| ұајӯНЖјц: |
| ұҫОДАҙЧФУЪcsdnЈ¬ұҫОДЦчТӘҪйЙЬОӘБЛёьәГВъЧгDevOpsЈ¬ОТГЗІЙУГБЛҝӘФҙҝтјЬSpinnakerЧчОӘіЦРшҪ»ё¶ЖҪМЁЈ¬НкіЙ·юОсөДҝмЛЩІҝКрЎЈ |
|
ТөДЪёчҙуФЖ·юОсЙМТФј°№«ЛҫЦрҪҘСЎФсKubernetesУлDockerЧчОӘОў·юОсЦ§іЕөДКЧСЎЖҪМЁЎЈОӘБЛёьәГВъЧгDevOpsЈ¬ОТГЗІЙУГБЛҝӘФҙҝтјЬSpinnakerЧчОӘіЦРшҪ»ё¶ЖҪМЁЈ¬НкіЙ·юОсөДҝмЛЩІҝК𣬻عцЈ¬A/BІвКФЈ¬ТФј°ҪрЛҝИёөИөИөДІҝКр·ҪКҪЈ¬Н¬КұОТГЗФЪЙъІъЧцБЛ¶аЗшөДИЭФЦЈ¬ёьәГөДұЈХППЯЙП·юОсЎЈ
SpinnakerҪйЙЬ
SpinnakerКЗNetflixөДҝӘФҙПоДҝЈ¬КЗТ»ёціЦРшҪ»ё¶ЖҪМЁЈ¬Ль¶ЁО»УЪҪ«ІъЖ·ҝмЛЩЗТіЦРшөДІҝКрөҪ¶аЦЦФЖЖҪМЁЙПЎЈSpinnakerУРБҪёцәЛРДөД№ҰДЬјҜИә№ЬАнәНІҝКр№ЬАнЎЈSpinnakerНЁ№эҪ«·ўІјәНёчёцФЖЖҪМЁҪвсоЈ¬АҙҪ«ІҝКрБчіМБчЛ®ПЯ»ҜЈ¬ҙУ¶шҪөөНЖҪМЁЗЁТЖ»т¶аФЖЖҪМЁІҝКрУҰУГөДёҙФУ¶ИЈ¬ЛьұҫЙнДЪІҝЦ§іЦGoogleЎўAWS
EC2ЎўMicrosoft AzureЎўKubernetesәНOpenStackөИФЖЖҪМЁЈ¬ІўЗТЛьҝЙТФОЮ·мјҜіЙЖдЛыіЦРшјҜіЙЈЁCIЈ©БчіМЈ¬ИзGitЎўJenkinsЎўTravis
CIЎўDocker registryЎўcronөч¶ИЖчөИЎЈ
УҰУГ№ЬАн
SpinnakerЦчТӘУГУЪХ№КҫУл№ЬАнДгөДФЖ¶ЛЧКФҙЎЈ
ПИТӘБЛҪвТ»Р©№ШјьөДёЕДоЈәApplicationsЈ¬ClusterЈ¬and Server GroupsЈ¬НЁ№эLoad
balancers and firewallsҪ«·юОсХ№КҫёшУГ»§ЎЈ№Щ·ҪёшөДҪб№№ИзПВЈә
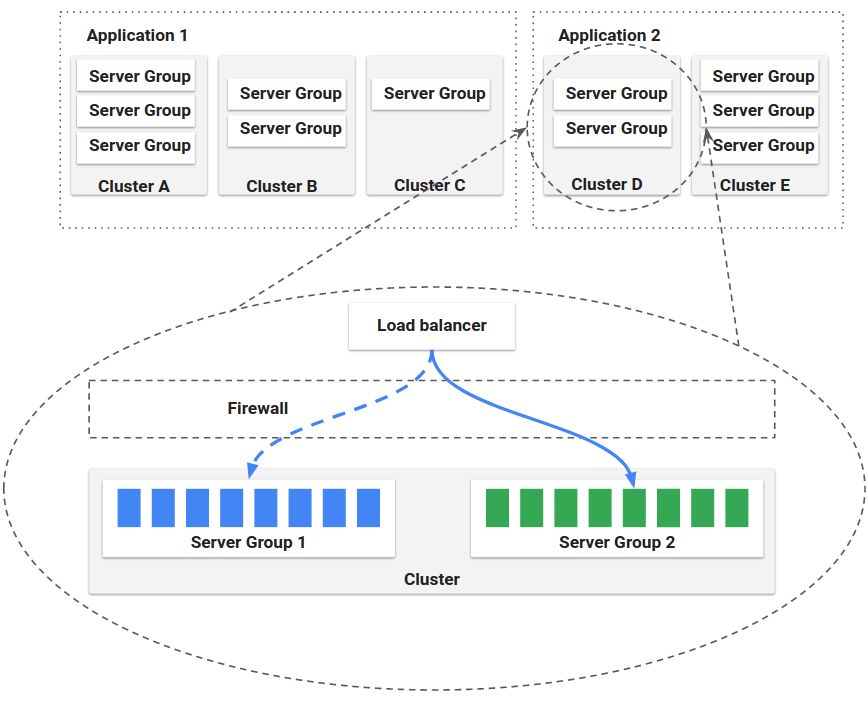
Application
¶ЁТеБЛјҜИәЦРТ»ЧйөДClusterөДјҜәПЈ¬ТІ°ьАЁБЛFirewallsУлLoad BalancersЈ¬ҙжҙўБЛ·юОсЛщУРөДІҝКрПа№ШөДөДРЕПўЎЈ
Server Group
¶ЁТеБЛТ»Р©»щҙЎөДФҙұИИзЈЁVM imageЎўDocker imageЈ©Ј¬ТФј°Т»Р©»щҙЎөДЕдЦГРЕПўЈ¬Т»ө©ІҝКрәуЈ¬ФЪИЭЖчЦР¶ФУҰKubernetes
PodөДјҜәПЎЈ
Cluster
Server GroupsөДУР№ШБӘөДјҜәПЎЈЈЁClusterЦРҝЙТФ°ҙХХdevЈ¬prodөДИҘҙҙҪЁІ»Н¬өД·юОсЧйЈ©Ј¬ТІҝЙТФАнҪвОӘ¶ФУЪТ»ёцУҰУГҙжФЪ¶аёц·ЦЦ§өДЗйҝцЎЈ
Load Balancer
ЛьФЪКөАэЦ®јдЧцёәФШҫщәвБчБҝЎЈДъ»№ҝЙТФОӘёәФШҫщәвЖчЖфУГҪЎҝөјмІйЈ¬Бй»оөШ¶ЁТеҪЎҝөұкЧјІўЦё¶ЁҪЎҝөјмІй¶ЛөгЈ¬УРөгАаЛЖУЪKubernetesЦРIngressЎЈ
Firewall
·А»рЗҪ¶ЁТеБЛНшВзБчБҝ·ГОКЈ¬¶ЁТеБЛТ»Р©·ГОКөД№жФтЈ¬Из°ІИ«ЧйөИөИЎЈ
ТіГжФӨАА
ТіГжХ№КҫИзПВЈ¬»№КЗұИҪПҫ«јтөДЈ¬ҝЙТФФЪЛьөДІЩЧчТіГжЙПҝҙөҪПоДҝТФј°УҰУГөДПкПёРЕПўЈ¬»№ҝЙТФҪшРРјҜИәөДЙмЛхЎў»Ш№цЎўРЮёДТФј°ЙҫіэөДІЩЧчЎЈ
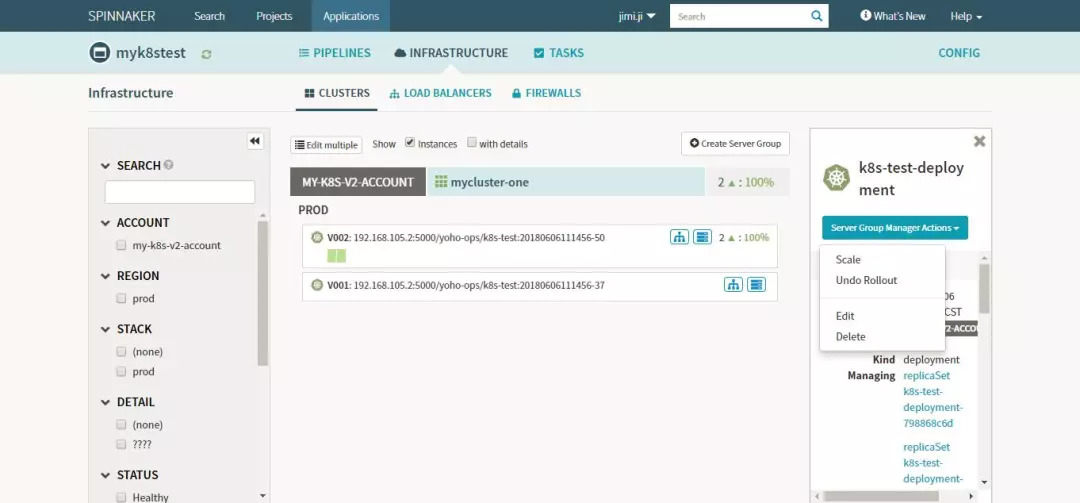
ІҝКр№ЬАн
ЙПНјЦРЈ¬InfrastructureЧуІаОӘPipelineөДЙијЖЈәЦчТӘҪІБҪҝйДЪИЭЈәPipelineөДҙҙҪЁТФј°»щҙЎ№ҰДЬЈ¬УлІҝКрөДІЯВФЎЈ
Pipeline
1.ҪПЗҝөДPipelineөДДЬБҰЈәЛьөДPipelineҝЙТФёҙФУөҪОЮТФёҙјУЈ¬Ль»№УРәЬЗҝөДұнҙпКҪ№ҰДЬЈЁәуРшөДІЩЧчЦРЗ°ГжөДІОКэҫщНЁ№эұнҙпКҪ»сИЎЈ©ЎЈ
2.ҙҘ·ўөД·ҪКҪЈә¶ЁКұИООсЎўИЛ№ӨҙҘ·ўЎўJenkins jobЎўDocker
imagesЈ¬»тХЯЖдЛыөДPipelineөДІҪЦиЎЈ
3.НЁЦӘ·ҪКҪЈәEmailЎўSMS or HipChatЎЈ
4.Ҫ«ЛщУРөДІЩЧч¶јИЪәПөҪPipelineЦРЈ¬ұИИз»Ш№цЎўҪрЛҝИё·ЦОцЎў№ШБӘCIөИөИЎЈ
ІҝКрІЯВФ
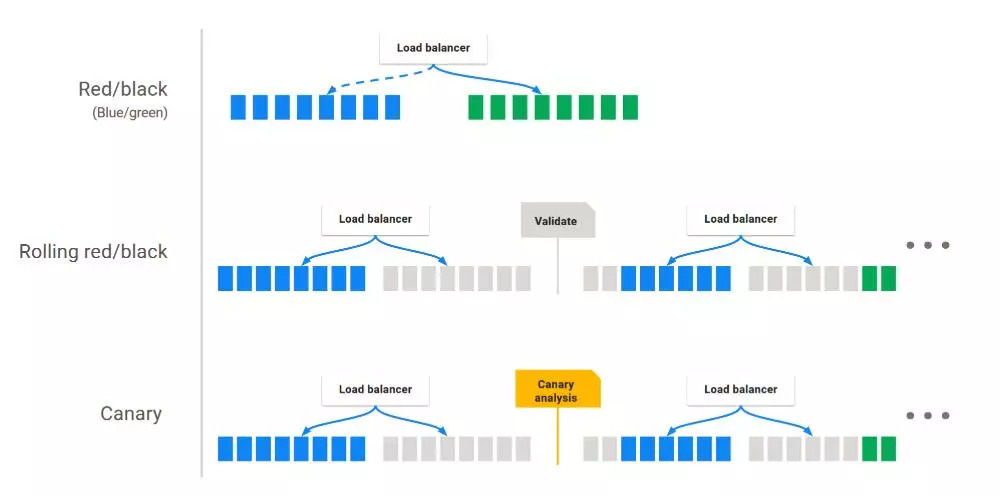
УЙУЪОТГЗУГөДКЗKubernetes Provider V2ЈЁManifest BasedЈ©·ҪКҪЈәҝЙРЮёДyamlЦРЈәspec.strategy.typeЎЈ
1.RecreateЈ¬ПИҪ«ЛщУРҫЙөДPodНЈЦ№Ј¬И»әуФЩЖф¶ҜРВөДPod¶ФУҰЖдЦРөДөЪТ»ЦЦ·ҪКҪЎЈ
2.RollingUpdateЈ¬јҙ№ц¶ҜЙэј¶Ј¬¶ФУҰПВНјЦРөЪ¶юЦЦ·ҪКҪЎЈ
3.CanaryПВГж»бөҘ¶АөДҪйЙЬЖдЦРөДК№УГЎЈ
Spinnaker°ІЧ°ІИ№эөДҝУ
әЬ¶аИЛ¶јКЗёРҫхХвёцәЬДС°ІЧ°Ј¬ЖдКөЦчТӘөДФӯТт»№КЗЗҪөДОКМвЈ¬Ц»ТӘ°СХвёцҪвҫцБЛҫН»б·ҪұгәЬ¶аЈ¬№Щ·ҪөДОДөөРҙөДәЬПкПёЈ¬¶шЗТSpinnakerөДЙзЗшТІ·ЗіЈөД»оФҫЈ¬УРОКМвҫщҝЙТФФЪЙПГжҪшРРМбОКЎЈ
°ІЧ°МṩөД·ҪКҪ
1.Halyard°ІЧ°·ҪКҪЈЁ№Щ·ҪНЖјц°ІЧ°·ҪКҪЈ©
2.HelmҙоҪЁSpinnakerЖҪМЁ
3.Development°жұҫ°ІЧ°
ОТІЙУГHalyard°ІЧ°·ҪКҪЈ¬ТтОӘәуЖЪОТГЗ»бјҜіЙәЬ¶аЖдЛыөДІејюЈ¬АаЛЖУЪGitLabЎўLDAPЎўKayentaЈ¬ЙхЦБ¶аёцJenkinsЈ¬Kubernetes·юОсөИөИЈ¬ҝЙЕдЦГРФҪПЗҝЎЈHelm·ҪКҪИфКЗРиТӘЧФ¶ЁТеТ»Р©ёцРФ»ҜөДДЪИЭ»бұИҪПёҙФУЈ¬НкИ«ТААөУЪФӯКјҫөПсЈ¬¶шDevelopmentРиТӘ¶ФSpinnaker·ЗіЈөДКмПӨЈ¬ТФј°Гҝёц°жұҫЦ®јдөД¶ФУҰ№ШПөҫщТӘБЛҪвЎЈ
Halyard·ҪКҪ°ІЧ°ЧўТвөг
HalyardҙъАнөДЕдЦГ
| vim
/opt/halyard/bin/halyard
DEFAULT_JVM_OPTS='-Dhttp.proxyHost=192.168.102.10
-Dhttps.proxyPort=3128' |
ІҝКр»ъЖчСЎФс
УЙУЪSpinnakerЙжј°өДУҰУГҪП¶аЈ¬ПВГж»бөҘ¶АөДҪйЙЬЈ¬РиТӘПыәДұИҪПҙуөДДЪҙжЈ¬№Щ·ҪНЖјцөДЕдЦГИзПВЈә
| 18
GB of RAM
A 4 core CPU
Ubuntu 14.04, 16.04 or 18.04 |
Spinnaker°ІЧ°ІҪЦи
HalyardПВФШТФј°°ІЧ°ЎЈ
1.СЎФсФЖМṩХЯЈәОТСЎФсөДКЗKubernetes Provider
V2ЈЁManifest BasedЈ©Ј¬РиТӘФЪІҝКрSpinnakerөД»ъЖчЙПНкіЙKubernetesјҜИәөДИПЦӨЈ¬ТФј°ИЁПЮ№ЬАнЎЈ
2.ІҝКрөДКұәтСЎФс°ІЧ°»·ҫіЈәОТСЎФсөДКЗDebian°ьөД·ҪКҪЎЈ
3.СЎФсҙжҙўЈә№Щ·ҪНЖјцК№УГMinioЈ¬ОТСЎФсөДКЗMinioөД·ҪКҪЎЈ
4.СЎФс°ІЧ°өД°жұҫЈәОТөұКұЧоРВөДКЗV1.8.0ЎЈ
5.ҪУПВАҙҪшРРІҝКр№ӨЧчЈ¬іхҙОІҝКрКұјдҪПіӨЈ¬»бБ¬ҪУҙъАнПВФШ¶ФУҰөД°ьЎЈ
6.И«ІҝПВФШУлНкіЙәуЈ¬Ійҝҙ¶ФУҰөДИХЦҫЈ¬јҙҝЙК№УГlocalhost:9000·ГОКјҙҝЙЎЈ
НкіЙТФЙПөДІҪЦиФтҝЙТФФЪKubernetesЙПГжІҝКр¶ФУҰөДУҰУГБЛЎЈ
Йжј°өДЧйјю
ПВНјКЗSpinnakerөДёчёцЧйјюЦ®јдөД№ШПөЎЈ 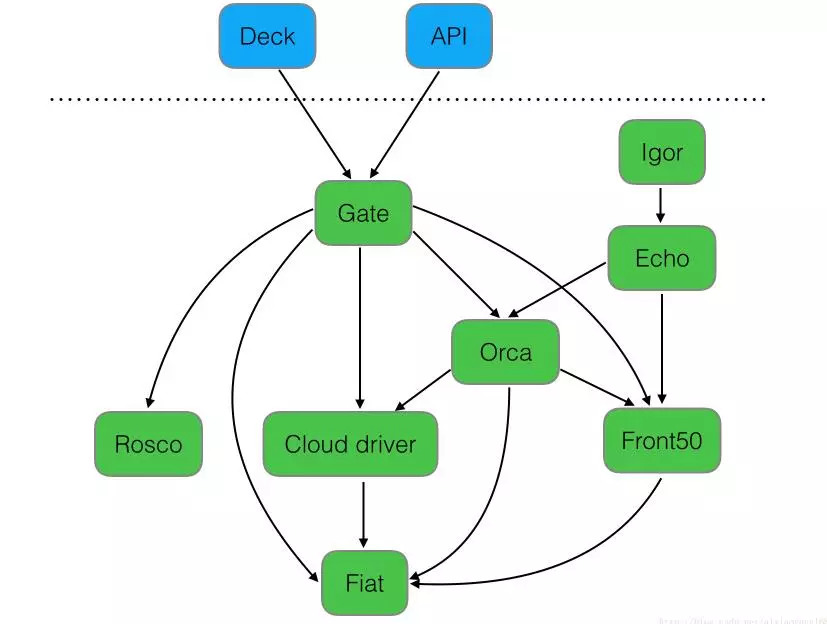
DeckЈәГжПтУГ»§UIҪзГжЧйјюЈ¬МṩЦұ№ЫјтҪйөДІЩЧчҪзГжЈ¬ҝЙКУ»ҜІЩЧч·ўІјІҝКрБчіМЎЈ
APIЈәГжПтөчУГAPIЧйјюЈ¬ОТГЗҝЙТФІ»К№УГМṩөДUIЈ¬ЦұҪУөчУГAPIІЩЧчЈ¬УЙЛьәуМЁ°пОТГЗЦҙРР·ўІјөИИООсЎЈ
GateЈәКЗAPIөДНш№ШЧйјюЈ¬ҝЙТФАнҪвОӘҙъАнЈ¬ЛщУРЗлЗуУЙЖдҙъАнЧӘ·ўЎЈ
RoscoЈәКЗ№№ҪЁbetaҫөПсөДЧйјюЈ¬РиТӘЕдЦГPackerЧйјюК№УГЎЈ
OrcaЈәКЗәЛРДБчіМТэЗжЧйјюЈ¬УГАҙ№ЬАнБчіМЎЈ
IgorЈәКЗУГАҙјҜіЙЖдЛыCIПөНіЧйјюЈ¬ИзJenkinsөИТ»ёцЧйјюЎЈ
EchoЈәКЗНЁЦӘПөНіЧйјюЈ¬·ўЛНУКјюөИРЕПўЎЈ
Front50ЈәКЗҙжҙў№ЬАнЧйјюЈ¬РиТӘЕдЦГRedisЎўCassandraөИЧйјюК№УГЎЈ
Cloud driverЈәКЗУГАҙККЕдІ»Н¬өДФЖЖҪМЁөДЧйјюЈ¬ұИИзKubernetesЎўGoogleЎўAWS
EC2ЎўMicrosoft AzureөИЎЈ
FiatЈәКЗјшИЁөДЧйјюЈ¬ЕдЦГИЁПЮ№ЬАнЈ¬Ц§іЦOAuthЎўSAMLЎўLDAPЎўGitHub teamsЎўAzure
groupsЎў Google GroupsөИЎЈ
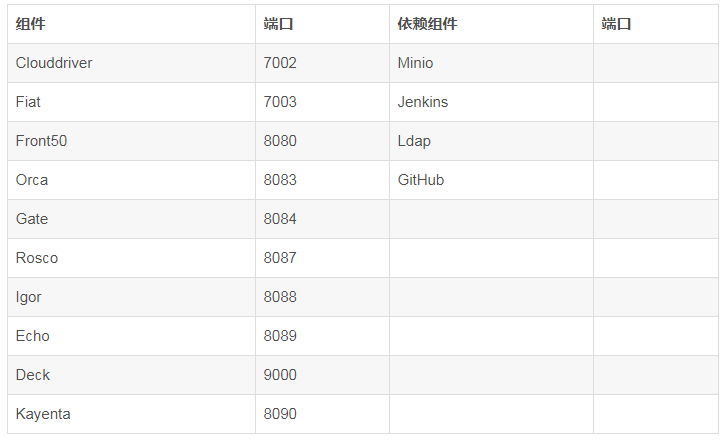
PipelineІҝКрКҫАэ
ИзПВPipelineЙијЖҫНКЗҝӘ·ўҪ«°жұҫәПөҪДіТ»ёц·ЦЦ§әуЈ¬НЁ№эJenkinsҫөПс№№ҪЁЈ¬·ўІјІвКФ»·ҫіЈ¬Ҫш¶шЧФ¶Ҝ»ҜТФј°ИЛ№ӨСйЦӨЈ¬ФЪУЙИЛ№ӨЕР¶ПКЗ·сРиТӘ·ўІјөҪПЯЙПТФј°»Ш№цЈ¬ИфКЗСЎФс·ўІјөҪПЯЙПФт·ўІјөҪprod»·ҫіЈ¬ҙУ¶шҪшРРprodЧФ¶Ҝ»ҜөДCIЎЈИфКЗСЎФс»Ш№цФт»Ш№цөҪЙПёц°жұҫЈ¬ҙУ¶шҪшРРdevЧФ¶Ҝ»ҜөДCIЎЈ
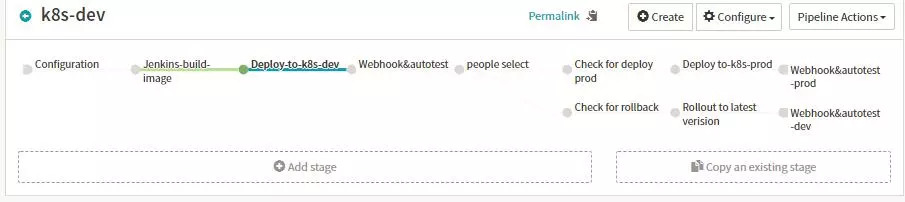
Stage-configuration
ЙиЦГҙҘ·ўөД·ҪКҪЈ¬¶ЁТеИ«ҫЦұдБҝЈ¬ЦҙРРұЁёжөДНЁЦӘ·ҪКҪЈ¬КЗPipelineөДЖрөгЎЈ
Automated TriggersЈ¬ЖдЦРЦ§іЦ¶аЦЦҙҘ·ўөД·ҪКҪЈә¶ЁКұИООсCornЈ¬GitЈ¬JenkinsЈ¬Docker
RegistryЈ¬TravisЈ¬PipelineЈ¬WebhookөИҙҘ·ў·ҪКҪЈ¬ҙУ¶шДЬ№»ВъЧгОТГЗЧФ¶Ҝ»ШөчөД№ҰДЬЎЈ
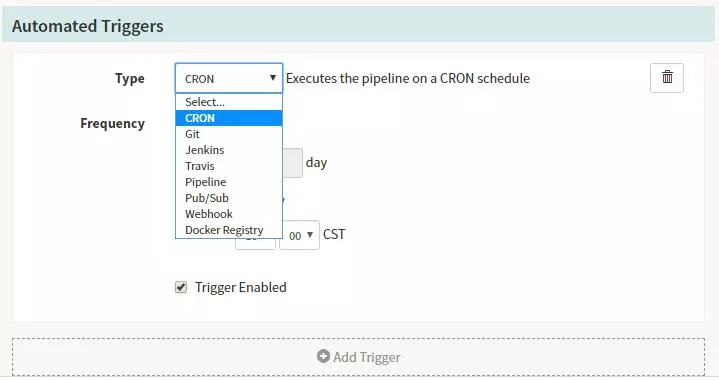
ParametersЈ¬ҙЛҙҰ¶ЁТеөДИ«ҫЦұдБҝ»бФЪХыёцPipelineЦРК№УГ${ parameters['branch']}өГөҪЈ¬ХвСщҙуҙуөДјт»ҜБЛОТГЗЙијЖPipelineөДНЁУГРФЎЈ
NotificationsЈ¬ХвАпНЁЦӘЦ§іЦЈәSMSЈ¬EmailЈ¬HipChatөИөИөД·ҪКҪЎЈ
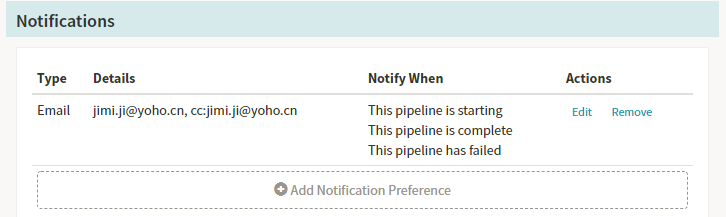
ОТГЗК№УГБЛУКјюНЁЦӘөД№ҰДЬЈәРиТӘФЪechoөДЕдЦГОДјюЦРјУИл·ўјюУКПдөД»щұҫРЕПўЎЈ
Stage-jenkins
өчУГJenkinsАҙЦҙРРПа№ШөДИООсЈ¬ЖдЦРJenkinsөД·юОсРЕПўҙжФЪ·ЕhalөДЕдЦГОДјюЦРЈЁИзПВХ№КҫЈ©Ј¬SpinnakerҝЙЧФ¶ҜТФН¬ІҪJenkinsөДJobТФј°ІОКэөИөИөДРЕПўЈ¬ФЛРРәуДЬ№»ҝҙөҪ¶ФУҰөДJob
IDТФј°ЧҙМ¬Јә
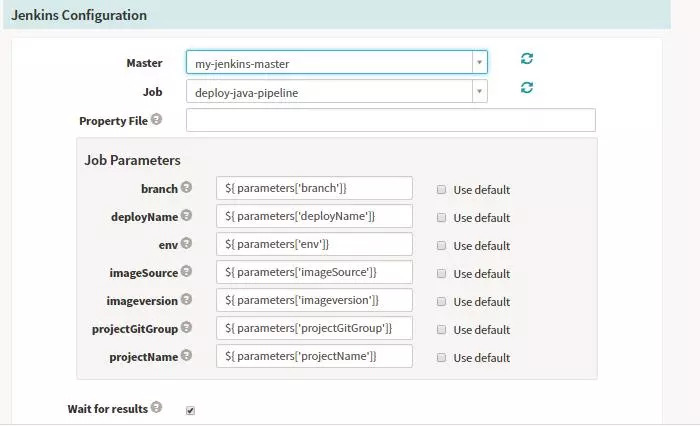
ФЛРРНкіЙәуХ№КҫИзПВЈ¬ОТГЗҝЙТФІйҝҙПа№ШөДbuildөДРЕПўЈ¬ТФј°ҙЛstageЦҙРРөДПа№ШРЕПўЈ¬өг»чbuildҝЙТФМшөҪ¶ФУҰөДJenkinsөДJobІйҝҙПа№ШөДИООсРЕПўЎЈ
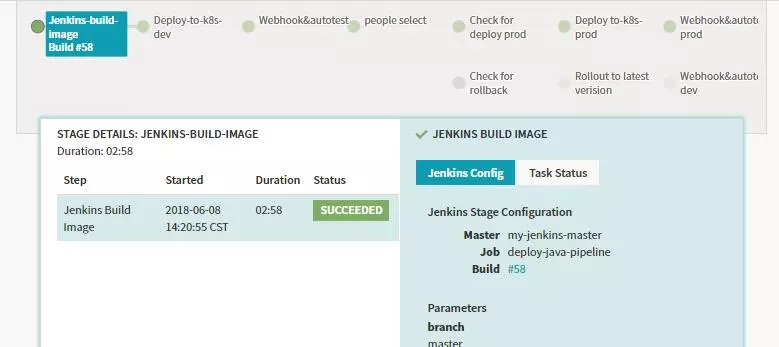
Stage-deploy
УЙУЪОТГЗЕдЦГSpinnakerөДКұәтІЙУГөДКЗKubernetes Provider V2·ҪКҪЈ¬ОТГЗөД·ўІјҫщІЙУГyamlөД·ҪКҪАҙКөПЦЈ¬ҝЙТФҪ«ОДјюҙж·ЕФЪGitHubЦР»тХЯЦұҪУФЪТіГжЙПҪшРРЕдЦГЈ¬Н¬КұyamlЦРОДјюЦ§іЦБЛәЬ¶аөДІОКэ»ҜЈ¬ХвСщҙуҙуөД·ҪұгБЛОТГЗИХіЈөДК№УГЎЈ
Halyard№ШБӘKubernetesөДЕдЦГРЕПўЈәУЙУЪОТГЗІЙУГөДФЖ·юОсКЗKubernetesЈ¬ЕдЦГөДКұәтРиТӘҪ«ІҝКрSpinnakerөД»ъЖч¶ФKubernetesјҜИәЧцИПЦӨЎЈ
Spinnaker·ўІјРЕПўХ№КҫЈәҙЛҙҰManifest SourceЦ§іЦІОКэ»ҜРОКҪЈ¬АаЛЖУЪОТГЗРҙИлөДyamlІҝКрОДјюЈ¬ө«КЗХвАпЦ§іЦІОКэ»ҜөД·ҪКҪЎЈ
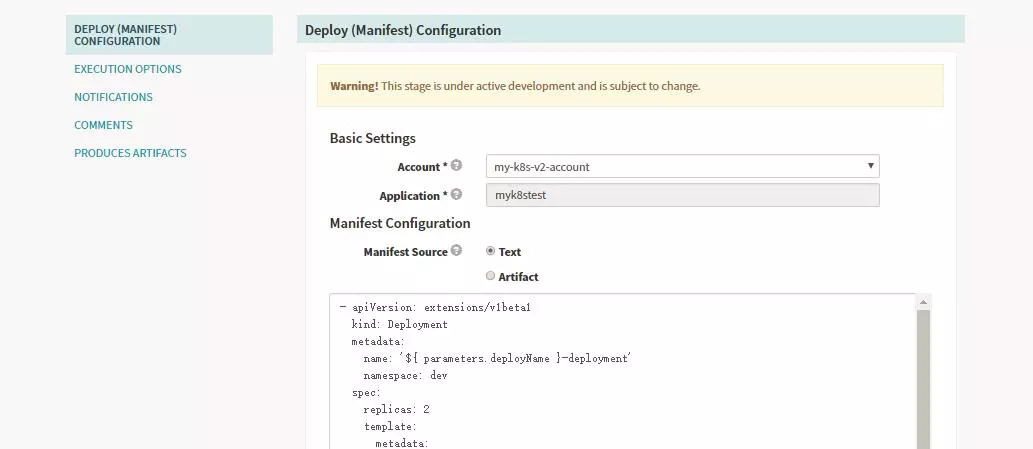
ҫЯМеөДЕдЦГПоИзПВЈә
| -
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: '${ parameters.deployName }-deployment'
namespace: dev
spec:
replicas: 2
template:
metadata:
labels:
name: '${ parameters.deployName }-deployment'
spec:
containers:
- image: >-
192.168.105.2:5000/${ parameters.imageSource
}/${
parameters.deployName }:${ parameters.imageversion
}
name: '${ parameters.deployName }-deployment'
ports:
- containerPort: 8080
imagePullSecrets:
- name: registrypullsecret
- apiVersion: v1
kind: Service
metadata:
name: '${ parameters.deployName }-service'
namespace: dev
spec:
ports:
- port: 8080
targetPort: 8080
selector:
name: '${ parameters.deployName }-deployment'
- apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: '${ parameters.deployName }-ingress'
namespace: dev
spec:
rules:
- host: '${ parameters.deployName }-dev.ingress.dev.yohocorp.com'
http:
paths:
- backend:
serviceName: '${ parameters.deployName }-service'
servicePort: 8080
path: / |
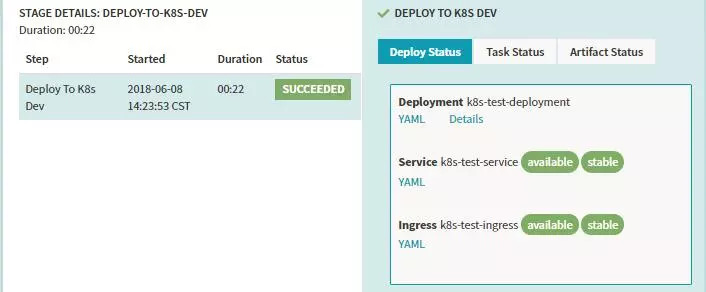
ФЛРРҪб№ыөДКҫАэЈә
Stage-Webhook
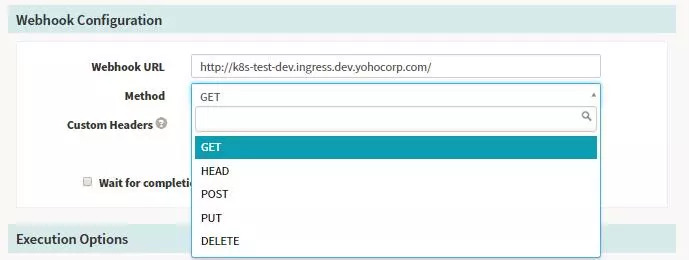
WebhookОТГЗҝЙТФЧцТ»Р©јтөҘөД»·ҫіСйЦӨТФј°ИҘөчУГЖдЛыөД·юОсөД№ҰДЬЈ¬ЛьЧФЙнТІМṩБЛТ»Р©Ҫб№ыөДСйЦӨ№ҰДЬЈ¬Ц§іЦ¶аЦЦЗлЗуөД·ҪКҪЎЈ
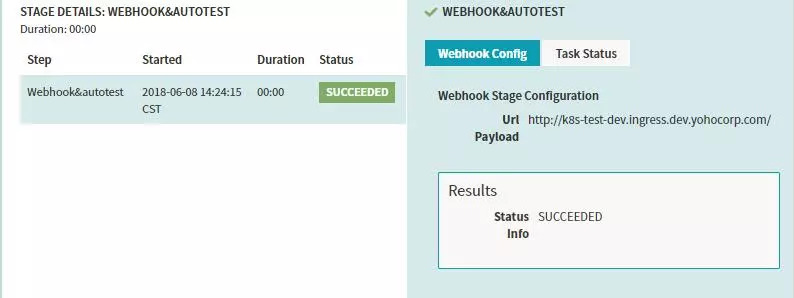
ФЛРРҪб№ыөДКҫАэЈә
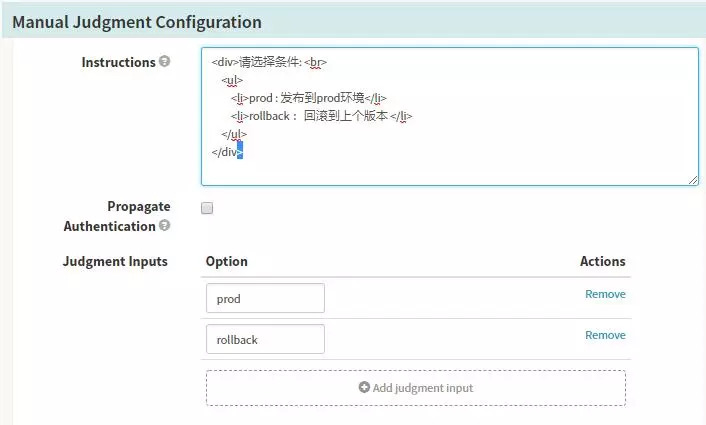
Stage-Manual Judgment
SpinnakerЕдЦГРЕПўЈ¬УГУЪИЛ№ӨөДВЯјӯЕР¶ПЈ¬ФцјУPipelineөДҝШЦЖРФЈЁұИИз·ўІјөҪПЯЙПРиТӘІвКФИЛФұИПЦӨТФј°БмөјЙуЕъЈ©Ј¬ДЪИЭЦ§іЦ¶аЦЦУп·ЁұнҙпөД·ҪКҪЎЈ
ФЛРРҪб№ыөДКҫАэЈә
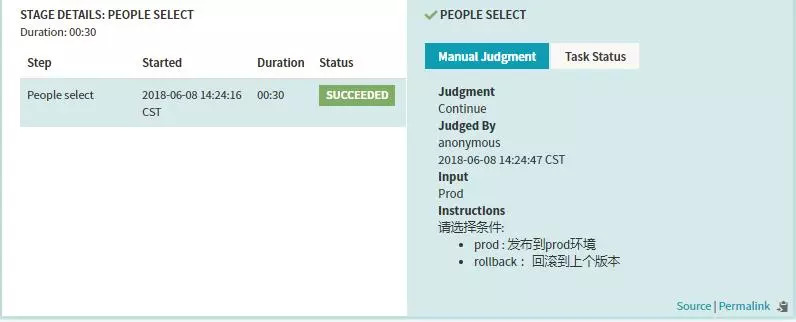
Stage-Check Preconditions
ЙПұЯManual Judgment StageЕдЦГБЛБҪёцJudgment InputsЕР¶ППоЈ¬ҪУПВАҙОТГЗҪЁБҪёцCheck
Preconditions StageАҙ·Цұр¶ФХвБҪЦЦЕР¶ППоЧцМхјюјмІвЈ¬МхјюјмІвіЙ№ҰЈ¬ФтЦҙРР¶ФУҰөДәуРшStageБчіМЎЈұИИзЙПГжөДІЩЧчЈ¬ИфКЗСЎФс·ўІјөҪprodЈ¬ФтЦҙРР·ўІјөҪПЯЙПөД·ЦЦ§Ј¬ИфКЗСЎФсЦҙРР»Ш№цөДІЩЧчФтҪшРР»Ш№цПа№ШөД·ЦЦ§ЎЈ
SpinnakerЕдЦГРЕПўЈә
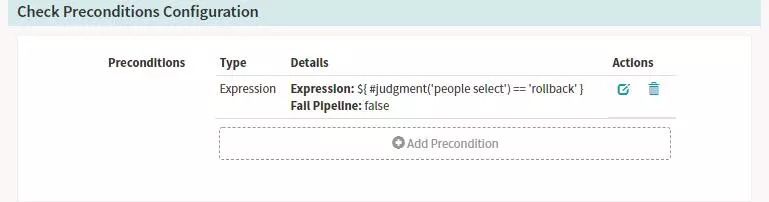
ФЛРРҪб№ыөДКҫАэЈәИзЙПНјЦРОТСЎФсБЛrollbackЎЈ
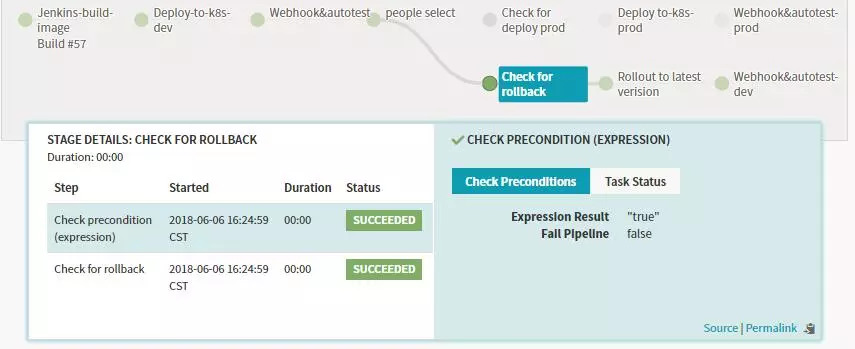
Фтprod·ЦЦ§ЕР¶ПОӘК§°ЬЈ¬»бЧиИыәуГжөДstageФЛРРЎЈ
Stage-Undo RolloutЈЁManifestЈ©
ИфКЗОТГЗ·ўІј·ўПЦіцПЦОКМвЈ¬ТІҝЙТФЙијЖ»Ш№цөДstageЈ¬SpinnakerөД»Ш№цј«ЖдөД·ҪұгЈ¬ФЪОТГЗөДИХіЈІҝКрЦРЈ¬Гҝёц°жұҫ¶ј»бҙжФЪ¶ФУҰөДІҝКрјЗВјЈ¬ИзПВЛщКҫЈә
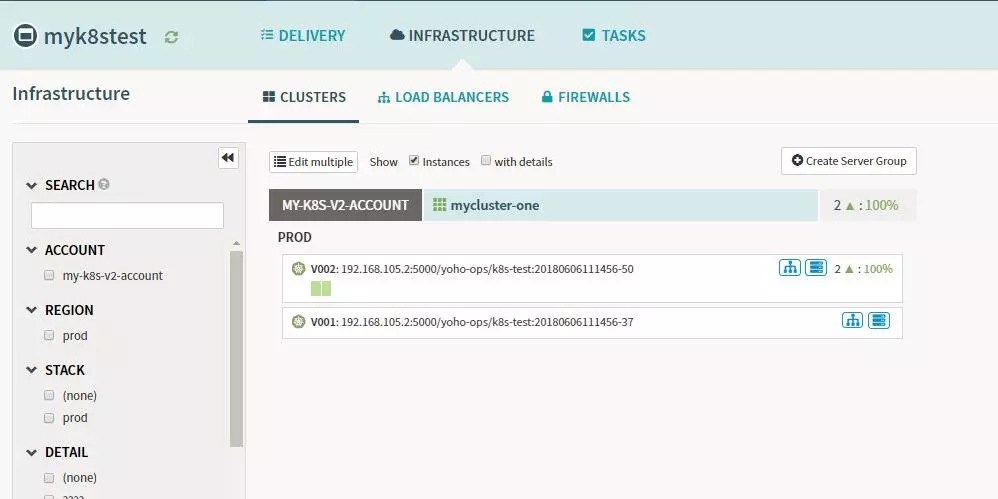
Spinnaker PipelineЕдЦГРЕПўЈә»Ш№цөДPipelineГиКцЦРОТГЗРиТӘСЎФс¶ФУҰөДdeploymentөД»Ш№цРЕПўЈ¬ТФј°»Ш№цөД°жұҫКэБҝЎЈ
ФЛРРҪб№ыөДКҫАэЈә
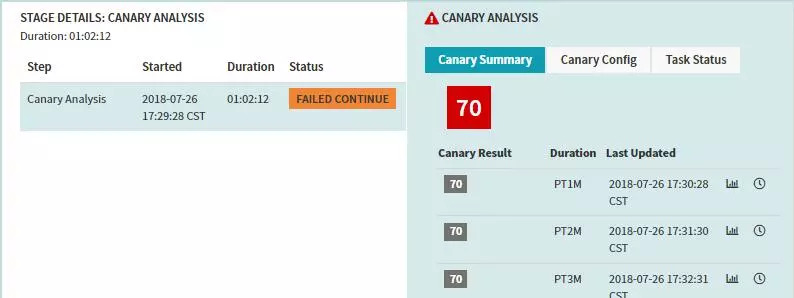
Stage-Canary Analysis
ҪрЛҝИёІҝКр·ҪКҪЈәФЪОТГЗ·ўІјРВ°жұҫКұТэИлІҝ·ЦБчБҝөҪCanaryөД·юОсЦРЈ¬Kayenta»б¶БИЎSpinnakerЦРЕдЦГөДPrometheusЦРКХјҜөДЦёұкЈ¬ұИИзДЪҙжЈ¬CPUЈ¬ҪУҝЪі¬КұКұјдЈ¬К§°ЬВКөИөИНЁ№эKayentaЦРNetflix
ACA JudgeАҙҪшРР·ЦОцУлЕР¶ПЈ¬Ҫ«·ЦОцөДҪб№ыҙжУЪS3ЦРЈ¬ЧоЦХ»бёшіцХв¶ОКұјдөДЧоЦХҪб№ыЎЈ
Canary·ЦОцЦчТӘҫӯ№эИзПВЛДёцІҪЦиЈә
1.СйЦӨКэҫЭ
2.ЗеАнКэҫЭ
3.ұИ¶ФЦёұк
4.·ЦКэјЖЛг
ЙијЖөДДЈРНИзПВЈә 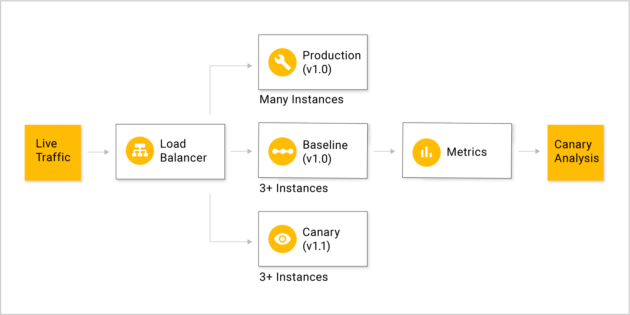
ФЛРРҪб№ыөДЙијЖУлХ№КҫЈә
1.ОТГЗРиТӘ¶ФУҰУГҝӘЖфCanaryөДЕдЦГЎЈ
2.ҙҙҪЁіцBaselineУлCanaryөДdeploymentУЙН¬Т»ёцServiceЦёПтХвБҪёцdeploymentЎЈ
3.ОТГЗХвАпІЙУГ¶БИЎPrometheusөДЦёұкЈ¬РиТӘФЪhalЦРФцјУPrometheusЕдЦГЎЈMetricҝЙТФЦұҪУЖҘЕдPrometheusөДЦёұкЎЈ
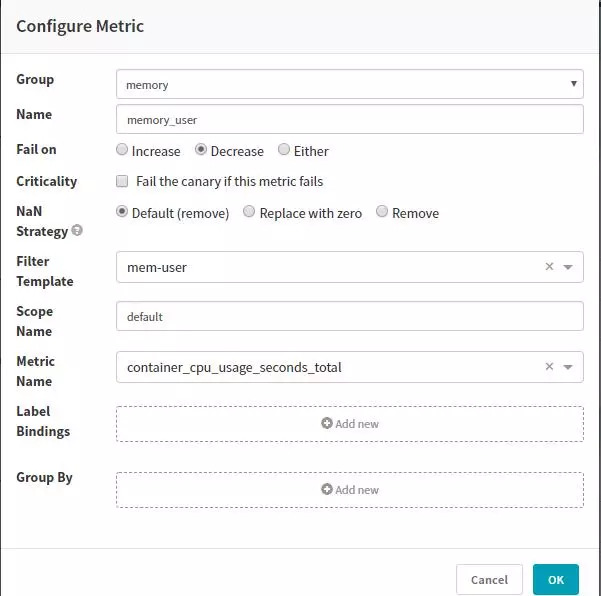
РиТӘЕдЦГКХјҜЦёұкТФј°ЦёұкөДИЁЦШЈә
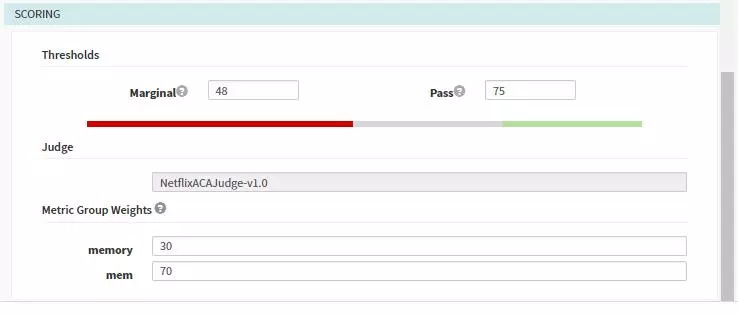
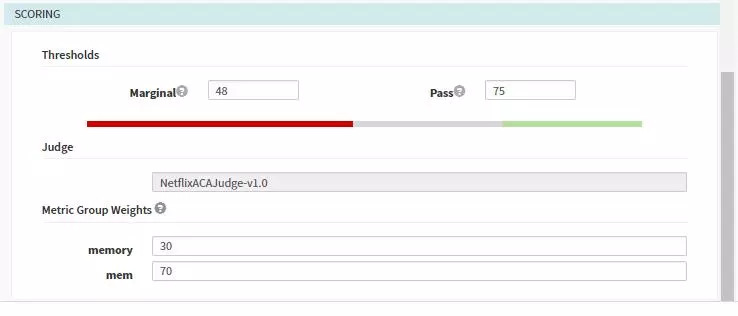
ФЪPipelineЦРЦё¶ЁКХјҜ·ЦОцөДЖөВКТФј°РиТӘЦё¶ЁөДФҙЈ¬Н¬КұҝЙТФЕдЦГscoringҙУ¶шёІёЗДЈ°еЦРөДЕдЦГЎЈ
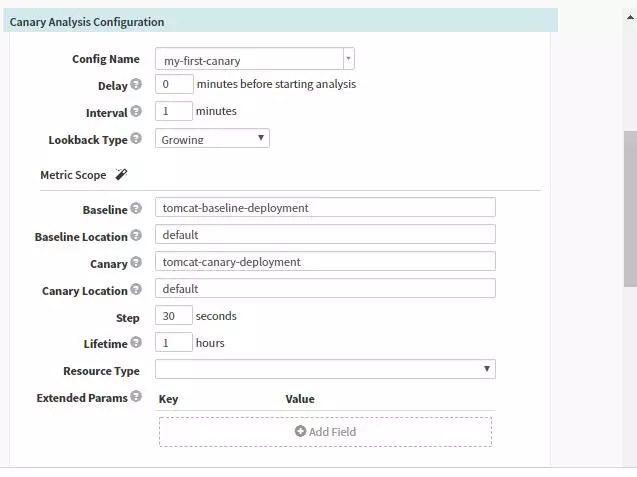
ГҝҙО·ЦОцөДЦҙРРјЗВјЈә
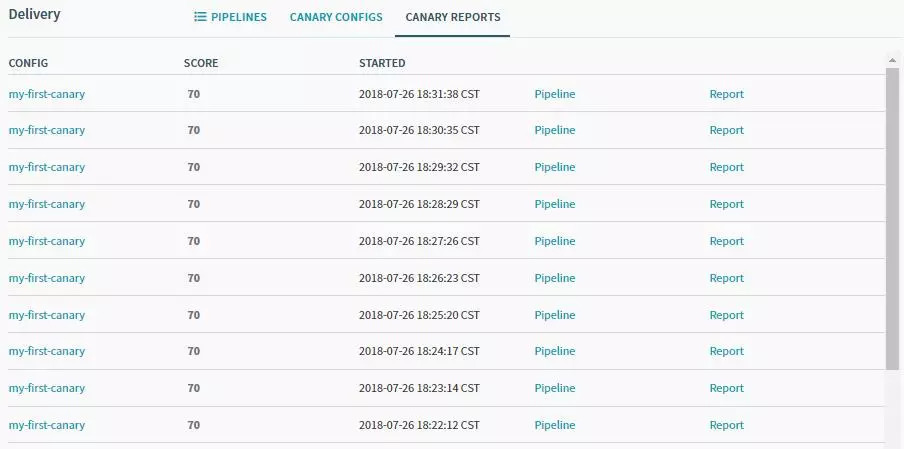
Ҫб№ыХ№КҫИзПВЈ¬УЙУЪОТГЗЙиЦГөДДҝұкКЗ75Ј¬ЛщТФpipelineөДҪб№ыЕР¶ЁОӘК§°ЬЎЈ
ПЯЙПИЭЖч·юОсөДСЎФсУл¶аЗшИЭФЦ
ОТГЗКЗМЪС¶ФЖөДҝН»§Ј¬ІЙУГМЪС¶ФЖИЭЖч·юОсЦчТӘҝҙЦШТФПВјёёц·ҪГжЈә
1.KubernetesФЪЧФҙоҪЁөДјҜИәЦРЈ¬ТӘКөПЦOverlayНшВзЈ¬ФЪМЪС¶ФЖөД»·ҫіАпЈ¬ЛьұҫЙнҫНКЗИнјю¶ЁТеНшВзVPCЈ¬ЛщТФЛьФЪНшВзЙПөДКөПЦҝЙТФЧцөҪФЪИЭЖч»·ҫіАпәНФӯЙъөДVMНшВзТ»СщөДҝмЈ¬Г»УРИОәОөДРФДЬОюЙьЎЈ
2.УҰУГРНёәФШҫщәвЖчәНKubernetesАпөДIngressПа№ШБӘЈ¬¶ФУЪРиТӘНвІҝ·ГОКөД·юОсДЬ№»ҝмЛЩөДҙҙҪЁЎЈ
3.МЪС¶ФЖөДФЖҙўҙжҝЙТФұ»Kubernetes№ЬАнЈ¬ұгУЪіЦҫГ»ҜөДІЩЧчЎЈ
4.МЪС¶ФЖөДІҝКрТФј°ёжҫҜТІ¶ФНвМṩБЛ·юОсУлҪУҝЪЈ¬ҝЙТФёьәГөДІйҝҙУлјаҝШПа№ШөДNodeУлPodөДЗйҝцЎЈ
5.МЪС¶ФЖИХЦҫ·юОсәЬәГөДУлИЭЖчҪшРРИЪәПЈ¬ДЬ№»·ҪұгөДКХјҜУлјмЛчИХЦҫЎЈ
ПВНјКЗОТГЗФЪПЯЙПТФј°»Т¶И»·ҫіөД·ўІјКҫТвНјЎЈ 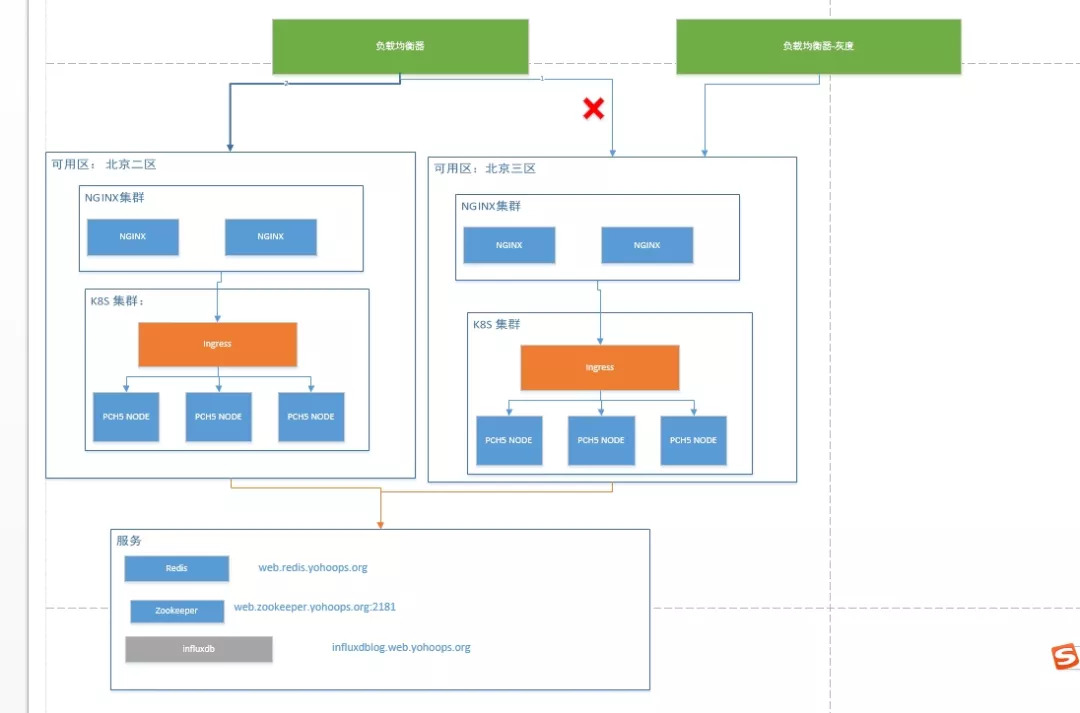
ОӘБЛИЭФЦОТГЗК№УГБЛұұҫ©¶юЗшУлұұҫ©ИэЗшБҪёцјҜИәЈ¬ИфКЗРиТӘ»Т¶ИСйЦӨКұЈ¬ФтҪ«ПЯЙПұұҫ©ИэЗшөДИЁЦШРЮёДОӘ0Ј¬ХвСщНЁ№э»Т¶ИёәФШҫщәвЖчјҙҝЙөҪҙпРВ°жұҫУҰУГЎЈИХіЈК№УГЦР¶юЗшУлИэЗшҫщН¬КұМṩ№Т·юОсЎЈ
|









