| БрМЭЦМі: |
БОЮФжївЊДгЛљДЁЩшЪЉЁЂЪ§ОнПтЁЂМмЙЙЁЂгІгУЁЂЙцЗЖетМИЗНУцЬИЬИШчКЮНЈЩшИпВЂЗЂЕФЯЕЭГ
ЁЃ
РДздгк
ЬкбЖММЪѕЙЄГЬ,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд
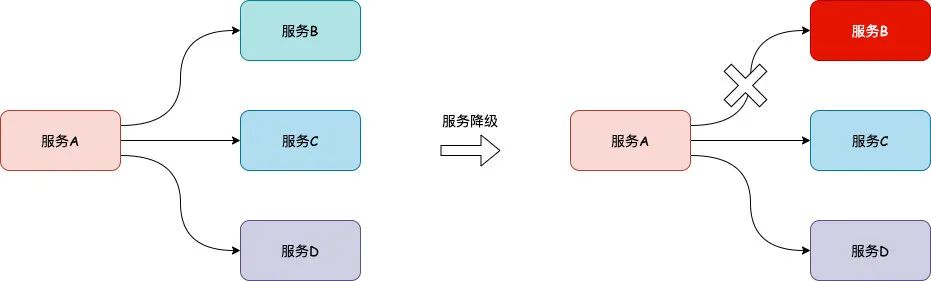
дчЦкДгЪТдЫЕЅЯЕЭГЕФПЊЗЂКЭЮЌЛЄЙЄзїЃЌДгзюдчЕФШеОљАйЭђЕЅЃЌЕНШеОљЧЇЭђЕЅЃЌвЕЮёЕФПьЫйЗЂеЙдйМгЩЯЭтТєвЕЮёЕФЬиЕуЪЧЃЌвЕЮёСПМЏжадкЮчИпЗхКЭЭэИпЗхСНИіИпЗхЦкЃЌЫљвдИпЗхЦкВЂЗЂЧыЧѓСПвВЪЧЫЎеЧДЌИпЃЌУПЬьЖМвЊУцЖдИпВЂЗЂЕФЬєеНЁЃФУдЫЕЅЯЕЭГРДОйР§ЃЌШеГЃЮчИпЗхКЫаФВщбЏЗўЮёЕФ QPS дк 20 ЭђвдЩЯЃЌRedis МЏШКЕФ QPS ИќЪЧдкАйЭђМЖЃЌЪ§ОнПт QPS вВдк 10 ЭђМЖвдЩЯЃЌTPS дк 2 ЭђвдЩЯЁЃ
дкетУДДѓЕФСїСПЯТЃЌжївЊЕФЙЄзївВЪЧвдЮЇШЦШчКЮНЈЩшЯЕЭГЕФЮШЖЈадКЭЬсЩ§ШнСПеЙПЊЃЌЯТУцжївЊДгЛљДЁЩшЪЉЁЂЪ§ОнПтЁЂМмЙЙЁЂгІгУЁЂЙцЗЖетМИЗНУцЬИЬИШчКЮНЈЩшИпВЂЗЂЕФЯЕЭГЁЃвдЯТЖМЪЧЮвИіШЫетМИФъЕФвЛаЉОбщзмНсЃЌМмЙЙУЛгавјЕЏЃЌвђДЫвВГЦВЛЩЯЪЧзюМбЪЕМљЃЌНіЙЉВЮПМЁЃ
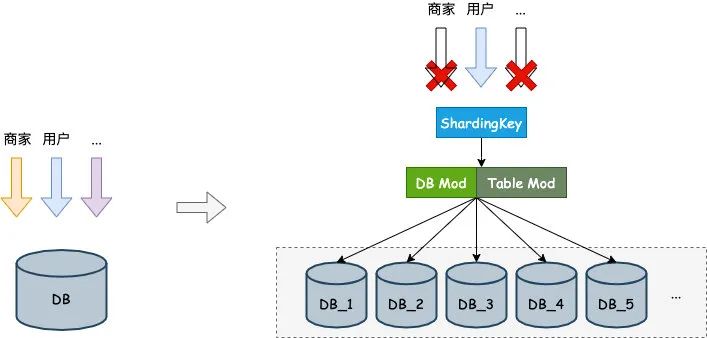
ЛљДЁЩшЪЉ
дкЗжВуМмЙЙжаЃЌзюЕзВуЕФОЭЪЧЛљДЁЩшЪЉЁЃЛљДЁЩшжУвЛАуРДЫЕАќКЌСЫЮяРэЗўЮёЦїЁЂIDCЁЂВПЪ№ЗНЪНЕШЕШЁЃОЭЯёвЛИіН№зжЫўЃЌЛљДЁЩшЪЉОЭЪЧН№зжЫўЕФЕззљЃЌжЛгаЕззљЮШЖЈСЫЃЌЩЯВуВХФмЮШЖЈЁЃ
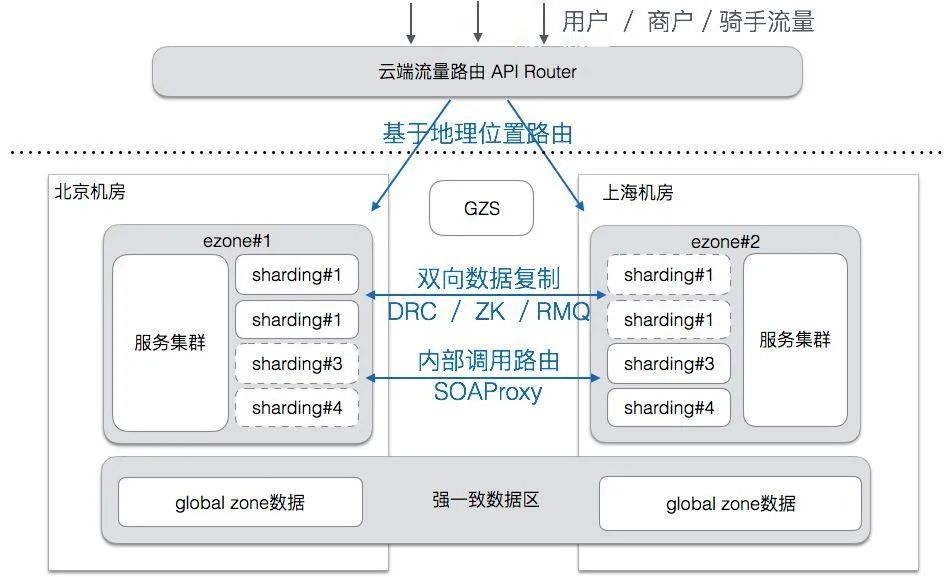
вьЕиЖрЛю
ЖрЛюПЩвдЗжЮЊЭЌГЧЖрЛюЁЂвьЕиЖрЛюЕШЕШЃЌЪЕЯжЗНЪНвВгаЖржжЃЌБШШчАЂРяЪЙгУЕФЕЅдЊЛЏЗНАИЃЌЖіСЫУДЪЙгУЕФЪЧЖржааФЕФЗНАИЃЌЙигкЖрЛюЕФЪЕЯжПЩвдВЮПМЃКЖіСЫУДЖрЛюЪЕЯжЗжЯэЁЃЕБЪБзіЖрЛюЕФжївЊГіЗЂЕуЪЧБЃжЄЯЕЭГЕФИпПЩгУадЃЌБмУтЕЅ IDC ЕФЕЅЕуЙЪеЯЮЪЬтЃЌЭЌЪБгЩгкУПИіЛњЗПЕФСїСПЖМБфГЩСЫзмСїСПЕФ 1/NЃЌвВБфЯрЬсЩ§СЫЯЕЭГШнСПЃЌдкИпВЂЗЂЕФГЁОАЯТПЩвдПЙИќЖрЕФСїСПЁЃЯТЭМЪЧЛюЕФећЬхМмЙЙЃЌРДдДгкЩЯУцЖрЛюЪЕЯжЕФЗжЯэЮФеТжаЁЃ
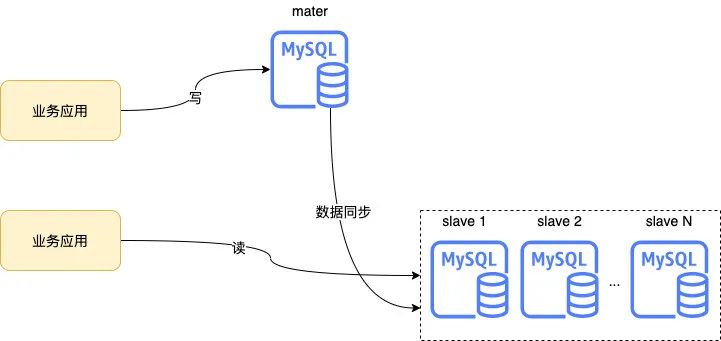
Ъ§ОнПт
Ъ§ОнПтЪЧећИіЯЕЭГзюживЊЕФзщГЩВПЗжжЎвЛЃЌдкИпВЂЗЂЕФГЁОАЯТКмДѓвЛВПЗжЙЄзїЪЧЮЇШЦЪ§ОнПтеЙПЊЕФЃЌжївЊашвЊНтОіЕФЮЪЬтЪЧШчКЮЬсЩ§Ъ§ОнПтШнСПЁЃ
ЖСаДЗжРы
ЛЅСЊЭјЕФДѓВПЗжвЕЮёЬиЕуЪЧЖСЖраДЩйЃЌвђДЫЪЙгУЖСаДЗжРыМмЙЙПЩвдгааЇНЕЕЭЪ§ОнПтЕФИКдиЃЌЬсЩ§ЯЕЭГШнСПКЭЮШЖЈадЁЃКЫаФЫМТЗЪЧгЩжїПтГаЕЃаДСїСПЃЌДгПтГаЕЃЖССїСПЃЌЧвдкЖСаДЗжРыМмЙЙжавЛАуЖМЪЧ 1 жїЖрДгЕФХфжУЃЌЭЈЙ§ЖрИіДгПтРДЗжЕЃИпВЂЗЂЕФВщбЏСїСПЁЃБШШчЯждкга 1 Эђ QPS ЕФвдМА 1K ЕФ TPSЃЌМйЩшдк 1 жї 5 ДгЕФХфжУЯТЃЌжїПтжЛГаЕЃ 1K ЕФ TPSЃЌУПИіДгПтГаЕЃ 2K ЕФ QPSЃЌетжжСПМЖЖд DB РДЫЕЪЧЭъШЋПЩНгЪмЕФЃЌЯрБШЖСаДЗжРыИФдьЧАЃЌDB ЕФбЙСІУїЯдаЁСЫаэЖрЁЃ
етжжФЃЪНЕФКУДІЪЧМђЕЅЃЌМИКѕУЛгаДњТыИФдьГЩБОЛђжЛгаЩйСПЕФДњТыИФдьГЩБОЃЌжЛашвЊХфжУЪ§ОнПтжїДгМДПЩЁЃШБЕувВЪЧЭЌбљУїЯдЕФЃК
жїДгбгГй
MySQL ФЌШЯЕФжїДгИДжЦЪЧвьВНЕФЃЌШчЙћдкжїПтВхШыЪ§ОнКѓТэЩЯШЅДгПтВщбЏЃЌПЩФмЛсЗЂЩњВщВЛЕНЕФЧщПіЁЃе§ГЃЧщПіЯТжїДгИДжЦЛсДцдкКСУыМЖЕФбгГйЃЌдк DB ИКдиНЯИпЕФЧщПіЯТПЩФмДцдкУыМЖбгГйЩѕжСИќОУЃЌЕЋМДЪЙЪЧКСУыМЖЕФбгГйЃЌЖдгкЪЕЪБадвЊЧѓНЯИпЕФвЕЮёРДЫЕвВЪЧВЛПЩКіЪгЕФЁЃЫљвддквЛаЉЙиМќЕФВщбЏГЁОАЃЌЮвУЧЛсНЋВщбЏЧыЧѓАѓЖЈЕНжїПтРДБмУтжїДгбгГйЕФЮЪЬтЁЃЙигкжїДгбгГйЕФгХЛЏЭјЩЯвВгаВЛЩйЕФЮФеТЗжЯэЃЌетРяОЭВЛдйзИЪіЁЃ
ДгПтЕФЪ§СПЪЧгаЯоЕФ
вЛИіжїПтФмЙвдиЕФДгПтЪ§СПЪЧКмгаЯоЕФЃЌУЛАьЗЈзіЕНЮоЯоЕФЫЎЦНРЉеЙЁЃДгПтдНЖрЃЌЫфШЛРэТлЩЯФмГаЪмЕФ QPS ОЭдНИпЃЌЕЋЪЧДгПтЙ§ЖрЛсЕМжТжїПтжїДгИДжЦ IO бЙСІИќДѓЃЌдьГЩИќИпЕФбгГйЃЌДгЖјгАЯьвЕЮёЃЌЫљвдвЛАуРДЫЕжЛЛсдкжїПтКѓЙвдигаЯоЕФМИИіДгПтЁЃ
ЮоЗЈНтОі TPS ИпЕФЮЪЬт
ДгПтЫфШЛФмНтОі QPS ИпЕФЮЪЬтЃЌЕЋУЛАьЗЈНтОі TPS ИпЕФЮЪЬтЃЌЫљгаЕФаДЧыЧѓжЛгажїПтФмДІРэЃЌвЛЕЉ TPS Й§ИпЃЌDB вРШЛгахДЛњЕФЗчЯеЁЃ
ЗжПтЗжБэ
ЕБЖСаДЗжРыВЛФмТњзувЕЮёашвЊЪБЃЌОЭашвЊПМТЧЪЙгУЗжПтЗжБэФЃЪНСЫЁЃЕБШЗЖЈвЊЖдЪ§ОнПтзігХЛЏЪБЃЌгІИУгХЯШПМТЧЪЙгУЖСаДЗжРыЕФФЃЪНЃЌжЛгадкЖСаДЗжРыЕФФЃЪНвбОУЛАьЗЈГаЪмвЕЮёЕФСїСПЪБЃЌЮвУЧВХПМТЧЗжПтЗжБэЕФФЃЪНЁЃЗжПтЗжБэФЃЪНЕФзюжеаЇЙћЪЧАбЕЅПтЕЅБэБфГЩЖрПтЖрБэЃЌШчЯТЭМЁЃ
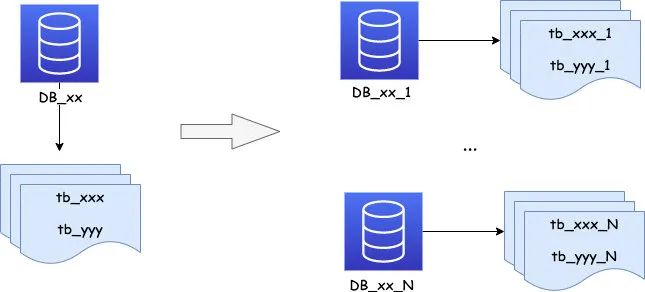
ЪзЯШРДЫЕЯТЗжБэЃЌЗжБэПЩвдЗжЮЊДЙжБВ№ЗжКЭЫЎЦНВ№ЗжЁЃДЙжБВ№ЗжОЭЪЧАДвЕЮёЮЌЖШВ№ЃЌМйЩшдРДгаеХЖЉЕЅБэга 100 ИізжЖЮЃЌПЩвдАДВЛЭЌЕФвЕЮёЮГЖШВ№ГЩЖреХБэЃЌБШШчгУЛЇаХЯЂвЛеХБэЃЌжЇИЖаХЯЂвЛеХБэЕШЕШЃЌетбљУПеХБэЕФзжЖЮЯрЖдРДЫЕЖМВЛЛсЬиБ№ЖрЁЃ
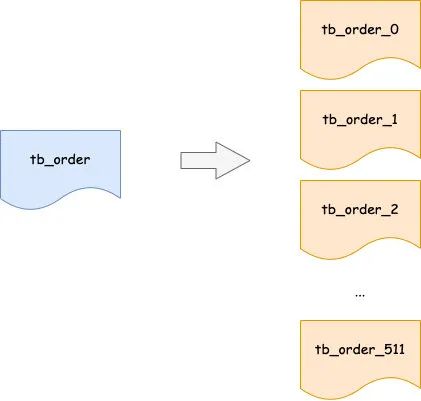
ЫЎЦНВ№ЗжЪЧАбвЛеХБэВ№ЗжГЩ N еХБэЃЌБШШчАб 1 еХЖЉЕЅБэЃЌВ№ГЩ 512 еХЖЉЕЅзгБэЁЃ
дкЪЕМљжаПЩвджЛзіЫЎЦНВ№ЗжЛђДЙжБВ№ЗжЃЌвВПЩвдЭЌЪБзіЫЎЦНМАДЙжБВ№ЗжЁЃ 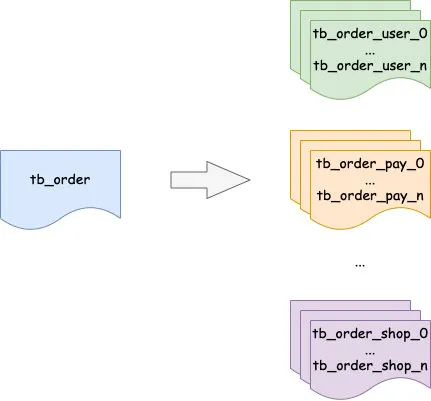
ЫЕЭъСЫЗжБэЃЌФЧЗжПтЪЧЪВУДФиЃПЗжПтОЭЪЧАбдРДЖМдквЛИі DB ЪЕР§жаЕФБэЃЌАДвЛЖЈЕФЙцдђВ№ЗжЕН N Иі DB ЪЕР§жаЃЌУПИі DB ЪЕР§ЖМЛсгавЛИі masterЃЌЯрЕБгкЪЧЖр mater ЕФМмЙЙЃЌЭЌЪБЮЊСЫБЃжЄИпПЩгУадЃЌУПИі master жСЩйвЊга 1 Иі slaveЃЌРДБЃжЄ master хДЛњЪБ slave ФмМАЪБЖЅЩЯЃЌЭЌЪБвВФмБЃжЄЪ§ОнВЛЖЊЪЇЁЃВ№ЗжЭъКѓУПИі DB ЪЕР§жажЛЛсгаВПЗжБэЁЃ
гЩгкЪЧЖр master ЕФМмЙЙЃЌЗжПтЗжБэГ§СЫАќКЌЖСаДЗжРыФЃЪНЕФЫљгагХЕуЭтЃЌЛЙПЩвдНтОіЖСаДЗжРыМмЙЙжаЮоЗЈНтОіЕФ TPS Й§ИпЕФЮЪЬтЃЌЭЌЪБЗжПтЗжБэРэТлЩЯЪЧПЩвдЮоЯоКсЯђРЉеЙЕФЃЌвВНтОіСЫЖСаДЗжРыМмЙЙЯТДгПтЪ§СПгаЯоЕФЮЪЬтЁЃЕБШЛдкЪЕМЪЕФЙЄГЬЪЕМљжавЛАуашвЊЬсЧАдЄЙРКУШнСПЃЌвђЮЊЪ§ОнПтЪЧгазДЬЌЕФЃЌШчЙћЗЂЯжШнСПВЛзудйРЉШнЪЧЗЧГЃТщЗГЕФЃЌгІИУОЁСПБмУтЁЃ
дкЗжПтЗжБэЕФФЃЪНЯТПЩвдЭЈЙ§ВЛЦєгУВщбЏДгПтЕФЗНЪНРДБмУтжїДгбгГйЕФЮЪЬтЃЌвВОЭЪЧЫЕЖСаДЖМдкжїПтЃЌвђЮЊдкЗжПтКѓЃЌУПИі master ЩЯЕФСїСПжЛеМзмСїСПЕФ 1/NЃЌДѓВПЗжЧщПіЯТФмПИзЁвЕЮёЕФСїСПЃЌДгПтжЛзїЮЊ master ЕФБИЗнЃЌдкжїПтхДЛњЪБжДаажїДгЧаЛЛЖЅЬц master ЬсЙЉЗўЮёЪЙгУЁЃЫЕЭъСЫКУДІЃЌдйРДЫЕЫЕЗжПтЗжБэЛсДјРДЕФЮЪЬтЃЌжївЊгавдЯТМИЕуЃК
ИФдьГЩБОИп
ЗжПтЗжБэвЛАуашвЊжаМфМўЕФжЇГжЃЌГЃМћЕФФЃЪНгаСНжжЃКПЭЛЇЖЫФЃЪНКЭДњРэФЃЪНЁЃПЭЛЇЖЫФЃЪНЛсЭЈЙ§дкЗўЮёЩЯв§гУ client АќЕФЗНЪНРДЪЕЯжЗжПтЗжБэЕФТпМЃЌБШНЯгаДњБэЕФЪЧПЊдДЕФ sharding JDBCЁЃДњРэФЃЪНЪЧжИЫљгаЕФЗўЮёВЛЪЧжБНгСЌНг MySQLЃЌЖјЪЧЭЈЙ§СЌНгДњРэЃЌДњРэдйСЌНгЕН MySQL ЕФЗНЪНЃЌДњРэашвЊЪЕЯж MySQL ЯрЙиЕФавщЁЃ
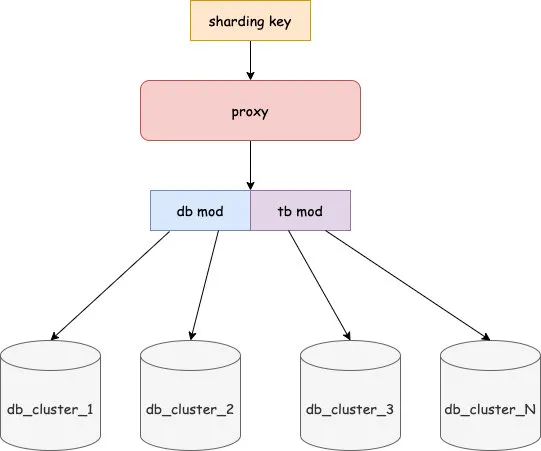
СНжжФЃЪНИїгагХСгЪЦЃЌДњРэФЃЪНЯрЖдРДЫЕЛсИќИДдгЃЌЕЋЪЧвђЮЊЖрСЫвЛВуДњРэЃЌдкДњРэетВуФмзіИќЖрЕФЪТЧщЃЌвВБШНЯЗНБуЩ§МЖЃЌЖјЧвЭЈЙ§ДњРэСЌНгЪ§ОнПтЃЌвВФмБЃжЄЪ§ОнПтЕФСЌНгЪ§ЮШЖЈЁЃЪЙгУПЭЛЇЖЫФЃЪНКУДІЪЧЯрЖдРДЫЕЪЕЯжБШНЯМђЕЅЃЌЮожаМфДњРэЃЌРэТлЩЯадФмвВЛсИќКУЃЌЕЋЪЧдкЩ§МЖЕФЪБКђашвЊвЕЮёЗНИФдьДњТыЃЌвђДЫЩ§МЖЛсБШДњРэФЃЪНИќРЇФбЁЃ
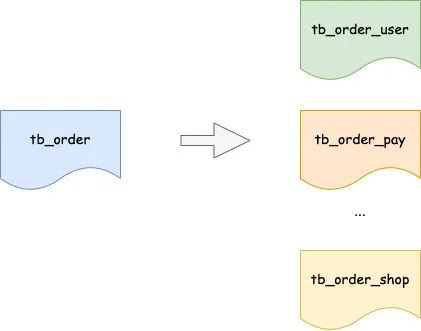
ЪТЮёЮЪЬт
дквЕЮёжаЮвУЧЛсЪЙгУЪТЮёРДДІРэЖрИіЪ§ОнПтВйзїЃЌЭЈЙ§ЪТЮёЕФ 4 ИіЬиадЁЊЁЊвЛжТадЁЂдзгадЁЂГжОУадЁЂИєРыадРДБЃжЄвЕЮёСїГЬЕФе§ШЗадЁЃдкЗжПтЗжБэКѓЃЌЛсНЋвЛеХБэВ№ЗжГЩ N еХзгБэЃЌет N еХзгБэПЩФмгждкВЛЭЌЕФ DB ЪЕР§жаЃЌвђДЫЫфШЛТпМЩЯПДЦ№РДЛЙЪЧвЛеХБэЃЌЕЋЦфЪЕвбОВЛдквЛИі DB ЪЕР§жаСЫЃЌетОЭдьГЩСЫЮоЗЈЪЙгУЪТЮёЕФЮЪЬтЁЃ
зюГЃМћЕФОЭЪЧдкХњСПВйзїжаЃЌдкЗжПтЗжБэЧАЮвУЧПЩвдЭЌЪБАбЖдЖрИіЖЉЕЅЕФВйзїЗХдквЛИіЪТЮёжаЃЌЕЋдкЗжПтЗжБэКѓОЭВЛФметУДИЩСЫЃЌвђЮЊВЛЭЌЕФЖЉЕЅПЩФмЪєгкВЛЭЌгУЛЇЃЌМйЩшЮвУЧАДгУЛЇРДЗжПтЗжБэЃЌФЧУДВЛЭЌгУЛЇЕФЖЉЕЅБэЮЛгкВЛЭЌЕФ DB ЪЕР§жаЃЌЖрИі DB ЪЕР§ЯдШЛУЛАьЗЈЪЙгУвЛИіЪТЮёРДДІРэЃЌетОЭашвЊНшжњвЛаЉЦфЫћЕФЪжЖЮРДНтОіетИіЮЪЬтЁЃдкЗжПтЗжБэКѓгІИУвЊОЁСПБмУтетжжПч DB ЪЕР§ЕФВйзїЃЌШчЙћвЛЖЈвЊетУДЪЙгУЃЌгХЯШПМТЧЪЙгУВЙГЅЕШЗНЪНБЃжЄЪ§ОнзюжевЛжТадЃЌШчЙћвЛЖЈвЊЧПвЛжТадЃЌГЃгУЕФЗНАИЪЧЭЈЙ§ЗжВМЪНЪТЮёЕФЗНЪНЁЃ
ЮоЗЈжЇГжЖрЮЌЖШВщбЏ
ЗжПтЗжБэвЛАужЛФмАД 1-2 ИіЮГЖШРДЗжЃЌетИіЮЌЖШОЭЪЧЫљЮНЕФsharding keyЁЃГЃгУЕФЮЌЖШгагУЛЇЁЂЩЬЛЇЕШЮЌЖШЃЌШчЙћАДгУЛЇЕФЮЌЖШРДЗжБэЃЌзюМђЕЅЕФЪЕЯжЗНЪНОЭЪЧАДгУЛЇ ID РДШЁФЃЖЈЮЛЕНдкФФИіЗжПтФФИіЗжБэЃЌетвВОЭвтЮЖзХжЎКѓЫљгаЕФЖСаДЧыЧѓЖМБиаыДјЩЯгУЛЇ IDЃЌЕЋдкЪЕМЪвЕЮёжаВЛПЩБмУтЕФЛсДцдкЖрИіЮЌЖШЕФВщбЏЃЌВЛвЛЖЈЫљгаЕФВщбЏЖМЛсгагУЛЇ IDЃЌетОЭашвЊЮвУЧЖдЯЕЭГНјааИФдьЁЃ
ЮЊСЫФмдкЗжПтЗжБэКѓвВжЇГжЖрЮЌЖШВщбЏЃЌГЃгУЕФНтОіЗНАИгаСНжжЃЌЕквЛжжЪЧв§ШывЛеХЫїв§БэЃЌетеХЫїв§БэЪЧУЛгаЗжПтЗжБэЕФЃЌЛЙЪЧвдАДгУЛЇ ID ЗжПтЗжБэЮЊР§ЃЌЫїв§БэЩЯМЧТМИїжжЮЌЖШгыгУЛЇ ID жЎМфЕФгГЩфЙиЯЕЃЌЧыЧѓашвЊЯШЭЈЙ§ЦфЫћЮЌЖШВщбЏЫїв§БэЕУЕНгУЛЇ IDЃЌдйЭЈЙ§гУЛЇ ID ВщбЏЗжПтЗжБэКѓЕФБэЁЃетбљЃЌвЛРДашвЊЖрвЛДЮ IOЃЌЖўРДЫїв§БэгЩгкЪЧУЛгаЗжПтЗжБэЕФЃЌКмШнвзГЩЮЊЯЕЭГЦПОБЁЃ
ЕкЖўжжЗНАИЪЧЭЈЙ§в§ШыNoSQLЕФЗНЪНЃЌБШНЯГЃМћЕФзщКЯЪЧES+MySQLЃЌЛђепHBase+MySQLЕФзщКЯЕШЃЌетжжЗНАИБОжЪЩЯЛЙЪЧЭЈЙ§ NoSQL РДГфЕБЕквЛжжЗНАИжаЕФЫїв§БэЕФНЧЩЋЃЌЕЋЪЧЯрЖдгкжБНгЪЙгУЫїв§БэРДЫЕЃЌNoSQLОпгаИќКУЕФЫЎЦНРЉеЙадКЭЩьЫѕадЃЌжЛвЊЩшМЦЕУЕБЃЌвЛАуВЛШнвзГЩЮЊЯЕЭГЕФЦПОБЁЃ
Ъ§ОнЧЈвЦ
ЗжПтЗжБэвЛАуЪЧашвЊНјааЪ§ОнЧЈвЦЕФЃЌЭЈЙ§Ъ§ОнЧЈвЦНЋдгаЕФЕЅБэЪ§ОнЧЈвЦЕНЗжПтЗжБэКѓЕФПтБэжаЁЃЪ§ОнЧЈвЦЕФЗНАИГЃМћЕФгаСНжжЃЌЕквЛжжЪЧЭЃЛњЧЈвЦЃЌЙЫУћЫМвхЃЌетжжЗНЪНМђЕЅДжБЉЃЌКУДІЪЧФмвЛВНЕНЮЛЃЌЧЈвЦжмЦкЖЬЃЌЧвФмБЃжЄЪ§ОнвЛжТадЃЌЛЕДІЪЧЖдвЕЮёгаЫ№ЃЌФГаЉЙиМќвЕЮёПЩФмЮоЗЈНгЪмМИЗжжгЛђИќОУЕФЭЃЛњЧЈвЦДјРДЕФвЕЮёЫ№ЪЇЁЃ
СэЭтвЛжжЗНАИЪЧЫЋаДЃЌетжївЊЪЧеыЖдаТдіЕФдіСПЪ§ОнЃЌДцСПЪ§ОнПЩвджБНгНјааЪ§ОнЭЌВНЃЌЙигкШчКЮНјааЫЋаДЧЈвЦЭјЩЯвбОгаКмЖрЗжЯэСЫЃЌетРявВОЭВЛзИЪіЃЌКЫаФЫМЯыЪЧЭЌЪБаДРЯПтКЭаТПтЁЃЫЋаДЕФКУДІЪЧЖдвЕЮёЕФгАЯьаЁЃЌЕЋвВИќИДдгЃЌЧЈвЦжмЦкИќГЄЃЌШнвзГіЯжЪ§ОнВЛвЛжТЮЪЬтЃЌашвЊгаЭъећЕФЪ§ОнвЛжТадБЃжЄЗНАИжЇГжЁЃ
аЁНс
ЖСаДЗжРыФЃЪНКЭЗжПтЗжБэФЃЪНЭЦМігХЯШЪЙгУЖСаДЗжРыФЃЪНЃЌжЛгадкВЛТњвЕЮёашЧѓЕФЧщПіВХВХПМТЧЪЙгУЗжПтЗжБэФЃЪНЁЃдвђЪЧЗжПтЗжБэФЃЪНЫфШЛФмЯджјЬсЩ§Ъ§ОнПтЕФШнСПЃЌЕЋЛсдіМгЯЕЭГИДдгадЃЌЖјЧвгЩгкжЛФмжЇГжЩйЪ§ЕФМИИіЮЌЖШЖСаДЃЌДгФГжжвтвхЩЯРДЫЕЖдвЕЮёЯЕЭГвВЪЧвЛжжЯожЦЃЌвђДЫдкЩшМЦЗжПтЗжБэЗНАИЕФЪБКђашвЊНсКЯОпЬхвЕЮёГЁОАЃЌИќШЋУцЕФПМТЧЁЃ
МмЙЙ
дкИпВЂЗЂЯЕЭГНЈЩшжаЃЌМмЙЙЭЌбљвВЪЧЗЧГЃживЊЕФЃЌетРяЗжЯэЛКДцЁЂЯћЯЂЖгСаЁЂзЪдДИєРыЕШЕШФЃЪНЕФвЛаЉОбщЁЃ
ЛКДц
дкИпВЂЗЂЕФЯЕЭГМмЙЙжаЛКДцЪЧзюгааЇЕФРћЦїЃЌПЩвдЫЕУЛгажЎвЛЁЃЛКДцЕФзюДѓзїгУЪЧПЩвдЬсЩ§ЯЕЭГадФмЃЌБЃЛЄКѓЖЫДцДЂВЛБЛДѓСїСПДђПхЃЌдіМгЯЕЭГЕФЩьЫѕадЁЃЛКДцЕФИХФюзюдчРДдДгк CPU жаЃЌЮЊСЫЬсИп CPU ЕФДІРэЫйЖШЃЌв§ШыСЫ L1ЁЂL2ЁЂL3 Ш§МЖИпЫйЛКДцРДМгЫйЗУЮЪЃЌЯждкЯЕЭГжаЪЙгУЕФЛКДцвВЪЧНшМјСЫ CPU жаЛКДцЕФзіЗЈЁЃ
ЛКДцЪЧИіЗЧГЃДѓЕФЛАЬтЃЌПЩвдЕЅЖРаДвЛБОЪщвВКСВЛПфеХЃЌдкетРязмНсвЛЯТЮвИіШЫдкдЫЕЅЯЕЭГЩшМЦКЭЪЕЯжЛКДцЕФЪБКђгіЕНЕФвЛаЉЮЪЬтКЭНтОіЗНАИЁЃЛКДцжївЊЗжЮЊБОЕиЛКДцКЭЗжВМЪНЛКДцЃЌБОЕиЛКДцШчGuava CacheЁЂEHCacheЕШЃЌЗжВМЪНЛКДцШчRedisЁЂMemcachedЕШЃЌдкдЫЕЅЯЕЭГжаЪЙгУЕФжївЊвдЗжВМЪНЛКДцЮЊжїЁЃ
ШчКЮБЃжЄЛКДцгыЪ§ОнПтЕФЪ§ОнвЛжТад
ЪзЯШЪЧШчКЮБЃжЄЛКДцгыЪ§ОнПтЕФЪ§ОнвЛжТадЮЪЬтЃЌЛљБОдкЪЙгУЛКДцЕФЪБКђЖМЛсгіЕНетИіЮЪЬтЃЌЭЌЪБетвВЪЧИіИпЦЕЕФУцЪдЬтЁЃдкЮвИКд№ЕФдЫЕЅЯЕЭГжаЪЙгУЛКДцетИіЮЪЬтОЭИќЭЛГіСЫЃЌЪзЯШдЫЕЅЪЧЛсЦЕЗБИќаТЕФЃЌВЂЧвдЫЕЅЯЕЭГЖдЪ§ОнвЛжТадЕФвЊЧѓЪЧЗЧГЃИпЕФЃЌЛљБОВЛЬЋФмНгЪмЪ§ОнВЛвЛжТЃЌЫљвдВЛФмМђЕЅЕФЭЈЙ§ЩшжУвЛИіЙ§ЦкЪБМфЕФЗНЪНРДЪЇаЇЛКДцЁЃ
ЙигкЛКДцЖСаДЕФФЃЪНЭЦМідФЖСКФзгЪхЕФЮФеТЃКЛКДцИќаТЕФЬзТЗЃЌРяУцзмНсСЫМИжжГЃгУЕФЖСаДЛКДцЕФЬзТЗЃЌЮвдкдЫЕЅЯЕЭГжаЕФЛКДцЖСаДФЃЪНвВЪЧВЮПМСЫЮФеТжаЕФWrite throughФЃЪНЃЌЭЈЙ§ЮБДњТыЕФЗНЪНДѓИХЪЧетбљЕФЃК
lock(дЫЕЅID) {
//...
// ЩОГ§ЛКДц
deleteCache();
// ИќаТDB
updateDB();
// жиНЈЛКДц
reloadCache()
}
МШШЛЪЧWrite throughФЃЪНЃЌФЧЖдЛКДцЕФИќаТОЭЪЧдкаДЧыЧѓжаНјааЕФЁЃЪзЯШЮЊСЫЗРжЙВЂЗЂЮЪЬтЃЌаДЧыЧѓЖМашвЊМгЗжВМЪНЫјЃЌЫјЕФСЃЖШЪЧвддЫЕЅ ID ЮЊ keyЃЌдкжДааЭъвЕЮёТпМКѓЃЌЯШЩОГ§ЛКДцЃЌдйИќаТ DBЃЌзюКѓдйжиНЈЛКДцЃЌетаЉВйзїЖМЪЧЭЌВННјааЕФЃЌдкЖСЧыЧѓжаЯШВщбЏЛКДцЃЌШчЙћЛКДцУќжадђжБНгЗЕЛиЃЌШчЙћЛКДцВЛУќжадђВщбЏ DBЃЌШЛКѓжБНгЗЕЛиЃЌвВОЭЪЧЫЕдкЖСЧыЧѓжаВЛЛсВйзїЛКДцЃЌетжжЗНЪНАбЛКДцВйзїЖМЪеСВдкаДЧыЧѓжаЃЌЧваДЧыЧѓЪЧМгЫјЕФЃЌгааЇЗРжЙСЫЖСаДВЂЗЂЕМжТЕФаДШыдрЛКДцЪ§ОнЕФЮЪЬтЁЃ
ЛКДцЪ§ОнНсЙЙЕФЩшМЦ
ЛКДцвЊБмУтДѓ key КЭШШ key ЕФЮЪЬтЁЃОйИіР§згЃЌШчЙћЪЙгУredisжаЕФhashЪ§ОнНсЙЙЃЌФЧОЭБШЦеЭЈзжЗћДЎРраЭЕФ key ИќШнвзгаДѓ key КЭШШ key ЮЪЬтЃЌЫљвдШчЙћВЛЪЧЗЧвЊЪЙгУhashЕФФГаЉЬиЖЈВйзїЃЌПЩвдПМТЧАбhashВ№ЩЂГЩвЛИівЛИіЕЅЖРЕФ key/value ЖдЃЌЪЙгУЦеЭЈЕФstringРраЭЕФ key ДцДЂЃЌетбљПЩвдЗРжЙhashдЊЫиЙ§ЖрдьГЩЕФДѓ key ЮЪЬтЃЌЭЌЪБвВПЩвдБмУтЕЅhash keyЙ§ШШЕФЮЪЬтЁЃ
ЖСаДадФм
ЙигкЖСаДадФмжївЊгаСНЕуашвЊПМТЧЃЌЪзЯШЪЧаДадФмЃЌгАЯьаДадФмЕФжївЊвђЫиЪЧ key/value ЕФЪ§ОнДѓаЁЃЌБШНЯМђЕЅЕФГЁОАПЩвдЪЙгУJSONЕФађСаЛЏЗНЪНДцДЂЃЌЕЋЪЧдкИпВЂЗЂГЁОАЯТЪЙгУ JSON ВЛФмКмКУЕФТњзуадФмвЊЧѓЃЌЖјЧввВБШНЯеМДцДЂПеМфЃЌБШНЯГЃМћЕФЬцДњЗНАИгаprotobufЁЂthriftЕШЕШЃЌЙигкетаЉађСаЛЏ/ЗДађСаЛЏЗНАИЭјЩЯвВгавЛаЉадФмЖдБШЃЌВЮПМthrift-protobuf-compare - Benchmarking.wikiЁЃ
ЖСадФмЕФжївЊгАЯьвђЫиЪЧУПДЮЖСШЁЕФЪ§ОнАќЕФДѓаЁЁЃдкЪЕМљжаЭЦМіЪЙгУredis pipeline+ХњСПВйзїЕФЗНЪНЃЌБШШчЫЕШчЙћЪЧзжЗћДЎРраЭЕФ keyЃЌФЧОЭЪЧpipeline+mgetЕФЗНЪНЃЌМйЩшвЛДЮmget10 Иі keyЃЌ100 ИіmgetЮЊвЛХњ pipelineЃЌФЧвЛДЮЭјТч IO ОЭПЩвдВщбЏ 1000 ИіЛКДц keyЃЌЕБШЛетРяОпЬхвЛХњЕФЪ§СПвЊПДЛКДц key ЕФЪ§ОнАќДѓаЁЃЌУЛгаЭГвЛЕФжЕЁЃ
ЪЪЕБШпгр
ЪЪЕБШпгрЕФвтЫМЪЧЫЕЮвУЧдкЩшМЦЖдЭтЕФвЕЮёВщбЏНгПкЕФЪБКђЃЌПЩвдЪЪЕБЕФзівЛаЉШпгрЁЃетИіОбщЪЧРДздгкЕБЪБЮвУЧдкЩшМЦдЫЕЅЯЕЭГЖдЭтВщбЏНгПкЕФЪБКђЃЌЮЊСЫзЗЧѓЭЈгУадЃЌНЋНгПкЕФЗЕЛижЕЩшМЦГЩвЛИіДѓЖдЯѓЃЌАбдЫЕЅЩЯЕФЫљгазжЖЮЖМЗХдкСЫетИіДѓЖдЯѓРяУцжБНгЖдЭтБЉТЖСЫЃЌетбљЕФКУДІЪЧВЛашвЊеыЖдВЛЭЌЕФВщбЏЗНПЊЗЂВЛЭЌЕФНгПкСЫЃЌЗДе§зжЖЮОЭдкНгПкРяСЫЃЌвЊЪВУДОЭздМКШЁЁЃ
етУДзівЛПЊЪМЪЧУЛЮЪЬтЕФЃЌЕЋЕНЮвУЧашвЊЖдВщбЏНгПкдіМгЛКДцЕФЪБКђЗЂЯжЃЌгЩгкЫљгавЕЮёЗНЖМЭЈЙ§етвЛИіНгПкВщбЏдЫЕЅЪ§ОнЃЌЮвУЧУЛАьЗЈжЊЕРЫћУЧЕФвЕЮёГЁОАЃЌвВОЭВЛжЊЕРЫћУЧЖдНгПкЪ§ОнвЛжТадЕФвЊЧѓЪЧдѕУДбљЕФЃЌБШШчФмЗёНгЪмЖЬднЕФЪ§ОнвЛжТадЃЌЖјЧвЮвУЧвВВЛжЊЕРЫћУЧОпЬхЪЙгУСЫНгПкжаЕФФФаЉзжЖЮЃЌНгПкжагааЉзжЖЮЪЧВЛЛсБфЕФЃЌгааЉзжЖЮЪЧЛсЦЕЗББфИќЕФЃЌеыЖдВЛЭЌЕФИќаТЦЕТЪЦфЪЕПЩвдВЩгУВЛЭЌЕФЛКДцЩшМЦЗНАИЃЌЕЋКмПЩЯЇЃЌвђЮЊЮвУЧЩшМЦНгПкЕФЪБКђЙ§гкзЗЧѓЭЈгУадЃЌдкзіЛКДцгХЛЏЕФЪБКђОЭЗЧГЃТщЗГЃЌжЛФмАДзюЛЕЕФЧщПіДђЫуЃЌвВОЭЪЧЫљгавЕЮёЗНЖМЖдЪ§ОнвЛжТадвЊЧѓКмИпРДЩшМЦЗНАИЃЌЕМжТзюКѓЕФЗНАИдкЪ§ОнвЛжТадетПщЛЈСЫДѓСПЕФОЋСІЁЃ
ШчЙћЮвУЧвЛПЊЪМЩшМЦЖдЭтВщбЏНгПкЕФЪБКђФмзівЛаЉЪЪЕБЕФШпгрЃЌЧјЗжВЛЭЌЕФвЕЮёГЁОАЃЌЫфШЛетбљЪЦБиЛсдьГЩгааЉНгПкЕФЙІФмЪЧРрЫЦЕФЃЌЕЋдкМгЛКДцЕФЪБКђОЭФмгаЕФЗХЪИЃЌеыЖдВЛЭЌЕФвЕЮёГЁОАЩшМЦВЛЭЌЕФЗНАИЃЌБШШчЙиМќЕФСїГЬвЊзЂжиЪ§ОнвЛжжЕФБЃжЄЃЌЖјЗЧЙиМќГЁОАдђдЪаэЪ§ОнЖЬднЕФВЛвЛжТРДНЕЕЭЛКДцЪЕЯжЕФГЩБОЁЃЭЌЪБдкНгПкжазюКУвВФмНЋЛсИќаТЕФзжЖЮКЭВЛЛсИќаТЕФзжЖЮзівЛЖЈЕФЧјЗжЃЌетбљдкЩшМЦЛКДцЗНАИЕФЪБКђЃЌеыЖдВЛЛсИќаТЕФзжЖЮЃЌПЩвдЩшжУвЛИіНЯГЄЕФЙ§ЦкЪБМфЃЌЖјЛсИќаТЕФзжЖЮЃЌдђжЛФмЩшжУНЯЖЬЕФЙ§ЦкЪБМфЃЌВЂЧвашвЊзіКУЛКДцИќаТЕФЗНАИЩшМЦРДБЃжЄЪ§ОнвЛжТадЁЃ
ЯћЯЂЖгСа
дкИпВЂЗЂЯЕЭГЕФМмЙЙжаЃЌЯћЯЂЖгСаЃЈMQЃЉЪЧБиВЛПЩЩйЕФЃЌЕБДѓСїСПРДСйЪБЃЌЮвУЧЭЈЙ§ЯћЯЂЖгСаЕФвьВНДІРэКЭЯїЗхЬюЙШЕФЬиадРДдіМгЯЕЭГЕФЩьЫѕадЃЌЗРжЙДѓСїСПДђПхЯЕЭГЃЌДЫЭтЃЌЪЙгУЯћЯЂЖгСаЛЙФмЪЙЯЕЭГМфДяЕНГфЗжНтёюЕФФПЕФЁЃ 
ЯћЯЂЖгСаЕФКЫаФФЃаЭгЩЩњВњепЃЈProducerЃЉЁЂЯћЗбепЃЈConsumerЃЉКЭЯћЯЂжаМфМўЃЈBrokerЃЉзщГЩЁЃФПЧАвЕНчГЃгУЕФПЊдДНтОіЗНАИгаActiveMQЁЂRabbitMQЁЂKafkaЁЂRocketMQКЭНќФъБШНЯЛ№ЕФPulsarЃЌЙигкИїжжЯћЯЂжаМфМўЕФЖдБШПЩвдВЮПМЮФеТЃКЯћЯЂЖгСаБГКѓЕФЩшМЦЫМЯыЁЃ
ЪЙгУЯћЯЂЖгСаКѓЃЌПЩвдНЋдБОЭЌВНДІРэЕФЧыЧѓЃЌИФЮЊЭЈЙ§ЯћЗб MQ ЯћЯЂвьВНЯћЗбЃЌетбљПЩвдМѕЩйЯЕЭГДІРэЕФбЙСІЃЌдіМгЯЕЭГЭЬЭТСПЃЌЙигкШчКЮЪЙгУЯћЯЂЖгСагааэЖрЕФЗжЯэЕФЮФеТЃЌетРяЮвЕФОбщЪЧдкПМТЧЪЙгУЯћЯЂЖгСаЪБвЊНсКЯОпЬхЕФвЕЮёГЁОАРДОіЖЈЪЧЗёв§ШыЯћЯЂЖгСаЃЌвђЮЊЪЙгУЯћЯЂЖгСаКѓЦфЪЕЪЧдіМгСЫЯЕЭГЕФИДдгадЕФЃЌдРДЭЈЙ§вЛИіЭЌВНЧыЧѓОЭФмИуЖЈЕФЪТЧщЃЌашвЊв§ШыЖюЭтЕФвРРЕЃЌВЂЧвЯћЗбЯћЯЂЪЧвьВНЕФЃЌвьВНЬьЩњвЊБШЭЌВНИќИДдгЃЌЛЙашвЊЖюЭтПМТЧЯћЯЂТвађЁЂбгГйЁЂЖЊЪЇЕШЮЪЬтЃЌШчКЮНтОіетаЉЮЪЬтгжЪЧвЛИіКмДѓЛАЬтЃЌЬьЯТУЛгаУтЗбЕФЮчВЭЃЌзіШЮКЮМмЙЙЩшМЦЪЧвЛИіШЁЩсЕФЙ§ГЬЃЌашвЊзаЯИПМТЧЕУЪЇКѓдйзіОіЖЈЁЃ
ЗўЮёжЮРэ
ЗўЮёжЮРэЪЧИіКмДѓЕФЛАЬтЃЌПЩвдЕЅЖРФУГіРДЫЕЃЌдкетРяЮввВАбЫќЙщЕНМмЙЙжаЁЃЗўЮёжЮРэЕФЖЈвхЪЧ
вЛАужИЖРСЂгквЕЮёТпМжЎЭтЃЌИјЯЕЭГЬсЙЉвЛаЉПЩППдЫааЕФЯЕЭГБЃеЯДыЪЉЁЃ
ГЃМћЕФБЃеЯДыЪЉАќРЈЗўЮёЕФзЂВсЗЂЯжЁЂПЩЙлВтадЃЈМрПиЃЉЁЂЯоСїЁЂГЌЪБЁЂШлЖЯЕШЕШЃЌдкЮЂЗўЮёМмЙЙжавЛАуЭЈЙ§ЗўЮёжЮРэПђМмРДЭъГЩЗўЮёжЮРэЃЌПЊдДЕФНтОіЗНАИАќРЈSpring CloudЁЂDubboЕШЁЃ
дкИпВЂЗЂЕФЯЕЭГжаЃЌЗўЮёжЮРэЪЧЗЧГЃживЊЕФвЛПщФкШнЃЌЯрБШгкЛКДцЁЂЪ§ОнПтетаЉДѓПщЕФФкШнЃЌЗўЮёжЮРэИќЖрЕФЪЧЯИНкЃЌБШШчЖдНгПкЕФГЌЪБЩшжУЕНЕзЪЧ 1 УыЛЙЪЧ 3 УыЃЌдѕУДбљзіМрПиЕШЕШЃЌгаОфЛАНаЯИНкОіЖЈГЩАмЃЌгаЪБКђОЭЪЧвђЮЊвЛИіНгПкЕФГЌЪБЩшжУВЛКЯРэЖјЕМжТДѓУцЛ§ЙЪеЯЕФЪТЧщЃЌЮвдјОвВЪЧМћЪЖЙ§ЕФЃЌЬиБ№ЪЧдкИпВЂЗЂЕФЯЕЭГжаЃЌвЛЖЈвЊзЂвтетаЉЯИНкЁЃ 
ГЌЪБ
ЖдгкГЌЪБЕФддђЪЧЃКвЛЧаНдгаГЌЪБЁЃВЛЙмЪЧ RPC ЕїгУЁЂRedis ВйзїЁЂЯћЗбЯћЯЂ/ЗЂЫЭЯћЯЂЁЂDB ВйзїЕШЕШЃЌЖМвЊгаГЌЪБЁЃжЎЧАОЭгіЕНЙ§вРРЕСЫЭтВПзщМўЃЌЕЋЪЧУЛгаЩшжУКЯРэЕФГЌЪБЃЌЕБЭтВПвРРЕГіЯжЙЪеЯЪБЃЌАбЗўЮёЫљгаЕФЯпГЬШЋВПзшШћЕМжТзЪдДКФОЁЃЌЮоЗЈЯьгІЭтВПЧыЧѓЃЌДгЖјв§ЗЂЙЪеЯЃЌетаЉЖМЪЧЁАбЊЁБЕФНЬбЕЁЃ
Г§СЫвЊЩшжУГЌЪБЃЌЛЙвЊЩшжУКЯРэЕФГЌЪБвВЭЌбљживЊЃЌЯёЩЯУцЬсЕНЕФЙЪеЯМДЪЙЩшжУСЫГЌЪБЃЌЕЋЪЧГЌЪБЬЋОУЕФЛАвРШЛЛсвђЮЊЭтВПвРРЕЙЪеЯЖјАбЗўЮёЭЯПхЁЃШчКЮЩшжУвЛИіКЯРэЕФГЌЪБЪЧКмгаНВОПЕФЃЌПЩвдДгЪЧЗёЙиМќвЕЮёГЁОАЁЂЪЧЗёЧПвРРЕЕШЗНУцШЅПМТЧЃЌУЛгаЪВУДЭЈгУЕФЙцдђЃЌашвЊНсКЯОпЬхЕФвЕЮёГЁОАРДПДЁЃБШШчдквЛаЉ C ЖЫеЙЪОНгПкжаЃЌЩшжУ 1 УыЕФГЌЪБЫЦКѕУЛЪВУДЮЪЬтЃЌЕЋдквЛаЉЖдадФмЗЧГЃУєИаЕФГЁОАЯТ 1 УыПЩФмОЭЬЋОУСЫЃЌзмжЎЃЌашвЊНсКЯОпЬхЕФвЕЮёГЁОАШЅЩшжУЃЌЕЋЮоТлдѕУДбљЃЌддђЛЙЪЧФЧОфЛАЃКвЛЧаНдгаГЌЪБЁЃ
МрПи
МрПиОЭЪЧЯЕЭГЕФблОІЃЌУЛгаМрПиЕФЯЕЭГОЭЯёвЛИіКкКаЃЌДгЭтВПЭъШЋВЛжЊЕРРяУцЕФдЫааЧщПіЃЌЮвУЧОЭЮоЗЈЙмРэКЭдЫЮЌетИіЯЕЭГЁЃЫљвдЃЌМрПиЯЕЭГЪЧЗЧГЃживЊЕФЁЃЯЕЭГЕФПЩЙлВтаджївЊАќКЌШ§ИіВПЗжЁЊЁЊloggingЁЂtracingЁЂmetricsЁЃжївЊЪЧЪЙгУЕФздбаЕФМрПиЯЕЭГЃЌВЛЕУВЛЫЕецЕФЪЧЗЧГЃЕФКУгУЃЌОпЬхЕФНщЩмПЩвдВЮПМЃКЖіСЫУД EMonitor бнНјЪЗ
ШлЖЯ
дкЮЂЗўЮёПђМмжавЛАуЖМЛсФкжУШлЖЯЕФЬиадЃЌШлЖЯЕФФПЕФЪЧЮЊСЫдкЯТгЮЗўЮёГіЙЪеЯЪББЃЛЄздЩэЗўЮёЁЃШлЖЯЕФЪЕЯжвЛАуЛсгавЛИіЖЯТЗЦїЃЈCrit BreakerЃЉЃЌЖЯТЗЦїЛсИљОнНгПкГЩЙІТЪ/ДЮЪ§ЕШЙцдђРДХаЖЯЪЧЗёДЅЗЂШлЖЯЃЌЖЯТЗЦїЛсПижЦШлЖЯЕФзДЬЌдкЙиБе-ДђПЊ-АыДђПЊжаСїзЊЁЃШлЖЯЕФЛжИДЛсЭЈЙ§ЪБМфДАПкЕФЛњжЦЃЌЯШОРњАыДђПЊзДЬЌЃЌШчЙћГЩЙІТЪДяЕНуажЕдђЙиБеШлЖЯзДЬЌЁЃ
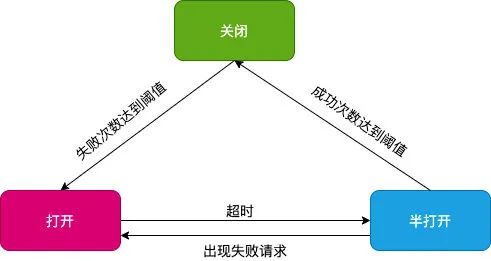
ШчЙћУЛгаЪВУДЬиЪташЧѓЕФЛАдквЕЮёЯЕЭГжавЛАуЪЧВЛашвЊеыЖдШлЖЯзіЪВУДЕФЃЌПђМмЛсздЖЏДђПЊКЭЙиБеШлЖЯПЊЙиЁЃПЩФмашвЊзЂвтЕФЕуЪЧвЊБмУтЮоаЇЕФШлЖЯЃЌЪВУДЪЧЮоаЇЕФШлЖЯФиЃПдквдЧАХіЕНЙ§вЛИіЙЪеЯЃЌЪЧЗўЮёЕФЬсЙЉЗНдквЛаЉе§ГЃЕФвЕЮёаЃбщжаХзГіСЫВЛКЯРэЕФвьГЃЃЈБШШчЯЕЭГвьГЃЃЉЃЌЕМжТНгПкШлЖЯгАЯье§ГЃвЕЮёЁЃЫљвдЮвУЧдкНгПкжаХзГівьГЃЛђепЗЕЛивьГЃТыЕФЪБКђвЛЖЈвЊЧјЗжвЕЮёКЭЯЕЭГвьГЃЃЌвЛАуРДЫЕвЕЮёвьГЃЪЧВЛашвЊШлЖЯЕФЃЌШчЙћЪЧвЕЮёвьГЃЖјХзГіСЫЯЕЭГвьГЃЃЌЛсЕМжТБЛШлЖЯЃЌе§ГЃЕФвЕЮёСїГЬОЭЛсЪмЕНгАЯьЁЃ
НЕМЖ
НЕМЖВЛЪЧвЛжжОпЬхЕФММЪѕЃЌИќЯёЪЧвЛжжМмЙЙЩшМЦЕФЗНЗЈТлЃЌЪЧвЛжжЖЊзфБЃЫЇЕФВпТдЃЌКЫаФЫМЯыОЭЪЧдквьГЃЕФЧщПіЯТЯожЦздЩэЕФвЛаЉФмСІЃЌРДБЃжЄКЫаФЙІФмЕФПЩгУадЁЃНЕМЖЕФЪЕЯжЗНЪНгааэЖрЃЌБШШчЭЈЙ§ХфжУЁЂПЊЙиЁЂЯоСїЕШЕШЗНЪНЁЃНЕМЖЗжЮЊжїЖЏНЕМЖКЭБЛЖЏНЕМЖЁЃ
дкЕчЩЬЯЕЭГДѓДйЕФЪБКђЛсАбвЛаЉЗЧКЫаФЕФЙІФмднЪБЙиБеЃЌРДБЃжЄКЫаФЙІФмЕФЮШЖЈадЃЌЛђепЕБЯТгЮЗўЮёГіЯжЙЪеЯЧвЖЬЪБМфФкЮоЗЈЛжИДЪБЃЌЮЊСЫБЃжЄздЩэЗўЮёЕФЮШЖЈадЖјАбЯТгЮЗўЮёНЕМЖЃЌетаЉЖМЪЧжїЖЏНЕМЖЁЃ
БЛЖЏНЕМЖжИЕФЪЧЃЌБШШчЕїгУСЫЯТгЮвЛИіНгПкЃЌЕЋЪЧНгПкГЌЪБСЫЃЌетИіЪБКђЮЊСЫШУвЕЮёСїГЬФмМЬајжДааЯТШЅЃЌвЛАуЛсбЁдёдкДњТыжаcatchвьГЃЃЌДђгЁвЛЬѕДэЮѓШежОЃЌШЛКѓМЬајжДаавЕЮёТпМЃЌетжжНЕМЖЪЧБЛЖЏЕФЁЃ
дкИпВЂЗЂЕФЯЕЭГжазіКУНЕМЖЪЧЗЧГЃживЊЕФЁЃОйИіР§згРДЫЕЃЌЕБЧыЧѓСПКмДѓЕФЪБКђФбУтгаГЌЪБЃЌШчЙћУПДЮГЌЪБвЕЮёСїГЬЖМжаЖЯСЫЃЌФЧУДЛсДѓДѓгАЯье§ГЃвЕЮёЃЌКЯРэЕФзіЗЈЪЧЮвУЧгІИУзаЯИЧјЗжЧПШѕвРРЕЃЌЖдгкШѕвРРЕВЩгУБЛЖЏНЕМЖЕФНЕМЖЗНЪНЃЌЖјЖдгкЧПвРРЕЪЧВЛФмНјааНЕМЖЕФЁЃНЕМЖгыШлЖЯРрЫЦЃЌвВЪЧЖдздЩэЗўЮёЕФБЃЛЄЃЌБмУтЕБЭтВПвРРЕЙЪеЯЪБЭЯПхздЩэЗўЮёЃЌЫљвдЃЌЮвУЧвЊзіКУГфЗжЕФНЕМЖдЄАИЁЃ
ЯоСї
ЙигкЯоСїЕФЮФеТКЭНщЩмЭјЩЯвВгааэЖрЃЌОпЬхЕФММЪѕЪЕЯжПЩвдВЮПМЭјЩЯЮФеТЁЃЙигкЯоСїЮвИіШЫЕФОбщЪЧдкЩшжУЯоСїЧАвЛЖЈвЊЭЈЙ§бЙВтЕШЗНЪНГфЗжзіКУЯЕЭГШнСПЕФдЄЙРЃЌВЛвЊХФФдДќЃЌЯоСївЛАуРДЫЕЪЧгаЫ№гУЛЇЬхбщЕФЃЌгІИУзїЮЊвЛжжЖЕЕзЪжЖЮЃЌЖјВЛЪЧГЃЙцЪжЖЮЁЃ
зЪдДИєРы
зЪдДИєРыгаИїжжРраЭЃЌЮяРэВуУцЕФЗўЮёЦїзЪдДЁЂжаМфМўзЪдДЃЌДњТыВуУцЕФЯпГЬГиЁЂСЌНгГиЃЌетаЉЖМПЩвдзіИєРыЁЃетРяНщЩмЕФзЪдДИєРыжївЊЪЧгІгУВПЪ№ВуУцЕФЃЌБШШчSetЛЏЕШЕШЁЃЩЯЮФЬсЕНЕФвьЕиЖрЛювВЫуЪЧ Set ЛЏЕФвЛжжЁЃ
ИКд№дЫЕЅЯЕЭГЕФЦкМфвВзіЙ§вЛаЉРрЫЦЕФзЪдДИєРыЩЯЕФгХЛЏЁЃБГОАЪЧЕБЪБГігіЕНЙ§вЛИіЯпЩЯЙЪеЯЃЌдвђЪЧФГЗўЮёВПЪ№ЕФЗўЮёЦїЖМдквЛИіМЏШКЃЌУЛгаАДСїСПЛЎЗжИїздЕЅЖРЕФМЏШКЃЌЕМжТЙиМќвЕЮёКЭЗЧЙиМќвЕЮёСїСПЛЅЯргАЯьЖјЕМжТЕФЙЪеЯЁЃвђДЫЃЌдкетИіЙЪеЯКѓЮввВЪЧОіЖЈЖдЗўЮёЦїзіАДМЏШКИєРыВПЪ№ЃЌИєРыЕФЮЌЖШжївЊЪЧАДвЕЮёГЁОАЧјЗжЃЌЗжЮЊЙиМќМЏШКЁЂДЮЙиМќМЏШККЭЗЧЙиМќМЏШКШ§РрЃЌетбљФмБмУтЙиМќКЭЗЧЙиМќвЕЮёЛЅЯргАЯьЁЃ 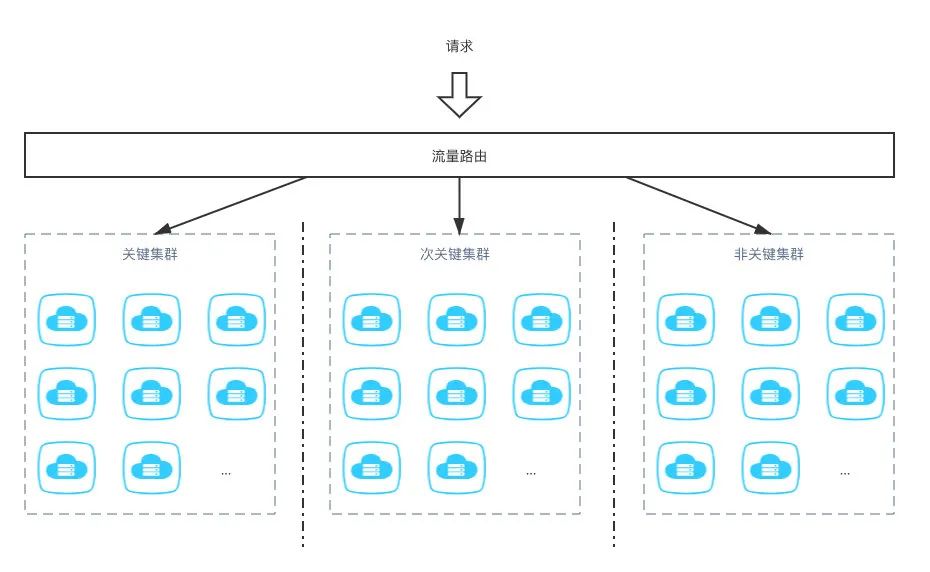
аЁНс
дкМмЙЙЗНУцЃЌЮвИіШЫвВВЛЪЧзЈвЕЕФМмЙЙЪІЃЌвВЪЧвЛжБдкбЇЯАЯрЙиММЪѕКЭЗНЗЈТлЃЌЩЯУцНщЩмЕФКмЖрММЪѕКЭМмЙЙЩшМЦФЃЪНЖМЪЧдкЙЄзїжаБпбЇЯАБпЪЕМљЁЃШчЙћЫЕЗЧвЊзмНсвЛЕуОбщаФЕУЕФЛАЃЌЮвОѕЕУЪЧзЂжиЯИНкЁЃИіШЫШЯЮЊМмЙЙВЛжЙИпДѓЩЯЕФЗНЗЈТлЃЌММЪѕЯИНквВЪЧЭЌбљживЊЕФЃЌе§ЫљЮНЯИНкОіЖЈГЩАмЃЌгаЪБКђЭќМЧЩшжУвЛИіаЁаЁЕФГЌЪБЃЌПЩФмЕМжТећИіЯЕЭГЕФБРРЃЁЃ
гІгУ
дкИпВЂЗЂЕФЯЕЭГжаЃЌдкгІгУВуУцФмзіЕФгХЛЏвВЪЧЗЧГЃЖрЕФЃЌетВПЗжжївЊЗжЯэЙигкВЙГЅЁЂУнЕШЁЂвьВНЛЏЁЂдЄШШЕШетМИЗНУцЕФгХЛЏЁЃ
ВЙГЅ
дкЮЂЗўЮёМмЙЙЯТЃЌЛсАДИївЕЮёСьгђВ№ЗжВЛЭЌЕФЗўЮёЃЌЗўЮёгыЗўЮёжЎЧАЭЈЙ§ RPC ЧыЧѓЛђ MQ ЯћЯЂЕФЗНЪНРДНЛЛЅЃЌдкЗжВМЪНЛЗОГЯТБиШЛЛсДцдкЕїгУЪЇАмЕФЧщПіЃЌЬиБ№ЪЧдкИпВЂЗЂЕФЯЕЭГжаЃЌгЩгкЗўЮёЦїИКдиИќИпЃЌЗЂЩњЪЇАмЕФИХТЪЛсИќДѓЃЌвђДЫВЙГЅОЭИќЮЊживЊЁЃГЃгУЕФВЙГЅФЃЪНгаСНжжЃКЖЈЪБШЮЮёФЃЪНЛђепЯћЯЂЖгСаФЃЪНЁЃ
ЖЈЪБШЮЮёФЃЪН
ЖЈЪБШЮЮёВЙГЅЕФФЃЪНвЛАуЪЧашвЊХфКЯЪ§ОнПтЕФЃЌВЙГЅЪБЛсЦ№вЛИіЖЈЪБШЮЮёЃЌЖЈЪБШЮЮёжДааЕФЪБКђЛсЩЈУшЪ§ОнПтжаЪЧЗёгаашвЊВЙГЅЕФЪ§ОнЃЌШчЙћгадђжДааВЙГЅТпМЃЌетжжЗНАИЕФКУДІЪЧгЩгкЪ§ОнЖМГжОУЛЏдкЪ§ОнПтжаСЫЃЌЯрЖдРДЫЕБШНЯЮШЖЈЃЌВЛШнвзГіЮЪЬтЃЌВЛзуЕФЕиЗНЪЧвђЮЊвРРЕСЫЪ§ОнПтЃЌдкЪ§ОнСПНЯДѓЕФЪБКђЃЌЛсЖдЪ§ОнПтдьГЩвЛЖЈЕФбЙСІЃЌЖјЧвЖЈЪБШЮЮёЪЧжмЦкаджДааЕФЃЌвђДЫвЛАуВЙГЅЛсгавЛЖЈЕФбгГйЁЃ
ЯћЯЂЖгСаФЃЪН
ЯћЯЂЖгСаВЙГЅЕФФЃЪНвЛАуЛсЪЙгУЯћЯЂЖгСажабгГйЯћЯЂЕФЬиадЁЃШчЙћДІРэЪЇАмЃЌдђЗЂЫЭвЛИібгГйЯћЯЂЃЌбгГй N Зжжг/Уы/аЁЪБКѓдйжиЪдЃЌетжжЗНАИЕФКУДІЪЧБШНЯЧсСПМЖЃЌГ§СЫ MQ ЭтУЛгаЭтВПвРРЕЃЌЪЕЯжвВБШНЯМђЕЅЃЌЯрЖдРДЫЕвВИќЪЕЪБЃЌВЛзуЕФЕиЗНЪЧгЩгкУЛгаГжОУЛЏЕНЪ§ОнПтжаЃЌгаЖЊЪЇЪ§ОнЕФЗчЯеЃЌВЛЙЛЮШЖЈЁЃвђДЫЃЌЮвИіШЫЕФОбщЪЧдкЙиМќСДТЗЕФВЙГЅжаЪЙгУЖЈЪБШЮЮёЕФФЃЪНЃЌЗЧЙиМќСДТЗжаЕФВЙГЅПЩвдЪЙгУЯћЯЂЖгСаЕФФЃЪНЁЃГ§ДЫжЎЭтЃЌдкВЙГЅЕФЪБКђЛЙгавЛИіЬиБ№живЊЕФЕуОЭЪЧУнЕШадЩшМЦЁЃ
УнЕШ
УнЕШВйзїЕФЬиЕуЪЧЦфШЮвтЖрДЮжДааЫљВњЩњЕФгАЯьОљгывЛДЮжДааЕФгАЯьЯрЭЌЃЌЬхЯждквЕЮёЩЯОЭЪЧгУЛЇЖдгкЭЌвЛВйзїЗЂЦ№ЕФвЛДЮЧыЧѓЛђепЖрДЮЧыЧѓЕФНсЙћЪЧвЛжТЕФЃЌВЛЛсвђЮЊЗЂЦ№ЖрДЮЖјВњЩњИБзїгУЁЃдкЗжВМЪНЯЕЭГжаЗЂЩњЯЕЭГДэЮѓЪЧдкЫљФбУтЕФЃЌЕБЗЂЩњДэЮѓЪБЃЌЛсЪЙгУжиЪдЁЂВЙГЅЕШЪжЖЮРДЬсИпШнДэадЃЌдкИпВЂЗЂЕФЯЕЭГжаЗЂЩњЯЕЭГДэЮѓЕФИХТЪОЭИќИпСЫЃЌЫљвдетЪБКђНгПкУнЕШОЭЗЧГЃживЊСЫЃЌПЩвдЗРжЙЖрДЮЧыЧѓЖјв§Ц№ЕФИБзїгУЁЃ
УнЕШЕФЪЕЯжашвЊЭЈЙ§вЛИіЮЈвЛЕФвЕЮё ID Лђеп Token РДЪЕЯжЃЌвЛАуЕФСїГЬЪЧЯШдк DB ЛђепЛКДцжаВщбЏЮЈвЛЕФвЕЮё ID Лђеп token ЪЧЗёДцдкЃЌЧвзДЬЌЪЧЗёЮЊвбДІРэЃЌШчЙћЪЧдђБэЪОЪЧжиИДЧыЧѓЃЌФЧУДЮвУЧашвЊУнЕШДІРэЃЌМДВЛзіШЮКЮВйзїЃЌжБНгЗЕЛиМДПЩЁЃ 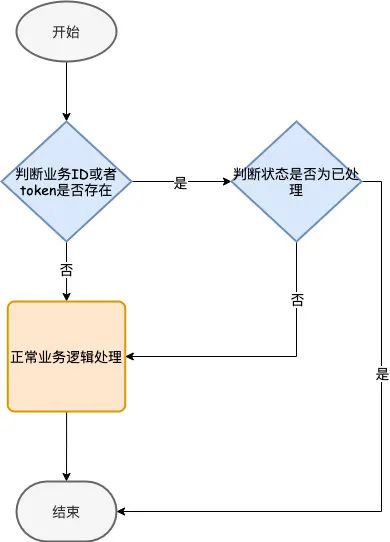
дкзіУнЕШадЩшМЦЕФЪБКђашвЊзЂвтЕФЪЧВЂВЛЪЧЫљгаЕФГЁОАЖМвЊзіУнЕШЃЌБШШчгУЛЇжиИДзЊеЫЁЂЬсЯжЕШЕШЃЌвђЮЊУнЕШЛсШУЭтВПЯЕЭГЕФИажЊЪЧЕїгУГЩЙІСЫЃЌВЂУЛгазшШћКѓајСїГЬЃЌЕЋЦфЪЕЮвУЧЯЕЭГФкВПЪЧУЛгазіШЮКЮВйзїЕФЃЌРрЫЦЩЯУцЬсЕНЕФГЁОАЃЌЛсШУгУЛЇЮѓвдЮЊВйзївбГЩЙІЁЃЫљвдЫЕвЊзаЯИЧјЗжашвЊУнЕШЕФвЕЮёГЁОАКЭВЛФмУнЕШЕФвЕЮёГЁОАЃЌЖдгкВЛФмУнЕШЕФвЕЮёГЁОАЛЙЪЧашвЊХзГівЕЮёвьГЃЛђепЗЕЛиЬиЖЈЕФвьГЃТыРДзшШћКѓајСїГЬЃЌЗРжЙв§ЗЂвЕЮёЮЪЬтЁЃ
вьВНЛЏ
ЩЯЮФЬсЕНЕФЯћЯЂЖгСавВЪЧвЛжжвьВНЛЏЃЌГ§СЫвРРЕЭтВПжаМфМўЃЌдкгІгУФкЮвУЧвВПЩвдЭЈЙ§ЯпГЬГиЁЂаГЬЕФЗНЪНзівьВНЛЏЁЃ 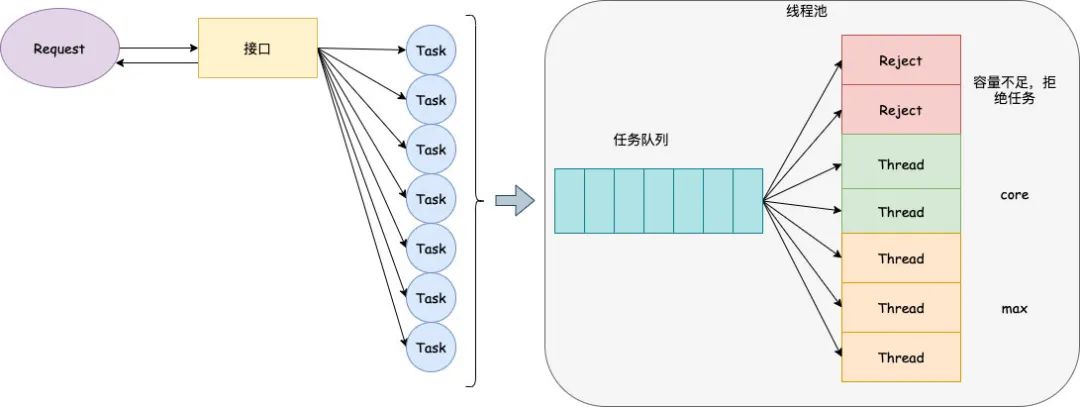
ЙигкЯпГЬГиЕФЪЕЯждРэЃЌФУ Java жаЯпГЬГиЕФФЃаЭРДОйР§ЃЌКЫаФЪЧЭЈЙ§ШЮЮёЖгСаКЭИДгУЯпГЬЕФЗНЪНЯрХфКЯРДЪЕЯжЕФЃЌЭјЩЯЙигкетаЉЗжЯэЕФЮФеТвВКмЖрЁЃдкЪЙгУЯпГЬГиЛђепаГЬЕШРрЫЦММЪѕЕФЪБКђЃЌЮвИіШЫЕФОбщЪЧгавдЯТСНЕуЪЧашвЊЬиБ№зЂвтЕФЃК
ЙиМќвЕЮёГЁОАашвЊХфКЯВЙГЅ
ЮвУЧЖМжЊЕРЃЌВЛЙмЪЧЯпГЬГивВКУЃЌаГЬвВКУЃЌЖМЪЧЛљгкФкДцЕФЃЌШчЙћЗўЮёЦївтЭтхДЛњЛђепжиЦєЃЌФкДцжаЕФЪ§ОнЪЧЛсЖЊЪЇЕФЃЌЖјЧвЯпГЬГидкзЪдДВЛзуЕФЪБКђвВЛсОмОјШЮЮёЃЌЫљвддквЛаЉЙиМќЕФвЕЮёГЁОАжаШчЙћЪЙгУСЫЯпГЬГиЕШРрЫЦЕФММЪѕЃЌашвЊХфКЯВЙГЅвЛПщЪЙгУЃЌБмУтФкДцжаЪ§ОнЖЊЪЇдьГЩЕФвЕЮёгАЯьЁЃдкЮвЮЌЛЄЕФдЫЕЅЯЕЭГжагавЛИіЙиМќЕФвЕЮёГЁОАЪЧШыЕЅЃЌМђЕЅРДЫЕОЭЪЧНгЪеЩЯгЮЧыЧѓЃЌдкЯЕЭГжаЩњГЩдЫЕЅЃЌетЪЧећИіЮяСїТФдМСїСПЕФШыПкЃЌЪЧЬиБ№ЙиМќЕФвЛИівЕЮёГЁОАЁЃ
вђЮЊЩњГЩдЫЕЅЕФећИіСїГЬБШНЯГЄЃЌвРРЕЭтВПНгПкга 10 МИИіЃЌЫљвдЕБЪБЮЊСЫзЗЧѓИпадФмКЭЭЬЭТТЪЃЌЩшМЦГЩСЫвьВНЕФФЃЪНЃЌвВОЭЪЧдкЯпГЬГижаДІРэЃЌЭЌЪБЮЊСЫЗРжЙЪ§ОнЖЊЪЇЃЌвВзіСЫЭъЩЦЕФВЙГЅДыЪЉЃЌетМИФъЪБМфШыЕЅетПщЛљБОУЛгаГіЙ§ЮЪЬтЃЌВЂЧвгЩгкВЩгУСЫвьВНЕФЩшМЦЃЌадФмЗЧГЃКУЃЌФЧЮвУЧОпЬхЪЧдѕУДзіЕФФиЁЃ 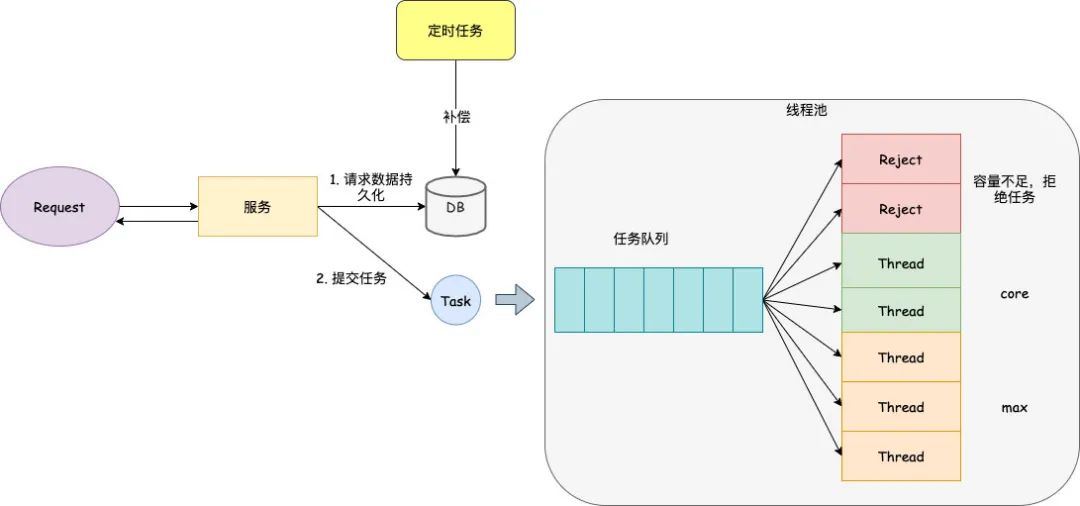
змЕФСїГЬЪЧдкНгЪеЕНЩЯгЮЕФЧыЧѓКѓЃЌЕквЛВНЪЧНЋЫљгаЕФЧыЧѓВЮЪ§ТфПтЃЌетвЛВНЪЧЗЧГЃЙиМќЕФЃЌШчЙћетвЛВНЪЇАмЃЌФЧећИіЧыЧѓОЭЪЇАмСЫЁЃдкГЩЙІТфПтКѓЃЌЗтзАвЛИі Task ЬсНЛЕНЯпГЬГижаЃЌШЛКѓжБНгЖдЩЯгЮЗЕЛиГЩЙІЁЃКѓајЕФЫљгаДІРэЖМЪЧдкЯпГЬГижаНјааЕФЃЌДЫЭтЃЌЛЙгавЛИіЖЈЪБШЮЮёЛсЖЈЪБВЙГЅЃЌВЙГЅЕФЪ§ОндДОЭЪЧдкЕквЛВНжаТфПтЕФЪ§ОнЃЌУПвЛЬѕТфПтЕФМЧТМЛсгавЛИі flag зжЖЮРДБэЪОДІРэзДЬЌЃЌШчЙћЗЂЯжЪЧЮДДІРэЛђепДІРэЪЇАмЃЌдђЭЈЙ§ЖЈЪБШЮЮёдйДЅЗЂВЙГЅТпМЃЌВЙГЅГЩЙІКѓдйНЋ flag зжЖЮИќаТЮЊДІРэГЩЙІЁЃ
зіКУМрПи
дкЮЂЗўЮёжаЯё RPC НгПкЕїгУЁЂMQ ЯћЯЂЯћЗбЃЌАќРЈжаМфМўЁЂЛљДЁЩшЪЉЕШЕФМрПиЃЌетаЉЛљБОЖМЛсеыЖдадЕФзіЭъЩЦЕФМрПиЃЌЕЋЪЧРрЫЦЯёЯпГЬГивЛАуЪЧУЛгаЯжГЩМрПиЕФЃЌашвЊЪЙгУЗНздааЪЕЯжЩЯБЈДђЕуМрПиЃЌетЕуКмШнвзБЛвХТЉЁЃЮвУЧжЊЕРЯпГЬГиЕФЪЕЯжЪЧЛсгаФкДцЖгСаЕФЃЌЖјЮвУЧвВвЛАуЛсЖдФкДцЖгСаЩшжУвЛИізюДѓжЕЃЌШчЙћГЌГіСЫзюДѓжЕПЩФмЛсЖЊЦњШЮЮёЃЌетЪБКђШчЙћУЛгаМрПиЪЧЗЂЯжВЛСЫРрЫЦЕФЮЪЬтЕФЃЌЫљвдЃЌЪЙгУЯпГЬГивЛЖЈвЊзіКУМрПиЁЃФЧУДЯпГЬГигаФФаЉПЩвдМрПиЕФжИБъФиЃЌАДЮвЕФОбщРДЫЕЃЌвЛАуЛсЩЯБЈЯпГЬГиЕФЛюдОЯпГЬЪ§вдМАЙЄзїЖгСаЕФШЮЮёИіЪ§ЃЌетСНИіжИБъЮвШЯЮЊЪЧзюживЊЕФЃЌЦфЫћЕФжИБъОЭМћШЪМћжЧСЫЃЌПЩвдНсКЯОпЬхвЕЮёГЁОАРДбЁдёадЩЯБЈЁЃ
дЄШШ
Warm UpЁЃЕБЯЕЭГГЄЦкДІгкЕЭЫЎЮЛЕФЧщПіЯТЃЌСїСПЭЛШЛдіМгЪБЃЌжБНгАбЯЕЭГРЩ§ЕНИпЫЎЮЛПЩФмЫВМфАбЯЕЭГбЙПхЁЃЭЈЙ§"РфЦєЖЏ"ЃЌШУЭЈЙ§ЕФСїСПЛКТ§діМгЃЌдквЛЖЈЪБМфФкж№НЅдіМгЕНуажЕЩЯЯоЃЌИјРфЯЕЭГвЛИідЄШШЕФЪБМфЃЌБмУтРфЯЕЭГБЛбЙПхЁЃ
ВЮПМЭјЩЯЕФЖЈвхЃЌЫЕАзСЫЃЌОЭЪЧШчЙћЗўЮёвЛжБдкЕЭЫЎЮЛЃЌетЪБКђЭЛШЛРДвЛВЈИпВЂЗЂЕФСїСПЃЌПЩФмЛсвЛЯТзгАбЯЕЭГДђПхЁЃЯЕЭГЕФдЄШШвЛАуга JVM дЄШШЁЂЛКДцдЄШШЁЂDB дЄШШЕШЃЌЭЈЙ§дЄШШЕФЗНЪНШУЯЕЭГЯШЁАШШЁБЦ№РДЃЌЮЊИпВЂЗЂСїСПЕФЕНРДзіКУзМБИЁЃдЄШШЪЕМЪгІгУЕФГЁОАгаКмЖрЃЌБШШчдкЕчЩЬЕФДѓДйЕНРДЧАЃЌЮвУЧПЩвдАбвЛаЉШШЕуЕФЩЬЦЗЬсЧАМгдиЕНЛКДцжаЃЌЗРжЙДѓСїСПГхЛї DBЃЌдйБШШч Java ЗўЮёгЩгк JVM ЕФЖЏЬЌРрМгдиЛњжЦЃЌПЩвддкЦєЖЏКѓЖдЗўЮёзівЛВЈбЙВтЃЌАбРрЬсЧАМгдиЕНФкДцжаЃЌЭЌЪБЛЙгаПЩвдЬсЧАДЅЗЂ JIT БрвыЁЂCode cache ЕШЕШКУДІЁЃ
ЛЙгавЛжждЄШШЕФЫМТЗЪЧРћгУвЕЮёЕФЬиадзівЛаЉдЄМгдиЃЌБШШчЮвУЧдкЮЌЛЄдЫЕЅЯЕЭГЕФЪБКђзіЙ§етбљвЛИігХЛЏЃЌдквЛИіе§ГЃЕФЭтТєвЕЮёСїГЬжаЪЧгУЛЇЯТЕЅКѓЕНгУЛЇНЛвзЯЕЭГЩњГЩЖЉЕЅЃЌШЛКѓОРњжЇИЖ->ЩЬМвНгЕЅ->ЧыЧѓХфЫЭетбљвЛИіСїГЬЃЌЫљвдЫЕДггУЛЇЯТЕЅЕНЧыЧѓХфЫЭетжЎМфгаУыМЖЕНЗжжгМЖЕФЪБМфВюЃЌЮвУЧПЩвдЭЈЙ§ИажЊгУЛЇЯТЕЅЕФЖЏзїЃЌРћгУетЪБМфВюРДЬсЧАМгдивЛаЉЪ§ОнЁЃ 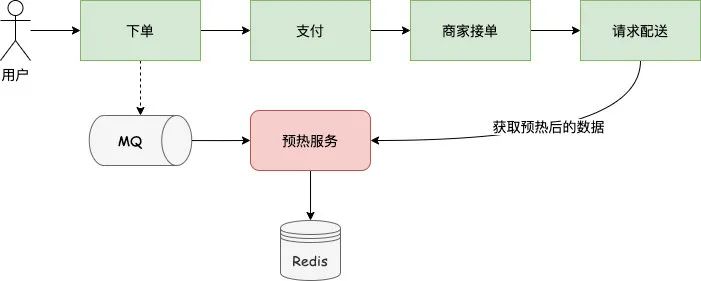
етбљдкЪЕМЪЧыЧѓЕНРДЕФЪБКђжЛашвЊЕНЛКДцжаЛёШЁМДПЩЃЌетЖдгквЛаЉБШНЯКФЪБЕФВйзїЬсЩ§ЪЧЗЧГЃДѓЕФЃЌжЎЧАЮвУЧРћгУетжжЗНЪНФмЬсЩ§НгПкадФм 50%вдЩЯЁЃЕБШЛгаИіЕуашвЊзЂвтЕФОЭЪЧШчЙћЖдгквЛаЉПЩФмЛсБфИќЕФЪ§ОнЃЌПЩФмОЭВЛЪЪКЯдЄШШЃЌвђЮЊдЄШШКѓЪ§ОнДцдкЛКДцжаЃЌКѓУцОЭВЛЛсдйШЅЧыЧѓНгПкСЫЃЌетбљЛсЕМжТЪ§ОнВЛвЛжТЃЌетЪЧашвЊЬиБ№зЂвтЕФЁЃ
аЁНс
дкзіИпВЂЗЂЯЕЭГЩшМЦЕФЪБКђЮвУЧзмЪЧЛсЬиБ№ЙизЂМмЙЙЁЂЛљДЁЩшЪЉЕШЕШЃЌетаЉЕФШЗЗЧГЃживЊЃЌЕЋЦфЪЕдкгІгУВуУцФмзіЕФгХЛЏвВЪЧЗЧГЃЖрЕФЃЌЖјЧвГЩБОЛсБШМмЙЙЁЂЛљДЁЩшЪЉЕФМмЙЙгХЛЏЕЭКмЖрЁЃКмЖрЪБКђдкгІгУВуУцзіЕФгХЛЏашвЊНсКЯОпЬхЕФвЕЮёГЁОАЃЌРћгУЬиЖЈЕФвЕЮёГЁОАШЅзіГіКЯРэЕФЩшМЦЃЌБШШчЛКДцЁЂвьВНЛЏЃЌЮвУЧОЭашвЊЫМПМФФаЉвЕЮёГЁОАФмЛКДцЃЌФмвьВНЛЏЃЌФФаЉОЭЪЧашвЊЭЌВНЛђепВщбЏ DBЃЌвЛЖЈвЊНсКЯвЕЮёВХФмзіГіИќКУЕФЩшМЦКЭгХЛЏЁЃ
ЙцЗЖ
етЪЧЙигкНЈЩшИпВЂЗЂЯЕЭГОбщЗжЯэЕФзюКѓвЛИіВПЗжСЫЃЌЕЋЮвШЯЮЊЙцЗЖЕФживЊадвЛЕуЖМВЛБШЛљДЁЩшЪЉЁЂМмЙЙЁЂЪ§ОнПтЁЂгІгУЕЭЃЌПЩФмЛЙБШетаЉЖМИќживЊЁЃИљОнЖўАЫЖЈТЩЃЌдкШэМўЕФећИіЩњУќжмЦкжаЃЌЮвУЧЛЈСЫ 20%ЪБМфДДдьСЫЯЕЭГЃЌЕЋвЊЛЈ 80%ЕФЪБМфРДЮЌЛЄЯЕЭГЃЌетвВШУЮвЯыЦ№РДвЛОфЛАЃЌгаШЫЫЕДњТыжївЊЪЧИјШЫЖСЕФЃЌЫГБуИјЛњЦїдЫааЃЌЦфЪЕЖМЪЧЬхЯжСЫПЩЮЌЛЄадЕФживЊадЁЃ
дкЮвУЧЪЙгУСЫИпДѓЩЯЕФМмЙЙЁЂзіСЫИїжжгХЛЏжЎКѓЃЌЯЕЭГШЗЪЕгаСЫвЛИіБШНЯКУЕФЩшМЦЃЌЕЋЮЪЬтЪЧдѕУДдкКѓајЕФЮЌЛЄЙ§ГЬжаЗРжЙМмЙЙИЏЛЏФиЃЌетЪБКђОЭашвЊЙцЗЖСЫЁЃ
ЙцЗЖАќРЈДњТыЙцЗЖЁЂБфИќЙцЗЖЁЂЩшМЦЙцЗЖЕШЕШЃЌЕБШЛетРяЮвВЛЛсНщЩмШчКЮШЅЩшМЦетаЉЙцЗЖЃЌЮвИќЯыЫЕЕФЪЧЮвУЧвЛЖЈвЊжиЪгЙцЗЖЃЌжЛгадкгаСЫЙцЗЖжЎКѓЃЌЯЕЭГЕФПЩЮЌЛЄадВХФмгаБЃжЄЁЃИљОнЦЦДАРэТлЃЌЭЈЙ§ИїжжЙцЗЖЮвУЧОЁСПВЛШУЯЕЭГгаЕквЛЩШЦЦДАВњЩњЁЃ
змНс
ЫЕСЫетУДЖрЙигкЩшМЦЁЂгХЛЏЕФЗНЗЈЃЌзюКѓЯыдйЗжЯэСНЕуЁЃ
ЕквЛЕуОЭЪЧгаОфжјУћЕФЛАЁЊЁЊЁАЙ§дчгХЛЏЪЧЭђЖёжЎдДЁБЃЌИіШЫЗЧГЃШЯЭЌЃЌЮвзіЕФЫљгаетаЉЩшМЦКЭгХЛЏЃЌЖМЪЧдкЯЕЭГгіЕНЪЕМЪЕФЮЪЬтЛђЦПОБЕФЪБКђВХзіЕФЃЌЧаМЩВЛвЊЭбРыЪЕМЪГЁОАЙ§дчгХЛЏЃЌВЛШЛКмПЩФмзіЮогУЙІЩѕжСЕУВЛГЅЪЇЁЃ
ЕкЖўЕуЪЧдкЩшМЦЕФЪБКђвЊзёбKISS ддђЃЌвВОЭЪЧ Keep it simple, stupidЁЃМђЕЅвтЮЖзХЮЌЛЄадИќИпЃЌИќВЛШнвзГіЮЪЬтЃЌе§ЫљЮНДѓЕРжСМђЃЌЛђаэОЭЪЧетИіЕРРэЁЃ 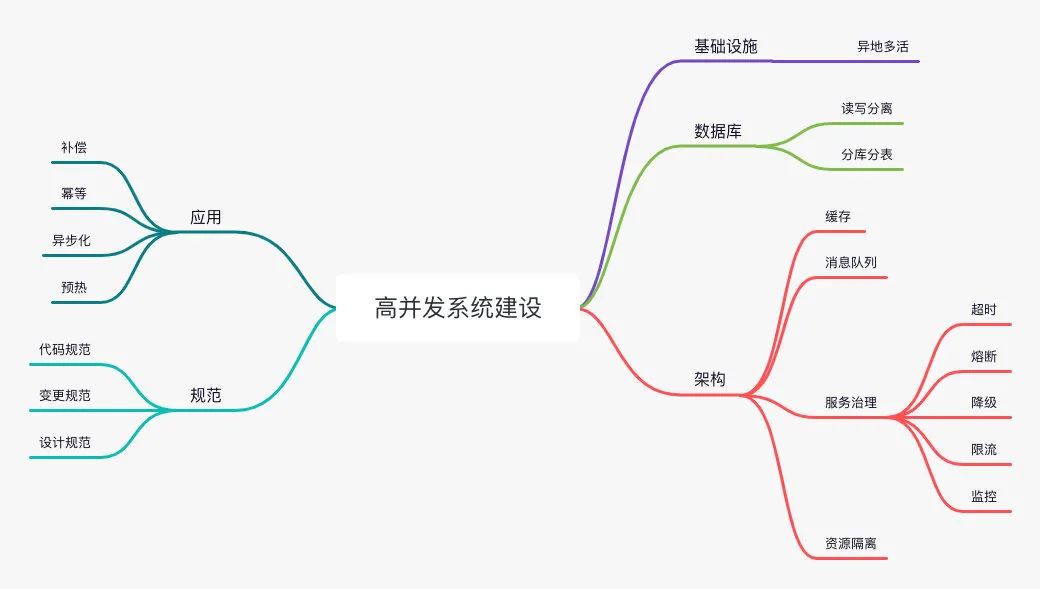
вдЩЯетаЉЖМЪЧЮвдкЙЄзїЦкМфЮЌЛЄИпВЂЗЂЯЕЭГЕФвЛаЉОбщзмНсЃЌМјгкЦЊЗљКЭИіШЫММЪѕЫЎЦНдвђЃЌПЩФмгааЉВПЗжУЛгаНщЩмЕФЬиБ№ЯъЯИКЭЩюШыЃЌЫуЪЧХззЉв§гёАЩЁЃШчЙћгаЪВУДЫЕЕФВЛЖдЕФЕиЗНвВЛЖгжИГіЃЌЭЌЪБвВЛЖгНЛСїКЭЬНЬжЁЃ
дЮФСДНг
|









