| ЕБЧАЪ§ОнжааФДцдкЕФЮЪЬт

Ъ§ОнжааФжаЕФгІгУвЛАуЖРСЂВПЪ№ЃЌЮЊСЫБЃжЄЛЗОГИєРыгыЗНБуЙмРэЃЌБЃжЄгІгУзюДѓзЪдД Ъ§ОнжааФжаЦеБщДцдкШчЯТЮЪЬтЃК
жїЛњзЪдДРћгУТЪЕЭ
ВПЪ№КЭРЉеЙИДдг
зЪдДИєРыЮоЗЈЖЏЬЌЕїећ
ЮоЗЈПьЫйЯьгІвЕЮё
ЗНАИбЁаЭ
Yarn on DockerгаФФаЉЬиЕуЃП
ГЙЕзИєРыЖгСа
ЮЊСЫКЯРэРћгУHadoop yarnЕФзЪдДЃЌЖгСаМфЛсЛЅЯрЧРеММЦЫузЪдДЃЌдьГЩживЊШЮЮёзшШћ
ИљОнВПУХЩъЧыЕФЛњЦїЪ§СПЛЎЗжYarnМЏШКЗНБуВЦЮёЙмРэ
ИќЯИСЃЖШЕФзЪдДЗжХф
ЭГвЛЕФзЪдДЗжХф
УПИіNodeManagerКЭШнЦїЖМПЩвдЯоЖЈCPUЁЂФкДцзЪдД
YarnзЪдДЛЎЗжОЋШЗЕНCPUКЫЪ§КЭФкДцДѓаЁ
ЕЏадЩьЫѕадЗўЮё
УПИіШнЦїжадЫаавЛИіNodeManagerЃЌдіМѕyarnзЪдДжЛашдіМѕШнЦїИіЪ§
ПЩвджИЖЈУПИіNodeManagerгЕгаЕФМЦЫузЪдДЖрЩйЃЌАДашЩъЧызЪдД
DockerМЏШКЙмРэЯЕЭГЃКKubernetes or SwarmЃП
ЙигкШнЦїМЏШКЙмРэЯЕЭГЕФбЁаЭЃЌгУKubernetesЛЙЪЧSwarmЃПЮвУЧНсКЯздМКЕФОбщКЭвЕЮёашЧѓЃЌЖдБШШчЯТЃК
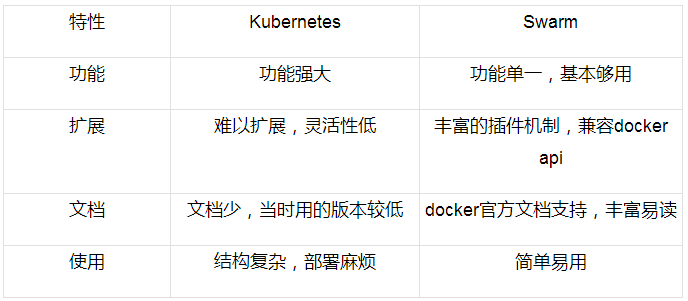
ЛљгквдЩЯЫФЕуЃЌЮвУЧзюжебЁдёСЫSwarmЃЌЫќЛљБОТњзуЮвУЧЕФашЧѓЃЌеЦЮеКЭПЊЗЂЪБГЃНЯЖЬЁЃ
НтОіЗНАИЕФгХЪЦ
бЁгУYarn on DockerЕФКУДІгавдЯТСНЕуЃК
SwarmЭГвЛМЏШКзЪдДЕїЖШ
ЭГвЛзЪдД
діМгDockerащФтЛЏВуЃЌНЕЕЭдЫЮЌГЩБО
діМгHadoopМЏШКзЪдДРћгУТЪ
For datacenterЃКБмУтСЫОВЬЌзЪдДИєРы
For clusterЃКМгЧПМЏШКФкВПзЪдДИєРы
ЯЕЭГМмЙЙ
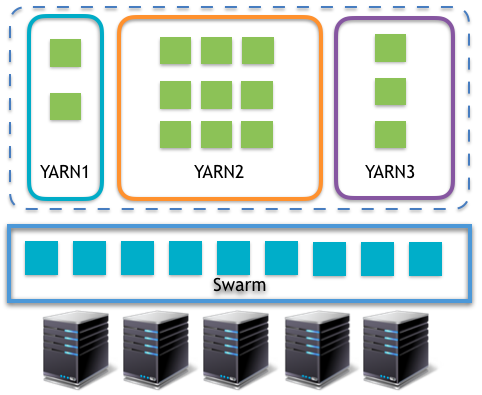

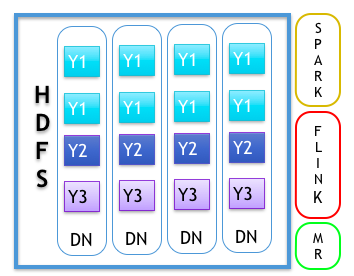

БШШчЪ§ОнжааФжадЫааЕФHadoopМЏШКЃЌЮвУЧНЋHDFSвРШЛдЫаадкЮяРэЛњЩЯЃЌМДDataNodeвРШЛВПЪ№дкЪЕЬхЛњЦїЩЯЃЌНЋYarnМЦЫуВудЫаадкDockerШнЦїжаЃЌећИіЯЕЭГЪЙгУЖўВузЪдДЕїЖШЃЌSparkЁЂFlinekЁЂMapReduceЕШгІгУдЫаадкYarnЩЯЁЃ
SwarmЕїЖШзюЕзВуЕФжїЛњгВМўзЪдДЃЌCPUКЭФкДцЗтзАЮЊDockerШнЦїЃЌШнЦїжадЫааNodeManagerЃЌЬсЙЉИјYarnМЏШКЃЌвЛИіSwarmМЏШКжаПЩвддЫааЖрИіYarnМЏШКЃЌаЮГЩШІЕиЪНЕФYarnМЦЫуМЏШКЁЃ
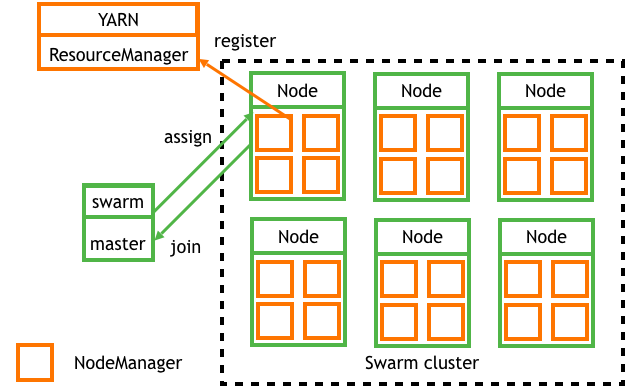
ОпЬхСїГЬ
1.swarm nodeЯђswarm masterзЂВсжїЛњзЪдДВЂМгШыЕНswarm
clusterжа
2.swarm masterЯђclusterЩъЧызЪдДЧыЧѓЦєЖЏШнЦї
3.swarmИљОнЕїЖШВпТдбЁдёдкФГИіnodeЩЯЦєЖЏdocker container
4.swarm nodeЕФdocker deamonИљОнШнЦїЦєЖЏВЮЪ§ЦєЖЏЯргІзЪдДДѓаЁЕФNodeManager
5.NodeManagerздЖЏЯђYARNЕФResourceManagerзЂВсзЪдДвЛИіNodeManagerзЪдДЬэМгЭъГЩЁЃ
SwarmЮЊЪ§ОнжааФзіШнЦїМДжїЛњзЪдДЕїЖШЃЌУПИіswarm nodeЕФНкЕуНсЙЙШчЭМЃК
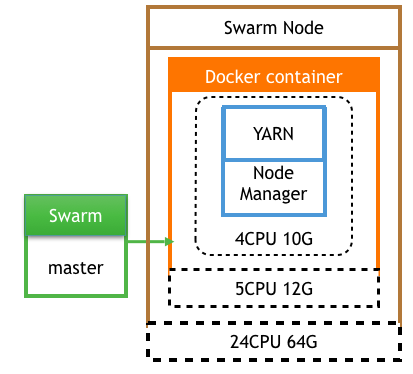
вЛИіSwarm nodeОЭЪЧвЛЬЈЮяРэЛњЃЌУПЬЈжїЛњЩЯПЩвдЦ№ЖрИіЭЌРраЭЕФdocker containerЃЌУПИіcontainerЕФзЪдДЖМгаЯожЦАќРЈCPUЁЂФкДцNodeManagerШнЦїжЛашвЊПМТЧБОЩэНјГЬеМгУЕФзЪдДКЭашвЊИјжїЛњдЄСєзЪдДЁЃМйШчжїЛњЪЧ24КЫ64GЃЌЮвУЧПЩвдЗжИјвЛИіШнЦї5КЫ12GЃЌNodeManagerеМгУ4КЫ10GЕФзЪдДЬсЙЉИјYarnЁЃ
ММЪѕЯъНт
(вЛ)ОЕЯёжЦзїгыЗЂВМ
ОЕЯёжЦзїКЭЗЂВМСїГЬШчЯТЭМЃК
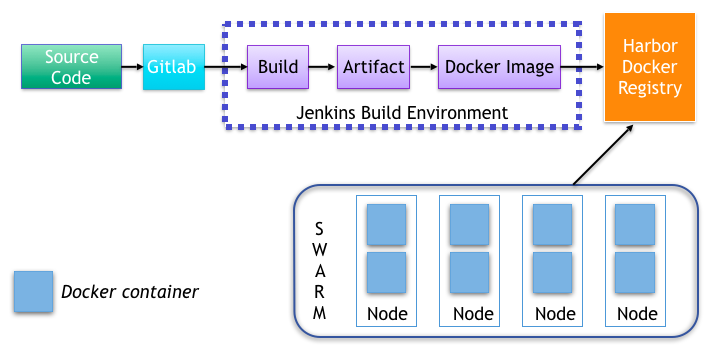
гУЛЇДгПЭЛЇЖЫЬсНЛДњТыЕНGitlabжаЃЌашвЊАќКЌDockerfileЮФМўЃЌЭЈЙ§МЏГЩСЫdockerВхМўЕФJenkinsЕФздЖЏБрвыЗЂВМЛњжЦЃЌздЖЏbuildОЕЯёКѓpushЕНdockerОЕЯёВжПтжаЃЌЭЌвЛИіЯюФПУПЬсНЛвЛДЮДњТыЖМЛсжиаТbuildвЛДЮОЕЯёЃЌЩњГЩВЛЭЌЕФtagРДБъЪЖОЕЯёЃЌSwarmМЏШКЪЙгУИУОЕЯёВжПтОЭПЩвджБНгРШЁОЕЯёЁЃ
DockerfileЕФБраДММЧЩ
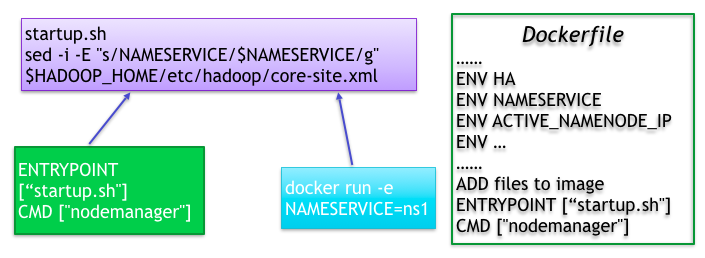
DockerfileЯрЕБгкdockerОЕЯёЕФБрвыДђАќСїГЬЫЕУїЃЌЦфжавВВЛЗІвЛаЉММЧЩЁЃ
КмЖргІгУашвЊХфжУЮФМўЃЌШчЙћЯыЮЊУПДЮЦєЖЏШнЦїЕФЪБКђЪЙгУВЛЭЌЕФХфжУВЮЪ§ЃЌПЩвдЭЈЙ§ДЋЕнЛЗОГБфСПЕФЗНЪНРДаоИФХфжУЮФМўЃЌЧАЬсЪЧашвЊаДвЛИіbashНХБОЃЌНХБОжаРДДІРэХфжУЮФМўЃЌдйНЋетИіНХБОзїЮЊentrypointШыПкЃЌУПЕБШнЦїЦєЖЏЪБОЭЛсжДааетИіНХБОДгЖјЬцЛЛХфжУЮФМўжаЕФВЮЪ§ЃЌвВПЩвдЭЈЙ§CMDДЋЕнВЮЪ§ИјИУНХБОЁЃ
ЦєЖЏШнЦїЕФЪБКђЭЈЙ§ДЋЕнЛЗОГБфСПЕФЗНЪНаоИФХфжУЮФМўЃК
docker run -d
--net=mynet
-e NAMESERVICE=nameservice
-e ACTIVE_NAMENODE_ID=namenode29 \
-e STANDBY_NAMENODE_ID=namenode63 \
-e HA_ZOOKEEPER_QUORUM=zk1:2181,zk2:2181,zk3:2181
\
-e YARN_ZK_DIR=rmstore \
-e YARN_CLUSTER_ID=yarnRM \
-e YARN_RM1_IP=rm1 \
-e YARN_RM2_IP=rm2 \
-e CPU_CORE_NUM=5
-e NODEMANAGER_MEMORY_MB=12288 \
-e YARN_JOBHISTORY_IP=jobhistory \
-e ACTIVE_NAMENODE_IP=active-namenode \
-e STANDBY_NAMENODE_IP=standby-namenode \
-e HA=yes \
docker-registry/library/hadoop-yarn:v0.1 resourcemanager |
зюКѓДЋЕнresourcemanagerЛђепnodemanagerВЮЪ§жИЖЈЦєЖЏЯргІЕФЗўЮёЁЃ
(Жў)МЏШКЙмРэ
ЮвУЧздааПЊЗЂГЬађЕїгУdockerЕФAPIРДЙмРэМЏШКЃЌвВПЩвдЭЈЙ§ЦфЫћПЊдДПЩЪгЛЏвГУцРДЙмРэМЏШКЃЌБШШчshipyardЁЃ
ЃЈШ§ЃЉздЖЈвхЭјТч
DockerШнЦїПчжїЛњЛЅЗУвЛжБЪЧвЛИіЮЪЬтЃЌDockerЙйЗНЮЊСЫБмУтЭјТчЩЯДјРДЕФжюЖрТщЗГЃЌЙЪНЋПчжїЛњЭјТчПЊСЫБШНЯДѓЕФПкзгЃЌЖјгЩгУЛЇздМКШЅЪЕЯжЁЃЮвУЧПЊЗЂВЂПЊдДСЫShrikeетИіdockerЭјТчВхМўЃЌДѓМвПЩвддкетРяЯТдиЕНЃКhttps://github.com/talkingdata/shrike
ФПЧАDockerПчжїЛњЕФЭјТчЪЕЯжЗНАИвВгаКмЖржж, жївЊАќРЈЖЫПкгГЩфЃЌovs, fannelЕШЁЃЕЋЪЧетаЉЗНАИЖМЮоЗЈТњзуЮвУЧЕФашЧѓЃЌЖЫПкгГЩфЗўЮёФкЕФФкЭјIPЛсгГЩфГЩЭтЭјЕФIPЃЌетбљЛсИјПЊЗЂДјРДРЇЛѓЃЌвђЮЊЫћУЧЭљЭљдкПчЭјТчНЛЛЅЪБЪЧВЛашвЊФкЭјIPЕФЃЌЖјovsгыfannelдђЪЧдкЛљДЁЭјТчавщЩЯгжАќзАСЫвЛВуздЖЈвхавщЃЌетбљЕБЭјТчСїСПДѓЪБЃЌШДгжЮоЖЫЕФдіМгСЫЭјТчИКдиЃЌзюКѓЮвУЧВЩШЁСЫзджїбаЗЂБтЦНЛЏЭјТчВхМўЃЌвВОЭЪЧЫЕШУЫљгаЕФШнЦїЭГЭГдкДѓЖўВуЩЯЛЅЭЈЁЃМмЙЙШчЯТЃК
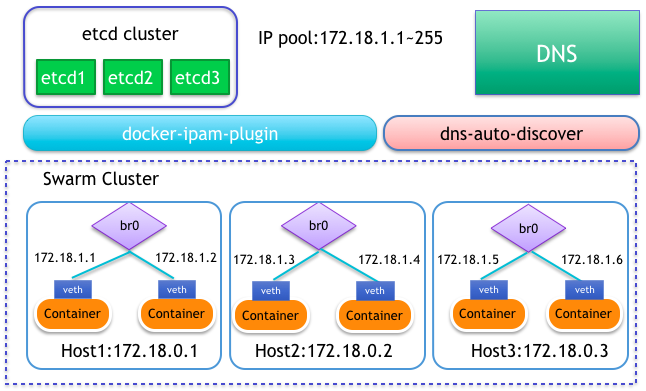
ЮвУЧЪзЯШашвЊДДНЈвЛИіbr0здЖЈвхЭјЧХЃЌетИіЭјЧХВЂВЛЪЧЭЈЙ§ЯЕЭГУќСюЪжЖЏНЈСЂЕФдЪМLinuxЭјЧХЃЌЖјЪЧЭЈЙ§DockerЕФcerate
networkУќСюРДНЈСЂЕФздЖЈвхЭјЧХЃЌетбљБмУтСЫвЛИіКмживЊЕФЮЪЬтОЭЪЧЮвУЧПЩвдЭЈЙ§ЩшжУDefaultGatewayIPv4ВЮЪ§РДЩшжУШнЦїЕФФЌШЯТЗгЩЃЌетИіНтОіСЫдЪМLinuxздНЈЭјЧХВЛФмНтОіЕФЮЪЬт.
гУDockerДДНЈЭјТчЪБЮвУЧПЩвдЭЈЙ§ЩшжУsubnetВЮЪ§РДЩшжУзгЭјIPЗЖЮЇЃЌФЌШЯЮвУЧПЩвдАбећИіЭјЖЮИјетИізгЭјЃЌКѓУцПЩвдгУipam
driverЃЈЕижЗЙмРэВхМўЃЉРДНјааПижЦЁЃЛЙгавЛИіВЮЪ§gatewayЪЧгУРДЩшжУbr0здЖЈвхЭјЧХЕижЗЕФЃЌЦфЪЕвВОЭЪЧФуетЬЈЫожїЛњЕФЕижЗЁЃ
docker network
create
--opt=com.docker.network.bridge.enable_icc=true
--opt=com.docker.network.bridge.enable_ip_masquerade=false
--opt=com.docker.network.bridge.host_binding_ipv4=0.0.0.0
--opt=com.docker.network.bridge.name=br0
--opt=com.docker.network.driver.mtu=1500
--ipam-driver=talkingdata
--subnet=ШнЦїIPЕФзгЭјЗЖЮЇ
--gateway=br0ЭјЧХЪЙгУЕФIP,вВОЭЪЧЫожїЛњЕФЕижЗ
--aux-address =DefaultGatewayIPv4=ШнЦїЪЙгУЕФЭјЙиЕижЗ
mynet |
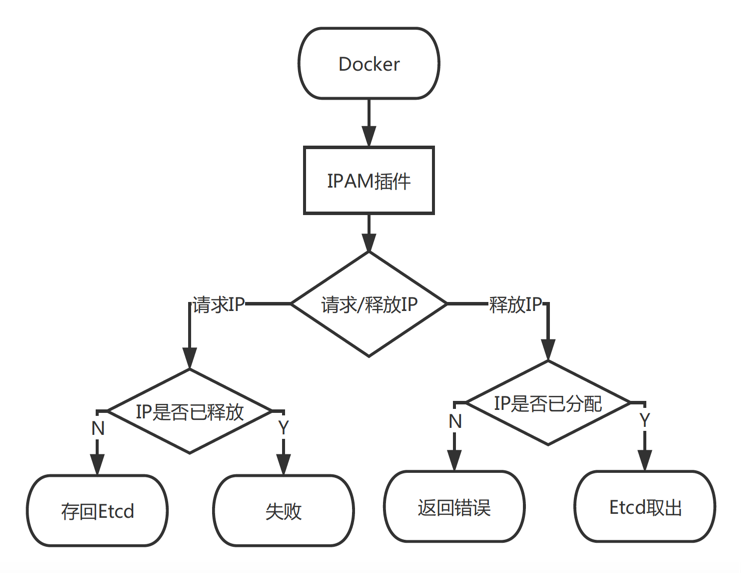
IPAMЧ§ЖЏЪЧзЈУХЙмРэDocker ШнЦїIPЕФ, Docker УПДЮЦєЭЃгыЩОГ§ШнЦїЖМЛсЕїгУетИіЧ§ЖЏЬсЙЉЕФIPЙмРэНгПкЃЌШЛКѓIPНгПкЛсЖдДцДЂIPЕижЗЕФEtcdгавЛИідіЩОИФВщЕФВйзїЁЃДЫВхМўдЫааЪБЛсЦ№вЛИіUnix
Socket, ШЛКѓЛсдкdocker/run/plugins ФПТМЯТЩњГЩвЛИі.sockЮФМўЃЌDocker
daemonжЎКѓЛсКЭетИіsock ЮФМўНјааЙЕЭЈШЅЕїгУЮвУЧжЎЧАЪЕЯжКУЕФМИИіНгПкНјааIPЙмРэЃЌвдДЫРДДяЕНIPЙмРэЕФФПЕФЃЌЗРжЙIPГхЭЛЁЃ
ЭЈЙ§DockerУќСюШЅДДНЈвЛИіздЖЈвхЕФЭјТчЦ№УћЮЊЁАmynetЁБЃЌЭЌЪБЛсВњЩњвЛИіЭјЧХbr0ЃЌжЎКѓЭЈЙ§ИќИФЭјТчХфжУЮФМўЃЈдк/etc/sysconfig/network-scripts/ЯТifcfg-br0ЁЂifcfg-ФЌШЯЭјТчНгПкУћЃЉНЋФЌШЯЭјТчНгПкЧХНгЕНbr0ЩЯЃЌжиЦєЭјТчКѓЃЌЧХНгЭјТчОЭЛсЩњаЇЁЃDockerФЌШЯдкУПДЮЦєЖЏШнЦїЪБЖМЛсНЋШнЦїФкЕФФЌШЯЭјПЈЧХНгЕНbr0ЩЯЃЌЖјЧвЫожїЛњЕФЮяРэЭјПЈвВЭЌбљЧХНгЕНСЫbr0ЩЯСЫЁЃЦфЪЕЧХНгЕФдРэОЭКУЯёЪЧвЛЬЈНЛЛЛЛњЃЌDocker
ШнЦїКЭЫожїЛњЮяРэЭјТчНгПкЖМЪЧЗўЮёЦїЃЌЭЈЙ§veth pairетИіЭјТчЩшБИЯёвЛИљЭјЯпВхЕННЛЛЛЛњЩЯЁЃжСДЫЃЌЫљгаЕФШнЦїЭјТчвбОдкЭЌвЛИіЭјТчЩЯПЩвдЭЈаХСЫЃЌУПвЛИіDockerШнЦїОЭКУБШЪЧвЛЬЈЖРСЂЕФащФтЛњЃЌгЕгаКЭЫожїЛњЭЌвЛЭјЖЮЕФIPЃЌПЩвдЪЕЯжПчжїЛњЗУЮЪСЫЁЃ
ЃЈЫФЃЉМЏШКМрПи
ШчЙћЪЙгУshipyardЙмРэМЏШКЛсгавЛИіЕЅЖРЕФМрПивГУцЃЌПЩвдПДЕНвЛЖЈЪБМфЖЮФкЕФCPUЁЂФкДцЁЂIOЁЂЭјТчЪЙгУзДПіЁЃ
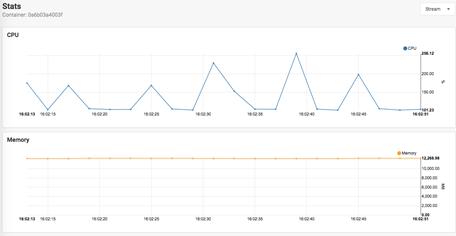
ЮвУЧздМКПЊЗЂСЫЛљгкДѓЪ§ОнЕФМрПиЯЕЭГOwlвВМДНЋжЇГжdockerШнЦїЕФМрПиЁЃhttps://github.com/TalkingData/OWL-v3
адФмЦПОБгыгХЛЏ
ДѓМвПЩФмЛсЕЃаФздЖЈвхЭјТчЕФадФмЮЪЬтЃЌЮЊДЫЮвУЧгУiperfНјааСЫЭјТчадФмВтЪдЁЃЮвУЧЖдБШСЫВЛЭЌжїЛњШнЦїМфЕФЭјЫйЃЌЭЌвЛжїЛњЩЯЕФВЛЭЌШнЦїКЭВЛЭЌжїЛњМфЕФЭјЫйЃЌНсЙћШчЯТБэЃК

ДгБэжаЮвУЧПЩвдПДЕНЃЌдкетвЛзщВтЪджаЃЌШнЦїМфЕФЭјЫйгыШнЦїЪЧдкЯыЭЈжїЛњЛЙЪЧдкВЛЭЌжїЛњЩЯЕФВюБ№ВЛДѓЃЌЫЕУїЮвУЧЕФЭјТчВхМўадФмЛЙЪЧКмгХвьЕФЁЃ
HadoopХфжУгХЛЏ
вђЮЊЪЙгУdockerНЋдРДвЛЬЈЛњЦївЛИіnodemanagerИјЯИЛЏЮЊСЫЖрИіЃЌЛсдьГЩnodemanagerИіЪ§ЕФГЩБЖдіМгЃЌвђДЫhadoopЕФвЛаЉХфжУашвЊЯргІгХЛЏЁЃ
yarn.nodemanager.localizer.fetch.thread-count ЫцзХШнЦїЪ§СПдіМгЃЌашвЊЯргІЕїећИУВЮЪ§
yarn.resourcemanager.amliveliness-monitor.interval-msФЌШЯ1УыЃЌИФЮЊ10УыЃЌЗёдђЪБМфЬЋЖЬПЩФмЕМжТгааЉНкЕуЮоЗЈзЂВс
yarn.resourcemanager.resource-tracker.client.thread-countФЌШЯ50ЃЌИФЮЊ100ЃЌЫцзХШнЦїЪ§СПдіМгЃЌашвЊЯргІЕїећИУВЮЪ§
yarn.nodemanager.pmem-check-enabledФЌШЯtrueЃЌИФЮЊfalseЃЌВЛМьВщШЮЮёе§дкЪЙгУЕФЮяРэФкДцСП
ШнЦїжаhadoop ulimitжЕаоИФЃЌФЌШЯ4096ЃЌИФГЩ655350
ЙигкЮДРД
ЮвУЧЮДРДЙцЛЎзіЕФЪЧDCЃЏOSЃЌЛљгкDockerЕФгІгУздЖЏДђАќБрвыЗжЗЂЯЕЭГЃЌШУПЊЗЂШЫдБПЩвдКмБуНнЕФЩъЧызЪдДЃЌЩЯЯТЯпЗўЮёЃЌЙмРэгІгУЁЃвЊДяЕНетИіФПБъЛЙгаКмЖрЪТЧщвЊзіЃК
Service Control PanelЃКЭГвЛЕФИљОнЗўЮёРДЙмРэЕФwebвГУц
Load balanceЃКШнЦїИљОнЛњЦїИКдиЧщПіздЖЏЧЈвЦ
SchedulerЃКswarmЕїЖШВпТдгХЛЏ
ЗўЮёХфжУЮФМўЃКЬсЙЉОЕЯёЦєЖЏВЮЪ§ЕФХфжУЮФМўЃЌЫљгаЦєЖЏВЮЪ§ПЩЭЈЙ§ЮФМўХфжУ
МрПиЃКЗўЮёМЖБ№ЕФМрПи 
|









