| БрМЭЦМі: |
| БОЮФРДздгкВЉПЭдАЃЌНщЩмСЫДгЦѓвЕЩЯдЦЕФШ§ДѓМмЙЙПДШнЦїЦНЬЈЕФШ§жжЪгНЧ
ЃЌ Kubernetes ЪЧЮЂЗўЮёКЭ DevOps ЕФЧХСКЃЌ ЮЂЗўЮёЛЏЕФЪЎИіЩшМЦвЊЕуЃЌ
Kubernetes ИќМгЪЪКЯЮЂЗўЮёКЭ DevOps ЕФЩшМЦЕШжЊЪЖЁЃ |
|
вЛЁЂДгЦѓвЕЩЯдЦЕФШ§ДѓМмЙЙПДШнЦїЦНЬЈЕФШ§жжЪгНЧ
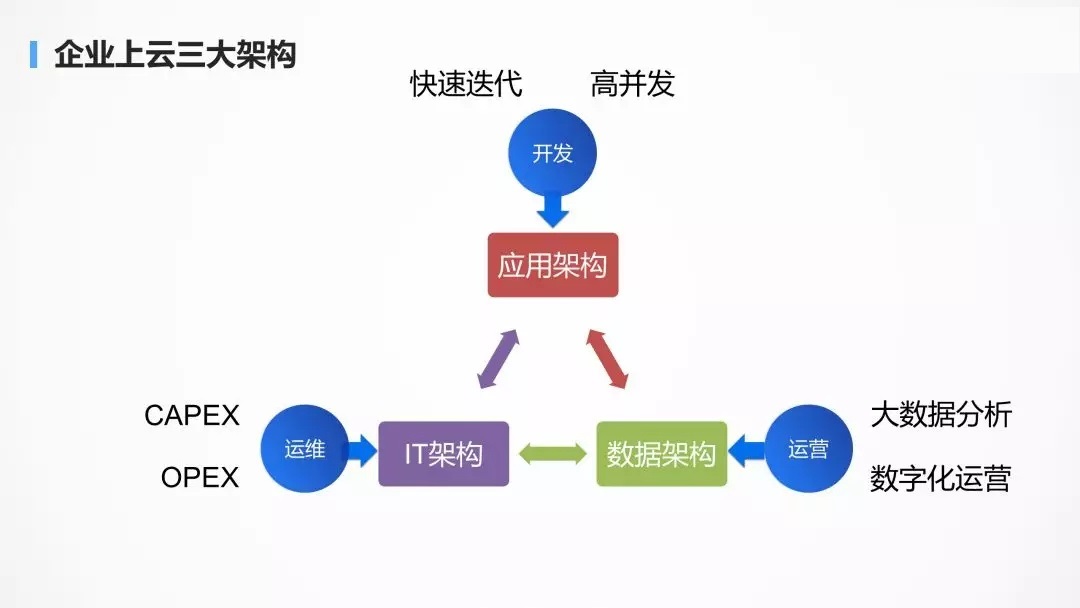
ШчЭМЫљЪОЃЌЦѓвЕЩЯдЦЕФШ§ДѓМмЙЙЮЊ IT МмЙЙЁЂгІгУМмЙЙКЭЪ§ОнМмЙЙЃЌдкВЛЭЌЕФЙЋЫОЃЌВЛЭЌЕФШЫЁЂВЛЭЌЕФНЧЩЋЃЌЙизЂЕФжиЕуВЛЭЌЁЃ
ЖдДѓВПЗжЕФЦѓвЕРДНВЃЌЩЯдЦЕФЫпЧѓЪЧДг IT ВПУХЗЂЦ№ЕФЃЌЗЂЦ№ШЫЭљЭљЪЧдЫЮЌВПУХЃЌЫћУЧЙизЂМЦЫуЁЂЭјТчЁЂДцДЂЃЌЪдЭМЭЈЙ§дЦМЦЫуЗўЮёРДМѕЧс
CAPEX КЭ OPEXЁЃ
гаЕФЙЋЫОга ToC ЕФвЕЮёЃЌвђЖјРлЛ§СЫДѓСПЕФгУЛЇЪ§ОнЃЌЙЋЫОЕФдЫгЊашвЊЭЈЙ§етВПЗжЪ§ОнНјааДѓЪ§ОнЗжЮіКЭЪ§зжЛЏдЫгЊЃЌвђЖјдкетаЉЦѓвЕРяУцЭљЭљЛЙашвЊЙизЂЪ§ОнМмЙЙЁЃ
ДгЪТЛЅСЊЭјгІгУЕФЦѓвЕЃЌЭљЭљЪзЯШЙизЂЕФЪЧгІгУМмЙЙЃЌЪЧЗёФмЙЛТњзужеЖЫПЭЛЇЕФашЧѓЃЌДјИјПЭЛЇСМКУЕФгУЛЇЬхбщЁЃвЕЮёСПЩЯЭљЭљЛсгаЖЬЦкФкГіЯжБЌеЈЪНдіГЄЕФЯжЯѓЃЌвђЖјЙизЂИпВЂЗЂгІгУМмЙЙЃЌВЂЯЃЭћетИіМмЙЙПЩвдПьЫйЕќДњЃЌДгЖјЧРеМЗчПкЁЃ
дкШнЦїГіЯжжЎЧАЃЌетШ§жжМмЙЙЭљЭљЭЈЙ§ащФтЛњдЦЦНЬЈЕФЗНЪННтОіЁЃЕБШнЦїГіЯжжЎКѓЃЌШнЦїЕФИїжжСМКУЕФЬиадШУШЫблЧАвЛССЃЌЫќЕФЧсСПМЖЁЂЗтзАЁЂБъзМЁЂвзЧЈвЦЁЂвзНЛИЖЕФЬиадЃЌЪЙЕУШнЦїММЪѕбИЫйБЛЙуЗКЪЙгУЁЃ
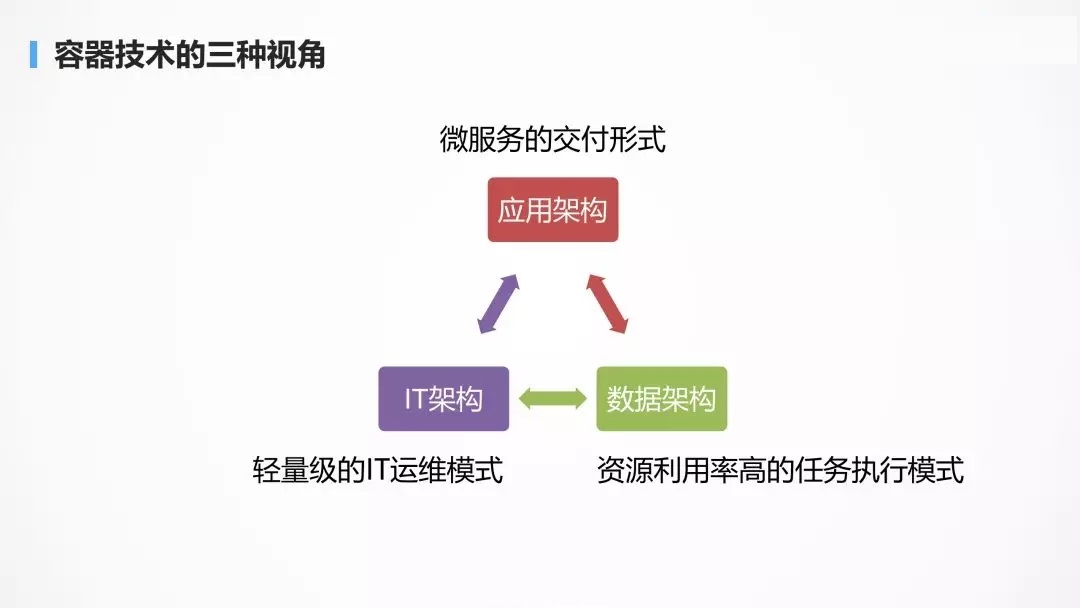
ШЛЖјвЛЧЇИіШЫаФжагавЛЧЇИіЙўФЗРзЬиЃЌгЩгкдРДЙЄзїЕФЙиЯЕЃЌШ§РрНЧЩЋЗжБ№ДгздЩэЕФНЧЖШПДЕНСЫШнЦїЕФгХЪЦИјздМКДјРДЕФБуНнЁЃ
ЖдгкдРДдкЛњЗПРяЙмМЦЫуЁЂЭјТчЁЂДцДЂЕФ IT дЫЮЌЙЄГЬЪІРДНВЃЌШнЦїИќЯёЪЧвЛжжЧсСПМЖЕФдЫЮЌФЃЪНЃЌдкЫћУЧПДРДЃЌШнЦїКЭащФтЛњЕФзюДѓЕФЧјБ№ОЭЪЧЧсСПМЖЃЌЦєЖЏЫйЖШПьЃЌЫћУЧЭљЭљИќдИвтЭЦГіащФтЛњФЃЪНЕФШнЦїЁЃ
ЖдгкЪ§ОнМмЙЙРДНВЃЌЫћУЧУПЬьЖМдкжДааИїжжИїбљЕФЪ§ОнМЦЫуШЮЮёЃЌШнЦїЯрЖдгкдРДЕФ
JVMЃЌЪЧвЛжжИєРыадНЯКУЃЌзЪдДРћгУТЪИпЕФШЮЮёжДааФЃЪНЁЃ
ДггІгУМмЙЙЕФНЧЖШГіЗЂЃЌШнЦїЪЧЮЂЗўЮёЕФНЛИЖаЮЪНЃЌШнЦїВЛНіНіЪЧзіВПЪ№ЕФЃЌЖјЧвЪЧзіНЛИЖЕФЃЌCI/CD
жаЕФ D ЕФЁЃ
ЫљвдетШ§жжЪгНЧЕФШЫЃЌдкЪЙгУШнЦїКЭбЁдёШнЦїЦНЬЈЪБЗНЗЈЛсВЛвЛбљЁЃ
ЖўЁЂKubernetes ВХЪЧЮЂЗўЮёКЭ DevOps ЕФЧХСК
SwarmЃКIT дЫЮЌЙЄГЬЪІ
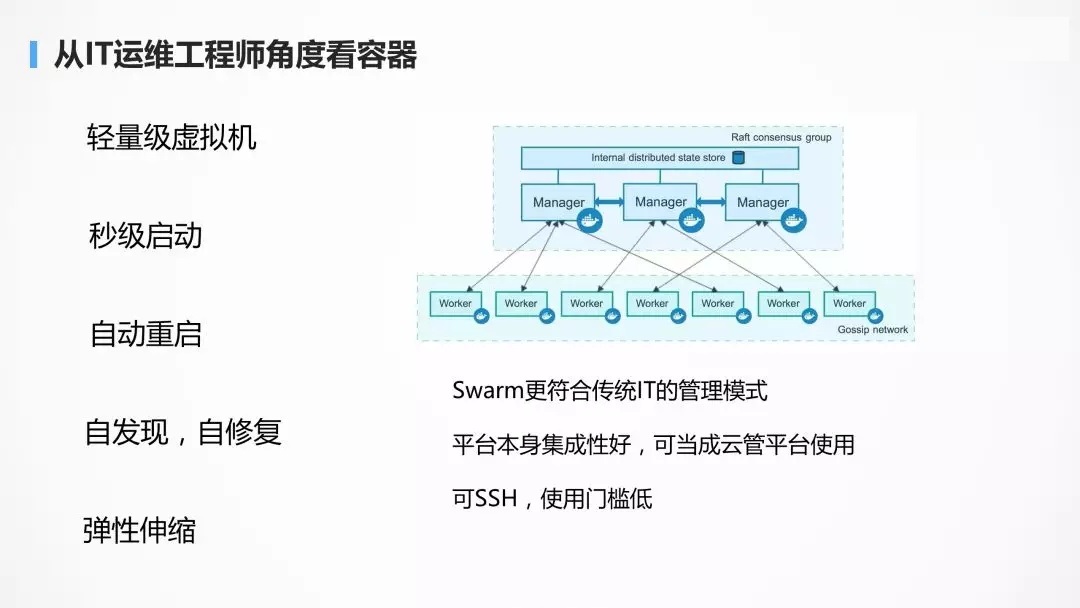
Дг IT дЫЮЌЙЄГЬЪІЕФНЧЖШРДПДЃКШнЦїжївЊЪЧЧсСПМЖЁЂЦєЖЏПьЃЌВЂЧвздЖЏжиЦєЃЌздЖЏЙиСЊЃЌЕЏадЩьЫѕЕФММЪѕЃЌЪЙЕУ
IT дЫЮЌЙЄГЬЪІЫЦКѕВЛгУдйМгАрЁЃ
Swarm ЕФЩшМЦЯдШЛИќМгЗћКЯДЋЭГ IT ЙЄГЬЪІЕФЙмРэФЃЪНЁЃ
ЫћУЧЯЃЭћФмЙЛЧхЮњЕиПДЕНШнЦїдкВЛЭЌЛњЦїЕФЗжВМКЭзДЬЌЃЌПЩвдИљОнашвЊКмЗНБуЕи
SSH ЕНвЛИіШнЦїРяУцШЅВщПДЧщПіЁЃ
ШнЦїзюКУФмЙЛдЕижиЦєЃЌЖјЗЧЫцЛњЕїЖШвЛИіаТЕФШнЦїЃЌетбљдРДдкШнЦїРяУцАВзАЕФвЛЧаЖМЪЧгаЕФЁЃ
ПЩвдКмЗНБуЕиНЋФГИідЫааЕФШнЦїДђвЛИіОЕЯёЃЌЖјЗЧДг Dockerfile
ПЊЪМЃЌетбљвдКѓЦєЖЏОЭПЩвдИДгУдкетИіШнЦїРяУцЪжЖЏзіЕФ 100 ЯюЙЄзїЁЃ
ШнЦїЦНЬЈЕФМЏГЩадвЊКУЃЌгУетИіЦНЬЈБОРДЪЧЮЊСЫМђЛЏдЫЮЌЕФЃЌШчЙћШнЦїЦНЬЈБОЩэОЭКмИДдгЃЌЯё
Kubernetes етжжБОЩэОЭетУДЖрНјГЬЃЌЛЙашвЊПМТЧЫќЕФИпПЩгУКЭдЫЮЌГЩБОЃЌетИіВЛЛЎЫуЃЌвЛЕуЖМУЛгаБШдРДЪЁЪТЃЌЖјЧвГЩБОЛЙЬсИпСЫЁЃ
зюКУБЁБЁЕФвЛВуЃЌЯёвЛИідЦЙмРэЦНЬЈвЛбљЃЌжЛВЛЙ§ИќМгЗНБузіПчдЦЙмРэЃЌБЯОЙШнЦїОЕЯёКмШнвзПчдЦЧЈвЦЁЃ
Swarm ЕФЪЙгУЗНЪНБШНЯШУ IT ЙЄГЬЪІгаЪьЯЄЕФЮЖЕРЃЌЦфЪЕ OpenStack
ЫљзіЕФЪТЧщЫќЖМФмзіЃЌЫйЖШЛЙПьЁЃ

Swarm ЕФЮЪЬт
ШЛЖјШнЦїзїЮЊЧсСПМЖащФтЛњЃЌБЉТЖГіШЅИјПЭЛЇЪЙгУЃЌЮоТлЪЧЭтВППЭЛЇЃЌЛЙЪЧЙЋЫОФкЕФПЊЗЂЃЌЖјЗЧ
IT ШЫдБздМКЪЙгУЕФЪБКђЃЌЫћУЧвдЮЊКЭащФтЛњвЛбљЃЌЕЋЪЧЗЂЯжСЫВЛвЛбљЕФВПЗжЃЌОЭЛсгаКмЖрЕФБЇдЙЁЃ
Р§ШчздаоИДЙІФмЃЌжиЦєжЎКѓЃЌдРД SSH НјШЅЪжЖЏАВзАЕФШэМўВЛМћСЫЃЌЩѕжСЗХдкгВХЬЩЯЕФЮФМўвВВЛМћСЫЃЌЖјЧвгІгУУЛгаЗХдк
Entrypoint РяУцздЖЏЦєЖЏЃЌздаоИДжЎКѓНјГЬУЛгаХмЦ№РДЃЌЛЙашвЊЪжЖЏНјШЅЦєЖЏНјГЬЃЌПЭЛЇЛсБЇдЙФуетИіздаоИДЙІФмгаЩЖгУЃП
Р§ШчгаЕФгУЛЇЛс ps вЛЯТЃЌЗЂЯжгаИіНјГЬЫћВЛШЯЪЖЃЌгкЪЧжБНг kill
ЕєСЫЃЌНсЙћЪЧ Entrypoint ЕФНјГЬЃЌећИіШнЦїжБНгОЭЙвСЫЃЌПЭЛЇБЇдЙФуУЧЕФШнЦїЬЋВЛЮШЖЈЃЌРЯЪЧЙвЁЃ
ШнЦїздЖЏЕїЖШЕФЪБКђЃЌIP ЪЧВЛБЃГжЕФЃЌЫљвдЭљЭљжиЦєКѓдРДЕФ IP ОЭУЛСЫЃЌКмЖргУЛЇЛсЬсашЧѓЃЌетИіФмВЛФмБЃГжАЁЃЌдРДХфжУЮФМўРяУцЖМХфжУЕФетИі
IP ЃЌЙвСЫжиЦєОЭБфСЫЃЌетИідѕУДгУАЁЃЌЛЙВЛШчгУащФтЛњЃЌжСЩйУЛФЧУДШнвзЙвЁЃ
ШнЦїЕФЯЕЭГХЬЃЌвВМДВйзїЯЕЭГЕФФЧИіХЬЭљЭљДѓаЁЪЧЙЬЖЈЕФЃЌЫфШЛЧАЦкПЩвдХфжУЃЌКѓЦкКмФбИФБфЃЌЖјЧвУЛАьЗЈУПИігУЛЇПЩвдбЁдёЯЕЭГХЬЕФДѓаЁЁЃгаЕФгУЛЇЛсБЇдЙЃЌЮвУЧдРДБОРДОЭКмЖрЖЋЮїжБНгЗХдкЯЕЭГХЬЕФЃЌетИіЖМВЛФмЕїећЃЌНаЪВУДдЦМЦЫуЕФЕЏадАЁЁЃ
ШчЙћИјПЭЛЇЫЕШнЦїЙвдиЪ§ОнХЬЃЌШнЦїЖМЦєЖЏЦ№РДСЫЃЌгаЕФПЭЛЇЯыЯёдЦжїЛњвЛбљЃЌдйЙвдивЛИіХЬЃЌШнЦїБШНЯФбзіЕНЃЌвВЛсБЛПЭЛЇТюЁЃ
ШчЙћШнЦїЕФЪЙгУепВЛжЊЕРЫћУЧдкгУШнЦїЃЌЕБащФтЛњРДгУЃЌЫћУЧЛсОѕЕУКмФбгУЃЌетИіЦНЬЈвЛЕуЖМВЛКУЁЃ
Swarm ЩЯЪжЫфШЛЯрЖдБШНЯШнвзЃЌЕЋЪЧЕБГіЯжЮЪЬтЕФЪБКђЃЌзїЮЊдЫЮЌШнЦїЦНЬЈЕФШЫЃЌЛсЗЂЯжЮЪЬтБШНЯФбНтОіЁЃ
Swarm ФкжУЕФЙІФмЬЋЖрЃЌЖМёюКЯдкСЫвЛЦ№ЃЌвЛЕЉГіЯжДэЮѓЃЌВЛШнвз debugЁЃШчЙћЕБЧАЕФЙІФмВЛФмТњзуашЧѓЃЌКмФбЖЈжЦЛЏЁЃКмЖрЙІФмЖМЪЧёюКЯдк
Manager РяУцЕФЃЌЖд Manager ЕФВйзїКЭжиЦєгАЯьУцЬЋДѓЁЃ
MesosЃКЪ§ОндЫЮЌЙЄГЬЪІ
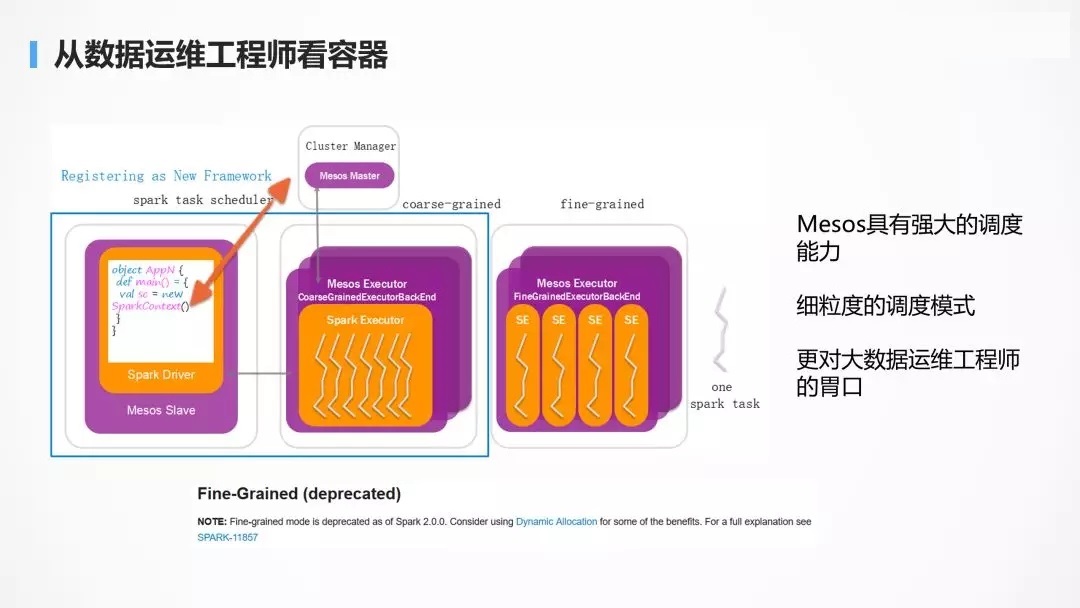
ДгДѓЪ§ОнЦНЬЈдЫЮЌЕФНЧЖШРДНВЃЌШчКЮИќПьЕиЕїЖШДѓЪ§ОнДІРэШЮЮёЃЌдкгаЯоЕФЪБМфКЭПеМфРяУцЃЌИќПьЕиХмИќЖрЕФШЮЮёЃЌЪЧвЛИіЗЧГЃживЊЕФвЊЫиЁЃ
ЫљвдЕБЮвУЧЦРЙРДѓЪ§ОнЦНЬЈХЃВЛХЃЕФЪБКђЃЌЭљЭљвдЕЅЮЛЪБМфФкХмЕФШЮЮёЪ§ФПвдМАФмЙЛДІРэЕФЪ§ОнСПРДКтСПЁЃ
ДгЪ§ОндЫЮЌЕФНЧЖШРДНВЃЌMesos ЪЧвЛИіКмКУЕФЕїЖШЦїЁЃМШШЛФмЙЛХмШЮЮёЃЌвВОЭФмЙЛХмШнЦїЃЌSpark
КЭ Mesos ЬьШЛЕФМЏГЩЃЌгаСЫШнЦїжЎКѓЃЌПЩвдгУИќМгЯИСЃЖШЕФШЮЮёжДааЗНЪНЁЃ
дкУЛгаЯИСЃЖШЕФШЮЮёЕїЖШжЎЧАЃЌШЮЮёЕФжДааЙ§ГЬЪЧетбљЕФЁЃШЮЮёЕФжДааашвЊ
Master ЕФНкЕуРДЙмРэећИіШЮЮёЕФжДааЙ§ГЬЃЌашвЊ Worker НкЕуРДжДаавЛИіИізгШЮЮёЁЃдкећИізмШЮЮёЕФвЛПЊЪМЃЌОЭЗжХфКУ
Master КЭЫљгаЕФ Work ЫљеМгУЕФзЪдДЃЌНЋЛЗОГХфжУКУЃЌЕШдкФЧРяжДаазгШЮЮёЃЌУЛгазгШЮЮёжДааЕФЪБКђЃЌетИіЛЗОГЕФзЪдДЖМЪЧдЄСєдкФЧРяЕФЃЌЯдШЛВЛЪЧУПИі
Work змЪЧШЋВПХмТњЕФЃЌДцдкКмЖрЕФзЪдДРЫЗбЁЃ
дкЯИСЃЖШЕФФЃЪНЯТЃЌдкећИізмШЮЮёПЊЪМЕФЪБКђЃЌжЛЛсЮЊ Master ЗжХфКУзЪдДЃЌВЛИј
Worker ЗжХфШЮКЮЕФзЪдДЃЌЕБашвЊжДаавЛИізгШЮЮёЕФЪБКђЃЌMaster ВХСйЪБЯђ Mesos ЩъЧызЪдДЃЌЛЗОГУЛгазМБИКУдѕУДАьЃПКУдкга
DockerЃЌЦєЖЏвЛИі DockerЃЌЛЗОГОЭЖМгаСЫЃЌдкРяУцХмзгШЮЮёЁЃдкУЛгаШЮЮёЕФЪБКђЃЌЫљгаНкЕуЩЯЕФзЪдДЖМЪЧПЩБЛЦфЫћШЮЮёЪЙгУЕФЃЌДѓДѓЬсЩ§СЫзЪдДРћгУаЇТЪЁЃ
етОЭЪЧ Mesos зюДѓЕФгХЪЦЃЌдк Mesos ЕФТлЮФжаЃЌзюживЊВћЪіЕФОЭЪЧзЪдДРћгУТЪЕФЬсЩ§ЃЌЖј
Mesos ЕФЫЋВуЕїЖШЫуЗЈЪЧКЫаФЁЃ
дРДДѓЪ§ОндЫЮЌЙЄГЬЪІГіЩэЕФЃЌЛсБШНЯШнвзбЁдё Mesos зїЮЊШнЦїЙмРэЦНЬЈЁЃВЛЙ§дРДЪЧХмЖЬШЮЮёЃЌМгЩЯ
marathon ОЭФмХмГЄШЮЮёЁЃЕЋЪЧКѓРД Spark НЋЯИСЃЖШЕФФЃЪН deprecated ЕєСЫЃЌвђЮЊаЇТЪЛЙЪЧБШНЯВюЁЃ
Mesos ЕФЮЪЬт
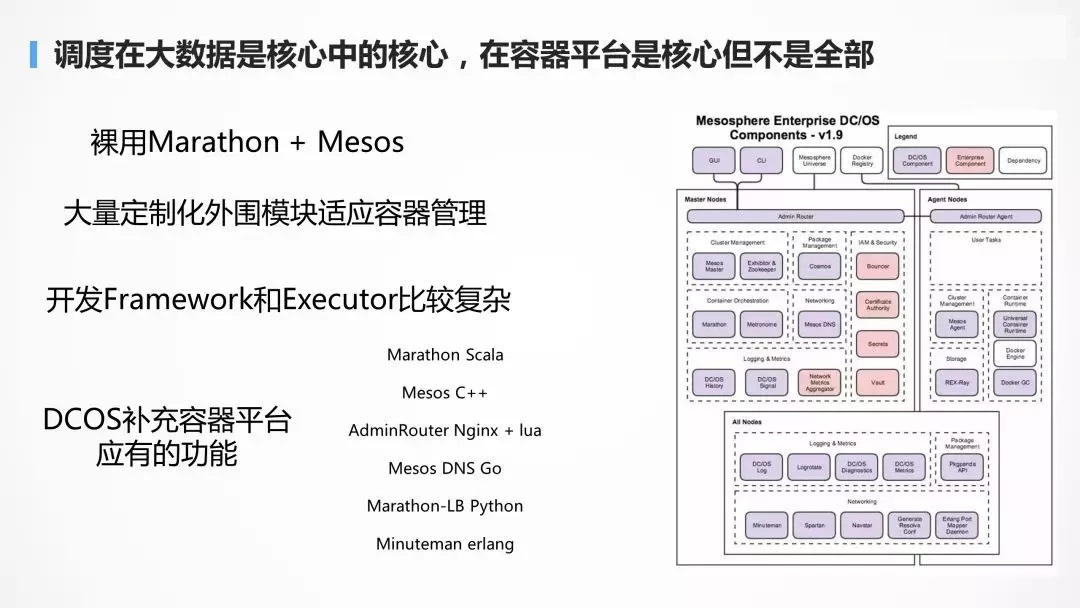
ЕїЖШдкДѓЪ§ОнСьгђЪЧКЫаФжаЕФКЫаФЃЌдкШнЦїЦНЬЈжаЪЧживЊЕФЃЌЕЋВЛЪЧШЋВПЁЃЫљвдШнЦїЛЙашвЊБрХХЃЌашвЊИїжжЭтЮЇзщМўЃЌШУШнЦїХмЦ№РДдЫааГЄШЮЮёЃЌВЂЧвЯрЛЅЗУЮЪЁЃMarathon
жЛЪЧЭђРяГЄеїЕФЕквЛВНЁЃ
ЫљвддчЦкгУ Marathon + Mesos ЕФГЇЩЬЃЌЖрЪЧТугУ Marathon
КЭ Mesos ЕФЃЌгЩгкжмБпВЛШЋЃЌвђЖјвЊзіИїжжЕФЗтзАЃЌИїМвВЛЭЌЁЃДѓМвгааЫШЄПЩвдЕНЩчЧјЩЯШЅПДТугУ Marathon
КЭ Mesos ЕФГЇЩЬЃЌИїгаИїЕФИКдиОљКтЗНАИЃЌИїгаИїЕФЗўЮёЗЂЯжЗНАИЁЃ
ЫљвдКѓРДгаСЫ DCOSЃЌвВОЭЪЧдк Marathon КЭ Mesos
жЎЭтЃЌМгСЫДѓСПЕФжмБпзщМўЃЌВЙГфвЛИіШнЦїЦНЬЈгІгаЕФЙІФмЃЌЕЋЪЧКмПЩЯЇЃЌКмЖрГЇЩЬЖМздМКЖЈжЦЙ§СЫЃЌЛЙЪЧТугУ
Marathon КЭ Mesos ЕФБШНЯЖрЁЃ
ЖјЧв Mesos ЫфШЛЕїЖШХЃЃЌЕЋЪЧжЛНтОівЛВПЗжЕїЖШЃЌСэвЛВПЗжППгУЛЇздМКаД
framework вдМАРяУцЕФЕїЖШЃЌгаЪБКђЛЙашвЊПЊЗЂ ExecutorЃЌетИіПЊЗЂЦ№РДЛЙЪЧКмИДдгЕФЃЌбЇЯАГЩБОвВБШНЯИпЁЃ
ЫфЫЕКѓРДЕФ DCOS ЙІФмвВБШНЯШЋСЫЃЌЕЋЪЧИаОѕУЛгаШч Kubernetes
вЛбљЪЙгУЭГвЛЕФгябдЃЌЖјЪЧВЩШЁДѓдгЛтЕФЗНЪНЁЃдк DCOS ЕФећИіЩњЬЌжаЃЌMarathon ЪЧ Scala
аДЕФЃЌMesos ЪЧ C++ аДЕФЃЌAdmin Router ЪЧ Nginx+luaЃЌMesos-DNS
ЪЧGoЃЌMarathon-lb ЪЧ PythonЃЌMinuteman ЪЧ ErlangЃЌетбљЬЋИДдгСЫАЩЃЌСжСжзмзмЃЌГіЯжСЫ
Bug ЕФЛАЃЌБШНЯФбздМКаоИДЁЃ
Kubernetes
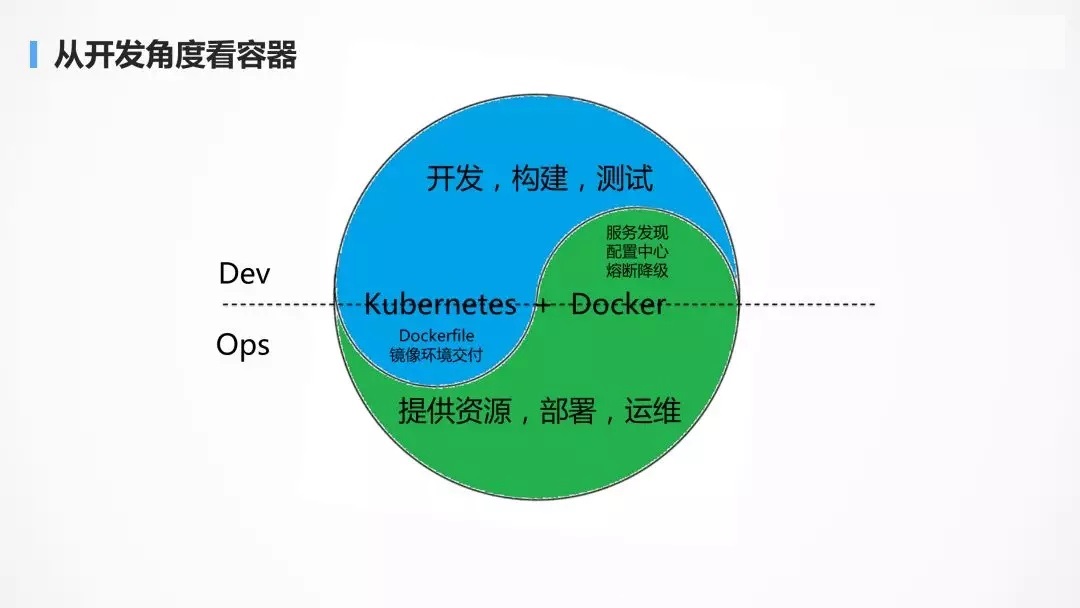
Жј Kubernetes ВЛЭЌЃЌГѕПД Kubernetes ЕФШЫОѕЕУЫћЪЧИіЦцнтЫљдкЃЌШнЦїЛЙУЛДДНЈГіРДЃЌИХФюЯШРДвЛДѓЖбЃЌЮФЕЕЯШЖСвЛДѓАбЃЌБрХХЮФМўвВИДдгЃЌзщМўвВЖрЃЌШУКмЖрШЫЭћЖјШДВНЁЃЮвОЭЯыДДНЈвЛИіШнЦїЃЌдѕУДетУДЖрЕФЧАжУЬѕМўЁЃШчЙћФуНЋ
Kubernetes ЕФИХФюЗХдкНчУцЩЯЃЌШУПЭЛЇШЅДДНЈШнЦїЃЌвЛЖЈЛсБЛПЭЛЇТюЁЃ
дкПЊЗЂШЫдБНЧЖШЃЌЪЙгУ Kubernetes ОјЖдВЛЪЧЯёЪЙгУащФтЛњвЛбљЃЌПЊЗЂГ§СЫаДДњТыЃЌзіЙЙНЈЃЌзіВтЪдЃЌЛЙашвЊжЊЕРздМКЕФгІгУЪЧХмдкШнЦїЩЯЕФЃЌЖјВЛЪЧЕБЫІЪжеЦЙёЁЃПЊЗЂШЫдБашвЊжЊЕРЃЌШнЦїЪЧКЭдРДЕФВПЪ№ЗНЪНВЛвЛбљЕФДцдкЃЌФуашвЊЧјЗжгазДЬЌКЭЮозДЬЌЃЌШнЦїЙвСЫЦ№РДЃЌОЭЛсАДееОЕЯёЛЙдСЫЁЃПЊЗЂШЫдБашвЊаД
DockerfileЃЌашвЊЙиаФЛЗОГЕФНЛИЖЃЌашвЊСЫНтЬЋЖрдРДВЛСЫНтЕФЖЋЮїЁЃЪЕЛАЪЕЫЕЃЌвЛЕуЖМВЛЗНБуЁЃ
дкдЫЮЌШЫдБНЧЖШЃЌЪЙгУ Kubernetes вВОјЖдВЛЪЧЯёдЫЮЌащФтЛњвЛбљЃЌЮвНЛИЖГіРДСЫЛЗОГЃЌгІгУжЎМфЛЅЯрдѕУДЕїгУЃЌЮвВХВЛЙмЃЌЮвОЭЙмЭјТчЭЈВЛЭЈЁЃдкдЫЮЌблжаЫћзіСЫЙ§ЖрВЛИУЙиаФЕФЪТЧщЃЌР§ШчЗўЮёЕФЗЂЯжЃЌХфжУжааФЃЌШлЖЯНЕМЖЃЌетЖМгІИУЪЧДњТыВуУцЙиаФЕФЪТЧщЃЌгІИУЪЧ
SpringCloud КЭ Dubbo ЙиаФЕФЪТЧщЃЌЮЊЪВУДвЊЕНШнЦїЦНЬЈВуРДЙиаФетИіЁЃ
Kubernetes + DockerЃЌШДЪЧ Dev КЭ Ops
ШкКЯЕФвЛИіЧХСКЁЃ
Docker ЪЧЮЂЗўЮёЕФНЛИЖЙЄОпЃЌЮЂЗўЮёжЎКѓЃЌЗўЮёЬЋЖрСЫЃЌЕЅППдЫЮЌИљБОЙмВЛЙ§РДЃЌЖјЧвКмШнвзГіДэЃЌетОЭашвЊбаЗЂПЊЪМЙиаФЛЗОГНЛИЖетМўЪТЧщЁЃР§ШчХфжУИФСЫЪВУДЃЌДДНЈСЫФФаЉФПТМЃЌШчКЮХфжУШЈЯоЃЌжЛгаПЊЗЂзюЧхГўЃЌетаЉаХЯЂКмФбЭЈЙ§ЮФЕЕЕФЗНЪНгжМАЪБгжзМШЗЕиЭЌВНЕНдЫЮЌВПУХРДЃЌОЭЫуЪЧЭЌВНЙ§РДСЫЃЌдЫЮЌВПУХЕФЮЌЛЄСПвВЗЧГЃЕФДѓЁЃ
ЫљвдЃЌгаСЫШнЦїЃЌзюДѓЕФИФБфЪЧЛЗОГНЛИЖЕФЬсЧАЃЌЪЧУПИіПЊЗЂЖрЛЈ 5% ЕФЪБМфЃЌШЅЛЛШЁдЫЮЌ
200% ЕФРЭЖЏЃЌВЂЧвЬсИпЮШЖЈадЁЃ
ЖјСэвЛЗНУцЃЌБОРДдЫЮЌжЛЙмНЛИЖзЪдДЃЌИјФуИіащФтЛњЃЌащФтЛњРяУцЕФгІгУШчКЮЯрЛЅЗУЮЪЮвВЛЙмЃЌФуУЧАЎеІЕиеІЕиЃЌгаСЫ
Kubernetes вдКѓЃЌдЫЮЌВувЊЙизЂЗўЮёЗЂЯжЃЌХфжУжааФЃЌШлЖЯНЕМЖЁЃ
СНепШкКЯдкСЫвЛЦ№ЁЃдкЮЂЗўЮёЛЏЕФбаЗЂЕФНЧЖШРДНВЃЌKubernetes
ЫфШЛИДдгЃЌЕЋЪЧЩшМЦЕФЖМЪЧгаЕРРэЕФЃЌЗћКЯЮЂЗўЮёЕФЫМЯыЁЃ
Ш§ЁЂЮЂЗўЮёЛЏЕФЪЎИіЩшМЦвЊЕу
ЮЂЗўЮёгаФФаЉвЊЕуФиЃПЕквЛеХЭМЪЧ SpringCloud ЕФећИіЩњЬЌЁЃ
ЕкЖўеХЭМЪЧЮЂЗўЮёЕФ 12 вЊЫивдМАдкЭјвздЦЕФЪЕМљЁЃ
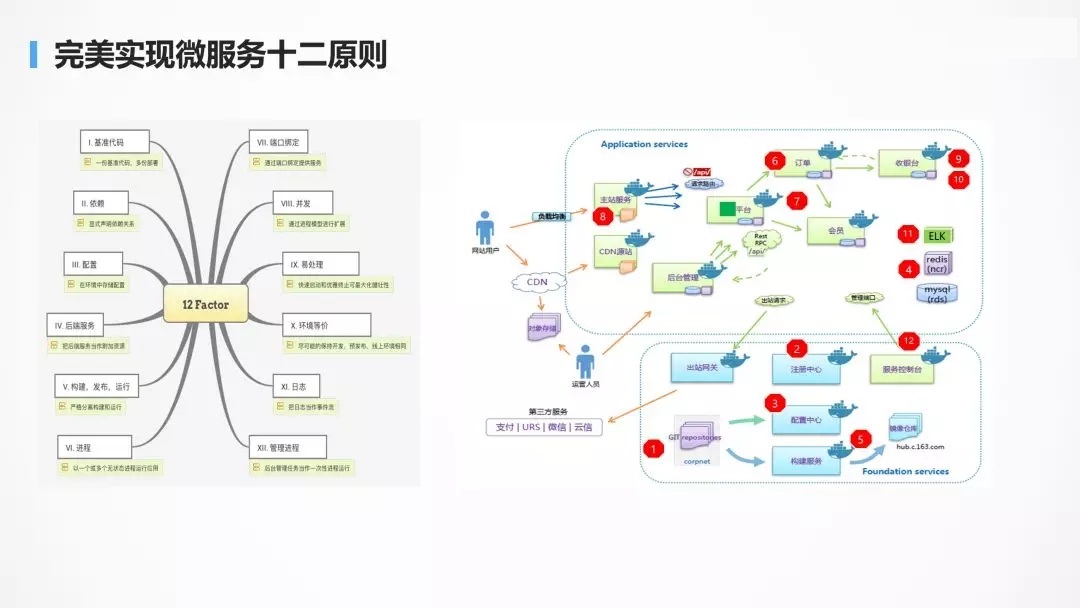
ЕкШ§еХЭМЪЧЙЙНЈвЛИіИпВЂЗЂЕФЮЂЗўЮёЃЌашвЊПМТЧЕФЫљгаЕФЕуЁЃ

НгЯТРДЯИЫЕЮЂЗўЮёЕФЩшМЦвЊЕуЁЃ
ЩшМЦвЊЕувЛЃКAPI ЭјЙиЁЃ
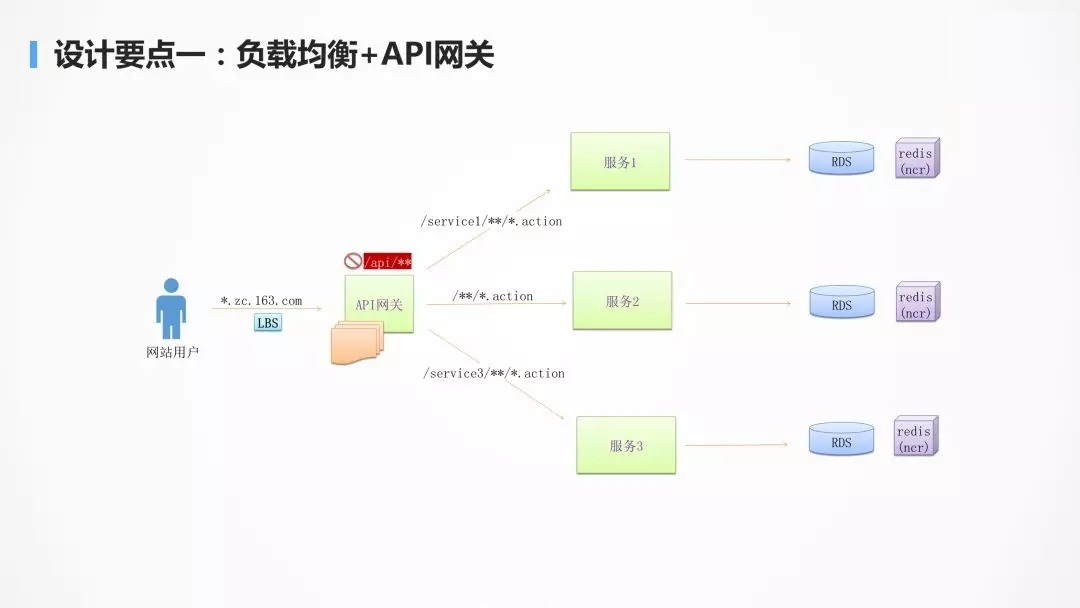
дкЪЕЪЉЮЂЗўЮёЕФЙ§ГЬжаЃЌВЛУтвЊУцСйЗўЮёЕФОлКЯгыВ№ЗжЃЌЕБКѓЖЫЗўЮёЕФВ№ЗжЯрЖдБШНЯЦЕЗБЕФЪБКђЃЌзїЮЊЪжЛњ
App РДНВЃЌЭљЭљашвЊвЛИіЭГвЛЕФШыПкЃЌНЋВЛЭЌЕФЧыЧѓТЗгЩЕНВЛЭЌЕФЗўЮёЃЌЮоТлКѓУцШчКЮВ№ЗжгыОлКЯЃЌЖдгкЪжЛњЖЫРДНВЖМЪЧЭИУїЕФЁЃ
гаСЫ API ЭјЙивдКѓЃЌМђЕЅЕФЪ§ОнОлКЯПЩвддкЭјЙиВуЭъГЩЃЌетбљОЭВЛгУдкЪжЛњ
App ЖЫЭъГЩЃЌДгЖјЪжЛњ App КФЕчСПНЯаЁЃЌгУЛЇЬхбщНЯКУЁЃ
гаСЫЭГвЛЕФ API ЭјЙиЃЌЛЙПЩвдНјааЭГвЛЕФШЯжЄКЭМјШЈЃЌОЁЙмЗўЮёжЎМфЕФЯрЛЅЕїгУБШНЯИДдгЃЌНгПквВЛсБШНЯЖрЃЌAPI
ЭјЙиЭљЭљжЛБЉТЖБиаыЕФЖдЭтНгПкЃЌВЂЧвЖдНгПкНјааЭГвЛЕФШЯжЄКЭМјШЈЃЌЪЙЕУФкВПЕФЗўЮёЯрЛЅЗУЮЪЕФЪБКђЃЌВЛгУдйНјааШЯжЄКЭМјШЈЃЌаЇТЪЛсБШНЯИпЁЃ
гаСЫЭГвЛЕФ API ЭјЙиЃЌПЩвддкетвЛВуЩшЖЈвЛЖЈЕФВпТдЃЌНјаа A/B
ВтЪдЃЌРЖТЬЗЂВМЃЌдЄЗЂЛЗОГЕМСїЕШЕШЁЃAPI ЭјЙиЭљЭљЪЧЮозДЬЌЕФЃЌПЩвдКсЯђРЉеЙЃЌДгЖјВЛЛсГЩЮЊадФмЦПОБЁЃ
ЩшМЦвЊЕуЖўЃКЮозДЬЌЛЏЃЌЧјЗжгазДЬЌЕФКЭЮозДЬЌЕФгІгУЁЃ
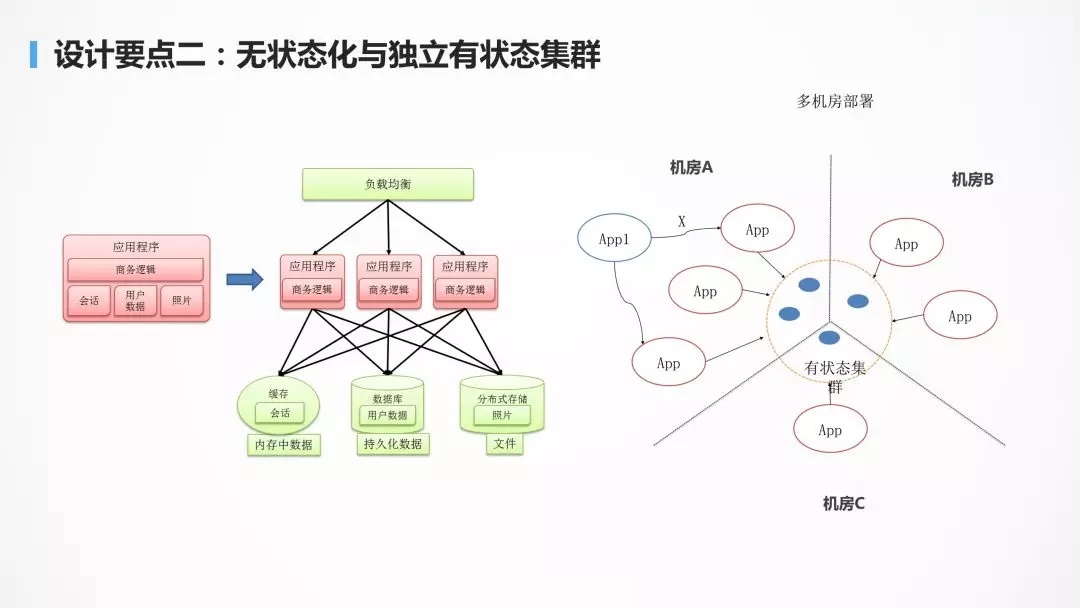
гАЯьгІгУЧЈвЦКЭКсЯђРЉеЙЕФживЊвђЫиОЭЪЧгІгУЕФзДЬЌЃЌЮозДЬЌЗўЮёЃЌЪЧвЊАбетИізДЬЌЭљЭтвЦЃЌНЋ
Session Ъ§ОнЃЌЮФМўЪ§ОнЃЌНсЙЙЛЏЪ§ОнБЃДцдкКѓЖЫЭГвЛЕФДцДЂжаЃЌДгЖјгІгУНіНіАќКЌЩЬЮёТпМЁЃ
зДЬЌЪЧВЛПЩБмУтЕФЃЌР§Шч ZooKeeper, DBЃЌCache ЕШЃЌАбетаЉЫљгагазДЬЌЕФЖЋЮїЪеСВдквЛИіЗЧГЃМЏжаЕФМЏШКРяУцЁЃ
ећИівЕЮёОЭЗжСНВПЗжЃЌвЛИіЪЧЮозДЬЌЕФВПЗжЃЌвЛИіЪЧгазДЬЌЕФВПЗжЁЃ
ЮозДЬЌЕФВПЗжФмЪЕЯжСНЕуЃЌвЛЪЧПчЛњЗПЫцвтЕиВПЪ№ЃЌвВМДЧЈвЦадЃЌвЛЪЧЕЏадЩьЫѕЃЌКмШнвзЕиНјааРЉШнЁЃ
газДЬЌЕФВПЗжЃЌШч DBЃЌCacheЃЌZooKeeper газдМКЕФИпПЩгУЛњжЦЃЌвЊРћгУЕНЫћУЧздМКИпПЩгУЕФЛњжЦРДЪЕЯжетИізДЬЌЕФМЏШКЁЃ
ЫфЫЕЮозДЬЌЛЏЃЌЕЋЪЧЕБЧАДІРэЕФЪ§ОнЃЌЛЙЪЧЛсдкФкДцРяУцЕФЃЌЕБЧАЕФНјГЬЙвЕєЪ§ОнЃЌПЯЖЈвВЪЧгавЛВПЗжЖЊЪЇЕФЃЌЮЊСЫЪЕЯжетвЛЕуЃЌЗўЮёвЊгажиЪдЕФЛњжЦЃЌНгПквЊгаУнЕШЕФЛњжЦЃЌЭЈЙ§ЗўЮёЗЂЯжЛњжЦЃЌжиаТЕїгУвЛДЮКѓЖЫЗўЮёЕФСэвЛИіЪЕР§ОЭПЩвдСЫЁЃ
ЩшМЦвЊЕуШ§ЃКЪ§ОнПтЕФКсЯђРЉеЙЁЃ
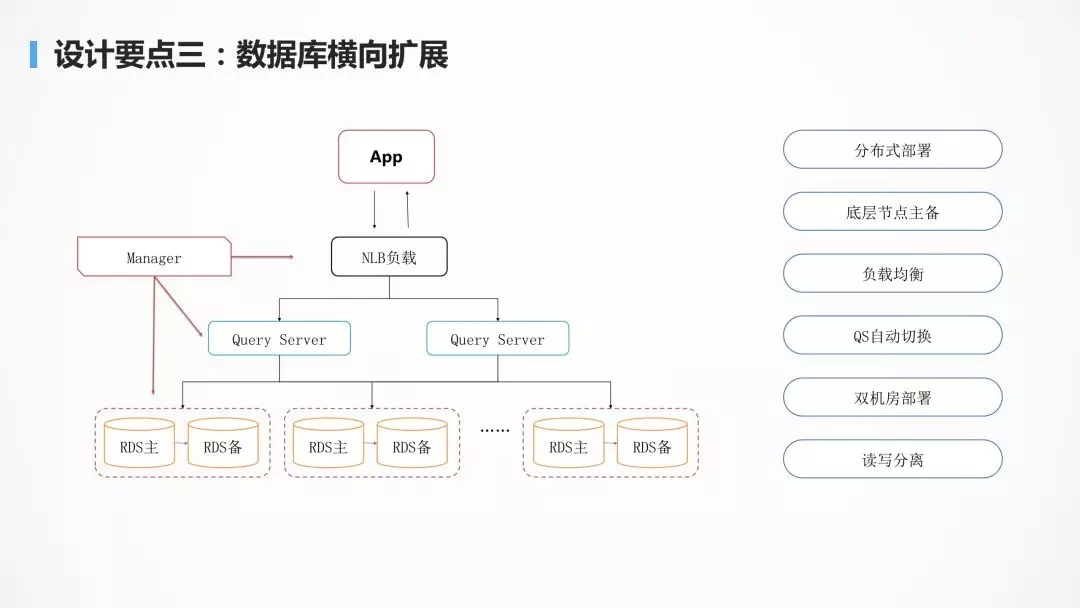
Ъ§ОнПтЪЧБЃДцзДЬЌЃЌЪЧзюживЊЕФвВЪЧзюШнвзГіЯжЦПОБЕФЁЃгаСЫЗжВМЪНЪ§ОнПтПЩвдЪЙЪ§ОнПтЕФадФмПЩвдЫцзХНкЕудіМгЯпадЕидіМгЁЃ
ЗжВМЪНЪ§ОнПтзюзюЯТУцЪЧ RDSЃЌЪЧжїБИЕФЃЌЭЈЙ§ MySql ЕФФкКЫПЊЗЂФмСІЃЌЮвУЧФмЙЛЪЕЯжжїБИЧаЛЛЪ§ОнСуЖЊЪЇЃЌЫљвдЪ§ОнТфдкетИі
RDS РяУцЃЌЪЧЗЧГЃЗХаФЕФЃЌФФХТЪЧЙвСЫвЛИіНкЕуЃЌЧаЛЛЭъСЫвдКѓЃЌФуЕФЪ§ОнвВЪЧВЛЛсЖЊЕФЁЃ
дйЭљЩЯОЭЪЧКсЯђдѕУДГадиДѓЕФЭЬЭТСПЕФЮЪЬтЃЌЩЯУцгавЛИіИКдиОљКт NLBЃЌгУ
LVSЃЌHAProxy, KeepalivedЃЌЯТУцНгСЫвЛВу Query ServerЁЃQuery
Server ЪЧПЩвдИљОнМрПиЪ§ОнНјааКсЯђРЉеЙЕФЃЌШчЙћГіЯжСЫЙЪеЯЃЌПЩвдЫцЪБНјааЬцЛЛЕФаоИДЃЌЖдгквЕЮёВуЪЧУЛгаШЮКЮИажЊЕФЁЃ
СэЭтвЛИіОЭЪЧЫЋЛњЗПЕФВПЪ№ЃЌDDB ПЊЗЂСЫвЛИіЪ§ОндЫКг NDC ЕФзщМўЃЌПЩвдЪЙЕУВЛЭЌЕФ
DDB жЎМфдкВЛЭЌЕФЛњЗПРяУцНјааЭЌВНЃЌетЪБКђВЛЕЋдквЛИіЪ§ОнжааФРяУцЪЧЗжВМЪНЕФЃЌдкЖрИіЪ§ОнжааФРяУцвВЛсгавЛИіРрЫЦЫЋЛюЕФвЛИіБИЗнЃЌИпПЩгУадгаЗЧГЃКУЕФБЃжЄЁЃ
ЩшМЦвЊЕуЫФЃКЛКДц
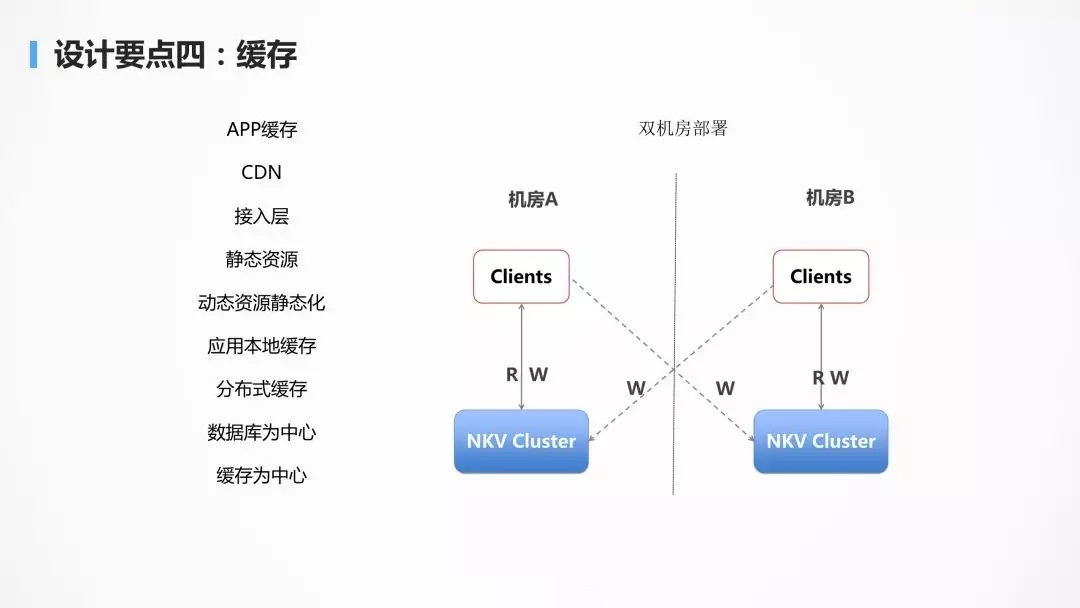
дкИпВЂЗЂГЁОАЯТЛКДцЪЧЗЧГЃживЊЕФЁЃвЊгаВуДЮЕФЛКДцЃЌЪЙЕУЪ§ОнОЁСПППНќгУЛЇЁЃЪ§ОндНППНќгУЛЇФмГадиЕФВЂЗЂСПвВдНДѓЃЌЯьгІЪБМфдНЖЬЁЃ
дкЪжЛњПЭЛЇЖЫ App ЩЯОЭгІИУгавЛВуЛКДцЃЌВЛЪЧЫљгаЕФЪ§ОнЖМУПЪБУППЬДгКѓЖЫФУЃЌЖјЪЧжЛФУживЊЕФЃЌЙиМќЕФЃЌЪБГЃБфЛЏЕФЪ§ОнЁЃ
гШЦфЖдгкОВЬЌЪ§ОнЃЌПЩвдЙ§вЛЖЮЪБМфШЅШЁвЛДЮЃЌЖјЧввВУЛБивЊЕНЪ§ОнжааФШЅШЁЃЌПЩвдЭЈЙ§
CDNЃЌНЋЪ§ОнЛКДцдкОрРыПЭЛЇЖЫзюНќЕФНкЕуЩЯЃЌНјааОЭНќЯТдиЁЃ
гаЪБКђ CDN РяУцУЛгаЃЌЛЙЪЧвЊЛиЕНЪ§ОнжааФШЅЯТдиЃЌГЦЮЊЛидДЃЌдкЪ§ОнжааФЕФзюЭтВуЃЌЮвУЧГЦЮЊНгШыВуЃЌПЩвдЩшжУвЛВуЛКДцЃЌНЋДѓВПЗжЕФЧыЧѓРЙНиЃЌДгЖјВЛЛсЖдКѓЬЈЕФЪ§ОнПтдьГЩбЙСІЁЃ
ШчЙћЪЧЖЏЬЌЪ§ОнЃЌЛЙЪЧашвЊЗУЮЪгІгУЃЌЭЈЙ§гІгУжаЕФЩЬЮёТпМЩњГЩЃЌЛђепШЅЪ§ОнПтЖСШЁЃЌЮЊСЫМѕЧсЪ§ОнПтЕФбЙСІЃЌгІгУПЩвдЪЙгУБОЕиЕФЛКДцЃЌвВПЩвдЪЙгУЗжВМЪНЛКДцЃЌШч
Memcached Лђеп RedisЃЌЪЙЕУДѓВПЗжЧыЧѓЖСШЁЛКДцМДПЩЃЌВЛБиЗУЮЪЪ§ОнПтЁЃ
ЕБШЛЖЏЬЌЪ§ОнЛЙПЩвдзівЛЖЈЕФОВЬЌЛЏЃЌвВМДНЕМЖГЩОВЬЌЪ§ОнЃЌДгЖјМѕЩйКѓЖЫЕФбЙСІЁЃ
ЩшМЦвЊЕуЮхЃКЗўЮёВ№ЗжКЭЗўЮёЗЂЯж
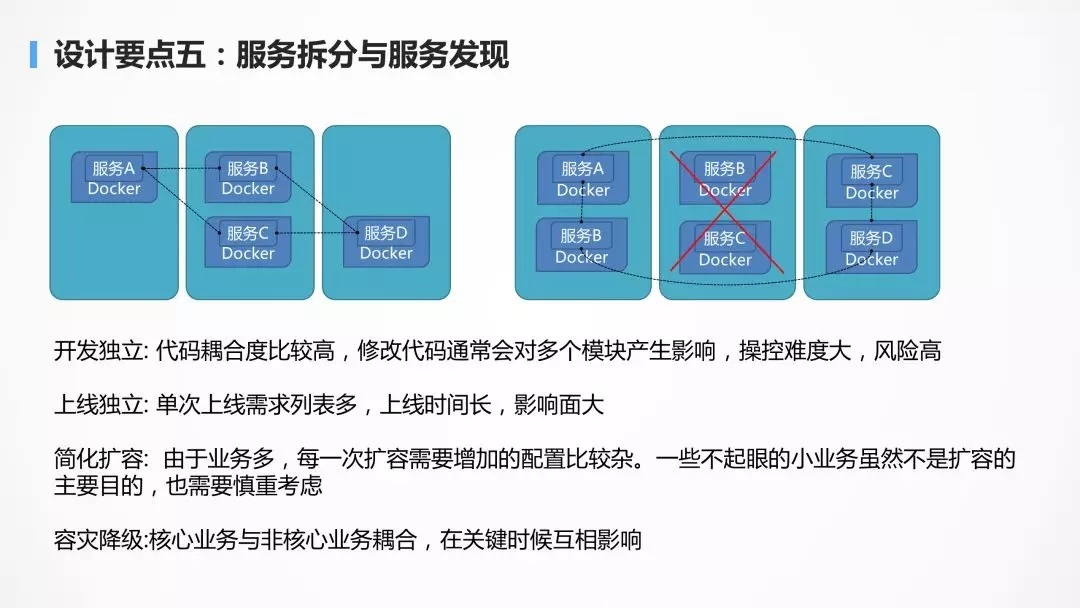
ЕБЯЕЭГПИВЛзЁЃЌгІгУБфЛЏПьЕФЪБКђЃЌЭљЭљвЊПМТЧНЋБШНЯДѓЕФЗўЮёВ№ЗжЮЊвЛЯЕСааЁЕФЗўЮёЁЃ
етбљЕквЛИіКУДІОЭЪЧПЊЗЂБШНЯЖРСЂЃЌЕБЗЧГЃЖрЕФШЫдкЮЌЛЄЭЌвЛИіДњТыВжПтЕФЪБКђЃЌЭљЭљЖдДњТыЕФаоИФОЭЛсЯрЛЅгАЯьЃЌГЃГЃЛсГіЯжЮвУЛИФЪВУДВтЪдОЭВЛЭЈЙ§СЫЃЌЖјЧвДњТыЬсНЛЕФЪБКђЃЌОГЃЛсГіЯжГхЭЛЃЌашвЊНјааДњТыКЯВЂЃЌДѓДѓНЕЕЭСЫПЊЗЂЕФаЇТЪЁЃ
СэвЛИіКУДІОЭЪЧЩЯЯпЖРСЂЃЌЮяСїФЃПщЖдНгСЫвЛМваТЕФПьЕнЙЋЫОЃЌашвЊСЌЭЌЯТЕЅвЛЦ№ЩЯЯпЃЌетЪЧЗЧГЃВЛКЯРэЕФааЮЊЃЌЮвУЛИФЛЙвЊЮвжиЦєЃЌЮвУЛИФЛЙШУЮвЗЂВМЃЌЮвУЛИФЛЙвЊЮвПЊЛсЃЌЖМЪЧгІИУВ№ЗжЕФЪБЛњЁЃ
СэЭтдйОЭЪЧИпВЂЗЂЪБЖЮЕФРЉШнЃЌЭљЭљжЛгазюЙиМќЕФЯТЕЅКЭжЇИЖСїГЬЪЧКЫаФЃЌжЛвЊНЋЙиМќЕФНЛвзСДТЗНјааРЉШнМДПЩЃЌШчЙћетЪБКђИНДјКмЖрЦфЫћЕФЗўЮёЃЌРЉШнМДЪЧВЛОМУЕФЃЌвВЪЧКмгаЗчЯеЕФЁЃ
дйОЭЪЧШнджКЭНЕМЖЃЌдкДѓДйЕФЪБКђЃЌПЩФмашвЊЮўЩќвЛВПЗжЕФБпНЧЙІФмЃЌЕЋЪЧШчЙћЫљгаЕФДњТыёюКЯдквЛЦ№ЃЌКмФбНЋБпНЧЕФВПЗжЙІФмНјааНЕМЖЁЃ
ЕБШЛВ№ЗжЭъБЯвдКѓЃЌгІгУжЎМфЕФЙиЯЕОЭИќМгИДдгСЫЃЌвђЖјашвЊЗўЮёЗЂЯжЕФЛњжЦЃЌРДЙмРэгІгУЯрЛЅЕФЙиЯЕЃЌЪЕЯжздЖЏЕФаоИДЃЌздЖЏЕФЙиСЊЃЌздЖЏЕФИКдиОљКтЃЌздЖЏЕФШнДэЧаЛЛЁЃ
ЩшМЦвЊЕуСљЃКЗўЮёБрХХгыЕЏадЩьЫѕ

ЕБЗўЮёВ№ЗжСЫЃЌНјГЬОЭЛсЗЧГЃЕФЖрЃЌвђЖјашвЊЗўЮёБрХХРДЙмРэЗўЮёжЎМфЕФвРРЕЙиЯЕЃЌвдМАНЋЗўЮёЕФВПЪ№ДњТыЛЏЃЌвВОЭЪЧЮвУЧГЃЫЕЕФЛљДЁЩшЪЉМДДњТыЁЃетбљЖдгкЗўЮёЕФЗЂВМЃЌИќаТЃЌЛиЙіЃЌРЉШнЃЌЫѕШнЃЌЖМПЩвдЭЈЙ§аоИФБрХХЮФМўРДЪЕЯжЃЌДгЖјдіМгСЫПЩзЗЫнадЃЌвзЙмРэадЃЌКЭздЖЏЛЏЕФФмСІЁЃ
МШШЛБрХХЮФМўвВПЩвдгУДњТыВжПтНјааЙмРэЃЌОЭПЩвдЪЕЯжвЛАйИіЗўЮёжаЃЌИќаТЦфжаЮхИіЗўЮёЃЌжЛвЊаоИФБрХХЮФМўжаЕФЮхИіЗўЮёЕФХфжУОЭПЩвдЃЌЕББрХХЮФМўЬсНЛЕФЪБКђЃЌДњТыВжПтздЖЏДЅЗЂздЖЏВПЪ№Щ§МЖНХБОЃЌДгЖјИќаТЯпЩЯЕФЛЗОГЃЌЕБЗЂЯжаТЕФЛЗОГгаЮЪЬтЪБЃЌЕБШЛЯЃЭћНЋетЮхИіЗўЮёдзгадЕиЛиЙіЃЌШчЙћУЛгаБрХХЮФМўЃЌашвЊШЫЙЄМЧТМетДЮЩ§МЖСЫФФЮхИіЗўЮёЁЃгаСЫБрХХЮФМўЃЌжЛвЊдкДњТыВжПтРяУц
revertЃЌОЭЛиЙіЕНЩЯвЛИіАцБОСЫЁЃЫљгаЕФВйзїдкДњТыВжПтРяЖМЪЧПЩвдПДЕНЕФЁЃ
ЩшМЦвЊЕуЦпЃКЭГвЛХфжУжааФ
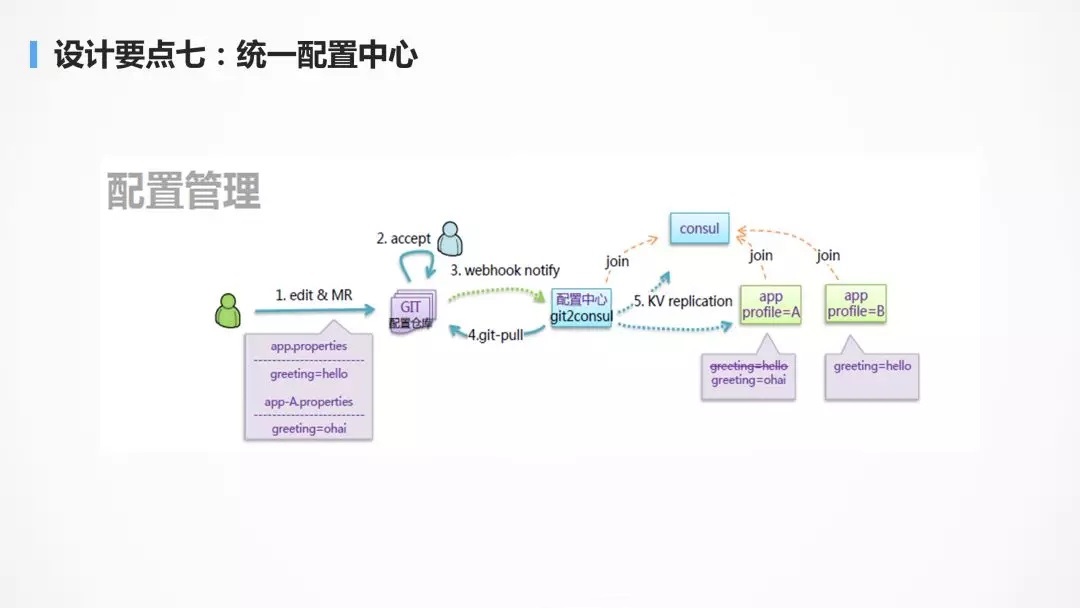
ЗўЮёВ№ЗжвдКѓЃЌЗўЮёЕФЪ§СПЗЧГЃЖрЃЌШчЙћЫљгаЕФХфжУЖМвдХфжУЮФМўЕФЗНЪНЗХдкгІгУБОЕиЕФЛАЃЌЗЧГЃФбвдЙмРэЃЌПЩвдЯыЯѓЕБгаМИАйЩЯЧЇИіНјГЬжагавЛИіХфжУГіЯжСЫЮЪЬтЃЌЪЧКмФбНЋЫќевГіРДЕФЃЌвђЖјашвЊгаЭГвЛЕФХфжУжааФЃЌРДЙмРэЫљгаЕФХфжУЃЌНјааЭГвЛЕФХфжУЯТЗЂЁЃ
дкЮЂЗўЮёжаЃЌХфжУЭљЭљЗжЮЊМИРрЃЌвЛРрЪЧМИКѕВЛБфЕФХфжУЃЌетжжХфжУПЩвджБНгДђдкШнЦїОЕЯёРяУцЃЌЕкЖўРрЪЧЦєЖЏЪБОЭЛсШЗЖЈЕФХфжУЃЌетжжХфжУЭљЭљЭЈЙ§ЛЗОГБфСПЃЌдкШнЦїЦєЖЏЕФЪБКђДЋНјШЅЃЌЕкШ§РрОЭЪЧЭГвЛЕФХфжУЃЌашвЊЭЈЙ§ХфжУжааФНјааЯТЗЂЃЌР§ШчдкДѓДйЕФЧщПіЯТЃЌгааЉЙІФмашвЊНЕМЖЃЌФФаЉЙІФмПЩвдНЕМЖЃЌФФаЉЙІФмВЛФмНЕМЖЃЌЖМПЩвддкХфжУЮФМўжаЭГвЛХфжУЁЃ
ЩшМЦвЊЕуАЫЃКЭГвЛЕФШежОжааФ
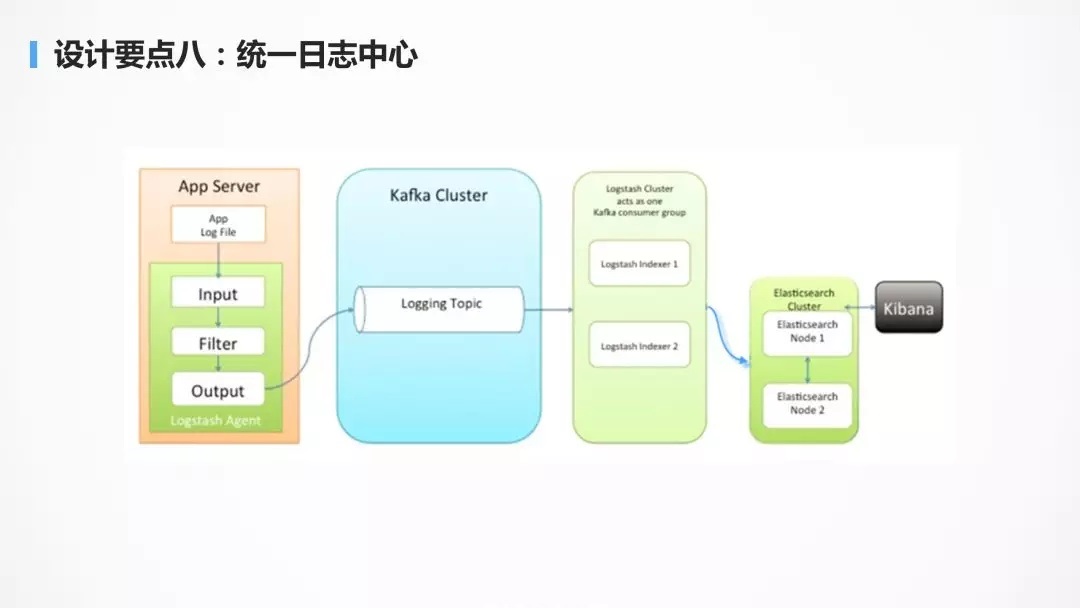
ЭЌбљЪЧНјГЬЪ§ФПЗЧГЃЖрЕФЪБКђЃЌКмФбЖдГЩЧЇЩЯАйИіШнЦїЃЌвЛИівЛИіЕЧТМНјШЅВщПДШежОЃЌЫљвдашвЊЭГвЛЕФШежОжааФРДЪеМЏШежОЃЌЮЊСЫЪЙЪеМЏЕНЕФШежОШнвзЗжЮіЃЌЖдгкШежОЕФЙцЗЖЃЌашвЊгавЛЖЈЕФвЊЧѓЃЌЕБЫљгаЕФЗўЮёЖМзёЪиЭГвЛЕФШежОЙцЗЖЕФЪБКђЃЌдкШежОжааФОЭПЩвдЖдвЛИіНЛвзСїГЬНјааЭГвЛЕФзЗЫнЁЃР§ШчдкзюКѓЕФШежОЫбЫїв§ЧцжаЃЌЫбЫїНЛвзКХЃЌОЭФмЙЛПДЕНдкФФИіЙ§ГЬГіЯжСЫДэЮѓЛђепвьГЃЁЃ
ЩшМЦвЊЕуОХЃКШлЖЯЃЌЯоСїЃЌНЕМЖ
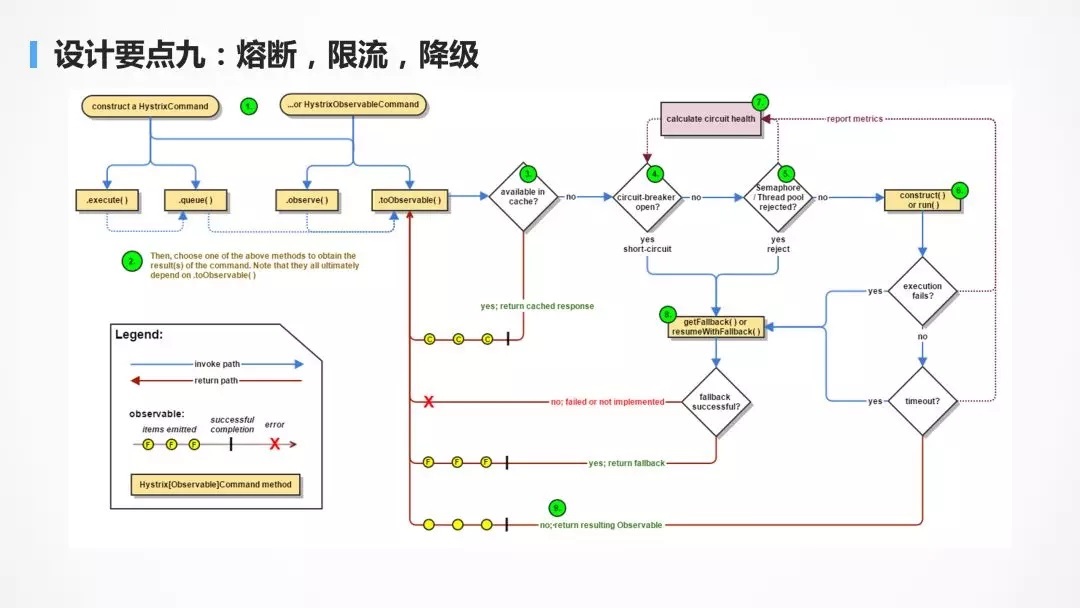
ЗўЮёвЊгаШлЖЯЃЌЯоСїЃЌНЕМЖЕФФмСІЃЌЕБвЛИіЗўЮёЕїгУСэвЛИіЗўЮёЃЌГіЯжГЌЪБЕФЪБКђЃЌгІМАЪБЗЕЛиЃЌЖјЗЧзшШћдкФЧИіЕиЗНЃЌДгЖјгАЯьЦфЫћгУЛЇЕФНЛвзЃЌПЩвдЗЕЛиФЌШЯЕФЭаЕзЪ§ОнЁЃ
ЕБвЛИіЗўЮёЗЂЯжБЛЕїгУЕФЗўЮёЃЌвђЮЊЙ§гкЗБУІЃЌЯпГЬГиТњЃЌСЌНгГиТњЃЌЛђепзмЪЧГіДэЃЌдђгІИУМАЪБШлЖЯЃЌЗРжЙвђЮЊЯТвЛИіЗўЮёЕФДэЮѓЛђЗБУІЃЌЕМжТБОЗўЮёЕФВЛе§ГЃЃЌДгЖјж№НЅЭљЧАДЋЕМЃЌЕМжТећИігІгУЕФбЉБРЁЃ
ЕБЗЂЯжећИіЯЕЭГЕФШЗИКдиЙ§ИпЕФЪБКђЃЌПЩвдбЁдёНЕМЖФГаЉЙІФмЛђФГаЉЕїгУЃЌБЃжЄзюживЊЕФНЛвзСїГЬЕФЭЈЙ§ЃЌвдМАзюживЊЕФзЪдДШЋВПгУгкБЃжЄзюКЫаФЕФСїГЬЁЃ
ЛЙгавЛжжЪжЖЮОЭЪЧЯоСїЃЌЕБМШЩшжУСЫШлЖЯВпТдЃЌгжЩшжУСЫНЕМЖВпТдЃЌЭЈЙ§ШЋСДТЗЕФбЙСІВтЪдЃЌгІИУФмЙЛжЊЕРећИіЯЕЭГЕФжЇГХФмСІЃЌвђЖјОЭашвЊжЦЖЈЯоСїВпТдЃЌБЃжЄЯЕЭГдкВтЪдЙ§ЕФжЇГХФмСІЗЖЮЇФкНјааЗўЮёЃЌГЌГіжЇГХФмСІЗЖЮЇЕФЃЌПЩОмОјЗўЮёЁЃЕБФуЯТЕЅЕФЪБКђЃЌЯЕЭГЕЏГіЖдЛАПђЫЕ
ЁАЯЕЭГУІЃЌЧыжиЪдЁБЃЌВЂВЛДњБэЯЕЭГЙвСЫЃЌЖјЪЧЫЕУїЯЕЭГЪЧе§ГЃЙЄзїЕФЃЌжЛВЛЙ§ЯоСїВпТдЦ№ЕНСЫзїгУЁЃ
ЩшМЦвЊЕуЪЎЃКШЋЗНЮЛЕФМрПи

ЕБЯЕЭГЗЧГЃИДдгЕФЪБКђЃЌвЊгаЭГвЛЕФМрПиЃЌжївЊгаСНИіЗНУцЃЌвЛИіЪЧЪЧЗёНЁПЕЃЌвЛИіЪЧадФмЦПОБдкФФРяЁЃЕБЯЕЭГГіЯжвьГЃЕФЪБКђЃЌМрПиЯЕЭГПЩвдХфКЯИцОЏЯЕЭГЃЌМАЪБЕиЗЂЯжЃЌЭЈжЊЃЌИЩдЄЃЌДгЖјБЃеЯЯЕЭГЕФЫГРћдЫааЁЃ
ЕБбЙСІВтЪдЕФЪБКђЃЌЭљЭљЛсдтгіЦПОБЃЌвВашвЊгаШЋЗНЮЛЕФМрПиРДевГіЦПОБЕуЃЌЭЌЪБФмЙЛБЃСєЯжГЁЃЌДгЖјПЩвдзЗЫнКЭЗжЮіЃЌНјааШЋЗНЮЛЕФгХЛЏЁЃ
ЫФЁЂKubernetes БОЩэОЭЪЧЮЂЗўЮёМмЙЙ
ЛљгкЩЯУцетЪЎИіЩшМЦвЊЕуЃЌЮвУЧдйЛиРДПД KubernetesЃЌЛсЗЂЯждНПДдНЫГблЁЃ
ЪзЯШ Kubernetes БОЩэОЭЪЧЮЂЗўЮёЕФМмЙЙЃЌЫфШЛПДЦ№РДИДдгЃЌЕЋЪЧШнвзЖЈжЦЛЏЃЌШнвзКсЯђРЉеЙЁЃ
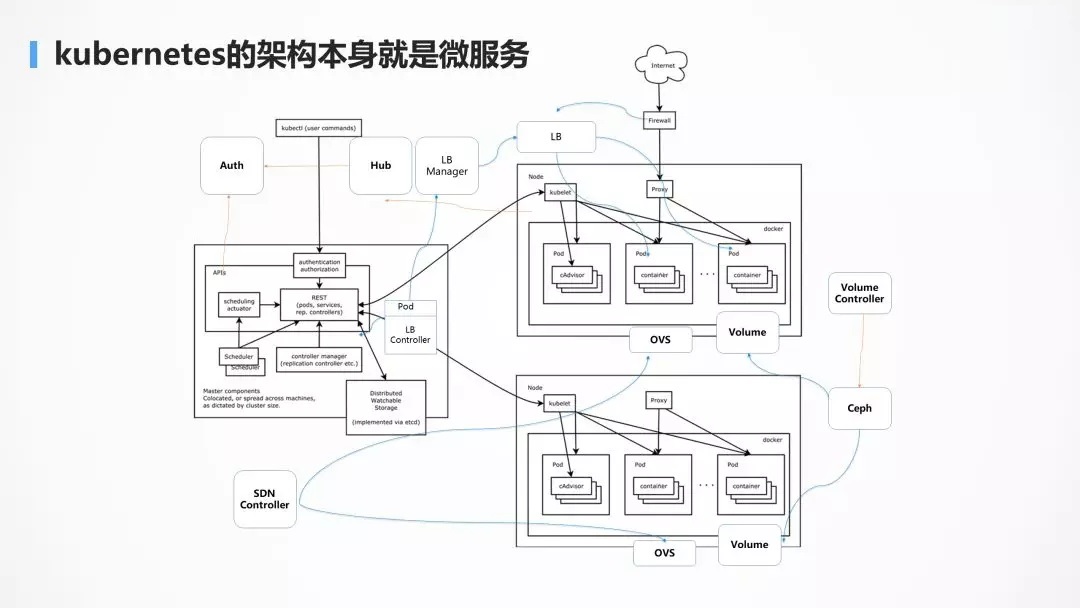
ШчЭМКкЩЋЕФВПЗжЪЧ Kubernetes дЩњЕФВПЗжЃЌЖјРЖЩЋЕФВПЗжЪЧЭјвздЦЮЊСЫжЇГХДѓЙцФЃИпВЂЗЂгІгУЖјзіЕФЖЈжЦЛЏВПЗжЁЃ
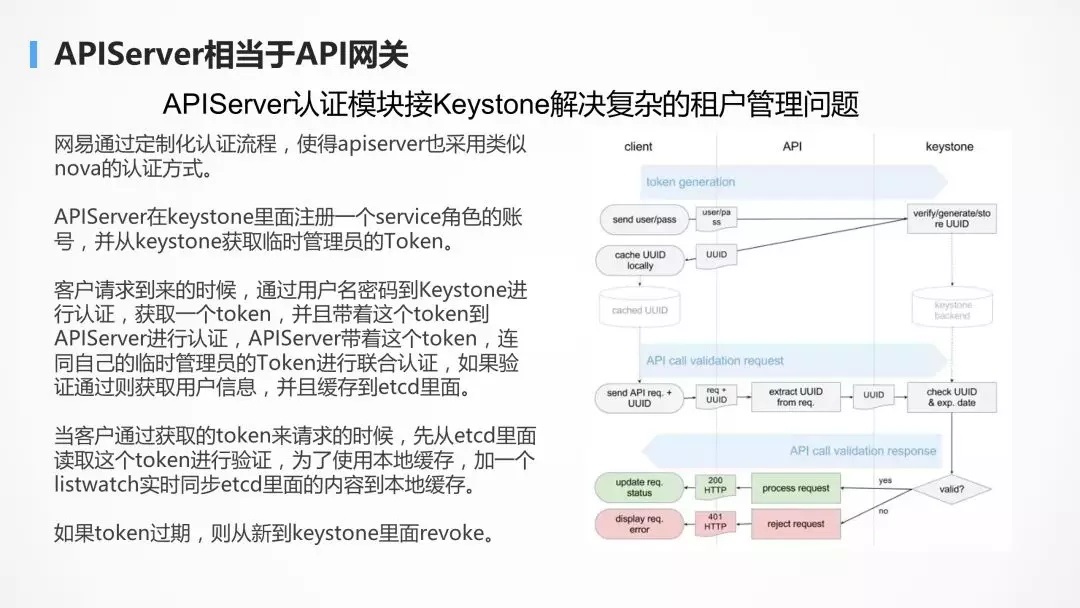
Kubernetes ЕФ API Server ИќЯёЭјЙиЃЌЬсЙЉЭГвЛЕФМјШЈКЭЗУЮЪНгПкЁЃ
жкЫљжмжЊЃЌKubernetes ЕФзтЛЇЙмРэЯрЖдБШНЯШѕЃЌгШЦфЪЧЖдгкЙЋгадЦГЁОАЃЌИДдгЕФзтЛЇЙиЯЕЕФЙмРэЃЌЮвУЧжЛвЊЖЈжЦЛЏ
API ServerЃЌЖдНг KeystoneЃЌОЭПЩвдЙмРэИДдгЕФзтЛЇЙиЯЕЃЌЖјВЛгУЙмЦфЫћЕФзщМўЁЃ
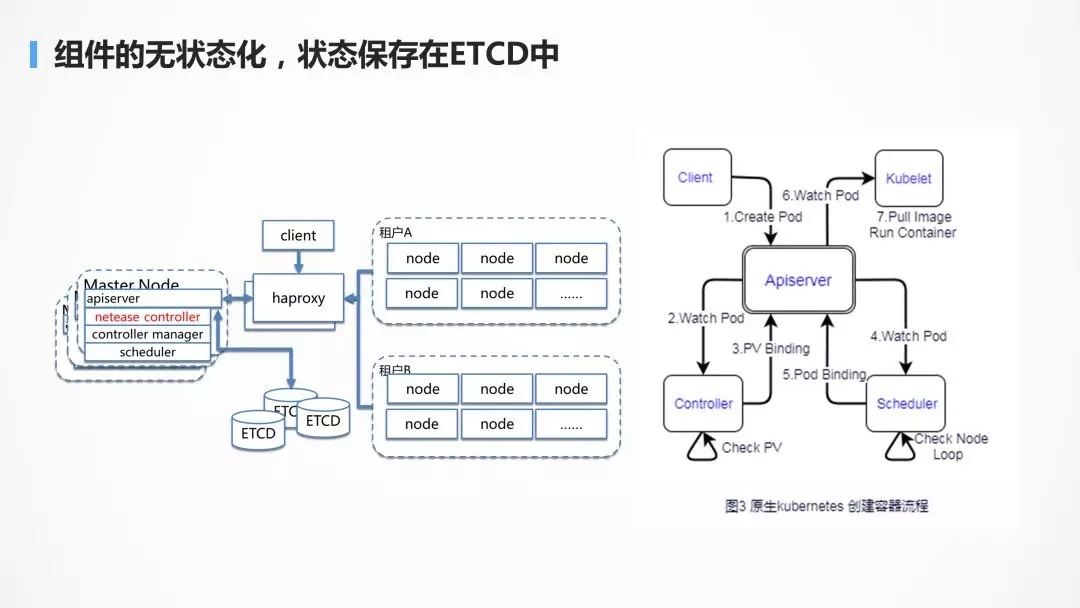
дк Kubernetes жаМИКѕЫљгаЕФзщМўЖМЪЧЮозДЬЌЛЏЕФЃЌзДЬЌЖМБЃДцдкЭГвЛЕФ
etcd РяУцЃЌетЪЙЕУРЉеЙадЗЧГЃКУЃЌзщМўжЎМфвьВНЭъГЩздМКЕФШЮЮёЃЌНЋНсЙћЗХдк etcd РяУцЃЌЛЅЯрВЛёюКЯЁЃ
Р§ШчЭМжа pod ЕФДДНЈЙ§ГЬЃЌПЭЛЇЖЫЕФДДНЈНіНіЪЧдк etcd жаЩњГЩвЛИіМЧТМЃЌЖјЦфЫћЕФзщМўМрЬ§ЕНетИіЪТМўКѓЃЌвВЯргІвьВНЕФзіздМКЕФЪТЧщЃЌВЂНЋДІРэЕФНсЙћЭЌбљЗХдк
etcd жаЃЌЭЌбљВЂВЛЪЧФФвЛИізщМўдЖГЬЕїгУ kubeletЃЌУќСюЫќНјааШнЦїЕФДДНЈЃЌЖјЪЧЗЂЯж etcd
жаЃЌpod БЛАѓЖЈЕНСЫздМКетРяЃЌЗНВХРЦ№ЁЃ
ЮЊСЫдкЙЋгадЦжаЪЕЯжзтЛЇЕФИєРыадЃЌЮвУЧЕФВпТдЪЧВЛЭЌЕФзтЛЇЃЌВЛЙВЯэНкЕуЃЌетОЭашвЊ
Kubernetes Ждгк IaaS ВугаЫљИажЊЃЌвђЖјашвЊЪЕЯжздМКЕФ ControllerЃЌKubernetes
ЕФЩшМЦЪЙЕУЮвУЧПЩвдЖРСЂДДНЈздМКЕФ ControllerЃЌЖјВЛЪЧжБНгИФДњТыЁЃ
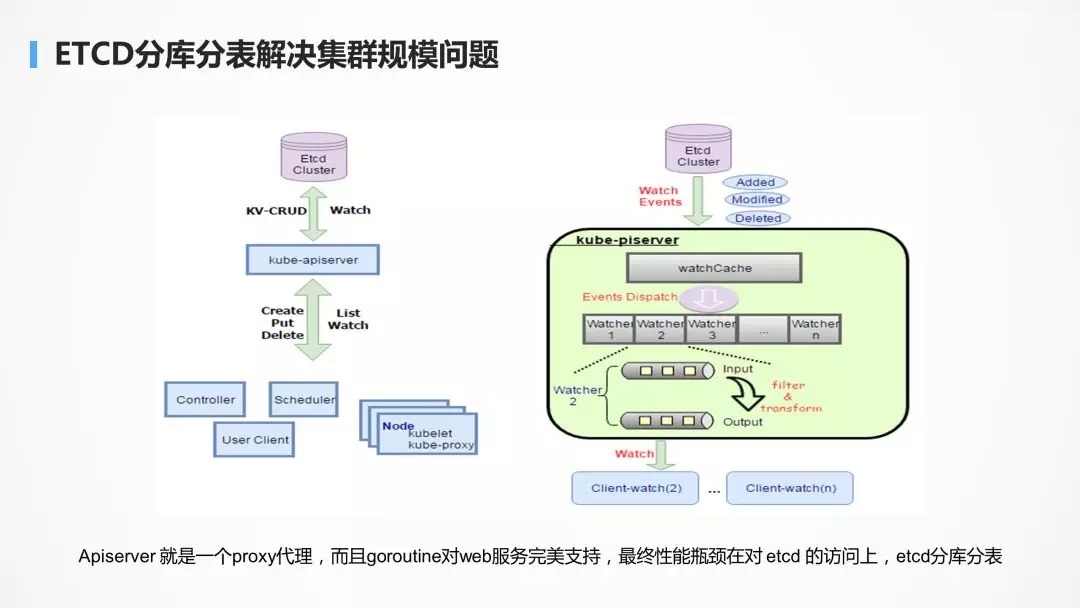
API-Server зїЮЊНгШыВуЃЌЪЧгаздМКЕФЛКДцЛњжЦЕФЃЌЗРжЙЫљгаЕФЧыЧѓбЙСІжБНгЕНКѓЖЫЪ§ОнПтЩЯЁЃЕЋЪЧЕБШдШЛЮоЗЈГадиИпВЂЗЂЧыЧѓЪБЃЌЦПОБвРШЛдкКѓЖЫЕФ
etcd ДцДЂЩЯЃЌетКЭЕчЩЬгІгУвЛУўвЛбљЁЃЕБШЛФмЙЛЯыЕНЕФЗНЪНвВЪЧЖд etcd НјааЗжПтЗжБэЃЌВЛЭЌЕФзтЛЇБЃДцдкВЛЭЌЕФ
etcd МЏШКжаЁЃ
гаСЫ API Server зі API ЭјЙиЃЌКѓЖЫЕФЗўЮёНјааЖЈжЦЛЏЃЌЖдгк
client КЭ kubelet ЪЧЭИУїЕФЁЃ
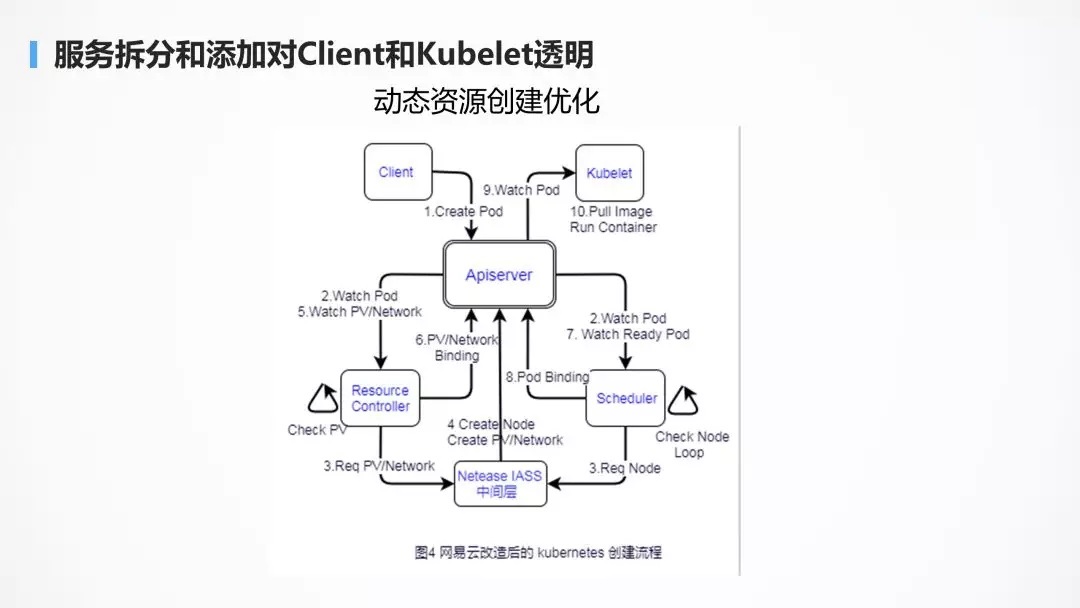
ШчЭМЪЧЖЈжЦЛЏЕФШнЦїДДНЈСїГЬЃЌгЩгкДѓДйКЭЗЧДѓДйЦкМфЃЌНкЕуЕФЪ§ФПЯрВюБШНЯДѓЃЌвђЖјВЛФмВЩгУЪТЯШШЋВПДДНЈКУНкЕуЕФЗНЪНЃЌетбљЛсдьГЩзЪдДЕФРЫЗбЃЌвђЖјжаМфЬэМгСЫЭјвздЦздМКЕФФЃПщ
Controller КЭ IaaS ЕФЙмРэВуЃЌЪЙЕУЕБДДНЈШнЦїзЪдДВЛзуЕФЪБКђЃЌЖЏЬЌЕїгУ IaaS ЕФНгПкЃЌЖЏЬЌЕФДДНЈзЪдДЁЃетвЛЧаЖдгкПЭЛЇЖЫКЭ
kubelet ЮоИажЊЁЃ
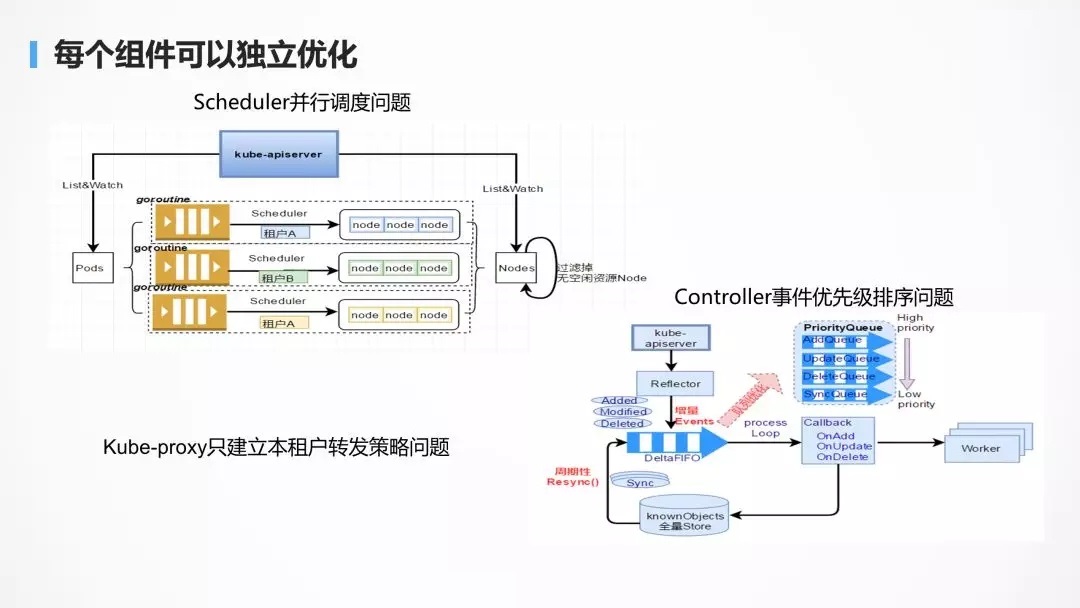
ЮЊСЫНтОіГЌЙ§ 3 ЭђИіНкЕуЕФЙцФЃЮЪЬтЃЌЭјвздЦашвЊЖдИїИіФЃПщНјаагХЛЏЃЌгЩгкУПИізгФЃПщНіНіЭъГЩздМКЕФЙІФмЃЌScheduler
жЛЙмЕїЖШЃЌProxy жЛЙмзЊЗЂЃЌЖјЗЧёюКЯдквЛЦ№ЃЌвђЖјУПИізщМўЖМПЩвдНјааЖРСЂЕФгХЛЏЃЌетЗћКЯЮЂЗўЮёжаЕФЖРСЂЙІФмЃЌЖРСЂгХЛЏЃЌЛЅВЛгАЯьЁЃЖјЧв
Kubernetes ЕФЫљгазщМўЖМЪЧ Go ПЊЗЂЕФЃЌИќМгШнвзвЛаЉЁЃЫљвд Kubernetes ЩЯЪжТ§ЃЌЕЋЪЧвЛЕЉашвЊЖЈжЦЛЏЃЌЛсЗЂЯжИќМгШнвзЁЃ
ЮхЁЂKubernetes ИќМгЪЪКЯЮЂЗўЮёКЭ DevOps ЕФЩшМЦ
КУСЫЃЌЫЕСЫ K8S БОЩэЃЌНгЯТРДЫЕЫЕ K8S ЕФРэФюЩшМЦЃЌЮЊЪВУДетУДЪЪКЯЮЂЗўЮёЁЃ

ЧАУцЮЂЗўЮёЩшМЦЕФЪЎДѓФЃЪНЃЌЦфжавЛИіОЭЪЧЧјЗжЮозДЬЌКЭгазДЬЌЃЌдк K8S
жаЃЌЮозДЬЌЖдгІ deploymentЃЌгазДЬЌЖдгІ StatefulSetЁЃ
deployment жївЊЭЈЙ§ИББОЪ§ЃЌНтОіКсЯђРЉеЙЕФЮЪЬтЁЃ
Жј StatefulSet ЭЈЙ§вЛжТЕФЭјТч IDЃЌвЛжТЕФДцДЂЃЌЫГађЕФЩ§МЖЃЌРЉеЙЃЌЛиЙіЕШЛњжЦЃЌБЃжЄгазДЬЌгІгУЃЌКмКУЕиРћгУздМКЕФИпПЩгУЛњжЦЁЃвђЮЊДѓЖрЪ§МЏШКЕФИпПЩгУЛњжЦЃЌЖМЪЧПЩвдШнШЬвЛИіНкЕуднЪБЙвЕєЕФЃЌЕЋЪЧВЛФмШнШЬДѓЖрЪ§НкЕуЭЌЪБЙвЕєЁЃЖјЧвИпПЩгУЛњжЦЫфШЛПЩвдБЃжЄвЛИіНкЕуЙвЕєКѓЛиРДЃЌгавЛЖЈЕФаоИДЛњжЦЃЌЕЋЪЧашвЊжЊЕРИеВХЙвЕєЕФЕНЕзЪЧФФИіНкЕуЃЌStatefulSet
ЕФЛњжЦПЩвдШУШнЦїРяУцЕФНХБОгазуЙЛЕФаХЯЂЃЌДІРэетаЉЧщПіЃЌЪЕЯжФФХТЪЧгазДЬЌЃЌвВФмОЁПьаоИДЁЃ

дкЮЂЗўЮёжаЃЌБШНЯЭЦМіЪЙгУдЦЦНЬЈЕФ PaaSЃЌР§ШчЪ§ОнПтЃЌЯћЯЂзмЯпЃЌЛКДцЕШЁЃЕЋЪЧХфжУвВЪЧЗЧГЃИДдгЕФЃЌвђЮЊВЛЭЌЕФЛЗОГашвЊСЌНгВЛЭЌЕФ
PaaS ЗўЮёЁЃ
K8S РяУцЕФ headless service ЪЧПЩвдКмКУЕиНтОіетИіЮЪЬтЕФЃЌжЛвЊИјЭтВПЗўЮёДДНЈвЛИі
headless serviceЃЌжИЯђЯргІЕФ PaaS ЗўЮёЃЌВЂЧвНЋЗўЮёУћХфжУЕНгІгУжаЁЃгЩгкЩњВњКЭВтЪдЛЗОГЗжГЩ
NamespaceЃЌЫфШЛХфжУСЫЯрЭЌЕФЗўЮёУћЃЌЕЋЪЧВЛЛсДэЮѓЗУЮЪЃЌМђЛЏСЫХфжУЁЃ
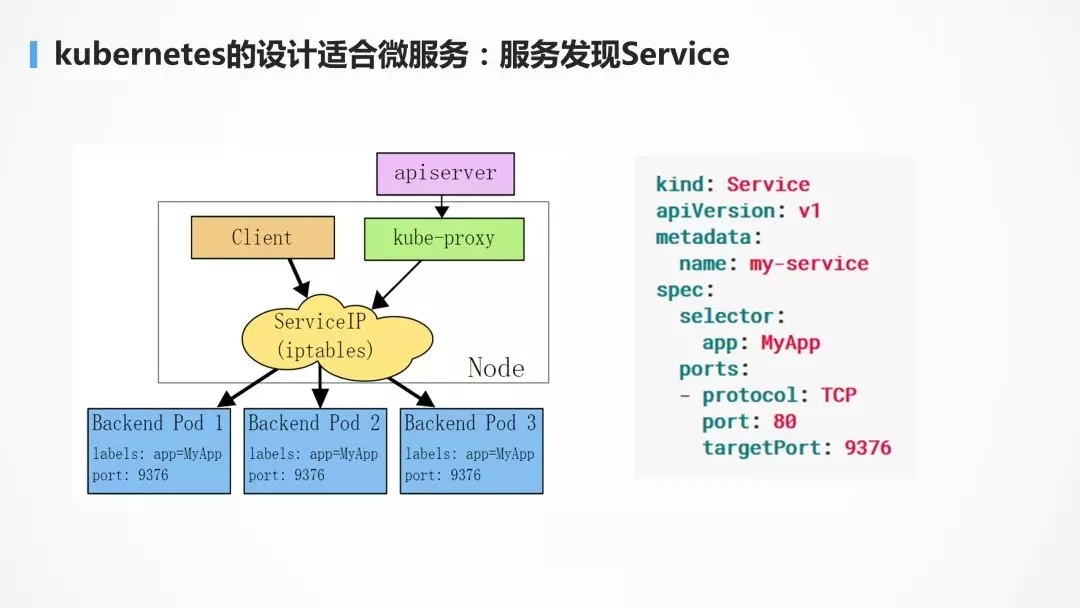
ЮЂЗўЮёЩйВЛСЫЗўЮёЗЂЯжЃЌГ§СЫгІгУВуПЩвдЪЙгУ SpringCloud Лђеп
Dubbo НјааЗўЮёЗЂЯжЃЌдкШнЦїЦНЬЈВуЕБШЛЪЧгУ ServiceСЫЃЌПЩвдЪЕЯжИКдиОљКтЃЌздаоИДЃЌздЖЏЙиСЊЁЃ
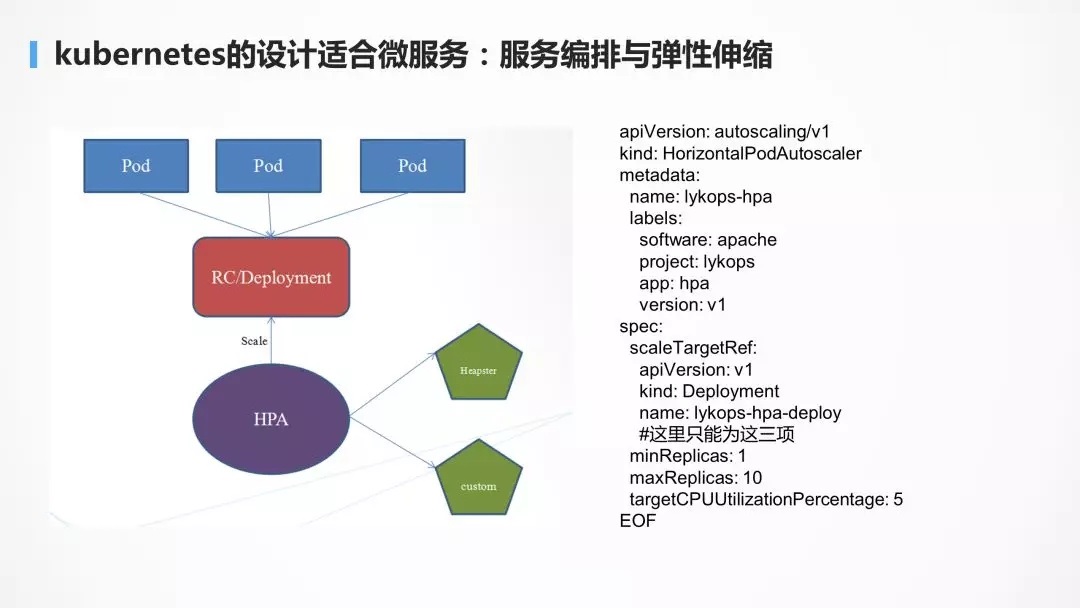
ЗўЮёБрХХЃЌБОРД K8S ОЭЪЧБрХХЕФБъзМЃЌПЩвдНЋ yml ЮФМўЗХЕНДњТыВжПтжаНјааЙмРэЃЌЖјЭЈЙ§
deployment ЕФИББОЪ§ЃЌПЩвдЪЕЯжЕЏадЩьЫѕЁЃ

ЖдгкХфжУжааФЃЌK8S ЬсЙЉСЫ configMapЃЌПЩвддкШнЦїЦєЖЏЕФЪБКђЃЌНЋХфжУзЂШыЕНЛЗОГБфСПЛђеп
Volume РяУцЁЃЕЋЪЧЮЈвЛЕФШБЕуЪЧЃЌзЂШыЕНЛЗОГБфСПжаЕФХфжУВЛФмЖЏЬЌИФБфСЫЃЌКУдк Volume РяУцЕФПЩвдЃЌжЛвЊШнЦїжаЕФНјГЬга
reload ЛњжЦЃЌОЭПЩвдЪЕЯжХфжУЕФЖЏЬЌЯТЗЂСЫЁЃ

ЭГвЛШежОКЭМрПиЭљЭљашвЊдк Node ЩЯВПЪ№ AgentЃЌРДЖдШежОКЭжИБъНјааЪеМЏЃЌЕБШЛУПИі
Node ЩЯЖМгаЃЌdaemonset ЕФЩшМЦЃЌЪЙЕУИќШнвзЪЕЯжЁЃ
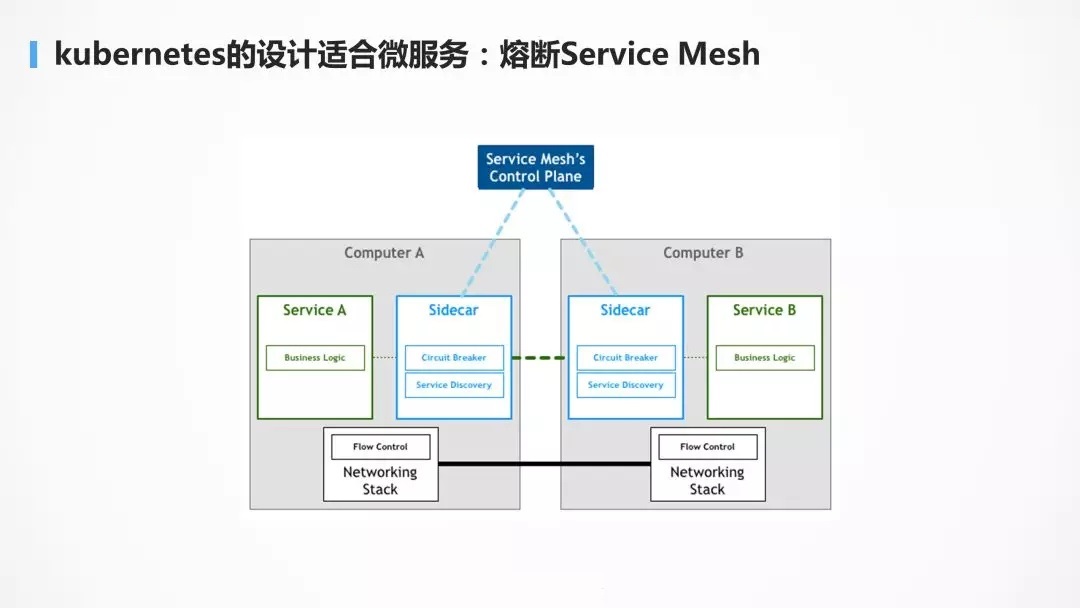
ЕБШЛФПЧАзюзюЛ№ЕФ Service MeshЃЌПЩвдЪЕЯжИќМгОЋЯИЛЏЕФЗўЮёжЮРэЃЌНјааШлЖЯЃЌТЗгЩЃЌНЕМЖЕШВпТдЁЃService
Mesh ЕФЪЕЯжЭљЭљЭЈЙ§ sidecar ЕФЗНЪНЃЌРЙНиЗўЮёЕФСїСПЃЌНјаажЮРэЁЃетвВЕУСІгк Pod ЕФРэФюЃЌвЛИі
Pod ПЩвдгаЖрИіШнЦїЃЌШчЙћЕБГѕЕФЩшМЦУЛга PodЃЌжБНгЦєЖЏЕФОЭЪЧШнЦїЃЌЛсЗЧГЃЕФВЛЗНБуЁЃ
Ыљвд K8S ЕФИїжжЩшМЦЃЌПДЦ№РДЗЧГЃШпгрКЭИДдгЃЌШыУХУХМїБШНЯИпЃЌЕЋЪЧвЛЕЉЯыЪЕЯжеце§ЕФЮЂЗўЮёЃЌK8S
ПЩвдИјФуИїжжПЩФмЕФзщКЯЗНЪНЁЃЪЕМљЙ§ЮЂЗўЮёЕФШЫЃЌЭљЭљЛсЖдетвЛЕуЩюгаЬхЛсЁЃ
|









