| 编辑推荐: |
本文主要介绍工作中用到的数据库高可用方案,以及采用这些方案所遇到的问题
,希望对您的学习有所帮助。
来自于
首席架构师专栏
,由火龙果软件Alice编辑、推荐。 |
|
又赶上一年一度的金九银十的日子,这段期间的招聘岗位相对前几个月会多些,如果在目前公司没有进步、没有前途时,这段时间可以准备一下,去外面看看机会。不过在外面找工作时,可以提前在网上看看招聘信息,看看自己是否达到公司要求。如果多看下高薪资的技术人员招聘要求时,就会发现对三高都有一定的要求,比如下面一家公司的要求就对 高并发、高负载和高可用性 系统设计要有开发经验。
现实是我们大部分的公司都很少会遇到三高的场景,即很少有这方面的设计开发经验,不过我们可以提前学习三高的方案,尽量把这些方案用在工作上,即使在工作中用不到,那么在面试中也会有好处或者对以后的工作也会起到一定的帮助。这篇文章我就来和大家聊一聊,我在工作中用到的数据库高可用方案,以及采用这些方案所遇到的问题,希望这些心得可以帮助到你。
一、 高可用背景
高可用概念
高可用(High Availability) 是系统所能提供无故障服务的一种能力 。简单地说就是避免因服务器宕机而造成的服务不可用。
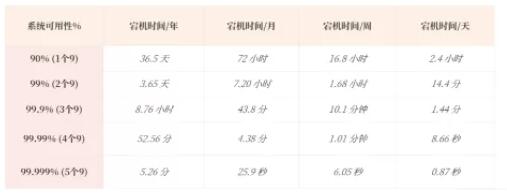
通常来说,系统至少要达到 4 个 9(99.99%),也就是每年宕机时间不超过 52.56 分钟,否则用户体验会非常差,感觉系统不稳定。
99.99% = 1 - 52.56 / (365*24*60)
不过 4 个 9 宕机 52 分钟对于生产环境的影响还是比较大,但是 5 个 9 对大部分系统来说要求又太高。所以一些云服务商会提出一个 99.995% 的可用性概念,那么系统一年的不可用时长为:不可用时长 = (1 - 99.995%)*365*24*60 = 26.28 (分钟),即一年最多的影响服务的时间为 26.28 分钟。
简单了解“高可用”有多么重要之后,接下来我们就来看一下,怎么设计数据库高可用架构。系统要达到高可用,一定要做好软硬件的冗余,消除单点故障(SPOF single point of failure)。冗余是高可用的基础,通常认为,系统投入硬件资源越多,冗余也就越多,系统可用性也就越高。除了做好冗余,系统还要做好故障转移(Failover)的处理。也就是在最短的时间内发现故障,然后把业务切换到冗余的资源上。在介绍高可用架构之前,我们先了解一下 数据库复制的原理 。
二、 数据库复制原理
数据库复制本质上就是数据同步。MySQL 数据库是基于 二进制日志 (binary log)进行数据增量同步,而二进制日志记录了所有对于 MySQL 数据库的修改操作。
在默认 ROW 格式二进制日志中,一条 SQL 操作影响的记录会被全部记录下来,比如一条 SQL语句更新了三行记录,在二进制日志中会记录被修改的这三条记录的前项(before image)和后项(after image)。
在有二进制日志的基础上,MySQL 数据库就可以通过数据复制技术实现数据同步了。而数据复制的本质就是把一台 MySQL 数据库上的变更同步到另一台 MySQL 数据库上,下面这张图显示了当前 MySQL 数据库的复制架构:
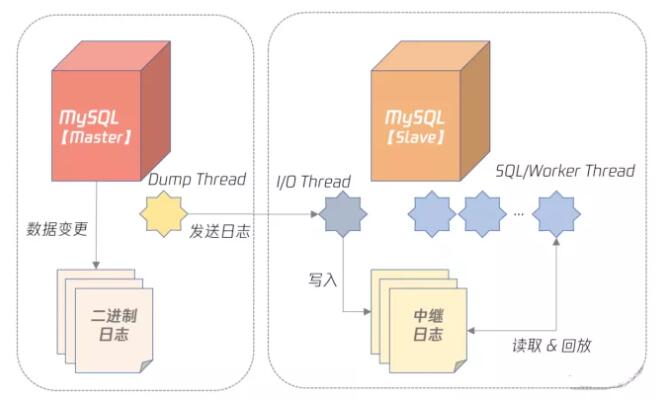
可以看到,在 MySQL 复制中,一台是数据库的角色是 Master(也叫 Primary),剩下的服务器角色是 Slave(也叫 Standby):
a. Master 服务器会把数据变更产生的二进制日志通过 Dump 线程发送给 Slave 服务器;
b. Slave 服务器中的 I/O 线程负责接受二进制日志,并保存为中继日志;
c. SQL/Worker 线程负责并行执行中继日志,即在 Slave 服务器上回放 Master 产生的日志。
得益于二进制日志,MySQL 的复制相比其他数据库,如 Oracle、PostgreSQL 等,非常灵活,用户可以根据自己的需要构建所需要的复制拓扑结构,比如:
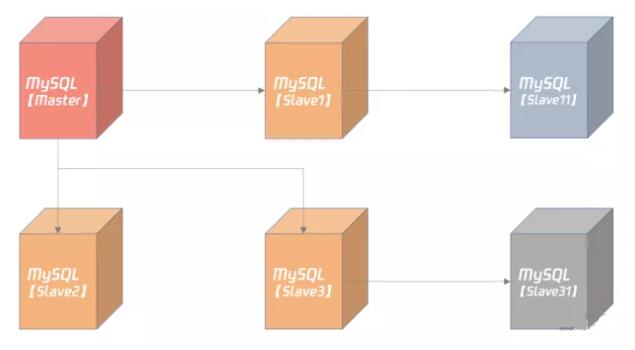
在上图中,Slave1、Slave2、Slave3 都是 Master 的从服务器,而 Slave11 是 Slave1 的从服务器,Slave1 服务器既是 Master 的从机,又是 Slave11 的主机,所以 Slave1 是个级联的从机。同理,Slave3 也是台级联的从机。
MySQL复制类型及应用选项
MySQL 复制可以分为以下几种类型:
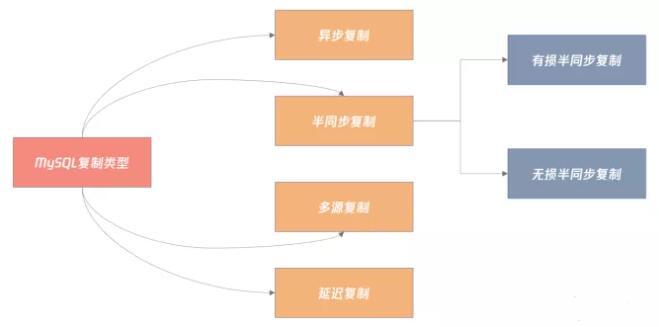
默认的复制是异步复制 ,而很多新同学因为不了解 MySQL 除了异步复制还有其他复制的类型,所以错误地在业务中使用了异步复制。为了解决这个问题,我们一起详细了解一下每种复制类型,以及它们在业务中的选型,方便你在业务做正确的选型。
异步复制
在异步复制(async replication)中,Master 不用关心 Slave 是否接收到二进制日志,所以 Master 与 Slave 没有任何的依赖关系。你可以认为 Master 和 Slave 是分别独自工作的两台服务器,数据最终会通过二进制日志达到一致。
异步复制的性能最好,因为它对数据库本身几乎没有任何开销,除非主从延迟非常大,Dump Thread 需要读取大量二进制日志文件。
如果业务对于数据一致性要求不高,当发生故障时,能容忍数据的丢失,甚至大量的丢失,推荐用异步复制,这样性能最好(比如像微博这样的业务,虽然它对性能的要求极高,但对于数据丢失,通常可以容忍)。但往往核心业务系统最关心的就是数据安全,比如监控业务、告警系统 。
半同步复制
半同步复制要求 Master 事务提交过程中,至少有 N 个 Slave 接收到二进制日志,这样就能保证当 Master 发生宕机,至少有 N 台 Slave 服务器中的数据是完整的。
半同步复制并不是 MySQL 内置的功能,而是要安装半同步插件,并启用半同步复制功能,设置 N 个 Slave 接受二进制日志成功,比如:
plugin-load="rpl_semi_sync_master=semisync_ master.so ; rpl_semi_sync_slave = semisync_slave.so"
rpl-semi-sync-master-enabled = 1
rpl-semi-sync-slave-enabled = 1
rpl_semi_sync_master_wait_no_slave = 1
上面的配置中:
第 1 行要求数据库启动时安装半同步插件;
第 2、3 行表示分别启用半同步 Master 和半同步 Slave 插件;
第 4 行表示半同步复制过程中,提交的事务必须至少有一个 Slave 接收到二进制日志。
在半同步复制中,有损半同步复制是 MySQL 5.7 版本前的半同步复制机制,这种半同步复制在Master 发生宕机时, Slave 会丢失最后一批提交的数据 ,若这时 Slave 提升(Failover)为Master,可能会发生已经提交的事情不见了,发生了回滚的情况。
有损半同步复制原理如下图所示:
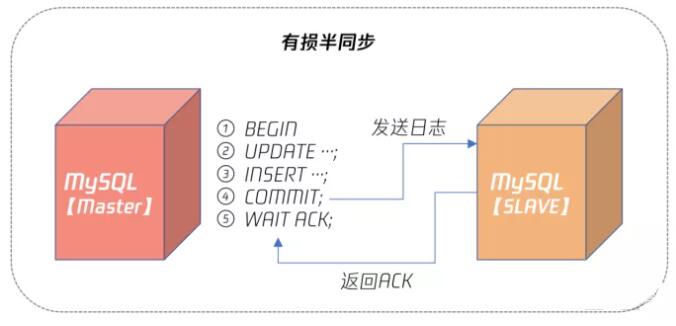
可以看到,有损半同步是在 Master 事务提交后,即步骤 4 后,等待 Slave 返回 ACK,表示至少有 Slave 接收到了二进制日志,如果这时二进制日志还未发送到 Slave,Master 就发生宕机,则此时 Slave 就会丢失 Master 已经提交的数据。
而 MySQL 5.7 的无损半同步复制解决了这个问题,其原理如下图所示:
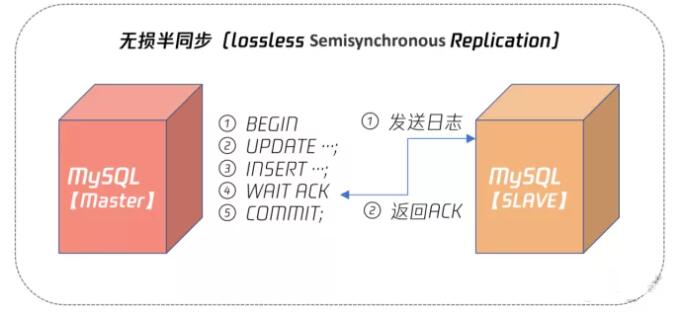
从上图可以看到,无损半同步复制 WAIT ACK 发生在事务提交之前,这样即便 Slave 没有收到二进制日志,但是 Master 宕机了,由于最后一个事务还没有提交,所以本身这个数据对外也不可见,不存在丢失的问题。
所以,对于任何有数据一致性要求的业务,如电商的核心订单业务、银行、保险、证券等与资金密切相关的业务,务必使用无损半同步复制。这样数据才是安全的、有保障的、即使发生宕机,从机也有一份完整的数据。
多源复制
无论是异步复制还是半同步复制,都是 1 个 Master 对应 N 个 Slave。其实 MySQL 也支持 N 个 Master 对应 1 个 Slave,这种架构就称之为多源复制。
多源复制允许在不同 MySQL 实例上的数据同步到 1 台 MySQL 实例上,方便在 1 台 Slave 服务器上进行一些统计查询, 如常见的 OLAP 业务查询 。
多源复制的架构如下所示:
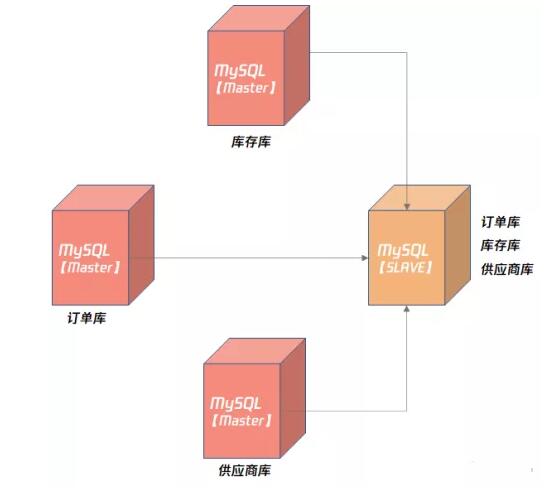
上图显示了订单库、库存库、供应商库,通过多源复制同步到了一台 MySQL 实例上,接着就可以通过 MySQL 8.0 提供的复杂 SQL 能力,对业务进行深度的数据分析和挖掘。
延迟复制
前面介绍的复制架构,Slave 在接收二进制日志后会尽可能快地回放日志,这样是为了避免主从之间出现延迟。而延迟复制却允许Slave 延迟回放接收到的二进制日志,为了避免主服务器上的误操作,马上又同步到了从服务器,导致数据完全丢失。
我们可以通过以下命令设置延迟复制:
CHANGE MASTER TO master_delay = 3600
这样就人为设置了 Slave 落后 Master 服务器1个小时。
延迟复制主要用于误操作防范,也在数据库的备份架构设计中非常常见 ,比如可以设置一个延迟一天的延迟备机,这样本质上说,用户可以有 1 份 24 小时前的快照。
那么当线上发生误操作,如 DROP TABLE、DROP DATABASE 这样灾难性的命令时,用户有一个 24 小时前的快照,数据可以快速恢复 。
对金融行业来说,延迟复制是你备份设计中,必须考虑的一个架构部分。
在我们了解了数据同步的原理后,接下来我们进入常见的数据库高可用架构方案。
三、 常见的架构方案
1. 常见的架构方案
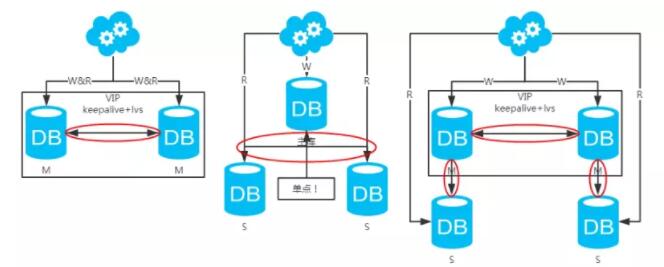
方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用
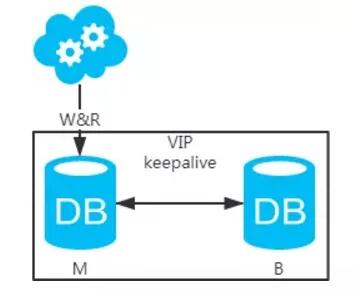
1、 高可用分析: 高可用,主库挂了,keepalive(只是一种工具)会自动切换到备库。这个过程对业务层是透明的,无需修改代码或配置。
2、 高性能分析: 读写都操作主库,很容易产生瓶颈。大部分互联网应用读多写少,读会先成为瓶颈,进而影响写性能。另外,备库只是单纯的备份,资源利用率50%,这点方案二可解决。
3、 一致性分析: 读写都操作主库,不存在数据一致性问题。
4、 扩展性分析: 无法通过加从库来扩展读性能,进而提高整体性能。
5、 可落地分析: 两点影响落地使用。第一,性能一般,这点可以通过建立高效的索引和引入缓存来增加读性能,进而提高性能。这也是通用的方案。第二,扩展性差,这点可以通过 分库分表 来扩展。
方案二:双主架构,两个主库同时提供服务,负载均衡
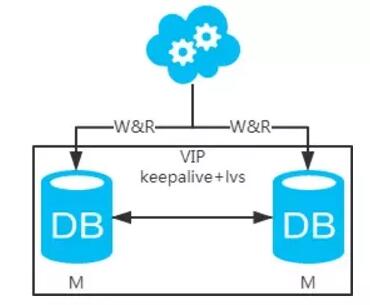
1、 高可用分析: 高可用,一个主库挂了,不影响另一台主库提供服务。这个过程对业务层是透明的,无需修改代码或配置。
2、 高性能分析: 读写性能相比于方案一都得到提升,提升一倍。
3、 一致性分析: 存在数据一致性问题。请看, 一致性解决方案 。
4、 扩展性分析: 当然可以扩展成三主循环,但笔者不建议(会多一层 数据同步 ,这样同步的时间会更长)。如果非得在数据库架构层面扩展的话,扩展为方案四。
5、 可落地分析: 两点影响落地使用。第一,数据一致性问题, 一致性解决方案 可解决问题 。 第二,主键冲突问题,ID统一地由分布式ID生成服务来生成可解决问题。
方案三:主从架构,一主多从,读写分离
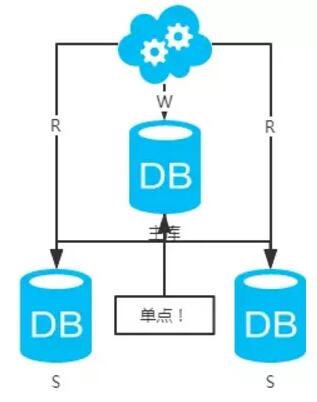
1、 高可用分析: 主库单点,从库高可用。一旦主库挂了,写服务也就无法提供。
2、 高性能分析: 大部分互联网应用读多写少,读会先成为瓶颈,进而影响整体性能。读的性能提高了,整体性能也提高了。另外,主库可以不用索引,线上从库和线下从库也可以建立不同的索引(线上从库如果有多个还是要建立相同的索引,不然得不偿失;线下从库是平时开发人员排查线上问题时查的库,可以建更多的索引)。
3、 一致性分析: 存在数据一致性问题。请看, 一致性解决方案 。
4、 扩展性分析: 可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题是,从库越多需要从主库拉取binlog日志的端就越多,进而影响主库的性能,并且 数据同步 完成的时间也会更长)
5、 可落地分析: 两点影响落地使用。第一,数据一致性问题, 一致性解决方案 可解决问题 。 第二,主库单点问题,笔者暂时没想到很好的解决方案。
注:思考一个问题,一台从库挂了会怎样?读写分离之读的负载均衡策略怎么容错?
方案四:双主+主从架构,看似完美的方案
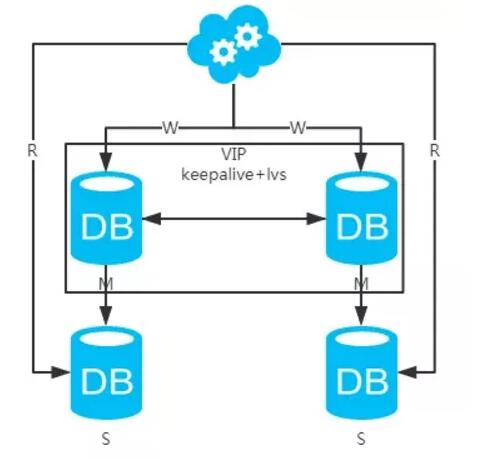
1、 高可用分析: 高可用。
2、 高性能分析: 高性能。
3、 一致性分析: 存在数据一致性问题。请看, 一致性解决方案 。
4、 扩展性分析: 可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题 同方案二 )
5、 可落地分析:同方案二 ,但 数据同步 又多了一层,数据延迟更严重 。
2. 一致性问题解决方案
第一类:主库和从库一致性解决方案
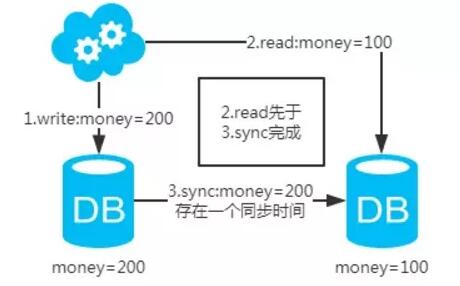
注:图中圈出的是数据同步的地方,数据同步(从库从主库拉取binlog日志,再执行一遍)是需要时间的,这个同步时间内主库和从库的数据会存在不一致的情况。如果同步过程中有读请求,那么读到的就是从库中的老数据。如下图。
既然知道了数据不一致性产生的原因,有下面几个解决方案供参考:
1、直接忽略,如果业务允许延时存在,那么就不去管它。
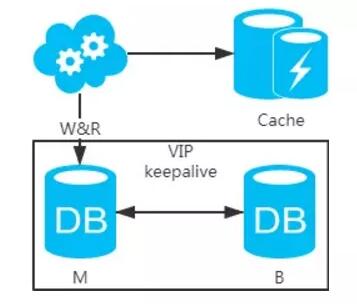
2、强制读主,采用 主备架构 方案,读写都走主库。用缓存来扩展数据库读性能 。
有一点需要知道:如果缓存挂了,可能会产生雪崩现象,不过一般分布式缓存都是高可用的。
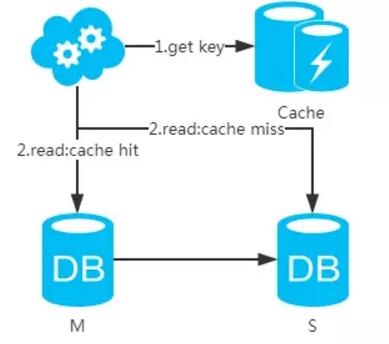
3、选择读主,写操作时根据库+表+业务特征生成一个key放到Cache里并设置超时时间(大于等于主从数据同步时间)。读请求时,同样的方式生成key先去查Cache,再判断是否命中。若命中,则读主库,否则读从库。代价是多了一次缓存读写,基本可以忽略。
4、半同步复制,等主从同步完成,写请求才返回。就是大家常说的“半同步复制”semi-sync。这可以利用数据库原生功能,实现比较简单。代价是写请求时延增长,吞吐量降低。
5、数据库中间件,引入开源(mycat等)或自研的数据库中间层。个人理解,思路同 选择读主。 数据库中间件的成本比较高,并且还多引入了一层。
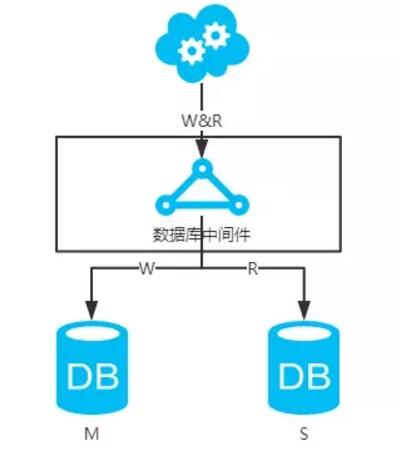
第二类:DB和缓存一致性解决方案
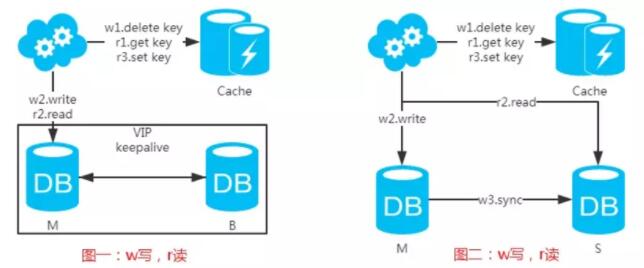
先来看一下常用的缓存使用方式:
第一步:淘汰缓存;
第二步:写入数据库;
第三步:读取缓存?返回:读取数据库;
第四步:读取数据库后写入缓存。
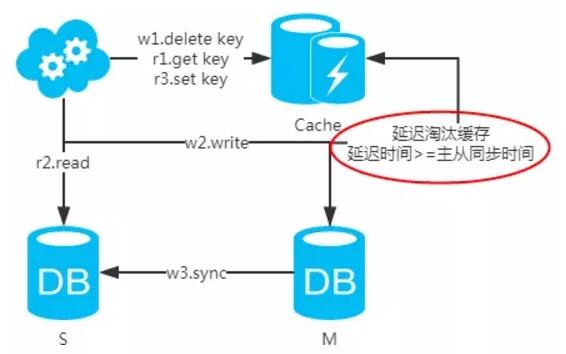
注:如果按照这种方式,图一,不会产生DB和缓存不一致问题;图二,会产生DB和缓存不一致问题,即r2.read先于w3.sync执行。如果不做处理,缓存里的数据可能一直是脏数据。解决方式如下:
3. 总结
1、架构演变
1、架构演变一:方案一 -> 方案一+分库分表 -> 方案二+分库分表 -> 方案四+分库分表;
2、架构演变二:方案一 -> 方案一+分库分表 -> 方案三+分库分表 -> 方案四+分库分表;
3、架构演变三:方案一 -> 方案二 -> 方案四 -> 方案四+分库分表;
4、架构演变四:方案一 -> 方案三 -> 方案四 -> 方案四+分库分表;
2、个人见解
1、加缓存和索引是通用的提升数据库性能的方式;
2、分库分表带来的好处是巨大的,但同样也会带来一些问题。
3、不管是主备+分库分表还是主从+读写分离+分库分表,都要考虑具体的业务场景。58到家发展四年,绝大部分的数据库架构还是采用方案一和方案一+分库分表,只有极少部分用方案三+读写分离+分库分表。另外,阿里云提供的数据库云服务也都是主备方案,要想主从+读写分离需要二次架构。
4、记住一句话:不考虑业务场景的架构都是耍流氓。
四、 容灾方案
高可用用于处理各种宕机问题,而宕机可以分成 服务器宕机、机房级宕机 ,甚至是一个城市发生宕机。
机房级宕机 :机房光纤不通/被挖断,机房整体掉电(双路备用电源也不可用);
城市级宕机 :一般指整个城市的进出口网络,骨干交换机发生的故障(这种情况发生的概率很小)。
如果综合考虑的话,高可用就成了一种容灾处理机制,对应的高可用架构的评判标准就上升了。
机房内容灾 :机房内某台数据库服务器不可用,切换到同机房的数据库实例,保障业务连续性;
同城容灾 :机房不可用,切换到同城机房的数据库实例,保障业务连续性;
跨城容灾 :单个城市机房都不可用,切换到跨城机房的数据库实例,保障业务连续性。
前面我们谈到的高可用设计,都只是机房内的容灾。也就是说,我们的主服务器和从服务器都在一个机房内,现在我们来看一下同城和跨城的容灾设计(我提醒一下,不论是 机房内容灾、同城容灾,还是跨城容灾,都是基于 MySQL 的无损半同步复制 ,只是物理部署方式不同,解决不同的问题)。
对于同城容灾,我看到很多这样的设计:
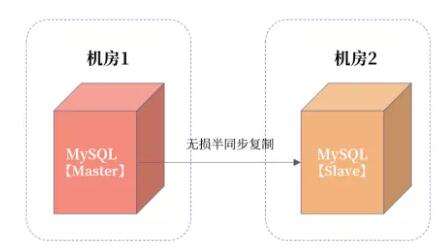
这种设计没有考虑到机房网络的抖动。如果机房 1 和机房 2 之间的 网络发生抖动 ,那么因为事务提交需要机房 2 中的从服务器接收日志,所以会出现事务提交被 hang 住的问题。
而 机房网络抖动非常常见,所以核心业务同城容灾务要采用三园区的架构 ,如下图所示:
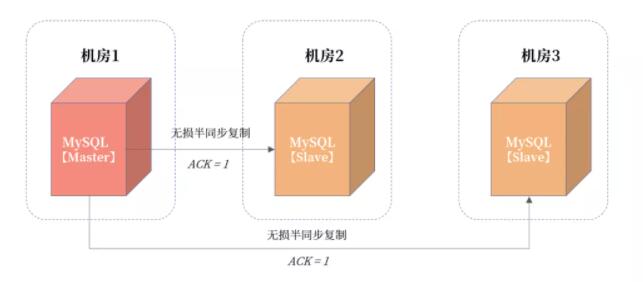
该架构称为“ 三园区的架构 ”,如果三个机房都在一个城市,则称为“ 一地三中心”,如果在相邻两个城市,那么就叫“两地三中心”。但 这种同城/近城容灾,要求机房网络之间的延迟不超过 5ms 。
在三园区架构中,一份数据被存放在了 3 个机房,机房之间根据半同步复制。这里将 MySQL 的半同步复制参数 rpl_semi_sync_master_wait_for_slave_count 设置为 1,表示只要有 1 个半同步备机接收到日志,主服务器上的事务就可以提交。
这样的设计,保证除主机房外,数据在其他机房至少一份完整的数据。
另外,即便机房 1 与机房 2 发生网络抖动,因为机房 1 与机房 3 之间的网络很好,不会影响事务在主服务器上的提交。如果机房 1 的出口交换机或光纤发生故障,那么这时高可用套件会 FAILOVER 到机房 2 或机房 3,因为至少有一份数据是完整的。
机房 2、机房 3 的数据用于保障数据一致性,但是如果要实现读写分离,或备份,还需要引入异步复制的备机节点。所以整体架构调整为:
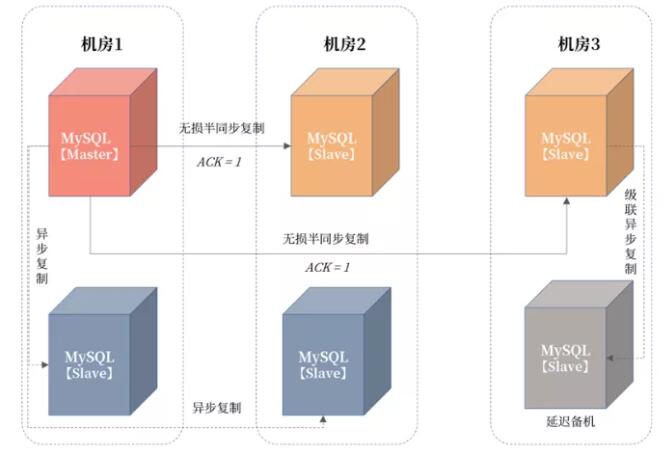
从图中可以看到,我们加入两个异步复制的节点,用于业务实现读写分离,另外再从机房 3 的备机中, 引入一个异步复制的延迟备机,用于做数据误删除操作的恢复 。
当设计成类似上述的架构时,你才能认为自己的同城容灾架构是合格的!
另一个重要的点:因为机房 1 中的主服务器要向四个从服务器发送日志, 这时网卡有成为瓶颈的可能,所以请务必配置万兆网卡 。
在明白三园区架构后,要实现跨城容灾也就非常简单了, 只要把三个机房放在不同城市就行。但这样的设计,当主服务器发生宕机时,数据库就会切到跨城,而跨城之间的网络延迟超过了25 ms。所以, 跨城容灾一般设计成“三地五中心”的架构 ,如下图所示:
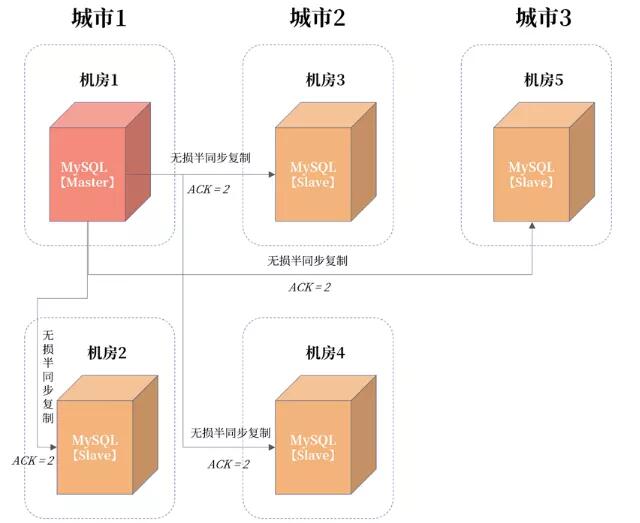
由于有五个机房,所以 ACK 设置为 2,保证至少一份数据在两个机房有数据。这样当发生城市级故障,则城市 2 或城市 3 中,至少有一份完整的数据。
在真实的互联网业务场景中,“三地五中心”应用并不像“三园区”那样普遍。这是因为 25ms的延迟对业务的影响非常大, 一般这种架构应用于读多写少的场景,比如用户中心 。
另外,真实的互联网业务场景中,实现跨城容灾,一般基于同城容灾架构,然后再由业务层来保障跨城的数据一致性。
五、 兜底策略:数据核对
到目前为止,我们的高可用是基于 MySQL 的复制技术。但你有没有想过这样几个问题:
万一数据库的复制有 Bug 呢?导致最终的数据在逻辑上不一致呢?主从的数据一定一致吗?你如何判断一定一致呢?
所以,除了高可用的容灾架构设计,我们还要做一层兜底服务,用于判断数据的一致性。这里要引入数据核对,用来解决以下两方面的问题。
数据在业务逻辑上一致 :这个保障业务是对的;
主从服务器之间的数据一致 :这个保障从服务器的数据是安全的、可切的。
业务逻辑核对由业务的同学负责编写 , 从整个业务逻辑调度看账平不平。例如“今天库存的消耗”是否等于“订单明细表中的总和”,“在途快递” + “已收快递”是否等于“已下快递总和”。总之,这是个业务逻辑,用于对账。
主从服务器之间的核对,是由数据库团队负责的 。需要额外写一个主从核对服务,用于保障主从数据的一致性。这个核对不依赖复制本身,也是一种逻辑核对。思路是:将最近一段时间内主服务器上变更过的记录与从服务器核对,从逻辑上验证是否一致。其实现如图所示:
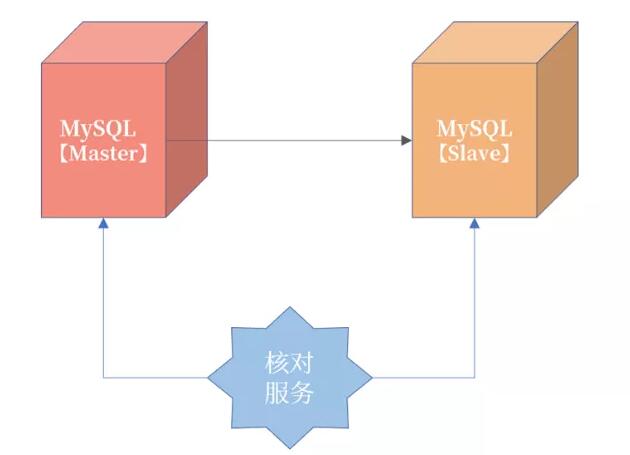
那么现在的难题是:如何判断最近一段时间内主服务器上变更过的记录?这里有两种思路:
1) 表结构设计规范中,有讲过每张表有一个 last_modify_date,用于记录每条记录的最后修改时间,按照这个条件过滤就能查出最近更新的记录,然后每条记录比较即可。
2) 核对服务扫描最近的二进制日志,筛选出最近更新过记录的表和主键,然后核对数据。这种的实现难度会更大一些,但是不要求在数据库上进行查询。
如果在核对过程中,记录又在主上发生了变化,但是还没有同步到从机,我们可以加入复核逻辑,按理来说多复核几次,主从数据应该就一致了。如果复核多次不一致,那么大概率,主从数据就已经是不一致的了。
核对服务的逻辑比较简单,但是要实现线上业务的数据核对,开发上还是有一些挑战,但这不就是我们 DBA 的价值所在吗?
总结
小编沐子总结了数据库高可用的架构设计,内容非常干货,建议你反复阅读,其中涉及的内容在原理上并不复杂,但在实现细节上需要不断打磨,欢迎你在后续的架构设计过程中与我交流,总结来说:
1. 核心业务复制务必为无损半同步复制;
2. 同城容灾使用三园区架构,一地三中心,或者两地三中心,机房见网络延迟不超过5ms;
3. 跨城容灾使用"三地五中心",跨城机房距离超过200KM,延迟超过25ms;
4. 跨城容灾架构由于网络耗时高,因此一般仅用于读多写少的业务,例如用户中心;
5. 除了复制进行数据同步外,还需要额外的核对程序进行逻辑核对;
6. 数据库层的逻辑核对,可以使用last_modify_date字段,取出最近修改的记录。
|









