| 编辑推荐: |
本文探索 K8S 原理,用 K8S 原生的方式来解决这个集群资源利用率
的问题
,希望对您的学习有所帮助。
本文来自于百度云原生
,由Alice编辑、推荐。 |
|
随着Kubernetes(以下简称『K8S』)被业界越来越广泛地使用,单个集群规模也逐渐增大,很多人都会发现自己维护的 K8S 集群普遍存在一个问题:分配率较高,而利用率偏低。
比如,一个有1000+节点的集群,在分配率达到80%后,常常会因为集群碎片的原因,很多大规格的 Pod 就无法再被创建出来。而与此同时,整个集群的日均 CPU 利用率却不足15%,常态使用率偏低。那么,如何才能把剩余的闲置资源尽可能利用到极致呢?
1. 原生 K8S 能否解决资源利用率问题?
首先,我们来看下图这个示例。图中黄色框代表2个 Node,这两个 Node 的 CPU 总数都是40核,并且都已经分配了38核。其中 NodeA 的真实用量是35核,NodeB 的真实用量是10核。而蓝色框则代表现在我们还有3个待调度的 Pod。
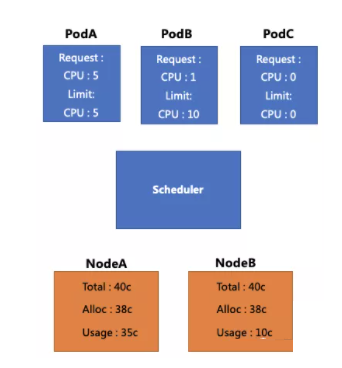
若想调度3个 Pod:
- PodA 的 Request 和 Limit 都是5c,此时它无法被调度,即使Node B上还有空闲资源;
- PodB 的 Request 为1c,Limit 为10c,该 Pod 超发比较严重,它可以被调度到 NodeA 或 NodeB,但是调度到 NodeA 时可能被驱逐;
- PodC 的 Request 和 Limit 都没有填写,此时它可以被调度,但是当调度到 NodeA 时可能被驱逐
基于以上场景,可以尝试总结一下为什么原生 K8S 没办法直接解决资源利用率的问题:
第一,资源使用是动态的,而配额是静态限制。在线业务会根据其使用的峰值去预估Quota(Request和Limit),配额申请之后就不能再修改,但资源用量却是动态的,白天和晚上的用量可能都不一样。
第二,原生调度器并不感知真实资源的使用情况。所以对于 PodB,PodC 这种想要超发的业务来说,无法做到合理的配置。
基于这些原因,团队进行了下一阶段的方案设计:引入动态资源视图
2. 引入动态资源视图
通过添加一个 Agent 去收集单机的资源用量情况,并且汇总计算得到动态的资源视图(机器真实的用量情况),将其上报到调度器,在调度器中配置相关策略,可以将上文中提到的 PodB 和 PodC 准确的调度到 NodeB 上。
也就是说通过构建资源视图,可以将 Limit 大于 Request 的 Pod 或者没填 Request 和Limit 的 Pod,调用到真实用量更少的 Node。这个方法可以解决由于不知道机器到底用了多少资源,所以调度失败被驱逐的问题,最终达到提升 CPU 利用率的效果。
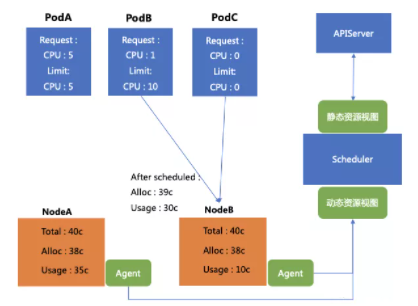
但是这样做需要付出什么代价?如果要将 PodB 和 PodC 调度到 NodeB 上,NodeB 的配额只多分配了1核,但是用量却上升了20核,这就造成了超量使用。(申请量非常少,但是用量非常多)
对于 Node B,多用的20核其实是已经分配出去的 Pod 没有用到,暂时让出的。
为了方便理解举个例子:因为工作需要,我申请了三台电脑,平时大部分情况只用一台,剩下的两台可以借给其他同事暂时用一用;但是我申请3台也是有原因的,有时候是真的要用到的,那当有用到的时候,同事就必须要还给我,所以这就涉及到一个『如何借』和『如何还』的问题。
2.1 借用的代价:不稳定的生命周期
在上述的调度情况下,如果 PodC 用量持续增长,整体的负载可能超过了对单机设备的驱逐上限,会触发单机 kubelet 的驱逐行为。
对应到上述的例子中,如果我共有三台电脑,平时只用一台,外借了两台。现在由于工作需要我要多用一台(整体用量上涨),在这种情况下我并不需要一次性把两台电脑都收回(驱逐 Pod),而是仅收回我需要的那一台即可。
比如在 CPU 层面,可以尝试先降低 PodC 的 CPU Quota;在内存层面,可以先尝试进行内存回收。换句话说,可以优先考虑降低资源使用情况,而不是直接驱逐掉 Pod。
因此有两个核心问题要解决:第一,动态资源视图要如何做;第二个单机资源的调配如何保证供给。
2.2 单机引擎:隔离与退避
名词解释:Guaranteed-Pod、Burstable、BestEffort
K8S中的QoS是根据request 和limit动态算而来:
- request等于limit,会被放到Guaranteed-Pod之中
- request不等于limit,会被放在这个Burstable(突发型)目录下
- request和limit都没有填,会被放在BestEffort目录下
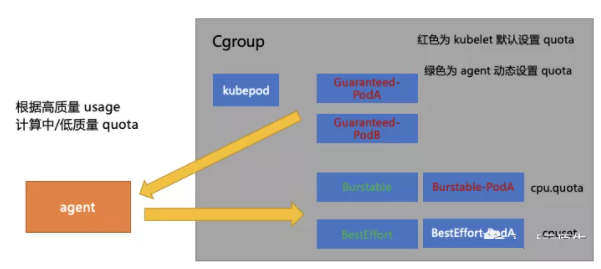
上图灰色框的部分是 kubelet 为每个 Pod 设置 Cgroup 的目录结构:首先有一个一级目录叫 kubepod,所有 Pod 的 Cgroup 都会被挂到它下面,图中有两个红色字体的 Guaranteed-Pod 是直接被挂载到 kubepod 目录下。
图中红色字体部分(Guaranteed-Pod, Burstable-Pod)的目录由 kubelet 给它们设置 Quota。以CPU为例,比如 Limit 填 5,Quota 就会设置为 5。白色字体部分是没有 Quota 限制的( kubepod 和 BestEffort-Pod),可以看到的是 Burstable,BestEffort 这两种 Pod 没有直接挂在 kubepod 目录下,而是自己有一个原本是空白的没有值的二级目录。
在树形结构下 Cgroup 有如下特点:单个目录下进程使用的资源限制并不仅仅受自己所在节点的限制,还要受父节点的限制。比如在 Burstable 的框下边有两个Pod(图无关),在 Burstable 那个框设置了一个 Quota 是 10c,那这两个 Burstable-Pod 的 CPU 用量总和不能超过 10c。
基于这个原理团队设计了对应的压制策略,单机引擎会根据 Guaranteed-Pod 的真实用量去给 Burstable 目录整体设置了一个值,这个值通过动态计算而来。简单来说,会先计算一下 Guaranteed-Pod 现在用多少,还剩多少资源可以给到 Burstable。BestEffort也是类似的,会先计算 Guaranteed 和 Burstable 现在的 Pod 的用量是多少,然后给框整体设定一个值。
如果单机的用量起来了,即申请的 Pod 现在要把自己借出去的这部分资源拿回来了,如何处理?此时会通过动态计算缩小 Burstable 和 BestEffort 的这两个框的值,达到一个压制的效果。
考虑整机 Quota 超发的情况下,如果整机 Quota 都分完了, 整机 Pod 资源用量又在持续上涨,这种情况要如何处理?
当资源用量持续上涨时,如果 BestEffort 框整体 CPU 用量小于 1c ,单机引擎会把 BestEffort Pod 全部驱逐掉。K8S 本身在单机发生资源紧张的时候,也是会按照这种顺序去驱逐相应的Pod。当Guaranteed-Pod的用量还在持续上涨的时候,就会持续的压低 Burstable 整框 CPU 的Quota,从而达到压制的效果。
Burstable 类型的 Pod 的特征是 Request 不等于 Limit , 该类型的 Pod 申请了相应资源的 Quota, 在这个前提下,Burstable 框内的Pod,最低会压到本来申请的资源量。比如 Burstable 框下只有一个Pod,Request是1c,Limit是10c,那么单机引擎最低会将 Burstable 整框压制到 1c。
换言之, 对于 Request,就是说那些用户真实申请了 Quota 的资源,一定会得到得到供给;对于 Limit - Request 这部分资源,单机引擎和调度器会让它尽量能够得到供给;对于 BestEffort,也就是 No Limit 这部分资源,只要单机的波动存在,就存在被优先驱逐的风险.
但是对于一些长尾延迟来说,仅仅通过上述 K8S 的手段,保证不了服务质量。发生争抢时,系统 load 就会比较高。所以团队引入了内部的一些内核功能,并且对它进行一些扩展和支持,基本包括以下几类:

2.3 单机引擎:构建资源视图
单机 Agent 需要收集两部分资源:Pod 的资源使用情况以及整机的资源使用情况(包括机器内核指标),实时计算实时发生行为同时实时计算上报一份已经算好的数据,可以减轻调度器的计算压力。
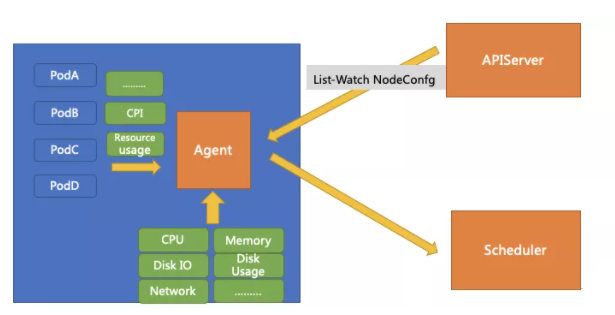
- 中等质量容器可用量 = 单机最大 CPU 用量 - 高质量容器用量 - Safety-Margin
- 低等质量容器可用量 = 单机最大 CPU 用量 - 高质量容器用量 - 中等质量容器用量 - Safety-Margin
这里的 Safety-Margin 是安全水位线,作为预留buffer能够避免用量突然的上涨导致整机突然被打满。
这样就构造出了一个单机的资源视图,将其上报到调度器,调度器将此视图来作为调度依据进行优选和预选的策略。
同时单机上还有一些可定制化的策略。通过给这些策略设计了一个这个 CRD ,单机引擎通过对 APIServer 发起 List-watch,实时的 Watch CR 的变更,实时调整参数和相关策略。
2.4 超发的结果:质量分级
以上,团队完成了在 K8S 上混部探索的第一阶段,这个方案基于 K8S 没有做侵入式改动。
但是在对接用户时经常要面对两个问题: 一是用户不知道 Request 和 Limit 要怎么填?
需要先对相关概念做科普:
- Request 部分,代表是稳定的,安全的,只要申请了就一定可以用到的资源.。
- Limit 减去 Request 部分,比如说申请的 Request 是5,Limit 是10,中间的 5核 的差距是相对来说不稳定,但大概率能够得到供给的资源。如果说有需要的时候,系统会尝试把该 Pod 超用的资源压缩回去。
- No Limit,就是既不写 Request 也不写 Limit 的部分会尽量保证,但是资源供给 sla 会是一个比较低的数字,用这部分资源就要有随时被杀掉的准备。
第二个问题是如果可能,用户是否都倾向于用第一种 Request 级别的资源?
答案是否定的。事实证明,如果能把成本降下,一些鲁棒性高的业务是愿意接受低质量资源的。
比如一些不敏感的离线业务,如果被 kill,代价就是过一会再跑或者重新算一遍,它是乐于接受这种这个低质量资源的,前提条件是系统要给一个很低的成本。
因此团队构造了下图的成本模型,对于不同质量的资源,有不同的定价。作为平台方给用户结算计费的时候,会根据实际的用量和质量的乘积进行结算。
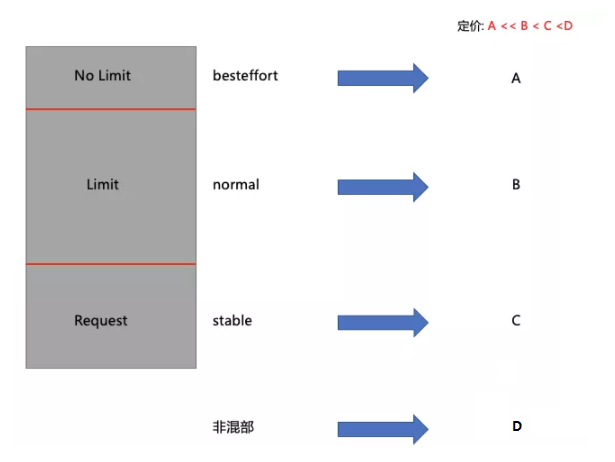
比如 K8S 集群中托管的机器没开混部,定价可能是D(假设D为1);在开了混部的集群当中,用户去用这些 Request,价格可能就是0.85;在开了混部的很多集群当中,用户用 Limit 部分的话,价格可能就是0.5;如果用 Besteffort 部分,那可能它的价格是0.1。
通过这种方式,找到了第一批的这个种子用户。不管是在线业务、离线业务、测试业务,还有一些内部 DevOps 业务,都非常愿意根据这个成本模型再重新审视自己的业务模型, 选择对应的资源等级来运行自己的业务。
3.落地之后遇到了哪些问题
热点问题 : 保证了用量, 如何保证质量?
热点问题并不仅仅是混部带来的,在线跟在线业务部署在同一台机器上也有这个问题。比如资源的争抢、内核关键路径的争抢都可能导致延迟的上升。在百度内部如果搜索的一个接口,由于混部质量导致延迟超过一百毫秒的话,影响面就会非常大,因为业务的链路通常都比较长,延迟累计最终给用户响应的时间可能达到秒级,这种情况是不可接受的。
除了内核提供的隔离技术外,如何给出热点问题的兜底方案?
答案是热点迁移,出现热点,系统自动迁移容器。具体而言,单机引擎会通过收集应用的一些指标来判断这个应用是否发生热点。如果发生热点的话,就会给一个机器上打一个 Annotation,然后当调度器 Watch 到这个 Annotation 时,它就会认为台机器上发生了热点,就要迁移热点容器。
Pending Pod : 低质量需求激增带来的调度性能需求
以某用户跑数的场景为例,假设他预计需要1000核资源,要在明天早上9点完成,因此他就申请了1000核高质量的资源,同时他又申请了1万核 Besteffort 的资源一块跑,通过了1万核的低质量的资源加速,可能不用明早9点,半夜1点就跑完了,剩下的这部分成本就了省下来。
但是用户这种使用方法会给调度器的性能带来很大影响,在集群负载较高时,用户创建的 BestEffort Pod 由于资源不足导致全部 Pending,而这些 Pending Pod 会反复的出现在调度队列中,针对这种场景,我们尝试对离线调度器进行功能和性能上的优化 :
- 副本数托管 : 基于集群负载对应用进行动态扩缩容。社区叫 HCPA,用户通过创建一个 CR 来描述任务的最低的副本数是多少,最高的副本数是多少,当集群负载发生变化的时候,Controller 可以动态的扩缩用户的任务副本数,而不再是静态的创建出海量的 Pending Pod, 阻塞在队列中。
- 多调度器 : 基于质量的多调度器。对 Besteffort 的容器来说, 在调度时调度器并不关心静态资源视图,也就是 Node Allocatable Resource。调度器只关心这台机器上现在还剩多少可用资源,所以在资源视图的角度,天然就和其他两种质量的 Pod 不冲突. 基于这个前提,我们将 Guaranteed 和 Burstable 两种类型的 Pod 归并到一个调度器内进行调度, 而 BestEffort 类型的 Pod 则在另外一个离线调度器内调度。
- 等价类合并 : 在一个调度周期内, 使用相同 Pod Template 生成的 Pod, 在进行调度计算时一定会得到相同的 Node 列表。基于这个前提, 在调度上我们构造了等价类的概念,在调度时单位从 Pod 变成了 PodEquivalenceGroup. 在优选结束后, 会按照 Node 分数的顺序来依次调度 PodEquivalenceGroup 中的所有 Pod。这样处理相当于将 O(n) 的调度计算降为了 O(1)。
- 乐观并发调度 : 目前开源的 Kubernetes 调度器, 无论是默认调度器还是社区的 kube-batch, volcano 都是依次进行调度的,队头阻塞的现象较为严重。在优先级相同的情况下, 最后一个 Pod 的调度延迟约等于队列内所有 Pod 的调度延迟之和。并发的关键在于如何解决冲突 : 在调度器内存中为每一个 Node 维护了一个版本号, 当 Pod 与 Node 进行 Bind 操作时, 会尝试对 Node 版本号进行 +1 的 CAS 操作, 如果失败,则说明该 Node 已经发生过 Bind 操作, 此时会将该 Node 重算并重新尝试调度。基于 CAS + Version 的机制, 我们实现了同优先级情况下, Pod 并发调度的方案。该方案可以带来 4 ~ 8 倍的调度性能提升。
4.总结
- K8S 原本的资源模型存在局限性。 我们可以基于原生的 QOS 体系做一些不修改原本语义的扩展行为,并且基于质量建立相应的定价体系,通过给出不同质量的资源供给 SLA,来对资源进行差异化定价,从而引导用户更加合理地使用资源。目前我们在做的进一步探索是,如何根据业务特征,来划分出更适合业务的,更细粒度的资源模型。
- 建立云原生可观测体系,根据质量去做单机资源的隔离/压制以及驱逐行为。 因为在常见混部的情况下热点问题经常发生,由于热点对延迟敏感型业务会造成较大的影响,所以热点问题事实上限制了整机最大的资源利用率。而热点问题根因通常在内核层面,内核的可观测性又比较差,因此目前百度云原生团队在探索基于 ebpf 来建立更细粒度的热点探测/分析体系。
- 大规模混部落地后,需要对热点问题、调度性能等问题给出解决方案。 后续持续迭代相应的调度功能,在调度性能和支撑大数据业务容器化上做出更进一步的探索。
|









