| БрМЭЦМі: |
БОЮФжївЊНщЩмЪВУДЪЧЛьучЙЄГЬЃЌЛьучЙЄГЬЕФЮхДѓддђЃЌЛьучЙЄГЬГЩЪьЖШФЃаЭЃЈCMMЃЉвдМАЛьучЙЄГЬЕФФПБъЁЊЁЊШЭадМмЙЙЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЙЋжкКХЃКжьаЁиЫЕФВЉПЭ,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЛьучЙЄГЬЪЧдкЗжВМЪНЯЕЭГЩЯНјааЪЕбщЕФбЇПЦЃЌФПЕФЪЧНЈСЂЖдЯЕЭГЕжгљЩњВњЛЗОГжаЪЇПиЬѕМўЕФФмСІвдМАаХаФЁЃ
вЛЁЂИХЪі
ЙЄГЬЪІЭХЖгзюВЛдИХіЕНЕФБуЪЧДѓАывЙБЛЕчЛАНаабЃЌПЊЪМНєеХЕиВщбщЮЪЬтЃЌДІРэЙЪеЯвдМАЛжИДЗўЮёЁЃвВаэОЭЪЧвђЮЊЫЏЧАЕФвЛИіКмаЁЕФБфИќЃЌвђФГжжЮДдЄСЯЕНЕФГЁОАЃЌв§Ц№КћЕћаЇгІЃЌЕМжТДѓУцЛ§ЕФЯЕЭГЛьТвЁЂЙЪеЯКЭЗўЮёжаЖЯЃЌЖдПЭЛЇЕФвЕЮёдьГЩгАЯьЁЃЬиБ№ЪЧНќМИФъЃЌОЁЙмгаГфЗжЕФМрПиИцОЏКЭЙЪеЯДІРэСїГЬЃЌетбљЕФаТЮХдк
IT аавЕШдЪБгаЖњЮХЁЃЮЪЬтЕФжЂНсБудкгкЃЌЖдЭЖШыЩњВњЕФИДдгЯЕЭГгаЖрЩйаХаФЁЃМрПиИцОЏКЭЙЪеЯДІРэЖМЪЧЪТКѓЕФЯьгІгыБЛЖЏЕФгІЖдЃЌФЧгаУЛгаПЩФмЬсЧАЗЂЯжетаЉИДдгЯЕЭГЕФШБЯнФиЃП

ЛьучЙЄГЬдкЗжВМЪНЯЕЭГЩЯНјаагЩОбщжИЕМЕФЪмПиЪЕбщЃЌЙлВьЯЕЭГааЮЊВЂЗЂЯжЯЕЭГШБЯнЃЌвдНЈСЂЖдЯЕЭГдкЙцФЃдіДѓЪБвђвтЭтЬѕМўв§ЗЂЛьТвЕФФмСІКЭаХаФЁЃ
1. ЛьучЙЄГЬЕФЗЂеЙМђЪЗ
2008Фъ8дТЃЌ Netflix жївЊЪ§ОнПтЕФЙЪеЯЕМжТСЫШ§ЬьЕФЭЃЛњЃЌ DVD зтСовЕЮёжаЖЯЃЌЖрИіЙњМвЕФДѓСПгУЛЇЪмДЫгАЯьЁЃжЎКѓ
Netflix ЙЄГЬЪІзХЪжбАевЬцДњМмЙЙЃЌВЂдк2011ФъЦ№ЃЌж№ВННЋЯЕЭГЧЈвЦЕН AWS ЩЯЃЌдЫааЛљгкЮЂЗўЮёЕФаТаЭЗжВМЪНМмЙЙЁЃетжжМмЙЙЯћГ§СЫЕЅЕуЙЪеЯЃЌЕЋвВв§ШыСЫаТЕФИДдгадРраЭЃЌашвЊИќМгПЩППКЭШнДэЕФЯЕЭГЁЃЮЊДЫЃЌ
Netflix ЙЄГЬЪІДДНЈСЫ Chaos Monkey ЃЌЛсЫцЛњжежЙдкЩњВњЛЗОГжадЫааЕФ EC2 ЪЕР§ЁЃЙЄГЬЪІПЩвдПьЫйСЫНтЫћУЧе§дкЙЙНЈЕФЗўЮёЪЧЗёНЁзГЃЌгазуЙЛЕФЕЏадЃЌПЩвдШнШЬМЦЛЎЭтЕФЙЪеЯЁЃжСДЫЃЌЛьучЙЄГЬПЊЪМаЫЦ№ЁЃ

ЭМжаеЙЪОСЫЛьучЙЄГЬДг2010ФъбнНјЗЂеЙЕФЪБМфЯпЃК
2010Фъ Netflix ФкВППЊЗЂСЫ AWS дЦЩЯЫцЛњжежЙ EC2 ЪЕР§ЕФЛьучЪЕбщЙЄОпЃКChaos
Monkey
2011Фъ Netflix releaseСЫЦфКязгОќЭХЙЄОпМЏЃКSimian Army
2012Фъ Netflix ЯђЩчЧјПЊдДгЩ Java ЙЙНЈ Simian ArmyЃЌЦфжаАќРЈ Chaos
Monkey V1 АцБО
2014Фъ Netflix ПЊЪМе§ЪНЙЋПЊеаЦИ Chaos Engineer
2014Фъ Netflix ЬсГіСЫЙЪеЯзЂШыВтЪдЃЈFITЃЉЃЌРћгУЮЂЗўЮёМмЙЙЕФЬиадЃЌПижЦЛьучЪЕбщЕФБЌеЈАыОЖ
2015Фъ Netflix releaseСЫ Chaos Kong ЃЌФЃФтAWSЧјгђЃЈRegionЃЉжаЖЯЕФГЁОА
2015Фъ Netflix КЭЩчЧје§ЪНЬсГіЛьучЙЄГЬЕФжИЕМЫМЯы ЈC Principles of Chaos
Engineering
2016Фъ Kolton AndrusЃЈЧА Netflix КЭ Amazon Chaos Engineer
ЃЉДДСЂСЫ Gremlin ЃЌе§ЪННЋЛьучЪЕбщЙЄОпЩЬгУЛЏ
2017Фъ Netflix ПЊдД Chaos Monkey гЩ Golang жиЙЙЕФ V2 АцБОЃЌБиаыМЏГЩ
CD ЙЄОп SpinnakerЃЈГжајЗЂВМЦНЬЈЃЉРДЪЙгУ
2017Фъ Netflix releaseСЫ ChAP ЃЈChaos Automation Platform,
ЛьучЪЕбщздЖЏЦНЬЈЃЉЃЌПЩЪгЮЊгІгУЙЪеЯзЂШыВтЪдЃЈFITЃЉЕФМгЧПАц
2017Фъ гЩNetflix ЧАЛьучЙЄГЬЪІзЋаДЕФаТЪщЁАЛьучЙЄГЬЁБдкЭјЩЯГіАц
2017Фъ Russell Miles ДДСЂСЫ ChaosIQ ЙЋЫОЃЌВЂПЊдДСЫ chaostoolkit
ЛьучЪЕбщПђМм
NetflixЙЋЫОНщЩм
2. Chaos Monkey & Simian Army
ЮЊСЫИќКУЕФРэНтЛьучЙЄГЬЃЌетРяЮвУЧдйзХжиНщЩмвЛЯТChaos MonkeyКЭSimian ArmyЁЃChaos
Monkey ЭЈЙ§ЙиЭЃвЛИіЛђЖрИіащФтЛњРДФЃФт service ЪЕР§ЕФЪЇаЇЁЃChaos Monkey
ЕФУћзжРДдДгкЦфЙЄзїЕФЗНЪНЃКШчЭЌвЛжЛвАЩњЕФЁЂЮфзАСЫЕФКязгЃЌдкЪ§ОнжааФЪЭЗХКѓЃЌдьГЩЕФбЯжиЦЦЛЕЁЃ
Chaos Monkey ЕФддђЃКБмУтДѓЖрЪ§ЪЇаЇЕФжївЊЗНЪНОЭЪЧОГЃЪЇаЇЁЃЪЇаЇвЛЖЈЛсЗЂЩњЃЌВЂЧвЮоЗЈБмУтЁЃдкДѓЖрЪ§ЧщПіЯТЃЌЮвУЧЕФгІгУЩшМЦвЊБЃжЄЕБЗўЮёЕФФГИіЪЕР§ЯТЯпЪБШдФмМЬајЙЄзїЃЌЕЋЪЧдкФЧаЉЬиЪтЕФГЁОАЯТЃЌЮвУЧашвЊШЗБЃгаШЫдкжЕЪиЃЌвдБуНтОіЮЪЬтЃЌВЂДгЮЪЬтжаНјааОбщбЇЯАЁЃЛљгкетИіЯыЗЈЃЌChaos
Monkey НіЛсдкЙЄзїЪБМфФкБЛЪЙгУЃЌвдБЃжЄЙЄГЬЪІФмЗЂЯжОЏИцаХЯЂЃЌВЂзїГіЪЪЕБЕФЛигІЁЃ
ЛьучЙЄГЬЪЕбщЯё Chaos Monkey жЛЪЧЩБЩБЛњЦїЖјвбЃПетЪЧДэЮѓЕФРэНтЁЃЛиЫнЛьучЙЄГЬЗЂеЙЕФЪБМфЯпЃЌвЕНчЖдЛьучЙЄГЬЕФРэНтЪЧж№ВНЩюШыЕФЁЃNetflix
ПЊЗЂЕФ Chaos Monkey ГЩЮЊСЫЛьучЙЄГЬЕФПЊЖЫЃЌЕЋЛьучЙЄГЬВЛНіНіЪЧ Chaos Monkey
етбљвЛИіЫцЛњжежЙ EC2 ЪЕР§ЕФЪЕбщЙЄОпЁЃЫцКѓЛьучЙЄГЬЪІУЧЗЂЯжЃЌжежЙ EC2 ЪЕР§жЛЪЧЦфжавЛжжЪЕбщГЁОАЁЃвђДЫЃЌ
Netflix ЬсГіСЫ Simian Army КязгОќЭХЙЄОпМЏЃЌГ§СЫ Chaos Monkey ЭтЛЙАќРЈЃК
Chaos GorillaЃКChaos MonkeyЕФЩ§МЖАцЃЌФЃФтећИіAmazon Availability
ZoneЕФЙЪеЯЃЌвдДЫбщжЄдкВЛгАЯьгУЛЇЃЌЧвЮоашШЫЙЄИЩдЄЕФЧщПіЯТЃЌФмЙЛздЖЏНјааПЩгУЧјЕФжиаТЦНКтЁЃ
Chaos KongЃКChaos GorillaЕФЩ§МЖАцЃЌФЃФтећИіregionЃЈвЛИіregionгЩЖрИіAmazon
Availability ZoneзщГЩЃЉЕФЙЪеЯЁЃ
Latency MonkeyЃКдкRESTfulЗўЮёЕФЕїгУжав§ШыШЫЮЊЕФбгЪБРДФЃФтЗўЮёНЕМЖЃЌВтСПЩЯгЮЗўЮёЪЧЗёЛсзіГіЧЁЕБЯьгІЁЃЭЈЙ§в§ШыГЄЪБМфбгЪБЃЌЛЙПЩвдФЃФтНкЕуЩѕжСећИіЗўЮёВЛПЩгУЁЃ
Conformity MonkeyЃКВщевВЛЗћКЯзюМбЪЕМљЕФЪЕР§ЃЌВЂНЋЦфЙиБеЁЃР§ШчЃЌШчЙћФГИіЪЕР§ВЛдкздЖЏЩьЫѕзщРяЃЌФЧУДОЭИУНЋЦфЙиБеЃЌШУЗўЮёЫљгаепФмжиаТШУЦфе§ГЃЦєЖЏЁЃ
Doctor MonkeyЃКВщевВЛНЁПЕЪЕР§ЕФЙЄОпЃЌГ§СЫдЫаадкУПИіЪЕР§ЩЯЕФНЁПЕМьВщЃЌЛЙЛсМрПиЭтВПНЁПЕаХКХЃЌвЛЕЉЗЂЯжВЛНЁПЕЪЕР§ОЭЛсНЋЦфвЦГіЗўЮёзщЁЃЃЈИєРыГіЗўЮёЃЌВЂЧвИјЯрЙиШЫдБзуЙЛЕФОРДэЪБМфЃЌзюжедйЙиБеЁЃЃЉ
Janitor MonkeyЃКВщевВЛдйашвЊЕФзЪдДЃЌНЋЦфЛиЪеЃЌетФмдквЛЖЈГЬЖШЩЯНЕЕЭдЦзЪдДЕФРЫЗбЁЃ
Security MonkeyЃКетЪЧConformity MonkeyЕФвЛИіРЉеЙЃЌМьВщЯЕЭГЕФАВШЋТЉЖДЃЌЭЌЪБвВЛсБЃжЄSSLКЭDRMжЄЪщШдШЛгааЇЁЃ
10-18 MonkeyЃКНјааБОЕиЛЏМАЙњМЪЛЏЕФХфжУМьВщЃЌШЗБЃВЛЭЌЕиЧјЁЂЪЙгУВЛЭЌгябдКЭзжЗћМЏЕФгУЛЇФме§ГЃЪЙгУNetflixЁЃ
ЪЙгУ Simian Army НјааЛьучЙЄГЬЪЕбщЃЌПДЦ№РДЫЦКѕвбОКмЭъУРЁЃРрЫЦЯё Latency Monkey
ЕФв§ШыЃЌгЩгкЗўЮёжЎМфЕФЕїгУСДДЋЕнЃЌЕНзюКѓетИіаЁЕФШХЖЏЕНЕзЛсв§ЗЂЖрДѓЕФЙЪеЯЃЌУЛгаШЫПЩвддЄВтЁЃдкЩњВњЩЯзіетбљВЛПЩПиЕФЪЕбщЃЌЪЧКмЮЃЯеЕФЁЃЫцзХЙЪеЯзЂШыВтЪдЃЈFITЃЌFailure
Injection TestingЃЉЕФЬсГіЃЌЩчЧјПЊЪМЙизЂРћгУгІгУМмЙЙЕФЬиадЃЈЬиБ№ЪЧЮЂЗўЮёМмЙЙЃЉРДПижЦЪЕбщЕФБЌеЈАыОЖЃЌБШШч
Netflix ЪЙгУ Zuul ЧПДѓЕФСїСПМьВщКЭЙмРэЙІФмЃЌНЋЪмгАЯьЕФЧыЧѓИєРыЕНЬиЖЈЕФВтЪдеЪЛЇЛђЬиЖЈЩшБИЃЌБмУт100ЃЅЕФЛьТвЁЃЃЈБОЮФРДздЙЋжкКХЃКжьаЁиЫЕФВЉПЭЃЌID:
hiddenkafkaЃЉ
НјвЛВНЗжЮіЗЂЯжЃЌ FIT ЕФжДааЙ§ГЬвВгАЯьСЫећИіЯЕЭГЕФМрПижИБъЃЌМДЪЕбщШКЬхгыЦфЫћЗЧЪЕбщШКЬхЕФЭГМЦжИБъЛьКЯВЛПЩЗжБцЃКЮоЗЈШЗЖЈЪЕбщЕФНјааЪБМфЃЌЮоЗЈЦРЙРЦфгАЯьЪЧЗёГЌЙ§СЫЯЕЭГБОЩэЕФдывєЁЃЮЊСЫНјвЛВНЕФЧјЗжЃЌдђашвЊНјааИќЖрИќДѓЕФЪЕбщЃЌетНЋгаПЩФмИјгУЛЇДјРДВЛБивЊЕФжаЖЯЁЃвђДЫашвЊЖдЪЕбщМЏШККЭЗЧЪЕбщШКМЏЕФСїСПХфБШНјааОЋЯИПижЦЃЌЭЌЪБвђгІЮоШЫжЕЪиЕФЪЕбщвЊЧѓЃЌдђв§ШыЮЂЗўЮёМмЙЙжаЕФЖЯТЗЦїЃЌШчЦфГЌГідЄЖЈвхЕФЮѓВюдЄЫуЃЌздЖЏНсЪјЪЕбщЁЃетОЭЪЧЮЊКЮ
Netflix ЬсГіСЫаТЕФ ChAP вдМгЧПЙЪеЯзЂШыВтЪдЁЃ
злЩЯЫљЪіЃЌЛьучЙЄГЬЕФЗЂеЙВЛЪЧвЛѕэЖјОЭЕФЃЌ Chaos Monkey ЪЧЦфПЊЖЫЃЌЕЋЩчЧјЖдЛьучЙЄГЬЕФРэНтдкж№ВНЩюШыЃЌДгЖдЛљДЁЩшЪЉЕФШХЖЏЃЈ
EC2 ЪЕР§ЫцЛњжежЙЕШЃЉЃЌЕНРћгУгІгУЭјЙиПижЦБЌеЈАыОЖЃЌдйЕНОЋЯИЛЏСїСПХфБШвдЧјЗжгАЯьЃЌжБжСв§ШыЖЯТЗЦїЪЕЯжеце§ЕФЮоШЫжЕЪиЁЃ
ЛьучЙЄГЬ9ФъРДЕФЗЂеЙЃЌгЩЧГШыЩюЃЌгЩЛљДЁЩшЪЉбнНјЕНгІгУМмЙЙЃЌВЛЪЧЕЅЕЅдЫЮЌПДПДОЭКУЁЃНёЬьЃЌаэЖрЙЋЫО(АќРЈGoogleЁЂAmazonЁЂMicrosoftЁЂGermlin
Inc.ЁЂUniversity of CaliforniaЁЂGithubЁЂThoughtworksЕШЃЉЖМЪЙгУФГжжаЮЪНЕФЛьучЙЄГЬЪЕбщЃЌРДЬсИпЯжДњМмЙЙЕФПЩППадЁЃ
ЛьучЙЄГЬвВЭЌбљЪЪгУгкДЋЭГаавЕЃЌШчДѓаЭН№ШкЛњЙЙЁЂжЦдьвЕКЭвНСЦЛњЙЙЁЃНЛвзвРРЕИДдгЯЕЭГТ№ЃПгаДѓаЭвјаае§дкЪЙгУЛьучЙЄГЬРДбщжЄНЛвзЯЕЭГЪЧЗёгазуЙЛЕФШпгрЁЃЪЧЗёгаШЫУќаќвЛЯпЃПдкУРЙњЃЌЛьучЙЄГЬдкаэЖрЗНУцБЛЕБзіФЃаЭгІгУдкСЫСйДВЪдбщЯЕЭГжаЃЌДгЖјаЮГЩСЫУРЙњвНСЦбщжЄЕФЛЦН№БъзМЁЃКсПчН№ШкЁЂвНСЦЁЂБЃЯеЁЂЛ№М§жЦдьЁЂХЉвЕЛњаЕЁЂЙЄОпжЦдьЁЂдйЕНЪ§зжОоЭЗКЭДДвЕЙЋЫОЃЌЛьучЙЄГЬе§дкГЩЮЊИДдгЯЕЭГИФНјбЇПЦЕФСЂзуЕуЁЃ
3. ЛьучЙЄГЬгыДЋЭГВтЪджЎМфЕФЧјБ№
ЛьучЙЄГЬКЭДЋЭГВтЪдЃЈЙЪеЯзЂШыFITЁЂЙЪеЯВтЪдЃЉдкЙизЂЕуКЭЙЄОпМЏЩЯЖМгаКмДѓЕФжиЕўЁЃЦЉШчЃЌдкNetflixЕФКмЖрЛьучЙЄГЬЪЕбщбаОПЕФЖдЯѓЖМЪЧЛљгкЙЪеЯзЂШыРДв§ШыЕФЁЃЛьучЙЄГЬКЭетаЉДЋЭГВтЪдЗНЗЈЕФжївЊЧјБ№дкгкЃКЛьучЙЄГЬЪЧЗЂЯжаТаХЯЂЕФЪЕМљЙ§ГЬЃЌЖјЙЪеЯзЂШыдђЪЧЖдвЛИіЬиЖЈЕФЬѕМўЁЂБфСПЕФбщжЄЗНЗЈЁЃ
ЕБФуЯЃЭћЬНОПИДдгЯЕЭГШчКЮгІЖдвьГЃЪБЃЌЖдЯЕЭГжаЕФЗўЮёзЂШыЭЈаХЙЪеЯЃЈШчГЌЪБЁЂДэЮѓЕШЃЉВЛЪЇЮЊвЛжжКмКУЕФЗНЗЈЁЃЕЋгаЪБЮвУЧЯЃЭћЬНОПИќЖрЦфЫћЕФЗЧЙЪеЯРрЕФГЁОАЃЌШчСїСПМЄдіЁЂзЪдДОКељЬѕМўЁЂАнеМЭЅЙЪеЯЃЈР§ШчадФмВюЛђгавьГЃЕФНкЕуЗЂГігаДэЮѓЕФЯьгІЁЂвьГЃЕФааЮЊЁЂЖдЕїгУепЫцЛњадЕФЗЕЛиВЛЭЌЕФЯьгІЃЌЕШЕШЃЉЁЂЗЧМЦЛЎжаЕФЛђЗЧе§ГЃзщКЯЕФЯћЯЂДІРэЕШЕШЁЃвђЮЊШчЙћвЛИіУцЯђЙЋжкгУЛЇЕФЭјеОЭЛШЛЪеЕНМЄдіЕФСїСПЃЌДгЖјВњЩњИќЖрЕФЪеШыЪБЮвУЧКмФбГЦжЎЮЊЙЪеЯЃЌЕЋЮвУЧШдШЛашвЊЬНОПЧхГўЯЕЭГдкетжжЧщПіЯТЕФгАЯьЁЃ
КЭЙЪеЯзЂШыРрЫЦЃЌЙЪеЯВтЪдЗНЗЈЭЈЙ§ЖддЄЯШЩшЯыЕНЕФПЩвдЦЦЛЕЯЕЭГЕФЕуНјааВтЪдЃЌЕЋЪЧВЂУЛФмШЅЬНОПЩЯЪіетРрИќЙуРЋСьгђРяЕФЁЂВЛПЩдЄжЊЕФЁЂЕЋКмПЩФмЗЂЩњЕФЪТЧщЁЃ
дкДЋЭГВтЪджаЃЌЮвУЧПЩвдаДвЛИіЖЯбдЃЈassertionЃЉЃЌМДЮвУЧИјЖЈвЛИіЬиЖЈЕФЬѕМўЃЌВњЩњвЛИіЬиЖЈЕФЪфГіЁЃВтЪдвЛАуРДЫЕжЛЛсВњЩњЖўдЊЕФНсЙћЃЌбщжЄвЛИіНсЙћЪЧецЛЙЪЧМйЃЌДгЖјХаЖЈВтЪдЪЧЗёЭЈЙ§ЁЃбЯИёвтвхЩЯРДЫЕЃЌетИіЙ§ГЬВЂВЛФмШУЮвУЧЗЂОђГіЖдгкЯЕЭГЮДжЊЕФЁЂЩаВЛУїШЗЕФШЯжЊЃЌЫќНіНіЪЧЖдЮвУЧвбжЊЕФЯЕЭГЪєадПЩФмЕФШЁжЕНјааВтбщЁЃЖјЪЕбщПЩвдВњЩњаТЕФШЯжЊЃЌЖјЧвЭЈГЃЛЙФмПЊБйГівЛИіИќЙуйѓЕФЖдИДдгЯЕЭГЕФШЯжЊПеМфЁЃ
ЛьучЙЄГЬЪЧвЛжжАяжњЮвУЧЛёЕУИќЖрЕФЙигкЯЕЭГЕФаТШЯжЊЕФЪЕбщЗНЗЈЁЃЫќКЭвбгаЕФЙІФмВтЪдЁЂМЏГЩВтЪдЕШвдВтЪдвбжЊЪєадЕФЗНЗЈгаБОжЪЩЯЕФЧјБ№ЁЃЃЈБОЮФРДздЙЋжкКХЃКжьаЁиЫЕФВЉПЭЃЌID:
hiddenkafkaЃЉ
ЛьучЙЄГЬЪЕбщЕФПЩФмадЪЧЮоЯоЕФЃЌИљОнВЛЭЌЕФЗжВМЪНЯЕЭГМмЙЙКЭВЛЭЌЕФКЫаФвЕЮёМлжЕЃЌЪЕбщПЩвдЧЇБфЭђЛЏЁЃЯТУцЪЧВПЗжЛьучЪЕбщЕФЪфШыЪОР§ЃК
ФЃФтећИідЦЗўЮёЧјгђЛђећИіЪ§ОнжааФЙЪеЯЃЛ
ПчЖрЪЕР§ЩОГ§ВПЗж Kafka жїЬтРДжиЯжЩњВњЛЗОГжаЗЂЩњЙ§ЕФЮЪЬтЃЛ
ЬєбЁвЛИіЪБМфЖЮЃЌКЭеыЖдвЛВПЗжСїСПЃЌЖдЦфЩцМАЕФЗўЮёМфЕїгУзЂШывЛаЉЬиЖЈЕФбгЪБЃЛ
ЗНЗЈМЖБ№ЕФЛьТвЃЈдЫааЪБзЂШыЃЉЃКШУЗНЗЈЫцЛњХзГіИїжжвьГЃЃЛ
дкДњТыжаВхШывЛаЉжИСюПЩвддЪаэдкетаЉжИСюжЎЧАдЫааЙЪеЯзЂШыЃЛ
ЧПжЦЯЕЭГНкЕуМфЕФЪБМфВЛЭЌВНЃЛ
дкЧ§ЖЏГЬађжажДааФЃФт I/O ДэЮѓЕФГЬађЃЛ
ШУФГИі Elasticsearch МЏШК CPU ГЌИККЩЁЃ
4. ЪЕЪЉЛьучЙЄГЬЕФЯШОіЬѕМў
дкв§ШыЛьучЙЄГЬжЎЧАЯШвЊШЗЖЈФуЕФЯЕЭГЪЧЗёвбООпБИвЛаЉЕЏадРДгІЖдецЪЕЛЗОГжаЕФвЛаЉвьГЃЪТМўЃЌЯёФГИіЗўЮёвьГЃЁЂЭјТчЩСЖЯЁЂЫВМфбгГйЬсИпЕШЁЃ
ЛьучЙЄГЬЗЧГЃЪЪКЯНвТЖЩњВњЯЕЭГжаЕФЮДжЊШБЯнЃЌЕЋШчЙћШЗЖЈЛьучЙЄГЬЪЕбщЛсЕМжТЯЕЭГГіЯжбЯжиЕФЮЪЬтЃЌФЧУДдЫааетбљЕФЪЕбщЪЧУЛгаШЮКЮвтвхЕФЁЃФуашвЊЯШНтОіетИіШБЯнЃЌШЛКѓдйв§ШыЛьучЙЄГЬЃЌШЛКѓФуВЛНіФмМЬајЗЂЯжИќЖрВЛжЊЕРЕФШБЯнЃЌЛЙФмЬсИпЖдЯЕЭГецЪЕЕЏадЫЎЦНЃЈresilientЃЉЕФаХаФЁЃ
в§ШыЛьучЙЄГЬЕФСэвЛИіЯШОіЬѕМўЪЧМрПиЯЕЭГЃЌФуашвЊгУЫќРДХаЖЯЯЕЭГЕБЧАЕФИїЯюзДЬЌЁЃШчЙћФуУЛгаЖдЯЕЭГааЮЊЕФПЩМћФмСІЃЌФЧУДвВОЭЮоЗЈДгЪЕбщжаЕУГігааЇЕФНсТлЁЃ
ЖўЁЂЛьучЙЄГЬЕФЮхДѓддђ
ЮЊСЫОпЬхЕиНтОіЗжВМЪНЯЕЭГдкЙцФЃЩЯЕФВЛШЗЖЈадЃЌПЩвдАбЛьучЙЄГЬПДзїЪЧЮЊСЫНвЪОЯЕЭГШБЯнЖјНјааЕФЪЕбщЁЃЦЦЛЕЮШЬЌЕФФбЖШдНДѓЃЌЮвУЧЖдЯЕЭГааЮЊЕФаХаФОЭдНЧПЁЃШчЙћЗЂЯжСЫвЛИіШБЯнЃЌФЧУДЮвУЧОЭгаСЫвЛИіИФНјФПБъЁЃБмУтдкЯЕЭГЙцФЃЛЏжЎКѓЮЪЬтБЛЗХДѓЁЃ
вдЯТддђУшЪіСЫгІгУЛьучЙЄГЬЕФРэЯыЗНЪНЃЌетаЉддђРДЪЕЪЉЪЕбщЙ§ГЬЃЌЖдетаЉддђЕФЦЅХфГЬЖШФмЙЛдіЧПЮвУЧдкДѓЙцФЃЗжВМЪНЯЕЭГЕФаХаФЁЃ
1. НЈСЂвЛИіЮЇШЦЮШЖЈзДЬЌааЮЊЕФМйЫЕЃЈBuild a Hypothesis around Steady
State BehaviorЃЉ
ЁАЮШЖЈзДЬЌЁБЪЧжИЯЕЭГе§ГЃдЫааЪБЕФзДЬЌЁЃОпЬхРДЫЕЃЌЯЕЭГЕФЮШЖЈзДЬЌПЩвдЭЈЙ§вЛаЉжИБъРДЖЈвхЃЌЕБЯЕЭГжИБъдкВтЪдЭъГЩКѓЃЌЮоЗЈПьЫйЛжИДЮШЬЌвЊЧѓЃЌПЩвдШЯЮЊетИіЯЕЭГЪЧВЛЮШЖЈЕФЁЃ
жИБъПЩвдЗжЮЊЯЕЭГжИБъКЭвЕЮёжИБъЁЃЯЕЭГжИБъЃЈШчCPU ИКдиЁЂФкДцЪЙгУЧщПіЁЂЭјТч I/OЕШЃЉгажњгкАяжњЮвУЧеяЖЯадФмЮЪЬтЃЌгаЪБвВФмАяжњЮвУЧЗЂЯжЙІФмШБЯнЁЃдкЛьучЙЄГЬжаЃЌвЕЮёжИБъЭЈГЃБШЯЕЭГжИБъИќгагУЃЌвђЮЊЫќУЧИќЪЪКЯКтСПгУЛЇЬхбщЛђдЫгЊЁЃвЕЮёжИБъЭЈГЃЛиД№етбљЕФЮЪЬтЃК
ЮвУЧе§дкСїЪЇгУЛЇТ№ЃП
гУЛЇФПЧАПЩвдВйзїЭјеОЕФЙиМќЙІФмТ№ЃПР§ШчдкЕчЩЬЭјеОРяЮЊЖЉЕЅИЖПюЃЌЬэМгЙКЮяГЕЕШЁЃ
ФПЧАДцдкНЯИпЕФбгГйжТЪЙгУЛЇВЛФме§ГЃЪЙгУЮвУЧЕФЗўЮёТ№ЃП
NetflixЪЙгУПЭЛЇЕуЛїЪгЦЕСїЩшБИЩЯВЅЗХАДХЅЕФЫйТЪзїЮЊжИБъЃЌГЦЮЊЁАЪгЦЕУПУыПЊЪМВЅЗХЪ§ЃЈSPSЃЉЁБЃЌдкЮФФЉЛсгаЯрЙиНщЩмЁЃ
ШчЙћФуЛЙВЛФмжБНгЛёШЁКЭвЕЮёжБНгЯрЙиЕФжИБъЃЌПЩвдднЪБЯШРћгУвЛаЉЯЕЭГжИБъЃЌБШШчЯЕЭГЭЬЭТТЪЃЌДэЮѓТЪЃЌpct99бгГйЕШЁЃФубЁдёЕФжИБъКЭвЕЮёЙиЯЕдНЧПЃЌЕУЕНЕФПЩвдВЩШЁПЩжДааВпТдОЭдНЧПЁЃЭЌбљживЊЕФЪЧЃЌдкПЭЛЇЖЫбщжЄЗўЮёВњЩњЕФИцОЏПЩвдЬсИпећЬхаЇТЪЃЌЖјЧвПЩвдзїЮЊЖдЗўЮёЖЫжИБъЕФВЙГфЃЌвдЙЙГЩФГвЛЪБПЬгУЛЇЬхбщЕФЭъећЛУцЁЃ
ЖЈвхКУжИБъВЂРэНтЦфЮШЖЈзДЬЌЕФааЮЊжЎКѓЃЌФуОЭПЩвдЪЙгУЫќУЧРДНЈСЂЖдЪЕбщЕФМйЩшЁЃЫМПМвЛЯТЕБФуЯђЯЕЭГзЂШыВЛЭЌРраЭЕФЪТМўЪБЃЌЮШЖЈзДЬЌааЮЊЛсЗЂЩњЪВУДБфЛЏЁЃР§ШчЃЌФуЯђФГИіЗўЮёдіМгЧыЧѓЪ§ЃЌЦфЮШЖЈзДЬЌЪЧБЛЦЦЛЕЛЙЪЧБЃГжВЛБфЃПШчЙћБЛЦЦЛЕСЫЃЌФуЫљЦкД§ЯЕЭГИУШчКЮБэЯжЃП
ЮвУЧЕФМйЩшПЩвдЪЧЪЕбщДыЪЉВЛЛсЪЙЯЕЭГааЮЊЦЋРыЮШЖЈзДЬЌЃЌБШШчЃКЯђЮвУЧЕФЯЕЭГжазЂШыЕФЪТМўВЛЛсЕМжТЯЕЭГЮШЖЈзДЬЌЗЂЩњУїЯдЕФБфЛЏЁЃ
зюКѓЮвУЧЛЙашвЊЫМПМвЛЯТетИіЮЪЬтЃКШчКЮКтСПЮШЖЈзДЬЌааЮЊЕФБфЛЏЁЃМДБуФувбОНЈСЂСЫЮШЖЈзДЬЌааЮЊФЃаЭЃЌФувВашвЊЖЈвхЧхГўЃЌЕБЦЋРыЮШЖЈзДЬЌааЮЊЗЂЩњЪБФувЊШчКЮВтСПетИіЦЋВюЁЃжЛгаЖЈвхЧхГўЁАе§ГЃЁБЕФЦЋВюЗЖЮЇЃЌВХПЩвдЛёЕУвЛЬзбщжЄМйЩшЕФЭъЩЦЕФВтЪдМЏЁЃ
2. ЖрбљЛЏецЪЕЪРНчЕФЪТМў ЃЈVary Real-world EventsЃЉ
УПИіЯЕЭГЃЌДгМђЕЅЕНИДдгЃЌжЛвЊдЫааЪБМфзуЙЛГЄЃЌЖМЛсЪмЕНВЛПЩдЄВтЕФЪТМўКЭЬѕМўЕФгАЯьЁЃР§ШчИКдиЕФдіМгЁЂгВМўЙЪеЯЁЂШэМўШБЯнЁЂЛЙгаЗЧЗЈЪ§ОнЃЈгаЪБГЦЮЊдрЪ§ОнЃЉЕФв§ШыЁЃ
ЮвУЧЮоЗЈЧюОйЫљгаПЩФмЕФЪТМўЛђЬѕМўЃЌЕЋГЃМћЕФгавдЯТМИРрЃК
1.гВМўЙЪеЯЃЛ
2.ЙІФмШБЯнЃЛ
3.зДЬЌзЊЛЛвьГЃЃЈР§ШчЗЂЫЭЗНКЭНгЪеЗНЕФзДЬЌВЛвЛжТЃЉЃЛ
4.ЭјТчбгГйЛђИєРыЃЛ
5.ЩЯааЛђЯТааЪфШыЕФДѓЗљВЈЖЏвдМАжиЪдЗчБЉЃЛ
6.зЪдДКФОЁЃЛ
7.ЗўЮёжЎМфЕФВЛе§ГЃЕФЛђепдЄСЯжЎЭтЕФзщКЯЕїгУЃЛ
8.АнеМЭЅЙЪеЯЃЛ
9.зЪдДОКељЬѕМўЃЛ
10.ЯТгЮвРРЕЙЪеЯЁЃ
вВаэзюИДдгЕФЧщПіЪЧЩЯЪіЪТМўЕФИїРрзщКЯЕМжТЯЕЭГЗЂЩњвьГЃааЮЊЁЃ
вЊГЙЕззшжЙЖдПЩгУадЕФИїжжЭўаВЪЧВЛПЩФмЕФЃЌЕЋЪЧЮвУЧПЩвдОЁПЩФмМѕЧсетаЉЭўаВЁЃ**дкОіЖЈв§ШыФФаЉЪТМўЪБЃЌЮвУЧгІЕБЙРЫуетаЉЪТМўЗЂЩњЕФЦЕТЪКЭгАЯьЗЖЮЇЃЌШЛКѓШЈКтв§ШыЫћУЧЕФГЩБОКЭИДдгЖШЁЃ**ЮвУЧВЛашвЊЧюОйЫљгаПЩФмЖдЯЕЭГдьГЩИФБфЕФЪТМўЃЌжЛашвЊзЂШыФЧаЉЦЕЗБЗЂЩњЧвгАЯьжиДѓЕФЪТМўЃЌЭЌЪБвЊзуЙЛРэНтЛсБЛгАЯьЕФЙЪеЯгђЃЈЙЪеЯЕФгАЯьЗЖЮЇКЭИєРыЗЖЮЇБЛГЦЮЊЙЪеЯЕФЙЪеЯгђЃЉЁЃ
3. дкЩњВњЛЗОГжадЫааЪЕбщ ЃЈRun Experiments in ProductionЃЉ
ИљОнЛЗОГгыСїСПФЃЪНЕФВЛЭЌЃЌЯЕЭГдЫаааЇЙћврНЋЪмЕНгАЯьЁЃгЩгкдЫаааЇЙћПЩФмЫцЪБИФБфЃЌвђДЫЮвУЧгІНЋЖдЪЕМЪСїСПНјааВЩбљзїЮЊЛёШЁПЩППЧыЧѓТЗОЖЕФЮЉвЛЗНЗЈЁЃЮЊСЫБЃжЄЯЕЭГдЫааЗНЪНЕФецЪЕадвдМАЭЌЯжгаВПЪ№ЯЕЭГМфЕФЙиСЊадЃЌЛьучЙЄГЬддђЧПСвНЈвщФњжБНгУцЯђЩњВњСїСПНјааЪЕбщЁЃ
МДБуФуВЛФмдкЩњВњЛЗОГжажДааЪЕбщЃЌФувВвЊОЁПЩФмЕФдкРыЩњВњЛЗОГзюНгНќЕФЛЗОГжадЫааЁЃдННгНќЩњВњЛЗОГЃЌЖдЪЕбщЭтВПгааЇадЕФЭўаВОЭдНЩйЃЌЖдЪЕбщНсЙћЕФаХаФОЭдНзуЁЃ
4. ГжајздЖЏЛЏдЫааЪЕбщ ЃЈAutomate Experiments to Run ContinuouslyЃЉ
ЕБНёЕФЯЕЭГдНРДдНИДдгЃЌетвтЮЖзХЮвУЧЮоЗЈдЄЯШЕижЊЕРЩњВњЛЗОГЕФФФаЉБфЖЏЛсИФБфЛьучЙЄГЬЪЕбщЕФНсЙћЁЃЛљгкетИідвђЃЌЮвУЧБиаыМйЩшЫљгаБфЖЏЖМЛсИФБфЪЕбщНсЙћЁЃдкЙВЯэзДЬЌЁЂЛКДцЁЂЖЏЬЌХфжУЙмРэЁЂГжајНЛИЖЁЂздЖЏЩьЫѕЁЂЪБМфУєИаЕФДњТыЕШЕШЕФзїгУжЎЯТЃЌЩњВњЛЗОГЪЕМЪЩЯДІдквЛИіЮоЪБВЛдкБфЛЏЕФзДЬЌЁЃ
зюПЊЪМжДааЛьучЪЕбщЃЌПЩФмОЭЪЧЪжЖЏжДааЃЌЕЋЪЧЪЕбщЕФЪжЖЏдЫааЙЄзїЪєгкРЭЖЏСІУмМЏаЭШЮЮёЃЌвђДЫФбвдГЄОУГжајЁЃЯрЗДЕФЃЌЮвУЧгІИУздМКЭЖШыОЋСІРДПЊЗЂЛьучЙЄГЬЕФЙЄОпКЭЦНЬЈЃЌвдЦкВЛЖЯНЕЕЭДДНЈаТЪЕбщЕФУХМїЃЌВЂФмЙЛЭъШЋздЖЏдЫааетаЉЪЕбщЁЃ
5. зюаЁЛЏБЌеЈАыОЖ ЃЈMinimize Blast RadiusЃЉ
ЛьучЪЕбщЭЈЙ§КмЖрЗНЗЈРДЬНбАЙЪеЯЛсдьГЩЕФЮДжЊЕФЁЂВЛПЩдЄМћЕФгАЯьЃЌЙиМќдкгкШчКЮШУетаЉБЁШѕЛЗНкЦиЙтГіРДЖјВЛЛсвтЭтдьГЩИќДѓЙцФЃЕФЙЪеЯЁЃЮвУЧГЦжЎЮЊзюаЁЛЏЁАБЌеЈАыОЖЁБЁЃ
ЕБЮвжДааЛьучЪЕбщЪБЃЌвЛАуЯШжЛзїгУгкКмЩйЕФгУЛЇжЎЩЯЃЌетбљЕФЗчЯевВзюаЁЃЌЫћУЧВЛФмДњБэШЋВПЩњВњСїСПЃЌЕЋЫћУЧЪЧКмКУЕФдчЦкжИБъЁЃЕБздЖЏЛЏЪЕбщГЩЙІжЎКѓЃЌОЭашвЊРЉДѓЪЕбщЗЖЮЇЃКдЫаааЁЙцФЃЕФРЉЩЂЪЕбщЃЌдйНјаааЁЙцФЃЕФМЏжаЪЕбщЃЌзюКѓОЭЪЧДѓЙцФЃЮоздЖЈвхТЗгЩЕФЪЕбщЁЃРЉДѓЪЕбщЗЖЮЇЕФФПЕФЪЧНјвЛВНБЉТЖаЁЗЖЮЇЪЕбщЮоЗЈЗЂЯжЕФвЛаЉЮЪЬтЁЃ
Г§СЫВЛЖЯРЉДѓЪЕбщЗЖЮЇЃЌдкЪЕбщдьГЩЙ§ЖрЮЃКІЪБМАЪБжежЙЪЕбщвВЪЧБиВЛПЩЩйЕФЁЃгааЉЯЕЭГЩшМЦЛсЪЙгУНЕМЖФЃЪНРДИјгУЛЇДјРДЩдаЁЕФгАЯьЃЌетЛЙКУЃЌЕЋЪЧЕБЯЕЭГЭъШЋжаЖЯЗўЮёЕФЪБКђЃЌОЭгІИУСЂМДжежЙЪЕбщЁЃЃЈБОЮФРДздЙЋжкКХЃКжьаЁиЫЕФВЉПЭЃЌID:
hiddenkafkaЃЉ
ЮвУЧвВЛсОГЃдЫааБОРДжЛЛсгАЯьвЛаЁВПЗжгУЛЇЕФВтЪдЃЌШДгЩгкМЖСЊЙЪеЯЮовтжагАЯьЕНСЫИќЖрЕФгУЛЇЁЃдкетаЉЧщПіЯТЃЌЮвУЧВЛЕУВЛСЂМДжаЖЯЪЕбщЁЃЫфШЛЮвУЧОјВЛЯыЗЂЩњетжжЧщПіЃЌЕЋЫцЪБЖєжЦКЭЭЃжЙЪЕбщЕФФмСІЪЧБиБИЕФЃЌПЩвдБмУтдьГЩИќДѓЕФЮЃЛњЁЃ
ЮЊСЫШУОЁПЩФмИпаЇЕигІЖдЪЕбщЗЂЩњВЛПЩдЄЦкЕФЧщПіЃЌЮвУЧвЊБмУтдкИпЗчЯеЕФЪБМфЖЮдЫааЪЕбщЁЃР§ШчЮвУЧжЛдкЫљгаШЫЖМдкАьЙЋЪвЙЄзїЕФЪБМфЖЮдЫааЪЕбщЁЃ
Ш§ЁЂЛьучГЩЪьЖШФЃаЭЃЈChaos Maturity ModelЃЉ
БъзМЛЏЛьучЙЄГЬЖЈвхЕФвЛИіФПЕФЪЧЃЌдкжДааЛьучЙЄГЬЯюФПЪБЃЌЮвУЧгаБъзМРДХаЖЯетИіЯюФПзіЕУЪЧКУЪЧЛЕЃЌвдМАШчКЮПЩвдзіЕУИќКУЁЃЛьучЙЄГЬГЩЪьЖШФЃаЭЃЈCMMЃЉИјЮвУЧЬсЙЉСЫвЛИіЦРЙРЕБЧАЛьучЙЄГЬЯюФПГЩЪьЖШзДЬЌЕФЙЄОпЁЃАбФуЕБЧАЯюФПЕФзДЬЌЗХдкетИіЭМЩЯЃЌОЭПЩвдОнДЫЩшЖЈЯывЊДяЕНЕФФПБъЃЌвВПЩвдЖдБШЦфЫћЯюФПЕФзДЬЌЁЃ
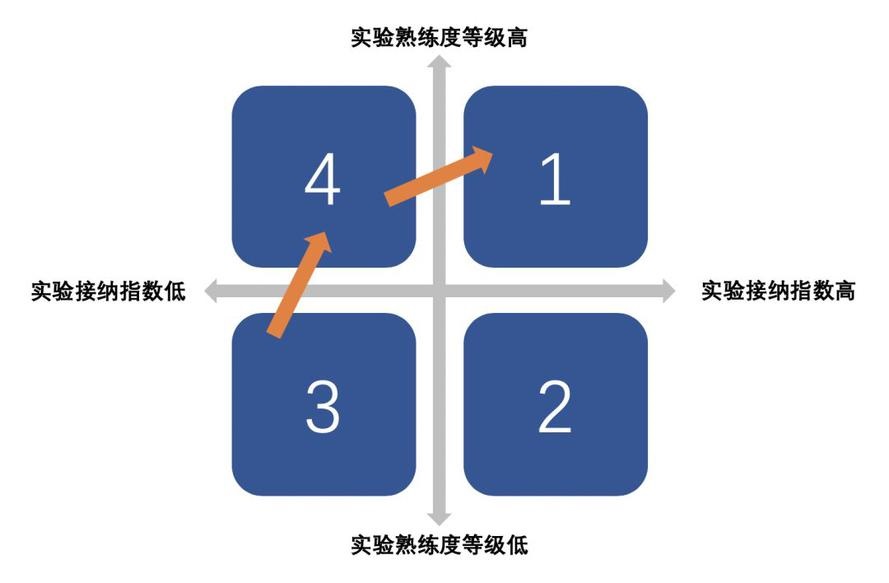
CMM ЕФСНИізјБъжсЗжБ№ЪЧЁАЪьСЗЖШЃЈSophisticationЃЉЁБКЭЁАНгФЩЖШЃЈAdoptionЃЉЁБЁЃШБЗІЪьСЗЖШЪБЃЌЪЕбщЛсБШНЯЮЃЯеЁЂВЛПЩППЁЂЧвгаПЩФмЪЧЮоаЇЕФЁЃШБЗІНгФЩЖШЪБЃЌЫљзіЕФЪЕбщОЭВЛЛсгаЪВУДвтвхКЭгАЯьЁЃвЊдкЪЪЕБЕФЪБКђБфЛЛдкСНИіВЛЭЌЮЌЖШЕФЭЖШыЃЌвђЮЊдкШЮКЮвЛИіЪБЦкЃЌвЊЗЂЛгЛьучЙЄГЬЯюФПЕФзюДѓаЇЙћашвЊдкетСНИіЮЌЖШЩЯБЃГжвЛЖЈЕФЦНКтЁЃ
1.ЛьучЙЄГЬЪЕбщЪьСЗЖШЕШМЖ
ЪьСЗЖШПЩвдЗДгГГіЃЌдкФуЕФзщжЏжаЛьучЙЄГЬЯюФПЕФгааЇадКЭАВШЋадЁЃЯюФПИїздЕФЬиадЛсЗДгГГіВЛЭЌГЬЖШЕФЪьСЗЖШЃЌгааЉЭъШЋВЛОпБИЪьСЗЖШЃЌЖјгааЉПЩФмОпБИКмИпЕФЪьСЗЖШЁЃ
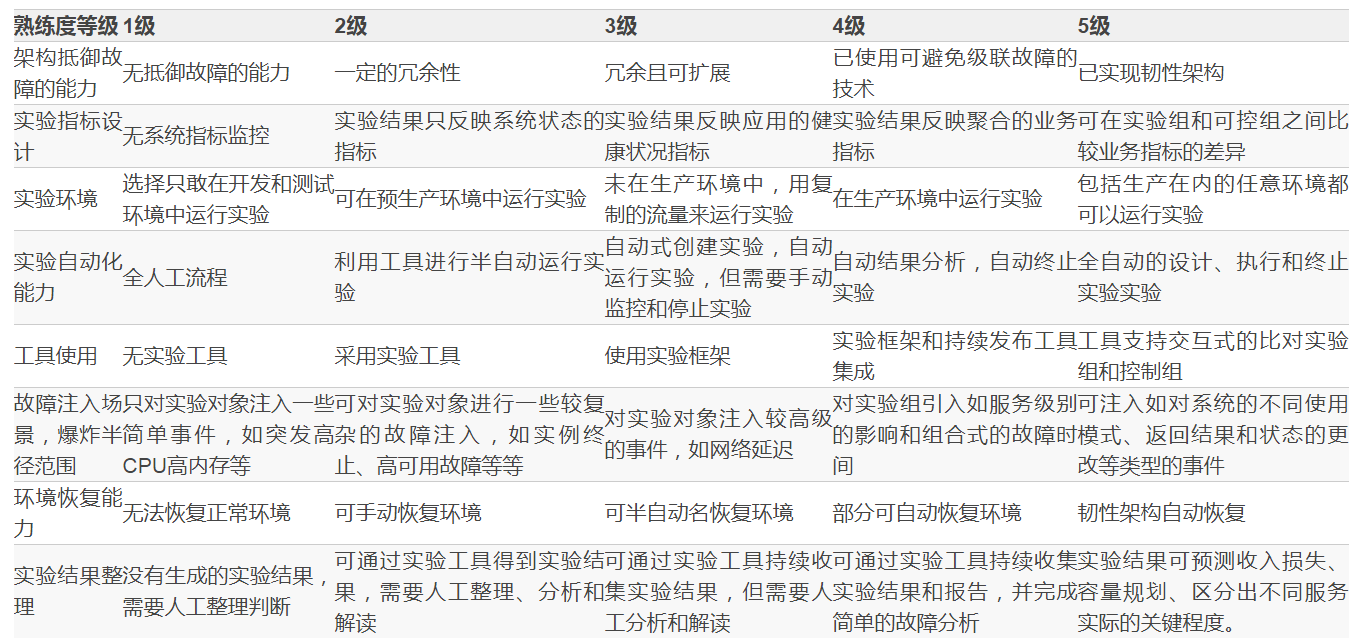
ПЩвдЛљгкЪЕбщГЩЪьЖШЕШМЖЕФ8ИіЗНУцНјааЛьучЪЕбщПЩааадЦРЙРЁЃ
2. ЛьучЙЄГЬЪЕбщНгФЩЖШЕШМЖ
НгФЩЖШгУРДКтСПЛьучЙЄГЬЪЕбщИВИЧЕФЙуЖШКЭЩюЖШЁЃНгФЩЖШдНИпЃЌБЉТЖЕФДрШѕЕуОЭдНЖрЃЌФуЖдЯЕЭГЕФаХаФвВОЭдНзуЁЃ

ЫФЁЂЛьучЙЄГЬЕФФПБъЁЊЁЊШЭадМмЙЙ
ЁАЙЪеЯЪЧзЂЖЈЕФЃЌЫцзХЪБМфЕФСїЪХЃЌвЛЧажеНЋЙщгкЪЇАмЁБЁЃЮвУЧБиаыНгЪмЙЪеЯЗЂЩњЪЧаТГЃЬЌЕФЯыЗЈЃЌДІдкВПЗжЙЪеЯЕФЯЕЭГе§ГЃдЫааЪЧЭъШЋПЩааЕФЁЃЕБЮвУЧДІРэЖрДяМИЪЎИіЗўЮёЪЕР§ЕФаЁаЭЯЕЭГЪБЃЌ100ЃЅЕФНЁПЕдЫааЭЈГЃЪЧе§ГЃзДЬЌЃЌЙЪеЯдђЪЧвЛжжЬиЪтЧщПіЁЃШЛЖјЃЌдкДІРэДѓЙцФЃЯЕЭГЪБЃЌМД100ЃЅЕФНЁПЕдЫааМИКѕЪЧВЛПЩФмЪЕЯжЕФЁЃвђДЫЃЌдЫЮЌЕФаТГЃЬЌБуЪЧНгЪмВПЗжЙЪеЯЁЃДІдкВПЗжЙЪеЯжаЕФЯЕЭГвЊЧѓШдФме§ГЃдЫааЖдЭтЬсЙЉЗўЮёЃЌетОЭашвЊМмЙЙБОЩэОпБИ
Resilient ФмСІЃЌетРяЕФResilientМДЮЊШЭадЃЈОпБИЛжИДФмСІЃЉЁЃ
ЛьучЙЄГЬОЭЪЧРћгУЪЕбщЬсЧАЬНжЊЯЕЭГЗчЯеЃЌЭЈЙ§МмЙЙгХЛЏКЭдЫЮЌФЃЪНЕФИФНјРДНтОіЯЕЭГЗчЯеЃЌеце§ЪЕЯжЩЯЪіШЭадМмЙЙЃЌНЕЕЭЦѓвЕЫ№ЪЇЃЌЬсИпЙЪеЯУтвпСІЁЃ
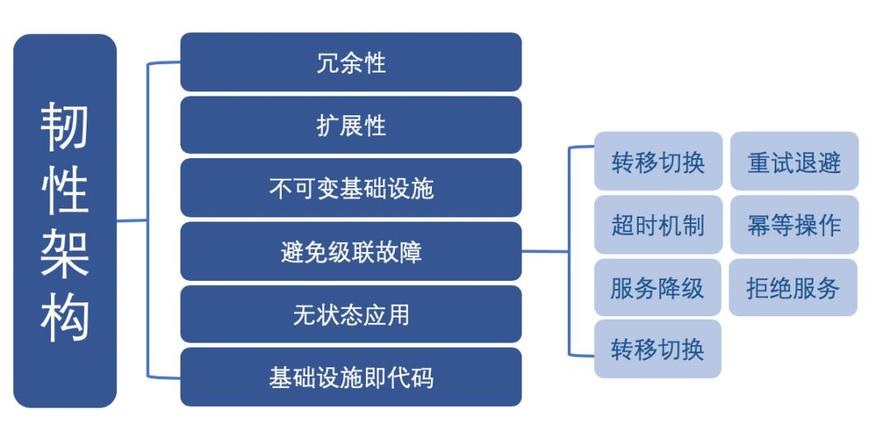
ШЭадМмЙЙЕФживЊЬиеїЃК
ШпградЁЃМмЙЙЕФЩшМЦвЊдіМгШпградЃЌвдБуЬсИпИУЯЕЭГЕФећЬхПЩгУадЁЃ
РЉеЙадЁЃМмЙЙЕФЩшМЦБиаывЊПМТЧРЉеЙадЃЌМДЦєгУ Auto Scaling ЃЌИљОнашЧѓЖЏЬЌРЉеЙзЪдДЃЈ ЖјВЛЪЧЪжЖЏжДааЃЉ
ЃЌШЗБЃПЩвдТњзуИїжжСїСПФЃЪНЁЃ
ВЛПЩБфЛљДЁЩшЪЉЁЃВЛПЩБфЛљДЁЩшЪЉжИЕФЪЧЃЌУПДЮВПЪ№ЖМЛсЬцЛЛЯргІЕФзщМўЃЌВЛзіИќаТЁЃгІгУВПЪ№дђЪЙгУН№ЫПШИЗЂВМЃЈЫзГЦЛвЖШЗЂВМЃЉЃЌвдМѕЩйВПЪ№аТАцБОгІгУЪБГіЯжЙЪеЯЕФЗчЯеЁЃЪЙгУетжжММЪѕЃЌПЩвддкецЪЕЕФЩњВњЛЗОГжаНјааВтЪдЃЌВЂдкашвЊЪБНјааПьЫйЛиЙіЁЃ
БмУтМЖСЊЙЪеЯЁЃМЖСЊЙЪеЯжИЕФЪЧвђвРРЕЙиЯЕв§ЗЂЕФОжВПЙЪеЯЕМжТећИіЯЕЭГБРРЃЃЈЫзГЦКћЕћаЇгІЃЉЁЃМмЙЙЩшМЦБиаыПМТЧМЖСЊЙЪеЯЕФДІРэЗНЪНЃК
зЊвЦЧаЛЛЃКЕБвЛИіМЏШКхДЛњЪБЃЌЫљгаЕФСїСПЖМзЊвЦЕНСэвЛИіМЏШКЃЌШчПчПЩгУЧјЧаЛЛЃЌЛђепПчЧјгђЧаЛЛЁЃ
жиЪдЭЫБмЃКжИЪ§ЭЫБмЫуЗЈж№НЅЖдПЭЛЇЖЫжиЪдЧыЧѓМѕЫйЃЌБмУтЭјТчгЕШћЃЌЭЌЪБЬэМгЖЖЖЏБЃжЄадФмЁЃ
ГЌЪБЛњжЦЃКЙ§диЧыЧѓЛсНЋСЌНгКФОЁЃЌЕМжТЯЕЭГхДЛњЁЃГЌЪБЛњжЦЕФв§ШыЃЌЗўЮёЕФжЪСПЛсЯТНЕЕЋВЛжСгкЯЕЭГШЋУцБРРЃЁЃ
УнЕШВйзїЃКгЩгкднЪБЕФДэЮѓЃЌПЭЛЇЖЫПЩФмЖрДЮЗЂЫЭЯрЭЌЕФЧыЧѓЃЌПЩФмЕМжТЯЕЭГДІРэДэЮѓЁЃУнЕШВйзїЃЌвЛжжПЩвдЗДИДжиИДЕФВйзїЃЌУЛгаИБзїгУЛђгІгУГЬађЕФЪЇАмЃЌПЩвдЯћГ§ЩЯЪівўЛМЁЃ
ЗўЮёНЕМЖЃКЕБЗўЮёЦїбЙСІОчдіЕФЧщПіЯТЃЌгаВпТдЕиМѕЩйЛђЭЫЛЏВПЗжЗўЮёЃЌвдДЫЪЭЗХЗўЮёЦїзЪдДвдБЃжЄКЫаФШЮЮёЕФе§ГЃдЫааЃЌШчжЛЖСФЃЪНЁЂЭЃгУКФЪБКФзЪдДЕФЙІФмЕШЕШЁЃ
ОмОјЗўЮёЃКЧыЧѓЙ§диЪБЃЌАДгХЯШМЖПЊЪМЖЊЦњЯргІЕФЧыЧѓЁЃ
ЗўЮёШлЖЯЃКШєФГИіФПБъЗўЮёЕїгУЙ§Т§ЛђепгаДѓСПГЌЪБЃЌжБНгШлЖЯИУЗўЮёЕФЕїгУЃЌЖдгкКѓајЕїгУЧыЧѓЃЌВЛдкМЬајЕїгУФПБъЗўЮёЃЌжБНгЗЕЛиЯьгІЃЌПьЫйЪЭЗХзЪдДЃЌД§ФПБъЗўЮёЧщПіКУзЊдђЛжИДЕїгУЁЃ
ЮозДЬЌгІгУЁЃЮозДЬЌгІгУЪЧздЖЏРЉеЙКЭВЛПЩБфЛљДЁЩшЪЉЕФЯШОіЬѕМўЃЌвЊЧѓгІгУБиаыЖРСЂгкЯШЧАЕФЧыЧѓЛђЛсЛАЃЌДІРэЫљгаПЭЛЇЖЫЧыЧѓЃЌВЂЧвВЛЛсДцДЂдкБОЕиДХХЬЛђФкДцжаЁЃ
ЛљДЁЩшЪЉМДДњТыЁЃЛљДЁЩшЪЉМДДњТыПЩМѕЧсЗБЫіЕФЪжЙЄХфжУКЭВПЪ№ШЮЮёЃЌгЩгкПЩгУЭъШЋЯрЭЌЕФЗНЪНЗДИДжДааЃЌвђДЫНтОіСЫЫцЪБМфЭЦвЦв§ЗЂЕФХфжУЦЏвЦЮЪЬтЃЌЕБгаЙЪеЯЗЂЩњЃЌЛљДЁЩшЪЉЕФЛжИДПьЫйЧвгааЇЁЃЭЌЪБПЩЖдЛљДЁМмЙЙвдДњТыЕФаЮЪННјааАцБОПижЦЃЌЙмРэЦфИќаТЁЂЩѓКЫЁЂбщжЄКЭЛиЫнЗжЮіЁЃЃЈБОЮФРДздЙЋжкКХЃКжьаЁиЫЕФВЉПЭЃЌID:
hiddenkafkaЃЉ
ЮхЁЂЛьучЙЄГЬЪЕМљ
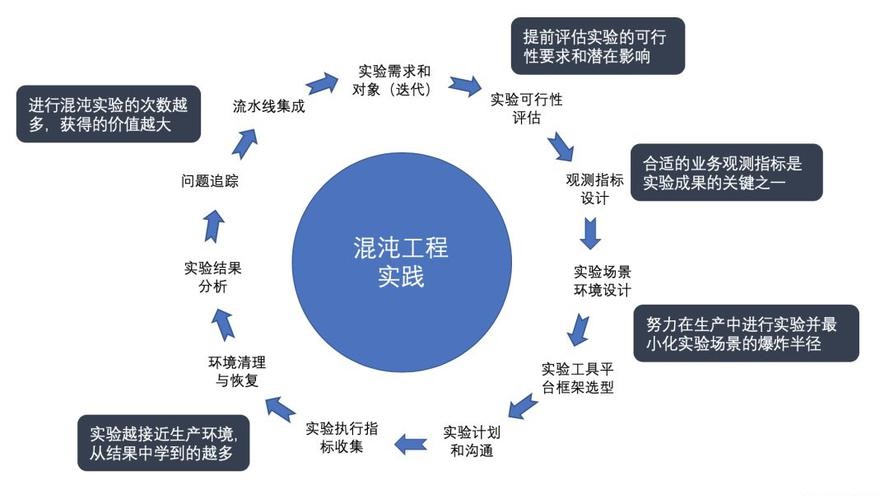
ЭъећЕФЛьучЙЄГЬЪЕбщЪЧвЛИіГжајадЕќДњЕФБеЛЗЬхЯЕЃЌДѓжТЗжЮЊвдЯТМИИіВНжшЃК
ШЗЖЈГѕВНЕФЪЕбщашЧѓКЭЪЕбщЖдЯѓЃЛ
ЭЈЙ§ЪЕбщПЩааадЦРЙРЃЌШЗЖЈЪЕбщЗЖЮЇЃЛ
ЩшМЦКЯЪЪЕФЙлВтжИБъЃЛ
ЩшМЦКЯЪЪЕФЪЕбщГЁОАКЭЛЗОГЃЛ
бЁдёКЯЪЪЕФЪЕбщЙЄОпКЭЦНЬЈПђМмЃЛ
НЈСЂЪЕбщМЦЛЎЃЌКЭЪЕбщЖдЯѓЕФИЩЯЕШЫГфЗжЙЕЭЈЃЌНјЖјСЊКЯжДааЪЕбщЙ§ГЬЃЛ
ЫбМЏдЄЯШЩшМЦКУЕФЪЕбщжИБъЃЛ
Д§ЪЕбщЭъГЩКѓЃЌЧхРэКЭЛжИДЪЕбщЛЗОГЃЛ
ЖдЪЕбщНсЙћНјааЗжЮіЃЛ
зЗзйИљдДВЂНтОіЮЪЬтЃЛ
НЋвдЩЯЪЕбщГЁОАздЖЏЛЏЃЌВЂШыСїЫЎЯпЃЌЖЈЦкжДааЃЛжЎКѓЃЌБуПЩПЊЪМдіМгаТЕФЪЕбщЗЖЮЇЃЌГжајЕќДњКЭгаађИФНјЁЃ
1. ЪЕбщПЩааадЦРЙР
дкЧАУцЕФЬсМАСЫЛьучГЩЪьЖШФЃаЭCMMЃЌДгЪьСЗЖШКЭНгФЩЖШЖдЪЕбщММЪѕЕФГЩЪьЖШзіСЫЖЈЯТЗжЮіЁЃДЫДІЕФЪЕбщПЩааадЦРЙРЃЌвРееетИіПЩааадЦРЙРФЃаЭЃЌЛсеыЖдОпЬхЕФЪЕбщашЧѓКЭЪЕбщЖдЯѓНјааЯИжТЦРЙРЁЃГЃМћЕФвЛИіаЮЪНЪЧЖдееЁАПЩааадЦРЙРЮЪЬтБэЁБЃЌЖдЪЕбщЖдЯѓЕФИЩЯЕШЫНјааЗУЬИЁЃПЩааадЦРЙРЮЪЬтБэЕФФкШнЛсАќКЌвдЯТМИИіЗНУцЃК
МмЙЙЕжгљЙЪеЯЕФФмСІЃКЭЈЙ§ЖдЪЕбщЖдЯѓЕФМмЙЙИпПЩгУадЕФЗжЮіКЭЦРЙРЃЌевГіЧБдкЕФЯЕЭГЕЅЕуЗчЯеЃЌШЗЖЈКЯРэЕФЪЕбщЗЖЮЇЁЃ
ЪЕбщжИБъЩшМЦЃКЦРЙРФПЧАЪЕбщЖдЯѓХаЖЈвЕЮёе§ГЃдЫааЫљашЕФвЕЮёжИБъЁЂгІгУНЁПЕзДПіжИБъКЭЦфЫћЯЕЭГжИБъЁЃ
ЪЕбщЛЗОГбЁдёЃКбЁдёЪЕбщЖдЯѓПЩвдгІгУЕФЪЕбщЛЗОГЃКПЊЗЂЁЂВтЪдЁЂдЄЩњВњЁЂЩњВњЁЃ
ЪЕбщЙЄОпЪЙгУЃКЦРЙРФПЧАЪЕбщЖдЯѓЖдЪЕбщЙЄОпЕФЪьЯЄГЬЖШЁЃ
ЙЪеЯзЂШыГЁОАМАБЌеЈАыОЖЃКЬжТлКЭбЁдёПЩааЕФЙЪеЯзЂШыГЁОАЃЌВЂЦРЙРУПИіГЁОАЕФБЌеЈАыОЖЁЃ
ЪЕбщздЖЏЛЏФмСІЃККтСПФПЧАЪЕбщЖдЯѓЕФЦНЬЈздЖЏЛЏЪЕЪЉФмСІЁЃ
ЛЗОГЛжИДФмСІЃКИљОнбЁЖЈЕФЙЪеЯзЂШыГЁОАЃЌЦРЙРЪЕбщЖдЯѓЖдЛЗОГЕФЧхРэКЭЛжИДФмСІЁЃ
ЪЕбщНсЙћећРэЃКИљОнЪЕбщашЧѓЃЌЬжТлШЗЖЈЪЕбщНсЙћКЭНтЖСЗжЮіБЈИцЕФФкШнЯюЁЃ
2. ЙлВтжИБъЩшМЦгыЖдее
ЙлВтжИБъЕФЩшМЦЪЧећИіЛьучЙЄГЬЪЕбщГЩЙІгыЗёЕФЙиМќжЎвЛЁЃдкНјааЛьучЙЄГЬЪЕбщЙ§ГЬжаЃЌЯЕЭГПЩЙлВтадвбГЩЮЊвЛжжЁАЧПжЦадЙІФмЁБЃЌСМКУЕФЯЕЭГПЩЙлВтадЛсИјЛьучЙЄГЬЪЕбщДјРДвЛИіЧПгаСІЕФЪ§ОнжЇГХЃЌЮЊКѓајЕФЪЕбщНсЙћНтЖСЁЂЮЪЬтзЗзйКЭзюжеНтОіЬсЙЉСЫМсЪЕЕФЛљДЁЁЃ
вдЯТЪЧГЃМћЛьучЙЄГЬЪЕбщЕФЙлВтжИБъРраЭЃК
вЕЮёаджИБъЃКМлжЕзюДѓЃЌЬНВтФбЖШзюДѓ
гІгУНЁПЕжИБъЃКЗДгГгІгУЕФНЁПЕзДПі
ЦфЫћЯЕЭГжИБъЃКНЯвзЛёШЁЃЌЗДгГЛљДЁЩшЪЉКЭЯЕЭГЕФдЫаазДПі
жИБъЖдееЪЧжИНЋЁАЙлВтжИБъЁБгыЁАжИБъЕФЮШЖЈзДЬЌЁБНјааЖдееЁЃКмЖрЕФгУЛЇЛЙЪЧЮоЗЈЖЈвхвЛИіКЯЪЪЕФвЕЮёжИБъЃЌШчЮоЗЈзМШЗЖЈвхвЛИіЮШЖЈзДЬЌЃЌФЧУДЮвУЧвВПЩвдЭЫЖјЧѓЦфДЮЃЌЪЙгУЖрИіжИБъНјааСЊКЯЗжЮіРДЖдееЁЃ
3. ЪЕбщГЁОАКЭЛЗОГЕФЩшМЦ
ЪЕбщГЁОАКЭЛЗОГЕФЩшМЦвЊХЌСІзёбвдЯТШ§ДѓЩшМЦФПБъЃК
дкЩњВњЛЗОГдЫааЪЕбщ
ГжајздЖЏЛЏдЫааЪЕбщ
зюаЁЛЏЪЕбщГЁОАЕФЁАБЌеЈАыОЖЁБ
ЪЕбщГЁОАЃЈЙЪеЯзЂШыЃЉЩшМЦ

ЪЕбщЛЗОГЩшМЦ
ЪЕбщЛЗОГЕФВЛЭЌЃЌДјРДВЛЭЌЕФвЕЮёЗчЯеЁЃЩњВњЛЗОГЕФвЕЮёЗчЯезюДѓЃЌПЊЗЂЛЗОГЕФвЕЮёЗчЯезюаЁЃЌЦфЫћвРДЮРрЭЦЁЃЃЈБОЮФРДздЙЋжкКХЃКжьаЁиЫЕФВЉПЭЃЌID:
hiddenkafkaЃЉ
НЈвщгУЛЇдкЩњВњЛЗОГЩЯНјааЛьучЙЄГЬЪЕбщЃЌЕБШЛЧАЬсЪЧетаЉЪЕбщГЁОАКЭЙЄОпвбОдкПЊЗЂЁЂВтЪдКЭдЄЩњВњЛЗОГЕУЕНСЫбщжЄЁЃЕБШЛдкЩњВњЛЗОГЩЯНјааЛьучЙЄГЬЪЕбщвВВЛЪЧЧПжЦЕФЃЌгУЛЇПЩвдбЁдёЪЪКЯздМКЕФЭЦНјНкзрЃЌж№ВНЯђЩњВњЛЗОГППТЃЁЃвђЮЊЪЕбщдННгНќЩњВњЛЗОГЃЌДгНсЙћжабЇЕНЕФдНЖрЁЃЭЌЪБЃЌЮЊСЫЬхЯжЪЕбщЖдееЕФаЇЙћЃЌдкЩњВњЛЗОГНјааЕФЛьучЪЕбщПЩвдЭЈЙ§ецЪЕЩњВњСїСПЗжжЇЕФЗНЪНЃЌзщНЈПижЦзщКЭЖдеезщЃЌвдДЫЧјЗжЙЪеЯзЂШыЕФгАЯьЃЌДгвЛЖЈГЬЖШЩЯПижЦСЫБЌеЈАыОЖЁЃЖдгкЗЧЩњВњЛЗОГЕФЛьучЙЄГЬЪЕбщЃЌПЩВЩгУФЃФтЩњВњСїСПЕФЗНЪНЃЌОЁСПКЭЩњВњСїСПЯрЫЦЃЌРДбщжЄЪЕбщГЁОАКЭЙЄОпЕФПЩППадЁЃ
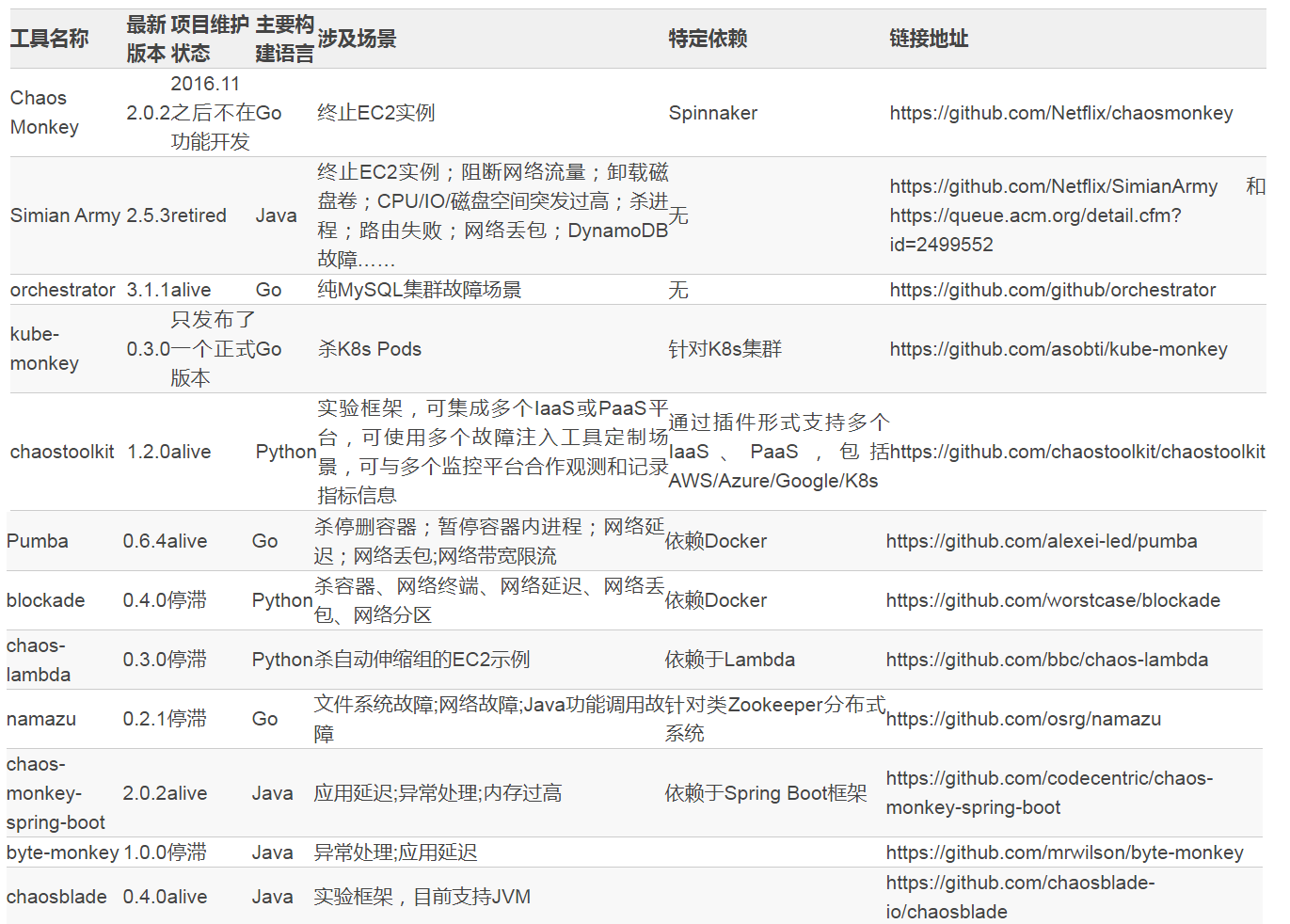
СљЁЂЛьучЪЕбщЙЄОпећРэ
ЦпЁЂЛьучЙЄГЬАИР§
1. Netflix: SPS
ФГаЉзщжЏгаЗЧГЃУїШЗЕФЃЌКЭЪеШыжБНгЯрЙиЕФЪЕЪБжИБъЁЃР§ШчЯё Amazon КЭ eBay ЛсИњзйЯњЪлСПЃЌGoogle
КЭ Facebook ЛсИњзйЙуИцЦиЙтДЮЪ§ЁЃгЩгк Netflix ЪЙгУЕФЪЧАДдТЖЉдФФЃЪНЃЌЫљвдУЛгаетРржИБъЁЃNetflixвВЛсВтСПзЂВсТЪЃЌетЪЧвЛИіживЊЕФжИБъЃЌЕЋЪЧжЛПДзЂВсТЪВЛФмЗДгГећЬхЯЕЭГЕФНЁПЕзДПіЁЃ
Netflixеце§ЯывЊЕФЪЧвЛИіПЩвдЗДгГЕБЧАЛюдОгУЛЇЕФТњвтзДПіЕФжИБъЃЌвђЮЊТњвтЕФгУЛЇВХгаПЩФмСЌајЖЉдФЁЃПЩвдетУДЫЕЃЌШчЙћЕБЧАКЭЯЕЭГзіНЛЛЅЕФгУЛЇЪЧТњвтЕФЃЌФЧУДЮвУЧЛљБОПЩвдШЗЖЈЯЕЭГФПЧАЪЧНЁПЕЕФЁЃ
вХКЖЕФЪЧЃЌNetflixФПЧАЛЙУЛевЕНвЛИіжБНгЁЂЪЕЪБЕФПЩвдЗДгГгУЛЇТњвтЖШЕФжИБъЁЃNetflixЛсМрПиПЭЗўЕчЛАЕФКєНаСПЃЌетЛђаэЪЧвЛИіПЩвдМфНгЗДгГПЭЛЇТњвтЖШЕФжИБъЃЌЕЋЪЧДгдЫгЊНЧЖШГіЗЂЃЌЮвУЧашвЊИќПьЁЂИќЯИСЃЖШЕФЗДРЁЁЃNetflix
гавЛИіЛЙВЛДэЕФПЩвдМфНгЗДгГгУЛЇТњвтЖШЕФжИБъЁЊЁЊВЅЗХАДХЅЕФЕуЛїТЪЁЃNetflixЙметИіжИБъНазіЪгЦЕУПУыПЊЪМВЅЗХЪ§ЃЌМђГЦЮЊ
SPSЃЈStarts per sencondЃЉЁЃ
SPS КмШнвзВтСПЃЌЖјЧввђЮЊгУЛЇИЖЗбЖЉдФЗўЮёЕФжБНгФПЕФОЭЪЧПДЪгЦЕЃЌЫљвд SPS гІИУКЭгУЛЇТњвтЖШУмЧаЯрЙиЁЃетИіжИБъдкУРЙњЖЋКЃАЖЯТЮч
6 ЕуЛсУїЯдИпгкдчЩЯ 6 ЕуЁЃNetflixОЭПЩвдОнДЫРДЖЈвхЯЕЭГЕФЮШЖЈзДЬЌСЫЁЃ
ЯрБШФГИіЗўЮёЕФ CPU ИКдиРДЫЕЃЌNetflix ЕФПЩППадЙЄГЬЪІЃЈSREsЃЉИќЙизЂ SPS ЕФЯТНЕЃКSPS
ЯТНЕЛсСЂПЬЯђЫћУЧЗЂЫЭИцОЏЁЃCPU ИКдиЕФМтДЬгаЪБживЊгаЪБВЛживЊЃЌЖјЯё SPS етбљЕФвЕЮёжИБъВХЪЧЯЕЭГБпНчЕФБэЪіЁЃетВХЪЧашвЊЙизЂВЂбщжЄЕФЕиЗНЃЌЖјВЛЪЧФЧаЉЯё
CPU ИКдиРрЕФФкВПжИБъЁЃ
дк NetflixЃЌSPS вВВЛЪЧвЛИіКЭШЫЬхЬхЮТвЛбљЕФЮШЖЈжИБъЃЌЫќвВЫцзХЪБМфВЈЖЏЁЃЯТЭМУшЛцЕФОЭЪЧ
SPS ЫцЪБМфБфЛЏЕФВЈЖЏЧщПіЃЌПЩвдПДГіЃЌЫќгавЛИіЮШЖЈЕФФЃЪНЁЃетЪЧвђЮЊШЫУЧЯАЙпгкдкЭэВЭЪБМфПДЕчЪгНкФПЁЃвђЮЊ
SPS ЫцЪБМфЕФБфЛЏПЩвддЄЦкЃЌЫљвдЮвУЧОЭПЩвдгУвЛжмЧАЕФ SPS ВЈЖЏЭМзїЮЊЮШЖЈзДЬЌЕФФЃаЭЁЃNetflix
ЕФПЩППадЙЄГЬЪІУЧзмЪЧНЋЙ§ШЅвЛжмЕФВЈЖЏЭМЗХдкЕБЧАЕФВЈЖЏЭМжЎЩЯЃЌвдЗЂЯжВювьЁЃОЭЯёЯТЭМжаЕБЧАЕФЭМЯпЪЧКьЩЋЃЌЩЯвЛжмЕФЭМЯпЪЧКкЩЋЁЃ
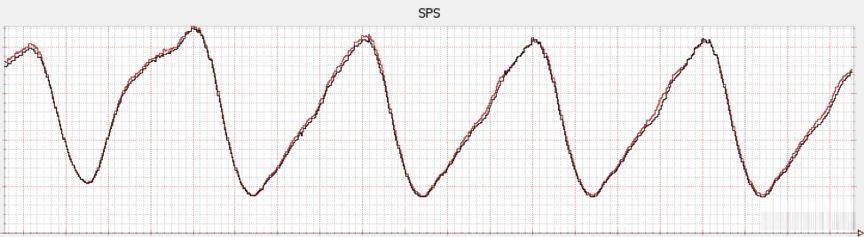
ФуЫљДІЕФаавЕОіЖЈСЫФуЕФжИБъЪЧЗёвдвЛжжПЩвддЄЦкЕФЗНЪНЫцЪБМфВЈЖЏЁЃР§ШчЃЌШчЙћФуИКд№вЛИіаТЮХЭјеОЃЌСїСПЕФМтДЬПЩФмРДдДгквЛИіДѓжкЙизЂЖШИпЕФаТЮХЪТМўЁЃФГаЉЪТМўЕФМтДЬПЩвддЄЦкЃЌБШШчбЁОйЁЂжиДѓШќЪТЃЌЕЋЪЧЦфЫћРраЭЕФЪТМўВЛЬЋПЩФмБЛдЄВтЕНЁЃдкетвЛРрГЁОАжаЃЌзМШЗУшЪіЯЕЭГЕФЮШЖЈзДЬЌНЋЛсЗЧГЃИДдгЁЃЮоТлФФжжЧщПіЃЌУшЪіЮШЖЈзДЬЌЖМЪЧНЈСЂгавтвхМйЩшЕФБивЊЧАЬсЁЃ
2. АЂРяАЭАЭChaosBlade
2012 ФъАЂРяФкВПОЭЩЯЯпСЫ EOS ЯюФПЃЌгУгкЪсРэЗжВМЪНЗўЮёЧПШѕвРРЕЮЪЬтЃЌЭЌФъНјааСЫЭЌГЧШнджЕФЖЯЭјбнСЗЁЃ15
Фъ ЪЕЯжвьЕиЖрЛюЃЌ16 ФъФкВПЭЦГіЙЪеЯбнСЗЦНЬЈ MonkeyKingЃЌПЊЪМдкЯпЩЯЛЗОГЪЕЪЉЛьучЪЕбщЃЌШЛКѓ
18 ФъЪфГіСЫ ACP зЈгадЦВњЦЗ КЭ AHAS ЙЋгадЦВњЦЗЃЌЦфжа AHAS жМдкНЋАЂРяЕФИпПЩгУМмЙЙОбщвдВњЦЗЕФаЮЪНЖдЭтЪфГіЃЌЗўЮёгкЭтВПЁЃ19
ФъЭЦГі ChaosBlade ЯюФПЃЌНЋЕзВуЕФЙЪеЯзЂШыФмСІЖдЭтПЊдДЃЌЭЌФъвВЭЦГіЛьучЪЕбщЦНЬЈзЈгадЦАцБО
AHAS ChaosЁЃ
ChaosBlade жаЮФУћЛьучжЎШаЃЌЪЧвЛПюЛьучЪЕбщЪЕЪЉЙЄОпЃЌжЇГжЗсИЛЕФЪЕбщГЁОАЃЌБШШчгІгУЁЂШнЦїЁЂЛљДЁзЪдДЕШЁЃЙЄОпЪЙгУМђЕЅЃЌРЉеЙЗНБуЃЌЦфзёбЩчЧјЬсГіЕФЛьучЪЕбщФЃаЭЁЃОпЬхПЩвдВЮПМЃКАЂРяАЭАЭЛьучВтЪдЙЄОпChaosBladeСНЭђзжНтЖСЁЃ
|









