| ±ύΦ≠ΆΤΦω: |
| ±ΨΈΡά¥Ή‘”Ύ51ctoΘ§±ΨΈΡ÷ς“ΣΫι…ήΝΥ»γΚΈΟφΕ‘≥ΘΦϊΒΡΜλΚœ‘ΤΖΰΈώΘ§Έ“Ο«ΗΟ»γΚΈ”ΟΜυ”Ύ»ίΤςΒΡΡΘ Ϋά¥Ϋχ––Ιήάμ |
|
÷ΎΥυ÷ή÷ΣΘ§ΈΔΖΰΈώΚΆ»ίΤς±Ψ…μΫαΚœΫœΈΣΟή«–Θ§ΥφΉ≈‘ΤΖΰΈώΒΡΤ’ΦΑΘ§ΥϋΟ«¥”Τσ“ΒΜζΖΩΡΎ≤ΩΒΡΖΰΈώΤς…œ÷πΫΞ―”…λΒΫΝΥΗς÷÷‘ΤΖΰΈώΒΡ≥ΓΨΑ÷–ΓΘ
“ρ¥ΥΟφΕ‘≥ΘΦϊΒΡΜλΚœ‘ΤΖΰΈώΘ§Έ“Ο«ΗΟ»γΚΈ”ΟΜυ”Ύ»ίΤςΒΡΡΘ Ϋά¥Ϋχ––ΙήάμΡΊΘΩ
‘ΎΓΑΈΔΖΰΈώΦήΙΙ…ηΦΤΓ±Ζ÷¬έΧ≥…œΘ§ά¥Ή‘ΕωΝΥΟ¥ΦΤΥψΝΠΫΜΗΕ≤ΩΟ≈ΒΡΉ …νΙΛ≥Χ ΠάνΫΓ¥χά¥ΝΥ÷ςΧβΈΣΓΕΕωΝΥΟ¥Μυ”Ύ»ίΤςΒΡΜλΚœ‘Τ ΒΦυΓΖΒΡΨΪ≤ ―ίΫ≤ΓΘ
±ΨΈΡΫΪΑ¥’’»γœ¬ΥΡΗω≤ΩΖ÷’ΙΩΣΖ÷œμΘΚ
1.ΦΤΥψΝΠΫΜΗΕ
2.ΦΦ θ―Γ–Ά
3.Μυ”Ύ Kubernetes ΒΡΓΑΥψΝΠΆβ¬τΓ±
4.Kubernetes ΒΡά©’ΙΖΫΑΗ

ΥφΉ≈“ΒΈώΒΡΩλΥΌ‘ω≥ΛΘ§Ε‘”ΠΒΡΉ ‘¥ΙφΡΘ“≤‘Ύ―ΗΥΌ‘ω≥Λ÷°÷–ΓΘΕχ’β÷÷‘ω≥Λ÷±Ϋ”ΒΦ÷¬ΝΥΖΰΈώΤςάύ–ΆΒΡ‘ωΕύΓΔΙήάμ»ΈΈώΒΡΦ”ΨγΓΔΚΆΫΜΗΕ–η«σΒΡΕύ―υ–‘ΓΘ
±»»γ‘ΎΡ≥–©≥ΓΨΑœ¬Θ§Έ“Ο«–η“Σ‘ΎΫΜΗΕΒΡΖΰΈώΤς…œΘ§‘ΛΑ≤ΉΑΡ≥÷÷”Π”ΟΘΜΕχ”––© ±ΚρΘ§Έ“Ο«–η“ΣΫΜΗΕ≥ω“ΜΗωΓΑ”–“άάΒ–‘Γ±ΒΡΖΰΈώΓΔΜρ «“ΜΉιΖΰΈώΒΡΦ·ΚœΓΘ
ΦΤΥψΝΠΫΜΗΕ
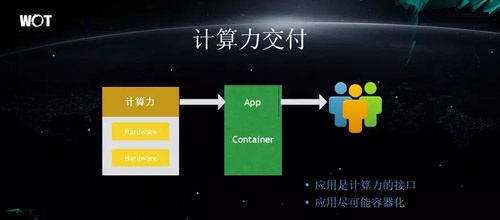
ΨΓΙήΈ“Ο«ΥυΟφΕ‘ΒΡΈοάμΉ ‘¥ΚΆ–ιΡβΜζΉ ‘¥ΒΡ ΐΝΩ «≈”¥σΒΡΘ§ΒΪΈ“Ο«‘ΥΈ§»Υ‘±»¥ «”–œόΒΡΘ§ΈόΖ®ΉωΒΫΈόœόΝΩΒΊά©’≈ΓΘ“ρ¥ΥΈ“Ο«–η“ΣΫΪΈοάμΉ ‘¥Ά≥“Μ≥ιœσ≥ωά¥Θ§¥”Εχ δ≥ωΗχΩΣΖΔ»Υ‘±ΓΘ
Εχ’β÷÷±ξΉΦΜ· ΫΒΡ≥ιœσΘ§ΡήΙΜΗχΤσ“Β¥χά¥ΝΫ¥σΚΟ¥ΠΘΚΦΪ¥σΒΊΦθ…ΌΝΥ≥…±ΨΚΆ‘ωΦ”ΝΥΖΰΈώΤςΙήάμ…œΒΡ‘ΥΡήΓΘΆ§ ±Θ§’β÷÷Ά≥“Μ≥ιœσ¥Ώ…ζΝΥΈ“Ο«ΦΤΥψΝΠΫΜΗΕ≤ΩΟ≈ΒΡ≥ωœ÷ΓΘ

ΨΏΧεΕχ―‘Θ§ΤΫ ±Έ“Ο«ΥυΫΜΗΕΒΡΖΰΈώΤςΘ§Αϋά®“‘‘ΤΖΰΈώ IaaS –Έ ΫΒΡΫΜΗΕΘ§ ΒΦ …œ”κ”Π”ΟΒΡΫΜΗΕΘ§»γ SaaS
–Έ Ϋ «“Μ―υΒΡΓΘ
‘Ύ»γΫώ–ιΡβΜ·ΒΡ‘Τ ±¥ζΘ§Έ“Ο«Ά®ΙΐΦρΒΞΒΡΟϋΝν δ»κΘ§ΨΆΡήΈΣΡ≥ΗωΈΡΦΰœΒΆ≥ΉΦ±ΗΚΟ CentOS Μρ Ubuntu
≤ΌΉςœΒΆ≥ΓΘ“ρ¥ΥΘ§ΖΰΈώΤς ΒΦ …œ“≤≥…ΈΣΝΥ“Μ÷÷»μΦΰΖΰΈώΓΔΜρ «“Μ÷÷ AppΓΘ
Ά®Ιΐ“‘≥ιœσΒΡΖΫ ΫΕ‘ΖΰΈώΤςΚΆ”Π”Ο≤…»Γ±ξΉΦΜ·Θ§Έ“Ο«Ω…“‘Α―Υυ”–ΒΡΈοάμΉ ‘¥≥ιœσ≥ωά¥Θ§–Έ≥…“Μ÷÷ΨΏ”–ΙήΩΊΡήΝΠΒΡΦΤΥψΝΠΘ§¥”Εχ¥οΒΫΕ‘”ΎœΒΆ≥ΒΡ–≠ΒςΡήΝΠΓΘΩ…“‘ΥΒΘ§“Μ«–ΫΜΗΕΒΡ––ΈΣΕΦ τ”Ύ”Π”ΟΓΘ
“ρ¥ΥΈ“Ο«ΦΤΥψΝΠΫΜΗΕΒΡΙΊΦϋ“≤ΨΆ¬δΫ≈‘ΎΝΥΕ‘”Π”ΟΒΡΙήάμ÷°…œΘ§’βΆ§ ±“≤ «Έ“Ο«ΙΊΉΔΕ»ΒΡΉΣ±δΓΘ
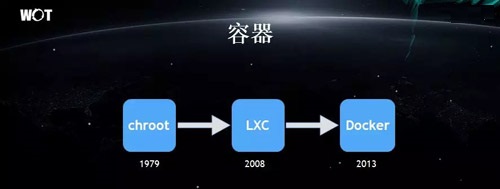
»ίΤςΦΦ θΒΡ‘≠–Ά Φ”ΎΤΏ °Ρξ¥ζΡ©Θ§ΒΪ÷±ΒΫ 2013 Ρξ Docker ΒΡΈ άΘ§»ίΤς≤≈≥…ΈΣΝΥ÷ςΝςΒΡΦΦ θΓΘ

Docker Ε‘”Ύ»ίΤςΦΦ θΒΡΉν¥σΙ±œΉ‘Ύ”ΎΘΚΆ®Ιΐ’φ’ΐΒΊΟφœρ”Π”ΟΒΡΖΫ ΫΘ§ΥϋΨΏ”–ΩγΤΫΧ®ΒΡΩ…“Τ÷≤ΧΊ–‘Θ§ΫΪΥυ”–ΒΡΖΰΈώΘ§Ά≥“Μ“‘
Image ¥ρΑϋΒΡΖΫ Ϋά¥Ϋχ––”Π”ΟΒΡΫΜΗΕΓΘ
ΝμΆβΘ§Υϋ «”Π”ΟΒΡ“Μ÷÷ΖβΉΑ±ξΉΦΓΘ‘Ύ¥Υ±ξΉΦ÷°…œΘ§Έ“Ο«Ω…“‘»Ο”Π”Ο‘Υ––‘Ύ»ΈΚΈ“ΜΗωΤΫΧ®÷°÷–ΓΘ
Ά§ ±Θ§’β“≤Ϋχ“Μ≤Ϋ¥ΌΫχΝΥΉ‘Ε·Μ·‘ΥΈ§ΓΔAIOps ΚΆ¥σ ΐΨίΒ»”Π”ΟΒΡΖΔ’ΙΓΘ“ρ¥ΥΘ§Υϋ‘ΎΫΒΒΆ»ΥΝΠ≥…±ΨΒΡΆ§ ±Θ§“≤ΧαΗΏΝΥΉ ‘¥ΒΡάϊ”Ο¬ ΓΘ
Έ“Ο«ΫΪΦΤΥψΝΠΫΜΗΕΖ÷ΈΣ»ΐ¥σάύΘΚ
ΩΆΜß”Π”ΟΒΡ≤Ω πΓΘ‘ΎΫ”ΒΫΖΰΈώ«κ«σΚσΘ§Έ“Ο«ΜαΉ≈ ÷≤Ω πΘ§≤Δ»ΟΖΰΈώΥ≥άϊ‘Υ––Τπά¥ΓΘ
±ξΉΦΖΰΈώΒΡ“ΜΦϋΫΜΗΕΓΘάΐ»γΡ≥≤ΩΟ≈ΒΡ¥σ ΐΨί“ΒΈώ–η“Σ”–“ΜΧΉΜΖΨ≥Θ§ΗΟΜΖΨ≥άοΥυΑϋΚ§ΒΡ–μΕύ÷÷ΖΰΈώΘ§œύΜΞ÷°ΦδΡ§»œ «œύΜΞΗτάκΒΡΘ§ΒΪΆ§ ±“≤“Σ±Θ÷Λ≤ΩΖ÷ΖΰΈώΡήΙΜœύΜΞΝΣœΒΓΘ
Ρ«Ο¥Έ“Ο«ΨΆ–η“ΣΉΦ±ΗΚΟ“Μ–©Ω…Η¥÷ΤΒΡ±ξΉΦΜ·ΖΰΈώΡΘΑεΘ§“‘±Θ÷ΛΨΆΥψ‘ΎΗ¥‘”ΒΡ SOA ΧεœΒ÷–Θ§“≤Ρή Βœ÷”Π”ΟΖΰΈώΒΡΥ≥≥©ΖΔœ÷ΓΘ
ΖΰΈώΤςΒΡΫΜΗΕΓΘ»γ«ΑΥυ ωΘ§ΖΰΈώΤςΫΜΗΕΒΡ±ξΉΦΜ·Θ§’ΐ «Έ“Ο«ΦΤΥψΝΠΫΜΗΕ≤ΩΟ≈ΡήΝΠΒΡ“Μ÷÷Χεœ÷ΓΘ
ΦΦ θ―Γ–Ά

»γΫώΘ§Ω…―ΓΒΡ»ίΤςΦΦ θ”–ΚήΕύΘ§Αϋά® KubernetesΓΔSwarmΓΔΚΆ AWSECS Β»Θ§Τδ÷– Kubernetes
±»Ϋœ»»Ο≈ΓΘ
“ρ¥ΥΈ“Ο«‘Ύ―Γ–Ά ±Θ§–η“ΣΩΦ¬«»γœ¬“ρΥΊΘΚ
1.Kubernetes œνΡΩ“―≥…ΈΣΝΥ»ίΤς±ύ≈≈ΒΡ ¬ Β±ξΉΦΓΘ”…”Ύ¥σΦ“ΕΦ‘ΎΤ’±ι Ι”ΟΘ§»γΙϊ≈ωΒΫΝΥΈ ΧβΘ§Ω…“‘ΒΫ…γ«χάο»ΞΥ――Α¥πΑΗΓΘ’βΈό–Έ÷–¥χά¥ΝΥ≥…±Ψœ¬ΫΒΒΡ”≈ ΤΓΘ
2. ΒΦ –η«σ«ιΩωΚΆΦΦ θΒΡΤθΚœΕ»ΓΘ
3.ά©’Ι–‘”κ…ζΧ§ΖΔ’ΙΓΘ“Μ–©”…¥σΙΪΥΨΒΡ≤…”ΟΉςΈΣ±≥ ιΒΡΦΦ θΘ§“ΜΑψΕΦ”–Ή≈«Ω¥σΒΡΚσΧ®÷ß≥÷ΚΆ“ΜΕ®ΒΡ«Α’Α–‘Θ§Ά§ ±“≤ΖΫ±ψΫ®ΝΔΤπ“ΜΕ®ΒΡ…ζΧ§ΧεœΒΓΘ
Μυ”Ύ Kubernetes ΒΡΓΑΥψΝΠΆβ¬τΓ±
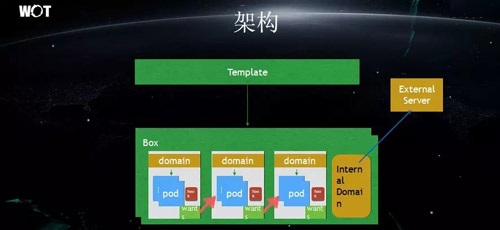
Έ“Ο«ΩΣΖΔ»Υ‘±ΤΫ ±Ε‘”Ύ”Π”ΟΖΰΈώάύ–ΆΒΡ–η«σΚΆ±ΨΙΪΥΨΥυΉωΒΡΒψ≤ΆΖΰΈώ «ΦΪΤδάύΥΤΒΡΓΘ…œΆΦ÷–ΒΡ¬Χ…Ϊ BoxΘ§ ΒΦ …œΨΆœώΈ“Ο«≥ιœσ≥ωΒΡ“ΜΗωΆβ¬τΚ–ΓΘ
Τδ÷–ΟΩ“Μ÷÷ΖΰΈώœύΜΞ÷°ΦδΒΡΒς”ΟΘ§ΕΦ «Ά®Ιΐ DomainName »Ξ Βœ÷ΒΡΓΘΕχ«“’β–© Box ΨΏ”–Η¥÷Τ–‘Θ§Έ“Ο«Ω…“‘“άΨίΡΘΑεά¥¥¥Ϋ®≥ωΕύΗω
BoxΓΘ
ΕχΟΩΗω Box ΡΎ≤Ω‘ΎΒς”Ο≤ΜΆ§ΒΡΖΰΈώ ±Θ§ΥϋΒΡ”ρΟϊ‘ΎœΒΆ≥÷– «Έ®“ΜΒΡΓΘ“ρ¥ΥΘ§ΥϋΟ«Ω…“‘ΚαΩγ≤ΜΆ§ΒΡΜΖΨ≥Ϋχ––Βς”ΟΘ§¥”ΕχΦθ…ΌΝΥΩΣΖΔ»Υ‘±ΒΡΙΛΉςΝΩΓΘ
Ιΐ»ΞΘ§‘ΎΖΰΈώΤτΕ·ΒΡ ±ΚρΘ§œΒΆ≥ΜαΉ‘Ε·…ζ≥…“ΜΗωΆχ¬γ±ξ ΕΘ§ΕχΒ± IP ΒΊ÷ΖΜρ”ρΟϊΖΔ…ζ±δΜ· ±Θ§ΥϊΟ«≤ΜΒΟ≤ΜΫχ––œύ”ΠΒΡ≈δ÷Ο–όΗΡΓΘ
»γΫώΘ§÷Μ“Σ»ίΤςΜΖΨ≥ΚΆœύ”ΠΒΡ”Π”Ο‘Υ––Τπά¥ΝΥΘ§≤ΜΆ§ΖΰΈώ÷°ΦδΨΆΡήΙΜΗυΨίΈ®“ΜΒΡΆχ¬γ±ξ Ε Βœ÷œύΜΞΒς”ΟΓΘ
‘ΎΨΏΧε Βœ÷÷–Θ§Έ“Ο«άϊ”Ο Kubernetes Ήω≥ωΝΥ“ΜΗωΒΉ≤ψΒΡ»ίΤς“ΐ«φΓΘ‘ΎΤδ÷–ΒΡΟΩΗω Unit άοΘ§ΕΦΜαΑϋά®”–
Domain ΚΆ PodΓΘΕχ«“ΟΩΗω Unit ΕΦ”–Ή‘ΦΚΒΡΗ±±ΨΘ§“‘ Βœ÷ΗΚ‘ΊΨυΚβΓΘ
Έ“Ο«Ά®Ιΐ Ι”Ο SystemdΘ§’β÷÷ΤτΕ·ΖΫ Ϋ»ΞΝΥΫβΗςΗωΖΰΈώ÷°ΦδΒΡœύΜΞ“άάΒΙΊœΒΓΘ
ΥϋΆ®ΙΐΤτΕ· ςΘ§‘Ύ Box ÷– Βœ÷ΝΥΆ§―υΒΡΙΠΡήΘ§“‘±Θ÷Λ Box ‘ΎΤτΕ·ΒΡ ±ΚρΘ§ΡήΙΜΗυΨίΈ“Ο«Φ»Ε®ΒΡ“άάΒΟη ωΘ§Α¥’’œ»Κσ¥Έ–ρΫΪ”Π”ΟΤτΕ·‘Υ––Τπά¥ΓΘ
Υδ»Μ¥”ΦΦ θΖΔ’ΙΒΡΫ«Ε»ά¥ΥΒΘ§ΖΰΈώ÷°Φδ≤Μ”ΠΗΟ¥φ‘ΎΙΐΕύΒΡ“άάΒΙΊœΒΘ§ΒΪ «”…”ΎΈ“Ο«≤ΩΟ≈ «Οφœρ“ΒΈώ≤ΩΟ≈ΧαΙ©ΖΰΈώΒΡΘ§Υυ“‘Έ“Ο«–η“ΣΉωΒΡ÷Μ «»ΞΆΤΕ·±ξΉΦΜ·Θ§¥”Εχ»ΞΦφ»ίΩΣΖΔΒΡœΑΙΏΚΆΥϊϫ±«ΑΒΡœνΡΩΓΘ
»γ…œΆΦΥυ ΨΘ§ΟΩΗω Unit ÷–ΜΙ”–“ΜΗω HookΘ§ΥϋΩ…“‘–≠÷ζΖΰΈώΒΡΤτ/ΆΘ”κ≥θ ΦΜ·ΓΘάΐ»γΘ§‘ΎΡ≥–©ΖΰΈώΆξ≥…ΝΥ÷°ΚσΘ§ΥϋΜα»ΞΒς”ΟΝμΆβ“ΜΗω
Pod Ϋχ––≥θ ΦΜ·ΓΘ
Β±»ΜΘ§Έ“Ο«“≤…φΦΑΒΫΕ‘ΙΪΙ≤ΖΰΈώΒΡ Ι”ΟΓΘάΐ»γΘ§Box1 ΚΆ Box2 ΕΦ“ΣΆ®Ιΐ“ΜΗωΙΪΙ≤ΖΰΈώά¥¥ΪΒί ΐΨίΓΘΕχΙΪΙ≤ΖΰΈώΒΡΈ®“Μ–‘Άχ¬γ
IDΘ§‘ρΩ…Ρή“ρΈΣ÷ΊΤτΒ»Άβ≤Ω“ρΥΊΕχΖΔ…ζ±δΜ·ΓΘ
“ρ¥ΥΈΣΝΥ±Θ≥÷“Μ÷¬–‘Θ§Έ“Ο«≥Δ ‘Ή≈ΫΪ…œ ωΧαΒΫΒΡΡΎ≤Ω±ξ ΕΉΣΜΜΈΣΆβ≤Ω±ξ ΕΓΘ ΒΦ …œΘ§Έ“Ο«ΒΡΡΎ≤Ω±ξ Ε «”ά‘Ε≤Μ±δΒΡΘ§ΕχΆβΟφΙΊœΒ‘ρ–η“ΣΆ®ΙΐΖΰΈώΖΔœ÷ΒΡΜζ÷ΤΘ§”κΡΎ≤ΩΖΰΈώΕ·Χ§Ϋ®ΝΔΙΊΝΣΓΘ
’β―υ“Μά¥Θ§ΡΎ≤ΩΒΡΖΰΈώΨΆ≤Μ±ΊΩΦ¬«≈δ÷Ο±δΗϋΓΔ“‘ΦΑΖΰΈώΖΔœ÷Β»Έ ΧβΝΥΓΘ…œΆΦΨΆ «Έ“Ο«Ε‘”ΎΆβ¬τΖΰΈώΖΫ ΫΒΡ“Μ÷÷ΉνΦρΒΞΒΡ≥ιœσΓΘ
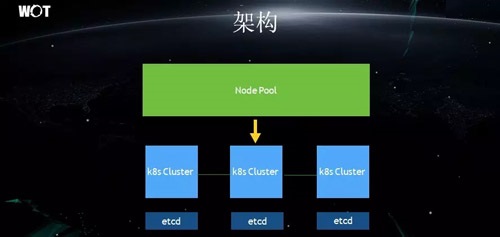
÷ΎΥυ÷ή÷ΣΘ§Kubernetes ΒΡΖΰΈώ÷ς“Σ“άάΒ”Ύ Etcd ΒΡΤτΕ·Θ§ΒΪ « Etcd ±Ψ…μ‘Ύ Kubernetes
ΒΡ”Π”Ο≥ΓΨΑœ¬≤Δ≤ΜΡή÷ß≥÷¥σΝΩΒΡ“ΒΈώΓΘ
“ρ¥ΥΘ§ΩΦ¬«ΒΫΝΥ“ΒΈώΝΩΒΡ÷πΫΞ‘ω¥σΚΆΕ‘”ΎΖΰΈώΒΡΈ»Ε®–‘“Σ«σΘ§Έ“Ο«–η“ΣΕ‘ Kubernetes ΨΓΝΩΫχ––≤πΖ÷ΓΘ
‘Ύ≤πΖ÷ΒΡΙΐ≥Χ÷–Θ§Έ“Ο«ΫΪ‘≠ά¥ΒΞΗωΜζΖΩΆχ¬γ÷–ΒΡΉ ‘¥≥Ί≤πΖ÷≥…»ΐΒΫΥΡΗω Kubernetes Φ·»ΚΓΘ
‘Ύ≤πΖ÷Άξ≥…÷°ΚσΘ§Έ“Ο«‘χ≈ωΒΫΝΥ“ΜΗωΈ ΧβΘΚ”…”Ύ≤πΖ÷ΒΟΧΪœΗΘ§Φ·»ΚΉ ‘¥≥ωœ÷ΝΥάϊ”Ο¬ ≤ΜΨυΒΡ«ιΩωΘΚ”–ΒΡΦ·»ΚΗΚ‘Ί≤ΜΙΜΓΔΕχ”–ΒΡΦ·»Κ‘ρΗΚ‘ΊΙΐΕύΓΘ
“ρ¥ΥΘ§Έ“Ο«‘Υ”Ο≤ΜΆ§ΒΡ Etcd Ε‘”Π≤ΜΆ§ΒΡ Kubernetes Φ·»ΚΘ§Ά®ΙΐΒςΕ»ΒΡΖΫ ΫΘ§»ΟΖΰΈώΡήΙΜ‘ΎΦ·»Κ÷°ΦδΤ°“ΤΘ§¥”ΕχΦ»ΫβΨωΝΥΉ ‘¥–߬ ΒΡΈ ΧβΘ§”÷ΫβΨωΝΥΩ…ΩΩ–‘ΒΡΈ ΧβΓΘ
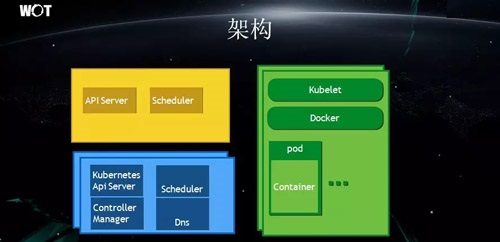
‘Ύ…œ ωΦρΒΞΒΡΫαΙΙ÷–Θ§≥ΐΝΥΜΤ…ΪΒΡ≤ΩΖ÷Θ§ΤδΥϊΕΦ « Kubernetes ‘≠…ζΒΡΉιΦΰΘ§Αϋά®άΕ…Ϊ≤ΩΖ÷άοΨΏ”–ΒςΕ»
Pod ΙΠΡήΒΡΒςΕ»ΤςΘ®SchedulerΘ©ΓΘ
Έ“Ο«ΗυΨί…œ ω≤ΜΆ§ Node ≤ψΒΡ τ–‘ΚΆΖΰΈώ–≈œΔΫχ––≈–ΕœΘ§“‘»ΖΕ®“ΣΒς”ΟΡΡΗωΦ·»ΚΓΘ
”…”ΎΈ“Ο«≤…»ΓΒΡ «ΝΫ≤ψΒςΕ»ΒΡΖΫ ΫΘ§“ρ¥Υ‘ΎΒςΒΫΒΎ“Μ≤ψΒΡ ±ΚρΘ§Έ“Ο«≤ΔΟΜ”–ΗΟΦ·»ΚΒΡ Β ±–≈œΔΘ§“≤ΈόΖ®÷ΣΒά¥ΥΦ·»ΚΑ―ΖΰΈώΒςΒΫΝΥΚΈ¥ΠΓΘ
Ε‘¥ΥΘ§Έ“Ο«Ή‘––ΩΣΖΔΝΥ“ΜΗω SchedulerΘ®»γΜΤ…Ϊ≤ΩΖ÷Υυ ΨΘ©ΓΘΝμΆβΘ§Έ“Ο«ΜΙΩΣΖΔΝΥ“ΜΗωάύΥΤ”Ύ Kubernetes
ΒΡ APIServer ΖΰΈώΓΘ
Ω…ΦϊΘ§Έ“Ο«ΒΡΡΩΒΡΨΆ‘Ύ”ΎΘΚ“‘ΆβΈßΒΡΖΫ Ϋ»Ξά©’Ι Kubernetes Φ·»ΚΘ§Εχ≤Μ «»ΞΗΡΕ· Kubernetes
±Ψ…μΓΘ
Φ¥ΘΚ‘Ύ Kubernetes ΒΡΆβΈßΘ§‘ωΦ”ΝΥ“Μ≤ψ APIServer ΚΆ SchedulerΓΘ¥ΥΨΌΒΡ÷±Ϋ”ΚΟ¥ΠΧεœ÷‘ΎΘΚΈ“Ο«ΫΎ‘ΦΝΥ‘ΎΩρΦή…œΒΡΩΣΖΔ”κΈ§ΜΛ≥…±ΨΓΘ

œ¬ΟφΈ“Ο«ά¥ΨΏΧεΩ¥Ω¥’φ ΒΒΡ»ίΤςΜΖΨ≥ΘΚ
1.»γ«ΑΥυ ωΘ§Έ“Ο« «Μυ”Ύ Kubernetes ΒΡΓΘ
2.‘ΎΆχ¬γ…œΈ“Ο« Ι”ΟΒΡ «ΑΔάο‘ΤΒΡ–ιΡβΜζΓΘ»γΙϊΙφΡΘ–ΓΒΡΜΑΘ§Έ“Ο«Μα”Ο
Vroute ΒΡΖΫ ΫΘΜ»γΙϊ «Ή‘Ϋ®ΜζΖΩΒΡΜΑΈ“Ο«ΨΆ Ι”Ο LinuxBridge ΒΡΖΫ ΫΓΘΆ§ ±Θ§Έ“Ο«ΒΡ Storage
Driver ”ΟΒΡ « Overlay2ΓΘ
3.‘Ύ≤ΌΉςœΒΆ≥ΖΫΟφΘ§Έ“Ο«ΕΦ Ι”ΟΒΡ « Centos7-3.10.0-693ΓΘ
4.‘Ύ Docker ΒΡΑφ±Ψ…œΘ§Έ“Ο«”ΟΒΡ « 17.06ΓΘ÷ΒΒΟ≤Ι≥δΒΡ «ΘΚ»γΫώ…γ«χάο¥ΪΈ≈ΗΟΑφ±ΨΦ¥ΫΪ±ΜΆΘ÷ΙΈ§ΜΛΝΥΘ§“ρ¥ΥΈ“Ο«ΫϋΤΎΜαΉ≈ ÷…ΐΦΕΓΘ
Registry
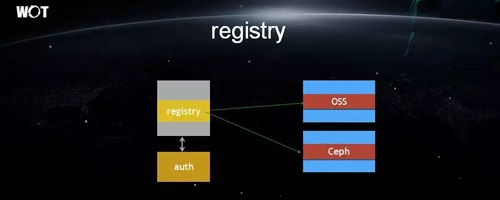
ΥΒΒΫ RegistryΘ§‘Ύ“‘«ΑΙφΡΘ–ΓΒΡ ±Κρ≤Δ≤Μ¥φ‘ΎΈ ΧβΓΘΒΪ «»γΫώΈ“Ο«ΒΡΙφΡΘ“―¥σΒΫΚαΩγΦΗΗωΜζΖΩΓΘ
“ρ¥ΥΈ“Ο«ΨΆ–η“ΣΕ‘ Registry ¥ΪΙΐά¥ΒΡ ΐΨίΫχ––Ά§≤ΫΘ§≤ΔΓΑΥΪ–¥Γ±ΒΫ OSS(Object Storage
Service)ΚΆ Ceph(“ΜΗωΩΣ‘¥ΒΡΖ÷≤Φ Ϋ¥φ¥ΔœΒΆ≥Θ§ΧαΙ©Ε‘œσ¥φ¥ΔΓΔΩι¥φ¥ΔΚΆΈΡΦΰœΒΆ≥ΒΡ¥φ¥ΔΜζ÷Τ)÷°÷–ΝΥΓΘ
”…”ΎΈ“Ο«‘ΎΉ‘ΦΚΒΡΈοάμΜζΖΩ÷–ΕΦ”– CephΘ§“ρ¥Υ‘Ύœ¬‘Ί ±Ω…“‘Ήώ―≠ΨΆΫϋœ¬‘ΊΒΡ‘≠‘ρΘ§Εχ≤Μ±ΊΩγ≥ω±ΨΜζΖΩΓΘ
¥ΥΨΌΒΡΚΟ¥ΠΨΆ‘Ύ”ΎΘΚΫΒΒΆΝΥ‘ΎΜζΖΩ÷°Φδ¥Ϊ δΥυ¥χά¥ΒΡ¥χΩμΤΩΨ±Έ ΧβΓΘ
Ρ«Ο¥Έ“Ο«ΈΣ ≤Ο¥“ΣΉωΆ§≤ΫΡΊΘΩ”…”ΎΈ“Ο«ΒΡΖΰΈώ“ΜΒ©±ΜΖΔ≤Φ≥ω»ΞΘ§ΥϋΟ«ΨΆΜαΉ‘Ε·»ΞΫχ––“λ≤Ϋ≤Ω πΓΘ
ΒΪ «Θ§”––©ΜζΖΩάοΩ…ΡήΗυ±ΨΟΜ”–Υυ–ηΒΡΨΒœώΘ§Ρ«Ο¥ΥϋΟ«‘ΎΫχ––ΓΑά≠»ΓΓ±≤ΌΉς ±ΨΆΜα±®¥μΓΘ
“ρ¥ΥΜυ”Ύ¥ΥΖΫΟφΒΡΩΦ¬«Θ§Έ“Ο«≤…”ΟΝΥΓΑΆ§≤ΫΥΪ–¥Γ±ΡΘ ΫΘ§≤Δ‘ωΦ”ΝΥ»œ÷ΛΒΡΜΖΫΎΓΘ

œκ±Ί¥σΦ“ΕΦ÷ΣΒάΘΚRegistry ‘Ύ≥Λ ±Φδ‘Υ––ΚσΘ§ΨΒœώάοΜα”–‘Ϋά¥‘ΫΕύΒΡ BlobΓΘ
Έ“Ο«Φ»Ω…“‘Ή‘––«εάμΘ§“≤Ω…“‘ΗυΨίΙΌΖΫΧαΙ©ΒΡΖΫ Ϋά¥«εάμΘ§ΒΪ ««εάμΒΡ ±Φδ“ΜΑψΕΦΜαΖ«≥Θ≥ΛΓΘ
“ρ¥Υ«εάμΙΛΉςΜα¥χά¥ΖΰΈώΒΡ‘ΥΈ§–‘÷–ΕœΘ§’βΕ‘”Ύ“ΜΑψΙΪΥΨά¥ΥΒ «ΈόΖ®Ϋ” ήΒΡΓΘ
Ε‘¥ΥΘ§Έ“Ο«œκΒΫ“Μ÷÷ΓΑBucket ¬÷ΉΣΓ±ΒΡΖΫΖ®ΓΘ”…”Ύ‘Ύ CIΘ®≥÷–χΦ·≥…Θ©ΒΡΙΐ≥Χ÷–Θ§Έ“Ο«Μα≤ζ…ζ¥σΝΩΒΡΨΒœώΘ§“ρ¥ΥΈ“Ο«ΫΪΨΒœώ“‘ΝΫΗωΦΨΕ»ΈΣ“ΜΗω±Θ¥φ÷ήΤΎΫχ––Μ°Ζ÷Θ§Φ¥ΘΚ
1.ΈΣΒΎ“ΜΗωΦΨΕ»–¬Ϋ®“ΜΗω BucketΘ§”Οά¥¥φ¥ΔΨΒœώΓΘ
2.‘ΎΒΎΕΰΗωΦΨΕ» ±Θ§ΫΪ–¬ΒΡΨΒœώ≤ζ…ζΒΫΒΎΕΰΗω Bucket ÷°÷–ΓΘ
3.Β»ΒΫΝΥΒΎ»ΐΗωΦΨΕ»Θ§Έ“Ο«ΨΆΫΪΒΎ“ΜΗω Bucket άοΒΡΨΒœώ«εάμΒτΘ§“‘¥φ»κ–¬ΒΡΨΒœώΓΘ
“‘¥ΥάύΆΤΘ§Ά®ΙΐΗΟΖΫΖ®Θ§Έ“Ο«ΨΆΡήΙΜœό÷ΤΨΒœώΘ§≤Μ÷Ν”ΎΈόœόΒΊ‘ω≥Λœ¬»ΞΓΘ
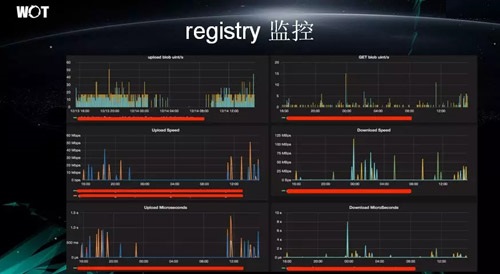
Έ“ϫ±«ΑΒΡ 8 Χ® Registry ΥυΖΰΈώΒΡ Docker Ε‘œσΨΏ”–≥…«ß…œΆρΒΡΧεΝΩΙφΡΘΓΘ
»γΙϊ Registry “ΜΒ©≥ωœ÷Έ ΧβΘ§Έ“Ο«ΨΆ–η“Σ―ΗΥΌΒΊΡήΙΜΕ®ΈΜΒΫΈ ΧβΘ§“ρ¥ΥΘ§Ε‘”Ύ Registry
≤…»ΓœύΙΊΒΡΦύΩΊ «Ζ«≥Θ±Ί“ΣΒΡΓΘ
Ά§ ±Θ§Έ“Ο«“≤–η“ΣΆ®ΙΐΦύΩΊά¥ Β ±ΝΥΫβœΒΆ≥ΒΡ Ι”Ο≥ΧΕ»Θ§“‘±ψΉω≥ω±Ί“ΣΒΡά©»ίΓΘ
‘Ύ Βœ÷ΖΫ Ϋ…œΘ§Έ“Ο« ΒΦ …œ÷Μ «…‘ΈΔΦ”»κΝΥ“Μ–©Ή‘ΦΚ–¥ΒΡ≥Χ–ρΘ§Εχ’ϊΧε…œ»‘±ΘΝτΉ≈”κΤδΥϊ≥Χ–ρΒΡΫβώνΙΊœΒΓΘ
»γΆΦΥυ ΨΘ§Έ“Ο«Ά®Ιΐ…œ¥ΪΓΔœ¬‘ΊΒΡΥΌΕ»Θ§Αϋά® Blob ΒΡ ΐΝΩΒ»ΦύΩΊ÷Η±ξΘ§ΡήΙΜ Β ±ΒΊΗζΉΌ Registry
ΒΡ‘Υ––Ή¥Χ§ΓΘ
Docker

Έ“Ο« Ι”Ο Docker syslog driver ΫΪ≤…Φ·ΒΫΒΡ”ΟΜßΫχ≥Χ δ≥ωΒΫ ELK ÷°÷–Ϋχ––≥ œ÷ΓΘ≤ΜΙΐ‘Ύ»’÷ΨΝΩΙΐ”ΎΤΒΖ±ΒΡ ±ΚρΘ§ELK
Μα≥ωœ÷ΚΝΟκΦΕ±πΒΡ¬“–ρΓΘ
’β―υΒΡ¬“–ρΜαΗχ“ΒΈώ≤ΩΟ≈¥χά¥ΈόΖ®Ϋχ––Έ Χβ≈≈≤ιΒΡάßΡ―ΓΘ“ρ¥ΥΘ§Έ“Ο«ΗΡΕ·ΝΥ Docker ΒΡœύΙΊ¥ζ¬κΘ§ΗχΟΩ“ΜΧθ»’÷ΨΕΦ»ΥΈΣ‘ωΦ”“ΜΗωΒί‘ωΒΡ–ρΝ–Κ≈ΓΘ
’κΕ‘“Μ–©Ω…ΩΩ–‘“Σ«σΫœΗΏΒΡ LogΘ§Έ“Ο«―Γ‘ώΝΥ TCP ΡΘ ΫΓΘΒΪ «‘Ύ TCP ΡΘ Ϋœ¬Θ§»γΙϊΡ≥Ηω»’÷Ψ±Μ δ≥ωΒΫ“ΜΗωΖΰΈώ ±Θ§ΤδΫ” ’ΖΰΈώΒΡ
Socket ”…”Ύ¬ζ‘ΊΕχΓΑΚΜΉΓΓ±ΝΥΓΘ
Ρ«Ο¥ΗΟ»ίΤςΨΆΈόΖ®ΦΧ–χΘ§Τδ Docker ps ΟϋΝν“≤ΨΆ÷ΜΡήΆΘ‘ΎΡ«ΕυΝΥΓΘΝμΆβΨΆΥψ TCP ΡΘ ΫΩΣΤτΝΥΘ§ΒΪ «ΤδΫ” ’»’÷Ψ
TCPServer …–Έ¥ΤτΕ·“≤ «ΈόΦΟ”Ύ ¬ΒΡΓΘ
”…¥ΥΩ…ΦϊΘ§‘ΎΟφΕ‘“Μ–©ΨΏΧε Ι”Ο÷–ΒΡΈ Χβ ±Θ§Έ“Ο«ΒΡ–η«σ”κΩΣ‘¥œνΡΩ±Ψ…μΥυΡήΧαΙ©ΒΡΖΰΈώΜΙ «”–“ΜΕ®ΨύάκΒΡΓΘ»ΈΚΈ“ΜΗωΩΣ‘¥œνΡΩ‘ΎΤσ“Β¬δΒΊ ±Θ§ΕΦ≤ΜΩ…Ρή «ΆξΟάΒΡΓΘ
ΩΣ‘¥œνΡΩΆυΆυΧαΙ©ΒΡ «±ξΉΦΜ·ΒΡΖΰΈώΘ§ΕχΈ“Ο«ΒΡ–η«σ»¥Ψ≠≥Θ «ΗυΨίΉ‘ΦΚΒΡΨΏΧε≥ΓΨΑΕχΕ®÷ΤΜ·ΒΡΓΘ
Έ“Ο«Τσ“ΒΒΡ»μΦΰΜΖΨ≥Θ§ΕΦ «ΗυΨίΉ‘…μΜΖΨ≥“ΜΒψΓΔ“ΜΒψΒΊ≥Λ≥ωά¥ΒΡΘ§“ρ¥Υ¥φ‘Ύ≤ν“λ–‘ «±Ί»ΜΒΡΓΘ
Έ“Ο«≤ΜΩ…Ρή»ΟΩΣ‘¥»μΦΰΈΣΈ“Ο«ΕχΗΡ±δΘ§÷ΜΡήΆ®Ιΐ–όΗΡ≥Χ–ρΘ§»ΟΩΣ‘¥»μΦΰά¥ ”ΠΈ“ϫ±«ΑΒΡ»μΦΰΉ¥Χ§”κΜΖΨ≥Θ§ΫχΕχΫβΨωΗς÷÷ΨΏΧεΒΡΈ ΧβΓΘ
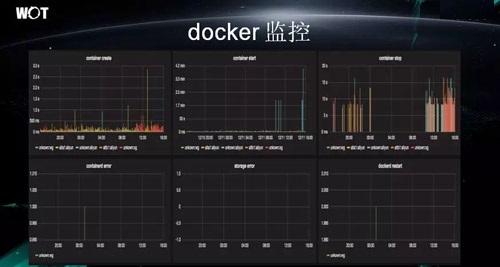
…œΆΦ « Docker ΒΡ“Μ–©ΦύΩΊΘ§ΥϋΡήΙΜΑο÷ζΈ“Ο«ΖΔœ÷Ης÷÷Έ ΧβΓΔBugΓΔ“‘ΦΑΓΑΚΜΉΓΓ±ΒΡΒΊΖΫΓΘ
Init Ϋχ≥Χ
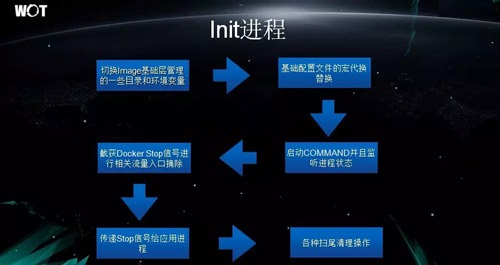
‘ΎΫΪ¥ΪΆ≥ΒΡ“ΒΈώΫχ––»ίΤςΜ·ΉΣ±δΒΡΙΐ≥Χ÷–Θ§Έ“Ο«’κΕ‘»ίΤςΕ®÷Τ≤ΔΗΡΫχΝΥ Init Ϋχ≥ΧΓΘ
ΗΟ Init Ϋχ≥ΧΡήΙΜ«–ΜΜ Image Μυ¥Γ≤ψΙήάμΒΡ“Μ–©ΡΩ¬ΦΚΆΜΖΨ≥±δΝΩΘ§Ά®Ιΐ“≤Ω…“‘ΧφΜΜΜυ¥Γ≈δ÷ΟΈΡΦΰΒΡΚξ¥ζΜΜΓΘ
Ε‘”Ύ“Μ–©«®“ΤΙΐά¥ΒΡΖΰΈώΘ§Τδ±Ψ…μΨΆ‘χ¥χ”–≈δ÷ΟœνΘ§ΥϋΟ«Ά®≥Θ Ι”ΟΜΖΨ≥±δΝΩά¥ΕΝ»Γ≈δ÷Ο–≈œΔΓΘΡ«Ο¥’βΕ‘”ΎΈ“Ο«ΫΪΤδ–όΗΡ≥…»ίΤςΒΡΙΛΉςΘ§ΨΆΈό–Έ÷–‘ωΦ”ΝΥ≥…±ΨΓΘ
“ρ¥ΥΈ“Ο«ΥυΧαΙ©ΒΡΖΫΖ® «ΘΚΥδ»Μ±δΝΩ±Μ–¥‘ΎΝΥ≈δ÷ΟάοΘ§ΒΪ «Έ“Ο«ΡήΙΜΗυΨί»ίΤςΒΡΜΖΨ≥±δΝΩ…η÷ΟΘ§Ή‘Ε·»ΞΧφΜΜΖΰΈώ–¥ΓΑΥάΓ±ΒΡ≈δ÷ΟΓΘ
Init Ϋχ≥ΧΒΡ’β÷÷ΖΫΖ®Ε‘”Ύ‘Ύ»ίΤς…–Έ¥ΤτΕ·Θ§«“≤Μ÷ΣΒάΖΰΈώΒΡ IP ΒΊ÷Ζ ±”»ΈΣ”–”ΟΓΘ
Ε‘”Ύ»ίΤςΒΡΙήάμΘ§Έ“Ο«“≤ΤτΕ·ΝΥ CommandΘ§ά¥≥÷–χΦύΧΐΫχ≥ΧΒΡΉ¥Χ§Θ§“‘±ήΟβΫ© §Ϋχ≥ΧΒΡ≥ωœ÷ΓΘ
ΝμΆβΘ§”…”ΎΈ“Ο«ΙΪΥΨ”–Ή≈ΡΎ≤ΩΒΡ SOA ΧεœΒΘ§‘Ύ Docker ≤ζ…ζΆΘ÷Ι–≈Κ≈÷°ΚσΘ§–η“ΣΫΪΝςΝΩ¥”ΙΪΥΨΒΡ’ϊΗωΦ·»Κάο’Σ≥ΐΒτΓΘ
“ρ¥ΥΘ§Έ“Ο«Ά®ΙΐΫΊΜώ–≈œΔΘ§ΉωΒΫΝΥ‘ΎœύΙΊΒΡΝςΝΩ»κΩΎ”η“‘ΖΰΈώΒΡ’Σ≥ΐΕ·ΉςΓΘ
Ά§ ±Θ§Έ“Ο«ΜΙΆ®Ιΐ¥ΪΒίΆΘ÷Ι–≈Κ≈Ηχ”Π”ΟΫχ≥ΧΘ§“‘Άξ≥…’κΕ‘»μΦΰΒΡΗς÷÷…®Έ≤«εάμ≤ΌΉςΘ§ΫχΕχ Βœ÷ΝΥΕ‘¥ΪΆ≥“ΒΈώ”η“‘»ίΤςΜ·ΒΡΤΫΜ§ΙΐΕ…ΓΘ
Kubernetes Ή ‘¥Ιήάμά©’Ι

œ¬ΟφΆ®ΙΐΑΗάΐά¥Ω¥Ω¥Θ§Έ“Ο« «»γΚΈΆ®Ιΐά©’Ιά¥¬ζΉψ“ΒΈώ–η«σΒΡΓΘ
Έ“Ο«ΕΦ÷ΣΒάΘ§Kubernetes ΒΡ APIServer «ΫœΈΣΚΥ–ΡΒΡΉιΦΰΘ§Υϋ ΙΒΟΥυ”–ΒΡΉ ‘¥ΕΦΩ…“‘±ΜΟη ωΚΆ≈δ÷ΟΓΘ’β”κ
LinuxΓΑ“Μ«–Ϋ‘ΈΡΦΰΓ±ΒΡ’ή―ßΨΏ”–“λ«ζΆ§ΙΛ÷°ΟνΓΘ
Kubernetes Φ·»ΚΫΪΥυ”–ΒΡ≤ΌΉςΘ§Αϋά®ΦύΩΊΚΆΤδΥϊΉ ‘¥Θ§ΕΦΆ®ΙΐΕΝΈΡΦΰΒΡΖΫ Ϋά¥’ΤΈ’ΖΰΈώΒΡΉ¥Χ§Θ§≤ΔΆ®Ιΐ–¥ΈΡΦΰΒΡΖΫ Ϋά¥–όΗΡΖΰΈώΒΡΉ¥Χ§ΓΘ
Ϋη”Ο’β÷÷ΖΫ ΫΘ§Έ“Ο«œύΦΧΩΣΖΔΝΥ≤ΜΆ§ΒΡΉιΦΰΚΆ APIServer ΒΡΫ”ΩΎΘ§≤Δ“‘ Restful ΒΡΫ”ΩΎ–Έ ΫΕ‘ΖΰΈώ Βœ÷ΝΥΈΔΖΰΈώΜ·ΓΘ
‘Ύ ΒΦ ≤Ω π÷–Θ§Υδ»ΜΈ“Ο«≤ΔΟΜ”–”ΟΒΫ Kubernetes ProxyΘ§ΒΪ «’β―υΖ¥ΕχΫΒΒΆΝΥ APIServer
ΒΡΗΚ‘ΊΓΘ
Β±»Μ»γΙϊ–η“ΣΒΡΜΑΘ§Έ“Ο«Άξ»ΪΩ…“‘Α¥–ηΦ”‘Ί”κ≤Ω πΘ§¥”Εχ±Θ÷Λ≤Δ‘ω«ΩœΒΆ≥’ϊΧεΒΡά©’Ι–‘ΓΘ
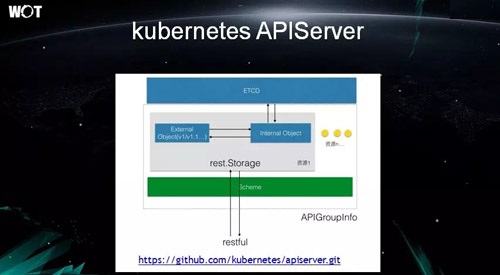
Kubernetes APIServer
…œΆΦ÷±ΙέΒΊ’Ι ΨΝΥ APIServer ΒΡΦρΒΞΡΎ≤ΩΫαΙΙΓΘΥυ”–ΒΡΉ ‘¥ ΒΦ …œΕΦ“Σ±ΜΖ≈»κ Etcd ÷°÷–ΓΘ
Ά§ ±Θ§ΟΩ“Μ÷÷Ή ‘¥ΕΦ”–“ΜΗω InternalObjectΘ§ΥϋΕ‘”ΠΉ≈ Etcd άοΒΡ“Μ–©¥φ¥Δάύ Key/ValueΘ§’β―υ±Θ÷ΛΝΥΟΩΗωΕ‘œσΒΡΈ®“Μ–‘ΓΘ
Β±”–ΆβΟφ«κ«σά¥ΖΟΈ ΖΰΈώ ±Θ§‘ρ–η“ΣΆ®Ιΐ ExternalObject ΚΆ InternalObject
Ϋχ––ΉΣΜΜ≤≈Ρή Βœ÷ΓΘ
άΐ»γΘΚΈ“Ο«Ω…Ρή Ι”Ο≤ΜΆ§Αφ±ΨΒΡ API Ϋχ––≥Χ–ρΩΣΖΔΘ§Εχ¥Υ ±≥ωœ÷ΝΥ–η«σ±δΗϋΘ§–η“ΣΈ“Ο«‘ωΦ”“ΜΗωΉ÷ΕΈΓΘ
Εχ ΒΦ …œΗΟΉ÷ΕΈΩ…Ρή“―Ψ≠¥φ‘Ύ”Ύ InternalObject ÷°÷–ΝΥΘ§Ρ«Ο¥Έ“Ο«÷Μ–ηΨ≠Ιΐ“Μ–©¥Πάμ±ψΩ…÷±Ϋ”…ζ≥…ΗΟΉ÷ΕΈΓΘ
Ω…ΦϊΘ§Έ“Ο«’φ’ΐ“Σ»Ξ Βœ÷ΒΡ÷Μ « ExternalObjectΘ§ΕχΟΜ±Ί“Σ»ΞΗΡΕ· InternalObjectΓΘ
»γ¥ΥΘ§Έ“Ο«‘Ύ≤Μ–όΗΡ¥φ¥ΔΒΡΜυ¥Γ…œΘ§ΨΓΝΩΉωΒΫΝΥΖΰΈώ”κ¥φ¥Δ÷°ΦδΒΡΫβώνΘ§“‘ΗϋΚΟΒΊ”ΠΕ‘ΆβΫγΒΡΗς÷÷±δΜ·ΓΘ
Β±»ΜΘ§’βΆ§ ±“≤ « Kubernetes APIServer άοΕ‘œσΖΰΈώΒΡ“ΜΗωΙΐ≥ΧΓΘ
”κ¥ΥΆ§ ±Θ§Έ“Ο«“≤ΫΪ≤ΩΖ÷ API Μ°ΙιΒΫΝΥ“ΜΗω APIGroup ÷°÷–ΓΘ‘ΎΆ§“ΜΗω APIGroup
άοΘ§≤ΜΆ§ΒΡΉ ‘¥œύΜΞ÷°Φδ «ΫβώνΓΔ≤Δ––ΒΡΘ§Έ“Ο«ΡήΙΜ“‘ΧμΦ”Ϋ”ΩΎΒΡΖΫ ΫΫχ––Ή ‘¥ΒΡά©’ΙΓΘ
Εχ…œ ωΧαΒΫΒΡΝΫΗωΕ‘œσ÷°ΦδΒΡΉΣΜΜΘ§“‘ΦΑάύ–ΆΒΡΉΔ≤αΘ§ΕΦ «‘ΎΆΦ÷–ΒΡ Scheme άοΟφΆξ≥…ΒΡΓΘ
»γΙϊ¥σΦ“œκΉ‘ΦΚΉω APIServer ΒΡΜΑΘ§Ι»ΗηΙΌΖΫΨΆ”Β”–ΗΟœνΡΩΒΡΕ‘”ΠΖΫΑΗΘ§≤ΔΧαΙ©ΝΥΉ®Ο≈ΒΡΦΦ θ÷ß≥÷ΓΘ»γΙϊΡζΗ––Υ»ΛΒΡΜΑΘ§Ω…“‘≤ΈΩΦΆΦ÷–œ¬ΖΫΕ‘”ΠΒΡ
Github œνΡΩΒΡΆχ÷ΖΓΘ
ΝμΆβΘ§Ι»ΗηΜΙΧαΙ©ΝΥΉ‘Ε·…ζ≥…¥ζ¬κΒΡΙΛΨΏΓΘœύ”ΠΒΊΘ§Έ“Ο«‘ΎΩΣΖΔΒΡΙΐ≥Χ÷–“≤ΉωΝΥ“ΜΗω÷±Ϋ”Ά®ΙΐΕ‘œσά¥…ζ≥… ΐΨίΩβΥυ”–œύΙΊ≤ΌΉςΒΡ–ΓΙΛΨΏΘ§ΥϋΫΎ‘ΦΝΥΈ“Ο«¥σΝΩΒΡ ±ΦδΓΘ
Kubernetes ¬δΒΊ
ΉνΚσΚΆ¥σΦ“Ζ÷œμ“Μœ¬Θ§Έ“Ο«‘Ύ Kubernetes ¬δΒΊΙΐ≥Χ÷–Υυ”ωΒΫΒΡ“Μ–©Έ ΧβΘΚ
1.Pod ÷ΊΤτΖΫ ΫΓΘ”…”Ύ Pod ΥυΈΫΒΡ÷ΊΤτ ΒΦ …œ «–¬Ϋ®“ΜΗω PodΘ§≤Δ«“Ζ≈Τζ“‘«ΑΡ«ΗωΨ…ΒΡΘ§“ρ¥Υ’βΕ‘”ΎΈ“Ο«ΒΡΤσ“ΒΜΖΨ≥ά¥ΥΒ «ΈόΖ®Ϋ” ήΒΡΓΘ
2.Kubernetes ΈόΖ®œό÷Τ»ίΤςΈΡΦΰœΒΆ≥¥σ–ΓΓΘ”– ±Κρ≥Χ–ρ‘±‘Ύ–¥“ΒΈώ¥ζ¬κ ±Θ§”…”Ύ≤Μ…ςΘ§ΜαΒΦ÷¬»’÷ΨΈΡΦΰ‘Ύ“ΜΧλ÷°ΡΎΦΛ‘ω
100 Εύ GBΘ§¥”Εχ’Φ¬ζΝΥ¥≈≈Χ≤ΔΒΦ÷¬±®Ψ·ΓΘ
3.»ΜΕχΈ“Ο«ΖΔœ÷Θ§‘Ύ Kubernetes άοΚΟœώ≤ΔΟΜ”–œύΙΊΒΡ τ–‘»Ξœό÷ΤΈΡΦΰœΒΆ≥ΒΡ¥σ–ΓΘ§“ρ¥ΥΈ“Ο«≤ΜΒΟ≤ΜΕ‘ΥϋΫχ––ΝΥ¬‘ΈΔΒΡ–όΗΡΓΘ
4.DNS ΗΡ‘λΓΘΡζΩ…“‘≤…”ΟΉ‘ΦΚΒΡ DNSΘ§“≤Ω…“‘ Ι”Ο Kubernetes
ΒΡ DNSΓΘ≤ΜΙΐΈ“Ο«‘Ύ Ι”Ο Kubernetes DNS ÷°«ΑΘ§Ή®Ο≈Μ® ±ΦδΕ‘ΥϋΫχ––ΝΥΕ®÷Τ”κΗΡ‘λΓΘ
5.Memory.kmem.slabinfoΓΘΒ±Έ“Ο«¥¥Ϋ®»ίΤςΒΫΝΥ“ΜΕ®≥ΧΕ» ±Θ§ΜαΖΔœ÷»ίΤς‘Ό‘θΟ¥“≤ΈόΖ®±Μ¥¥Ϋ®ΝΥΓΘΈ“Ο«Υδ»Μ≥Δ ‘Ιΐ ΆΖ≈»ίΤςΘ§ΒΪ «ΖΔœ÷ΜΙ « ήΒΫΝΥΡΎ¥φ“―¬ζΒΡœό÷ΤΓΘ
6.Ψ≠ΙΐΖ÷ΈωΘ§Έ“Ο«ΖΔœ÷ΘΚ”…”ΎΈ“Ο« Ι”ΟΒΡ Kernel Αφ±ΨΈΣ 3Θ§Εχ
Kubelet ΦΛΜνΩΣΤτΝΥ cgroupkernel-memory ’β“Μ≤β ‘ τ–‘ΧΊ–‘Θ§Ά§ ± Centos7-3.10.0-693
ΒΡ Kernel 3 Ε‘”ΎΗΟΧΊ–‘÷ß≥÷≤Δ≤ΜΚΟΘ§“ρ¥ΥΚΡΙβΝΥΥυ”–ΒΡΡΎ¥φΓΘ
|









