| 编辑推荐: |
本章将以新浪微博Feed系统架构的发展历程作为背景,
基于一个典型的社交网络Feed系统架构, 介绍Feed系统的缓存模型、缓存体系架构,以及缓存体系如何伴随业务规模来扩展及演进。
来自于s搜狐网,由火龙果软件Alice编辑、推荐。 |
|
在社交网络发展如火如荼的今天,人们越来越倾向于用新媒介来展现自我和沟通交互。以新浪微博为例,作为移动社交时代的重量级社交分享平台,2017年初日活跃用户1.6亿,月活跃用户近3.3亿,每天新增数亿条数据,总数据量达千亿级,核心单个业务的后端数据访问QPS高达百万级。
在社交网络系统运行过程中,面对庞大用户群的海量访问,良好架构且不断改进的缓存体系具有非常重要的支撑作用。
Feed系统架构
互联网从门户/搜索时代进入移动社交时代,互联网产品从满足单向浏览的需求,发展到今天的以用户、关系为基础,通过对海量数据进行实时分析计算,来满足用户的个性信息获取及社交的需求。
类似微博的信息条目在技术上也称之为status或feed,其技术的核心主要包含三个方面:
1.Feed的聚合与分发,用户打开Feed首页后能看到关注人的feed信息列表,同时用户发表的feed需要分发给粉丝或指定用户;
2.Feed信息的组装与展现;
3.用户关系管理,即用户及其关注/粉丝关系的管理。
对于中小型的Feed系统,feed数据可以通过同步push模式进行分发。如图12-1,用户每发表一条feed,后端系统根据用户的粉丝列表进行全量推送,粉丝用户通过自己的inbox来查看所有最新的feed。新浪微博发展初期也是采用类似方案,通过LAMP架构进行feed
push分发,从而实现快速开发及上线。
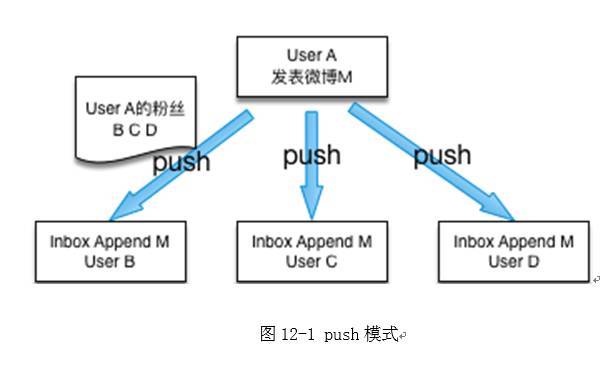
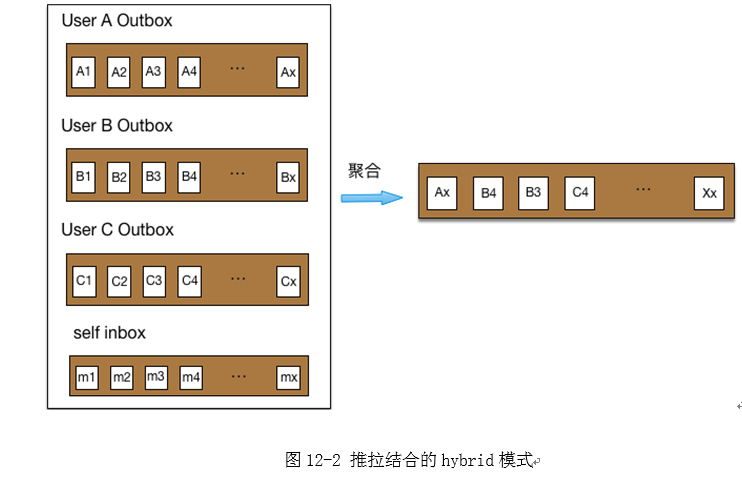
随着业务规模的增长,用户的平均粉丝不断增加,特别是V用户的粉丝的大幅增长,信息延迟就会时有发生,单纯的push无法满足性能要求。同时考虑社交网络中多种接入源,移动端、PC端、第三方都需要接入业务系统。于是就需要对原有架构进行模块化、平台化改进,把底层存储构建为基础服务,然后基于基础服务构建业务服务平台。对数据存储进行了多维度拆分,并大量使用cache进行性能加速,同时将同步push模式改成了异步hybrid模式,即pull+push模式。用户发表feed后首先写入消息队列,由队列处理机进行异步更新,更新时不再push到所有粉丝的inbox,而是存放到发表者自己的outbox;用户查看时,通过pull模式对关注人的outbox进行实时聚合获取。基于性能方面的考虑,部分个性化数据仍然先push到目标用户的inbox。用户访问时,系统将用户自己的inbox和TA所有的关注人outbox一起进行聚合,最终得到Feed列表(如图12-2)。
对于大型Feed系统,还可以在此基础之上继续对Feed架构进行服务化、云化改进,最终形成如图12-3所示的一个典型的Feed系统架构。其对外主要以移动客户端、web主站、开放平台三种方式提供服务,并通过平台接入层访问Feed平台体系。其中平台服务层把各种业务进行模块化拆分,把诸如Feed计算、Feed内容、关系、用户、评论等分解为独立的服务模块,对每个模块实现服务化架构,通过标准化协议进行统一访问。中间层通过各种服务组件来构建统一的标准化服务体系,如motan提供统一的rpc远程访问,configService提供统一的服务发布、订阅,cacheService提供通用的缓存访问,SLA体系、Trace体系、TouchStore体系提供系统通用的健康监测、跟踪、测试及分析等。存储层主要通过Mysql、HBase、Redis、分布式文件等对业务数据提供落地存储服务。
为了满足海量用户的实时请求,大型Feed系统一般都有着较为严格的SLA,如微博业务中核心接口可用性要达到99.99%,响应时间在10-40ms以内,对应到后端资源,核心单个业务的数据访问高达百万级QPS,数据的平均获取时间要在5ms以内。因此在整个Feed系统中,需要对缓存体系进行良好的架构并不断改进。
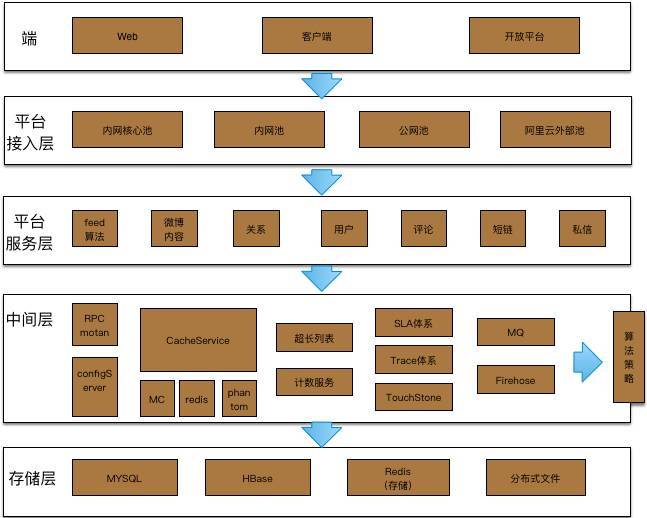
12-3 Feed 系统架构
Feed缓存模型
Feed系统的核心数据主要包括:用户/关系、feed id/content 以及包含计数在内的各种feed状态。Feed系统处理用户的各种操作的过程,实际是一个以核心数据为基础的实时获取并计算更新的过程。
以刷新微博首页为例,处理用户的一个操作请求,主要包括关注关系的获取、feed id的聚合、feed内容的聚合三部分,最终转换到资源后端就是一个获取各种关系、feed、状态等资源数据并进行聚合组装的过程(如图12-4)。这个过程中,一个前端请求会触发一次对核心接口friends_timeline
的请求,到资源后端可能会存在1-2+个数量级的请求数据放大,即Feed系统收到一个此类请求后,可能需要到资源层获取几十数百甚至上千个的资源数据,并聚合组装出最新若干条(如15条)微博给用户。整个Feed流构建过程中,
Feed系统主要进行了如下操作:
根据用户uid获取关注列表;
获取用户自己收到的微博 ID 列表(即 inbox);
对这些 ID 列表进行合并、排序及分页处理后,拿到需要展现的微博 ID 列表;
根据这些 ID 获取对应的微博内容;
对于转发feed进一步获取源feed的内容;
获取用户设置的过滤条件进行过滤。
获取feed/源feed作者的 user 信息并进行组装;
获取请求者对这些feed是否收藏、是否赞等进行组装;
获取这些feed的转发、评论、赞等计数等进行组装;
组装完毕,转换成标准格式返回给请求方。
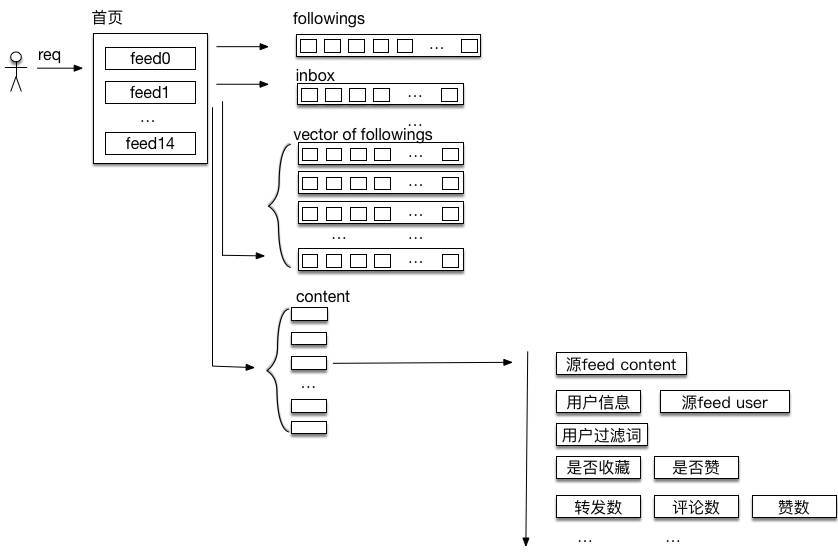
图 12-4 Feed聚合生成的过程
Feed请求需要获取并组装如此多的后端资源数据,同时考虑用户体验,接口请求耗时要在100ms(微博业务要求小于40ms)以下,因此Feed系统需要大量使用缓存(cache),并对缓存体系进行良好的架构。缓存体系在Feed系统占有重要位置,可以说缓存设计决定了一个Feed系统的优劣。
一个典型的Feed系统的缓存设计如图12-5,主要分为INBOX、OUTBOX、SOCIAL GRAPH、CONTENT、EXISTENCE、CONTENT共六部分。
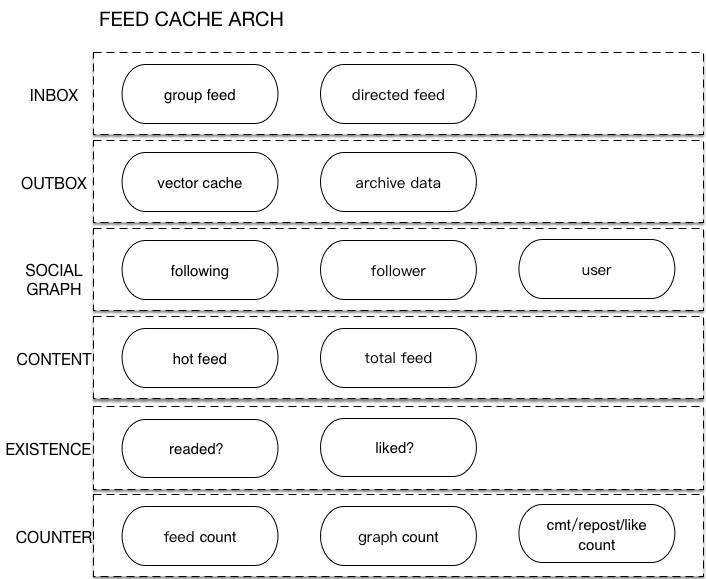
图 12-5 Feed 缓存设计
Feed id存放在INBOX cache和OUTBOX cache中,存放格式是vector(即有序数组)格式如图12-6。

图12-6 vector 存储格式
其中INBOX缓存层用于存放聚合效率低的feed id(类似定向微博directed feed)。当用户发表只展现给特定粉丝、特定成员组织的feed时,Feed系统会首先拿到待推送(push)的用户列表,然后将这个feed
id推送(push)给对应粉丝的INBOX。因此INBOX是以访问者UID来构建key的,其更新方式是先gets并本地,变更后再cas到异地Memcached缓存。
OUTBOX 缓存层用于直接缓存用户发表的普通类型feed id,这个cache以发表者UID来构建key。其中outbox又主要分为vectorcache和archive
data cache;vectorcache用于缓存最新发表的feed id、commentid等,按具体业务类型分池放置。如果用户最近没有发表新feed,vector
cache为空,就要获取archive data里的feed id。
SOCIAL GRAPH缓存层主要包括用户的关注关系及用户的user信息。用户的关注关系主要包括用户的关注(following)列表、粉丝(follower)列表、双向列表等。
CONTENT 缓存层主要包括热门feed的content、全量feed的content。热门feed是指热点事件爆发时,引发热点事件的源feed。由于热门feed被访问的频率远大于普通feed,比如微博中单条热门feed的QPS可能达到数十万的级别,所以热门feed需要独立缓存,并缓存多份,以提高缓存的访问性能。
EXISTENCE 缓存层主要用于缓存各种存在性判断的业务,诸如是否已赞(liked)、是否已阅读(readed)这类需求。
COUNTER缓存用于缓存各种计数。Feed系统中计数众多,如用户的feed发表数、关注数、粉丝数,单条feed的评论数、转发数、赞数及阅读数,话题相关计数等。
Feed系统中的缓存一般可以直接采用Memcached、Redis、Pika等开源组件,必要时可以根据业务需要进行缓存组件的定制自研。新浪微博也是如此,在Feed平台内,Memcached使用最为广泛,占有60%以上的内存容量和访问量,Redis、Pika主要用于缓存social
graph相关数据,自研类组件主要用于计数、存在性判断等业务。结合feed cache架构,INBOX、OUTBOX、CONTENT主要用Memcached来缓存数据,SOCIAL
GRAPH根据场景同时采用Memcached、Redis、Pika作为缓存组件,EXISTENCE采用自研的缓存组件Phantom,COUNTER采用自研的计数服务组件CounterService。
|









