| KubernetesΒΡΧΊΒψ
ΫϋΡξά¥Docker»ίΤςΉςΈΣ“Μ÷÷«αΝΩΦΕ–ιΡβΜ·ΦΦ θΗο–¬ΝΥ’ϊΗωITΝλ”ρ»μΦΰΩΣΖΔ≤Ω πΝς≥ΧΘ§»γΚΈΗΏ–ßΉ‘Ε·Ιήάμ»ίΤςΚΆœύΙΊΒΡΦΤΥψΓΔ¥φ¥ΔΒ»Ή ‘¥Θ§ΫΪ»ίΤςΦΦ θ’φ’ΐ¬δΒΊ…œœΏΘ§‘ρ–η“Σ“ΜΧΉ«Ω¥σ»ίΤς±ύ≈≈ΖΰΈώΘ§Β±«Α¥σΚλ¥σΉœΒΡKubernetes“―Ψ≠±ΜΙΪ»œΈΣ’βΗωΝλ”ρΒΡΝλΒΦ’ΏΓΘGoogleΜυ”ΎΡΎ≤ΩBorg °ΕύΡξ¥σΙφΡΘΦ·»ΚΙήάμΨ≠―ι‘Ύ2014Ρξ«ΉΉ‘«ψ–Ρ¥ρ‘λΝΥKubernetes’βΗωΩΣ‘¥œνΡΩΘ§”ϊ“–÷°”κAWS‘Ύ‘ΤΦΤΥψ2.0 ±¥ζ“Μ’υΗΏœ¬Θ§Φ¥±ψ»γ¥ΥΘ§KubernetesΒΡΕ®ΈΜ÷ς“Σ «ΟφœρΥΫ”–‘Τ –≥ΓΘ§ΥϋΉνΒδ–ΆΒΡ≤Ω πΡΘ Ϋ «‘ΎGCEΜρAWSΤΫΧ®…œΜυ”Ύ‘Τ÷ςΜζΓΔ‘ΤΆχ¬γΓΔ‘Τ”≤≈ΧΦΑΗΚ‘ΊΨυΚβΒ»ΦΦ θΗχ”ΟΜßΒΞΕά≤Ω π“Μ’ϊΧΉKubernetes»ίΤςΙήάμΦ·»ΚΘ§Τδ±Ψ÷ …œ «¬τΒΡIAASΖΰΈώΘ§KubernetesΦ·»ΚΜΙ «–η“ΣΩΩ”ΟΜßΉ‘ΦΚΈ§ΜΛΘ§¥σΦ“÷ΣΒάKubernetesΥδ»ΜΙΠΡή«Ω¥σΒΪ Ι”ΟΓΔΙήάμΓΔ‘ΥΈ§Ο≈Φς“≤ΗΏΘ§≥ωΈ ΧβΝΥ¥σΕύ ΐ”ΟΜßΜα χ ÷Έό≤ΏΓΘ
’βΦΗΡξΙζΡΎ»ίΤς‘ΤΝλ”ρ“≤ «»Κ–έΗνΨίΘ§ΒΪΕύ ΐΜΙ «“‘ΥΫ”–‘ΤΈΣ÷ςΘ§ΧαΙ©ΙΪ”–‘Τ»ίΤςΖΰΈώΒΡ»¥Κή…ΌΘ§÷ς“Σ «ΙΪ”–‘Τ“ΣΩΦ¬«ΒΡΈ ΧβΕύΓΔΧτ’Ϋ¥σΓΘΥδ»Μ»γ¥ΥΘ§Άχ“Ή‘ΤΒΡΜΙ «ΧαΙ©ΝΥΙΪ”–‘ΤΡΘ ΫΒΡ»ίΤςΖΰΈώΓΘΆχ“Ή‘Τ¥”2015ΡξΩΣ ΦΉω»ίΤςΖΰΈώ ±“≤±ΜKubernetes«Ω¥σΒΡΙΠΡήΓΔ≤εΦΰΜ·ΥΦœκΚΆ±≥Κσ«Ω¥σΒΡΦΦ θ ΒΝΠΥΒΈϋ“ΐΘ§÷ΝΫώ“―Ψ≠ΗζΥφKubernetes“ΜΤπΉΏΙΐΝΫΡξΕύΘ§ΜΐάέΝΥ≤Μ…ΌΨ≠―ιΓΘ“ρΈΣΈ“Ο«ΧΊ±πœΘΆϊ“‘ΙΪ”–‘ΤΒΡΖΫ ΫΧαΙ©“Μ÷÷Ηϋ“Ή”Ο»ίΤςΖΰΈώΘ§»ΈΚΈΕ‘»ίΤςΗ––Υ»ΛΒΡ”ΟΜßΕΦΡήΩλΥΌ…œ ÷Θ§ΈΣ¥Υ“≤”ωΒΫΝΥΚήΕύΥΫ”–‘Τœ¬≤ΜΜα≥ωœ÷ΒΡΈ ΧβΓΘ
Ν–ΨΌΦΗΗωKubernetes‘ΎΙΪ”–‘Τ»ίΤς≥ΓΨΑœ¬ΒΡ–η“ΣΧΊ±πΫβΨωΒΡΙΊΦϋΈ ΧβΓΘ“Μ «KubernetesάοΟΜ”–”ΟΜßΘ®ΉβΜßΘ©ΒΡΗ≈ΡνΘ§÷Μ”–“ΜΗωΚή»θΒΡΟϋΟϊΩ’Φδά¥Ήω¬ΏΦ≠ΗτάκΓΘΕΰ «KubernetesΚΆDockerΒΡΑ≤»ΪΈ ΧβΚήΆΜ≥ωΘ§APIΖΟΈ ΩΊ÷ΤΫœ»θ«“ΟΜ”–”ΟΜßΝςΩΊΜζ÷ΤΘ§“Μ–©Ή ‘¥»ΪΨ÷Ω…ΦϊΓΘΕχDocker»ίΤς”κΥό÷ςΜζΙ≤œμΡΎΚΥΒΡ«αΝΩΦΕΗτάκ¥”Ηυ±Ψ…œΟΜΖ®ΉωΒΫ≥ΙΒΉΑ≤»ΪΓΘ»ΐ «KubernetesΦ·»ΚΥυ–η“ΣIAASΉ ‘¥Θ®»γNodeΘ§PVΘ©ΕΦ“Σ‘Λœ»ΉΦ±ΗΉψΙΜΘ§Ζώ‘ρ»ίΤςΥφ ±Μα¥¥Ϋ® ßΑήΘ§ΙΪ”–‘Τ’β―υΒΡΜΑΜα‘λ≥…―œ÷ΊΒΡΉ ‘¥άΥΖ―Θ§≤ζ…ζΨό¥σΒΡ≥…±ΨΈ ΧβΓΘΥΡ «KubernetesΒΞΗωΦ·»ΚΡή÷ß≥≈ΒΡΫΎΒψΉή ΐ”–œόΘ§Ήν¥σΑ≤»ΪΙφΡΘ÷Μ”–5«ßΗωNodeΘ§ΙΪ”–‘Τœ¬ά©’Ι–‘ΫΪΜα”–Έ ΧβΓΘ
Άχ“Ή‘Τ»ίΤς»γΚΈΫβΨωKubernetes‘ΎΙΪ”–‘Τ…œΒΡΈ Χβ
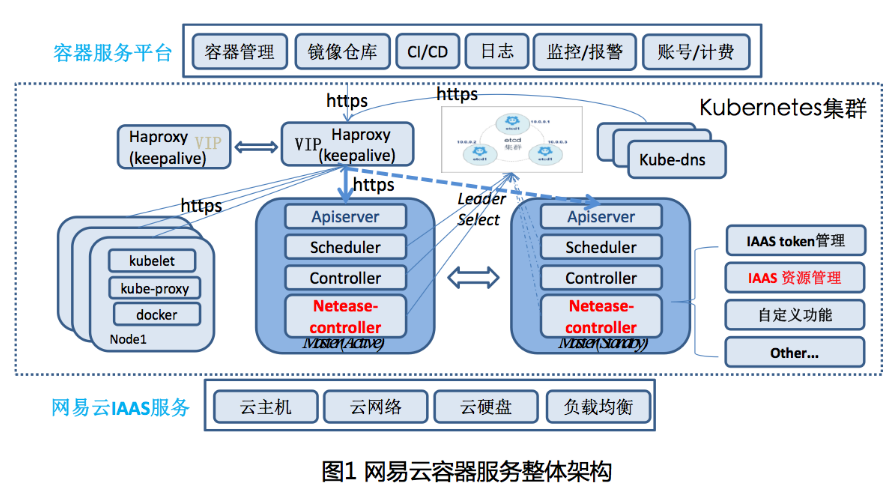
œ»Ω¥œ¬Άχ“Ή‘Τ»ίΤςΖΰΈώΒΡΦήΙΙΆΦΘ®»γΆΦ1Θ©Θ§’βάοΒΡKubernetes¥Π”ΎΒΉ≤ψIAASΖΰΈώΚΆ…œ≤ψ»ίΤςΤΫΧ®ΒΡ÷–ΦδΘ§“ρΈΣΈ“Ο«ΒΡ»ίΤςΖΰΈώ≤ΜΫωΫωΧαΙ©Kubernetes±Ψ…μ»ίΤς±ύ≈≈ΙήάμΙΠΡήΘ§Ηϋ «ΈΣΧαΙ©“Μ’ϊΧΉΉ®“ΒΒΡ»ίΤςΫβΨωΖΫΑΗΘ§ΜΙΑϋά®»ίΤςΨΒœώΖΰΈώΘ§ΗΚ‘ΊΨυΚβΖΰΈώΘ§Ά®Ιΐ Ι”ΟDevOps
ΙΛΨΏΝ¥ΗΏ–ßΙήάμΈΔΖΰΈώΦήΙΙΓΘΩΦ¬«ΒΫKubernetesΗ≈ΡνΫœΕύΓΔΤ’Ά®”ΟΜß Ι”ΟΗ¥‘”Θ§“≤ΈΣΝΥ±ψ”Ύ’ϊΚœΤδΥϊ≈δΧΉΖΰΈώΘ§Έ“Ο«≤ΔΟΜ”–÷±Ϋ”±©¬ΕKubernetesΒΡAPIΚΆΥυ”–Η≈ΡνΗχΤ’Ά®”ΟΜßΓΘ
ΙΪ”–‘ΤΉβΜßΗ≈Ρν
Άχ“Ή‘Τ»ίΤςΖΰΈώΜυ”ΎKubernetes“―”–ΒΡNamespaceΒΡ¬ΏΦ≠ΗτάκΧΊ–‘Θ§–ιΡβ≥ω“ΜΗωΉβΜßΒΡΗ≈ΡνΘ§≤Δ”κNamespaceΫχ––”άΨΟΑσΕ®ΘΚ“ΜΗωNamespace÷ΜΡή τ”Ύ“ΜΗωΉβΜßΘ§“ΜΗωΉβΜß‘ρΩ…“‘”–ΕύΗωNamespaceΓΘ’β―υKubernetesάο≤ΜΆ§ΉβΜß÷°ΦδΒΡPodΓΔServiceΓΔSecretΨΆΡήΉ‘»ΜΖ÷ΗνΘ§Εχ«“Ω…“‘÷±Ϋ”‘Ύ‘≠…ζΒΡNamespace/ResouceΦΕ±πΒΡ»œ÷Λ Ύ»®…œΫχ––ΉβΜßΦΕ±πΒΡΑ≤»ΪΗΡ‘λΓΘ
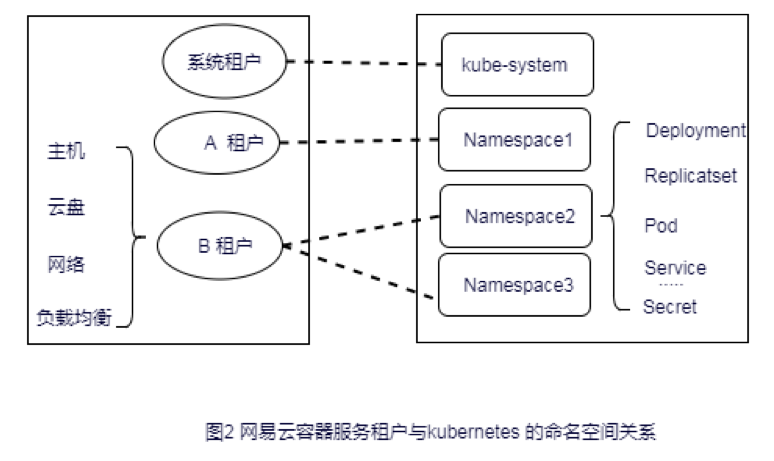
ΕύΉβΜßΑ≤»ΪΈ Χβ
ΙΊ”ΎKubernetesΒΡAPIΒΡΑ≤»ΪΖΟΈ ΩΊ÷ΤΘ§ΨΓΙήΆχ“Ή‘Τ»ίΤςΟΜ”–÷±Ϋ”±©¬ΕKubernetesΒΡAPIΗχ”ΟΜßΘ§ΒΪ”ΟΜß»ίΤςΥυ‘ΎΒΡNodeΕΥ“≤ΕΦ“ΣΖΟΈ APIΘ§Node±Ψ÷ ΨΆ «”ΟΜßΒΡΉ ‘¥ΓΘΈ“Ο«‘ΎΉν‘γΜυ”ΎKubernetes
1.0ΩΣΖΔΒΡ ±ΚρΨΆΉ®Ο≈‘ωΦ”ΝΥ“ΜΧΉ«αΝΩΦΕά©’Ι Ύ»®ΩΊ÷Τ≤εΦΰΘΚΜυ”ΎΙφ‘ρΖΟΈ ΩΊ÷ΤΘ§±»»γ≈δ÷ΟΗςΉβΜß÷ΜΡήGetΚΆWatch τ”ΎΉ‘ΦΚNamespaceœ¬ΒΡPodΉ ‘¥Θ§ΫβΨωΕ‘KubernetesΉ ‘¥API»®œόΩΊ÷ΤΝΘΕ»≤ΜΙΜΨΪ»Ζ«“ΈόΖ®Ε·Χ§‘ωΦθΉβΜßΒΡΈ ΧβΓΘ÷ΒΒΟ–άΈΩΒΡ «ΦΗΗω‘¬«ΑΙΌΖΫΖΔ≤ΦΒΡ1.
6–¬ΆΤ≥ωRBACΘ®Μυ”ΎΫ«…ΪΖΟΈ ΩΊ÷ΤΘ©ΙΠΡήΘ§ ΙΒΟ Ύ»®ΙήάμΜζ÷ΤΒΟ“‘‘ω«ΩΘ§ΒΪΖΰΈώΕΥΕ‘”ΟΜßNodeΕΥΖΟΈ ΒΡ“λ≥ΘΝςΝΩΩΊ÷ΤΒΡ»±ΖΠ“ά»Μ «“ΜΗω“ΰΜΦΘ§ΈΣ¥ΥΘ§Έ“Ο«“≤‘ΎapiserverΕΥ‘ωΦ”«κ«σ ΐά¥‘¥Ζ÷άύΆ≥ΦΤΚΆΩΊ÷ΤΡΘΩιΘ§±ήΟβ”–≤ΜΝΦ”ΟΜߥ”»ίΤςάοΧ”“ίΒΫNode…œΫχ––Εώ“βΙΞΜςΓΘ
‘≠…ζΒΡkube-proxyΧαΙ©ΒΡΡΎ≤ΩΗΚ‘Ί±Ί–κ“ΣList&WatchΦ·»ΚΥυ”–ServiceΚΆEndpointΘ§ΒΦ÷¬ΨΆΥψ‘ΎΕύΉβΜß≥ΓΨΑœ¬ServiceΚΆEndpoint“≤“Σ»Ϊ≤Ω±©¬ΕΘ§Ά§ ±ΒΦ÷¬iptablesΙφ‘ρ≈ρ’ΆΉΣΖΔ–ß¬ ΦΪΒΆΘΜΈΣ¥ΥΈ“Ο«Ε‘kube-proxy“≤ΉωΝΥ”≈Μ·ΗΡ‘λΘΚΟΩΗωΉβΜßΒΡNode…œ÷ΜΜαList&WatchΉ‘ΦΚΒΡœύΙΊNamespaceœ¬Ή ‘¥Φ¥Ω…Θ§’β―υΦ»ΫβΨωΝΥΑ≤»ΪΈ Χβ”÷”≈Μ·–‘ΡήΘ§“ΜΦΐΥΪΒώΓΘ
÷Ν”ΎDockerΒΡΗτάκ≤Μ≥ΙΒΉΒΡΈ ΧβΘ§Έ“Ο«‘ρ―Γ‘ώΝΥΉν≥ΙΒΉΒΡΉωΖ®ΘΚ‘Ύ»ίΤςΆβΦ”ΝΥ“Μ≤ψ”ΟΜßΩ¥≤ΜΦϊΒΡ–ιΡβΜζΘ§Ά®ΙΐIAAS≤ψ–ιΡβΜζΒΡOS
ΡΎΚΥΗτάκ±Θ÷Λ»ίΤςΒΡΑ≤»ΪΓΘ
»ίΤςΒΡIAASΉ ‘¥Ιήάμ
»ίΤς‘ΤΉςΈΣ–¬“Μ¥ζΒΡΜυ¥Γ…η ©‘ΤΖΰΈώΘ§Ή ‘¥Ιήάμ±Ί»Μ“≤ «Ζ«≥ΘΙΊΦϋΒΡΓΘΥΫ”–‘Τ≥ΓΨΑœ¬’ϊΗωΦ·»ΚΉ ‘¥ΕΦ τ”ΎΤσ“ΒΉ‘ΦΚΘ§‘ΛΝτΒΡΥυ”–Ή ‘¥ΕΦΩ…“‘“ΜΤπ÷±Ϋ” Ι”ΟΓΔ ΆΖ≈ΓΔ÷Ί”ΟΘΜΕχΙΪ”–‘ΤΕύΉβΜßœ¬ΒΡΥυ”–Ή ‘¥ Ήœ» «“ΣΫχ––ΉβΜßΜ°Ζ÷ΒΡΘ§“ΜΒ©Φ”»κkubernetesΦ·»ΚΘ§NodeΓΔPVΓΔNetworkΒΡ τ÷ςΉβΜß±ψ“―»ΖΕ®≤Μ±δΘ§»γΙϊΗχΟΩΗωΉβΜßΕΦ‘ΛΝτΉ ‘¥Θ§ΚΘΝΩΉβΜßάέΦΤΤπά¥ΨΆΖ«≥ΘΩ÷≤άΝΥΘ§ΟΜΖ®Ϋ” ήΓΘΒ±»ΜΘ§Ω…“‘»ΟΙΪ”–‘Τ”ΟΜß‘Ύ¥¥Ϋ®»ίΤς«ΑΘ§Χα«ΑΑ―Υυ”––η“ΣΒΡΉ ‘¥ΕΦΉΦ±ΗΚΟΘ§ΒΪ’β―υ”÷Μα»Ο”ΟΜß”ΟΤπά¥ΗϋΗ¥‘”Θ§”κ»ίΤςΤΫΧ®“Ή”Ο–‘ΒΡ≥θ÷‘≤ΜΖϊΘ§Έ“Ο«ΗϋœΘΆϊΡήΑο”ΟΜßΑ―ΨΪΝΠΜ®‘Ύ“ΒΈώ±Ψ…μΓΘ
”Ύ «Έ“Ο«–η“ΣΗΡ‘λkubernetesΘ§“‘÷ß≥÷Α¥–ηΕ·Χ§…ξ«κΓΔ ΆΖ≈Ή ‘¥ΓΘΦ»»Μ“ΣΑ¥–η Β ±…ξ«κΉ ‘¥Θ§Ρ«ΨΆœ»άμœ¬»ίΤςΒΡ¥¥Ϋ®Νς≥ΧΘ§ΦρΒΞΤπΦϊΘ§Έ“Ο«÷±Ϋ”¥¥Ϋ®Podά¥ΥΒΟς’βΗωΙΐ≥ΧΘ§»γΆΦ3Υυ ΨΓΘ
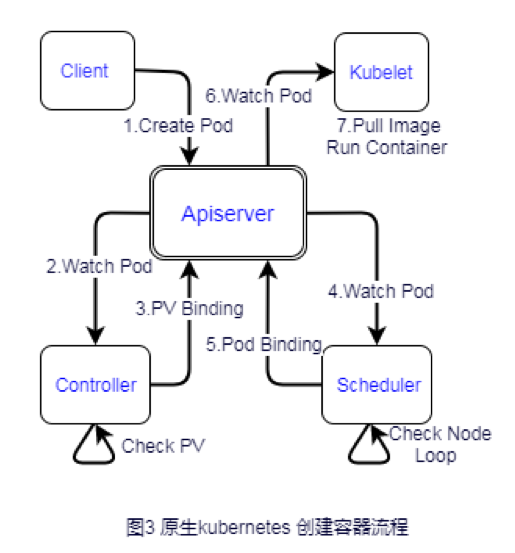
Pod¥¥Ϋ®≥ωά¥ΚσΘ§ Ήœ»ΩΊ÷ΤΤςΜαΦλ≤ι «Ζώ”–PVΘ®Άχ“Ή‘Τ»ίΤςΈΣ÷ß≥÷Άχ¬γΗτάκΜΙ‘ωΦ”ΉβΜßNetworkΉ ‘¥Θ©Θ§PVΉ ‘¥ «ΖώΤΞ≈δΘ§≤ΜΤΞ≈δ‘ρΒ»¥ΐΓΘ»γΙϊPod≤Μ–η“ΣPVΜρ’ΏPVΤΞ≈δΚσΒςΕ»Τς≤≈Ρή’ΐ≥ΘΒςΕ»PodΘ§»ΜΚσscheduler¥”Φ·»ΚΥυ”–ReadyΒΡ
NodeΝ–±μ’“Κœ NodeΑσΕ®ΒΫPod…œΘ§ΟΜ”–‘ρΒςΕ» ßΑήΘ§≤Δ¥”1ΟκΩΣ Φ“‘2ΒΡ÷Η ΐ±ΕΜΊΆΥΘ®backoffΘ©Β»¥ΐ≤Δ÷Ί–¬Φ”»κΒςΕ»Ε”Ν–Θ§÷±ΒΫΒςΕ»≥…ΙΠΓΘΉνΚσ‘ΎΒςΕ»ΒΡNodeΒΡkubelet…œά≠ΨΒœώ≤ΔΑ―»ίΤς¥¥Ϋ®≤Δ‘Υ––Τπά¥ΓΘ
Ά®ΙΐΖ÷Έω…œ ωΝς≥ΧΩ…“‘ΖΔœ÷Θ§Ω…“‘‘ΎΩΊ÷ΤΤς…œΤΞ≈δPVΜρNetwork ± Β ±¥¥Ϋ®Ή ‘¥Θ§»ΜΚσ‘ΎΒςΕ»Τς“ρ»±…ΌNodeΕχΒςΕ» ßΑή ±‘Ό Β ±¥¥Ϋ®NodeΘ®–ιΡβΜζVMΘ©Θ§‘ΌΒ»œ¬¥Έ ßΑήbackoff÷Ί–¬ΒςΕ»ΓΘΒΪ «Ή–œΗΖ÷ΈωΚσΜαΖΔœ÷ΜΙ”–ΚήΕύΈ ΧβΘ§ Ήœ» «IAAS÷–Φδ≤ψΧαΙ©ΒΡ¥¥Ϋ®Ή ‘¥Ϋ”ΩΎΕΦ «“λ≤ΫΒΡΘ§¬÷―·Β»¥ΐ–߬ ΜαΚήΕύΘ§Εχ«“PVΘ§NetworkΘ§NodeΕΦ¥°––…ξ«κΜαΖ«≥Θ¬ΐΘ§»ίΤς±Ψά¥ΨΆ «ΟκΦΕΤτΕ·Θ§≤ΜΡήΒΫ‘ΤΖΰΈώ…œΨΆ±δ≥…Ζ÷÷”ΦΕ±πΘΜΤδ¥ΈNode¥”¥¥Ϋ®VMΘ§≥θ ΦΜ·Α≤ΉΑDockerΓΔkubeletΓΔkube-proxyΒΫΤτΕ·Ϋχ≥Χ≤ΔΉΔ≤αΒΫKubernetes…œ ±Φδ¬ΰ≥ΛΘ§ΒςΕ»Τςbackoff÷Ί–¬ΒςΕ»Εύ¥Έ“≤≤Μ“ΜΕ®ΨΆ–ςΘ§ΉνΚσΘ§Μυ”ΎKubernetesΒΡ–όΗΡ“ΣΩΦ¬«…Ό«÷»κΘ§Kubernetes…γ«χΦΪΕ»Μν‘Ψ“Μ÷±±Θ≥÷3Ηω‘¬ΖΔ≤Φ“ΜΗω¥σΑφ±ΨΒΡΫΎΉύΘ§“ΣΗζ…œ…γ«χΖΔ’ΙΩ…Ρή–η“Σ≤ΜΕœ…ΐΦΕœΏ…œΑφ±ΨΓΘ
Ήν÷’Θ§Έ“Ο«Ά®Ιΐ‘ωΦ”ΕάΝΔΒΡResourceControllerΘ§Ϋη÷ζwatchΜζ÷Τ≤…”Ο»Ϊ“λ≤ΫΖ«Ήη»ϊΓΔ»Ϊ ¬Φΰ«ΐΕ·ΡΘ ΫΓΘΉ ‘¥≤ΜΉψΨΆΖΔΤπΉ ‘¥“λ≤Ϋ…ξ«κΘ§≤ΔΫ”Ή≈¥ΠάμΚσΟφΝς≥ΧΘ§ΕχΉ ‘¥“ΜΒ©ΨΆ–ςΝΔ¬μ¥ΞΖΔ‘ΌΒςΕ»Θ§…ξ«κNode ±÷–Φδ≤ψ“≤Χα«ΑΉΦ±Η–ιΡβΜζΉ ‘¥≥ΊΘ§≤ΔΫΪNode≥θ ΦΜ·ΓΔΑ≤ΉΑ≤Ϋ÷η‘Λœ»‘Ύ–ιΡβΜζΨΒœώ÷–ΉΦ±ΗΚΟΓΘ”Ύ «Θ§Έ“Ο«œξœΗΒΡ¥¥Ϋ®Νς≥Χ―ί±δΈΣΆΦ4Υυ ΨΓΘΘ®ΉΔΘΚΉν–¬Kubernetes
“―Ψ≠Ά®ΙΐStorageClassάύ–Ά÷ß≥÷PV dynamic provisioningΘ©
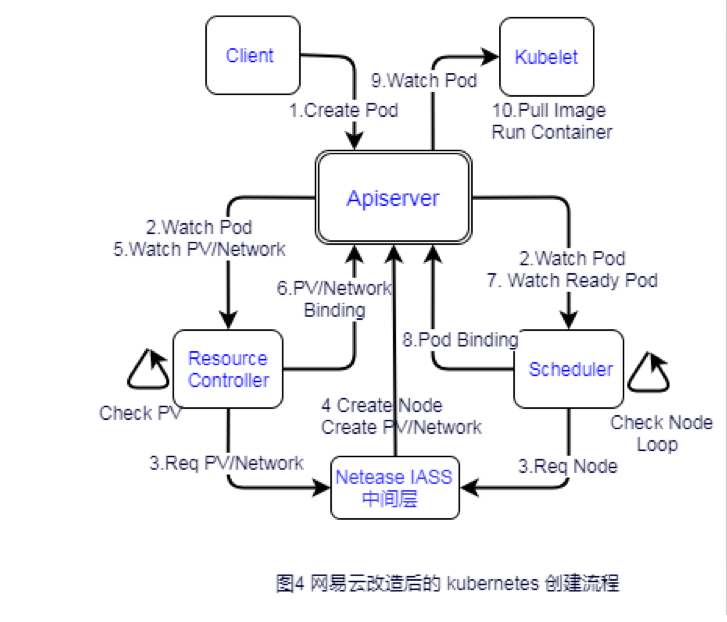
”κ‘≠…ζΒΡKubernetesœύ±»Θ§Έ“Ο«‘ωΦ”ΝΥ“ΜΗωΕάΝΔΒΡ ResourceControllerΙήάμΥυ”–IAASΉ ‘¥œύΙΊΒΡ ¬«ιΘ§ΨΏΧεΒΡPod¥¥Ϋ®≤Ϋ÷η»γœ¬ΘΚ
1ΓΔ…œ≤ψclient«κ«σapiserver¥¥Ϋ®“ΜΗωPodΓΘ
2ΓΔResourceController watchΒΫ”––¬‘ωPodΘ§Φλ≤ιPVΚΆNetwork «Ζώ“―Ψ≠¥¥Ϋ®ΘΜ
Ά§ ±Θ§Νμ“Μ±ΏΒΡscheduler“≤ΖΔœ÷”––¬Pod…–Έ¥ΒςΕ»Θ§“≤≥Δ ‘Ε‘PodΫχ––ΒςΕ»ΓΘ
3ΓΔ“ρΈΣΉ ‘¥ΕΦΟΜ”–Χα«ΑΉΦ±ΗΘ§Ήν≥θResourceControllerΦλ≤ι ±ΖΔœ÷ΟΜ”–”κPodΤΞ≈δΒΡPVΚΆNetworkΘ§ΜαœρIAAS÷–Φδ≤ψ«κ«σ¥¥Ϋ®‘Τ≈ΧΚΆΆχ¬γΉ ‘¥ΘΜ
scheduler ‘ρ“≤“ρΈΣ’“≤ΜΒΫΩ…ΒςΕ»ΒΡNode“≤Ά§ ±œρIAAS÷–Φδ≤ψ«κ«σ¥¥Ϋ®Ε‘”ΠΙφΗώΒΡVMΉ ‘¥Θ®NodeΘ©Θ§’β ±Pod“≤≤Μ‘Ό÷Ί»κΒςΕ»Ε”Ν–Θ§ΚσΟφ“Μ«–ΉΦ±ΗΨΆ–ς≤≈Μα÷ΊΒςΕ»ΓΘ
4ΓΔ“ρΈΣIAAS÷–Φδ≤ψ¥¥Ϋ®Ή ‘¥œύΕ‘Ϋœ¬ΐΘ§“≤÷ΜΧαΙ©“λ≤ΫΫ”ΩΎΘ§¥ΐΒΉ≤ψΉ ‘¥ΉΦ±ΗΆξ±œΘ§±ψΝΔΦ¥Ά®ΙΐapiserverΉΔ≤αPVΓΔNetworkΓΔNodeΉ ‘¥
5~6ΓΔResourceControllerΒ±ΖΔœ÷PVΚΆNetworkΕΦ¬ζΉψΝΥΘ§ΨΆΫΪΥϊΟ«”κPodΑσΕ®ΘΜΒ±ΖΔœ÷Pod…ξ«κΒΡNodeΉΔ≤α…œά¥Θ§«“PVΚΆNetworkΨυΑσΕ®Θ§ΜαΑ―Pod…η÷ΟΈΣResourceReadyΨΆ–ςΉ¥Χ§
7ΓΔScheduler‘Ό¥ΈwatchΒΫPod¥Π”ΎResourceReadyΉ¥Χ§Θ§‘ρ÷Ί–¬¥ΞΖΔΒςΕ»Ιΐ≥ΧΘ§
8ΓΔPodΒςΕ»≥…ΙΠ”κ–¬Ε·Χ§¥¥Ϋ®NodeΫχ––ΑσΕ®
9~10ΓΔΕ‘”ΠNodeΒΡkubelet watchΒΫ–¬ΒςΕ»ΒΡPodΜΙΟΜ”–ΤτΕ·Θ§‘ρΜαœ»ά≠»ΓΨΒœώ‘ΌΤτΕ·»ίΤςΓΘ
Φ·»ΚΉν¥σΙφΡΘΈ Χβ
¥”’ΐ ΫΖΔ≤Φ1.0Αφ±Ψ÷ΝΫώΉν–¬ΒΡ1.7Θ§KubernetesΙ≤Ψ≠άζΝΥ2¥Έ¥σΙφΡΘΒΡ–‘Ρή”≈Μ·Θ§¥”1.0ΒΡ200Ηωnode÷ς“ΣΆ®Ιΐ‘ωΦ”apiserver
cacheΧα…ΐΒΫ1000ΗωnodeΘ§‘ΌΒΫ1.6Ά®Ιΐ…ΐΦΕetcdv3ΚΆjsonΗΡprotobufΉν÷’Χα…ΐΒΫ5000
nodeΓΘΒΪ «ΙΌΖΫ≥ΤΚσ–χ≤ΜΜα‘ΌΩΦ¬«ΦΧ–χ”≈Μ·ΒΞΦ·»ΚΙφΡΘΝΥΘ§“―”–ΒΡΦ·»ΚΝΣΑνΙΠΡή”÷ΧΪΙΐΦρ¬ΣΓΘ»γΙϊΙΪ”–‘Τ≥ΓΨΑœ¬ΥφΉ≈“―”–”ΟΜßΙφΡΘ≤ΜΕœ‘ω¥σΘ§“ΜΒ©ΩλΫ”ΫϋΦ·»ΚΉν¥σΙφΡΘ ±Θ§ΨΆ÷ΜΡήΫΪΤδ÷–“Μ–©¥σ”ΟΜß“Μ≈ζ≈ζ«®“Τ≥ω»Ξά¥ΧΎΩ’ΦδΗχ Θ”ύ”ΟΜßΓΘ
”Ύ «Έ“Ο«Ή‘ΦΚ‘Ύ…γ«χΑφ±ΨΜυ¥Γ…œ”÷ΉωΝΥ¥σΝΩΕ®÷ΤΜ·ΒΡ–‘Ρή”≈Μ·Θ§ΡΩ«ΑΒΞΦ·»Κ–‘Ρή≤β ‘Ήν¥σΑ≤»ΪΙφΡΘ“―Ψ≠≥§Ιΐ3ΆρΘ§―ι ’≤β ‘Αϋά®Φ·»ΚΗΏΥ°ΈΜœ¬Θ§¥σ≤ΔΖΔ¥¥Ϋ®ΥΌΕ»deploymentΚΆΩλΥΌ÷ΊΤτmasterΕΥΖΰΈώΚΆΥυ”–nodeΕΥkubeletΒ»‘ΎΡΎΒΡΕύ÷÷ΦΪΕΥ“λ≥Θ≤ΌΉςΘ§±Θ÷Λ¥¥Ϋ® ±ΦδΨυ÷Β<5sΘ§99÷Β<15sΘ§Φ·»Κ÷––ΡΙήΩΊΖΰΈώΉν≤ν‘Ύ3Ζ÷÷”ΡΎΩλΥΌΜ÷Η¥’ΐ≥ΘΓΘ
ΨΏΧεΒΡ”≈Μ·¥κ ©Αϋά®ΘΚ
1ΓΔ scheduler”≈Μ·
ΗυΨίΉβΜß÷°ΦδΉ ‘¥Άξ»ΪΗτάκΜΞ≤Ι”ΑœλΒΡΧΊ–‘Θ§Έ“Ο«ΫΪ‘≠”–ΒΡ¥°––ΒςΕ»Νς≥ΧΘ§ΗΡ‘λΈΣΉβΜßΦδΆξ»Ϊ≤Δ––ΒΡΒςΕ»ΡΘ ΫΘ§‘Ό≈δΚœ–≠≥Χ≥Ίά¥’υΕαΩ…≤Δ––ΒΡΒςΕ»»ΈΈώΓΘ‘ΎΒςΕ»ΥψΖ®…œΘ§ΜΙ≤…”Ο‘Λœ»≈≈≥ΐΉ ‘¥≤ΜΉψΒΡnodeΓΔ”≈Μ·Ιΐ¬ΥΚ· ΐΥ≥–ρΒ»≤Ώ¬‘Ϋχ––Ψ÷≤Ω”≈Μ·ΓΘ
2ΓΔ Controller”≈Μ·
λœΛKubernetesΒΡ»ΥΕΦ÷ΣΒάΘ§Kubernetes”–ΗωΚΥ–ΡΧΊΒψΨΆ « ¬Φΰ«ΐΕ·Θ§ Β ±–‘ΚήΚΟΘ§ΒΪ «”–ΗωSync ¬Φ໥Dž»≈ΝΥFIFOΒΡΥ≥–ρΘ§Έ“Ο«Ά®ΙΐΫΪAddΓΔUpdateΓΔDeleteΓΔSync ¬Φΰ≈≈–ρ≤Δ‘ωΦ”Εύ”≈œ»ΦΕΕ”Ν–ΒΡΖΫ ΫΫβΨω’β÷÷“λ≥ΘΗ…»≈ΓΘ
‘ωΦ”Secret±ΨΒΊΜΚ¥φ
3ΓΔ apiserver”≈Μ·
apiserverΒΡΚΥ–Ρ «ΧαΙ©άύΥΤCRUDΒΡrestfulΫ”ΩΎΘ§”≈Μ·ΖΫœρΈόΆβΚθΫΒΒΆœλ”Π ±ΦδΘ§Φθ…ΌcpuΓΔΡΎ¥φœϊΚΡ“‘ΧαΗΏΆΧΆ¬ΝΩΘ§Έ“Ο«Ήν÷ς“ΣΒΡ“ΜΗω”≈Μ· «‘ωΦ”“‘ΉβΜßIDΈΣΙΐ¬ΥΧθΦΰΒΡ≤ι―·Υς“ΐΘ§’β―υΨΆΡή Βœ÷‘ΎΉβΜßΡΎΩγNamespaceΨέΚœ≤ι―·ΒΡ–ßΙϊΓΘΝμΆβapiserverΒΡΩΆΜßΕΥ‘≠…ζΒΡΝςΩΊ≤Ώ¬‘ΧΪ±©ΝΠΘ§ΩΆΜßΕΥΡ§»œ‘ΎΝςΩΊ±Μœό÷ΤΚσΜαΖ¥Η¥÷Ί ‘Θ§Ϋχ“Μ≤ΫΦ”ΨγapiserverΒΡ―ΙΝΠΘ§Έ“Ο«‘ωΦ”ΝΥ“Μ÷÷Μυ”ΎΖ¥άΓΒΡ÷«Ρή÷Ί ‘ΒΡ≤Ώ¬‘Ρ®ΤΫ’β÷÷ΆΜΖΔΝςΝΩΓΘ
4ΓΔNodeΕΥ”≈Μ·
kube-proxy±Ψά¥–η“ΣΩΊ÷Τ’ϊΗωΦ·»ΚΗΚ‘ΊΉΣΖΔΒΡΘ§Apiserver”–ΝΥΉβΜß≤ι―·Υς“ΐΚσΘ§Έ“Ο«ΨΆΡή÷ΜwatchΉ‘ΦΚΉβΜßΡΎΒΡService/EndpointΘ§Φ±ΨγΥθ–ΓiptablesΙφ‘ρ ΐΝΩΘ§ΧαΗΏ≤ι’“ΉΣΖΔ–ß¬ ΓΘΕχ«“Έ“Ο«ΜΙΨΪΦρkubeletΚΆkube-proxyΡΎ¥φ’Φ”ΟΚΆΝ§Ϋ” ΐΓΘ
Άχ“Ή‘Τ»ίΤςΖΰΈώΒΡΤδΥϊ ΒΦυΦΑΉήΫα
»ίΤςΒΡΆχ¬γ «Ζ«≥ΘΗ¥‘”“ΜΩιΘ§»ίΤς‘ΤΖΰΈώ÷Ν…Ό“ΣΧαΙ©Έ»Ε®ΓΔΝιΜνΓΔΗΏ–ßΒΡΩγ÷ςΜζΆχ¬γΘ§Υδ»ΜΩΣ‘¥Άχ¬γ Βœ÷ΚήΕύΘ§ΒΪ «ΥϋΟ«“ΣΟ¥≤Μ÷ß≥÷ΕύΉβΜßΓΔ“ΣΟ¥–‘Ρή≤ΜΚΟΘ§«“÷±Ϋ”ΡΟΟΜ”–Ψ≠Ιΐ¥σΙφΡΘœΏ…œΩΦ―ιΒΡΩΣ‘¥»μΦΰΈ ΧβΉήΜαΚήΕύΓΘ–“‘ΥΒΡ ±Άχ“Ή‘Τ”–Ή‘ΦΚΉ®“ΒΒΡIAAS‘ΤΆχ¬γΆ≈Ε”Θ§ΥϊΟ«ΡήΧαΙ©Ή®“ΒΦΕΒΡVPCΆχ¬γΫβΨωΖΫΑΗΘ§Χλ…ζΨΆ÷ß≥÷ΕύΉβΜßΓΔΑ≤»Ϊ≤Ώ¬‘ΩΊ÷ΤΚΆΗΏ–‘Ρήά©’ΙΘ§“―Ψ≠ΉωΒΫ»ίΤς”κ–ιΡβ÷ςΜζΒΡΆχ¬γ «Άξ»ΪΜΞΆ®«“ΒΊΈΜΕ‘Β»ΒΡΓΘ
Άχ“Ή‘Τ»ίΤςΖΰΈώΜΙ‘ΎKubernetes…γ«χΑφ±ΨΜυ¥Γ…œΫαΚœ≤ζΤΖ–η«σ–¬‘ωΝΥΚήΕύΙΠΡήΘ§Αϋά®÷ß≥÷ΧΊ”–ΒΡ”–Ή¥Χ§»ίΤςΘ§ΦΑNodeΙ ’œ ±»ίΤςœΒΆ≥ΡΩ¬Φ“≤ΡήΉ‘Ε·«®“Τ“‘±Θ≥÷ ΐΨί≤Μ±δΘ§ΕύΗ±±ΨPodΩ…Α¥NodeΒΡAvailableZoneΖ÷≤Φ«Ω÷ΤΨυΚβΒςΕ»Θ®…γ«χ÷ΜΨΓΝΠΨυΚβΘ©ΓΔ»ίΤς¥Ι÷±ά©»ίΓΔ”–Ή¥Χ§»ίΤςΕ·Χ§Ι“–Ε‘ΊΆβΆχIPΒ»ΓΘ
œύ±»»ίΤςΒΡ«αΝΩΦΕ–ιΡβΜ·Θ§–ιΡβΜζΥδ»ΜΑ≤»ΪΦΕ±πΗϋΗΏΘ§ΒΪ «‘ΎcpuΓΔ¥≈≈ΧΓΔΆχ¬γΒ»ΖΫΟφΕΦ¥φ‘Ύ“ΜΕ®ΒΡ–‘ΡήΥπΚΡΘ§Εχ”––©“ΒΈώ»¥”÷Ε‘–‘Ρή“Σ«σΖ«≥ΘΗΏΓΘ’κΕ‘’β–©ΧΊ β–η«σΘ§ΉνΫϋΈ“Ο«“≤‘ΎΩΣΖΔΜυ”ΎKubernetesΒΡΗΏ–‘Ρή¬ψΜζ»ίΤςΘ§»ΤΙΐ–ιΡβΜζΫΪΆχ¬γΓΔ¥φ¥ΔΒ»–ιΡβΜ·ΦΦ θ÷±Ϋ”Ε‘Ϋ”ΒΫDocker»ίΤςάοΘ§‘ΎΫαΚœSR-IOVΆχ¬γΦΦ θΓΔΆχ“ΉΗΏ–‘Ρή‘Τ≈ΧNBSΘ®netease
block storageΘ©Β»ΦΦ θΫΪ–ιΡβΜ·ΒΡ–‘ΡήΥπΚΡΫΒΒΫΉνΒΆΓΘ
ΉνΚσΘ§Ζ÷œμ“Μ–©Άχ“Ή‘Τ»ίΤςΖΰΈώ…œœΏΫϋΝΫΡξά¥ΒΡ”ωΒΫΒΡ±»ΫœΒδ–ΆΒΡΩ”ΓΘ
1ΓΔApiserverΉςΈΣΦ·»Κhub÷––Ρ±Ψ…μ «ΈόΉ¥Χ§ΒΡΩ…Υ°ΤΫά©’ΙΘ§ΒΪ «ΕύapiserverΕΝ–¥Μα‘ΎApiserver«–ΜΜ ±Ω…ΡήΜα≥ωœ÷–¥»κΒΡ ΐΨί≤ΜΡήΝΔ¬μΕΝΒΫΒΡΈ ΧβΘ§‘≠“ρ «etcdΒΡraft–≠“ι≤Μ «Υυ”–ΫΎΒψ«Ω“Μ÷¬–¥ΒΡΓΘ
2ΓΔhaproxyΝ§Ϋ”ΒΡΈ ΧβΘ§ΕύApiserver«Α”ΟhaproxyΉωΗΚ‘ΊΨυΚβΘ§haproxyΚή»ί“Ή≥ωœ÷ΩΆΜßΕΥΕΥΩΎ≤ΜΙΜ”ΟΚΆΝ§Ϋ” ΐΙΐΕύΒΡΈ ΧβΘ§Ω…“‘Ά®Ιΐά©¥σΕΥΩΎΖΕΈßΓΔ‘ωΦ”‘¥ipΒΊ÷ΖΒ»ΖΫ ΫΫβΨωΕΥΩΎΈ ΧβΘ§Ά®Ιΐ‘ωΦ”client/serviceΒΡ–ΡΧχΧΫΜνΫβΨω“λ≥ΘΝ§Ϋ”GCΒΡΈ ΧβΓΘ
3ΓΔ”ΟΜßΗ≤Η«Ηϋ–¬“―”–tagΒΡΥΫ”–»ίΤςΨΒœώΈ ΧβΘ§«ΩΝ“Ϋ®“ι¥σΦ“≤Μ“ΣΗ≤Η«“―”–tagΒΡΨΒœώΘ§“≤≤Μ“Σ Ι”Οlatest’β―υΡΘΚΐΒΡΨΒœώ±ξ«©Θ§Ζώ‘ρRSΕύPodΗ±±ΨΜρ’ΏΆ§“ΜΗωNode…œΆ§ΨΒœώ»ίΤςΚή»ί“Ή≥ωœ÷Αφ±Ψ≤Μ“Μ÷¬ΒΡΙν“λΈ ΧβΓΘ
4ΓΔ”––©»ίΤς–ΓΈΡΦΰΖ«≥ΘΕύΘ§Κή»ί“ΉΑ―inode”ΟΙβΕχ¥≈≈ΧΩ’Φ以 Θ”ύΚήΕύΒΡΈ ΧβΘ§Ϋ®“ιΑ―’β÷÷άύ–Ά”Π”ΟΒςΕ»ΒΫinode≈δ÷ΟΕύΒΡnode…œΘ§ΝμΆβ‘≠…ζkubelet“≤¥φ‘Ύ≤ΜΜαΦλ≤ιinodeΙΐΕύ¥ΞΖΔΨΒœώΜΊ ’ΒΡΈ ΧβΓΘ
5ΓΔ”––©Pod…Ψ≥ΐ ±œζΜΌΙΐ¬ΐΒΡΈ ΧβΘ§Pod÷ß≥÷graceful…Ψ≥ΐΘ§ΒΪ «»γΙϊ»ίΤςΨΒœώΤτΕ·ΟϋΝν–¥ΒΟ≤ΜΚΟΘ§Ω…ΡήΜαΒΦ÷¬–≈Κ≈ΕΣ ß≤ΜΙβΟΜΖ®graceful…Ψ≥ΐΜΙΜαΒΦ÷¬―”≥Ό30sΒΡΈ Χβ
Ήή÷°Θ§‘ΎΙΪ”–‘Τ≥ΓΨΑœ¬Θ§”ΟΜßά¥‘¥ΙψΖΚΘ§ Ι”ΟœΑΙΏ«ß±δΆρΜ·ΟΜΖ®ΩΊ÷ΤΘ§Έ“Ο«“―Ψ≠≈ωΒΫΙΐΚήΕύ¥ΩΥΫ”–‘Τ≥ΓΨΑœ¬ΚήΡ―≥ωœ÷ΒΡΈ ΧβΘ§»γ”ΟΜßΨΒœώ≈ήΤπ≤Μά¥Θ§PodΕύ»ίΤςΕΥΩΎ≥εΆΜΘ§»’÷Ψ÷±Ϋ” δ≥ωΒΫ±ξΉΦ δ≥ωΘ§Μρ’Ώ»’÷Ψ–¥ΧΪΩλΟΜ”–«–ΗνΘ§…θ÷ΝΑ―»ίΤς¥≈≈Χ100%–¥¬ζΒ»Θ§“ρΈΣΤΣΖυ”–œόΘ§Υυ“‘÷ΜΡήΧτ―ΓΦΗΗω”–¥ζ±μ–‘ΒΡΉ®Ο≈ΥΒΟςΓΘ“ρΈΣ‘Τ…œ“ΣΩΦ¬«ΒΡΈ ΧβΧΪΕύΘ§ΧΊ±π «’β÷÷Μυ¥Γ…η ©ΖΰΈώάύΒΡΘ§ Ι”Ο≥ΓΨΑ”÷Ζ«≥ΘΝιΜνΘ§œΏ…œ≥ωœ÷ΒΡ“Μ–©Έ Χβ÷°«ΑΆξ»Ϊœκ≤ΜΒΫΘ§Αϋά®ΚήΕύΜΙ «”ΟΜßΉ‘ΦΚ Ι”ΟΒΡΈ ΧβΘ§ΒΪΈΣΝΥ“Σ»Ο”ΟΜß”–ΗϋΚΟΒΡΧε―ιΘ§“≤÷ΜΡήΨΓΝΠΕχΈΣΘ§”≈œ»―Γ‘ώ“Μ–©Ά®”ΟΒΡΈ Χβ»ΞΫβΨωΓΘ |









