| Īŗľ≠Õ∆ľŲ: |
| Īĺőńņī◊‘”ŕCSDN£¨Īĺőń÷ų“™Ĺť…‹Ķń «kubernetes‘ŕŐŕ—∂”őŌ∑÷–Ķń”¶”√ Ķľý£¨ļ£ŃŅ”¶”√Ļż≥Ő÷–”ŲĶĹĶńő Ő‚”ŽĹ‚ĺŲ∑Ĺįł°£ |
|
Őŕ—∂‘ŕŌŖ”őŌ∑Ķń»›∆ųĽĮ”¶”√≥°ĺį
2014ńÍ£¨ő“√«Ņ™∆ŰŃň»›∆ųĽĮŐĹňų÷ģ¬∑£¨Ō»ĽōĻň“ĽŌ¬÷ģ«į”ŲĶĹĶń“Ľ–©ő Ő‚°£
‘ŕőÔņŪĽķ Īīķ£¨◊ ‘īĶńĹĽł∂ ĪľšĹŌ≥§£¨◊ ‘īĶńņŻ”√¬ ĹŌĶÕ£¨“≤≤Ľń‹◊ŲĶĹłŰņŽ°£ĶĹŃňxen\kvm–ťń‚Ľķ Īīķ£¨ő Ő‚Ķ√ĶĹŃň≥ű≤ĹĶńĹ‚ĺŲ£¨Ķę‘ŕĶĮ–‘…žňű∑Ĺ√ś»‘”–≤Ľ◊„°£ňś◊ŇDockerľľ űĶń–ň∆ū£¨ő“√«Ņ™ ľĶų—–Docker‘ŕ”őŌ∑»›∆ųĽĮ∑Ĺ√śĶń”¶”√°£ő“√«ĶńńŅĪÍ”–ŃĹłŲ£¨“Ľ «ŐŠłŖ◊ ‘īņŻ”√¬ £¨∂Ģ «Õ®ĻżDockerĺĶŌŮņīĪÍ◊ľĽĮ≤Ņ ūŃų≥Ő°£
—°‘ŮDockerľľ ű÷ģļů£¨ő“√«Ņ™ ľŃň»›∆ųĶų∂»∆ĹŐ®Ķń—°–Õ°£ő“√«ĶĪ Ī“≤Ķų—–Ńň∆šňŁĶń“Ľ–©◊ťľĢ£¨Ī»»ÁShipyard°ĘFigĶ»£¨Ķę’‚–©◊ťľĢőř∑®÷ß≥Ňļ£ŃŅ”őŌ∑»›∆ųĶų∂»°£∂Ý◊‘Ĺ®Ķų∂»∆ĹŐ®ĶńĽį£¨ Īľš≥…Īĺ∑«≥£ĶńłŖ°£ĺÕ‘ŕń« Ī£¨GoogleŅ™‘īŃňkubernetes£®ĶĪ ĪĶńįśĪĺ «kubernetes
v0.4£©£¨ő“√«Ľý”ŕ’‚łŲįśĪĺĹÝ––Ńň∂®÷∆ļÕŅ™∑Ę£¨ Ļ∆š≥…ő™ő“√«”őŌ∑»›∆ųĶńĶų∂»Ļ‹ņŪ∆ĹŐ®°£
‘ŕ2015ńÍ≥űĶń ĪļÚ£¨TDocker∆ĹŐ®…ŌŌŖ°£÷ģļů£¨ő“√«Ņ™ ľ÷ū≤ĹĹ”»Ž“ĶőŮ°£“ĽŅ™ ľĶńń£ Ĺ∑«≥£ľÚĶ•£¨ĺÕ «į—DockerĶĪ≥…–ťń‚Ľķņī Ļ”√£¨Ķę’‚≤Ľ“‚ő∂◊Ň”őŌ∑»ę»›∆ųĽĮĶń ĶŌ÷°£
īůľ“÷™Ķņ£¨∂‘”ŕ“ĽŌÓ–¬ľľ űņīňĶ£¨īůľ“∂ľļ‹Ĺų…ų£¨ĽŠÕ®Ļż≤Ľ∂ŌĶńĽ“∂»…ŌŌŖ£¨”…Ķ„ĶĹ√śĶń≤Ŗ¬‘Õ∆∂Į°£Ĺō÷ŃńŅ«į£¨‘ŕ»ęĻķłųĶō“‘ľįľ”ń√īůĶ»Ķō«Ý£¨∂ľ”–ő“√«Ķń≤Ņ ūĶ„£ĽĹ”»Ž»›∆ų ż≥¨ĻżŃĹÕÚ£¨Ĺ”»ŽĶń“ĶőŮ“≤”–ŃĹįŔ∂ŗŅÓ£¨įŁņ® ÷”ő°Ę∂ň”ő°Ę“≥”ő°£‘ŕ’‚√ī∂ŗĶń“ĶőŮ÷–£¨÷ų“™∑÷ő™ŃĹ÷÷≥°ĺį£¨Ķŕ“Ľ÷÷≥°ĺį ««ŠŃŅľ∂–ťń‚Ľķń£ Ĺ£¨’‚ņŗ»›∆ų≥–‘ō∂ŗłŲ∑ĢőŮĹÝ≥Ő£¨–Ť“™“ĽłŲĺŖŐŚĶńńŕÕÝIP£¨Ņ…“‘Õ®łŚSSHĶ«¬ľ°£ŃŪ“Ľ÷÷ «őĘ∑ĢőŮĽĮń£ Ĺ£¨’‚÷÷ń£ ĹĽŠ≤ū∑÷Ķ√∑«≥£Ōł£¨√Ņ“ĽłŲ»›∆ų∂‘”¶“ĽłŲ∑ĢőŮĹÝ≥Ő£¨≤Ľ–Ť“™∂‘Õ‚Ņ…ľŻĶńńŕÕÝIP£¨Ņ…“‘ Ļ”√–ťń‚IP°£
Ĺ”Ō¬ņīĽŠ∂‘√Ņ“ĽłŲ≥°ĺį◊Ų“Ľ–©∑÷ŌŪ°£ ◊Ō»ņīŅī“ĽŌ¬īęÕ≥”őŌ∑Ō¬Ķńľ‹ĻĻ°£’‚ «∑«≥£Ķš–ÕĶń»ż≤„∑ĢőŮľ‹ĻĻ£¨įŁņ®ŃňĹ”»Ž≤„°Ę¬Ŗľ≠≤„°Ę żĺ›Ņ‚≤„°£Õ¨ Ī£¨”őŌ∑”÷∑÷ő™£ļ»ę«Ý»ę∑Ģ°Ę∑÷«Ý∑÷∑ĢŃĹ÷÷ņŗ–Õ°£∂‘”ŕ∑÷«Ý∑÷∑Ģņŗ”őŌ∑£¨ĻŲ∑Ģ∂‘◊ ‘īĶńĶų∂»∑«≥£∆Ķ∑Ī£¨ňý“‘ő“√«–Ť“™“ĽłŲłŖ–ßĶńĶų∂»∆ĹŐ®°£
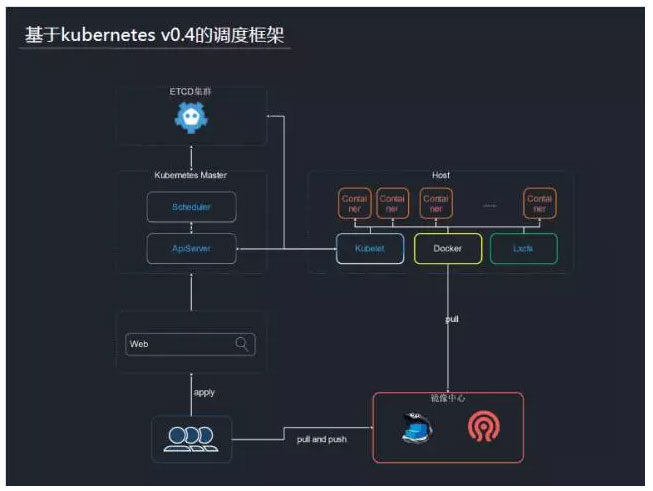
»›∆ų◊ ‘īĶńĶų∂»Ļ‹ņŪĽý”ŕkubernetes v0.4įśĪĺ£¨…ŌÕľ «“ĽłŲľÚĽĮļůĶńĶų∂»ŅÚľ‹°£‘ŕMaster∂ňįŁņ®ApiServerļÕScheduler£¨Ĺ” ’Web«Ž«ů£¨»Ľļů◊Ų◊ ‘īĶų∂»°£‘ŕ√ŅłŲnodeĹŕĶ„…Ō£¨įŁņ®agentĹÝ≥Ő°ĘDockerĹÝ≥Ő£¨ĽĻ”–LxcfsĹÝ≥Ő°£‘ŕĺĶŌŮīśīĘ∑Ĺ√ś£¨ĶĪ Ī”√Ķń «Registry
V1įś£¨ļů∂ň”√Ķń «cephīśīĘ°£Ō÷‘ŕ£¨ő“√«◊‘ľļő¨Ľ§Ńň“ĽłŲ∑÷÷ߣ¨Ļ¶ń‹…Ō“—¬ķ◊„ĶĪ«įĶń”őŌ∑–Ť«ů£¨≤ĘĪ£÷§‘ň––Ķńő»∂®°£ňý“‘‘ŕ–ťń‚Ľķń£ ĹŌ¬£¨ő“√«≤ĽĽŠ…żľ∂kubernetes£¨∂Ý «į—“Ľ–©ļ√”√ĶńĻ¶ń‹ļŌ≤ĘĹÝņī°£
Ľý”ŕkubernetesĶńĻ¶ń‹∂®÷∆”Ž”ŇĽĮ
◊Ō»Ĺ≤Ķų∂»∆ų£¨Ķų∂»∆ųő™ ż“‘ÕÚľ∆Ķń»›∆ųŐŠĻ©Ńň“ĽłŲŃťĽÓ°Ęő»∂®°ĘŅ…ŅŅĶńĶ◊≤„◊ ‘īľ∆ň„Ķų∂»“ż«ś°£◊ ‘īĶńļŌņŪ∑÷ŇšŌŮ «“Ľ≥°≤©řń£¨ņÔ√ś”–ļ‹∂ŗ√¨∂‹ĶńĶō∑Ĺ£¨–Ť“™ő“√«łýĺ›”őŌ∑ĶńŐōĶ„◊Ų»°…Š°£
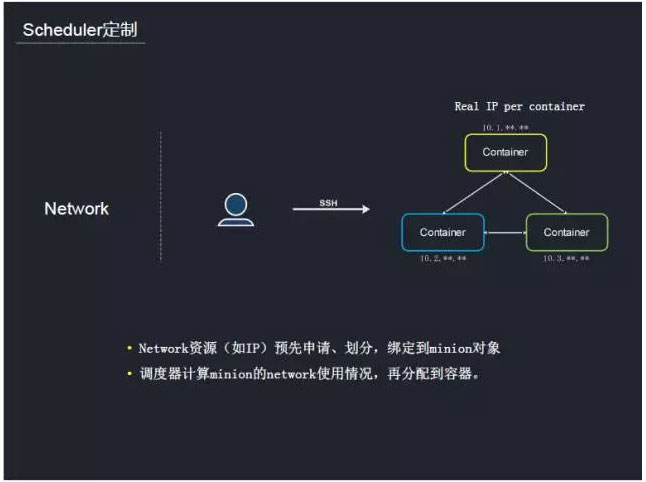
ő“√«‘ŕ‘≠”–ĶńĶų∂»≤Ŗ¬‘…Ōłýĺ›”őŌ∑ŐōĶ„◊ŲŃň“Ľ–©∂®÷∆°£Ī»»Á‘ŕÕݬÁ∑Ĺ√ś£¨īęÕ≥”őŌ∑Ķń√ŅłŲ»›∆ų∂ľ–Ť“™“ĽłŲ∂‘Õ‚Ņ…ľŻĶń ĶŐŚIP£¨”√ĽßŅ…“‘Õ®ĻżSSHĶ«¬ľĶĹ»›∆ųņÔ√ś£¨“Úīň∂‘ÕݬÁ◊ ‘īĹÝ––Ķų∂»°£≤Ņ ū»›∆ųĶń ĪļÚ£¨ĽŠ…Í«ŽnetworkĶń◊ ‘ī£®Ī»»ÁIP£©»ĽļůĹÝ––Ľģ∑÷£¨įů∂®ĶĹminions∂‘Ōů°£’‚—ýĶų∂»∆ųĶų∂»Ķń ĪļÚ£¨ĺÕŅ…“‘Õ®Ļż’‚–©Ňš÷√–ŇŌʳݻ›∆ų∑÷Ňšļ√ÕݬÁ◊ ‘ī°£
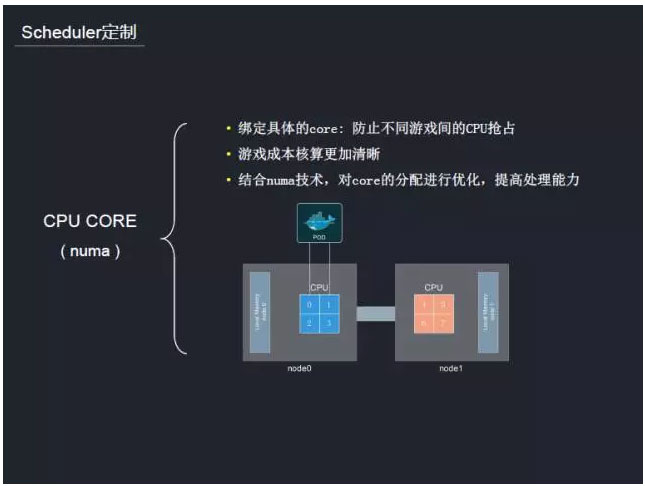
‘ŕ…Á«Ý÷–£¨CPUĶń∑÷Ňš”√Ķń «Ļ≤ŌŪCPUĶń∑Ĺ Ĺ£¨”őŌ∑≤…”√Ķń «“Ľ÷÷Ľž≤ŅĶńń£ Ĺ°£“≤ĺÕ «ňĶ£¨Ĺę≤ĽÕ¨”őŌ∑“ĶőŮ≤Ņ ūĶĹÕ¨“ĽŐ®ńłĽķ£¨≤…”√įů∂®ļňĶń∑Ĺ Ĺ°£’‚—ý◊Ų“Ľ∑Ĺ√śŅ…“‘∑ņ÷Ļ≤ĽÕ¨”őŌ∑÷ģľšĶńCPU«ņ’ľ£¨ŃŪ“Ľ∑Ĺ√ś∂‘”őŌ∑≥…ĪĺĶńļňň„“≤ĽŠłŁľ”ĺęŌł°£ņż»Á£¨ń≥łŲ”őŌ∑”√Ńň∂ŗ…ŔCPU’‚–©÷łĪÍ∂ľ «Ņ…“‘ŃŅĽĮĶń°£‘ŕ»›∆ų∑÷ŇšCPU Ī£¨ĹŠ»ęnumaľľ ű£¨∂‘”ŕCPU
COREĶń∑÷ŇšĽŠĺ°ŃŅĶō∑÷ŇšĶĹÕ¨“ĽłŲnuma node…Ō£¨’‚—ýŅ…“‘ŐŠ…ż–‘ń‹,“Úő™Õ¨łŲnuma nodeĶńCPU∑√ő ÷Ľ–ŤÕ®Ļż◊‘…ŪĶńlocal
memory£¨őř–ŤÕ®ĻżŌĶÕ≥◊‹ŌŖ°£

‘ŕīŇŇŐ»›ŃŅ∑÷Ňš∑Ĺ√ś£¨”…”ŕ”őŌ∑“ĶőŮ «”–◊īŐ¨Ķń∑ĢőŮ£¨–Ť“™īśīĘ£¨ňý“‘ő“√«į—īŇŇŐ“≤◊ųő™“ĽłŲŅ…Ķų∂»Ķń◊ ‘ī∑÷ŇšłÝ»›∆ų°£ĽĻ”–∑««◊ļÕ–‘ĶńĶų∂»°£ő“√«÷™Ķņ£¨‘ŕ»›∆ųĶńŅ…ŅŅ–‘”Žňť∆¨”ŇĽĮ÷ģľš–Ť“™“ĽłŲ»®ļ‚£¨»√”√Ľßłýĺ›’‚–©≤Ŗ¬‘»•—°‘Ů°Ę≤Ņ ū◊‘ľļĶń»›∆ų°£ņż»Á‘ŕ∑««◊ļÕ–‘Ķń≤Ŗ¬‘÷–£¨”√ĽßŌ£ÕŻį—»›∆ų «∑÷…ĘĶĹłųłŲńłĽķ…ŌĶń£¨‘ŕńłĽķŚīĽķ Ī£¨Ņ…“‘ľű…Ŕ∂‘”őŌ∑Ķń”įŌž°£
‘ŕIDC Module∑÷Ňš∑Ĺ√ś£¨”őŌ∑»›∆ųĶń≤Ņ ūĽŠįīĶō«ÝĽģ∑÷£¨Ī»»Áįī’’…Ōļ£°Ę…ÓŘŕĽÚŐžĹÚĶō«ÝĶńIDCņīĽģ∑÷£¨ňý“‘ő“√«ŐŠĻ©ŃňIDC≤Ņ ū≤Ŗ¬‘°£”…”ŕ”őŌ∑–Ť“™Ņľ¬«IDCĶńī©‘ĹŃųŃŅő Ő‚£¨ĽĻ”–ÕݬÁ—” ĪĶńő Ő‚£¨ňý“‘Õ¨“ĽłŲ”őŌ∑ĶńĶń≤ĽÕ¨ń£Ņť“Ľį„ĽŠ≤Ņ ūĶĹÕ¨“ĽłŲIDC
ModuleŌ¬√ś°£
ļ£ŃŅ”¶”√Ļż≥Ő÷–”ŲĶĹĶńő Ő‚”ŽĹ‚ĺŲ∑Ĺįł
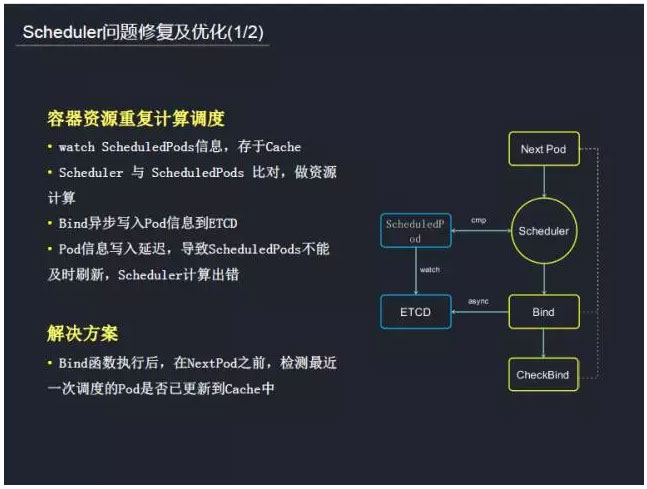
“‘…Ō «Ľý”ŕ”őŌ∑––“ĶŐōĶ„∂®÷∆ĶńĶų∂»ĻśĽģ°£‘ŕ◊ ‘īĶų∂»Ļż≥Ő÷–£¨“≤”ŲĶĹĻż“Ľ–©ő Ő‚£¨ņż»Á»›∆ų◊ ‘īĶń÷ōłīĶų∂»°£ ◊Ō»‘ŕĶų∂»Ļż≥Ő÷–ňŁĽŠłķScheduledPod£®“—ÕÍ»ęĶų∂»Ķń»›∆ų£©ĹÝ––Ī»ĹŌ£¨Ň–∂ŌŌ÷‘ŕ «≤Ľ «”–◊„ĻĽĶń◊ ‘ī∑÷ŇšłÝīżĶų∂»»›∆ų£¨◊ÓļůÕ®ĻżBind£®“ž≤Ĺ£©į—Pod–ŇŌĘ–ī»ŽĶĹETCD°£’‚ņÔĺÕĽŠ≥ŲŌ÷“ĽłŲő Ő‚£¨ń«ĺÕ «“ž≤Ĺ–ī»Ž¬żŃňĽÚ’ŖScheduledPodÕ¨≤ŬżŃňĶľ÷¬ScheduledPods≤Ľń‹ľį ĪňĘ–¬£¨Schedulerľ∆ň„≥ŲīŪ£¨ī”∂Ý‘ž≥…◊ ‘ī÷ōłīľ∆ň„°£’Ž∂‘’‚łŲő Ő‚£¨ő“√«ĶńĹ‚ĺŲ∑Ĺįł «‘ŕ◊ ‘īĶų∂»ÕÍ≥…ļů£¨◊Ų“ĽłŲľž≤‚Ķń¬Ŗľ≠£¨ľž≤‚Ķų∂»Ķń»›∆ų–ŇŌĘ «∑Ů“—‘ŕScheduledPod
Cache’‚ņÔ£¨»Ľļů‘ŔĹÝ»ŽŌ¬“ĽłŲ»›∆ųĶńĶų∂»°£ĶĪ»Ľ’‚ĽŠīÝņī“Ľ∂®Ķń–‘ń‹ňūļń°£
Ĺ‚ĺŲŃň’‚łŲő Ő‚£¨”÷≤ķ…ķŃňŃŪÕ‚“Ľ–©ő Ő‚£¨ń«ĺÕ «–‘ń‹Ķńő Ő‚°£‘ŕ0.4įśĪĺĶńpodĹ”Ņŕ «∑«≥£ĶÕ–ßĶń£¨‘ŕ≤ť√Ņ“ĽłŲpod◊īŐ¨Ķń ĪļÚ£¨ĽŠÕ®Ļż Ķ Ī≤ťňý”–ĶńHostņī»∑∂®£¨…Ťľ∆≤ĽŐęļŌņŪ°£…Á«Ý“≤◊ŲŃň“Ľ–©∑Ĺįł£¨ĶĪ Īő“√«“≤ «≤őŅľŃň…Á«ÝĶń“Ľ–©∑Ĺįł◊ŲŃň“Ľ–©łń‘ž£¨į—pod◊īŐ¨∑Ň‘ŕCacheņÔ√ś£¨∂® ĪłŁ–¬£¨ī”∂ÝŐŠłŖ≤ť—Į–߬ °£
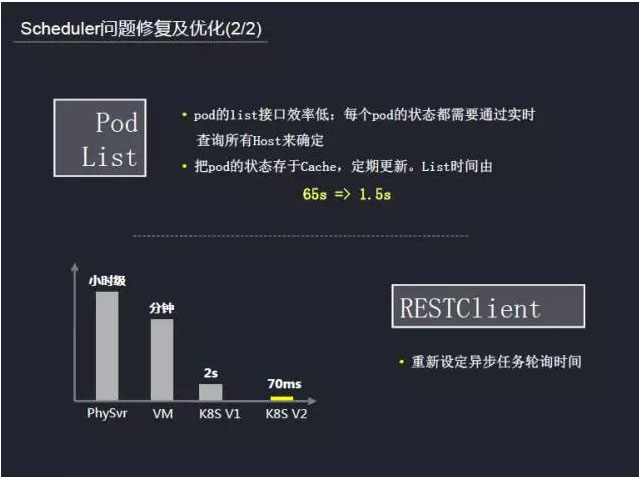
ĽĻ”–“ĽĶ„ĺÕ «RESTClient°£‘ŕkubernetes÷–£¨rest APIīů≤Ņ∑÷ «“ž≤ĹĹÝ––£¨∂‘”ŕ’‚–©“ž≤ĹĶńĹ”ŅŕĶń«Ž«ů£¨≤Ę≤ĽĽŠŃĘŅŐ∑ĶĽōĹŠĻŻ°£’‚ņÔ”–“ĽłŲ¬÷—Įľž≤‚◊īŐ¨Ķń¬Ŗľ≠£¨‘ŕľž≤‚¬÷—ĮĶń ĪļÚ”–ľł√ŽĶń–›√Ŗ£¨»ĽļůĹÝ‘Ŕ––Ō¬“ĽłŲ¬÷—Į°£ń¨»ŌĶń–›√Ŗ Īľš «2√Ž£¨’‚łŲ Īľš∂‘īů≤Ņ∑÷≥°ĺįņīňĶ”–Ķ„Ļż≥§£¨ő“√«Õ®Ļż“Ľ–©Ļ¶ń‹Ķ„ĶńĶų’Ż£¨ī”őÔņŪĽķĶń–° Īľ∂ĶĹ–ťń‚Ľķ∑÷÷”ľ∂ĶńĶų∂»£¨‘ŔĶĹĽĻőīĶų’Ż÷ģ«įĶń√Žľ∂Ķų∂»£¨ĶĹŌ÷‘ŕīÔĶĹĶńļŃ√Žľ∂Ķų∂»£¨Ō÷‘ŕĶńĶų∂»ń‹Ń¶“—ń‹¬ķ◊„”őŌ∑Ķń–Ť«ů°£
Ĺ≤ÕÍĶų∂»£¨‘ŔŅī“ĽŌ¬ÕݬÁ∑Ĺ√ś°£ÕݬÁ «∑«≥£ĻōľŁ°Ę“≤ «◊Óő™łī‘”Ķń“ĽĽ∑°£‘ŕ–ťń‚Ľķń£ ĹŌ¬£¨ĹŠļŌĻęňĺÕݬÁĽ∑ĺ≥ő™”őŌ∑ŐŠĻ©łŖ–‘ń‹°Ęő»∂®ĶńÕݬÁĽ∑ĺ≥£¨įŁņ®Bridge+VLAN\SR-IOVŃĹ÷÷∑Ĺįł°£
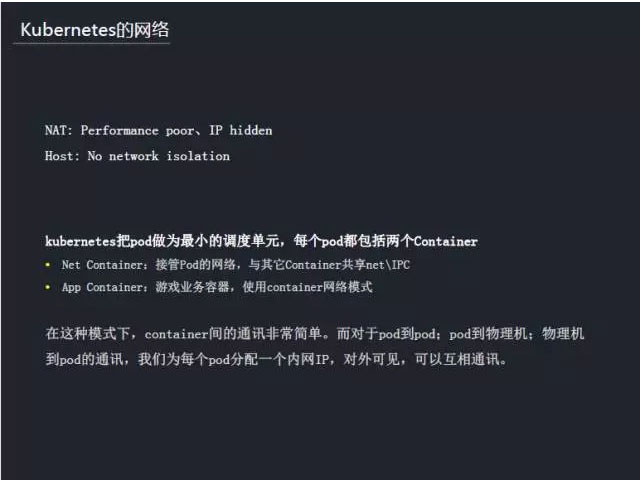
Ō»ņīňĶ£¨DockerĶńÕݬÁĽĻ”–kubernetesĶńÕݬÁ°£∂‘”ŕDockerĶńNATÕݬÁņīňĶ£¨–‘ń‹ «◊ÓīůĶń∆ŅĺĪ£¨Õ¨ ĪňŁ”ŽőÔņŪĽķĽÚ–ťń‚ĽķĶńÕ®–Ҭ∑ĺ∂≤Ľ“Ľ÷¬“≤ĽŠ∂‘“ĶőŮīÝņī“Ľ–©őī÷™Ķń”įŌž°£Ī»»Á£¨Õ‚ĹÁ≤Ľń‹ŅīĶĹ»›∆ų’ś ĶĶńIP(Īō–Ž“™ Ļ”√÷ųĽķIP+port∑Ĺ Ĺ,∂ňŅŕĪĺ…ŪĺÕ «Ō°»Ī◊ ‘ī£¨≤Ę«“ip+portĶń∑Ĺ Ĺ£¨őř“…‘Ųľ”Ńňłī‘”∂»)£¨TGW»‘»ĽŅ…“‘ő™“ĶőŮ≥Ő–Ú∑ĢőŮ°£Hostń£ Ĺ√Ľ”–łŰņŽ£¨“≤≤Ľ∑ŻļŌ–Ť«ů°£‘ŕkubernetes÷–£¨pod◊ųő™◊Ó–°Ķų∂»Ķ•‘™£¨√ŅłŲpod”–ŃĹłŲ»›∆ų£¨“ĽłŲĺÕ «ÕݬÁ»›∆ų£¨Ĺ”Ļ‹podĶńÕݬÁ£¨ŐŠĻ©ÕݬÁ∑ĢőŮ£¨≤Ę”Ž∆šňŁ»›∆ųĻ≤ŌŪnet\IPC°£ŃŪ“ĽłŲ «App
Container£¨“≤ĺÕ «“ĶőŮ»›∆ų£¨ Ļ”√Ķŕ“ĽłŲÕݬÁ»›∆ųĶńÕݬÁ°£‘ŕ’‚÷÷ń£ ĹŌ¬£¨»›∆ų÷ģľšĶńÕ®—∂ «∑«≥£ľÚĶ•Ķń°£∂‘”ŕpodĶĹpod°ĘpodĶĹőÔņŪĽķ°ĘőÔņŪĽķĶĹpodĶńÕ®—∂£¨ő“√«ő™√ŅłŲpod∑÷Ňš“ĽłŲńŕÕÝIP£¨∂‘Õ‚Ņ…ľŻ£¨“≤Ņ…“‘Ľ•ŌŗÕ®—∂°£
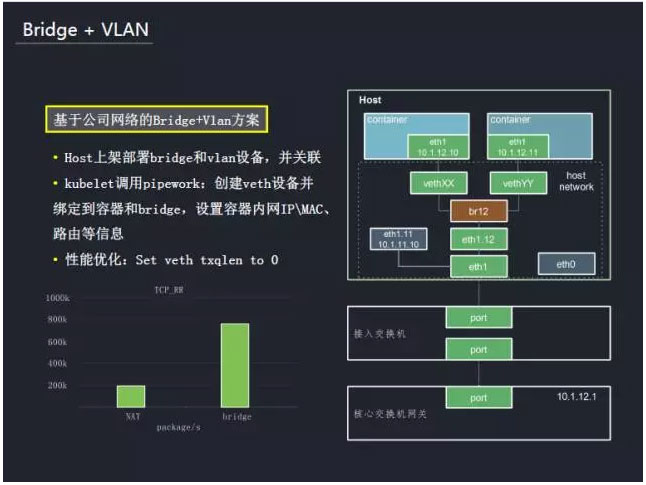
Ĺ”Ō¬ņī£¨Õ®ĻżŃĹłŲ∑ĹįłłÝīůľ“∑÷őŲ°£ ◊Ō» «Bridge+VlanĶń∑Ĺįł£¨ńłĽķ∂ľ «≤Ņ ū‘ŕ–ťń‚ĽĮ«Ý…Ō£¨Õ®ĻżVlan◊ŲÕݬÁĶńłŰņŽ°£‘ŕńłĽķ…Ōľ‹≤Ņ ū Ī£¨īīĹ®Bridge…ŤĪłļÕVLAN…ŤĪł≤ĘĹęňŁ√«ĹÝ––ĻōŃ™°£īīĹ®»›∆ųĶń ĪļÚ, Ļ”√pipeworkĹŇĪĺīīĹ®»›∆ųňý–Ť“™Ķń–ťń‚ÕÝŅ®…ŤĪł£¨≤Ęį—ňŁ√«įů∂®ĶĹ»›∆ųļÕBridge…Ō£¨Õ¨ ĪĽŠ…Ť÷√»›∆ųńŕĶńIP°ĘMACĶō÷∑“‘ľį¬∑”…Ķ»–ŇŌĘ°£ī”∂ÝīÚÕ®»›∆ųĶĹÕ‚ĹÁĶńÕݬÁÕ®–Ň°£’‚ņÔ“≤◊ŲŃň“Ľ–©”ŇĽĮ“‘ŐŠłŖ–‘ń‹£¨’‚ņÔŅ…“‘ŅīĶĹ“ĽłŲ–‘ń‹Ķń∂‘Ī»£¨∆š÷–BridgeŌŗ∂‘NATÕݬÁ”–ŌŗĶĪīůĶńŐŠ…ż°£’‚÷÷∑Ĺ ĹŅ…“‘¬ķ◊„“Ľ≤Ņ∑÷”őŌ∑Ķń–Ť«ů£¨∂Ý”–“Ľ–©“ĶőŮ£¨ŌŮFPS°ĘMoba”őŌ∑Ķ»īůŃųŃŅ£¨∂‘ÕݬÁ“™«ů∑«≥£łŖĶń“ĶőŮ£¨ĽĻ”–ņŗň∆MySQL-Proxy’‚÷÷◊ťľĢ£¨‘ŕBridge≥°ĺįŌ¬ «őř∑®¬ķ◊„–Ť«ůĶń°£
ňý“‘ő“√«ŐĹňųŃňŃŪ“Ľ÷÷ÕݬÁ∑Ĺ Ĺ£¨ĺÕ «SR-IOVń£ Ĺ£¨’‚÷÷ń£ Ĺ‘ŕzen\kvm–ťń‚ĽĮ…Ō”√ĶńĪ»ĹŌ∂ŗ£¨”őŌ∑“≤–Ť“™’‚÷÷ÕݬÁ∑Ĺįł£¨“Úīňő“√«į—’‚÷÷ÕݬÁ∑Ĺįł“≤ĹŠļŌĶĹDocker»›∆ųņÔ√ś°£
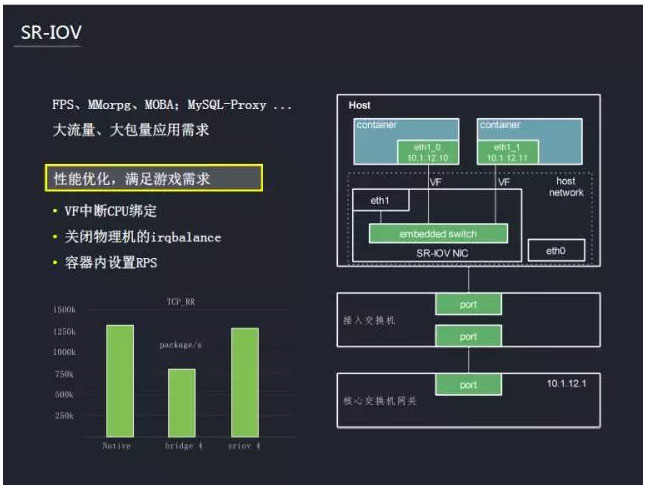
’‚ņÔ–Ť“™”≤ľĢĶń÷ß≥÷£¨ĹŠļŌSR-IOVľľ űĶńÕÝŅ®£¨‘ŕDocker»›∆ųńŕĺÕŅ…“‘÷ĪĹ”Õ®Ļż«ż∂Įņīľ”‘ō–ťń‚ĶńÕÝŅ®≤Ę Ļ”√°£ Ļ”√Ķń∑Ĺ ĹĺÕ»ÁÕ¨‘ŕ“ĽŐ®őÔņŪĽķ…Ō Ļ”√“ĽłŲ’ś ĶĶńőÔņŪÕÝŅ®“Ľ—ý£¨’‚łŲ–ťń‚ÕÝŅ®“≤”Ķ”–«ż∂Į≥Ő–Ú£¨“≤”Ķ”–PCI
BUSID£¨“Úīňňý”–Ķń–ťń‚ĽķÕݬÁ≤Ŕ◊ų∂ľ»ÁÕ¨≤Ŕ◊ų∆’Õ®ÕÝŅ®“Ľį„£¨ī”∂Ý‘ŕ–‘ń‹…ŌĶ√ĶĹŐŠ…ż°£ő™ŃňĹÝ“Ľ≤Ĺ∑ĘĽ”SR-IOVĶńÕݬÁ–‘ń‹£¨ĽĻ–Ť“™∂‘»›∆ųĶńŌŗĻōÕݬÁ≤ő żĹÝ––Ňš÷√£¨÷ų“™įŁņ®“‘Ō¬ľłłŲ∑Ĺ√ś£ļVF÷–∂ŌCPUįů∂®£ĽĻōĪ’őÔņŪĽķĶńirqbalance£Ľ»›∆ųńŕ…Ť÷√RPS£®»Ū÷–∂Ōĺýļ‚£©ÕÝŅ®≤Ľń‹÷–∂Ōĺýļ‚£¨∂‘łŖ–‘ń‹ĶńÕݬÁ–ő≥…Ńň◊Ťį≠°£ő™ŃňĹ‚ĺŲ’‚łŲő Ő‚£¨–Ť“™…Ť÷√»›∆ųńŕĶń»Ū÷–∂Ōĺýļ‚°£Õ®Ļż…Ō ŲĶńĶų’Ż£¨–‘ń‹Ķ√ĶĹŃňīů∑ý∂»ŐŠ…ż°£
’‚ «ő“√«≤‚ ‘Ķń“ĽłŲĹŠĻŻ£¨’‚ĪŖ «őÔņŪĽķĶń£¨’‚ «Bridge£¨’‚ «SR-IOV£¨SR-IOV‘ŕÕݬÁ–‘ń‹∑Ĺ√śĽýĪĺ…Ō“—ĺ≠ŔţŃňőÔņŪĽķ£¨ňý“‘’‚łŲ∂‘”ŕ”őŌ∑īůįŁŃŅ°ĘīůŃųŃŅĶń”¶”√ «∑«≥£ ļŌĶń£¨Ō÷‘ŕő“√«į—SR-IOVÕݬÁ◊ųő™īęÕ≥”őŌ∑ņÔń¨»ŌĶńÕݬÁń£ Ĺ°£
‘ŕ”őŌ∑»›∆ųĽĮĻż≥Ő÷–£¨ő“√«Ō£ÕŻ◊ ‘īĶń Ļ”√ «√ų»∑Ķń°ĘļŌņŪĶń°ĘŅ…ŃŅĽĮĶń°£ňý“‘ő“√«ĽŠő™√ŅłŲ»›∆ų∑÷ŇšĻŐ∂®Ķń◊ ‘ī£¨Ī»»Á∂ŗ…ŔCPU°Ę∂ŗ…Ŕńŕīś£¨ĽĻ”––Ť“™∂ŗīůīŇŇŐ°ĘIOīÝŅŪ°£‘ŕ∆Ű∂Į»›∆ųĶń ĪļÚ£¨Ī»»ÁCPU/Memory£¨Õ®ĻżCgroup»•◊Ų“ĽłŲŌř÷∆£¨diskÕ®Ļżxfs
quota»•◊ŲŇš∂ÓĶńŌř÷∆°£ĽĻ”–Buffered-IOīÝŅŪĶńŌř÷∆°£
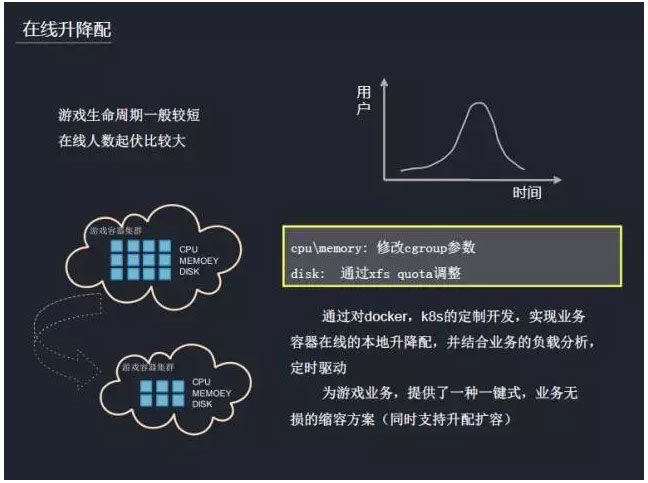
‘ŕ◊ ‘ī∑÷Ňš∑Ĺ√ś£¨ő“√«Ņ™ ľ◊ŲĶń «Ōř∂®ĶńCPU°ĘńŕīśĶń∑÷Ňš°£‘ŕ»›∆ųĶń’ŻłŲ…ķ√Ł÷‹∆ŕ£¨’‚łŲŇš÷√≤Ę∑«“Ľ≥Ń≤ĽĪš£¨Ī»»Á‘ŕ“ĶőŮ‘ň––Ļż≥Ő÷–∂ľĽŠ”–“Ľ–©∆ū∑ŁļÕ∂ĮŐ¨Ķų’Ż£¨’‚ «”őŌ∑Ķń“Ľ’Ň…ķ√Ł÷‹∆ŕÕľŌŮ£¨…ķ√Ł÷‹∆ŕĪ»ĹŌ∂Ő£¨Ņ…ń‹ «“ĽńÍįŽ‘ōĶń Īľš£¨∂Ý«“’‚ņÔ‘ŕŌŖ»ň ż∆ū∑Ł“≤ĽŠĪ»ĹŌīů£¨–Ť“™∂ĮŐ¨Ķų’Ż°£∂Ý∂ĮŐ¨Ķų’ŻĺÕĽŠ…śľįŃĹłŲ∑Ĺ√ś£¨“Ľ «ļŠŌÚĶńňģ∆Ĺņ©’Ļ£¨∂Ģ «īĻ÷Ī…žňű°£
√ŅłŲ”őŌ∑∂ľĽŠ”–“ĽłŲIP£¨“ÚīňļŠŌÚÕō’ĻĪ»ĹŌņßń—£¨“Ú∂ÝłŁ«„ŌÚ”ŕő»∂®ĶńīĻ÷Īņ©ňű°£‘ŕ–ťń‚ĽĮ Īīķ£¨ņ©ňű»› «”–ňūĶń£¨–Ť“™÷ō∆ŰĽķ∆ųņī ĶŌ÷£¨∂ÝDockerŅ…“‘◊ŲĶĹőřňūĶńņ©ňű»›°£ő“√«∂‘’‚łŲ–Ť«ů◊ŲŃň“Ľ–©∂®÷∆Ņ™∑Ę£¨Ī»»ÁCPUĽÚ’Ŗńŕīś£¨Õ®Ļż–řłńCgroupĶńŇš∂Ó»•į—ňŁŐŠ…ż…Ō»•ĽÚ «ŌųľűŌ¬ņī°£
ĶĪ‘ŕŌŖ»ň ż…ŌņīĶń ĪļÚ£¨ő“√«Ņ…“‘łÝ“ĶőŮ◊ŲĶĹőřňūņ©»›£¨≤Ľ”įŌž“ĶőŮ∑ĢőŮ°£ĻżŃň“Ľ∂ő Īľš£¨ĶĪ»ň żĹĶŌ¬ņī Ī£¨◊ ‘īĽŠŌ–÷√£¨ő“√«ĽŠ∂‘Ņ’Ō–Ķń◊ ‘ī◊Ų“Ľ–©÷ōłīņŻ”√£¨Ĺę∆šĽō ’°£’‚łŲ ĪļÚ◊Ų“Ľ–©ňű»›£¨’Ž∂‘ňű»›ő“√«◊Ų“ĽłŲ≥£Ő¨Ķń∂Į◊ų£¨ľž≤‚’‚–©»›∆ųĶńCPU°Ęńŕīś£¨ĹŠļŌ“ĶőŮĶńłļ‘ō°ĘĽÓ∂Į°Ę∂® Ī«ż∂Į°£
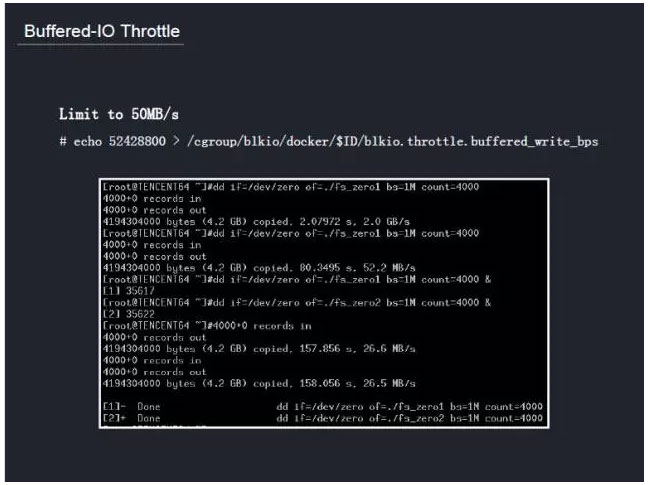
Buffered IO Throttle–Ť“™ńŕļň÷ß≥÷£¨ő“√«”ŽńŕļňÕŇ∂”ĹÝĶōŃňĹŰ√‹ĶńļŌ◊ų£¨ŐŠĻ©Ńň÷ß≥÷
Buffered IO ThrottleĻ¶ń‹ĶńńŕļňįśĪĺ°£łýĺ›»›∆ų‘ŕńłĽķ◊ ‘īĶń’ľĪ»∑÷Ňš“Ľ∂®Ī»ņżĶńIOīÝŅŪ°£’‚‘ŕń≥÷÷≥Ő–Ú…ŌĹ‚ĺŲŃň”őŌ∑÷ģľšĽ•Ōŗ”įŌžĶńő Ő‚°£
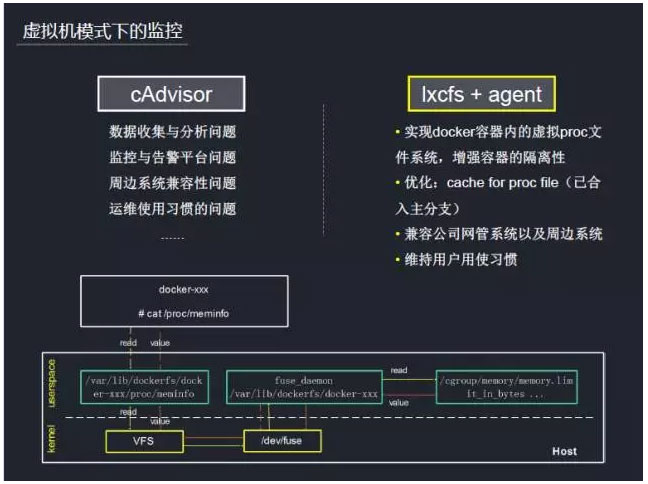
ľŗŅō°ĘłśĺĮ «’ŻłŲ”őŌ∑‘ň”™Ļż≥Ő÷–◊Óő™ļň–ńĶńĻ¶ń‹÷ģ“Ľ°£»›∆ų…ŌĶńľŗŅō”–Īū”ŕőÔņŪĽķ£¨cAdvisorļÕkubenetesĹŠļŌĶ√Ī»ĹŌĹŰ√‹£¨ «łŲ≤ĽīŪĶń∑Ĺįł°£ĶęňŁ“≤ĽŠīÝņīő Ő‚£¨ń«ĺÕ «–Ť“™◊‘Ĺ®ľŗŅō∆ĹŐ®£¨∂Ý«“ňŁ”Ž÷‹ĪŖłųŌĶÕ≥Ķńľś»›–‘“≤”–īżŅľ—ť£¨Õ¨ ĪłńĪš‘ňő¨Ķń Ļ”√ŌįĻŖ“≤–Ť“™ Īľš°£◊ŘļŌŅľ¬«łų÷÷“Úňōļů£¨ő“√«∑Ň∆ķŃňcAdvisor£¨÷ō–¬Ķų—–∆šňŁ∑Ĺįł£¨Ō£ÕŻŅ…“‘—ō”√Ļęňĺ≥… žĶńľŗŅō∆ĹŐ®£¨∂Ý«“ľś»›÷‹ĪŖŌĶÕ≥°£◊Ó÷’ő“√«—°”√Ķń «lxcfs
+ ĻęňĺagentĶń∑Ĺįł£¨Õ®Ļżlxcfs»• ĶŌ÷Docker»›∆ųńŕĶń–ťń‚procőńľĢŌĶÕ≥£¨‘Ų«Ņ»›∆ųĶńłŰņŽ–‘°£
ő“√«’‚ņÔ“‘meminfońŕīśÕ≥ľ∆–ŇŌĘő™ņż£¨ő™īůľ“Ĺ≤Ĺ‚»ÁļőÕ®Ļżlxcfs”√ĽßŐ¨őńľĢŌĶÕ≥ ĶŌ÷Docker»›∆ųńŕĶń–ťń‚procőńľĢŌĶ°£Ļ“‘ō–ťń‚procőńľĢŌĶÕ≥ĶĹDocker»›∆ų£¨Õ®ĻżDockerĶńvolumeĻ¶ń‹£¨ĹęńłĽķ…ŌĶń/var/lib/dockerfs/docker-xxx/procĻ“‘ōĶĹDocker»›∆ųńŕ≤ŅĶń–ťń‚procőńľĢŌĶÕ≥ńŅ¬ľŌ¬/proc/°£īň Ī‘ŕ»›∆ųńŕ≤Ņ/proc/ńŅ¬ľŌ¬Ņ…“‘ŅīĶĹ“Ľ–©Ń–procőńľĢ£¨∆š÷–įŁņ®meminfo°£”√Ľß‘ŕ»›∆ųńŕ∂Ń»°/proc/meminfo Ī£¨ Ķľ …Ō «∂Ń»°ňř÷ųĽķ…ŌĶń/var/lib/dockerfs/docker-xxx/proc/meminfoĻ“‘ōĶĹ»›∆ųńŕ≤ŅĶńmeminfoőńľĢ°£ńŕļňVFSĹę”√Ľß«Ž«ů◊™∑ĘĶĹĺŖŐŚőńľĢŌĶÕ≥°™°™fuse£¨fuseőńľĢŌĶÕ≥∑‚◊įVFS«Ž«ů,Ĺę«Ž«ů◊™∑ĘłÝFuse…ŤĪł(/dev/fuse)°£»ÁĻŻ…ŤĪł…Ō”–“—ĺ≠ī¶ņŪÕÍ≥…Ķń«Ž«ů£®ņż»ÁCache£©£¨őńľĢŌĶÕ≥ĽŮ»°ī¶ņŪĹŠĻŻ≤Ę∑ĶĽōłÝVFS£¨VFS‘Ŕ∑īņ°łÝ”√Ľß°£”√ĽßŅ‚(fuse
daemon)÷ĪĹ”∑√ő Fuse…ŤĪł£¨∂Ń»°őńľĢŌĶÕ≥◊™∑ĘĶĹ…ŤĪł…ŌĶń«Ž«ů£¨∑÷őŲ«Ž«ůņŗ–Õ£¨Ķų”√”√ĽßĹ”Ņŕī¶ņŪ«Ž«ů£¨ī¶ņŪÕÍ≥…ļůĹęī¶ņŪĹŠĻŻ∑ĶĽōłÝ…ŤĪł£¨‘Ŕ”……ŤĪł∑ĶĽōłÝVFS£¨VFS‘Ŕ∑īņ°łÝ”√Ľß£¨ī”∂Ý ĶŌ÷»›∆ųńŕĶńłŰņŽ°£ĻęňĺagentŅ…“‘Õ®Ļż∂Ń»°memoryĶ»–ŇŌĘ£¨…ŌĪ®ĶĹľŗŅō∆ĹŐ®◊Ų∑÷őŲ”ŽĪ®ĺĮ°£Õ¨ Ī‘ňő¨Õ®ĻżSSHĶ«¬ľĶĹ’‚łŲ»›∆ų£¨Õ®Ļżfree°ĘtopĶ»√ŁŃÓ≤ťŅī–‘ń‹£¨ő¨≥÷Ńň‘ňő¨‘≠ņīĶń Ļ”√ŌįĻŖ°£

‘ŕīęÕ≥”őŌ∑ņÔ£¨łŁ∂ŗĶń «”–◊īŐ¨Ķń∑ĢőŮĽŠ…śľįĶĹ żĺ›ĶńīśīĘ£¨ő“√«Õ®ĻżDockerĶńvolumeŐŠĻ©≥÷ĺ√ĽĮīśīĘ°£◊ÓŅ™ ľő“√«≤…”√HostPath∑Ĺ Ĺ£¨į—host…ŌĶńńŅ¬ľĻ“‘ōĶĹ»›∆ųņÔ£®ņż»Á/data£©◊ųő™ żĺ›īśīĘ°£’‚÷÷◊Ų∑®∑«≥£∑ĹĪ„°ĘľÚĶ•£¨őř–Ť∂ÓÕ‚Ķń÷ß≥÷£¨Ķę żĺ›Ķńį≤»ę–‘°ĘŅ…ŅŅ–‘∑Ĺ√śĪ»ĹŌ≤Ó°£ňý“‘ő“√«≤…”√ŃňŃŪÕ‚“Ľ÷÷∑Ĺįł£¨ľīCeph°£łń‘žkubenetes÷ß≥÷ceph£¨Õ®ĻżvolumeĻ“‘ō£¨ŐŠĻ©łŁį≤»ę°ĘłŁŅ…ŅŅĶń żĺ›īśīĘ∑Ĺįł°£Ĺ‚ĺŲ‘ŕhostĻ ’Ō Ī£¨ żĺ›∂™ ßĶńő Ő‚£¨”¶”√≥°ĺį“≤ĪšĶ√łŁľ”Ļ„∑ļ£¨įŁņ® żĺ›Ņ‚īśīĘ£¨ĺĶŌŮīśīĘ£¨»›∆ų«®“∆Ķ»°£

ĹŮńÍ£¨ő“√«Ņ™ ľ÷ß≥ŇĶŕ“ĽŅÓőĘ∑ĢőŮĽĮ”őŌ∑(ľę∆∑∑…≥Ķonline)£¨‘ī”ŕ÷ģ«į∂‘kubernetesĶń Ļ”√ĺ≠—ť°£‘ŕőĘ∑ĢĽĮ»›∆ųĶńĶų∂»÷–ő“√«—ō”√Ńňkubernetes£¨Ķę‘ŕįśĪĺ…Ō÷ō–¬◊ŲŃň—°‘Ů£¨łķňś◊Ň…Á«ÝĶń∑Ę’Ļ£¨—°”√Ńňv1.2įś°£‘ŕőĘ∑ĢőŮĽĮń£ ĹŌ¬£¨”őŌ∑Ķńľ‹ĻĻ≤ķ…ķŃňļ‹īůĶńĪšĽĮ°£įīĻ¶ń‹Ōł∑÷ĶĹłųłŲ–°ń£Ņť£¨Õ®ĻżĺĶŌŮĹĽł∂°Ę∑÷∑Ę£¨◊Óļů“‘»›∆ųņī≤Ņ ū∑ĢőŮ°£√ŅłŲń£ŅťŌŗ∂‘∂ņŃĘ£¨÷ģľš–ŇŌĘŃųĹĽĽ•Õ®ĻżŌŻŌĘ◊ťľĢ£®ņż»ÁRabbitMQ)ņī ĶŌ÷°£Õ¨ Ī√ŅłŲ»›∆ųőř–ŽŇš÷√ńŕÕÝIP£¨Ņ…“‘Õ®Ļż”Ú√Żņī∑√ő °£ňý“‘‘ŕÕݬÁ∑Ĺ√ś“≤”–ňýĶų’Ż£¨ő“√«“≤∆ņĻņŃňdocker
overlay°Ęflannel°Ęvxlan°Ęmaxvlan°ĘSR-IOVĶ»£¨ĹŠļŌ∆š÷–Ķń”Ň»ĪĶ„£¨◊Óļůő“√«—°∂®Ķń∑Ĺįł»ÁŌ¬£ļ
1°ĘľĮ»ļńŕpod”ŽpodĶń÷ģľšĶńÕ®–Ň£¨”…”ŕ≤Ľ–Ť“™ńŕÕÝIP£®Ņ…“‘”√–ťń‚IP£©ňý“‘≤…”√overlayÕݬÁ£¨”…flannel◊ťľĢ ĶŌ÷°£
2°ĘĻęňĺńŕÕÝĶĹľĮ»ļńŕpodÕ®–Ň£¨ņż»ÁHAProxy£¨”őŌ∑ń≥–©ń£Ņť£¨≤…”√SR-IOVÕݬÁ£¨”…◊‘ľļ∂®÷∆Ķńsriov-cni◊ťľĢ ĶŌ÷°£’‚ņŗpodĺŖĪłňę÷ōÕݬÁ£¨eth0∂‘”¶overlayÕݬÁ£¨eth1∂‘”¶SR-IOVÕݬÁ°£
3°ĘpodĶĹĻęňĺńŕÕÝ÷ģľšĶńÕ®–Ň°£‘ŕőĘ∑ĢőŮ≥°ĺįŌ¬£¨”őŌ∑Ķń żĺ›īśīĘ£¨÷‹ĪŖŌĶÕ≥Ķ»£¨≤Ņ ū‘ŕőÔņŪĽķĽÚ’Ŗ–ťń‚Ľķ…Ō£¨“ÚīňpodĶĹ’‚–©ń£Ņť°ĘŌĶÕ≥Ķń∑√ő £¨◊ŖĶń «NATÕݬÁ°£
4°ĘĻęÕÝ(Internet)Ĺ”»Ž£¨≤…”√ĻęňĺĶńTGW∑Ĺįł°£
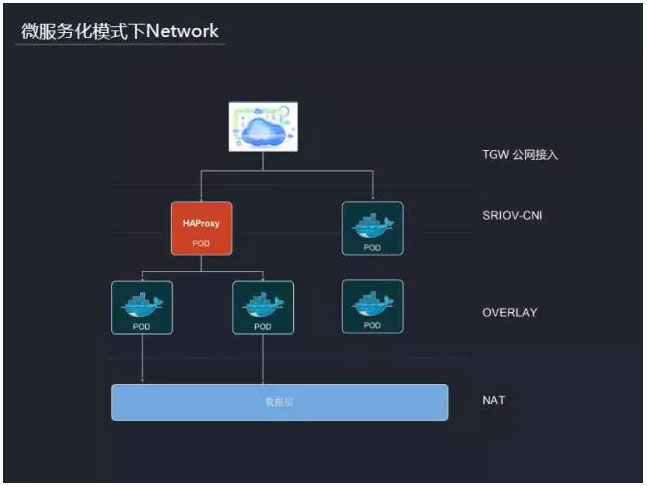
‘ŕ’ŻłŲőĘ∑ĢĽĮ∆ĹŐ®…Ō£¨…śľįĶĹĶńĻōĹ°ľľ űĶ„ĽŠłŁ∂ŗ£ļ
1°ĘÕݬÁ∑Ĺįł£ļľī…Ō ŲĹ≤ĶĹŃňoverlay + SR-IOV + TGW + NAT∑Ĺįł
2°Ę»’÷ĺ£¨ľŗŅō£ļ∂‘”ŕőĘ∑ĢőŮĽĮľ‹ĻĻĶń”őŌ∑£¨įśĪĺĶńĹĽł∂∂ľ «Õ®ĻżĺĶŌŮ£¨≤ĽĽŠį—ĻęňĺĶńagentīÚĶĹĺĶŌŮ£¨ňý“‘‘≠ņīĶńlxcfs
+ agentľŗŅōĺÕ≤Ľ ”¶Ńň£¨ňý“‘’‚ņÔő“√«÷ō–¬īÚ‘žŃň“ĽłŲ–¬Ķń»’÷ĺ°ĘľŗŅō∆ĹŐ®£¨”Žņ∂ĺ®ÕŇ∂”ļŌ◊ų£¨ ĶŌ÷Ńň”őŌ∑“ĶőŮ»’÷ĺ≤…ľĮ£Ľ»›∆ųĹ°ŅĶ◊īŐ¨°Ę–‘ń‹ĶńľŗŅō
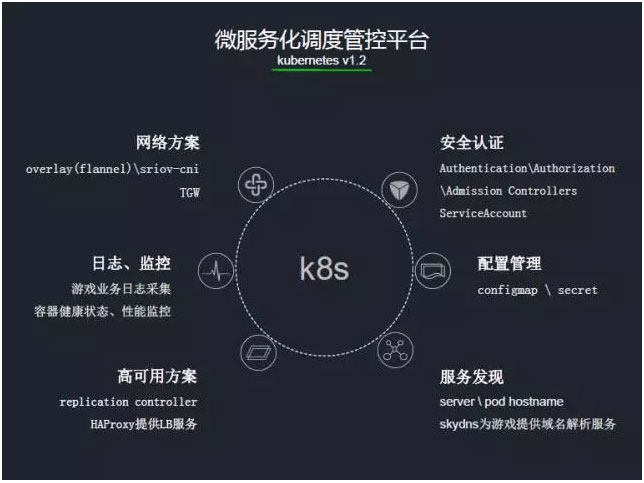
3°ĘłŖŅ…”√∑Ĺįł£ļ‘ŕ◊ ‘īĶń≤Ņ ū∑Ĺ√ś£¨ő“√«≤…”√Ńňreplication controller∑Ĺ Ĺ£¨Õ®ĻżkubernetesĶńcontroller
managerń£Ņťņīľŗ≤‚podĶń◊īŐ¨£¨‘ŕ∑Ę…ķĻ ’ŌĶń ĪļÚ£¨ ĶŌ÷ŅžňŔĶń«®“∆°ĘĽ÷łī∑ĢőŮ°£ŃŪ“Ľ∑Ĺ√ś£¨‘ŕload
balance≥°ĺįŌ¬£¨ő“√«≤…”√ŃňHAProxyņī ĶŌ÷
4°Ęį≤»ę∑Ĺ√ś£ļkubernetesľĮ»ļ≥–‘ō◊Ň’ŻłŲ”őŌ∑»›∆ų◊ ‘īĶńĶų∂»°ĘĻ‹ņŪ°£≤ĽĻ‹ «»ňő™őů≤Ŕ◊ų£¨ĽĻ «ļŕŅÕ»Ž«÷£¨‘ž≥…Ķń”įŌžĹę «∑«≥£÷ģīů°£ňý“‘į≤»ę «ő“√«–Ť“™Ņľ¬«Ķń÷ōĶ„£¨ĹŠļŌkubernetes£¨ő“√«ńŅ«į◊ŲŃň“‘ľł∑Ĺ√ś£¨ļů√śĽŠ”–łŁľ”Ķńį≤»ę≤Ŗ¬‘ŐŠĻ©°£
4.1 Authentication ļÕ Authorization°£ Ļ”√httpsņīľ”√‹ŃųŃŅ£¨Õ¨ Ī‘ŕ”√Ľß»®Ōř—ť÷§…Ō£¨ŐŠĻ©Ńňtoken—ť÷§∑Ĺ Ĺ°ĘABAC»®Ōř»Ō÷§∑Ĺ Ĺ
4.2 Admission Controllers£ļŇš÷√ĺŖŐŚĶń◊ľ»ŽĻś‘Ú
4.3 ServiceAccount£ļ÷ų“™Ĺ‚ĺŲ‘ň––‘ŕpodņÔĶńĹÝ≥Ő–Ť“™Ķų”√kubernetes API“‘ľį∑«kubernetes
APIĶń∆šňŁ∑ĢőŮő Ő‚
5°ĘŇš÷√Ļ‹ņŪ£ļÕ®Ļżconfigmap\secrető™”őŌ∑ŐŠĻ©ľÚ“◊ĶńŇš÷√Ļ‹ņŪ
6°Ę∑ĢőŮ∑ĘŌ÷£ļkubernetesĽŠő™√ŅłŲpod∑÷Ňš“ĽłŲ–ťń‚ĶńIP£¨Ķę’‚łŲIP «∑«ĻŐ∂®Ķń£¨ņż»Ápod∑Ę…ķĻ ’Ō«®“∆ļů£¨ń«√īIPĺÕĽŠ∑Ę…ķĪšĽĮ°£ňý“‘‘ŕőĘ∑ĢőŮĽĮ”őŌ∑ľ‹ĻĻŌ¬£¨“ĶőŮpod÷ģľšĶń∑√ő łŁ∂ŗĶō≤…”√”Ú√Ż∑Ĺ ĹĹÝ––∑√ő °£‘ŕkubernetes…ķŐ¨Ńī÷–£¨ŐŠĻ©Ńňskydns◊ųő™DNS∑ĢőŮ∆ų£¨ĹŠļŌkubernetesĶńserverŅ…“‘ļ‹ļ√ĶńĹ‚ĺŲ”Ú√Ż∑√ő ő Ő‚
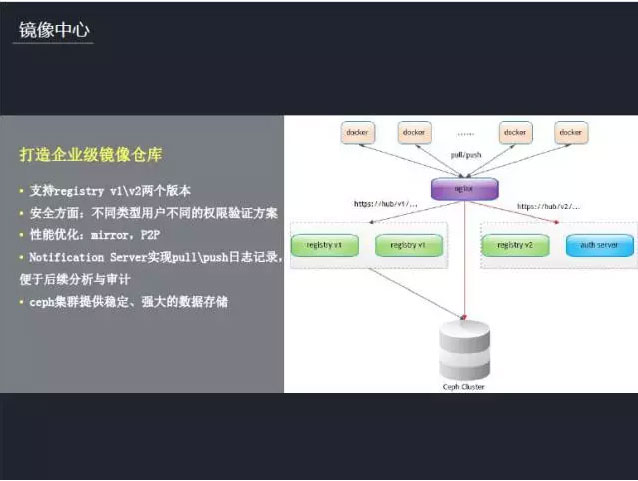
Ņ™ ľĹ≤”őŌ∑»›∆ųĽĮĶń ĪļÚŐłĶĹ”√ĺĶŌŮņīĪÍ◊ľĽĮ≤Ņ ū£¨ňý“‘ő“√«Ľ®Ńňļ‹∂ŗ ĪľšīÚ‘ž∆ů“Ķľ∂ĶńĺĶŌŮ≤÷Ņ‚°£ńŅ«į÷ß≥÷registry
v1\v2ŃĹłŲįśĪĺ£¨»Á”“Õľňý ĺ£¨‘ŕclient∂ň(docker)”Žregistry÷ģľš≤…”√nginx◊ųő™īķņŪ£¨ ĶŌ÷v1\v2≤ĽÕ¨«Ž«ůĶń◊™∑Ę£¨’‚—ý“Ľņī£¨”√Ľßőř–ŤĻō–ńĶĹĶ◊«Ž«ůĶń «v1ĽĻ «v2°£‘ŕį≤»ę∑Ĺ√ś£¨≤ĽÕ¨ņŗ–Õ”√Ľß≤ĽÕ¨Ķń»®Ōř—ť÷§∑Ĺįł°£Ļęňĺńŕ≤Ņ”√ĽßĹ”»ŽOA»Ō÷§£¨”ŽĻęňĺ∆ĹŐ®īÚÕ®°£Õ‚≤Ņ”√Ľß–Ť“™…Í«Ž∑√ő »®Ōř£¨”…Ļ‹ņŪ‘Ī∑÷Ňš’ ļŇ£¨»ĽļůÕ®Ļż∑÷ŇšĶń’ ļŇņī«Ž«ů°£‘ŕīůŇķŃŅņ≠»°ĺĶŌŮĶń ĪļÚ£¨ĺĶŌŮ÷––ńĶń–‘ń‹°Ę–߬ «ő“√«–Ť“™Ņľ¬«Ķńő Ő‚°£«į∆ŕő“√«Õ®Ļżmirror∑Ĺįłņī ĶŌ÷£¨‘ŕ÷ų“™≥« –≤Ņ ūmirror
registry£¨Õ®ĻżĺÕĹŁ‘≠‘Úņīņ≠»°ĺĶŌŮ£¨Ĺ‚ĺŲ–‘ń‹∆ŅĺĪ°£ļů–Ýő“√«ĽĻĽŠ≤…”√P2P∑ĹįłņīŐŠ…żĺĶŌŮņ≠»°–‘ń‹°£Õ¨ Īő“√«∂®÷∆ŃňNotification
Server£¨”√”ŕĺĶŌŮpull\push»’÷ĺľ«¬ľ£¨Ī„”ŕļů–Ý∑÷őŲ”Ž…ůľ∆°£‘ŕĺĶŌŮļů∂ňīśīĘ∑Ĺ√ś£¨≤…”√cephľĮ»ļ∑Ĺįł£¨ī”∂ÝŐŠĻ©ő»∂®°Ę«ŅīůĶń żĺ›īśīĘ°£
őĘ∑ĢőŮĽĮ÷ģ¬∑ő“√«ł’ł’∆ūļĹ£¨‘ŕ√śŃŔŐŰ’ĹĶńÕ¨ Ī“≤īÝņīŃňĽķ”Ų°£≤ĽĹŲĹŲ «‘ŕŌŖ“ĶőŮĶńŐĹňų£¨ő“√«“≤ĽŠŐĹňųņŽŌŖľ∆ň„°Ę…Ó∂»—ßŌįĶ»ŌĶÕ≥Ķń÷ß≥÷°£

|









