| ժҪ��Google��Borgϵͳ��һ�������ų�ǧ��������ҵ�ļ�Ⱥ����������ͬʱ�����źܶ��Ӧ�ü�Ⱥ��ÿ����Ⱥ���г�ǧ����̨��������Щ��Ⱥ֮��������Google�ĺܶͬ��Ӧ�á�Borgͨ������ƣ���Ч�����������������Դ����ͽ��̼�����Ļ�����������ʵ�ֳ��ߵ���Դ�����ʡ���ͨ����С�����ϻָ�ʱ�������ʱ���Ժͼ����������ʱ���ϵĵ��Ȳ�����֧�ָ߿��õ�Ӧ�ó���Borgͨ���ṩһ����ҵ�����ı����ԣ���������ļ��ɻ��ƣ�ʵʱ����ҵ��أ��Լ�һ������ģ��ϵͳ��Ϊ�Ĺ��������û���ʹ�á�
���ǽ�ͨ�������Ķ�Borgϵͳ�ļܹ�����Ҫ���Խ����ܽᣬ������Ҫ����ƾ�����һЩ���ȹ������ԵĶ����������Լ���ʮ���ʹ�þ����м�ȡ�Ľ�ѵ�Ķ��Է�����
1.���
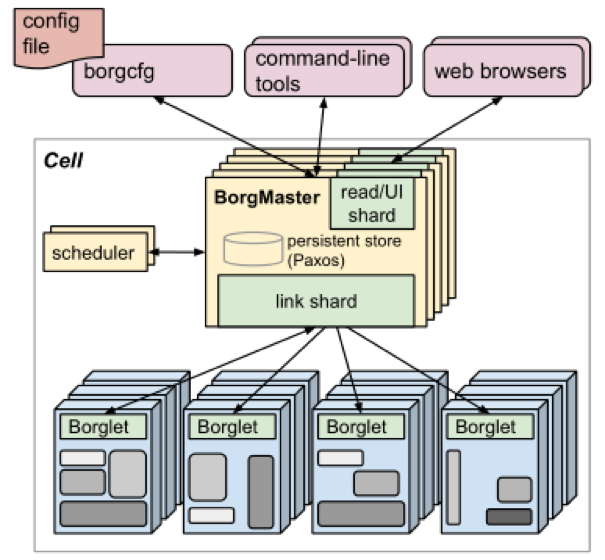
ͼ1 Borg�ĸ��ܹ�������ʾ�˳�ǧ�������ڵ��е�һС���֡�
����������ڲ���ΪBorg�ļ�Ⱥ����ϵͳ��������Ȩ���ơ����ȡ����������������ͼ���ȫ����Google�����е�Ӧ�ó����Ľ�����������������ġ�
�ܵ���˵��Brog��Ҫ�ṩ��������Ҫ�ĺô�����1��������Դ�������ϴ�����ϸ�ڣ�������û�����רע��Ӧ�ó���;
��2���ṩ�߿ɿ��Ժ߿����Բ�����֧�ֵ�Ӧ��Ҳ�����; ��3��ʹ�����ܹ���Ч��������̨���������й������ء�
Borg���ǽ����Щ����ĵ�һ��ϵͳ�����������ܹ���֤����Ժ�����������£��Դ��ģ���е���������ϵͳ֮һ��
���Ľ���ҪΧ����Щ���������֯������BorgͶ����������ʮ��������ʹ�þ�����Ϊ�ܽ� ��
2.�û���ͼ
Borg���û�������GoogleӦ�úͷ����Google������Ա��ϵͳ����Ա����վ�ɿ��Թ���ʦ��SRE����
�û�����ҵ����ʽ�����ǵĹ����ύ��Borg��ÿ����ҵ����һ�������������Ƕ�������ͬ�ij������ƣ���
ÿ����ҵ��һ��Borg��Ԫ�����У�һ�������֯Ϊһ����Ԫ�� ���ڵ�ʣ�ಿ��������Borg�û���ͼ��չ�ֵ���Ҫ���ܡ�
2.1 ��������
Borg�����е�Ԫ��ͬʱ�������������͵����ʹ������ء���һ���ǡ���Զ������ȥ���ij��������Ƕ��ӳٺ����ܲ������У�
����������������ն��û��IJ�Ʒ������Gmail��Google�ĵ���web�������ڲ�������ʩ�������磬BigTable����
�ڶ�������������ҵ����Ҫ���ѴӼ��뵽������ɣ���Щ����Զ������ܲ�����������ҪС�öࡣ ��Щ�������ػ��������Borg�ĸ������е�Ԫ�У����������Ҫ�⻧�����磬һЩ��Ԫ��ר���������������ܼ�����ģ����в�ͬ�Ļ��Ӧ�ã�����Ҳ��ʱ��仯����������ҵ��ɺ��������У����������ն��û��ķ�����ҵ�����ճ�ʹ��ģʽ��
Borgͬ����Ҫ������������Щ�����
Borg�Ĵ����Թ�������������Դ�2011��5�µ�һ���������·ݸ������ҵ�[80]���Ѿ������˹㷺����������[68]��[1,26,27,57]����
�ڹ�ȥ�����У�����Ӧ�ó������Ѿ�������Borg֮�ϣ����������ڲ���MapReduceϵͳ[23]��FlumeJava
[18]��Millwheel [3]��Pregel [59]�� ���������һ���������ύһ������ҵ��һ������������ҵ;
ǰ���߶�YARN��Ӧ�ó��������[76]�����Ƶ����á� ���ǵķֲ�ʽ�洢ϵͳ��GFS [34]������CFS��Bigtable
[19]��Megastore [8]��������Borg�ϡ�
���ڱ��ģ����ǽ����ȼ��ϸߵ�Borg��ҵ��Ϊ����������prod����ҵ��������Ϊ������������non-prod����ҵ��
������������еķ�������ҵ��prod;�������������ҵ�Ƿ�prod�ġ��ڴ����Ե�Ԫ�У������prod��ҵ��Լ��CPU��Դ��70������Լռ��CPUʹ������60��;
���������Լ���ڴ��55����Լռ���ڴ�ʹ�õ�85�����ڡ�5.5�ڣ������������ʹ��֮��IJ��콫�Ǻ���Ҫ�ġ�
2.2 ��Ⱥ�͵�Ԫ
��Ԫ�еĻ������ڵ�����Ⱥ�����������ǵĸ������������Ĺ�ģ������ܹ����塣
һ����Ⱥλ�ڵ����������Ĵ�¥�ڣ����ü��Ϲ���һ��վ�㡣һ����Ⱥͨ������һ�����͵�Ԫ��������һЩ��С��ģ�IJ��Ի�������;��Ԫ��
����Ŭ�������κε�����ϡ�
���뵥Ԫ��С���ų����Ե�Ԫ��Լ10k����; ��Щ�����һ����Ԫ�еĻ���������ά�������칹�ģ���С��CPU��RAM�����̣����磩�����������ͣ����ܺ��ܣ������ⲿIP��ַ������洢������Borgͨ��ȷ����Ԫ�е���������Ϊ���������Դ����װ������������������������״̬����ʧ��ʱ���������û��Ӵ���������и��������
2.3 ��ҵ������
Borg��ҵ�����������ƣ���������ӵ�е�������������ҵ���ܾ������ƣ�ʹ�������ھ����ض����ԣ����紦������ϵ�ṹ������ϵͳ�汾���ⲿIP��ַ���ļ���������С����ƿ�����Ӳ�Ļ�����;
�����ƾ�����ƫ�ö�����Ҫ����ҵ�Ŀ�ʼ�ܱ��Ƴٵ�ֱ��ǰһ����ҵ��ɡ� һ����ҵ����һ����Ԫ�����С�
ÿ������ӳ�䵽�ڻ����ϵ����������е�һ��Linux����[62]�� �����Borg�������ز����������VM�������У���Ϊ���Dz���֧�����⻯�ijɱ������⣬��ϵͳ�������Ƕ�û��Ӳ�������⻯֧�ֵĴ��������д���Ͷ�ʵ�ʱ����Ƶġ�
����Ҳ�������ԣ�������Դ�������������ҵ�е������� ������������Զ���ҵ�е�������������ͬ�ģ����ǿ��Ա���д
- ���磬���ṩָ������������б�־��ÿ����Դά�ȣ�CPU�ˣ�RAM�����̿ռ䣬���̷������ʣ�TCP�˿ڣ��ȣ���ϸ���ȶ���ָ��;
���Dz�ǿ�ӹ̶���С��Ͱ��ۣ���5.4������̬����Borg�����Լ��ٶ�������ʱ����������������Brog�����Ϊ�������ļ��������ļ�����Borg����װ��
�û�ͨ����Borg����Զ�̹��̵��ã�RPC����������ҵ���������ͨ�������й��ߣ�����Borg��ҵ�����ϵͳ����2.6�����������ҵ������������������������BCL��д�ġ�BCL��GCL��һ������[12]��������protobuf�ļ�[67]������չ��һЩBorg�ض��Ĺؼ��֡�GCL�ṩlambda�������������㣬Ӧ�ó������ʹ��������������������;
��ǧ�����BCL�ļ�����1k�г��������Ѿ���������ǧ���е�BCL��Borg��ҵ������Aurora�����ļ�����[6]��
ͼ2˵������ҵ�������������������о�����״̬��
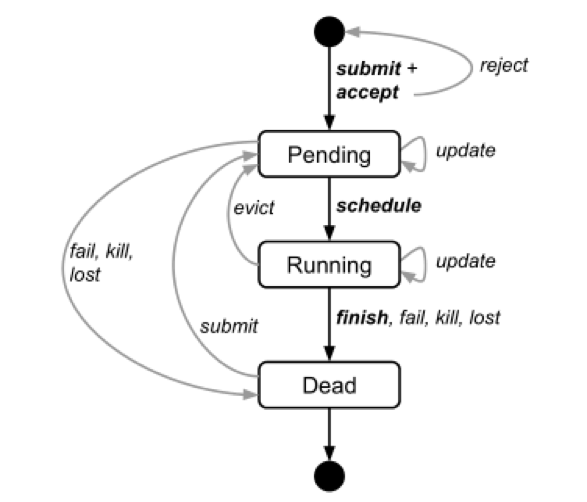
ͼ2����ҵ�������״̬ͼ�� �û����Դ����ύ����ֹ����ת����
�û�����ͨ�������µ���ҵ���õ�Borg����ָʾBorg��������µ������ã��������������е���ҵ�е�ijЩ�����������������ԡ�
����һ���������ķ�ԭ�������Ժ����ر�������ֱ�������رգ��ύ���� ����ͨ���Թ�����ʽ��ɣ����ҿ��ԶԸ��µ��µ������жϣ����¼ƻ�����ռ����������������;
�����ᵼ�¸����жϵ��κθ��ġ�
ijЩ������£����磬�����µĶ����ƣ�������Ҫ��������; ijЩ���£����磬���ӵ���Դ�������ӻ�Լ���ı䣩����ʹ���������ʺ�����̨����������������ֹͣ�����µ���;
��ijЩ���£����磬�ı����ȼ���ȴ���ڲ������������ƶ����������½��С�
�������Ҫ���ڱ�SIGKILL��ռ֮ǰͨ��Unix SIGTERM�źŻ�ȡ֪ͨ�������������ʱ���������������״̬����ɵ�ǰ����ִ�е����ܾ��µ�����
�����ռ�������ӳٽ��ޣ���ʵ��֪ͨ���ܸ��١� ��ʵ���У�֪ͨ����Լ80����ʱ�䡣
2.4 ����
Borg alloc������ļ�ƣ��ǿ�������һ����������Ļ����ϵ�һ�鱣����Դ;������Դ�Ƿ�ʹ����Ȼ�����䡣Alloc��������Ϊ����������������Դ����ֹͣ����������֮�䱣����Դ���Լ�����ͬ��ҵ�е������ռ���ͬһ̨������
- ���磬Web����ʵ������ص���־�������� ����������URL��־�ӱ��ش��̸��Ƶ��ֲ�ʽ�ļ�ϵͳ��
alloc����Դ�������ڻ�����Դ�ķ�ʽ����; �������������һ��alloc�У���������Դ�����һ��alloc�����ض�λ����һ̨�����������������µ��ȡ�
һ��alloc���Ͼ���һ����ҵ������һ���ڶ��������Ԥ����Դ��alloc�� һ��������һ��alloc���������ύһ��������ҵ���������С�
���ڼ䣬����һ���ʹ�á�task��������alloc��������alloc֮��ģ��͡�job��������һ����ҵ��alloc����
2.5 ���ȼ������ͽ��ɿ���
������Ĺ������ֶ����������ɵ���ʱ�ᷢ��ʲô�����ǵĽ�����������ȼ�����
ÿ����ҵ����һ�����ȼ�������һ��С���������������ȼ�������������������ȼ�����Ϊ���۶������Դ����ʹ�����ռ��ɱ�������ߡ�Borg����ͬ�������ҵ��Ϊ��ͬ��������ÿ���������˲��ص�������Ȩ�أ���Щ��ҵ�������������ҵ��������ҵ����������ҵ�;�����Ϊ����ҵ����֪�İ������Գ������ǵ����ȼ����εݼ������ڱ��ģ�prod��ҵ�Ǽ�����������Ĺ�����
��Ȼ����ռ������ͨ���������°����ڵ�Ԫ�е������ط�����ռ�������ܷ�������������ȼ�����������һ���Ե����ȼ�����������Ե����ȼ�������������һ���Ե����ȼ������ȵȡ�Ϊ��������������������Dz��������������е��������ռ��
ϸ�������ȼ��������������Ȼ���� - ���磬MapReduce�������Ա����ǿ��Ƶ�workers���ߵ����ȼ����У��������ɿ��ԡ�
���ȼ���ʾ��Ԫ���������л����ȴ����е���ҵ�������Ҫ�ԡ� ������ھ����������е��ȵ���ҵ�� ����ʾΪ�ڸ������ȼ��ϵ�һ��ʱ�䣨ͨ��Ϊ�����£��ڵ���Դ����CPU��RAM�����̵ȣ���������
����ָ���û�����ҵ�������һ���������Դ������������磬��������ֱ��7�µ��ڵ�Ԫxx�е�prod���ȼ���20TiBRAM������
����������ɿ��Ƶ�һ���֣������ǵ��ȣ��������ҵ�����ܾ��ύ��
�ϸ����ȼ����ijɱ����ڽϵ����ȼ����������ȼ��������ڵ�Ԫ�п��õ�ʵ����Դ����ˣ��ύ���������������ȼ���ҵ���û�����Ԥ�����С�
��ʹ���ǹ����û���������������ǵ������������û���Ȼ���ȹ�����Ϊ�����������Ӧ�ó�����û�Ⱥ����ʱ�˷����㡣����ͨ���ڽϵ����ȼ����Ϲ��������������Ӧ��һ�㣺ÿ���û����������ȼ���������������ⳣ������ִ�У���Ϊ��Դ�����ȶ��ġ�һ�������ȼ���ҵ���ܱ������ˣ�����������Դ��������ֵȴ���δ���ȣ���
��Borg������������䣬���������ǵ����������滮������أ�������ӳ�ڲ�ͬ�������ĵ����ļ۸�Ϳ������ϡ�
�����û���ҵ�����������ȼ����㹻���ʱ���������û���ҵ�� ����ʹ�ü����˶�������Դ��ƽ��DRF��[29,35,36,66]�Ȳ��Ե���Ҫ��
Borg��һ������ϵͳ���ܸ���һЩ�û������Ȩ��; ���磬��������Աɾ�����ĵ�Ԫ�е��κ���ҵ���������û����������ں˹��ܻ�Borg��Ϊ�������������ҵ����Դ���ƣ���5.5������
2.6 �����ͼ��
�������ͷ��������Dz����ģ�����Ŀͻ��˺�����ϵͳ��Ҫ�ܹ��ҵ����ǣ���ʹ���DZ��ض�λ���»������ˡ�Ҫ���ô˹��ܣ�Borg��Ϊÿ������һ���ȶ��ġ�Borg
name service����BNS�����ƣ����а�����Ԫ���ƣ���ҵ���ƺ������š�Borg��������������Ͷ˿�д��һ����BNS������һ�µĸ߿��õ�Chubby
[14]�ļ��У������ǵ�RPCϵͳʹ�ø��ļ�����������˵㡣BNS���ƻ��γ������DNS���ƵĻ�����������cc��Ԫ�е��û�ubarӵ�е���ҵ
jfoo�еĵ���ʮ������ͨ��50.jfoo.ubar.cc.borg.google.com���ʵ���Borg������Chubby�����仯ʱ����ҵ��С��������Ϣд��Chubby����˸���ƽ�������Բ鿴������·�ɵ����
������Borg�����е�ÿ��������һ�����õ�HTTP���������������й���������״������Ϣ�ͳ�ǧ���������ָ�꣨����RPC�ӳ٣���
Borg���health-check URL���������������ἰʱ��Ӧ��HTTP������������ �����������DZ��̼��ӹ��ߺ�Υ������Ŀ�꣨SLO���ľ������и��١�
��ΪSigma�ķ����ṩ�˻���Web���û����棨UI����ͨ����UI�û����Լ��������ҵ���ض���Ԫ��״̬����������ȡ��������ҵ�������Լ������Դ��Ϊ����ϸ��־��ִ����ʷ
�������յĽ���� ���ǵ�Ӧ�ò���������־; ��Щ���Զ���ת�Ա���������̿ռ䣬���������˳���һ��ʱ����Э�����ԡ�
�����ҵδ���У�Borg�ṩ�ˡ�Ϊʲô����������ע�ͣ��Լ��������ҵ����Դ�����Ը��õ���Ӧ��Ԫ��ָ����
���Ƿ����ˡ��кϡ������������ȵ���Դ��ʽ�Ĺ���
Borg��¼������ҵ�ύ�¼��������¼����Լ�ÿ��������Infrastore����ϸ����Դʹ����Ϣ������һ������չ��ֻ�����ݴ洢��ͨ��Dremel
[61]����һ������ʽ������SQL�Ľ��档���������ڻ���ʹ�õļƷѣ���ҵ���Ժ�ϵͳ�����Լ����������滮��
����ΪGoogleȺ���������ظ����ṩ����[80]��
������Щ���ܶ��������û�����͵���Borg����Ϊ���û�����ҵ�����������ǵ�SREsΪÿ���˹�������̨������
3.Borg��ϵ�ṹ
Borg��Ԫ��һ�������һ����ΪBorgmaster��������������͵�Ԫ��ÿ̨���������еij�ΪBorglet�Ĵ������̹��ɣ��μ�ͼ1����
Borg�������������C ++���
3.1 Borgmaster
ÿ����Ԫ��Borgmaster�����������̣�������Borgmaster�Ͷ����ĵ��ȳ���3.2����
��Borgmaster���̴����ͻ���RPC��״̬�仯�����磬������ҵ�����ṩ�����ݵ�ֻ�����ʣ����磬������ҵ������������ϵͳ�����ж�������������ȣ���״̬������Borglets����ͨ�ţ����ṩWeb
UI��ΪSigma�ı��ݡ�
Borgmaster��������һ����һ�Ľ��̣���ʵ���ϱ���������Ρ� ÿ������ά����һ�ݸõ�Ԫ��״̬���ڴ渱�������Ҹ�״̬Ҳ��¼�ڸø����ı��ش����ϵĸ߿����ԣ��ֲ�ʽ������Paxos�Ĵ洢[55]�С�ÿ����Ԫ�ĵ���ѡ����master������Paxos���쵼��������״̬mutator�������ı䵥Ԫ״̬�����в����������ύ��ҵ���ڻ�������ֹ������cell����ʱ��ֻҪ��ѡ���master���ֹ���ʱ���ͻ�ѡ��һ��master��ʹ��Paxos��;
����ȡһ��Chubby�����Ա�����ϵͳ�����ҵ�����ѡ��һ��master����ת�Ƶ��µ�masterͨ����Ҫ��Լ10s�������ڴ�Ԫ�п�����Ҫһ���ӣ���ΪһЩ�ڴ��е�״̬�����ؽ���
���������жϻָ�ʱ�������Զ�����ͬ���������µ�����Paxos������״̬��
Borgmaster��ij��ʱ����״̬��Ϊ���㣬�����ö��ڿ��յ���ʽ����һ��������־��������Paxos�洢�У���������������;��������Borgmaster��״̬�ָ�����ȥ������һ���㣨���磬�ڽ��ܴ���Borg�е�����ȱ�ݵ�����֮ǰ���Ա���Զ�����е��ԣ�;
��������δ����ѯ���¼��ij־���־; �Լ�����ģ�⡣
�߱����Borgmasterģ����Faokemaster�����ڶ�ȡ�����ļ�������������Borgmaster������������������а�����Borglets������ӿڡ�������RPC����״̬�����ĺ�ִ�в������硰�������й��������ͨ���������н�������������һ�����Borgmaster������ģ���Borglets�ɴӼ����ļ��ط���ʵ�Ľ�����������ʹ���������Թ��ϡ��û������۲��ڹ�ȥʵ�ʷ�����ϵͳ״̬�ĸı䡣
Fauxmaster���������滮�������϶����������͵�����ҵ�������Լ��ڸ��ĵ�Ԫ����֮ǰ���������Լ�飨�����ָ����Ƿ��������Ҫ�Ĺ���������Ҳ�����á�
3.2 ����
�ύ��ҵʱ��Borgmaster�Ὣ��־û���Paxos�洢�У�������ҵ���������ӵ��ȴ����С� �����ɵ��ȳ����첽ɨ��ģ�������㹻�Ŀ�����Դ������ҵ��Ҫ����Ὣ��������������
�����ȳ�����Ҫ��������������ҵ����ɨ��Ӹߵ������ȼ��������ȼ�ѭ���������ȣ���ȷ���û�֮��Ĺ�ƽ�ԣ������������ҵ����Ķ�ͷ������
�����㷨���������֣������Լ�飨�����ҵ�����������еĻ��������Լ����֣�������ѡһ�����еĻ�������
�ڿ����Լ���У��������ҵ��������������һ�������������������㹻�ġ����á���Դ - ��Щ��Դ�а����Ѿ���������Ա���ռ�Ľϵ����ȼ��������Դ��
�������У�������ȷ��ÿ�����л����ġ������ԡ����÷����������û�ָ����ƫ�ã�����Ҫ�������ñ�������������ȵؼ�����ռ��������������ȼ���ѡ���Ѿ�������������Ļ�������Խ��Դ�����������Լ���������������������ȼ�����͵����ȼ������ϵ����������ϣ������������ȼ������ڸ��ظ߷�����չ����
Borg���ʹ��E-PVM [4]�ı���������֣����ڲ�ͬ��Դ�����ɵ�һ�ɱ�ֵ�������ڷ�������ʱ��С���ɱ��ı仯����ʵ���У�E-PVM���������л�������չ���أ�Ϊ���ظ߷���������
- ������������ƬΪ���ۣ��ر��Ƕ�����Ҫ�ֻ����Ĵ�������; ������ʱ��֮Ϊ���պú��ʡ���
���ȵ���һ���ǡ���Ѻ��ʡ�������ͼ�����ܽ��ܵ��������� ��ʹһЩ����û���û���ҵ��������Ȼ���д洢������������˷��ô������Ǽ�ֱ�ӵģ������ϸ�ķ�װ�������û���Borg����Դ������κδ�����ơ�
����˺�ͻ�����ص�Ӧ�ó�����ָ����CPU�������������ҵ������⣬�Ա����ǿ������ɰ��Ų�������δʹ�õ���Դ���Ż����У�20���ķ�����������������0.1��CPU�ںˡ�
���ǵ�ǰ������ģ����һ�ֻ��ʽ�ģ�����ͼ���ٸ�����Դ������ - ���ڻ����ϵ���һ����Դ����ȫ�������ʹ�õ���Դ��
���ṩ�����ʺ����ǹ�������Լ3-5���ĸ��õİ�װЧ�ʣ���[78]�ж��壩��
����Ʒֽ�ѡ��Ļ���û���㹻�Ŀ�����Դ������������Borg����ռ��ɱ�����ϵ����ȼ�����������ȼ���������ȼ���ֱ������Ϊֹ��
���ǽ�����ռ���������ӵ����ȳ���Ĺ�����У�������Ǩ�ƻ��������ǡ�
���������ӳ٣�����ҵ�ύ���������е�ʱ�䣩��һ���Ѿ��������ܵ������ע���������Ǹ߶ȿɱ�ģ���ֵͨ��Լ25s��
��������װ��Լռȫ����80��������һ����֪��ƿ����������Ҫд��ı��ش��̵����á�Ϊ�˼�����������ʱ�䣬���ȳ�����������������Ѿ���װ�˱�Ҫ������������������ݣ��Ļ�����������������Dz��ɱ�ģ���˿��Թ����ͻ��档
������Borg���ȳ���֧�����ݱ��ػ���Ψһ��ʽ�������⣬Borgʹ����������torrent��Э�鲢�еؽ��������ַ���������
���⣬���ȳ���ʹ�ü��ּ�������չ���г�ǧ����̨�����ĵ�Ԫ����3.4����
3.3 Borglet
Borglet��һ������Borg�����������ڵ�Ԫ�е�ÿһ̨�����С���������ֹͣ����; ������Ͼ���������;
ͨ�����ݲ���ϵͳ�ں�����������������Դ; ��ת������־; ����Borgmaster�ȼ��ϵͳ���������״̬��
Borgmasterÿ����������ѯһ��Borglet�Լ��������ĵ�ǰ״̬����������δ��ɵ�����������
��ʹBorgmaster����ͨ�����ʣ���������ʽ�����ƻ��Ƶ���Ҫ������ֹ�ָ��籩[9]��
ѡ����master������Ҫ���͵�Borglets����Ϣ�����������cell����Ӧ����cell��״̬��Ϊ�����ܿ���չ�ԣ�ÿ��Borgmaster����������״̬���ӷ�Ƭ��������һЩBorglets��ͨ��;ÿ������Borgmasterѡ��ʱ���¼�����������ڵ��ԣ�Borgletʼ�ձ���������״̬�������ӷ�Ƭͨ��������״̬����IJ������ռ���ѹ������Ϣ���Լ���ѡ��master�ĸ��¸��ء�
���Borgletû����Ӧ������ѯ��Ϣ�����Ļ��������Ϊ�رգ����������е��κ��������°��������������ϡ����ͨ�Żָ���Borgmaster��֪ͨBorgletҪֹͣ��Щ�Ѿ����°��ŵ������Ա����ظ�����ʹ��Borgmasterʧȥ��ϵ��BorgletҲ�����������У���˼�ʹ����Borgmaster���������ˣ���ǰ���е�����ͷ���Ҳ�ᱣ�֡�
3.4����չ��
���Dz�ȷ��Borg�ļ���ʽ�ܹ������տ���չ�����ƽ������ںδ�; ��ĿǰΪֹ��ÿ�����ǽӽ�һ�����ޣ������Ѿ��跨��������һ��Borgmaster���Թ���һ��cell�е���ǧ̨���������Ҽ���cell����ÿ���ӳ���10000������ĵ������ʡ���æ��Borgmasterʹ��10-14��
CPU�ں˺ߴ�50GiB ��RAM������ʹ�ü��ּ�����ʵ�����ֹ�ģ��
���ڰ汾��Borgmaster��һ���ģ�ͬ����ѭ�����������ƻ�������Borgletsͨ�š�Ϊ�˴��������cell�����ǽ����ȳ�����������Ϊһ�������Ľ��̣�����������������Borgmaster�������в����������ޡ�
�����������Ե�Ԫ״̬�ĸ��ٻ��渱�����в���������������ѡ������������״̬���ģ������ѷ������Ĺ�����;
�����䱾�ظ���;ִ�е��ȴ����Է�������; ������Щ����֪ͨѡ����������master�����ܲ�������Щ���䣬���������Dz��ʵ��ģ����磬���ڹ���״̬�����⽫���������ڵ��ȳ������һ�δ����б����¿��ǡ��������������Omega
[69]��ʹ�õ��ֹ۲������Ʒdz����ƣ���ʵ�ϣ��������ΪBorg��������Բ�ͬ������������ʹ�ò�ͬ���ȳ���schedulers����������
Ϊ�������Ӧʱ�䣬���������˵������߳�����Borglets����ͨ�Ų���Ӧֻ��RPC��Ϊ�˸��õ����ܣ����������Borgmaster��������3.3���зָ��������Щ���ܡ�ͬʱ���Ᵽ����UI��99��ile����Ӧʱ�����1s��95��ile
��Borglet��ѯ�������10s��

ͼ3����������ͷ������������ص����������ʼ�ԭ��
������2013��8��1����
�м���ʹBorg���������߿���չ�ԣ�
�������棺���������Ժ����ۻ����ǰ���ģ����Borg�������ֱ����������������Ըı� - ���磬�����ϵ�������ֹ�����Ըı�����������ı䡣
������Դ������С�仯�ɼ��ٸ��ٻ���ʧЧ��
�ȼ��ࣺBorg��ҵ�е�����ͨ��������ͬ�������Լ������˲�����ȷ��ÿ�������ϵ�ÿ����������Ŀ����ԣ��������п��еĻ����������֣�Borgֻ��ÿ���ȼ����һ��������п����Է���������
- һ�������ͬ���������
����������������cell�����л����Ŀ����Ժͷ������˷ѵģ���˵��ȳ��������˳���������ֱ���ҵ����㹻�����еĻ����������֣�Ȼ��ѡ��ü����е���ѻ�����
����������������뿪ϵͳʱ��������ֺ��ٻ���ʧЧ�����������ӿ����������ķ��䡣�����������ʱ������Sparrow
[65]������������ͬʱ���������ȼ�����ռ�������Ժ���������װ�ijɱ���
�����ǵ�ʵ�飨��5���У���ͷ��ʼ���ŵ�Ԫ��������������ͨ����Ҫ�����룬�����ڽ�������������3���û����ɡ�
ͨ�����ڵȴ������ϵ����ߵ��ȴ����ڲ�����������ɡ�
4.������
�����Ǵ��ģϵͳ�еij�̬[10,11,22]��ͼ3�ṩ��15������cell����������ԭ��ķֽ⡣������Borg�ϵ�Ӧ�ó���Ӧ��ʹ�����縴�ƣ��ڷֲ�ʽ�ļ�ϵͳ�д洢�־�״̬��������ʵ��Ļ�������ʱ����ȼ��������������¼�����ʹ��ˣ�����Ҳ��ͼ������Щ�¼���Ӱ�졣���磬Borg��
���б�Ҫ�����»������Զ����°������������;
ͨ����������������ܺ͵�Դ��֮��Ĺ���������չ��ҵ����������ع���;
���������жϵ��������ʺ�������������Щ���������ά������������ϵͳ��������£��ڼ�ͬʱ�رգ� 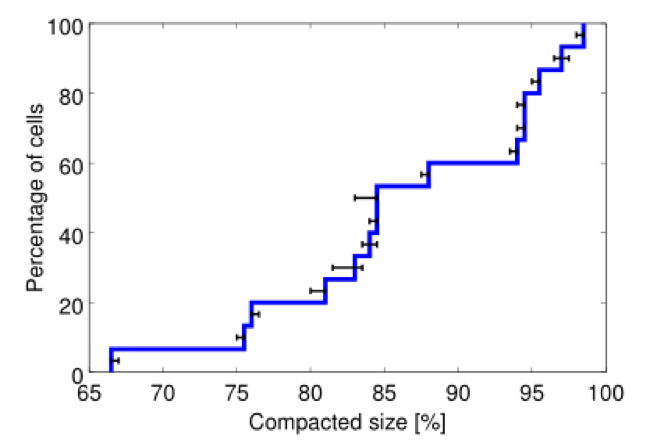
ͼ4��ѹ����Ч���� ��15��cell����ѹ�����õ�ԭʼcell��С�İٷֱȵ�CDF��
ʹ������������״̬��ʾ���ݵȱ任������ʹ��ʧ�ܵĿͻ��˿�������������ύ�κα�����������;
rate-limits�ҵ������ʵĻ������������λ�ã���Ϊ�������ִ��ͻ������Ϻ��������;
�����ظ�����::�����������������Ļ������;
ͨ����������������־��¼������2.4�����ָ�д�뱾�ش��̵Ĺؼ��м����ݣ���ʹ�����ӵ�alloc����ֹ���ƶ�������һ̨������
�û���������ϵͳ�������Ե�ʱ��;һ���Ǽ��졣
Borg��һ���ؼ�����ص��ǣ���ʹBorgmaster�������Borglet�رգ��Ѿ����е�����Ҳ��������С����DZ���master��Ȼ����Ҫ����Ϊ�����ر�ʱ�����ύ����ҵ��������е���ҵ�����������¼ƻ����ϵļ�����ϵ�����
Borgmasterʹ�õļ�����ϣ�ʹ����ʵ���дﵽ��99.99���Ŀ����ԣ��������ϸ���; ����Ʊ������;
��ʹ�üĵͼ����߲���ʵ������С���ⲿ�����ԡ� ÿ����Ԫ������������Ԫ������С�������IJ����ߴ�����ϴ����Ļ��ᡣ
��ЩĿ�꣬���ǿ���չ�����ƣ����Ƿ��Խϴ�cell����Ҫ��֤��
5.����
Borg����ҪĿ��֮һ�Ǹ�Ч����Google�Ļ���������ζ�ž�IJ���Ͷ�ʣ���������������ٷֵ���Խ�ʡ��������Ԫ��
�������ۺ�����Borgʹ�õ�һЩ���Ժͼ�����
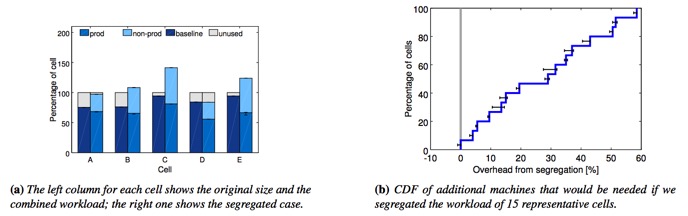
ͼ5����prod��non-prod�������뵽��ͬ�ĵ�Ԫ����Ҫ����Ļ�����������ͼ����ʾ���prod��non-prod�������ط��͵������ĵ�Ԫ����Ҫ���ٶ���Ļ�����ʹ�ðٷֱȱ�ʾ��һ����Ԫ�����й��������������С�����������ڵ�ǰ������CDFͼ�У�ÿ����Ԫ��ʾ��ֵ�Ƶ������ǵ�ʵ�鳢�Բ����IJ�ͬcell��С��90�����������ʾ�˳���ֵ��������Χ��
5.1 ��������
���ǵĹ������ڲ������ƣ���Ҫ����ϡ�ٵĹ������ط�ֵ���������칹�ģ��ڴӷ�����ҵ�л��յ���Դ��������������ҵ��
���ԣ�Ϊ����������ѡ����Ҫһ���ȡ�ƽ�������ʡ������ӵĶ������� �������ʵ�飬����ѡ����cell compaction������һ���������أ�ͨ��ɾ��cell�еĻ���ֱ��������Ӧ�����Է���������Ӧ��cell�ж�С������ͷ��ʼ���°�װ����������ȷ��û�й���һ���������á�
���ṩ�˸ɾ��������������ٽ����Զ����Ƚϣ�û�кϳɹ������ɺͽ�ģ������ [31]�������ۼ����Ķ����ȽϿ�����[78]���ҵ���ϸ�������˾��ȵ��
�����ܶ���ʵ������Ԫ����ʵ�飬������ʹ��Fauxmaster��ø߱����ģ������ʹ������ʵ��������Ԫ�������ص����ݣ�����������Լ����ʵ�����ơ�������ʹ�����ݣ���5.5
���� ��Щ��������2014-10-01 14��00 PDT��Borg���㡣 ������������������ƽ������ѡ��15��Borgcell���б��棬��������������;�����Ժ�С��<5000̨������cell��Ȼ���ʣ���cell����ȡ�����Ի�ô�С���ȵķ�Χ��
Ϊ����ѹ����cell��ά�ֻ����칹�ԣ����ѡ���������ɾ���� Ϊ�˱��ֹ������ص��칹�ԣ������������ض����������磬Borglets���ķ������ʹ洢�������һ�С�Ϊ����ԭcell��Сһ�����ҵ����ӲԼ��Ϊ��Լ�������������0.2��������ȴ���������Ƿdz������ޡ���ֻ�ܷ�����������̨������;
�㷺��ʵ�������������˵ͷ���Ŀ��ظ������ ���������Ҫ��ԭcell�����cell��������ѹ��֮ǰ��¡ԭʼcell����;
���������Ҫ����cell��ֻ��Ҫ��¡ԭ����cell���ɡ�
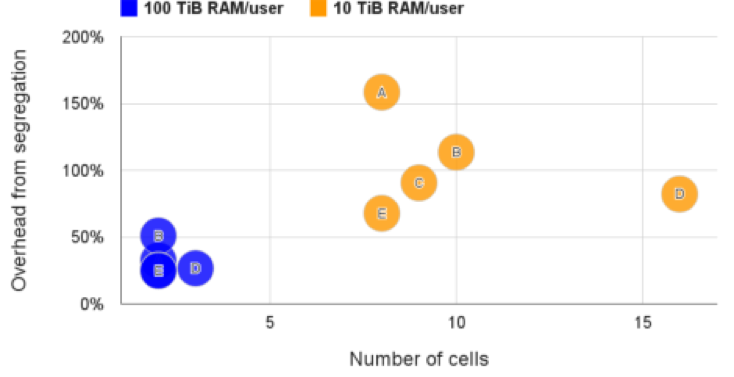
ͼ6�������û�����Ҫ����Ļ���������û�������ʾ����ֵ�����5����ͬ��cell�������˸�˽�е�Ԫ��
Cell��������Ҫ�Ķ��������
���ھ��в�ͬ��������ӵ�ÿ��cell��ÿ��ʵ���ظ�11�Ρ� ��ͼ���У�����ʹ�ô�������ʾ���������������Сֵ�����ֵ����ѡ��90��ileֵ��Ϊ�������-ƽ��ֵ����λ��������ӳϵͳ����Ա���ϣ��������ȷ�����������ʺ�ʱ����ʲô��
������Ϊcellѹ���ṩ��һ�ֹ�ƽ��һ�µķ������Ƚϵ��Ȳ��ԣ���ֱ��ת��Ϊ�ɱ�/Ч���������õIJ�����Ҫ���ٵĻ�����������ͬ�Ĺ������ء�
���ǵ�ʵ�鼯���ڴ�һ��ʱ�����ȣ�������������أ��������طų��ڹ������ظ��١� �ⲿ����Ϊ�˱���Ӧ�Կ��źͷ���Ŷ�ģ�͵�����[71,79]������ԭ���Ǵ�ͳ�����ʱ��ָ�겻�����ڳ������з���Ļ�����������Ϊ���ṩ�������ź�
���бȽϣ���������Ϊ���Dz����Ž���������ԵIJ�ͬ��������һ��ʵ�����⣺���Ƿ����Լ�������200000��Borg
CPU������ʵ�� - ��ʹ���ȸ�Ĺ�ģ����Ҳ��һ����ƽ����Ͷ�� ��
�ڲ�Ʒ�У���Թ������ص�����������Ч�Ŀռ䣬żȻ�ġ�black swan���¼������ظ߷壬�������ϣ�Ӳ�����£��Լ����ģ�ֲ����ϣ�e.g.,
a power supply bus duct����ͼ4��ʾ�����Ӧ����cellѹ������ʵ��cell�ж�С��ͼ�и���Ļ���ʹ����ѹ���Ĵ�С��
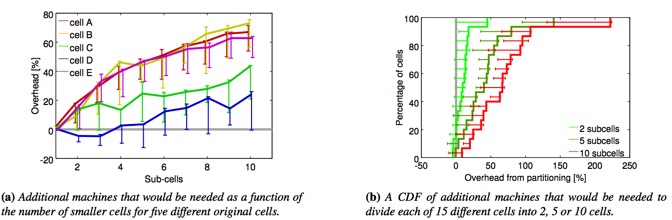
ͼ7����cellϸ�ֳɸ�С��cell����Ҫ����Ļ����� �������Щ�ض�cell����Ϊ��ͬ�����Ľ�Сcell������Ҫ����Ļ�������Ϊ����cell����İٷֱȣ���
5.2 cell����
�������л���ͬʱ������prod �� non-prod�����ڹ�����Borg cell��98%�Ļ�������83%��ԽBorg�����������Ļ������ϡ�����һЩ������;��ר��cell����
���ںܶ�������֯�ڵ����ļ�Ⱥ�����������û���������ҵ�����Ƕ��������Ҳ�������ᷢ��ʲô���˵��顣ͼ5��ʾ�˷��뿪proc��non-proc����������ֵ��cell�н���Ҫ20-30%�ĸ���Ļ��������й������ء�������Ϊproc��ҵ���ǻ�Ԥ����Դ������ϡ�еĸ��ظ߷壬����ʱ�䲢��ʹ����Щ��Դ��Borg����������Щδʹ�õ���Դ�����д�non-proc���������������Ͼ���Ҫ���ٵĻ����ˡ�
��Borg cell������ǧ�Ƶ��û�������ͼ6��ʾ��ԭ��������ԣ�����û��Ĺ�����������������10TiB������100
TiB�����ڴ棬�ͷ����û��Ĺ������ص�һ���µ�cell���ִ�IJ��Կ������Ǻõģ���ʹ�Ǹ���ļ��ޣ�����Ҫ2�C16����ΪһЩcell���Լ�20�C150%�Ķ���Ļ������ٴΣ��ϲ���Դ���������˳ɱ���
���ǿ��ܽ�����ص��û�����ҵ���ʹ����ͬһ̨�����ϻᵼ��CPU���ţ������Ҫ����Ļ������ֲ��� Ϊ��������һ�㣬�����о����ھ�����ͬʱ���ٶȵ���ͬ�������������еIJ�ͬ�����е������CPI��ÿ��ָ�������������θı䡣
����Щ�����£�CPIֵ�ǿɱȵģ����ҿ�������������ܸ��ŵĴ�������ΪCPI�ķ����ӱ���CPU���������ʱ�䡣��һ�������ڴ�Լ12000�����ѡ���prod�����ռ����ݣ�ʹ��[83]��������Ӳ�����üܹ�����5���ӵļ���ڶ����ں�ָ����м����������������м�Ȩ��ʹ��ÿ���ӵ�CPUʱ�䱻��ƽ������
�������������
��1�����Ƿ���CPI������ͬʱ�����ڵ����������������أ������ϵ�����CPUʹ���ʣ����ܴ�̶��϶����أ������ϵ���������;
�������������ʹ�����������CPI���0.3����ʹ���ʺ���Щ���ݵ�����ģ�ͣ�; ������CPUʹ�������10��ʹ��CPI���С��2����
���Ǽ�ʹ�������ͳ��������Ҫ�ģ�Ҳֻ��ʾ����CPI�����п����ķ����5��; ��������ռ������λ������Ӧ�õĹ��в�����ض��ĸ���ģʽ[24,83]��
��2�������Ǵӹ���cell�в�����CPI�����Ծ��н��ٲ�ͬӦ�õļ���ר��cell��CPI���бȽϣ����ǿ�������cell��ƽ��CPIΪ1.58����=
0.35����ר��cell��ƽ��CPIΪ1.53����= 0.32��- ����CPU�ڹ���cell�����ܽ���Լ3����
��3��Ϊ�˽����ͬcell�е�Ӧ�ÿ��ܾ��в�ͬ�������ػ�����ѡ��ƫ����ܽ����Ÿ����еij����Ѿ��ƶ���ר��cell���ĵ��ǣ�������Borglet��CPI�������������͵����л��������С�����ר��cell�е�CPIΪ1.20����=
0.29�����ڹ���cell�е�CPIΪ1.43����= 0.45������������ר��cell�е������ٶ�Ϊ1.19�������ڹ�����Ԫ��һ���죬��Ȼ��������Ḻ�ػ�����Ӱ�죬����ƫ����������ר��cell��
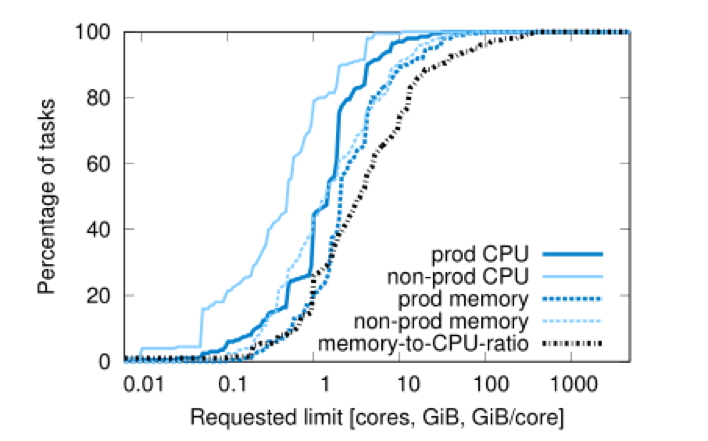
ͼ8��û���ʺϴ���������Ͱ��С�������CPU���ڴ��CDFҪ���Խ������Ԫ��
û��һ��ֵͻ������Ȼ��������CPU�˴�С�е���ܻ�ӭ��
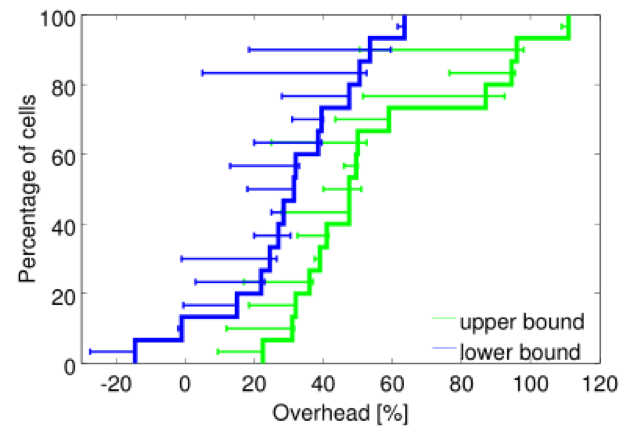
ͼ9����Bucketing����Դ������Ҫ����Ļ�����
��15����Ԫ�е�CPU�ʹ洢��������������Ϊ��һ����ӽ�2�����������Ķ������CDF�� ��������Խʵ��ֵ�����ı�����
��Щʵ��֤ʵ���ֿ��ģ�����ܱȽ��Ǽ��ֵģ���[51]�м�ǿ�˹۲죬���һ����������������������г���ijɱ���
����ʹ��������Ľ����������Ȼ��һ��ʤ����CPU���ٳ����˼��ֲ�ͬ���ַ�����������ļ��٣������ŵ�������������Դ�������ڴ�ʹ��̣�����������CPU
��
5.3 ��ϸ��
Google�����˴�cell�����������д��ͼ��㣬��������Դ��Ƭ��ͨ����cell�Ĺ������طֵ������С��cell�����Ժ��ߵ�Ч��
- �������������ҵ��Ȼ���ڷ���֮����ѭ����ʽ������ҵ�� ͼ7֤ʵʹ�ý�Сcell��������Ҫ����Ļ�����
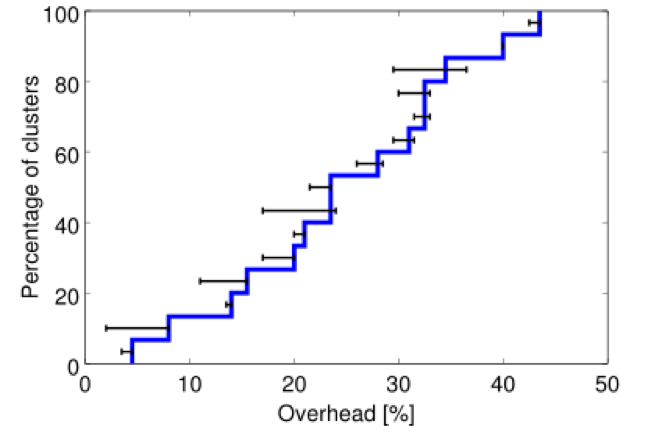
ͼ10����Դ�������൱��Ч�ġ� �������15��������cell������Ҫ���������CDF��
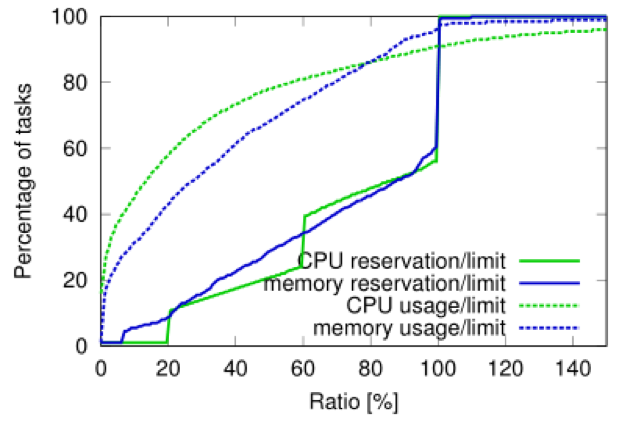
ͼ11����Դ������ʶ��δʹ�õ���Դ�����dzɹ��ġ�������ʾ��15��cell�е����������ޣ���CPU���ڴ�ʹ���ʵ�CDF�����������ʹ��ԶԶ�����伫�ޣ���Ȼ�����������ʹ���˸����CPU��ʵ����ʾ����CPU���ڴ汣�������ʵ�CDF;
��Щ�����ӽ�100����ֱ������Դ���ƴ�����α��
5.4 ϸ������Դ����
Borg�û�����CPU��milli-coresΪ��λ���ڴ�ʹ��̿ռ����ֽ�Ϊ��λ�� ��core�Ǵ��������̣߳���Ի������͵����ܽ��б�������ͼ8��ʾ�������������ȣ�����������ڴ��CPU�˵������ϼ���û�����Եġ�sweet
spots����������Щ��Դ֮�伸��û�����Ե�����ԡ�������90�������ϵ��ڴ������Դ�֮�⣬��Щ�ֲ���[68]������ķֲ��dz����ơ�
�ṩһ��̶���С���������������Ȼ��IaaS��������ʩ�������ṩ��[7,33]�кܳ����������ܺܺõ��������ǵ�����Ϊ��˵����һ�㣬ͨ����ÿ����Դά���Ͻ������������뵽��һ����ӽ���2���ݣ���CPU��0.5�ں˺�RAM��1GiB��ʼ����prod��ҵ�ͷ��䣨��2.4����bucketed��CPU�˺��ڴ���Դ���ơ�ͼ9��ʾ����������Ҫ��ƽ������¶�30-50������Դ�����������ڽ������������������������ѹ��ǰ��ԭʼϸ�����������ʺϣ�;
����������������Щ����������״̬������С��[37]�б���Ĵ�Լ100���Ŀ�������Ϊ����֧�ֳ���4��buckets��������CPU��RAM����������չ����
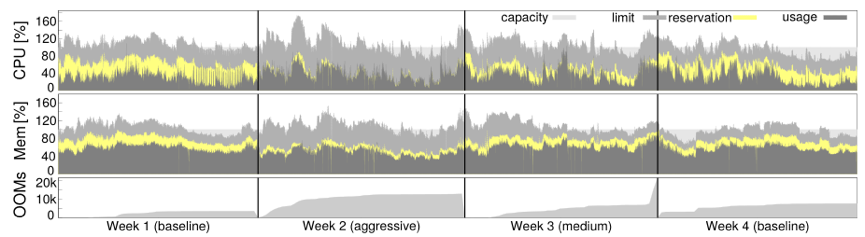
ͼ12������������Դ���ƿ��Ի��ո������Դ�����ڴ治���¼���OOM������û��Ӱ�졣һ������cellʹ�õ�ʱ���ߣ���2013-11-11��ʼ����5���Ӵ���ƽ����Ԥ���������Լ��ۻ����ڴ治���¼�;
���ߵ�б����OOM�������ʡ�����ʹ�ò�ͬ����Դ�������ð��ֿܷ���
5.5 ��Դ����
��ҵ����ָ����Դ���� - ÿ������Ӧ���������Դ�����ޡ� Borgʹ�ø�������ȷ���û��Ƿ����㹻�������������ҵ����ȷ���ض������Ƿ����㹻�������Դ����������
�������û����������Ҫ�ĸ���������û����������ʹ�õĸ������Դ����ΪBorgͨ����ɱ��һ����ͼʹ�ñ�����Ҫ�ĸ����RAM����̿ռ���������CPU��
������Ҫ��ġ� ���⣬ijЩ����ż����Ҫʹ����������Դ�����磬��һ��ĸ߷�ʱ�����Ӧ�Ծܾ�����ʱ�����������ʱ�䲻�ᡣ
�����˷ѵ�ǰδ�����ĵ��ѷ�����Դ�����ǹ�������ʹ�ö�����Դ�������տ������̵�������Դ��������������ҵ���Ĺ�����ʣ����Դ�����������̳�Ϊ��Դ���ա�
�ù��Ƴ�Ϊ�����Ԥ����������Borgmasterÿ������ʹ����Borglet�����ϸ����ʹ�ã���Դ���ģ���Ϣ�����㡣��ʼԤ��������Ϊ������Դ�������ƣ�;��300s��Ϊ������˲��������������ʵ��ʹ�ü��ϰ�ȫ����˥�������ʹ�ó�����Ԥ����Ѹ�����ӡ�
Borg���ȳ���ʹ�ü���������prod����Ŀ����ԣ���3.2������˵��ȳ���Ӳ��������ѻ��յ���Դ��Ҳû�б�¶����Դ�����;
����non-proc����ʹ�����������Ԥ�����Ա㽫�������ŵ��ѻ��յ���Դ�С�
����������ʱ���ܻ�ľ���Դ��������������Ԥ�⣩�Ǵ���� - ��ʹ��������ʹ�õ���ԴС���伫�ޡ� ����������������ɱ��������non-proc������������proc����
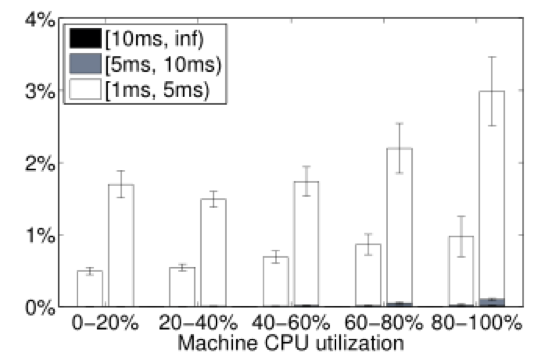
ͼ13�������ӳ���Ϊ���صĺ����� �����һ�������е��̱߳���ȴ�����1ms��ʱ��������CPU��Ƶ�ʣ�����Ϊ�����ж�æ�ĺ�����
��ÿ�������У��ӳ����е���������࣬�������������Ҳࡣ���ڼ���ʱ��İٷֱ��У��̱߳���ȴ�����5ms���ܷ���CPU����ɫ����;�����������صȴ�������ʱ�䣨���ڵ����������Դ�
2013��12�����������Ե�Ԫ������ݣ���������ʾÿ�ղ��졣
ͼ10��ʾ�˸���Ļ���������Դ���ա���Լ20���Ĺ������أ���6.2������ֵcell�Ļ�����Դ�����С�
������ͼ11�п�������ϸ�ڣ�������ʾ��Ԥ����ʹ�����Ƶı��ʡ� �����Ҫ��Դ���������ڴ����Ƶ��������ȱ���ռ�������������ȼ���Σ�����������ڴ������Ǻ��ټ��ġ�
��һ���棬CPU�������ر���������˶��ڷ�ֵ�����൱�����ƶ�ʹ�ø���Ԥ����push usage above
reservation fairly harmlessly����
ͼ11������Դ���տ������ޱ�Ҫ���صģ���Ԥ����ʹ����֮��������Ե����� Ϊ�˲�����һ�㣬ѡ����һ���������cell����ͨ�����ٰ�ȫ�߽磬�ڵ�һ�ܵ�����Դ�����㷨�IJ�����һ�����������ã�Ȼ������һ�ܵ��������ߺͻ�������֮����м����ã�Ȼ��ָ������ߡ�ͼ12��ʾ������ʲô���ڵڶ���
�������Ը��ӽ�ʹ�ã��������Բ���ܣ���һ�͵����ܣ���ʾ������ࡣ��Ԥ�ڵ��������ڴ棨OOM���¼��ķ������ڵ�2�ܺ͵�3�������ӡ���������������Ǿ��������泬���������棬�����е���Դ���ղ�����������
cell��
6.����
50���Ļ�������9������������; һ��90%ile�Ļ�����Լ��25���������д�Լ4500���߳�[83]����Ȼ��Ӧ��֮�乲�����������������ʣ�������Ҫ���õĻ�������ֹ����˴˸��š��ⶼ�����ڰ�ȫ�Ժ����ܡ�
6.1 ��ȫ����
ʹ��Linux chroot jail��Ϊͬһ̨�����϶������֮�����Ҫ��ȫ������ơ�Ϊ������Զ�̵��ԣ�ͨ��ʹ���Զ��ַ����ͳ�����ssh��Կ��ʹ���û�ֻ�е�������Ϊ���û���������ʱ���ܷ��ʸû�����
���ڴ�����û������ѱ��滻Ϊborgssh�������BorgletЭ������һ��ssh���ӵ�һ��shell����shell����������ͬ��chroot��cgroup�����У��Ӷ������ܵ��������ʡ�
VM�Ͱ�ȫɳ�м�������ͨ��Google��AppEngine��GAE��[38]��Google Compute
Engine��GCE�������ⲿ����������ΪBorg�������е�KVM����[54]������ÿ���йܵ�VM��
6.2 ���ܸ���
Borglet�����ڰ汾�������ԭʼ����Դ����ʵʩ���ڴ棬���̿ռ��CPU���ڵ��º�ʹ�ü�飬���ʹ�ù����ڴ����̵������Լ�����Ӧ��Linux��CPU���ȼ�������ʹ��̫��CPU������
������ƭ����Ի������������������Ӱ����Ȼ̫���ף����һЩ�û����������ǵ���Դ�����Լ���Borg���������ǹ�ͬ���ȵ������������⽵���������ʡ�
��Դ���տ����ջ�һЩʣ��ģ����������У���Ϊ�漰��ȫ�ʡ�����˵�����£��û�����ʹ��ר�û�����cell��
���ڣ�����Borg�����ڻ���Linux cgroup����Դ����������[17,58,62]��Borglet�����������ã��ṩ���õĿ���(��Ϊ����ϵͳ�ں���ѭ����)��
��ʹ��ˣ�ż���ĵͼ���Դ���ţ����磬�洢��������L3���ٻ�����Ⱦ����Ȼ����������[60,83]�С�
Ϊ�˰������غ���ʹ�ã�Borg������һ��Ӧ�����appclass�� ����Ҫ������������ӳ����У�LS��Ӧ����������Ӧ���ࣨ�ڱ����г�Ϊ���������С�LS�������������û���Ӧ�ó������Ҫ������Ӧ����Ĺ��������ṹ�������ȼ�LS����õ���Ѵ����������ܹ�һ����ʱʹ�������������ӡ�
���ηָ�����ڿ�ѹ����Դ�����磬CPU���ڣ�����I / O�������Ͳ���ѹ����Դ�����磬�洢�������̿ռ䣩�У���ѹ����Դ�ǻ������ʵIJ��ҿ���ͨ���ڲ�ɱ����������½���������������������л��գ�����ѹ����Դͨ�������ڲ�ɱ�����������±����ա�
��������ľ��˲���ѹ����Դ����Borglet������ֹ����������ȼ���������ȼ���ֱ����������ʣ�ౣ��Ϊֹ��
��������ľ��˿�ѹ����Դ��Borglet������ʹ�ã�������LS����ʹ�ÿ��Դ����̸��ظ߷����ɱ���κ�����
������û�и��ƣ�Borgmaster���ӻ�����ɾ��һ����������
Borglet�е��û��ռ����ѭ������Ԥ���δ��ʹ����������prod�����ڴ�ѹ������Է�prod������������������ڴ棻���������ں˵�Out-of-Memory��OOM���¼�;
���ҵ����Է��䳬�����ڴ�����ʱ�����ߵ������ύ�Ļ���ʵ���Ϻľ��ڴ�ʱ��ɱ������ Linux�Ŀ����ļ�����������Ҫȷ���ڴ���㣬���ŵ�ʹʵ�ָ��ӻ���
Ϊ��������ܸ��룬LS������Ա�����������CPU�ˣ��Ӷ���ֹ����LS����ʹ�á� �����������������κκ������У��������������LS�����С���ȳ�������Borglet��̬����̰��LS�������Դ���ޣ���ȷ������ʹ��������������ӣ�����Ҫʱѡ���Ե�Ӧ��CFS��������[75]��
�����Dz���ģ���Ϊ�����ж�����ȼ���
��Leverich [56]�����Ƿ��ֱ���Linux CPU��������CFS����Ҫ������������֧�ֵ��ӳٺ������ʡ�
Ϊ�˼��ٵ��ȣ� CFS�汾ʹ����չ��ÿ��Ⱥ��ĸ�����ʷ[16]��������LS������ռ�������ҵ����LS������һ��CPU���ǿ�����ʱ���ٵ�������
���˵��ǣ�����Ӧ�ó���ʹ���߳�����ģ�ͣ�������˳������ز�ƽ���Ӱ�졣����ʹ��cpusets��CPU�˷���������ر�����ӳ�Ҫ���Ӧ�ó���
��ЩŬ����һЩ�����ͼ13��ʾ����һ����Ĺ��������������̲߳��ֺ�CPU��������NUMA-�����̺߳��ʸ�֪�����磬[81]���������Borglet�Ŀ��Ʊ���ȡ�
��������ʹ�ôﵽ�����Ƶ���Դ�������������������������CPU�Ŀ�ѹ����Դ��������δʹ�ã��ɳڣ���Դ��
ֻ��5����LS������ô˹��ܣ����ܻ�ø��õĿ�Ԥ����; ����1������������ʹ�ô˹��ܡ�Ĭ������£���ֹʹ�������ڴ棬��Ϊ��������������ֹ�Ļ��ᣬ����ʹ��ˣ�10����LS����Ḳ�Ǵ˹��ܣ�����79������������������������Ϊ����MapReduce��ܵ�Ĭ�����á��ⲹ���˻�����Դ�Ľ������5.5����������������������δʹ�õ��Լ����յ��ڴ棺�����ʱ�����ǿ��еģ���Ȼż����һ��LS��������Դʱ������������ᱻ������
7.��ع���
�Ѿ��о��˼�ʮ�����Դ���ȣ��ڲ�ͬ���������У������HPC��������������վ����ʹ��ģ��������Ⱥ��
������ֻ��ע���ͷ�������Ⱥ��������������Ĺ�����
�����һЩ�о�����������Yahoo!��Google��Facebook�ļ�Ⱥ����[20,52,63,68,70,80,82]����˵������Щ�ִ��������ĺ��������й��еĹ�ģ���칹�Ե���ս��
[69]������Ⱥ�������ܹ��ķ��ࡣ
Apache Mesos [45]ʹ�û��ڹ�Ӧ�Ļ�����������Դ���������е���Borgmaster��ȥ����ȳ��Ͷ������ܡ�����Hadoop
[41]��Spark [73]��֮�仮����Դ�����ͷ��ù��ܡ� Borg��Ҫʹ�û�������Ļ��������л���Щ���ܣ����ֻ��ƿ��Ժܺõ���չ��
DRF [29,35,36,66]�����ΪMesos������; Borgʹ�����ȼ���������������档Mesos�������Ѿ�������չMesos����Ͷ������Դ����ͻ��գ������[69]��ȷ����һЩ���⡣
YARN [76]��һ����HadoopΪ���ĵļ�Ⱥ�������� ÿ��Ӧ�ó�����һ��������������������Դ������Э���������Դ;
����Google MapReduce��ҵ��2008���������ڴ�Borg��ȡ��Դ�ķ���������ͬ.YARN����Դ����������ű���ݴ���
��صĿ�Դ������Hadoop����������[42]����Ϊ������֤���ֲ���У����Թ�����ƽ���ṩ���⻧֧�֡�
YARN����Ѿ���չ��֧�ֶ�����Դ���ͣ����ȼ�����ռ�������[21]������˹�����о�ԭ��[40]֧�ֹ�ʱ��֪�ģ�makespan-aware����ҵ�����
Facebook��Tupperware [64]��һ������Borg��ϵͳ��������Ⱥ���ϵ���cgroup����;
ֻ��һЩϸ���Ѿ����������������ƺ��ṩ��һ����Դ���յ���ʽ�� Twitter�п�Դ��Aurora [5]��һ������Borg�ĵ�������������Mesos֮�����еij�ʱ�����еķ����������Ժ�״̬��������Borg��
Microsoft��Autopilotϵͳ�ṩ�ˡ��Զ����������úͲ���; ϵͳ���; ִ��������������������Ӳ�����ϡ���Borg��̬ϵͳ�ṩ�����ƵĹ��ܣ�������ƪ�����ﲻ�����ۣ�
Isaard [48]���������Ǽ�ֵ��������ʵ����
Quincy [49]ʹ��������ģ��Ϊ���ٸ��ڵ�ļ�Ⱥ�ϵ����ݴ���DAG�ṩ��ƽ�Ժ�����λ�ø�֪���ȡ�Borgʹ���������ȼ����û�֮�乲����Դ������չ������̨������Quincyֱ�Ӵ���ִ��ͼ�������ǵ���������Borg�Ķ�����
Cosmos [44]רע�����������ص���ȷ�����û��ܹ���ƽ�ط������Ǿ�������Ⱥ����Դ�� ��ʹ��ÿ��������������per-job
manager������ȡ��Դ; ����ϸ���ǹ����ġ�
����Apolloϵͳ[13]ʹ��ÿ����ҵ���������ж�����������ҵ�����ڿ�����Borg cell��С��ͬ�ļ�Ⱥ��ʵ�ָ���������
Apolloʹ�û�������ִ�е����ȼ���̨�������Զ����Ŷ��ӳ�Ϊ���ۣ���ʱ������������ʡ�Apollo�ڵ��ṩ����Ŀ�ʼʱ���Ԥ�������Ϊ������Դά���ϴ�С�ĺ��������е�������������ɱ��Ĺ��Ƽ�Զ�����ݷ����Խ��в��þ�����������ӳٵ����Լ��ٳ�ͻ��Borgʹ�����������������ǰ�����״̬�����þ������ܴ����������Դά�ȣ���רע�ڸ߿����ԡ��������е�Ӧ�ó��������;
Apollo���Դ������ߵ������ʡ�
����Ͱ͵�Fuxi [84]֧�����ݷ����������أ�����2009�꿪ʼ���С���Borgmasterһ��������FuxiMaster�����������ݴ����ӽڵ��ռ���Դ��������Ϣ����������Ӧ�ó����������һ��ƥ�䵽��һ����Fuxi�������Ȳ�����Borg�ĵȼ����෴��Fuxi���ǽ�ÿ��������һ����ʵĻ�����ƥ�䣬���ǽ��¿�����Դ���ѹ�Ĵ�������������ƥ�䡣
��Mesosһ����Fuxi�������塰������Դ�����͡� ֻ�кϳɹ������ؽ���ǹ����ġ�
Omega [69]֧�ֶ��ƽ�еģ�ר�ŵġ���ֱ����ÿ�������൱��Borgmaster��ȥ��־ô洢�����ӷ�Ƭ��
Omega������ʹ���ֹ۲��������������洢������־ô洢���е������۲쵽��cell״̬�Ĺ�����ʾ����ͨ����������·�����ͬ����Borglet��Omega�ܹ�ּ��֧�ֶ����ͬ�Ĺ������أ���Щ�������ؾ����ض���Ӧ�ó����RPC�ӿڣ�״̬���͵��Ȳ��ԣ����磬�������еķ����������Ը��ֿ�ܵ���������ҵ�������ܹ������缯Ⱥ�洢ϵͳ���������Google
Cloud Platform������һ���棬Borg�ṩ�ˡ�һ���ʺ����С���RPC�ӿڣ�״̬������͵��������ԣ�����ʱ������ƣ�������Ҫ֧�����ͬ�Ĺ������أ����ǵĹ�ģ�����Զ���������������չ����δ��Ϊ���⣨��3.4����
Google�Ŀ�ԴKubernetesϵͳ[53]��Ӧ�ó��������Docker����[28]�У��ڶ�������ڵ��ϣ������������������Borg���������й��ṩ���У���Google
Compute Engine�����������ཨ��Borg�Ĺ���ʦ���������ġ� Google�ṩ��һ����ΪGoogle
Container Engine���йܰ汾[39]��������һ��������ν�Borg�Ľ�ѵӦ����Kubernetes��
�����ܼ�����������һ���������ƾõĹ�����ͳ�����磬Maui��Moab��Platform LSF [2��47��50]��;
Ȼ������ģ���������غ��ݴ���Ҫ��ͬ�ڹȸ��cell��ͨ����������ϵͳͨ�����еȴ������Ĵ��ѹ�����У���ʵ�ָ������ʡ�
���⻯�ṩ����VMware [77]���������Ľ�������ṩ�̣���HP��IBM [46]���ṩ��Ⱥ�������������ͨ����չ��O��1000�����������⣬�����о����������ijЩ��ʽ�Ľ����Ⱦ���������ԭ��ϵͳ�����磬[25,40,72,74]����
��������Ѿ�ָ���ģ��������ģ��Ⱥ����һ����Ҫ�������Զ����͡������scaleout���� [43]��������μƻ����ϣ����⻧��������飬����ƺͿ����������Զ���ÿ����������ɴ��������DZ�Ҫ�ġ�Borg��������������Ƶģ��ܹ�Ϊÿ������Ա��SRE��֧������̨������
8.�����ѵ��δ������
���ڽ�����ʮ�������������в���Borg��ѧ����һЩ���Խ�ѵ���������������Kubernetesʱ���������Щ�۲���[53]��
8.1�����ѵ�����ķ���
��Borg��һЩ���Կ�ʼ����Ϊ������Kubernetes��֪��������ơ�
��Ϊ�����Ψһ������ƣ���ҵ�������Եġ� Borgû��һ���ķ�ʽ��������������ҵ������Ϊһ����һ��ʵ�壬��ָ���Ƿ�������ʵ�������磬canary�������켣������Ϊһ���ڿͣ��û�����ҵ�����б���������ˣ�������������Ĺ���������������Щ���ơ��ڷ�Χ����һ�ˣ�������������ҵ�������Ӽ����������������º���ҵ������С�IJ�����������⡣
Ϊ�˱����������ѣ�Kubernetes�ܾ�����ҵ�������ʹ�ñ�ǩ��֯���ȵ�Ԫ��pods�� - �û����Ը��ӵ�ϵͳ���κζ���������/ֵ�ԡ�ͬ�ȵģ�����ͨ�����ӵ�һ����ҵ��ʵ��Borg��ҵ������ҵ����ǩ���ӵ�һ��pod������Ҳ���Ա�ʾ�κ��������õķ��飬�������������ͣ����磬�������ֶΡ����ԣ���
Kubernetes�еIJ���ͨ����ǩ��ѯ��ʶ����Ŀ�꣬�ò�ѯѡ���˽�Ӧ�ò����Ķ��� ���ַ�������ҵ�ĵ����̶������ṩ���������ԡ�
ÿ������һ��IP��ַʹ���鸴�ӻ��� ��Borg�У������ϵ���������ʹ���������ĵ���IP��ַ���Ӷ����������Ķ˿ڿռ䡣�����һЩ���ѣ�Borg���������Ϊ��Դ�Ķ˿�;
�������Ԥ��������Ҫ���ٸ��˿ڣ�����Ը��������ʱ����֪ʹ����Щ�˿ڣ�Borglet����ǿ�ƶ˿ڸ��룻����������RPCϵͳ���봦���˿ں�IP��ַ��
����Linux�����ռ䣬�������IPv6��������������ij��֣�Kubernetes���Բ�ȡ���û������Ѻõķ�����������Щ�����ԣ�ÿ��pod�ͷ������Լ���IP��ַ������������Աѡ��˿ڣ�������Ҫ��������Ӧѡ��
���������˹����˿ڵĻ����ܹ������ԡ�
��Ը��û������Ż��������������û���Borg�ṩ��һ������ԡ������û����Ĺ��ܣ��Ա��û��������������з�ʽ��BCL�淶�г�Լ230����������������ص���֧�ֹȸ���������Դ�����ߣ����ǵ�Ч��������������Ҫ�ġ����ҵ��ǣ�����API�ķḻ��ʹ�����ø�����ԡ����С��û������������䷢չ����������ǹ�����Borg֮�����е��Զ������ߺͷ���ͨ��ʵ��ȷ�����ʵ����á���Щ���������ݴ�Ӧ�ó����ṩ��ʵ�����ɣ�����Զ������ִ�������һ���鷳�£����������ѡ�
8.2�����ѵ���õķ���
��һ���棬һЩBorg����������Ѿ��dz���Խ��������ס��ʱ��Ŀ��顣
Allocs�����õġ� Borg alloc�����������˹㷺ʹ�õ���־�洢ģʽ����2.4������һ�����е�ģʽ�Ǽ����ݼ����������ڸ���Web������ʹ�õ����ݡ�Allocs�Ͱ��������ְ��������ɲ�ͬ���Ŷӿ�����
Kubernetes��ͬalloc�ȼ۵���pod������һ��������������Դ��װ����Щ�������DZ����ȵ�ͬһ�����ϲ��ҿ��Թ�����Դ��Kubernetes����ͬ��pod��ʹ�ø�����������alloc�е��������뷨��һ���ġ�
��Ⱥ�������������������������Borg����Ҫ�����ǹ�������ͻ������������ڣ�����������Borg�ϵ�Ӧ�ó�����Դ�����������Ⱥ���������棬������������ƽ�⡣
Kubernetesʹ�÷������֧����������ƽ�⣺����������ƺ��ɱ�ǩѡ��������Ķ�̬pod����Ⱥ���е��κ�����������ʹ�÷����������ӵ������ڷ����£�Kubernetes�Զ�����ƽ�����ǩѡ����ƥ���pod�еķ������ӣ����Ҹ���pod�����ڹ��϶�����ʱ�����°���ʱ���е�λ�á�
��ʡ��������Ҫ�ġ� ��ȻBorg�������ǡ�ֻ�ǹ����������������⣬�ҵ�����ԭ���������ս�Եġ�Borg��һ����Ҫ����ƾ�����Ҫ�������û���ʾ������Ϣ�����������أ�Borg�г�ǧ������û������ԡ������������ǵ��Եĵ�һ����
��Ȼ��ʹ�ø������������Ժı��û��������ڲ����ԣ�������Ȼ��һ��Ӯ�ң���û���ҵ��κ���ʵ�����Ʒ��Ϊ�˴����������ݣ��ṩ�˶�������UI�͵��Թ��ߣ�����û����Կ���ʶ��������ҵ��ص��쳣�¼���Ȼ�����Ӧ�ó���ͻ����ܹ���������鿴��ϸ���¼��ʹ�����־��
Kubernetesּ�ڸ���Borg��������ʡ������ ���磬������������cAdvisor [15]��������Դ���Ӻͻ���Elasticsearch
/ Kibana [30]��Fluentd [32]����־�ۺϵĹ��ߡ����Բ�ѯ�����Ķ���״̬�Ŀ��ա�Kubernetes����ͳһ�Ļ��ƣ��������������������¼�¼������磬�����ȵ�pod������ʧ�ܣ�����Щ�¼��Կͻ���Ҳ�ǿ��õġ�
�����Ƿֲ�ʽϵͳ���ںˡ�Borgmaster������Ϊһ����Ƭϵͳ��������ʱ������ƣ�����ø���һ���ںˣ�λ�ڷ�����̬ϵͳ�ĺ��ģ�Э�������û���ҵ�����磬�����ȳ������UI��Sigma�����Ϊ�����Ľ��̣��������˷�����������ơ���ֱ��ˮƽ�Զ����ţ����´����������ҵ�ύ��cron���������������Լ��������߲�ѯ�Ĺ鵵ϵͳ������
��֮����ʹ���ܹ��ڲ��������ܻ��ά���Ե��������չ�������غ��ܼ���
Kubernetes�ܹ�����һ�������ĺ�����һ��API��������ֻ����������Ͳ����ײ�״̬����Ⱥ������������ΪС�Ŀ���ϵ�����API�������Ŀͻ��ˣ������縴�ƿ���������������Թ���ʱ����pod�����������ĸ������Լ��ڵ�����������ڹ���
�����������ڡ�
8.3����
�ڹ�ȥʮ����������е�Google��Ⱥ�������ض�ת��ʹ��Borg�����Ǽ�����չ������������ѧ���Ľ�ѵӦ�õ�Kubernetes��
|






