| 作为一个集中于复杂的项目集成的技术公司,不但统一遗留系统而且模块化的解决方案,确保持久的可扩展性,我们正在从事大量的项目,包括客户软件开发;打包,开源和SaaS软件集成;基础设施设置;和产品运营与维护。
从一个技术的角度来看,我们的方法永远是无关的。我们与Java和.NET后端、web和移动端(所有平台)、Amazon和Azure云服务和基础设施,和即使是本地部署一起工作。
对我们而言,容器化作为管理复杂系统和进程的一种方法,已经很长一段时间成为实际的标准,但是随着如此多的复杂性和技术在起作用,我们永远在寻找新的方法来提高我们的工作效率,重复我们所做的,并且让我们的团队集中于每个项目独特的业务需求。
实现这个的一个方法就是通过一个灵活可靠的平台的应用来管理复杂的多集群容器软件——为了各种各样的DevOps需要和支持产品运营和再使用,构建可重复使用的组件。
在平台需求中,我们确认了以下几点:
尽可能避免被厂商锁住可行性。平台需要可移植性(能够在不同的云和本地上运行),它必须依赖于开放标准和协议。它还需要作为大量项目、服务和组织的基础。
适用于不同的业务环境。这就需要有许可的开源技术、商业支持的可用性和免费选项。
可扩展性。支持从超小(例如一个物理或虚拟节点)到大型(几十个节点)到超大(成百上千个节点)的配置。
可靠性。对于不同的环境和缩放,我们需要对各种自我恢复和故障转移的支持。
灵活性和功能丰富。我们希望有一些开发、高效DevOps和产品运营自动化所需的功能和抽象。
部署简单。易于部署和设置不同的环境,最好是开箱即用。它还需要轻量级、生产就绪和经过实战测试。
解决方案路径
一些框架存在,但是下面的三个是现实的竞争者:
· Docker Swarm
· Kubernetes
· Hashicorp的stack 工具——nomad, consul, etc.
· (并且荣誉推荐 Apache Mesos)
在进行了一些研究和原型开发之后,我们将Kubernetes作为标准DevOps和集群编排平台的主要候选对象,原因有很多。
Kubernetes的优点
详细描述我们如何比较工具不是我们这篇文章的目的,但是我还是想给个小结来说明下Kubernetes到底哪里好:
pod理念,一套co-located容器非常强大,它解决了Docker Compose相同的问题,但更加优雅。pod,不是容器,实际上是Kubernetes的一个工作负载单元。
平覆盖网络地址空间,每个pod得到一个唯一的IP地址,通过本地主机和容器内pod通信。
“服务”概念通过稳定的覆盖网络IP地址的L3平衡的一套pod,提供了简单的服务发现。
DNSfurther提高服务发现。pod能够通过它们的名字找到服务。
名称空间。这些可以将对象分成组,并为单个集群中的多租户提供一种方法。
一套丰富的pod控制器可实现开箱即用:
用于对称集群的部署、副本和复制控制器;
为组件标识的集群设置pet是很重要的;
用于辅助组件的Daemon集,例如日志托运人和备份进程;
用于反向代理和L7负载平衡的lngresses,以及更多。
附件的概念,提供“横切关系”的特性。
丰富、持久存储管理功能。
与大多数IaaS云提供商实现良好的集成。
总而言之,在我看来,Kubernetes在“太少概念,需要写更多引用代码”和“太多概念,系统不够灵活”之间找到了正确的平衡。
Kubernetes的缺点
不幸的是,即便是太阳也有黑点。Kubernetes是出了名的在生产系统中难用。
我们平台构建进程的需求是主要来源于一般平台需求,我们想做的是以下几点:
设置一个“vanilla”Kubernetes集群,不是基于Kubernetes的自定义产品。
能够自定义集群配置并且易于构建进程。
简化构建进程和尽可能的减少管理员环境的需求。
让部署进程轻便和可重复使用,以便我们能够在多种平台上维护它——至少Azure,AWS和裸机。
依赖云供应商特定工具进行IaaS资源管理——AWS的Cloud Formation,Azure的Resource
Manager 。
保证作为结果的部署是生产就绪的,可靠的,自我修复的,可扩展的等等(即满足上述平台的所有要求)。
有许多方法构建一个Kubernetes集群——它们中的一些甚至是官方文件和描述中的内容——但是对他们每个进行调查,我们看到不同的问题,阻止了它们成为
EastBanc Technologies的项目的标准。结果,我们设计和构建了一个Kubernetes集群设置和配置进程,它将为我们工作。
重新构想Kubernetes部署
为了我们的Kubernetes部署程序,我们决定依赖云供应商工具进行IaaS资源管理,也就是 AWS的Cloud
Formation 和Azure的Resource Manager。
为了创建一个集群,不需要在你机器上设置任何东西,只用Cloud Formation模板和AWS控制台来创建一个新堆栈。我们实现的Kubernetes集群云形成模板创建了几个资源,如下图所示:
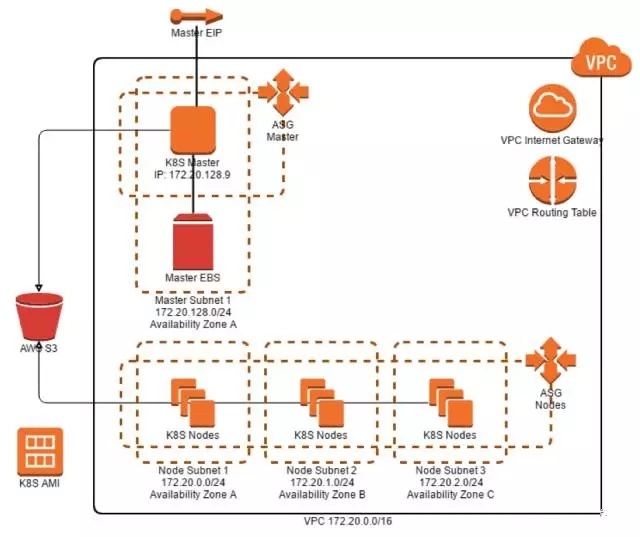
让我们更深入的看下这些资源:
Master EIP为Kubernetes主节点提供稳定的公共端点IP地址。
在启动时,Kubernetes主初始化脚本还分配标准的私有IP地址(127.20.128.9)以确保主节点也有一个稳定的私有IP,端点为节点Kubelets。
Master EBS在启动时附属于主节点,并且用于存储集群数据。
Kubernetesmaster在Auto Scaling Group中开始,以确保AWS万一故障能恢复。目前,master
Auto Scaling Group具有最小、想得到的和最大数量的实例设置为1。
在多个可用性区域中Auto Scaling Group中运行节点。
S3 bucket用于分享证书tokens,为了节点和客户连接到master。Master将在第一个启动时生成证书和tokens,并将它们上传到bucket中。
master和节点分配IAM的角色需要AWS资源的访问权限。
master和节点实例从一个AMI被创建,随着Kubernetes预先安装所需的所有软件组件。
为了配置Kubernetes软件组件在master和节点上运行,我们使用了编写的多节点集群配置方法,在Kubernetes的文档中有描述。
下图展示了配置结果:
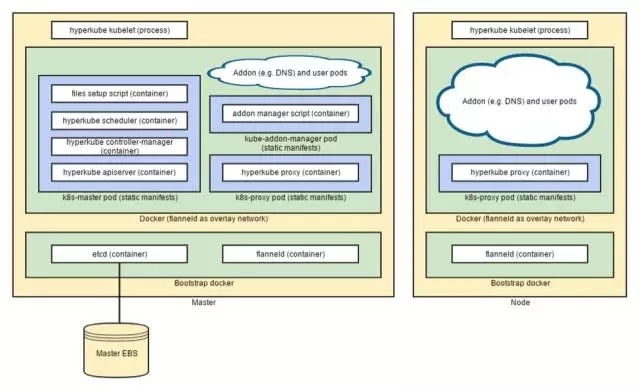
集群初始化设置分成3类:
Packer脚本为了集群准备AMI
Cloud Formation模板为了集群创建或更新AWS资源
Bootstrap脚本作为master或节点实例boot进程最后一步运行
AMI准备
我们基于官方Kubernetes AMI k8s-debian-jessie为集群构建了一个自定义AMI,它反过来也只是一个标准的Debian
Jessie映像,安装了一些附加包。
AMI准备通过packer脚本执行。接下来的步骤就要执行的:
更新安装包。
创建docker-bootstrap和kubelet-systemd服务。
更新docker-systemd flanneld服务配置,这样flanneld覆盖网络可以在服务器启动时配置。
Pull etcd、flanneld和 Kubernetes hyperkube Docker镜像,以确保快速启动。
创建/etc/rc. /etc/kubernetes/bootstrap脚本并添加其执行到 /etc/rc.local
脚本,所以它作为OS启动顺序的最后一步运行的。
从hyperkubedocker镜像提取hyperkube binary ,把它放到/usr/bin,以便kubelet进程可以在docker容器之外运行。
准备静态pod清单文件和在/etc/kubernetes里的Kubernetes配置文件。
准备其他辅助工具,在实例bootstrap期间使用(例如safe_format_and_mount.sh脚本)。
清理临时和日志文件。
Cloud Formation模板
Cloud Formation模板创建和初始化AWS资源已经在上面第一张图里展示了。作为这个配置的一部分,它为Kubernetes
master和节点实例创建了启动配置对象,并且将它们与master和节点Auto Scaling Groups关联起来。
Master和节点启动配置都包括AWS用户数据脚本,在几个环境变量设置里创建 /etc/kubernetes/stack-config.sh文件。
这些环境变量是被/etc/kubernetes/bootstrap脚本使用,来取得关于它所正在运行的环境的语境信息。
特别是Master EIP,实例角色(Kubernetes master或节点),和s3 bucket名称通过这种方式传递。
实例 Bootstrap脚本
实例bootstrap脚本作为在实例启动顺序的最后一步运行。脚本在master和节点上工作稍微有些不同。接下来的步骤必须作为这个进程的一部分执行:
在所有节点上:
从/etc/kubernetes/stack-config.sh 加载语境和环境信息。
为了Kubernetes叠加网络,禁用实例IP源目的地,检查使用AWS CLI来确保IP路由工作正常。
只在master上:
附加master EBS和确保它被格式化并安装。
附加EIP大师。
关联稳定的私有IP。
检查是否token和证书文件存在S3 bucket和证书文件。
如果S3 bucket不包含所需的文件,生成它们并上传到bucket。
如果S3 bucket包含所需的文件,下载到 /srv/kubernetes目录。
只在节点上:
等待知道S3 bucket包含所需文件。
下载文件到 /srv/kubernetes 目录。
确保docker-bootstrap服务已经启动。
只在master上:
在docker-bootstrap中当作一个容器运行etcd。
设置flanneld配置秘钥。
在docker-bootstrap中当作一个容器运行flanneld。
配置docker,为使用flanneld覆盖网络和重启。
配置kubelet和kube-proxy。
开始kubelet服务。
在kubelet在master上启动后,它负责在静态清单文件中定义的pod中启动其他Kubernetes组件(例如
apiserver, scheduler, controller-manager等等),然后保持他们运行。Kubelet在节点上启动只在一个pod里启动kube-proxy,然后连接到master进行进一步的指令。
新集群
一旦master启动并完全初始化,管理员就可以从S3 bucket下载Kubernetes客户端配置文件。bucket中的文件只能通过master
EC2实例角色、节点EC2实例角色和AWS帐户管理员访问。
集群REST API通过在标准端口上的标准端口上的HTTPS提供可用。
安全,可靠和作为标准的可扩展性
由于我们的努力,我们现在有了一个简单的方法在AWS上建立一个可靠的,生产就绪的Kubernetes集群。
Cloud Formation模板可以用或进一步定制,以满足特定的项目需求(例如添加额外的AWS资源,例如RDS,或更改集群运行的区域或可用性区(AZ))。我们还可以很容易地自定义在集群上运行的附加组件。
从安全性的角度来看,由于以下特性,默认方式下的新集群是安全的,感谢以下特性:
为客户和集群节点的访问,Kubernetes集群etcd配置了传输层安全性(TLS)。
为了客户端访问集群API服务器配置了TLS。
为了每个Kubernetes服务,默认Kubernetes访问控制配置了一个单独管理员用户帐户和不同的服务账户。
所有帐户token和密码是随机生成的。
所有TLS密钥、证书和Kubernetes秘密tokens和密码是通过一个独特的S3 bucket,在主服务器和分布式首次启动生成的。
密钥、证书和token文件用于在master和节点实例上配置Kubernetes组件,被放到临时文件系统安装目录,所以秘密信息不保存在磁盘上(S3
bucket除外)。
秘密文件放置到S3 bucket只通过ACL配置,只授权访问集群master和节点实例的角色(AWS帐户管理员)。
新的集群也是可靠的:
在节点失效的情况下,通过节点的Auto Scaling Group将启动一个新节点,并且新节点会自动加入集群,恢复可用的计算能力。
在master失败的情况下,通过master Auto Scaling Group一个新的master实例将开始。新的master实例将会自动重新连接masterEIP和master
EBS,从而恢复以前的集群功能和配置。
通过快照备份配置实现常规EBS,可靠性可以进一步提高。这个过程本身可以作为一个pod或在Kubernetes集群中的附加组件运行。
节点Auto Scaling Group默认配置跨越多个可用性区域。
集群也可伸缩:
最低的规模可能是是一个单独的master节点,可以运行用户负载,由于master kubelet配置注册主API服务器。
缩放可以通过在节点Auto Scaling Group添加更多的节点。
下一步及接下来的安排
已经实现了在生产中运行Kubernetes集群所需的最小特性集,仍然有改进的空间。
当前,集群很容易受到master节点正在运行的可用性区域失败的伤害。由于AWS EBS限制,master
Auto Scaling Group被故意限制在一个可用区域(EBS不能在与它最初创建的不同的AZ中使用)。克服这个问题有两种方法:
通过定期快照master EBS和从最新的快照在不同的AZ里自动恢复。这适用于特小型部署,只需要自我修复和一些停机时间是可以接受的。
通过设置多主机Kubernetes配置。用于大规模部署的默认配置(实际上是大多数部署)。
我们正在计划两个都执行。
即使上面描述的改进,集群仍然会受到整个区域失败的影响。因此,我们正在计划引入集群联合作为一个选项,并为跨区域和混合部署提供不同的自动化灾难恢复策略。
安全性也可以通过EBS加密改进,嵌入工具如HashiCorp Vault,以及可能改变的秘密分布策略。
|









