКѓЕФНсЙћОЭЛсЗжБ№ЖдгІЗХЕНетМИИіЧјгђРяУцСЫЁЃ
5.2. ПЩгУад
ИљОнЪТЮяЕФСНУцадЃЌдкЗжВМЪНЛКДцДјРДИпадФмЕФЭЌЪБЃЌЮвУЧвВашвЊжиЪгЫќЕФПЩгУадЁЃФЧУДФФаЉЧБдкЕФЗчЯеЪЧЮвУЧашвЊЗРЗЖЕФФиЃП
5.2.1. ЛКДцбЉБР
ЕБЛКДцЪЇаЇЃЌЛКДцЙ§ЦкБЛЧхГ§ЃЌЛКДцИќаТЕФЪБКђЁЃЧыЧѓЪЧЮоЗЈУќжаЛКДцЕФЃЌетИіЪБКђЧыЧѓЛсжБНгЛидДЕНЪ§ОнПтЁЃ
ШчЙћЩЯЪіЧщПіЦЕЗБЗЂЩњЛђепЭЌЪБЗЂЩњЕФЪБКђЃЌОЭЛсдьГЩДѓУцЛ§ЕФЧыЧѓжБНгЕНЪ§ОнПтЃЌдьГЩЪ§ОнПтЗУЮЪЦПОБЁЃЮвУЧГЦетжжЧщПіЮЊЛКДцбЉБРЁЃ
ДгШчЯТСНЗНУцРДЫМПМНтОіЗНАИЃК
ЛКДцЗНУцЃК
БмУтЛКДцЭЌЪБЪЇаЇЃЌВЛЭЌЕФ key ЩшжУВЛЭЌЕФГЌЪБЪБМфЁЃ
діМгЛЅГтЫјЃЌЖдЛКДцЕФИќаТВйзїНјааМгЫјБЃЛЄЃЌБЃжЄжЛгавЛИіЯпГЬНјааЛКДцИќаТЁЃЛКДцвЛЕЉЪЇаЇПЩвдЭЈЙ§ЛКДцПьееЕФЗНЪНбИЫйжиНЈЛКДцЁЃЖдЛКДцНкЕудіМгжїБИЛњжЦЃЌЕБжїЛКДцЪЇаЇвдКѓЧаЛЛЕНБИгУЛКДцМЬајЙЄзїЁЃ
ЩшМЦЗНУцЃЌетРяИјГіСЫМИЕуНЈвщЙЉДѓМвВЮПМЃК
ШлЖЯЛњжЦЃКФГИіЛКДцНкЕуВЛФмЙЄзїЕФЪБКђЃЌашвЊЭЈжЊЛКДцДњРэВЛвЊАбЧыЧѓТЗгЩЕНИУНкЕуЃЌМѕЩйгУЛЇЕШД§КЭЧыЧѓЪБГЄЁЃ
ЯоСїЛњжЦЃКдкНгШыВуКЭДњРэВуПЩвдзіЯоСїЃЌЕБЛКДцЗўЮёЮоЗЈжЇГжИпВЂЗЂЕФЪБКђЃЌЧАЖЫПЩвдАбЮоЗЈЯьгІЕФЧыЧѓЗХШыЕНЖгСаЛђепЖЊЦњЁЃ
ИєРыЛњжЦЃКЛКДцЮоЗЈЬсЙЉЗўЮёЛђепе§дкдЄШШжиНЈЕФЪБКђЃЌАбИУЧыЧѓЗХШыЖгСажаЃЌетбљИУЧыЧѓвђЮЊБЛИєРыОЭВЛЛсБЛТЗгЩЕНЦфЫћЕФЛКДцНкЕуЁЃ
ШчДЫОЭВЛЛсвђЮЊетИіНкЕуЕФЮЪЬтгАЯьЕНЦфЫћНкЕуЁЃЕБЛКДцжиНЈвдКѓЃЌдйДгЖгСажаШЁГіЧыЧѓвРДЮДІРэЁЃ
5.2.2. ЛКДцДЉЭИ
ЛКДцвЛАуЪЧ KeyЃЌValue ЗНЪНДцдкЃЌвЛИі Key ЖдгІЕФ Value ВЛДцдкЪБЃЌЧыЧѓЛсЛидДЕНЪ§ОнПтЁЃ
МйШчЖдгІЕФ Value вЛжБВЛДцдкЃЌдђЛсЦЕЗБЕФЧыЧѓЪ§ОнПтЃЌЖдЪ§ОнПтдьГЩЗУЮЪбЙСІЁЃШчЙћгаШЫРћгУетИіТЉЖДЙЅЛїЃЌОЭТщЗГСЫЁЃ
НтОіЗНЗЈЃКШчЙћвЛИі Key ЖдгІЕФ Value ВщбЏЗЕЛиЮЊПеЃЌЮвУЧШдШЛАбетИіПеНсЙћЛКДцЦ№РДЃЌШчЙћетИіжЕУЛгаБфЛЏЯТДЮВщбЏОЭВЛЛсЧыЧѓЪ§ОнПтСЫЁЃ
НЋЫљгаПЩФмДцдкЕФЪ§ОнЙўЯЃЕНвЛИізуЙЛДѓЕФ Bitmap жаЃЌФЧУДВЛДцдкЕФЪ§ОнЛсБЛетИі Bitmap
Й§ТЫЦїРЙНиЕєЃЌБмУтЖдЪ§ОнПтЕФВщбЏбЙСІЁЃ
5.2.3. ЛКДцЛїДЉ
дкЪ§ОнЧыЧѓЕФЪБКђЃЌФГвЛИіЛКДцИеКУЪЇаЇЛђепе§дкаДШыЛКДцЃЌЭЌЪБетИіЛКДцЪ§ОнПЩФмЛсдкетИіЪБМфЕуБЛГЌИпВЂЗЂЧыЧѓЃЌГЩЮЊЁАШШЕуЁБЪ§ОнЁЃ
етОЭЪЧЛКДцЛїДЉЮЪЬтЃЌетИіКЭЛКДцбЉБРЕФЧјБ№дкгкЃЌетРяЪЧеыЖдФГвЛИіЛКДцЃЌЧАепЪЧеыЖдЖрИіЛКДцЁЃ
НтОіЗНАИЃКЕМжТЮЪЬтЕФдвђЪЧдкЭЌвЛЪБМфЖС/аДЛКДцЃЌЫљвджЛгаБЃжЄЭЌвЛЪБМфжЛгавЛИіЯпГЬаДЃЌаДЭъГЩвдКѓЃЌЦфЫћЕФЧыЧѓдйЪЙгУЛКДцОЭПЩвдСЫЁЃ
БШНЯГЃгУЕФзіЗЈЪЧЪЙгУ mutexЃЈЛЅГтЫјЃЉЁЃдкЛКДцЪЇаЇЕФЪБКђЃЌВЛЪЧСЂМДаДШыЛКДцЃЌЖјЪЧЯШЩшжУвЛИі mutexЃЈЛЅГтЫјЃЉЁЃЕБЛКДцБЛаДШыЭъГЩвдКѓЃЌдйЗХПЊетИіЫјШУЧыЧѓНјааЗУЮЪЁЃ
аЁНс
змНсвЛЯТЃЌЛКДцЩшМЦгаЮхДѓВпТдЃЌДггУЛЇЧыЧѓПЊЪМвРДЮЪЧЃК
HTTP ЛКДц
CDN ЛКДц
ИКдиОљКтЛКДц
НјГЬФкЛКДц
ЗжВМЪНЛКДц
ЦфжаЃЌЧАСНжжЛКДцОВЬЌЪ§ОнЃЌКѓШ§жжЛКДцЖЏЬЌЪ§ОнЃК
HTTP ЛКДцАќРЈЧПжЦЛКДцКЭЖдБШЛКДцЁЃ
CDN ЛКДцКЭ HTTP ЛКДцЪЧКУДюЕЕЁЃ
ИКдиОљКтЦїЛКДцЯрЖдЮШЖЈзЪдДЃЌашвЊЗўЮёажњЙЄзїЁЃ
НјГЬФкЛКДцЃЌаЇТЪИпЃЌЕЋШнСПгаЯожЦЃЌгаСНИіЗНАИПЩвдгІЖдЛКДцЭЌВНЕФЮЪЬтЁЃ
ЗжВМЪНЛКДцШнСПДѓЃЌФмСІЧПЃЌРЮМЧШ§ИіадФмЫуЗЈВЂЧвЗРЗЖШ§ИіЛКДцЗчЯеЁЃ
ДѓСїСПЯТЖрМЖЛКДцЩшМЦ
ЪВУДЪЧЖрМЖЛКДц
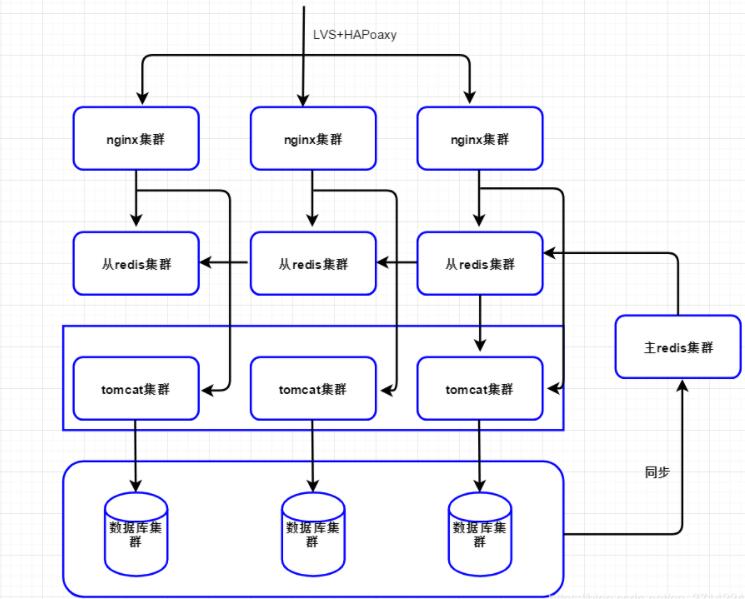
ЫљЮНЖрМЖЛКДцЃЌМДдкећИіЯЕЭГМмЙЙЕФВЛЭЌЯЕЭГВуМЖНјааЪ§ОнЛКДцЃЌвдЬсЩ§ЗУЮЪаЇТЪЃЌетвВЪЧгІгУзюЙуЕФЗНАИжЎвЛЁЃЮвУЧгІгУЕФећЬхМмЙЙШчЭМ1ЫљЪОЃК
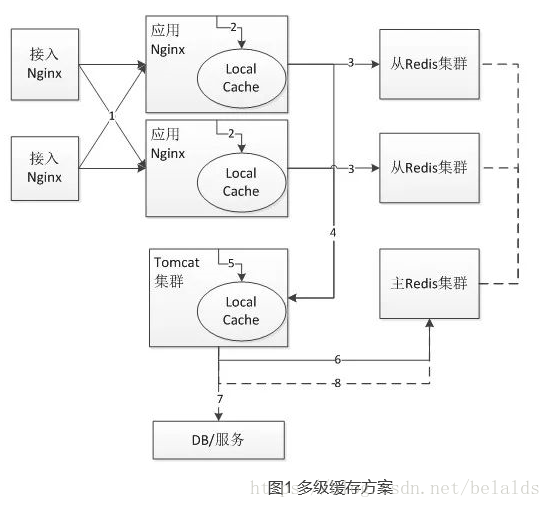
ЭМ1 ЖрМЖЛКДцЗНАИ
ећЬхСїГЬШчЩЯЭМЫљЪОЃК
1ЃЉЪзЯШНгШыNginxНЋЧыЧѓИКдиОљКтЕНгІгУNginxЃЌДЫДІГЃгУЕФИКдиОљКтЫуЗЈЪЧТжбЏЛђепвЛжТадЙўЯЃЃЌТжбЏПЩвдЪЙЗўЮёЦїЕФЧыЧѓИќМгОљКтЃЌЖјвЛжТадЙўЯЃПЩвдЬсЩ§гІгУNginxЕФЛКДцУќжаТЪЃЌЯрЖдгкТжбЏЃЌвЛжТадЙўЯЃЛсДцдкЕЅЛњШШЕуЮЪЬтЃЌвЛжжНтОіАьЗЈЪЧШШЕужБНгЭЦЫЭЕННгШыВуNginxЃЌвЛжжАьЗЈЪЧЩшжУвЛИіЗЇжЕЃЌЕБГЌЙ§ЗЇжЕЃЌИФЮЊТжбЏЫуЗЈЁЃ
2ЃЉНгзХгІгУNginxЖСШЁБОЕиЛКДцЃЈБОЕиЛКДцПЩвдЪЙгУLua Shared DictЁЂNginx Proxy
CacheЃЈДХХЬ/ФкДцЃЉЁЂLocal RedisЪЕЯжЃЉЃЌШчЙћБОЕиЛКДцУќжадђжБНгЗЕЛиЃЌЪЙгУгІгУNginxБОЕиЛКДцПЩвдЬсЩ§ећЬхЕФЭЬЭТСПЃЌНЕЕЭКѓЖЫЕФбЙСІЃЌгШЦфгІЖдШШЕуЮЪЬтЗЧГЃгааЇЁЃ
3ЃЉШчЙћNginxБОЕиЛКДцУЛУќжаЃЌдђЛсЖСШЁЯргІЕФЗжВМЪНЛКДцЃЈШчRedisЛКДцЃЌСэЭтПЩвдПМТЧЪЙгУжїДгМмЙЙРДЬсЩ§адФмКЭЭЬЭТСПЃЉЃЌШчЙћЗжВМЪНЛКДцУќжадђжБНгЗЕЛиЯргІЪ§ОнЃЈВЂЛиаДЕНNginxБОЕиЛКДцЃЉЁЃ
4ЃЉШчЙћЗжВМЪНЛКДцвВУЛгаУќжаЃЌдђЛсЛидДЕНTomcatМЏШКЃЌдкЛидДЕНTomcatМЏШКЪБвВПЩвдЪЙгУТжбЏКЭвЛжТадЙўЯЃзїЮЊИКдиОљКтЫуЗЈЁЃ
5ЃЉдкTomcatгІгУжаЃЌЪзЯШЖСШЁБОЕиЖбЛКДцЃЌШчЙћгадђжБНгЗЕЛиЃЈВЂЛсаДЕНжїRedisМЏШКЃЉЃЌЮЊЪВУДвЊМгвЛВуБОЕиЖбЛКДцНЋдкЛКДцБРРЃгыПьЫйаоИДВПЗжЯИСФЁЃ
6ЃЉзїЮЊПЩбЁВПЗжЃЌШчЙћВНжш4УЛгаУќжаПЩвддйГЂЪдвЛДЮЖСжїRedisМЏШКВйзїЁЃФПЕФЪЧЗРжЙЕБДггаЮЪЬтЪБЕФСїСПГхЛїЁЃ
7ЃЉШчЙћЫљгаЛКДцЖМУЛгаУќжажЛФмВщбЏDBЛђЯрЙиЗўЮёЛёШЁЯрЙиЪ§ОнВЂЗЕЛиЁЃ
8ЃЉВНжш7ЗЕЛиЕФЪ§ОнвьВНаДЕНжїRedisМЏШКЃЌДЫДІПЩФмЖрИіTomcatЪЕР§ЭЌЪБаДжїRedisМЏШКЃЌПЩФмдьГЩЪ§ОнДэТвЃЌШчКЮНтОіИУЮЪЬтНЋдкИќаТЛКДцгыдзгадВПЗжЯИСФЁЃ
гІгУећЬхЗжСЫШ§ВПЗжЛКДцЃКгІгУNginxБОЕиЛКДцЁЂЗжВМЪНЛКДцЁЂTomcatЖбЛКДцЃЌУПвЛВуЛКДцЖМгУРДНтОіЯрЙиЕФЮЪЬтЃЌШчгІгУNginxБОЕиЛКДцгУРДНтОіШШЕуЛКДцЮЪЬтЃЌЗжВМЪНЛКДцгУРДМѕЩйЗУЮЪЛидДТЪЁЂTomcatЖбЛКДцгУгкЗРжЙЯрЙиЛКДцЪЇаЇ/БРРЃжЎКѓЕФГхЛїЁЃ
ЫфШЛОЭЪЧМгЛКДцЃЌЕЋЪЧдѕУДМгЃЌдѕУДгУЯИЯыЯТРДЛЙЪЧгаКмЖрЮЪЬташвЊШЈКтКЭПМСПЕФЃЌНгЯТРДВПЗжЮвУЧОЭЯъЯИРДЬжТлвЛаЉЛКДцЯрЙиЕФЮЪЬтЁЃ
ШчКЮЛКДцЪ§Он
НгЯТРДВПНЋДгЛКДцЙ§ЦкЁЂЮЌЖШЛЏЛКДцЁЂдіСПЛКДцЁЂДѓValueЛКДцЁЂШШЕуЛКДцМИИіЗНУцРДЯъЯИНщЩмШчКЮЛКДцЪ§ОнЁЃ
Й§ЦкгыВЛЙ§Цк
ЖдгкЛКДцЕФЪ§ОнЮвУЧПЩвдПМТЧВЛЙ§ЦкЛКДцКЭДјЙ§ЦкЪБМфЛКДцЃЌЪВУДГЁОАгІИУбЁдёФФжжФЃЪНашвЊИљОнвЕЮёКЭЪ§ОнСПЕШвђЫиРДОіЖЈЁЃ
ВЛЙ§ЦкЛКДцГЁОАвЛАуЫМТЗШчЭМ2ЫљЪОЃК
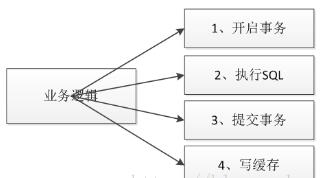
ЭМ2ВЛЙ§ЦкЛКДцЗНАИ
ЪЙгУCache-AsideФЃЪНЃЌЪзЯШаДЪ§ОнПтЃЌШчЙћГЩЙІЃЌдђаДЛКДцЁЃетжжГЁОАЯТДцдкЪТЮёГЩЙІЁЂЛКДцаДЪЇАмЕЋЮоЗЈЛиЙіЪТЮёЕФЧщПіЁЃСэЭтЃЌВЛвЊАбаДЛКДцЗХдкЪТЮёжаЃЌгШЦфаДЗжВМЪНЛКДцЃЌвђЮЊЭјТчЖЖЖЏПЩФмЕМжТаДЛКДцЯьгІЪБМфКмТ§ЃЌв§Ц№Ъ§ОнПтЪТЮёзшШћЁЃШчЙћЖдЛКДцЪ§ОнвЛжТадвЊЧѓВЛЪЧФЧУДИпЃЌЪ§ОнСПвВВЛЪЧКмДѓЃЌдђПЩвдПМТЧЖЈЦкШЋСПЭЌВНЛКДцЁЃ
вВгаЬсЕНШчЯТЫМТЗЃКЯШЩОЛКДцЃЌШЛКѓжДааЪ§ОнПтЪТЮёЃЛВЛЙ§етжжВйзїЖдгкШчЩЬЦЗетжжВщбЏЗЧГЃЦЕЗБЕФвЕЮёВЛЪЪгУЃЌвђЮЊдкФуЩОЛКДцЕФЭЌЪБЃЌвбОгаСэвЛИіЯЕЭГРДЖСЛКДцСЫЃЌДЫЪБЪТЮёЛЙУЛгаЬсНЛЁЃЕБШЛЖдгкШчгУЛЇЮЌЖШЕФвЕЮёЪЧПЩвдПМТЧЕФЁЃ
ВЛЙ§ЮЊСЫИќКУЕиНтОівдЩЯЖрИіЪТЮёЕФЮЪЬтЃЌПЩвдПМТЧЪЙгУЖЉдФЪ§ОнПтШежОЕФМмЙЙЃЌШчЪЙгУcanalЖЉдФmysqlЕФbinlogЪЕЯжЛКДцЭЌВНЁЃ
ЖдгкГЄЮВЗУЮЪЕФЪ§ОнЁЂДѓЖрЪ§Ъ§ОнЗУЮЪЦЕТЪЖМКмИпЕФГЁОАЁЂЛКДцПеМфзуЙЛЖМПЩвдПМТЧВЛЙ§ЦкЛКДцЃЌБШШчгУЛЇЁЂЗжРрЁЂЩЬЦЗЁЂМлИёЁЂЖЉЕЅЕШЃЌЕБЛКДцТњСЫПЩвдПМТЧLRUЛњжЦЧ§ж№РЯЕФЛКДцЪ§ОнЁЃ
1. Й§ЦкЛКДцЛњжЦ
МДВЩгУРСМгдиЃЌвЛАугУгкЛКДцБ№ЕФЯЕЭГЕФЪ§ОнЃЈЮоЗЈЖЉдФБфИќЯћЯЂЁЂЛђепГЩБОКмИпЃЉЁЂЛКДцПеМфгаЯоЁЂЕЭЦЕШШЕуЛКДцЕШГЁОАЃЛГЃМћВНжшЪЧЃКЪзЯШЖСШЁЛКДцШчЙћВЛУќжадђВщбЏЪ§ОнЃЌШЛКѓвьВНаДШыЛКДцВЂЙ§ЦкЛКДцЃЌЩшжУЙ§ЦкЪБМфЃЌЯТДЮЖСШЁНЋУќжаЛКДцЁЃШШЕуЪ§ОнОГЃЪЙгУМДдкгІгУЯЕЭГЩЯЛКДцБШНЯЖЬЕФЪБМфЁЃетжжЛКДцПЩФмДцдквЛЖЮЪБМфЕФЪ§ОнВЛвЛжТЧщПіЃЌашвЊИљОнГЁОАРДОіЖЈШчКЮЩшжУЙ§ЦкЪБМфЁЃШчПтДцЪ§ОнПЩвддкЧАЖЫгІгУЩЯЛКДцМИУыжгЃЌЖЬЪБМфЕФВЛвЛжТЪБПЩвдШЬЪмЕФЁЃ
2. ЮЌЖШЛЏЛКДцгыдіСПЛКДц
ЖдгкЕчЩЬЯЕЭГЃЌвЛИіЩЬЦЗПЩФмВ№ГЩШчЛљДЁЪєадЁЂЭМЦЌСаБэЁЂЩЯЯТМмЁЂЙцИёВЮЪ§ЁЂЩЬЦЗНщЩмЕШЃЛШчЙћЩЬЦЗБфИќСЫвЊАбетаЉЪ§ОнЖМИќаТвЛБщФЧУДећИіИќаТГЩБОКмИпЃКНгПкЕїгУСПКЭДјПэЃЛвђДЫзюКУНЋЪ§ОнНјааЮЌЖШЛЏВЂдіСПИќаТЃЈжЛИќаТБфЕФВПЗжЃЉЁЃгШЦфШчЩЯЯТМметжжжЛЪЧвЛИізДЬЌБфИќЃЌЕЋЪЧУПЬьЦЕЗБЕїгУЕФЃЌЮЌЖШЛЏКѓФмМѕЩйЗўЮёКмДѓЕФбЙСІЁЃ
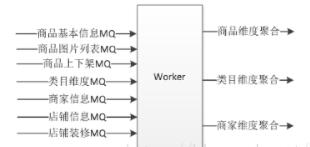
ЭМ3 ЮЌЖШЛЏЛКДцЗНАИ
АДееВЛЭЌЮЌЖШНгЪеMQНјааИќаТЁЃ
3. ДѓValue ЛКДц
вЊОЏЬшЛКДцжаЕФДѓValueЃЌгШЦфЪЧЪЙгУRedisЪБЁЃгіЕНетжжЧщПіЪБПЩвдПМТЧЪЙгУЖрЯпГЬЪЕЯжЕФЛКДцЃЌШчMemcachedЃЌРДЛКДцДѓValueЃЛЛђепЖдValueНјаабЙЫѕЃЛЛђепНЋValueВ№ЗжЮЊЖрИіаЁValueЃЌПЭЛЇЖЫдйНјааВщбЏЁЂОлКЯЁЃ
4. ШШЕуЛКДц
ЖдгкФЧаЉЗУЮЪЗЧГЃЦЕЗБЕФШШЕуЛКДцЃЌШчЙћУПДЮЖМШЅдЖГЬЛКДцЯЕЭГжаЛёШЁЃЌПЩФмЛсвђЮЊЗУЮЪСПЬЋДѓЕМжТдЖГЬЛКДцЯЕЭГЧыЧѓЙ§ЖрЁЂИКдиЙ§ИпЛђепДјПэЙ§ИпЕШЮЪЬтЃЌзюжеПЩФмЕМжТЛКДцЯьгІТ§ЃЌЪЙПЭЛЇЖЫЧыЧѓГЌЪБЁЃвЛжжНтОіЗНАИЪЧЭЈЙ§ЙвИќЖрЕФДгЛКДцЃЌПЭЛЇЖЫЭЈЙ§ИКдиОљКтЛњжЦЖСШЁДгЛКДцЯЕЭГЪ§ОнЁЃВЛЙ§вВПЩвддкПЭЛЇЖЫЫљдкЕФгІгУ/
ДњРэВуБОЕиДцДЂвЛЗнЃЌДгЖјБмУтЗУЮЪдЖГЬЛКДцЃЌМДЪЙЯёПтДцетжжЪ§ОнЃЌдкгааЉгІгУЯЕЭГжавВПЩвдНјааМИУыжгЕФБОЕиЛКДцЃЌДгЖјНЕЕЭдЖГЬЯЕЭГЕФбЙСІЁЃ
ЧЇЭђМЖВЂЗЂЃЁШчКЮЩшМЦвЛИіЖрМЖЛКДцЯЕЭГЃП
ЪзЯШЮвУЧашвЊУїАзЃЌЪВУДЪЧвЛИіЖрМЖЛКДцЯЕЭГЃЌЫќгаЪВУДгУЁЃЫљЮНЖрМЖЛКДцЯЕЭГЃЌОЭЪЧжИдквЛИіЯЕЭГ ЕФВЛЭЌЕФМмЙЙВуМЖНјааЪ§ОнЛКДцЃЌвдЬсЩ§ЗУЮЪаЇТЪЁЃ
ЮвУЧЖМжЊЕРЃЌвЛИіЛКДцЯЕЭГЃЌЫќУцСйзХаэЖрЮЪЬтЃЌБШШчЛКДцЛїДЉЃЌЛКДцДЉЭИЃЌЛКДцбЉБРЃЌЛКДцШШЕуЕШЕШЮЪЬтЃЌФЧУДЃЌЖдгквЛИіЖрМЖЛКДцЯЕЭГЃЌЫќгаЪВУДЮЪЬтФиЃП
ЛКДцШШЕуЃКЖрМЖЛКДцЯЕЭГДѓЖргІгУдкИпВЂЗЂГЁОАЯТЃЌЫљвдЮвУЧашвЊНтОіШШЕуKeyЮЪЬтЃЌШчКЮЬНВтШШЕуkeyЃП
Ъ§ОнвЛжТадЃКИїВуЛКДцжЎМфЕФЪ§ОнвЛжТадЮЪЬтЃЌШчгІгУВуЛКДцКЭЗжВМЪНЛКДцжЎЧАЕФЪ§ОнвЛжТадЮЪЬтЁЃ
ЛКДцЙ§ЦкЃКЛКДцЪ§ОнПЩвдЗжЮЊСНДѓРрЃЌЙ§ЦкЛКДцКЭВЛЙ§ЦкЛКДцЃПШчКЮЩшМЦЃЌШчКЮЩшМЦЙ§ЦкЛКДцЃП
дкетжЎЧАЃЌЮвУЧЯШПДПДвЛИіМђЕЅЕФЖрМЖЛКДцЯЕЭГЕФМмЙЙЭМЃК
ећИіЖрМЖЛКДцЯЕЭГБЛЗжЮЊШ§ВуЃЌгІгУВуnginxЛКДцЃЌЗжВМЪНredisЛКДцМЏШКЃЌtomcatЖбФкЛКДцЁЃећИіМмЙЙСїГЬШчЯТЃК
ЕБНгЪеЕНвЛИіЧыЧѓЪБЃЌЪзЯШЛсЗжЗЂЕНnginxМЏШКжаЃЌетРяПЩвдВЩгУnginxЕФИКдиОљКтЫуЗЈЗжЗЂИјФГвЛЬЈЛњЦїЃЌЪЙгУТжбЏПЩвдНЕЕЭИКдиЃЌЛђепВЩгУвЛжТадhashЫуЗЈРДЬсЩ§ЛКДцУќжаТЪЁЃ
ЕБnginxВуУЛгаЛКДцЪ§ОнЪБЃЌЛсМЬајЯђЯТЧыЧѓЃЌдкЗжВМЪНЛКДцМЏШКжаВщевЪ§ОнЃЌШчЙћЛКДцУќжаЃЌжБНгЗЕЛиЃЈВЂЧваДШыnginxгІгУЛКДцжаЃЉЃЌШчЙћЮДУќжаЃЌдђЛидДЕНtomcatМЏШКжаВщбЏЖбФкЛКДцЁЃ
дкЗжВМЪНЛКДцжаВщбЏВЛЕНЪ§ОнЃЌНЋЛсШЅtomcatМЏШКжаВщбЏЖбФкЛКДцЃЌВщбЏГЩЙІжБНгЗЕЛиЃЈВЂаДШыЗжredisжїМЏШКжаЃЉЃЌВщбЏЪЇАмЧыЧѓЪ§ОнПтЃЛЖбФкЛКДцЁЃ
ШчЙћвдЩЯЛКДцжаЖМУЛгаУќжаЃЌдђжБНгЧыЧѓЪ§ОнПтЃЌЗЕЛиНсЙћЃЌЭЌВНЪ§ОнЕНЗжВМЪНЛКДцжаЁЃ
дкМђЕЅСЫНтСЫЖрМЖЛКДцЕФЛљБОМмЙЙжЎКѓЃЌЮвУЧОЭИУЫМПМШчКЮНтОіЩЯУцЬсЕНЕФвЛЯЕСаЮЪЬтЁЃ
ЛКДцШШЕу
ЛКДцШШЕуЃЌЪЧвЛИіКмГЃМћЕФЮЪЬтЃЌБШШчЁАФГФГУїаЧаћВМНсЛщЁБЕШЕШЃЌЖМПЩФмВњЩњДѓСПЧыЧѓЗУЮЪЕФЮЪЬтЃЌвЛИізюТщЗГвВЪЧзюШнвзШУШЫКіЪгЕФЪТЧщОЭЪЧШчКЮЬНВтЕНШШЕуkeyЃЌдкЛКДцЯЕЭГжаЃЌГ§СЫвЛаЉГЃгУЕФШШЕуkeyЭтЃЌдкФГаЉЬиЪтГЁКЯЯТвВЛсГіЯжДѓСПЕФШШЕуkeyЃЌЮвУЧИУШчКЮЗЂЯжФиЃПгавдЯТВпТдЃК
Ъ§ОнЕїбаЁЃПЩвдЗжЮіРњЪЗЪ§ОнвдМАеыЖдВЛЭЌЕФГЁКЯШЅдЄВтГіШШЕуkeyЃЌетжжЗНЪНЫфШЛВЛФмАйЗжАйЪЙЕУЛКДцУќжаЃЌЕЋЪЧШДЪЧвЛжжзюМђЕЅКЭНкЪЁГЩБОЕФЗНАИЁЃ
ЪЕЪБМЦЫуЁЃПЩвдЪЙгУЯжгаЕФЪЕЪБМЦЫуПђМмЃЌБШШчstormЁЂspark streamingЁЂflinkЕШПђМмЭГМЦвЛИіЪБМфЖЮФкЕФЧыЧѓСПЃЌДгЖјХаЖЯШШЕуkeyЁЃЛђепвВПЩвдздМКЪЕЯжЖЈЪБШЮЮёШЅЭГМЦЧыЧѓСПЁЃ
етРяЮвУЧзХжиЬжТлвЛЯТЕкЖўжжНтОіЗНАИЃЌЖдгкШШЕуkeyЮЪЬтЃЌЕБЛКДцЯЕЭГжаУЛгаЗЂЯжЛКДцЪБЃЌашвЊШЅЪ§ОнПтжаЖСШЁЪ§ОнЃЌЕБДѓСПЧыЧѓРДЕФЪБКђЃЌвЛИіЧыЧѓЛёШЁЫјШЅЧыЧѓЪ§ОнПтЃЌЦфЫћзшШћЃЌНгзХШЋВПШЅЗУЮЪЛКДцЃЌетбљПЩФмвђЮЊвЛЬЈЗўЮёЦїГХВЛзЁДгЖјхДЛњЃЌБШШче§ГЃвЛЬЈЗўЮёЦїВЂЗЂСПЮЊ5wзѓгвЃЌВњЩњШШЕуkeyЕФЪБКђДяЕНСЫ10wЩѕжС20wЃЌетбљЗўЮёЦїПЯЖЈЛсБРЁЃЫљвдЮвУЧдкЗЂЯжШШЕуkeyжЎКѓЛЙашвЊзіЕНШчКЮздЖЏИКдиОљКтЁЃ
НсКЯвдЩЯЮЪЬтЮвУЧжиаТЩшМЦМмЙЙЃЌШчЯТЭМЫљЪОЃК
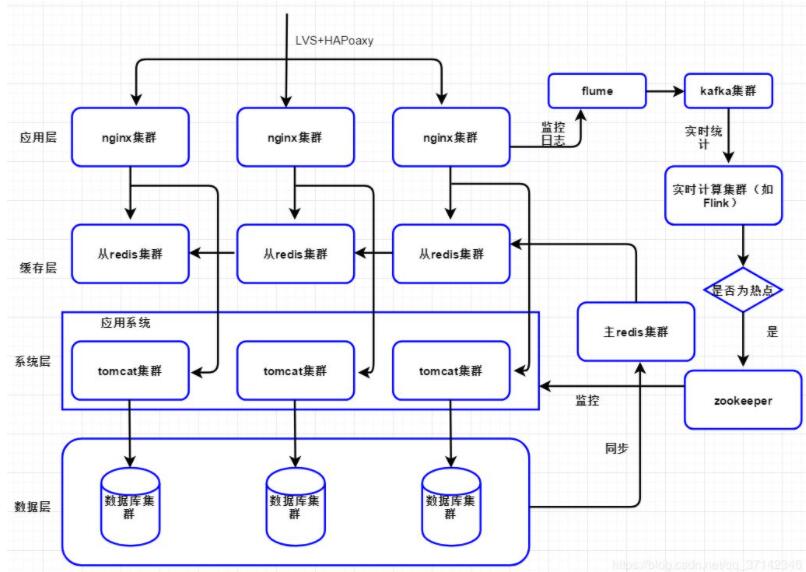
ЮвУЧНЋећИігІгУМмЙЙЗжЮЊгІгУВуЃЌЗжВМЪНЛКДцЁЂЯЕЭГВувдМАЪ§ОнВуЁЃ
дкгІгУВуЃЌЮвУЧВЩгУnginxМЏШКЃЌВЂЧвЖдНгЪЕЪБМЦЫуСДТЗЃЌЭЈЙ§flumeМрПиnginxШежОЃЌНЋЪ§ОнДЋЪфЕНkafkaМЏШКжаЃЌШЛКѓflinkМЏШКЯћЗбЪ§ОнНјааЭГМЦЃЌШчЙћЭГМЦ
НсЙћЮЊШШЕуkeyЃЌдђНЋЪ§ОнаДШыzookeeperЕФНкЕужаЃЌЖјгІгУЯЕЭГЭЈЙ§МрПиznodeНкЕуЃЌЖСШЁШШЕуkeyЪ§ОнЃЌШЅЪ§ОнПтжаМгдиЪ§ОнЕНЛКДцжаВЂЧвзіЕНИКдиОљКтЁЃ
ЪЕМЪЩЯЃЌЖдгкгІгУЯЕЭГжаЕФУПвЛЬЈЗўЮёЦїЃЌЛЙашвЊвЛВуЗРЛЄЛњжЦЃЌЯоСїШлЖЯЃЌетбљзіЕФФПЕФЪЧЮЊСЫЗРжЙЕЅЬЈЛњЦїЧыЧѓСПЙ§ИпЃЌЪЙЕУЗўЮёЦїИКдиЙ§ИпЃЌВЛжСгкЗўЮёЦїхДЛњЛђепДѓСПЧыЧѓЗУЮЪЪ§ОнПтЁЃМђЕЅЫМТЗОЭЪЧЮЊУПвЛЬЈЗўЮёЦїЩшМЦвЛИіЗЇжЕЃЌЕБЧыЧѓСПДѓгкИУжЕОЭжБНгЗЕЛигУЛЇПеАзвГУцЛђепЬсЪОгУЛЇМИУыКѓЫЂаТжиаТЗУЮЪЁЃ
Ъ§ОнвЛжТад
Ъ§ОнвЛжТадЮЪЬтжївЊЬхЯждкЛКДцИќаТЕФЪБКђЃЌШчКЮИќаТЛКДцЃЌБЃжЄЪ§ОнПтгыЛКДцвдМАИїВуЛКДцВужЎМфЕФвЛжТадЁЃ
ЖдгкЛКДцИќаТЮЪЬтЃЌЯШаДЛКДцЛЙЪЧЯШаДЪ§ОнПтЃЌетРяЪЁТдШєИЩзжЁЃжЎЧАЕФЮФеТНщЩмЙ§ЃЌгааЫШЄЕФЖСепПЩвдЗдФЁЃ
дкЕЅВуЛКДцЯЕЭГжаЃЌЮвУЧПЩвдЯШЩОГ§ЛКДцШЛКѓИќаТЪ§ОнПтЕФЗНАИРДНтОіЦфЪ§ОнвЛжТадЮЪЬтЃЌФЧУДЖдгкЖрМЖЛКДцФиЃПШчЙћЪЙгУетжжЗНАИЃЌЮвУЧашвЊПМТЧЃЌШчЙћЯШЩОГ§ЛКДцЃЌФЧУДашвЊж№ВуШЅзіЩОГ§ВйзїЃЌФЧУДетвЛЯЕСаВйзїЖдЯЕЭГДјРДЕФКФЪБвВЪЧКЭПЩЙлЕФЁЃ
ШчЙћЮвУЧЪЙгУЗжВМЪНЪТЮёЛњжЦЃЌОЭашвЊПМТЧИУВЛИУНЋаДЛКДцЗХШыЪТЮёЕБжаЃЌвђЮЊЮвУЧИќаТЗжВМЪНЛКДцЃЌашвЊзпЭјТчЭЈаХЃЌДѓСПЕФЧыЧѓНЋЕМжТЭјТЗЖЖЖЏЩѕжСзшШћЃЌдіМгСЫЯЕЭГЕФбгГйЃЌЕМжТЯЕЭГЖЬЪБМфФкВЛПЩгУЁЃШчЙћЮвУЧВЛНЋаДЛКДцетвЛВйзїЗХШыЪТЮёЕБжаЃЌФЧУДПЩФмв§Ц№ЖЬЪБМфФкЪ§ОнВЛвЛжТЁЃетвВОЭЪЧЗжВМЪНЯЕЭГЕФCAPРэТлЃЌЮвУЧВЛФмЭЌЪБДяЕНИпПЩгУКЭвЛжТадЁЃФЧУДИУШчКЮОёдёФиЃП
етРяЮвУЧбЁдёБЃжЄЯЕЭГЕФПЩгУадЃЌОЭвЛИіУыЩБЯЕЭГРДНВЃЌЖЬднЕФВЛвЛжТадЮЪЬтЖдгУЛЇЕФЬхбщгАЯьВЂВЛДѓЃЈЕБШЛЃЌетРяВЛЩцМАжЇИЖЯЕЭГЃЉЃЌЖјПЩгУадЖдгУЛЇРДЫЕШДКмживЊЃЌвЛИіЛюЖЏПЩФмдкКмЖЬЕФЪБМфФкНсЪјЃЌЖјгУЛЇашвЊдкетЖЮЪБМфФкЧРЕНздМКаФвЧЕФЩЬЦЗЃЌЫљвдПЩгУадИќживЊвЛаЉЃЈетРяашвЊИљОнОпЬхГЁОАНјааШЈКтЃЉЁЃ
дкБЃжЄСЫЯЕЭГЕФПЩгУадЕФЛљДЁЩЯЃЌЮвУЧИУШчКЮЪЕЯжФиЃПШчЙћЪЕЪБадвЊЧѓВЛЪЧКмИпЃЌЮвУЧПЩвдВЩгУШЋСП+діСПЭЌВНЕФЗНЪННјааЁЃЪзЯШЃЌЮвУЧПЩвдАДеедЄМЦЕФШШЕуkeyЖдЯЕЭГНјааЛКДцдЄШШЃЌШЋСПЭЌВНЪ§ОнЕНЛКДцЯЕЭГЁЃНгзХЃЌдкашвЊИќаТЛКДцЕФЪБКђЃЌЮвУЧПЩвдВЩгУдіСПЭЌВНЕФЗНЪНИќаТЛКДцЁЃБШШчЮвУЧПЩвдЪЙгУАЂРяCanalПђМмЭЌВНbinlogЕФЗНЪННјааЪ§ОнЕФЭЌВНЁЃ
ЛКДцЙ§Цк
ЛКДцЯЕЭГжаЕФЫљгаЪ§ОнЃЌИљОнЪ§ОнЕФЪЙгУЦЕТЪвдМАГЁОАЃЌЮвУЧПЩвдЗжЮЊЙ§ЦкkeyвдМАВЛЙ§ЦкkeyЃЌФЧУДЖдЦыЙ§ЦкЛКДцЮвУЧИУШчКЮЬдЬФиЃПЯТУцгаГЃгУЕФМИжжЗНАИЃК
FIFOЃКЪЙгУFIFOЫуЗЈРДЬдЬЙ§ЦкЛКДцЁЃ
LFUЃКЪЙгУLFUЫуЗЈРДЬдЬЙ§ЦкЛКДцЁЃ
LRUЃКЪЙгУLRUЫуЗЈРДЬдЬЙ§ЦкЛКДцЁЃ
вдЩЯМИжжЗНАИЪЧдкЛКДцДяЕНзюДѓЛКДцДѓаЁЕФЪБКђЕФЬдЬВпТдЃЌШчЙћУЛгаДяЕНзюДѓЛКДцДѓаЁЃЌЮвУЧгаЯТУцМИжжЗНЪНЃК
ЖЈЪБЩОГ§ВпТдЃКЩшжУвЛИіЖЈЪБШЮЮёЃЌдкЙцЖЈЪБМфФкМьВщВЂЧвЩОГ§Й§ЦкkeyЁЃ
ЖЈЦкЩОГ§ВпТдЃКетжжВпТдашвЊЩшжУЩОГ§ЕФжмЦквдМАЪБГЄЃЌШчКЮЩшжУЃЌашвЊИљОнОпЬхГЁКЯРДМЦЫуЁЃ
ЖшадЩОГ§ВпТдЃКдкЪЙгУЪБМьВщЪЧЗёЙ§ЦкЃЌШчЙћЙ§ЦкжБНгШЅИќаТЛКДцЃЌЗёдђжБНгЗЕЛиЁЃ
зюШЋУцЕФЛКДцМмЙЙЩшМЦ
1ЃКЛКДцММЪѕКЭПђМмЕФживЊад
ЛЅСЊЭјЕФвЛаЉИпВЂЗЂЃЌИпадФмЕФЯюФПКЭЯЕЭГжаЃЌЛКДцММЪѕЪЧЦ№зХЙІВЛПЩУЛЕФзїгУЁЃЛКДцВЛНіНіЪЧkey-valueЕФМђЕЅДцШЁЃЌЫќдкОпЬхЕФвЕЮёГЁОАжаЃЌЛЙЪЧКмИДдгЕФЃЌашвЊКмЧПЕФМмЙЙЩшМЦФмСІЁЃЮвдјООЭгіЕНЙ§вђЮЊЛКДцМмЙЙЩшМЦВЛЕНЮЛЃЌЕМжТСЫЯЕЭГБРРЃЕФАИР§ЁЃ
2ЃКЛКДцЕФММЪѕЗНАИЗжРр
1ЃЉЪЧзіЪЕЪБадБШНЯИпЕФФЧПщЪ§ОнЃЌБШШчЫЕПтДцЃЌЯњСПжЎРрЕФетжжЪ§ОнЃЌЮвУЧВЩШЁЕФЪЕЪБЕФЛКДц+Ъ§ОнПтЫЋаДЕФММЪѕЗНАИЃЌЫЋаДвЛжТадБЃеЯЕФЗНАИЁЃ
2ЃЉЪЧзіЪЕЪБадвЊЧѓВЛИпЕФЪ§ОнЃЌБШШчЫЕЩЬЦЗЕФЛљБОаХЯЂЃЌЕШЕШЃЌЮвУЧВЩШЁЕФЪЧШ§МЖЛКДцМмЙЙЕФММЪѕЗНАИЃЌОЭЪЧЫЕгЩвЛИізЈУХЕФЪ§ОнЩњВњЕФЗўЮёЃЌШЅЛёШЁећИіЩЬЦЗЯъЧщвГашвЊЕФИїжжЪ§ОнЃЌОЙ§ДІРэКѓЃЌНЋЪ§ОнЗХШыИїМЖЛКДцжаЁЃ
3ЃКИпВЂЗЂвдМАИпПЩгУЕФИДдгЯЕЭГжаЕФЛКДцМмЙЙЖМгаФФаЉЖЋЮї
1ЃЉдкДѓаЭЕФЛКДцМмЙЙжаЃЌredisЪЧзюзюЛљДЁЕФвЛВуЁЃИпВЂЗЂЃЌЛКДцМмЙЙжаГ§СЫredisЃЌЛЙгаЦфЫћЕФзщГЩВПЗжЃЌЕЋЪЧredisжСЙиживЊЁЃ
ШчЙћФуЕФЪ§ОнСПВЛДѓЃЈ10GвдФкЃЉЃЌЕЅmasterОЭПЩвдЁЃredisГжОУЛЏ+БИЗнЗНАИ+ШнджЗНАИ+replicationЃЈжїДг+ЖСаДЗжРыЃЉ+sentinalЃЈЩкБјМЏШКЃЌ3ИіНкЕуЃЌИпПЩгУадЃЉ
ШчЙћФуЕФЪ§ОнСПКмДѓЃЈ1T+ЃЉЃЌВЩгУredis clusterЁЃЖрmasterЗжВМЪНДцДЂЪ§ОнЃЌЫЎЦНРЉШн,здЖЏНјааmaster
-> slaveЕФжїБИЧаЛЛЁЃ
2ЃЉзюОЕфЕФЛКДц+Ъ§ОнПтЖСаДЕФФЃЪНЃЌcache aside patternЁЃЖСЕФЪБКђЃЌЯШЖСЛКДцЃЌЛКДцУЛгаЕФЛАЃЌФЧУДОЭЖСЪ§ОнПтЁЃИќаТЛКДцЗжвдЯТСНжжЗНЪНЃК
Ъ§ОнЗЂЩњБфЛЏЪБЃЌЯШИќаТЛКДцЃЌШЛКѓдйИќаТЪ§ОнПтЁЃетжжЪЪгУгкЛКДцЕФжЕЯрЖдМђЕЅЃЌКЭЪ§ОнПтЕФжЕвЛвЛЖдгІЃЌетбљИќаТБШНЯПьЁЃ
Ъ§ОнЗЂЩњБфЛЏЪБЃЌЯШЩОГ§ЛКДцЃЌШЛКѓдйИќаТЪ§ОнПтЃЌЖСЪ§ОнЕФЪБКђдйЩшжУЛКДцЁЃетжжЪЪгУгкЛКДцЕФжЕБШНЯИДдгЕФГЁОАЁЃБШШчПЩФмИќаТСЫФГИіБэЕФвЛИізжЖЮЃЌШЛКѓЦфЖдгІЕФЛКДцЃЌЪЧашвЊВщбЏСэЭтСНИіБэЕФЪ§ОнЃЌВЂНјаадЫЫуЃЌВХФмМЦЫуГіЛКДцзюаТЕФжЕЕФЁЃетбљИќаТЛКДцЕФДњМлЪЧКмИпЕФЁЃШчЙћФуЦЕЗБаоИФвЛИіЛКДцЩцМАЕФЖрИіБэЃЌФЧУДетИіЛКДцЛсБЛЦЕЗБЕФИќаТЃЌЦЕЗБЕФИќаТЛКДцДњМлКмИпЁЃЖјЧветИіЛКДцЕФжЕШчЙћВЛЪЧБЛЦЕЗБЗУЮЪЃЌОЭЕУВЛГЅЪЇСЫЁЃ
ДѓВПЗжЧщПіЯТЃЌНЈвщЪЪгУЩОГ§ИќаТЕФЗНЪНЁЃЦфЪЕЩОГ§ЛКДцЃЌЖјВЛЪЧИќаТЛКДцЃЌОЭЪЧвЛИіlazyМЦЫуЕФЫМЯыЃЌВЛвЊУПДЮЖМжиаТзіИДдгЕФМЦЫуЃЌВЛЙмЫќЛсВЛЛсгУЕНЃЌЖјЪЧШУЫќЕНашвЊБЛЪЙгУЕФЪБКђдйжиаТМЦЫуЁЃ
ОйИіР§згЃЌвЛИіЛКДцЩцМАЕФБэЕФзжЖЮЃЌдк1ЗжжгФкОЭаоИФСЫ20ДЮЃЌЛђепЪЧ100ДЮЃЌФЧУДЛКДцИњаТ20ДЮЃЌ100ДЮ;
ЕЋЪЧетИіЛКДцдк1ЗжжгФкОЭБЛЖСШЁСЫ1ДЮЃЌгаДѓСПЕФРфЪ§ОнЁЃ28ЛЦН№ЗЈдђЃЌ20%ЕФЪ§ОнЃЌеМгУСЫ80%ЕФЗУЮЪСПЁЃЪЕМЪЩЯЃЌШчЙћФужЛЪЧЩОГ§ЛКДцЕФЛАЃЌФЧУД1ЗжжгФкЃЌетИіЛКДцВЛЙ§ОЭжиаТМЦЫувЛДЮЖјвбЃЌПЊЯњДѓЗљЖШНЕЕЭЁЃУПДЮЪ§ОнЙ§РДЃЌОЭжЛЪЧЩОГ§ЛКДцЃЌШЛКѓаоИФЪ§ОнПтЃЌШчЙћетИіЛКДцЃЌдк1ЗжжгФкжЛЪЧБЛЗУЮЪСЫ1ДЮЃЌФЧУДжЛгаФЧ1ДЮЃЌЛКДцЪЧвЊБЛжиаТМЦЫуЕФЁЃ
3ЃЉЪ§ОнПтгыЛКДцЫЋаДВЛвЛжТЮЪЬтЕФНтОіЗНАИ
ЮЪЬтЃКВЂЗЂЧыЧѓЕФЪБКђЃЌЪ§ОнЗЂЩњСЫБфИќЃЌЯШЩОГ§СЫЛКДцЃЌШЛКѓвЊШЅаоИФЪ§ОнПтЃЌДЫЪБЛЙУЛаоИФЁЃСэвЛИіЧыЧѓЙ§РДЃЌШЅЖСЛКДцЃЌЗЂЯжЛКДцПеСЫЃЌШЅВщбЏЪ§ОнПтЃЌВщЕНСЫаоИФЧАЕФОЩЪ§ОнЃЌЗХЕНСЫЛКДцжаЁЃ
ЗНАИЃКЪ§ОнПтгыЛКДцИќаТгыЖСШЁВйзїНјаавьВНДЎааЛЏЁЃЃЈв§ШыЖгСаЃЉ
ИќаТЪ§ОнЕФЪБКђЃЌНЋЯргІВйзїЗЂЫЭЕНвЛИіjvmФкВПЕФЖгСажаЁЃЖСШЁЪ§ОнЕФЪБКђЃЌШчЙћЗЂЯжЪ§ОнВЛдкЛКДцжаЃЌФЧУДНЋжиаТЖСШЁЪ§ОнЕФВйзївВЗЂЫЭЕНЭЌвЛИіjvmФкВПЕФЖгСажаЁЃЖгСаЯћЗбепДЎааФУЕНЖдгІЕФВйзїЃЌШЛКѓвЛЬѕвЛЬѕЕФжДааЁЃетбљЕФЛАЃЌвЛИіЪ§ОнБфИќЕФВйзїЃЌЯШжДааЩОГ§ЛКДцЃЌШЛКѓдйШЅИќаТЪ§ОнПтЃЌЕЋЪЧЛЙУЛЭъГЩИќаТЁЃДЫЪБШчЙћвЛИіЖСЧыЧѓЙ§РДЃЌЖСЕНСЫПеЕФЛКДцЃЌФЧУДПЩвдЯШНЋЛКДцИќаТЕФЧыЧѓЗЂЫЭЕНЖгСажаЃЌДЫЪБЛсдкЖгСажаЛ§бЙЃЌШЛКѓЭЌВНЕШД§ЛКДцИќаТЭъГЩЁЃ
етРягаСНИіПЩвдгХЛЏЕФЕуЃК
вЛИіЖгСажаЃЌЦфЪЕЖрИіЖСЛКДцЃЌИќаТЛКДцЕФЧыЧѓДЎдквЛЦ№ЪЧУЛвтвхЕФЃЌЖјЧвШчЙћЖСЭЌвЛЛКДцЕФДѓСПЧыЧѓЕНРДЪБЃЌЛсвРДЮНјШыЖгСаЕШД§ЃЌетбљЛсЕМжТЖгСазюКѓвЛИіЕФЧыЧѓЯьгІЪБМфГЌЪБЁЃвђДЫПЩвдзіЙ§ТЫЃЌШчЙћЗЂЯжЖгСажавбОгавЛИіЖСЛКДцЃЌИќаТЛКДцЕФЧыЧѓСЫЃЌФЧУДОЭВЛгУдйЗХИіаТЧыЧѓВйзїНјШЅСЫЃЌжБНгЕШД§ЧАУцЕФИќаТВйзїЧыЧѓЭъГЩМДПЩЁЃШчЙћЧыЧѓЛЙдкЕШД§ЪБМфЗЖЮЇФкЃЌВЛЖЯТжбЏЗЂЯжПЩвдШЁЕНжЕСЫЃЌФЧУДОЭжБНгЗЕЛи;
ШчЙћЧыЧѓЕШД§ЕФЪБМфГЌЙ§вЛЖЈЪБГЄЃЌФЧУДетвЛДЮжБНгДгЪ§ОнПтжаЖСШЁЕБЧАЕФОЩжЕЁЃ
ШчЙћЧыЧѓСПЬиБ№ДѓЕФЪБКђЃЌПЩвдгУЖрИіЖгСаЃЌУПИіЖгСаЖдгІвЛИіЯпГЬЁЃУПИіЧыЧѓРДЪБПЩвдИљОнЧыЧѓЕФБъЪЖidНјааhashТЗгЩНјШыЕНВЛЭЌЕФЖгСаЁЃ
зюКѓЃЌвЛЖЈвЊзіИљОнЪЕМЪвЕЮёЯЕЭГЕФдЫааЧщПіЃЌШЅНјаавЛаЉбЙСІВтЪдЃЌКЭФЃФтЯпЩЯЛЗОГЃЌШЅПДПДзюЗБУІЕФЪБКђЃЌФкДцЖгСаПЩФмЛсМЗбЙЖрЩйИќаТВйзїЃЌПЩФмЛсЕМжТзюКѓвЛИіИќаТВйзїЖдгІЕФЖСЧыЧѓЃЌЛсhangЖрЩйЪБМфЃЌШчЙћЖСЧыЧѓдк200msЗЕЛиЃЌШчЙћФуМЦЫуЙ§КѓЃЌФФХТЪЧзюЗБУІЕФЪБКђЃЌЛ§бЙ10ИіИќаТВйзїЃЌзюЖрЕШД§200msЃЌФЧЛЙПЩвдЕФЁЃШчЙћвЛИіФкДцЖгСаПЩФмЛ§бЙЕФИќаТВйзїЬиБ№ЖрЃЌФЧУДФуОЭвЊМгЛњЦїЃЌШУУПИіЛњЦїЩЯВПЪ№ЕФЗўЮёЪЕР§ДІРэИќЩйЕФЪ§ОнЃЌФЧУДУПИіФкДцЖгСажаЛ§бЙЕФИќаТВйзїОЭЛсдНЩйЁЃЦфЪЕИљОнжЎЧАЕФЯюФПОбщЃЌвЛАуРДЫЕЪ§ОнЕФаДЦЕТЪЪЧКмЕЭЕФЃЌвђДЫЪЕМЪЩЯе§ГЃРДЫЕЃЌдкЖгСажаЛ§бЙЕФИќаТВйзїгІИУЪЧКмЩйЕФЁЃ
ОйИіР§згЃКвЛУыОЭ100ИіаДВйзїЁЃЕЅЬЈЛњЦїЃЌ20ИіФкДцЖгСаЃЌУПИіФкДцЖгСаЃЌПЩФмОЭЛ§бЙ5ИіаДВйзїЃЌУПИіаДВйзїадФмВтЪдКѓЃЌвЛАудк20msзѓгвОЭЭъГЩЃЌФЧУДеыЖдУПИіФкДцЖгСажаЕФЪ§ОнЕФЖСЧыЧѓЃЌвВОЭзюЖрhangвЛЛсЖљЃЌ200msвдФкПЯЖЈФмЗЕЛиСЫЁЃШчЙћАбаДQPSРЉДѓ10БЖЃЌЕЋЪЧОЙ§ИеВХЕФВтЫуЃЌОЭжЊЕРЃЌЕЅЛњжЇГХаДQPSМИАйУЛЮЪЬтЃЌФЧУДОЭРЉШнЛњЦїЃЌРЉШн10БЖЕФЛњЦїЃЌ10ЬЈЛњЦїЃЌУПИіЛњЦї20ИіЖгСаЃЌ200ИіЖгСаЁЃДѓВПЗжЕФЧщПіЯТЃЌгІИУЪЧетбљЕФЃЌДѓСПЕФЖСЧыЧѓЙ§РДЃЌЖМЪЧжБНгзпЛКДцШЁЕНЪ§ОнЕФЃЌЩйСПЧщПіЯТЃЌПЩФмгіЕНЖСИњЪ§ОнИќаТГхЭЛЕФЧщПіЃЌШчЩЯЫљЪіЃЌФЧУДДЫЪБИќаТВйзїШчЙћЯШШыЖгСаЃЌжЎКѓПЩФмЛсЫВМфРДСЫЖдетИіЪ§ОнДѓСПЕФЖСЧыЧѓЃЌЕЋЪЧвђЮЊзіСЫШЅжиЕФгХЛЏЃЌЫљвдвВОЭвЛИіИќаТЛКДцЕФВйзїИњдкЫќКѓУцЁЃ
4ЃЉДѓаЭЛКДцШЋСПИќаТЮЪЬтЕФНтОіЗНАИ
ЮЪЬтЃКЛКДцЪ§ОнКмДѓЪБЃЌПЩФмЕМжТredisЕФЭЬЭТСПОЭЛсМБОчЯТНЕЃЌЭјТчКФЗбЕФзЪдДДѓЁЃШчЙћВЛЮЌЖШЛЏЃЌОЭЕМжТЖрИіЮЌЖШЕФЪ§ОнЛьКЯдквЛИіЛКДцvalueжаЁЃЖјЧвВЛЭЌЮЌЖШЕФЪ§ОнЃЌПЩФмИќаТЕФЦЕТЪЖМДѓВЛвЛбљЁЃФУЩЬЦЗЯъЧщвГРДЫЕЃЌШчЙћЯждкжЛЪЧНЋ1000ИіЩЬЦЗЕФЗжРрХњСПЕїећСЫвЛЯТЃЌЕЋЪЧШчЙћЩЬЦЗЗжРрЕФЪ§ОнКЭЩЬЦЗБОЩэЕФЪ§ОнЛьдгдквЛЦ№ЁЃФЧУДПЩФмЕМжТашвЊНЋАќРЈЩЬЦЗдкФкЕФДѓЛКДцvalueШЁГіРДЃЌНјааИќаТЃЌдйаДЛиШЅЃЌОЭЛсКмПгЕљЃЌКФЗбДѓСПЕФзЪдДЃЌredisбЙСІвВКмДѓ
ЗНАИЃКЛКДцЮЌЖШЛЏЁЃОйИіР§згЃКЩЬЦЗЯъЧщвГЗжШ§ИіЮЌЖШЃКЩЬЦЗЮЌЖШЃЌЩЬЦЗЗжРрЮЌЖШЃЌЩЬЦЗЕъЦЬЮЌЖШЁЃНЋУПИіЮЌЖШЕФЪ§ОнЖМДцвЛЗнЃЌБШШчЫЕЩЬЦЗЮЌЖШЕФЪ§ОнДцвЛЗнЃЌЩЬЦЗЗжРрЕФЪ§ОнДцвЛЗнЃЌЩЬЦЗЕъЦЬЕФЪ§ОнДцвЛЗнЁЃФЧУДдкВЛЭЌЕФЮЌЖШЪ§ОнИќаТЕФЪБКђЃЌжЛвЊШЅИќаТЖдгІЕФЮЌЖШОЭПЩвдСЫЁЃДѓДѓМѕЧсСЫredisЕФбЙСІЁЃ
5ЃЉЭЈЙ§ЖрМЖЛКДцЃЌДяЕНИпВЂЗЂМЋжТЃЌЭЌЪБИјЛКДцМмЙЙзюКѓЕФАВШЋБЃЛЄВуЁЃОпЬхПЩвдВЮееЩЯвЛЦЊЮФеТЁОвкМЖСїСПЕФЩЬЦЗЯъЧщвГМмЙЙЗжЮіЁПЁЃ
6ЃЉЗжВМЪНВЂЗЂЛКДцжиНЈЕФГхЭЛЮЪЬтЕФНтОіЗНАИ
ЮЪЬтЃКМйШчЪ§ОндкЫљгаЕФЛКДцжаЖМВЛДцдкСЫЃЈLRUЫуЗЈХЊЕєСЫЃЉЃЌОЭашвЊжиаТВщбЏЪ§ОнаДШыЛКДцЁЃЖдгкЗжВМЪНЕФжиНЈЛКДцЃЌдкВЛЭЌЕФЛњЦїЩЯЃЌВЛЭЌЕФЗўЮёЪЕР§жаЃЌШЅзіЩЯУцЕФЪТЧщЃЌОЭЛсГіЯжЖрИіЛњЦїЗжВМЪНжиНЈШЅЖСШЁЯрЭЌЕФЪ§ОнЃЌШЛКѓаДШыЛКДцжаЁЃ
ЗНАИЃКЗжВМЪНЫјЃКШчЙћФугаЖрИіЛњЦїдкЗУЮЪЭЌвЛИіЙВЯэзЪдДЃЌФЧУДетИіЪБКђЃЌШчЙћФуашвЊМгИіЫјЃЌШУЖрИіЗжВМЪНЕФЛњЦїдкЗУЮЪЙВЯэзЪдДЕФЪБКђДЎааЦ№РДЁЃЗжВМЪНЫјЕБШЛгаКмЖржжВЛЭЌЕФЪЕЯжЗНАИЃЌredisЗжВМЪНЫјЃЌzookeeperЗжВМЪНЫјЁЃ
zookeeperЗжВМЪНЫјЕФНтОіВЂЗЂГхЭЛЕФЗНАИ
ЃЈ1ЃЉБфИќЛКДцжиНЈвдМАПеЛКДцЧыЧѓжиНЈЃЌИќаТredisжЎЧАЃЌЖМашвЊЯШЛёШЁЖдгІЩЬЦЗidЕФЗжВМЪНЫј
ЃЈ2ЃЉФУЕНЗжВМЪНЫјжЎКѓЃЌашвЊИљОнЪБМфАцБОШЅБШНЯвЛЯТЃЌШчЙћздМКЕФАцБОаТгкredisжаЕФАцБОЃЌФЧУДОЭИќаТЃЌЗёдђОЭВЛИќаТ
ЃЈ3ЃЉШчЙћФУВЛЕНЗжВМЪНЫјЃЌФЧУДОЭЕШД§ЃЌВЛЖЯТжбЏЕШД§ЃЌжБЕНздМКЛёШЁЕНЗжВМЪНЕФЫј
7ЃЉЛКДцРфЦєЖЏЕФЮЪЬтЕФНтОіЗНАИ
ЮЪЬтЃКаТЯЕЭГЕквЛДЮЩЯЯпЃЌДЫЪБдкЛКДцРяПЩФмЪЧУЛгаЪ§ОнЕФЁЃЛђепredisЛКДцШЋХЬБРРЃСЫЃЌЪ§ОнвВЖЊСЫЁЃЕМжТЫљгаЧыЧѓДђЕНСЫmysqlЁЃЕМжТmysqlжБНгЙвЕєЁЃ
ЗНАИЃКЛКДцдЄШШЁЃ
ЬсЧАИјredisжаЙрШыВПЗжЪ§ОнЃЌдйЬсЙЉЗўЮё
ПЯЖЈВЛПЩФмНЋЫљгаЪ§ОнЖМаДШыredisЃЌвђЮЊЪ§ОнСПЬЋДѓСЫЃЌЕквЛКФЗбЕФЪБМфЬЋГЄСЫЃЌЕкЖўИљБОredisШнФЩВЛЯТЫљгаЕФЪ§ОнЃЌашвЊИљОнЕБЬьЕФОпЬхЗУЮЪЧщПіЃЌЪЕЪБЭГМЦГіЗУЮЪЦЕТЪНЯИпЕФШШЪ§ОнЃЌШЛКѓНЋЗУЮЪЦЕТЪНЯИпЕФШШЪ§ОнаДШыredisжаЃЌПЯЖЈЪЧШШЪ§ОнвВБШНЯЖрЃЌЮвУЧвВЕУЖрИіЗўЮёВЂааЖСШЁЪ§ОнШЅаДЃЌВЂааЕФЗжВМЪНЕФЛКДцдЄШШЁЃ
8ЃЉПжВРЕФЛКДцбЉБРЮЪЬтЕФНтОіЗНАИ
ЮЪЬтЃКЛКДцЗўЮёДѓСПЕФзЪдДШЋВПКФЗбдкЗУЮЪredisКЭдДЗўЮёЮоЙћЃЌзюКѓздМКБЛЭЯЫРЃЌЮоЗЈЬсЙЉЗўЮёЁЃ
ЗНАИЃКЯрЖдРДЫЕЃЌПМТЧЕФБШНЯЭъЩЦЕФвЛЬзЗНАИЃЌЗжЮЊЪТЧАЃЌЪТжаЃЌЪТКѓШ§ИіВуДЮШЅЫМПМдѕУДРДгІЖдЛКДцбЉБРЕФГЁОАЁЃ
ЪТЧАЃКИпПЩгУМмЙЙЁЃжїДгМмЙЙЃЌВйзїжїНкЕуЃЌЖСаДЃЌЪ§ОнЭЌВНЕНДгНкЕуЃЌвЛЕЉжїНкЕуЙвЕєЃЌДгНкЕуИњЩЯЁЃ
ЪТжаЃКЖрМЖЛКДцЁЃredis clusterвбОГЙЕзБРРЃСЫЃЌЛКДцЗўЮёЪЕР§ЕФehcacheЕФЛКДцЛЙФмЦ№ЕНзїгУЁЃ
ЪТКѓЃКredisЪ§ОнПЩвдЛжИДЃЌзіСЫБИЗнЃЌredisЪ§ОнБИЗнКЭЛжИДЃЌredisжиаТЦєЖЏЦ№РДЁЃ
9ЃЉЛКДцДЉЭИЮЪЬтЕФНтОіЗНАИ
ЮЪЬтЃКЛКДцжаУЛгаетбљЕФЪ§ОнЃЌЪ§ОнПтжавВУЛгаетбљЕФЪ§ОнЁЃгЩгкЛКДцЪЧВЛУќжаЪББЛЖЏаДЕФЃЌВЂЧвГігкШнДэПМТЧЃЌШчЙћДгДцДЂВуВщВЛЕНЪ§ОндђВЛаДШыЛКДцЃЌетНЋЕМжТетИіВЛДцдкЕФЪ§ОнУПДЮЧыЧѓЖМвЊЕНДцДЂВуШЅВщбЏЃЌЪЇШЅСЫЛКДцЕФвтвхЁЃдкСїСПДѓЪБЃЌПЩФмDBОЭЙвЕєСЫЃЌвЊЪЧгаШЫРћгУВЛДцдкЕФkeyЦЕЗБЙЅЛїЮвУЧЕФгІгУЃЌетОЭЪЧТЉЖДЁЃ
ЗНАИЃКгаКмЖржжЗНЗЈПЩвдгааЇЕиНтОіЛКДцДЉЭИЮЪЬтЃЌзюГЃМћЕФдђЪЧВЩгУВМТЁЙ§ТЫЦїЃЌНЋЫљгаПЩФмДцдкЕФЪ§ОнЙўЯЃЕНвЛИізуЙЛДѓЕФbitmapжаЃЌвЛИівЛЖЈВЛДцдкЕФЪ§ОнЛсБЛ
етИіbitmapРЙНиЕєЃЌДгЖјБмУтСЫЖдЕзВуДцДЂЯЕЭГЕФВщбЏбЙСІЁЃСэЭтвВгавЛИіИќЮЊМђЕЅДжБЉЕФЗНЗЈЃЈЮвУЧВЩгУЕФОЭЪЧетжжЃЉЃЌШчЙћвЛИіВщбЏЗЕЛиЕФЪ§ОнЮЊПеЃЈВЛЙмЪЧЪ§
ОнВЛДцдкЃЌЛЙЪЧЯЕЭГЙЪеЯЃЉЃЌЮвУЧШдШЛАбетИіПеНсЙћНјааЛКДцЃЌЕЋЫќЕФЙ§ЦкЪБМфЛсКмЖЬЃЌзюГЄВЛГЌЙ§ЮхЗжжгЁЃ
ЛКДцЛїДЉЮЪЬт
ЛКДцЛїДЉЃЌЪЧжИФГИіМЋЖШ ЁА ШШЕу ЁБ Ъ§ОндкФГИіЪБМфЕуЙ§ЦкЪБЃЌЧЁКУдкетИіЪБМфЕуЖдетИі KEY гаДѓСПЕФВЂЗЂЧыЧѓЙ§РДЃЌетаЉЧыЧѓЗЂЯжЛКДцЙ§ЦквЛАуЖМЛсДг
DB МгдиЪ§ОнВЂЛиЩшЕНЛКДцЃЌЕЋЪЧетИіЪБКђДѓВЂЗЂЕФЧыЧѓПЩФмЛсЫВМф DB бЙПхЁЃ
ЯШРДЩшЯыЯТУцетУДвЛИіГЁОАЁЃЪ§ОндДдк MySQL Ъ§ОнПтжаЃЌЛКДцЕФЪ§ОнЗХдкЙВЯэзжЕфжаЃЌГЌЪБЪБМфЮЊ 1
ЗжжгЁЃдкет 1 ЗжжгФкЕФЪБМфРяЃЌЫљгаЕФЧыЧѓЖМДгЛКДцжаЛёШЁЪ§ОнЃЌMySQL УЛгаШЮКЮЕФбЙСІЁЃЕЋЪЧЃЌвЛЕЉЕНДя
1 ЗжжгЃЌвВОЭЪЧЛКДцЪ§ОнЪЇаЇЕФФЧвЛПЬЃЌШчЙће§КУгаДѓСПЕФВЂЗЂЧыЧѓНјРДЃЌдкЛКДцжаУЛгаВщбЏЕННсЙћЃЌОЭвЊДЅЗЂВщбЏЪ§ОндДЕФКЏЪ§ЃЌФЧУДетаЉЧыЧѓШЋВПЖМНЋШЅВщбЏ
MySQL Ъ§ОнПтЃЌ жБНгдьГЩЪ§ОнПтЗўЮёЦїПЈЖйЃЌЩѕжСПЈЫРЁЃ
ЖдгквЛаЉЩшжУСЫЙ§ЦкЪБМфЕФ KEY ЃЌШчЙћетаЉ KEY ПЩФмЛсдкФГаЉЪБМфЕуБЛГЌИпВЂЗЂЕиЗУЮЪЃЌЪЧвЛжжЗЧГЃ
ЁА ШШЕу ЁБ ЕФЪ§ОнЁЃетИіЪБКђЃЌашвЊПМТЧетИіИіЮЪЬтЁЃ
ШчКЮБмУтЛКДцЛїДЉЃП
1 ЁЂжїЖЏИќаТЛКДцЃКФЌШЯЛКДцЪЧБЛЖЏИќаТЕФЁЃжЛгадкжеЖЫЧыЧѓЗЂЯжЛКДцЪЇаЇЪБЃЌЫќВХЛсШЅЪ§ОнПтВщбЏаТЕФЪ§ОнЁЃФЧУДЃЌШчЙћЮвУЧАбЛКДцЕФИќаТЃЌДгБЛЖЏИФЮЊжїЖЏЃЌвВОЭПЩвджБНгШЦПЊЛКДцЗч
БЉЕФЮЪЬтСЫЃЌдк OpenResty жаЃЌЮвУЧПЩвдЪЙгУ ngx.timer.every РДДДНЈвЛИіЖЈЪБЦїШЅЖЈЪБИќаТЁЃ
ШБЕуЃКУПвЛИіЛКДцЖМвЊЖдгІвЛИіжмЦкадЕФШЮЮёЃЛЖјЧвЛКДцЙ§ЦкЪБМфКЭМЦЛЎШЮЮёЕФжмЦкЪБМфЛЙвЊЖдгІКУЃЌШчЙћетжаМфГіЯжСЫЪВУДчЂТЉЃЌ
жеЖЫОЭПЩФм вЛжБЛёШЁЕНЕФЖМЪЧПеЪ§Он
2 ЁЂЪЙгУЛЅГтЫјЃКЧыЧѓЗЂЯжЛКДцВЛДцдкКѓЃЌШЅВщбЏ DB ЧАЃЌЪЙгУЫјЃЌБЃжЄгаЧвжЛгавЛИіЧыЧѓШЅВщбЏ DB
ЃЌВЂИќаТЕНЛКДцЁЃСїГЬШчЯТЃК
ЛёШЁЫјЃЌжБЕНГЩЙІЛђГЌЪБЁЃШчЙћГЌЪБЃЌдђХзГівьГЃЃЌЗЕЛиЁЃШчЙћГЩЙІЃЌМЬајЯђЯТжДааЁЃ
дйШЅЛКДцжаЁЃШчЙћДцдкжЕЃЌдђжБНгЗЕЛиЃЛШчЙћВЛДцдкЃЌдђМЬајЭљЯТжДааШчЙћГЩЙІЛёШЁЕНЫјЕФЛАЃЌОЭПЩвдБЃжЄжЛгавЛИіЧыЧѓШЅЪ§ОндДИќаТЪ§ОнЃЌВЂИќаТЕНЛКДцжаСЫЁЃ
ВщбЏ DB ЃЌВЂИќаТЕНЛКДцжаЃЌЗЕЛижЕЁЃ |









