| ����Ħ�����ɣ��Դ�1958�귢�����ɵ�·�����������ٶȺʹ洢����һֱ����ÿ���귭һ�����ٶ�������
��������ϵͳ�ķ�չ�ٶ�ò�Ʋ��ɱ���س�������һ�е�ָ�������ٶȡ�SOA��Ӧ��Խ��Խ�㷺��������֮���з���֮���XML���ݴ��ݷ�ʽ��������ΪѸ�ٵ�����Ӧ�á���Ȼ��ȡ���˳ɹ����������ϵͳ�ܿ��ܻ����ϳ��أ����������������벻����ʱ��
��ô����ⳡΣ���أ�������ҵ������ڴ�ʹ洢����ij�������������Ҳ��Ҫά����Ӧ�IJ��������Ǵ�һ��ʼ��Ҫʹ����ȷ�ķ�����ȡ�ÿɿ����ӳٵ����Կ���չ�ԡ������ļ�����Ϣ������Ҳ�ڳ�����������Ҫ����Ĵ���������Ҳʹ��Щ��ʹ��ǰ��Ҫ�Ƚ�����廯�������Եø�Ϊ���ء���ijЩ����£���Щ������ִ��ǰ����Ҫ������롣
��Щ����������������XTP����Ӧ�á�������绰��˾���н����ͼƷѡ�������Ϸ����ȫ���ס����չ������������ζ�Ʊ�������˶��ⷽ��Ӧ�ú����˽⡣���и��㷺��������������Ӧ����Ҫ����������������������ߣ����Ǻ�̨ϵͳȴ��Ӧ������Ѹ�͵�������
�߽�ɱ�
����ͻ����۶�SOA�����ӳٿɿص���չʱ�����Ǿ���ʹ��һ����Ϊ"�߽�ɱ�"��Boundary
Costs�������Ϊ�������⣬�뿼�������龰����һ������Ӧ�ã������ݿ⡢�ⲿҵ���顢��EDI�ĵ�ת�����������ɵ�XML�ĵ���Ҫ�����������Ĵ����������������BPEL��ESB����Э����ͨ���ķ����ǰ�XML�������ߣ������߸��ݴ������������Ӧ�ķ�����XML�ĵ���Ϊ���������ص�һ���ִ��ݸ�������Ҫ�����ݽ��д����ķ������˶�XML���ж�ȡ��������Ҫ�����ݿ⽻������������ַ�������ͼ1���������dz���
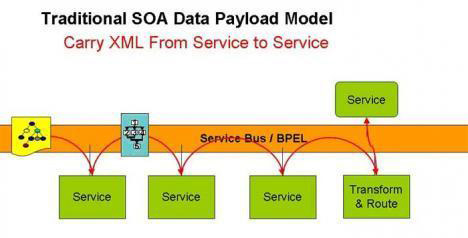 |
| ��ͼ1��ʹ��BPEL���̻�������ߵ��÷���
|
���ǣ���ʵ����ʹ�����ַ�����ʱ��ȴ��������չ���ϵ����⡣��һ��������һ������ijɱ��Ƕ����أ��ڵ���һ����ҵ����̵�ʱ������ɱ�����Ҫ�������ٴ��أ����XML�ĵ��dz��ﵽ��M�ķ�Χ�������ɰ���ǧ�������������ͬʱ�����أ�
���ҿ��ǵ����IT�����Ƕ�ƽ̨�Ͷ��ּ����ĸ����壬����ָ���������������µ����ѡ���ʹ���������������ߵ����ܷdz���ɫ�������ն˵Ĵ���������Ȼ���Ϊƿ���������һ�ҿͻ���վ����ʾ��һ��ԭ��ͨ����Ҫ15�봦��ʱ���ҵ����̣�����ڷ�ֵ����ʱ����������SLAЭ��Լ����30�롣�ڹ�ȥ�����������Ա�Ѵ�ʱ�䶼�������Ż�������15�������ÿһ��ϸ�ڣ���������ĺ���ȴ�Ǹ�����֮��ı߽�ɱ������ǽ��е�һ����ϸ�����ʾ����15��������ö�Ҫ����1��2���ʱ����һ����Դ������߰����XML���н����������Ⲣ�����������↑Դ������߰���ֻ�Ǽ�˵��һ�����ն˽�������XML�������ӳ٣��������Ч���dz��ɹۡ�
��ͼ2��ʾ�������õĸ���������Ҫ��XML�����ߴ��л���ʽ�ж�ȡ����Ч���ݲ�����Ϊ����Java��.NET������ʽ��Ȼ����ܱ�ҵ�������������ң�������漰�������ݿ�Ľ�������ô���ᷢ����������ƥ��������Ҫ�����෴�Ĺ��̣����������������Ӧ����Ӧ������ҵ����̽��䷢�͵����η���
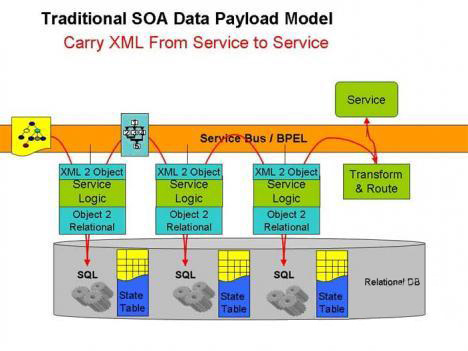 |
| ͼ2��XML�����ϵ���ݿ�֮��ķ��������෴���̵ı߽�ɱ�
|
��SOA�У��Ƚϳ��õĴ���XML�ķ�ʽ��ʹ����������XMLBeans��ͨ��XMLBeans�ɰ�����������ȫ���廯Ȼ�������ɶ�����������������Ժʹ������ܡ��ڴ洦�����ܰ������ࡢ���ˡ��ϲ��Ȳ�������������Щ�����������Ӵ���ÿ�ε�������������ڴ����������ַ�ʽȱ����չ�ԣ�������Ӧ�õ������������ೡ���С������Ʒ֧��XML���������ַ�ʽҲ�о����ԣ���������ȴ�����ݿ��ܾ��������κ�������IJ�����
��ô���ܲ������һ�ַ�ʽ������Ϣ������һ�����Ժ������ݴ�С�͵�������������Ӧ���������أ���Ӧ������������ö�̨����������ڴ�ʹ������������һ����������紦��һ�����ӵĹ�ʽ��Ժ������ݽ��й��ˡ���Ӧ�����ɽ����ݵ����������ӳ���������������֮�⣬������������������������Խ����߽硣
������ܽ��������ݴ洢��������Ч����������ϵ�һ�𣬾��ܹ�����һ����������Զ������ǰ�ġ��߶ȵġ�����չ��ϵͳ��ͨ����һЩ���似����ϵ�һ�����Ǿ���ȡ�ðѼ��������չ���ֲ�ʽ�ļ��������У�����SOA����Ӧ�÷������Ϳͻ�Ӧ�õ����������ߵĴ������ڴ��������ǻ����������ݴ��������ж��м�洢���ݿ������ͨ��Ӧ���������ǻ����Դ������ݵIJ������������ݱ������������Լ�������ͨ�Ų��Ч�ʲ��Ҽ������������߽�ɱ���
���Ļ���һ����ʾӦ�������д�������XML�ļ��Ĵ���ʾ�����ڵ��͵�XML�ļ���ͨ����һЩԪ����û���κ�Ԥ�������Ƶ�������ظ���ͨ��STAX��������XML���д�����������JAXB����XML��Java����֮��ĻỰ�����ǿ��Խ���Щ�ظ���Ԫ�ش�XML������ȡ������Ȼ��ŵ�Ӧ����������Ϊ�����Ķ��������������䵽�������У�����ֻ�����������ڴ���Դ����䵽����֮����������ʹ�ù�������Ķ�̨���������ݽ��д�����ÿ�������Ա����һ���������ǣ�Ȼ���м������ݸ�����ͻ��˲����䴦�������ս����
ʲô��Ӧ������
Ӧ���������һ�����ڣ�Ӧ��״̬���ݣ��ڴ�洢�����ˮƽ����չ�Ĵ��������ַ�ʽ�����γ�һ���ֲ�ʽ�ڴ�أ����ڽ���������չ�����κθ߶˶��ͼ۵ı�Ӳ����ɵ�����������Ӧ����ʹ��Ӧ�������ͬʱ���ܻ�ø����ܡ���չ�ԺͿɿ��ԡ�
Ӧ������Ӧ�������һ�ַ�ʽ��ʹ��APIˮƽ�Ľӿ�ģ��Java Hashmap��.NET Dictionary��JPA�ӿڡ�����һ�ַ�ʽ��ʹ��SOA�����еķ���ӿڡ�����Ӧ�úͷ������ݷ���Ӧ������һ�鹲ͬ��ת�Ļ������������Ⱥ���п��Ƶķ�ʽ����������ݶ���ĸ��ºͱ��ݡ�
��ͼ3��ʾ��Ӧ������������������ݵ�����ͨ����Ч����Э�鴫�͵�ӵ��ԭʼʵ�����ݵ�����ڵ�P��Ȼ��ԭʼ�ڵ㽫���µ�ֵ���Ƶ��ڶ��ڵ�B�Խ��б��ݣ��ٰѿ���Ȩ���ظ�����
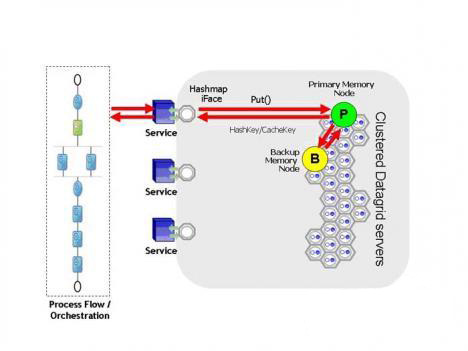 |
| ͼ3��Ӧ������Ⱥ���ڲ�ͬ�����ϱ�֤�ڴ����ݵ�ԭʼ�����ͱ��� |
Ӧ�������ڶ�̨�������Ժ��ʵ�λ�����Դ������ݡ�����Ӧ���������ݴ�����ʲô�ط���ֻҪ��Hashֵ�Ϳ���ʱ��ȡ���洢�����ݡ������Ͳ�����Ҫ���ӵĴ���λ�������Ժ��ֶ�������Ӧ�����ˡ���������е�һ�������Ľڵ���ֹ��ϣ�������������ԭ��������з��ʣ���ôӦ�������������������Ӧ�������������Ľڵ������²������ݡ���������������ӹ��Ͻڵ���������������¡���ͼ4�У���ȡ����ʱԭʼ�ڵ�P���ֹ��ϡ�����Get()�������ϱ������˱��ݽڵ㲢��������ԭʼ�뱸�ݽڵ�ԡ�
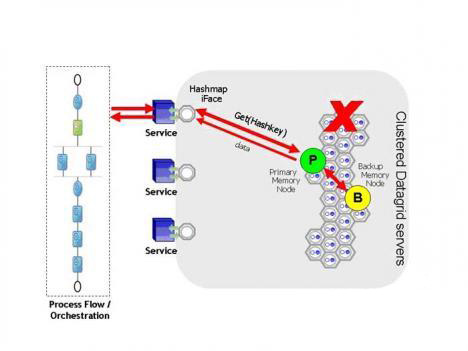 |
| ͼ4��Ӧ����������ṩ�ڴ�״̬���ݵĹ���ת��
|
�洢�������е����ݿ����ǴӼı��������ӵĶ�����������XML�ĵ����κζ���������ѡ��ѿ����Ƿdz����XML�ĵ��ֳ�С�鲢��Java����ķ�ʽ������Ӧ�������С��������Ǿ���ʹ��Java
APIƽ�д��������ݵIJ�ѯ����
Ӧ������֧��һϵ�еIJ������������д�����ѯ���¼��������ڴ������ݼ������ܽ��������ݼ�����Ϊһ��������������Ȼ��������Խ����ݷַ������ԭʼ�ͱ��ݽڵ���ʵ�ֿ���չ�ԡ��ڸ�����Ӧ���У�������������ֱ�������ݴ���ڵ��ϲ���ִ��ҵ���������Ҿ��������������������Ӷ���֤������������ص����ݴ洢������ִ������
SOA��Ӧ������
��һ������Ӧ�������SOAƽ̨�����ṩ����ܹ������ṩ��һ�㹦�ܣ������������ȡ������ת����·�ɵ��н顢��Э��֧�֡��������ȣ���������Ӧ�������ܽ������ʵ�ַ��������ء���������״̬���ݡ�������������¼������ܹ���EDA�����ڴ����ݻ��档
��ô��������ʵ����Щ�ŵ��أ��ڵ��͵�SOA�龰�У�һ�����������еĶ���������Ҫ��ͬ�������ݽ��н��������û��������ôÿ�ε��÷���ʱ������Ϊ�����ṩ��������ݡ�ͨ����������ʵ����һ��"�����ǩ"��Claim
Check����ģʽ��
��ģʽ����ʹ�����ݿ����洢��Ϣ����Ч���ݣ�����ʹ��Ӧ���������Ϣ�������ڴ��У���Ϊ��������һ����һ�����ݵĹؼ��֡�����ζ����Ȼ��һ�����ݵ���һ������Ĺؼ��ֻ����ESB����������ʹ�����仯������ͨ����������ڷ�����������ΪЭ��ͷ���Ե�һ���ֻ�XML��Ч���ص���֤Ԫ�ء�����ʼ����"������ʶ"�����Ը��������ȡ���ݲ����ö����ݼ��ĺϲ����㡣�������֮�����ݼ����Լ����������ڴ����Խ��и��ٶ�ȡ������Ҳ�������Ӽ��ͺ��ʵĸ�ʽ�첽д�����ݿ���Ϊ���ڴ洢�Ĺ�ϵ���ݣ���ͼ5����
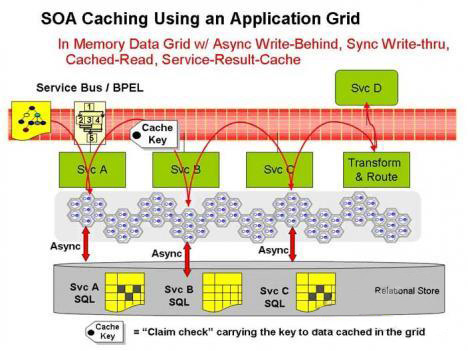 |
| ͼ5��SOA��Ӧ��������ṩ�Է���״̬���ݵ��ڴ��ȡ����ʹ��"�����ǩ"ģʽ��С���߽�ɱ� |
XML����ʾ��
1. ��������
���ĵı�����Ϣ����ͨ������洢����������������ʵ�ֶಽҵ����̵������ǩģʽ���������ǵ�ʾ������ҪĿ����չʾ����������д洢����XML�ĵ���������в�����Ȼ�����ʹ�������ǩģʽ������д�������
ʾ���������£�һ������XML�ĵ���Ҫ�������������������ĵ����з����л����������������ٴ��л������ĵ���ֻ�ǰ��ĵ��ֳ�С�飬ת����Java��������Ӧ�������С�����������ɷ������еĵ�һ��������У������ɵ�һ������֮ǰ�ĸ���������ɡ��ӷ�������ݵ���С�ö��XML��Ϣ--"�����ǩ�����а�����ȡӦ�������е���������Ĺؼ��֡�
���⣬������ֻ�������л��ķ�ʽִ�ж�������ʱ�����ģʽ�����á�Ҳ������ÿ�����һ�ε���һֱҪ����������������û�ͨ���Ż�Ӧ�ò�ѯ�����������������ʻ����ݵȲο����ݡ�
2. ���XML
����ʹ��STAX��������XML�ĵ��ֽ�ɶ����ɲ��֡���ΪSTAX��ʼ��ʱ���Ի���廯������������������Ϊ��Ѱ������ظ�Ԫ���еĵ�һ�������XML��һ����Ϊ"����"�������ڵ��к��ж��"��"���������ʹ�"��"��ʼ�Ա�����廯����"����"�����б�1����������Ĺؼ����֡�
�б�1��ͨ��STAX�����ֽ�XML������ȡ�ظ���Ԫ��
EventFilter filter = new EventFilter() {
public boolean accept(XMLEvent event) {
//first off, we need a startElement
if (!event.isStartElement()) return false;
StartElement e = (StartElement)event;
//more importantly, it must be the first "item"
if ((e.getName().getLocalPart()).equals("item"))
return true;
return false;
}
};
Ȼ������ʹ��JAXB������XMLԪ��ת��ΪJava����JAXB����XML��POJO���֣���ʹ�䴮�л�������XML��Java����������������δ���֮ǰ����������Eclipse
XJC�����XML Schema��������JAXB�ࡣ�б�2��ʾ�����XML��ѭ���Ŀ�ʼ���֣���ÿһ��ѭ����������һ��JAXB����
�б�2��ͨ��JAXB���ý�XMLԪ��ת��ΪJava ����
while (xmlfer.peek() != null) {
JAXBElement<Item> o = (JAXBElement<Item>)um.unmarshal(xmler);
if (o.getValue() instanceof Item)
{
Item ii = (Item)
o.getValue();
��
}
һ����������ָ��"��"�IJ�����JAXB�������ǾͰ����ŵ�Ӧ�������С��ڱ����У�����ʹ���˿���ģ�⣨Java��C++��Java
Map API�ͣ�.NET��Dictionary�ӿڵ�Oracle Coherence�����б�3����
�б�3��ʹ��Map API��Java����洢��Ӧ������
//put into grid
String itemKey = ii.getPartNum();
itemCache.put(itemKey, ii);
3. �ھ�Ӧ������DZ��
����洢������֮�������ڴ�Java��C++��C#����ķ�ʽ��ȡ���ݡ����ǻ���������Ӧ�������һЩ�����ܣ�������ڴ�������ݵIJ��в�ѯ������������ѯ�����д����ȡ�
�ڱ����У�����ֻ�������е����ݽ���һ�μIJ�ѯ���б�4�еĴ��뼴��һ�������а���"foo"����ļ�������
�б�4��ͨ��Ӧ������ִ�в��в�ѯ
public Object process(Entry en) {
Item i = (Item)en.getValue();
if (i != null) {
i.setComment(i.getComment() + " (modified)");
en.setValue(i);
}
return i;
}
��and to invoke this��
//Create a filter to find items in the grid
Filter theFilter = new LikeFilter("getProductName",
"%foo%");
//Pass in a filter and an operation (class)
Map result = itemCache.invokeAll(theFilter, new UpdateComment());
4. ���¼���ʽִ����������
ͨ����JavaBean������ģʽ����ʹӦ���������¼��ķ�ʽ����Java��������������д����ȡ����ʱ���ɴ����������Java�Ķ�д��������洢���̡��б�5��һ����ʾ�����еĸ���ֵ���¼���
�б�5�����������ݸ��º���ȡʱ�������¼�
public void entryUpdated(MapEvent me) {
Item i = (Item) me.getNewValue();
System.out.println("Updated Item: "
+ i.getComment());
}
5. �ع�XML
��XML�ĵ����д�����ҵ��������ڽӽ���β������������Ҫ���������е����ݣ����乲��������Ӧ�û�������Ҫ�����ݴ洢����ϵ���ݿ��У���ô��̨�ͻ��й�ϵӳ����������Բ����������Ӧ������֮���ʵ�ʽ����ķ�ʽ���ڡ�
�����κ������ǩģʽ��ʵ����˵����Ҫע��������صķ�����Ŀ�Ķ���ʵ�����ģʽ���ܴ������ŵ㡣����������̻���Ҫ��������δ֧�������ǩģʽ�ĵķ�����Ϣ����˻���Ҫͼ5�е�"ת����·��"�ⲽ�������ݴ��л���XML���߸�ʽ����Ȼ����������»�������߽�ɱ������Dz���1��2��3��Ч���Ѿ�����˺ܶࡣ
�б�6��ʾ����ʹ��Ӧ������APIͨ���ؼ����������ж����ʹ��JAXB����XML�ļ�������ֻ��һ����ʹ��Java����XML��ʾ�������Ǵ�ҿ��Դ����ܵ�������ʹ��XSLT��ʽ����ͨ��������Ķ�β�ѯ�����ʽ����������ݡ����⣬����������������������ɷ�ɢ��XML��������ȫ���廯�ڴ�DOM����
�б�6���������XML��ת�����ⲿ����
Filter theFilter = new LikeFilter("getProductName",
Constants.PRODUCT_FILTER);
Set filtered = itemCache.keySet(theFilter);
// Create a blank Purchase Order and populate it.
The non-cached // parts could come from elsewhere and
merged using XSLT
ObjectFactory of = new ObjectFactory();
PurchaseOrderType po = of.createPurchaseOrderType();
po.setItems(of.createItems());
// Loop over items and add to an object
for (Iterator it = filtered.iterator(); it.hasNext();)
{
Object key = it.next();
Item i = (Item) itemCache.get(key);
po.getItems().getItem().add(i);
}
��֮��Ӧ��������Լ������ߴ����������ݵ�SOAӦ�õ�Ч�ʺͿ���չ�ԡ�ʹ��ˮƽ����չ��Ӧ������洢���������������أ��������ڿɼ������ӳٷ�Χ�ڶ�Ӧ�ý�����չ�����ң�ͨ��Ӧ�������ǿ���ܣ����ǻ������ڴ��ȡ�ٶ�ִ�зֲ�ʽ���в�ѯ���¡����ݱ��֮������ֻҪ��չ������Ӧ������������ͨ�����ٵ�Ӳ����������˱��������ߵĴ������������ҿ��Դ�һ��ʼ�ʹ����չ�Ļ�����������ÿ������ʱ�����ó�Ӧ�õ����ͼֽ�
| 