| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌЮФеТНВЪіШчКЮдкswarmМЏШКЩЯВПЪ№вЛИіЗўЮёЃЌвдМАШчКЮМьВщSwarmМЏШКЩЯЕФЗўЮёЕШЯрЙижЊЪЖЁЃ |
|
SwarmМђНщ
SwarmЪЧDockerЕФвЛИіБрХХЙЄОпЃЌВЮПМЙйЭјЃК
https://docs.docker.com/engine/swarm/
Swarm ФЃЪНМђНщ
вЊдкSwarmФЃЪНЯТдЫааdockerЃЌашвЊЯШАВзАdockerЃЌВЮПМАВзАНЬГЬ
ЕБЧААцБОЕФdockerАќКЌСЫswarmФЃЪНЃЌгУгкЙмРэdockerМЏШКЁЃПЩвдЪЙгУУќСюааРДДДНЈswarmМЏШКЃЌВПЪ№гІгУЃЌЙмРэswarmЕФааЮЊЁЃ
ШчЙћФуЪЙгУЕЭгк1.12.0АцБОЕФdockerЃЌПЩвдЪЙгУЖРСЂФЃЪНЕФЪЧswarmЃЌЕЋЪЧНЈвщЪЙгУзюаТАцБО
Ьиад
гыdockerМЏГЩЕФМЏШКЙмРэЙЄОп
ШЅжааФЛЏЩшМЦЃЌжЛЪЙгУdockerв§ЧцМДПЩДДНЈИїРрНкЕу
ЩљУїЪНЗўЮёФЃаЭЁЃПЩвдЩљУїЕФЗНЪНРДЖЈвхгІгУЁЃ
ЖЏЬЌЩьЫѕЁЃЙмРэНкЕуздЖЏЕїећЗўЮёЪ§СПЁЃ
ИпПЩгУЃЌЖдгкЗўЮёЦкЭћзДЬЌзіЕНЖЏЬЌЕїећЃЌswarmЕФЙмРэНкЕуЛсГжајМрПиМЏШКзДЬЌЃЌМЏШКжагаУЛгаДяЕНЦкЭћзДЬЌЕФЗўЮёЃЌЙмРэНкЕуЛсздЖЏЕїЖШРДДяЕНЦкЭћзДЬЌЁЃ
здЖЈвхЭјТчЁЃПЩвдЮЊФуЕФЗўЮёжИЖЈвЛИіЭјТчЃЌШнЦїДДНЈЕФЪБКђЗжХфвЛИіIP
ЗўЮёЗЂЯжЁЃЙмРэНкЕуИјМЏШКжаУПИіЗўЮёвЛИіЬиЖЈЕФDNSУћзжЃЌВЂИјдЫааЕФШнЦїЬсЙЉИКдиОљКтЁЃ
ИКдиОљКтЁЃФуПЩвдБЉТЖЗўЮёЖЫПкИјЭтВПЕФИКдиОљКтЁЃФкВПswarmЬсЙЉПЩХфжУЕФШнЦїЗжХфЕННкЕуЕФВпТдЁЃ
ФЌШЯЕФАВШЋЛњжЦЁЃswarmМЏШКжаИїИіНкЕуЧПжЦTLSавщбщжЄЁЃСЌНгМгУмЃЌФуПЩвдздЖЈвхИљжЄЪщЁЃ
ЙіЖЏИќаТЁЃдіСПИњаТЃЌПЩвдздЖЈвхИќаТЯТИіНкЕуЕФЪБМфМфИєЃЌШчЙћгаЮЪЬтЃЌПЩвдЛсЙіЕНЩЯИіАцБОЁЃ
SwarmжївЊИХФю
ПЊЪМЪЙгУSwarmФЃЪН
БОНЬГЬНјааШчЯТжИЕМЃК
дкswarmФЃЪНЯТГѕЪМЛЏвЛИіЛљгкdockerв§ЧцЕФswarmМЏШК
дкswarmМЏШКжаЬэМгНкЕу
ВПЪ№гІгУЗўЮёЕНswarmМЏШКжа
ЙмРэswarmМЏШК
БОНЬГЬЪЙгУdockerУќСюааЕФЗНЪННЛЛЅ
АВзА
АВзАЛЗОГвЊЧѓЃК
3ЬЈПЩвдЭјТчЭЈаХЕФLinuxжїЛњЃЌВЂЧвАВзАСЫdocker
АВзА1.12.0вдЩЯЕФdocker
ЙмРэНкЕуЕФIPЕижЗ
жїЛњжЎМфПЊЗХЖЫПк
зМБИ3ЬЈжїЛњ
3ЬЈжїЛњПЩвдЪЧЮяРэЛњЃЌащФтЛњЃЌдЦжїЛњЃЌЩѕжСЪЧdocker machineДДНЈЕФжїЛњЁЃВЂАВзАdockerЁЃШ§ЬЈжїЛњЗжБ№ЪЧmanager1ЃЌwork1КЭworker2.
АВзА1.12.0вдЩЯЕФdocker
ВЮПМЃКдкlinuxЩЯАВзАdocker
ЙмРэНкЕуЕФIPЕижЗ
ЫљгаswarmМЏШКжаЕФНкЕуЖМЛсСЌНгЕНЙмРэНкЕуЕФIPЕижЗ
жїЛњМфПЊЗХЖЫПк
вдЯТЖЫПкБиаыЪЧПЊЗХЕФЃК
TCP port 2377ЮЊМЏШКЙмРэЭЈаХ
TCP and UDP port 7946 ЮЊНкЕуМфЭЈаХ
UDP port 4789 ЮЊЭјТчМфСїСП
ШчЙћФуЯыЪЙгУМгУмЭјТчЃЈ--opt encryptedЃЉвВашвЊШЗБЃip protocol 50 (ESP)ЪЧПЩгУЕФ
ДДНЈвЛИіSwarmМЏШК
ЭъГЩЩЯУцЕФПЊЪМЙ§ГЬКѓЃЌПЩвдПЊЪМДДНЈвЛИіswarmМЏШКЁЃШЗБЃdockerЕФКѓЬЈгІгУвбОдкжїЛњЩЯдЫааСЫЁЃ
ЕЧТНЕНmanager1ЩЯЃЌШчЙћЪЙгУdocker-machineДДНЈЕФжїЛњЃЌПЩвдdocker-machine
ssh manager1
дЫаавдЯТУќСюРДДДНЈвЛИіаТЕФswarmМЏШКЃК
| docker swarm
init --advertise-addr <MANAGER1-IP> |
БОНЬГЬжаЪЙгУШчЯТУќСюдкmanager1ЩЯДДНЈswarmМЏШКЃК
james@james-CW65:~
> docker swarm init --advertise-addr 192.168.99.1
Swarm initialized: current node (5n1l6261akogeuxysrgn2ipxz)
is now a manager.
To add a worker to this swarm, run the following
command:
docker swarm join --token SWMTKN-1-2bgkinnbc0rmlj6kpotyrlj0uz51l2ikinttsk960dxro558x4-6zajfnahtv9ye39momddh5kru
192.168.99.1:2377
To add a manager to this swarm, run 'docker
swarm join-token manager' and follow the instructions.
|
--advertise-addrбЁЯюБэЪОЙмРэНкЕуЙЋВМЫќЕФIPЪЧЖрЩйЁЃЦфЫќНкЕуБиаыФмЭЈЙ§етИіIPевЕНЙмРэНкЕуЁЃ
УќСюЪфГіСЫМгШыswarmМЏШКЕФУќСюЁЃЭЈЙ§--tokenбЁЯюРДХаЖЯЪЧМгШыЮЊЙмРэНкЕуЛЙЪЧЙЄзїНкЕу
дЫааdocker infoРДВщПДЕБЧАswarmМЏШКЕФзДЬЌЃК
james@james-CW65:~
> docker info
Containers: 4
Running: 2
Paused: 0
Stopped: 2
Images: 7
Server Version: 17.12.0-ce
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Backing Filesystem: extfs
Dirs: 37
Dirperm1 Supported: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file
logentries splunk syslog
Swarm: active
NodeID: 5n1l6261akogeuxysrgn2ipxz
Is Manager: true
ClusterID: nhkp9f1l5yq76e0zu0bage2h4
Managers: 1
Nodes: 1
Orchestration:
Task History Retention Limit: 5
Raft:
Snapshot Interval: 10000
Number of Old Snapshots to Retain: 0
Heartbeat Tick: 1
Election Tick: 3
Dispatcher:
Heartbeat Period: 5 seconds
CA Configuration:
Expiry Duration: 3 months
Force Rotate: 0
Autolock Managers: false
Root Rotation In Progress: false
Node Address: 192.168.99.1
Manager Addresses:
192.168.99.1:2377
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 89623f28b87a6004d4b785663257362d1658a729
runc version: b2567b37d7b75eb4cf325b77297b140ea686ce8f
init version: 949e6fa
Security Options:
apparmor
Kernel Version: 3.19.0-32-generic
Operating System: Ubuntu 14.04.3 LTS
OSType: linux
Architecture: x86_64
CPUs: 4
Total Memory: 3.755GiB
Name: james-CW65
ID: EMVF:D3TL:KMEY:2QTR:HESQ:J5ZA:WDYM:GSEV:
INSU:Z4QI:DCIX:LMGK
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
|
дЫааdocker node lsРДВщПДНкЕуаХЯЂЃК
james@james-CW65:~
> docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
n1l6261akogeuxysrgn2ipxz * james-CW65 Ready Active
Leader |
nodeIdХдБпЕФ*КХБэЪОФуЕБЧАСЌНгЕНЕФНкЕуЁЃ
dockerв§ЧцЕФswarmФЃЪНздЖЏЪЙгУЫожїЛњЕФжїЛњУћзїЮЊНкЕуУћЁЃ
НЋНкЕуМгШыЕНswarmМЏШКжа
вЛЕЉЧАУцЕФДДНЈswarmМЏШКЭъГЩЃЌФуОЭПЩвдМгШыЙЄзїНкЕуСЫЁЃ
sshЕНвЊМгШыМЏШКЕФНкЕуЩЯЃЌЮвУЧвЊМгШыworker1.
дЫааДДНЈswarmМЏШКЪБКђВњЩњЕФУќСюРДНЋwoker1МгШыЕНМЏШКжаЃК
docker@default:~$
docker swarm join --token SWMTKN-1-2bgkinnbc0rmlj6kpotyrlj0uz51l2ikinttsk960dxro558x4-6zajfnahtv9ye39momd
dh5kru 192.168.99.1:2377
This node joined a swarm as a worker. |
ШчЙћФуевВЛЕНМгШыУќСюСЫЃЌПЩвддкЙмРэНкЕудЫааЯТСаУќСюевЛиМгШыУќСюЃК
james@james-CW65:~
> docker swarm join-token worker
To add a worker to this swarm, run the following
command:
docker swarm join --token SWMTKN-1-2bgkinnbc0rmlj6kpotyrlj0uz51l2ikinttsk960dxro558x4-6zajfnahtv9ye39momddh5kru
192.168.99.1:2377 |
sshЕНworker2
дЫааМгШыМЏШКЕФУќСюРДНЋworker2МгШыЕНМЏШКЃК
Boot2Docker
version 17.12.0-ce, build HEAD : 378b049 - Wed
Dec 27 23:39:20 UTC 2017
Docker version 17.12.0-ce, build c97c6d6
docker@lab:~$ docker swarm join --token SWMTKN-1-2bgkinnbc0rmlj6kpotyrlj0uz51l2ikinttsk960dxro558x4-6zajfnahtv9ye39momddh5k
ru 192.168.99.1:2377
This node joined a swarm as a worker. |
sshЕНmanagerНкЕудЫааdocker node lsУќСюРДВщПДМЏШКНкЕуЧщПіЃК
james@james-CW65:~
> docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
k89s71elf81vbn7pytwszmgr5 default Ready Active
n1l6261akogeuxysrgn2ipxz * james-CW65 Ready Active
Leader
ye5x8hci1chmo8nyjx8y4thhy lab Ready Active |
MANAGERСаБэУїСЫМЏШКжаЕФЙмРэНкЕуЁЃworkerНкЕуЕФПевтЮЖзХЫќУЧЪЧЙЄзїНкЕу
дкswarmМЏШКЩЯВПЪ№вЛИіЗўЮё
дкДДНЈвЛИіswarmМЏШККѓЃЌОЭПЩвдВПЪ№ЗўЮёСЫЁЃБОНЬГЬжаФувВПЩвдМгШыЙЄзїНкЕуЃЌЕЋЪЧВЛЪЧБиаыЕФЁЃ
sshЕНmanagerНкЕу
дЫааШчЯТУќСюЃК
james@james-CW65:~
> docker service create --replicas 1 --name
helloworld alpine ping docker.com
060zo3u0g3mjdmrilezzbckbe
overall progress: 1 out of 1 tasks
1/1: running [=========================================>]
verify: Service converged |
docker service createгУРДДДНЈЗўЮё
--nameБэУїЗўЮёУћзжЪЧhelloworld
--replicas БэЪОЦкЭћ1ИіЗўЮёЪЕР§
alpine ping docker.com БэЪОдЫааОЕЯёЪЧalpineЃЌУќСюЪЧping
дЫааdocker service lsРДВщПДдЫааЕФЗўЮёЃК
james@james-CW65:~
> docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
060zo3u0g3mj helloworld replicated 1/1 alpine:latest |
МьВщSwarmМЏШКЩЯЕФЗўЮё
дкФуВПЪ№ЗўЮёЕНSwarmМЏШКЩЯКѓЃЌПЩвдЪЙгУУќСюааРДМьВщдЫааЕФЗўЮё
sshЕНЙмРэНкЕу
дЫааУќСюdocker service inspect --pretty РДВщПДгХЛЏЯдЪОЕФЗўЮёЯъЧщ
james@james-CW65:~
> docker service inspect --pretty 060zo3u0g3mj
ID: 060zo3u0g3mjdmrilezzbckbe
Name: helloworld
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:7b848083f93822dd21b0a2f14a1
10bd99f6efb4b838d499df6d04a49d0debf8b
Args: ping docker.com
Resources:
Endpoint Mode: vip |
ШЅЕє--prettyбЁЯюНЋвдjsonИёЪНЪфГі
дЫааdocker service ps НЋВщПДЕНФФаЉНкЕудкдЫааИУЗўЮёЪЕР§ЃК
james@james-CW65:~
> docker service ps 060zo3u0g3mj
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ERROR PORTS
cbiq1ne3ij9a helloworld.1 alpine:latest james-CW65
Running Running 9 minutes ago |
ЗўЮёПЩФмдЫаадкЙмРэЛђЙЄзїНкЕуЩЯЃЌФЌШЯЕФЙмРэНкЕуПЩвдЯёЙЄзїНкЕувЛбљдЫааШЮЮёЁЃ
ИУУќСювВЯдЪОЗўЮёЦкЭћЕФзДЬЌDESIRED STATE ЃЌКЭЪЕМЪЕФзДЬЌCURRENT STATEЁЃ
дкдЫааШЮЮёЕФНкЕуЩЯдЫааdocker psвВФмПДЕНетИіШЮЮёдЫааЕФШнЦї
james@james-CW65:~
> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES
cad59e7398de alpine:latest "ping docker.com"
2 minutes ago Up 2 minutes helloworld.1.ngbknb89dzyxdas81emw0jz63 |
дкswarmМЏШКжаЖЏЬЌЩьЫѕЗўЮёЪЕР§Ъ§
вЛЕЉФудкswarmМЏШКжаВПЪ№вЛИіЗўЮёКѓЃЌФуОЭПЩвдЪЙгУУќСюааРДИФБфЗўЮёЕФЪЕР§ИіЪ§ЁЃдкЗўЮёжадЫааЕФШнЦїГЦЮЊЁАШЮЮёЁБ
sshЕНmanagerНкЕу
дЫаавдЯТУќСюРДИФБфЗўЮёЕФЦкЭћЪЕР§Ъ§ЃК
james@james-CW65:~
> docker service scale 60zo3u0g3mj=3
60zo3u0g3mj scaled to 3
overall progress: 3 out of 3 tasks
1/3: running [=============================================>]
2/3: running [=============================================>]
3/3: running [=============================================>]
verify: Waiting 1 seconds to verify that tasks
are stable...
verify: Service converged |
дЫаавдЯТУќСюРДВщПДИќаТЕФШЮЮёСаБэЃК
james@james-CW65:~
> docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
060zo3u0g3mj helloworld replicated 3/3 alpine:latest
james@james-CW65:~ > docker service ps 060zo3u0g3mj
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ERROR PORTS
ngbknb89dzyx helloworld.1 alpine:latest james-CW65
Running Running 9 minutes ago
cbiq1ne3ij9a \_ helloworld.1 alpine:latest james-CW65
Shutdown Failed 9 minutes ago "task: non-zero
exit (1)"
3fl3mfrvubu1 helloworld.2 alpine:latest default
Running Running about a minute ago
hy5pqcmqfw67 helloworld.3 alpine:latest lab Running
Running about a minute ago |
ПЩвдПДЕНет3ИіШЮЮёБЛЗжВМЕНСЫМЏШКжаЕФВЛЭЌНкЕу
sshЕНдЫааЗўЮёЕФжїЛњЩЯдЫааdocker psВщПДдЫааЕФШнЦїЃК
docker@default:~$
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES
cad897086027 alpine:latest "ping docker.com"
4 minutes ago Up 4 minutes helloworld.2.3fl3mfrvubu1hf16argabe5qt |
ДгswarmМЏШКЩЯЩОГ§гІгУ
НгЯТРДЩОГ§гІгУ
sshЕНЙмРэНкЕу
дЫааdocker service rm helloworldРДЩОГ§ЗўЮёЃК
james@james-CW65:~
> docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
060zo3u0g3mj helloworld replicated 3/3 alpine:latest
james@james-CW65:~ > docker service rm 060zo3u0g3mj
060zo3u0g3mj
james@james-CW65:~ > docker service ls
ID NAME MODE REPLICAS IMAGE PORTS |
дЫааdocker service inspect ЛсЗЂЯжЗўЮёВЛДцдкСЫ
james@james-CW65:~
> docker service inspect 060zo3u0g3mj
[]
Status: Error: no such service: 060zo3u0g3mj,
Code: 1 |
ОЁЙмЗўЮёВЛДцдкСЫЃЌШЮЮёШнЦїЛЙашвЊМИУыжгРДЧхРэЃЌФуПЩвддкНкЕуЩЯdocker psВщПДШЮЮёЪВУДЪБКђБЛвЦГ§ЁЃ
ЙіЖЏИќаТ
дкЧАУцЕФеТНкжаЃЌаоИФСЫЪЕР§Ъ§ЁЃБОНкЪЙгУGhost0.11.12 ОЕЯёРДВПЪ№ЗўЮёЃЌШЛКѓЙіЖЏЩ§МЖЕНGhost1.21.3
sshЕНЙмРэНкЕу
ВПЪ№Ghost0.11.12 ЗўЮёЃЌХфжУ10sЕФИќаТМфИє:
james@james-CW65:~
> docker service create --replicas 2 --name
ghost --update-delay 10s ghost:0.11.12
tynb9d9pu0nqm7f1vmmffy9j0
overall progress: 2 out of 2 tasks
1/2: running [==========================================>]
2/2: running [==========================================>]
verify: Service converged |
зЂвтЃКНЬГЬЪЙгУЕФЪЧredisОЕЯёЃЌЮвЪЙгУЕФЪЧGhostВЉПЭОЕЯёЃЌР
дкЗўЮёВПЪ№НзЖЮОЭжИЖЈЙіЖЏЩ§МЖВпТд
--update-delayХфжУСЫИќаТЗўЮёЕФЪБМфМфИє,ФуПЩвджИЖЈЪБМфTЮЊУыЪЧTsЃЌЗжЪЧTmЃЌЛђЪБЪЧThЃЌЫљвд10m30sОЭЪЧ10Зж30УыЕФбгГй
ФЌШЯЕФЕїЖШЦїschedulerвЛДЮИќаТвЛИіШЮЮё.ФуПЩвдДЋШыВЮЪ§--update-parallelismРДХфжУЕїЖШЦїЭЌЪБИќаТЕФзюДѓШЮЮёЪ§СП
ФЌШЯЕФЕБвЛИіИќаТШЮЮёЗЕЛиRUNNINGзДЬЌКѓЃЌЕїЖШЦїВХЕїЖШСэвЛИіИќаТШЮЮёЃЌжБЕНЫљгаШЮЮёЖМИќаТСЫЁЃШчЙћИќаТЙ§ГЬжаШЮКЮШЮЮёЗЕЛиСЫFAILEDЃЌЕїЖШЦїОЭЛсЭЃжЙИќаТЁЃФуПЩвдИјУќСюdocker
service create or docker service updateХфжУХфжУ--update-failure-actionЃЌРДХфжУетИіааЮЊЁЃ
ВщПДredisЗўЮёЃК
james@james-CW65:~
> docker service inspect --pretty ghost
ID: tynb9d9pu0nqm7f1vmmffy9j0
Name: ghost
Service Mode: Replicated
Replicas: 2
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: ghost:0.11.12@sha256:45811b5a50254bdf0a05d68
3ddf1dd9eb1be98640305fb82317bcaa35a00c20e
Resources:
Endpoint Mode: vip |
ЯждкПЩвдИќаТredisЕФШнЦїОЕЯёСЫЁЃдЫаавдЯТУќСюЃЌswarmЕФЙмРэНкЕуНЋЛсИљОнИќаТВпТдUpdateConfigРДИќаТИїИіНкЕуЃК
james@james-CW65:~
> docker service update --image ghost:1.21.3
ghost
ghost
overall progress: 2 out of 2 tasks
1/2: running [===========================================>]
2/2: running [===========================================>]
verify: Service converged |
ЕїЖШЦївРеевдЯТВНжшРДЙіЖЏИќаТЃК
ЭЃжЙЕквЛИіШЮЮё
ЖдЭЃжЙЕФШЮЮёНјааИќаТ
ЖдИќаТЕФШЮЮёНјааЦєЖЏ
ШчЙћИќаТЕФШЮЮёЗЕЛиRUNNINGЃЌЕШД§ЬиЖЈМфИєКѓЦєЖЏЯТвЛИіШЮЮё
ШчЙћдкШЮКЮИќаТЕФЪБМфЃЌШЮЮёЗЕЛиСЫFAILEDЃЌдђЭЃжЙИќаТЁЃ
дЫааУќСюdocker service inspect --pretty redisРДВщПДаТОЕЯёЕФЦкЭћзДЬЌ,ПЩвдПДЕНЯдЪОСЫUpdateStatusЭъГЩЁЃ
james@james-CW65:~
> docker service inspect --pretty ghost
ID: tynb9d9pu0nqm7f1vmmffy9j0
Name: ghost
Service Mode: Replicated
Replicas: 2
UpdateStatus:
State: completed
Started: 2 minutes ago
Completed: 2 minutes ago
Message: update completed
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: ghost:1.21.3@sha256:4c8868f41180589583e6eb20
8a8529ca8dad3d18bddf56834740b715f3e6b691
Resources:
Endpoint Mode: vip
james@james-CW65:~ > |
ШчЙћжаМфгаЩ§МЖЪЇАмЕФЃЌдђЛсЯдЪОШчЯТаХЯЂЃК
$ docker service
inspect --pretty redis
ID: 0u6a4s31ybk7yw2wyvtikmu50
Name: redis
...snip...
Update status:
State: paused
Started: 11 seconds ago
Message: update paused due to failure or early
termination of task 9p7ith557h8ndf0ui9s0q951b
...snip... |
жиаТПЊЪМвЛИіЩ§МЖЙ§ГЬЃКdocker service update
ЮЊСЫБмУтжиИДЪЇАмЩ§МЖЃЌвЊжиаТХфжУЗўЮёЗўЮёЃЌЬэМгЪЪЕБЕФВЮЪ§дкдЫааdocker service update
дЫааdocker service ps РДВщПДБОДЮЙіЖЏИќаТЕФЙ§ГЬЃК
james@james-CW65:~
> docker service ps ghost
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ERROR PORTS
5ae8hwemegrg ghost.1 ghost:1.21.3 james-CW65 Running
Running 54 seconds ago
akwqfsarjvy1 \_ ghost.1 ghost:0.11.12 james-CW65
Shutdown Shutdown 54 seconds ago
hzzq00ckovdg ghost.2 ghost:1.21.3 default Running
Running 41 seconds ago
ivtd60xuggk0 \_ ghost.2 ghost:0.11.12 default
Shutdown Shutdown 42 seconds ago
james@james-CW65:~ > |
зЂвтЩ§МЖКѓРЯЕФШнЦїжЛЪЧЭЃжЙСЫЃЌВЂУЛгаЩОГ§
docker@default:~$
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES
f855c00da7b7 ghost:1.21.3 "docker-entrypoint.sЁ"
6 minutes ago Up 6 minutes 2368/tcp ghost.2.hzzq00ckovdgb48373lwn8xp6
c151f3535a3b ghost:0.11.12 "docker-entrypoint.sЁ"
32 minutes ago Exited (0) 6 minutes ago ghost.2.ivtd60xuggk0y56oguehtirni |
ДгМЏШКжаЯТЯпвЛИіНкЕу
ЧАУцЕФНЬГЬжаЙмРэНкЕуЛсАбШЮЮёЗжХфИјACTIVEЕФНкЕуЃЌЫљгаACTIVEЕФНкЕуЖМФмНгЕНШЮЮё
гаЪБКђЃЌР§ШчЬиЖЈЕФЮЌЛЄЪБМфЃЌЮвУЧОЭашвЊДгМЏШКжаЯТЯпвЛИіНкЕуЁЃЯТЯпНкЕуЪЙНкЕуВЛЛсНгЪмаТШЮЮёЃЌЙмРэНкЕуЛсЭЃжЙИУНкЕуЩЯЕФШЮЮёЃЌЗжХфЕНБ№ЕФACTIVEЕФНкЕуЩЯЁЃ
зЂвтЃКЯТЯпвЛИіНкЕуВЛвЦГ§НкЕужаЕФЖРСЂШнЦїЃЌШчdocker runЃЌdocker-compose upЛђdocker
APIЦєЖЏЕФШнЦїЖМВЛЛсЩОГ§ЁЃНкЕуЕФзДЬЌНігАЯьМЏШКЗўЮёЕФИКдиЪЧЗёЗжЕНИУНкЕуЁЃ
sshЕНmanageer1
дЫааdocker node lsЃЌбщжЄЫљгаНкЕуЖМЪЧACTIVEЕФЃК
james@james-CW65:~
> docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
k89s71elf81vbn7pytwszmgr5 default Ready Active
n1l6261akogeuxysrgn2ipxz * james-CW65 Ready Active
Leader |
ШчЙћХЊЕФredisЗўЮёЛЙУЛгаДгЙіЖЏИќаТжаЦ№РДЃЌашвЊЦєЖЏЦ№РДЃК
дЫааdocker service ps redisВщПДЙмРэНкЕуШчКЮЗжХфШЮЮёЕНВЛЭЌНкЕуЃК
james@james-CW65:~
> docker service ps ghost
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ERROR PORTS
5ae8hwemegrg ghost.1 ghost:1.21.3 james-CW65 Running
Running 19 minutes ago
akwqfsarjvy1 \_ ghost.1 ghost:0.11.12 james-CW65
Shutdown Shutdown 19 minutes ago
hzzq00ckovdg ghost.2 ghost:1.21.3 default Running
Running 19 minutes ago
ivtd60xuggk0 \_ ghost.2 ghost:0.11.12 default
Shutdown Shutdown 19 minutes ago |
дЫааdocker node update --availability drain РДЯТЯпвЛИіНкЕуЃК
james@james-CW65:~
> docker node update --availability drain default
default |
дЫаавдЯТРДМьВщНкЕуЕФПЩгУадЃК
ПЩвдПДЕНИУНкЕуЕФПЩгУадЪЧDrain
james@james-CW65:~
> docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
k89s71elf81vbn7pytwszmgr5 default Ready Drain
5n1l6261akogeuxysrgn2ipxz * james-CW65 Ready Active
Leader
james@james-CW65:~ > docker node inspect --pretty
default
ID: k89s71elf81vbn7pytwszmgr5
Hostname: default
Joined at: 2018-02-28 06:25:23.718220559 +0000
utc
Status:
State: Ready
Availability: Drain
Address: 192.168.99.100
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 995.9MiB
Plugins:
Log: awslogs, fluentd, gcplogs, gelf, journald,
json-file, logentries, splunk, syslog
Network: bridge, host, macvlan, null, overlay
Volume: local
Engine Version: 17.12.0-ce
Engine Labels:
- provider=virtualbox
TLS Info:
TrustRoot:
-----BEGIN CERTIFICATE-----
MIIBajCCARCgAwIBAgIUJdysIbjEKr/Xr+SvWKd8S0Upgqcw
CgYIKoZIzj0EAwIw
EzERMA8GA1UEAxMIc3dhcm0tY2EwHhcNM
TgwMjI4MDYwNDAwWhcNMzgwMjIzMDYw
NDAwWjATMREwDw
YDVQQDEwhzd2FybS1jYTBZMBMGByqGSM49AgEGCCqGSM49AwEH
A0IABFgzZnc/77Zo87KKNrJK83z6ASk1YNHwXYWQvfny
f5aqhLUuOOdGXMgvEj5s
GHGkNitCK2y11XQdSzsRQE5
JsGKjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB
Af8EBTADAQH/MB0GA1UdDgQWBBSaliomGnuL2p+
xndnzrIfncS9TezAKBggqhkjO
PQQDAgNIADBFAiA8c
7Qn3OA62I4APdAqzwK8z4rNgJug7Nheuo7pOOBybgIhAM5W
t2NvL1EBMjCQZGRk45W/X0C2UN2NQ+cA7
CVBHh7I
-----END CERTIFICATE-----
Issuer Subject: MBMxETAPBgNVBAMTCHN3YXJtLWNh
Issuer Public Key: MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEWDNm
dz/vtmjzsoo2skrzfPoBKTVg0fBdhZC9+fJ/lqqEtS4450Zc
yC8SPmwYcaQ2K0IrbLXVdB1LOxFATkmwYg== |
дЫааdocker service ps redisРДВщПДЙмРэНкЕуЪЧШчКЮжиаТЗжХфШЮЮёЕФЃК
ПЩвдПДЕНЙмРэНкЕуНЋЯТЯпНкЕуЕФШЮЮёЭЃжЙСЫЃЌЮЊСЫБЃеЯИББОЪ§СПЃЌжиаТдкactiveЕФНкЕуЩЯЕїЖШСЫШЮЮёЁЃ
james@james-CW65:~
> docker service ps ghost
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ERROR PORTS
5ae8hwemegrg ghost.1 ghost:1.21.3 james-CW65 Running
Running 21 minutes ago
akwqfsarjvy1 \_ ghost.1 ghost:0.11.12 james-CW65
Shutdown Shutdown 21 minutes ago
lefwcfo1s44k ghost.2 ghost:1.21.3 james-CW65 Running
Running 22 seconds ago
hzzq00ckovdg \_ ghost.2 ghost:1.21.3 default Shutdown
Shutdown 22 seconds ago
ivtd60xuggk0 \_ ghost.2 ghost:0.11.12 default
Shutdown Shutdown 21 minutes ago |
дЫааdocker node update --availability active РДжиаТactiveИУНкЕуЃК
james@james-CW65:~
> docker node update --availability active
default
default
james@james-CW65:~ > docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
k89s71elf81vbn7pytwszmgr5 default Ready Active
5n1l6261akogeuxysrgn2ipxz * james-CW65 Ready Active
Leader |
ВщПДНкЕузДЬЌЃЌПЩвдПДЕННкЕузДЬЌжиаТЮЊACtiveЃК
james@james-CW65:~
> docker node inspect --pretty default
ID: k89s71elf81vbn7pytwszmgr5
Hostname: default
Joined at: 2018-02-28 06:25:23.718220559 +0000
utc
Status:
State: Ready
Availability: Active
Address: 192.168.99.100
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 995.9MiB
Plugins:
Log: awslogs, fluentd, gcplogs, gelf, journald,
json-file, logentries, splunk, syslog
Network: bridge, host, macvlan, null, overlay
Volume: local
Engine Version: 17.12.0-ce
Engine Labels:
- provider=virtualbox
TLS Info:
TrustRoot: |
ЕБНкЕужиаТactiveЕФЪБКђЃЌдквдЯТЧщПіЯТЫќЛсжиаТНгЪмШЮЮёЃК
ЕБвЛИіЗўЮёЫѕШнРЉШнЪБ
дкЙіЖЏИќаТЕФЪБКђ
ЕБСэвЛИіНкЕуDrainЯТЯпЕФЪБКђ
ЕБвЛИіШЮЮёдкСэвЛИіactiveНкЕуЩЯдЫааЪЇАмЕФЪБКђ
ЪЙгУswarmФЃЪНЕФТЗгЩЭјТч
dockerЕФswarmФЃЪНЪЙЗўЮёБЉТЖИјЭтВПЖЫПкИќМгЗНБуЁЃЫљгаЕФНкЕуЖМдквЛИіТЗгЩЭјТчРяЁЃетИіТЗгЩЭјТчЪЙЕУМЏШКФкЕФЫљгаНкЕуЖМФмдкПЊЗХЕФЖЫПкЩЯНгЪмЧыЧѓЁЃМДЪЙНкЕуЩЯУЛгаШЮЮёдЫааЃЌетИіЗўЮёЕФЖЫПквВБЉТЖЕФЁЃТЗгЩЭјТчТЗгЩЫљгаЕФЧыЧѓЕНБЉТЖЖЫПкЕФНкЕуЩЯЁЃ
ЧАЬсЪЧашвЊБЉТЖвдЯТЖЫПкРДЪЙНкЕуМфФмЭЈаХ
Port 7946 TCP/UDP for container network discovery.гУгкШнЦїМфЭјТчЗЂЯж
Port 4789 UDP for the container ingress network.гУгкШнЦїНјШыЭјТч
ФувВБиаыПЊЗХНкЕужЎМфЕФЙЋПЊЖЫПкЃЌКЭШЮКЮЭтВПзЪдДЖЫПкЃЌР§ШчвЛИіЭтВПЕФИКдиОљКтЁЃ
ФувВПЩвдЪЙЬиЖЈЗўЮёШЦЙ§ТЗгЩЭјТч
ЮЊвЛИіЗўЮёБЉТЖЖЫПк
ЪЙгУ--publishРДдкДДНЈвЛИіЗўЮёЕФЪБКђБЉТЖЖЫПкЁЃtargetжИУїШнЦїФкБЉТЖЕФЖЫПкЁЃpublishedжИУїАѓЖЈЕНТЗгЩЭјТчЩЯЕФЖЫПкЁЃШчЙћВЛаДpublishedЃЌОЭЛсЮЊУПИіЗўЮёАѓЖЈвЛИіЫцЛњЕФИпЪ§зжЖЫПкЁЃФуашвЊМьВщШЮЮёВХФмШЗЖЈЖЫПк
james@james-CW65:~
> docker service create --name ghostBlog --publish
published=80,target=2368 --replicas 1 ghost:1.21.3
xpnc3ga8yvh71zx5dvq94fbsn
overall progress: 1 out of 1 tasks
1/1: running [============================================>]
verify: Service converged
james@james-CW65:~ > docker service ps ghostBlog
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ERROR PORTS
5a0tepfqasqu ghostBlog.1 ghost:1.21.3 default
Running Running 18 seconds ago |
зЂвтОЩАцЕФгяЗЈЪЧУАКХЗжПЊЕФpublishedЃКtargetЃЌР§Шч -p 8080:80ЁЃаТгяЗЈИќвзЖСЧвСщЛюЁЃ
ЕБФудкШЮКЮНкЕуЗУЮЪ8080ЖЫПкЪБЃЌТЗгЩЭјТчНЋАбЧыЧѓЗжЗЂЕНвЛИіactiveЕФШнЦїжаЁЃдкИїИіНкЕуЃЌ8080ЖЫПкПЩФмВЂУЛгаАѓЖЈЃЌЕЋЪЧТЗгЩЭјТчжЊЕРШчКЮТЗгЩСїСПЃЌВЂЗРжЙШЮКЮЖЫПкГхЭЛЁЃ
ТЗгЩЭјТчМрЬ§ИїИіНкЕуЕФIPЩЯЕФ published port ЁЃДгЭтУцПДЃЌетаЉЖЫПкЪЧИїИіНкЕуБЉТЖЕФЁЃЖдгкБ№ЕФIPЕижЗЃЌжЛдкИУжїЛњФкПЩвдЗУЮЪЁЃ
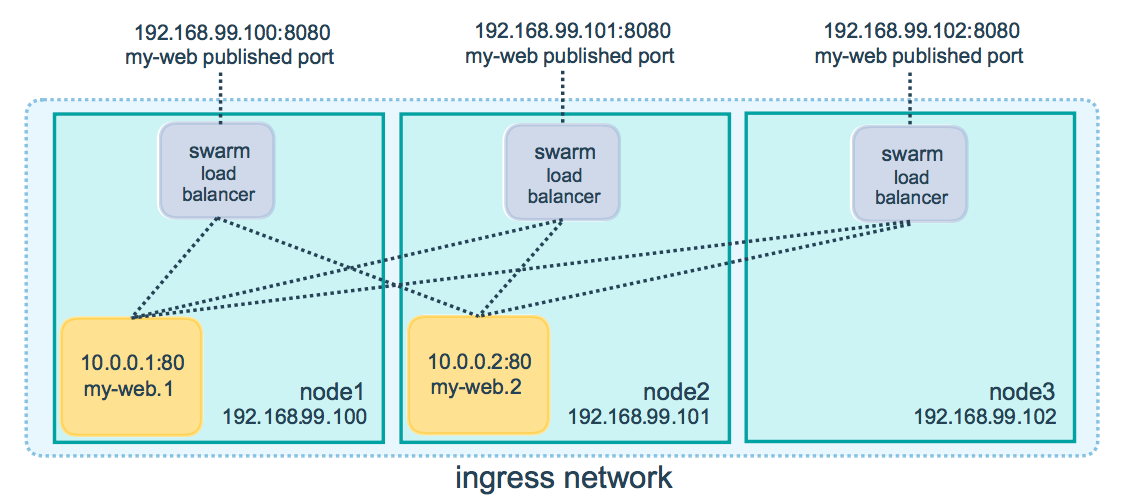
ФуПЩвдгУвдЯТУќСюИјвЛИівбОДцдкЕФЗўЮёБЉТЖЖЫПкЁЃ
james@james-CW65:~
> docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
tynb9d9pu0nq ghost replicated 2/2 ghost:1.21.3
xpnc3ga8yvh7 ghostBlog replicated 1/1 ghost:1.21.3
*:80->2368/tcp
james@james-CW65:~ > docker service update
--publish-add published=8080,target=2368 ghost
ghost
overall progress: 2 out of 2 tasks
1/2: running [============================================>]
2/2: running [============================================>]
verify: Service converged |
ФуПЩвдЪЙгУdocker service inspectРДВщПДЗўЮёБЉТЖЕФЖЫПкЃК
james@james-CW65:~
> docker service inspect --format="{{json
.Endpoint.Spec.Ports}}" ghost
[{"Protocol":"tcp","TargetPort":2368,"PublishedPort":
8080,"PublishMode":"ingress"}]
james@james-CW65:~ > docker service inspect
--format="{{json .Endpoint.Spec.Ports}}"
ghostBlog
[{"Protocol":"tcp","TargetPort":2368,"PublishedPort"
:80,"PublishMode":"ingress"}] |
НіБЉТЖвЛИіTCPЛђUDPЖЫПк
ФЌШЯФуБЉТЖЕФЖЫПкЖМЪЧTCPЕФЁЃШчЙћФуЪЙгУГЄгяЗЈЃЈDocker 1.13 and higherЃЉЃЌЩшжУprotocolЮЊtcpЛђudpМДПЩБЉТЖЯргІЖЫПк
НіTCP
ГЄгяЗЈ
$ docker service create --name dns-cache \
--publish published=53,target=53 \
dns-cache
ЖЬгяЗЈ
$ docker service create --name dns-cache \
-p 53:53 \
dns-cache |
TCPКЭUDP
ГЄгяЗЈ
$ docker service create --name dns-cache \
--publish published=53,target=53 \
--publish published=53,target=53,protocol=udp
\
dns-cache
ЖЬгяЗЈ
$ docker service create --name dns-cache \
-p 53:53 \
-p 53:53/udp \
dns-cache |
жЛБЉТЖUDP
ГЄгяЗЈ
$ docker service create --name dns-cache \
--publish published=53,target=53,protocol=udp
\
dns-cache
ЖЬгяЗЈ
$ docker service create --name dns-cache \
-p 53:53/udp \
dns-cache |
ШЦЙ§ТЗгЩЭјТч
ФуПЩвдШЦЙ§ТЗгЩЭјТчЃЌжБНгКЭвЛИіНкЕуЩЯЕФЖЫПкЭЈаХЃЌРДЗУЮЪЗўЮёЁЃетНазіHostФЃЪНЃК
ШчЙћИУНкЕуЩЯУЛгаЗўЮёдЫааЃЌЗўЮёвВУЛгаМрЬ§ЖЫПкЃЌдђПЩФмЮоЗЈЭЈаХЁЃ
ФуВЛФмдквЛИіНкЕуЩЯдЫааЖрИіЗўЮёЪЕР§ЫћУЧАѓЖЈЭЌвЛИіОВЬЌtargetЖЫПкЁЃЛђепФуШУdockerЗжХфЫцЛњИпЪ§зжЖЫПкЃЈЭЈЙ§ПеХфжУtargetЃЉЃЌЛђепШЗБЃИУНкЕуЩЯжЛдЫаавЛИіЗўЮёЪЕР§ЃЈЭЈЙ§ХфжУШЋОжЗўЮёglobal
service ЖјВЛЪЧИББОЗўЮёЃЌЛђепЪЙгУХфжУЯожЦЃЉЁЃ
ЮЊСЫШЦЙ§ТЗгЩЭјТчЃЌБиаыЪЙгУГЄИёЪН--publishЃЌЩшжУФЃЪНmodeЮЊhostФЃЪНЁЃШчЙћФуКіТдСЫmodeЩшжУЛђепЩшжУЮЊФкЭјingressЃЌдђТЗгЩЭјТчНЋЦєЖЏЁЃЯТУцЕФУќСюДДНЈСЫШЋОжгІгУЪЙгУhostФЃЪНШЦЙ§ТЗгЩЭјТчЃК
$ docker service
create --name dns-cache \
--publish published=53,target=53,protocol=udp,mode=host
\
--mode global \
dns-cache |
ХфжУЭтВПЕФИКдиОљКт
ФуПЩвдЮЊswarmМЏШКХфжУЭтВПЕФИКдиОљКтЃЌЛђепНсКЯТЗгЩЭјТчЪЙгУЛђепЭъШЋВЛЪЙгУЃК
ЪЙгУТЗгЩЭјТч
ФуПЩвдЪЙгУвЛИіЭтВПЕФHAProxyРДИКдиОљКтЃЌЗўЮёЪЧ8080ЖЫПкЩЯЕФnginxЗўЮёЃК
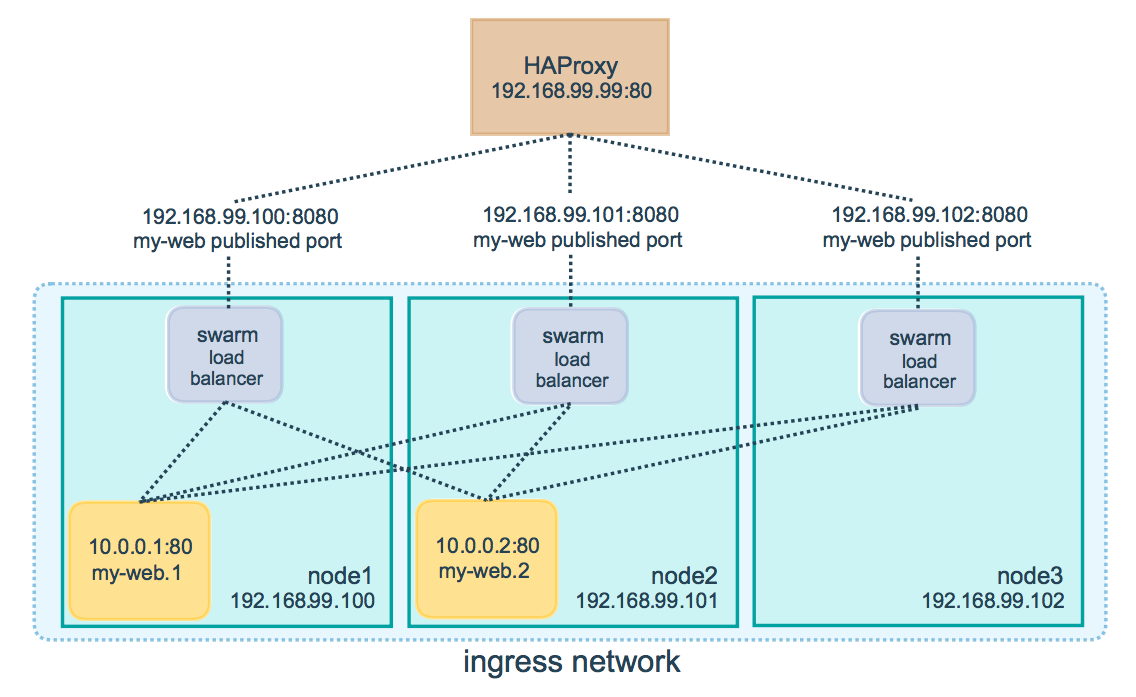
дкетИіР§згжаИКдиОљКтЦїКЭМЏШКНкЕужЎМфЕФ8080ЖЫПкБиаыЪЧПЊЗХЕФЁЃswarmМЏШКНкЕудквЛИіЭтВПВЛПЩЗУЮЪЕФФкЭјжаЃЌНкЕуПЩвдгыHAProxyЭЈаХЁЃ
ФуПЩвдХфжУИКдиОљКтЦїЗжСїЧыЧѓЕНВЛЭЌЕФМЏШКНкЕуЃЌМДЪЙНкЕуЩЯУЛгаЗўЮёдЫааЁЃР§ШчФуПЩвдШчЯТХфжУHAProxyЃК/etc/haproxy/haproxy.cfgЃК
global
log /dev/log local0
log /dev/log local1 notice
...snip...
# Configure HAProxy to listen on port 80
frontend http_front
bind *:80
stats uri /haproxy?stats
default_backend http_back
# Configure HAProxy to route requests to swarm
nodes on port 8080
backend http_back
balance roundrobin
server node1 192.168.99.100:8080 check
server node2 192.168.99.101:8080 check
server node3 192.168.99.102:8080 check |
ЕБФуЧыЧѓHAProxyЕФ80ЖЫПкЕФЪБКђЃЌЫќЛсзЊЗЂЧыЧѓЕНКѓЖЫНкЕуЁЃswarmЕФТЗгЩЭјТчЛсТЗгЩЕНЯргІЕФЗўЮёНкЕуЁЃетбљЮоТлШЮКЮдвђswarmЕФЕїЖШЦїЕїЖШЗўЮёЕНВЛЭЌНкЕуЃЌЖМВЛашвЊжиаТХфжУИКдиОљКтЁЃ
ФуПЩвдХфжУШЮКЮРраЭЕФИКдиОљКтРДЗжСїЧыЧѓЁЃЙигкHAProxyВЮПМ HAProxy documentation
ВЛЪЙгУТЗгЩЭјТч
ШчЙћВЛЪЙгУТЗгЩЭјТчЃЌХфжУ--endpoint-modeЕФжЕЮЊdnsrrЃЌЖјВЛЪЧvipЁЃдкБОР§згжаУЛгавЛИіЙЬЖЈЕФащФтIPЁЃDockerЮЊЗўЮёзіСЫDNSзЂВсЃЌетбљвЛИіЗўЮёЕФDNSВщбЏЛсЗЕЛивЛЯЕСаIPЕижЗЁЃПЭЛЇЖЫОЭПЩвджБНгСЌНгЦфжавЛИіНкЕуЁЃФуИКд№ЬсЙЉетвЛЯЕСаЕФIPЕижЗЃЌПЊЗХЖЫПкИјФуЕФИКдиОљКтЦїЁЃВЮПМConfigure
service discovery.
|