| ±ύΦ≠ΆΤΦω: |
| ±ΨΈΡά¥Ή‘”ΎinfoqΘ§Ϋι…ή»γΚΈ»ΪΟφΝΥΫβKubernetesΜυ¥Γ…η ©“‘ΦΑ»γΚΈ‘ΎΜυ”Ύ»ίΤςΒΡΜυ¥Γ…η ©÷– Ι”ΟIstioΖΰΈώΆχΗώΓΘ |
|
‘Υ”Σ»ίΤςΜ·ΒΡΜυ¥Γ…η ©¥χά¥ΝΥ“ΜœΒΝ––¬ΒΡΧτ’ΫΓΘΈ“Ο«–η“Σ‘ω«Ω»ίΤςΓΔΤάΙάAPIΕΥΒψΒΡ–‘Ρή“‘ΦΑ Ε±π≥ωΜυ¥Γ…η ©÷–ΒΡ”–ΚΠ≤ΩΖ÷ΓΘIstioΖΰΈώΆχΗώΩ…‘Ύ≤Μ–όΗΡ¥ζ¬κΒΡ«ιΩωœ¬ Βœ÷API‘ω«ΩΘ§≤Δ«“≤ΜΜα¥χά¥ΖΰΈώ―”≥ΌΓΘ’βΤΣΈΡ’¬ΫΪΫι…ή»γΚΈ»ΪΟφΝΥΫβKubernetesΜυ¥Γ…η ©“‘ΦΑ»γΚΈ‘ΎΜυ”Ύ»ίΤςΒΡΜυ¥Γ…η ©÷– Ι”ΟIstioΖΰΈώΆχΗώΓΘ
IstioΗ≈άά
Istio «”Ο”ΎKubernetesΒΡΖΰΈώΆχΗώΘ§ΗΚ‘π¥ΠάμΖΰΈώ÷°ΦδΒΡΆ®–≈Θ§ΨΆœώΆχ¬γ¬Ζ”…»μΦΰ¥ΠάμTCP/IPΝςΝΩΡ«―υΓΘ≥ΐΝΥKubernetes÷°ΆβΘ§IstioΜΙΩ…“‘”κΜυ”ΎDockerΚΆConsulΒΡΖΰΈώΖΔ…ζΫΜΜΞΓΘΥϋ”κ“―Ψ≠¥φ‘ΎΝΥ“ΜΕΈ ±ΦδΒΡLinkerD”–ΒψœύΥΤΓΘ
Istio «”…ά¥Ή‘Ι»ΗηΓΔIBMΓΔΥΦΩΤΚΆLyft EnvoyΒΡΆ≈Ε”Ι≤Ά§ΩΣΖΔΒΡ“ΜΗωΩΣ‘¥œνΡΩΓΘIstioΉνΫϋΗ’¬ζ“ΜΥξΘ§»¥“―Ψ≠±Μ¥σΙφΡΘ≤Ω πΒΫ…ζ≤ζΜΖΨ≥÷–ΓΘ‘Ύ–¥’βΤΣΈΡ’¬ ±
Θ®2018Ρξ1‘¬10»’Θ©Θ§IstioΑφ±ΨΈΣ0.8ΓΘ
Ρ«Ο¥Θ§»γΚΈ‘ΎKubernetes…ζΧ§œΒΆ≥÷– Ι”ΟIstioΘΩΩ…“‘’βΟ¥ΥΒΘ§Kubernetes≥δΒ±ΒΡ « ΐΨίΤΫΟφΘ§Istio‘ρ≥δΒ±ΩΊ÷ΤΤΫΟφΓΘKubernetesΗΚ‘π≥–‘Ί”Π”Ο≥Χ–ρΝςΝΩΘ§Ϋχ––»ίΤςΒΡ±ύ≈δΓΔ≤Ω πΚΆά©’ΙΓΘIstio‘ρΗΚ‘π¬Ζ”…”Π”Ο≥Χ–ρΝςΝΩΘ§¥Πάμ≤Ώ¬‘÷¥––ΓΔΝςΝΩΙήάμΚΆΗΚ‘ΊΨυΚβΈ ΧβΓΘΥϋΜΙΨέΚœ“Θ≤β‘ΣΥΊΘ§»γ÷Η±ξΓΔ»’÷ΨΚΆΗζΉΌΓΘIstio «Μυ”Ύ»ίΤςΜυ¥Γ…η ©ΒΡ–≠Ιή‘±ΚΆΨ·±®‘±ΓΘ
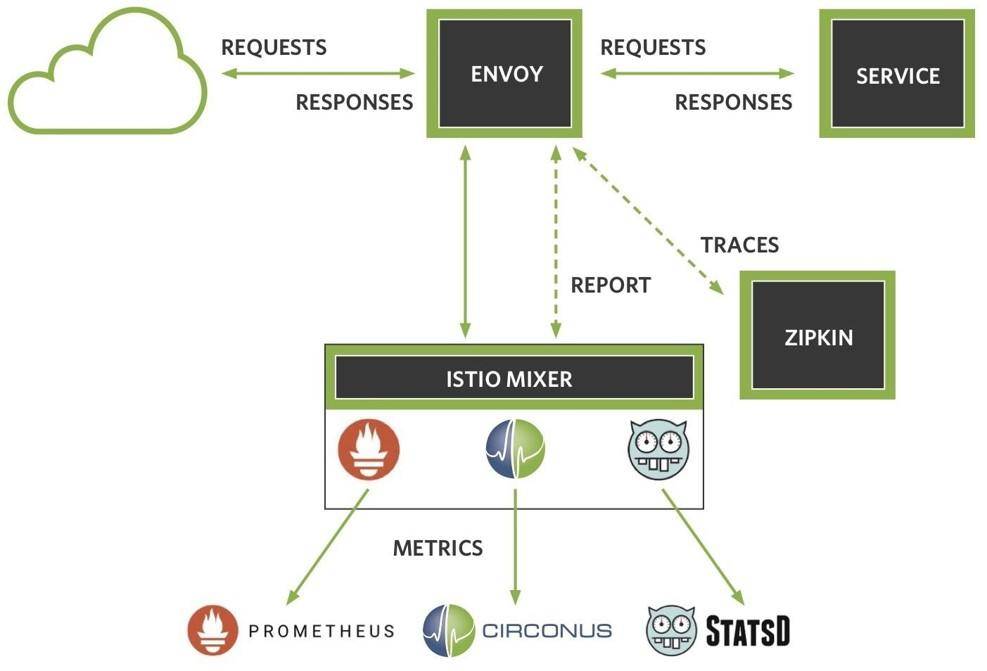
…œΆΦΟηΜφΝΥΖΰΈώΆχΗώΒΡΦήΙΙΓΘIstioΈΣΟΩœνΖΰΈώ‘Υ––“ΜΗωEnvoy±Ώ≥Β¥ζάμΓΘEnvoy¥ζάμΆ®ΙΐGRPCΒς”ΟΫΪ»κ’Ψ«κ«σΉΣΖΔ÷ΝIstio
MixerΖΰΈώΓΘ»ΜΚσΘ§Mixer”Π”ΟΝςΝΩΙήάμΙφ‘ρά¥ΨέΚœ“Θ≤β‘ΣΥΊΓΘMixer «IstioΒΡ¥σΡ‘ΓΘ‘ΥΈ§»Υ‘±Ω…“‘Ά®Ιΐ±ύ–¥YAMLΈΡΦΰά¥÷ΗΕ®Envoy»γΚΈ÷ΊΕ®œρΝςΝΩΘ§ΜΙΩ…“‘÷ΗΕ®ΫΪΡΡ–©“Θ≤β‘ΣΥΊΆΤΥΆΒΫΦύΩΊœΒΆ≥ΚΆΙέ≤βœΒΆ≥ΓΘΈ“Ο«Ω…“‘‘Ύ‘Υ–– ±ΗυΨίΨΏΧε«ιΩω”Π”Οœύ”ΠΒΡΙφ‘ρΘ§Έό–η÷Ί–¬ΤτΕ·»ΈΚΈIstioΉιΦΰΓΘ
Istio÷ß≥÷Εύ÷÷ ≈δΤςΘ§”Ο”ΎΫΪ ΐΨίΖΔΥΆΒΫΗς÷÷ΦύΩΊΙΛΨΏΘ§»γPrometheusΓΔCirconusΜρStatsdΓΘΈ“Ο«“≤Ω…“‘Ά§ ±Ττ”ΟZipkinΚΆJaegerΗζΉΌΘ§…ζ≥…ΆΦ–Έ“‘±ψΕ‘ΖΰΈώΫχ––Ω… ”Μ·ΓΘ
IstioΒΡ≤Ω πΖ«≥ΘΦρΒΞΓΘ¥σΗ≈ΤΏΑΥΗω‘¬÷°«ΑΘ§Έ“Ο«±Ί–κΆ®Ιΐ“ΜœΒΝ–kubectlΟϋΝνΫΪIstioΑ≤ΉΑΒΫKubernetes»ΚΦ·…œΓΘœ÷‘ΎΒ±»Μ“≤Ω…“‘’βΟ¥ΉωΘ§≤ΜΙΐ”–Νμ“Μ÷÷ΗϋΦ”Φρ±ψΒΡΖΫ ΫΘ§ΨΆ «‘ΎΙ»Ηη‘ΤΤΫΧ®…œΒψΜςΦΗœ¬ σ±ξΦ¥Ω…≤Ω πΤτ”ΟΝΥIstioΒΡKubernetes»ΚΦ·Θ§Αϋά®ΦύΩΊΓΔΗζΉΌΚΆ Ψάΐ”Π”Ο≥Χ–ρΓΘ
Νμ“ΜΗωΚΟ¥Π «Θ§Έ“Ο«Ω…“‘‘Ύ≤Μ“Σ«σΩΣΖΔ»Υ‘±Ε‘ΥϊΟ«ΒΡΖΰΈώΫχ––‘ω«ΩΒΡ«ιΩωœ¬ ’Φ·ΖΰΈώ ΐΨίΓΘ’β―υΩ…“‘Φθ…ΌΈ§ΜΛΙΛΉςΓΔœϊ≥ΐ¥ζ¬κ÷–ΒΡ ßΑήΒψΓΘΥϋΜΙΧαΙ©ΝΥ”κΙ©”Π…ΧΈόΙΊΒΡΫ”ΩΎΘ§ΫΒΒΆΝΥ±ΜΙ©”Π…ΧΥχΕ®ΒΡΩ…Ρή–‘ΓΘ
Ϋη÷ζIstioΘ§Έ“Ο«Ω…“‘≤Ω πΒΞΗωΖΰΈώΒΡ≤ΜΆ§Αφ±ΨΘ§≤Δ»®ΚβΥϋΟ«÷°ΦδΒΡΝςΝΩΓΘIstio±Ψ…μ Ι”ΟΝΥΕύΗω≤ΜΆ§ΒΡpodΘ§»γœ¬Υυ ΨΘΚ
> kubectl
get pods -n istio-system
NAME READY STATUS RESTARTS AGE
istio-ca-797dfb66c5 1/1 Running 0 2m
istio-ingress-84f75844c4 1/1 Running 0 2m
istio-egress-29a16321d3 1/1 Running 0 2m
istio-mixer-9bf85fc68 3/3 Running 0 2m
istio-pilot-575679c565 2/2 Running 0 2m
grafana-182346ba12 2/2 Running 0 2m
prometheus-837521fe34 2/2 Running 0 2m |
Istio ΒΦ …œ≤Μ ««αΝΩΦΕΒΡΓΘIstioΒΡ«Ω¥σΙΠΡήΚΆΝιΜν–‘¥χά¥ΝΥ“Μ–©‘Υ”Σ≥…±ΨΓΘΒΪ «Θ§»γΙϊ”Π”Ο≥Χ–ρ÷–ΑϋΚ§ΕύΗωΈΔΖΰΈώΘ§Ρ«Ο¥”Π”Ο≥Χ–ρ»ίΤςΚήΩλΜα±μœ÷≥ω±»œΒΆ≥≈δ÷Ο»ίΤςΗϋ¥σΒΡ”≈ ΤΓΘ
ΖΰΈώΥ°ΤΫΡΩ±ξ
ΙΊ”ΎΖΰΈώΥ°ΤΫΡΩ±ξΒΡΗ≈ ωΫΪΈΣΈ“Ο«»γΚΈΚβΝΩΖΰΈώΫΓΩΒΉ¥ΩωΒλΕ®Μυ¥ΓΓΘΖΰΈώΥ°ΤΫ–≠“ιΘ®Service Level
AgreementΘ§SLAΘ©ΒΡΗ≈Ρν“―Ψ≠¥φ‘ΎΝΥ÷Ν…Ό °ΡξΓΘΕχ÷±ΒΫΉνΫϋΘ§”κΖΰΈώΥ°ΤΫΡΩ±ξΘ®Service Level
ObjectiveΘ§SLOΘ©ΚΆΖΰΈώΥ°ΤΫ÷Η ΨΤςΘ®Service Level IndicatorΘ§SLIΘ©œύΙΊΒΡΆχ¬γΡΎ»ί≤≈≥ωœ÷±§ΖΔ ΫΒΡ‘ω≥ΛΓΘ
≥ΐΝΥΙ»ΗηΒΡΡ«±ΨΓΑSite Reliability EngineeringΓ±÷°ΆβΘ§ΜΙ”–ΝΫ±Ψ”–ΙΊSLOΒΡ–¬ ιΦ¥ΫΪΈ άΓΘΓΑThe
Site Reliability WorkbookΓ±”–Ή®Ο≈ΒΡ’¬ΫΎΫι…ήΝΥSLOΘ§ΕχCirconus¥¥ Φ»ΥΦφ Ήœ·÷¥––ΙΌTheo
Schlossnagle‘ΎΓΑSeeking SREΓ±ΒΡ“ΜΗω’¬ΫΎ÷–Ε‘SLOΒΡΡΩ±ξΫχ––ΝΥΕ®“εΓΘΫ®“ιΙέΩ¥”…Seth
VargoΚΆLiz Fong Jones≥ œΉΒΡYouTube ”ΤΒΓΑSLIs,SLOs,SLAs,oh
my!Γ± Θ®Ν¥Ϋ”ΘΚhttps://youtu.be/tEylFyxbDLEΘ©Θ§“‘±ψ…ν»κΝΥΫβSLIΓΔSLOΚΆSLA÷°ΦδΒΡ≤ν±πΓΘ
ΉήΒΡά¥ΥΒΘΚSLI«ΐΕ·SLOΘ§SLOΆ®÷ΣSLAΓΘ
SLI «ΚβΝΩΖΰΈώΫΓΩΒΉ¥ΩωΒΡ÷Η±ξΓΘάΐ»γΘ§Έ“Ο«Ω…“‘”–’β―υΒΡ“ΜΗωSLIΘ§Υϋ±μ Ψ‘ΎΙΐ»Ξ5Ζ÷÷”ΡΎΘ§95%ΒΡ÷ς“≥Οφ«κ«σ―”≥Ό”Π–Γ”Ύ300ΚΝΟκΓΘ
SLO «SLIΒΡΡΩ±ξΓΘΈ“Ο«Ε‘SLIΫχ––ά©’ΙΘ§”Ο“‘ΝΩΜ·Έ“Ο«Ε‘ΖΰΈώ‘ΎΗχΕ® ±ΦδΦδΗτΡΎ÷¥––«ιΩωΒΡΤΎΆϊΓΘ“‘…œΟφΒΡSLIΈΣάΐΘ§Έ“Ο«Ω…“‘ΥΒΘ§Έ“Ο«œΘΆϊ’βΗωSLI…ηΕ®ΒΡ±ξΉΦ‘Ύœ¬“ΜΡξΩ…“‘¥οΒΫ99.9ΘΞΓΘ
SLA «Τσ“Β”κΩΆΜß÷°ΦδΒΡ–≠“ιΘ§Ε®“εΝΥΈ¥Ρή¬ζΉψSLOΒΡΚσΙϊΓΘ“ΜΑψά¥ΥΒΘ§SLAΥυ“άΨίΒΡSLO±»ΡΎ≤ΩSLOΗϋΩμΥ…Θ§“ρΈΣΈ“Ο«œΘΆϊΡΎ≤ΩΡΩ±ξ±»Άβ≤ΩΡΩ±ξΗϋΈΣ―œΗώΓΘ
RED“«±μ≈Χ
‘θ―υΒΡSLIΉιΚœΉν Κœ”Ο”ΎΝΩΜ·÷ςΜζΚΆΖΰΈώΒΡΫΓΩΒ≥ΧΕ»ΘΩ‘ΎΙΐ»ΞΦΗΡξ÷–Θ§≥ωœ÷ΝΥ“Μ–©–¬–ΥΒΡ±ξΉΦΓΘΤδ÷–Ήν”–”ΑœλΝΠΒΡ «USEΖΫΖ®ΓΔREDΖΫΖ®ΚΆΙ»ΗηSRE ÷≤α÷–Χ÷¬έΒΡΓΑΥΡΗωΜΤΫπ–≈Κ≈Γ±ΓΘ
USEΖΫΖ®”…Brendan GreggΧα≥ωΘ§÷Φ‘ΎΗυΨίάϊ”Ο¬ ΓΔ±ΞΚΆΕ»ΚΆ¥μΈσ÷Η±ξΝΩΜ·œΒΆ≥÷ςΜζΒΡΫΓΩΒΉ¥ΩωΓΘΕ‘”ΎœώCPU’β―υΒΡ≤ζΤΖΘ§Έ“Ο«Ω…“‘ Ι”Ο≥Θ”ΟΒΡ÷Η±ξΘ§»γ”ΟΜßΓΔœΒΆ≥ΚΆœ–÷ΟΑΌΖ÷±»ΓΘΈ“Ο«Ω…“‘ Ι”ΟΤΫΨυΗΚ‘ΊΚΆ‘Υ––Ε”Ν–ά¥ΚβΝΩ±ΞΚΆΕ»ΓΘUNIXΒΡperfΖ÷ΈωΤς «”Οά¥≤βΝΩCPU¥μΈσ ¬ΦΰΒΡ“ΜΗωΚήΚΟΒΡΙΛΨΏΓΘ
ΦΗΡξ«ΑΘ§Tom WilkieΧα≥ωΝΥREDΖΫΖ®ΓΘΫη÷ζREDΖΫΖ®Θ§Έ“Ο«Ε‘«κ«σ¬ ΓΔ«κ«σ¥μΈσΚΆ«κ«σ≥÷–χ ±ΦδΫχ––ΦύΩΊΓΘΙ»ΗηSRE ÷≤αΧ÷¬έΝΥ»γΚΈ Ι”Ο―”≥ΌΓΔΝςΝΩΓΔ¥μΈσΚΆ±ΞΚΆΕ»’βΥΡΗω÷Η±ξΓΘ’βΓΑΥΡΗωΜΤΫπ–≈Κ≈Γ±÷ς“Σ’κΕ‘ΖΰΈώΫΓΩΒΘ§”κREDΖΫΖ®άύΥΤΘ§÷Μ «ΕύΝΥ±ΞΚΆΕ»’β“ΜœνΓΘΒΪ‘Ύ ΒΦυ÷–Θ§Ω…ΡήΡ―“‘ΝΩΜ·ΖΰΈώ±ΞΚΆΕ»ΓΘ
Ρ«Ο¥Θ§Έ“Ο«»γΚΈΦύΩΊ»ίΤςΘΩ»ίΤς¥φΜνΤΎΕΧΘ§Ά®Ιΐ÷±Ϋ”ΦύΩΊΥϋΟ«ά¥ Ε±πΖΰΈώΫΓΩΒΉ¥ΩωΫΪ¥χά¥ΚήΕύΗ¥‘”ΒΡΈ ΧβΘ§άΐ»γΗΏΜυ ΐΈ ΧβΓΘΆ®ΙΐΨέΚœ’β–©»ίΤςΒΡ δ≥ωά¥ΦύΩΊΥϋΟ«ΜαΗϋ»ί“ΉΚΆ”––ßΓΘ»γΙϊ“ΜΗωΖΰΈώ «ΫΓΩΒΒΡΘ§Έ“Ο«ΨΆ≤ΜΜα‘ΎΚθ»ίΤςΒΡ––ΈΣ «Ζώ’ΐ≥ΘΓΘΈ“Ο«ΒΡ±ύ≈δΩρΦήΜα≤ΕΜώΒΫ’βΗω»ίΤςΘ§≤Δ”Ο–¬ΒΡ»ίΤς»ΓΕχ¥ζ÷°ΓΘ
»ΟΈ“Ο«ά¥Ω¥Ω¥»γΚΈΫΪIstioΒΡSLIΉςΈΣRED“«±μ≈ΧΒΡ“Μ≤ΩΖ÷ΓΘ Ήœ»Ω¥Ω¥IstioΕΦΧαΙ©ΝΥΡΡ–©“Θ≤β‘ΣΥΊΘΚ
Μυ”Ύœλ”Π¬κΒΡ«κ«σ ΐ
«κ«σ ±≥Λ
«κ«σ¥σ–Γ
œλ”Π¥σ–Γ
Ν§Ϋ” ’ΒΫΒΡΉ÷ΫΎ
Ν§Ϋ”ΖΔΥΆΒΡΉ÷ΫΎ
Ν§Ϋ” ±≥Λ
Μυ”ΎΡΘΑεΒΡ‘Σ ΐΨίΘ®Ε»ΝΩ±ξ«©Θ©
IstioΧαΙ©ΝΥΦΗΗω”–ΙΊ ’ΒΫΒΡ«κ«σΓΔœλ”Π―”≥ΌΚΆΝ§Ϋ”–≈œΔΒΡ÷Η±ξΓΘ«κΉΔ“β…œ ωΝ–±μ÷–ΒΡ«ΑΝΫœνΘ§Έ“Ο«œΘΆϊΫΪΥϋΟ«ΑϋΚ§‘ΎRED“«±μ≈Χ÷–ΓΘ
IstioΜΙΗ≥”ηΈ“Ο«ΧμΦ”Ε»ΝΩ±ξ«©ΒΡΡήΝΠΘ§ΨΆ «ΥυΈΫΒΡΈ§Ε»ΓΘΈ“Ο«Ω…“‘Α¥’’÷ςΜζΓΔΦ·»ΚΒ»Ε‘“Θ≤β‘ΣΥΊΫχ––≤πΫβΓΘΈ“Ο«Ω…“‘Ά®ΙΐΦΤΥψ«κ«σ ΐΒΡ“ΜΫΉΒΦ ΐά¥ΜώΒΟΟΩΟκ«κ«σΥΌ¬ ΓΘΈ“Ο«ΜΙΩ…“‘Ά®ΙΐΦΤΥψ≤Μ≥…ΙΠ«κ«σ ΐΒΡΒΦ ΐά¥ΜώΒΟ¥μΈσ¬ ΓΘIstioΜΙΈΣΈ“Ο«ΧαΙ©ΝΥΟΩΗω«κ«σΒΡ―”≥ΌΘ§“ρ¥ΥΈ“Ο«Ω…“‘Φ«¬ΦΟΩΗωΖΰΈώ«κ«σ–η“ΣΕύ…Ό ±Φδ≤≈Ρή¥ΠάμΆξΓΘ
ΝμΆβΘ§IstioΜΙΈΣΈ“Ο«ΧαΙ©ΝΥ“ΜΗωGrafana“«±μ≈ΧΘ§ΥϋΑϋΚ§ΝΥΈ“Ο«œκ“ΣΒΡ≤ΩΖ÷ΘΚ
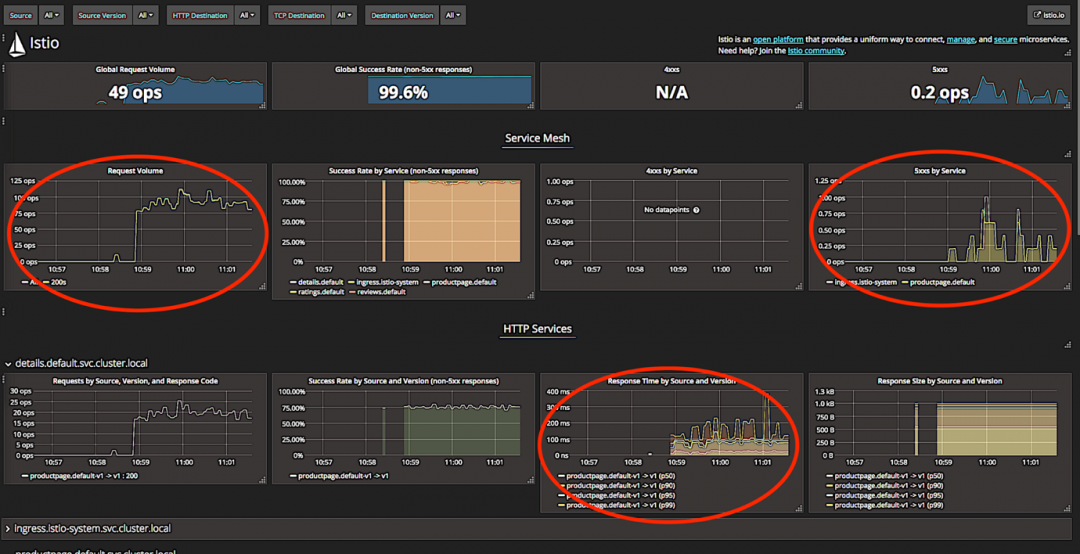
…œΟφΫΊΆΦ÷–“‘Κλ…Ϊ»ΠΤπά¥ΒΡ≤ΩΖ÷ «Έ“Ο«œκ“ΣΒΡΉιΦΰΓΘΉσ…œΫ« «ΟΩΟκ≤ΌΉς«κ«σΥΌ¬ Θ§”“…œΫ« «ΟΩΟκ ßΑή«κ«σ ΐΘ§ΒΉœ¬ «œλ”Π ±ΦδΓΘœ÷‘Ύ»ΟΈ“Ο«ά¥Ή–œΗΩ¥Ω¥»Π≥ωΒΡΡ«ΦΗΗω÷Η±ξΘΚ
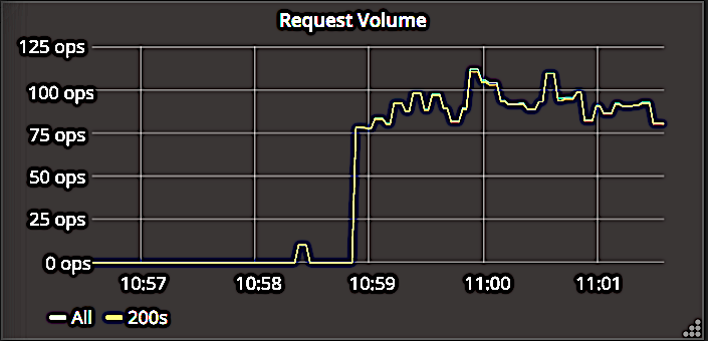
’βΗωΫΊΆΦœ‘ ΨΝΥ“«±μ≈ΧΒΡΥΌ¬ ΉιΦΰΓΘΈ“Ο«Ά≥ΦΤΖΒΜΊ200œλ”Π¬κΒΡ«κ«σ ΐΘ§≤ΔΜφ÷Τ≥…ΆΦ–ΈΓΘ
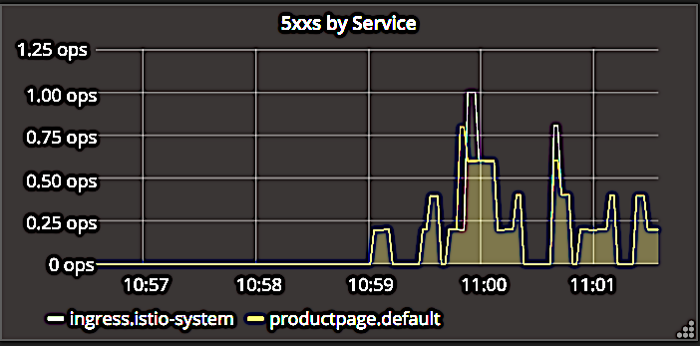
Istio“«±μ≈ΧΈΣΖΒΜΊ5xx¥μΈσ¬κΒΡœλ”ΠΉωΝΥάύΥΤΒΡ≤ΌΉςΓΘ‘Ύ…œΟφΒΡΫΊΆΦ÷–Θ§Ω…“‘Ω¥ΒΫΘ§ΥϋΑ¥’’…ψ»κΩΊ÷ΤΤςΜρ”Π”Ο≥Χ–ρ≤ζΤΖ“≥ΒΡ¥μΈσά¥«χΖ÷¥μΈσΓΘ
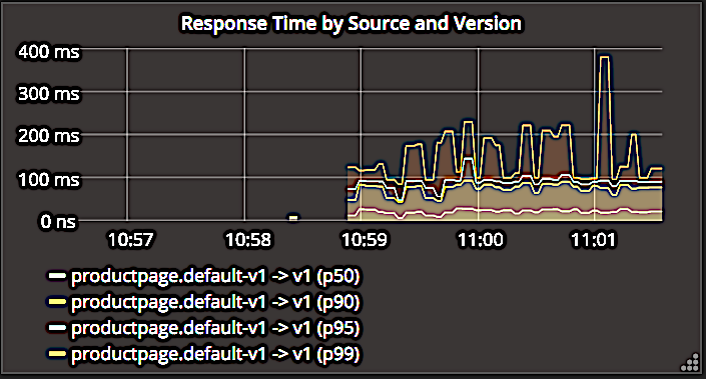
’βΗωΫΊΆΦœ‘ ΨΝΥ«κ«σ≥÷–χ ±ΦδΘ§ΧαΙ©ΝΥΖαΗΜΒΡ”–ΙΊΖΰΈώΫΓΩΒΉ¥ΩωΒΡ–≈œΔΓΘ’β–© ΐΨί”…PrometheusΦύΩΊœΒΆ≥ΧαΙ©Θ§“ρ¥ΥΈ“Ο«Ω…“‘Ω¥ΒΫ«κ«σ ±ΦδΑΌΖ÷ΈΜΘ§Αϋά®÷–ΈΜ ΐΓΔ90thΓΔ95thΚΆ99th’β–©ΑΌΖ÷ΈΜΓΘ
’β–©ΑΌΖ÷ΈΜΈΣΈ“Ο«ΧαΙ©ΝΥ”–ΙΊΖΰΈώ÷¥––«ιΩωΒΡ»ΪΟφ÷Η ΨΓΘΒΪ «Θ§’β÷÷ΖΫΖ®“≤¥φ‘Ύ“Μ–©»±œίΓΘ‘ΎΜνΕ·≤Μ «ΚήΜν‘ΨΒΡ ±ΚρΘ§”…”Ύ―υ±Ψ ΐΝΩ”–œόΘ§’β–©ΑΌΖ÷ΈΜΩ…ΡήΜα¥σΖυΤΪάκΘ§ΗχΈ“Ο«¥χά¥ΈσΒΦΓΘ’β÷÷ΖΫΖ®Ω…Ρή≥ωœ÷ΒΡΤδΥϊΈ ΧβΘΚ
≥÷–χ ±ΦδΈ ΧβΘΚ
ΑΌΖ÷ΈΜ «Μυ”ΎΙΧΕ® ±Φδ¥ΑΩΎΒΡΨέΚœ÷Η±ξΓΘ
ΈόΖ®ΈΣ»ΚΦ·ΫΓΩΒ÷Ί–¬ΨέΚœΑΌΖ÷ΈΜΓΘ
≤ΜΡήΦΤΥψΑΌΖ÷ΈΜΤΫΨυ ΐΘ®’β «“ΜΗω≥ΘΦϊΒΡ¥μΈσΘ©ΓΘ
’β÷÷ΖΫΖ®¥φ¥ΔΒΡΨέΚœ « δ≥ωΘ§Εχ≤Μ « δ»κΓΘ
ΚήΡ―”Ο’β÷÷ΖΫΖ®≤βΝΩΦ·»ΚSLIΓΘ
ΑΌΖ÷ΈΜΆ®≥Θ±»ΤΫΨυ ΐΧαΙ©Ηϋ…νΩΧΒΡΕ¥ΦϊΘ§“ρΈΣΥϋΟ« Ι”ΟΕύΗω ΐΨίΒψά¥±μ Ψ ΐ÷ΒΖΕΈßΓΘΒΪ”κΤΫΨυ ΐ“Μ―υΘ§ΑΌΖ÷ΈΜ «“Μ÷÷ΨέΚœΕ»ΝΩΓΘΥϋΟ« «Μυ”ΎΙΧΕ® ±Φδ¥ΑΩΎΕ‘ΙΧΕ® ΐΨίΦ·ΦΤΥψΒΟ≥ωΒΡΓΘ»γΙϊΈ“Ο«“ΣΦΤΥψΡ≥ΗωΦ·»Κ≥…‘±ΒΡ≥÷–χ ±ΦδΑΌΖ÷±»Θ§ΨΆ≤ΜΡήΫΪΤδ”κΝμ“ΜΗωΦ·»Κ≥…‘±Κœ≤ΔΘ§“ρΈΣ’β―υΒΟΒΫΒΡ «’ϊΗωΦ·»ΚΒΡΨέΚœ÷Η±ξΓΘ
Έ“Ο«≤ΜΡήΦΤΥψΑΌΖ÷ΈΜΒΡΤΫΨυ ΐΘ§≥ΐΖ«≤ζ…ζ’β–©ΑΌΖ÷ΈΜΒΡΖ÷≤ΦΦΗΚθ «“Μ―υΒΡΘ§ΒΪ’β÷÷«ιΩωΚή…ΌΦϊΓΘ»γΙϊΡψ÷Μ”–ΑΌΖ÷ΈΜΘ§Εχ≤Μ «‘¥ ΐΨίΘ§Ρ«Ο¥ΨΆ≤Μ÷ΣΒάΥϋ «≤Μ «’β÷÷«ιΩωΓΘ’β «“ΜΗωΦΠ…ζΒΑΚΆΒΑ…ζΦΠΒΡΈ ΧβΓΘ
’β“≤“βΈΕΉ≈Θ§»γΙϊΡψ÷Μ «Μυ”ΎΑΌΖ÷±»ΚβΝΩΒΞΗωΦ·»Κ≥…‘±ΒΡ–‘ΡήΘ§ΨΆΜα“ρ»±…ΌΨέΚœΕχΈόΖ®ΈΣ’ϊΗωΖΰΈώ…η÷ΟSLIΓΘ
”…”Ύ‘ΎΙΧΕ® ±Φδ¥ΑΩΎΡΎ÷Μ”–4Ηω―”≥Ό ΐΨίΒψΘ§Έ“Ο«÷ΜΡή‘Ύ”–œόΒΡΖΕΈßΡΎ…η÷Ο”–“β“εΒΡSLIΓΘ“ρ¥ΥΘ§‘ΎΡψ Ι”ΟΜυ”ΎΑΌΖ÷ΈΜΒΡ≥÷–χ ±Φδ÷Η±ξ ±Θ§±Ί–κΈ Ή‘ΦΚΘ§ΡψΒΡSLI «Ζώ’φΒΡΉψΙΜΚΟΓΘΈ“Ο«Ω…“‘Ϋη÷ζ ΐ―ßά¥…ηΕ®ΗϋΚΟΒΡSLIΘ§¥”Εχ»ΪΟφΝΥΫβΖΰΈώΒΡ–‘ΡήΚΆΫΓΩΒΉ¥ΩωΓΘ
÷±ΖΫΆΦ“Θ≤β
…œΟφ «“‘ΈΔΟκΈΣΒΞΈΜœ‘ ΨΖΰΈώ―”≥Ό ΐΨίΒΡ“ΜΗω÷±ΖΫΆΦΓΘ―υ±Ψ ΐΝΩΈΜ”ΎY÷α…œΘ§―υ±Ψ÷ΒΘ®ΈΔΟκΦΕ―”≥ΌΘ©ΈΜ”ΎX÷α…œΓΘ’β «Έ“Ο«‘ΎCirconusΩΣΖΔΒΡΩΣ‘¥÷±ΖΫΆΦΘ§“≤«κ≤ΈΩΦC”ο―‘Θ®https://github.com/circonus-labs/libcircllhistΘ©ΚΆGolangΘ®https://github.com/circonus-labs/circonusllhistΘ©ΒΡ÷±ΖΫΆΦΩΣ‘¥ Βœ÷ΓΘΜΙ”–ΤδΥϊ“Μ–©ΩΣ‘¥ΒΡ÷±ΖΫΆΦ Βœ÷Θ§»γTed
DunningΒΡt-digest÷±ΖΫΆΦΘ®https://github.com/tdunning/t-digestΘ©ΚΆHDR÷±ΖΫΆΦΘ®http://hdrhistogram.org/Θ©ΓΘ
EnvoyœνΡΩΉνΫϋ≤…”ΟΝΥCirconusΩΣΖΔΒΡC”ο―‘Αφ±ΨΒΡΕ‘ ΐœΏ–‘÷±ΖΫΆΦΩβΘ§“ρ¥ΥΩ…“‘œ‘ ΨΥυ ’Φ· ΐΨίΒΡΖ÷≤Φ«ιΩωΓΘ
÷±ΖΫΆΦ «Ω…“‘Κœ≤ΔΒΡΘ§÷Μ“ΣbinΒΡ±ΏΫγœύΆ§Θ§»ΈΚΈΝΫΗωΜρΕύΗω÷±ΖΫΆΦΕΦΩ…“‘Κœ≤Δ‘Ύ“ΜΤπΓΘ’β“βΈΕΉ≈Έ“Ο«Ω…“‘ΫΪΕύΗωΖ÷≤ΦΉιΚœ‘Ύ“ΜΤπΓΘΩ…Κœ≤ΔΒΡΕ»ΝΩ÷Η±ξΕ‘”ΎΦύΩΊΚΆΩ…Ιέ≤β–‘ά¥ΥΒΖ«≥Θ”–”ΟΓΘΈ“Ο«“ρ¥ΥΩ…“‘Κœ≤Δά¥Ή‘œύΥΤΉ ‘¥Θ®»γΖΰΈώ≥…‘±Θ©ΒΡ δ≥ωΘ§≤ΔΜώΒΟΨέΚœΒΡΖΰΈώ÷Η±ξΓΘ
»γ…œΆΦΥυ ΨΘ§‘Ύ’βΗωΕ‘ ΐœΏ–‘÷±ΖΫΆΦ÷–Θ§ΟΩ10¥ΈΟίΕ‘”Π90ΗωbinΓΘ¥”ΆΦ÷–Ω…“‘Ω¥ΒΫ100KΒΫ1MΗω÷°ΦδΒΡ90ΗωbinΓΘΕ‘”ΎΟΩ10¥ΈΟίΘ§binΒΡ¥σ–ΓΨΆ“‘10ΒΡ±Ε ΐ‘ω≥ΛΓΘ’β―υΈ“Ο«ΨΆΡήΙΜ“‘ΫœΗΏΒΡœύΕ‘ΨΪΕ»Φ«¬ΦΗς÷÷ ΐ÷ΒΘ§Εχ≤Μ–η“ΣΧα«Α÷ΣΒά ΐΨίΒΡΖ÷≤Φ«ιΩωΓΘ»γΙϊΈ“Ο«ΫΪ“Μ–©ΑΌΖ÷ΈΜ÷ΊΒΰΤπά¥Μα « ≤Ο¥―υΉ”ΘΚ
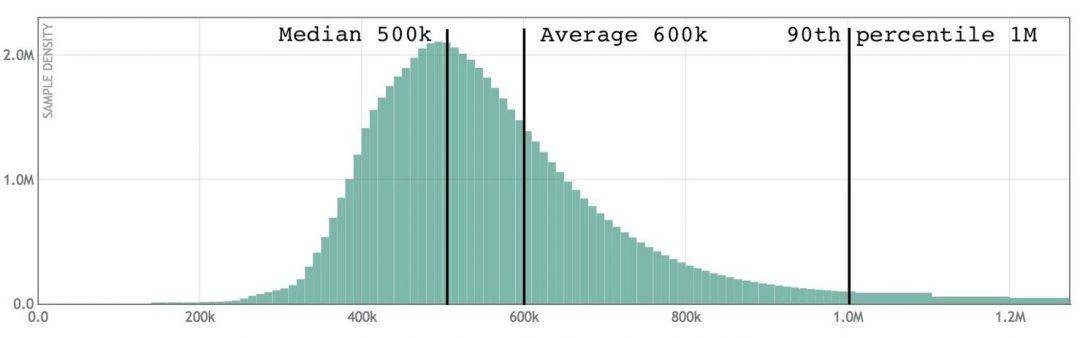
Ω…“‘Ω¥ΒΫΘ§œ÷‘Ύ”–ΤΫΨυ÷ΒΓΔ50thΑΌΖ÷ΈΜΘ®“≤≥ΤΈΣ÷–ΈΜ ΐΘ©ΚΆ90thΑΌΖ÷ΈΜΓΘ90thΑΌΖ÷ΈΜ «÷Η90ΘΞ―υ±ΨΒΆ”ΎΗΟ÷ΒΓΘ
œ÷‘ΎΜΊΒΫ÷°«ΑΒΡSLI ΨάΐΘ§»γΙϊΑ¥’’’β÷÷Ηώ Ϋά¥œ‘ Ψ―”≥Ό ΐΨίΘ§ΨΆΩ…“‘Ά®ΙΐΫΪ÷±ΖΫΆΦΚœ≤Δ‘Ύ“ΜΤπά¥ΜώΒΟ5Ζ÷÷”ΒΡ ΐΨί ”ΆΦΘ§»ΜΚσΦΤΥψ≥ωΗΟΖ÷≤ΦΒΡ90thΑΌΖ÷ΈΜΘ§¥”ΕχΒΟΒΫΖΰΈώΒΡSLIΓΘ»γΙϊΥϋΒΆ”Ύ1,000ΚΝΟκΘ§ΨΆ¥οΒΫΝΥΈ“Ο«ΒΡΡΩ±ξΓΘ
…œΟφΫΊΆΦ÷–ΒΡRED“«±μ≈ΧΑϋΚ§ΝΥΥΡΗωΑΌΖ÷ΈΜΘΚ50thΓΔ90thΓΔ95thΚΆ99thΓΘΈ“Ο«“≤Ω…“‘÷ΊΒΰ’β–©ΑΌΖ÷ΈΜΓΘΦ¥ Ι‘ΎΟΜ”– ΐΨίΒΡ«ιΩωœ¬Θ§Έ“Ο«“≤Ω…“‘Ω¥ΒΫ«κ«σΖ÷≤ΦΒΡ¥σ÷¬¬÷άΣΘ§Β±»ΜΘ§’βάο–ηΉω≥ωΚήΕύΦΌ…ηΓΘ“Σœκ÷ΣΒάΫωΜυ”ΎΦΗΗωΑΌΖ÷ΈΜΉω≥ωΒΡΦΌ…ηΫΪΗχΈ“Ο«‘λ≥…‘θ―υΒΡΈσΒΦΘ§Ω…“‘Ω¥Ω¥’βΗω¥χ”–ΤδΥϊΡΘ ΫΒΡΖ÷≤ΦΘΚ
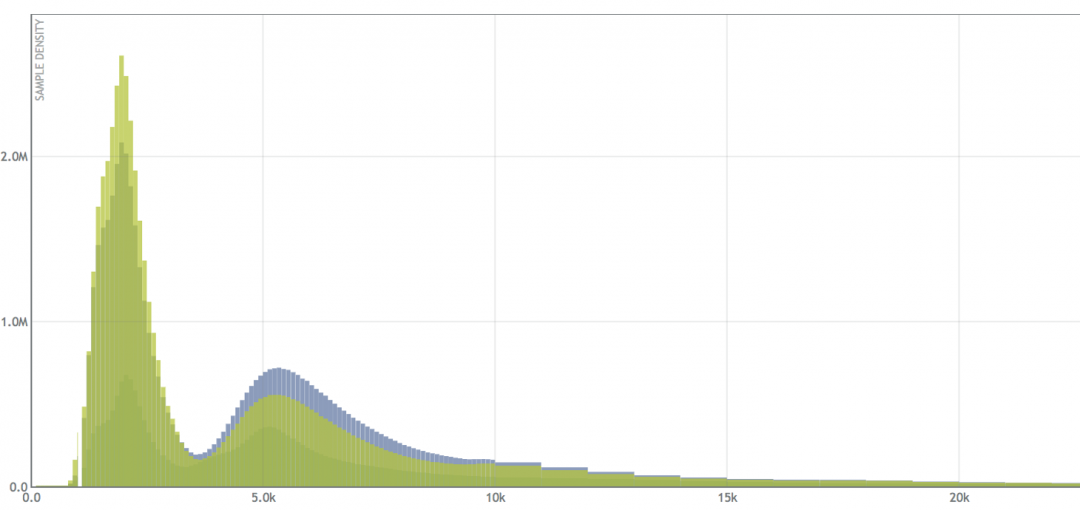
’βΗω÷±ΖΫΆΦœ‘ ΨΝΥΝΫ÷÷≤ΜΆ§ΡΘ ΫΒΡΖ÷≤ΦΓΘΉσ±ΏΒΡΡΘ Ϋ±μ ΨΩλΥΌœλ”ΠΘ§Ω…Ρή «“ρΈΣ Ι”ΟΝΥΜΚ¥φΘ§Εχ”“±ΏΒΡ±μ Ψ¥”¥≈≈Χ…œΕΝ»Γ ΐΨί‘ΌΉω≥ωœλ”ΠΓΘΫω Ι”ΟΥΡΗωΑΌΖ÷ΈΜά¥ΚβΝΩ―”≥ΌΦΗΚθ≤ΜΩ…Ρή±φ±π’β÷÷Ζ÷≤ΦΓΘΩ…ΦϊΘ§ΑΌΖ÷ΈΜΜα“ΰ≤ΊΒτ“Μ–©Η¥‘”–‘ΓΘœ÷‘Ύ»ΟΈ“Ο«ά¥Ω¥Ω¥ΨΏ”–ΝΫ÷÷“‘…œΡΘ ΫΒΡΖ÷≤ΦΘΚ
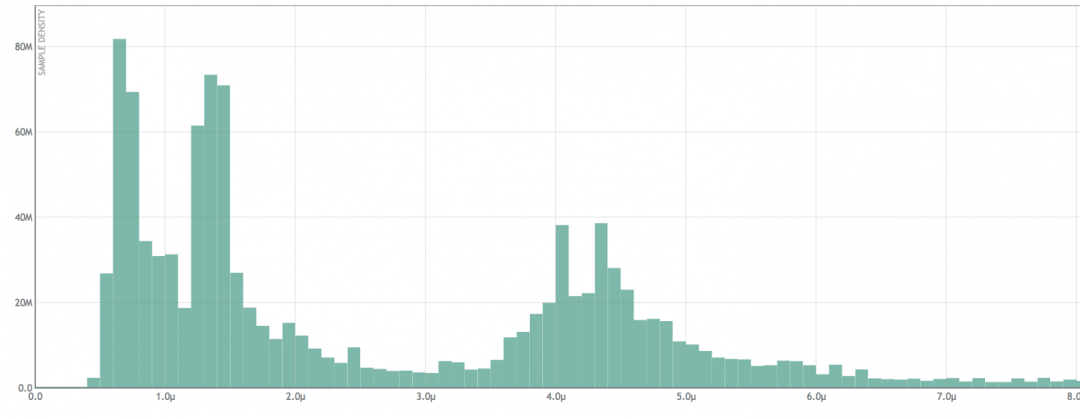
’βΗωΖ÷≤Φ÷Ν…Ό”–ΥΡ÷÷ΡΘ ΫΓΘ»γΙϊΈ“Ο«‘Ύ»ΪΖ÷≤Φ…œ‘Υ–– ΐ―ß‘ΥΥψΘ§Ω…“‘’“ΒΫ20Εύ÷÷ΡΘ ΫΓΘΡ«Ο¥Έ“Ο«–η“ΣΦ«¬ΦΕύ…ΌΗωΑΌΖ÷ΈΜ≤≈ΡήΜώΒΟ“ΜΗωΫϋΥΤ”Ύ…œΟφ’β―υΒΡ―”≥ΌΖ÷≤ΦΡΊΘΩ”÷±»»γœ¬Οφ’βΗωΖ÷≤ΦΡΊΘΩ
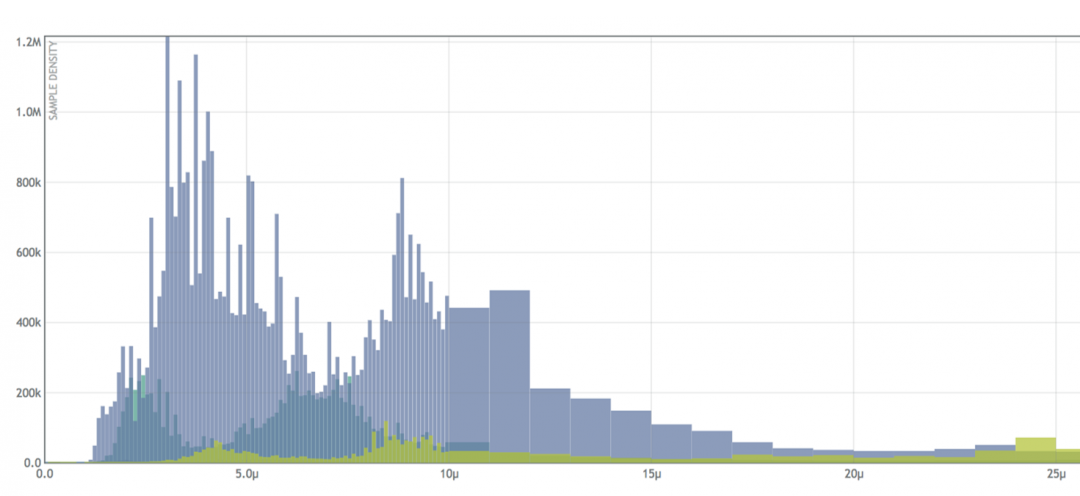
”…ΚήΕύΖΰΈώΉι≥…ΒΡΗ¥‘”œΒΆ≥ΫΪ…ζ≥…ΈόΖ®”ΟΑΌΖ÷ΈΜΉΦ»Ζ±μ ΨΒΡ―”≥ΌΖ÷≤ΦΘ§Έ“Ο«±Ί–κΦ«¬Φ’ϊΗω―”≥ΌΖ÷≤Φ≤≈ΡήΆξ’ϊΒΊ±μ ΨΥϋΓΘ’βΨΆ «ΈΣ ≤Ο¥“ΣΫΪ ΐΨίΒΡΆξ’ϊΖ÷≤ΦΖ≈‘Ύ÷±ΖΫΆΦ÷–Θ§≤ΔΗυΨί ΒΦ –η“ΣΦΤΥψ≥ωΑΌΖ÷ΈΜΘ§Εχ≤Μ÷Μ «±Θ¥φΦΗΗωΑΌΖ÷ΈΜΓΘ
’β÷÷÷±ΖΫΆΦœ‘ ΨΝΥΙΧΕ® ±Φδ¥ΑΩΎ…œΒΡΖ÷≤ΦΓΘΈ“Ο«Ω…“‘¥φ¥ΔΕύΗωΖ÷≤ΦΘ§“‘ΝΥΫβΥϋΥφ ±Φδ±δΜ·ΒΡ«ιΩωΘ§»γœ¬Υυ ΨΘΚ
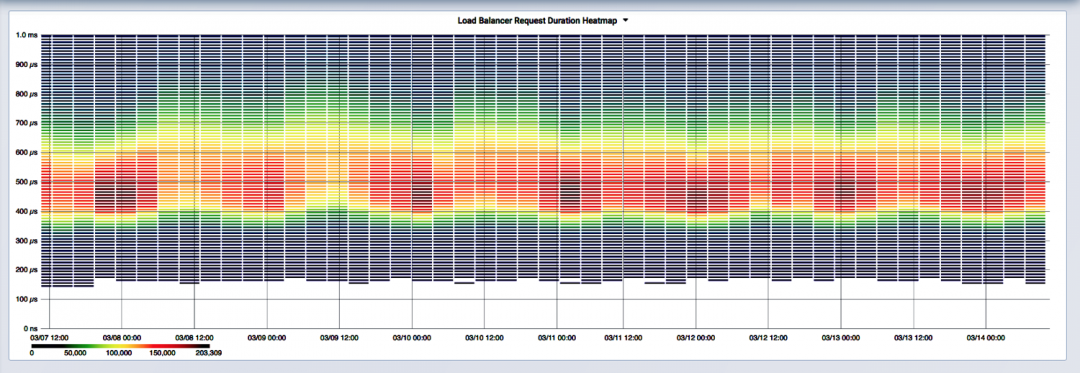
’β «“ΜΗω»»ΆΦΘ§¥ζ±μ“ΜΉιΥφ ±Φδ±δΜ·ΒΡ÷±ΖΫΆΦΓΘœκœσ“Μœ¬Θ§’βΗω»»ΆΦ÷–ΒΡΟΩ“ΜΝ–ΕΦ”–“ΜΗωΒΞΕάΒΡΧθ–ΈΆΦΘ§”Ο―’…Ϊά¥±μ ΨΟΩΗωbinΒΡΗΏΕ»ΓΘ’β «“ΜΗωΦ·»ΚΘ®ΑϋΚ§10ΗωΗΚ‘ΊΨυΚβΤςΘ©œλ”Π―”≥Ό‘ΎGrafana÷–ΒΡΩ… ”Μ·ΓΘΈ“Ο«“ρ¥ΥΡήΙΜ…ν»κΝΥΫβ’ϊΗωΦ·»Κ“Μ÷ή÷°ΡΎΒΡ––ΈΣΘ§’βάοΑϋΚ§ΝΥ100ΆρΗω ΐΨί―υ±ΨΓΘ’βάοΒΡ÷–ΈΜ ΐ¥σ‘Φ‘Ύ500ΈΔΟκΉσ”“Θ§“‘Κλ…ΪΧθ–Έ±μ ΨΓΘ
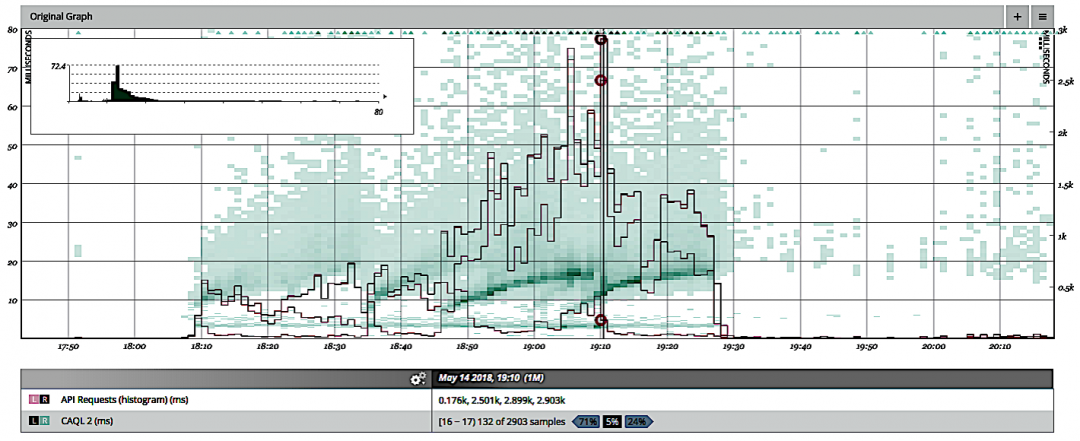
…œΟφ «Νμ“Μ÷÷άύ–ΆΒΡ»»ΆΦΘ§Τδ÷– Ι”Ο±ΞΚΆΕ»±μ ΨΟΩΗωbinΒΡΓΑΗΏΕ»Γ±Θ®Ωι―’…Ϊ‘Ϋ…ν±μ Ψ‘ΫΓΑ±ΞΚΆΓ±Θ©ΓΘ¥ΥΆβΘ§’β¥ΈΈ“Ο«‘Ύ»»ΆΦ…œ÷ΊΒΰΝΥΥφ ±Φδ±δΜ·ΒΡΑΌΖ÷ΈΜΓΘΑΌΖ÷ΈΜ «Ω…ΩΩΒΡΕ»ΝΩ÷Η±ξΘ§Εχ«“Ζ«≥Θ”–”ΟΘ§ΒΪΥϋΟ«±Ψ…μ≤Δ≤ΜΡήΖΔΜ”’β÷÷Ής”ΟΓΘΈ“Ο«Ω…“‘Ω¥ΒΫ90“‘…œΒΡΑΌΖ÷ΈΜΫΪ»γΚΈΥφΉ≈―”≥ΌΖ÷≤Φœρ…œ“ΤΕ·Εχ‘ωΦ”ΓΘ
»ΟΈ“Ο«ά¥Ω¥Ω¥’β–© ±ΦδΕΈΖ÷≤ΦΆΦΘ§Ω¥Ω¥ «ΖώΩ…“‘…ζ≥…±»―υ±Ψ“«±μ≈ΧΑϋΚ§ΗϋΕύ–≈œΔΒΡΕΪΈςΘΚ
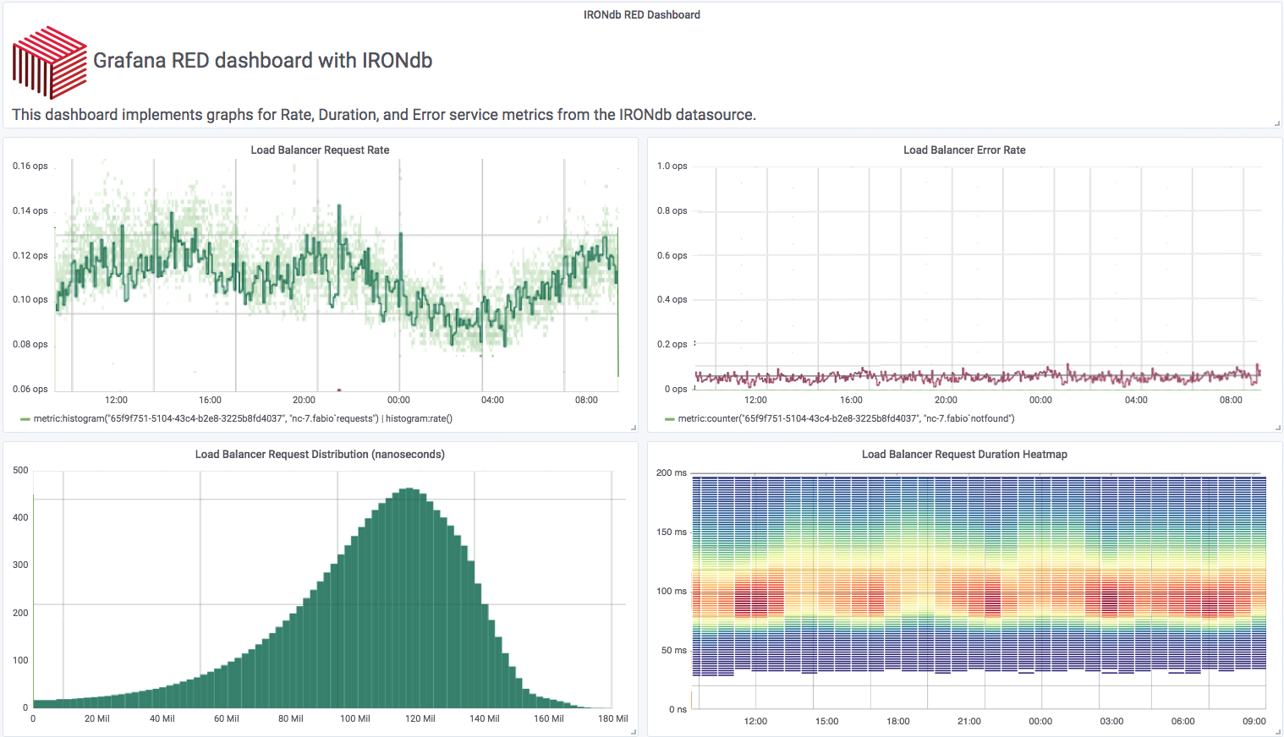
…œΟφΒΡΫΊΆΦ «–όΗΡΚσΒΡRED“«±μ≈ΧΘ§œ‘ ΨΝΥΜυ”ΎΖ÷≤ΦΒΡ―”≥Ό ΐΨίΓΘΉσœ¬Ϋ«œ‘ ΨΝΥΙΧΕ® ±Φδ¥ΑΩΎΒΡ―”≥Ό÷±ΖΫΆΦΓΘ‘ΎΥϋΒΡ”“±ΏΘ§Έ“Ο« Ι”Ο»»ΆΦΫΪΖ÷≤ΦΖ÷Ϋβ≥…Ηϋ–ΓΒΡ ±Φδ¥ΑΩΎΓΘάϊ”ΟRED“«±μ≈ΧΒΡ≤ΦΨ÷Θ§Έ“Ο«÷Μ–η“ΣΫη÷ζΦΗΗω–≈œΔΟφΑεΨΆΩ…“‘»ΪΟφΝΥΫβΈ“Ο«ΒΡΖΰΈώ «»γΚΈ‘ΥΉςΒΡΓΘ’βΗω“«±μ≈Χ « Ι”ΟGrafana Βœ÷ΒΡΘ§ΚσΧ® Ι”ΟΝΥIRONdb ±Φδ–ρΝ– ΐΨίΩβΘ§ΗΟ ΐΨίΩβ‘Ύ±ΨΒΊ¥φ¥Δ―”≥Ό ΐΨίΘ§”Ο”ΎΙΙΫ®Ε‘ ΐœΏ–‘÷±ΖΫΆΦΓΘ
Έ“Ο«Ω…“‘Ϋχ“Μ≤Ϋά©’Ι’βΗωRED“«±μ≈ΧΘ§≤ΔΫΪSLI÷ΊΒΰΒΫ…œΟφΘΚ
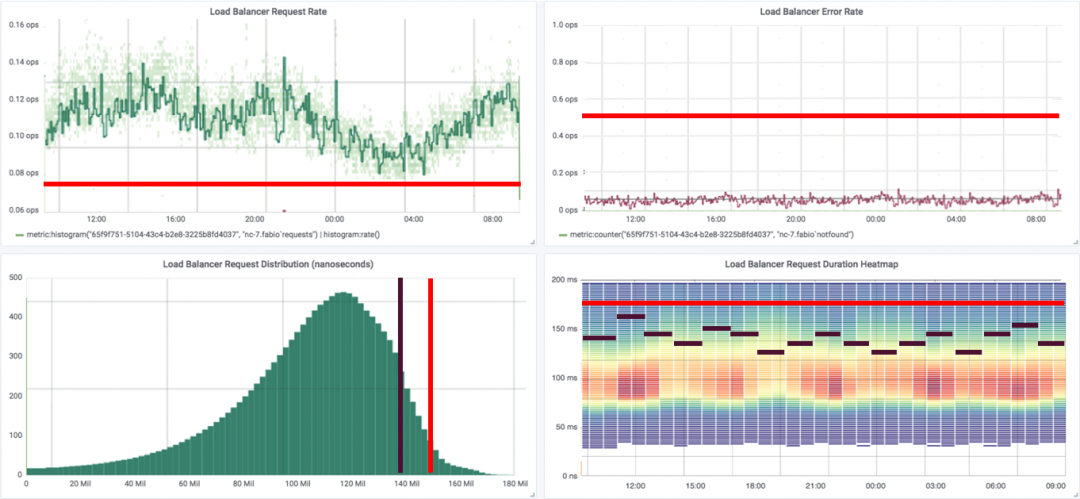
Ε‘”ΎΥΌ¬ ΟφΑεΘ§Έ“Ο«ΒΡSLIΩ…ΡήΜα±Θ≥÷ΉνΒΆΥ°ΤΫΒΡΟΩΟκ«κ«σ ΐΘ§ΟΩΟκ¥μΈσ ΐ“≤Ω…Ρή±Θ≥÷‘ΎΡ≥Ηω÷Β÷°œ¬ΓΘ’ΐ»γΈ“Ο«÷°«Α―–ΨΩΙΐΒΡSLIΘ§Έ“Ο«Ω…ΡήœΘΆϊ’ϊΗωΖΰΈώΒΡ99thΑΌΖ÷ΈΜ‘ΎΙΧΕ® ±Φδ¥ΑΩΎΡΎ±Θ≥÷“ΜΕ®ΒΡ―”≥ΌΓΘΈ“Ο«Ω…“‘Ϋη÷ζ’β–©÷±ΖΫΆΦά¥…η÷Ο”–“β“εΒΡSLIΓΘœ÷‘ΎΈ“Ο«ΜΙ”–ΚήΕύΙΛΉς“ΣΉωΘ§Εχ«“Ω…“‘ΗϋΚΟΒΊ…σ≤ιΈ“Ο«ΒΡ ΐΨίΓΘ
Έ ’ΐ»ΖΒΡΈ Χβ
Έ“Ο«“―Ψ≠Α―Υυ”–ΒΡΕΪΈςΕΦΖ≈‘ΎΝΥ“ΜΤπΘ§≤ΔΩ¥ΒΫΝΥ»γΚΈάϊ”ΟIstio¥”ΖΰΈώ÷–Μώ»Γ”–“β“εΒΡ ΐΨίΘ§œ÷‘Ύ»ΟΈ“Ο«Ω¥Ω¥Ω…“‘ΫβΨωΡΡ–©Έ ΧβΓΘ
Έ“Ο«ΕΦœΘΆϊΡήΙΜΫβΨωΦΦ θΈ ΧβΘ§ΒΪ≤Μ «ΟΩΗω»ΥΕΦΉ®ΉΔ”Ύ¥ΥΓΘ“ΒΈώ»Υ‘±ΜαΈ “ΒΈώΖΫΟφΒΡΈ ΧβΘ§Υυ“‘Ρψ“ΣΡήΙΜΜΊ¥π’β–©Έ ΧβΓΘΫ”œ¬ά¥»ΟΈ“Ο«Ω¥Ω¥“―Ψ≠ΉιΉΑΚΟΒΡΙΛΨΏΫΪ‘θ―υΫβΨω“ΒΈώ»Υ‘±œρSREΧα≥ωΒΡΈ ΧβΘΚ
ΨάΐΈ ΧβΘΚ
‘Ύ÷ήΕΰΒΡ¥σ¥ΌΜνΕ·ΚσΘ§”–Εύ…Ό”ΟΜß“ρΈΣΥΌΕ»±δ¬ΐΕχΗ–ΒΫ≤Μ”δΩλΘΩ
Έ“Ο«ΒΡΫα’ ΖΰΈώ «ΙΐΕ»≈δ÷ΟΝΥΜΙ «≈δ÷Ο≤ΜΉψΘΩ
œ»Ω¥ΒΎ“ΜΗωάΐΉ”ΓΘΟΩΗω»ΥΩ…ΡήΕΦ”–ΙΐΖΟΈ ΙξΥΌΆχ’ΨΒΡΧε―ιΓΘΦΌ…η“Μ¥Έ –≥Γ¥σΆΤΙψΒΦ÷¬ΝςΝΩ±©‘ωΘ§–‘Ρήœ¬ΫΒΘ§”ΟΜß±ß‘ΙΆχ’ΨΥΌΕ»ΧΪ¬ΐΓΘΈ“Ο«»γΚΈΝΩΜ·ΥΌΕ»”–Εύ¬ΐΘΩ”–Εύ…Ό”ΟΜßΗ–ΒΫ≤Μ”δΩλΘΩΦΌ…η –≥Γ”Σœζ≤ΩΟ≈œκ÷ΣΒά’β–©Έ ΧβΒΡ¥πΑΗΘ§»ΜΚσΨΆΩ…“‘œρ ή”ΑœλΒΡ”ΟΜßΖΔΥΆ10ΘΞ’έΩέΒΡΒγΉ”” ΦΰΘ§Ά§ ±œΘΆϊ±ήΟβΆ§―υΈ Χβ‘Ό¥ΈΖΔ…ζΓΘΈ“Ο«Ε®“εΝΥ“ΜΗωSLIΘ§ΦΌ…η”ΟΜßΉΔ“βΒΫΥΌΕ»±δ¬ΐΘ§≤Δ‘Ύ«κ«σ≥§Ιΐ500ΚΝΟκ ±Η–ΒΫ…ζΤχΓΘΈ“Ο«»γΚΈΜυ”Ύ’βΗω500ΚΝΟκΒΡSLIΦΤΥψ”–Εύ…Ό”ΟΜßΗ–ΒΫ…ζΤχΘΩ
Ήœ»Θ§Έ“Ο«–η“ΣΦ«¬Φ«κ«σ―”≥ΌΘ§»ΜΚσΫΪΥϋΟ«Μφ÷Τ≥…»»ΆΦΓΘΈ“Ο«Ω…“‘ Ι”ΟΖ÷≤Φ ΐΨίά¥ΦΤΥψ≥§Ιΐ500ΚΝΟκSLIΒΡ«κ«σΒΡΑΌΖ÷±»Θ®Ϋη÷ζΖ¥œρΑΌΖ÷ΈΜΘ©Θ§»ΜΚσΫΪΤδ≥Υ“‘ΗΟ ±Φδ¥ΑΩΎ÷–ΒΡ«κ«σΉή ΐΘ§ΉνΚσΫΪΥφ ±Φδ±δΜ·ΒΡΫαΙϊ÷ΊΒΰ‘Ύ»»ΆΦ…œΘΚ
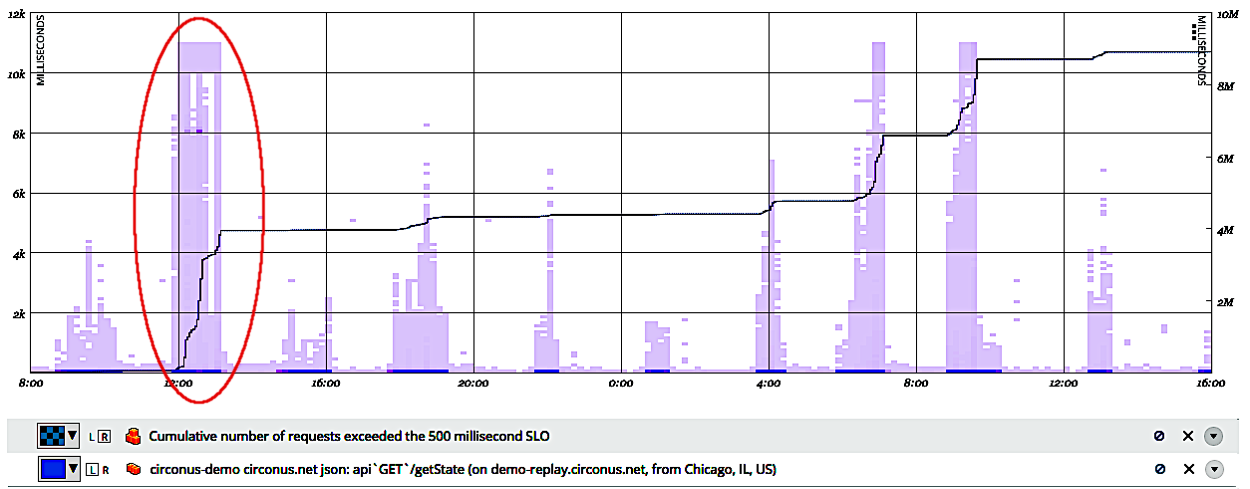
‘Ύ…œΟφΒΡΫΊΆΦ÷–Θ§Έ“Ο«“―Ψ≠‘Ύ»»ΆΦ…œ»Π≥ωΝΥΥΌΕ»±δ¬ΐΒΡ≤ΩΖ÷ΓΘ‘ωΦ”ΒΡ―”≥ΌΖ÷≤ΦΉψ“‘ΗφΥΏΈ“Ο«ΥΌΕ»±δ¬ΐΝΥΓΘΆΦ÷–ΒΡœΏ±μ Ψ ή”ΑœλΒΡ«κ«σΉή ΐΥφ ±Φδ±δΜ·ΒΡ«ιΩωΓΘ
‘Ύ’βΗωάΐΉ”÷–Θ§”–400ΆρΗω«κ«σ¥ο≤ΜΒΫΈ“Ο«ΒΡSLIΓΘ”“±ΏΒΡΝΫ¥ΠΥΌΕ»±δ¬ΐ≤Μ «ΚήΟςœ‘Θ§“ρΈΣΥϋΟ«ΒΡΖυΕ»Ϋœ–ΓΘ§ΒΪΟΩ¥ΠΕΦ”–200ΆρΗω«κ«σ¥ο≤ΜΒΫSLIΓΘ
Έ“Ο«Ω…“‘ΦΧ–χΫχ––’βάύ ΐ―ßΖ÷ΈωΘ§“ρΈΣ ΐΨί±Μ¥φ¥ΔΈΣΖ÷≤ΦΘ§Εχ≤Μ÷Μ «ΨέΚœΒΡΑΌΖ÷ΈΜΓΘ
œ÷‘Ύ»ΟΈ“Ο«ά¥ΩΦ¬«Νμ“ΜΗωΈ ΧβΘ§Φ¥Έ“Ο«ΒΡΖΰΈώ «≈δ÷Ο≤ΜΉψΜΙ «≈δ÷ΟΙΐΕ»ΘΩ
¥πΑΗΆ®≥Θ «ΓΑ ”«ιΩωΕχΕ®Γ±ΓΘ≥ΐΝΥ≈ω…œΧΊ β»’Ή”Θ§ΗΚ‘Ί‘Ύ“ΜΧλ÷–ΚΆ“Μ÷ή÷–ΒΡΟΩ“ΜΧλ“≤ΕΦ”–Υυ≤ΜΆ§ΓΘ‘ΎΈ“Ο«Ηψ«ε≥ΰœΒΆ≥‘ΎΧΊΕ®ΗΚ‘Ίœ¬ΒΡ––ΈΣ÷°«ΑΘ§Έ“Ο«Υυ÷ΣΒάΒΡΨΆ «’β–©ΓΘœ÷‘ΎΈ“Ο«ά¥Ήω“Μ–©ΦρΒΞΒΡ ΐ―ß‘ΥΥψΘ§ Ι”Ο―”≥Όά¥Ω… ”Μ·œΒΆ≥ «»γΚΈ‘Υ––ΒΡΘΚ
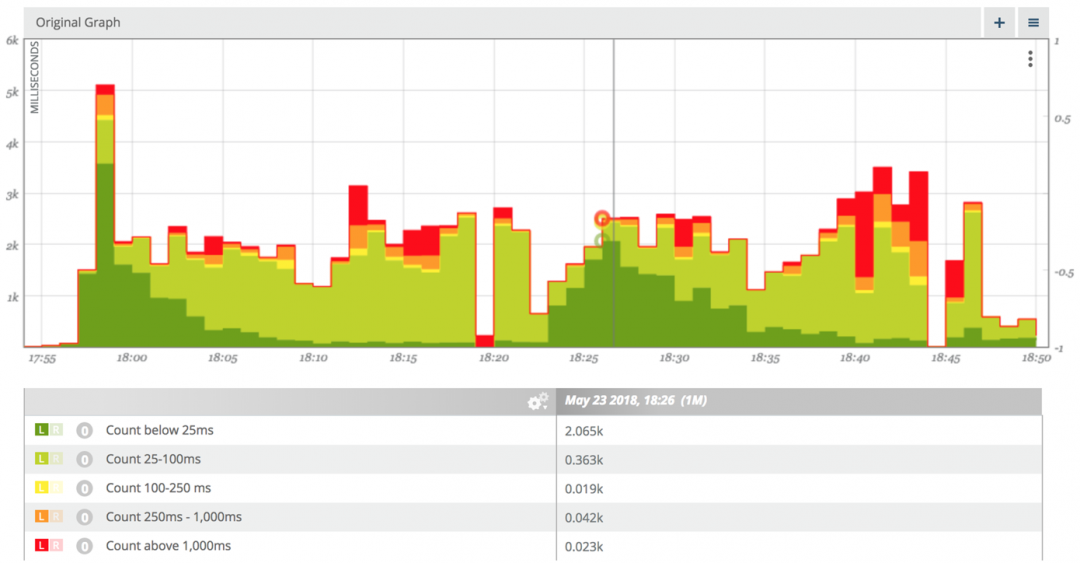
…œΟφΒΡΩ… ”Μ·œ‘ ΨΝΥ―”≥ΌΖ÷≤ΦΥφ ±Φδ±δΜ·ΒΡ«ιΩωΘ§Αϋά®ΒΆ”Ύ25ΚΝΟκΒΡ«κ«σ ΐΓΔ25ΚΝΟκΒΫ100ΚΝΟκΒΡ«κ«σ ΐΓΔ100ΚΝΟκΒΫ250ΚΝΟκΒΡ«κ«σ ΐΓΔ250ΚΝΟκΒΫ1000ΚΝΟκΒΡ«κ«σ ΐ“‘ΦΑ≥§Ιΐ1000ΚΝΟκΒΡ«κ«σ ΐΓΘΥϋΟ«Α¥’’―’…ΪΫχ––Ζ÷ΉιΘ§¬Χ…Ϊ±μ ΨΩλΥΌ«κ«σΘ§Κλ…Ϊ±μ Ψ¬ΐ«κ«σΓΘ
’β÷÷Ω… ”Μ·ΗφΥΏΝΥΈ“Ο« ≤Ο¥ΘΩΈ“Ο«Ω…“‘Ω¥ΒΫΘ§ΖΰΈώ«κ«σ‘Ύ“ΜΩΣ ΦΖ«≥ΘΩλΘ§ΦΗΖ÷÷”ΚσΩλ«κ«σΒΡΑΌΖ÷±»œ¬ΫΒΘ§¥σ‘Φ10Ζ÷÷”Κσ¬ΐ«κ«σΒΡΑΌΖ÷±»‘ωΦ”ΓΘ’β÷÷ΡΘ Ϋ‘ΎΝΫ¥ΈΝςΝΩΜαΜΑ÷–÷ΊΗ¥≥ωœ÷ΓΘ’β”÷ΗφΥΏΝΥΈ“Ο« ≤Ο¥ΘΩ’β±μΟςΘ§Ήν≥θΖΰΈώΙΐΕ»≈δ÷ΟΘ§ΒΪ‘ΎΥφΚσΒΡ10ΒΫ20Ζ÷÷”ΡΎ≈δ÷Ο≤ΜΉψΓΘΩ¥Τπά¥Θ§’βάοΚή Κœ Ι”ΟΉ‘Ε·…λΥθΓΘ
Έ“Ο«“≤Ω…“‘ΫΪ’β÷÷άύ–ΆΒΡΩ… ”Μ·ΧμΦ”ΒΫRED“«±μ≈Χ÷–ΓΘ’β÷÷άύ–ΆΒΡ ΐΨίΕ‘“ΒΈώάϊ“φœύΙΊ’Ώά¥ΥΒΖ«≥Θ”–”ΟΘ§Εχ«“ΥϊΟ«≤Μ–η“Σ’ΤΈ’¥σΝΩΒΡΦΦ θ÷Σ ΕΨΆΩ…“‘ΝΥΫβΥϋΟ«Ε‘“ΒΈώΒΡ”ΑœλΓΘ
Ϋα¬έ
Έ“Ο«”ΠΗΟΦύΩΊΖΰΈώΘ§Εχ≤Μ «»ίΤςΓΘΖΰΈώ «≥ΛΤΎ¥φΜνΒΡ ΒΧεΘ§Εχ»ίΤς≤Μ «ΓΘ”ΟΜß≤Δ≤ΜΙΊ–Ρ»ίΤς»γΚΈ‘Υ––Θ§ΥϊΟ«÷ΜΙΊ–ΡΖΰΈώ»γΚΈ‘Υ––ΓΘ
Έ“Ο«”ΠΗΟΦ«¬ΦΖ÷≤ΦΕχ≤Μ «ΨέΚœΘ§≤ΜΙΐ“ΣΡήΙΜ¥”’β–©Ζ÷≤Φ÷–…ζ≥…ΨέΚœΓΘΨέΚœ «Ζ«≥Θ”–Φέ÷ΒΒΡ–≈œΔά¥‘¥ΓΘΒΪΥϋΟ« «≤ΜΩ…Κœ≤ΔΒΡΘ§“ρ¥Υ≤Μ ”Ο”ΎΆ≥ΦΤΖ÷ΈωΓΘ
IstioΧαΙ©ΝΥΚήΕύœ÷≥…ΒΡΕΪΈςΘ§Έ“Ο«ΟΜ”–±Ί“Σ»Ξ–όΗΡΈ“Ο«ΒΡ¥ζ¬κΘ§“≤ΟΜ±Ί“Σ¥”ΆΖΩΣ ΦΙΙΫ®ΗΏ÷ ΝΩΒΡ”Π”Ο≥Χ–ρΩρΦήΓΘ
Ι”Ο ΐ―ßΖΫΖ®Χα≥ω≤ΔΜΊ¥π”–ΙΊΖΰΈώΒΡΈ ΧβΓΘΒ±Έ“Ο«Ά®ΙΐΫβΨω÷Ί“ΣΒΡ“ΒΈώΈ Χβ»ΟœΒΆ≥±δΒΟΗϋΦ”Ω…ΩΩ ±Θ§Τδ Β « Βœ÷ΝΥΉι÷·ΒΡΡΩ±ξΓΘ |









