| 编辑推荐: |
现在的分布式系统大部分已经离不开zookeeper(或者类似的解决方案)了,zookeeper简化了分布式应用的管理和部署,本文就通过实例来探讨学习下zookeeper。
来自于博客园,由火龙果软件Alice编辑、推荐。 |
|
引言
之前就了解过kafka,看的似懂非懂,最近项目组中引入了kafka,刚好接着这个机会再次学习下。

Kafka在很多公司被用作分布式高性能消息队列,kafka之前我只用过redis的list来做简单的队列处理,也还算好用,可能数据量比较小,也是单机运行,未出现过问题,用作轻量级消息队列还是比较好用的。而redis的作者antirez,设计redis的初衷并不是用来做消息队列,但用它做消息队列的人貌似还挺多,以至于后来antirez后来新开了个项目disque,专门用来做消息队列,但这个不是本文的重点。
在了解kafka的时候,发现他与zookeeper绑定的比较紧密,为了更好的理解kafka,我必须先将zookeeper搞明白。

ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。
ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
这是从互联网上引用的一段话,分布式应用不同于单机引用,维护起来非常复杂,现在的分布式系统大部分已经离不开zookeeper(或者类似的解决方案)了,zookeeper简化了分布式应用的管理和部署,本文就通过实例来探讨学习下zookeeper。
实例
本人也是持着学习的态度来写本篇文章的,后文的实例都未在生产环境中使用过,都是学习之后的实践整理,偏向于应用,对其中的算法原理并未深究。有瑕疵遗漏的地方还望斧正。
配置管理
假如,我们线上有个服务器集群,成百上千台服务器,如果更新代码的时候怎么更新呢,一台台机器去更新?就算是强大的麒麟臂爬也要累折了,今天我们就试试用zookeeper来给服务器集群部署代码。
原理
zookeeper提供了节点watch的功能,zookeeper的client(对外提供服务的server)监控zookeeper上的节点(znode),当节点变动的时候,client会收到变动事件和变动后的内容,基于zookeeper的这个特性,我们可以给服务器集群中的所有机器(client)都注册watch事件,监控特定znode,节点中存储部署代码的配置信息,需要更新代码的时候,修改znode中的值,服务器集群中的每一台server都会收到代码更新事件,然后触发调用,更新目标代码。也可以很容易的横向扩展,可以随意的增删机器,机器启动的时候注册监控节点事件即可。
我的机器数量有限,在本地模拟zookeeper集群和服务器集群,原理都是一样的,可能具体实施的时候有些小异。
在本机通过3个端口模拟zookeeper集群,多个目录模拟服务器集群。
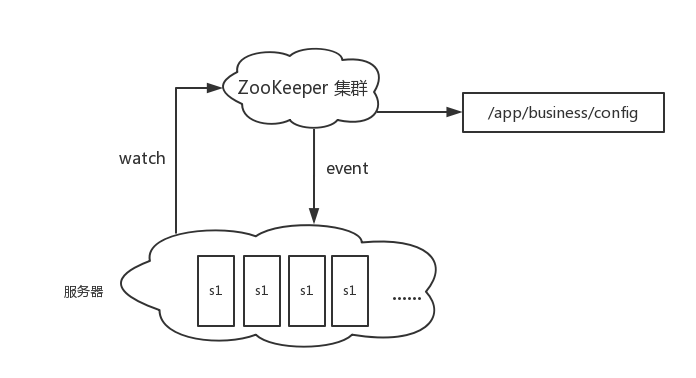
zookeeper配置
本文只是模拟,为了方便,所有的节点全在一台机器上,效果是类似的。
创建/path/to/zookeeper/conf/zoo1.cfg
, /path/to/zookeeper/conf/zoo2.cfg ,/path/to/zookeeper/conf/zoo3.cfg
三个文件,配置分别如下:
zoo1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zk1/data
dataLogDir=/tmp/zk1/log
clientPort=2181
server.1=localhost:2888:3888
server.2=localhost:2899:3899
server.3=localhost:2877:3877 |
zoo2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zk2/data
dataLogDir=/tmp/zk2/log
clientPort=2182
server.1=localhost:2888:3888
server.2=localhost:2899:3899
server.3=localhost:2877:3877 |
zoo3.cfg
ickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zk3/data
dataLogDir=/tmp/zk3/log
clientPort=2183
server.1=localhost:2888:3888
server.2=localhost:2899:3899
server.3=localhost:2877:3877 |
配置文件中dataDir,dataLogDir,clientPort这三个配置是有差别的。
分别在3个节点对应的dataDir中建立myid文件,里面输入服务器标识号
echo 1 > /tmp/zk1/data/myid
echo 2 > /tmp/zk2/data/myid
echo 3 > /tmp/zk3/data/myid |
启动三个节点
bin/zkServer.sh
start conf/zoo1.cfg
bin/zkServer.sh start conf/zoo2.cfg
bin/zkServer.sh start conf/zoo3.cfg |
查看三个节点,可以看到1、3号接节点是follower节点,2号节点是leader节点
zookeeper bin/zkServer.sh
status conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: conf/zoo3.cfg
Mode: follower
zookeeper bin/zkServer.sh status conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: conf/zoo2.cfg
Mode: leader
zookeeper bin/zkServer.sh status conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: conf/zoo1.cfg
Mode: follower |
客户端代码模拟
from kazoo.client
import KazooClient
import time
import json
import subprocess
import os
zk = KazooClient(hosts="10.222.76.148:2181,
10.222.76.148:2182, 10.222.76.148:2183")
zk.start()
FILE_DIR = os.path.split(os.path.realpath(__file__))[0]
'''切换到指定文件夹,不存在的话创建并切换'''
def go_dir(dir_name):
if os.path.exists(dir_name):
pass
else:
os.makedirs(dir_name)
os.chdir(dir_name)
'''从git获取代码'''
def handle_watch(data):
try:
info = json.loads(data)
if not isinstance(info, dict):
raise Exception("节点数据不是json穿")
if not "relativePath" in info:
raise Exception("节点json缺少[relativePath]字段")
if not "url" in info:
raise Exception("节点json缺少[url]字段")
if not "commitId" in info:
raise Exception("节点json缺少[commitId]字段")
chdir = os.path.join(FILE_DIR, info["relativePath"])
go_dir(chdir)
print("开始执行git clone ...")
res = subprocess.call(['git', 'status'])
if 0 == res:
res = subprocess.call(['git', 'pull'])
else:
res = subprocess.call(['git', 'clone', info["url"],
'.'])
if 0 != res:
raise Exception("clone/pull代码失败")
commitId = subprocess.check_output(["git",
"rev-parse", "HEAD"])
commitId = commitId.decode()
commitId = commitId.strip()
if commitId != info["commitId"]:
raise Exception("正确版本Id[%s],当前版本Id[%s]"
% (commitId, info["commitId"]))
except Exception as e:
print(e)
print("更新失败")
return 1
else:
print("正确版本Id[%s],当前版本Id[%s]" % (commitId,
info["commitId"]))
print("更新成功")
return 0
finally:
pass
@zk.DataWatch("/app/business/config")
def watch_node(data, stat):
if data:
data = data.decode("utf-8")
handle_watch(data)
else:
print("数据为空")
while True:
time.sleep(100)
print('tick') |
新建2个文件夹模拟server集群,复制client.py到每个服务器中
mkdir /tmp/server1
mkdir /tmp/server2 |
分别运行服务器上监控zookeeper节点变动的代码:
python3 /tmp/server1/client.py
python3 /tmp/server2/client.py |
启动之后,像znode节点/app/business/config中写入信息:
from kazoo.client
import KazooClient
import json
zk = KazooClient(hosts="192.168.0.105:2181,
192.168.0.105:2182, 192.168.0.105:2183")
zk.start()
znode = {
"url": "https://github.com/aizuyan/daemon.git",
"commitId": "d5f5f144c66f0a36d452e9e13067b21d3d89b743",
"relativePath": "daemon"
}
znode = json.dumps(znode)
znode = bytes(znode, encoding="utf-8")
zk.set("/app/business/config", znode); |
写完之后,会看到上面两个模拟的服务器会马上收到信息:
开始执行git clone
...
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working tree clean
Already up-to-date.
正确版本Id[aea4096f490ff9556124fa5059ca702cc2acdf0e],当前版本Id[aea4096f490ff9556124fa5059ca702cc2acdf0e]
更新成功
开始执行git clone ...
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working tree clean
Already up-to-date.
正确版本Id[aea4096f490ff9556124fa5059ca702cc2acdf0e],当前版本Id[aea4096f490ff9556124fa5059ca702cc2acdf0e]
更新成功 |
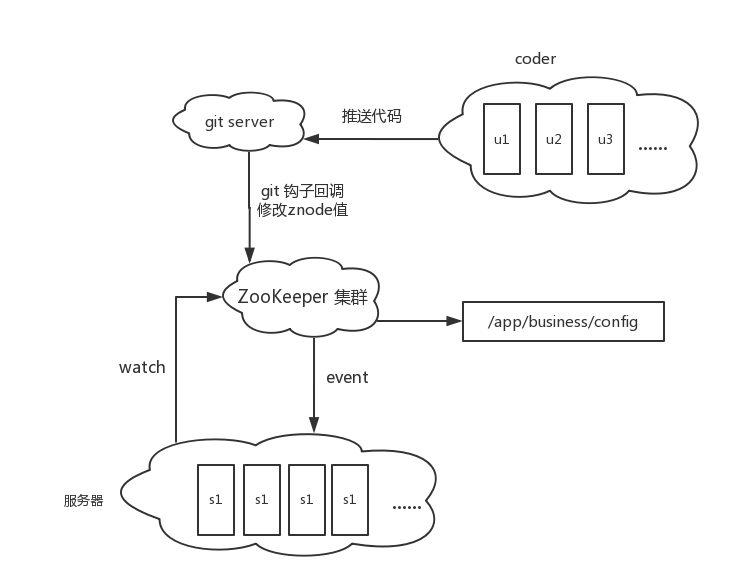
配合上git的hook机制,可以做一个完整的系统,当代码有更新的时候更新保存代码信息znode上的数据,zookeeper
push到所有watch这个节点的服务器,服务器更新代码,所有服务器完成一次更新操作。
服务发现
原理
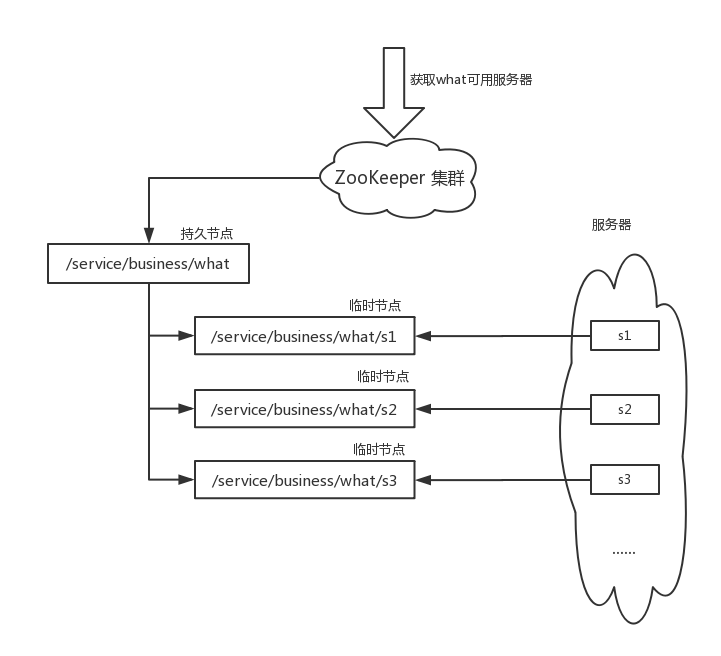
注册一个持久节点/service/business/what,他下面的每个子节点都是一个可用服务,保存了服务的地址端口等信息,服务调用者通过zookeeper获取/service/business/what所有子节点信息来得到可用的服务。下面的节点都是临时节点,服务器启动的时候会过来注册一个临时节点,服务器挂掉之后或主动关闭之后,临时节点会自动移除,这样就可以保证使用者获取的what服务都是可用的,而且可以动态的扩容缩容。
我在本地通过docker来模拟服务器集群,集群中的所有nginx都通过各自的80端口对外提供服务。通过python-nmap定时扫描端口占用情况,如果是open状态则可对外提供服务,如果是closed状态,则停止对外提供服务。如果由于网络抖动删除了临时节点,网络恢复之后,会重新扫描到自身服务可用,然后创建临时节点。
监控服务
容器中启动一个nginx,通过一个进程监控nginx绑定的端口,当端口对外提供服务时,我就认为服务可用,当端口停止对外提供服务时,我就认为服务不可用,相应的删除或者创建临时节点,代码如下所示:
from kazoo.client
import KazooClient
import time
import nmap
import os
import json
ZNODE_BASE_PATH="/service/business/what/"
zk = KazooClient(
hosts="192.168.0.105:2181, 192.168.0.105:2182,
192.168.0.105:2183"
)
zk.start()
znode = ZNODE_BASE_PATH+"/s"+os.environ["PORT"]
def get_server_info():
server_info = (os.environ["URL"],
os.environ["PORT"])
return server_info
def is_port_run(ip, port):
nm = nmap.PortScanner()
info = nm.scan(ip, port)
state = info['scan'][ip]['tcp'][int(port)]['state']
ret = False
if state == "open":
ret = True
return ret
server_info = get_server_info()
server_info = json.dumps(server_info).encode("utf-8")
while True:
time.sleep(2)
is_alive = is_port_run("127.0.0.1",
"80")
if is_alive:
if not zk.exists(znode):
zk.create(znode, server_info, ephemeral=True,
makepath=True)
else:
if zk.exists(znode):
zk.delete(znode) |
docker配置
每个服务器绑定的端口信息通过docker运行的时候传入参数决定,这样就可以通过同一个镜像方便的创建多个容器实例了,方便快捷,下面是dockerfile:
FROM python:latest
MAINTAINER Liam Yan
# 扩充源
RUN grep '^deb ' /etc/apt/sources.list | sed
's/^deb/deb-src/g' > /etc/apt/sources.list.d/deb-src.list
RUN apt-get update -y
RUN apt-get install nginx -y
RUN mkdir /usr/share/nginx/logs
RUN apt-get install nmap -y
RUN pip3 install python-nmap
RUN pip3 install kazoo
ADD nginx.conf /etc/nginx/nginx.conf
ADD is_alive.py /usr/local/is_alive.py
ADD run.sh /usr/local/run.sh
EXPOSE 80
CMD ["/bin/bash", "/usr/local/run.sh"] |
其中nginx.conf是容器中的nginx配置文件,最简单的就可以,只要可以验证该服务器是否可用即可,但一定要注意,要在nginx配置文件中加入daemon
off;,不然docker可能会启动之后马上退出。is_alive.py就是上面的用来检测容器中的服务是否可用。run.sh内容如下,启动一个后台监控进程之后,再启动nginx。
nohup python3
/usr/local/is_alive.py &
nginx |
创建镜像并运行
通过dockerfile创建镜像docker build --rm -t zookeeper_test
.,创建成功之后运行5个服务器:
docker run -e
"URL=127.0.0.1" -e "PORT=9099"
--name yrt5 -p 9099:80 -d nzookeeper_test
docker run -e "URL=127.0.0.1" -e "PORT=9098"
--name yrt4 -p 9098:80 -d nzookeeper_test
docker run -e "URL=127.0.0.1" -e "PORT=9097"
--name yrt3 -p 9097:80 -d nzookeeper_test
docker run -e "URL=127.0.0.1" -e "PORT=9096"
--name yrt2 -p 9096:80 -d nzookeeper_test
docker run -e "URL=127.0.0.1" -e "PORT=9095"
--name yrt1 -p 9095:80 -d nzookeeper_test |
启动之后运行docker ps -a,可以看到,端口可以随便取,只要别冲突就行,
zookeeper git:(master)
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES
5ae23ae351ed nginx_python_alive "/bin/bash
/usr/loca…" Less than a second ago Up 2 seconds
0.0.0.0:9096->80/tcp yrt5
e4a961e7853e nginx_python_alive "/bin/bash
/usr/loca…" 44 seconds ago Up 49 seconds
0.0.0.0:9095->80/tcp yrt4
f96650b188be nginx_python_alive "/bin/bash
/usr/loca…" 35 minutes ago Up 35 minutes
0.0.0.0:9099->80/tcp yrt3
084f71db25f2 nginx_python_alive "/bin/bash
/usr/loca…" 35 minutes ago Up 35 minutes
0.0.0.0:9090->80/tcp yrt2
159199bee2ed nginx_python_alive "/bin/bash
/usr/loca…" 36 minutes ago Up 36 minutes
0.0.0.0:8080->80/tcp yrt1 |
对外提供服务
通过读取/service/business/what节点下的所有子节点就可以获取到所有的可用服务,代码如下:
from kazoo.client
import KazooClient
import json
def get_servers():
zk = KazooClient(hosts="192.168.0.105:2181,
192.168.0.105:2182, 192.168.0.105:2183")
zk.start()
ZNODE = "/service/business/what"
children = zk.get_children(ZNODE)
servers = []
for child in children:
child_znode = ZNODE + "/" + child
child_server_info, stat = zk.get(child_znode)
child_server_info = child_server_info.decode()
child_server_info = json.loads(child_server_info)
servers.append(child_server_info[0] + ":"
+ child_server_info[1])
return servers |
运行之后得到可用服务列表['127.0.0.1:9096', '127.0.0.1:9095', '127.0.0.1:8080',
'127.0.0.1:9099', '127.0.0.1:9090'],使用者只需要随机选择一个使用就可以了。
除此之外,还可以在从zookeeper获取可用服务列表的时候加一层缓存,提高性能,额外一个进程watch/service/business/what的子节点变动,当有子节点变动的时候,删除缓存,这样就可以做到缓存中的内容'时时'和zookeeper中保持一致了

在kafka中的作用
至此大概对zookeeper在实际应用中的作用有了大概了解,这对我理解他在kafka中的作用有很大的帮助。在kafka中,zookeeper负责的是存储kafka中的元数据信息,队列的数据是不会存储到zookeeper的,kafka是分布式的,zookeeper协调broker、producer、consumer之间的关系,当有新的角色加入的时候,更新zookeeper中的数据,其他角色就可以得到通知,并作出相应的调整,不需要停机更新配置,做到动态扩容。下图来自互联网,比较清晰的展示了zookeeper中存储的kafka元信息数据。
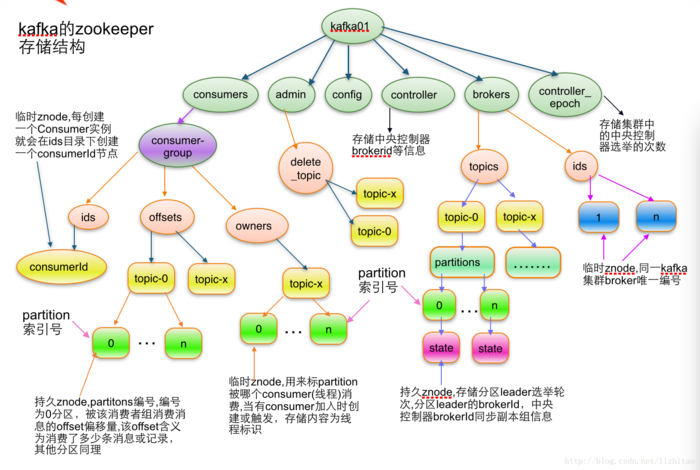
zookeeper在kafka中充当的更像是分布式服务中配置中心的角色,所有配置信息、公共信息都丢到这里来了,此为吾之愚见,望斧正
|








