ȥ��8�µף��ٷֵ�����֪�����Ϸ�����Google��Դ�ļ�Ⱥ����ϵͳKubernetes�ġ����а桱����Sextant���ڰٷֵ���ģKubernetes��Ⱥ����������µ�Ӧ��ʵ����ĿǰΪֹ����Ⱥ���Ѿ������˰ٷֵ��Ƽ�ϵͳ�Ĵ�ҵ������Ͳ��ֵ���ά�������ô����ʹ�ù����л�������Щ���⣿��ν������ƪ���꾡�ܽ�ٷֵ���ʵ���еľ����ѵ�������ܹ�����ػ���������
��0��1
�ڴ�ͳ�ļ�Ⱥ���������£��ٷֵ�����������ʳ��ڴ���20%���¡�ͨ��Ϊ�����ij��ҵ��Ŀ�꣬�Ŷӻ�������Եķ�������Ȼ��ʦʹ���������½����Щ����������ɳ���IJ���
�����ı��ǣ����ȣ���Щ�������ϵĿ�����Դ�����ṱ�׳���Ϊ�����Ŷ���ʹ�ã���Σ���Щ�������ڽ��ҵ��߷�����֮�����½�������ʱ�ŶӲ���ϣ�������������գ���Ϊ��֪����α��ݷ�����֮�ϵ����ݡ�
��������Ⱥ���������������ͣ����弯Ⱥ��ά������Ҳ����쳣���ѣ��ڰٷֵ�AI������������������£�������������Դ���������ҵ���չ�����������
��ν���أ�
�������˺ܶೢ�ԣ����վ���ѡ��CoreOS��Kubernetes�����¼��K8s����Ceph���ϵļ���������
����Kubernetes�����������е�Ӧ�ã��ٷֵ��DZȽ����һ��ʵ���ߣ��ӿ�ʼ��עKubernetes1.0������1.2�汾ʵ�ʲ������ǵ����������У�Χ��Kubernetes���˺ܶ��ܱ߹�����ʹKubernetes�ܹ����õط�����ҵ����
����ƪ��ԭ�����ﲻչ������Kubernetes�Ļ���ԭ�������ˣ�����Ȥ�Ķ��߿��������ǵ�githubsextant��Ŀ�У��ҵ��൱�ḻ���ĵ���
Ϊ�˴��������Ŀ�꣬����Ҫ����ʹ��Docker���Լ���Ӧ�ó�����ɷ�װ�����ֶ��ļ�Ⱥ�����л���ʹ��K8S�ļ�Ⱥ��������֮�ϡ�����ͼ��ʾ����Ҫ���Ŷ���Ŀ��gitlab
repo��������Ӧ��Dockerfile�ͱ����ļ����ݣ�CI�������Զ���Ӧ����ɱ���->��Ԫ����->docker������->�����ύ�Ĺ�������װ�������е�Ӧ��ʹ��Ceph�洢���ݣ���ͨ��ingress
LoadBalancer���ⲿ�ṩ����
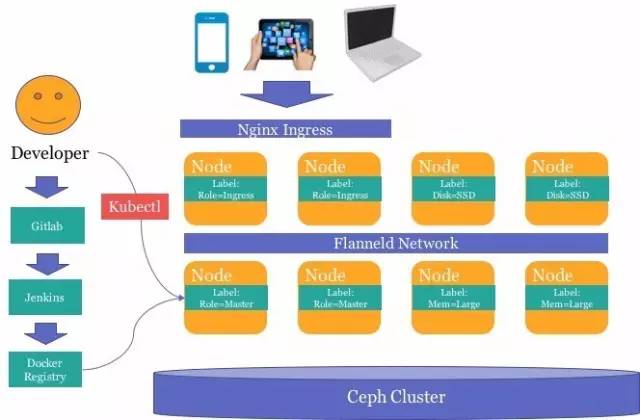
����Kubernetes�����������ϵIJ�������ϣ������ȵļ�K8S��Ⱥά����Ա�Ĺ�������������һ̨�������¼�ά��һ̨�����ȣ�ֻ��Ҫά����Աֱ����ɿ������ػ��IJ������ɡ�����K8S�ĵ��ȱ��ţ������������������Ӧ�õ�Ӱ�졣
������ɼ�Ⱥ��װ
����Ҫ��������⣬��������ܹ���Ч�ġ��Զ����Ľ�������IJ����Լ����ֶ�������ܴ��������⡣
�ٷֵ㡢��֪���ڰٶȿ�ѧ����������£����������˻���PXE�Զ�����װCoreOS+Kubernetes��Ⱥ�Ŀ�ԴSextant��Ŀ��ֻ��Ҫ���������輴����ɼ�Ⱥ�İ�װ���滮��Ⱥ->����bootstrapper->�ڵ㿪���Զ���װ��

1.PXE����PXE�ļ����������簲װCoreOS�IJ���ϵͳ����ɽڵ����ϵͳ�ij�ʼ����
2.cluster-desc.yaml�Ǽ�Ⱥ�������ļ����������ϵͳ���͡�Flanneld����ģʽ��Kubernetes�汾�ȶ�������������ļ��С�����ÿ������װ�Ľڵ㣬��Ҫ����MAC��ַ������Ӧ�Ľ�ɫ������Kube-master��flanneld-master�ȡ�
3.Bootstrapper��Sextant��Ŀ�ĺ��ķ�������cluster-desc.yaml�����ļ������ṩweb�����ݽڵ��MAC��ַ������Ӧ��cloud-config.yaml�ļ����Ӷ���װ������kubernetes��������
����˳��
1.Step 0��Ⱥ�滮
�滮��Ⱥ������Ⱥ��Ϣ����Ϊcluster-desc.yaml�����ļ����������ϵͳ�����͡�etcd�ڵ��������flanneldЭ�����ͣ���Щ�ڵ���Ϊmaster�ȵȡ�
2.Step 1���롢����bootstrapper
ͨ����һ�����cluster-desc.yaml�ļ�������bootstrapper��docker image��������bootstrapper���ṩPXE��DHCP��DNS�Լ�Docker
Registry�ȷ���
3.Step 2��װkubernetes�ڵ�
�����������뼯Ⱥ��������������������װ�������Զ����CoreOS�Լ�K8s����İ�װ���̡�
��һ������Ӧ��Ǩ�ƣ����ջ���Ҳ������ʹ��
�ջ��ʹ
���ˣ���������Ϊ���Կ�ʼ��ϰ���Ԫ������˵��������ߣ�����ӡ���������Ǩ�ƹ����ˡ������������ܲ��Ժ���������롣������K8S֮�ϵķ�����Ӧ�ӳ٣����³�������20%��������ġ��ڲȿ�֮�����Ƕ�K8S���������˸�����������⡣
һ������kubernetes����������
��ϤDocker�Ķ��߿��ܻ��˽��Docker��������������ģʽ����Ϊ�˴ﵽ�����ڵ����绷�����룬ͨ����ѡ��ʹ��NAT��ʽ��������ڵ������ת����ת������������ͬһ̨������������������ͬ��������������֮�䣬��������NAT�˿ڵ�4���ַ�ɷ����⣬��������ֱ�ӻ�����ʡ�
Kubernetes�Ľ��˼·��Bridgedģʽ�������Ⱥ������һ��ͨ�õ�IP��ַ�������Ϊ�����ڸ���host�ϵ�containerͳһ����IP��ַ�����������ڲ�ͬhost�ϵ�containers֮��ͨ�ţ�ֱ��ʹ�öԷ���container
IP��ַ�Ϳ����ˣ�������Ҫ����host IP����ʵ���ϰ�Dockerģʽ�е�host IP��containerIP������IP��ַ�����һ�㡣
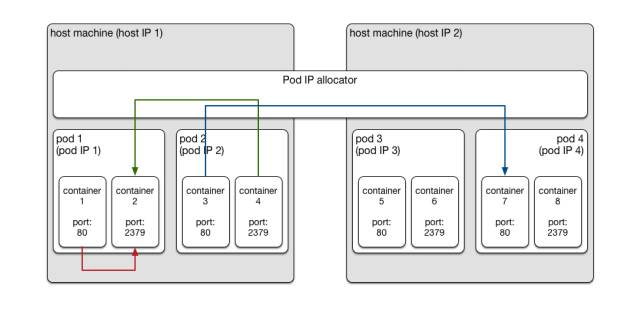
��Kubernetes���ĵ��������һ����Pod�ĸ�����ҽ���һ��Pod���������һ�����߶��Docker
containers��ʵ���ϣ�һ��Pod����һ��Docker container����ν��Pod�����еĶ��containers��ʵ������������ʱ����˨Cnet=container:������containers�����Dz���õ��Լ���IP��ַ�����Ǻ�pod
container����IP��ַ������һ����һ��pod���containers֮��ͨ�ŵ�ʱ�������localhost��ַ������Խpod��ͨ����pod
IP�� ����ȥKubernetes�������������Docker������������һ��Pod�ĸ��
����ʵ����ÿ��container��Լ���׳ɵ�ֻ����һ��������̣����Ի���������
1.�ڵ㣨node��
2.Pod
3.Container
Kubernetesʵ����������ṹ�ж��ַ�������overlay networking��BGP������SDN������������ʵ�ְ�����Flannel��
Calico�� L2 networking��OpenVSwitch�ȣ����ǶԳ��ò���Ծ����Ŀ��������������⣬�������£�
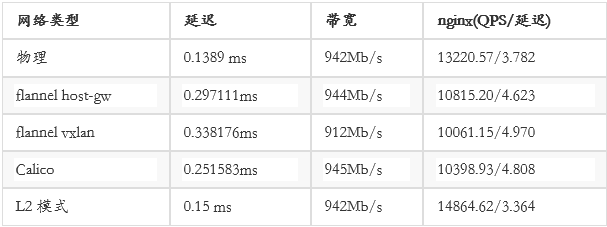
���Կ�������L2ģʽ�£���Ը�����webӦ�ó������Դﵽ������ܡ���Ȼ�����ר�õ�SDN�������豸��Ҳ���Դ�����SDN���������ܡ����ۺϳɱ����������ӳ̶ȡ�������������չ�Կ��ǣ�����ѡ��flannel
host-gwģʽ�����ģʽ��Ҫ������host�����ȶ���2���������ӣ�Ȼ��ͨ��Linux·�ɱ�����Docker
bridge�İ����3��ת����
����һ�㣬����������з��֣�linux����netfilter��iptables����ں�ģ��֮��ƽ�������ӳٻ��½�10%���ҡ�����Ŀǰ״̬��˵��ʹ��iptables
NAT��ΪKubernetes��service���ؾ�����Ȼ��������ߡ���ķ�ʽ�������������ʹ�ø�����ķ����ṩservice���ؾ��⣬����ȥ��iptables�Խ�������֮��������ӳ١�
���������粿���£�ʹ����ͨ��ǧ��������ǧ�������������Խϵͳɱ�������ģ�ļ�Ⱥ���������Կɹ۵����ܡ�����������ӳ��и���Ҫ��ķ�����Redis�ȣ�����ֱ������������Ϊ���з�����
��������߿��õ�ǰ�˸��ؾ�����
������Ľ��ܿ��Կ�����Kubernetes service��Ҫ����������������ڲ�������ʣ���Ҫ������ṩHTTP
web����Ĵ���������Ҫ����Ingress�ĸ��
������֪���ǣ�Kubernetes�е�Service���Խ�һ��pod�ṩ�ķ���¶�������ⲿʹ�ã���Ĭ��ʹ��iptables�ķ�ʽ�ṩ���ؾ����������Serviceͨ��ʹ��iptables����ÿ�������ϸ���Kubernetes
service���壬�Զ�ͬ��NAT��������������ת�������pod�ϣ�����pod����ʱ�Զ�����NAT���������ʹ��userspace��ʽֱ��ת�������и��ߵ�Ч�ʡ����õ�Service��ClusterIP��Loadbalancer�Լ�NodePort��ʽ��
ClusterIP��ͨ��ÿ���ڵ��kuber-proxy�����ı��ص�iptables��ʹ��DNAT�ķ�ʽ��ClusterIPת��Ϊʵ�ʵ�endpoint��ַ��
NodePort��Ϊ��Kubernetes��Ⱥ�ⲿ��Ӧ�÷������kubernetes�ķ�����ṩ��һ�ַ�����������ÿ�������ϡ�
����NAT���ܵ����⣬NodePort�����һ����������ʧ����һЩ�����£�����Ҳ��ѡ��Loadbalancer��Ϊk8s��Ⱥ�ⲿӦ�÷���K8s��Ⱥ�ڲ�Ӧ�õ�ͳһ��ڡ��ٷֵ���õ�Loadbalancer���ؾ������ǻ���haproxy��ͨ��watcher
Kubernetes-apiserver��service�Լ�endpoint��Ϣ����̬��haproxyת��������ʵ�ֵġ�
������Ľ��ܿ��Կ�����Kubernetes service������Ҫ������������ڲ�������ʣ���Ҫ������ṩHTTP
web����Ĵ���������Ҫ����Ingress�ĸ��
1.Ingress
���ڶ����ṩ�����webӦ����˵����Ҫ�ṩ7�㷴������Ļ��ƣ�ʹ�ù�������������ת�뼯Ⱥ֮�С��ٷֵ���õ���Nginx��ͨ��WatcherKubernetes��Ingress��Դ��Ϣ����̬�Ķ�Ӧ��serviceƥ��endpoint�ĵ�ַ��ʹ��������������ֻ��ͨ��kubctl�ύһ�����ü��ɡ�Ingress��Ϊ��������web�������ڣ����������뵽��Ⱥ�ڲ�����ɴ�������Ingress�����ⲿ�����ߡ�����һ�����κ�һ��������kubernetes�ϵ�webӦ�ã������Լ�ͨ���ύһ��Ingress��Դ�����web�������Ŀ�ͨ��
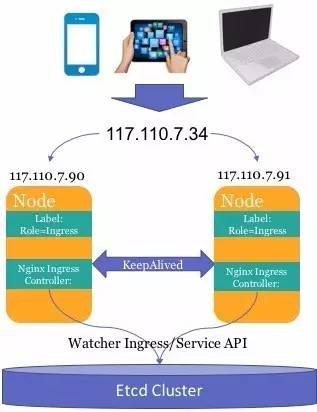
2.Ingress HA
Ingress�Ļ�����������Ⱥ����ڣ��������һ̨�������ֹ��ϣ�������Ӱ�콫���������ġ�����Ҳ�����ǹ�ʹ��F5�ȼ�����ǰ�˵ĸ߿��ã��������ڳɱ��Ϳ�ά���Կ��ǣ�����ʹ��Keepalived+vip�ķ�����
3.Ingress�Ż�
�����Ż�
����NginxIngress ControllerҪ�����������ϵ�80�˿ڣ���������������Ǹ���������hosrtport����������ҵ������ʱ�����Ƿ���QPS����500/s�ͻ������ת�����ݰ�������������Ų鷢�֣�ϵͳ���ж�ռ�õ�CPU�ر�ߣ�hostport��ʹ��iptables�������ݰ���ת����������Ingress
Controller��Ϊhostnetworkģʽ��ֱ��ʹ��Docker��hostģʽ�����ܵõ�������QPS���Դﵽ5k���ϡ�
Nginx�����Ż�
Nginx IngressController���µĹ�����������ͨ������Service��Ingress����Դ�ı仯Ȼ�����Service��Ingress����Ϣ�Լ�nginx.temple�ļ�����ÿ��service��Ӧ��endpoint����ģ�����������յ�Nginx���á����Ǻܶ������ģ����Ĭ�ϵ����ò��������������ǵ�������ʱ��Ҫͨ��kubernetes��ConfigMap���ƻ���Nginx
Ingress Controllerʹ�����Ƕ��ƻ���ģ�塣
��־�ع�
Ĭ�������Docker�Ὣ��־��¼��ϵͳ��/var/lib/docker/container/xxxx������ļ������ǰ����־���Ƿdz���ģ������ͻὫϵͳ��д����ͨ������ConfigMap�ķ�ʽ�����Խ���־Ŀ¼�ĵ������ϣ�ͨ������logrotate�������ʵ����־�Ķ�ʱ�ع���ѹ���Ȳ�����
����Ӧ��
�����Ϸ�����ֲ����õ����ʱ�����ǻ���һ��Ӧ���ķ�����Ϊ���ã�һ������������⣬���ǿ��Խ������л���Ӧ���ķ�����ȥ����k8s�ϣ���һϵ�в�����ø��Ӽ���������һ��ingress��������������Servuce��ΪӦ����Service���л���ʱ��ͨ��kubectl
replace -f xxx.yaml ����Ӧ��Ingress�滻������ʵ�ַ������֪�л���
��������һ�廯Kubernetes��Ⱥ����
��Ϊһ����Ⱥ���IJ���ϵͳ����������ز����٣�������ͨ����Ҫ�����鿴�������־���鿴������ݣ��鿴����״̬�ȡ�����ΪKubernetes��Ⱥ�����˺ܶ���������ʹ��Ⱥʹ���������Ӹ�Ч��
1.��־����
�����ǵ�Ӧ�������ڼ�Ⱥ����ϵͳ��ʱ����θ�Ч�ز鿴������������־��һ������Ҫ��������⡣�ٷֵ������Fluented+Elasticsearch+Kibana�ķ�����������Ҳ����������Kubernetes��Ⱥ�ϵġ�
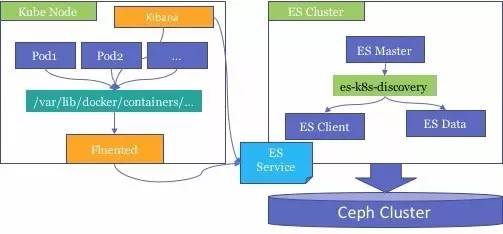
Fluentd
Fluented��ʹ��Kubernetes��Daemonset�Ļ��ƣ�ʹ��fluented������ÿһ���ڵ��ϣ����Զ��ɼ�Docker
Container����־��ES��Ⱥ�С�
Elasticsearch
ES�Դ���Discovery���Ʋ�������kubernetes�����������У�����ʹ��kubernetes�IJ����ʹ����ͨ��Service�ķ�ʽʹmaster�ڵ��ܹ��Զ�����client��data�ڵ��endpoint��ַ����ɼ�Ⱥ��ES�����ݽڵ�Ĵ洢�Ƿ���Ceph��Ⱥ�еģ���֤�����ݿɿ��ԡ�
Kibana
Kibana���ܹ������û��Զ���ɸѡ���ۺϣ������û���ѯʹ�á�
2 . ϵͳ���
ͨ��heapster+collectd+influxdb+grafana�����Դ���ݲɼ���������ݴ洢����ѯչ�ֵ����⡣

heapster�����cAdvisor�вɼ��������Լ�container�еļ�����ݲ�д��influxdb�С�
collectd����ɼ�����nginx����ļ������д��influxdb�С�
influxdb����ʱ�����д洢������ݣ�����֧����SQL������������� ��
grafana�ṩ��WebUI��ͨ���û��Զ���IJ�ѯ��������SQL�������ѯinfluxdb�е����ݣ���������ͼ������ʽչ�ָ��û���
3.ͳһDashboard
Ϊ�˼�kubernetes��Ⱥ��ʹ�ã��ٷֵ�ļ����Ŷӿ�����Siriusϵͳ��ʹ�û�ʹ���������ӵķ��㣬���Ҵ���ĿҲ��Github�Ͻ����˿�Դ��
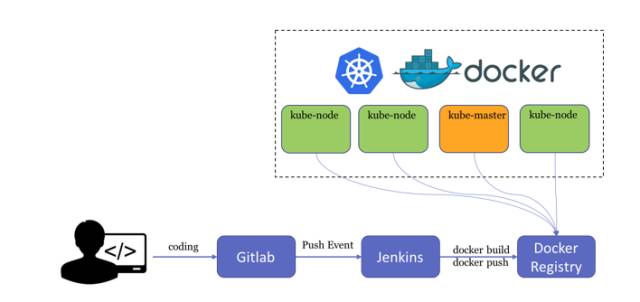
4.����������
Docker���������Devops����ĺ��ļ������ӿ�����Աд�µ�һ�д��뿪ʼ�����ǹ���������һ���������ɵ���ˮ�ߡ�
����ѡ����Gitlab��Ϊ����ֿ⣬��������Ա��Gitlab�ύ���룬Jenkins�����ÿ��tag��ÿ��push�¼�����ѡ����Զ�����Ϊdocker
image��������Docker Registry���洢�����ǵ�Docker�ֿ��С����Jenkins�Ὣ�°汾�ľ����Ƶ����ɲ��Ե�Kubernetes��Ⱥ�У����һ�ι��������ԡ�Ԥ���ߵ����̡�������ͨ�����ٷ���������������
5.����������
��������Ӧ��Ǩ�Ƶ�kubernetes��Ⱥ�����У���ȻҲ�����������⣬ÿ��Ӧ�����ύ֮����Ҫ��������ĺ��²ſ�����ʽ���ߣ�Ϊ�˷�����¡�������������Ϊ������ʧ������ʹ�á������ļ��汾����+kubernetes
deployment����ɳ���������
ʲô��Deployment��
Deployment�����˴�����Pod��״̬��ֻ��Ҫ��������������һ��Pod��״̬��kube-controller����������ڼ�Ⱥ��ά����һ״̬�����ҿ��Ժܷ������������roll-out��roll-back��
����Deployment?
ֱ��ʹ��kubectl editdeployment/{your deployment}���ɶ���Ӧdeployment�����ġ����ҿ���ָ������õ�Pod���������ƹ������µĽ��ȡ�ÿ��ִ��edit����֮�ͻᴥ��deployment��rolling
update��Ӧ�û��ں�̨������ƽ��������
��������
��ÿ��Ӧ�õĴ���ֿ��У�������һ��.kube��Ŀ¼�������ű�Ӧ�õ�yaml�����ļ���ÿ�β���������ֱ��ʹ�ö�Ӧ�汾�ı����ļ�������ɲ���
�ġ�����ͳһ�־û��洢ƽ̨
Kubernetes������ʱ�ǻ������������ģ������ζ��������ֹͣ�����������е����ݡ���Ӧ��Ҫʹ�ó־û��Ĵ洢�����ֱ�ӹ����������������Ĵ���Ŀ¼���������ϵͳ���Ե�ʮ�ֻ��ҡ���ȻKubernetes�ṩ������hostPath���ƣ�����Ӧ�ú��������зdz���ȷ�İ�ϵ�������Ƽ�ʹ�á�������������Ҫһ��ͨ������ɷ��ʵĴ洢�أ���Ϊͳһ�ļ�Ⱥ�洢ƽ̨��ѡ�͵��������ﲻ��ϸչ������������ʹ��ceph��ΪKubernetes�ĺ�˴洢��
�ڲ���ʱ�����ǵ�kubernetes���ŵ�����������ܺ�ceph�����ݴ洢������ռ�����������������弯Ⱥ̱����Ԥ�Ƚ�kubernetes����ceph��Ⱥ������ʹ�õ���������������bond0֮������ceph��Ⱥ�Ľ�������ͬʱΪ�˷�ֹ�������ͻ���Եĸ�IOPS��ceph��Ⱥ�ķ��ʣ��������ڿ���storage-iops��qos���ƹ��ܡ�
��Ȼceph�ṩ��3�ִ洢���ʵķ�ʽ�����ǻ���ѡ��������ȶ���rbd��û��ʹ��ceph filesystemģʽ����rbdģʽ�£�����Ҫ��֤�ں��Ѿ�������rbd.ko�ں�ģ�飬��ceph-common������һ����������ǰ���ᵽ��sextant�Զ���װϵͳ���Ѿ���ɴ����
��������ʹ��rbd��Ϊpod�洢ʱ���Բο�ʾ����
{
"apiVersion": "v1beta3",
"id": "rbdpd2",
"kind": "Pod",
"metadata": {
"name": "rbd2"
},
"spec": {
"containers": [
{
"name": "rbd-rw",
"image": "kubernetes/pause",
"volumeMounts": [
{
"mountPath": "/mnt/rbd",
"name": "rbdpd"
}
]
}
],
"volumes": [
{
"name": "rbdpd",
"rbd": {
"monitors": [
"192.168.0.1:6789"
],
"pool": "rbd",
"image": "foo",
"user": "admin",
"secretRef": {
"name": "ceph-secret"
},
"fsType": "ext4",
"readOnly": true
}
}
]
}
} |
Ŀǰ�������Ѿ�ʹ��kubernetes+ceph rbd����ʹ����MySQL��MongoDB��Redis��InfluxDB��ElasticSearch�ȷ����Ӧ�á�
�ٷֵ�ʵ���ܽ�
��ĿǰΪֹ���ٷֵ��Kubernetes��Ⱥ�ϳ������Ƽ�ϵͳ�Ĵ�ҵ������Ͳ��ֵ���ά�����Kubernetes�����˵���Ƚ��£���Ⱥ��Ҳ��Ҫ����Ĺ��߲������û�Ӧ���������ӵķ��㡣�dz���лKubernetes�����������Լ���֪����˾�ļ����Ŷӣ��ٷֵ�����רע��Kubernetes�Ľ��裬�����ܹ�����ػ��������� |






