| БрМЭЦМі: |
БОЮФжївЊећРэСЫвЛаЉеыЖдКЃСПЪ§ОнКЭИпВЂЗЂЧщПіЯТЕФНтОіЗНАИ
ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
РДздгкCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЭјеОгІгУБГОА
ПЊЗЂвЛИіЭјеОЕФгІгУГЬађЃЌЕБгУЛЇЙцФЃБШНЯаЁЕФЪБКђЃЌЪЙгУМђЕЅЕФЃКвЛЬЈгІгУЗўЮёЦї+вЛЬЈЪ§ОнПтЗўЮёЦї+вЛЬЈЮФМўЗўЮёЦїЃЌетбљЕФЛАЭъШЋПЩвдНтОівЛВПЗжЮЪЬтЃЌвВПЩвдЭЈЙ§ЖбгВМўЕФЗНЪНРДЬсИпЭјеОгІгУЕФЗУЮЪадФмЃЌЕБШЛЃЌвВвЊПМТЧГЩБОЕФЮЪЬтЁЃ
ЕБЮЪЬтЕФЙцФЃдкОМУЬѕМўЯТЭЈЙ§ЖбгВМўЕФЗНЪННтОіВЛСЫЕФЪБКђЃЌЮвУЧгІИУЭЈЙ§ЦфЫћЕФЫМТЗШЅНтОіЮЪЬтЃЌЛЅСЊЭјЗЂеЙжСНёЃЌвбОЬсЙЉСЫКмЖрГЩЪьЕФНтОіЗНАИЃЌЕЋВЂВЛЪЧЖМОпгаЪЪгУадЃЌФуАбЬдБІЕФММЪѕШЋВПЖМАсЙ§РДвВВЛвЛЖЈДяЕНЯждкЬдБІЕФЫЎЦНЃЌЕРРэКмМђЕЅЁЃ
ЕБШЛЃЌКмЖрЮФеТЖМдкЧПЕїЃЌвЛИіЭјеОЕФЗЂеЙЫЎЦНЃЌЪЧж№НЅЕФбнБфЙ§РДЕФЃЌВЂВЛЪЧвЛГЏвЛЯІЕФЪТЧщЁЃЫфШЛФПЧАЕФЧщПіЛЅСЊЭјЕФХнФдНРДдНДѓЃЌЕЋЪЧећИіЛЅСЊЭјММЪѕЕФЗЂеЙШЗЪЕЮЊЮвУЧЬсЙЉСЫЗНБуПьНнЕФЩЯЭјЬхбщЁЃЯТБпЪЧвЛеХдчЦкЕФЬдБІЙйЭјЕФНчУцЃК

ЖўЁЂеыЖдКЃСПЪ§ОнКЭИпВЂЗЂЕФжївЊНтОіЗНАИ
КЃСПЪ§ОнЕФНтОіЗНАИЃК
1.ЪЙгУЛКДцЃЛ
2.вГУцОВЬЌЛЏММЪѕЃЛ
3.Ъ§ОнПтгХЛЏЃЛ
4.ЗжРыЪ§ОнПтжаЛюдОЕФЪ§ОнЃЛ
5.ХњСПЖСШЁКЭбгГйаоИФЃЛ
6.ЖСаДЗжРыЃЛ
7.ЪЙгУNoSQLКЭHadoopЕШММЪѕЃЛ
8.ЗжВМЪНВПЪ№Ъ§ОнПтЃЛ
9.гІгУЗўЮёКЭЪ§ОнЗўЮёЗжРыЃЛ
10.ЪЙгУЫбЫїв§ЧцЫбЫїЪ§ОнПтжаЕФЪ§ОнЃЛ
11.НјаавЕЮёЕФВ№ЗжЃЛ
ИпВЂЗЂЧщПіЯТЕФНтОіЗНАИЃК
1.гІгУГЬађКЭОВЬЌзЪдДЮФМўНјааЗжРыЃЛ
2.вГУцЛКДцЃЛ
3.МЏШКгыЗжВМЪНЃЛ
4.ЗДЯђДњРэЃЛ
5.CDNЃЛ
Ш§ЁЂКЃСПЪ§ОнЕФНтОіЗНАИ
ЃЈ1ЃЉЪЙгУЛКДц
ЭјеОЗУЮЪЪ§ОнЕФЬиЕуДѓЖрЪ§ГЪЯжЮЊЁАЖўАЫЖЈТЩЁБЃК80%ЕФвЕЮёЗУЮЪМЏжадк20%ЕФЪ§ОнЩЯЁЃ
Р§ШчЃКдкФГвЛЖЮЪБМфФкАйЖШЕФЫбЫїШШДЪПЩФмМЏжадкЩйВПЗжЕФШШУХДЪЛуЩЯЃЛаТРЫЮЂВЉФГвЛЪБЦквВПЩФмДѓМвЙуЗКЙизЂЕФжїЬтвВЪЧЩйВПЗжЪТМўЁЃ
змЕФРДЫЕОЭЪЧгУЛЇжЛгУЕНСЫзмЪ§ОнЬѕФПЕФвЛаЁВПЗжЃЌЕБЭјеОЗЂеЙЕНвЛЖЈЙцФЃЃЌЪ§ОнПтIOВйзїГЩЮЊадФмЦПОБЕФЪБКђЃЌЪЙгУЛКДцНЋетвЛаЁВПЗжЕФШШУХЪ§ОнЛКДцдкФкДцжаЪЧвЛИіКмВЛДэЕФбЁдёЃЌВЛЕЋПЩвдМѕЧсЪ§ОнПтЕФбЙСІЃЌЛЙПЩвдЬсИпећЬхЭјеОЕФЪ§ОнЗУЮЪЫйЖШЁЃ
ЪЙгУЛКДцЕФЗНЪНПЩвдЭЈЙ§ГЬађДњТыНЋЪ§ОнжБНгБЃДцЕНФкДцжаЃЌР§ШчЭЈЙ§ЪЙгУMapЛђепConcurrentHashMapЃЛСэвЛжжЃЌОЭЪЧЪЙгУЛКДцПђМмЃКRedisЁЂEhcacheЁЂMemcacheЕШЁЃ

ЪЙгУЛКДцПђМмЕФЪБКђЃЌЮвУЧашвЊЙиаФЕФОЭЪЧЪВУДЪБКђДДНЈЛКДцКЭЛКДцЪЇаЇВпТдЁЃ
ЛКДцЕФДДНЈПЩвдЭЈЙ§КмЖрЕФЗНЪННјааДДНЈЃЌОпЬхвВашвЊИљОнздМКЕФвЕЮёНјаабЁдёЁЃР§ШчЃЌаТЮХЪзвГЕФаТЮХгІИУдкЕквЛДЮЖСШЁЪ§ОнЕФЪБКђОЭНјааЛКДцЃЛЖдгкЕуЛїТЪБШНЯИпЕФЮФеТЃЌПЩвдНЋЦфЮФеТФкШнНјааЛКДцЕШЁЃ
ФкДцзЪдДгаЯоЃЌбЁдёШчКЮДДНЈЛКДцЪЧвЛИіжЕЕУЫМПМЕФЮЪЬтЁЃСэЭтЃЌЖдгкЛКДцЕФЪЇаЇЛњжЦвВЪЧашвЊКУКУбаОПЕФЃЌПЩвдЭЈЙ§ЩшжУЪЇаЇЪБМфЕФЗНЪННјааЩшжУЃЛвВПЩвдЭЈЙ§ЖдШШУХЪ§ОнЩшжУгХЯШМЖЃЌИљОнВЛЭЌЕФгХЯШМЖЩшжУВЛЭЌЕФЪЇаЇЪБМфЕШЃЛ
ашвЊзЂвтЕФЪЧЃЌЕБЮвУЧЩОГ§вЛЬѕЪ§ОнЕФЪБКђЃЌЮвУЧвЊПМТЧЕНЩОГ§ИУЬѕЛКДцЃЌЛЙвЊПМТЧдкЩОГ§ИУЬѕЛКДцжЎЧАИУЬѕЪ§ОнЪЧЗёвбОЕНДяЛКДцЪЇаЇЪБМфЕШИїжжЧщПіЃЁ
ЪЙгУЛКДцЕФЪБКђЛЙвЊПМТЧЕНЛКДцЗўЮёЦїЗЂЩњЙЪеЯЪБКђШчКЮНјааШнДэДІРэЃЌЪЧЪЙгУNЖрЬЈЗўЮёЦїЛКДцЯрЭЌЕФЪ§ОнЃЌЭЈЙ§ЗжВМЪНВПЪ№ЕФЗНЪНЖдЛКДцЪ§ОнНјааПижЦЃЌЕБвЛЬЈЗЂЩњЙЪеЯЕФЪБКђздЖЏЧаЛЛЕНЦфЫћЕФЛњЦїЩЯШЅЃЛЛЙЪЧЭЈЙ§HashвЛжТадЕФЗНЪНЃЌЕШД§ЛКДцЗўЮёЦїЛжИДе§ГЃЪЙгУЕФЪБКђжиаТжИЖЈЕНИУЛКДцЗўЮёЦїЁЃHashвЛжТадЕФСэвЛИізїгУОЭЪЧдкЗжВМЪНЛКДцЗўЮёЦїЯТЖдЪ§ОнНјааЖЈЮЛЃЌНЋЪ§ОнЗжВМдкВЛгУЛКДцЗўЮёЦїЩЯЁЃЙигкЪ§ОнЛКДцЕФHashвЛжТадвВЪЧвЛИіБШНЯДђЕФЮЪЬтЃЌетРяжЛФмДѓжТУшЪівЛЯТЃЌЙигкHashвЛжТадЕФСЫНтЁЃ
ЃЈ2ЃЉвГУцОВЬЌЛЏММЪѕ
ЪЙгУДЋЭГЕФJSPНчУцЃЌЧАЖЫНчУцЕФЯдЪОЪЧЭЈЙ§КѓЬЈЗўЮёЦїНјаафжШОКѓЗЕЛиИјЧАЖЫгЮРРЦїНјааНтЮіжДааЃЌШчЯТЭМЃК
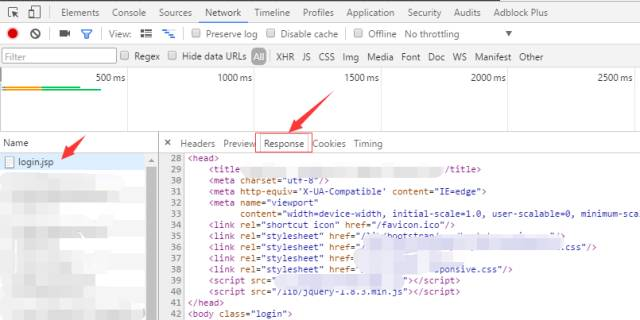
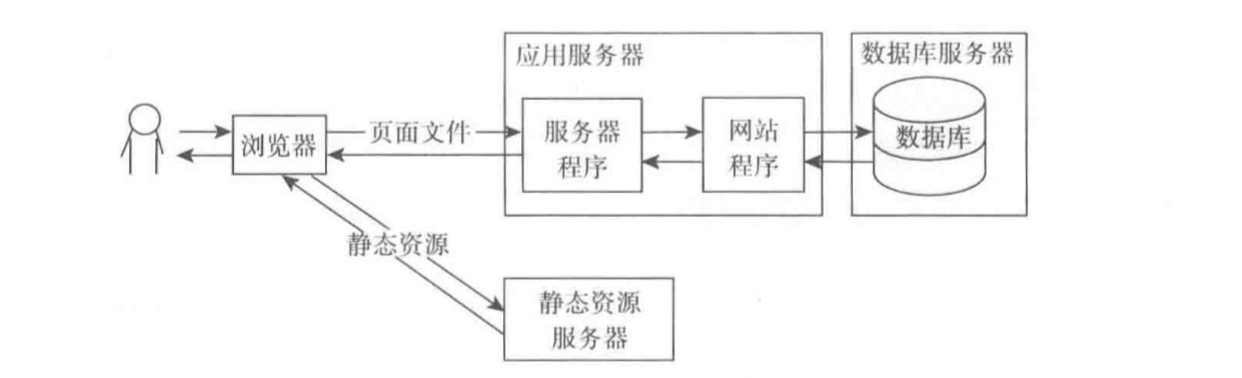
ЕБШЛЃЌЯждкЬсГЋЧАКѓЖЫЗжРыЃЌЧАЖЫНчУцЛљБОЖМЪЧHTMLЭјвГДњТыЃЌЭЈЙ§Angular JSЛђепNodeJSЬсЙЉЕФТЗгЩЯђКѓЖЫЗўЮёЦїЗЂГіЧыЧѓЛёШЁЪ§ОнЃЌШЛКѓдкгЮРРЦїЖдЪ§ОнНјаафжШОЃЌетбљдкКмДѓГЬЖШЩЯНЕЕЭСЫКѓЖЫЗўЮёЦїЕФбЙСІЁЃ
ЛЙПЩвдНЋетаЉОВЬЌЕФHTMLЁЂCSSЁЂJSЁЂЭМЦЌзЪдДЕШЗХжУдкЛКДцЗўЮёЦїЩЯЛђепCDNЗўЮёЦїЩЯЃЌвЛАуЪЙгУзюЖрЕФгІИУЪЧCDNЗўЮёЦїЛђепNginxЗўЮёЦїЬсЙЉЕФОВЬЌзЪдДЙІФмЁЃ
СэЭтЃЌдкЁЖИпадФмЭјеОНЈЩшНјНзжИФЯ-WebПЊЗЂепадФмгХЛЏзюМбЪЕМљЃЈПкБЎЭјЧАЖЫЭХЖг ЗвыЃЉЁЗетБОЪщжаЃЌЖдЭјеОадФмЕФЧАЖЫНчУцЬсЙЉСЫвЛаЉКмБІЙѓЕФОбщЃЌШчЯТЃК

вђДЫЃЌдкетаЉОВЬЌзЪдДЕФДІРэЩЯЃЌбЁдёе§ШЗЕФДІРэЗНЪНЛЙЪЧЖдећЬхЭјеОадФмЛЙЪЧгаКмДѓАяжњЕФЃЁ
ЃЈ3ЃЉЪ§ОнПтгХЛЏ
Ъ§ОнПтгХЛЏЪЧећИіЭјеОадФмгХЛЏЕФзюЛљДЁЕФвЛИіЛЗНкЃЌвђЮЊЃЌДѓЖрЪ§ЭјеОадФмЕФЦПОБЖМЪЧПЊдкЪ§ОнПтIOВйзїЩЯЃЌЫфШЛЬсЙЉСЫЛКДцММЪѕЃЌЕЋЪЧЖдЪ§ОнПтЕФгХЛЏЛЙЪЧвЛИіашвЊШЯецЕФЖдД§ЁЃвЛАуЙЋЫОЖМгаздМКЕФDBAЭХЖгЃЌИКд№Ъ§ОнПтЕФДДНЈЃЌЪ§ОнФЃаЭЕФШЗСЂЕШЮЪЬтЃЌВЛЯёЮвУЧЯждкМИИіВЛЖЎЪ§ОнПтгХЛЏЕФШЫжЛФмдкЭјЩЯеввЛЦЊЦЊЪ§ОнПтгХЛЏЕФЮФеТЃЌздМКШЅУўЫїЃЌВЂУЛгааЮГЩвЛИіЯЕЭГЕФЪ§ОнПтгХЛЏЫМТЗЁЃ
ЖдгкЪ§ОнПтЕФгХЛЏРДЫЕЃЌЪЧвЛжжгУММЪѕЛЛН№ЧЎЕФЗНЪНЁЃЪ§ОнПтгХЛЏЕФЗНЪНКмЖрЃЌГЃМћЕФПЩвдЗжЮЊЃКЪ§ОнПтБэНсЙЙгХЛЏЁЂSQLгяОфгХЛЏЁЂЗжЧјЁЂЗжБэЁЂЫїв§гХЛЏЁЂЪЙгУДцДЂЙ§ГЬДњЬцжБНгВйзїЕШ
ЁЃ
1ЁЂБэНсЙЙгХЛЏ
ЖдгкЪ§ОнПтЕФ ПЊЗЂЙцЗЖгыЪЙгУММЧЩвдМАЩшМЦКЭгХЛЏЃЌЧАБпЕФЪБКђзмНсСЫвЛаЉЮФеТЃЌетРяЭЕИіРСжБНгЗХЕижЗЃЌгаашвЊЕФПЩвдвЦВНПДвЛЯТЃК
a) MySQLПЊЗЂЙцЗЖгыЪЙгУММЧЩзмНсЃКhttp://blog.csdn.net/xlgen157387/article/details/48086607
b) дквЛИіЧЇЭђМЖЕФЪ§ОнПтВщбАжаЃЌШчКЮЬсИпВщбЏаЇТЪhttp://blog.csdn.net/xlgen157387/article/details/44156679
СэЭтЃЌдйЩшМЦЪ§ОнПтБэЕФЪБКђашВЛашвЊДДНЈЭтМќЃЌЪЙгУЭтМќЕФКУДІжЎвЛПЩвдЗНБуЕФНјааМЖСЊЩОГ§ВйзїЃЌЕЋЪЧЯждкдкНјааЪ§ОнвЕЮёВйзїЕФЪБКђЃЌЮвУЧЖМЭЈЙ§ЪТЮяЕФЗНЪНРДБЃжЄЪ§ОнЖСШЁВйзїЕФвЛжТадЃЌЮвИаОѕЯрБШгкЪЙгУЭтМќЙиСЊMySQLздЖЏАяЮвУЧЭъГЩМЖСЊЩОГ§ЕФВйзїРДЫЕЃЌЛЙЪЧздМКЪЙгУЪТЮяНјааЩОГ§ВйзїРДЕФИќЗХаФвЛаЉЁЃЕБШЛПЩФмвВЪЧгаЪЪгУЕФГЁОАЃЌДѓМвШчгаКмКУЕФНЈвщЃЌЛЖгСєбдЃЁ
2ЁЂSQLгХЛЏ
ЖдгкSQLЕФгХЛЏЃЌжївЊЪЧеыЖдSQLгяОфДІРэТпМЕФгХЛЏЃЌЖјЧвЛЙвЊИљОнЫїв§НјааХфКЯЪЙгУЁЃСэЭтЃЌЖдгкSQLгяОфЕФгХЛЏЮвУЧПЩвдеыЖдОпЬхЕФвЕЮёЗНЗЈНјаагХЛЏЃЌЮвУЧПЩвдНЋжДаавЕЮёТпМВйзїЕФЪ§ОнПтжДааЪБМфМЧТМЯТРДЃЌРДНјаагаеыЖдадЕФгХЛЏЃЌетбљЕФЛАаЇЙћЛЙЪЧКмВЛДэЕФЃЁР§ШчЯТЭМЃЌеЙЪОСЫвЛЬѕЪ§ОнПтВйзїжДааЕїгУЕФЪБМфЃК

ЙигкSQLгХЛЏЕФвЛаЉНЈвщЃЌвдЧАећРэСЫвЛаЉЃЌЛЙЧывЦВНВщПДЃК
a) 19ИіMySQLадФмгХЛЏвЊЕуНтЮіЃКhttp://blog.csdn.net/xlgen157387/article/details/50735269
b) MySQLХњСПSQLВхШыИїжжадФмгХЛЏЃКhttp://blog.csdn.net/xlgen157387/article/details/50949930
ЗжБэ
ЗжБэЪЧНЋвЛИіДѓБэАДеевЛЖЈЕФЙцдђЗжНтГЩЖреХОпгаЖРСЂДцДЂПеМфЕФЪЕЬхБэЃЌЮвУЧПЩвдГЦЮЊзгБэЃЌУПИіБэЖМЖдгІШ§ИіЮФМўЃЌMYDЪ§ОнЮФМўЃЌ.MYIЫїв§ЮФМўЃЌ.frmБэНсЙЙЮФМўЁЃетаЉзгБэПЩвдЗжВМдкЭЌвЛПщДХХЬЩЯЃЌвВПЩвддкВЛЭЌЕФЛњЦїЩЯЁЃЪ§ОнПтЖСаДВйзїЕФЪБКђИљОнЪТЯШЖЈвхКУЕФЙцдђЕУЕНЖдгІЕФзгБэУћЃЌШЛКѓШЅВйзїЫќЁЃ
Р§ШчЃКгУЛЇБэ
гУЛЇЕФНЧЩЋгаКмЖржжЃЌПЩвдЭЈЙ§УЖОйРраЭЕФЗНЪННЋгУЛЇЗжЮЊВЛЭЌРрБ№categoryЃКбЇЩњЁЂНЬЪІЁЂЦѓвЕЕШ ЃЌетбљЕФЛАЃЌЮвУЧОЭПЩвдИљОнРрБ№categoryРДЖдЪ§ОнПтНјааЗжБэЃЌетбљЕФЛАУПДЮВщбЏЕФЪБКђЯжИљОнгУЛЇЕФРраЭЫјЖЈвЛИіНЯаЁЕФЗЖЮЇЁЃ
ВЛЙ§ЗжБэжЎКѓЃЌШчЙћашвЊВщбЏЭъећЕФЫГађОЭашвЊЪЙгУЖрБэВйзїСЫЁЃ
ЗжЧј
Ъ§ОнПтЗжЧјЪЧвЛжжЮяРэЪ§ОнПтЩшМЦММЪѕЃЌDBAКЭЪ§ОнПтНЈФЃШЫдБЖдЦфЯрЕБЪьЯЄЁЃЫфШЛЗжЧјММЪѕПЩвдЪЕЯжКмЖраЇЙћЃЌЕЋЦфжївЊФПЕФЪЧЮЊСЫдкЬиЖЈЕФSQLВйзїжаМѕЩйЪ§ОнЖСаДЕФзмСПвдЫѕМѕЯьгІЪБМфЁЃ
ЗжЧјКЭЗжБэЯрЫЦЃЌЖМЪЧАДееЙцдђЗжНтБэЁЃВЛЭЌдкгкЗжБэНЋДѓБэЗжНтЮЊШєИЩИіЖРСЂЕФЪЕЬхБэЃЌЖјЗжЧјЪЧНЋЪ§ОнЗжЖЮЛЎЗждкЖрИіЮЛжУДцЗХЃЌПЩвдЪЧЭЌвЛПщДХХЬвВПЩвддкВЛЭЌЕФЛњЦїЁЃЗжЧјКѓЃЌБэУцЩЯЛЙЪЧвЛеХБэЃЌЕЋЪ§ОнЩЂСаЕНЖрИіЮЛжУСЫЁЃЪ§ОнПтЖСаДВйзїЕФЪБКђВйзїЕФЛЙЪЧДѓБэУћзжЃЌDMSздЖЏШЅзщжЏЗжЧјЕФЪ§ОнЁЃ
ЕБвЛеХБэжаЕФЪ§ОнБфЕУКмДѓЕФЪБКђЃЌЖСШЁЪ§ОнЃЌВщбЏЪ§ОнЕФаЇТЪЗЧГЃЕЭЯТЃЌКмШнвзЕФОЭЪЧНВЪ§ОнЗжЕНВЛЭЌЕФЪ§ОнБэжаНјааБЃДцЃЌЕЋЪЧетбљЗжБэжЎКѓЛсЪЙЕУВйзїЦ№РДБШНЯТщЗГЃЌвђЮЊЃЌНЋЭЌРрЕФЪ§ОнЗжБ№ЗХдкВЛЭЌЕФБэжаЕФЛАЃЌдкЫбЫїЪ§ОнЕФЪБКђашвЊБуРћВщбЏетаЉБэжаЕФЪ§ОнЁЃЯыНјааCRUDВйзїЛЙашвЊЯШевЕНЖдгІЕФЫљгаБэЃЌШчЙћЩцМАЕНВЛЭЌЕФБэЕФЛАЛЙвЊНјааПчБэВйзїЃЌетбљВйзїЦ№РДЛЙЪЧКмТщЗГЕФЁЃ
ЪЙгУЗжЧјЕФЗНЪНПЩвдНтОіетИіЮЪЬтЃЌЗжЧјЪЧНЋвЛеХБэжаЕФЪ§ОнАДеевЛЖЈЕФЙцдђЗжЕНВЛЭЌЕФЧјжаНјааБЃДцЃЌетбљНјааЪ§ОнВщбЏЕФЪБКђШчЙћЪ§ОнЕФЗЖЮЇдкЭЌвЛИіЧјгђФкФЧУДОЭПЩвджЇЖгвЛИіЧјжаЕФЪ§ОнНјааВйзїЃЌетбљЕФЛАВйзїЦ№РДЪ§ОнСПИќЩйЃЌВйзїЫйЖШИќПьЃЌЖјЧвИУЗНЗЈЪЧЖдГЬађЭИУїЕФЃЌГЬађВЛашвЊНјааШЮКЮЕФаоИФЁЃ
Ыїв§гХЛЏ
Ыїв§ЕФДѓжТдРэЪЧдкЪ§ОнЗЂЩњБфЛЏЕФЪБКђОЭдЄЯШАДжИЖЈзжЖЮЕФЫГађХХСаКѓБЃДцЕНвЛИіРрЫЦБэЕФНсЙЙжаЃЌетбљдкВщевЫїв§зжЖЮЮЊЬѕМўМЧТМЪБОЭПЩвдКмПьЕиДгЫїв§жаевЕНЖдгІМЧТМЕФжИеыВЂДгБэжаЛёШЁЕНЯргІЕФЪ§ОнЃЌетбљЫйЖШЪЧКмПьЕиЁЃ
ВЛЙ§ЃЌЫфШЛВщбЏЕФаЇТЪДѓДѓЬсИпСЫЃЌЕЋЪЧдкНјаадіЩОИФЕФЪБКђЃЌвђЮЊЪ§ОнЕФБфЛЏЖМашвЊИќаТЯргІЕФЫїв§ЃЌвВЪЧвЛжжзЪдДЕФРЫЗбЁЃ
ЙигкЪЙгУЫїв§ЕФЮЪЬтЃЌЖдД§ВЛЭЌЕФЮЪЬтЃЌЛЙЪЧашвЊНјааВЛЭЌЕФЬжТлЃЌИљОнОпЬхЕФвЕЮёашЧѓбЁдёКЯЪЪЕФЫїв§ЖдадФмЕФЬсИпаЇЙћЪЧКмУїЯдЕФвЛИіОйДыЃЁ
ЭЦМіЮФеТдФЖСЃК
a) Ъ§ОнПтЫїв§ЕФзїгУКЭгХЕуШБЕувдМАЫїв§ЕФ11жагУЗЈЃКhttp://blog.csdn.net/xlgen157387/article/details/45030829
b) Ъ§ОнПтЫїв§дРэЃКhttp://blog.csdn.net/kennyrose/article/details/7532032
ЪЙгУДцДЂЙ§ГЬДњЬцжБНгВйзї
ДцДЂЙ§ГЬЃЈStored ProcedureЃЉЪЧдкДѓаЭЪ§ОнПтЯЕЭГжаЃЌвЛзщЮЊСЫЭъГЩЬиЖЈЙІФмЕФSQL гяОфМЏЃЌДцДЂдкЪ§ОнПтжаЃЌОЙ§ЕквЛДЮБрвыКѓдйДЮЕїгУВЛашвЊдйДЮБрвыЃЌгУЛЇЭЈЙ§жИЖЈДцДЂЙ§ГЬЕФУћзжВЂИјГіВЮЪ§ЃЈШчЙћИУДцДЂЙ§ГЬДјгаВЮЪ§ЃЉРДжДааЫќЁЃДцДЂЙ§ГЬЪЧЪ§ОнПтжаЕФвЛИіживЊЖдЯѓЃЌШЮКЮвЛИіЩшМЦСМКУЕФЪ§ОнПтгІгУГЬађЖМгІИУгУЕНДцДЂЙ§ГЬЁЃ
дкВйзїЙ§ГЬБШНЯИДдгВЂЧвЕїгУЦЕТЪБШНЯИпЕФвЕЮёжаЃЌПЩвдНЋБраДКУЕФsqlгяОфгУДцДЂЙ§ГЬЕФЗНЪНРДДњЬцЃЌЪЙгУДцДЂЙ§ГЬжЛашвЊНјаавЛДЮБфвьЃЌЖјЧвПЩвддквЛИіДцДЂЙ§ГЬРязівЛаЉИДдгЕФВйзїЁЃ
ЃЈ4ЃЉЗжРыЪ§ОнПтжаЛюдОЕФЪ§Он
е§ШчЧАБпЬсЕНЕФЁАЖўАЫЖЈТЩЁБвЛбљЃЌЭјеОЕФЪ§ОнЫфШЛКмЖрЃЌЕЋЪЧОГЃБЛЗУЮЪЕФЪ§ОнЛЙЪЧгаЯоЕФЃЌвђДЫПЩвдНВетаЉЯрЖдЛюдОЕФЪ§ОнНјааЗжРыГіРДЕЅЖРНјааБЃДцРДЬсИпДІРэаЇТЪЁЃ
ЦфЪЕЧАБпЪЙгУЛКДцЕФЫМЯыОЭЪЧвЛИіКмУїЯдЕФЗжРыЪ§ОнПтжаЛюдОЕФЪ§ОнЕФЪЙгУАИР§ЃЌНЋШШУХЪ§ОнЛКДцдкФкДцжаЁЃ
ЛЙгавЛжжГЁОАОЭЪЧЃЌР§ШчвЛИіЭјеОЕФЫљгУзЂВсгУЛЇСПКмДѓЧЇЭђМЖБ№ЃЌЕЋЪЧОГЃЕЧТМЕФгУЛЇжЛгаАйЭђМЖБ№ЃЌЪЃЯТЕФЛљБОЖМЪЧКмГЄЪБМфЖМУЛгаНјааЕЧТМВйзїЃЌШчЙћВЛАбетаЉЁАНЉЪЌгУЛЇЁБЕЅЖРЗжРыГіШЅЃЌФЧУДЮвУЧУПДЮВщбЏЦфЫћЕЧТМгУЛЇЕФЪБКђЃЌОЭАзАзРЫЗбСЫетаЉНЉЪЌгУЛЇЕФВщбЏВйзїЁЃ
ЃЈ5ЃЉХњСПЖСШЁКЭбгГйаоИФ
ХњСПЖСШЁКЭбгГйаоИФЕФдРэЪЧЭЈЙ§МѕЩйВйзїЪ§ОнПтЕФВйзїРДЬсИпаЇТЪЁЃ
ХњСПЖСШЁЪЧНЋЖрДЮВщбЏКЯВЂЕНвЛДЮжаНјааЖСШЁЃЌвђЮЊУПвЛИіЪ§ОнПтЕФЧыЧѓВйзїЖМашвЊСДНгЕФНЈСЂКЭСДНгЕФЪЭЗХЃЌЛЙЪЧеМгУвЛВПЗжзЪдДЕФЃЌХњСПЖСШЁПЩвдЭЈЙ§вьВНЕФЗНЪННјааЖСШЁЁЃ
бгГйаоИФЪЧЖдгквЛаЉИпВЂЗЂЕФВЂЧваоИФЦЕЗБаоИФЕФЪ§ОнЃЌдкУПДЮаоИФЕФЪБКђЪзЯШНЋЪ§ОнБЃДцЕНЛКДцжаЃЌШЛКѓЖЈЪБНЋЛКДцжаЕФЪ§ОнБЃДцЕНЪ§ОнПтжаЃЌГЬађПЩвддкЖСШЁЪ§ОнЪБПЩвдЭЌЪБЖСШЁЪ§ОнПтжаКЭЛКДцжаЕФЪ§ОнЁЃ
Р§ШчЃКЮвЯждкдкБраДетЗнВЉПЭЃЌЮввЛПЊЪМаДСЫвЛаДФкШнШЛКѓЕуЛїЗЂВМСЫЃЌдкДЮЛиЕНMarkdownНјаааоИФВйзїЃЌЮвгавЛИіЯАЙпЃЌУЛаДвЛаЉЖЋЮїзмЪЧАДвЛЯТЩЯБпЕФ
ЁАБЃДцЁБАДХЅЃЌШЛКѓЮвдкСэвЛИівГУцДђПЊетЦЊВЉПЭВщПДЃЌЮвЕФаоИФвбОБЛИќаТЃЌЕЋЪЧЮвЛЙдк БрМЃЁ

ВЛжЊЕРCSDNЕФММЪѕЪЧВЛЪЧдкЮвУЛгаЕуЛїЗЂВМжЎЧАЃЌетаЉЪ§ОнЖМЪЧЯШЗХЕНЛКДцРяБпЕФЁЃ
ЃЈ6ЃЉ ЖСаДЗжРы
ЖСаДЗжРыЕФЪЕжЪЪЧНЋгІгУГЬађЖдЪ§ОнПтЕФЖСаДВйзїЗжХфЕНЖрИіЪ§ОнПтЗўЮёЦїЩЯЃЌДгЖјНЕЕЭЕЅЬЈЪ§ОнПтЕФЗУЮЪбЙСІЁЃ
ЖСаДЗжРывЛАуЭЈЙ§ХфжУжїДгЪ§ОнПтЕФЗНЪНЃЌЪ§ОнЕФЖСШЁРДздДгПтЃЌЖдЪ§ОнПтдіМгаоИФЩОГ§ВйзїжїПтЁЃ

ЯрЙиЮФеТЧывЦВНЙлПДЃК
a) MySQL5.6 Ъ§ОнПтжїДгЃЈMaster/SlaveЃЉЭЌВНАВзАгыХфжУЯъНтЃКhttp://blog.csdn.net/xlgen157387/article/details/51331244
b) MySQLжїДгИДжЦЕФГЃМћЭиЦЫЁЂдРэЗжЮівдМАШчКЮЬсИпжїДгИДжЦЕФаЇТЪзмНс:http://blog.csdn.net/xlgen157387/article/details/52451613
ЃЈ7ЃЉЪЙгУNoSQLКЭHadoopЕШММЪѕ
NoSQLЪЧвЛжжЗЧНсЙЙЛЏЕФЗЧЙиЯЕаЭЪ§ОнПтЃЌгЩгкЦфСщЛюадЃЌЭЛЦЦСЫЙиЯЕаЭЪ§ОнПтЕФЬѕЬѕПђПђЃЌПЩвдСщЛюЕФНјааВйзїЃЌСэЭтЃЌвђЮЊNoSQLЭЈЙ§ЖрИіПщДцДЂЪ§ОнЕФЬиЕуЃЌЦфВйзїДѓЪ§ОнЕФЫйЖШвВЪЧЯрЕБПьЕФЁЃ
ЃЈ8ЃЉЗжВМЪНВПЪ№Ъ§ОнПт
ШЮКЮЧПДѓЕФЕЅвЛЗўЮёЦїЖМТњзуВЛСЫДѓаЭЭјеОГжајдіГЄЕФвЕЮёашЧѓЁЃЪ§ОнПтЭЈЙ§ЖСаДЗжРыжЎКѓНЋвЛЬЈЪ§ОнПтЗўЮёЦїВ№ЗжЮЊСНЬЈЛђепЖрЬЈЪ§ОнПтЗўЮёЦїЃЌЕЋЪЧШдШЛТњзуВЛСЫГжајдіГЄЕФвЕЮёашЧѓЁЃЗжВМЪНВПЪ№Ъ§ОнПтЪЧНЋЭјеОЪ§ОнПтВ№ЗжЕФзюКѓЪжЖЮЃЌжЛгадкЕЅБэЪ§ОнЙцФЃЗЧГЃХгДѓЕФЪБКђВХЪЙгУЁЃ
ЗжВМЪНВПЪ№Ъ§ОнПтЪЧвЛжжКмРэЯыЕФЧщПіЃЌЗжВМЪНЪ§ОнПтЪЧНЋБэДцЗХдкВЛЭЌЕФЪ§ОнПтжаШЛКѓдйЗХЕНВЛЭЌЕФЪ§ОнПтжаЃЌетбљдкДІРэЧыЧѓЕФЪБКђЃЌШчЙћашвЊЕїгУЖрИіБэЃЌдђПЩвдШУЖрЬЈЗўЮёЦїЭЌЪБДІРэЃЌДгЖјЬсИпДІРэаЇТЪЁЃ
ЗжВМЪНЪ§ОнПтМђЕЅЕФМмЙЙЭМШчЯТЃК

ЃЈ9ЃЉгІгУЗўЮёКЭЪ§ОнЗўЮёЗжРы
гІгУЗўЮёЦїКЭЪ§ОнПтЗўЮёЦїНјааЗжРыЕФФПЕФЪЧЮЊСЫИљОнгІгУЗўЮёЦїЕФЬиЕуКЭЪ§ОнПтЗўЮёЦїЕФЬиЕуНјааЕзВуЕФгХЛЏЃЌетбљЕФЛАФмЙЛИќКУЕФЗЂЛгУПвЛЬЈЗўЮёЦїЕФЬиадЃЌЪ§ОнПтЗўЮёЦїЕБШЛЪЧгавЛЖЈЕФДХХЬПеМфЃЌЖјгІгУЗўЮёЦїЯрЖдВЛашвЊЬЋДѓЕФДХХЬПеМфЃЌетбљЕФЛАНјааЗжРыЪЧгаКУДІЕФЃЌвВФмЗРжЙвЛЬЈЗўЮёЦїГіЯжЮЪЬтСЌДјЕФЦфЫћЗўЮёвВВЛПЩвдЪЙгУЁЃ

ЃЈ10ЃЉЪЙгУЫбЫїв§ЧцЫбЫїЪ§ОнПтжаЕФЪ§Он
ЪЙгУЫбЫїв§ЧцетжжЗЧЪ§ОнПтВщбЏММЪѕЖдЭјеОгІгУЕФПЩЩьЫѕЗжВМЪНЬиадОпгаИќКУЕФжЇГжЁЃ
ГЃМћЕФЫбЫїв§ЧцШчSolrЭЈЙ§вЛжжЗДЯђЫїв§ЕФЗНЪНЃЌЮЌЛЄЙиМќзжЕНЮФЕЕЕФгГЩфЙиЯЕЃЌРрЫЦгкЮвУЧЪЙгУЁЖаТЛЊзжЕфЁЗНјааЫбЫївЛИіЙиМќзжЃЌЪзЯШгІИУЪЧПДзжЕфЕФФПТМНјааВщевШЛКѓЖЈЮЛЕНОпЬхЕФЮЛжУЁЃ
ЫбЫїв§ЧцЭЈЙ§ЮЌЛЄвЛЖЈЕФЙиМќзжЕНЮФЕЕЕФгГЩфЙиЯЕЃЌФмЙЛПьЫйЕФЖЈЮЛЕНашвЊВщевЕФЪ§ОнЃЌЯрБШгкДЋЭГЕФЪ§ОнПтЫбЫїЕФЗНЪНЃЌаЇТЪЛЙЪЧКмИпЕФЁЃ
ФПЧАвЛжжБШНЯЛ№ЕФELK stackММЪѕЃЌЛЙЪЧжЕЕУбЇЯАЕФЁЃ
вЛЦЊЙигкSolrгыMySQLВщбЏадФмЖдБШЮФеТ
SolrгыMySQLВщбЏадФмЖдБШ
ЃЈ11ЃЉ НјаавЕЮёЕФВ№Зж
ЮЊЪВУДНјаавЕЮёЕФВ№ЗжЃЌЙщИљНсЕзЩЯЛЙЪЧЪЙгУЕФЛЙЪЧНВВЛЭЈЕФвЕЮёЪ§ОнБэВПЪ№ЕНВЛгУЕФЗўЮёЦїЩЯЃЌЗжБ№ВщевЖдгІЕФЪ§ОнвдТњзуЭјеОЕФашЧѓЁЃИїИігІгУжЎМфгУЙ§жИЖЈЕФURLСЌНгЛёШЁВЛЭЌЕФЗўЮёЃЌ
Р§ШчвЛИіДѓаЭЕФЙКЮяЭјеООЭЛсНЋЪзвГЁЂЩЬЦЬЁЂЖЉЕЅЁЂТђМвЁЂТєМвЕШВ№ЗжЮЊВЛЭЈЕФзгвЕЮёЃЌвЛЗНУцНЋвЕЮёФЃПщЗжЙщЮЊВЛЭЌЕФЭХЖгНјааПЊЗЂЃЌСэЭтвЛЗНУцВЛЭЌЕФвЕЮёЪЙгУЕФЪ§ОнПтБэВПЪ№ЕНВЛЭЈЕФЗўЮёЦїЩЯЃЌЬхЯжЕНВ№ЗжЕФЫМЯыЃЌЕБвЛИівЕЮёФЃПщЪЙгУЕФЪ§ОнПтЗўЮёЦїЗЂЩњЙЪеЯвВВЛЛсгАЯьЦфЫћвЕЮёФЃПщЕФЪ§ОнПте§ГЃЪЙгУЁЃСэЭтЃЌЕБЦфжавЛИіФЃПщЕФЗУЮЪСПМЄдіЕФЪБКђЛЙПЩвдЖЏЬЌЕФРЉеЙетИіФЃПщЪЙгУЕНЕФЪ§ОнПтЕФЪ§СПДгЖјТњзувЕЮёЕФашЧѓЁЃ
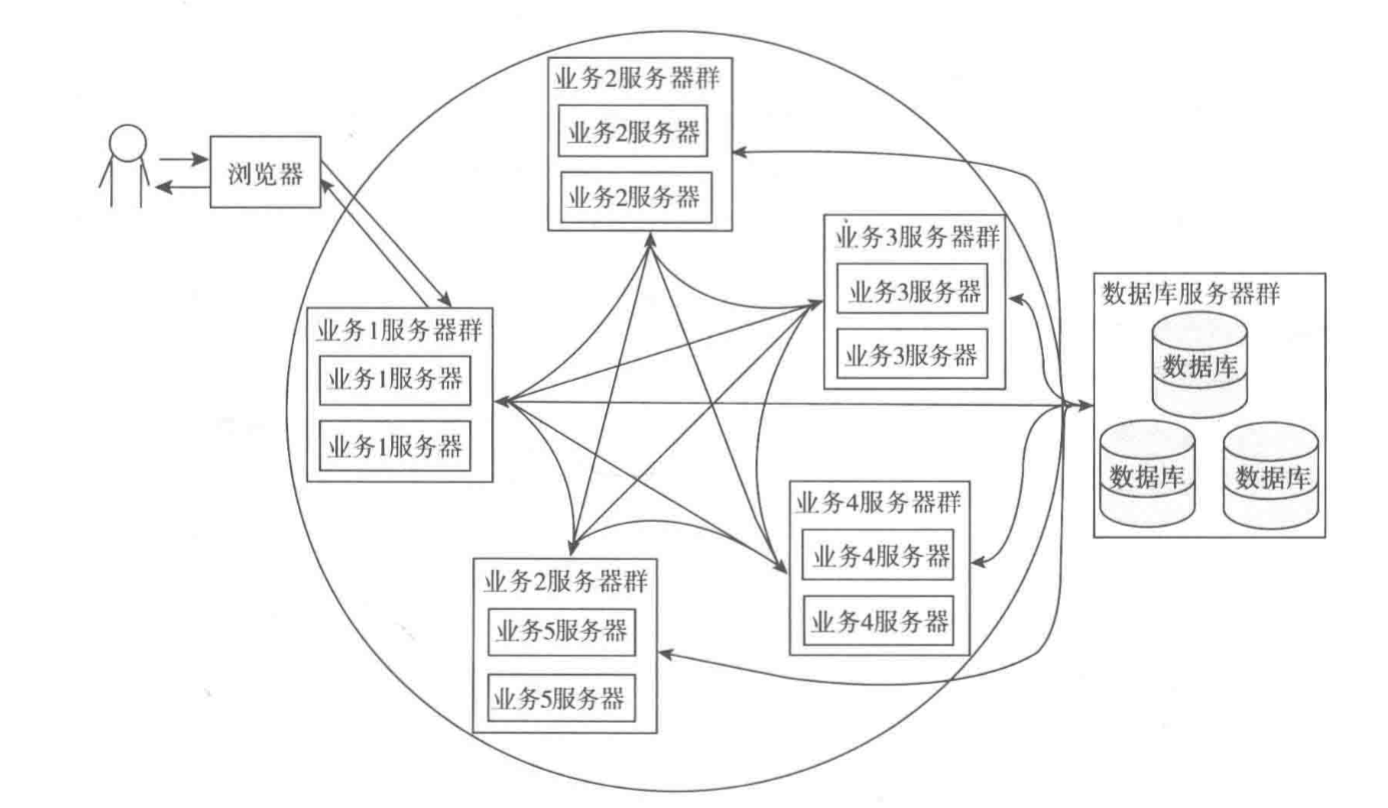
ЫФЁЂИпВЂЗЂЧщПіЯТЕФНтОіЗНАИ
ЃЈ1ЃЉгІгУГЬађКЭОВЬЌзЪдДЮФМўНјааЗжРы
ЫљЮНЕФОВЬЌзЪдДОЭЪЧЮвУЧЭјеОжагУЕНЕФHtmlЁЂCssЁЂJsЁЂImageЁЂVideoЁЂGifЕШОВЬЌзЪдДЁЃгІгУГЬађКЭОВЬЌзЪдДЮФМўНјааЗжРывВЪЧГЃМћЕФЧАКѓЖЫЗжРыЕФНтОіЗНАИЃЌгІгУЗўЮёжЛЬсЙЉЯргІЕФЪ§ОнЗўЮёЃЌОВЬЌзЪдДВПЪ№дкжИЖЈЕФЗўЮёЦїЩЯЃЈNginxЗўЮёЦїЛђепЪЧCDNЗўЮёЦїЩЯЃЉЃЌЧАЖЫНчУцЭЈЙ§Angular
JSЛђепNode JSЬсЙЉЕФТЗгЩММЪѕЗУЮЪгІгУЗўЮёЦїЕФОпЬхЗўЮёЛёШЁЯргІЕФЪ§ОндкЧАЖЫгЮРРЦїЩЯНјаафжШОЁЃетбљПЩвддкКмДѓГЬЖШЩЯМѕЧсКѓЖЫЗўЮёЦїЕФбЙСІЁЃ
Р§ШчЃЌАйЖШжївГЪЙгУЕФЭМЦЌОЭЪЧЕЅЖРЕФвЛИігђУћЗўЮёЦїЩЯНјааВПЪ№ЕФ
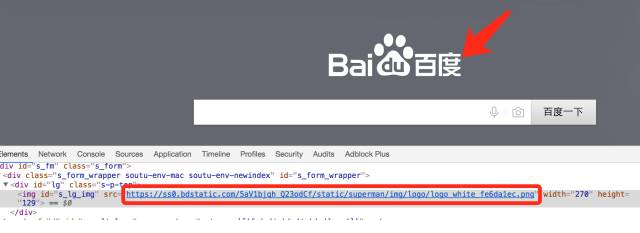
ЃЈ2ЃЉвГУцЛКДц
вГУцЛКДцЪЧНЋгІгУЩњГЩЕФКмЩйЗЂЩњЪ§ОнБфЛЏЕФвГУцЛКДцЦ№РДЃЌетбљОЭВЛашвЊУПДЮЖМжиаТЩњГЩвГУцСЫЃЌДгЖјНкЪЁДѓСПCPUзЪдДЃЌШчЙћНЋЛКДцЕФвГУцЗХЕНФкДцжаЫйЖШОЭИќПьЁЃ
ПЩвдЪЙгУNginxЬсЙЉЕФЛКДцЙІФмЃЌЛђепПЩвдЪЙгУзЈУХЕФвГУцЛКДцЗўЮёЦїSquidЁЃ
ЃЈ3ЃЉМЏШКгыЗжВМЪН
ЃЈ4ЃЉЗДЯђДњРэ
ВЮПМЮФеТ
ЃЈ5ЃЉCDN
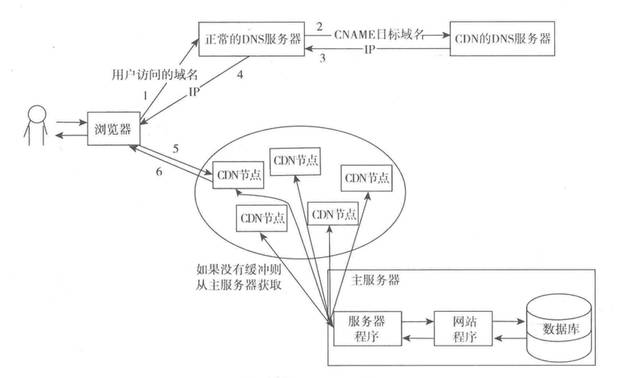
CDNЗўЮёЦїЦфЪЕЪЧвЛжжМЏШКвГУцЛКДцЗўЮёЦїЃЌЦфФПЕФОЭЪЧОЁдчЕФЗЕЛигУЛЇЫљашвЊЕФЪ§ОнЃЌвЛЗНУцМгЫйгУЛЇЗУЮЪЫйЖШЃЌСэвЛЗНУцвВМѕЧсКѓЖЫЗўЮёЦїЕФИКдибЙСІЁЃ
CDNЕФШЋГЦЪЧContent Delivery NetworkЃЌМДФкШнЗжЗЂЭјТчЁЃЦфЛљБОЫМТЗЪЧОЁПЩФмБмПЊЛЅСЊЭјЩЯгаПЩФмгАЯьЪ§ОнДЋЪфЫйЖШКЭЮШЖЈадЕФЦПОБКЭЛЗНкЃЌЪЙФкШнДЋЪфЕФИќПьЁЂИќЮШЖЈЁЃ
CDNЭЈЙ§дкЭјТчИїДІЗХжУНкЕуЗўЮёЦїЫљЙЙГЩЕФдкЯжгаЕФЛЅСЊЭјЛљДЁжЎЩЯЕФвЛВужЧФмащФтЭјТчЃЌCDNЯЕЭГФмЙЛЪЕЪБЕиИљОнЭјТчСїСПКЭИїНкЕуЕФСЌНгЁЂИКдизДПівдМАЕНгУЛЇЕФОрРыКЭЯьгІЪБМфЕШзлКЯаХЯЂНЋгУЛЇЕФЧыЧѓжиаТЕМЯђРыгУЛЇзюНќЕФЗўЮёНкЕуЩЯЁЃЦфФПЕФЪЧЪЙгУЛЇПЩОЭНќШЁЕУЫљашФкШнЃЌНтОі
InternetЭјТчгЕМЗЕФзДПіЃЌЬсИпгУЛЇЗУЮЪЭјеОЕФЯьгІЫйЖШЁЃ
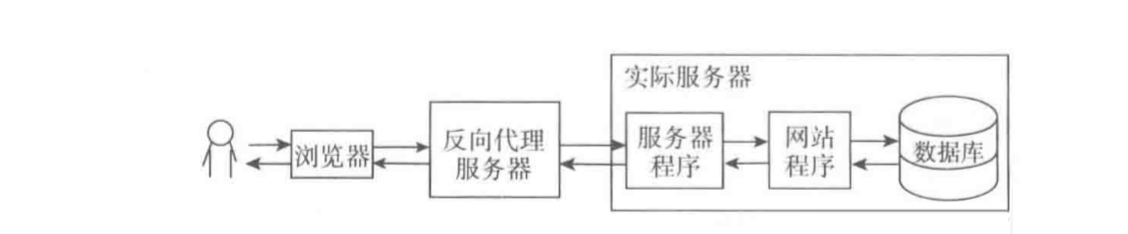
вВОЭЪЧЫЕCDNЗўЮёЦїЪЧВПЪ№дкЭјТчдЫааЩЬЕФЛњЗПЃЌЬсЙЉЕФРыгУЛЇзюНќЕФвЛВуЪ§ОнЗУЮЪЗўЮёЃЌгУЛЇдкЧыЧѓЭјеОЗўЮёЕФЪБКђЃЌПЩвдДгОрРыгУЛЇзюНќЕФЭјТчЬсЙЉЩЬЛњЗПЛёШЁЪ§ОнЁЃЕчаХЕФгУЛЇЛсЗжХфЕчаХЕФНкЕуЃЌСЊЭЈЕФЛсЗжХфСЊЭЈЕФНкЕуЁЃ
CDNЗжХфЧыЧѓЕФЗНЪНЪЧЬиЪтЕФЃЌВЛЪЧЦеЭЈЕФИКдиОљКтЗўЮёЦїРДЗжХфЕФФЧжжЃЌЖјЪЧгУзЈУХЕФCDNгђУћНтЮіЗўЮёЦїдкНтЮігыУћЕФЪБКђОЭЗжХфКУЕФЁЃ
CDNНсЙЙЭМШчЯТЫљЪОЃК
ЮхЁЂзмНс
ЮФеТЬсЕНЕФМИЕуВЂУЛгаЯъЯИЕФНщЩмЃЌШчашвЊЖдЦфжаЕФвЛжжЗНЪННјаабаОПЃЌПЩвдздааШЅевзЪдДбЇЯАбаОПЃЌетРяжЛЦ№ЕНХззЉв§гёЕФзїгУЁЃЕБШЛЖдгкДѓаЭЭјеОгІгУжЎКЃСПЪ§ОнКЭИпВЂЗЂНтОіЗНАИВЛОжЯогкетаЉММЧЩЛђММЪѕЃЌЛЙгаКмЖрГЩЪьЕФНтОіЗНАИЃЌгаашвЊЕФПЩвдздааСЫНтЁЃ
ЬиДЫЫЕУїЃКБОЮФЕФХфЭМРДздЁЖЭјеОМмЙЙМАЦфбнБфЙ§ГЬЈCКЋТЗБыЁЗЃЌЖраЛдзїепЬсЙЉЕФОЋУРХфЭМЃЌВЂЧвЮФеТЕФНсЙЙДѓжТвВВЮПМСЫзїепЕФЫМТЗЃЌжЛВЛЙ§ФкШнЪЧздМКЕФвЛаЉОбщКЭбЇЯАЕНЕФЖЋЮїНјааећРэЕФЁЃ
ЯждкЮоТлЪЧЦѓвЕЕФвЕЮёЯЕЭГЛЙЪЧЛЅСЊЭјЩЯЕФЭјеОГЬађЖМУцСйзХЪ§ОнСПДѓЕФЮЪЬтЃЌетИіЮЪЬтШчЙћНтОіВЛКУНЋбЯжиЕФгАЯьЯЕЭГЕФдЫааЫйЖШЃЌЯТУцОЭеыЖдетИіЮЪЬтЕФИїжжНтОіНтОіЗНАИНјааНщЩмЁЃ
1. ЛКДцКЭвГУцОВЬЌЛЏ
1.1 ЛКДц
Ъ§ОнСПДѓетИіЮЪЬтзюжБНгЕФНтОіЗНАИОЭЪЧЪЙгУЛКДцЃЌЛКДцОЭЪЧНЋЪ§ОнПтжаЛёШЁЕФНсЙћднЪББЃДцЦ№РДдкЃЌдкЯТДЮЪЙгУЕФЪБКђЮоашДгЪ§ОнПтжаЬсШЁЃЌетбљПЩвдДѓДѓНЕЕЭЪ§ОнПтбЙСІЁЃГЃгУЕФЛКДцПђМмгаEhcacheЁЂMemcache
КЭ RedisЕШЁЃ
ВЛЙ§ЛКДцвВВЛЪЧЪВУДЧщПіЖМЪЪгУЃЌЫќжївЊгУгкЪ§ОнБфЛЏВЛЪЧКмЦЕЗБЕФЧщПіЁЃЖјЧвШчЙћЪЧЖЈЦкЪЇаЇЃЈЪ§ОнаоИФЪБВЛЪЇаЇЃЉЕФЪЇаЇЛњжЦЃЌЪЕЪБадвЊЧѓвВВЛФмЬЋИпЃЌвђЮЊетбљЛКДцжаЕФЪ§ОнКЭецЪЕЪ§ОнПЩФмЛсВЛвЛжТЁЃ
2.1 вГУцОВЬЌЛЏ
вГУцОВЬЌЛЏЪЧНЋГЬађзюКѓЩњГЩЕФвГУцБЃДцЦ№РДЃЌвдКѓОЭВЛгУУПДЮЖМЕїгУжиаТЩњГЩвГУцСЫЁЃвГУцОВЬЌЛЏЭЌЪБЖдЪ§ОнСПДѓКЭВЂЗЂСПИпСНДѓЮЪЬтЖМгаКУДІЁЃ
вГУцОВЬЌЛЏПЩвддкГЬађжаЪЙгУФЃАцММЪѕЩњГЩЃЌШчГЃгУЕФFreemarker КЭ Velocity ЖМПЩвдИљОнФЃАцЩњГЩОВЬЌвГУцЁЃСэЭтвВПЩвдЪЙгУЛКДцЗўЮёЦїдкгІгУЗўЮёЦїЕФЩЯвЛВуЩњГЩвГУцЃЌШчПЩвдЪЙгУSquidЃЌСэЭтNginx
вВЬсЙЉСЫЯьгІЕФЙІФмЁЃ
2. Ъ§ОнПтгХЛЏ
вЊНтОіЪ§ОнСПДѓЕФЮЪЬтЃЌЪЧБмВЛПЊЪ§ОнПтгХЛЏЕФЁЃЪ§ОнПтгХЛЏЪЧВЛдіМггВМўЕФЧщПіЯТЬсИпДІРэаЇТЪЃЌЪЧвЛжжгУММЪѕЛЛН№ЧЎЕФЗНЪНЁЃвдЯТЪЧГЃгУЕФЪ§ОнПтгХЛЏЗНЗЈЁЃ
2.1 БэНсЙЙгХЛЏ
БэНсЙЙгХЛЏЪЧЪ§ОнПтжазюЛљДЁвВЪЧзюживЊЕФЃЌШчЙћБэНсЙЙгХЛЏЕУВЛКЯРэЃЌОЭПЩФмЕМжТбЯжиЕФадФмЮЪЬтЃЌОпЬхдѕУДЩшМЦИќКЯРэвВУЛгаЙЬЖЈВЛБфЕФзМдђЃЌашвЊИљОнЪЕМЪЧщПіОпЬхДІРэЁЃ
2.2 SQL гяОфгХЛЏ
sqlгяОфгХЛЏвВЪЧЗЧГЃживЊЕФЃЌЛљДЁЕФsql гХЛЏЪЧгяЗЈВуУцЕФгХЛЏЃЌВЛЙ§ИќживЊЕФЪЧДІРэТпМЕФгХЛЏЃЌетвВашвЊИљОнЪЕМЪЧщПіОпЬхДІРэЃЌЖјЧввЊКЭЫїв§ЛКДцЕШХфКЯЪГгУЁЃsql
гХЛЏгавЛИіЭЈгУЕФзіЗЈОЭЪЧЃЌЪзЯШвЊНЋЩцМАДѓЪ§ОнвЕЮёЕФsql гяОфЃЌЭЈЙ§заЯИЗжЮіШежОаХЯЂЃЌКЭВЛЭЌЬѕМўЕФжДааЪБМфЃЌевГіашвЊгХЛЏЕФгяОфКЭЦфжаЕФЮЪЬтЃЌШЛКѓдйгаЕФЗХЪИЕигХЛЏЁЃЖјВЛЪЧВЛЗжжиЕуЕФЖдУПЬѕгяОфЖМЛЈЭЌбљЕФЪТМўКЭОЋСІгХЛЏЁЃ
2.3 ЗжЧј
ЕБвЛеХБэжаЕФЪ§ОнСПБфЖрЕФЪБКђВйзїЫйЖШОЭБфТ§СЫЃЌШнвзЯыЕНЕФНтОіЗНЗЈОЭЪЧЗжБэЃЌЕЋЪЧЗжБэВйзїЦ№РДОЭБШНЯТщЗГЁЃЦфЪЕдкГЃгУЪ§ОнПтжаПЩвдВЛЗжБэЖјДяЕНИњЗжБэРрЫЦЕФаЇЙћЃЌФЧОЭЪЧЗжЧјЁЃ
ЗжЧјОЭЪЧНЋвЛеХБэжаЕФЪ§ОнАДеевЛЖЈЕФЙцдђЗжЕНВЛЭЌЕФЧјНјааБЃДцЃЌдкВщбЏЪ§ОнЪБШчЙћЗЖЮЇдкЭЌвЛИіЧјФкФФУДПЩвджЛЖдвЛИіЧјЕФЪ§ОнНјааВйзїЁЃетбљВйзїЕФЪ§ОнСПИќЩйЃЌЫйЖШИќПьЁЃ
2.4 ЗжБэ
ШчЙћвЛеХБэжаЕФЪ§ОнПЩвдЗжЮЊМИжжЙЬЖЈВЛБфЕФРраЭЃЌЖјЧвШчЙћЭЌЪБЖдЖржжРраЭЙВЭЌВйзїЕФЧщПіВЛЖрЃЌФФУДЖМПЩвдЭЈЙ§ЗжБэРДДІРэЁЃ
ЗжБэЗНЗЈЗжЮЊСНжжЃЌКсЧа КЭзнЧаЁЃ
КсЧаЃК
МйЩшЪ§ОнПтБэжаЕФЪ§ОнгаШ§ИізДЬЌЃЌДІРэЁЂНтОіЁЂЙиБеЁЃгЩгкЪ§ОнСПЗЧГЃЕФДѓЫљвдОЭПЩвдНЋЪ§ОнЗжБ№ДцдкШ§ИіБэжаЁЃЕквЛИіБэжаБЃДцДІРэзДЬЌЕФЪ§ОнЃЌЕкЖўИіБэБЃДц
НтОізДЬЌЕФЪ§ОнЃЌЕкШ§ИіБэБЃДцЙиБезДЬЌЕФЪ§ОнЃЌВЂЧвЖдУПИіБэНјааЗжЧјЁЃгЩгкБЈБэвЛАуЖМЪЧАДдТЗнЁЂМОЖШЁЂАыФъЁЂКЭФъРДзіЕФЃЌЫљвдЗжЧјвВАДдТЗнЃЌУПвЛИідТзівЛИіЗжЧјЁЃетбљОЭПЩвдДѓДѓЕФЬсИпДІРэКЭЭГМЦЫйЖШХЖ
ЪњЧаЃК
ШчЙћвЛИіБэЕФВйзїЦЕТЪКмИпУЧдкдіЩОИФЦфжавЛВПЗжзжЖЮЪ§ОнЕФЭЌЪБСэвЛВПЗжзжЖЮвВПЩФмБЛВйзїЃЌЖјЧвЃЈжївЊжИВщбЏЃЉгУВЛЕНБЛдіЩОИФЕФзжЖЮЃЌФФУДОЭПЩвдАЩВЛЭЌРраЭЕФЕиЖЮЗжБ№БЃДцЕНВЛЭЌЕФБэжаЃЌетбљПЩвдМѕЩйВйзїЪБЫјЖЈЪ§ОнЕФЗЖЮЇЁЃВЛЙ§етбљЗжБэКѓашвЊВщбЏЭъећЪ§ОнОЭЕУЖрБэВйзїСЫЁЃ
2.5 Ыїв§гХЛЏ
Ыїв§ЕФДѓжТдРэЪЧдкЪ§ОнЗЂЩњБфЛЏЃЈдіЩОИФЃЉЕФЪБКђОЭдЄЯШжИЖЈзжЖЮХХађКѓБЃДцЕНвЛИіРрЫЦБэЕФНсЙЙжаЃЌетбљдкВщбЏЫїв§зжЖЮЮЊЬѕМўЕФМЧТМЪБОЭПЩвдКмПьЕФДгЫїв§жаевЕНЖдгІМЧТМЕФжИеыВЂДгБэжаЛёШЁЕНМЧТМЃЌетбљЫйЖШОЭПьЖрСЫЁЃВЛЙ§Ыїв§вВЪЧвЛАбЫЋШаНЃЃЌЫќдкЬсИпВщбЏЫйЖШЕФЭЌЪБвВНЕЕЭСЫдіЩОИФВщЕФЫйЖШЃЌвђЮЊУПДЮЪ§ОнЕФБэЛАЖМашвЊИќаТЯргІЕФЫїв§ЁЃ
2.6 ЪЙгУДцДЂЙ§ГЬДњЬцВйзї
дкВйзїЙ§ГЬИДдгЖјЧвЕїгУЦЕТЪИпЕФвЕЮёжаЃЌПЩвдЭЈЙ§ЪЙгУДцДЂЙ§ГЬДњЬцжБНгВйзїРДЬсИпаЇТЪЃЌвђЮЊДцДЂЙ§ГЬжїашвЊБрвывЛДЮЃЌЖјЧвПЩвддквЛИіДцДЂЙ§ГЬРяУцзівЛаЉИДдгЕФВйзїЁЃ
3. ЗжРыЛюдОЪ§Он
гааЉЪ§ОнзмЪ§ОнСПЗЧГЃДѓЃЌЕЋЪЧЛюдОЪ§ОнВЂВЛЖрЃЌетжжЧщПіОЭПЩвдНЋЛюдОЪ§ОнЕЅЖРБЃДцЦ№РДДгЖјЬсИпДІРэаЇТЪЁЃ
БШШчЫЕЭјеОЕФгУЛЇЃЌНЋОГЃЕЧТМЕФвЛВПЗжЛюдОгУЛЇаХЯЂДцдквЛеХБэЃЌНЋВЛЛюдОЕФгУЛЇДцдкСэЭтвЛеХБэЁЃЃЈПЩвдХмвЛИіЖЈЪБШЮЮёНЋВЛОГЃЕЧТМЕФгУЛЇзЊвЦЕНВЛЛюдОгУЛЇБэЃЉЕБгУЛЇЕЧТМЪБЯШДгЛюдОгУЛЇЕФБэжаВщбЏЁЃВщбЏВЛЕНКѓдйШЅВЛЛюдОгУЛЇЕФБэжаВщбЏЁЃетбљОЭПЩвдЬсИпВщбЏЕФаЇТЪЁЃ
4. ХњСПЖСШЁКЭбгГйаоИФ
ХњСПЖСШЁКЭбгГйаоИФЕФдРэЪЧЭЈЙ§МѕЩйВйзїЕФДЮЪ§РДЬсИпаЇТЪЃЌШчЙћЪЙгУЕФЧЁЕБЃЌаЇТЪНЋГЪЪ§СПМЖЬсЩ§ЁЃ
ХњСПЖСШЁЪЧНЋЖрДЮЕФВщбЏКЯВЂЕНвЛДЮжаНјааЁЃ
бгГйаоИФжївЊеыЖдИпВЂЗЂЖјЧвЦЕЗБаоИФЃЈАќРЈаТдіЃЉЕФЪ§ОнЃЌШчвЛаЉЭГМЦЪ§ОнЁЃПЩвдЯШНЋашвЊаоИФЕФЪ§ОнднЪББЃДцЕНЛКДцжаЃЌШЛКѓЖЈЪБНЋЛКДцжаЕФЪ§ОнБЃДцЕНЪ§ОнПтжаЃЌГЬађЖСШЁЪ§ОнПЩвдЭЌЪБЖСШЁЪ§ОнПтжаЕФЪ§ОнКЭЛКДцЕФЪ§ОнЁЃЃЈетжжЗНЪНЯТШчЙћБЃДцЛКДцЕФЛњЦїГіЯжСЫЙЪеЯПЩФмЛсЖЊЪЇЪ§ОнЁЃЃЉЫљвдШчЙћЪЧживЊЪ§ОнОЭашвЊзівЛаЉЬиЪтДІРэЁЃ
5. ЖСаДЗжРы
ЖСаДЗжРыЕФБОжЪЪЧЖдЪ§ОнПтНјааМЏШКЃЌетбљОЭПЩвддкИпВЂЗЂЕФЧщПіЯТНЋЪ§ОнПтЕФВйзїЗжХфЕНЖрИіЪ§ОнПтЗўЮёЦїШЅДІРэДгЖјНЕЕЭСЫЕЅЬЈЗўЮёЦїЕФбЙСІЁЃВЛЙ§гЩгкЪ§ОнПтЕФЬиЪтадЃЃУПЬЈЗўЮёЦїЫљБЃДцЕФЪ§ОнЖМашвЊвЛжТЃЌЫљвдЪ§ОнЭЌВНОЭГЩСЫЪ§ОнПтМЏШКжазюКЫаФЕФЮЪЬтСЫЁЃ
вЛАуЕФНтОіЗНАИЪЧЃКНЋаДВйзїНЛИјзЈУХЕФвЛЬЈЗўЮёЦїЃЌетЬЈзЈУХИКд№аДВйзїЕФЗўЮёЦїНазіжїЗўЮёЦїЁЃЕБжїЗўЮёЦїаДШыЃЈдіЩОИФЃЉЪ§ОнКѓДгЕзВуЭЌВНЕНБ№ЕФЗўЮёЦїЃЈДгЗўЮёЦїЃЉЃЌЖСШЁЪ§ОнЕФЪБКђЕНДгЗўЮёЦїЖСШЁЃЌДгЗўЮёЦїПЩвдгаЖрЬЈЃЌетбљОЭПЩвдЪЕЯжЖСаДЗжРыСЫЁЃВЂЧвНЋЧыЧѓЗжХфЕНЖрИіЗўЮёЦїДІРэЁЃШчЙћДгЗўЮёЦїЬЋЖрЃЌжїЗўЮёЦїЭЌВНЪ§ОнЪБЃЌЯШЭЌВНЕНвЛВПЗжДгЗўЮёЦїЃЌЭЌВНЙ§Ъ§ОнЕФДгЗўЮёЦїдйНЋЪ§ОнЭЌВНЕНСэЭтвЛВПЗжУЛгаЭЌВНЪ§ОнЕФДгЗўЮёЦїЁЃ
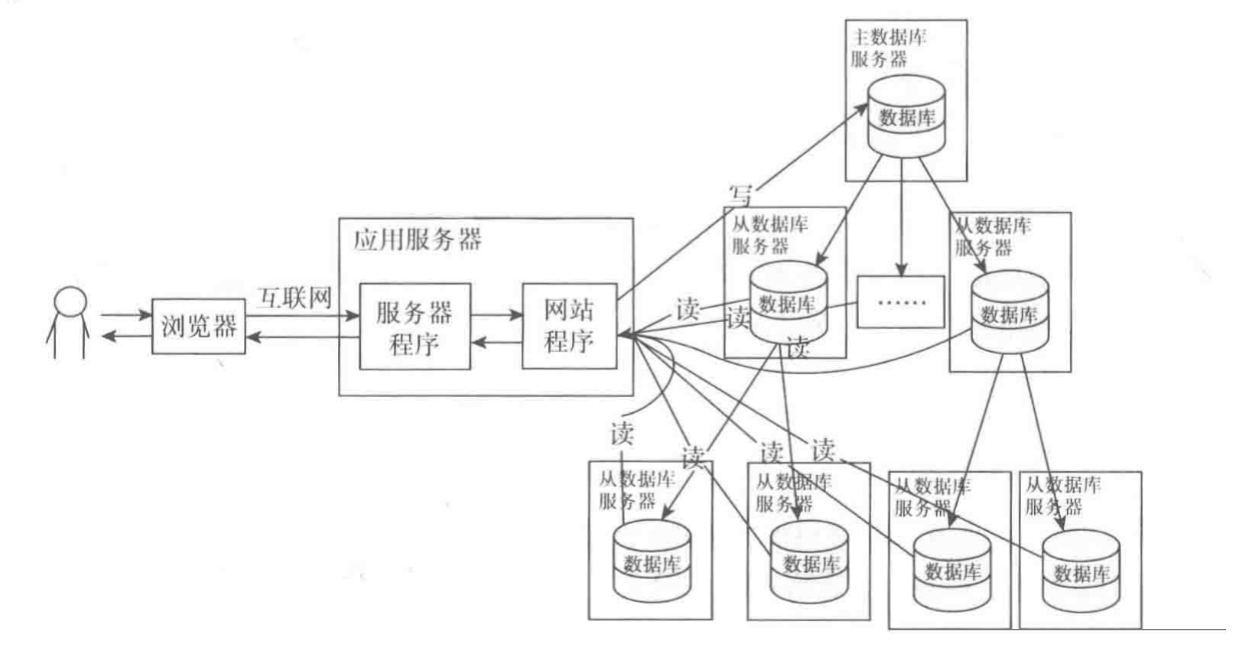
МђЕЅЕФЪ§ОнЭЌВНЗНЪНПЩвдВЩгУЪ§ОнПтЕФШШБИЗнЙІФмЃЌВЛЙ§ЖСШЁЕНЕФЪ§ОнПЩФмЛсДцдквЛЖЈЕФжЭКѓадЁЃМШШЛЪЧМЏШКОЭЛсЩцМАЕНИКдиОљКтЮЪЬтЃЌИКдиОљКтКЭЖСаДЗжРыВйзївЛАуВЩгУзЈУХЕФГЬађДІРэЃЌЖјЧвЖдгІгУЯЕЭГРДЫЕЪЧЭИУїЕФЁЃ
6. ЗжВМЪНЪ§ОнПт
ЗжВМЪНЪ§ОнПтЪЧНЋВЛЭЌЕФБэЗХЕНВЛЭЌЕФЪ§ОнПтжаШЛКѓЗХЕНВЛЭЌЕФЗўЮёЦїЁЃетбљашвЊЕїгУЖрИіБэЃЌдђПЩвдШУЖрЬЈЗўЮёЦїЭЌЪБДІРэЃЌДгЖјЬсИпДІРэЫйЖШЁЃ
ЗжВМЪНЪ§ОнПтЪЧНтОіЕЅИіЧыЧѓБОЩэОЭЗЧГЃИДдгЕФЮЪЬтЃЌЫќПЩвдНЋЕЅИіЧыЧѓЗжХфЕНЖрИіЗўЮёЦїЃЌЪЙгУЗжВМЪНКѓЕФУПИіНкЕуЛЙПЩвдЭЌЪБЪЙгУЖСаДЗжРыЃЌДгРДзщГЩЖрИіНкШКЁЃ
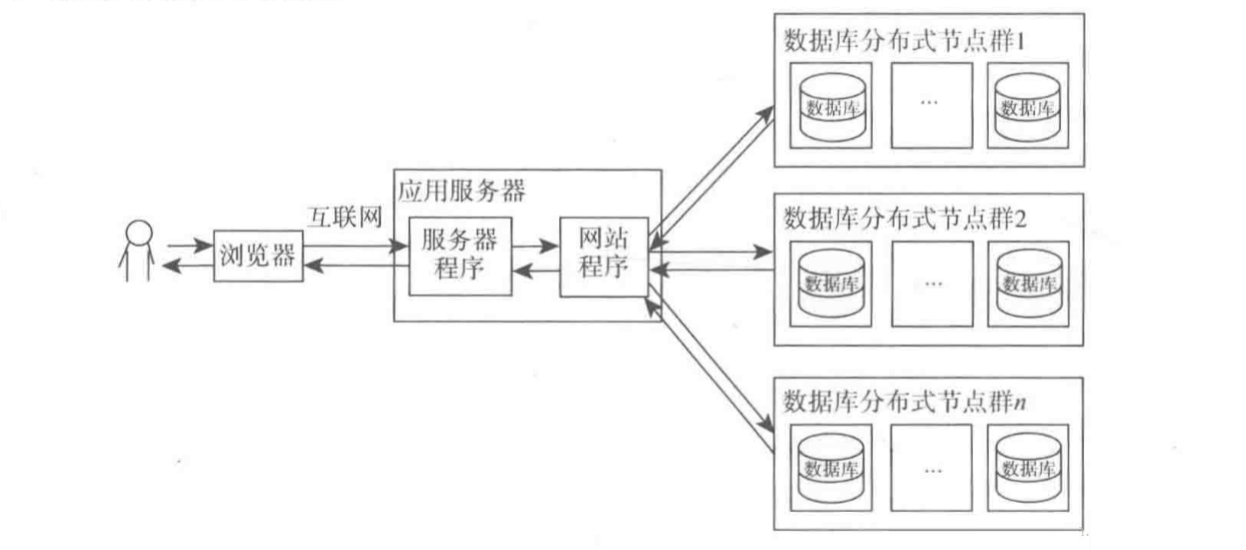
ЪЙгУЗжВМЪНЪ§ОнПтгаКмЖрЕФЮЪЬташвЊНтОіЃЌШчЗжВМЪНЪТЮёДІРэЁЂЖрБэВщбЏЕШЁЃ
ЗжВМЪНЕФСэЭтвЛжжЪЙгУЫМТЗЪЧНЋВЛЭЌЕФвЕЮёЪ§ОнБэБЃДцЕНВЛЭЌЕФНкЕуЃЌШУВЛЭЌЕФвЕЮёЕїгУВЛЭЌЕФЪ§ОнПтЃЌетбљЕФзіЗЈЦфЪЕОЭЪЧКЭМЏШКвЛбљЦ№ЗжСїзїгУЃЌВЛЙ§етжжзіЗЈОЭВЛгУЭЌВНЪ§ОнСЫЁЃ
7. Nosql КЭ hadoop
Nosql ЪЧНќФъРДЗЂеЙЗЧГЃбИЫйЕФвЛЯюММЪѕЃЌЫћЕФКЫаФЪЧЗЧНсЙЙЛЏЁЃNosql ЭЈЙ§ЖрИіПщДцДЂЪ§ОнЃЌВйзїДѓЪ§ОнЕФЫйЖШЗЧГЃПьЁЃ
Йигкhadoop ЧыПДЃК
hadoop ГѕЪЖ
еЊв§здЃКПДЭИspring mvc дДДњТыЗжЮігыЪЕеН
ИпВЂЗЂЕФНтОіЗНАИ
Г§СЫЪ§ОнСПДѓЃЌСэЭтвЛИіГЃМћЕФЮЪЬтОЭЪЧВЂЗЂСПИпЃЌКмЖрМмЙЙОЭЪЧеыЖдетИіЮЪЬтЩшМЦГіРДЕФЁЃ
1.гІгУКЭОВЬЌзЪдДЗжРы
ИеПЊЪМЕФЪБКђгІгУКЭОВЬЌзЪдДЪЧБЃДцдквЛЦ№ЕФЃЌЕБВЂЗЂСПДяЕНвЛЖЈГЬЖШЕФЪБКђОЭашвЊНЋОВЬЌзЪдДБЃДцЕНзЈУХЕФЗўЮёЦїжаЃЌОВЬЌзЪдДжївЊАќРЈЭМЦЌЁЂЪгЦЕЁЂjsЁЂcssКЭвЛаЉзЪдДЮФМўЕШЃЌетаЉЮФМўвђЮЊУЛгазДЬЌЫљвдЗжРыБШНЯМђЕЅЃЌжБНгДцЗХЕНЯьгІЕФЗўЮёЦїОЭПЩвдСЫЃЌвЛАуЛсЪЙгУзЈУХЕФгђУћШЅЗУЮЪЁЃ
ЭЈЙ§ВЛЭЌЕФгђУћПЩвдШУфЏРРЦїжБНгЗУЮЪзЪдДЗўЮёЦїЖјВЛашвЊдйЗУЮЪгІгУЗўЮёЦїСЫЁЃМмЙЙЭМШчЯТЃК
2.вГУцЛКДц
вГУцЛКДцЪЧНЋгІгУЩњГЩЕФвГУцЛКДцЦ№РДЃЌетбљОЭВЛашвЊУПДЮЖМЩњГЩвГУцСЫЃЌДгЖјПЩвдНкЪЁДѓСПЕФCPUзЪдДЃЌШчЙћНЋЛКДцЕФвГУцЗХЕНФкДцжаЫйЖШОЭИќПьСЫЁЃШчЙћЪЙгУNginxЗўЮёЦїОЭПЩвдЪЙгУЫќздДјЕФЛКДцЙІФмЃЌЕБШЛвВПЩвдЪЙгУзЈУХЕФSquid
ЗўЮёЦїЁЃвГУцЛКДцЕФФЌШЯЪЇаЇЛњжЦвЛАрЖМЪЧАДЛКДцЪБМфДІРэЕФЃЌЕБШЛвВПЩвддкаоИФЪ§ОнжЎКѓЪжЖЏШУЯргІЕФЛКДцЪЇаЇЁЃ
вГУцЛКДцжївЊЪЧЪЙгУдкЪ§ОнКмЩйЗЂЩњБфЛЏЕФвГУцЃЌЕЋЪЧКмЖрвГУцЪЧДѓВПЗжЪ§ОнЖМКмЩйЗЂЩњБфЛЏЃЌЖјЦфжаКмЩйвЛВПЗжЪ§ОнБфЛЏЦЕТЪШДЗЧГЃИпЃЌБШШчЫЕвЛИіЯдЪОЮФеТЕФвГУцЃЌе§ГЃРДЫЕЭъШЋПЩвдОВЬЌЛЏЃЌЕЋЪЧШчЙћЮФеТКѓУцгаЁАЖЅЁБКЭЁАВШЁБЕФЙІФмЖјЧвЯдЪОЕФгаЯьгІЕФЪ§СПЃЌетИіЪ§ОнЕФБфЛЏЦЕТЪОЭБШНЯИпСЫЃЌетОЭЛсгАЯьОВЬЌЛЏЁЃетИіЮЪЬтПЩвдгУЯШЩњГЩОВЬЌвГУцШЛКѓЪЙгУAjaxРДЖСШЁВЂаоИФЯьгІЕФЪ§ОнЃЌетбљОЭПЩвдвЛОйСНЕУРДЃЌМШПЩвдЪЙгУвГУцЛКДцвВПЩвдЪЕЪБЯдЪОвЛаЉБфЛЏЦЕТЪИпЕФЪ§ОнРДЁЃ
3.МЏШКгыЗжВМЪН
МЏШКЪЧУПЬЈЗўЮёЦїЖМОпгаЯрЭЌЕФЙІФмЃЌДІРэЧыЧѓЪБЕїгУФЧЬЈЗўЮёЦїЖМПЩвдЃЌжївЊЦ№ЗжСїзїгУЁЃ
ЗжВМЪНЪЧНЋВЛЭЌЕФвЕЮёЗХЕНВЛЭЌЕФЗўЮёЦїжаЃЌДІРэвЛИіЧыЧѓПЩФмашвЊгУЕНЖрЬЈЗўЮёЦїЃЌетбљОЭПЩвдЬсИпвЛИіЧыЧѓЕФДІРэЫйЖШЃЌЖјЧвМЏШККЭЗжВМЪНвВПЩвдЭЌЪБЪЙгУЁЃ
МЏШКгаСНИіЗНЪНЃКвЛжжЪЧдкОВЬЌзЪдДМЏШКЁЃСэвЛжжЪЧгІгУГЬађМЏШКЁЃОВЬЌзЪдДМЏШКБШНЯМђЕЅЁЃгІгУГЬађМЏШКдкДІРэЙ§ГЬжазюКЫаФЕФЮЪЬтОЭЪЧSession
ЭЌВНЮЪЬтЁЃ
Session ЭЌВНгаСНжжДІРэЗНЪНЃКвЛжжЪЧдкSession ЗЂЩњБфЛЏКѓздЖЏЭЌВНЕНЦфЫћЗўЮёЦїЃЌСэвЛжжОЭЪЧгУИіГЬађЭГвЛЙмРэSessionЁЃЫљгаМЏШКЕФЗўЮёЦїЖМЪЙгУЭЌвЛИіSessionЃЌTomcat
ФЌШЯЪЙгУОЭЪЧЕквЛжжЗНЪНЃЌЭЈЙ§МђЕЅЕФХфжУОЭПЩвдЪЕЯжЃЌЕкЖўжжЗНЪНПЩвдЪЙгУзЈУХЕФЗўЮёЦїАВзАMencachedЕШИпаЇЕФЛКДцГЬађЭГвЛРДЙмРэsessionЃЌШЛКѓдйгІгУГЬађжаЭЈЙ§жиаДRequestВЂИВИЧgetSession
ЗНЗЈРДЛёШЁжЦЖЈЗўЮёЦїжаЕФSessionЁЃ
ЖдгкМЏШКРДЫЕЛЙгавЛИіКЫаФЕФЮЪЬтОЭЪЧИКдиОљКтЃЌвВОЭЪЧНгЪеЕНвЛИіЧыЧѓКѓОпЬхЗжХфЕНФЧИіЗўЮёЦїШЅДІРэЕФЮЪЬтЃЌетИіЮЪЬтПЩвдЭЈЙ§ШэМўДІРэвВПЩвдЪЙгУзЈУХЕФгВМўЃЈШчЃКF5ЃЉНтОіЁЃ
4. ЗДЯђДњРэ
ЗДЯђДњРэжИЕФЪЧПЭЛЇЖЫжБНгЗУЮЪЕФЗўЮёЦїВЂВЛеце§ЬсЙЉЗўЮёЃЌЫќДгБ№ЕФЗўЮёЦїЛёШЁзЪдДШЛКѓНЋНсЙћЗЕЛиИјгУЛЇЁЃ
ЭМЃК
4.1 ЗДЯђДњРэЗўЮёЦїКЭДњРэЗўЮёЦїЕФЧјБ№
ДњРэЗўЮёЦїЕФзїгУЪЧДњЮвУХЛёШЁЯывЊЕФзЪдДШЛКѓНЋНсЙћЗЕЛиИјЮвУЧЃЌЫљвЊЛёШЁЕФзЪдДЪЧЮвУХжїЖЏИцЫпДњРэЗўЮёЦїЕФЃЌБШШчЃЌЮвУХЯыЗУЮЪFacebookЃЌЕЋЪЧжБНгЗУЮЪВЛСЫЃЌетЪБОЭПЩвдШУДњРэЗўЮёЦїЗУЮЪЃЌШЛКѓНЋНсЙћЗЕЛиИјЮвУЧЁЃ
ЗДЯђДњРэЗўЮёЦїЪЧЮвУХе§ГЃЗУЮЪвЛЬЈЗўЮёЦїЕФЪБКђЃЌЗўЮёЦїздМКШЅЕїгУСЫБ№ЕФЗўЮёЦїзЪдДВЂНЋНсЙћЗЕЛиИјЮвУЧЃЌЮвУХздМКВЂВЛжЊЕРЁЃ
ДњРэЗўЮёЦїЪЧЮвУЧжїЖЏЪЙгУЕФЃЌЪЧЮЊЮвУЧЗўЮёЕФЃЌЫћВЛашвЊгаздМКЕФгђУћЃЛЗДЯђДњРэЗўЮёЦїЪЧЗўЮёЦїздМКЪдгУЕФЃЌЮвУХВЂВЛжЊЕРЃЌЫќгаздМКЕФгђУћЃЌЮвУХЗУЮЪЫќКЭЗУЮЪе§ГЃЕФЭјжЗУЛгаШЮКЮЧјБ№ЁЃ
ЗДЯђДњРэЗўЮёЦїжївЊгаШ§ИізїгУЃК
1. ПЩвдзїЮЊЧАЖЫЗўЮёЦїИњЪЕМЪДІРэЧыЧѓЕФЗўЮёЦїМЏГЩЃЛ
2. ПЩвдзіИКдиОљКт
3. зЊЗЂЧыЧѓЃЌБШШчЫЕПЩвдНЋВЛЭЌРраЭЕФзЪдДЧыЧѓзЊЗЂЕНВЛЭЌЕФЗўЮёЦїШЅДІРэЁЃ
5. CDN
cdnЦфЪЕЪЧвЛжжЬиЪтЕФМЏШКвГУцЛКДцЗўЮёЦїЃЌЫћКЭЦеЭЈМЏШКЕФЖрЬЈвГУцЛКДцЗўЮёЦїЯрБШЃЌжївЊЪЧЫќДцЗХЕФЮЛжУКЭЗжХфЧыЧѓЕФЗНЪНгаЕуЬиЪтЁЃCDN
ЗўЮёЦїЪЧЗжВМдкШЋЙњИїЕиЕФЃЌЕБНгЪеЕНгУЛЇЧыЧѓКѓЛсНЋЧыЧѓЗжХфЕНзюКЯЪЪЕФCDNЗўЮёЦїНкЕуЛёШЁЪ§ОнЁЃБШШчСЊЭЈЕФгУЛЇЗжХфЕНСЊЭЈЕФНкЕуЃЌЩЯКЃЕФгУЛЇЗжХфЕНЩЯКЃЕФНкЕуЁЃ
CDNЕФУПИіНкЕуЦфЪЕОЭЪЧвЛИівГУцЛКДцЗўЮёЦїЃЌШчЙћУЛгаЧыЧѓзЪдДЕФЛКДцОЭЛсДгжїЗўЮёЦїЛёШЁЃЌЗёдђжБНгЗЕЛиЛКДцЕФвГУцЁЃ
CDNЗжХфЧыЧѓЃЈИКдиОљКтЃЉЕФЗНЪНЪЧгУзЈУХЕФCDNгђУћНтЮіЗўЮёЦїдкНтЮігђУћЕФЪБКђОЭЗжХфКУЕФЁЃвЛАуЕФзіЗЈЪЧдкISPФФРяЪдгУCNAMEНЋгђУћНтЮіЕНвЛИіЬиЖЈЕФгђУћЃЌШЛКѓдйНЋНтЮіЕНЕФФЧИігђУћгУзЈУХЕФCDNЗўЮёЦїНтЮіЕРЯргІЕФCDNНкЕуЁЃШчЭМЁЃ
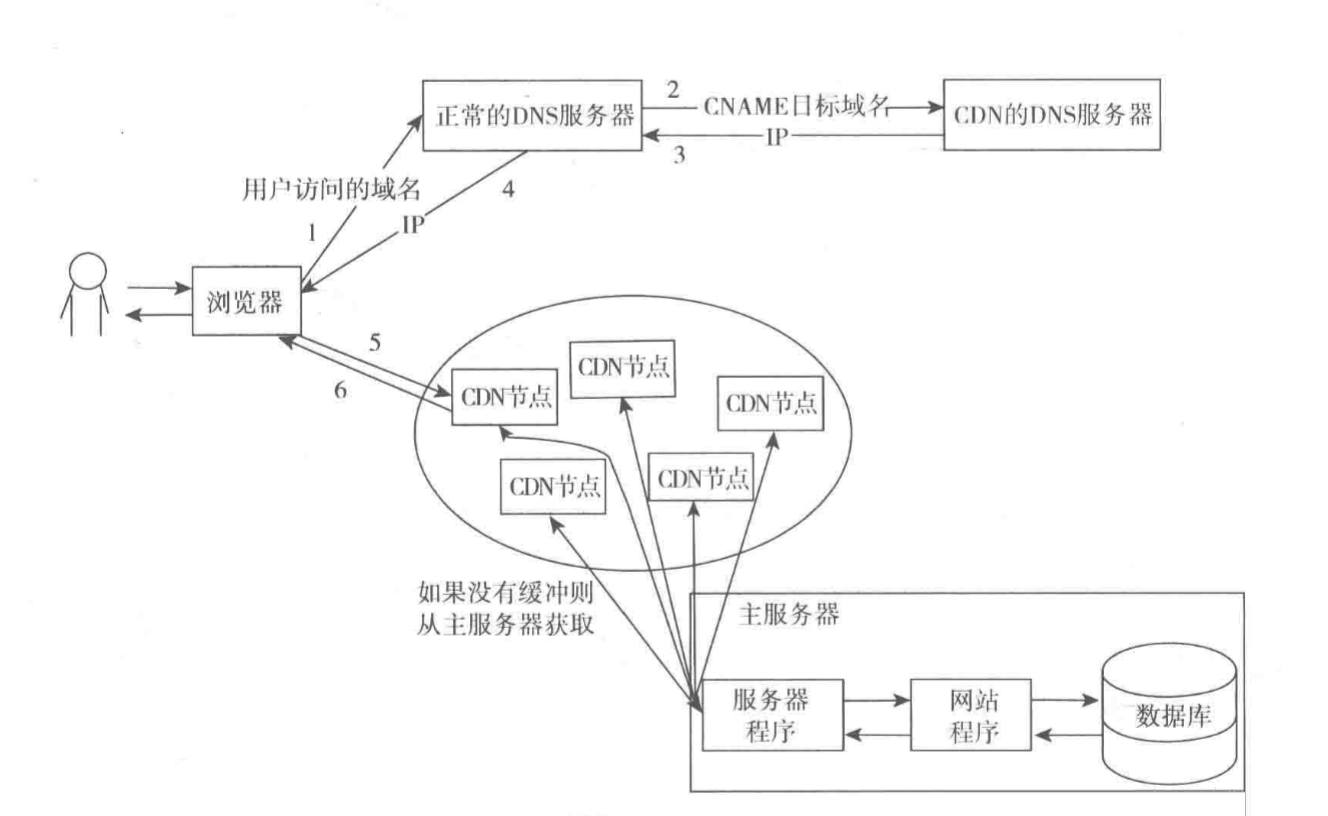
ЕкЖўВНЗУЮЪCDNЕФDNSЗўЮёЦїЪЧгІЮЊCNAMEМЧТМЕФФПБъгђУћЪЙгУNSМЧТМжИЯђСЫCDNЕФDNSЗўЮёЦїЁЃCDNЕФУПИіНкЕуПЩФмвВЪЧМЏШКСЫЖрЬЈЗўЮёЦїЁЃ
6. ЕзВуЕФгХЛЏ
ЧАУцЫЕЕФЫљгаЖМЪЧМмЙЙЖМЪЧНЈСЂдкзюЧАУцНщЩмЕФЛљДЁНсЙЙжЎЩЯЕФЁЃКмЖрЕиЗНЖМашвЊЭЈЙ§ЭјТчДЋЪфЪ§ОнЃЌШчЙћПЩвдМгПьЭјТчДЋЪфЕФЫйЖШЃЌФЧНЋЛсШУећИіЯЕЭГЕУЕНИФЩЦЁЃ
7. аЁНс
ЭјеОМмЙЙЕФећИібнБфЙ§ГЬжївЊЪЧЮЇШЦДѓЪ§ОнКЭИпВЂЗЂетСНИіЮЪЬтеЙПЊЕФЃЌНтОіЗНАИжївЊЗжЮЊЪЙгУЛКДцКЭЖрзЪдДСНжжРраЭЁЃЖрзЪдДжївЊжИЖрДцДЂЃЈАќРЈЖрФкДцЃЉЁЂЖрCPUКЭЖрЭјТчЃЌЖдгкЖрзЪдДРДЫЕгжПЩвдЗжЮЊЕЅИізЪдДДІРэвЛИіЭъећЕФЧыЧѓКЭЖрИізЪдДКЯзїДІРэвЛИіЧыЧѓСНжжРраЭЃЌШчЖрДцДЂКЭЖрCPUжаЕФМЏШККЭЗжВМЪНЃЌЖрЭјТчжаЕФCDNКЭОВЬЌзЪдДЗжРыЁЃРэНтСЫећИіЫМТЗжЎКѓОЭзЅзЁСЫМмЙЙбнБфЕФБОжЪЃЌЖјЧвздМКПЩФмЛЙПЩвдЩшМЦГіИќКУЕФМмЙЙЁЃ
|








