| БОЮФЪЧЪ§ШЫдЦМмЙЙЪІЗЖБђЕФЯпЩЯЗжЯэЃЌЭЈЙ§вЛДЮПЭЛЇЪЕЪЉАИР§ЩюШыЕиНтЮіDockerЕФДцДЂЗНЪНЃЌВЂИјГівЛаЉММЪѕбЁаЭЕФНЈвщЁЃМЮБіЪЧУШУШпеУУзгЃЌЗжЯэЪЧТњТњпеИЩЛѕЃКЃЉ
ЕквЛВПЗж ЮЪЬтеяЖЯ
ЪТЧщДгвЛДЮЪЕЪЉЯюФПЫЕЦ№ЃЌЮвУЧашвЊАяжњПЭЛЇНЋЫћУЧЕФгІгУШнЦїЛЏВЂдкЪ§ШЫдЦЦНЬЈЩЯЗЂВМДЫгІгУЁЃПЭЛЇЕФгІгУЪЧДЋЭГWASгІгУЁЃгІгУЪЧЭЈЙ§WAS
consoleНчУцНјааЪжЙЄВПЪ№ЃЌднЪБЮоЗЈЭЈЙ§DockerfileНјааздЖЏЛЏгІгУВПЪ№ЃЌзюКѓЕФОЕЯёЪЧЭЈЙ§Docker
commitЭъГЩЁЃОЕЯёЦєЖЏжДааУќСюЪЧstartwas.sh,ВЂЭЈЙ§tailНЋгІгУШежОЪфГіЕНБъзМЪфГіЁЃ
ЦєЖЏШнЦїЃЌWAS ServerЦєЖЏЪЇАмЃЌДэЮѓШежОШчЯТЃК 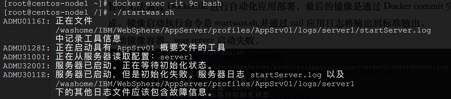
WAS ServerБъзМШежОЮФМўstartServer.logКЭnativestderr.logЖМУЛгаИќМгЯъЯИЕФДэЮѓаХЯЂЁЃзюКѓЙІЗђВЛИКгааФШЫЃЌ
дкconfigurationФПТМЯТевЕНПЩвдЖЈЮЛЕФДэЮѓаХЯЂ ==!ЃК
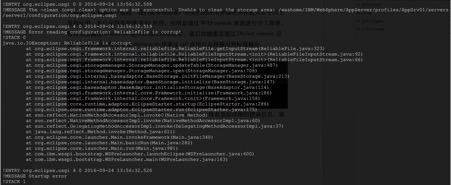
ЮФМўЗУЮЪIOвьГЃЃЌВщПДЯргІФПТМЮФМўЕФЪєадЃК
ЕНЯждкЮЊжЙЃЌПЩвдГѕВНХаЖЯЪЧDockerДцДЂЗНЪН(storage drive)дкОЕЯёШнЦїЗжВуЙмРэЩЯЕФЮЪЬтЁЃ
ЕБЧАЫожїЛњЪЧCentos7.2ЃЌФкКЫ3.10.0ЁЃВЂЧвВщПДЕБЧАЫожїЛњаХЯЂЪЧDocker1.12.0ЃЌДцДЂЗНЪНЪЧOverlayЃЌЫожїЛњЕФЮФМўЯЕЭГЪЧxfs:
ЮЊСЫбщжЄЮвУЧЕФЭЦЖЯЃЌЮвУЧзіСЫШчЯТМИЗНУцЕФГЂЪдЃК
ГЂЪд1: ЪЙгУЪ§ОнОэЙвдиЕФЗНЪНЃЌЙвдиећИіwashome ФПТМЁЃЃЈЪ§ОнОэЪЧDockerЫожїЛњЕФФПТМЛђЮФМўЃЌЭЈЙ§mountЕФЗНЪНМгдиЕНШнЦїРяЃЌВЛЪмДцДЂЧ§ЖЏЕФПижЦЁЃЃЉжиаТжЦзїОЕЯёЦєЖЏШнЦїЃЌWAS
ServerФме§ГЃЦєЖЏЁЃ
ГЂЪд2: ИФБфDocker engineЕФДцДЂЗНЪНЃЌИФГЩDevice mapperЃЌжиаТРШЁОЕЯёЃЌВЂЦєЖЏШнЦїЃЌWAS
ServerФме§ГЃЦєЖЏЁЃ
ФЧУДетИіЮЪЬтЪЧЦеБщЮЪЬтТ№ЃП
ГЂЪд3: дкЦфЫћЕФЫожїЛњЩЯЃЌЦєЖЏдОЕЯёЃЌетИіЮЪЬтЪЧЮоЗЈИДЯжЕФЁЃ
ОЙ§ЖрДЮВтЪдЗЂЯждкЯрЭЌФкКЫЁЂЯЕЭГАцБОЁЂdockerАцБОгааЉЛњЦїгаЮЪЬтгааЉЛњЦїУЛгаЮЪЬтЃЌзюжеЗЂЯжЪЧ
Centos ЬсЙЉЕФаТЮФМўЯЕЭГ XFS КЭ Overlay МцШнЮЪЬтЕМжТЁЃЭЌЪБЃЌЮвУЧДгDockerЩчЧјевЕНЯрЙиЮЪЬтЕФissueБЈИцЃКhttps://github.com/docker/docker/issues/9572
етИіЮЪЬтЕФаоИДдкФкКЫ 4.4.6вдЩЯЁЃзлЩЯЫљЪіЃЌЮвУЧЕУЕНСЫвЛИіНсТлЃЌетИіЮЪЬтЕФИљБОдвђЪЧoverlayFSдкxfsЩЯГіЯжСЫМцШнадЕФЮЪЬтЁЃ
ЪТЧщЕФЦ№вђЕНДЫЮЊжЙЃЌЯТУцШУЮвУЧЩюШыЕФПДПДDockerЕФМИжжДцДЂЗНЪНЃЌВЂИјГівЛаЉММЪѕбЁаЭЕФНЈвщЁЃ
ЕкЖўВПЗж ИХЪі
DockerдкЦєЖЏШнЦїЕФЪБКђЃЌашвЊДДНЈЮФМўЯЕЭГЃЌЮЊrootfsЬсЙЉЙвдиЕуЁЃзюЕзВуЕФв§ЕМЮФМўЯЕЭГbootfsжївЊАќКЌ
bootloaderКЭkernelЃЌbootloaderжївЊЪЧв§ЕММгдиkernelЃЌЕБkernelБЛМгдиЕНФкДцжаКѓ
bootfsОЭБЛumountСЫЁЃ rootfsАќКЌЕФОЭЪЧЕфаЭ Linux ЯЕЭГжаЕФ/devЃЌ/procЃЌ/binЃЌ/etcЕШБъзМФПТМКЭЮФМўЁЃ
Docker ФЃаЭЕФКЫаФВПЗжЪЧгааЇРћгУЗжВуОЕЯёЛњжЦЃЌОЕЯёПЩвдЭЈЙ§ЗжВуРДНјааМЬГаЃЌЛљгкЛљДЁОЕЯёЃЈУЛгаИИОЕЯёЃЉЃЌПЩвджЦзїИїжжОпЬхЕФгІгУОЕЯёЁЃDocker1.10в§ШыаТЕФПЩбАжЗДцДЂФЃаЭЃЌЪЙгУАВШЋФкШнЙўЯЃДњЬцЫцЛњЕФUUIDЙмРэОЕЯёЁЃЭЌЪБЃЌDockerЬсЙЉСЫЧЈвЦЙЄОпЃЌНЋвбОДцдкЕФОЕЯёЧЈвЦЕНаТФЃаЭЩЯЁЃВЛЭЌ
Docker ШнЦїОЭПЩвдЙВЯэвЛаЉЛљДЁЕФЮФМўЯЕЭГВуЃЌЭЌЪБдйМгЩЯздМКЖРгаЕФПЩЖСаДВуЃЌДѓДѓЬсИпСЫДцДЂЕФаЇТЪЁЃЦфжажївЊЕФЛњжЦОЭЪЧЗжВуФЃаЭКЭНЋВЛЭЌФПТМЙвдиЕНЭЌвЛИіащФтЮФМўЯЕЭГЁЃ
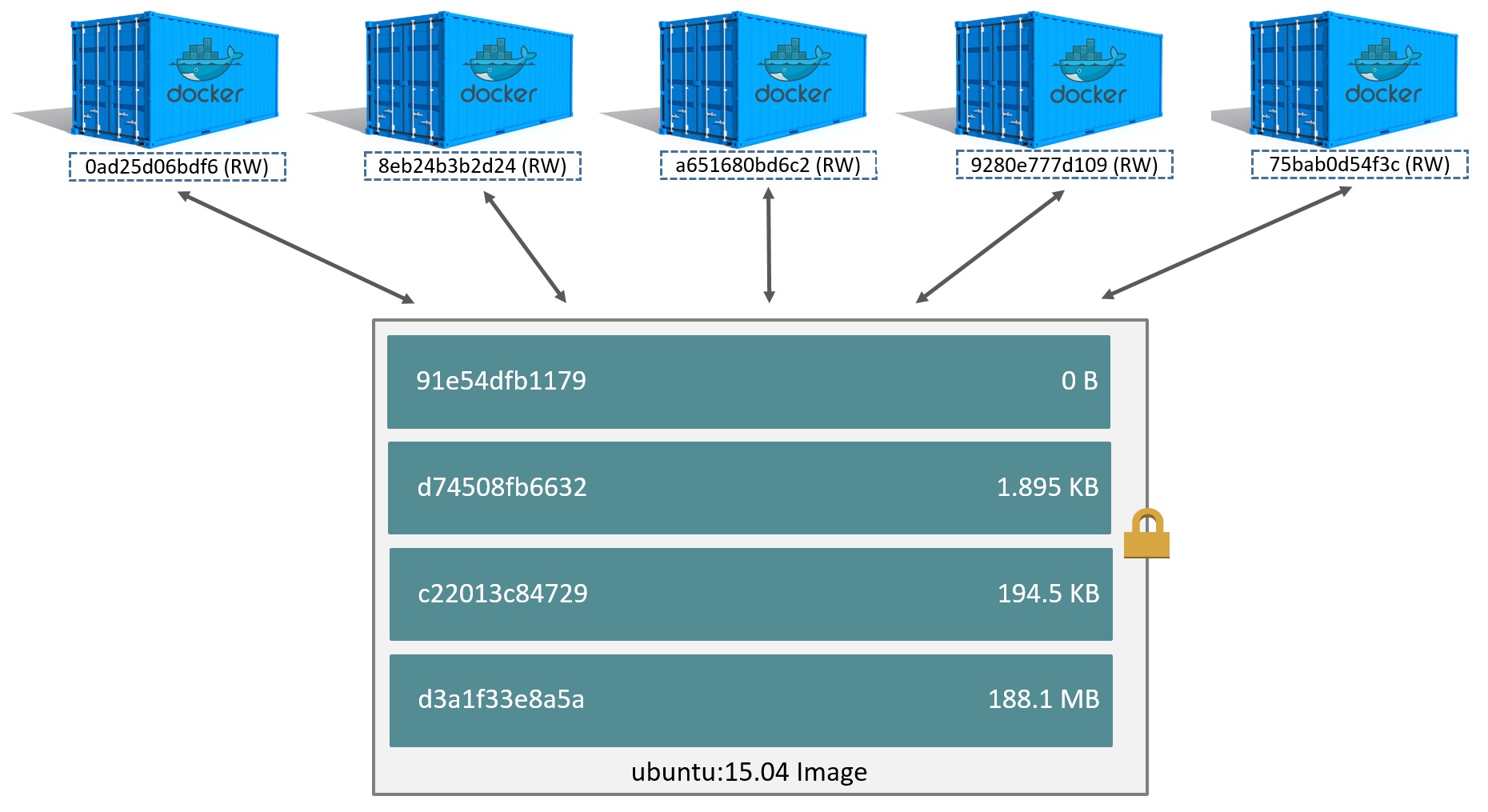
DockerДцДЂЗНЪНЬсЙЉЙмРэЗжВуОЕЯёКЭШнЦїЕФПЩЖСаДВуЕФОпЬхЪЕЯжЁЃзюГѕDockerНіФмдкжЇГжAUFSЮФМўЯЕЭГЕФubuntuЗЂааАцЩЯдЫааЃЌЕЋЪЧгЩгкAUFSЮДФмМгШыLinuxФкКЫЃЌЮЊСЫбАЧѓМцШнадЁЂРЉеЙадЃЌDockerдкФкВПЭЈЙ§graphdriverЛњжЦетжжПЩРЉеЙЕФЗНЪНРДЪЕЯжЖдВЛЭЌЮФМўЯЕЭГЕФжЇГжЁЃ
DockerгаШчЯТМИжжВЛЭЌЕФdriversЃК
AUFS
Device mapper
Btrfs
OverlayFS
ZFS
ЕкШ§ВПЗж ЗНАИЗжЮі
AUFS
AUFSЃЈAnotherUnionFSЃЉЪЧвЛжжUnion FSЃЌЪЧЮФМўМЖЕФДцДЂЧ§ЖЏЁЃЫљЮН UnionFS
ОЭЪЧАбВЛЭЌЮяРэЮЛжУЕФФПТМКЯВЂ mount ЕНЭЌвЛИіФПТМжаЁЃМђЕЅРДЫЕОЭЪЧжЇГжНЋВЛЭЌФПТМЙвдиЕНЭЌвЛИіащФтЮФМўЯЕЭГЯТЕФЮФМўЯЕЭГЁЃетжжЮФМўЯЕЭГПЩвдвЛВувЛВуЕиЕўМгаоИФЮФМўЁЃЮоТлЕзЯТгаЖрЩйВуЖМЪЧжЛЖСЕФЃЌжЛгазюЩЯВуЕФЮФМўЯЕЭГЪЧПЩаДЕФЁЃЕБашвЊаоИФвЛИіЮФМўЪБЃЌAUFSДДНЈИУЮФМўЕФвЛИіИББОЃЌЪЙгУCoWНЋЮФМўДгжЛЖСВуИДжЦЕНПЩаДВуНјаааоИФЃЌНсЙћвВБЃДцдкПЩаДВуЁЃдкDockerжаЃЌЕзЯТЕФжЛЖСВуОЭЪЧimageЃЌПЩаДВуОЭЪЧContainerЁЃНсЙЙШчЯТЭМЫљЪОЃК
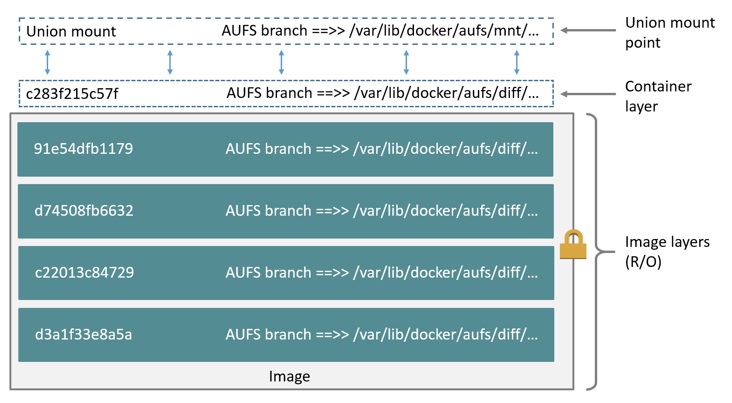
Р§зг
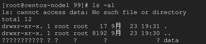
дЫаавЛИіЪЕР§гІгУЪЧЩОГ§вЛИіЮФМў/etc/shadowЃЌПДaufsЕФНсЙћ
# docker run centos
rm /etc/shadow
# ls -la /var/lib/docker/aufs/diff/$(docker ps
--no-trunc -lq)/etc
total 8
drwxr-xr-x 2 root root 4096 Sep 2 18:35 .
drwxr-xr-x 5 root root 4096 Sep 2 18:35 ..
-r--r--r-- 2 root root 0 Sep 2 18:35 .wh.shadow |
ФПТМНсЙЙ
ШнЦїЙвдиЕу(жЛгаШнЦїдЫааЪБВХБЛМгди)
/var/lib/docker/aufs/mnt/$CONTAINER_ID/
ЗжжЇ(КЭОЕЯёВЛЭЌЕФЮФМўЃЌжЛЖСЛюзХЖСаД)
/var/lib/docker/aufs/diff/$CONTAINER_OR_IMAGE_ID/
ОЕЯёЫїв§Бэ(УПИіОЕЯёв§гУОЕЯёУћ)
/var/lib/docker/aufs/layers/
ЦфЫћ
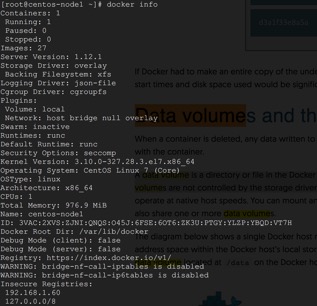
AUFS ЮФМўЯЕЭГПЩЪЙгУЕФДХХЬПеМфДѓаЁ
| # df -h /var/lib/docker/
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 20G 4.0G 15G 22% /
|
ЯЕЭГЙвдиЗНЪН
ЦєЖЏЕФ Docker

ЖдееЯЕЭГЙвдиЕу

ЗжЮі
ЫфШЛAUFSЪЧDocker ЕквЛАцжЇГжЕФДцДЂЗНЪНЃЌЕЋЕНЯждкЛЙУЛгаМгШыФкКЫжїЯп( centos ЮоЗЈжБНгЪЙгУ)
ДгдРэЗжЮіПДЃЌAUFS mount()ЗНЗЈКмПьЃЌЫљвдДДНЈШнЦїКмПьЃЛЖСаДЗУЮЪЖМОпгаБОЛњаЇТЪЃЛЫГађЖСаДКЭЫцЛњЖСаДЕФадФмДѓгкkvmЃЛВЂЧвDockerЕФAUFSПЩвдгааЇЕФЪЙгУДцДЂКЭФкДц
ЁЃ
AUFSадФмЮШЖЈЃЌВЂЧвгаДѓСПЩњВњВПЪ№МАЗсИЛЕФЩчЧјжЇГж
ВЛжЇГжrenameЯЕЭГЕїгУЃЌжДааЁАcopyЁБКЭЁАunlinkЁБЪБЃЌЛсЕМжТЪЇАмЁЃ
ЕБаДШыДѓЮФМўЕФЪБКђ(БШШчШежОЛђепЪ§ОнПтЕШ)ЖЏЬЌmountЖрФПТМТЗОЖЕФЮЪЬт,ЕМжТbranchдНЖрЃЌВщевЮФМўЕФадФмвВОЭдНТ§ЁЃ(НтОіАьЗЈ:живЊЪ§ОнжБНгЪЙгУ
-v ВЮЪ§ЙвдиЁЃ)
Device mapper
Device mapperЪЧLinuxФкКЫ2.6.9КѓжЇГжЕФЃЌЬсЙЉЕФвЛжжДгТпМЩшБИЕНЮяРэЩшБИЕФгГЩфПђМмЛњжЦЃЌдкИУЛњжЦЯТЃЌгУЛЇПЩвдКмЗНБуЕФИљОнздМКЕФашвЊжЦЖЈЪЕЯжДцДЂзЪдДЕФЙмРэВпТдЁЃDockerЕФDevice
mapperРћгУ Thin provisioning snapshotЙмРэОЕЯёКЭШнЦїЁЃ
Thin-provisioning Snapshot
SnapshotЪЧLvmЬсЙЉЕФвЛжжЬиадЃЌЫќПЩвддкВЛжаЖЯЗўЮёдЫааЕФЧщПіЯТЮЊthe originЃЈoriginal
deviceЃЉДДНЈвЛИіащФтПьее(Snapshot)ЁЃThin-ProvisioningЪЧвЛЯюРћгУащФтЛЏЗНЗЈМѕЩйЮяРэДцДЂВПЪ№ЕФММЪѕЁЃThin-provisioning
SnapshotЪЧНсКЯThin-ProvisioningКЭSnapshotingСНжжММЪѕЃЌдЪаэЖрИіащФтЩшБИЭЌЪБЙвдиЕНвЛИіЪ§ОнОэвдДяЕНЪ§ОнЙВЯэЕФФПЕФЁЃThin-Provisioning
SnapshotЕФЬиЕуШчЯТЃК
ПЩвдНЋВЛЭЌЕФsnaptshotЙвдиЕНЭЌвЛИіthe originЩЯЃЌНкЪЁСЫДХХЬПеМфЁЃ
ЕБЖрИіSnapshotЙвдиЕНСЫЭЌвЛИіthe originЩЯЃЌВЂдкthe originЩЯЗЂЩњаДВйзїЪБЃЌНЋЛсДЅЗЂCOWВйзїЁЃетбљВЛЛсНЕЕЭаЇТЪЁЃ
Thin-Provisioning SnapshotжЇГжЕнЙщВйзїЃЌМДвЛИіSnapshotПЩвдзїЮЊСэвЛИіSnapshotЕФthe
originЃЌЧвУЛгаЩюЖШЯожЦЁЃ
дкSnapshotЩЯПЩвдДДНЈвЛИіТпМОэЃЌетИіТпМОэдкЪЕМЪаДВйзїЃЈCOWЃЌSnapshotаДВйзїЃЉЗЂЩњжЎЧАЪЧВЛеМгУДХХЬПеМфЕФЁЃ
ЯрБШAUFSКЭOverlayFSЪЧЮФМўМЖДцДЂЃЌDevice mapperЪЧПщМЖДцДЂЃЌЫљгаЕФВйзїЖМЪЧжБНгЖдПщНјааВйзїЃЌЖјВЛЪЧЮФМўЁЃDevice
mapperЧ§ЖЏЛсЯШдкПщЩшБИЩЯДДНЈвЛИізЪдДГиЃЌШЛКѓдкзЪдДГиЩЯДДНЈвЛИіДјгаЮФМўЯЕЭГЕФЛљБОЩшБИЃЌЫљгаОЕЯёЖМЪЧетИіЛљБОЩшБИЕФПьееЃЌЖјШнЦїдђЪЧОЕЯёЕФПьееЁЃЫљвддкШнЦїРяПДЕНЮФМўЯЕЭГЪЧзЪдДГиЩЯЛљБОЩшБИЕФЮФМўЯЕЭГЕФПьееЃЌВЂУЛгаЮЊШнЦїЗжХфПеМфЁЃЕБвЊаДШывЛИіаТЮФМўЪБЃЌдкШнЦїЕФОЕЯёФкЮЊЦфЗжХфаТЕФПщВЂаДШыЪ§ОнЃЌетИіНагУЪБЗжХфЁЃЕБвЊаоИФвбгаЮФМўЪБЃЌдйЪЙгУCoWЮЊШнЦїПьееЗжХфПщПеМфЃЌНЋвЊаоИФЕФЪ§ОнИДжЦЕНдкШнЦїПьеежааТЕФПщРядйНјаааоИФЁЃDevice
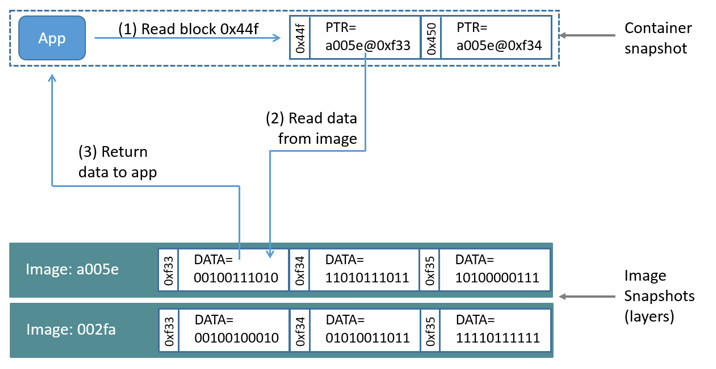
mapper Ч§ЖЏФЌШЯЛсДДНЈвЛИі100GЕФЮФМўАќКЌОЕЯёКЭШнЦїЁЃУПвЛИіШнЦїБЛЯожЦдк10GДѓаЁЕФОэФкЃЌПЩвдздМКХфжУЕїећЁЃНсЙЙШчЯТЭМЫљЪОЃК
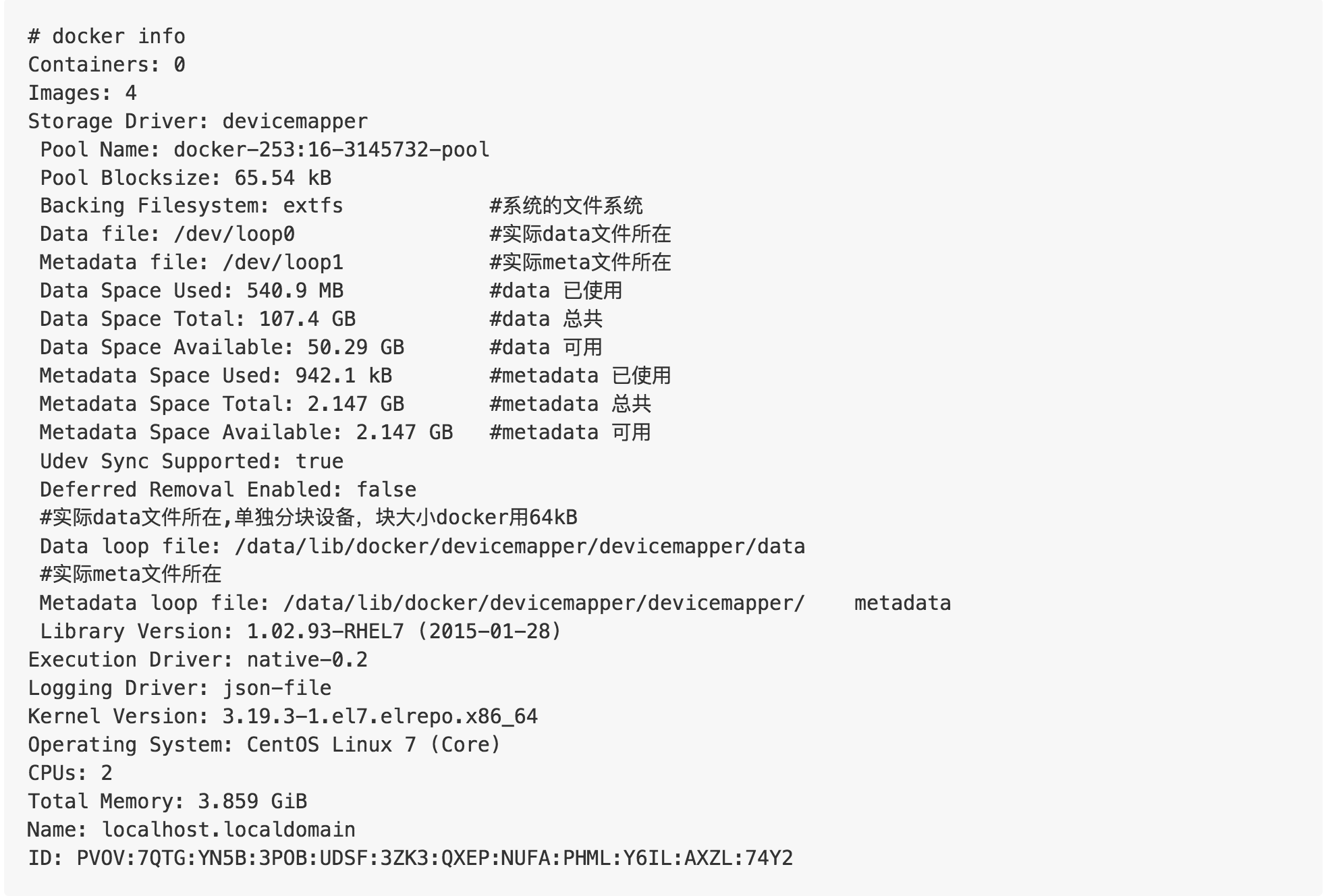
ПЩвдЭЈЙ§"docker info"ЛђЭЈЙ§dmsetup
lsЛёШЁЯывЊЕФИќЖраХЯЂЁЃВщПДdockerЕФDevice mapperЕФаХЯЂЃК
ЗжЮі
Device mapperЮФМўЯЕЭГМцШнадБШНЯКУЃЌВЂЧвДцДЂЮЊвЛИіЮФМўЃЌМѕЩйСЫinodeЯћКФЁЃ
УПДЮвЛИіШнЦїаДЪ§ОнЖМЪЧвЛИіаТПщЃЌПщБиаыДгГижаЗжХфЃЌеце§аДЕФЪБКђЪЧЯЁЫЩЮФМў,ЫфШЛЫќЕФРћгУТЪКмИпЃЌЕЋадФмВЛКУЃЌвђЮЊЖюЭтдіМгСЫvfsПЊЯњЁЃ
УПИіШнЦїЖМгаздМКЕФПщЩшБИЪБЃЌЫќУЧЪЧеце§ЕФДХХЬДцДЂЃЌЫљвдЕБЦєЖЏNИіШнЦїЪБЃЌЫќЖМЛсДгДХХЬМгдиNДЮЕНФкДцжаЃЌЯћКФФкДцДѓЁЃ
DockerЕФDevice mapperФЌШЯФЃЪНЪЧloop-lvmЃЌадФмДяВЛЕНЩњВњвЊЧѓЁЃдкЩњВњЛЗОГЭЦМіdirect-lvmФЃЪНжБНгаДдПщЩшБИЃЌадФмКУЁЃ
OverlayFS
OverlayЪЧLinuxФкКЫ3.18КѓжЇГжЕФЃЌвВЪЧвЛжжUnion FSЃЌКЭAUFSЕФЖрВуВЛЭЌЕФЪЧOverlayжЛгаСНВуЃКвЛИіupperЮФМўЯЕЭГКЭвЛИіlowerЮФМўЯЕЭГЃЌЗжБ№ДњБэDockerЕФОЕЯёВуКЭШнЦїВуЁЃЕБашвЊаоИФвЛИіЮФМўЪБЃЌЪЙгУCoWНЋЮФМўДгжЛЖСЕФlowerИДжЦЕНПЩаДЕФupperНјаааоИФЃЌНсЙћвВБЃДцдкupperВуЁЃдкDockerжаЃЌЕзЯТЕФжЛЖСВуОЭЪЧimageЃЌПЩаДВуОЭЪЧContainerЁЃНсЙЙШчЯТЭМЫљЪОЃК
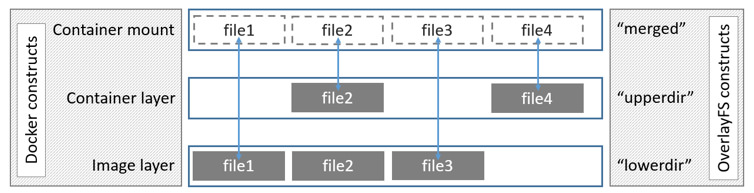
ЗжЮі
Дгkernel3.18НјШыжїСїLinuxФкКЫЁЃЩшМЦМђЕЅЃЌЫйЖШПьЃЌБШAUFSКЭDevice mapperЫйЖШПьЁЃдкФГаЉЧщПіЯТЃЌвВБШBtrfsЫйЖШПьЁЃЪЧDockerДцДЂЗНЪНбЁдёЕФЮДРДЁЃвђЮЊOverlayFSжЛгаСНВуЃЌВЛЪЧЖрВуЃЌЫљвдOverlayFS
ЁАcopy-upЁБВйзїПьгкAUFSЁЃвдДЫПЩвдМѕЩйВйзїбгЪБЁЃ
OverlayFSжЇГжвГЛКДцЙВЯэЃЌЖрИіШнЦїЗУЮЪЭЌвЛИіЮФМўФмЙВЯэвЛИівГЛКДцЃЌвдДЫЬсИпФкДцЪЙгУТЪЁЃ
OverlayFSЯћКФinodeЃЌЫцзХОЕЯёКЭШнЦїдіМгЃЌinodeЛсгіЕНЦПОБЁЃOverlay2ФмНтОіетИіЮЪЬтЁЃдкOverlayЯТЃЌЮЊСЫНтОіinodeЮЪЬтЃЌПЩвдПМТЧНЋ/var/lib/dockerЙвдкЕЅЖРЕФЮФМўЯЕЭГЩЯЃЌЛђепдіМгЯЕЭГinodeЩшжУЁЃ
гаМцШнадЮЪЬтЁЃopen(2)жЛЭъГЩВПЗжPOSIXБъзМЃЌOverlayFSЕФФГаЉВйзїВЛЗћКЯPOSIXБъзМЁЃР§ШчЃК
ЕїгУfd1=open("foo", ORDONLY) ЃЌШЛКѓЕїгУfd2=open("foo",
ORDWR) гІгУЦкЭћfd1 КЭfd2ЪЧЭЌвЛИіЮФМўЁЃШЛКѓгЩгкИДжЦВйзїЗЂЩњдкЕквЛИіopen(2)ВйзїКѓЃЌЫљвдШЯЮЊЪЧСНИіВЛЭЌЕФЮФМўЁЃ
ВЛжЇГжrenameЯЕЭГЕїгУЃЌжДааЁАcopyЁБКЭЁАunlinkЁБЪБЃЌНЋЕМжТЪЇАмЁЃ
Btrfs
BtrfsБЛГЦЮЊЯТвЛДњаДЪБИДжЦЮФМўЯЕЭГЃЌВЂШыLinuxФкКЫЃЌвВЪЧЮФМўМЖМЖДцДЂЃЌЕЋПЩвдЯёDevice
mapperвЛжБНгВйзїЕзВуЩшБИЁЃBtrfsРћгУ subvolumesКЭsnapshotsЙмРэОЕЯёШнЦїЗжВуЁЃBtrfsАбЮФМўЯЕЭГЕФвЛВПЗжХфжУЮЊвЛИіЭъећЕФзгЮФМўЯЕЭГЃЌГЦжЎЮЊsubvolume
ЃЌsnapshotЪЧsubvolumnЕФЪЕЪБЖСаДПНБДЃЌchunkЪЧЗжХфЕЅЮЛЃЌЭЈГЃЪЧ1GBЁЃФЧУДВЩгУ
subvolumeЃЌвЛИіДѓЕФЮФМўЯЕЭГПЩвдБЛЛЎЗжЮЊЖрИізгЮФМўЯЕЭГЃЌетаЉзгЮФМўЯЕЭГЙВЯэЕзВуЕФЩшБИПеМфЃЌдкашвЊДХХЬПеМфЪББуДгЕзВуЩшБИжаЗжХфЃЌРрЫЦгІгУГЬађЕїгУ
malloc()ЗжХфФкДцвЛбљЁЃЮЊСЫСщЛюРћгУЩшБИПеМфЃЌBtrfs НЋДХХЬПеМфЛЎЗжЮЊЖрИіchunk ЁЃУПИіchunkПЩвдЪЙгУВЛЭЌЕФДХХЬПеМфЗжХфВпТдЁЃБШШчФГаЉchunkжЛДцЗХmetadataЃЌФГаЉchunkжЛДцЗХЪ§ОнЁЃетжжФЃаЭгаКмЖргХЕуЃЌБШШчBtrfsжЇГжЖЏЬЌЬэМгЩшБИЁЃгУЛЇдкЯЕЭГжадіМгаТЕФДХХЬжЎКѓЃЌПЩвдЪЙгУBtrfsЕФУќСюНЋИУЩшБИЬэМгЕНЮФМўЯЕЭГжаЁЃBtrfsАбвЛИіДѓЕФЮФМўЯЕЭГЕБГЩвЛИізЪдДГиЃЌХфжУГЩЖрИіЭъећЕФзгЮФМўЯЕЭГЃЌЛЙПЩвдЭљзЪдДГиРяМгаТЕФзгЮФМўЯЕЭГЃЌЖјЛљДЁОЕЯёдђЪЧзгЮФМўЯЕЭГЕФПьееЃЌУПИізгОЕЯёКЭШнЦїЖМгаздМКЕФПьееЃЌетаЉПьеедђЖМЪЧsubvolumeЕФПьееЁЃ
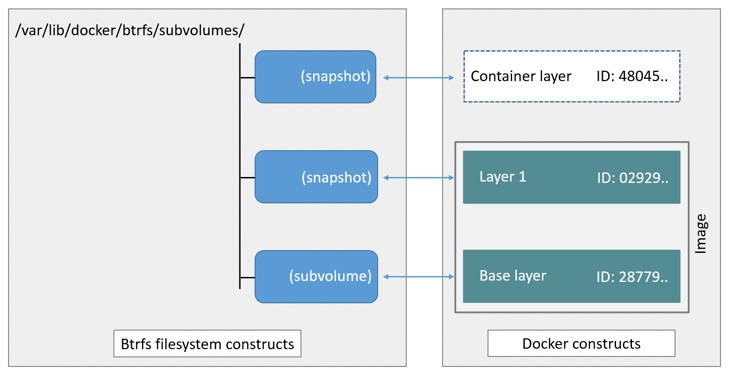
ЗжЮі
BtrfsЪЧЬцЛЛDevice mapperЕФЯТвЛДњЮФМўЯЕЭГЃЌ КмЖрЙІФмЛЙдкПЊЗЂНзЖЮЃЌЛЙУЛгаЗЂВМе§ЪНАцБОЃЌЯрБШEXT4ЛђЦфЫќИќГЩЪьЕФЮФМўЯЕЭГЃЌЫќдкММЪѕЗНУцЕФгХЪЦАќРЈЗсИЛЕФЬиеїЃЌШчЃКжЇГжзгОэЁЂПьееЁЂЮФМўЯЕЭГФкжУбЙЫѕКЭФкжУRAIDжЇГжЕШЁЃ
ВЛжЇГжвГЛКДцЙВЯэЃЌNИіШнЦїЗУЮЪЯрЭЌЕФЮФМўашвЊЛКДцNДЮЁЃВЛЪЪКЯИпУмЖШШнЦїГЁОАЁЃ
ЕБЧАBtrfsАцБОЪЙгУЁАsmall writesЁБ,ЕМжТадФмЮЪЬтЁЃВЂЧвашвЊЪЙгУBtrfsдЩњУќСюbtrfs
filesys showЬцДњdf
BtrfsЪЙгУЁАjournalingЁБаДЪ§ОнЕНДХХЬЃЌетНЋгАЯьЫГађаДЕФадФмЁЃ
BtrfsЮФМўЯЕЭГЛсгаЫщЦЌЃЌЕМжТадФмЮЪЬтЁЃЕБЧАBtrfsАцБОЃЌФмЭЈЙ§mountЪБжИЖЈautodefrag
зіМьВтЫцЛњаДКЭЫщЦЌећРэЁЃ
ZFS
ZFS ЮФМўЯЕЭГЪЧвЛИіИяУќадЕФШЋаТЕФЮФМўЯЕЭГЃЌЫќДгИљБОЩЯИФБфСЫЮФМўЯЕЭГЕФЙмРэЗНЪНЃЌZFS ЭъШЋХзЦњСЫЁАОэЙмРэЁБЃЌВЛдйДДНЈащФтЕФОэЃЌЖјЪЧАбЫљгаЩшБИМЏжаЕНвЛИіДцДЂГижаРДНјааЙмРэЃЌгУЁАДцДЂГиЁБЕФИХФюРДЙмРэЮяРэДцДЂПеМфЁЃЙ§ШЅЃЌЮФМўЯЕЭГЖМЪЧЙЙНЈдкЮяРэЩшБИжЎЩЯЕФЁЃЮЊСЫЙмРэетаЉЮяРэЩшБИЃЌВЂЮЊЪ§ОнЬсЙЉШпгрЃЌЁАОэЙмРэЁБЕФИХФюЬсЙЉСЫвЛИіЕЅЩшБИЕФгГЯёЁЃЖјZFSДДНЈдкащФтЕФЃЌБЛГЦЮЊЁАzpoolsЁБЕФДцДЂГижЎЩЯЁЃУПИіДцДЂГигЩШєИЩащФтЩшБИЃЈvirtual
devicesЃЌvdevsЃЉзщГЩЁЃетаЉащФтЩшБИПЩвдЪЧдЪМДХХЬЃЌвВПЩФмЪЧвЛИіRAID1ОЕЯёЩшБИЃЌЛђЪЧЗЧБъзМRAIDЕШМЖЕФЖрДХХЬзщЁЃгкЪЧzpoolЩЯЕФЮФМўЯЕЭГПЩвдЪЙгУетаЉащФтЩшБИЕФзмДцДЂШнСПЁЃDockerЕФZFSРћгУsnapshotsКЭclonesЃЌЫќУЧЪЧZFSЕФЪЕЪБПНБДЃЌsnapshotsЪЧжЛЖСЕФЃЌclonesЪЧЖСаДЕФЃЌclonesДгsnapshotДДНЈЁЃ
ЯТУцПДвЛЯТдкDockerРяZFSЕФЪЙгУЁЃЪзЯШДгzpoolРяЗжХфвЛИіZFSЮФМўЯЕЭГИјОЕЯёЕФЛљДЁВуЃЌЖјЦфЫћОЕЯёВудђЪЧетИіZFSЮФМўЯЕЭГПьееЕФПЫТЁЃЌПьееЪЧжЛЖСЕФЃЌЖјПЫТЁЪЧПЩаДЕФЃЌЕБШнЦїЦєЖЏЪБдђдкОЕЯёЕФзюЖЅВуЩњГЩвЛИіПЩаДВуЁЃШчЯТЭМЫљЪОЃК
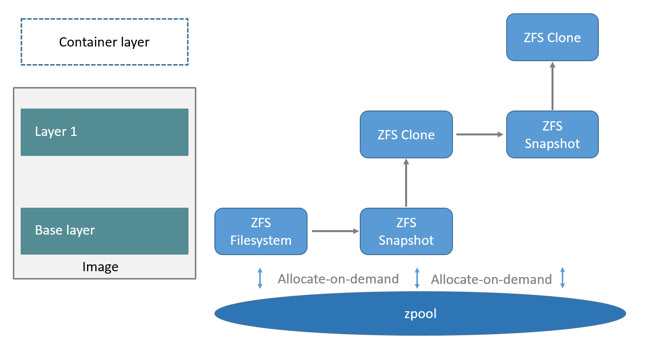
ЗжЮі
ZFSЭЌ BtrfsРрЫЦЪЧЯТвЛДњЮФМўЯЕЭГЁЃZFSдкLinux(ZoL)portЪЧГЩЪьЕФЃЌЕЋВЛЭЦМідкЩњВњЛЗОГЩЯЪЙгУDockerЕФ
ZFSДцДЂЗНЪНЃЌГ§ЗЧФугаZFSЮФМўЯЕЭГЕФОбщЁЃ
ОЏЬшZFSФкДцЮЪЬтЃЌвђЮЊЃЌZFSзюГѕЪЧЮЊСЫгаДѓСПФкДцЕФSun SolarisЗўЮёЦїЖјЩшМЦ ЁЃ
ZFSЕФЁАdeduplicationЁБЬиадЃЌвђЮЊеМгУДѓСПФкДцЃЌЭЦМіЙиЕєЁЃЕЋШчЙћЪЙгУSANЃЌNASЛђепЦфЫћгВХЬRAIDММЪѕЃЌПЩвдМЬајЪЙгУДЫЬиадЁЃ
ZFS cachingЬиадЪЪКЯИпУмЖШГЁОАЁЃ
ZFSЕФ128KПщаДЃЌintent logМАбгГйаДПЩвдМѕЩйЫщЦЌВњЩњЁЃ
КЭZFS FUSEЪЕЯжЖдБШЃЌЭЦМіЪЙгУLinuxдЩњZFSЧ§ЖЏЁЃ
ЕкЫФВПЗж змНс
СэЭтЃЌЯТЭМСаГіDockerИїжжДцДЂЗНЪНЕФгХЕуШБЕуЃК
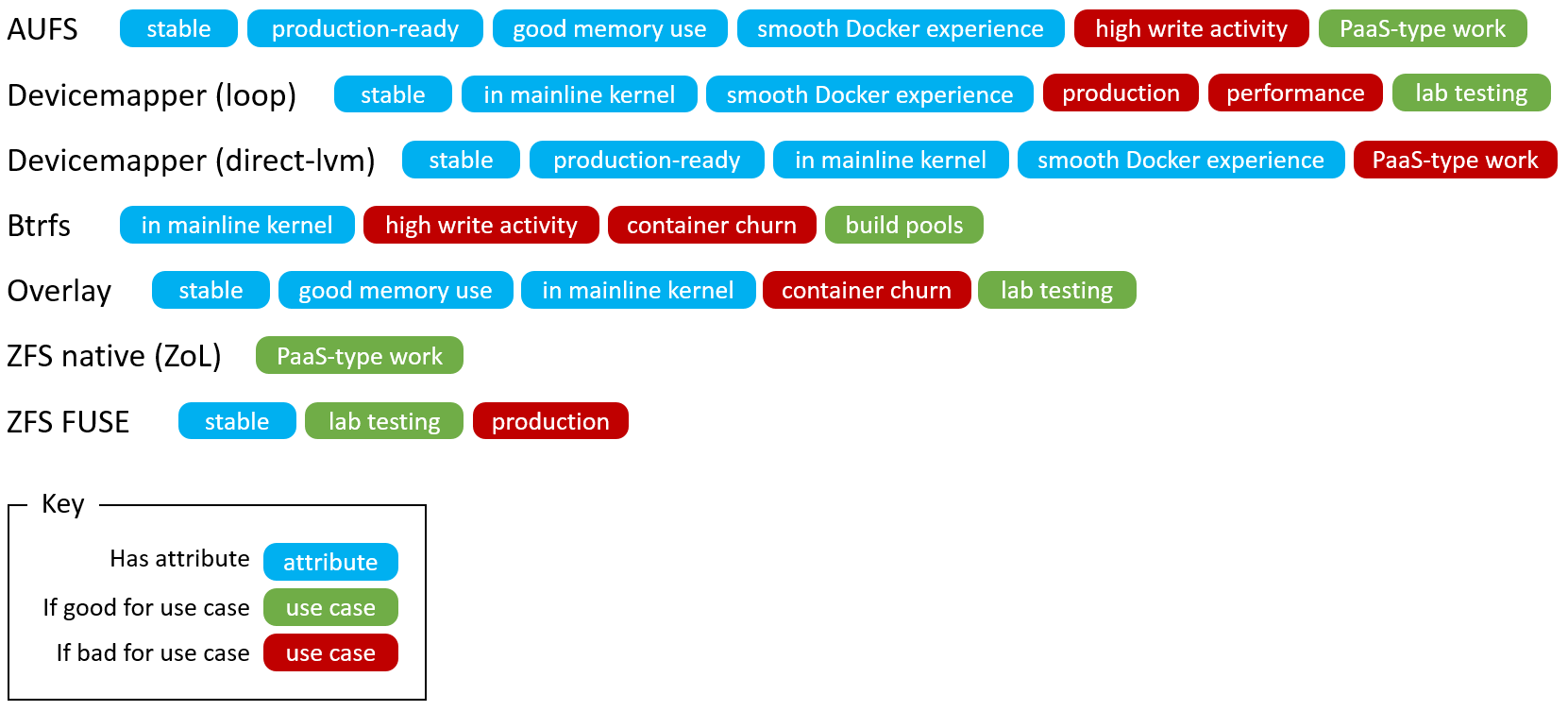
вдЩЯЪЧЮхжжDockerДцДЂЗНЪНЕФНщЩмМАЗжЮіЃЌвдДЫЮЊРэТлвРОнЃЌбЁдёздМКЕФDockerДцДЂЗНЪНЁЃЭЌЪБПЩвдзівЛаЉбщжЄВтЪдЃКШчIOадФмВтЪдЃЌвдДЫШЗЖЈЪЪКЯздМКгІгУГЁОАЕФДцДЂЗНЪНЁЃЭЌЪБЃЌгаСНЕужЕЕУЬсГіЃК
ЪЙгУSSD(Solid State Devices)ДцДЂЃЌЬсИпадФмЁЃ
ПМТЧЪЙгУЪ§ОнОэЙвдиЬсИпадФмЁЃ |









