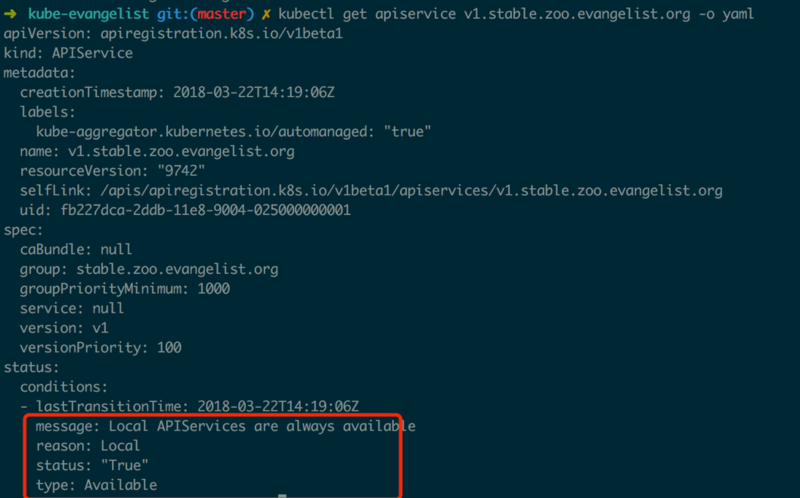
| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌБОЮФжївЊЭЈЙ§вЛИіОпЬхЪЕР§НщЩмKubernetes,ЭЌЪБЯъЯИЗжЮіСЫAPI ServerКЭKubernetesЬсЙЉЕФЙЄОпСДКЭПЭЛЇЖЫГщЯѓЕШжЊЪЖ
ЁЃ |
|
БОЮФЭЈЙ§вЛИіОпЬхЪЕР§НщЩмKubernetes РЉеЙПЊЗЂЃЌЗжЮіСЫAPI
ServerЕФМцШнадЩшМЦЃЛЛљгкВПЗждДТыНщЩмСЫKubernetes APIОлКЯВудРэКЭЪЕЯжЃЛзюКѓЛЙЗжЮіСЫKubernetesЬсЙЉЕФЙЄОпСДКЭПЭЛЇЖЫГщЯѓЃЌЯЃЭћЮЊKubernetesРЉеЙПЊЗЂЬсЙЉвЛаЉЦєЗЂ
ЁЃ
зДЬЌЙмРэВЂЗЧаТЯЪЛАЬтЃЌЫќЮЊжааФЛЏЯЕЭГЗжЗЂвЛжТЕФзДЬЌЃЌШЗБЃЗжВМЪНЯЕЭГзмЪЧГЏдЄЦкЕФзДЬЌЪеСВЃЌЪЧжааФЛЏЯЕЭГЕФЛљЪЏжЎвЛ
ЁЃ
вдPodЃЈШчЯТЭМЃЉЮЊР§ЃЌЫќГщЯѓСЫПЩвдЖРСЂВПЪ№ЕФзюаЁШнЦїЕЅЮЛЃЌPodУшЪіЕФБфЛЏашвЊЗДгГЕНЖдгІЕФШнЦїЩЯЃЌБШШчаоИФСЫPod
ЕФimageЃЌЫќЖдгІЕФШнЦїОЭЛсЪЙгУжИЖЈЕФimageРДжиНЈ ЁЃ

KubernetesДгv1.0ПЊЪМж№НЅаЮГЩСЫЭъЩЦЕФAPIПђМмКЭЙЄОпСДЃЌВЂвдДЫЮЊЛљДЁЪЕЯжСЫШнЦїЙмРэЦНЬЈЁЃЪБжСНёШеЃЈ2018ЩЯАыФъЃЉЃЌетЬзAPIПђМмКЭЙЄОпСДвбОбнБфЮЊGoЩњЬЌШІжаЕФЭЈгУзДЬЌЙмРэНтОіЗНАИЃЌДѓДѓНЕЕЭСЫНЈСЂЗжВМЪНЯЕЭГЕФФбЖШЁЃ
ПЩЯЇЕФЪЧЃЌЩчЧјЩаЮДГіЯжЖдKubernetesзДЬЌЙмРэКЭРЉеЙЕФЯъЯИНщЩмЃЌЙйЗНЮФЕЕжаЕФжЛбдЦЌгяФбвджЇГХИДдгЕФРЉеЙПЊЗЂашЧѓЃЌБОЮФЭЈЙ§вЛИіОпЬхЪЕР§НщЩмKubernetes
РЉеЙПЊЗЂЃЌЗжЮіСЫAPI ServerЕФМцШнадЩшМЦЃЛЛљгкВПЗждДТыНщЩмСЫKubernetes APIОлКЯВудРэКЭЪЕЯжЃЛзюКѓЛЙЗжЮіСЫKubernetesЬсЙЉЕФЙЄОпСДКЭПЭЛЇЖЫГщЯѓЃЌЯЃЭћЮЊKubernetesРЉеЙПЊЗЂЬсЙЉвЛаЉЦєЗЂ
ЁЃ
РЉеЙПЊЗЂЪЕР§
БОНкНщЩмвЛИіМђЕЅЕФРЉеЙПЊЗЂЯюФПРДНщЩмKubernetesРЉеЙЕФПЊЗЂФЃЪНЃЈДњТыЩњГЩЛљгкhttps://github.com/kubernetes-incubator/apiserver-builderЃЉЃЌетЪЧЕфаЭЕФC/SМмЙЙЃЌЗжЮЊAPIServerКЭПЭЛЇЖЫСНВПЗжЃЌAPIServerЬсЙЉСЫИпПЩгУЕФзДЬЌДцДЂЃЌЖјПЭЛЇЖЫЬсЙЉСЫзЪдДЕФCRUDКЭПЩППЕФзДЬЌЗжЗЂНгПкЁЃ
ЯШРДГѕЪМЛЏећИіЯюФППђМмЃЈетИіЙЄОпЕФЪЕЯжФПЧАЛЙВЛЮШЖЈЃЌВЛЭЌАцБОЕФapiserver-bootЩњГЩЕФДњТыПЩФмДцдкВювьЃЉЁЃ

КѓајеТНкНЋНщЩмЯъЯИНщЩмРЉеЙПЊЗЂЕФЙ§ГЬЁЃ
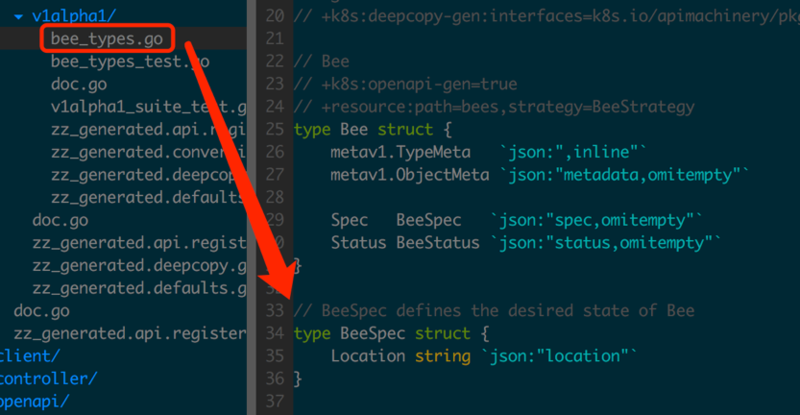
API Server
ЯюФПГѕЪМЛЏЭъГЩжЎКѓОЭПЩвдЖЈвхзДЬЌСЫЃЌЮЊСЫШУР§згИќОпвЛАуадЃЌБОЮФНЋЖЈвхЖрИіАцБОЕФзДЬЌВЂдкКѓајеТНкНщЩмAPIServerЕФМцШнадЩшМЦЁЃ
жДааШчЯТУќСюЩњГЩЕквЛИіАцБОЕФзДЬЌЖЈвхФЃАхЃКv1alpha1.BeeЁЃ
| $ apiserver-boot create resource --group alpha --version v1alpha1 --kind Bee |
ШЛКѓЮЊЩњГЩЕФv1alpha1.BeeЬэМгздЖЈвхЕФаХЯЂЃЈШчЭМ1.1.1ЃЉЁЃ
дЫаавдЯТУќСюНЋаоИФКѓЕФзДЬЌЖЈвхБфЛЏгІгУЕНећИіЯюФПжаШЅЁЃ
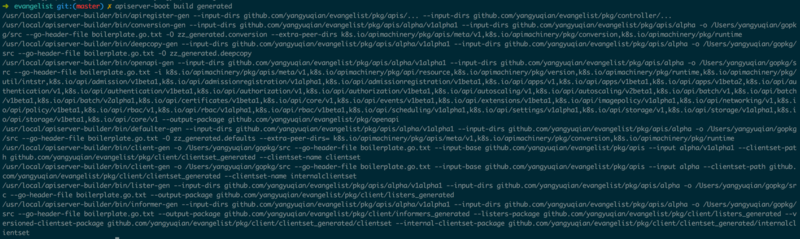
| $ apiserver-boot build generated |
ЩњГЩДњТыЪБЛсАбЫљгаЕФзгУќСюДђгЁГіРДЃЈШчЭМ1.1.2ЃЉЃЌЫцКѓПЩвдРћгУОжВПДњТыЩњГЩРДЖдЩњГЩДњТыНјааЮЂЕїЁЃ
ШЛКѓНЋетИіздЖЈвхЕФAPI ServerВПЪ№ЕНвЛИіKubernetesМЏШКжаЃЌзЂвтетРяВПЪ№ЕФAPI
ServerЪЧвЛИіЪЕЯжСЫKubernetes APIЙцЗЖЕФЖРСЂЕФWebЗўЮёЃЌгыМЏШКMasterЪЧЭъШЋЖРСЂЕФЃЌНіНіЪЧМЏШКжаЕФвЛИіЦеЭЈЕФPodЖјвбЃЌПЩвдгаЭъШЋЖРСЂгкMaster
API ServerЕФETCDДцДЂЁЃ

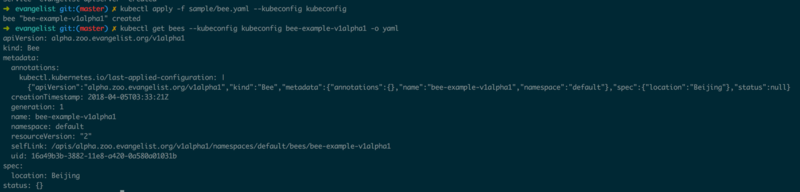
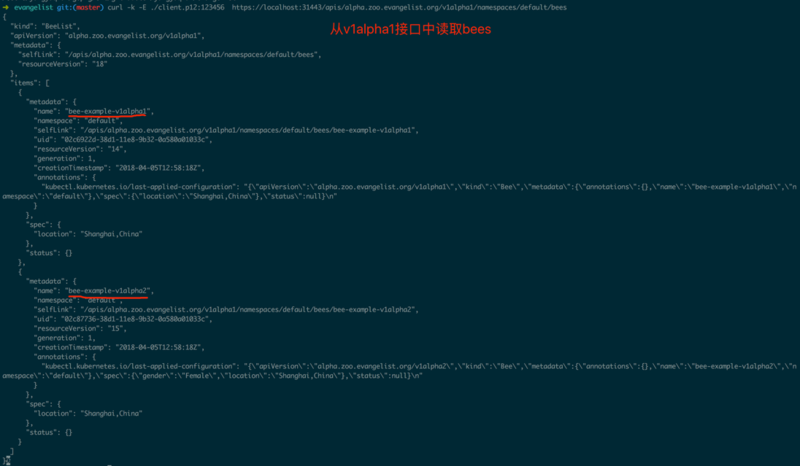
гЩгкДЫДІЕФAPIServerЪЕЯжСЫKubernetes APIЙцЗЖЃЌПЩвдЭЈЙ§kubectlРДжБНгаДШывЛИіv1alpha1.BeeЃЌШЛКѓдйгУkubectlЖСШЁИеИеаДШыЕФv1alpha1.BeeЃЈШчЭМ1.1.3ЃЉЃЌвВПЩвдгУkubectlРДаоИФЭМ1.1.3жааДШыЕФBeeЕФlocationаХЯЂЃЈШчЭМ1.1.4ЃЉЁЃ
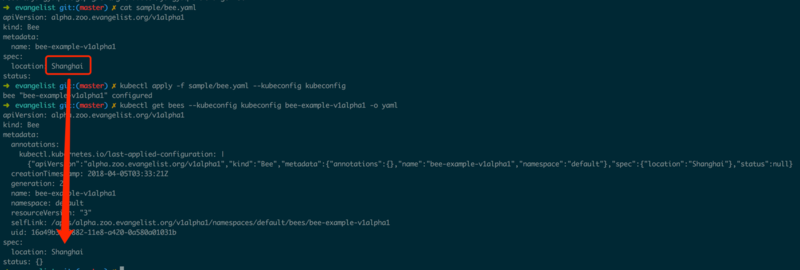
гаСЫЛљБОЕФДцДЂжЎКѓОЭашвЊПМТЧзДЬЌаоИФЪБЕФаЃбщЃЌПЩвдЮЊзДЬЌУшЪіЪЕЯжШЮвтаЮЪНЕФРЉеЙТпМЃЌЭМ1.1.5жаЮЊv1alpha1.BeeЬэМгздЖЈвхаЃбщЃЌЯоЖЈlocationБиаывдChinaНсЮВЁЃ
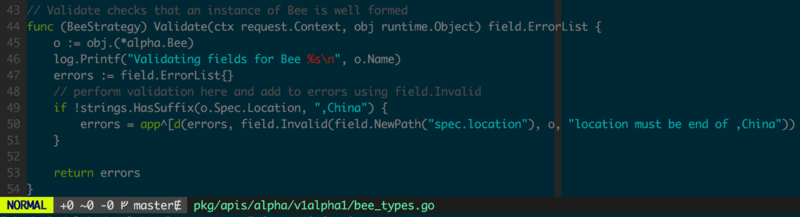
ЬэМгСЫЭМ1.1.5жаЕФаЃбщжЎКѓЃЌЭМ1.1.3жаИјГіЕФBeeУшЪівбОВЛдйКЯЗЈЃЌетЪБШчЙћГЂЪддйДЮаДШыИУЪ§ОнОЭЛсГіЯжаЃбщЪЇАмЃЈШчЭМ1.1.6ЃЉЁЃ

ЭМ1.1.7НЋlocationИќе§ЮЊChinaНсЮВКѓОЭПЩвде§ГЃаДШыv1alpha1.BeeСЫЁЃ
вдЩЯЪЧЖЈвхвЛИіv1alpha1.BeeзДЬЌУшЪіЕФЛљБОЙ§ГЬЁЃ
ЯИаФЕФЖСепПЩФмвбОЗЂЯжЃЌдкаДШывЛИіBeeжЎКѓЃЌШчЙћаоИФСЫBeeЕФаЃбщЙцдђЃЌФЧУДЧАУцвбОаДШыЕФBeeПЩФмвбОВЛКЯЗЈСЫЃЌОЭЛсГіЯждрЪ§ОнЃЌетИіЮЪЬтдѕУДНтОіФиЃПЙЄГЬЩЯЮвУЧгІИУЙцБметжжЧщПіЃЌRESTful
APIжавЛИіЛљБОЩшМЦддђОЭЪЧЁАВЛПЩБфзЪдДЁБЃЌетРяЫљЮНЕФЁАВЛПЩБфЁБжИЕФЪЧзЪдДЩцМАЕФИїжжЩЯЯТЮФЃЌАќРЈSchemaЁЂаЃбщЁЂАВШЋЁЂSLAЕШЕШЃЌШчЙћГіЯжЩЯЯТЮФИФБфЃЌгІИУЮЊзЪдДЬсЙЉаТЕФАцБОЁЃ
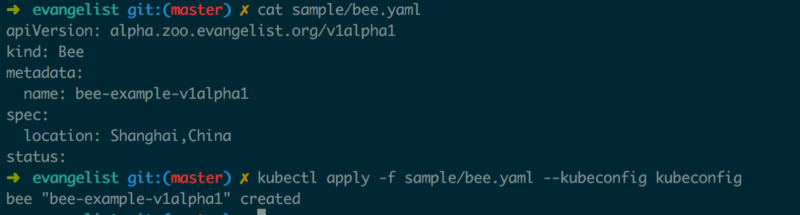
ЮЊСЫНщЩмзДЬЌЖЈвхЕФМцШнадЩшМЦЃЌЭМ1.1.8ЮЊBeeетИізДЬЌдіМгвЛИіаТАцБОv1alpha2.BeeЃЌSpecЛЙашвЊдіМгвЛИіЖюЭтЕФзжЖЮGenderЃЈзїепАДЃКЫфШЛУлЗфЗжФаХЎгаЕуГЖЃЌетРяНіНіЪЧЮЊСЫБэДядквЛИіаТАцБОЕФBeeжаЬэМгзжЖЮЃЌКѓЮФВЛдйНтЪЭЃЉЁЃ
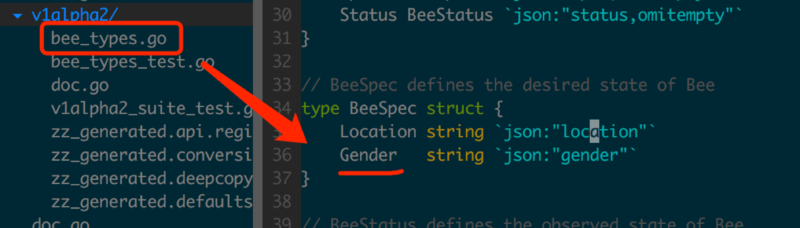
ЭМ1.1.9жаЪЙгУkubectlЭЌЪБаДШыv1alpha1.BeeКЭv1alpha2.BeeЁЃ
ПЭЛЇЖЫ
РЉеЙПЭЛЇЖЫСЌНгЕНЧАЮФЪЕЯжЕФAPI ServerРДМрЬ§BeeЕФБфЛЏЃЌНјЖјдкПЭЛЇЖЫЪЕЯжздЖЈвхРЉеЙТпМЃЌЭМ1.2.1жаЮЊBeeЪЕЯжЕФПЭЛЇЖЫРЉеЙЕФЛљБОЙЄзїСїЁЃ

ЧАЮФздЖЏЩњГЩЕФДњТыжаЮЊBeeЩњГЩСЫФЌШЯЕФBeeControllerЃЌШчЭМ1.2.2ЫљЪОЁЃ
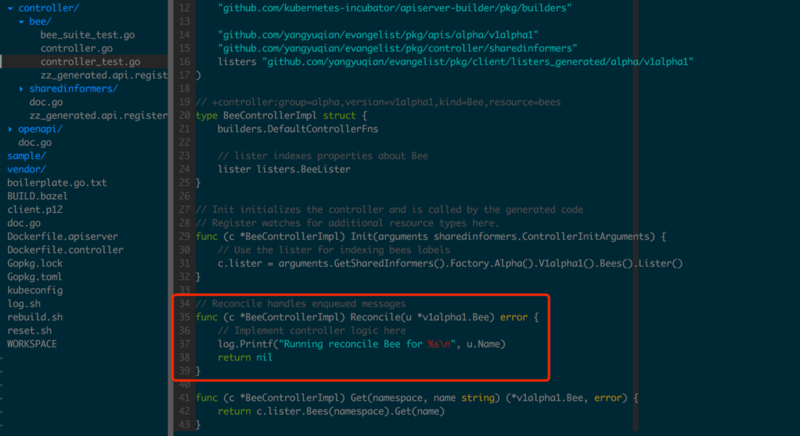
ЕБМрЬ§ЕНДДНЈЛђИќаТBeeзДЬЌЕФЪБКђЃЌПЩвдЭЈЙ§ЪЕЯжReconcileжаЕФТпМРДДІРэЖдBeeЕФЖюЭтРЉеЙЃЌЯждкРДАбControllerВПЪ№ЕНМЏШКжаШЅЁЃ
НЋЧАУцаДШыЕФBeeШЋВПЩОГ§КѓжиаТаДШыЃЌПЩвдПДЕНControllerДђгЁСЫСНЬѕШежОЗжБ№ЮЊаДШыЕФBee.NameЃЌШчЭМ1.2.3ЫљЪОЁЃ


ДЫДІЬсЕНЕФReconcileНгПкжЛФмЯьгІДцдкзДЬЌаоИФЕФГЁОАЃЌЪЧвЛжжЮозДЬЌЕФРЉеЙФЃЪНЃЌШчЙћашвЊЯьгІЩОГ§ЃЌПЩвдРћгУКѓЮФНщЩмЕФInformerНгПкРДЪЕЯжЃЌДЫДІВЛзИЪіЃЌжЛИјвЛИіМђЕЅР§згЃЈШчЭМ1.2.4ЃЉЁЃгаШЄЕФЪЧЃЌBeeControllerВПЪ№ЕНМЏШКРяУцЃЌУЛгаНјааЖюЭтХфжУОЭПЩвдСЌНгЕНЖдгІЕФAPIServerе§ГЃдЫзЊСЫЃЌЫќЪЧШчКЮздЖЏгыЧАЮФВПЪ№ЕФAPI
ServerНЈСЂСЌНгФиЃПетдкКѓЮФЁАAPIОлКЯВуЁБжаЛсОпЬхНщЩмЃЌДЫДІврВЛзИЪіЁЃ
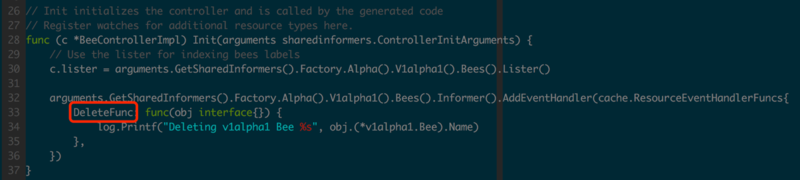

зЂвтЩОГ§СЫЧАУцаДШыЕФv1alpha1.BeeКЭv1alpha2.BeeСНИіАцБОЕФBeeЃЌЕЋЪЕМЪЩЯBeeControllerЪЧРћгУv1alpha1ПЭЛЇЖЫМрЬ§BeeЕФЩОГ§ЪТМўЃЌЯдШЛv1alpha1ЕФInformerвВПЩвдИажЊЕНЫљгаАцБОBeeЕФБфЛЏЃЌетЦфЪЕОЭЪЧМцШнадЩшМЦЕФУРУюжЎДІСЫЃЌВЛзИЪіЁЃ
аЁНс
ИДдгЯЕЭГжаЃЌПЭЛЇЖЫЕФЮЌЛЄжмЦкЪЧЫцЛњЕФЃЌЩшЯывЛИіУЛгаМцШнадЕФЯЕЭГЃЌдкдЫгЊвЛЖЮЪБМфКѓЃЌПЭЛЇЖЫРЉеЙгЩгкЩ§МЖЮЌЛЄжмЦкЕФВювьЪЙгУСЫВЛЭЌАцБОЕФПЭЛЇЖЫЪЕЯжЃЌетбљЕФЯЕЭГШЮКЮвЛИіЕуЕФБфЛЏЖдЯЕЭГжаЦфЫћФЃПщПЩФмЖМДцдкЧПвРРЕЃЌетжжёюКЯПЩФмЕМжТЯЕЭГВЛЕУВЛВПЗжжиЦєЃЌзюжеетИіЯЕЭГНЋЯнШыОйВНЮЌМшЕФФрЬЖЁЃПЩвдЫЕМцШнадЩшМЦЪЧKubernetesИпЖШПЩРЉеЙадЕФЛљДЁжЎвЛЃЌЭМ1.3.1ЮЊЖрАцБОBeeЕФМцШнадЩшМЦФЃаЭЁЃ
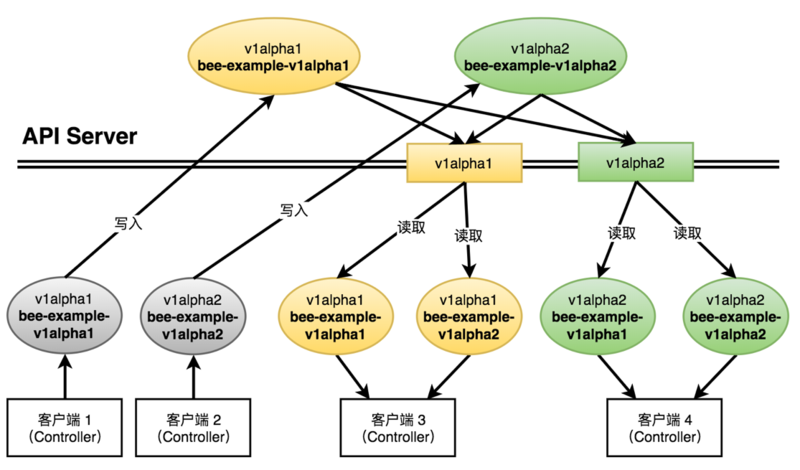
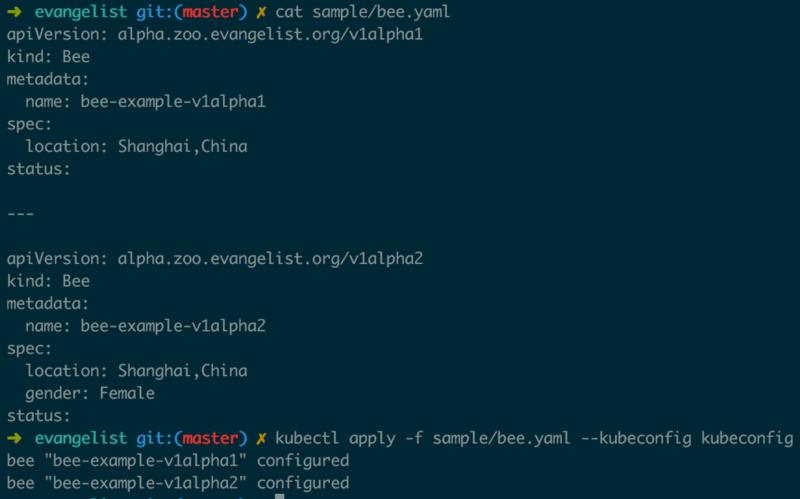
ЭМ1.3.1жааДШыКЭДцДЂBeeЕФЪБКђжЇГжШЋВПАцБОЃЌЖјAPI ServerЮЊУПИіАцБОЕФBeeЕФЖСШЁНгПкЪЕЯжСЫМцШнадЪЪХфЁЃЕБаДШыдЪМзДЬЌЮЊv1alpha1.BeeЃЌЫљгаПЭЛЇЖЫЖМПЩвдИажЊЕНетИізДЬЌЃЌЭЌРэаДШызДЬЌv1alpha2.BeeЪБЃЌЫљгаПЭЛЇЖЫвВЖМПЩвдИажЊЕНетИізДЬЌБфЛЏЁЃ
ЯШЭљAPI ServerаДШыv1alpha1.BeeКЭ v1alpha2.BeeСНИіBeeзДЬЌУшЪіЃЌШчЭМ1.3.2ЫљЪО
ЁЃ
НјШыetcdжаПДЪЕМЪаДШыЕФv1alpha1.BeeКЭv1alpha2.BeeЪ§ОнЃЈШчЭМ1.3.3ЃЉЃЌПЩМћзДЬЌДцДЂКЭаДШыЪБЕФЪфШыЪЧвЛжТЕФЁЃ

ЬиБ№ЬсвЛЯТЃЌдкKubernetes APIЩшМЦЙцЗЖжаЃЌ{Group, Namespace, metadata.name}
етИіШ§дЊзщЪЧШЋОжЮЈвЛЕФЃЌОЁЙмДЫДІаДШыЕФСНИіBeeЗжБ№ЮЊВЛЭЌЕФАцБОЃЌЛЙЪЧПЩвдДгЫљгаАцБОЕФЖСШЁНгПкФУЕНетаЉзДЬЌЃЈШчЭМ1.3.4ЃЌ1.3.5ЃЉЃЌетОЭЪЧЮЊЪВУДЭМ1.2.4жажЛашЪЙгУv1alpha1ПЭЛЇЖЫОЭПЩвдНгЪмЕНЩОГ§
v1alpha1.BeeКЭv1alpha2.BeeЕФЪТМўЁЃ
ЭМ1.3.4КЭ1.3.5жБНгЪЙгУcurlУќСюЗжБ№Дгv1alpha1КЭv1alpha2ЕФAPIРДЛёШЁBeeСаБэЃЌетНјвЛВНзєжЄСЫМцШнадЩшМЦЪЧдкAPI
ServerЪЕЯжЕФЁЃ
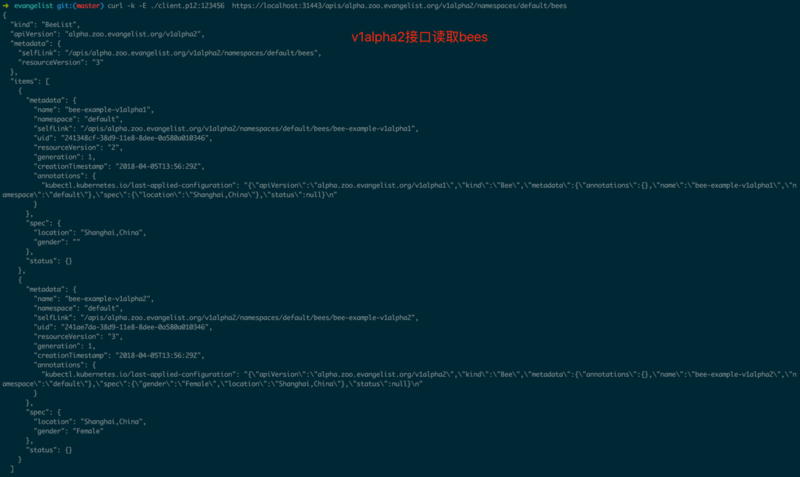
дкВЛЭЌАцБОЕФBeeжЎМфЛЅЯрзЊЛЛШчЙћЩйСЫзжЖЮЃЌБШШчЭМ1.3.5жаЭЈЙ§v1alpha2ПЭЛЇЖЫЖСШЁv1alpha1.BeeЃЌgenderзжЖЮЮЊПеЃЌетПЩФмЪЧгаЮЪЬтЕФЃЌv1alpha2ПЭЛЇЖЫФУЕНетбљЕФЪ§ОнПЩФмЛсГіЯжВЛдЄЦкЕФааЮЊЃЌгІИУБЃжЄПЭЛЇЖЫШЁЕНЕФЪ§ОнТњзуЯргІАцБОЕФдМЪјЁЃ
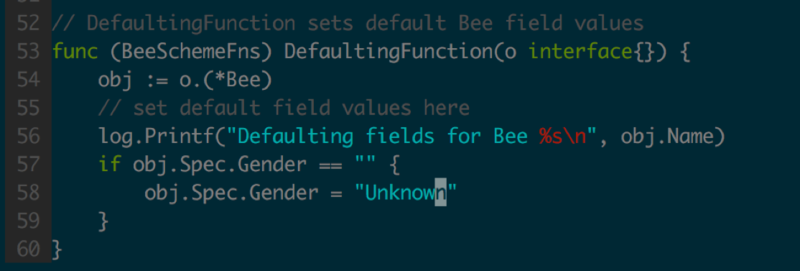
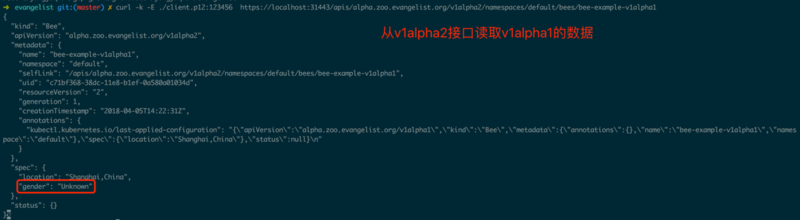
етОЭашвЊAPIServerЬсЙЉФЌШЯжЕЕФжЇГжСЫЃЌЯТУцРДЮЊv1alpha2ЬэМгФЌШЯжЕжЇГжЃЌНЋgenderФЌШЯЩшжУЮЊUnknown
ЃЌШчЭМ1.3.6ЫљЪОЁЃ
МцШнадЩшМЦЪЧРЇШХКмЖрИДдгЯЕЭГЩшМЦепЕФЮЪЬтЃЌKubernetesжаЕФМцШнадЩшМЦФЃЪНВЛНіЪЧRESTfulЩшМЦФЃЪНЕФГЩЙІгІгУЃЌвВЮЊИДдгЯЕЭГЩшМЦЬсЙЉСЫвЛжжЭЈгУНтОіЗНАИЁЃ
APIОлКЯВу
ЧАУцЕФЪЕР§жаЃЌControllerВПЪ№ЕНМЏШКжаОЭФмжБНгЗУЮЪBeeзЪдДЃЌЪЕМЪЩЯдкВПЪ№API ServerЪБЛЙЮЊЦфХфжУСЫAPIОлКЯВуЃЌНЋетИіЖРСЂЕФAPI
ServerећКЯЕНМЏШКЕФAPI ServerжаШЅСЫЃЌОЭКУЯёЪЧKubernetes APIЬсЙЉСЫBeeетИіResourceвЛбљЁЃ
APIОлКЯВуЪЧKubernetes APIРЉеЙадЕФЛљДЁЃЌНЋздЖЈвхзЪдДећКЯЕНKubernetes APIжаЃЌЮЊШнЦїЙмРэЦНЬЈЛђЯрЙиВхМўЬсЙЉзДЬЌДцДЂЃЈдДТыЗжЮіЛљгкЃКf7aafaeb404563cda07b182ad9679f54afd227feЃЉЁЃ
API Service
KubernetesдкдчЦкАцБОжаОЭЬсЙЉСЫAPI ServiceжЇГжЃЌзюГѕЪЧЮЊСЫжЇГжНЋХгДѓЕФAPI
ServerЗжЩЂдкЖрИіЖРСЂЕФAPI ServerжаШЅЁЃЫќЖЈвхСЫвЛзщСщЛюЕФЗДЯђДњРэНгПкЃЌжЛвЊНгШыЕФAPI
ServerЕФЩшМЦТњзуKubernetesЕФAPIЩшМЦЃЌОЭПЩвдећКЯЕНKubernetesЕФAPIжаШЅЃЌМЏШКвбгаЕФзщМўПЩвджБНггыаТМгШыЕФAPI
ServerРДзіМЏГЩЃЌЭМ2.1.1ЮЊAPI Service(v1)ЕФЖЈвхЁЃ
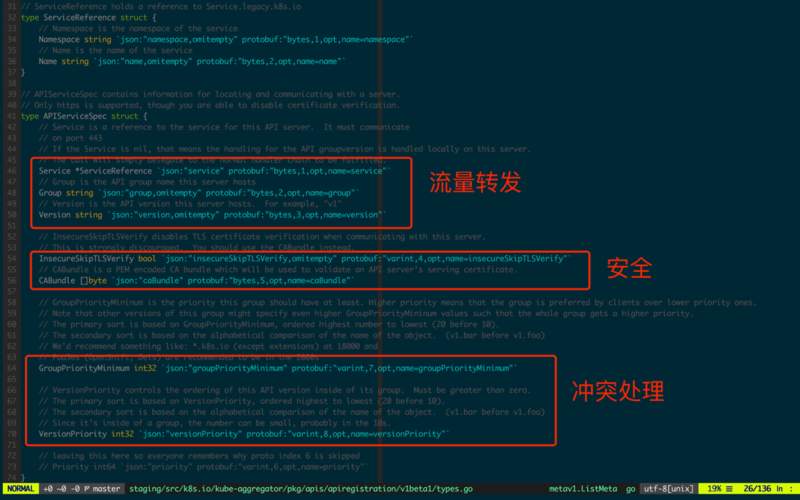
ЭМ2.1.2жаНЋздЖЈвхЕФAPI Server(evangelist-apiserver)ећКЯЕНKubernetes
APIжаШЅЁЃ
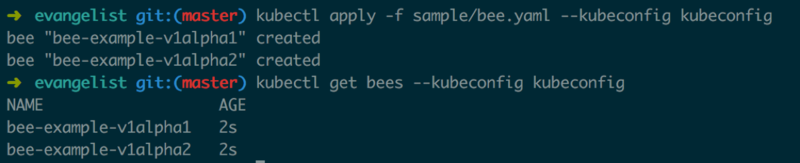
етбљОЭПЩвджБНгЭЈЙ§kubectlРДЙмРэИУAPIРЉеЙЕФзДЬЌСЫЃЌЭМ2.1.3жаЪЙгУkubectlРДЙмРэBeesЁЃ

API ServiceЖЈвхжаШчЙћжИЖЈСЫ ServiceЃЌAPI AggregatorЛсЮЊИУServiceЬэМгвЛИіЗДЯђДњРэХфжУЃЌЭМ2.1.4ЪЧAPI
ServiceзЪдДИФЖЏКѓЩњГЩЗДЯђДњРэЕФЪЕЯжЁЃ
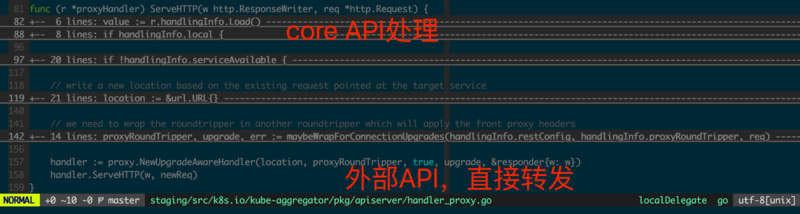

УПИіAPI ServiceЖдЖМЖдгІСЫЖРСЂЕФproxyHandlerЃЌЪЧеыЖдЬиЖЈURLЕФЗДЯђДњРэЁЃ
Custom Resource Definition
Custom Resource Definition(CRD)ЕФЧАЩэЪЧThird Party Resource(TPR)ЃЌЪЧAPI
ServiceЕФвЛжжРЉеЙНгПкЃЌЦфжаTPRвбОдкv1.7жЎКѓБЛЗЯЦњЃЌv1.8жЎКѓГЙЕзДгДњТыжавЦГ§ЃЌвђДЫетРяжЛНщЩмCRDЕФЛљБОЪЕЯждРэЁЃCRDЮЊзДЬЌЙмРэРЉеЙЖЈвхСЫвдЯТШ§жжФмСІЃК
ЖЈвхШЮвтРраЭЕФзЪдД
ЖЈвхЛљгкOpen API SchemaЕФаЃбщ
ЖЈвхзЪдДЃЈResourceЃЉЩњУќжмЦкжаЙГзгЃЈHookЃЉ

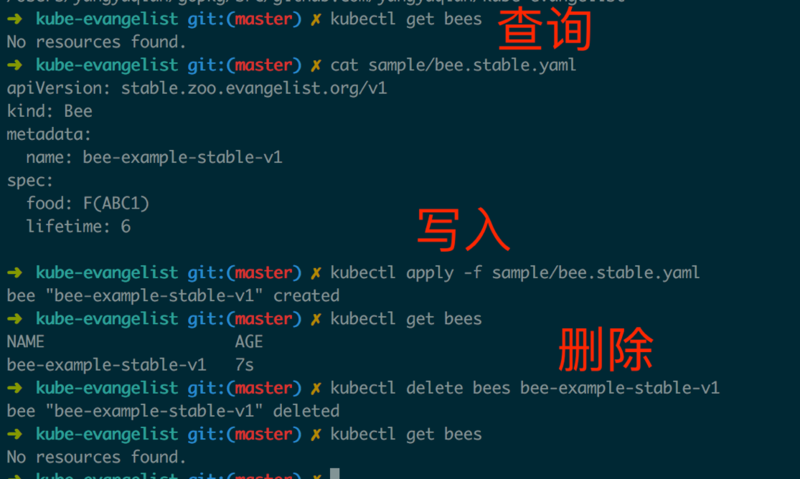
ЯђМЏШКжааДШыИУCRDЃЌОЭдкИУAPIServerжазЂВсСЫвЛИіУћЮЊBeeЕФзЪдДЃЌВЂЧвЖдзЪдДМгШыКЭаЃбщжЇГжЃЌНгЯТРДОЭПЩвдгУkubectlжБНгЙмРэЭМ2.2.1жаЖЈвхЕФBeeзЪдДСЫЃЈШчЭМ2.2.2ЃЉЁЃ
CRDЪЧЛљгкAPI ServiceЪЕЯжЕФЃЌKubernetesЮЊCRDздЖЏБЃГжвЛИіеыЖдKube APIЕФAPI
ServiceХфжУЃЈШчЭМ2.2.3ЃЉЁЃ
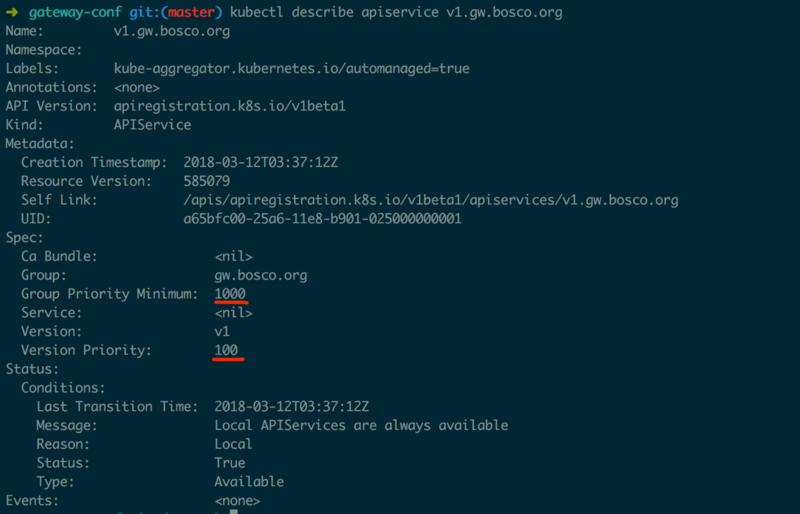
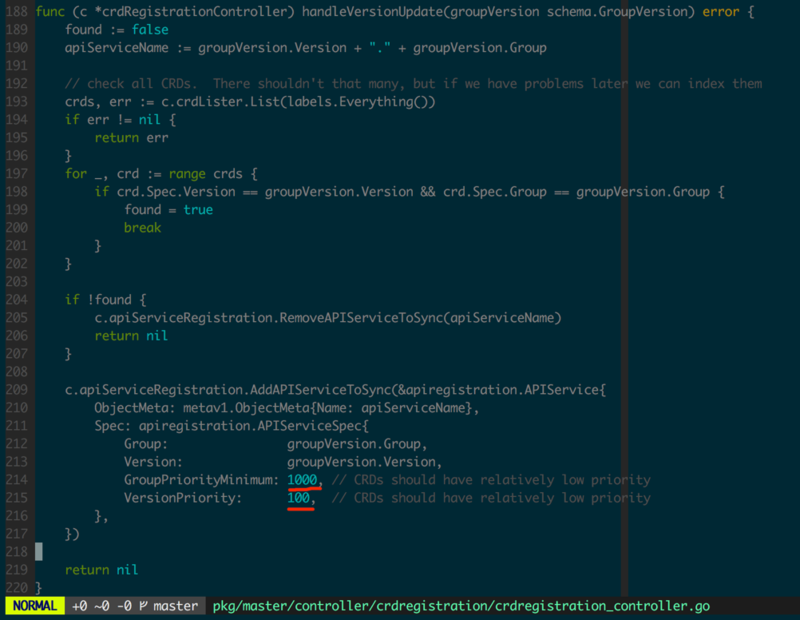
жЕЕУвЛЬсЕФЪЧЃЌCRDЕФСНИіЬиЕуЃК
гЩKube APIЬсЙЉЗўЮё
ДњТыРяУцаДЫРСЫгХЯШМЖЃЈШчЭМ2.2.4ЃЉЃЌМДversionPriority(100)КЭgroupPriorityMinimum(1000)
аЁНс
Kubernetes APIServerЕФЛљБОЙІФмжЎвЛЪЧЗДЯђДњРэЃЌAPIServiceЬсЙЉСЫЖЏЬЌХфжУНгПкЃЌПЩвдЮЊЯрЭЌЕФзЊЗЂЬѕМўЖЈвхЖрИігХЯШМЖВЛЭЌЕФAPIServiceЃЌетбљЕФЩшМЦКмживЊЃЌБЃжЄСЫKubernetes
APIServerдкЧаЛЛзЊЗЂХфжУЖдПЭЛЇЖЫЭъШЋЭИУїЃЈZero DowntimeЃЉЁЃ
дкЧАЮФЁАРЉеЙПЊЗЂЪЕР§ЁБжаУЛгаВЩгУCRDРДЪЕЯжAPIServerРЉеЙЃЌетЪЧвђЮЊCRDДцдкСНЗНУцЕФОжЯоадЃК
УЛгаsub-resourceжЇГжЃКвђДЫstatusКЭspecвЛбљЖМЪЧПЩвдБЛkubectlаоИФЕФЃЌетЦфЪЕДђЦЦСЫKubernetes
APIЩшМЦЕФЛљБОМйЩш
ШБЩйМцШнаджЇГжЃКЖрАцБОSchemaжЎМфЛЅЯрзЊЛЏЭЈГЃашвЊздЖЈвхДњТыТпМРДЪЕЯжЃЌетдкЮДРДCRDжавВЪЧВЛПЩФмжЇГжЕФ
CRDЬсЙЉСЫвЛжжгаЯоЕФЁЂЧсСПМЖЕФAPIServerРЉеЙЃЌдкММЪѕбЁаЭжаашвЊПМВьЪЧЗёДцдкЯТУцЕФашЧѓРДОіЖЈЪЧЗёбЁдёCRDЃК
БмУтstatusБЛkubectlДлИФЃКдкЖрИіПЭЛЇЖЫЙВЯэзДЬЌЃЌШчЙћstatusБЛkubectlШЫЮЊДлИФПЩФмЕМжТЯЕЭГГіЯжВЛдЄЦкЕФааЮЊ
СухДЛњЃЈZero DowntimeЃЉЩ§МЖЃКПЭЛЇЖЫКЭAPIServerашвЊдкЩ§МЖЮЌЛЄЕФШЮвтЪБМфЕуБЃжЄМцШнадКЭе§ШЗПЩдЄЦкЕФааЮЊ
CRDЛсздЖЏБЃГжЯргІЕФAPIServiceЩшжУЃЌМДЪЙИУAPIServiceБЛДлИФЃЌCRD ControllerвВФмЙЛздЖЏЛжИДе§ШЗЕФAPI
ServiceХфжУЃЌетвВвтЮЖзХШчЙћвЊгУздЖЈвхAPIServerРДЬцЛЛвбгаЕФCRDЗўЮёЃЌашвЊЯШНЋCRDЩОГ§дйаДШыаТЕФAPIServiceХфжУЃЌЗёдђИУХфжУЛсБЛCRDздЖЏИВИЧЁЃ
ДњТыЩњГЩ
KubernetesЬсЙЉСЫЗсИЛЕФДњТыЩњГЩЙЄОпгУРДЙмРэRESTfulзДЬЌЕФЖЈвхКЭПЭЛЇЖЫДњТыЃЌЮЌЛЄзДЬЌЖЈвхЕФЙ§ГЬОЭЪЧЮЊИїФЃПщжЎМфзДЬЌСїзЊЖЈвхService
ContractЁЃ
ПЭЛЇЖЫЩњГЩ
БОНкНщЩмПЭЛЇЖЫДњТыЩњГЩЙЄОпЃЌЮФжаЬсЕНСЫTagЕФЁАзїгУгђЁБЃЌдкGoгябджаУЛгаОпЬхЕФЖЈвхЃЌетРяИјГівЛжжЗКЗКЕФУшЪіЃК
Local TagЃКStruct/Field/FunctionЖЈвхжЎЧАЃЌгУРДдМЪјОжВПДњТыЩњГЩЙцдђ
Global TagЃКPackageЯТdoc.goЕФpackageЙиМќзжЧАЃЌзїЮЊећИіPackageЯТЕФФЌШЯЩњГЩЙцдђЃЌПЩвдБЛLocal
TagИВИЧ
ЯШПДdeepcopy-genЃЌЫќЬсЙЉСЫЁАЩюИДжЦЁБНгПкЩњГЩФмСІЃЌдкжДаавЛаЉПЩФмЛсаоИФЖдЯѓФкШнЕФВйзїЪБЃЌЁАЩюИДжЦЁБПЩвдБЃЛЄдЪМЖдЯѓФкШнЃЌШУЯЕЭГжаЖдЯѓЕФБпНчИќЧхЮњЁЃ
ШчЭМ3.1.1жаМЦЫуШнЦїЕФResource LimitЪБЃЌашвЊЭЌЪБПМТЧНкЕуПЩЗжХфЕФзЪдДЃЌзюжеНсЙћЛсЪЧЖўепКЯВЂЕФНсЙћЃЌЫљвдетРядкМЦЫуЧАЯШНЋcontainerЩюИДжЦвЛИіСйЪБЖдЯѓЃЌШЛКѓКЯВЂжБНгдкетИіСйЪБЖдЯѓЩЯНјааЁЃ
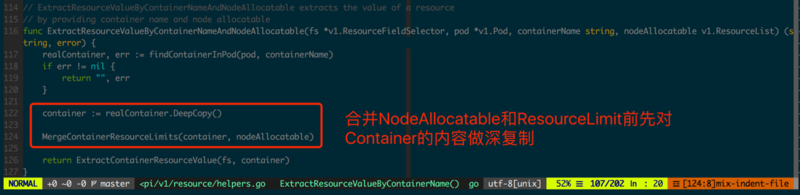
k8s:deepcopy-genЃКЩљУїЪЧЗёЩњГЩDeepCopyНгПкЃЌЬэМгЕФЮЛжУОіЖЈСЫИУTagЕФзїгУгђЃЌПЩвдЬэМгЕНPackageЃЈШЮвтЮФМўpackageЙиМќзжЧАЃЉЛђStructЧАЃЌШЁжЕЯрЙиКЌвхШчЯТ:
true/false: ЪЧЗёЩњГЩDeepCopyНгПкЃЌГЃгУгкЩљУїФГаЉStructВЛашвЊЩњГЩDeepCopy
package: жЛгУгкPackageгђЃЌЮЊИУPackageЯТЫљгаЮДЯдЪННћгУDeepCopyЕФРраЭШЋВПЩњГЩDeepCopyНгПк
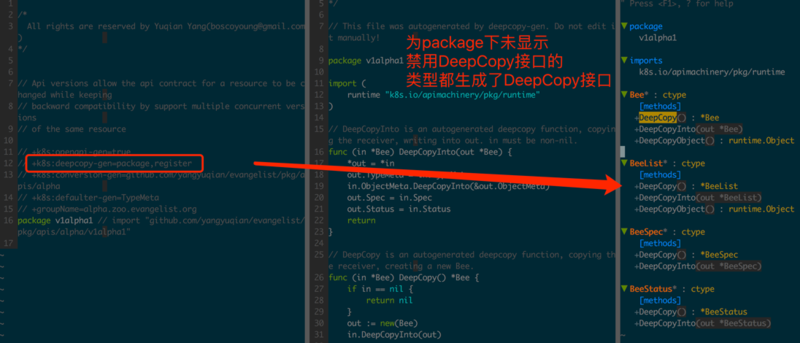
k8s:deepcopy-gen:nonpointer-interfaces: ЩљУїЪЧЗёЮЊФГРраЭЩњГЩжЕРраЭЕФDeepCopyНгПкЃЌжЛФмзїгУгкStructгђ
true/falseЃКЩњГЩжЕРраЭDeepCopyНгПкЃЌЗёдђЮЊжИеыРраЭ

k8s:deepcopy-gen:interfacesЃКжИЖЈЮЊStructЩњГЩЗЕЛиШЮвтНгПкРраЭЕФDeepCopyНгПкЃЌШЁжЕЮЊЖККХЗжИєЕФРраЭШЋУћЁЃ

НгЯТРДНщЩмconversion-genКЭdefaulter-genЃЌетСНИіЙЄОпЕФзїгУЪБЯрИЈЯрГЩЕФЃЌЫќУЧЮЊЖрАцБОResourceЬсЙЉСЫЗўЮёЖЫздЖЏзЊЛЛЕФФмСІЃЌБШШчЧАУцР§згжаЬсЕНЕФv1alpha1.BeeКЭv1alpha2.BeeжЎМфЕФздЖЏзЊЛЛЁЃ
ЭМ3.1.6ЕФР§згжаv1alpha1.BeeЯђv1alpha2.BeeзЊЛЛЪБЃЌШБЩйСЫgenderзжЖЮЃЌдкv1alpha2.BeeжаИГжЕЮЊШБЪЁжЕUnknownЃЛЖјv1alpha2.BeeЯђv1alpha1.BeeзЊЛЛЪБЃЌжЛашвЊНЋЫќЕФlocationзжЖЮИГжЕИјv1alpha1.BeeМДПЩЁЃ

дйПДconversion-genЃЌЫќЪЕЯжСЫВЛЭЌАцБОЕФResourceдкЗўЮёЖЫздЖЏзЊЛЛЕФФмСІЃЌетдкAPIМцШнадЩшМЦжаЦ№ЕНСЫжСЙиживЊЕФзїгУЃЌЪЧБЪепПДРДетвВЪЧзюГЃгУЕФДњТыЩњГЩЙЄОпЁЃ
k8s:conversion-gen ЮЊЁАдДPackageЁБКЭЁАФПБъPackageЁБжЎМфЕФЭЌУћStructЩњГЩздЖЏзЊЛЛДњТы:
true/false: ЩљУїЪЧЗёзЂВсConversionТпМЃЌзїгУгђПЩвдЮЊStructКЭFieldЁЃ
PackageУћЃКЩљУїЮЊЕБЧАPackageКЭДЋШыЕФPackageжаЭЌУћStructЩњГЩConversionТпМ

k8s:conversion-gen-external-types: жИЖЈЩњГЩConversionЕФЁАЕБЧАPackageЁБЮЛжУЃЌетЪЧвђЮЊгаЪБКђЕБЧАPackageжаResourceЖЈвхЪЧЖРСЂЮЌЛЄЕФЁЃ
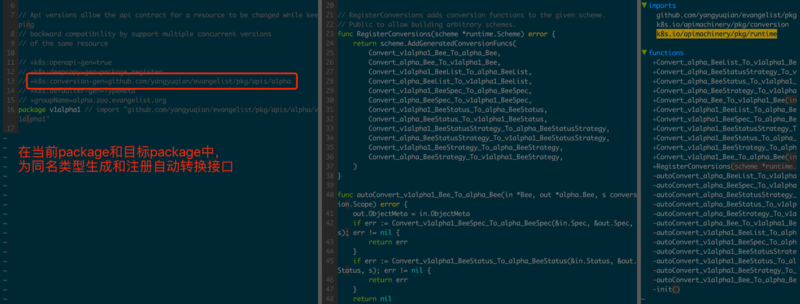
ашвЊзЂвтЕФЪЧЃЌЭМ3.1.8жаЁАдДРраЭЁБPackageашвЊБЃжЄКЭЁАФПБъЁБPackageЗжЪєВЛЭЌЕФАцБОЃЌЗёдђЩњГЩЕФMethodЛсГіЯжжиУћЕФЧщПіЃЌЮоЗЈБрвыЁЃ
РраЭзЊЛЛЪЧGoПЊЗЂжавЛИіБШНЯТщЗГЕФЕиЗНЃЌМгжЎгябдВуУцЗДЩфЕФадФмКЭБъзМПтжЇГжЖМЯожЦСЫПЊЗЂЕФСщЛюадЃЌздЖЏзЊЛЛНгПкЮЊAPIдкНјааМцШнадЕФзЊЛЛЪБзіЕНгЮШагагрЁЃ
зюКѓПДdefaulter-genЃЌдкЖЈвхСЫSetDefaultsКЏЪ§ЃЈЭМ3.1.9ЃЉжЎКѓЃЌЮЊжЎздЖЏЩњГЩObject/ListЕШЪЙгУГЁОАЕФDefaulterКЏЪ§КЭзЂВсТпМЁЃ
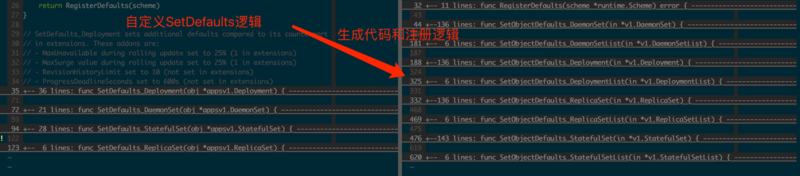
ЩњГЩDefaulterзЂВсКЏЪ§КѓЃЌЛЙашвЊзЂВсRegisterDefaultsЃЈЭМ3.1.10ЃЉКЏЪ§НЋИУФЌШЯжЕЙцдђгІгУгкШЮвтSchemeЕФГѕЪМЛЏНзЖЮЃЌдкИУSchemeЕФзїгУЗЖЮЇФкОЭЛсЪЙгУЪфШыЕФФЌШЯжЕЙцдђЁЃ
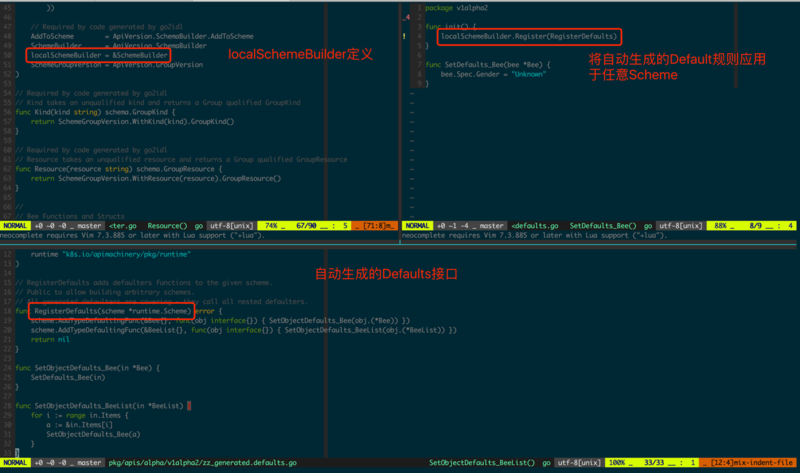
defaulter-genдкЮЌЛЄзДЬЌЭъећжаЦ№ЕНжСЙиживЊЕФзїгУЃЌШчЙћВЛЭЌАцБОЕФResourceЛЅЯрзЊЛЛЪБЃЌШБЪЇЕФзжЖЮФЌШЯЮЊСужЕЃЌЖјгаСЫГѕЪМЛЏФЌШЯжЕЕФФмСІКѓЃЌОЭФмБЃжЄзЊЛЛЕФНсЙћЪМжеТњзуЖдгІResourceЕФгявхдМЪјЃЌШчЧАУцР§згжаv1alpha2жадіМгСЫGender(адБ№)КѓЃЌЖСШЁv1alpha1Ъ§ОнЪБЃЌGenderзжЖЮФЌШЯИјГіЕФЪЧПезжЗћДЎЃЌетЯдШЛдкгявхЩЯЪЧЫЕВЛЭЈЕФЁЃ
k8s:defaulter-gen:
true/false: ШчЙћзїгУгђЮЊTypeЃЌдђЩљУїЪЧЗёЮЊTypeЩњГЩDefaulterЃЛШчЙћзїгУгк
FunctionГЃгУРДЩњГЩУїУїТњзуSetDefault_$NameИёЪНЕФFunction
FIELDNAME: ЩљУїЮЊЫљгаКЌгаДЋШыЕФFieldЕФTypeЩњГЩDefaulterЃЌзїгУгђЮЊPackage
k8s:defaulter-gen-inputЃКгУРДжИЖЈЩњГЩDefaulterЕФЪфШыPackageЁЃ
ЭМ3.1.11 жИЖЈ ЁА../../../../vendor/k8s.io/api/apps/v1ЁБ
зїЮЊЪЕМЪStructЕФЪфШыЃЌдкЕБЧАФПТМЩњГЩDefaulterзЂВсТпМЁЃ

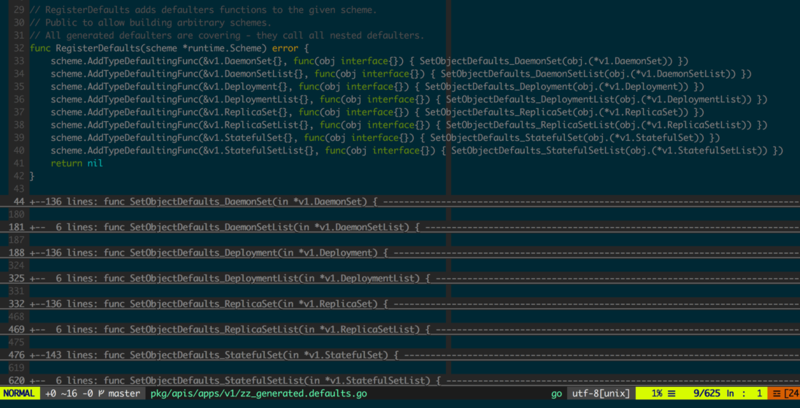
ДЫЭтKubernetesжаЮЊЙЙНЈСщЛюЕФРЉеЙЬсЙЉСЫЗсИЛЕФИпВуДњТыЩњГЩЙЄОпЃЌГЌГіБОЮФвЊТлЪіЕФЗЖГыЃЌВЛзИЪіЁЃ
ПЭЛЇЖЫГщЯѓ
ДњТыЩњГЩЙЄОпЛЙПЩвдЮЊРЉеЙГЬађЩњГЩШ§жжГЃгУЕФПЭЛЇЖЫГщЯѓЃКClientset, Lister, InformerЁЃ
ЯрБШзДЬЌЖЈвхЕФДњТыЩњГЩЙЄОпЕФИДдгХфжУЃЌПЭЛЇЖЫДњТыЩњГЩЭЈГЃЪЙгУФЌШЯХфжУМДПЩЁЃ
ЦфжаClientsetЗтзАСЫЖдResourceвдМАЖдгІМЏКЯРраЭЕФЛљДЁCRUDвдМАГЃгУИДдгЖСаДНгПкЃЛListerЗтзАСЫЖдResourceАДееLabelЙ§ТЫЕФНгПкЃЛInformerЬсЙЉСЫзДЬЌжїЖЏЗжЗЂФмСІЃЌШУПЭЛЇЖЫФмМрЬ§ЗўЮёЖЫзДЬЌЕФБфЛЏВЂжДааЯргІЕФЛиЕїТпМЁЃListerКЭInformerКЭAPI
ServerЭЈаХЖМЛљгкClientsetЪЕЯжЁЃ

client.AlphaV1alpha2().Bees("default")ЗЕЛиЕФBeeInterfaceЗтзАСЫОпЬхАцБОЕФRESTfulНгПкЃЌДЫДІОЭЪЧv1alpha2ЕФRESTfulНгПкЃЌе§ШчЧАЮФМцШнадЩшМЦНщЩмЕФЃЌv1alpha2ПЭЛЇЖЫЪЧПЩвдЖСШЁv1alpha1.BeeЕФ
ЁЃ
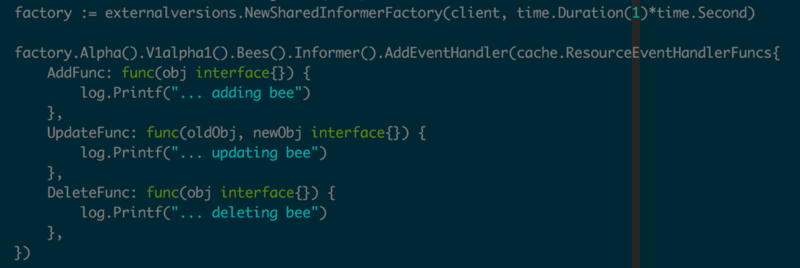
ДЫДІAddEventHandlerПЩвдДЋШыResourceEventHandlerНгПкЃЌдЪаэЪЕЯжШ§ИіЛиЕїКЏЪ§ЃЌШчЭМ3.2.3ЫљЪОЁЃ
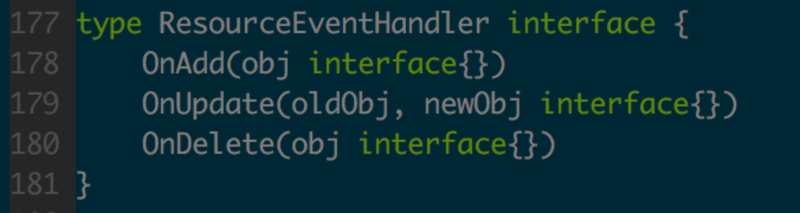
OnAddЃКДДНЈResourceЪБ
OnUpdateЃКаоИФResourceЪБЃЌЛђЖЈЪБЛёШЁзюаТЕФResourceзДЬЌЪБ
OnDeleteЃКЩОГ§ResourceЪБ
ЦфжажЕЕУвЛЬсЕФЪЧOnUpdateБЛЕїгУЪБЃЌResourceВЛвЛЖЈецЕФБЛаоИФЃЌвВПЩФмжЛЪЧЖЈЪБЛёШЁResourceзюаТЕФзДЬЌЃЌетИіЛиЕїКЏЪ§ГЃгУдкЦєЖЏКѓРДздЖЏЛжИДПЭЛЇЖЫЕФзДЬЌЁЃ
аЁНс
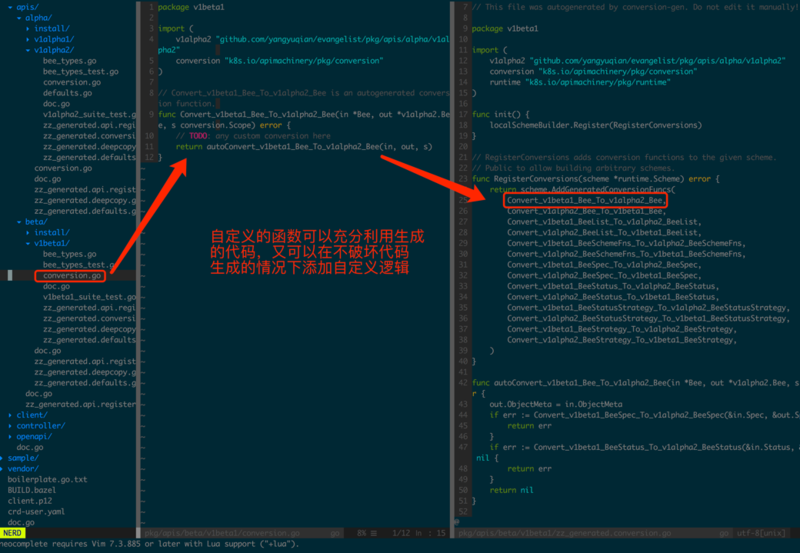
ДњТыЩњГЩГ§СЫашвЊНсКЯИїжжашЧѓСщЛюЪЙгУTagжЎЭтЃЌДѓВПЗжЕФЙЄОпЩњГЩЕФДњТыЖМЪЧПЩвдОжВПздЖЈвхЕФЃЌБШШчЯждкгаalpha/v1alpha2.BeeКЭbeta/v1beta1.BeeСНИіАцБОЕФBeeЃЌВЂЮЊЫќУЧЩњГЩСЫconversionТпМЃЌгаЪБЛсЯЃЭћздЖЈвхЩњГЩЕФТпМЃЌжЛашвЊдкconversionДњТыЫљдкPackageЯТШЮвтДњТыЮФМўЬэМгОпгаЯрЭЌЧЉУћЕФКЏЪ§ЃЌДњТыЩњГЩЙЄОпОЭЛсКіТдИУКЏЪ§ЃЌГфЗжРћгУДњТыЩњГЩЙЄОпЕФЧАЬсЯТгжВЛЪЇЦфСщЛюадЃЈШчЭМ3.3.1ЃЉЁЃ
змНс
здv1.0ПЊЪМЃЌKubernetes APIаЮГЩвЛЬзЭъећЕФзДЬЌЙмРэНтОіЗНАИЃЌ ЦфИпЖШСщЛюЕФAPI
ServerКЭПЭЛЇЖЫЪЕЯжПЩвдЮЊШЮвтИДдгЯЕЭГЬсЙЉзДЬЌЙмРэжЇГж ЁЃ
ШУШЫблЧАвЛССЕФЪЧЫќЕФМцШнадЩшМЦЃЌЫќЮЊЕкШ§ЗНРЉеЙЬсЙЉСЫЮШЖЈЕФНгПкЃЛЕкШ§ЗНРЉеЙМЏГЩЕНЦНЬЈжаКѓЃЌЮЌЛЄжмЦкПЩвдКЭЦНЬЈБЃГжЯрЖдЖРСЂЁЃМцШнадЩшМЦЖдЮЂЗўЮёФЃПщЕФЩшМЦКЭЪЕЯжвВОпгаМЋЧПЕФжИЕМвтвхЃЌЮЂЗўЮёжавЛИіживЊЕФжИЕМддђжЎвЛОЭЪЧЁАзджЮЁБЃЌФЃПщжЎМфЕФService
ContractВЛЕЋашвЊзіЕНЮШЖЈПЩППЃЌЛЙашвЊзіЕНЯђЯТМцШнЃЌЗёдђОЭЛсГіЯжФЃПщжЎМфЛЅЯргАЯьЃЌОЭгыЁАзджЮЁБетИіЛљБОМйЩшУЌЖмСЫЁЃ
APIОлКЯВуВЛНіЮЊKubernetes APIServerЬсЙЉСЫЮоЯоКсЯђРЉеЙФмСІЃЌЖРСЂЕФAPIServerПЩвдгЕгаЖРСЂЕФДцДЂЃЈВЛвЛЖЈЪЧETCDЃЉЃЌетвтЮЖзХЪ§ОнСПВЛдйЪЧAPIServerЕФЦПОБЃЌвВШУПЭЛЇЖЫВхМўЮоЗьМЏГЩГЩЮЊПЩФмЁЃ
ЛЙгаKubernetesЬсЙЉЕФДњТыЩњГЩЙЄОпСДвВКмжЕЕУНшМјЃЌ етаЉЙЄОпВЛЕЋМЋДѓЕФНЕЕЭСЫРЉеЙПЊЗЂЕФГЩБОЃЌЛЙЮЊздЖЏЩњГЩЕФДњТыЬсЙЉСЫЖЈжЦФмСІЁЃ
ЫћЩНжЎЪЏПЩвдЙЅгёЃЌKubernetesзїЮЊGoogleЕФживЊПЊдДЯюФПжЎвЛЃЌМЏжаЬхЯжСЫGoogleгХауЕФЗжВМЪНЯЕЭГЪЕМљЃЌвВЮЊGoЩчЧјЬсЙЉСЫжюЖрСМКУЕФЕфЗЖЁЃ
|









