|
дЦЦмTechDay31ЦкЃЌАЂРядЦШнЦїЗўЮёММЪѕзЈМвНфПеИјДѓМвДјРДDockerШежОЪеМЏзюМбЪЕМљЕФбнНВЁЃБОЮФжївЊДгДЋЭГШежОДІРэПЊЪМЬИЦ№ЃЌНгЯТРДзХжиЗжЮіDockerШежОДІРэЃЌАќРЈstdoutКЭЮФМўШежОЃЌЦфжаЛЙгаfluentd-pilotЃЌНгзХЗжЯэСЫШежОДцДЂЗНАИElasticsearchЁЂgraylog2КЭSLSЃЌзюКѓЖде§ШЗаДШежОИјГіСЫНЈвщЁЃ
вдЯТЪЧОЋВЪФкШнећРэЃК
ДЋЭГШежОДІРэ
ЫЕЕНШежОЃЌЮвУЧвдЧАДІРэШежОЕФЗНЪНШчЯТЃК
ШежОаДЕНБОЛњДХХЬЩЯ
ЭЈГЃНігУгкХХВщЯпЩЯЮЪЬтЃЌКмЩйгУгкЪ§ОнЗжЮі
ашвЊЪБЕЧТМЕНЛњЦїЩЯЃЌгУgrepЁЂawkЕШЙЄОпЗжЮі
ФЧУДЃЌетжжЗНЪНгаЪВУДШБЕуФиЃП
ЕквЛЃЌ ЫќЕФаЇТЪЗЧГЃЕЭЃЌвђЮЊУПвЛДЮвЊХХВщЮЪЬтЕФЪБКђЖМвЊЕЧЕНЛњЦїЩЯШЅЃЌЕБгаМИЪЎЬЈЛђепЪЧЩЯАйЬЈЛњЦїЕФЪБКђЃЌУПвЛЬЈЛњЦїШЅЕЧТНетЪЧвЛИіУЛАьЗЈНгЪмЕФЪТЧщЃЌПЩФмвЛЬЈЛњЦїРЫЗбСНЗжжгЃЌећИіМИаЁЪБОЭЙ§ШЅСЫЁЃ
ЕкЖўЃЌ ШчЙћвЊНјаавЛаЉБШНЯИДдгЕФЗжЮіЃЌЯёgrepЁЂawkСНИіМђЕЅЕФУќСюВЛФмЙЛТњзуашЧѓЪБЃЌОЭашвЊдЫаавЛаЉБШНЯИДдгЕФГЬађНјааЗжЮіЁЃ
ЕкШ§ЃЌ ШежОБОЩэЫќЕФМлжЕВЛЙтдкгкХХВщвЛаЉЯЕЭГЮЪЬтЩЯУцЃЌПЩФмдквЛаЉЪ§ОнЕФЗжЮіЩЯЃЌПЩФмРћгУШежОРДзівЛаЉгУЛЇЕФОіВпЃЌетвВЪЧЫќЕФМлжЕЃЌШчЙћВЛФмАбЫќРћгУЦ№РДЃЌМлжЕОЭВЛФмГфЗжЕФЗЂЛгГіРДЁЃ
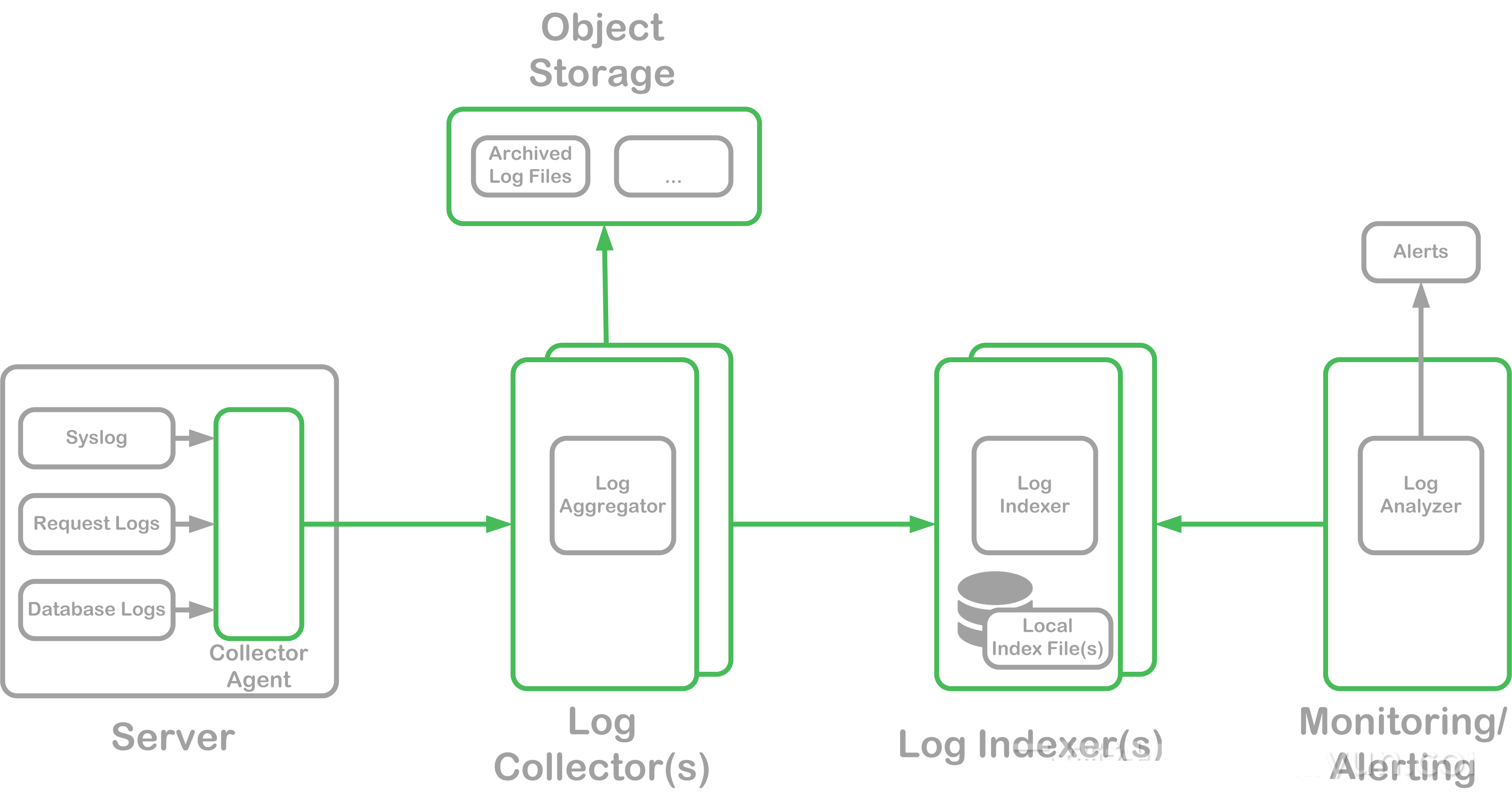
ЫљвдЃЌЯждкКмЖрЙЋЫОЛсВЩгУМЏжаЪНШежОЪеМЏЕФШежОДІРэЗНЪНЃЌЮвУЧЛсАбШежОЗжВМЪНЪеМЏЃЌМЏжаРДДцДЂЃЌЮвУЧЛсдкЫљгаЛњЦїЩЯУцАбШежОЖМЪеМЏЦ№ЕНвЛИіжааФЃЌдкжааФРяУцзівЛИіШежОШЋЮФЫїв§ЫбЫїЃЌПЩвдЭЈЙ§вЛИіНчУцШЅВщбЏЃЌЭЌЪБетИіШежОЯЕЭГКѓЖЫПЩвдЖдНгвЛаЉИќИДдгЕФЪ§ОнДІРэЯЕЭГЃЌПЩвдЖдНгМрПиЁЂБЈОЏЯЕЭГЃЌЖдНгЪ§ОнЭкОђЪ§ОнЗжЮіЯЕЭГЃЌГфЗжЗЂЛгШежОЕФМлжЕЁЃ
DockerЕФШежОДІРэ
ЪЙгУЙ§DockerЕФШЫгШЦфЪЧЪЙгУЙ§ШнЦїБрХХЯЕЭГЃЌБШШчЫЕЮвУЧЕФШнЦїЗўЮёЃЌПЩФмвбОзЂвтЕНетбљЕФвЛаЉЬиЕуЃК
ШнЦїБрХХИњДЋЭГЕФВМжУЗНЪНЪЧВЛвЛбљЕФЃЌдкШнЦїБрХХРяУцЃЌзЪдДЗжХфгІгУХмЕНФФЬЈЛњЦїЩЯУцЕФОіВпЪЧгЩШнЦїВуРДзіЕФЃЌЫљвдФуЪТЯШВЛжЊЕРФуЕФШнЦїгІгУЛсХмЕНФФЬЈЛњЦїЩЯУцЃЛЛЙгаздЖЏЩьЫѕЃЌИљОнИКдиздЖЏдіМгЛђепМѕЩйШнЦїЪ§СПЃЛСэЭтЃЌдкећИідЫааЙ§ГЬжаЃЌЯЕЭГЗЂЩњвЛаЉЧщПіЪБЃЌБШШчЫЕФуЕФШнЦїхДЕєСЫЃЌШнЦїЗўЮёЛсздЖЏАбШнЦїгІгУЧЈЕНЦфЫћЕФЛњЦїЩЯШЅЃЌећИіЙ§ГЬЗЧГЃЖЏЬЌЃЌШчЙћЯёДЋЭГЗНЪНШЅХфжЦШежОЕФЪеМЏЙЄОпЃЌДгвЛЬЈЛњЦїЩЯУцЪеМЏФГвЛИігІгУЃЌдкетИіЖЏЬЌЯТУцЃЌКмФбгУдРДЕФЗНЪНШЅХфжУЁЃ
ЛљгкетаЉЬиЕуЃЌдкDockerЕФШежОРяУцЃЌ ЮвУЧжЛФмЙЛВЩгУжааФЛЏЕФШежОЪеМЏЗНАИЃЌФувбОУЛАьЗЈдйЯёдРДЕЧЕНвЛЬЈЛњЦїЩЯУцШЅПДЫќЕФШежОЪЧЪВУДЃЌвђЮЊФуВЛжЊЕРЫќЦфЪЕдкФФИіЛњЦїЩЯУцЁЃ
stdoutКЭЮФМўШежО
DockerЕФШежОЮвУЧПЩвдАбЫќЗжГЩСНРрЃЌвЛРрЪЧstdoutБъзМЪфГіЃЌСэЭтвЛРрЪЧЮФМўШежОЁЃstdoutЪЧаДдкБъзМЪфГіРяУцЕФШежОЃЌБШШчФудкГЬађРяУцЃЌЭЈЙ§printЛђепechoРДЪфГіЕФЪБКђЃЌетжжЪфГіБъзМдкlinuxЩЯУцЦфЪЕЪЧЭљвЛИіIDЮЊСуЕФЮФМўБэЪіЪщРяУцШЅаДЃЛСэЭтЕФОЭЪЧЮФМўШежОЃЌЮФМўШежООЭЪЧаДдкДХХЬЩЯЕФШежОЃЌвЛАуРДЫЕЮвУЧЛсдкДЋЭГЕФгІгУРяУцЛсгУЕУЖрвЛаЉЁЃ
stdout
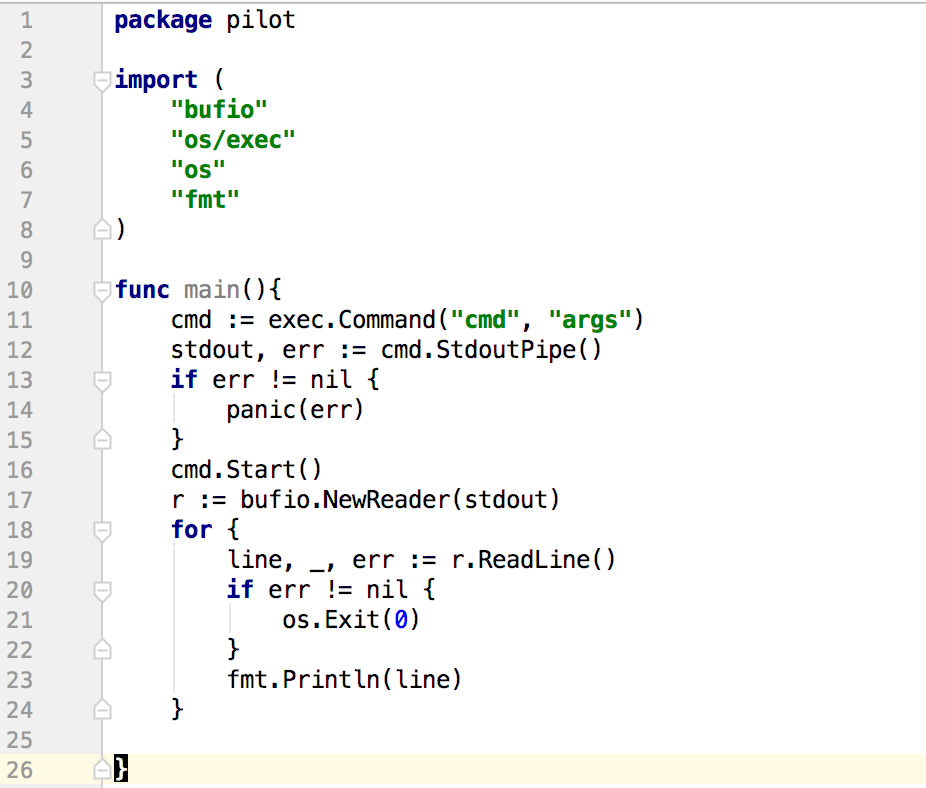
дкDockerЕФГЁОАРяУцЃЌФПЧАБШНЯЭЦГчетжжБъзМЪфГіЕФШежОЃЌБъзМЪфГіШежООпЬхЙ§ГЬШчЭМЁЃБъзМЪфГіШежОЕФдРэдкгкЃЌЕБдкЦєЖЏНјГЬЕФЪБКђЃЌНјГЬжЎМфгавЛИіИИзгЙиЯЕЃЌИИНјГЬПЩвдФУЕНзгНјГЬЕФБъзМЪфГіЁЃФУЕНзгНјГЬБъзМЪфГіЕФКѓЃЌИИНјГЬПЩвдЖдБъзМЪфГізіЫљгаЯЃЭћЕФДІРэЁЃ
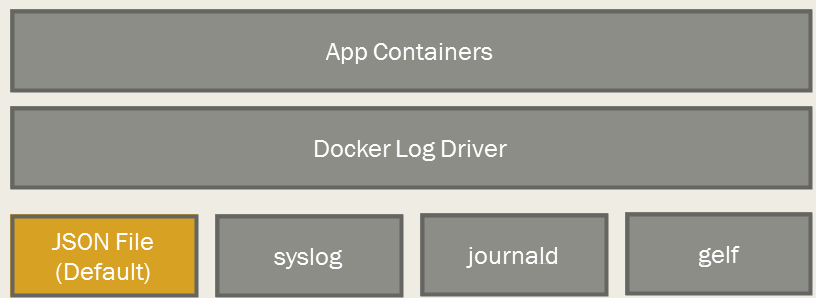
Р§ШчЃЌЮвУЧЭЈЙ§exec.CommandЦєЖЏСЫвЛИіУќСюЃЌДјвЛаЉВЮЪ§ЃЌШЛКѓОЭПЩвдЭЈЙ§БъзМЕФpipelineФУЕНБъзМЪфГіЃЌКѓУцОЭПЩвдФУЕНГЬађдЫааЙ§ГЬжаВњЩњБъзМЪфГіЁЃ
DockerвВЪЧгУетИідРэРДФУЕФЃЌЫљгаЕФШнЦїЭЈЙ§Docker DaemonЦєЖЏЃЌЪЕМЪЩЯЪєгкDockerЕФвЛИізгНјГЬЃЌ
ЫќПЩвдФУЕНФуЕФШнЦїРяУцНјГЬЕФБъзМЪфГіЃЌШЛКѓФУЕНБъзМЪфГіжЎКѓЃЌЛсЭЈЙ§ЫќздЩэЕФвЛИіНазіLogDriverЕФФЃПщРДДІРэЃЌLogDriverОЭЪЧDockerгУРДДІРэШнЦїБъзМЪфГіЕФвЛИіФЃПщЁЃ
DockerжЇГжКмЖржжВЛЭЌЕФДІРэЗНЪНЃЌБШШчФуЕФБъзМЪфГіжЎКѓЃЌдкФГвЛжжЧщПіЯТЛсАбЫќаДЕНвЛИіШежОРяУцЃЌDockerФЌШЯЕФJSON
FileШежОЃЌГ§ДЫжЎЭтЃЌDockerЛЙПЩвдАбЫќЗЂЫЭЕНsyslogРяУцЃЌЛђепЪЧЗЂЫЭЕНjournaldРяУцШЅЃЌЛђепЪЧgelfЕФвЛИіЯЕЭГЁЃ
дѕУДХфжУlog driverФиЃП
гУDockerРДЦєЖЏШнЦїЕФЛАЃЌФугаСНжжЗНЪНРДХфжУLogDriverЃК

ЕквЛжжЗНЪНЪЧдкDaemonЩЯХфжУЃЌЖдЫљгаЕФШнЦїЩњаЇЁЃФуХфжУжЎКѓЃЌЫљгаЕФШнЦїЦєЖЏЃЌШчЙћУЛгаЖюЭтЕФЦфЫћХфжЦЃЌФЌШЯЧщПіЯТОЭЛсАбЫљгаШнЦїБъзМЪфГіШЋВПЖМЗЂЫЭИјSyslogЗўЮёЃЌетбљОЭПЩвддкетИіSyslogЗўЮёЩЯУцЪеМЏетЬЈЛњЦїЩЯЕФЫљгаШнЦїЕФБъзМЪфГіЃЛ
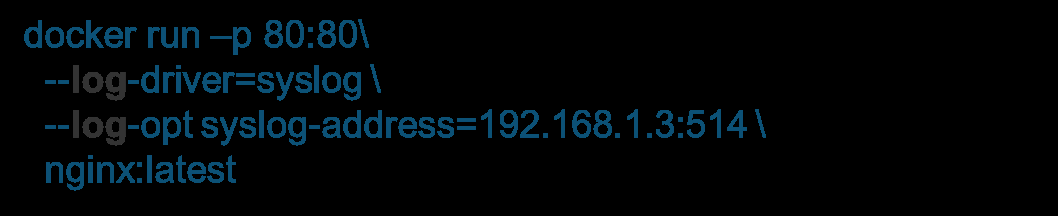
ЕкЖўжжЗНЪНЪЧдкШнЦїЩЯХфжУЃЌжЛЖдЕБЧАШнЦїЩњаЇЁЃШчЙћФуЯЃЭћетИіХфжУжЛЖдвЛИіШнЦїЩњаЇЃЌВЛЯЃЭћЫљгаШнЦїЖМЪмЕНгАЯьЃЌФуПЩвддкШнЦїЩЯУцХфжУЁЃЦєЖЏвЛИіШнЦїЃЌЕЅЖРХфжУЫќздЩэЪЙгУЕФlogdriverЁЃ
ЦфЪЕDockerжЎЧАвбОжЇГжСЫКмЖрЕФlogdriverЃЌЭМжаСаБэЪЧжБНгДгDockerЕФЙйЗНЮФЕЕЩЯУцФУЕНЕФЁЃ
ЮФМўШежО
ЖдгкstdoutЕФетжжШежОЃЌдкDockerРяУцЯждкДІРэЦ№РДЛЙЪЧБШНЯЗНБуЕФЃЌШчЙћУЛгаЯжГЩLogdriverЕФвВПЩвдздМКЪЕЯжвЛИіЃЌЕЋЪЧЖдгкЮФМўШежОДІРэЦ№РДОЭУЛгаетУДМђЕЅСЫЁЃШчЙћдквЛИіШнЦїРяУцаДСЫШежОЃЌЮФМўЮЛгкШнЦїФкВПЃЌДгЫожїЛњЩЯЮоЗЈЗУЮЪЃЌЕФШЗФуЪЧПЩвдИљОнDockerгУЕФdevicemapperЁЂoverlayfsЗУЮЪЕНЫќРяУцЕФвЛИіЮФМўЃЌЕЋЪЧетжжЗНЪНИњDockerЕФЪЕЯжЛњжЦЪЧгаЙиЯЕЕФЃЌНЋРДЫќШчЙћИФБфЃЌФуЕФЗНАИОЭЪЇаЇСЫЃЛСэЭтЃЌШнЦїдЫааЗЧГЃЖЏЬЌЃЌШежОЪеМЏГЬађФбвдХфжУЃЌШчЙћгавЛИіШежОЪеМЏЕФГЬађЃЌдкЛњЦїЩЯУцХфжУвЊЪеМЏФФИіЮФМўЃЌЫќЕФИёЪНЪЧЪВУДбљзгЕФЁЂЗЂЫЭЕНФФЖљЃПвђЮЊвЛЬЈЛњЦїЩЯУцШнЦїЪЧвЛжБдкЖЏЬЌБфЕФЃЌЫќЫцЪБПЩФмдкдіМгвЛИіЛђепЩОГ§вЛИіЃЌЪТЯШФуВЂВЛжЊЕРетЬЈЛњЦїЩЯЛсХмСЫЖрЩйИіШнЦїЃЌЫћУЧЕФХфжУЪЧдѕУДбљзгЕФЃЌЫћУЧЕФШежОЪЧаДдкФФЖљЕФЃЌЫљвдУЛАьЗЈдЄЯШдквЛЬЈЛњЦїЩЯУцАбетИіВЩМЏГЬађХфКУЃЌетОЭЪЧЮФМўЪеМЏБШНЯФбЕФСНИіЕиЗНЁЃ
зюМђЕЅЕФвЛИіЗНАИЃЌИјУПИіШнЦїХЊвЛИіШежОВЩМЏНјГЬЃЌетИіНјГЬХмЕНШнЦїРяУцЃЌОЭПЩвдНтОівдЩЯЕФСНИіЮЪЬтЃЌЕквЛвђЮЊЫќХмЕНШнЦїРяУцЃЌОЭПЩвдЗУЮЪЕНШнЦїРяУцЫљгаЕФЮФМўЃЌАќРЈШежОЮФМўЃЛЕкЖўЫќИњШнЦїдквЛЦ№ЃЌЕБШнЦїЦєЖЏЕФЪБКђЃЌЪеМЏШежОЕФНјГЬвВЦєЖЏСЫЃЌЕБШнЦїЯњЛйЕФЪБКђЃЌНјГЬвВОЭБЛЯњЛйЕєСЫЁЃ
етИіЗНАИЗЧГЃМђЕЅЃЌЕЋЪЧЦфЪЕЛсгаКмЖрЕФШБЕуЃК
ЕквЛЃЌ вђЮЊУПИіШнЦїЖМгавЛИіШежОЕФНјГЬЃЌвтЮЖзХФуЕФЛњЦїЩЯУцга100ИіШнЦїЃЌОЭашвЊЦєЖЏвЛАйИіШежОЩшБИЕФГЬађЃЌзЪдДЕФРЫЗбЗЧГЃРїКІЁЃ
ЕкЖўЃЌ дкзіОЕЯёЕФЪБКђЃЌашвЊАбШнЦїРяУцШежОВЩМЏГЬађзіЕНОЕЯёРяУцШЅЃЌЖдФуЕФОЕЯёЦфЪЕЪЧгаШыЧжЕФЃЌЮЊСЫШежОВЩМЏЃЌВЛЕУВЛАбздМКЕФШежОГЬађдйзіИіаТОЕЯёЃЌШЛКѓАбЖЋЮїЗХНјШЅЃЌЫљвдЖдФуЕФОЕЯёЙ§ГЬЪЧгаШыЧжадЕФЁЃ
ЕкШ§ЃЌ ЕБвЛИіШнЦїРяУцКУЖрИіНјГЬЕФЪБКђЃЌЖдгкШнЦїЕФзЪдДЙмРэЃЌЛсИЩШХФуЖдШнЦїЕФзЪдДЪЙгУЕФХаЖЯЃЌАќРЈЖдгкдкзізЪдДЗжХфКЭМрПиЕФЪБКђЃЌЖМЛсгавЛаЉетбљЕФИЩШХЁЃ
fluentd-pilot
дкШнЦїЗўЮёЩЯУцЃЌЮвУЧаТПЊЗЂСЫвЛИіЙЄОпЃЌГЦжЎЮЊfluentd-pilotЁЃ
fluentd-pilotЪЧвЛИіПЊдДЕФШежОВЩМЏЙЄОпЃЌЪЪКЯжБНгдквЛЬЈЛњЦїЩЯУцХмЕЅИіНјГЬФЃЪНЁЃfluentd-pilotгаетбљЕФвЛаЉЬиЕуЃК
вЛИіЕЅЖРfluentdНјГЬЃЌЪеМЏЛњЦїЩЯЫљгаШнЦїЕФШежОЁЃВЛашвЊЮЊУПИіШнЦїЦєЖЏвЛИіfluentdНјГЬЃЛ
ЩљУїЪНХфжУЁЃЪЙгУlabelЩљУївЊЪеМЏЕФШежОЮФМўЕФТЗОЖЃЛ
жЇГжЮФМўКЭstdoutЃЛ
жЇГжЖржжКѓЖЫДцДЂЃКelasticsearch, АЂРядЦШежОЗўЮё,
graylog2Ё
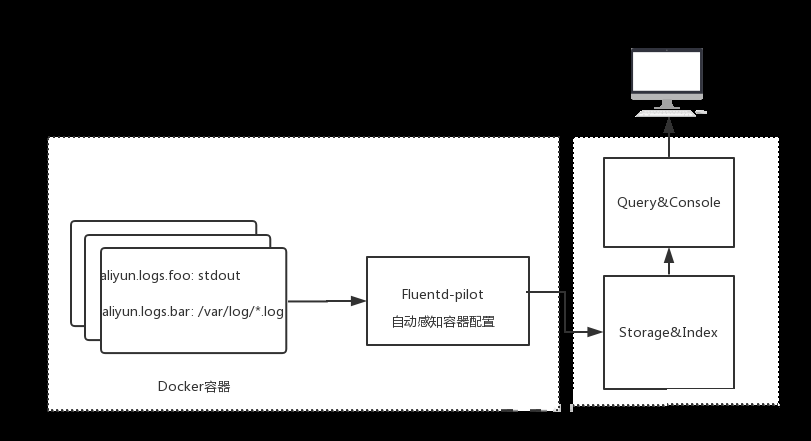
ОпЬхЪЧдѕУДзіФиЃПШчЭМЃЌетЪЧвЛИіМђЕЅЕФНсЙЙЃЌдкDockerЫожїЛњЩЯУцВПЪ№вЛИіfluentd-pilotШнЦїЃЌШЛКѓдкШнЦїРяУцЦєЖЏЕФЪБКђЃЌЮвУЧвЊЩљУїШнЦїЕФШежОаХЯЂЃЌfluentd-pilotЛсздЖЏИажЊЫљгаШнЦїЕФХфжУЁЃУПДЮЦєЖЏШнЦїЛђепЩОГ§ШнЦїЕФЪБКђЃЌЫќФмЙЛПДЕУЕНЃЌЕБПДЕНШнЦїгааТШнЦїВњЩњжЎКѓЃЌЫќОЭЛсздЖЏИјаТШнЦїАДееФуЕФХфжУЩњГЩЖдгІЕФХфжУЮФМўЃЌШЛКѓШЅВЩМЏЃЌзюКѓВЩМЏЛиРДЕФШежОЭЌбљвВЛсИљОнХфжУЗЂЫЭЕНКѓЖЫДцДЂРяУцШЅЃЌетРяУцКѓЖЫжївЊжИЕФelasticsearchЛђепЪЧSLSетбљЕФЯЕЭГЃЌНгЯТРДФуПЩвддкетИіЯЕЭГЩЯУцгУвЛаЉЙЄОпРДВщбЏЕШЕШЁЃећИіетвЛПщдкDockerЫожїЛњЩЯУцЃЌЭтУцЕФОЭЪЧЭтВПЯЕЭГЃЌгЩетСНИіВПЗжРДзщГЩЁЃ
| docker run -d \
-v /var/run/docker.sock:/var/run/docker.sock
\
-v /:/host \
-e FLUENTD_OUTPUT=elasticsearch \
-e ELASTICSEARCH_HOST=${ELASTICSEARCH_HOST}
\
-e ELASTICSEARCH_PORT=${ELASTICSEARCH_PORT}
\
registry.cn-hangzhou.aliyuncs.com/acs-sample/fluentd-pilot:0.1 |
ЮвУЧМШШЛвЊгУfluentd-pilotЃЌОЭЕУЯШАбЫќЦєЖЏЦ№РДЁЃЛЙвЊгавЛИіШежОЯЕЭГЃЌШежОвЊМЏжаЪеМЏЃЌБиШЛвЊгавЛИіжаМфЗўЮёШЅЪеМЏКЭДцДЂЃЌЫљвдвЊЯШАбетжжЖЋЮїзМБИКУЃЌШЛКѓЮвУЧдкУПвЛИіЪеМЏШежОЕФЛњЦїЩЯУцВПЪ№вЛИіfluentd-pilotЃЌгУетИіУќСюРДВПЪ№ЃЌЦфЪЕЯждкЫќЪЧвЛИіБъзМЕФDockerОЕЯёЃЌФкВПжЇГжвЛаЉКѓЖЫДцДЂЃЌПЩвдЭЈЙ§ЛЗОГБфСПРДжИЖЈШежОЗХЕНФФЖљШЅЃЌетбљЕФХфжУЗНЪНЛсАбЫљгаЕФЪеМЏЕНЕФШежОШЋВПЖМЗЂЫЭЕНelasticsearchРяУцШЅЃЌЕБШЛСНИіЙмЙвдиЪЧашвЊЕФЃЌвђЮЊЫќСЌНгDockerЃЌвЊИажЊЕНDockerРяУцЫљгаШнЦїЕФБфЛЏЃЌЫќвЊЭЈЙ§етжжЗНЪНРДЗУЮЪЫожїЛњЕФвЛаЉаХЯЂЁЃ
| docker run -it --rm -p 10080:8080 \
-v /usr/local/tomcat/logs \
--label aliyun.logs.catalina=stdout \
--label aliyun.logs.access= /usr/local/tomcat/logs/localhost_access_log.*.txt
\
tomcat |
ХфжУКУжЎКѓЦєЖЏгІгУЃЌЮвУЧПДгІгУЩЯУцвЊЪеМЏЕФШежОЃЌЮвИУдкЩЯУцзіЪВУДбљЕФЩљУїЃПЙиМќЕФХфжУгаСНИіЃЌвЛЪЧlabel
catalinaЃЌЩљУїЕФЪБКђвЊЪеМЏШнЦїЕФШежОЃЌЫљгаЕФУћзжЖМПЩвдЃЛЖўЪЧЩљУїaccessЃЌетвВЪЧИіУћзжЃЌЖМПЩвдгУФуЯВЛЖЕФУћзжЁЃетбљвЛИіТЗОЖЕФЕижЗЃЌЕБФуЭЈЙ§етбљЕФХфжУРДШЅЦєЖЏfluentd-pilotШнЦїжЎКѓЃЌЫќОЭФмЙЛИаОѕЕНетбљвЛИіШнЦїЕФЦєЖЏЪТМўЃЌЫќЛсШЅПДШнЦїЕФХфжУЪЧЪВУДЃЌвЊЪеМЏетИіФПТМЯТУцЕФЮФМўШежОЃЌШЛКѓИцЫпfluentd-pilotШЅжааФХфжУВЂЧвШЅВЩМЏЃЌетРягавЛИі-VЃЌЪЕМЪЩЯИњLogsЪЧвЛжТЕФЃЌдкШнЦїЭтУцЪЕМЪЩЯУЛгавЛжжЭЈгУЕФЗНЪНФмЙЛЛёШЁЕНШнЦїРяУцЕФЮФМўЃЌЫљгаЮвУЧжїЖЏАбФПТМДгЫожїЛњЩЯЙвдиНјРДЃЌетбљОЭПЩвддкЫожїЛњЩЯПДЕНФПТМЯТУцЫљгаЕФЖЋЮїЁЃ
Г§СЫзюМђЕЅЕФГЁОАжЎЭтЃЌФуЕФШежОПЩФмЛсгавЛаЉИќИДдгЕФЬиадЃЌБШШчФуЕФШежОИёЪНЪЧЪВУДбљзгЃЌФуПЩФмЯЃЭћдкЪеМЏжЎКѓМгвЛаЉФкШнЃЌБугкЫбЫїЃЌЕБФудкецгУЕФЪБКђЃЌЫќВЛЙтЪЧвЛИіЗЧГЃМђЕЅЕФШнЦїЃЌЫќПЩФмЪєгкФГвЛИівЕЮёЛђепЪєгкФГвЛИігІгУЃЌФЧУДЃЌФуЯЃЭћдкЪеМЏЕФЪБКђФмЙЛгавЛаЉЙиСЊаХЯЂЃЌЫљвдФуПЩвджИЖЈШежОИёЪНЪЧЪВУДбљзгЃЌШЛКѓПЩвддкШежОРяЬэМгtagЃЌетаЉtagЯрЕБгквЛаЉЙиМќаХЯЂЃЌПЩвдИНМгШЮКЮашвЊЕФЙиСЊаХЯЂЃЌетбљНЋРДдкЫбЫїЕФЪБКђПЩвдИќЗНБуЕФАбетаЉШежООлдквЛПщЃЛЖјЧвЃЌЫќПЩвджИЖЈКмЖрЕФКѓЖЫЃЌfluetnd-pilotжЇГжЖржжКѓЖЫЃЌЪЙгУЛЗОГБфСПFLUENTD_OUTPUTжИЖЈКѓЖЫРраЭЁЃ
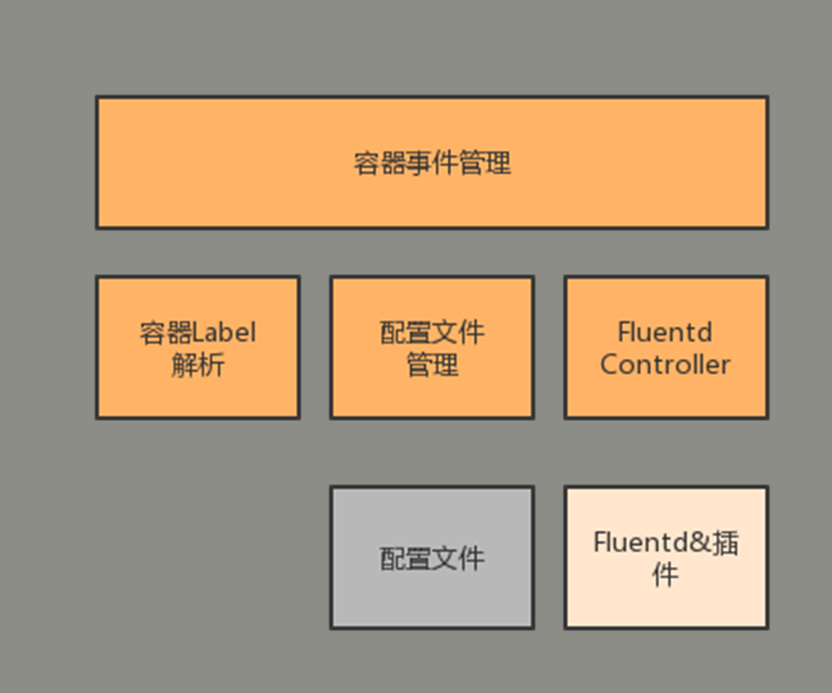
fluent-pilotвбОПЊдДЃЌШчЙћЙІФмВЛТњзуашЧѓЃЌПЩвдздМКЖЈжЦЃЌздМКаоИФДњТыЪЕЯжашвЊЕФЙІФмЁЃЫќЕФНсЙЙБШНЯМђЕЅЃЌгаетбљМИИіФЃПщЃК
зюЩЯВуЪЧШнЦїЪТМўЙмРэЃЌетвЛПщИњDockerНјааНЛЛЅЃЌЫќЛсИажЊDockerЕФДДНЈШнЦїЃЌШЛКѓзіГіЯргІЕФЩњГЩХфжУЛђепЧхРэХфжУЩЯЕФЪТЧщЃЛНтЮіШнЦїlabelИњШнЦїХфжУЃЌЕБФуДДНЈвЛИіаТШнЦїжЎКѓЃЌОЭЛсгУетИіФЃПщФУЕНаТШнЦїЕФХфжУЃЌШЛКѓЩњГЩЖдгІЕФХфжУЮФМўЃЛFluentdControllerжївЊЪЧгУРДЮЌЛЄЖдгІНјГЬЃЌАќРЈПижЦЪВУДЪБКђМгдиаТХфжУЃЌШЛКѓМьВтвЛаЉНЁПЕзДЬЌЕШЕШЃЛдйЯТУцОЭЪЧFluentdЕФвЛаЉВхМўЃЌШчЙћФуашвЊдіМгвЛаЉШежОЕФКѓЖЫЃЌОЭПЩвдздМКЪЕЯжвЛаЉВхМўЃЌЗХдкетИіРяУцЃЌШЛКѓдйЩњГЩИњЖдгІЕФВхМўЯрЙиЕФвЛаЉХфжУЁЃ
fleuntd-pilot+АЂРядЦШнЦїЗўЮё
вдЩЯЪЧfleuntd-pilotБОЩэЕФвЛаЉФмСІЃЌЯждкФуПЩвддкШЮКЮЕиЗНЪЙгУЫќЃЌЕЋЪЧдкШнЦїЗўЮёЩЯУцЮвУЧеыЖдЫќзіСЫвЛаЉИќМгСщЛюЗНБуЁЂИќПсЕФвЛаЉЪТЧщЃЌШнЦїЗўЮёЮЊfluentd-pilotНјаагХЛЏЃК
ЕквЛЃЌ здЖЏЪЖБ№aliyun.logsБъЧЉЃЌВЂДДНЈVolumeЃЛ
ЕкЖўЃЌ жиаТВПЪ№ЃЌаТШнЦїздЖЏИДгУвбгаЕФVolumeЃЌБмУтШежОЖЊЪЇЁЃ
дЩњжЇГжSLS
ШнЦїЗўЮёгавЛИіКмАєЕФЬиЕуЃЌЫќЛсИњЦфЫћЕФдЦВњЦЗзівЛаЉЗЧГЃЗНБуЕФМЏГЩЃЌетЖдгкгУЛЇРДЫЕЃЌдкЪЙгУШнЦїЗўЮёЕФЪБКђЃЌдЦВњЦЗФмЙЛИќМгЗНБуЕФЪЙгУЁЃБШШчЫЕдкШежОЗНУцЃЌАЂРядЦШнЦїЗўЮёзЈЮЊSLSзіСЫгХЛЏЃЌШУгУЛЇИќМђЕЅЕФдкШнЦїЗўЮёЩЯЪЙгУSLSЁЃSLSЪЧАЂРядЦЬсЙЉЕФШежОЗўЮёЃЌадФмЧПКЗЃЌЪЙгУЗНБуЃЌЛЙПЩвдЖдНгODPSЕШЪ§ОнЯЕЭГЃЛжЇГХ1WЬЈЮяРэЛњЃЌвЛЬь12TBШежОЪ§ОнЃЌIOPS>=
2WЃЌВЩМЏЦНОљ<1 S;ЕЅЛњЃКдк1ИіCPU coreЧщПіЯТЃЌПЩвдЪЕЪБВЩМЏ15-18MB/S ШежОСПЃЛШчЙћХфжУжадіМгПЩвдгУЯпГЬЪ§ФПЃЌПЩЫЎЦНРЉеЙЃЛЪЧАЂРядЦЛЗОГЯТЕФзюМбШежОЗНАИЁЃ
гХЛЏгХЕуОпЬхЬхЯждкЃКздЖЏДДНЈslsЕФproject, logstoreЃЛЭЌЪБжЇГжstdoutКЭЮФМўШежОЃЌЪЙгУЭЌбљЕФЗНЪНХфжУЁЃ
ШнЦїЗўЮёШежОЗНАИ
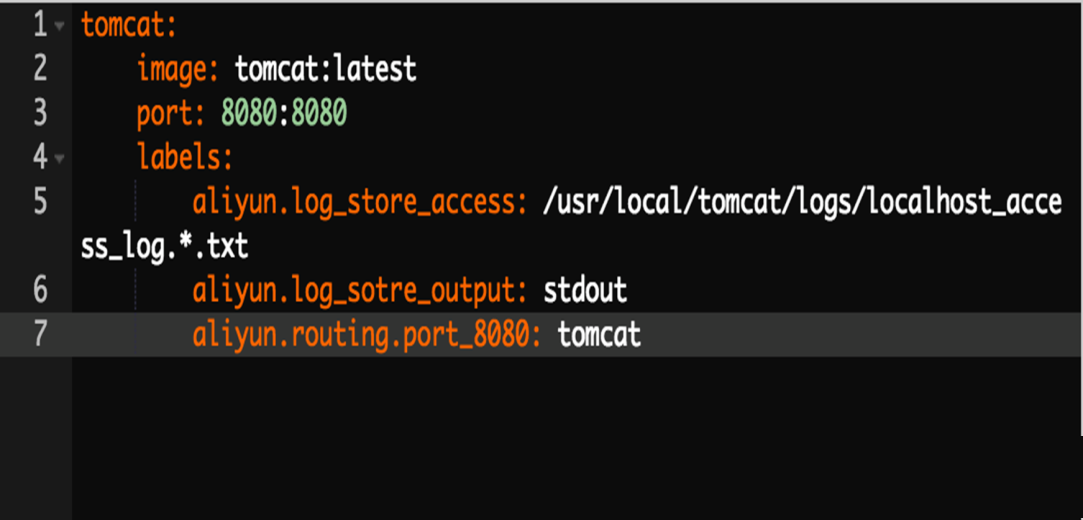
БШШчдкШнЦїЗўЮёЩЯУцВМвЛИіtomcatЃЌПЩФмЛсаДШчЭМЕФвЛИіБъзМDockerЕФФЃАхЁЃ
ЕБФуЭЈЙ§ВПЪ№жЎКѓЃЌОЭПЩвддкШежОЗўЮёЩЯУцПДЕНЛсЩњГЩСНИіЖЋЮїЃЌЖМЪЧДДНЈКУЕФЃЌМгвЛаЉЧАзКРДЧјЗжЃЌВЛгУЙмвЛаЉХфжУЃЌФуЮЈвЛвЊзіЕФЪТЪЧЪВУДФиЃПЕуШежОЫїв§ВщбЏЃЌШЛКѓЕНШежОЫбЫїНчУцЃЌИеВХЦєЖЏЕФЪБКђвЛаЉШежОЃЌПЩвдПДЕНДгФФЙ§РДЕФЃЌетЬѕШежОЕФФкШнЪЧЪВУДЃЌетаЉаХЯЂЖМвбОКмПьЕФГіЯжСЫЃЌАќРЈашвЊМьЫїПЩвдбЁжавЛИіЪБМфЖЮЃЌЪфШыЙиНЁДЪШЅзівЛаЉЫбЫїЃЌздЖЏдкШежОЗўЮёЩЯДДНЈВЂХфжУlogstoreЁЃ
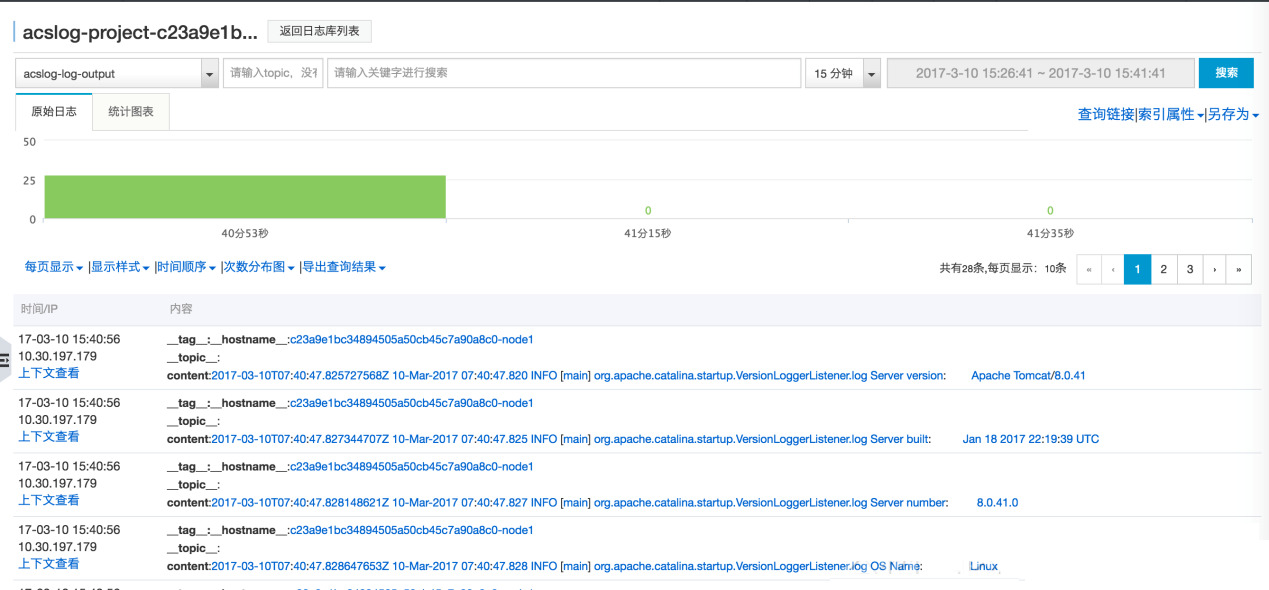
ЮвУЧдкШнЦїЗўЮёЩЯУцзіЕНСЫЖдгкЮФМўШежОЕФЪеМЏЃЌВЂЧвЗНЪНвВЖМЗЧГЃМђЕЅЃЌЖМЪЧФуПЩвдЩшСЂвЛИіlabelЃЌЭЈЙ§labelЗНЪНПЩвдЪеМЏЕНЫљгаЕФШежОЁЃ
ШежОДцДЂЗНАИ
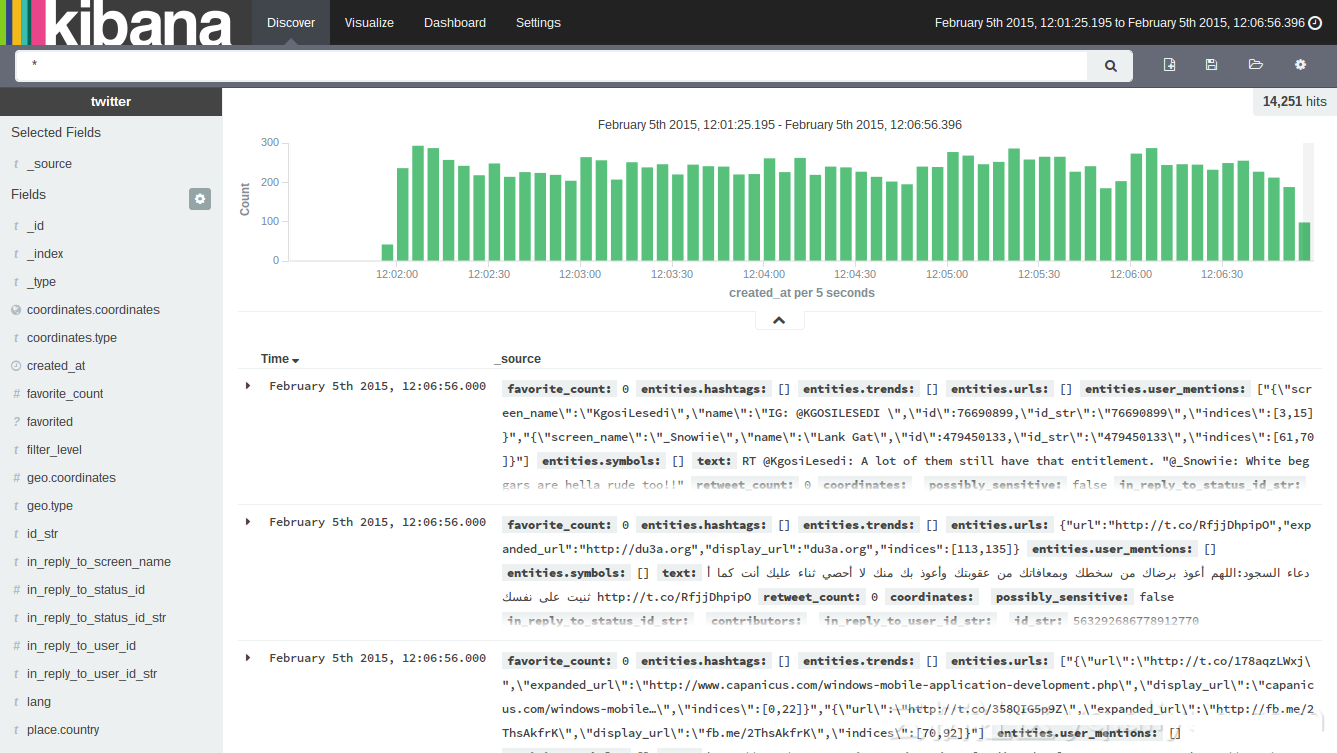
зюКѓМђЕЅЕФНщЩмМИжжШежОДцДЂЗНАИЕФЖдБШЃЌЭМЮЊЯждкБШНЯСїааЕФШежОЗНАИElasticsearchЃЌЫќБОЩэВЂВЛЬсЙЉНчУцЃЌELKжаЕФEЃЌЛљгкLuceneЃЌжївЊгУгкШежОЫїв§ЁЂДцДЂКЭЗжЮіЃЛЭЈГЃХфКЯKibanaеЙЪОШежОЃЌУтЗбЃЌжЇГжМЏШКФЃЪНЃЌПЩвдДювЛИіDockerгУЕФЩњВњЛЗОГПЩгУЕФЯЕЭГЁЃ
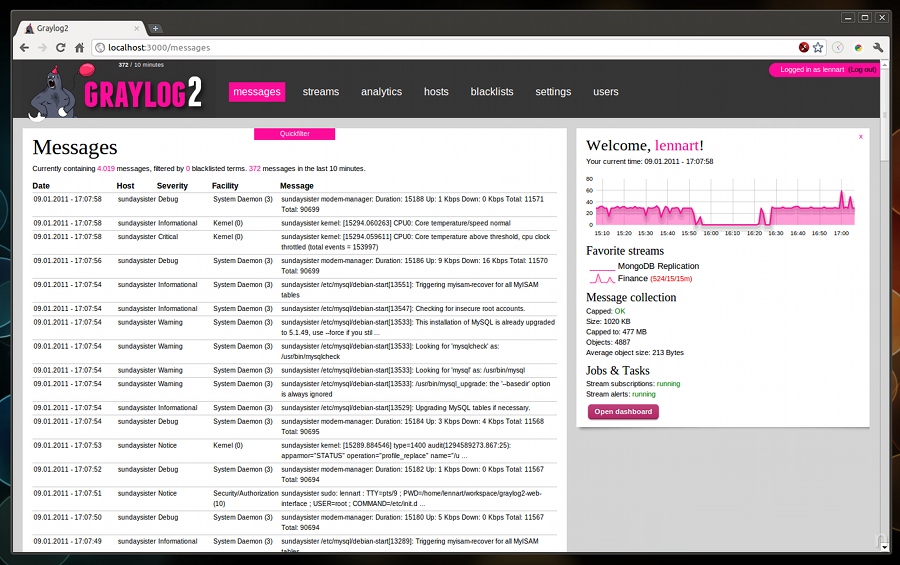
НгЯТРДЪЧgraylog2ЃЌФПЧАВЛЫуКмСїааЃЌЕЋЪЧвВЪЧЙІФмКмЧПДѓЕФЯЕЭГЃЌЫќВЛЯёElasticsearchЛЙашвЊХфКЯЦфЫќШЅЪЙгУЃЌЫќздЩэгЕгаШежОДцДЂЁЂЫїв§вдМАеЙЪОЫљгаЕФЙІФмЃЌЖМдквЛИіЯЕЭГРяУцЪЕЯжЃЌЫќПЩвдЩшжУвЛаЉБЈОЏЙцдђЃЌЕБШежОРяУцГіЯжвЛаЉЙиМќзжЕФЪБКђздЖЏБЈОЏЃЌетИіЙІФмЛЙЪЧЗЧГЃгагУЕФЃЌУтЗбЁЂжЇГжМЏШКФЃЪНЃЌПЩвддкЩњВњЛЗОГРяУцДювЛИіDockerгУЕФЩњВњЯЕЭГЁЃ
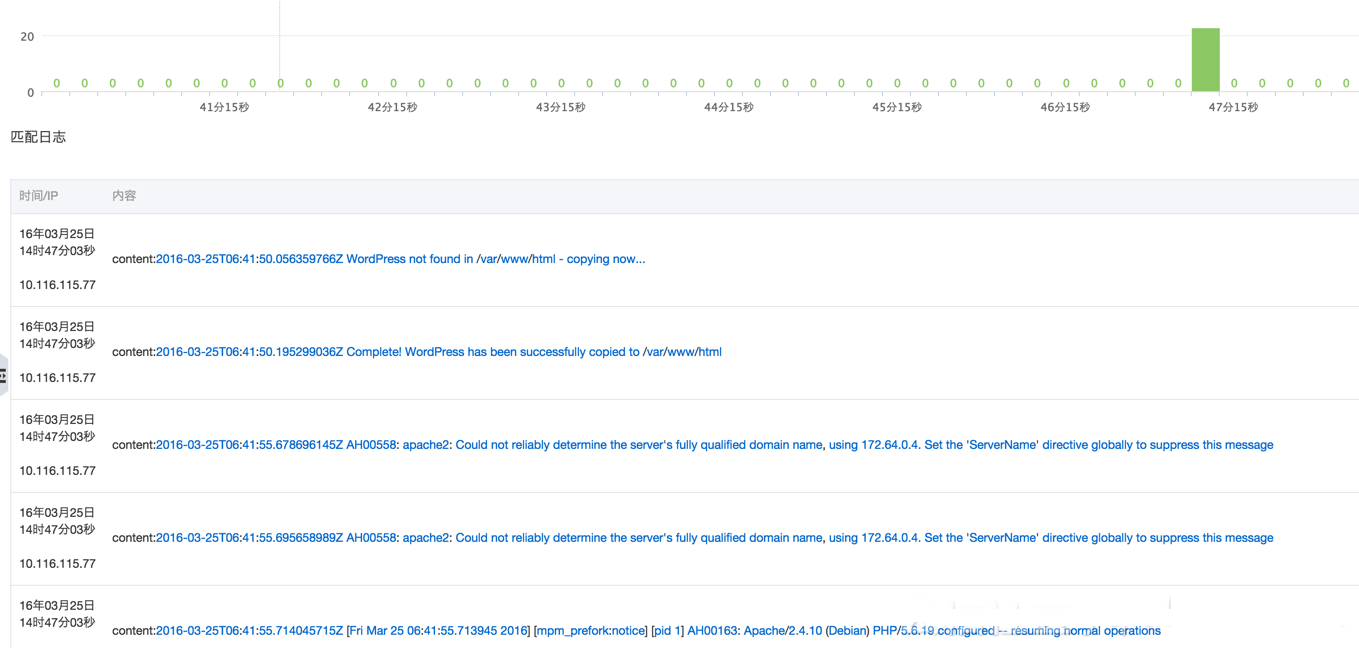
АЂРядЦЕФШежОЗўЮёSLSЬиЕуШчЯТЃК
АЂРядЦЭаЙмЃЌВЛашвЊздМКЮЌЛЄ
жЇГжЖргУЛЇКЭШЈЯоЙмРэ
ПЩвдЖдНгODPSЕШЯЕЭГ
жЇГХ1WЬЈЮяРэЛњЃЌвЛЬь12TBШежОЪ§ОнЃЌIOPS>= 2WЃЌВЩМЏЦНОљ<1
S;ЕЅЛњЃКдк1ИіCPU coreЧщПіЯТЃЌПЩвдЪЕЪБВЩМЏ15-18MB/S ШежОСПЃЛШчЙћХфжУжадіМгПЩвдгУЯпГЬЪ§ФПЃЌПЩЫЎЦНРЉеЙ
гУе§ШЗЕФЗНЪНаДШежО
ФЧУДЃЌЮвУЧдѕУДбљШЅЪеМЏШежОЁЂДцДЂШежОЃЌгУЪВУДбљЕФЯЕЭГЃЌШежОЕФдДЭЗКЭаДШежОЮвУЧгжИУдѕУДРДзіЃЌгаетбљМИИіНЈвщЃК
1. бЁдёКЯЪЪЕФШежОПђМмЃЌВЛвЊжБНгprintЃЛ
2. ЮЊУПвЛЬѕШежОбЁдёе§ШЗЕФlevelЃЌИУdebugЕФВЛвЊгУinfoЃЛ
3. ИНМгИќЖрЕФЩЯЯТЮФаХЯЂЃЛ
4. ЪЙгУjsonЁЂcsvЕШШежОИёЪНЃЌЗНБуЙЄОпНтЮіЃЛ
5. ОЁСПВЛвЊЪЙгУЖрааШежО(Java Exception Stack)ЁЃ
|