| 编辑推荐: |
文章主要介绍了KVM虚拟化架构、
CPU虚拟化、内存虚拟化、IO设备虚拟化等方面内容。
本文来自于知乎 ,由火龙果软件Anna编辑、推荐。 |
|
服务器虚拟化是云计算最核心的技术,而KVM是当前最主流的开源的服务器虚拟化技术。从Linux2.6.20起,KVM作为内核的一个模块
集成到Linux主要发行版本中。从技术架构(代码量、功能特性、调度管理、性能等)、社区活跃度,以及应用广泛度来看,KVM显现出明显优势,已逐渐替换另一开源虚拟化技术Xen。在公有云领域,2017年之后AWS、阿里云、华为云等厂商都逐渐从Xen转向KVM,而Google、腾讯云、百度云等也使用KVM。在私有云领域,目前VMware
ESXi是领导者,微软Hyper-V不少应用,随着公有云厂商不断推进专有云/私有云方案,未来KVM应用也会逐渐增加。KVM目前已支持x86、PowerPC、S/390、ARM等平台。本文参考《KVM实战:原理、进阶与性能调优》等材料,简要梳理总结KVM在x86平台的关键技术原理。
1. KVM 虚拟化架构
1.1 主流虚拟化架构
图1对比了几种主流虚拟化技术架构:ESXi、Xen与KVM,其主要差别在与各组件(CPU、内存、磁盘与网络IO)的虚拟化与调度管理实现组件有所不同。在ESXi中,所有虚拟化功能都在内核实现。Xen内核仅实现CPU与内存虚拟化,
IO虚拟化与调度管理由Domain0(主机上启动的第一个管理VM)实现。?KVM内核实现CPU与内存虚拟化,QEMU实现IO虚拟化,通过Linux进程调度器实现VM管理。
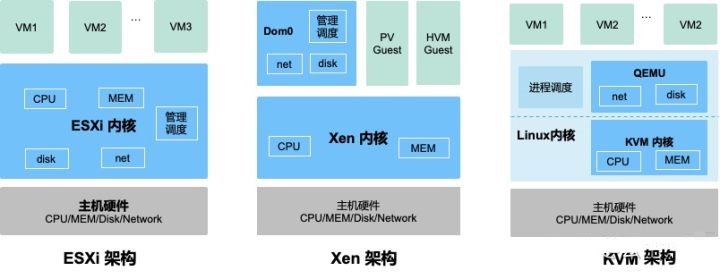
图1:虚拟化架构对比
1.2 KVM虚拟化架构
如图2,KVM虚拟化有两个核心模块:
1)KVM内核模块:主要包括KVM虚拟化核心模块KVM.ko,以及硬件相关的KVM_intel或KVM_AMD模块;负责CPU与内存虚拟化,包括VM创建,内存分配与管理、vCPU执行模式切换等。
2)QEMU设备模拟:实现IO虚拟化与各设备模拟(磁盘、网卡、显卡、声卡等),通过IOCTL系统调用与KVM内核交互。KVM仅支持基于硬件辅助的虚拟化(如Intel-VT与AMD-V),在内核加载时,KVM先初始化内部数据结构,打开CPU控制寄存器CR4里面的虚拟化模式开关,执行VMXON指令将Host
OS设置为root模式,并创建的特殊设备文件/dev/kvm等待来自用户空间的命令,然后由KVM内核与QEMU相互配合实现VM的管理。KVM会复用部分Linux内核的能力,如进程管理调度、设备驱动,内存管理等。
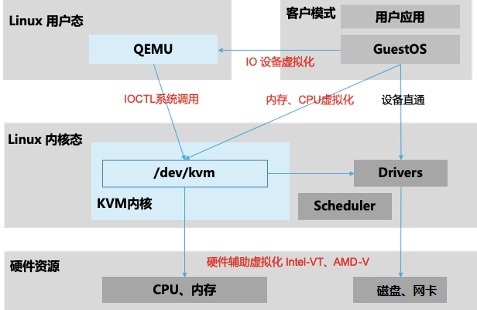
图2:KVM虚拟化架构
2. CPU虚拟化
2.1 pCPU与vCPU
如图3,物理服务器上通常配置2个物理pCPU(Socket),每个CPU有多个核(core);开启超线程Hyper-Threading技术后,每个core有2个线程(Thread);在虚拟化环境中一个Thread对应一个vCPU。在KVM中每一个VM就是一个用户空间的QEMU进程,分配给Guest的vCPU就是该进程派生的一个线程Thread,由Linux内核动态调度到基于时分复用的物理pCPU上运行。KVM支持设置CPU亲和性,将vCPU绑定到特定物理pCPU,如通过libvirt驱动指定从NUMA节点为Guest分配vCPU与内存。KVM支持vCPU超分(over-commit)使得分配给Guest的vCPU数量超过物理CPU线程总量。
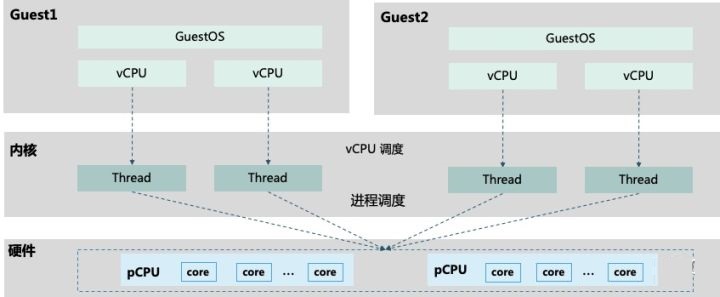
图3:pCPU与vCPU关系
2.2 虚拟化类型对比
Intel对x86 CPU指定了4种特权级别Ring0 - Ring3,其中Ring 0是内核态,运行OS内核,权限最高,可执行特权或敏感指令,对系统资源进行管理与分配等;ring
3权限最低,运行用户应用。如图4,ESXi属于全虚拟化,VMM运行在Ring0完整模拟底层硬件; GuestOS运行在ring1,无需任何修改即可运行,执行特权指令时需要通过VMM进行异常捕获、二进制翻译BT(Binary
Translation)和模拟执行。Xen支持全虚拟化(HVM Guest)与半虚拟化(PV Guest);使用半虚拟化时,GuestOS运行在Ring
0需要进行修改(如安装PV Driver),通过Hypercall调用VMM处理特权指令,无需异常捕获与模拟执行。
KVM是依赖于硬件辅助的全虚拟化(如Inter-VT、AMD-V),目前也通过virtio驱动实现半虚拟化以提升性能。Inter-VT引入新的执行模式:VMM运行在VMX
Root模式, GuestOS运行在VMX Non-root模式,执行特权指令时两种模式可以切换。
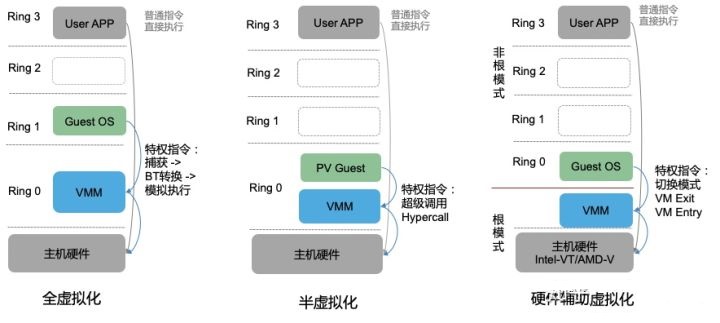
图4:x86 CPU 特权级别与虚拟化分类
2.3 KVM CPU虚拟化
KVM中vCPU在三种模式下执行:
1) 客户模式(Guest Mode)运行GuestOS,执行Guest非IO操作指令。
2) 用户模式(User Mode)运行QEMU,实现IO模拟与管理。
3) 内核模式(Kernel Mode)运行KVM内核,实现模式的切换(VM Exit/VM Entry),执行特权与敏感指令。
如图5,KVM内核加载时执行VMXON指令进入VMX操作模式,VMM进入VMX Root模式,可执行VMXOFF指令退出。GuestOS执行特权或敏感指令时触发VM
Exit,系统挂起GuestOS,通过VMCALL调用VMM切换到Root模式执行,VMExit开销是比较大的。VMM执行完成后,可执行VMLANCH或VMRESUME指令触发VM
Entry切换到Non-root模式,系统自动加载GuestOS运行。
VMX定义了VMCS(Virtual Machine Control Structure)数据结构来记录vCPU相关的寄存器内容与控制信息,发生VMExit或VMEntry时需要查询和更新VMCS。VMM为每个vCPU维护一个VMCS,大小不超过4KB,存储在内存中VMCS区域,通过VMCS指针进行管理。VMCS主要包括3部分信息,control
data主要保存触发模式切换的事件及原因;Guest state 保存Guest运行时状态,在VM
Entry时加载;Host state保存VMM运行时状态,在VM Exit时加载。通过读写VMCS结构对Guest进行控制。
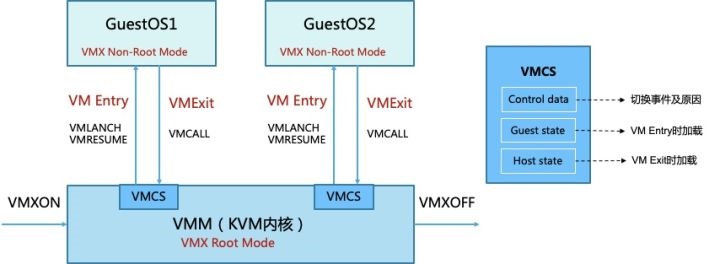
图5:VMX Root/Non-Root 模式切换
3. 内存虚拟化
3.1 EPT与VPID
内存存放CPU将要执行的指令或数据,内存大小与访问效率对系统性能至关重要。内存虚拟化目标是保障内存空间的合理分配、管理,隔离,以及高效可靠地使用。需要将Guest线性虚拟内存地址GVA(Guest
Virtual Address)转换为Host上的物理内存地址HPA(Host Virtual Address
)。没有硬件辅助虚拟化之前,VMM为每个Guest维护一份影子页表(Shadow Page Table),通过软件维护GVA到HPA的映射,由于内存访问与更新频繁导致影子页表的维护复杂,开销较大。
Intel引入了硬件辅助内存虚拟化扩展页表EPT(Extend Page Table),AMD 的是嵌入页表NPT(Nested
Page Table),作为CPU内存管理单元MMU的扩展,通过硬件来实现GVA、GPA到HPA的转换。如图6,首先Guest通过CR3寄存器将GVA转换为GPA,然后查询EPT将GPA转换为HPA。EPT的控制权在VMM上,只有CPU工作在Non-Root模式时才参与该内存转换。引入EPT后,Guest读写CR3寄存器或Guest
Page Fault,执行INVLPG指令等不会触发VM Exit,由此降低了内存转换复杂度,提升转换效率。
另外,CPU使用TLB(Translation Lookaside Buffer)缓存线性虚拟地址到物理地址的映射,地址转换时CPU先根据GPA先查找TLB,如果未找到映射的HPA,将根据页表中的映射填充TLB,再进行地址转换。不同Guest的vCPU切换执行时需要刷新TLB,影响了内存访问效率。Intel引入了VPID(Virtual-Processor
Identifier)技术在硬件上为TLB增加一个标志,每个TLB表项与一个VPID关联,唯一对应一个vCPU,当vCPU切换时可根据VPID找到并保留已有的TLB表项,减少TLB刷新。
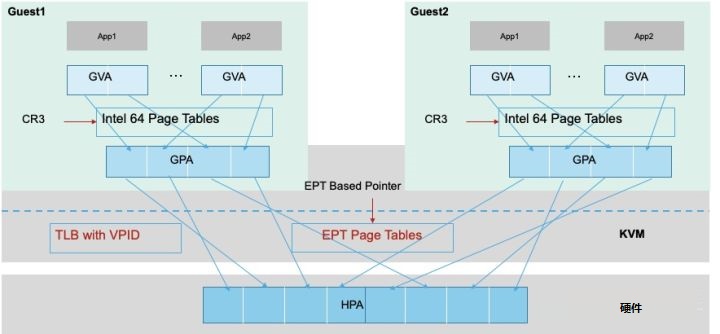
图6:基于EPT的内存地址转换
3.2 透明大页THP
x86 CPU默认使用4KB的内存页面,目前已经支持2MB,1GB的内存大页(Huge Page)。使用大页内存可减少内存页数与页表项数,节省了页表所占用的CPU缓存空间,同时也减少内存地址转换次数,以及TLB失效和刷新的次数,从而提升内存使用效率与性能。但使用内存大页也有一些弊端:如大页必须在使用前准备好;应用程序必须显式地使用大页(一般是调用mmap、shmget或使用libhugetlbfs库进行封装);需要超级用户权限来挂载hugetlbfs文件系统;如果大页内存没有实际使用会造成内存浪费等。2009年实现的透明大页THP(Transparent
Hugepage)技术创建了一个抽象层,能够自动创建、管理和使用传统大页,实现发挥大页优势同时也规避以上弊端。当前主流的Linux版本都默认支持。KVM中可以在Host和Guest中同时使用THB技术。
3.3 内存超分Over-Commit
由于Guest使用内存时采用瘦分配按需增加的模式,KVM支持内存超分(Over-Commit)使得分配给Guest的内存总量大于实际物理内存总量,从系统访问性能与稳定性考虑,在生产环境中一般不建议使用内存超分。内存超分有三种实现方式:
1) 内存交换(Swapping):当系统内存不够用时,把部分长时间未操作的内存交换到磁盘上配置的Swap分区,等相关程序需要运行时再恢复到内存中。
2) 气球(Ballooning):通过virtio_balloon驱动实现动态调整Guest与Host的可用内存空间。气球中的内存是Host可使用,Guest不能使用。当Host内存不足时,可以使气球膨胀,从而回收部分已分配给Guest的内存。当Guest内存不足时可请求压缩气球,从Host申请更多内存使用。
3) 页共享(Page Sharing):通过KSM(Kernel Samepage Merging)让内核扫描正在运行进程的内存。如果发现完全相同的内存页就会合并为单一内存页,并标志位写时复制COW(Copy
On Write)。如果有进程尝试修改该内存页,将复制一个新的内存页供其使用。KVM中QEMU通过madvise系统调用告知内核那些内存可以合并,通过配置开关控制是否企业KSM功能?。?Guest就是QEMU进程,如果多个Guest运行相同OS或应用,且不常更新,使用KSM能大幅提升内存使用效率与性能。当然扫描和对比内存需要消耗CPU资源对性能会有一定影响。
4. IO设备虚拟化
4.1 IO设备虚拟化概述
在虚拟化环境中,Guest的IO操作需要经过特殊处理才能在底层IO设备上执行。如表1,KVM支持5种IO虚拟化技术。
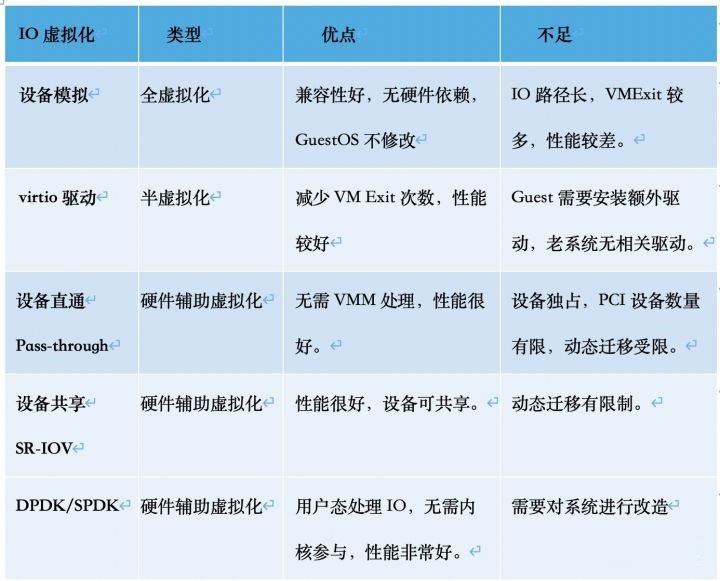
表1:虚拟化环境IO处理方式对比
4.2 设备模拟与virtio驱动
如图7,全虚拟化的设备模拟与半虚拟化的virtio驱动都是通过软件实现IO虚拟化。
设备模拟
KVM中通过QEMU来模拟网卡或磁盘设备。Guest发起IO操作时被KVM的内核捕获,处理后发送到IO共享页并通知QEMU;QEMU获取IO交给硬件模拟代码模拟IO操作,并发送IO请求到底层硬件处理,处理结果返回到IO共享页;然后通知IO捕获代码,读取结果并返回到Guest中。
Virtio驱动
在Guest中部署virtio前端驱动,如virtio-net、virtio-blk、virtio_pci、virtio_balloon、virtio_scsi、virtio_console等,然后在QEMU中部署对应的后端驱动,前后端之间定义了虚拟环形缓冲区队列virtio-ring,用于保存IO请求与执行信息。Guest的IO从前端驱动发送到virtio-ring,然后后端驱动或去IO并转发到底层设备处理,处理完后返回结果。目前主流的Linux与windows都支持virtio,以获得更好的IO性能。
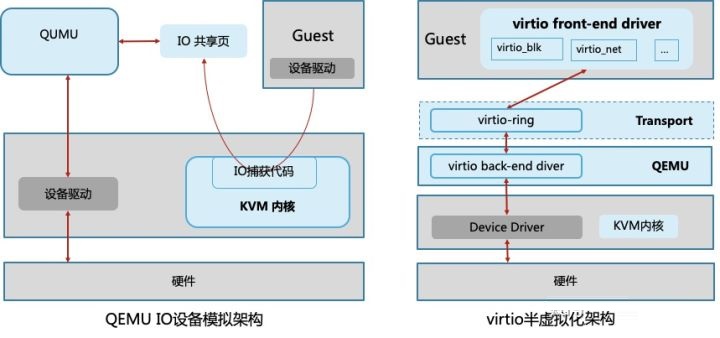
图7:基于软件的IO虚拟化
vhost-net与vhost-user
virtio中后端驱动由用户空间的QEMU提供,但网络协议栈处于内核中,如果通过内核空间来处理网络IO,可以减少了网络IO处理过程中的多次上下文切换,从而提高网络吞吐量与性能。所以,新的内核中提供vhost-net驱动,使前端网络驱动virtio-net的后端处理任务从用户态的QEMU改到Host内核空间执行。
大规模云计算环境中会使用OVS(Open vSwitch)或SDN方案,而进程运行在用户态,如果继续用使用内核态的vhost-net,依然存在大量用户态与内核态的切换,所以引入了vhost-user(内核态vhost功能在用户态实现)。vhost-user定义了Master(QEMU进程)和slave(OVS进程)作为通信两端,Master与slave之间控制面通过共享的虚拟队列virtqueure交换控制逻辑,数据面通过共享内存交换信息。结合vhost-user、vSwitch与DPDK可以在用户态完成网络数据包交换处理,从而大幅提升了网络虚拟化性能。
4.3 设备直通与共享
通过软件方式实现IO虚拟化存在一定系统开销与性能损耗,所以Intel推出了硬件辅助虚拟化技术(AMD-V类似)。

表2:Intel 硬件辅助虚拟化技术
设备直通PCI Pass-through
基于硬件辅助虚拟化技术,KVM支持将Host的PCI/PCI-E物理设备(如网卡、磁盘、USB、显卡、GPU等)直接分配给Guest使用。Guest的对该设备的IO操作与物理设备一样,不经过QEMU/KVM处理。直通设备不能共享给多个Guest使用,且不能随Guest进行动态迁移,需要通过热插拔或libvirt工具来解决。
设备共享SR-IOV
为了实现多个Guest可以共享同一个物理设备,PCI-SIG发布了SR-IOV(Single Root-IO
Virtualization)标准,让一个物理设备支持多个虚拟功能接口,可以独立分配给不同的Guest使用。SR-IOV定义了两个功能:
1) 物理功能PF(Physical Function):拥有物理PCI-e设备的完整功能,可独立使用;以及SR-IOV扩展能力,可配置管理VF。
2) 虚拟功能VF(Virtual Function):由PF衍生的轻量级PCI-e功能,包括数据传送的必要资源。不同的VF可以分配给不同的Guest,SR-IOV为Guest独立使用VF提供了独立的内存、中断与DMA流,数据传输过程无需VMM介入。
DPDK/SPDK
为了更好地提升虚拟化网络或磁盘IO性能,Intel等公司推出了数据平面开发工具集DPDK(Data
Plance Development Kit)与存储性能开发工具集SPDK(Storage Performace
Development Kit)。DPDK、vhost-user、OVS结合使用,可跳过Linux内核,直接在用户态完成网络数据包交换处理。SPDK通过环境抽象层EAL与UIO将存储驱动放在用户态处理,同时通过PMD轮询机制代替传统中断模式来处理IO。DPDK与SPDK大幅缩短了IO处理路径与系统开销,
IO性能提升非常明显。DPDK与SPDK详情参考云网络介绍与云存储介绍部分。
4.4 其他IO设备特性
图像与声音
QEMU中对Guest的图像显示默认使用SDL(Simple DirectMedia Layer)实现。SDL是一个基于C语言的、跨平台的,开源的多媒体程序库,提供了简单的接口用于操作硬件平台的图形显示、声音、输入设备等,广泛应用于各种操作系统。同时在虚拟化环境中也广泛使用虚拟网络控制台VNC(Virtual
Network Computing),采用RFB(Remote Frame Buffer)协议将客户端(浏览器或VNC
Viewer)的键盘与鼠标输入传递到远程服务端VNC Server中,并返回输出结果。VNC不依赖操作系统,在VNC窗口断开后,已发出操作仍然会在服务端继续执行。由于VNC是GPL授权,衍生出多个版本RealVNC、TightVNC与UltraVNC,其对比如表3。

表3:VNC版本对比
热插拔Hot Plugging
热插拔就是在服务器运行时插上或拔出硬件,以保障服务器的扩展性与灵活性。热插拔需要总线电气特性、主板BIOS、操作系统以及设备驱动的支持。目前支服务器持硬盘、CPU、内存、网卡、USB设备与风扇等部件热插拔。在KVM中在Guest不关机情况下支持PCI设备(如模拟、半虚拟化或直通的网卡、硬盘、USB设备)。CPU和内存热插拔硬件平台和OS层面的限制还比较多。 |









