| БрМЭЦМі: |
| БОЮФРДздгк
CC4.0ЃЌДгЛЗОГДюХфЕНОЕЯёдйЕНДюНЈМЏШКМАЦфЫћЯрЙиЃЌДњТыЪОР§ЭМЪОЪОР§ЯъЯИЫЕУїЁЃ |
|
вЛЁЂЛЗОГзМБИ
ЪзЯШЛЗОГЛЙЪЧШ§ЬЈащФтЛњЃЌащФтЛњЕижЗШчЯТ
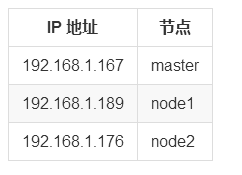
ШЛКѓУПЬЈЛњЦїАВзАКУ dockerЃЌжСгк rpm АВзААќАцБОЯТУцНщЩм
ЖўЁЂЫЕЕуе§ОЪТ
2.1ЁЂАВзААќДгФФРД
ЙйЗНЕФЮФЕЕвГУцИќаТВЂВЛМАЪБЃЌЭЌЪБЫћЕФ yum дДИќаТвВКмТ§ЃЌдйепЁФЧЫћТшПЩЪЧ Google ЕФЗўЮёЦїЃЌФмЬиУДСЌЩЯТ№ЃПвдЧАзмЪЧдкЙњЭтЗўЮёЦїЪЙгУ
yumdownloader ЯТдиЃЌШЛКѓ scp ЕНБОЕиЃЌЫфШЛФмНтОіЮЪЬтЃЌЕЋЪЧЕАЫщвЛЕиЁзюКѓевЕНСЫдДЭЗЃЌШчЯТ
Kubernetes БрвыЕФИїжжЗЂааАцАВзААќРДдДгк Github ЩЯЕФСэвЛИіНа release ЕФЯюФПЃЌЕижЗ
ЕуетРяЃЌАбетИіЯюФП clone ЯТРДЃЌгЩгкБОШЫЪЧ Centos гУЛЇЃЌЫљвдНјШы rpm ФПТМЃЌдкАВзАКУ
docker ЕФЛњЦїЩЯжДааФЧИі docker-build.sh НХБОМДПЩБрвы rpm АќЃЌзюКѓЛсЩњГЩЕНЕБЧАФПТМЕФ
output ФПТМЯТ,НиЭМШчЯТ
2.2ЁЂОЕЯёДгФФРД
ЖдЕФЃЌУЛДэЃЌgcr.io ОЭЪЧ Google ЕФгђУћЃЌЗўЮёЦїИќВЛгУЬсЃЌЫљвддкНјаа kubeadm
init ВйзїЪБШчЙћВЛЯШАбетаЉОЕЯё load НјШЅОјЖдЛсПЈЫРВЛЖЏЃЌвдЯТСаГіСЫЫљашОЕЯёЃЌЕЋЪЧАцБОКХИљОн
rpm АцБОВЛЭЌПЩФмТдгаВЛЭЌЃЌОпЬхдѕУДПДЯТУцНщЩм
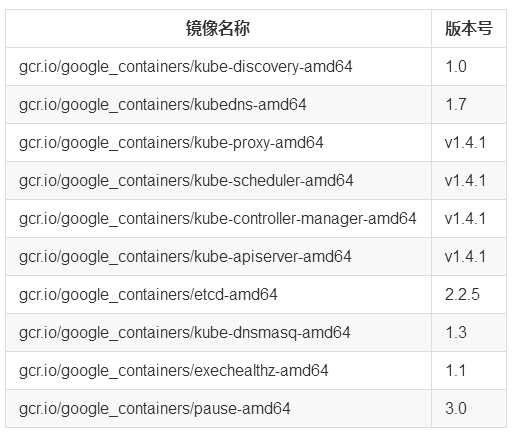
етаЉОЕЯёгаСНжжАьЗЈПЩвдЛёШЁЃЌЕквЛжжЪЧРћгУвЛЬЈЙњЭтЕФЗўЮёЦїЃЌдкЩЯУц pull ЯТРДЃЌШЛКѓдй save
ГЩ tar ЮФМўЃЌзюКѓ scp ЕНБОЕи load НјШЅЃЛЯрЖдгкЕквЛжжЗНЪНБШНЯПгЕФЪЧШЁОігкЗўЮёЦїЫйЖШЃЌУПДЮИуЦ№РДвВКмЕАЬлЃЌЕкЖўжжЗНЪНОЭЪЧРћгУ
docker hub зіжазЊЃЌМђЕЅЕФЫЕОЭЪЧРћгУ docker hub ЕФздЖЏЙЙНЈЙІФмЃЌдк Github
жаДДНЈвЛИі DockerfileЃЌРяУцжЛашвЊ FROM xxxx етаЉ gcr.io ЕФОЕЯёМДПЩЃЌзюКѓ
pull ЕНБОЕиЃЌШЛКѓдй tag вЛЯТ
ЪзЯШДДНЈвЛИі github ЯюФПЃЌПЩвджБНг fork ЮвЕФМДПЩ
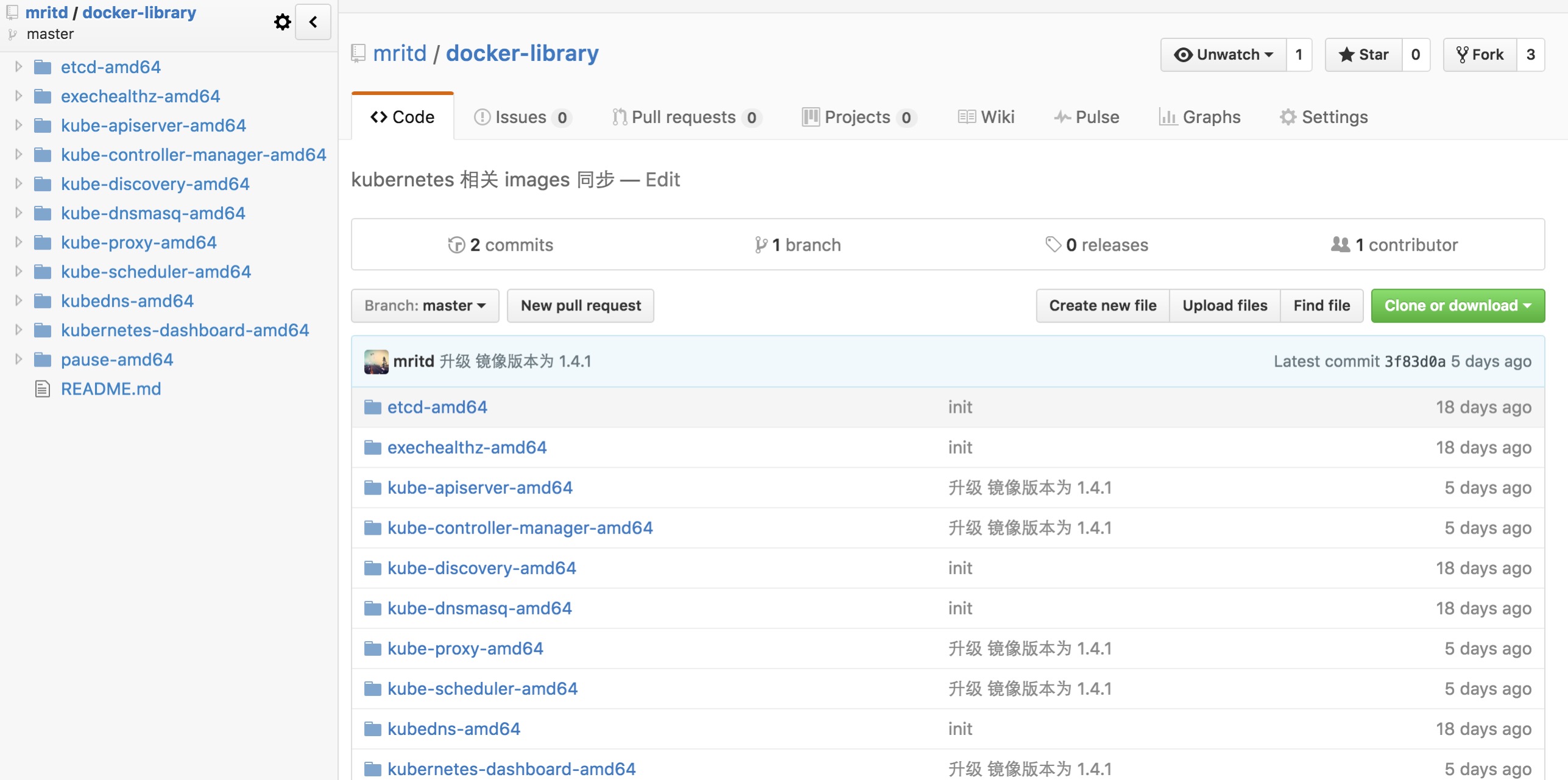
ЦфжаУПИі Dockerfile жЛашвЊ FROM вЛЯТМДПЩ
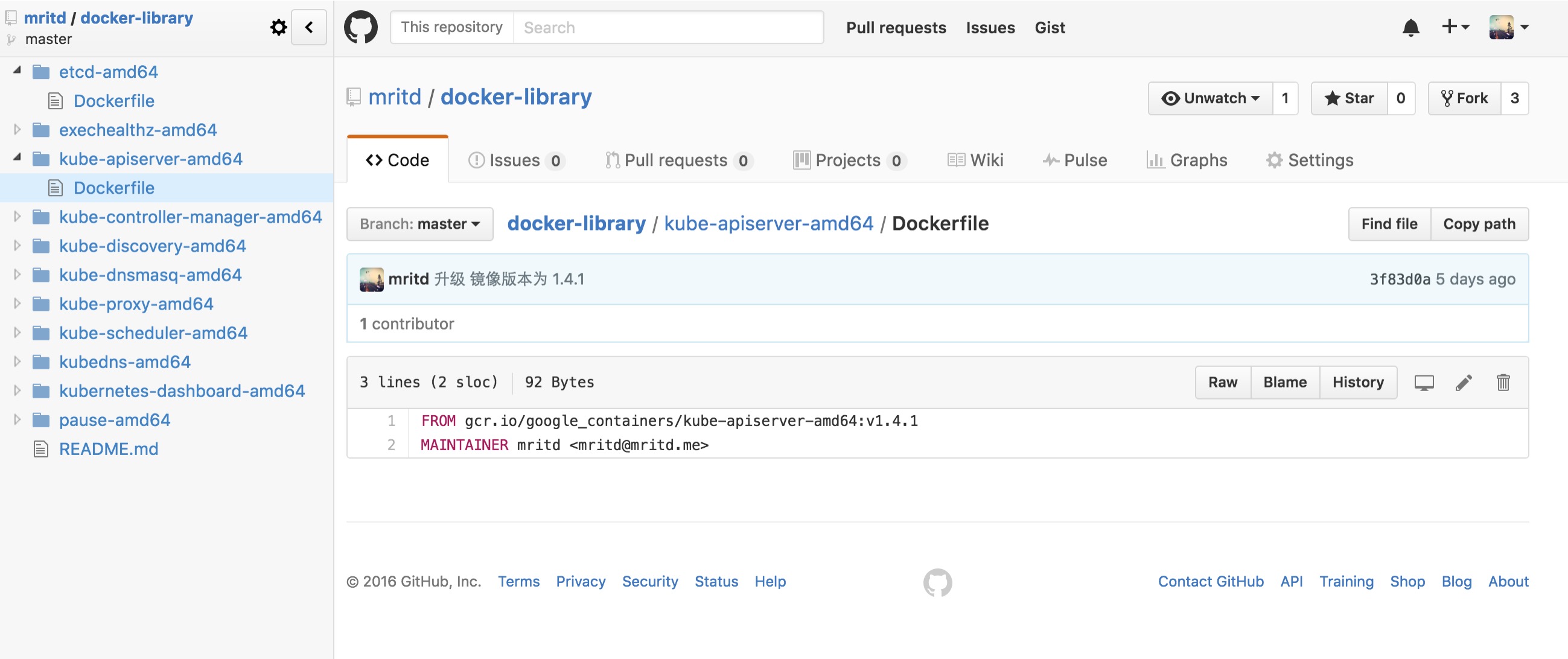
зюКѓдк Docker Hub ЩЯДДНЈздЖЏЙЙНЈЯюФП
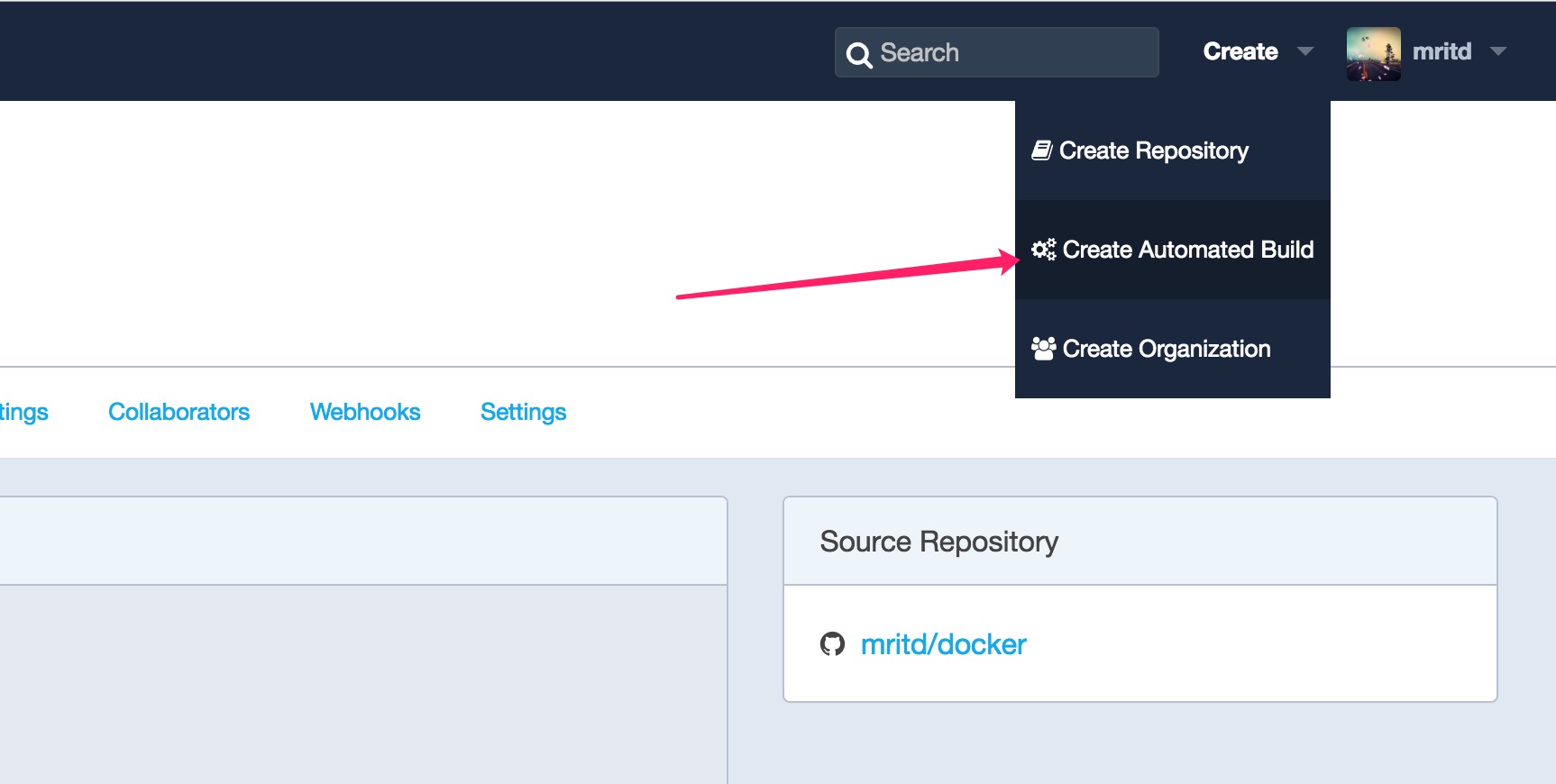

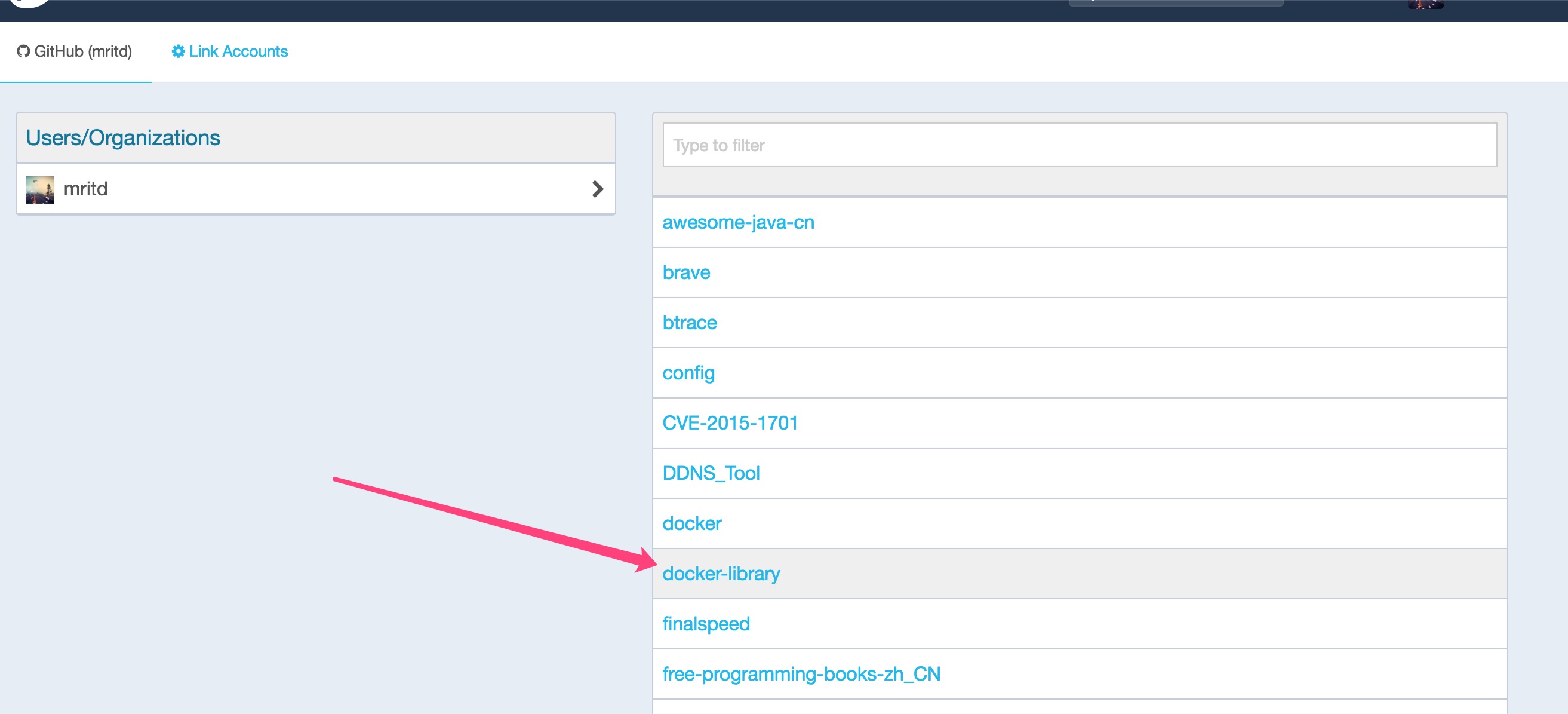
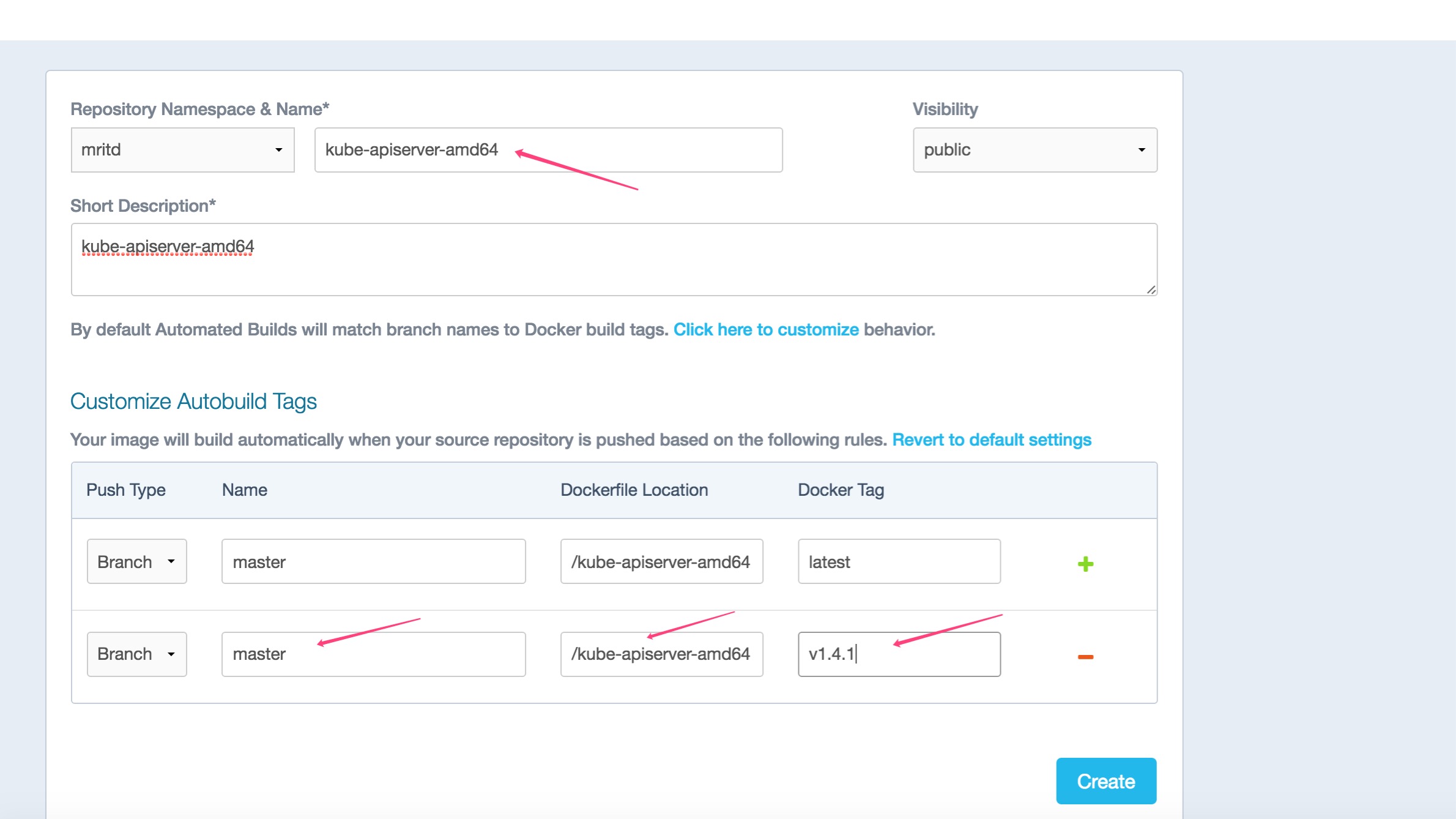
зюКѓвЊЪжЖЏДЅЗЂвЛЯТЃЌШЛКѓ Docker Hub ВХЛсПЊЪМИјФуБрвы
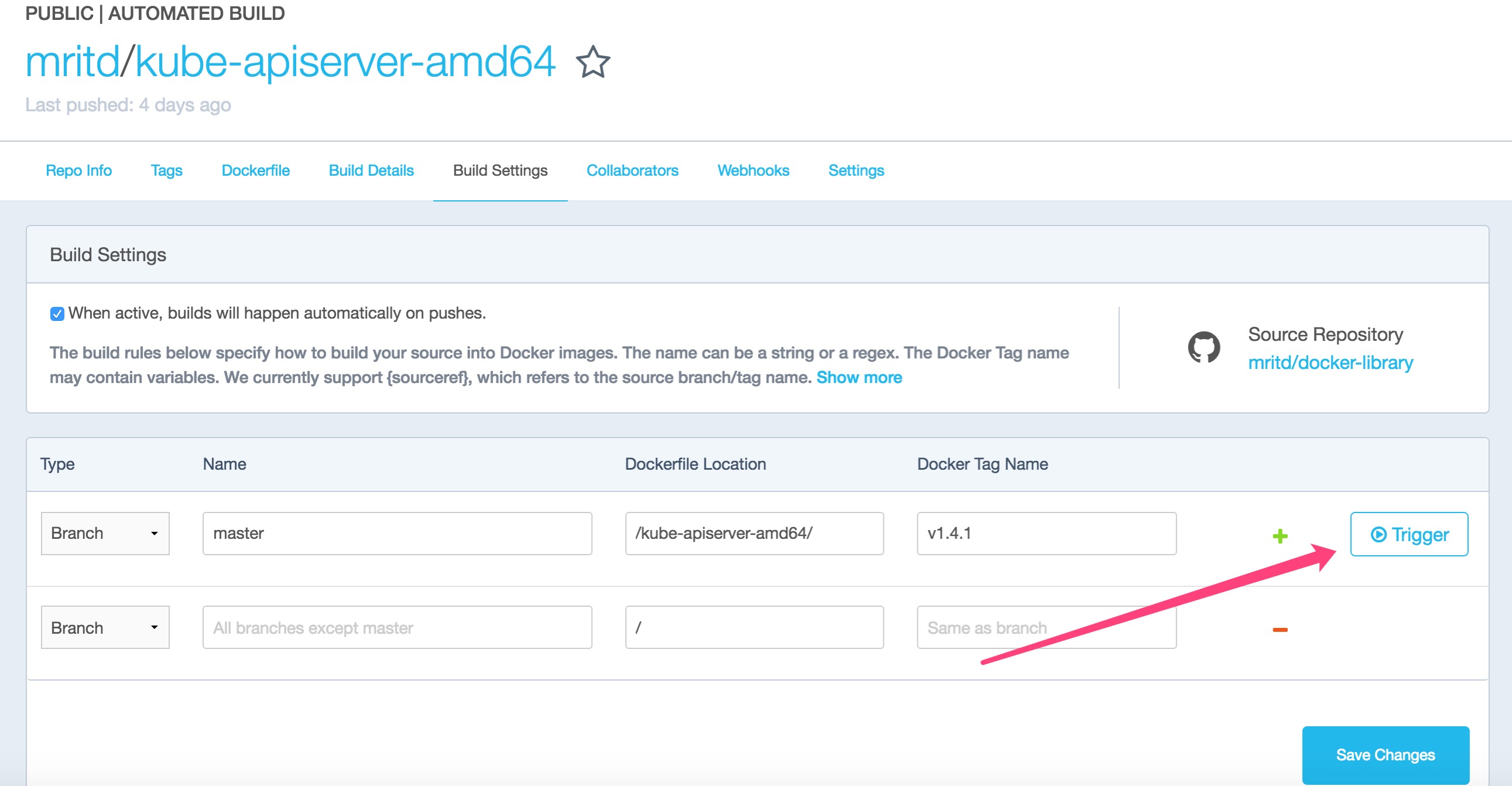
ЕШД§ЭъГЩМДПЩжБНг pull СЫ
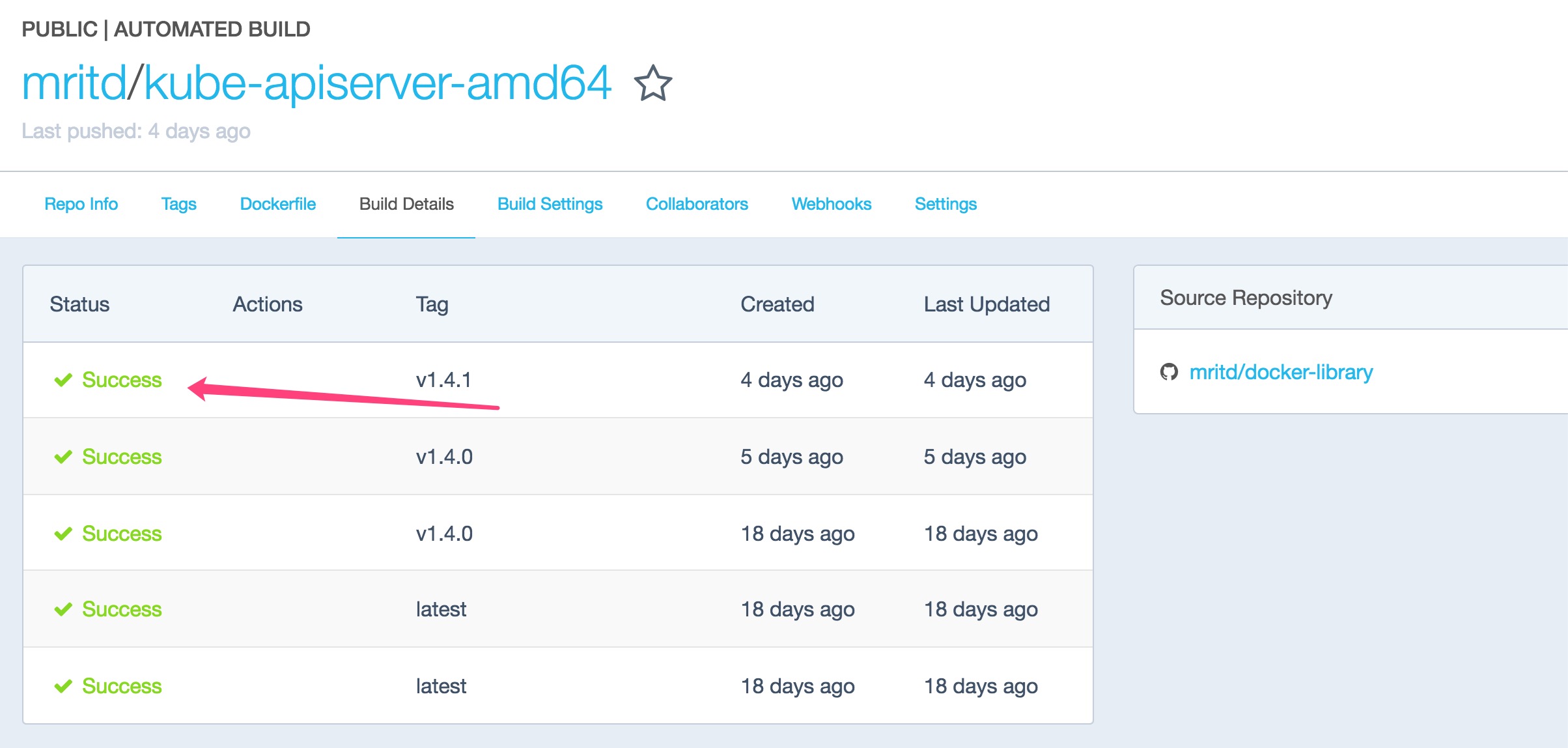
2.3ЁЂОЕЯёАцБОдѕУДећ
ЩЯУцвбОНтОіСЫОЕЯёЛёШЁЮЪЬтЃЌЕЋЪЧвЛДѓаФВЁОЭЪЧ ЁАЮвЬиУДдѕУДжЊЕРЪЧФФИіАцБОЕФЁБЃЌЮЊСЫЗЂбя ЁАХйИљЮЪЕзЁБ
ЕФОЋЩёЃЌЯШНјаавЛБщ kubeadm initЃЌетЪБКђОјЖдПЈЫРЃЌДЫЪБНјШы /etc/kubernetes/manifests
ПЩвдПДЕНаэЖр json ЮФМўЃЌетаЉЮФМўжаЖЈвхСЫашвЊФФаЉЛљДЁОЕЯё
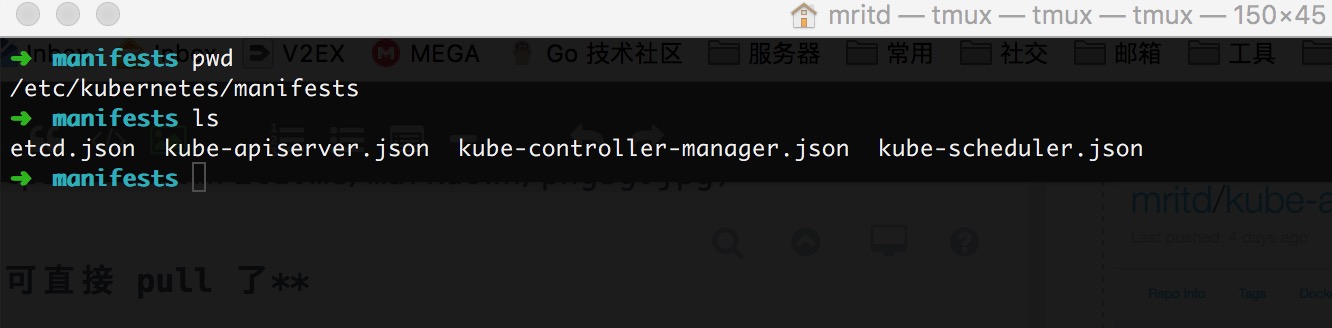
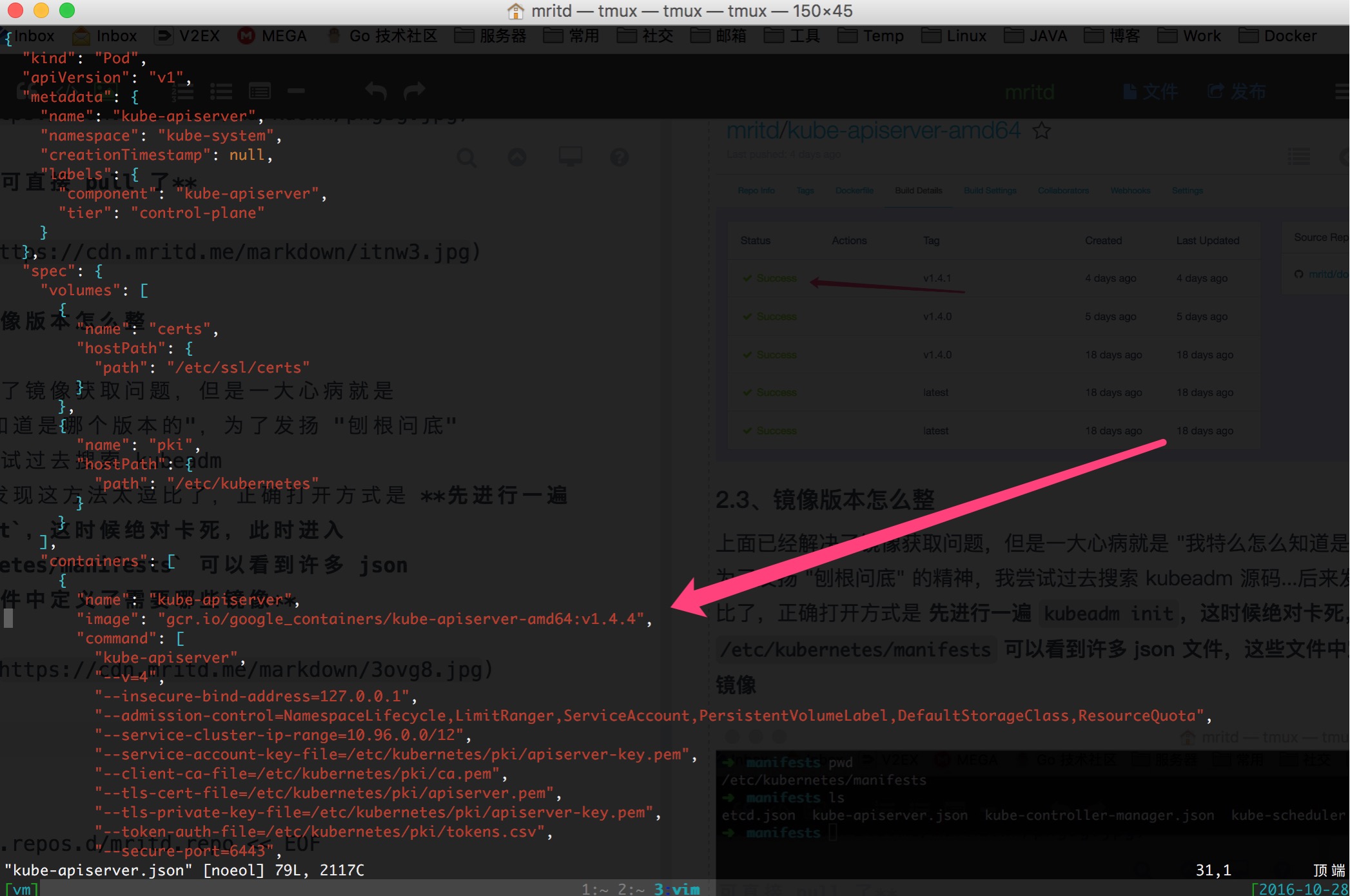
ДгЩЯЭМжаЛљБОПЩвдПДЕН kubeadm init ЕФЪБКђЛсРШЁФФаЉЛљДЁОЕЯёСЫЃЌЕЋЪЧЛЙгавЛаЉОЕЯёЃЌШдШЛЮоЗЈевЕНЃЌБШШчkubednsЁЂpause
ЕШЃЌжСгкЦфЫћЕФОЕЯёАцБОЃЌПЩвдДгдДТыжаевЕНЃЌдДТыЮЛжУЪЧ kubernetes/cmd/kubeadm/app/images/images.go
етИіЮФМўжаЃЌШчЯТЫљЪО:
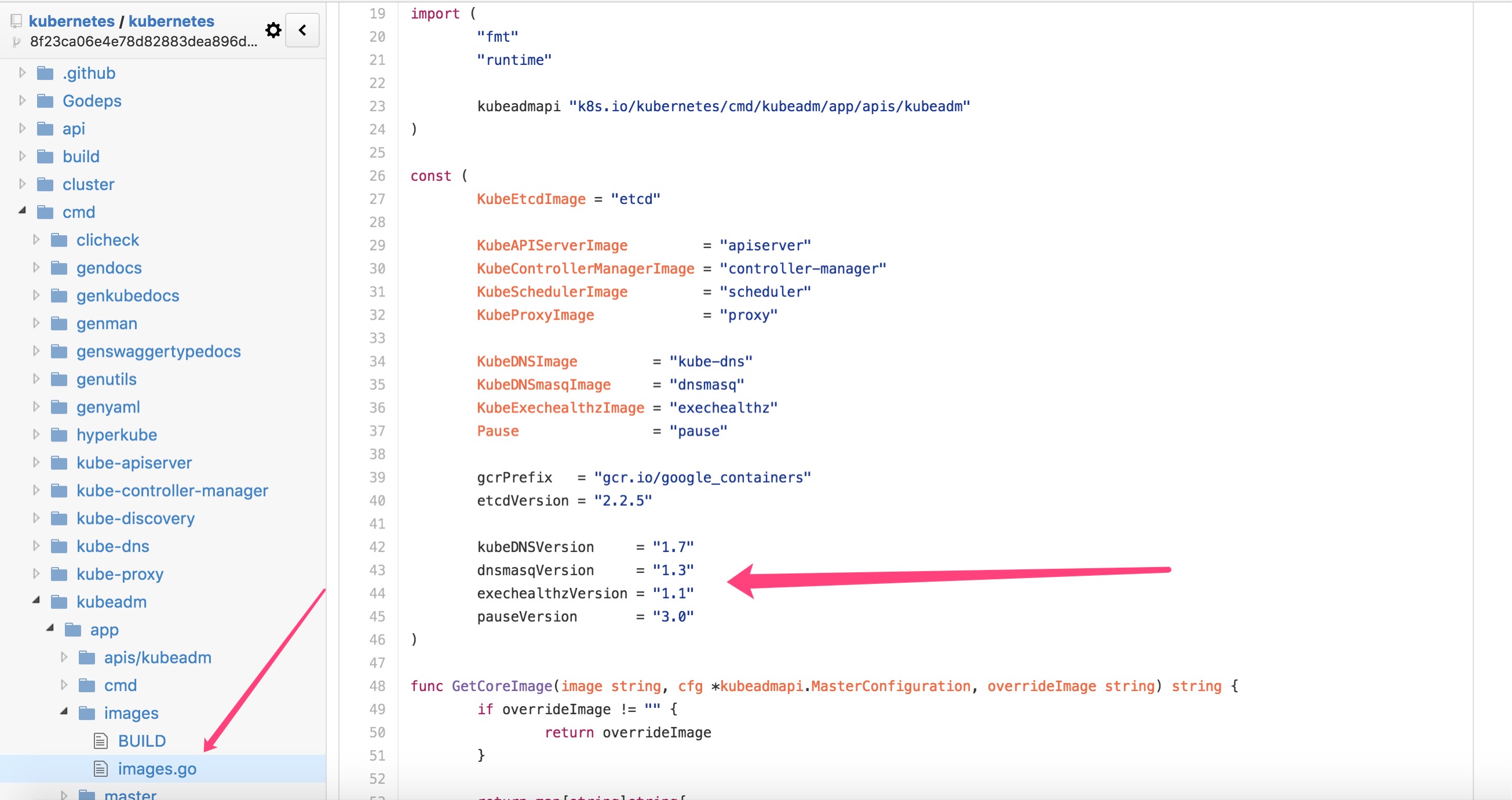
ЪЃгрЕФвЛаЉОЕЯёЃЌБШШч kube-proxy-amd64ЁЂkube-discovery-amd64
СНИіОЕЯёЃЌЦфжа kube-discovery-amd64 ЯждквЛжБЪЧ 1.0 АцБОЃЌдДТыШчЯТЫљЪО
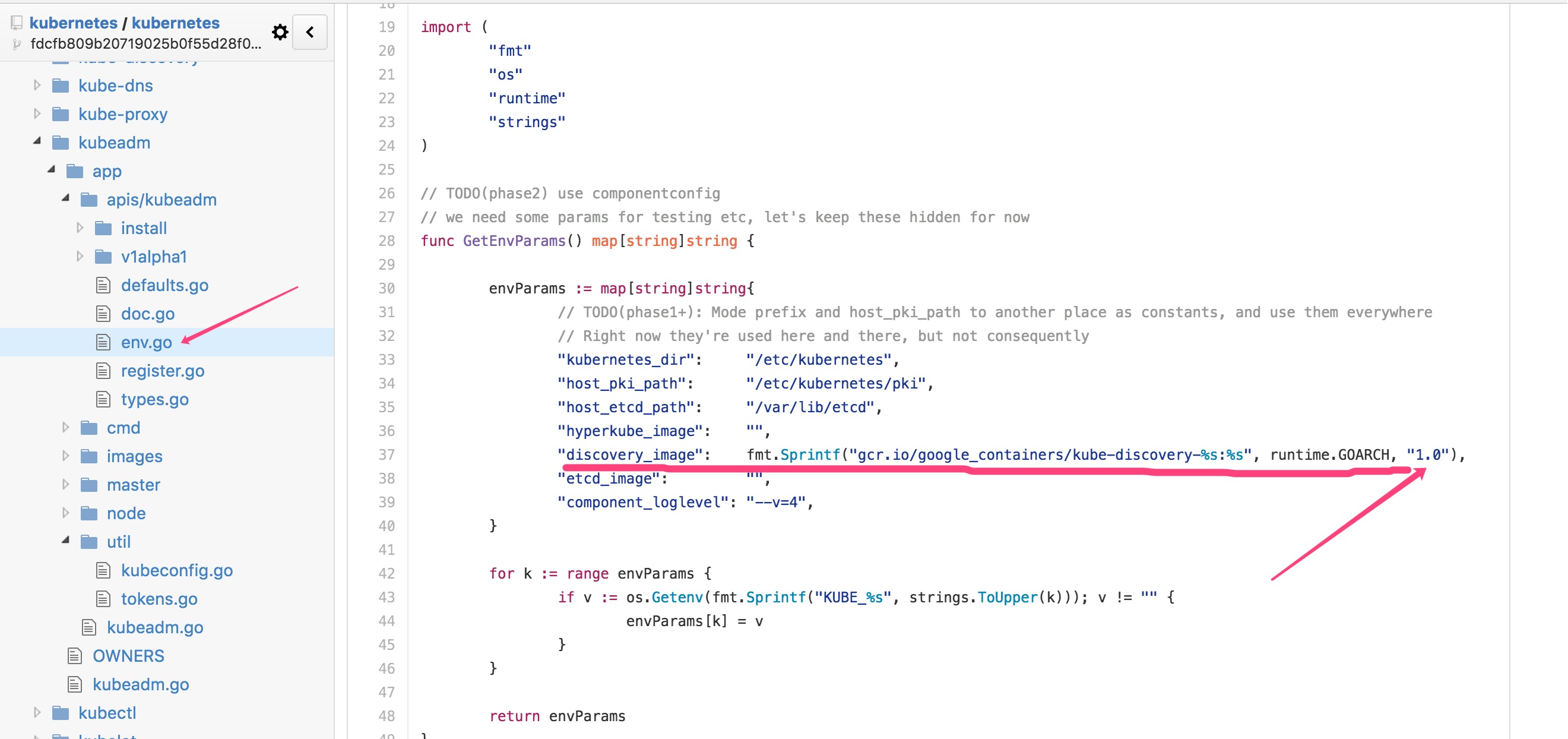
kube-proxy-amd64 дђЪЧвЛжБИњЫцЛљДЁзщМўЕФжїАцБОЃЌвВОЭЪЧЫЕШчЙћДг manifests
жаПДЕН controller ЕШАцБОЪЧ v.1.4.4ЃЌФЧУД kube-proxy-amd64 вВЪЧетИіАцБОЃЌдДТыШчЯТ
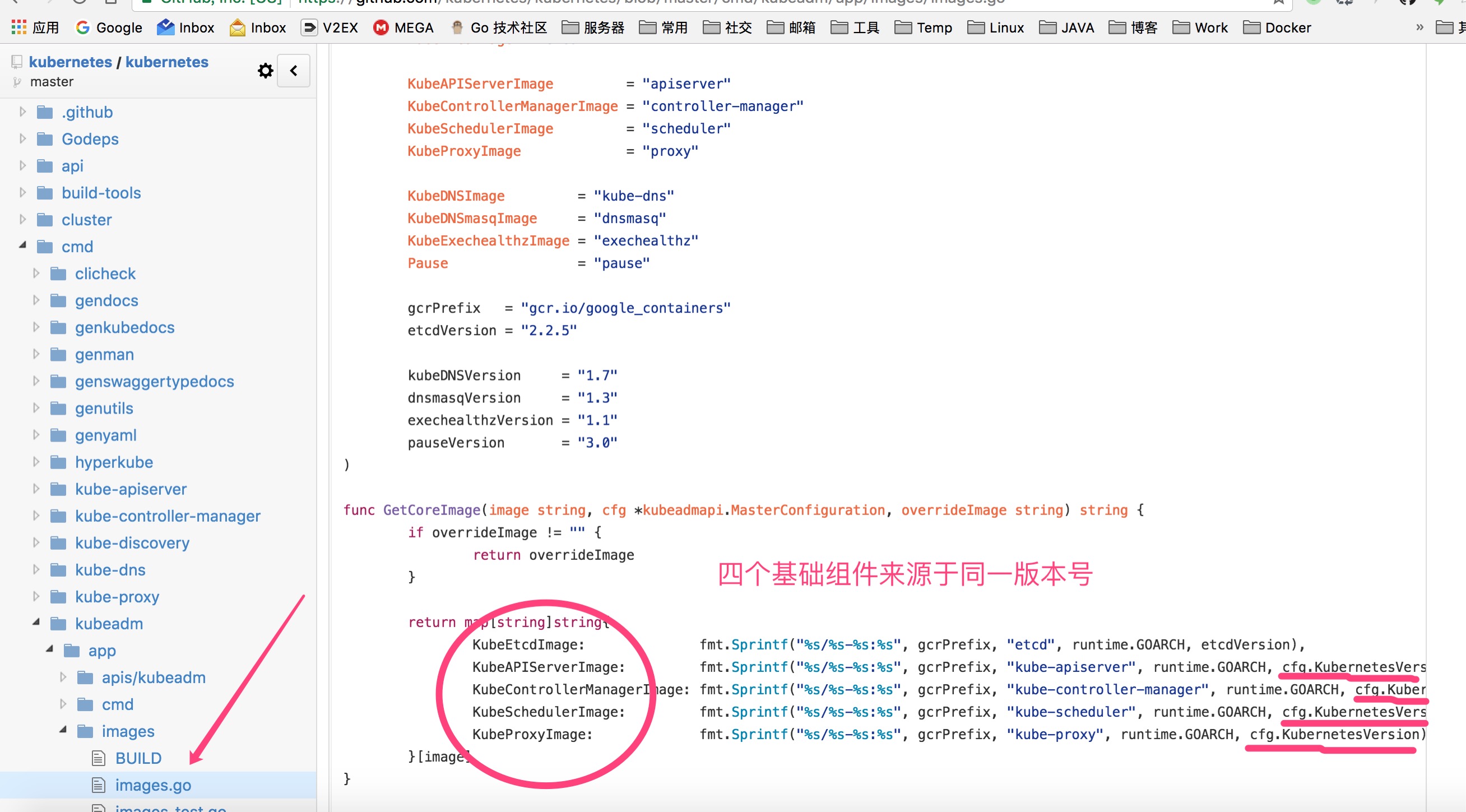
зюКѓИљОнетаЉАцБОШЅ github ЩЯзМБИЯргІЕФ DockerfileЃЌдкРћгУ Docker Hub
ЕФздЖЏЙЙНЈ build вЛЯТЃЌдй pull ЯТРД tag ГЩЖдгІЕФОЕЯёУћГЦМДПЩ
Ш§ЁЂДюНЈМЏШК
3.1ЁЂжїЛњУћДІРэ
ОЙ§ЧзВтЃЌНкЕужїЛњУћзюКУЮЊ xxx.xxx етжжгђУћИёЪНЃЌЗёдђдкФГаЉЧщПіЯТЃЌPOD жаХмЕФГЬађЪЙгУгђУћНтЮіЪБПЩФмГіЯжЮЪЬтЃЌЫљвдЯШвЊДІРэвЛЯТжїЛњУћ
# аДШы hostname(node
НкЕуКѓзКИФГЩ .node)
echo "192-168-1-167.master" > /etc/hostname
# МгШы hosts
echo "127.0.0.1 192-168-1-167.master"
>> /etc/hosts
# ВЛжиЦєЧщПіЯТЪЙФкКЫЩњаЇ
sysctl kernel.hostname=192-168-1-167.master
# бщжЄЪЧЗёаоИФГЩЙІ
? ~ hostname
192-168-1-167.master |
3.2ЁЂload ОЕЯё
гЩгкБОШЫвбОдк Docker Hub ЩЯДІРэКУСЫЯрЙиОЕЯёЃЌЫљвджБНг pull ЯТРД tag вЛЯТМДПЩЃЌ
images=(kube-proxy-amd64:v1.4.4
kube-discovery-amd64:1.0 kubedns-amd64:1.7 kube-scheduler-amd64:v1.4.4
kube-controller-manager-amd64:v1.4.4 kube-apiserver-amd64:v1.4.4
etcd-amd64:2.2.5 kube-dnsmasq-amd64:1.3 exechealthz-amd64:1.1
pause-amd64:3.0 kubernetes-dashboard-amd64:v1.4.1)
for imageName in ${images[@]} ; do
docker pull mritd/$imageName
docker tag mritd/$imageName gcr.io/google_containers/$imageName
docker rmi mritd/$imageName
done |
3.3ЁЂАВзА rpm
rpm ЛёШЁАьЗЈЩЯЮФвбОЬсЕНЃЌПЩвдздМКБрвыЃЌетРяЮввбОБрвыКУВЂЮЌЛЄСЫвЛИі yum дДЃЌжБНгyum
install МДПЩ(РС)
# ЬэМг yum дД
tee /etc/yum.repos.d/mritd.repo << EOF
[mritdrepo]
name=Mritd Repository
baseurl=https://rpm.mritd.me/centos/7/x86_64
enabled=1
gpgcheck=1
gpgkey=https://mritd.b0.upaiyun.com/keys/rpm.public.key
EOF
# ЫЂаТcache
yum makecache
# АВзА
yum install -y kubelet kubectl kubernetes-cni
kubeadm |
3.4ЁЂГѕЪМЛЏ master
ЕШЛсгаИіПгЃЌkubeadm ЕШЯрЙи rpm АВзАКѓЛсЩњГЩ /etc/kubernetes ФПТМЃЌЖј
kubeadm init ЪБКђгжЛсМьВтетаЉФПТМЪЧЗёДцдкЃЌШчЙћДцдкдђЭЃжЙГѕЪМЛЏЃЌЫљвдвЊЯШЧхРэвЛЯТЃЌвдЯТЧхРэНХБОРДдДгк
ЙйЗНЮФЕЕ Tear down ВПЗжЃЌИУНХБОЭЌбљЪЪгУгкГѕЪМЛЏЪЇАмНјаажижУ
systemctl stop
kubelet;
# зЂвт: ЯТУцетЬѕУќСюЛсИЩЕєЫљгае§дкдЫааЕФ docker ШнЦїЃЌ
# ШчЙћвЊНјаажижУВйзїЃЌзюКУЯШШЗЖЈЕБЧАдЫааЕФЫљгаШнЦїЖМФмИЩЕє(ИЩЕєВЛгАЯьвЕЮё)ЃЌ
# ЗёдђЕФЛАзюКУЪжЖЏЩОГ§ kubeadm ДДНЈЕФЯрЙиШнЦї(gcr.io ЯрЙиЕФ)
docker rm -f -v $(docker ps -q);
find /var/lib/kubelet | xargs -n 1 findmnt -n
-t tmpfs -o TARGET -T | uniq | xargs -r umount
-v;
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd; |
ЛЙгаИіПгЃЌГѕЪМЛЏвдЧАМЧЕУвЛЖЈвЊЦєЖЏ kubeletЃЌЫфШЛФу systemctl status kubelet
ПДзХЫћЪЧЦєЖЏЪЇАмЃЌЕЋЪЧвВЕУЦєЖЏЃЌЗёдђОјБкПЈЫР
systemctl enable
kubelet
systemctl start kubelet |
ЕШЛсЕШЛсЃЌЛЙгаПгЃЌаТАцБОжБНг init ЛсЬсЪО ebtables not found in system
path ДэЮѓЃЌЫљвдЛЙЕУЯШАВзАвЛЯТетИіАќдкГѕЪМЛЏ
# АВзА ebtables
yum install -y ebtables |
зюКѓМћжЄЦцМЃЕФЪБПЬ
# ГѕЪМЛЏВЂжИЖЈ apiserver
МрЬ§ЕижЗ
kubeadm init --api-advertise-addresses 192.168.1.167 |
ЭъУРНиЭМШчЯТ
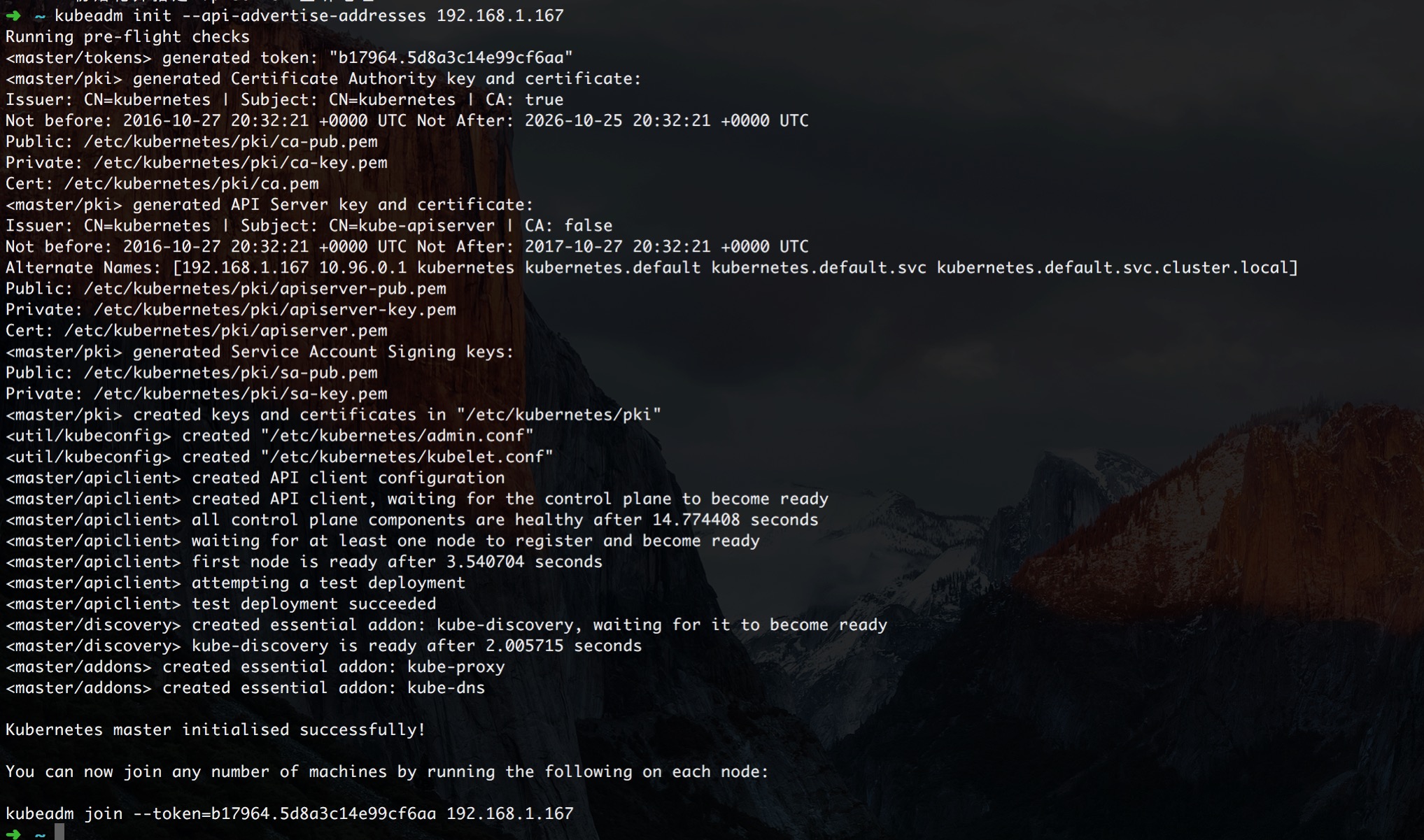
етРядйБЌСЯвЛИіПгЃЌЕзЯТЕФ kubeadm join --token=b17964.5d8a3c14e99cf6aa
192.168.1.167 етЬѕУќСювЛЖЈБЃДцКУЃЌвђЮЊКѓЦкУЛЗЈжиЯжЕФЃЌФуУЧРЯДѓдйШУФуЬэМгЛњЦїЕФЪБКђШчЙћУЛетИіФуЛсПоЕФ
3.5ЁЂМгШы node
ЩЯУцЫљгаПгДѓдМЫЕЕФВюВЛЖрСЫЃЌжБНгЩЯУќСюСЫ
# ДІРэжїЛњУћ
echo "192-168-1-189.node" > /etc/hostname
echo "127.0.0.1 192-168-1-189.node"
>> /etc/hosts
sysctl kernel.hostname=192-168-1-189.node
# РШЁОЕЯё
images=(kube-proxy-amd64:v1.4.4 kube-discovery-amd64:1.0
kubedns-amd64:1.7 kube-scheduler-amd64:v1.4.4
kube-controller-manager-amd64:v1.4.4 kube-apiserver-amd64:v1.4.4
etcd-amd64:2.2.5 kube-dnsmasq-amd64:1.3 exechealthz-amd64:1.1
pause-amd64:3.0 kubernetes-dashboard-amd64:v1.4.1)
for imageName in ${images[@]} ; do
docker pull mritd/$imageName
docker tag mritd/$imageName gcr.io/google_containers/$imageName
docker rmi mritd/$imageName
done
# зА rpm
tee /etc/yum.repos.d/mritd.repo << EOF
[mritdrepo]
name=Mritd Repository
baseurl=https://rpm.mritd.me/centos/7/x86_64
enabled=1
gpgcheck=1
gpgkey=https://mritd.b0.upaiyun.com/keys/rpm.public.key
EOF
yum makecache
yum install -y kubelet kubectl kubernetes-cni
kubeadm ebtables
# ЧхРэФПТМ(УЛГѕЪМЛЏЙ§жЛашвЊЩОФПТМ)
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd;
# ЦєЖЏ kubelet
systemctl enable kubelet
systemctl start kubelet
# ГѕЪМЛЏМгШыМЏШК
kubeadm join --token=b17964.5d8a3c14e99cf6aa 192.168.1.167 |
ЭЌбљЭъУРНиЭМ
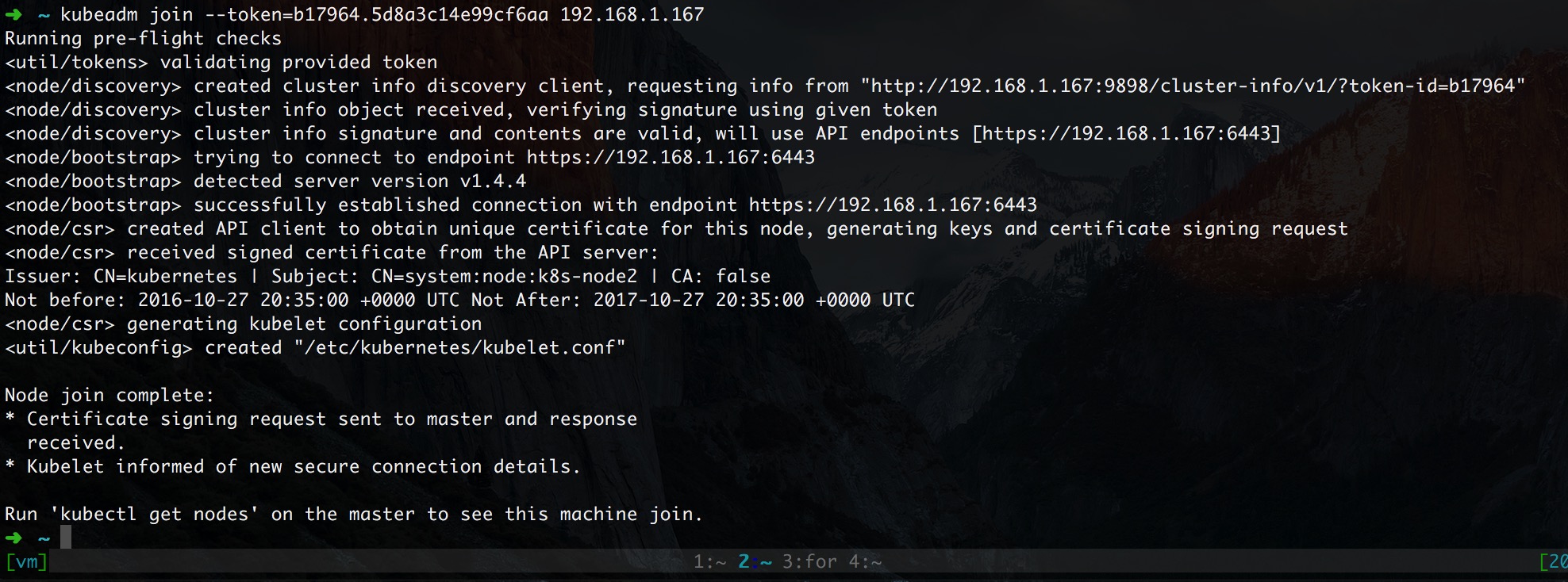
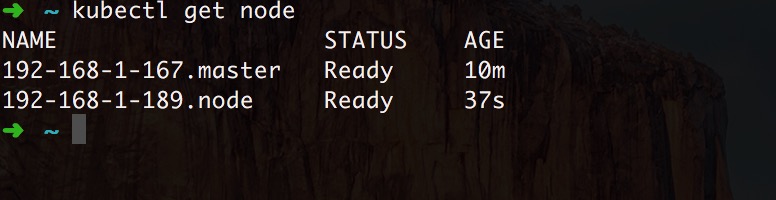
3.6ЁЂВПЪ№ weave ЭјТч
дйУЛВПЪ№ weave ЪБЃЌdns ЪЧЦєЖЏВЛСЫЕФЃЌШчЯТ
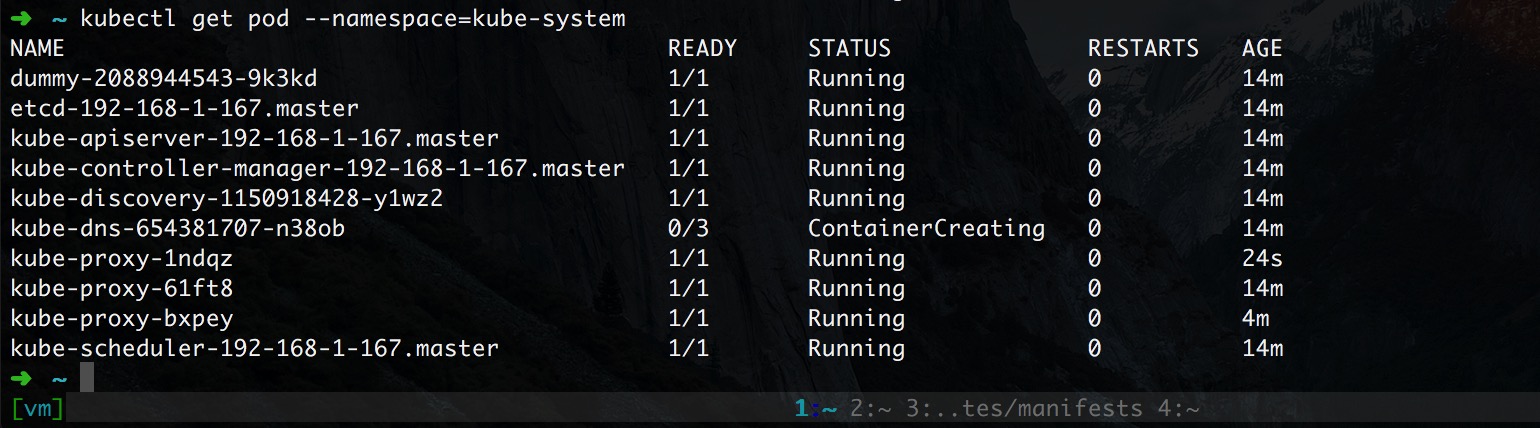
ЙйЗНИјГіЕФУќСюЪЧетбљЕФ
| kubectl create
-f https://git.io/weave-kube |
БОзХ ЁАХйИљЮЪЕзЭкзцЗиЁБ ЕФОЋЩёЃЌЯШАбетИі yaml ИуЯТРД
| wget https://git.io/weave-kube
-O weave-kube.yaml |
ШЛКѓЭЌбљЕФЬзТЗЃЌДђПЊПДвЛЯТОЕЯёЃЌРћгУ Docker Hub зіжазЊЃЌИуЯТРДдй load НјШЅЃЌШЛКѓ
create -f ОЭааСЫ
docker pull mritd/weave-kube:1.7.2
docker tag mritd/weave-kube:1.7.2 weaveworks/weave-kube:1.7.2
docker rmi mritd/weave-kube:1.7.2
kubectl create -f weave-kube.yaml |
ЭъУРНиЭМ
3.7ЁЂВПЪ№ dashboard
dashboard ЕФУќСювВИњ weave ЕФвЛбљЃЌВЛЙ§гаИіДѓПгЃЌФЌШЯЕФ yaml ЮФМўжаЖдгк image
РШЁВпТдЕФЖЈвхЪЧ ЮоТлКЮЪБЖМЛсШЅРШЁОЕЯёЃЌЕМжТМДЪЙФу load НјШЅвВЮоТбгУЃЌЫљвдЛЙЕУЯШАб yaml
ИуЯТРДШЛКѓИФвЛЯТОЕЯёРШЁВпТдЃЌзюКѓдй create -f МДПЩ
| wget https://rawgit.com/kubernetes
/dashboard/master/src/ deploy/kubernetes-dashboard.yaml
-O kubernetes-dashboard.yaml |
БрМ yaml ИФвЛЯТ imagePullPolicyЃЌАб Always ИФГЩ IfNotPresent(БОЕиУЛгадйШЅРШЁ)
Лђеп Never(ДгВЛШЅРШЁ) МДПЩ
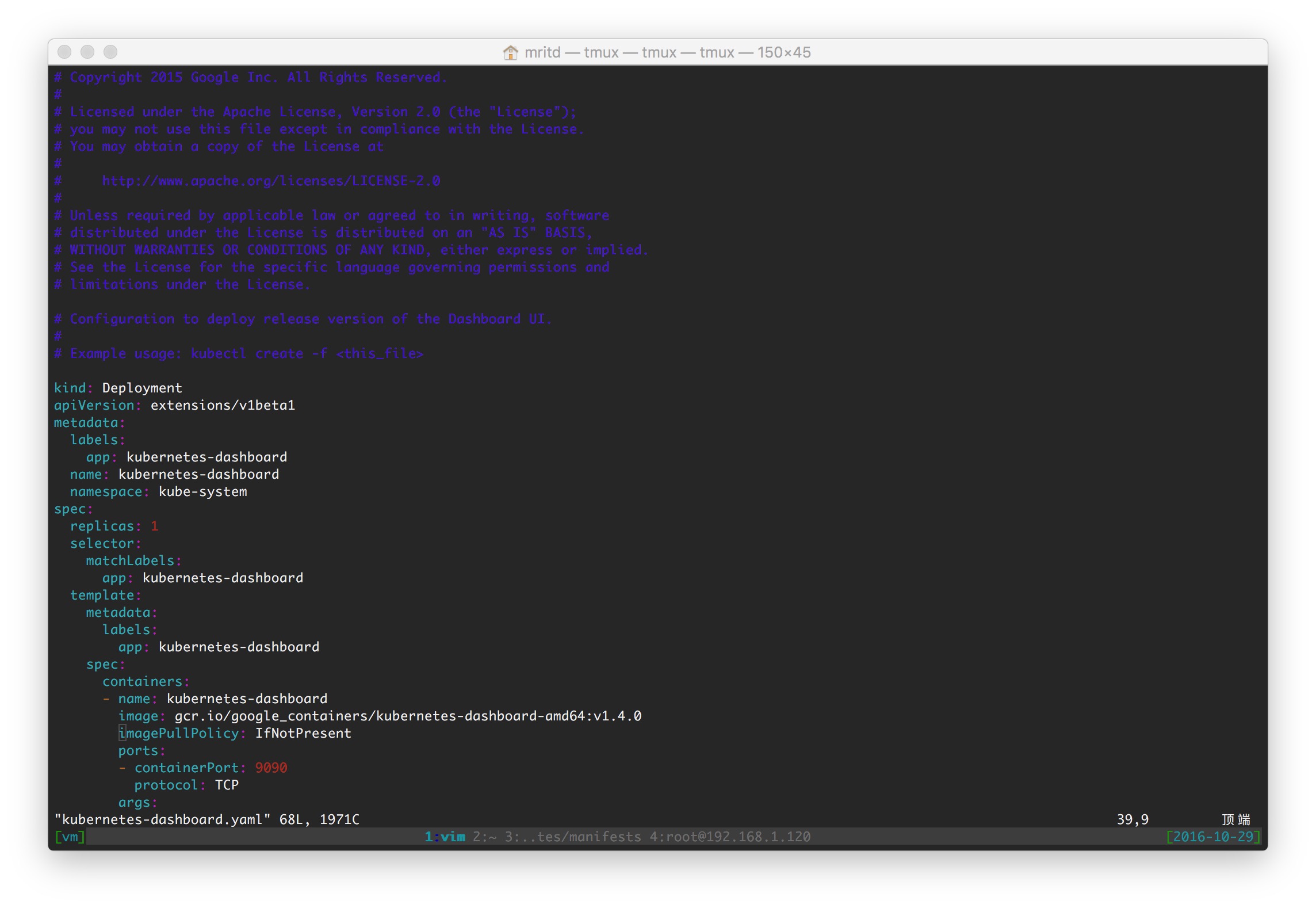
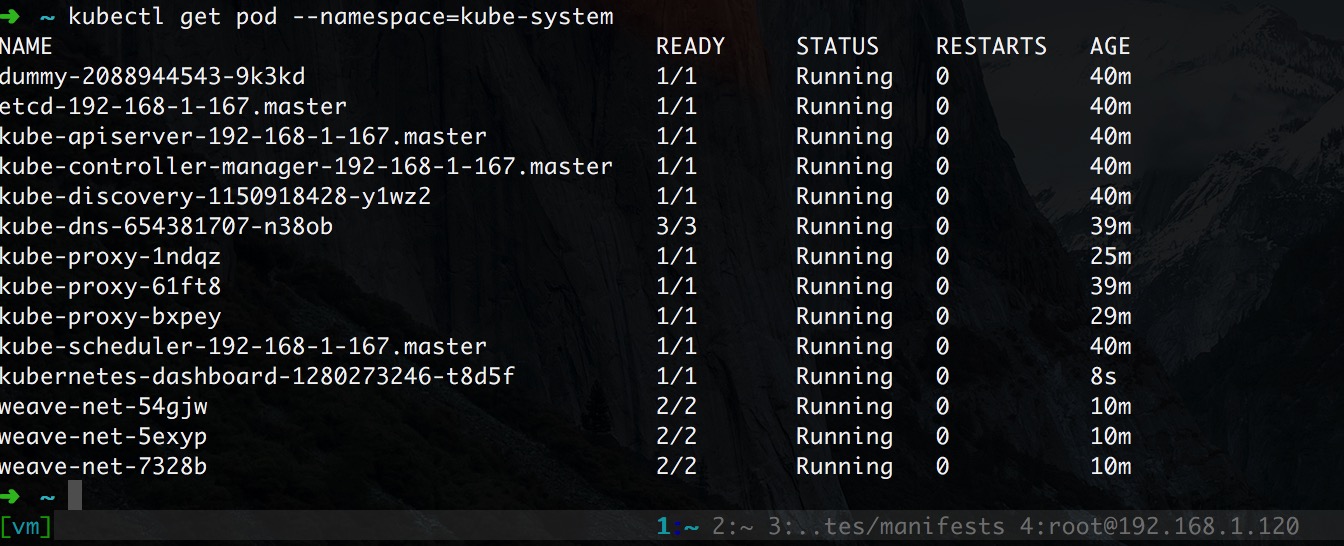
зюКѓдйРћгУ Dokcer Hub жазЊЃЌШЛКѓДДНЈ(ЪЕМЪЩЯ dashboard вбОгаСЫ v1.4.1ЃЌЮветРявбОИФСЫ)
| kubectl create
-f kubernetes-dashboard.yaml |
НиЭМШчЯТ
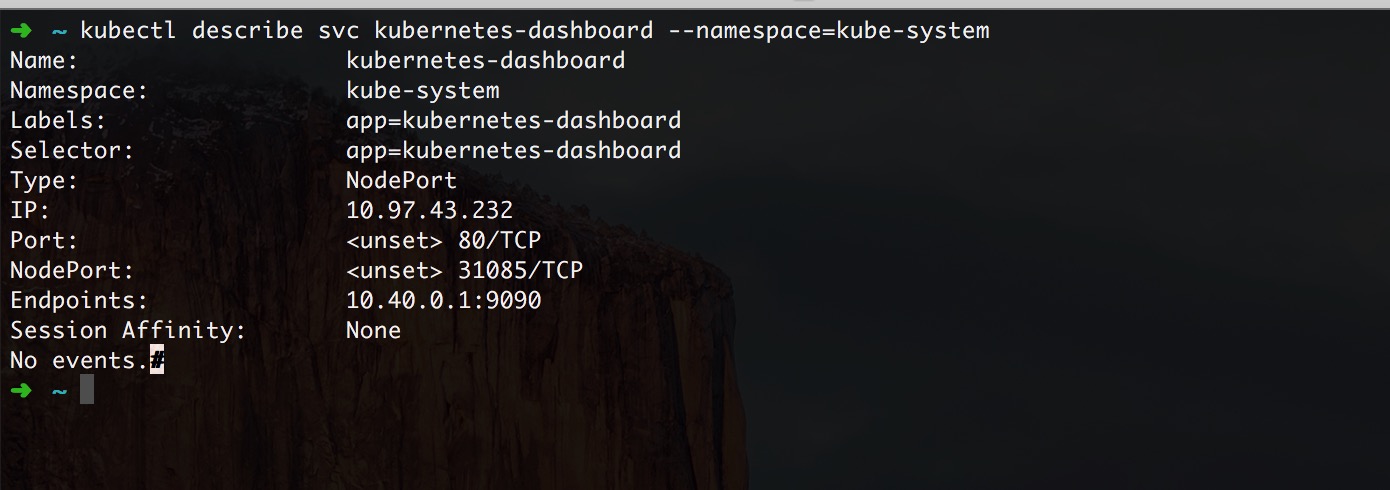
ЭЈЙ§ describe УќСюЮвУЧПЩвдВщПДЦфБЉТЖГіЕФ NodePoint,ШЛКѓБуПЩЗУЮЪ
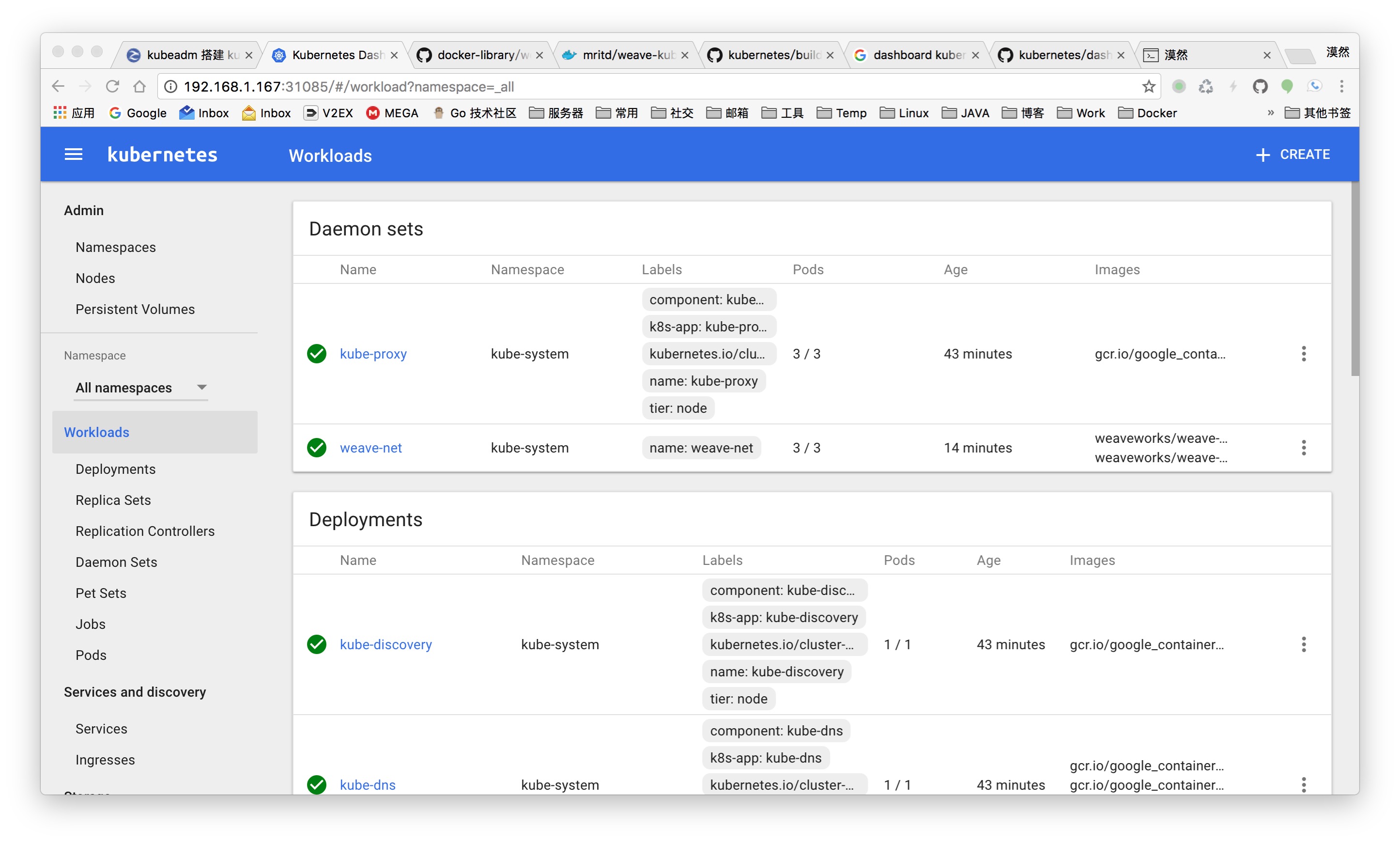
ЫФЁЂЦфЫћЕФвЛаЉПг
ЛЙгавЛаЉЦфЫћЕФПгЕШзХДѓМвШЅУўЫїЃЌЦфжагавЛИіЪЧ DNS НтЮіДэЮѓЃЌБэЯжаЮЪНЮЊ POD ФкЕФГЬађЭЈЙ§гђУћЗУЮЪНтЮіВЛСЫЃЌcat
вЛЯТШнЦїЕФ /etc/resolv.confЗЂЯжжИЯђЕФ dns ЗўЮёЦїгы kubectl get svc
--namespace=kube-system жаЕФ kube-dsn ЕижЗВЛЗћЃЛНтОіАьЗЈОЭЪЧ БрМНкЕуЕФ
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
ЮФМўЃЌИќИФ KUBELET_DNS_ARGS ЕижЗЮЊ get svc жаЕФ kube-dns ЕижЗЃЌШЛКѓжиЦє
kubelet ЗўЮёЃЌжиаТЩБЕє POD ШУ kubernetes жиНЈМДПЩ
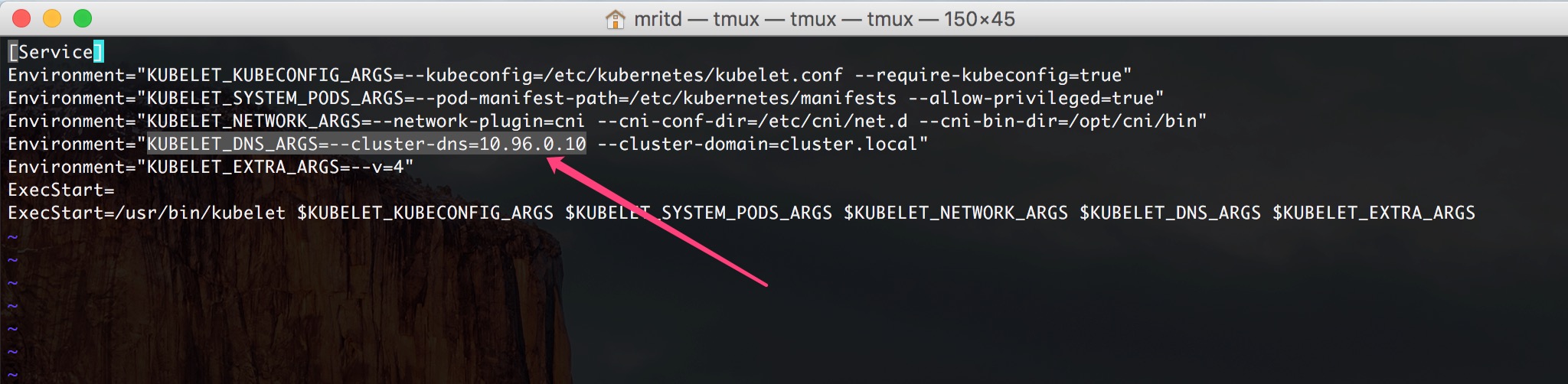
ЦфЫћПгЛЖгДѓМвВЙГф |









