| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫдѕУДБЃжЄПЩППадЕФЃПашвЊзЂвтФФаЉЕиЗН
ЁЂНсКЯDockerЪЙгУЁЂЯћЯЂЖгСажаМфМўЕФБШНЯЁЂМИИіживЊЕФИХФюЕШФкШнЁЃ
РДздгкMaxLeap ЭХЖг_Service&InfraЃЌ,гЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
дѕУДБЃжЄПЩППадЕФЃП
RabbitMQЬсЙЉСЫМИжжЬиадЃЌЮўЩќСЫвЛЕуадФмДњМлЃЌЬсЙЉСЫПЩППадЕФБЃжЄЁЃ
ГжОУЛЏ
ЕБRabbitMQЭЫГіЪБЃЌФЌШЯЛсНЋЯћЯЂКЭЖгСаЖМЧхГ§ЃЌЫљвдашвЊдкЕквЛДЮЩљУїЖгСаКЭЗЂЫЭЯћЯЂЪБжИЖЈЦфГжОУЛЏЪєадЮЊtrueЃЌетбљRabbitMQЛсНЋЖгСаЁЂЯћЯЂКЭзДЬЌДцЕНRabbitMQБОЕиЕФЪ§ОнПтЃЌжиЦєКѓЛсЛжИДЁЃ
java:
durable=true
channel.queueDeclare ("task_queue",
durable, false, false, null); // ЖгСа
channel.basicPublish("", "task_queue",
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes()); // ЯћЯЂ
|
зЂЃКЕБЩљУїЕФЖгСавбОДцдкЪБЃЌГЂЪджиаТЖЈвхЫќЕФdurableЪЧВЛЩњаЇЕФЁЃ
НгЪегІД№
ПЭЛЇЖЫНгЪеЯћЯЂЕФФЃЪНФЌШЯЪЧздЖЏгІД№ЃЌЕЋЪЧЭЈЙ§ЩшжУautoAckЮЊfalseПЩвдШУПЭЛЇЖЫжїЖЏгІД№ЯћЯЂЁЃЕБПЭЛЇЖЫОмОјДЫЯћЯЂЛђепЮДгІД№БуЖЯПЊСЌНгЪБЃЌОЭЛсЪЙЕУДЫЯћЯЂжиаТШыЖгЃЈдкАцБО2.7.0вдЧАЪЧЕНжиаТМгШыЕНЖгЮВЃЌ2.7.0МАвдКѓЪЧБЃСєЯћЯЂдкЖгСажаЕФдРДЮЛжУЃЉЁЃ
java:
autoAck =
false;
requeue = true;
channel.basicConsume(queue, autoAck, callback);
channel.basicAck();//гІД№
channel.basicReject(deliveryTag, requeue); //
ОмОј
channel.basicRecover(requeue); // ЛжИД |
ЗЂЫЭШЗШЯ
ФЌШЯЧщПіЯТЃЌЗЂЫЭЖЫВЛЙизЂЗЂГіШЅЕФЯћЯЂЪЧЗёБЛЯћЗбЕєСЫЁЃПЩЩшжУchannelЮЊconfirmФЃЪНЃЌЫљгаЗЂЫЭЕФЯћЯЂЖМЛсБЛШЗШЯвЛДЮЃЌгУЛЇПЩвдздааИљОнserverЗЂЛиЕФШЗШЯЯћЯЂВщПДзДЬЌЁЃЯъЯИНщЩмМћЃКconfirms
java:
channel.confirmSelect();
// НјШыconfirmФЃЪН
// do publish messages... УПЬѕЯћЯЂЖМЛсБЛБрКХЃЌДг1ПЊЪМ
channel.getNextPublishSeqNo() // ВщПДЯТвЛЬѕвЊЗЂЫЭЕФЯћЯЂЕФађКХ
channel.waitForConfirms(); // ЕШД§ЫљгаЯћЯЂЗЂЫЭВЂШЗШЯ |
ЪТЮёЃККЭconfirmФЃЪНВЛФмЭЌЪБЪЙгУЃЌЖјЧвЛсДјРДДѓСПЕФЖргрПЊЯњЃЌЕМжТЭЬЭТСПЯТНЕКмЖрЃЌЙЪЖјВЛЭЦМіЁЃ
java:
channel.txSelect();
try {
// do something...
channel.txCommit();
} catch (e){
channel.txRollback();
} |
<a name="ha" /> ЯћЯЂЖгСаЕФИпПЩгУЃЈжїБИФЃЪНЃЉ
ЯрБШгкТЗгЩКЭАѓЖЈЃЌПЩвдЪгЮЊЪЧЙВЯэгкЫљгаЕФНкЕуЕФЃЌЯћЯЂЖгСаФЌШЯжЛДцдкгкЕквЛДЮЩљУїЫќЕФНкЕуЩЯЃЌетбљвЛЕЉетИіНкЕуЙвСЫЃЌетИіЖгСажаЮДДІРэЕФЯћЯЂОЭУЛгаСЫЁЃ
авКУЃЌRabbitMQЬсЙЉСЫНЋЫќБИЗнЕНЦфЫћНкЕуЕФЛњжЦЃЌШЮКЮЪБКђЖМгавЛИіmasterИКд№ДІРэЧыЧѓЃЌЦфЫћslavesИКд№БИЗнЃЌЕБmasterЙвЕєЃЌЛсНЋзюдчДДНЈЕФФЧИіslaveЬсЩ§ЮЊmasterЁЃ
УќСюЃК
rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'ЃКЩшжУЫљгавд'ha'ПЊЭЗЕФqueueдкЫљгаНкЕуЩЯгЕгаБИЗнЁЃЯъЯИгяЗЈЕуетРяЃЛ
вВПЩвддкНчУцЩЯХфжУЁЃ
зЂЃКгЩгкexclusiveРраЭЕФЖгСаЛсдкclientКЭserverСЌНгЖЯПЊЪББЛЩОЕєЃЌЫљвдЖдЫќЩшжУГжОУЛЏЪєадКЭБИЗнЖМЪЧУЛгавтвхЕФЁЃ
ЫГађБЃжЄ
жБНгЩЯЭМКУСЫЃК
вЛаЉашвЊзЂвтЕФЕиЗН
МЏШКХфжУЃК
вЛИіМЏШКжаЖрИіНкЕуЙВЯэвЛЗн.erlang.cookieЮФМўЃЛШєЪЧУЛгаЦєгУRABBITMQ_USE_LONGNAMEЃЌашвЊдкУПИіНкЕуЕФhostsЮФМўжажИЖЈЦфЫћНкЕуЕФЕижЗЃЌВЛШЛЛсевВЛЕНЦфЫћМЏШКжаЕФНкЕуЁЃ
<a name="cluster_partion" /> ФдСбЃЈЭјТчЗжЧјЃЉЃК
RabbitMQМЏШКЖдгкЭјТчЗжЧјЕФДІРэКЭШЬЪмФмСІВЛЬЋКУЃЌЭЦМіЪЙгУfederationЛђепshovelВхМўШЅНтОіЁЃ
ЕЋЪЧЃЌЧщПівбОЗЂЩњСЫЃЌдѕУДШЅНтОіФиЃПЗХаФЃЌЛЙЪЧгаАьЗЈЛжИДЕФЁЃ
ЕБЭјТчЖЯЖЯајајЪБЃЌЛсЪЙЕУНкЕужЎМфЕФЭЈаХЖЯЕєЃЌНјЖјдьГЩМЏШКБЛЗжИєПЊЕФЧщПіЁЃ
етбљЃЌУПИіаЁМЏШКжЎКѓБужЛДІРэИїздБОЕиЕФСЌНгКЭЯћЯЂЃЌДгЖјЕМжТЪ§ОнВЛЭЌВНЁЃЕБжиаТЛжИДЭјТчСЌНгЪБЃЌЫќУЧБЫДЫЖМШЯЮЊЪЧЖдЗНЙвСЫ-_-||ЃЌБуПЩвдХаЖЯГігаЭјТчЗжЧјГіЯжСЫЁЃЕЋЪЧRabbitMQФЌШЯЪЧКіТдЕєВЛДІРэЕФЃЌдьГЩСНИіНкЕуМЬајИїздЮЊеўЃЈТЗгЩЃЌАѓЖЈЙиЯЕЃЌЖгСаЕШПЩвдЖРСЂЕиДДНЈЩОГ§ЃЌЩѕжСжїБИЖгСавВЛсУПвЛЗНгЕгаздМКЕФmasterЃЉЁЃ
ПЩвдИќИФХфжУЪЙЕУСЌНгЛжИДЪБЃЌЛсИљОнХфжУздЖЏЛжИДЃК
ignoreЃКФЌШЯЃЌВЛзіШЮКЮДІРэ
pause-minorityЃКЖЯПЊСЌНгЪБЃЌХаЖЯЕБЧАНкЕуЪЧЗёЪєгкЩйЪ§ХЩЃЈНкЕуЪ§ЩйгкЛђепЕШгквЛАыЃЉЃЌШчЙћЪЧЃЌдђднЭЃжБЕНЛжИДСЌНгЁЃ
{pause_if_all_down, [nodes], ignore | autoheal}ЃКЖЯПЊСЌНгЪБЃЌХаЖЯЕБЧАМЏШКжаНкЕуЪЧЗёгаНкЕудкnodesжаЃЌШчЙћгаЃЌдђМЬајдЫааЃЌЗёдђднЭЃжБЕНЛжИДСЌНгЁЃетжжВпТдЯТЃЌЕБЛжИДСЌНгЪБЃЌПЩФмЛсгаЖрИіЗжЧјДцЛюЃЌЫљвдЃЌзюКѓвЛИіВЮЪ§ОіЖЈЫќУЧдѕУДКЯВЂЁЃ
autohealЃКЕБЛжИДСЌНгЪБЃЌбЁдёПЭЛЇЖЫСЌНгЪ§зюЖрЕФНкЕузДЬЌЮЊжїЃЌжиЦєЦфЫћНкЕуЁЃ
ХфжУЃКМЏШКХфжУ
ЖрДЮack
ПЭЛЇЖЫЖрДЮгІД№ЭЌвЛЬѕЯћЯЂЃЌЛсЪЙЕУИУПЭЛЇЖЫЪеВЛЕНКѓајЯћЯЂЁЃ
НсКЯDockerЪЙгУ
МЏШКАцБОЕФЪЕЯжЃКЯъМћЮвздМКаДЕФвЛИіР§зг rabbitmq-server-cluster
ЯћЯЂЖгСажаМфМўЕФБШНЯ
RabbitMQЃК
гХЕуЃКжЇГжКмЖравщШчЃКAMQPЃЌXMPPЃЌSTMPЃЌSTOMPЃЛСщЛюЕФТЗгЩЃЛГЩЪьЮШЖЈЕФМЏШКЗНАИЃЛИКдиОљКтЃЛЪ§ОнГжОУЛЏЕШЁЃ
ШБЕуЃКЫйЖШНЯТ§ЃЛБШНЯжиСПМЖЃЌАВзАашвЊвРРЕErlangЛЗОГЁЃ
RedisЃК
гХЕуЃКБШНЯЧсСПМЖЃЌвзЩЯЪж
ШБЕуЃКЕЅЕуЮЪЬтЃЌЙІФмЕЅвЛ
KafkaЃК
гХЕуЃКИпЭЬЭТЃЛЗжВМЪНЃЛПьЫйГжОУЛЏЃЛИКдиОљКтЃЛЧсСПМЖ
ШБЕуЃКМЋЖЫЧщПіЯТЛсЖЊЯћЯЂ
зюКѓИНвЛеХЭјЩЯНиШЁЕФВтЪдНсЙћ: 
ИќЖрадФмВЮЪ§Мћ
ШчЙћгааЫШЄМђЕЅСЫНтЯТRabbitMQЕФМђЕЅНщЩмЃЌПЩвдМЬајЭљЯТПДЁЋ
МђНщ
МИИіживЊЕФИХФю
Virtual Host: АќКЌШєИЩИіExchangeКЭQueueЃЌБэЪОвЛИіНкЕуЃЛ
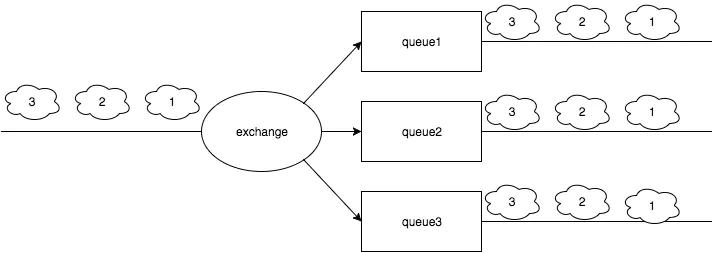
Exchange: НгЪмПЭЛЇЖЫЗЂЫЭЕФЯћЯЂЃЌВЂИљОнBindingНЋЯћЯЂТЗгЩИјЗўЮёЦїжаЕФЖгСаЃЌExchangeЗжЮЊdirect,
fanout, topicШ§жжЁЃ
Binding: СЌНгExchangeКЭQueueЃЌАќКЌТЗгЩЙцдђЁЃ
Queue: ЯћЯЂЖгСаЃЌДцДЂЛЙЮДБЛЯћЗбЕФЯћЯЂЁЃ
Message: Header+Body
Channel: ЭЈЕРЃЌжДааAMQPЕФУќСюЃЛвЛИіСЌНгПЩДДНЈЖрИіЭЈЕРвдНкЪЁзЪдДЁЃ
Client
RabbitMQЙйЗНЪЕЯжСЫКмЖрШШУХгябдЕФПЭЛЇЖЫЃЌОЭВЛвЛвЛСаОйРВЃЌвдjavaЮЊР§ЃЌжБНгПЊЪМе§ЬтЃК
НЈСЂСЌНгЃК
ConnectionFactory
factory = new ConnectionFactory();
factory.setHost("localhost"); |
ПЩвдМгЩЯЖЯПЊжиЪдЛњжЦЃК
factory.setAutomaticRecoveryEnabled(true);
factory.setNetworkRecoveryInterval(10000); |
ДДНЈСЌНгКЭЭЈЕРЃК
Connection
connection = factory.newConnection();
Channel channel = connection.createChannel(); |
вЛЖдвЛЃКвЛИіЩњВњепЃЌвЛИіЯћЗбеп

ЩњВњепЃК
channel.queueDeclare
(QUEUE_NAME, false, false, false, null);
channel.basicPublish ("", QUEUE_NAME,
null, message.getBytes()); |
ЯћЗбепЃК
Consumer
consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery (String consumerTag,
Envelope envelope, AMQP.BasicProperties properties,
byte[] body)
throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '"
+ message + "'");
}
};
channel.basicConsume (QUEUE_NAME, autoAck, consumer); |
вЛЖдЖрЃКвЛИіЩњВњепЃЌЖрИіЯћЗбеп 
ДњТыЭЌЩЯЃЌжЛВЛЙ§ЛсгаЖрИіЯћЗбепЃЌЯћЯЂЛсТжађЗЂИјИїИіЯћЗбепЁЃ
ШчЙћЩшжУСЫautoAck=falseЃЌФЧУДПЩвдЪЕЯжЙЋЦНЗжЗЂЃЈМДЖдгкФГИіЬиЖЈЕФЯћЗбепЃЌУПДЮзюЖржЛЗЂЫЭжИЖЈЬѕЪ§ЕФЯћЯЂЃЌжБЕНЦфжавЛЬѕЯћЯЂгІД№КѓЃЌдйЗЂЫЭЯТвЛЬѕЃЉЁЃашвЊдкЯћЗбепжаМгЩЯ:
int prefetchCount
= 1;
channel.basicQos(prefetchCount); |
ЦфЫћЭЌЩЯЁЃ
ЙуВЅ
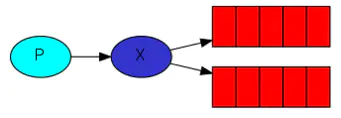
broadcast
ЩњВњепЃК
channel.exchangeDeclare
(EXCHANGE_NAME, "fanout");
String queueName = channel.queueDeclare().getQueue();
channel.queueBind (queueName, EXCHANGE_NAME,
"");
channel.basicPublish (EXCHANGE_NAME, "",
null, message.getBytes());; |
ЯћЗбепЭЌЩЯЁЃ
Routing: жИЖЈТЗгЩЙцдђ

routing
ЩњВњепЃК
String queueName
= channel.queueDeclare().getQueue();
channel.queueBind(queueName, EXCHANGE_NAME,
routingKey);
channel.basicPublish(EXCHANGE_NAME, routingKey,
null, message.getBytes()); |
ЯћЗбепЭЌЩЯЁЃ
Topics: жЇГжЭЈХфЗћЕФRouting
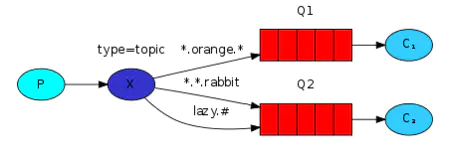
topics
*ПЩвдБэЪОвЛИіЕЅДЪ
#ПЩвдБэЪОвЛИіЛђЖрИіЕЅДЪ
ЩњВњепЃК
channel.exchangeDeclare (EXCHANGE_NAME,
"topic");
String queueName = channel.queueDeclare().getQueue();
channel.queueBind (queueName, EXCHANGE_NAME,
bindingKey); |
ЯћЗбепЭЌЩЯЁЃ
RPC
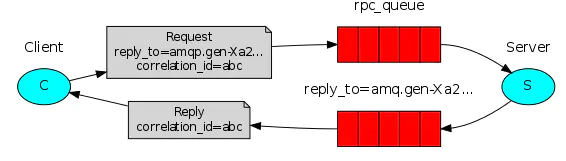
rpc
ЦфЪЕОЭЪЧвЛЖдвЛФЃЪНЕФвЛжжгУЗЈЃК
ЪзЯШЃЌПЭЛЇЖЫЗЂЫЭвЛЬѕЯћЯЂЕНЗўЮёЖЫЩљУїЕФЖгСаЃЌЯћЯЂЪєаджаАќКЌreply_toКЭcorrelation_id
- reply_to ЪЧПЭЛЇЖЫДДНЈЕФЯћЯЂЕФЖгСаЃЌгУРДНгЪедЖГЬЕїгУНсЙћ
- correlation_id ЪЧЯћЯЂЕФБъЪЖЃЌЗўЮёЖЫЛигІЕФЯћЯЂЪєаджаЛсДјЩЯвдБужЊЕРЪЧФФЬѕЯћЯЂЕФНсЙћЁЃ
ШЛКѓЃЌЗўЮёЖЫНгЪеЕНЯћЯЂЃЌДІРэЃЌВЂЗЕЛивЛЬѕНсЙћЕНreply_toЖгСажаЃЌ
зюжеЃЌПЭЛЇЖЫНгЪеЕНЗЕЛиЯћЯЂЃЌМЬајЯђЯТДІРэЁЃ
Server
жЇГжИїДѓжїСїВйзїЯЕЭГЃЌетРявдUnixЮЊР§НщЩмЯТГЃгУХфжУКЭУќСюЃК
АВзА
гЩгкRabbitMQЪЧвРРЕгкErlangЕФЃЌЫљвдЕУЪзЯШАВзАзюНќАцБОЕФErlangЁЃ
ЕЅЕуЕФАВзАБШНЯМђЕЅЃЌЯТдиНтбЙМДПЩЁЃЯТдиЕижЗ
ХфжУЃКЃЈвЛАуЕФЃЌгУФЌШЯЕФМДПЩЁЃЃЉ
$RABBITMQ_HOME/etc/rabbitmq/rabbitmq-env.conf: ЛЗОГБфСПФЌШЯХфжУЃЈвВПЩдкЦєЖЏНХБОжаЩшжУЃЌЧввдЦєЖЏУќСюжаЕФХфжУЮЊзМЃЉЁЃГЃгУЕФгаЃК
RABBITMQ_NODENAMEЃКНкЕуУћГЦЃЌФЌШЯЪЧrabbit@$HOSTNAMEЁЃ
RABBITMQ_NODE_PORTЃКавщЖЫПкКХЃЌФЌШЯ5672ЁЃ
RABBITMQ_SERVER_START_ARGSЃКИВИЧrabbitmq.configжаЕФвЛаЉХфжУЁЃ
$RABBITMQ_HOME/etc/rabbitmq/rabbitmq.config: КЫаФзщМўЃЌВхМўЃЌerlangЗўЮёЕШХфжУЃЌГЃгУЕФгаЃК
disk_free_limitЃКЖгСаГжОУЛЏЕШаХЯЂЖМЪЧДцЕНRabbitMQБОЕиЕФЪ§ОнПтжаЕФЃЌФЌШЯЯожЦ50000000ЃЈвВОЭЪЧзюЖржЛШУЫќЪЙгУ50MПеМфРВЃЌВЛЙЛПЩвдЩЯЕїЃЌвВжЇГжПеЯаПеМфАйЗжБШЕФХфжУЃЉЁЃвЊЪЧГЌБъСЫЃЌЫќОЭАеЙЄСЫЁЁ
vm_memory_high_watermarkЃКФкДцЪЙгУЃЌФЌШЯ0.4ЃЈзюЖрШУЫќЪЙгУ40%ЕФФкДцЃЌГЌБъАеЙЄЃЉ
зЂЃКШєЦєЖЏЪЇАмСЫЃЌПЩвддкЦєЖЏШежОжаВщПДЕНОпЬхЕФДэЮѓаХЯЂЁЃ
УќСюЃК
$RABBITMQ_HOME/sbin/rabbitmq-serverЃКЦєЖЏНХБОЃЌЛсДђгЁГіХфжУЮФМўЃЌВхМўЃЌМЏШКЕШаХЯЂЃЛМгЩЯ-detachedЮЊКѓЬЈЦєЖЏЃЛ
/sbin/rabbitmqctl statusЃКВщПДЦєЖЏзДЬЌ
/sbin/rabbitmqctl add_user admin adminЃКЬэМгаТгУЛЇadminЃЌУмТыadminЃЛФЌШЯжЛгавЛИіguestгУЛЇЃЌЕЋжЛЯоБОЛњЗУЮЪЁЃ
/sbin/rabbitmqctl set_user_tags admin administratorЃКНЋadminЩшжУЮЊЙмРэдБШЈЯо
/sbin/rabbitmqctl set_permissions -p / admin ".*"
".*" ".*" ИГгшadminЫљгаШЈЯо
/sbin/rabbitmqctl stopЃКЙиБе
МЏШК
МЏШКНкЕуЙВЯэЫљгаЕФзДЬЌКЭЪ§ОнЃЌШчЃКгУЛЇЁЂТЗгЩЁЂАѓЖЈЕШаХЯЂЃЈЖгСагаЕуЬиЪтЃЌЫфШЛДгЫљгаНкЕуЖМПЩДяЃЌЕЋЪЧжЛДцдкгкЕквЛДЮЩљУїЫќЕФФЧИіНкЕуЩЯЃЌНтОіЗНАИЃКЯћЯЂЖгСаЕФИпПЩгУЃЉЃЛУПИіНкЕуЖМПЩвдНгЪеСЌНгЃЌДІРэЪ§ОнЁЃ
МЏШКНкЕугаСНжжЃЌdiscЃКФЌШЯЃЌаХЯЂДцдкБОЕиЪ§ОнПтЃЛramЃКМгШыМЏШКЪБЃЌЬэМг--ramВЮЪ§ЃЌаХЯЂДцдкФкДцЃЌПЩЬсИпадФмЁЃ
ХфжУЃКЃЈвЛАуЕФЃЌгУФЌШЯЕФМДПЩЁЃЃЉ
$RABBITMQ_HOME/etc/rabbitmq/rabbitmq-env.confЃК
RABBITMQ_USE_LONGNAMEЃКФЌШЯfalseЃЌ(ФЌШЯЕФЃЌRABBITMQ_NODENAMEжа@КѓУцЕФ$HOSTNAMEЪЧжїЛњУћЃЌЫљвдашвЊМЏШКжаУПИіНкЕуЕФhostsЮФМўАќКЌЦфЫћНкЕужїЛњУћЕНЕижЗЕФгГЩфЁЃЕЋЪЧШчЙћЩшжУЮЊtrueЃЌОЭПЩвдЖЈвхRABBITMQ_NODENAMEжаЕФ$HOSTNAMEЮЊгђУћСЫЃЉ
RABBITMQ_DIST_PORTЃКМЏШКЖЫПкКХЃЌФЌШЯRABBITMQ_NODE_PORT + 20000
$RABBITMQ_HOME/etc/rabbitmq/rabbitmq.configЃК
cluster_nodesЃКЩшжУКѓЃЌдкЦєЖЏЪБЛсГЂЪдздЖЏСЌНгМгШыЕФНкЕуВЂзщГЩМЏШКЁЃ
cluster_partition_handlingЃКЭјТчЗжЧјЕФДІРэЁЃ
ИќЖрЯъЯИЕФХфжУМћЃКХфжУ
УќСю
rabbitmqctl stop_app
rabbitmqctl join_cluster [--ram] nodename@hostnameЃКНЋЕБЧАНкЕуМгШыЕНМЏШКжаЃЛФЌШЯЪЧвдdiscНкЕуМгШыМЏШКЃЌМгЩЯ--ramЮЊramНкЕуЁЃ
rabbitmqctl start_app
rabbitmqctl cluster_statusЃКВщПДМЏШКзДЬЌ
зЂЃКШчЙћМгШыМЏШКЪЇАмЃЌПЩЯШВщПД
УПИіНкЕуЕФ$HOME/.erlang.cookieФкШнвЛжТЃЛ
ШчЙћhostnameЪЧжїЛњУћЃЌФЧУДДЫhostnameКЭЕижЗЕФгГЩфашвЊМгШыhostsЮФМўжаЃЛ
ШчЙћЪЙгУЕФЪЧгђУћЃЌФЧУДашвЊЩшжУRABBITMQ_USE_LONGNAMEЮЊtrueЁЃ
зЂЃКdockerАцМЏШКЕФМћЃКrabbitmq-server-cluster
ИпМЖ
AMQPавщМђНщ
RabbitMQдЩњжЇГжAMQP 0-9-1ВЂРЉеЙЪЕЯжСЫСЫвЛаЉГЃгУЕФЙІФмЃКAMQP 0-9-1
АќКЌШ§ВуЃК
ФЃаЭВу: зюИпВуЃЌЬсЙЉСЫПЭЛЇЖЫЕїгУЕФУќСюЃЌШчЃКqueue.declare,basic.ack,consumeЕШЁЃ
ЛсЛАВуЃКНЋУќСюДгПЭЛЇЖЫДЋЕнИјЗўЮёЦїЃЌдйНЋЗўЮёЦїЕФгІД№ДЋЕнИјПЭЛЇЖЫЃЌЛсЛАВуЮЊетИіДЋЕнЙ§ГЬЬсЙЉПЩППадЁЂЭЌВНЛњжЦКЭДэЮѓДІРэЁЃ
ДЋЪфВуЃКжївЊДЋЪфЖўНјжЦЪ§ОнСїЃЌЬсЙЉжЁЕФДІРэЁЂаХЕРИДгУЁЂДэЮѓМьВтКЭЪ§ОнБэЪОЁЃ

зЂЃКЦфЫћавщЕФжЇГжМћЃКRabbitMQжЇГжЕФавщ
ГЃгУВхМў
ЙмРэНчУцЃЈЩёЦїЃЉ
ЦєЖЏКѓЃЌжДааrabbitmq-plugins enable rabbitmq_management->
ЗУЮЪhttp://localhost:15672->ВщПДНкЕузДЬЌЃЌЖгСааХЯЂЕШЕШЃЌЩѕжСПЩвдЖЏЬЌХфжУЯћЯЂЖгСаЕФжїБИВпТдЃЌШчЯТЭМЃК
management
Federation
ЦєгУFederationВхМўЃЌЪЙЕУВЛЭЌМЏШКЕФНкЕужЎМфПЩвдДЋЕнЯћЯЂЃЌДгЖјФЃФтГіРрЫЦМЏШКЕФаЇЙћЁЃетбљПЩвдгаМИЕуКУДІЃК
ЫЩёюКЯЃКСЊКЯдквЛЦ№ЕФВЛЭЌМЏШКПЩвдгаИїздЕФгУЛЇЃЌШЈЯоЕШаХЯЂЃЌЮоашвЛжТЃЛДЫЭтЃЌетаЉМЏШКЕФRabbitMQКЭErlangЕФАцБОПЩвдВЛвЛжТЁЃ
дЖГЬЭјТчСЌНггбКУЃКгЩгкЭЈаХЪЧзёбAMQPавщЕФЃЌЙЪЖјЖдЖЯЖЯајајЕФЭјТчСЌНгШнШЬЖШИпЁЃ
здЖЈвхЃКПЩвдзджїбЁдёФФаЉзщМўЦєгУfederationЁЃ
МИИіИХФюЃК
Upstreams: ЖЈвхЩЯгЮНкЕуаХЯЂЃЌШчЃК
rabbitmqctl set_parameter federation-upstream my-upstream
'{"uri":"amqp://server-name","expires":3600000}'
ЖЈвхвЛИіmy-upstream
uriЪЧЦфЩЯгЮНкЕуЕФЕижЗЃЌЖрИіupstreamЕФНкЕуЮоашдкЭЌвЛМЏШКжаЁЃ
expiresБэЪОЖЯПЊСЌНг3600000msКѓЦфЩЯгЮНкЕуЛсЛКДцЯћЯЂЁЃ
Upstream sets: ЖрИіUpstreamЕФМЏКЯЃЛФЌШЯгаИіallЃЌЛсНЋЫљгаЕФUpstreamМгНјШЅЁЃ
Policies: ЖЈвхФФаЉexchanges,queuesЙиСЊЕНФФИіUpstreamЛђепUpstream
setЃЌШчЃК
rabbitmqctl set_policy --apply-to exchanges federate-me
"^amq\." '{"federation-upstream-set":"all"}'
НЋДЫНкЕуЫљгавдamq.ПЊЭЗЕФexchangeСЊКЯЕНЩЯгЮНкЕуЕФЭЌУћexchangeЁЃ
зЂЃК
гЩгкЯТгЮНкЕуЕФexchangeПЩвдМЬајзїЮЊЦфЫћНкЕуЕФЩЯгЮЃЌЙЪПЩЩшжУГЩбЛЗЃЌЙуВЅЕШаЮЪНЁЃ
ЭЈЙ§max_hopsВЮЪ§ПижЦДЋЕнВуЪ§ЁЃ
ФЃФтМЏШКЃЌПЩвдНЋЖрИіНкЕуСНСНЛЅСЌЃЌВЂЩшжУmax_hops=1ЁЃ
federated_cluster
federated_broadcast
rabbitmq-plugins enable rabbitmq_federation
ШчЙћЦєгУСЫЙмРэНчУцЃЌПЩвдЬэМгЃК
rabbitmq-plugins enable rabbitmq_federation_management
етбљОЭПЩвддкНчУцХфжУUpstreamКЭPolicyСЫЁЃ
зЂЃКШчЙћдквЛИіМЏШКжаЪЙгУfederationЃЌашвЊИУМЏШКУПИіНкЕуЖМЦєгУFederationВхМў
зЂЃКИќЖрВхМўЧыМћЃКВхМў
|









