8ΥΫ”–‘ΤΤΫΧ® «58Ά§≥«ΦήΙΙœΏΜυ”Ύ»ίΤςΦΦ θΈΣΡΎ≤ΩΖΰΈώΩΣΖΔΒΡ“ΜΧΉ“ΒΈώ ΒάΐΙήάμΤΫΧ®Θ§÷ß≥÷“ΒΈώ ΒάΐΑ¥–ηά©’ΙΘ§ΟκΦΕ…λΥθΘ§ΤΫΧ®ΧαΙ©”―ΚΟΒΡ”ΟΜßΫΜΜΞΙΐ≥ΧΘ§ΙφΖΕΜ·ΒΡ≤β ‘ΓΔ…œœΏΝς≥ΧΘ§÷Φ‘ΎΫΪΩΣΖΔΓΔ≤β ‘»Υ‘±¥”Μυ¥ΓΜΖΨ≥ΒΡ≈δ÷Ο”κΙήάμ÷–ΫβΖ≈≥ωά¥Θ§ ΙΤδΗϋΨέΫΙ”ΎΉ‘ΦΚΒΡ“ΒΈώΓΘ±ΨΈΡΚΆ¥σΦ“Ζ÷œμ‘ΎΥΫ”–‘ΤΤΫΧ® Β ©Ιΐ≥Χ÷–ΒΡœύΙΊ»ίΤςΦΦ θ ΒΦυΓΘ
±ΨΈΡ÷ς“Σ¥”“‘œ¬»ΐΗω≤ΩΖ÷ά¥Ϋχ––Χ÷¬έΘΚ
- ±≥ΨΑΘΚΒ±«Α¥φ‘ΎΡΡ–©Έ ΧβΘ§ΈΣ ≤Ο¥ Ι”Ο»ίΤςΦΦ θ
- ’ϊΧεΦήΙΙΘΚ’ϊΗω»ίΤςΦΦ θΒΡΦήΙΙΖΫΑΗ
- ΚΥ–ΡΡΘΩιΒΡ…ηΦΤΖΫΑΗΘΚ“Μ–©ΚΥ–ΡΡΘΩιΒΡ―Γ–ΆΨω≤Ώ”κΫβΨωΖΫΑΗ
ΈΣ ≤Ο¥ Ι”Ο»ίΤςΦΦ θ
‘ΎΟΜ”–”Ο»ίΤςΜ·ΦΦ θ÷°«ΑΘ§Έ“Ο«¥φ‘Ύ’β–©Έ ΧβΘΚ
Ή ‘¥άϊ”Ο¬ Έ Χβ
≤ΜΆ§“ΒΈώ≥ΓΨΑΕ‘Ή ‘¥ΒΡ–η«σ «≤Μ“Μ―υΒΡΘ§”–CPUΟήΦ·–ΆΓΔΡΎ¥φΟήΦ·–ΆΓΔΆχ¬γΟήΦ·–ΆΘ§’βΨΆΩ…ΡήΜαΒΦ÷¬Ή ‘¥άϊ”Ο¬ ≤ΜΚœάμΒΡΈ ΧβΘ§±»»γ“ΜΗωΜζΤς…œ≤Ω πΒΡΖΰΈώΕΦ «Άχ¬γΟήΦ·–ΆΘ§Ρ«Ο¥CPUΉ ‘¥ΚΆΡΎ¥φΉ ‘¥ΨΆΕΦάΥΖ―ΝΥΓΘ”––©“ΒΈώΩ…Ρή÷ΜΨέΫΙ”ΎΖΰΈώ±Ψ…μΕχΚω¬‘ΜζΤςΉ ‘¥άϊ”Ο¬ ΒΡΈ ΧβΓΘ
ΜλΚœ≤Ω πΫΜ≤φ”Αœλ
Ε‘”ΎœΏ…œΖΰΈώΘ§“ΜΧ®ΜζΤς“ΣΜλΚœ≤Ω πΕύΗωΖΰΈώΘ§Ρ«Ο¥ΖΰΈώ÷°ΦδΩ…Ρή¥φ‘ΎœύΜΞ”ΑœλΒΡ«ιΩωΘ§±»»γΘΚ“ΜΗωΖΰΈώ”…”ΎΡ≥–©‘≠“ρΆΜ»ΜΆχ¬γΝςΝΩ±©’«Θ§Ω…ΡήΑ―’ϊΗωΜζΤςΒΡ¥χΩμΕΦ¥ρ¬ζΘ§Ρ«Ο¥ΤδΥϊΖΰΈώΨΆΜα ήΒΫ”ΑœλΓΘ
ά©/Υθ»ί–߬ ΒΆ
Β±“ΒΈώΫΎΒψ–η“ΣΫχ––ά©/Υθ ±Θ§¥”ΜζΤςœ¬œΏΒΫ”Π”Ο≤Ω πΓΔ≤β ‘Θ§÷ήΤΎΫœ≥ΛΓΘΒ±“ΒΈώ”ωΒΫΆΜΖΔΝςΝΩΗΏΖε ±Θ§ΜζΤςΒΫ ÷≤Ω πΚσΘ§Ω…ΡήΝςΝΩΗΏΖε“―Ψ≠Ιΐ»ΞΝΥΓΘ
ΕύΜΖΨ≥¥ζ¬κ≤Μ“Μ÷¬
”…”ΎΙΐ»ΞΡΎ≤ΩΩΣΖΔΝς≥ΧΒΡ≤ΜΙφΖΕΘ§¥φ‘Ύ“Μ–©Έ ΧβΘ§“ΒΈώΧα≤βΒΡ¥ζ¬κ‘Ύ≤β ‘ΜΖΨ≥≤β ‘Άξ±œΚσΘ§‘Ύ…≥œδΩ…ΡήΜαΫχ–––όΗΡΓΔΒς’ϊΘ§»ΜΚσ‘Ό¥ρΑϋ…œœΏΓΘ’βΨΆΜαΒΦ÷¬≤β ‘ΒΡ¥ζ¬κΚΆœΏ…œ‘Υ––ΒΡ¥ζ¬κ «≤Μ“Μ÷¬ΒΡΘ§‘ωΦ”ΝΥΖΰΈώ…œœΏΒΡΖγœ’Θ§“≤‘ωΦ”ΝΥœΏ…œΖΰΈώΙ ’œ≈≈≤ιΒΡΡ―Ε»ΓΘ
»±…ΌΈ»Ε®ΒΡœΏœ¬≤β ‘ΜΖΨ≥
‘Ύ≤β ‘Ιΐ≥Χ÷–Θ§Μα”ωΒΫ“ΜΗωΈ ΧβΘ§ΖΰΈώ“άάΒΒΡΤδΥϊœ¬”ΈΖΰΈώΕΦΟΜ”–ΧαΙ©Έ»Ε®ΒΡ≤β ‘ΜΖΨ≥Θ§’βΒΦ÷¬ΈόΖ®‘Ύ≤β ‘ΜΖΨ≥ΡΘΡβ’ϊΗωœΏ…œΝς≥ΧΫχ––≤β ‘Θ§Υυ“‘ΚήΕύ≤β ‘Ά§―ßΜα”ΟœΏ…œΖΰΈώΫχ––≤β ‘Θ§’βάο”–ΚήΗΏΒΡ«±‘ΎΖγœ’ΓΘ
ΈΣΝΥΫβΨω…œ ωΈ ΧβΘ§ΦήΙΙœΏ‘ΤΆ≈Ε”Ϋχ––ΝΥΦΦ θ―Γ–Ά”κΖ¥Η¥¬έ÷ΛΘ§Ήν÷’ΨωΕ® Ι”ΟDocker»ίΤςΦΦ θΓΘ
’ϊΧεΦήΙΙ
58ΥΫ”–‘ΤΒΡ’ϊΧεΦήΙΙ»γœ¬ΘΚ

Μυ¥Γ…η ©
’ϊΗωΥΫ”–‘ΤΤΫΧ®Ϋ”ΙήΝΥΥυ”–ΒΡΜυ¥Γ…η ©Θ§Αϋά®ΖΰΈώΤςΓΔ¥φ¥ΔΚΆΆχ¬γΒ»Ή ‘¥ΘΜ
»ίΤς≤ψ
Μυ¥Γ…η ©÷°…œΧαΙ©ΝΥ’ϊΗω»ίΤς≥θ ΦΜ·≤ψΘ§»ίΤς≥θ ΦΜ·≤ψΑϋΚ§KubernetesΓΔAgentΓΔIPAMΘΜKubernetes «DockerΒΡΒςΕ»ΚΆΙήάμΉιΦΰΘΜAgent≤Ω π‘ΎΥό÷ςΜζ…œΘ§”Ο”ΎœΒΆ≥Ή ‘¥ΚΆΒΉ≤ψΜυ¥Γ…η ©ΒΡΙήάμΘ§ΑϋΚ§ΦύΩΊ≤…Φ·ΓΔ»’÷Ψ≤…Φ·ΓΔ»ίΤςœόΥΌΒ»ΓΘIPAM «DockerΒΡΆχ¬γΙήάμΡΘΩιΘ§”Ο”ΎΙήάμ’ϊΗωΆχ¬γœΒΆ≥ΒΡIPΉ ‘¥ΘΜ
Ή ‘¥Ιήάμ
»ίΤς≤ψ÷°…œ «Ή ‘¥Ιήάμ≤ψΘ§ΑϋΚ§»ίΤςΙήάμΓΔΥθά©»ίΓΔΜΊΙωΫΒΦΕΓΔ…œœΏΖΔ≤ΦΓΔ≈δΕνΙήάμΓΔΉ ‘¥≥ΊΙήάμΒ»ΡΘΩιΘΜ
”Π”Ο≤ψ
‘Υ––”ΟΜßΧαΫΜΒΡ“ΒΈώ ΒάΐΘ§Ω…“‘ «»Έ“β±ύ≥Χ”ο―‘ΘΜ
Μυ¥ΓΉιΦΰ
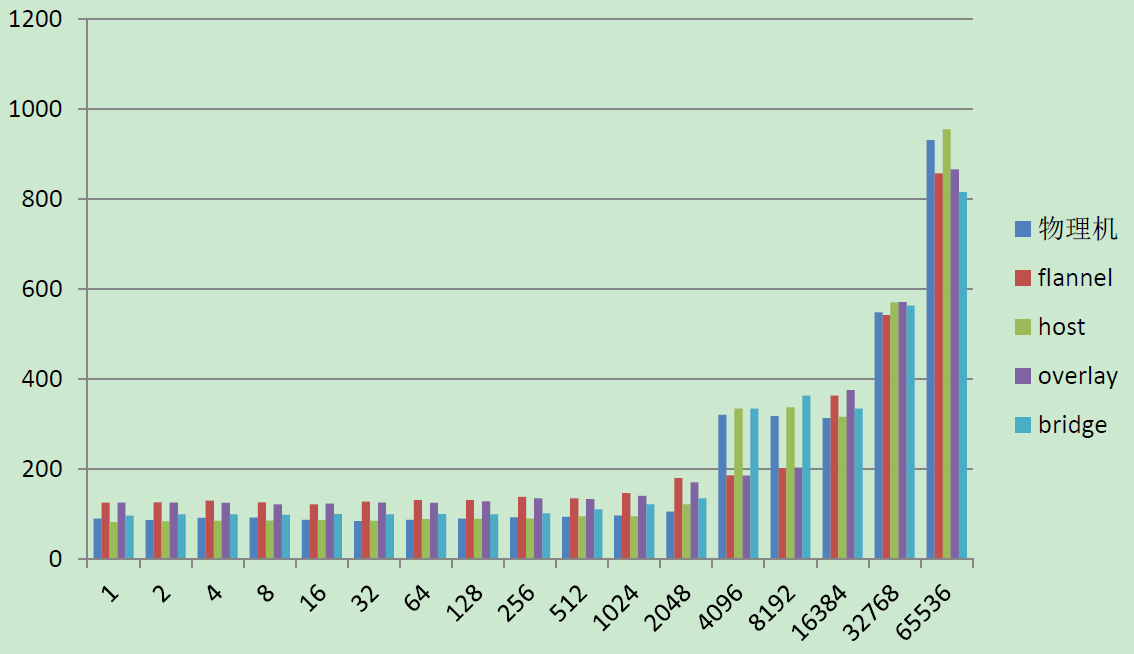
ΥΫ”–‘ΤΤΫΧ®ΈΣ»ίΤς‘Υ––ΜΖΨ≥ΧαΙ©±Ί±ΗΒΡΜυ¥ΓΉιΦΰΘ§ΑϋΚ§ΖΰΈώΖΔœ÷ΓΔΨΒœώ÷––ΡΓΔ»’÷Ψ÷––ΡΓΔΦύΩΊ÷––ΡΓΘ
ΖΰΈώΖΔœ÷
Ϋ”»κ‘ΤΤΫΧ®ΒΡΖΰΈώΧαΙ©Ά≥“ΜΒΡΖΰΈώΖΔœ÷Μζ÷ΤΘ§±ψΫί“ΒΈώΫ”»κ‘ΤΤΫΧ®ΘΜ
ΨΒœώ÷––Ρ
¥φ¥Δ“ΒΈώΨΒœώΘ§Ζ÷≤Φ Ϋ¥φ¥ΔΘ§Ω…Β·–‘ά©’ΙΘΜ
»’÷Ψ÷––Ρ
÷––ΡΜ· ’Φ·“ΒΈώ Βάΐ»’÷ΨΘ§ΧαΙ©Ά≥“ΜΒΡΩ… ”Μ·»κΩΎΘ§ΖΫ±ψ”ΟΜßΖ÷Έω”κ≤ι―·ΘΜ
ΦύΩΊ÷––Ρ
ΜψΉή»Ϊ≤ΩΒΡΥό÷ςΚΆ»ίΤςΦύΩΊ–≈œΔΘ§ΦύΩΊ ”ΆΦΜ·Θ§±®Ψ·Ε®÷ΤΜ·Θ§ΈΣ÷«ΡήΜ·ΒςΕ»ΧαΙ©Μυ¥ΓΘΜ
Ά≥“ΜΟ≈Μß
Ω… ”Μ·ΒΡUIΟ≈Μß“≥ΟφΘ§ΙφΖΕΜ·’ϊΗω“ΒΈώΝς≥ΧΘ§ΦρΫύΒΡ”ΟΜßΝς≥ΧΘ§Ω…Ε·Χ§Ιήάμ’ϊΗω‘ΤΜΖΨ≥ΒΡΥυ”–Ή ‘¥ΓΘ
»Ϊ–¬ΒΡΦήΙΙ¥χά¥»Ϊ–¬ΒΡ“ΒΈώΝςΉΣΖΫ ΫΘΚ
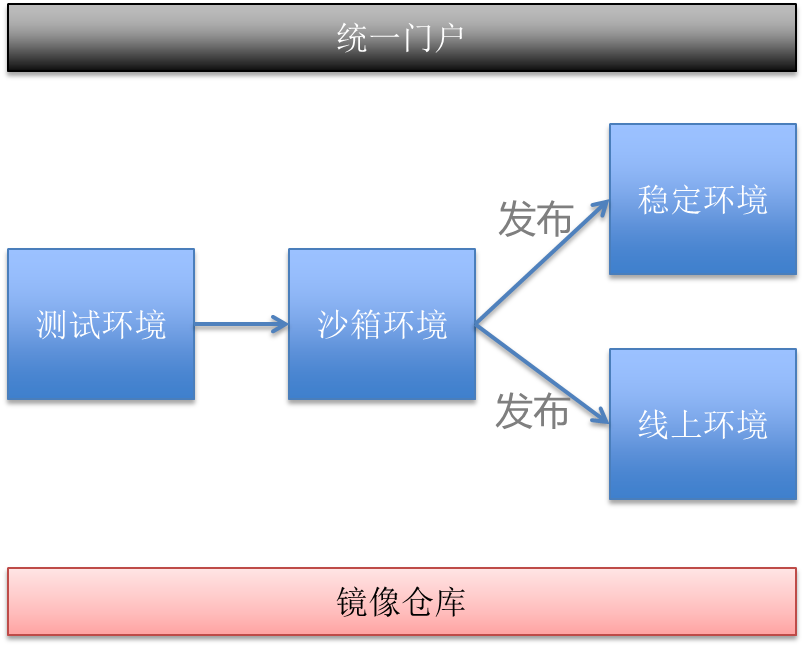
ΤΫΧ®Ε®“εΝΥΥΡΧΉΜυ¥ΓΜΖΨ≥ΘΚ≤β ‘ΜΖΨ≥ΓΔ…≥œδΜΖΨ≥ΓΔΈ»Ε®ΜΖΨ≥ΓΔœΏ…œΜΖΨ≥ΓΘ“ΒΈώΜυ”ΎSVNΧαΫΜΒΡ¥ζ¬κΙΙΫ®ΨΒœώΘ§ΨΒœώΒΡ’ϊΗω…ζΟϋ÷ήΤΎΨΆ «‘Ύ4ΗωΜΖΨ≥÷–ΝςΉΣΓΘ“ρΈΣ «Μυ”ΎΆ§“ΜΗωΨΒœώ¥¥Ϋ® ΒάΐΘ§Υυ“‘Ω…“‘±Θ÷Λ≤β ‘Ά®ΙΐΒΡ≥Χ–ρ”κœΏ…œ‘Υ––ΒΡ≥Χ–ρ «Άξ»Ϊ“Μ÷¬ΒΡΓΘ
≤β ‘ΜΖΨ≥ΘΚ≤β ‘»Υ‘±Ϋχ––ΙΠΡή≤β ‘Θ§Ε‘Ϋ”ΒΫœΏœ¬ΜΖΨ≥ΘΜ
…≥œδΜΖΨ≥ΘΚ≥Χ–ρ‘ΛΖΔ≤ΦΜΖΨ≥Θ§Ε‘Ϋ”ΒΫœΏ…œΜΖΨ≥ΘΜ
œΏ…œΜΖΨ≥ΘΚΧαΙ©ΖΰΈώΒΡœΏ…œΜΖΨ≥ΘΜ
Έ»Ε®ΜΖΨ≥ΘΚ‘Υ––‘ΎœΏœ¬ΜΖΨ≥ΒΡ ΒάΐΘ§ΈΣΤδΥϊ…œ”ΈΖΰΈώΧαΙ©Έ»Ε®ΒΡ≤β ‘ΜΖΨ≥ ΒάΐΘΜ
ΚΥ–ΡΡΘΩιΒΡ…ηΦΤΖΫΑΗ
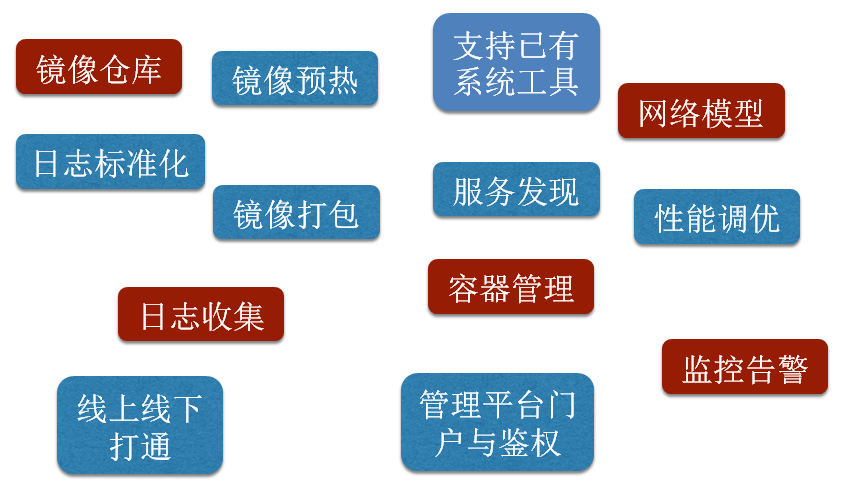
ΩΣΖΔ58ΥΫ”–‘ΤΤΫΧ®–η“ΣΩΦ¬«ΚήΕύœΗΫΎΘ§’βάο÷ς“ΣΚΆ¥σΦ“Ζ÷œμœ¬Τδ÷–ΒΡΈεΗωΚΥ–ΡΡΘΩιΘΚ»ίΤςΙήάμΓΔ»’÷Ψ ’Φ·ΓΔΆχ¬γΡΘ–ΆΓΔΦύΩΊΗφΨ·ΓΔΨΒœώ≤÷ΩβΓΘ”–ΝΥ’βΦΗΗωΚΥ–ΡΡΘΩιΘ§ΤΫΧ®ΨΆ”–ΝΥΜυ¥ΓΩρΦήΘ§Ω…“‘‘ΥΉΣΤπά¥ΓΘ
»ίΤςΙήάμ
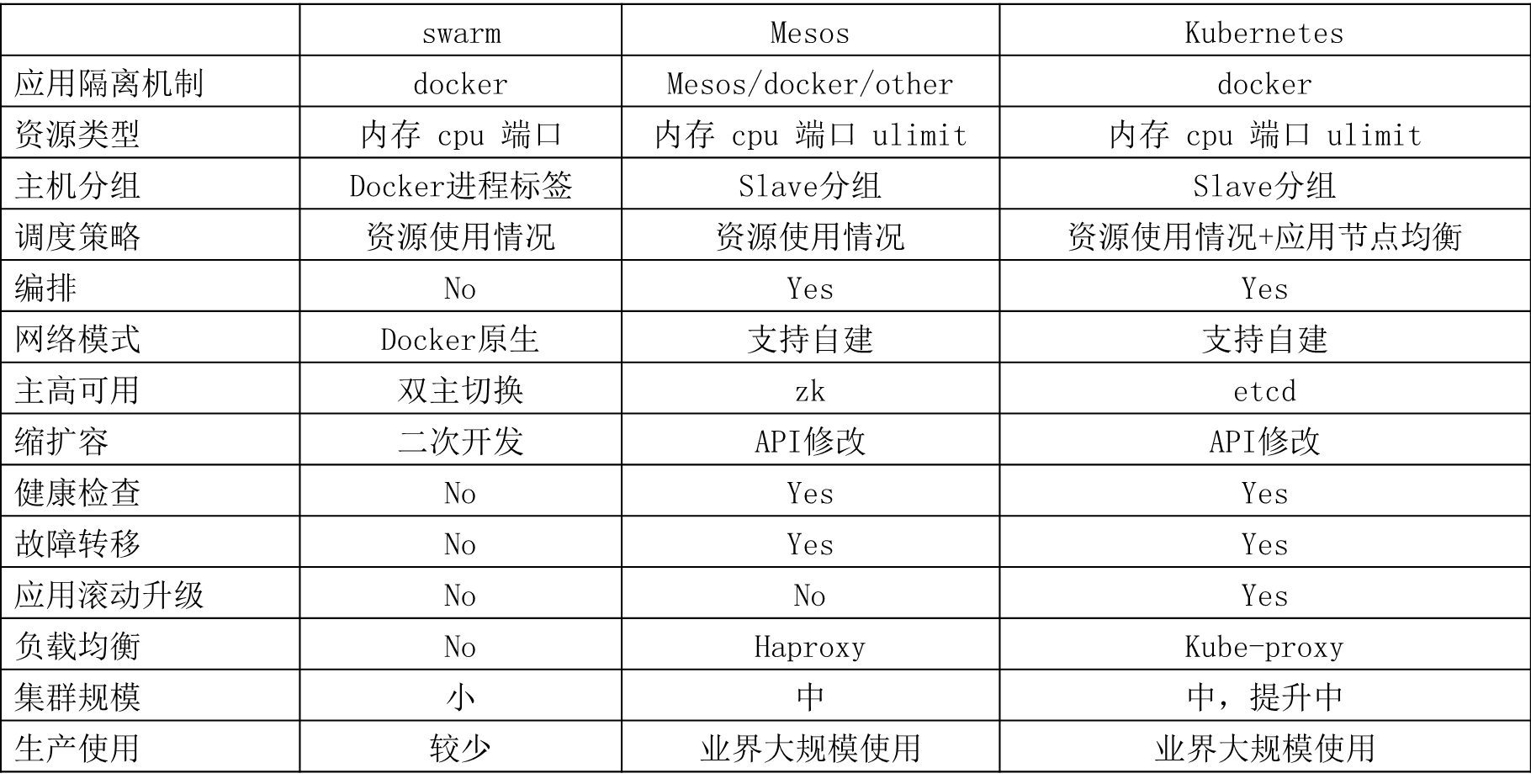
Έ“Ο«Βς―–ΒΡΜυ”ΎDockerΒΡΙήάμΤΫΧ®÷ς“Σ”–»ΐΗωΘΚSwarmΓΔMesosΓΔKubernetesΘ§Ά®ΙΐΕ‘±»Θ§Έ“Ο«Ήν÷’―Γ‘ώΝΥKubernetesΓΘSwarmΙΠΡήΙΐ”ΎΦρ¬ΣΘ§Υυ“‘Ήν‘γΨΆpassΝΥΘ§Mesos + Marathon «“ΜΗω≥… λΒΡΫβΨωΖΫΑΗΘ§ΒΪ «…γ«χ≤ΜΙΜΜν‘ΨΘ§Εχ«“ Ι”ΟΤπά¥“Σ λœΛΝΫΧΉΩρΦήΘΜKubernetes «Ή®Ο≈’κΕ‘»ίΤςΦΦ θΧαΙ©ΒΡΒςΕ»ΙήάμΤΫΧ®Θ§ΗϋΉ®“ΜΘ§…γ«χΖ«≥ΘΜν‘ΨΘ§≈δΧΉΒΡΉιΦΰ”κΫβΨωΖΫΑΗΫœΕύΘ§ Ι”ΟΤδΒΡΙΪΥΨ“≤‘Ϋά¥‘ΫΕύΘ§Ά®ΙΐΚΆ“Μ–©ΙΪΥΨΙΒΆ®Θ§ΥϊΟ«“≤‘Ύ÷π≤ΫΒΡΫΪDocker”Π”Ο¥”Mesos«®“ΤΒΫKubernetes…œΓΘœ¬Οφ±μΗώΈΣΈ“Ο«Ά≈Ε”ΙΊΉΔΒψΒΡ“Μ–©Ε‘±»«ιΩωΘΚ
Άχ¬γΡΘ–Ά
Άχ¬γΡΘ–Ά «»ΈΚΈ‘ΤΜΖΨ≥ΕΦ±Ί–κΟφΕ‘ΒΡΈ ΧβΘ§“ρΈΣΆχ¬γΙφΡΘ“ΜΒ©ά©¥σ÷°ΚσΘ§Μα¥χά¥Ης÷÷Έ ΧβΓΘΆχ¬γ―Γ–Ά’βΩιΘ§’κΕ‘DockerΚΆKubernetesΒΡΧΊ–‘Θ§Ε‘Νυ÷÷ΉιΆχΖΫ ΫΫχ––ΝΥΕ‘±»Θ§»γœ¬Υυ ΨΘΚ
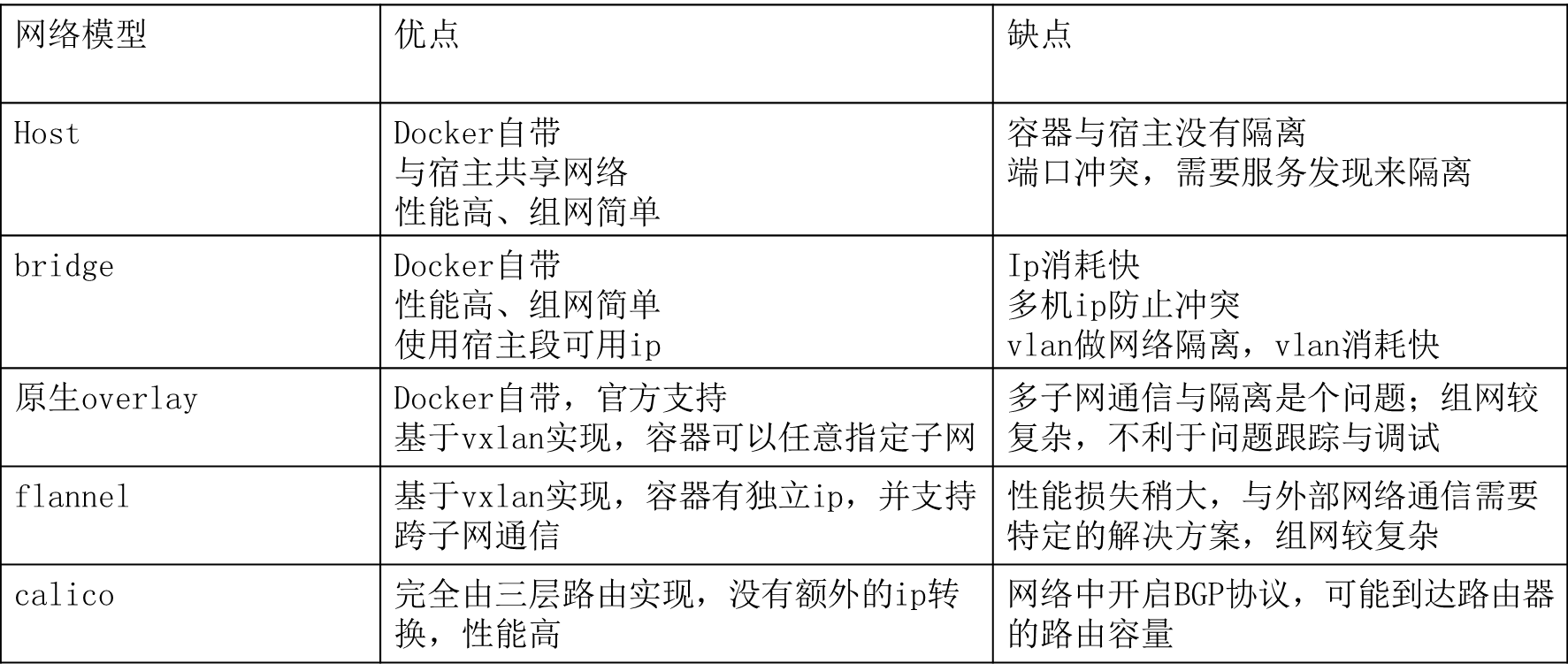
’κΕ‘ΟΩ÷÷Άχ¬γΡΘ–ΆΘ§‘ΤΆ≈Ε”ΕΦΉωΝΥœύ”ΠΒΡ–‘Ρή≤β ‘Θ§Calico≥ΐΆβΘ§“ρΈΣΙΪΥΨΥυ”ΟΒΡΜζΖΩ≤Μ÷ß≥÷ΩΣΤτBGP–≠“ιΘ§Υυ“‘ΟΜ”–Ϋχ––≤β ‘ΓΘ
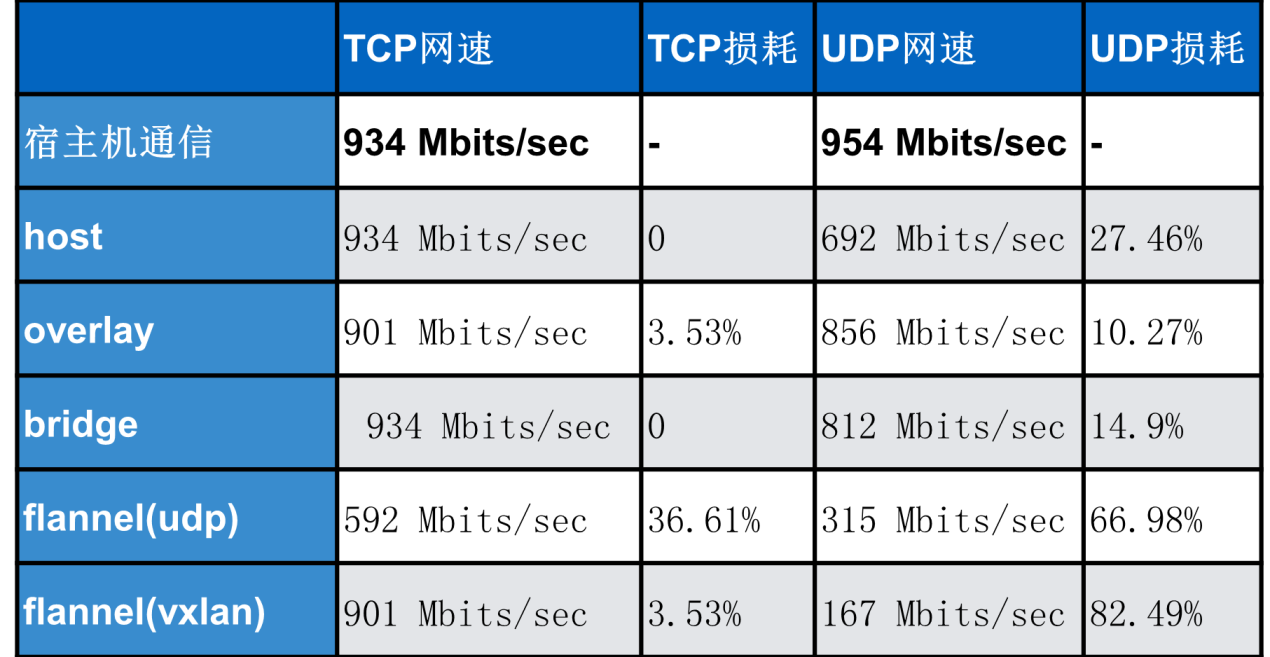
iPerf≤β ‘Άχ¬γ¥χΩμΫαΙϊ»γœ¬ΘΚ
Qperf≤β ‘TCP―”≥ΌΫαΙϊ»γœ¬ΘΚ
Qperf≤β ‘UDP―”≥ΌΫαΙϊ»γœ¬ΘΚ

Ά®Ιΐ≤β ‘ΫαΙϊΩ…“‘Ω¥≥ωΘΚHostΡΘ ΫΚΆBridgeΡΘ Ϋ–‘Ρή”κΥό÷ςΜζ «ΉνΫ”ΫϋΒΡΘ§ΤδΥϊΉιΆχΡΘ ΫΜΙ «”–“Μ–©≤νΨύΒΡΘ§’βΚΆOverlayΒΡ‘≠άμ”–ΙΊΓΘ
ΥΫ”–‘ΤΤΫΧ®Ήν÷’―Γ‘ώΝΥBridge + VLANΒΡΉιΆχΖΫ ΫΘ§‘≠“ρ»γœ¬ΘΚ
- –‘ΡήΫœΚΟΘ§ΉιΆχΦρΒΞΘ§Ω…“‘”κœ÷”–Άχ¬γΈόΖλΕ‘Ϋ”ΘΜΩ…“‘ΚήΚΟΒΡ Βœ÷»ίΤς”κ»ίΤςΓΔ»ίΤς”κΥό÷ςΜΞΆ®
- Ι ’œ“Ή”ΎΒς ‘Θ§¥ΪΆ≥ΒΡSAΦ¥Ω…ΫβΨωΘΜ ”Π»Έ“βΈοάμ…η±ΗΘ§Ω…¥σΙφΡΘά©’Ι
- ΙΪΥΨΡΎ≤ΩΖΰΈώ÷°ΦδΕΦ «Μυ”ΎRPC–≠“ιΘ§”–Ή‘ΦΚΒΡΖΰΈώΖΔœ÷Μζ÷ΤΘ§Ω…“‘ΚήΚΟΒΡΦφ»ίΘΜœ÷”–ΡΎ≤ΩΩρΦήΗΡΕ·–Γ
”…”ΎVLANΉνΕύ”–4096ΗωΘ§Υυ“‘VLAN «”–Ηω ΐœό÷ΤΒΡΘ§’β“≤ «ΈΣ ≤Ο¥Μα”–VLANΒΡ‘≠“ρΓΘ‘Ύ‘ΤΤΫΧ®Β±«ΑΒΡΆχ¬γΙφΜ°÷–Θ§VLAN «ΙΜ”ΟΒΡΘ§Έ¥ά¥ΥφΉ≈ Ι”ΟΙφΡΘΒΡά©¥σΘ§ΦΦ θΒΡΖΔ’ΙΘ§Έ“Ο«“≤Μα…ν»κ―–ΨΩΗϋΚœ ΒΡΉιΆχΖΫ ΫΓΘ
Άχ…œ“≤”–Ά§―ßΖ¥άΓCalicoΒΡIPIPΡΘ ΫΆχ¬γ–‘Ρή“≤ΚήΗΏΘΜΒΪ «ΩΦ¬«ΒΫCalicoΒ±«ΑΒΡΩ”±»ΫœΕύΘ§–η“Σ”–Ή®Ο≈ΒΡΆχ¬γΉιά¥÷ß≥≈Θ§Εχ’βΩι «‘ΤΆ≈Ε”Υυ«Ζ»±ΒΡΘ§Υυ“‘ΟΜ”–…ν»κΒς―–ΓΘ
’βάοΜΙ”–“ΜΗωΈ ΧβΘ§Ρ§»œΒΡ Ι”ΟBridgeΡΘ Ϋ «ΟΩΗωΥό÷ςΜζ≈δ÷Ο≤ΜΆ§ΆχΕΈΒΡΒΊ÷ΖΘ§’β―υΨΆΩ…“‘±Θ÷Λ≤ΜΆ§Υό÷ςΜζ…œΈΣ»ίΤςΖ÷≈δΒΡIP≤Μ≥εΆΜΘ§ΒΪ «’β―υ“≤ΜαΒΦ÷¬Μα≥ωœ÷¥σΝΩΒΡIPάΥΖ―ΘΜΜζΖΩΒΡΡΎΆχΜΖΨ≥IPΉ ‘¥”–œόΘ§ΟΜ”–ΑλΖ®’β―υ≈δ÷ΟΆχ¬γΘ§Υυ“‘÷ΜΡήΩΣΖΔIPAMΡΘΩιΫχ––»ΪΨ÷ΒΡIPΙήάμΓΘIPAMΡΘΩιΒΡ Βœ÷≤ΈΩΦΝΥΩΣ‘¥œνΡΩShrikeΒΡ Βœ÷Θ§ΫΪΩ…Ζ÷≈δΒΡΆχΕΈ–¥»κetcd÷–Θ§Docker ΒάΐΤτΕ· ±Θ§ΜαΆ®ΙΐIPAMΡΘΩι¥”etcd÷–Μώ»Γ“ΜΗωΩ…”ΟIPΘ§‘Ύ ΒάΐΙΊ±’ ±Θ§ΜαΕ‘IPΫχ––ΙιΜΙΘ§’ϊΧεΦήΙΙ»γœ¬Υυ ΨΘΚ
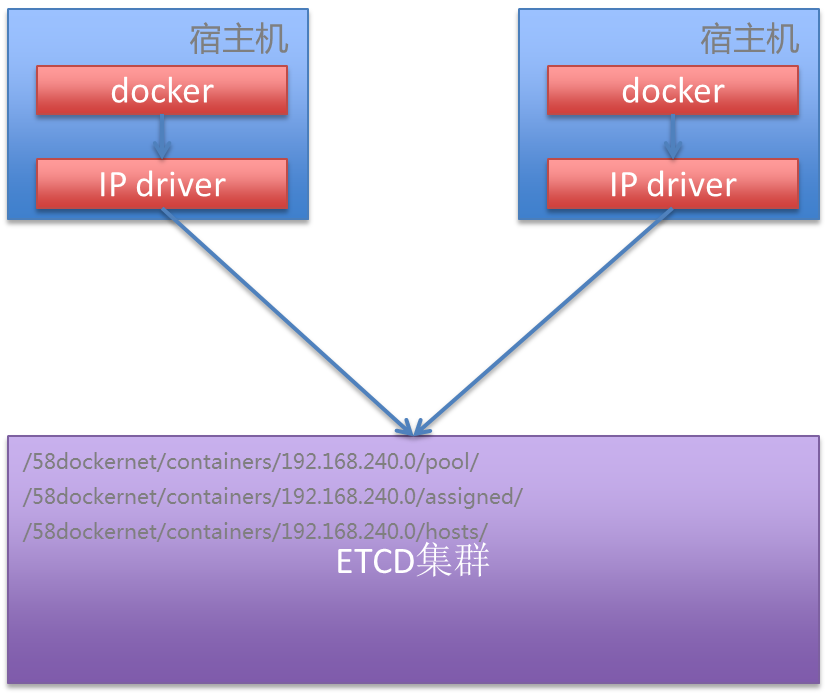
ΝμΆβΘ§”…”ΎKubernetes≤Μ÷ß≥÷ Ι”ΟCNMΘ§Υυ“‘Έ“Ο«’κΕ‘Kubernetes‘¥¬κΫχ––ΝΥ–όΗΡΓΘ
Άχ¬γΖΫΟφΜΙ”–“ΜΗωΒψ–η“ΣΩΦ¬«ΘΚΨΆ «Άχ¬γœόΥΌΓΘ”…”ΎΤΣΖυ‘≠“ρ’βάο≤ΜΉΗ ωΘ§“‘ΚσΉ®Ο≈ΧΫΧ÷ΓΘ
ΨΒœώ≤÷Ωβ
DockerΒΡΨΒœώ≤÷Ωβ Ι”ΟΙΌΖΫΧαΙ©ΒΡΨΒœώ≤÷ΩβΘ§ΒΪ «ΚσΕΥΧαΙ©ΒΡ¥φ¥ΔœΒΆ≥Έ“Ο«Ϋχ––―Γ–ΆΘ§Ρ§»œΒΡ¥φ‘Ύ±ΨΒΊ¥≈≈ΧΒΡΖΫ Ϋ «ΈόΖ®”Π”ΟΒΫœΏ…œœΒΆ≥ΒΡΓΘΨΏΧεΒΡ―Γ–Ά»γœ¬ΘΚ
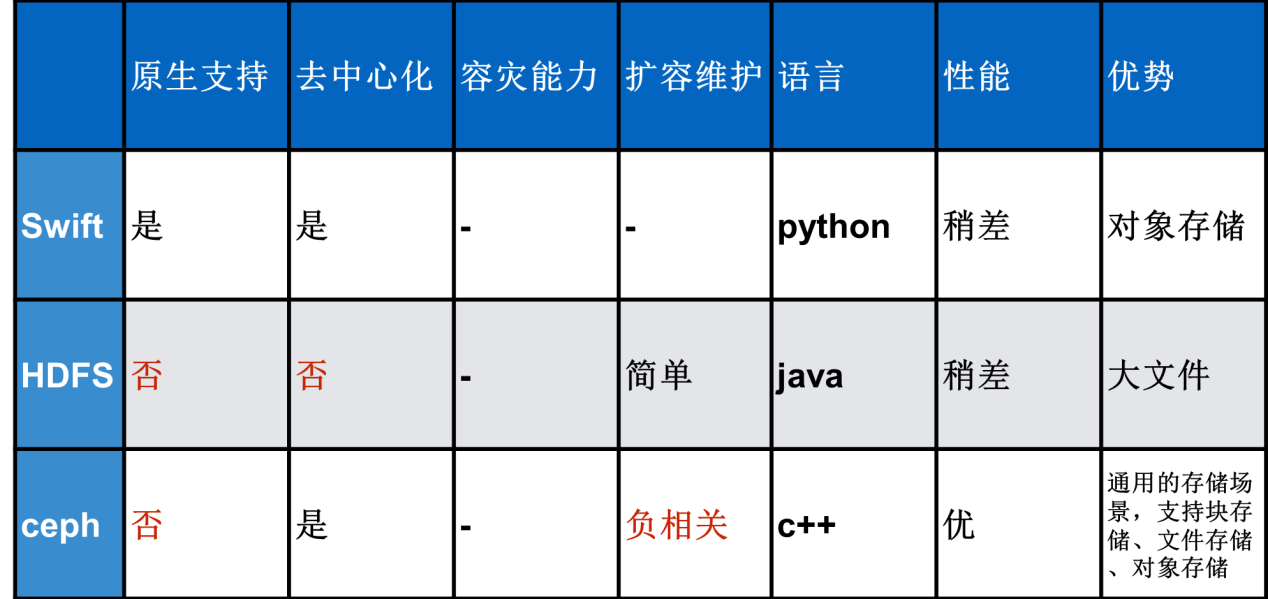
Ά®ΙΐΕ‘±»Θ§Ω…“‘Ω¥≥ωCeph «ΉνΚœ ΒΡΘ§ΒΪ «Ήν÷’‘ΤΆ≈Ε”―Γ‘ώ Ι”ΟHDFSΉςΈΣΨΒœώ≤÷ΩβΒΡΚσΕΥ¥φ¥ΔΘ§‘≠“ρ»γœ¬ΘΚSwift «ΙΌΖΫΡ§»œΧαΙ©÷ß≥÷ΒΡ¥φ¥Δάύ–ΆΘ§ΒΪ «¥νΫ®“ΜΧΉSwift≤Δ±Θ÷ΛΤδΈ»Ε®‘Υ–––η“ΣΉ®»Υ…ν»κ―–ΨΩΘ§”…”Ύ»Υ‘±”–œόΥυ”–‘ίΟΜ Ι”ΟΘ§Ceph“≤ «Μυ”ΎΆ§άμΟΜ”–Ϋχ––―Γ‘ώΓΘHDFSœΒΆ≥ΙΪΥΨ”–Ή®Ο≈ΒΡ ΐΨίΤΫΧ®≤ΩΟ≈‘ΎΙήάμΚΆΈ§ΜΛΘ§ΥϊΟ«ΗϋΉ®“ΒΘ§‘ΤΆ≈Ε”Ω…“‘Ζ≈–ΡΒΡΫΪDockerΨΒœώΆ–ΙήΒΫHDFS…œΓΘΒΪ «HDFS±Ψ…μ“≤¥φ‘Ύ“Μ–©Έ ΧβΘ§±»»γ―ΙΝΠ¥σ ±Θ§NameNodeΈόΖ®ΦΑ ±œλ”ΠΘ§Έ¥ά¥Έ“Ο«ΜαΩΦ¬«ΫΪΚσΕΥ¥φ¥Δ«®“ΤΒΫΦήΙΙœΏ≤ΩΟ≈ΡΎ≤ΩΉ‘―–ΒΡΕ‘œσ¥φ¥Δ÷–Θ§“‘ΧαΙ©Έ»Ε®ΗΏ–ßΒΡΖΰΈώΓΘ
»’÷ΨœΒΆ≥
¥ΪΆ≥ΖΰΈώ«®“ΤΒΫ»ίΤςΜΖΨ≥Θ§»’÷Ψ «“ΜΗω¥σΈ ΧβΓΘ“ρΈΣ»ίΤςΦ¥”ΟΦ¥œζΘ§»ίΤςΙΊ±’ΚσΘ§»ίΤςΒΡ¥φ¥Δ“≤Μα±Μ…Ψ≥ΐΓΘΥδ»ΜΩ…“‘Α―»ίΤς÷–ΒΡ»’÷ΨΒΦ≥ωΒΫΥό÷ςΜζ…œΒΡ÷ΗΕ®ΈΜ÷ΟΘ§ΒΪ «»ίΤςΜαΨ≠≥ΘΤ·“ΤΘ§‘Ύ≈≈≤ιΙ ’œ ±Θ§Έ“Ο«ΜΙ–η“Σ÷ΣΒάάζ Ζ…œΒΡΡ≥“Μ ±ΩΧΘ§Ρ≥Ηω»ίΤς‘ΎΡΡΧ®Υό÷ςΜζ…œ‘Υ––Θ§≤Δ«“”…”Ύ Ι”ΟΖΫΟΜ”–Υό÷ςΜζΒΡΒ«¬Ϋ»®œόΘ§Υυ“‘ Ι”ΟΖΫ“≤ΟΜΖ®ΚήΚΟΒΡΜώ»Γ»’÷ΨΓΘ‘Ύ»ίΤςΜΖΨ≥œ¬Θ§–η“Σ–¬ΒΡΙ ’œ≈≈≤ιΖΫ ΫΓΘ’βάοΘ§“ΜΗωΆ®”ΟΒΡΫβΨωΖΫΑΗΨΆ «≤…”Ο÷––ΡΜ·ΒΡ»’÷ΨΫβΨωΖΫΑΗΘ§ΫΪΝψ…ΔΒΡ»’÷ΨΆ≥“ΜΫχ–– ’Φ·¥φ¥ΔΘ§≤ΔΧαΙ©ΝιΜνΒΡ≤ι―·ΖΫ ΫΓΘΥΫ”–‘ΤΤΫΧ®ΒΡ≤…”ΟΒΡΖΫΑΗ»γœ¬ΘΚ
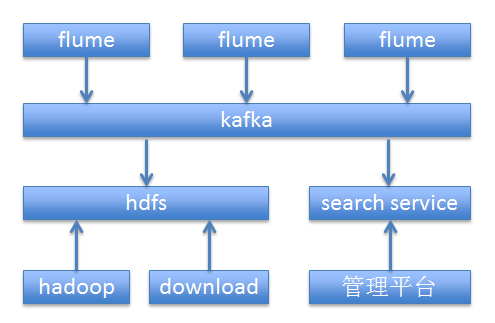
Ι”ΟΖΫ‘ΎΙήάμΟ≈Μß…œ≈δ÷Ο“Σ≤…Φ·ΒΡ»’÷ΨΘ§ΥΫ”–‘ΤΤΫΧ®Ά®ΙΐΜΖΨ≥±δΝΩΒΡΖΫ Ϋ”≥…δΒΫ»ίΤς÷–Θ§Υό÷ςΜζ…œ≤Ω πΒΡAgentΗυΨίΜΖΨ≥±δΝΩΜώ»Γ“Σ≤…Φ·ΒΡ»’÷ΨΘ§ΤτΕ·FlumeΫχ––≤…Φ·ΓΘFlumeΫΪ»’÷ΨΆ≥“Μ…œ¥ΪΒΫKafka÷–Θ§…œ¥ΪΒΫKafka÷–ΒΡ»’÷Ψ±Θ÷Λ―œΗώΒΡœ»ΚσΥ≥–ρΓΘKafka”–ΝΫΗωΕ©‘Ρ’ΏΘ§“ΜΗωΫΪ»’÷Ψ…œ¥ΪΒΫΥ―ΥςΖΰΈώ÷–Θ§Ι©ΙήάμΟ≈Μß≤ι―· Ι”ΟΘΜ“ΜΗωΫΪ»’÷Ψ…œ¥ΪΒΫHDFS÷–Θ§”Ο”Ύάζ Ζ»’÷ΨΒΡ≤ι―·ΚΆœ¬‘ΊΘ§ Ι”ΟΖΫ“≤Ω…“‘Ή‘ΦΚ±ύ–¥Hadoop≥Χ–ρΕ‘÷ΗΕ®»’÷ΨΫχ––Ζ÷ΈωΓΘ
ΦύΩΊΗφΨ·
Ή ‘¥ΒΡΦύΩΊΚΆ±®Ψ·“≤ «“ΜΗω‘ΤΤΫΧ®±Ί≤ΜΩ……ΌΒΡ≤ΩΖ÷ΓΘ’κΕ‘»ίΤςΒΡΦύΩΊ”–ΚήΕύ≥… λΒΡΩΣ‘¥»μΦΰΩ…Ι©―Γ‘ώΘ§58ΡΎ≤Ω“≤”–Ή®Ο≈ΒΡΦύΩΊΉιΦΰΘ§»γΚΈΗϋΚΟΒΡΦύΩΊΘ§‘ΤΆ≈Ε”“≤Ϋχ––ΝΥœύ”ΠΒΡ―Γ–ΆΓΘ
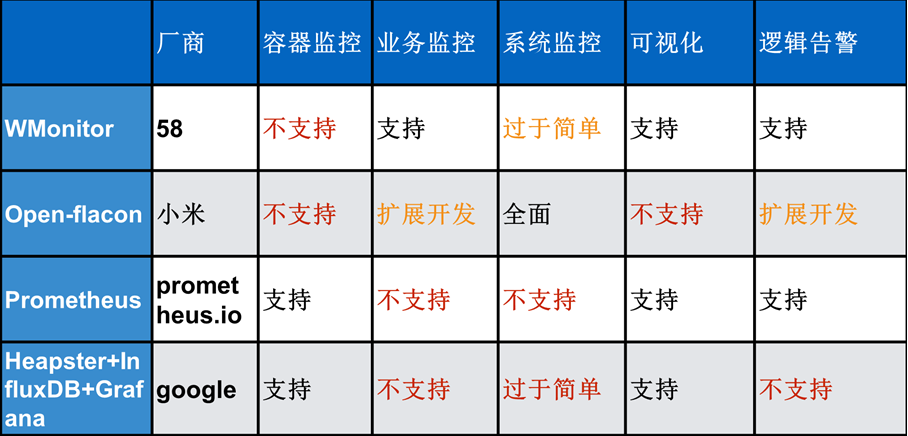
Ήν÷’Θ§‘ΤΆ≈Ε”―Γ‘ώ Ι”ΟWMonitorά¥ΉςΈΣ»ίΤςΒΡΦύΩΊΉιΦΰΘ§“ρΈΣWMonitor±Ψ…μΦ·≥…ΝΥΈοάμΜζΚΆ±®Ψ·¬ΏΦ≠Θ§Έ“Ο«≤Μ–η“Σ‘ΎΉωœύΕ‘”ΠΒΡΩΣΖΔΘ§÷Μ–η“ΣΩΣΖΔ»ίΤςΦύΩΊ≤ΩΖ÷ΒΡΉιΦΰΘ§≤Δ«“’κΕ‘ΡΎ≤ΩΒΡΦύΩΊ–η«σΘ§Έ“Ο«Ω…“‘ΚήΚΟΒΡΫχ––Ε®÷ΤΓΘHeapster + InfluxDB + Grafana «KubernetesΙΌΖΫΧαΙ©ΒΡΦύΩΊΉιΦΰΘ§ΙφΡΘ–Γ ±”ΟΥϋ“≤ΟΜ”–Έ ΧβΘ§ΒΪ «ΙφΡΘ¥σ ± Ι”ΟΥϋΩ…ΡήΜα¥φ‘ΎΈ ΧβΘ§“ρΈΣΥϋ «¬÷―·Μώ»ΓΥυ”–ΫΎΒψΦύΩΊ–≈œΔΒΡΓΘ
ΚσΦ«
“‘…œ «58Ά§≥«ΦήΙΙœΏ’κΕ‘»ίΤςΦΦ θ»γΚΈ¬δΒΊΫχ––ΝΥœύΙΊΧΫΥςΘ§ΚήΕύΦΦ θ―Γ–ΆΈόΙΊ”≈Ν”Θ§÷Μ―Γ‘ώ Κœ58œύΙΊ”Π”Ο≥ΓΨΑΒΡΓΘ’ϊΗω‘ΤΤΫΧ®“ΣΫβΨωΒΡΦΦ θΒψ”–ΚήΕύΘ§’βάο―Γ»ΓΤδ÷–ΦΗΗωΙΊΦϋΒΡΒψΚΆ¥σΦ“Ϋχ––Ζ÷œμΘ§Κσ–χΈ“Ο«‘ΤΆ≈Ε”ΜΙΜα’κΕ‘ΟΩΗωΦΦ θΒψΒΡ Β ©œΗΫΎ“‘ΦΑ”ωΒΫΒΡΈ ΧβΚΆ¥σΦ“Ϋχ––…ν»κΖ÷œμΓΘ |









