| БрМЭЦМі: |
БОЮФжївЊЪзЯШНщЩмЪВУДЪЧMQ
ЃЌMQЪЧИЩЪВУДгУЕФЃПMQКтСПБъзМЃЌжїСїОКЦЗЗжЮіЃЌЦфДЮЖдRabbitMQНјааЯъЯИЕФВћЪіЃЌЯЃЭћБОЮФЖдФњЕФбЇЯАгаЫљАяжњЁЃ
РДздгкМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЪВУДЪЧMQЃП
ЯћЯЂзмЯп(Message Queue)ЃЌЪЧвЛжжПчНјГЬЁЂвьВНЕФЭЈаХЛњжЦЃЌгУгкЩЯЯТгЮДЋЕнЯћЯЂЁЃгЩЯћЯЂЯЕЭГРДШЗБЃЯћЯЂЕФПЩППДЋЕнЁЃ
MQЪЧИЩЪВУДгУЕФЃП
гІгУНтёюЁЂвьВНЁЂСїСПЯїЗцЁЂЪ§ОнЗжЗЂЁЂДэЗхСїПиЁЂШежОЪеМЏЕШЕШ...
MQКтСПБъзМ
ЗўЮёадФмЁЂЪ§ОнДцДЂЁЂМЏШКМмЙЙ
жїСїОКЦЗЗжЮі
ЕБЧАЪаУцЩЯmqЕФВњЦЗКмЖрЃЌБШШчRabbitMQЁЂKafkaЁЂActiveMQЁЂZeroMQКЭАЂРяАЭАЭОшЯзИјApacheЕФRocketMQЁЃЩѕжССЌredisетжжNoSQLЖМжЇГжMQЕФЙІФмЁЃ
ActiveMQ
ActiveMQЪЧapacheГіЦЗЃЌзюСїааЕФЃЌФмСІЧПОЂЕФПЊдДЯћЯЂзмЯпЃЌВЂЧвЫќвЛИіЭъШЋжЇГжJMSЙцЗЖЕФЯћЯЂжаМфМўЁЃЦфЗсИЛЕФAPIЁЂЖржжМЏШКЙЙНЈФЃЪНЪЙЕУЫќГЩЮЊвЕНчРЯХЦЯћЯЂжаМфМўЃЌдкжааЁаЭЦѓвЕжагІгУЙуЗКЁЃ
ЕЋЪЧЦфадФмЩдВюЃЌдкУцЖдИпВЂЗЂЕФЧщПіЯТЃЌЛсГіЯжЯћЯЂзшШћЁЂЖбЛ§ЁЂбгГйЕШЮЪЬтЁЃ
ФЌШЯВЩгУСЫЛљгкФкДцЕФkahaDBНјааДцДЂЃЌШчЙћашвЊБЃжЄЯћЯЂЕФПЩППадЃЌвВПЩвдбЁдёЙиЯЕааЪ§ОнПтНјааДцДЂЁЃ
МЏШКМмЙЙФЃЪНШчЯТЃК
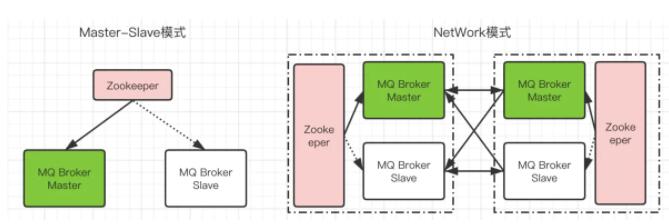
Master-SlaveФЃЪНЃКЭЈЙ§zookeeperЖджїДгНјааЙмРэЃЌе§ГЃЧщПіЯТЃЌДгНкЕуВЛЛсЬсЙЉЗўЮёЁЃЕБжїНкЕуГіЯжЮЪЬтКѓЃЌzookeeperЛсИпаЇЕФНЋжїНкЕуЯТЕєЃЌДгНкЕуРДЬсЙЉЗўЮёЁЃ
NetWorkФЃЪНЃКСНЬзжїДгMaster-SlaveНкЕуЁЃгЩЭјТчСЊЭЈЃЌНЋЦфБфЮЊЗжВМЪНЕФМЏШКМмЙЙЁЃ
Kafka
KafkaЪЧLinkedInПЊдДЕФЗжВМЪНЗЂВМ-ЖЉдФЯћЯЂЯЕЭГЃЌФПЧАЙщЪєгкApacheЖЅМЖЯюФПЁЃKafkaжївЊЬиЕуОЭЪЧЛљгкPullЕФФЃЪНРДДІРэЯћЯЂЯћЗбЃЌзЗЧѓИпЭЬЭТСПЃЌвЛПЊЪМЕФФПЕФОЭЪЧгУгкШежОЪеМЏКЭДЋЪфЁЃ0.8АцБОПЊЪМжЇГжИДжЦЃЌВЛжЇГжЪТЮёЃЌЖдЯћЯЂЕФжиИДЁЂЖЊЪЇЁЂДэЮѓУЛгабЯИёвЊЧѓЃЌЪЪКЯВњЩњДѓСПЪ§ОнЕФЛЅСЊЭјЗўЮёЕФЪ§ОнЪеМЏвЕЮёЁЃФмЙЛжЇГжСЎМлЕФЗўЮёЦїЩЯвдУПУы100kЬѕЪ§ОнЕФЭЬЭТСПЁЃ(гаackЛњжЦЃЌПЩвдБЃжЄВЛЖЊЪЇЃЌВЛФмБЃжЄВЛжиИДЁЃ)
ИпаЇЕФЖСаДЛљгкВйзїЯЕЭГЕЭВуЕФPage CacheЁЃНіНіЪЙгУФкДцЙмРэЃЌВЛДцдкФкДцКЭДХХЬжЎМфЕФIOВйзїЁЃ
МЏШКМмЙЙФЃЪНШчЯТЃК
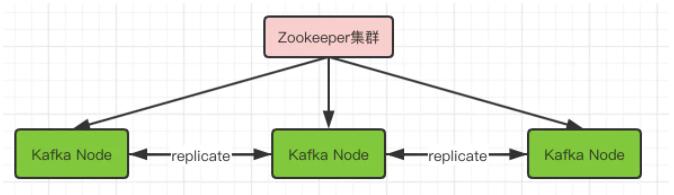
ЭЈЙ§replicateНјааНкЕуМфЪ§ОнЕФИДжЦЃЌОЁСПБЃжЄЪ§ОнЕФПЩППадЁЃ
RocketMQ
RocketMQЪЧАЂРяПЊдДЕФЯћЯЂжаМфМўЃЌФПЧАвВвбОЗѕЛЏЮЊApacheЖЅМЖЯюФПЃЌЫќЪЧДПJavaПЊЗЂЃЌОпгаИпЭЬЭТСПЁЂИпПЩППадЁЂЪЪКЯДѓЙцФЃЗжВМЪНЯЕЭГгІгУЕФЬиЕуЁЃRocketMQЫМТЗЦ№дДгкKafkaЃЌЫќЖдЯћЯЂЕФПЩППДЋЪфвдМАЪТЮёадзіСЫгХЛЏЃЌФПЧАдкАЂРяМЏЭХБЛЙуЗКгІгУгкНЛвзЁЂГфжЕЁЂСїМЦЫуЁЂЯћЯЂЭЦЫЭЁЂШежОСїЪНДІРэЁЂbinlogЗжЗЂЕШГЁОАЁЃ
дк2.0АцБОЃЌRocketMQМЏШКвВЪЧЭЈЙ§ZookeeperНјааЙмРэЁЃдк3.0жЎКѓЃЌЗХЦњZookeeperЃЌЪЙгУNameServerНјааМЏШКЕФЙмРэКЭаЕїЁЃ
ФмЙЛБЃеЯЯћЯЂЕФЫГађЯћЗбЃЌЬсЙЉСЫЗсИЛЕФЯћЯЂРШЁЕШДІРэФЃЪНЃЌЯћЗбепПЩвдИпаЇНјааЫЎЦНРЉеЙЃЌФмЙЛГадиЩЯвкМЖБ№Ъ§ОнСПМЖЁЃ
ПЩвджЇГжЖржжМЏШКМмЙЙФЃЪНЃКMaster-SlaveФЃЪНЁЂЫЋMaster-SlaveФЃЪНЁЂЖржїЖрДгФЃЪНЕШЕШЁЃ
жЇГжЖржжЫЂХЬВпТдЃКЭЌВНЫЋаДЁЂвьВНИДжЦЁЃНшжњСЫСуПНБДЕШММЪѕЁЃ
МЏШКМмЙЙФЃЪНШчЯТЃК
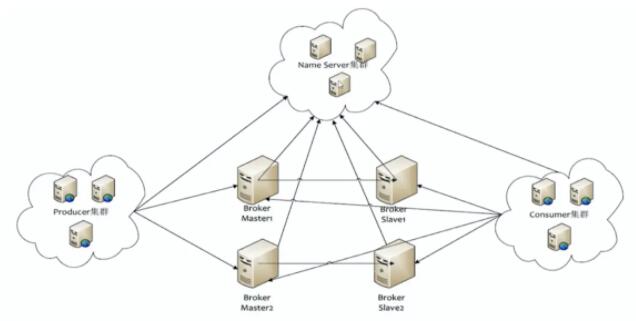
RocketMQМЏШК
ЪеЗбАцБОМЏШК
ММЪѕБГОАжЊЪЖНщЩм
AMQPИпМЖЯћЯЂЖгСаавщ
AMQP(Advanced Message Queuing Protocol)ИпМЖЯћЯЂЖгСаавщЃКИпМЖЯћЯЂЖгСаавщЁЃЫќЪЧгІгУВуавщЕФвЛИіПЊЗХБъзМЃЌЮЊУцЯђЯћЯЂЕФжаМфМўЩшМЦЃЌЛљгкДЫавщЕФПЭЛЇЖЫгыЯћЯЂжаМфМўПЩДЋЕнЯћЯЂЃЌВЂВЛЪмВњЦЗЁЂПЊЗЂгябдЕШЬѕМўЕФЯожЦЁЃ
AMQPжаЯћЯЂЕФТЗгЩЙ§ГЬКЭJMSДцдквЛаЉВюБ№ЁЃAMQPжадіМгСЫExchangeКЭBingingЕФНЧЩЋЁЃЩњВњепАбЯћЯЂЗЂВМЕНExchangeЩЯЃЌЯћЯЂзюжеЕНДяЖгСаВЂБЛЯћЗбепНгЪеЃЌЖјBindingОіЖЈНЛЛЛЦїЕФЯћЯЂгІИУЗЂЫЭЕНФФИіЖгСаЁЃ
AMQPЯћЯЂТЗгЩЙ§ГЬ
Erlangгябд
ErlangгябдзюГѕгУгкНЛЛЛЛњСьгђЕФМмЙЙФЃЪНЃЌетбљЪЙЕУRabbitMQдкBrokerжЎМфНјааЪ§ОнНЛЛЅЕФадФмЗЧГЃгХау(ErlangгазХКЭдЩњSocketвЛбљЕФбгГй)ЁЃ
RabbitMQ
RabbitMQЪЧвЛИіПЊдДЕФЯћЯЂДњРэКЭЖгСаЗўЮёЦїЃЌгУРДЭЈЙ§ЦеЭЈавщдкВЛЭЌЕФгІгУжЎМфЙВЯэЪ§Он(ПчЦНЬЈПчгябд)ЁЃRabbitMQЪЧЪЙгУErlangгябдБраДЃЌВЂЧвЛљгкAMQPавщЪЕЯжЁЃ
RabbitMQЕФгХЪЦЃК
ПЩППад(Reliablity)ЃКЪЙгУСЫвЛаЉЛњжЦРДБЃжЄПЩППадЃЌБШШчГжОУЛЏЁЂДЋЪфШЗШЯЁЂЗЂВМШЗШЯЁЃ
СщЛюЕФТЗгЩ(Flexible Routing)ЃКдкЯћЯЂНјШыЖгСажЎЧАЃЌЭЈЙ§ExchangeРДТЗгЩЯћЯЂЁЃЖдгкЕфаЭЕФТЗгЩЙІФмЃЌRabbitвбОЬсЙЉСЫвЛаЉФкжУЕФExchangeРДЪЕЯжЁЃеыЖдИќИДдгЕФТЗгЩЙІФмЃЌПЩвдНЋЖрИіExchangeАѓЖЈдквЛЦ№ЃЌвВЭЈЙ§ВхМўЛњжЦЪЕЯжздМКЕФExchangeЁЃ
ЯћЯЂМЏШК(Clustering)ЃКЖрИіRabbitMQЗўЮёЦїПЩвдзщГЩвЛИіМЏШКЃЌаЮГЩвЛИіТпМBrokerЁЃ
ИпПЩгУ(Highly Avaliable Queues)ЃКЖгСаПЩвддкМЏШКжаЕФЛњЦїЩЯНјааОЕЯёЃЌЪЙЕУдкВПЗжНкЕуГіЮЪЬтЕФЧщПіЯТЖгСаШдШЛПЩгУЁЃ
Жржжавщ(Multi-protocol)ЃКжЇГжЖржжЯћЯЂЖгСаавщЃЌШчSTOMPЁЂMQTTЕШЁЃ
ЖржжгябдПЭЛЇЖЫ(Many Clients)ЃКМИКѕжЇГжЫљгаГЃгУгябдЃЌБШШчJavaЁЂ.NETЁЂRubyЕШЁЃ
ЙмРэНчУц(Management UI)ЃКЬсЙЉСЫвзгУЕФгУЛЇНчУцЃЌЪЙЕУгУЛЇПЩвдМрПиКЭЙмРэЯћЯЂBrokerЕФаэЖрЗНУцЁЃ
ИњзйЛњжЦ(Tracing)ЃКШчЙћЯћЯЂвьГЃЃЌRabbitMQЬсЙЉСЫЯћЯЂЕФИњзйЛњжЦЃЌЪЙгУепПЩвдевГіЗЂЩњСЫЪВУДЁЃ
ВхМўЛњжЦ(Plugin System)ЃКЬсЙЉСЫаэЖрВхМўЃЌРДДгЖрЗНУцНјааРЉеЙЃЌвВПЩвдБрМздМКЕФВхМўЁЃ
RabbitMQЕФећЬхМмЙЙ
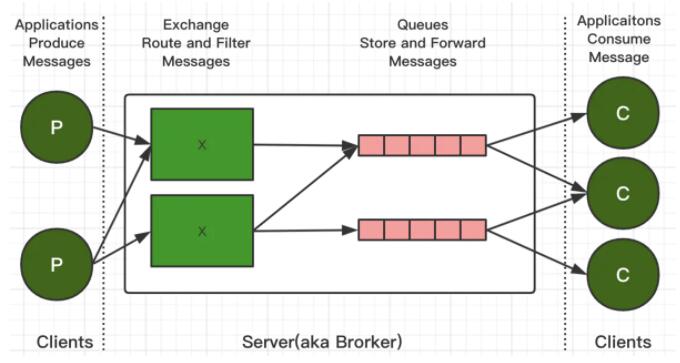
ећЬхМмЙЙ
RabbitMQЕФЯћЯЂСїзЊ
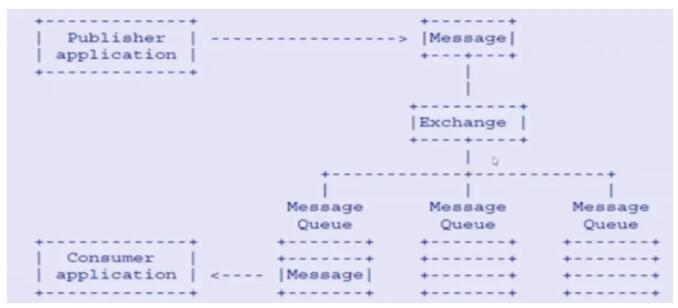
ЯћЯЂСїзЊ
RabbitMQИїзщМўЙІФм
MacDown Screenshot
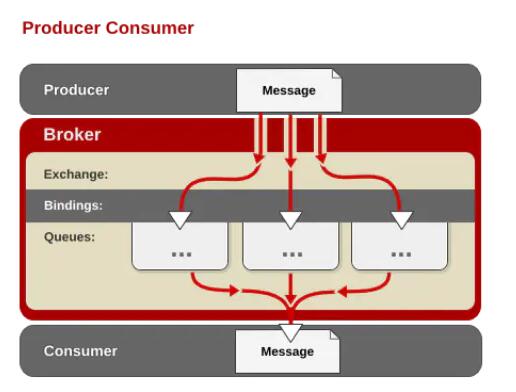
BrokerЃКБъЪЖЯћЯЂЖгСаЗўЮёЦїЪЕЬх.
Virtual HostЃКащФтжїЛњЁЃБъЪЖвЛХњНЛЛЛЛњЁЂЯћЯЂЖгСаКЭЯрЙиЖдЯѓЁЃащФтжїЛњЪЧЙВЯэЯрЭЌЕФЩэЗнШЯжЄКЭМгУмЛЗОГЕФЖРСЂЗўЮёЦїгђЁЃУПИіvhostБОжЪЩЯОЭЪЧвЛИіminiАцЕФRabbitMQЗўЮёЦїЃЌгЕгаздМКЕФЖгСаЁЂНЛЛЛЦїЁЂАѓЖЈКЭШЈЯоЛњжЦЁЃvhostЪЧAMQPИХФюЕФЛљДЁЃЌБиаыдкСДНгЪБжИЖЈЃЌRabbitMQФЌШЯЕФvhostЪЧ
/ЁЃ
ExchangeЃКНЛЛЛЦїЃЌгУРДНгЪеЩњВњепЗЂЫЭЕФЯћЯЂВЂНЋетаЉЯћЯЂТЗгЩИјЗўЮёЦїжаЕФЖгСаЁЃ
QueueЃКЯћЯЂЖгСаЃЌгУРДБЃДцЯћЯЂжБЕНЗЂЫЭИјЯћЗбепЁЃЫќЪЧЯћЯЂЕФШнЦїЃЌвВЪЧЯћЯЂЕФжеЕуЁЃвЛИіЯћЯЂПЩЭЖШывЛИіЛђЖрИіЖгСаЁЃЯћЯЂвЛжБдкЖгСаРяУцЃЌЕШД§ЯћЗбепСЌНгЕНетИіЖгСаНЋЦфШЁзпЁЃ
BandingЃКАѓЖЈЃЌгУгкЯћЯЂЖгСаКЭНЛЛЛЛњжЎМфЕФЙиСЊЁЃвЛИіАѓЖЈОЭЪЧЛљгкТЗгЩМќНЋНЛЛЛЛњКЭЯћЯЂЖгСаСЌНгЦ№РДЕФТЗгЩЙцдђЃЌЫљвдПЩвдНЋНЛЛЛЦїРэНтГЩвЛИігЩАѓЖЈЙЙГЩЕФТЗгЩБэЁЃ
ChannelЃКаХЕРЃЌЖрТЗИДгУСЌНгжаЕФвЛЬѕЖРСЂЕФЫЋЯђЪ§ОнСїЭЈЕРЁЃаХЕРЪЧНЈСЂдкецЪЕЕФTCPСЌНгФкЕиащФтСДНгЃЌAMQPУќСюЖМЪЧЭЈЙ§аХЕРЗЂГіШЅЕФЃЌВЛЙмЪЧЗЂВМЯћЯЂЁЂЖЉдФЖгСаЛЙЪЧНгЪеЯћЯЂЃЌетаЉЖЏзїЖМЪЧЭЈЙ§аХЕРЭъГЩЁЃвђЮЊЖдгкВйзїЯЕЭГРДЫЕЃЌНЈСЂКЭЯњЛйTCPЖМЪЧЗЧГЃАКЙѓЕФПЊЯњЃЌЫљвдв§ШыСЫаХЕРЕФИХФюЃЌвдИДгУвЛЬѕTCPСЌНгЁЃ
ConnectionЃКЭјТчСЌНгЃЌБШШчвЛИіTCPСЌНгЁЃ
PublisherЃКЯћЯЂЕФЩњВњепЃЌвВЪЧвЛИіЯђНЛЛЛЦїЗЂВМЯћЯЂЕФПЭЛЇЖЫгІгУГЬађЁЃ
ConsumerЃКЯћЯЂЕФЯћЗбепЃЌБэЪОвЛИіДгвЛИіЯћЯЂЖгСажаШЁЕУЯћЯЂЕФПЭЛЇЖЫгІгУГЬађЁЃ
MessageЃКЯћЯЂЃЌЯћЯЂЪЧВЛОпУћЕФЃЌЫќЪЧгЩЯћЯЂЭЗКЭЯћЯЂЬхзщГЩЁЃЯћЯЂЬхЪЧВЛЭИУїЕФЃЌЖјЯћЯЂЭЗдђЪЧгЩвЛЯЕСаЕФПЩбЁЪєадзщГЩЃЌетаЉЪєадАќРЈrouting-key(ТЗгЩМќ)ЁЂpriority(гХЯШМЖ)ЁЂdelivery-mode(ЯћЯЂПЩФмашвЊГжОУадДцДЂ[ЯћЯЂЕФТЗгЩФЃЪН])ЕШЁЃ
RabbitMQЕФЖржжExchangeРраЭ
ExchangeЗжЗЂЯћЯЂЪБЃЌИљОнРраЭЕФВЛЭЌЗжЗЂВпТдгаЧјБ№ЁЃФПЧАЙВЫФжжРраЭЃКdirectЁЂfanoutЁЂtopicЁЂheaders(headersЦЅХфAMQPЯћЯЂЕФheaderЖјВЛЪЧТЗгЩМќ(Routing-key)ЃЌДЫЭтheadersНЛЛЛЦїКЭdirectНЛЛЛЦїЭъШЋвЛжТЃЌЕЋЪЧадФмВюСЫКмЖрЃЌФПЧАМИКѕгУВЛЕНСЫЁЃЫљвджБНгПДСэЭтШ§жжРраЭЁЃ)ЁЃ
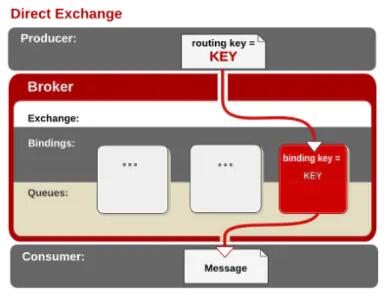
MacDown Screenshot
ЯћЯЂжаЕФТЗгЩМќ(routing key)ШчЙћКЭBindingжаЕФbinding keyвЛжТЃЌНЛЛЛЦїОЭНЋЯћЯЂЗЂЕНЖдгІЕФЖгСажаЁЃТЗгЩМќгыЖгСаУћЭъШЋЦЅХфЁЃ
fanout
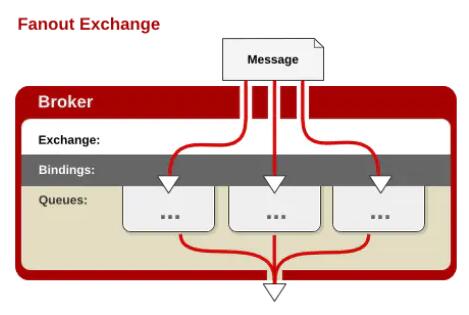
MacDown Screenshot
УПИіЗЂЕНfanoutРраЭНЛЛЛЦїЕФЯћЯЂЖМЛсЗжЕНЫљгаАѓЖЈЕФЖгСаЩЯШЅЁЃfanoutНЛЛЛЦїВЛДІРэИУТЗгЩМќЃЌжЛЪЧМђЕЅЕФНЋЖгСаАѓЖЈЕННЛЛЛЦїЩЯЃЌУПИіЗЂЫЭЕННЛЛЛЦїЕФЯћЯЂЖМЛсБЛзЊЗЂЕНгыИУНЛЛЛЦїАѓЖЈЕФЫљгаЖгСаЩЯЁЃКмЯёзгЭјЙуВЅЃЌУПЬЈзгЭјФкЕФжїЛњЖМЛёЕУСЫвЛЗнИДжЦЕФЯћЯЂЁЃfanoutРраЭзЊЗЂЯћЯЂЪЧзюПьЕФЁЃ
topic
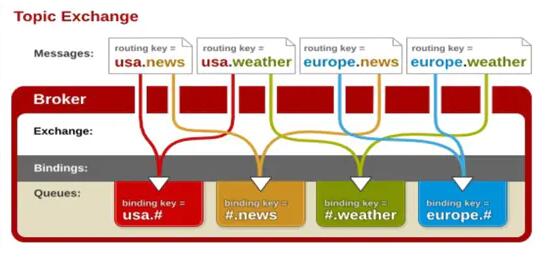
MacDown Screenshot
topicНЛЛЛЦїЭЈЙ§ФЃЪНЦЅХфЗжХфЯћЯЂЕФТЗгЩМќЪєадЃЌНЋТЗгЩМќКЭФГИіФЃЪННјааЦЅХфЃЌДЫЪБЖгСаашвЊАѓЖЈЕНвЛИіФЃЪНЩЯЁЃЫќНЋТЗгЩМќ(routing-key)КЭАѓЖЈМќ(bingding-key)ЕФзжЗћДЎЧаЗжГЩЕЅДЪЃЌетаЉЕЅДЪжЎМфгУЕуИєПЊЁЃЫќЭЌбљвВЛсЪЖБ№СНИіЭЈХфЗћЃК"#"КЭ"*"ЁЃ#ЦЅХф0ИіЛђЖрИіЕЅДЪЃЌЦЅХфВЛЖрВЛЩйвЛИіЕЅДЪЁЃ
TTL
TTL(Time To Live)ЃКЩњДцЪБМфЁЃRabbitMQжЇГжЯћЯЂЕФЙ§ЦкЪБМфЃЌвЛЙВСНжжЁЃ
дкЯћЯЂЗЂЫЭЪБПЩвдНјаажИЖЈЁЃЭЈЙ§ХфжУЯћЯЂЬхЕФpropertiesЃЌПЩвджИЖЈЕБЧАЯћЯЂЕФЙ§ЦкЪБМфЁЃ
дкДДНЈExchangeЪБПЩНјаажИЖЈЁЃДгНјШыЯћЯЂЖгСаПЊЪММЦЫуЃЌжЛвЊГЌЙ§СЫЖгСаЕФГЌЪБЪБМфХфжУЃЌФЧУДЯћЯЂЛсздЖЏЧхГ§ЁЃ
ЫРаХЖгСаDLX
ЫРаХЖгСа(DLX Dead-Letter-Exchange)ЃКРћгУDLXЃЌЕБЯћЯЂдквЛИіЖгСажаБфГЩЫРаХ(dead
message)жЎКѓЃЌЫќФмБЛжиаТpublishЕНСэвЛИіExchangeЃЌетИіExchangeОЭЪЧDLXЁЃ
DLXвВЪЧвЛИіе§ГЃЕФExchangeЃЌКЭвЛАуЕФExchangeУЛгаЧјБ№ЃЌЫќФмдкШЮКЮЕФЖгСаЩЯБЛжИЖЈЃЌЪЕМЪЩЯОЭЪЧЩшжУФГИіЖгСаЕФЪєадЁЃ
ЕБетИіЖгСажагаЫРаХЪБЃЌRabbitMQОЭЛсздЖЏЕФНЋетИіЯћЯЂжиаТЗЂВМЕНЩшжУЕФExchangeЩЯШЅЃЌНјЖјБЛТЗгЩЕНСэвЛИіЖгСаЁЃ
ПЩвдМрЬ§етИіЖгСажаЯћЯЂзіЯргІЕФДІРэЃЌетИіЬиадПЩвдУжВЙRabbitMQ3.0жЎЧАжЇГжЕФimmediateВЮЪ§ЕФЙІФмЁЃ
ЯћЯЂБфГЩЫРаХЕФМИжжЧщПіЃК
ЯћЯЂБЛОмОј(basic.reject/basic.nack)ВЂЧвrequeue=false
ЯћЯЂTTLЙ§Цк
ЖгСаДяЕНзюДѓГЄЖШ
ЫРаХЖгСаЩшжУЃКашвЊЩшжУЫРаХЖгСаЕФexchangeКЭqueueЃЌШЛКѓЭЈЙ§routing keyНјааАѓЖЈЁЃжЛВЛЙ§ЮвУЧашвЊдкЖгСаМгЩЯвЛИіВЮЪ§МДПЩЁЃ
Map<String,
Object> arguments = Maps.newHashMapWithExpectedSize(3);
arguments.put("x-message-ttl", dlx-ttl);
arguments.put("x-dead-letter-exchange","exchange-name");
arguments.put("x-dead-letter-routing-key",
"routing-key");
Queue ret = QueueBuilder.durable("queue-name".withArguments(arguments).build(); |
жЛашвЊЭЈЙ§МрЬ§ИУЫРаХЖгСаМДПЩДІРэЫРаХЯћЯЂЁЃЛЙПЩвдЭЈЙ§ЫРаХЖгСаЭъГЩбгЪБЖгСаЁЃ
ЯћЗбЖЫACKгыNACK
ЯћЗбЖЫНјааЯћЗбЕФЪБКђЃЌШчЙћгЩгквЕЮёвьГЃПЩвдНјааШежОЕФМЧТМЃЌШЛКѓНјааВЙГЅЁЃгЩгкЗўЮёЦїхДЛњЕШбЯжиЮЪЬтЃЌЮвУЧашвЊЪжЖЏНјааACKБЃеЯЯћЗбЖЫЯћЗбГЩЙІЁЃ
ЯћЗбЖЫжиЛиЖгСаЪЧЮЊСЫЖдУЛгаГЩЙІДІРэЯћЯЂЃЌАбЯћЯЂжиаТЗЕЛиЕНBrokerЁЃвЛАуРДЫЕЃЌЪЕМЪгІгУжаЖМЛсЙиБежиЛиЖгСаЃЌвВОЭЪЧЩшжУЮЊfalseЁЃ
// deliveryTagЃКЯћЯЂдкmqжаЕФЮЈвЛБъЪЖ
// multipleЃКЪЧЗёХњСП(КЭqosЩшжУРрЫЦЕФВЮЪ§)
// requeueЃКЪЧЗёашвЊжиЛиЖгСаЁЃЛђепЖЊЦњЛђепжиЛиЖгЪздйДЮЯћЗбЁЃ
public void basicNack(long deliveryTag, boolean
multiple, boolean requeue) |
ЩњВњепConfirmЛњжЦ
ЯћЯЂЕФШЗШЯЃЌЪЧжИЩњВњепЭЖЕнЯћЯЂКѓЃЌШчЙћBrokerЪеЕНЯћЯЂЃЌдђЛсИјЮвУЧЩњВњепвЛИігІД№ЁЃ
ЩњВњепНјааНгЪмгІД№ЃЌгУРДШЗШЯетЬѕЯћЯЂЪЧЗёе§ГЃЕФЗЂЫЭЕНСЫBrokerЃЌетжжЗНЪНвВЪЧЯћЯЂЕФПЩППадЭЖЕнЕФКЫаФБЃеЯЃЁ
ШчКЮЪЕЯжConfirmШЗШЯЯћЯЂЃП
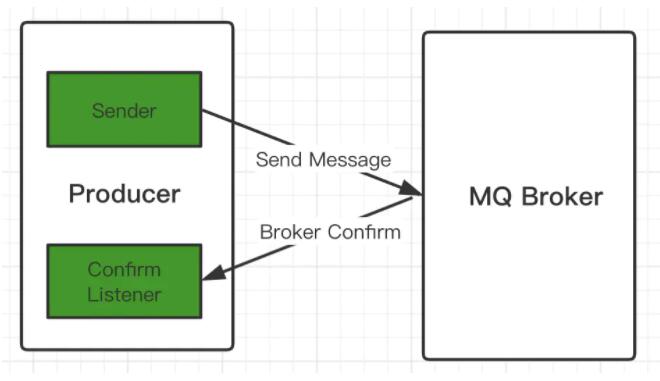
ШЗШЯЛњжЦСїГЬ
1ЁЂдкchannelЩЯПЊЦєШЗШЯФЃЪНЃКchannel.confirmSelect()
2ЁЂдкchannelЩЯПЊЦєМрЬ§ЃКaddConfirmListenerЃЌМрЬ§ГЩЙІКЭЪЇАмЕФДІРэНсЙћЃЌИљОнОпЬхЕФНсЙћЖдЯћЯЂНјаажиаТЗЂЫЭЛђМЧТМШежОДІРэЕШКѓајВйзїЁЃ
ReturnЯћЯЂЛњжЦ
Return ListenerгУгкДІРэвЛаЉВЛПЩТЗгЩЕФЯћЯЂЁЃ
ЮвУЧЕФЯћЯЂЩњВњепЃЌЭЈЙ§жИЖЈвЛИіExchangeКЭRoutingЃЌАбЯћЯЂЫЭДяЕНФГвЛИіЖгСажаШЅЃЌШЛКѓЮвУЧЕФЯћЗбепМрЬ§ЖгСаНјааЯћЯЂЕФЯћЗбДІРэВйзїЁЃ
ЕЋЪЧдкФГаЉЧщПіЯТЃЌШчЙћЮвУЧдкЗЂЫЭЯћЯЂЕФЪБКђЃЌЕБЧАЕФexchangeВЛДцдкЛђепжИЖЈЕФТЗгЩkeyТЗгЩВЛЕНЃЌетИіЪБКђЮвУЧашвЊМрЬ§етжжВЛПЩДяЯћЯЂЃЌОЭашвЊЪЙгУЕНReturrn
ListenerЁЃ
ЛљДЁAPIжагаИіЙиМќЕФХфжУЯюMandatoryЃКШчЙћЮЊtrueЃЌМрЬ§ЦїЛсЪеЕНТЗгЩВЛПЩДяЕФЯћЯЂЃЌШЛКѓНјааДІРэЁЃШчЙћЮЊfalseЃЌbrokerЖЫЛсздЖЏЩОГ§ИУЯћЯЂЁЃ
ЭЈЙ§chennel.addReturnListener(ReturnListener rl)ДЋШывбОжиаДЙ§handleReturnЗНЗЈЕФReturnListenerЁЃ
ЯћЗбЖЫздЖЈвхМрЬ§(ЭЦФЃЪНКЭРФЃЪНpull/push)
вЛАуЭЈЙ§whileбЛЗНјааconsumer.nextDelivery()ЗНЗЈНјааЛёШЁЯТвЛЬѕЯћЯЂНјааФЧИіЯћЗбЁЃ(ЭЈЙ§whileНЋРФЃЪНФЃФтГЩЭЦФЃЪНЃЌЕЋЪЧЫРбЛЗЛсКФЗбCPUзЪдДЁЃ)
ЭЈЙ§здЖЈвхConsumerЃЌЪЕЯжИќМгЗНБуЁЂПЩЖСадИќЧПЁЂНтёюадИќЧПЕФЗНЪНЁЃ(ЯжФЌШЯЪЙгУЕФФЃЪНЃЌжБНгЖЉдФЕНqueueЩЯЃЌШчЙћгаЪ§ОнЃЌОЭЕШД§mqЭЦЫЭЙ§РД)
1.Basic.ConsumeНЋаХЕР(Channel)жУЮЊНгЪеФЃЪНЃЌжБЕНШЁЯћЖгСаЕФЖЉдФЮЊжЙЁЃ
2.дкНгЪмФЃЪНЦкМфЃЌRabbitMQЛсВЛЖЯЕФЭЦЫЭЯћЯЂИјЯћЗбепЁЃ
3.ЕБШЛЭЦЫЭЯћЯЂЕФИіЪ§ЛЙЪЧЪмBasic.QosЕФЯожЦЁЃ
4.ШчЙћжЛЯыДгЖгСаЛёЕУЕЅЬѕЯћЯЂЖјВЛЪЧГжајЖЉдФЃЌНЈвщЛЙЪЧЪЙгУBasic.GetНјааЯћЗбЁЃ
5.ЕЋЪЧВЛФмНЋBasic.GetЗХдквЛИібЛЗРяРДДњЬцBasic.ConsumeЃЌетбљЛсбЯжигАЯьRabbitMQЕФадФмЁЃ
6.ШчЙћвЊЪЕЯжИпЭЬЭТСПЃЌЯћЗбепРэгІЪЙгУBasic.ConsumeЗНЗЈЁЃ
СНжжФЃаЭЖдБШ
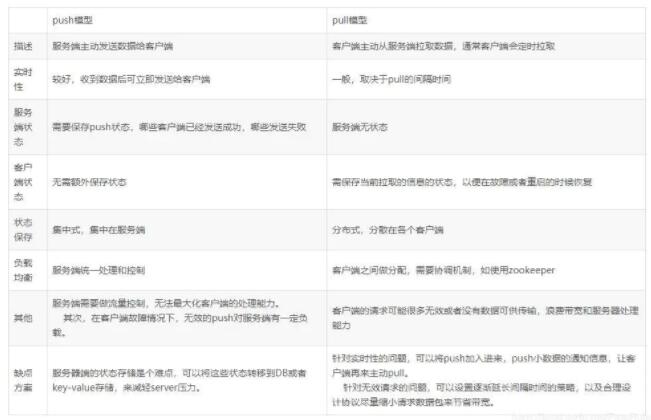
ШчКЮБЃжЄУнЕШад
ЯћЗбЖЫЪЕЯжУнЕШадЃЌОЭвтЮЖзХЮвУЧЕФЯћЯЂгРдЖВЛЛсЯћЗбЖрДЮЃЌМДЪЙЮвУЧЪеЕНСЫЖрЬѕвЛбљЕФаХЯЂЁЃ
1.ЮЈвЛID+жИЮЦТыЛњжЦЃЌРћгУЪ§ОнПтжїМќШЅжи
select count(1) from table where id = id+жИЮЦТы
гХЕуЃКЪЕЯжМђЕЅ
ШБЕуЃКИпВЂЗЂЯТгаЪ§ОнПтаДШыЕФадФмЦПОБ
НтОіЃКИњНјIDНјааЗжПтЗжБэНјааЫуЗЈТЗгЩ
2.РћгУredisЕФдзгадШЅЪЕЯж
ЮЪЬт1ЃКЪЧЗёашвЊТфПтЁЃШчЙћТфПтЃЌШчКЮБЃжЄЪ§ОнЕФвЛжТадКЭдзгадЃП
ЮЪЬт2ЃКШчЙћВЛНјааТфПтЃЌЛКДцжжЕФЪ§ОнШчЙћЩшжУЖЈЪБЭЌВНЕФВпТдЃП
ШчКЮБЃжЄПЩППадЃП
ЪВУДЪЧЩњВњЖЫЕФПЩППадЭЖЕнЃП
1.БЃжЄЯћЯЂЕФГЩЙІЗЂГі
2.БЃеЯMQНкЕуЕФГЩЙІНгЪм
3.ЗЂЫЭЖЫЪеЕНMQНкЕу(Broker)ШЗШЯгІД№
4.ЭъЩЦЯћЯЂЕФВЙГЅЛњжЦ
НтОіЗНАИ
ЯћЯЂТфПтЃЌЖдЯћЯЂзДЬЌНјааБфИќЁЃ
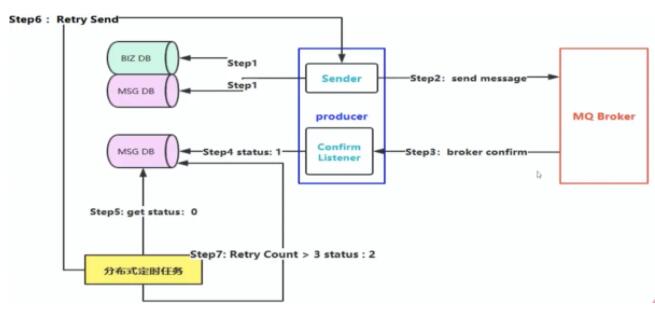
Ъ§ОнТфПт
ШБЕуЃКЖдЪ§ОнПтгаЖрДЮВйзїЁЃВЛЪЪгУгкИпВЂЗЂвЕЮёЁЃ
ЯћЯЂЕФбгГйЭЖЕнЃЌзіЖўДЮШЗШЯЃЌЛиЕїМьВщЁЃ
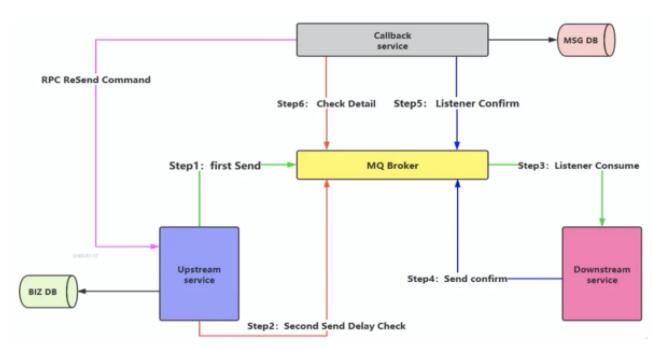
бгГйЭЖЕн
В№ГівЛИіЛиЕїЗўЮёЁЃНЋТфПтЁЂМьВщЕШВйзїАВХХжСЛиЕїЗўЮёЩЯЁЃ
1ЃКЗЂЫЭепЗЂЫЭаХЯЂжСMQЃЌЯћЗбепЮЊЯТгЮвЕЮёЗНЁЃ
1.1ЃКГЩЙІКѓЃЌзїЮЊЗЂЫЭепЗЂЫЭаХЯЂжСMQЃЌЯћЗбепЮЊЛиЕїЗўЮёЁЃ
1.1.1 ЛиЕїЗўЮёНгЪмЪ§ОнКѓЃЌТфПтЁЃ
1.2ЃКЪЇАмЃЌЕШД§ЗЂЫЭепЕФбгЪБЭЖЕнаХЯЂЁЃ
2ЁЂЗЂЫЭепЗЂЫЭбгГйЭЖЕнаХЯЂжСMQЃЌЯћЗбепЮЊЛиЕїЗўЮёЁЃ
1.1ЃКВщПтЃЌШЗШЯЯТгЮЗўЮёЗНЯћЗбвбГЩЙІЁЃ
1.2ЃКВщПтЃЌШЗШЯЯТгЮЗўЮёЗНЯћЗбЪЇАмЃЌЭЈЙ§rpcЕїгУЗЂЫЭепЕФНгПкжиаТЗЂЫЭЁЃ
ЯћЯЂЗЂЫЭепЗЂЫЭЕФСНЬѕаХЯЂЪЧЭЌЪБЗЂЫЭЕФЁЃ
МѕЩйСЫЖдПтЕФВйзїЃЌЭЌЪБНтёюЃЌБЃжЄСЫадФмЃЌВЛФмАйЗжАйБЃжЄПЩППад
ЯћЗбЖЫШчКЮЯоСї
ЕБКЃСПЯћЯЂЫВМфЭЦЫЭЙ§РДЃЌЕЅИіПЭЛЇЖЫЮоЗЈЭЌЪБДІРэФЧУДЖрЪ§ОнЃЌбЯжиЛсЕМжТЯЕЭГхДЛњЁЃетЪБЃЌашвЊЯїЗхЁЃ
RabbitMQЬсЙЉСЫвЛжжqos(ЗўЮёжЪСПБЃжЄ)ЙІФмЁЃМДдкЗЧздЖЏШЗШЯЯћЯЂЕФЧАЬсЯТ(ЗЧACK)ЃЌШчЙћвЛЖЈЪ§ФПЕФЯћЯЂ(ЭЈЙ§ЛљгкconsumeЛђепchannelЩшжУqosЕФжЕ)ЮДБЛШЗШЯЧАЃЌВЛНјааЯћЗбаТЕФЯћЯЂЁЃ
// prefetchSizeЃКЯћЯЂЬхДѓаЁЯожЦЃЛ0ЮЊВЛЯожЦ
// prefetchCountЃКRabbitMQЭЌЪБИјвЛИіЯћЗбепЭЦЫЭЕФЯћЯЂИіЪ§ЁЃМДвЛЕЉгаNИіЯћЯЂЛЙУЛгаackЃЌдђИУconsumerНЋblockЕєЃЌжБЕНгаЯћЯЂackЁЃФЌШЯЪЧ1.
// globalЃКЯоСїВпТдЕФгІгУМЖБ№ЁЃconsumer[false]ЁЂchannel[true]ЁЃ
void BasicQos(unit prefetchSize, unshort prefetchCount,
bool global);
channel.basicQos(...); |
ChannelФЃЪНКЭConnectionФЃЪН
ВЮПМЃКhttps://www.jianshu.com/p/2c2a7cfdd38a
ConnectionКЭChannelЪЧspring-amqpжаЕФИХФюЃЌВЂЗЧrabbitmqжаЕФИХФюЃЌЙйЗНЮФЕЕЖдConnectionКЭChannelгаетбљЕФУшЪіЃК
Sharing of the
connection
is possible since the "unit of work"
for messaging with AMQP
is actually a "channel"
(in some ways,
this is similar to the relationship
between a Connection and a Session in JMS). |
CHANNELФЃЪНЃКГЬађдЫааЦкМфConnectionFactoryЛсЮЌЛЄзХвЛИіConnectionЃЌЫљгаЕФВйзїЖМЛсЪЙгУетИіConnectionЃЌЕЋвЛИіConnectionжаПЩвдгаЖрИіChannelЃЌВйзїrabbitmqжЎЧАЖМБиаыЯШЛёШЁЕНвЛИіChannelЃЌЗёдђОЭЛсзшШћЃЈПЩвдЭЈЙ§setChannelCheckoutTimeout()ЩшжУЕШД§ЪБМфЃЉЃЌетаЉChannelЛсБЛЛКДцЃЈЛКДцЕФЪ§СППЩвдЭЈЙ§setChannelCacheSize()ЩшжУЃЉЃЛ
CONNECTIONФЃЪНЃКетИіФЃЪНЯТдЪаэДДНЈЖрИіConnectionЃЌЛсЛКДцвЛЖЈЪ§СПЕФConnectionЃЌУПИіConnectionжаЭЌбљЛсЛКДцвЛаЉChannelЃЌГ§СЫПЩвдгаЖрИіConnectionЃЌЦфЫќЖМИњCHANNELФЃЪНвЛбљЁЃ
ЙигкCONNECTIONФЃЪНжаЃЌПЩвдДцдкЖрИіConnectionЕФЪЙгУГЁОАЃЌЙйЗНЮФЕЕЕФУшЪіЃК
The use of separate
connections
might be useful in some environments,
such as consuming from an HA cluster,
in conjunction with a load balancer,
to connect to different cluster members. |
setChannelCacheSizeЃКЩшжУУПИіConnectionжаЃЈзЂвтЪЧУПИіConnectionЃЉПЩвдЛКДцЕФChannelЪ§СПЃЌзЂвтжЛЪЧЛКДцЕФChannelЪ§СПЃЌВЛЪЧChannelЕФЪ§СПЩЯЯоЃЌВйзїrabbitmqжЎЧАЃЈsend/receive
messageЕШЃЉвЊЯШЛёШЁЕНвЛИіChannelЃЌЛёШЁChannelЪБЛсЯШДгЛКДцжаевЯажУЕФChannelЃЌШчЙћУЛгадђДДНЈаТЕФChannelЃЌЕБChannelЪ§СПДѓгкЛКДцЪ§СПЪБЃЌЖрГіРДУЛЗЈЗХНјЛКДцЕФЛсБЛЙиБеЁЃ
зЂвтЃЌИФБфетИіжЕВЛЛсгАЯьвбОДцдкЕФConnectionЃЌжЛгАЯьжЎКѓДДНЈЕФConnectionЁЃ
гаЪБЛсГіЯжconnection closedДэЮѓЁЃrabbitTemplateзїепЖдгкетжжЮЪЬтЕФНтОіЗНАИЃЌЫћИјЕФЗНАИКмМђЕЅЃЌЕЅДПЕФдіМгconnectionЪ§ЃК
| connectionFactory.setChannelCacheSize(100); |
setChannelCheckoutTimeoutЃКЕБетИіжЕДѓгк0ЪБЃЌchannelCacheSizeВЛНіЪЧЛКДцЪ§СПЃЌЭЌЪБвВЛсБфГЩЪ§СПЩЯЯоЃЌДгЛКДцЛёШЁВЛЕНПЩгУЕФChannelЪБЃЌВЛЛсДДНЈаТЕФChannelЃЌЛсЕШД§етИіжЕЩшжУЕФКСУыЪ§ЃЌЕНЪБМфШдШЛЛёШЁВЛЕНПЩгУЕФChannelЛсХзГіAmqpTimeoutExceptionвьГЃЁЃ
ЭЌЪБЃЌдкCONNECTIONФЃЪНЃЌетИіжЕвВЛсгАЯьЛёШЁConnectionЕФЕШД§ЪБМфЃЌГЌЪБЛёШЁВЛЕНConnectionвВЛсХзГіAmqpTimeoutExceptionвьГЃЁЃ
ЯћЗбЖЫЕФConcurrencyКЭPrefetchФЃЪН
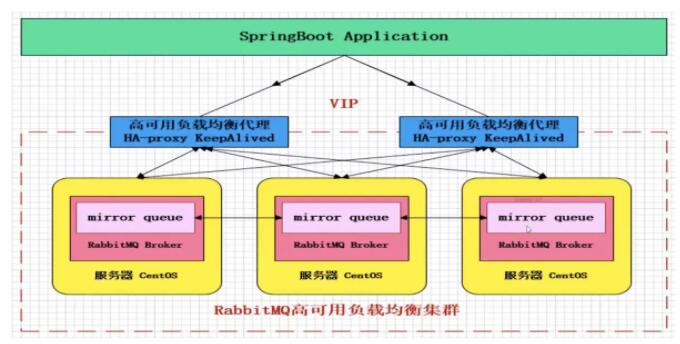
RabbitMQМЏШК
RabbitMQзюгХауЕФЙІФмжЎвЛОЭЪЧФкНЈМЏШКЃЌетИіЙІФмЩцМАЕФФПЕФЪЧдЪаэЯћЗбепКЭЩњВњепдкНкЕуБРРЃЕФЧщПіЯТМЬајдЫааЃЌвдМАЭЈЙ§ЬэМгИќЖрЕФНкЕуРДЯпадРЉеЙЯћЯЂЭЈаХЭЬЭТСПЁЃRabbitMQФкВПРћгУErlangЬсЙЉЕФЗжВМЪНЭЈаХПђМмOTPРДТњзуЩЯЪіашЧѓЃЌЪЙПЭЛЇЖЫдкЪЇШЅвЛИіRabbitMQНкЕуСЌНгЕФЧщПіЯТЃЌЛЙЪЧФмЙЛжиаТСЌНгЕНМЏШКжаЕФЦфЫћНкЕуМЬајЪЄГЁЁЂЯћЗбаХЯЂЁЃ
RabbitMQЛсЪМжеМЧТМвдЯТЫФжаРраЭЕФФкВПдЊЪ§ОнЃК
1.ЖгСадЊЪ§ОнЃКАќРЈЖгСаУћГЦКЭЫћУЧЕФЪєадЃЌБШШчЪЧЗёПЩГжОУЛЏЃЌЪЧЗёПЩГжОУЛЏЃЌЪЧЗёздЖЏЩОГ§ЁЃ
2.НЛЛЛЦїдЊЪ§ОнЃКНЛЛЛЦїУћГЦЁЂРраЭЁЂЪєадЁЃ
3.АѓЖЈдЊЪ§ОнЃКФкВПЪЧвЛеХБэИёЃЌМЧТМШчКЮНЋЯћЯЂТЗгЩЕНЖгСаЁЃ
4.vhostдЊЪ§ОнЃКЮЊvhostФкВПЕФЖгСаЁЂНЛЛЛЦїЁЂАѓЖЈЬсЙЉУќУћПеМфКЭАВШЋЪєадЁЃ
дкЕЅвЛНкЕужаЃЌRabbitMQЛсНЋЫљгаетаЉаХЯЂДцДЂдкФкДцжаЃЌЭЌЪБНЋБъМЧЮЊПЩГжОУЛЏЕФЖгСаЁЂНЛЛЛЦїЁЂ АѓЖЈДцДЂдкгВХЬЩЯЁЃДцЕНгВХЬЩЯПЩвдШЗБЃЖгСаКЭНЛЛЛЦїдкНкЕужиЦєКѓФмЙЛжиНЈЁЃЖјдкМЏШКФЃЪНЯТЃЌЭЌбљвВЬсЙЉСЫСНжжбЁдёЃКДцЕНгВХЬЩЯ(ЖРСЂНкЕуЕФФЌШЯХфжУ)ЃЌДцдкФкДцжаЁЃ
ШчЙћдкМЏШКжаДДНЈЖгСаЃЌМЏШКжЛЛсдкЕЅИіНкЕуЖјВЛЪЧЫљгаНкЕуЩЯДДНЈЭъећЕФЖгСааХЯЂЃЈдЊЪ§ОнЁЂзДЬЌЁЂФкШнЃЉЁЃНсЙћЪЧжЛгаЖгСаЕФЫљгаепНкЕужЊЕРгаЙиЖгСаЕФЫљгааХЯЂЃЌвђДЫЕБМЏШКНкЕуБРРЃЪБЃЌИУНкЕуЕФЖгСаКЭАѓЖЈОЭЯћЪЇСЫЃЌВЂЧвШЮКЮЦЅХфИУЖгСаЕФАѓЖЈЕФаТЯћЯЂвВЖЊЪЇСЫЁЃЛЙКУRabbitMQ
2.6.0жЎКѓЬсЙЉСЫОЕЯёЖгСавдБмУтМЏШКНкЕуЙЪеЯЕМжТЕФЖгСаФкШнВЛПЩгУЁЃ
RabbitMQ МЏШКжаПЩвдЙВЯэ userЁЂvhostЁЂexchangeЕШЃЌЫљгаЕФЪ§ОнКЭзДЬЌЖМЪЧБиаыдкЫљгаНкЕуЩЯИДжЦЕФЃЌР§ЭтОЭЪЧЩЯУцЫљЫЕЕФЯћЯЂЖгСаЁЃRabbitMQ
НкЕуПЩвдЖЏЬЌЕФМгШыЕНМЏШКжаЁЃ
ЕБдкМЏШКжаЩљУїЖгСаЁЂНЛЛЛЦїЁЂАѓЖЈЕФЪБКђЃЌетаЉВйзїЛсжБЕНЫљгаМЏШКНкЕуЖМГЩЙІЬсНЛдЊЪ§ОнБфИќКѓВХЗЕЛиЁЃМЏШКжагаФкДцНкЕуКЭДХХЬНкЕуСНжжРраЭЃЌФкДцНкЕуЫфШЛВЛаДШыДХХЬЃЌЕЋЪЧЫќЕФжДааБШДХХЬНкЕувЊКУЁЃФкДцНкЕуПЩвдЬсЙЉГіЩЋЕФадФмЃЌДХХЬНкЕуФмБЃеЯХфжУаХЯЂдкНкЕужиЦєКѓШдШЛПЩгУЃЌФЧМЏШКжаШчКЮЦНКтетСНепФиЃП
RabbitMQ жЛвЊЧѓМЏШКжажСЩйгавЛИіДХХЬНкЕуЃЌЫљгаЦфЫћНкЕуПЩвдЪЧФкДцНкЕуЃЌЕБНкЕуМгШыЛђРыПЊМЏШКЪБЃЌЫќУЧБиаывЊНЋИУБфИќЭЈжЊЕНжСЩйвЛИіДХХЬНкЕуЁЃШчЙћжЛгавЛИіДХХЬНкЕуЃЌИеКУгжЪЧИУНкЕуБРРЃСЫЃЌФЧУДМЏШКПЩвдМЬајТЗгЩЯћЯЂЃЌЕЋВЛФмДДНЈЖгСаЁЂДДНЈНЛЛЛЦїЁЂДДНЈАѓЖЈЁЂЬэМггУЛЇЁЂИќИФШЈЯоЁЂЬэМгЛђЩОГ§МЏШКНкЕуЁЃЛЛОфЛАЫЕМЏШКжаЕФЮЈвЛДХХЬНкЕуБРРЃЕФЛАЃЌМЏШКШдШЛПЩвддЫааЃЌЕЋжБЕНИУНкЕуЛжИДЃЌЗёдђЮоЗЈИќИФШЮКЮЖЋЮїЁЃ
|









