| 编辑推荐: |
本文主要分享了
VContainer 云原生相关基础组件的自动化实践,从半工具化人工维护,到白屏化流程的实践和落地。
本文来自 InfoQ,由Alice编辑、推荐。 |
|
背 景
2018 年底,vivo AI 研究院为了解决统一高性能训练环境、大规模分布式训练、计算资源的高效利用调度等痛点,着手建设
AI 计算平台。经过两年的持续迭代,平台建设和落地取得了很大进展,成为 vivo AI 领域的核心基础平台。平台从当初服务深度学习训练为主,到现在演进成包VTraining、VServing、VContainer
三大模块,对外提供模型训练、模型推理和容器化能力。VContainer 是计算平台的底座,基于 Kubernetes
构建的容器平台,具备资源调度、弹性伸缩、零一混部等核心能力。
VContainer 的容器集群有上千个节点,拥有超过 100PFLOPS 的 GPU 算力。集群里同时运行着上千个
VTraining 的训练任务和上百个 VServing 的推理服务以及上百个在线服务项目。本文主要分享了
VContainer 云原生相关基础组件的自动化实践,从半工具化人工维护,到白屏化流程的实践和落地。
早期的风险与踩坑
我们在 2018 年底开始使用 rke 来建设 k8s 集群,也算是 rke 项目早期的用户。根据实践经验,我们将
k8s 集群建设和维护划分为:机器管理、集群管理、容器网络管理 3 大步骤。在实施过程中,我们面对着一些风险,也踩过了一些坑。早期集群建设阶段,风险难以避免,会出现在变更的各个环节当中。但我们不应该害怕风险,也不能因为风险的存在而不做变更,我们应该保持平常心,敬畏风险,把稳定性放在首要位置。
·风险一,多集群场景:机器数据缺乏统一管控能力,集群 A 节点出现被添加到集群 B 的情况。
·风险二,集群节点被初始化:集群维护有标准流程,但是流程中不同操作,使用不同的工具完成,初始化过程出现集群节点遗漏在初始化列表的情况。
·风险三,变更配置错误:在集群建设和维护三个步骤中,配置项重复繁杂,变更工具缺乏校验功能,出现配置错误情况,导致底层组件故障,影响业务系统。
机器管理
机器管理有两个部分:数据信息管理和机器变更。风险和踩坑出现在机器变更过程,早期我们选择 ansible
批量操作工具,有 3 个变更操作频率很高:机器初始化、机器清理和其他非固定批量操作。初始化是机器添加到
k8s 集群前,安装 docker、gpu 软件、配置环境等等;同理,机器清理是卸载和清空 docker
软件和相关环境。ansible-play 模块允许我们定义 tasks 任务,管理相同类型操作的脚本。我们创建了初始化和清理脚本的
tasks 任务,一系列操作的脚本添加到对应的 tasks 任务下面,使用时运行相同命令完成变更。需要特别注意是:执行
tasks 任务需要配置机器列表,如下:
192.168.219.10 ansible_ssh_pass="123456"
192.168.219.11 ansible_ssh_pass="123456"
192.168.219.12 ansible_ssh_pass="123456"
192.168.219.13 ansible_ssh_pass="123456"
[rke-prepare]
192.168.219.10
192.168.219.11
192.168.219.12
192.168.219.13 |
这里存在操作风险,步骤重复繁多或者多人操作情况,机器列表有可能出现重复、错漏的情况,我们踩过这样的坑:
踩坑 1:ansible 初始化操作,错误把集群中工作节点或者核心节点执行了初始化。因为配置初始化机器列表,多人操作或者遗忘修改机器列表,导致集群节点被初始化。这样的后果非常严重,初始化了一般
worker 节点,影响业务容器;初始化了核心节点影响范围更加大,整个集群可用性都会被影响。本人之前把跑着在线业务的
worker 节点初始化掉,造成业务节点 Not Ready,直接影响了线上业务可用性。后来我们在
ansible 脚本中加上检查 k8s 集群节点的步骤,判断机器如果已经存在 k8s 相关组件即可跳过初始化操作。
集群管理
集群管理核心操作:集群创建、扩缩容、更新、容灾 4 个。前文提到的 rancher 开源的 k8s
集群管理项目 rke 满足我们基本需求。在其 官方介绍 中说到:RKE 是一款经过 CNCF 认证的开源
Kubernetes 发行工具,可以在 Docker 容器内运行。它通过删除大部分主机依赖项,并为部署、升级和回滚提供一个稳定的路径,从而解决了
Kubernetes 最常见的安装复杂性问题。借助 RKE,Kubernetes 可以完全独立于您正在运行的操作系统和平台,轻松实现
Kubernetes 的自动化运维。和其他云原生项目一样,rke 也使用 golang 开发,是一个命令行工具。使用配置文件
cluster.yml 管理 k8s 集群,并且通过 cluster.rkestate 维护 k8s
集群状态。rkestate 文件是 rke 命令行自行管理的 k8s 状态文件,用户不必过多关心。cluster.yml
才是用户管理 k8s 集群的配置文件,rke up 操作按照该 yml 配置文件更变 k8s 集群:节点增删、版本更新等,如下是
cluster.yaml 实例:
nodes:
address: 1.2.3.4
user: ubuntu
role:
controlplane
etcd
worker
services:
etcd:
image: rancher/coreos-etcd:v3.3.10-rancher1
kube-api:
image: rancher/hyperkube:v1.14.3-rancher1
extra_args: {}
... ...
network:
plugin: calico
options:
calico_cloud_provider: none
addons: ""
addons_include: []
... ... |
展示里是简化后的配置,详细的配置介绍可以参考 yaml 文件示例。尽管 rke 提供了单个 yml
配置文件管理 k8s 集群的功能,但是该文件配置繁杂重复,而且我们一开始就使用了较早版本的 rke,也碰到了一些坑:
·踩坑 1:rke 添加工作 (worker) 节点时,节点角色错误配置为核心节点
(controlplane\etcd) 角色,对于 etcd 的情况会导致 api-server 滚动重启,正在请求
api-server 的服务连接会被断开,对于重试服务影响不大。类似 kubectl logs、exec
等操作会被断开,重新执行解决。对于 controlplane 的情况,集群内部的 worker 节点会重启
kubelet 和 kube-proxy。
·踩坑 2:使用较早版本 rke 变更时,每次都会打印证书变更,需要强制更新的日志,是较早版本日志输出的
bug 不必惊慌,较新版本已经修复:https://github.com/rancher/rke/issues/1405
·踩坑 3:同样是较早版本 rke up,使用 update-only 仍然会操作所有 worker
节点,操作过程偶尔会出现某个节点长时间没有响应的情况,导致整个变更流程被堵塞,无法完成。我们增加了一个
ignore-hosts 字段,支持 rke up 跳过执行机器。
·踩坑 4:同样是较早版本 rke up,我们对 etcd 进行灾难恢复演练过程,发现 rke etcd
restore 的操作将整个 k8s 集群所有节点进行清理后再重建,其实我们的目是 etcd 集群挂掉后,可以快速重建
etcd 集群,而不需要变更 woker 和 controlplane 的系统组件和 calico、ingress-controller
等组件,造成业务层面的影响。对此我们进行了改造,rke etcd restore 命令恢复 etcd
集群时,默认只进行:清理 etcd 节点、etcd 重建、rke up 几个基本操作。
容器网络管理
容器网络我们使用的是 calico 插件,扁平化需求是与网络组配置系统交互完成。在日常维护工作中,我们踩过这样的坑:
·踩坑 1:ippool 配置错误,本人在新集群刚搭建时,在创建 ippool
步骤中,把容器网络的字段,填入了主机网段的值。导致的后果是,在物理主机节上创建了奇怪的路由规则,k8s
集群主机网络和容器网络都受到了不同程度影响,后来我们使用 ansible 批量删除异常路由。
·踩坑 2:扁平化节点集群配置错误,把集群 A 的节点配置到集群 B 的 RR 节点上面,当时验证只影响配置错误节点的扁平网络功能,其他节点不受影响。但是,错误配置的恢复过程比较麻烦。
k8s 集群作为基础设施,上面运行大量在线业务和训练任务。在集群变更过程中,小小失误都有可能导致业务层面直接不可用,我们必须想尽办法规避风险,力所能及填平所有坑坑洼洼。借鉴传统运维管理经验,k8s
集群运维管理也需要自动化。很多人看到自动化第一印象是代码程序,其实自动化的精髓是标准。如何将复杂、重复、分散的操作标准化、流程化,是自动化的关键。
自动化设计过程
设计思路
自动化前半阶段目标非常明确:减少人工手动操作,建立标准化流程和提高运维效率;降低操作风险,提高集群稳定性。根据我们目前探索和实践的经验,后半阶段的目标也逐渐清晰:高度自动化、半智能化方向设计,检测和分析定位集群问题,并提供快速恢复的办法。
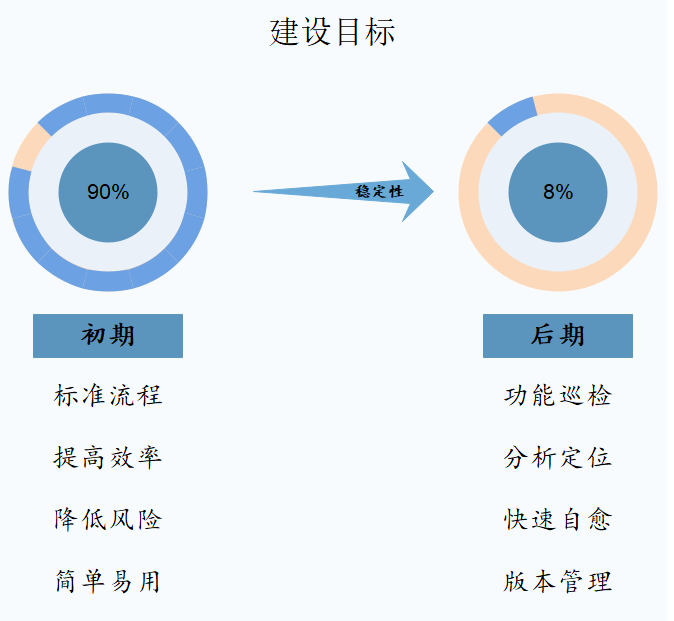
自动化建设目标
结合我们自动化设计的目标,和我们基础组件的使用情况,以下设计要点我们重点关注:
多集群:管理多个 k8s 集群和所有物理机信息,多个集群在工具化阶段信息分散,自动化首要任务是把数据同步到一起,用来帮助我们梳理自动化的流程、校验以及审核这
3 个方面的标准,并且设计 3 个方面要实现的功能。
标准流程:将我们日常重复和复杂的集群变更操作规范化,制定标准的变更流程,并且将其软件化、产品化。
自动校验:梳理集群变更过程需要人工校验的 case,并且设计自动化校验的步骤,把这些校验步骤作为标准变更流程中的必要前置执行条件。
流程可控:既然制定了标准流程,那么整个变更流程就可以全部自动化,一次性完成所有操作。但是,变更总是存在着风险和未知因素,因此流程中每个步骤的执行前后,对应设计人工审核和控制的环节。
最小变更原则:因蛭涓苁谴欧缦眨晕颐窍M涓缴僭胶茫詈檬侵蛔鲂枰谋涓薰亓谋涓×勘苊狻@纾缙诘?
rke up 进行 worker 节点扩缩容的情况,还是会牵连到对核心节点的一些操作。因为 rke
考虑到保证集群整个状态是健康可用的,所以 rke up 会尝试校验并且操作集群中所有节点。站在稳定性角度考虑,我们只想变更
worker 节点,不想牵连到核心节点,或者其他不用变更的节点也不想牵连。后来 rke up 可以指定角色变更:worker、controlplane、etcd,而我们也做了定制化,节点扩缩容只会操作需要变更的节点,其他一切节点保持不动。
前期自动化聚焦于日常 80% 集群运维工作,实现白屏化的建设:机器管理、集群管理、容器网络管理。机器管理包括:从
CMDB 同步机器信息、机器初始化、机器环境清理。集群管理包括:节点信息可视化、增删节点、更新节点、rke
配置和状态配置文件管理。而容器网络管理暂时是 ippool 的增删查改 4 个操作和 k8s 节点
calico 网络扁平化流程。
架构设计
按照设计思路,如下是我们自动化设计的简单架构图,AutoRke 自动化平台是我们建设的目标,底层操作
k8s、calico 和 docker 等云原生基础组件的变更,上层对接 vivo 基础平台完成同步数据和流程控制等功能。
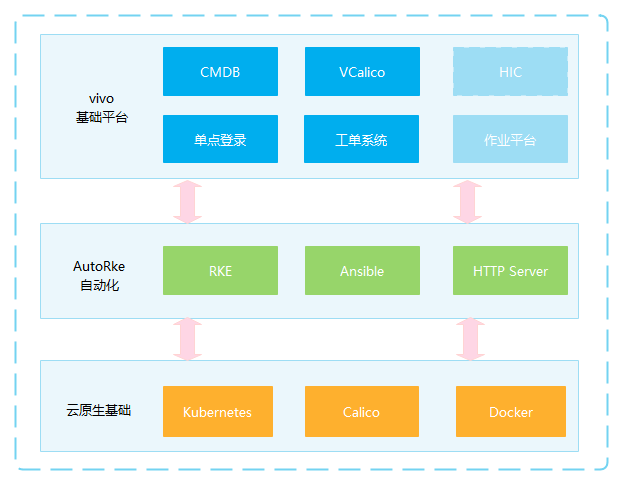
自动化实践简单架构
AutoRke:建设一个提供标准流程的白屏化平台,集成 rke 、ansible 等命令行的功能。
云原生基础:Autorke 自动化平台管理的目标对象:k8s、calico、docker。在物理机上安装配置
docker 环境,使用 docker api 接口部署和管理 k8s 组件。管理 calico 容器网络扁平化配置和容器网络地址池
ippool。
vivo 基础平台:Autorke 建设过程实现自动化流程依赖的关键系统。我们从 CMDB 同步机器信息,使用单点登录来验证用户权限。VCalico
通过工单流程的方式,完成 calico 扁平化配置的自动流程。HIC 是 vivo 机器硬件管理相关的系统,正在接入到
k8s 节点故障处理的流程,帮助我们提高稳定性。作业平台是 vivo 机器批量操作的系统,与 CMDB
信息打通,我们将用来做机器初始化和快速作业的操作。
自动化实践与落地
自动化实践最终产出工具化、系统化产品,我们的目标是白屏化的平台。能够管理多个 k8s 集群和所有的物理机,收拢日常分散的
k8s 集群变更操作,提供标准、可控、可审查的白屏化流程,完成日常 k8s 集群变更,提高变更效率,降低操作风险,提高集群稳定性。
核心技术
k8s 集群建设和维护是自动化的核心工作,前文介绍我们使用 rke 来开展相关工作。rke 使用 docker
的方式部署 k8s 集群,在容器中启动 k8s 组件。区别于我们平时使用 docker 命令管理容器生命周期,rke
使用 docker 服务的 API 接口管理容器。为了远程批量管理大量主机的 docker 服务,rke
构建 ssh 的 tcp 连接对象,在创建操作远程主机 docker 服务的 docker?client
时,使用该 tcp 连接对象为 docker client 创建 http client,并且绑定到
docker.sock。如下图,rke 通过 ssh 连接的方式构建远端 docker client,使用
docker.sock 实现 docker 服务的访问,其中堡垒机环节是 rke 支持安全要求的设计,一切物理机只能通过堡垒机
ssh 登陆。
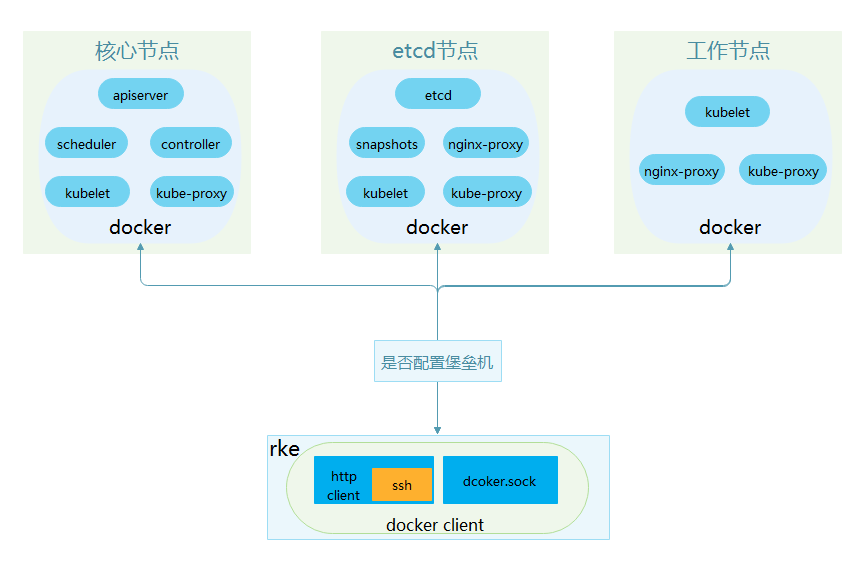
rke 工作流程
证书管理,可以分为 2 个关键点:证书发布和轮换证书。证书发布操作发生在集群初始化、master
集群变更以及 etcd 集群变更,通过容器的方式发布证书。证书轮换是在证书即将过期或者证书泄露后需要重新颁发证书,可以在
cluster.yml 配置,也可以使用 rke cert rotate 完成。
etcd 集群,rke 实现了 3 个重要的 etcd 操作:集群创建、扩缩容、数据备份与恢复。集群创建和扩缩容,在
cluster.yml 中配置 etcd 节点,执行 rke up 变更 etcd 集群。数据备份与恢复是日常
etcd 集群的数据备份,在出现故障时快速恢复数据与 k8s 集群的功能。上图 etcd 节点启动容器:etcd、snapshots,其他
kubelet 相关容器是 worker 角色所需组件,也就是 etcd 可以作为 worker 节点部署其他服务,但是我们不推荐这么做。snapshots
是 etcd 集群数据定期备份的容器。etcd 容器使用静态集群方式部署,启动时配置好 etcd 的集群规模和节点列表。
核心节点,需要部署 3 个核心服务 apiserver、scheduler、controller
的容器,服务参数配置在 cluster.yml 文件,启动过程读取并且设置在容器运行配置。可见,核心节点没有
nginx-proxy 组件,这个组件是用来反向代理连接 apiserver,核心节点内组件连接本机的
apiserver,所以不需要。rke 对 etcd 集群变更时,访问 etcd 集群证书和 IP
列表发生变更,需要按照顺序重启核心节点的 apiserver 服务,重新加载访问 etcd 集群配置。
工作节点,rke 对集群工作节点扩缩过程,管理节点上 3 个 k8s 组件 kubelet、nginx-proxy
和 kube-proxy 容器生命周期:创建、启动、重启、删除、查询。rke 变更核心节点时,会变更访问核心节点的配置,同理,要需要重启工作节点的服务。
插件部署,addons 是可选部署,用户可以通过其他 k8s 部署服务的方式。rke 对 addons
的部署划分了 3 部分:cni、k8sAddons 和 userAddons,部署过程使用 k8s
的 client,不再使用直连 docker api 接口方式部署。addons 基本以:daemonset、deployment
方式部署在 k8s 集群。
集群更新,rke 在 1.0.0 版本开始支持 k8s 集群更新,cluster.yml 配置支持了各个角色节点最大不可用数量、批量更新等参数,但是更新的要求比较苛刻:
1.只支持相邻的次要版本或者补丁版本更新
2.运行在 k8s 集群中的业务需要支持健康检查
3.k8s 集群角色节点、addon 组件、业务系统需要支持高可用
实践过程
我们明确实践计划分两步走:rke 工具定制化和 autorke 白屏化平台。定制化解决最初我们使用
rke 过程,出现的不符合我们预期的场景,同时,深入调研 rke 原理为白屏化提供技术基础。白屏化阶段实现变更云原生组件平台化,制定标准流程,降低变更门槛和风险。
RKE CLI 定制化:在原生 rke 命令基础上,扩展了 calico 和 worker2 个子命令,分别负责
calico 容器网络管理和 k8s worker 节点扩缩容,这两个子命令支撑我们完成了大部分 k8s
集群运维工作。
1.rke calico 支持容器网络扁平化配置:新增、删除和扩容。同时,也支持了 ippool 的增、删、查、改、启用、禁用。
2.rke worker,在 worker 节点扩缩容时,我们只希望做最小的变更,不执行不必要的操作。所以,rke
worker 命令只变更需要扩缩容的节点,其他不需要变更节点保持不动。
Autorke 白屏化:CLI 命令行的方式存在缺陷,只能胜任一次性的操作,不能满足交互的场景,而且变更的流程规范也没有完全统一,我们决定把
CLI 的工作做成白屏化。
目前平台功能围绕 k8s 集群管理开展:机器管理、集群节点管理、网段管理、配置管理。机器管理对物理机信息同步,从
CMDB 拉取全部机器信息,方便日常机器信息查询,同时为集群变更和日后集群稳定性建设提供数据基础。管理
k8s 集群 worker 节点日常变更:扩容、缩容、更新、容器网络配置。网段管理是容器网段的管理,calico
ippool 的增删查改。配置管理实现 rke 使用的集群配置文件和状态文件的版本管理。
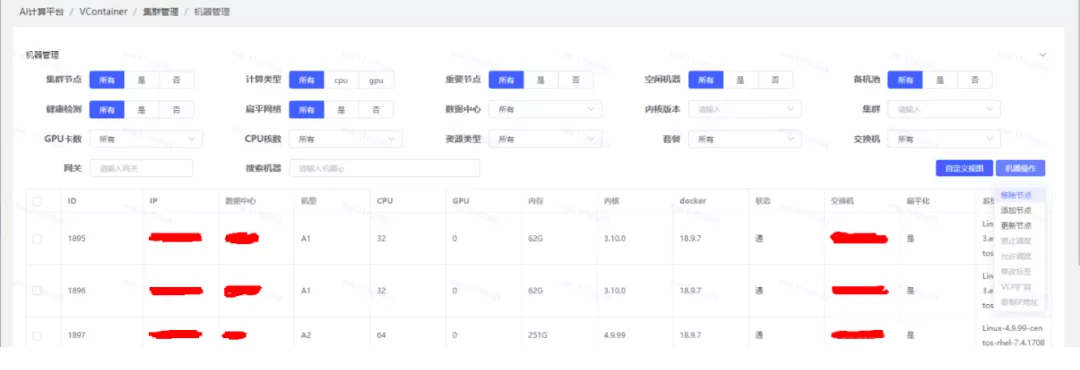
自动化功能简单展示—机器管理
上图是机器管理页面,统一管理机器关于:硬件、软件、k8s、网络各个方面的信息。最右边机器操作下拉框,目前支持
k8s 集群节点的添加、移除和更新 3 个功能。我们简单介绍集群添加节点的步骤,因为步骤较多,使用文字描述具体过程:
1.机器管理页面选中的准备添加到集群的机器,并且创建添加机器的配置,可以选择默认配置、自定义配置的方式。
2.运行添加机器校验,确认机器是否可以添加到 k8s 集群
3.初始化目标机器,安装所需软件、驱动,配置 docker 运行环境
4.添加机器到 k8s 集群,同步机器标签和污点,生成 calico 网络配置
5.创建 calico 扁平网络工单,给 VCalico 系统发起容器网络配置工单
6.创建 ippool 容器网段,调用 calico sdk 配置所需要的网段信息
7.监听 VCalico 回调信息,更新节点容器网络标签
落地情况
应用于 vivo AI 计算平台中 4 个 k8s 集群,上千台物理机。后续接入新建集群,物理机数量将达到数千台。按照实践过程两个迭代阶段:rke
定制化和 autorke 白屏化。定制化是对原生的 rke 命令行工具改造,实现符合我们场景的功能。autorke
白屏化是把前期定制化的功能和变更流程实现白屏化,从去年 12 月上线至今白屏化完成 k8s 集群变更工单
100+。
改进优化
针对使用过程出现的痛点,我们也做一些优化:
失败重试,在同一个节点变更流程中,存在部分节点执行结果返回失败,在变更流程实现重试失败节点,优化用户体验,提高异常情况的处理效率。
流程拆分,在 calico 扁平化配置中,我们需要与 VCalico 交互完成工单和回调,开始我们考虑自动化流程在提交工单后面的流程,不再需要人工干预。其实,VCalico
上报回调报文时,更加需要 k8s 管理员确认创建 ippool 的信息。提交容器网络申请的工单信息也需要人工校验,而不应该是自动生成配置后,立刻发起容器网络配置工单。
后续计划
自动化初期实现了云原生基础组件日常运维管理工作的白屏化功能,提高了工作效率,降低操作风险,一定程度上提高了基础组件的稳定性。在今后自动化建设过程中,我们希望丰富自动化的功能,探索半智能化方向,重点关注云原生基础组件稳定性和可用性方面的自动化建设。
·巡检,自动检测 k8s 集群存在的问题以及风险点
·自愈,告警与故障自动分析定位以及快速恢复
·更新,基础组件版本更新和机器升级流程等 |









