| 编辑推荐: |
单机时代的容器通信过程,然后做实验验证这一过程
,希望对您的学习有所帮助。
本文来自于CSDN
,由Alice编辑、推荐。 |
|
容器的本质是一个被隔离的进程,而这个进程又有其独立的网络栈,即网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。单机时代的容器网络实际上有三种通信需求,分别是:
容器之间通信
容器与宿主机之间通信
容器与外部主机通信
在docker中实现单机时代容器的网络,主要依靠以下这几个工具。

概念总是抽象的,后面我将会做实验使用这三种设备模拟主机上的容器通信流程,在这之前,让我们先搞明白单机时代的容器通信过程,然后做实验验证这一过程。
容器通信原理
容器之间通信
不同容器之间的通信,类似于不同主机之间的通信。如果你想要实现两台主机之间的通信,最直接的办法,就是把它们用一根网线连接起来;而如果你想要实现多台主机之间的通信,那就需要用网线,把它们连接在一台交换机上。在 Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge)。Docker 项目会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信。于是,问题的关键在如何将容器连接到docker0网桥上。使用一种名叫Veth Pair的虚拟设备。
Veth Pair 设备的特点是:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网 卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。
下图所示的container1中的eth0 网卡,是一个 Veth Pair,它的一端在这个容器的 Network Namespace 里,而另一端则位于宿主机上(Host Namespace),并且被“插”在 了宿主机的 docker0 网桥上。一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。从设备会被“剥夺”调用网络协议栈处理数据包的资格,从而“降级”成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥。
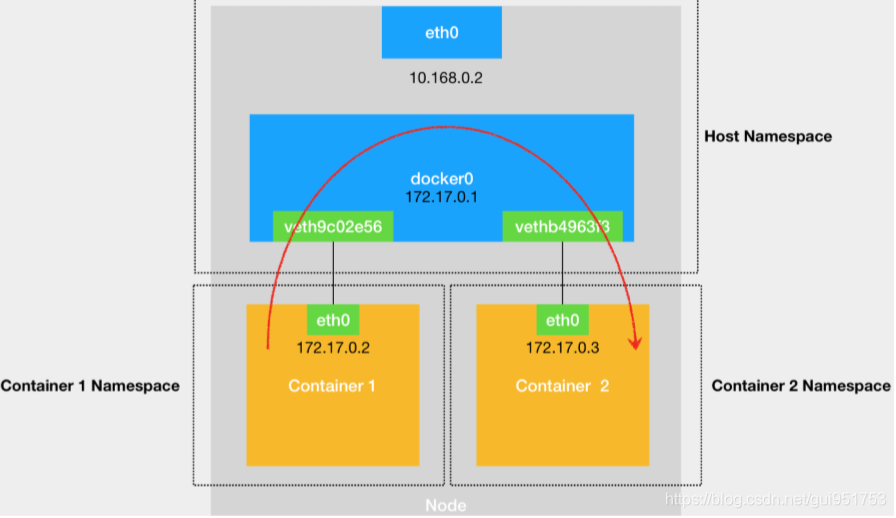
container1与container2的通信过程如下所示:
1.container 1查看自己的路由表,匹配到合适的路由。如下所示,container 1将会匹配到第二条路由,即直连路由(凡是匹配到这条规则的 IP 包,应该经过本机的eth0网卡,通过二层网络直接发往目的主机),即无需gateway转发便可以直接将数据包送达。
route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 * 255.255.0.0 U 0 0 0 eth0
|
2.发起arp请求,查询目标IP地址为172.17.0.3的容器的mac地址。arp查询后(要么从arp cache中找到,要么在docker0这个二层交换机中泛洪查询)获得172.17.0.3的mac地址。
arp -n
(172.17.0.1) at 02:42:3e:c5:c8:5c [ether] on eth0
(172.17.0.3) at 02:42:ac:11:00:03 [ether] on eth0
|
3.得到对应mac地址后,将数据包转发给该mac地址对应的网卡即可。类似局域网上两台主机之间的通信过程。此时两个container之间连通,主要还是通过直连网络,实质上是docker0在二层起到的作用。
容器与宿主机之间通信
当你在一台宿主机上,访问该宿主机上的容器的 IP 地址时,这个请求的数据包, 也是先根据路由规则到达 docker0 网桥,然后被转发到对应的 Veth Pair设备,最后出现在容器里。这个过程的示意图,如下所示:
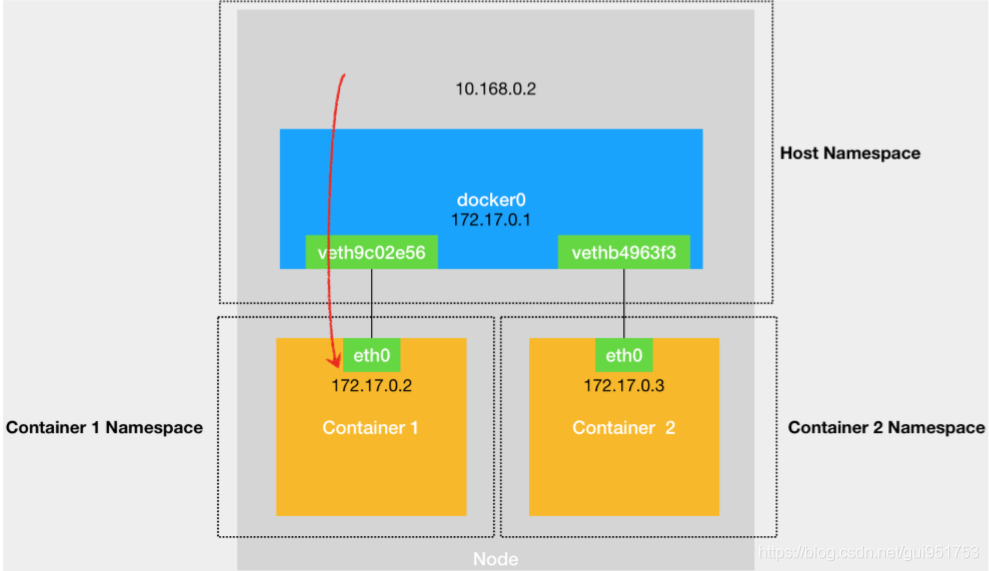
1.宿主机查看自己的路由信息,匹配到合适的路由,在本例中,匹配到了直连路由,无需gateway转发便可以直接将数据包送达。
[root@node2 ~]# ip route
...
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
... |
2.发起arp请求,查询目标IP地址为172.17.0.2的容器的mac地址。arp查询后(要么从arp cache中找到,要么在docker0这个二层交换机中泛洪查询)获得172.17.0.2的mac地址。
[root@node2 ~]# ip neigh show dev docker0
172.17.0.2 lladdr 02:42:ac:11:00:02 STALE
172.17.0.3 lladdr 02:42:ac:11:00:03 STALE |
3.得到对应mac地址后,将数据包转发给该mac地址对应的网卡即可。
容器与宿主机外部通信
当一个容器试图连接到另外一个宿主机时,比如:ping 10.168.0.3,它发出的请求数据包,首先经过 docker0 网桥出现在宿主机上。然后根据宿主机的路由表里的直连路由规则 (10.168.0.0/24 via eth0)),对 10.168.0.3 的访问请求就会交给宿主机的 eth0 处理。所以接下来,这个数据包就会经宿主机的 eth0 网卡转发到宿主机网络上,最终到达 10.168.0.3 对应的宿主机上。当然,这个过程的实现要求这两台宿主机本身是连通的。这个过程的示意图如下所示。
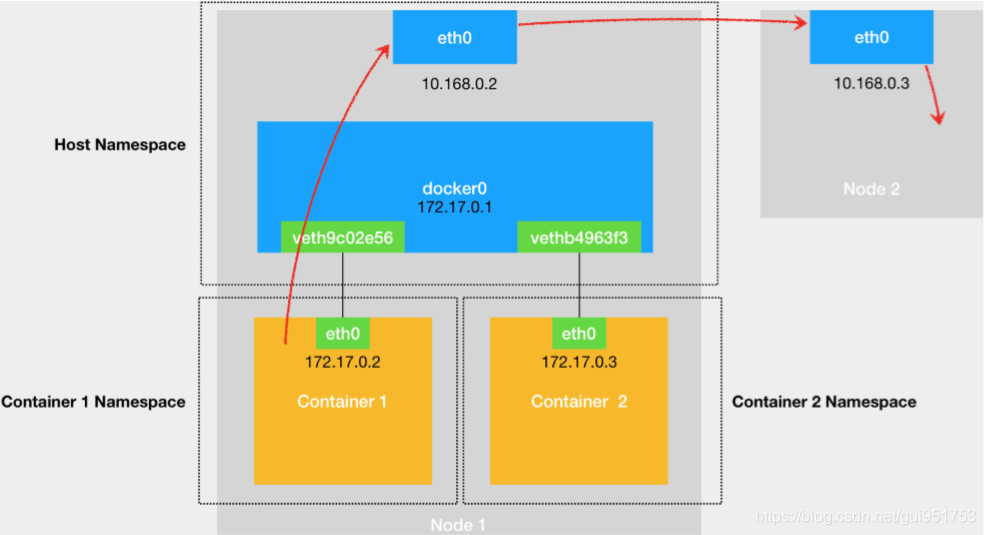
1.首先,根据上一个例子,可以知道,容器到宿主机之间的通信是通的,即数据包能够发送到docker0网卡上,进入到宿主机内核空间。那么问题的关键就在于,怎么把这个数据包发送到宿主机外部。
2.已知172.17.0.0/16网段,是docker专门用来给容器通信使用的私有网段。想要让数据包突破宿主机的关键就在于使用nat技术,将源ip地址为容器ip,目的是要与容器外部通信的的数据包,修改为MASQURADE模式,即修改为宿主机网卡的ip地址。查看iptables规则,发现如下一条规则。
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
#将数据包源地址属于docker网段的,并且出口网卡不是docker0的(即),都做nat技术伪装为其出口网卡地址。 |
3.被nat技术修改过的报文将会被发送到主机外部与主机进行通信。
[root@node2 ~]# docker exec -it busybox3 sh
/ # ping www.baidu.com
PING www.baidu.com (220.181.112.244): 56 data bytes
64 bytes from 220.181.112.244: seq=0 ttl=50 time=36.401 ms
64 bytes from 220.181.112.244: seq=1 ttl=50 time=38.166 ms |
docker0的多重身份
理解docker单机模式下的通信原理,其核心在于理解docker0网桥在整个容器通信过程中承担的作用。
下图中我们给出了Docker0的双重身份,并对比物理交换机,我们来理解一下Docker0这个软网桥。
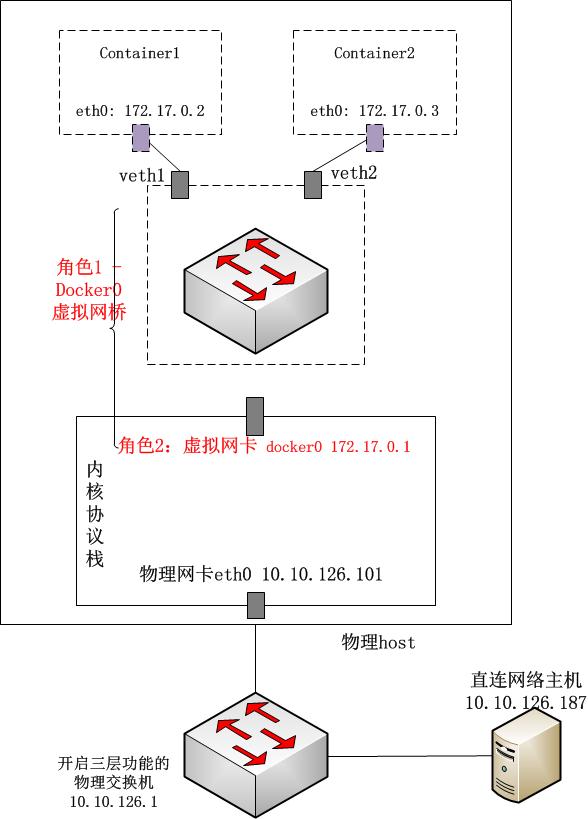
图2 docker0的多重身份
1、从容器视角,网桥(交换机)身份
docker0对于通过veth pair“插在”网桥上的container1和container2来说,首先就是一个二层的交换机的角色:泛洪、维护cam表,在二层转发数据包;同时由于docker0自身也具有mac地址(这个与纯二层交换机不同),并且绑定了ip(这里是172.17.0.1),因此在 container中还作为container default路由的默认Gateway而存在。
2、从宿主机视角,网卡身份
物理交换机提供了由硬件实现的高效的背板通道,供连接在交换机上的主机高效实现二层通信;对于开启了三层协议的物理交换机而言,其ip路由的处理 也是由物理交换机管理程序提供的。对于docker0而言,其负责处理二层交换机逻辑以及三层的处理程序其实就是宿主机上的Linux内核 tcp/ip协议栈程序。而从宿主机来看,所有docker0从veth(只是个二层的存在,没有绑定ipv4地址)接收到的数据包都会被宿主机 看成从docker0这块网卡(第二个身份,绑定172.17.0.1)接收进来的数据包,尤其是在进入三层时,宿主机上的iptables就会 对docker0进来的数据包按照rules进行相应处理(通过一些内核网络设置也可以忽略docker0 brigde数据的处理)。
在Docker容器网络通信流程分析中,docker0在这两种身份间来回切换。
实验:使用namespace模拟容器通信
为了进一步了解network namespace、bridge和veth在docker容器网络中的角色和作用,我们来做一个demo:用network namespace模拟Docker容器网络。
实验环境:
centos7
拓扑
已知,docker引擎中的容器网络如图1所示,因此,我们可以用network namespace来模拟出同样的效果,实验拓扑如图3所示。
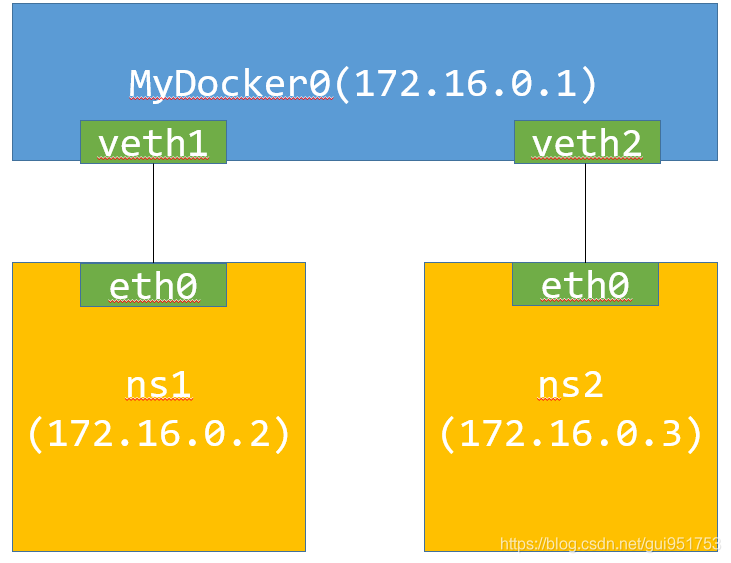
图3 实验模拟拓扑结构
实验步骤:
1.创建两个独立的ns
[root@node2 ~]# ip netns add ns1
[root@node2 ~]# ip netns add ns2
#查看创建的ns
[root@node2 ~]# ip netns list
ns2
ns1
#通过ip netns exec命令可以在特定ns的内部执行相关程序(虚拟网络空间除了网络是虚的以外,文件系统完全和当前系统共享,也就是说所有本地可以使用的命令都可以在虚拟网络中使用),这个exec命令是至关重要的,后续还会发挥更大作用
[root@node2 ~]# ip netns exec ns1 ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@node2 ~]# ip netns exec ns1 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
[root@node2 ~]# ip netns exec ns2 ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
#可以看到,新建的ns的网络设备只有一个loopback口,并且路由表为空。
|
2.创建网桥MyDocker0
[root@node2 ~]# brctl addbr MyDocker0
[root@node2 ~]# brctl show
bridge name bridge id STP enabled interfaces
MyDocker0 8000.000000000000 no
...
[root@node2 ~]# ip addr add 172.16.0.1/16 dev MyDocker0
#为MyDocker0网桥分配ip地址。
[root@node2 ~]# ip link set MyDocker0 up
#启用网桥设备
[root@node2 ~]# ip route show
...
172.16.0.0/16 dev MyDocker0 proto kernel scope link src 172.16.0.1
...
#查看相应的路由信息
|
3.创建并连接Veth Pair设备
到目前为止,default ns与ns1、ns2之间还没有任何联系,接下来,将使用veth pair将二者联系起来。接下来创建ns1和default之间的veth pair,veth1和veth1p,并将二者分别连接到MyDocker0网桥上和ns1中。
#创建连接default ns与ns1之间的veth pair。 veth1和veth1p
[root@node2 ~]# ip link add veth1 type veth peer name veth1p
[root@node2 ~]# ip link show
...
20: veth1p@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fa:06:c6:d6:53:bb brd ff:ff:ff:ff:ff:ff
21: veth1@veth1p: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 56:76:1d:19:69:77 brd ff:ff:ff:ff:ff:ff
...
#将网卡插到MyDocker0网桥上,并开启此网卡
[root@node2 ~]# brctl addif MyDocker0 veth1
[root@node2 ~]# ip link set veth1 up
[root@node2 ~]# brctl show
bridge name bridge id STP enabled interfaces
MyDocker0 8000.56761d196977 no veth1
...
#将veth1p放入ns1中:
[root@node2 ~]# ip link set veth1p netns ns1
[root@node2 ~]# ip netns exec ns1 ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
20: veth1p@if21: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether fa:06:c6:d6:53:bb brd ff:ff:ff:ff:ff:ff link-netnsid 0
#这时,你在default ns中将看不到veth1p这个虚拟网络设备了。按照图3中的拓扑,位于ns1中的veth1p应该更名为eth0
#修改网卡名字
[root@node2 ~]# ip netns exec ns1 ip link set veth1p name eth0
[root@node2 ~]# ip netns exec ns1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
20: eth0@if21: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether fa:06:c6:d6:53:bb brd ff:ff:ff:ff:ff:ff link-netnsid 0
#将ns1中的eth0生效并配置IP地址:
[root@node2 ~]# ip netns exec ns1 ip link set eth0 up
[root@node2 ~]# ip netns exec ns1 ip addr add 172.16.0.2/16 dev eth0
[root@node2 ~]# ip netns exec ns1 ip route add default via 172.16.0.1
#添加默认路由,使得ns与主机上的其他ns能够连通。 |
对ns2进行相同的步骤
ip link add veth2 type veth peer name veth2p
#新建veth pair设备
brctl addif MyDocker0 veth2
#将veth pair一端插入网桥
ip link set veth2 up
#开启网卡
ip link set veth2p netns ns2
#将vethpair一端放到指定ns中
ip netns exec ns2 ip link set veth2p name eth0
ip netns exec ns2 ip link set eth0 up
#修改ns2中的网卡名字,并重启。
ip netns exec ns2 ip addr add 172.16.0.3/16 dev eth0
#给ns2中的网卡添加地址
ip netns exec ns2 ip route add default via 172.16.0.1
#添加默认路由,使得ns与主机上的其他ns能够连通。 |
测试连通性:
- ns1和MyDocker0是否互通,
- ns1与ns2是否互通,
- ns1与宿主机的其他网卡(比如docker中的docker0网桥是否相通)
- ns1与宿主机外的其他主机是否互通
[root@node2 ~]# ip netns exec ns1 ping -c 3 172.16.0.1
PING 172.16.0.1 (172.16.0.1) 56(84) bytes of data.
64 bytes from 172.16.0.1: icmp_seq=1 ttl=64 time=0.236 ms
64 bytes from 172.16.0.1: icmp_seq=2 ttl=64 time=0.152 ms
64 bytes from 172.16.0.1: icmp_seq=3 ttl=64 time=0.238 ms
--- 172.16.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, t
#ns1和MyDocker0连通
[root@node2 ~]# ip netns exec ns1 ping -c 3 172.17.0.1
PING 172.17.0.1 (172.17.0.1) 56(84) bytes of data.
64 bytes from 172.17.0.1: icmp_seq=1 ttl=64 time=0.104 ms
64 bytes from 172.17.0.1: icmp_seq=2 ttl=64 time=0.117 ms
#ns1与docker0连通
[root@node2 ~]# ip netns exec ns1 ping -c 3 172.16.0.3
PING 172.16.0.3 (172.16.0.3) 56(84) bytes of data.
64 bytes from 172.16.0.3: icmp_seq=1 ttl=64 time=0.153 ms
64 bytes from 172.16.0.3: icmp_seq=2 ttl=64 time=0.146 ms
#ns1与ns2连通
#实现自制的ns与外网进行通信。
[root@node2 ~]# iptables -t nat -A POSTROUTING -s 172.16.0.0/16 ! -o mydocker0 -j MASQUERADE
#增加一条
[root@node2 ~]# ip netns exec ns1 ping www.baidu.com
PING www.wshifen.com (103.235.46.39) 56(84) bytes of data.
64 bytes from 103.235.46.39 (103.235.46.39): icmp_seq=1 ttl=42 time=247 ms
64 bytes from 103.235.46.39 (103.235.46.39): icmp_seq=2 ttl=42 time=235 ms
|
自制ns与docker容器之间的通信流程
如果是在ns1中ping某个docker container的地址,比如172.17.0.2,那么其流程如下所示。
1.当ping执行后,根据ns1下的路由表,没有匹配到直连网络,只能通过default路由将数据包转发给Gateway: 172.16.0.1。
2.MyDocker0接收到数据,数据进入到宿主机的内核空间。虽然都是MyDocker0接收数据,但这次更类似于“数据被直接发到 Bridge 上,而不是Bridge从一个端口接收。二层的目的mac地址填写的是gateway 172.16.0.1自己的mac地址(Bridge的mac地址),此时的MyDocker0更像是一块普通网卡的角色,工作在三层(而不是之前的二层网桥的角色)。
3.MyDocker0收到数据包后,发现并非是发给自己的ip包,通过主机路由表找到直连路由(凡是匹配到这条规则的 IP 包,通过二层网络直接发往目的主机),通过arp查询,查询到IP地址为172.17.0.2的mac地址。然后通过二层网络将数据包转发到docker container中。
[root@node2 ~]# ip neigh show dev docker0
172.17.0.2 lladdr 02:42:ac:11:00:02 STALE |
MyDocker0将数据包Forward到通过traceroute可以印证这一过程:
[root@node2 ~]# ip netns exec ns1 traceroute -n 172.17.0.2
traceroute to 172.17.0.2 (172.17.0.2), 30 hops max, 60 byte packets
1 172.16.0.1 0.100 ms 0.052 ms 0.050 ms
2 172.17.0.2 0.138 ms 0.117 ms 0.119 ms |
|









