|
ǰ��
����һ��ҵ��ϵͳ����θ�Ч��ƽ�ȵ�ʹ�����ݿ���ÿһ��������Ա�������������⣬OpenStack Ҳ�����⣬��
OpenStack ������������� Neutron Ϊ���������ݿ��漰�����ű�����Ҫά�����ݿ�汾���٣�һЩ����Ϊ���ԭ���γ��˺ܸߵġ��ȵ㡱����Ϊ
OpenStack �Ƿֲ�ʽ�ģ���Ҫ�����Сһ��Ĵ��۱�֤����ʱ��һ���ԡ�������Ҫ���ǣ�ÿ���˵����ݿ�ˮƽ����һ������ô��֤������Դ�����������ύ����һ�������ݿ����������ά����Щ���룿
OpenStack ��Ϊһ����ȫʹ�� Python ��������Ŀ���������еķḻģ���ǿ���ʱ��Ҫ������˼��֮һ��ͬʱΪ�˱�����������������������ͬˮƽ��ͬ�Ŀ�����Э��������ѡ����
SQLAlchemy �� Alembic ��Ϊ���ݿ���Ļ�����
Why SQLAlchemy
�ڻش�Ϊʲôʹ�� SQLAlchemy ֮ǰ���������̵�һ��Ŀǰ Python
���õ� ORM �⣬��Ϊ��һ�����ںܴ�̶���ʵ���������������Ұ����°�� release ʱ��Ҳд������
Storm�����°� 0.20��release �� 2013 �꣬�����Ѿ��Ƚϳ��š���������ĸ��¡�ɾ��Ҫ��Ƚ���֡�
SQLObject�����°� 1.7.3��release �� 2014.12.18��������ʷ�ã�Ŀǰ��Ծ�Ȳ��Ǻܸߡ�
Django��s ORM�������� Django��Django ���ã�ʹ�� Django �����Ļ���ܷ��㣬������������
Django ���У�Ҳ���ܴ���һЩ���ӵ�����
peewee�����°� 2.4.4 ������2014.12.3���������㣬���� SQLite��MySQL��PostgreSQL��֧�֡�
PonyORM�����°� 0.6��release �� 2014.11.5��ʹ�� AGPL ���ɡ���ͼ�λ��ı༭������Ϊ����Ӧ����ơ�
SQLAlchemy:���°� 0.9.8��release �� 2014.10.13����ҵ�� API�������������һЩ�Լ��ĸ��ѧϰ���߽ϸߡ�
�ܽ�һ�£�Storm ����Ӧ�ñȽϹ㷺���������������ٻ�Ծ�����ѱ�֤�������������ܷ��������������
Storm �����ݿ�ܹ�ͬ�������ıȽ���֣�����Ƶ������ DDL ���� ��ɿ⼶����Щ���������˷��ģ�SQLObject
Ҳ��һ���ܳ����� ORM �⣬���� SQLAlchemy ��ȣ�����Ч�ʸ��ߣ���һЩ�����Ե�֧�ֲ�����ߡ�
SQLAlchemy �ļܹ�
Summary
SQLAlchemy ������ɫ��һ����������ⱻ��Ϊ�����÷������� CORE
�� ORM�����������ļܹ������ġ�
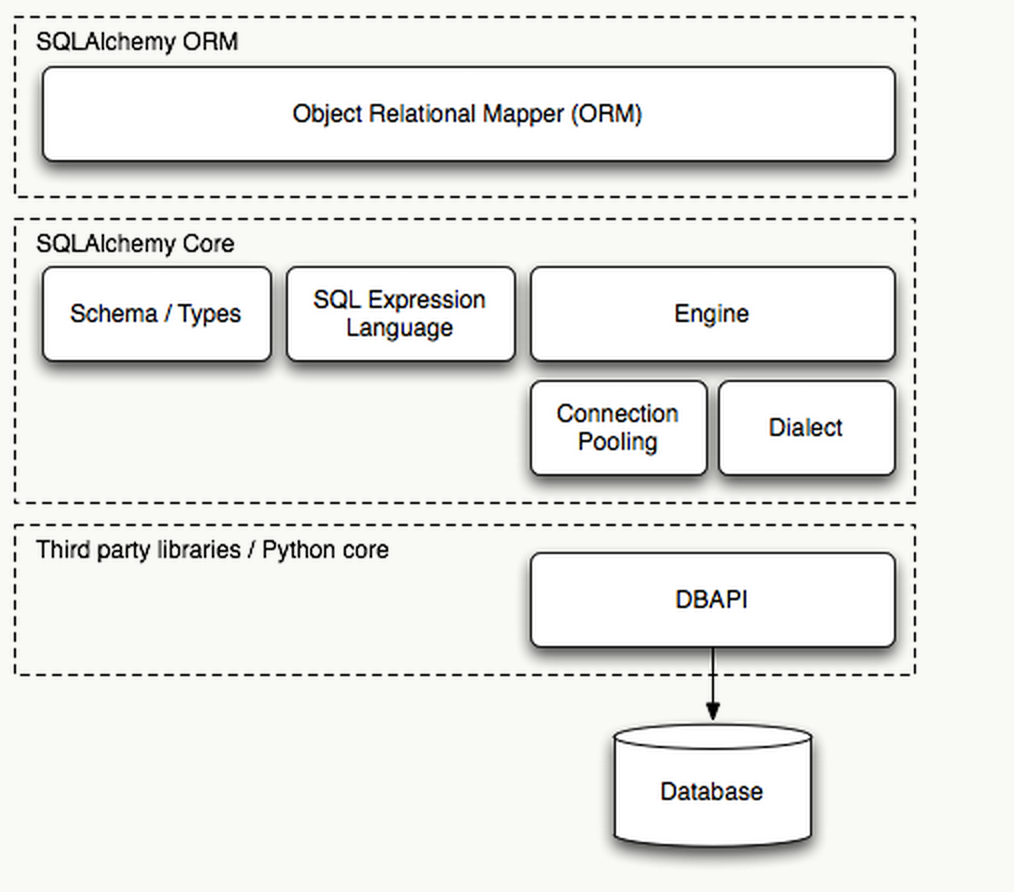
�����ļܹ��ĺô��Ǵ����� Core �� ORM �Ľ���ͣ���������Ҫ�����ܵ� SQL ִ�е��ֲ�������
SQLAlchemy ������session���������ӳع��������ݿ⡰������������д����Щ�ô�ʱ���ǿ���ֱ����
CORE��ֱ���� CORE ��ʲô��˼�أ����ǿ����ܹ���ֻ��Rational Mapper�� CORE
֮�ϣ�ʵ��Ҳȷʵ��ˣ���ΪSchema��SQL Expression Language���� CORE �ڣ�����ʹ��
CORE ����ֱ��д�� SQL ��䣬���dz�֮ΪRaw SQL��д����Ҳ������SQL Expression��������Ϊ���൱��д
Python ���룬���Կ��Դ������õ��Ķ��ԺͿ�ά���ԣ�����Raw SQL���������ںܸ��ӵ������ǰRaw
SQL��ռ�����ˡ�
�����¿����ͼ�����ǿ��Կ��� DBAPI ����Third party librariesʵ�ֵģ�Ҳ����˵
SQLAlchemy ��û���ṩֱ���������ݿ�Ĺ��ܣ�����ͨ��������ʵ�֣�
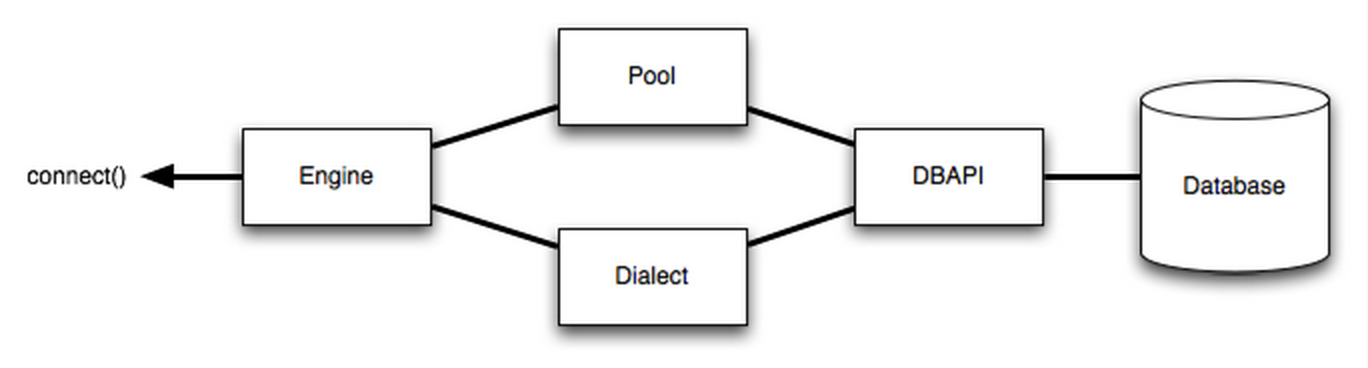
SQLalchemy ��dialect֧�ֺ�ȫ�����Գ����� MySQL Ϊ��������֧�֣�
MySQL-Python��OurSQL��PyMySQL��MySQL Connector/Python��CyMySQL��Google
Cloud SQL��PyODBC��zxjdbc for Jython����������� SQAlchemy ��dialectsҳ����鵽��
������ʲô�����أ������Եľ��ǵ�Ч����Ϊ��ͳ Python ������ CPython ��ʵ��ԭ����Ҫ��
C �����⣩���ĺ�������ջ������������������⡣ ����·�����������ɱ���ص�������ʱ�Ļ�����SQLAlchemy
���˺ܾ�ȥ���̵���·����ͨ�� C ���봦������ƿ����Ч����������������û���ϣ�� PyPy �ܹ��㷺����������ͨ��JIT����������⡣
Engine
�����ͼ����һ�ų���̶ȱȽϸߵģ�������ϸ�ڵ�Ľ����� SQLAlchemy
��Engine��
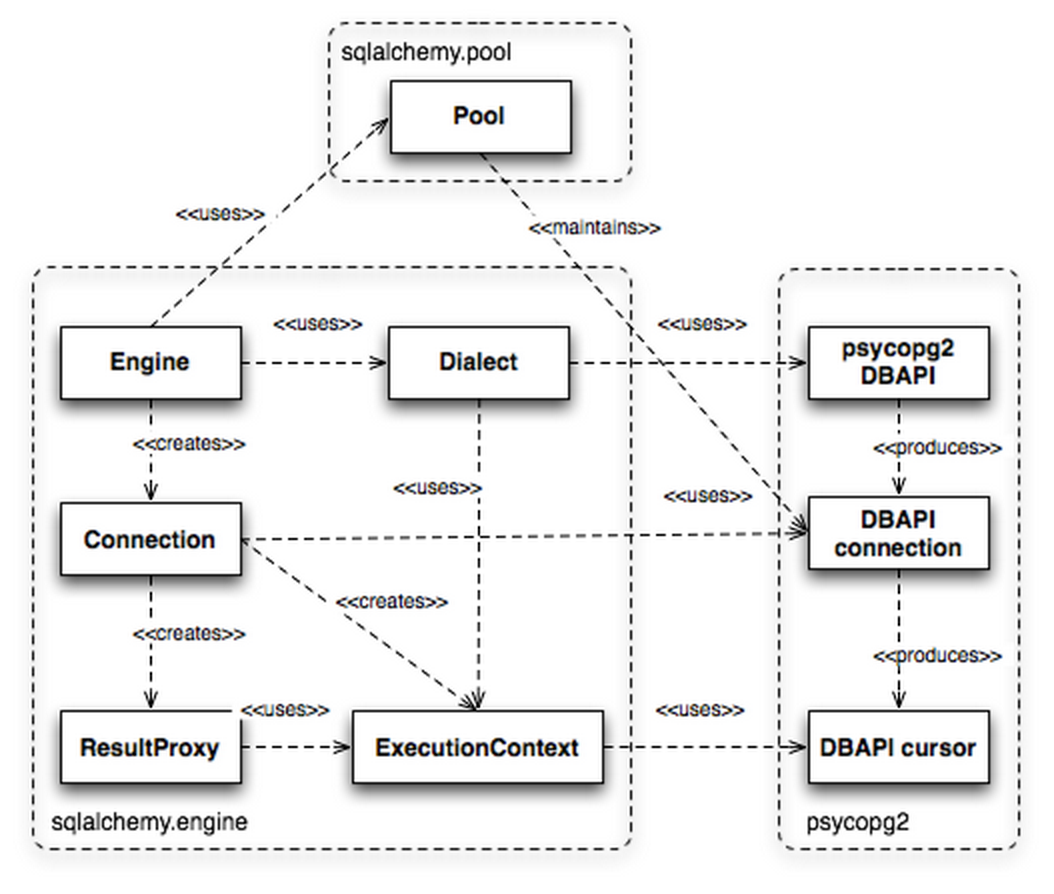
����ʹ������˵��Engine�Ǻ��ģ���ΪConnection��ResultProxy��Щ������Engine֮�����ɵģ�����Engine���������ص㣬����Pool��Dialect��ǰ���������ӳع���������������
DBAPI �Ĺ�ͨ����ͬ��������ʾ�����𡰷��ԡ��롰��ͨ�����ķ��롣��ͼ����psycopg2Ϊ���ģ�ʹ��
MySQL��PyODBC��Ҳ�����Ƶġ�
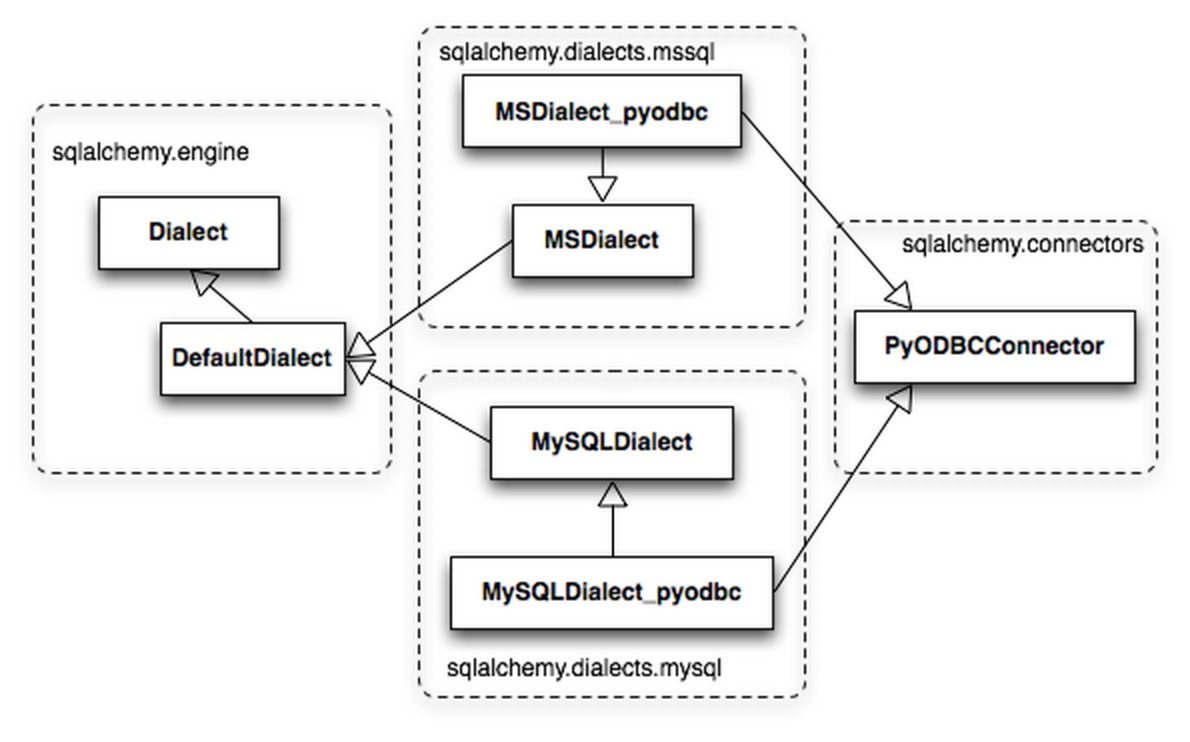
ͨ��Dialect��ExecutionContext�����ṩ��һ�µĽӿڣ�ǰ�ߴ��������ݿ�����ԣ�����ʹ��
PostgreSQL ���ݿ��� Array �������͡�schema��catalog�ȣ����ߴ���psycopg2
DBAPI ���÷������� unicode �ַ������������ cursor ����Ϊ��Щ��
����˵��DBAPI�е�cursor�� SQLAlchemy �лᱻ��װ��ExecutionContext��ResultProxy��ʹ�õġ�
Schema
�����ݿ�����Ӻͽ����������ˣ���һ�������ṩ���ض��ı����ֶεĽ����Ͳ���������������Ҫ���ȶ��������ݿ��еı����ֶεĶ��壬������֮��Ĺ�ϵ��Ҳ����
Schema���������ݿ��ʹ����˵�������������Ҫ������Ԫ�أ��Ǿ���Table��Column��SQLAlchemy
ʹ�������������������������ֶΡ����Column��ϳ�Table��Ȼ��һЩ Table����MetaData��Schema�Ľṹ�����Ҫ������
Martin Fowler � Patterns of Enterprise Application
Architecture��
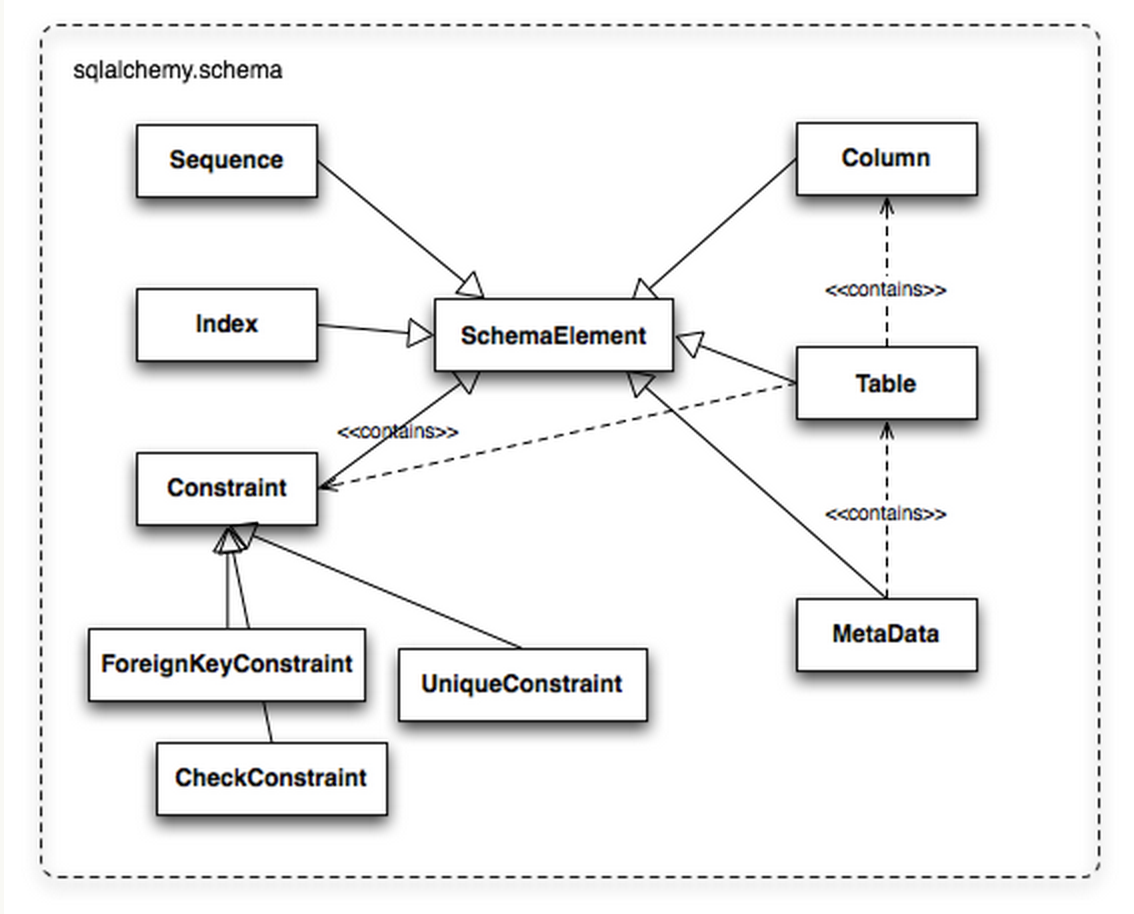
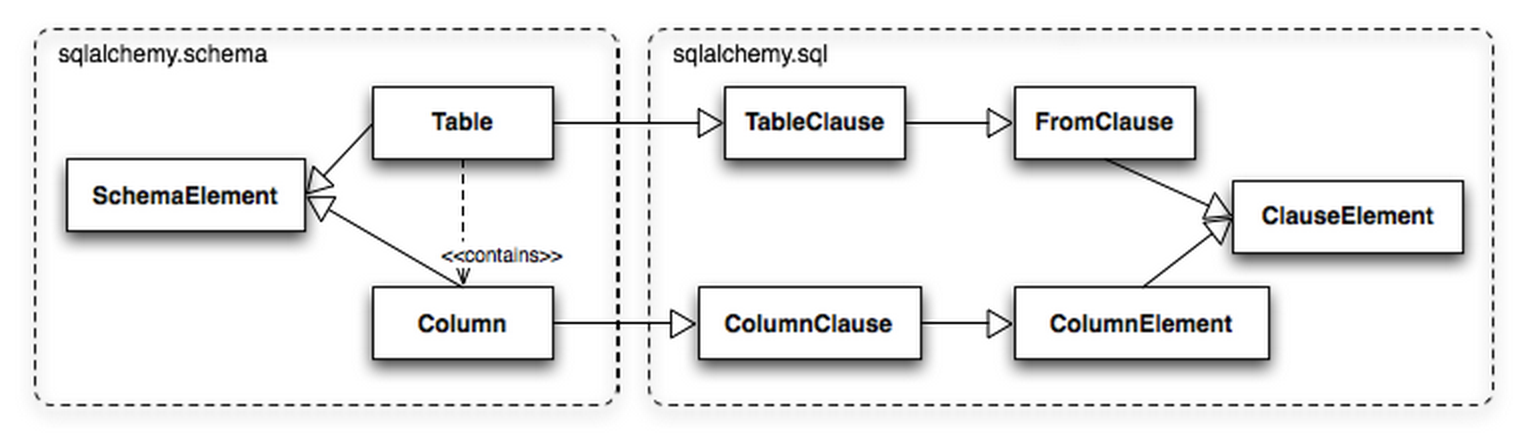
���⣬Table��Columnͬʱ�̳���sqlalchemy.schema��sqlalchemy.sql��ʹ��ʱ�ȿ�����
ORM �ķ�ʽ��ʹ�ã�Ҳ������ SQL Expression Language ʹ�á�����ͼ�����ǿ��Կ���Table��sqlalchemy.sql�С�����select
from������̳У�Coloumn�ӡ��������� SQL expression������̳С�
����ʽ��
SQLAlchemy �������ɽṹ�ḻ�ĸ�����䣬����һ���ʷ������������Ľṹ��ClauseElement��
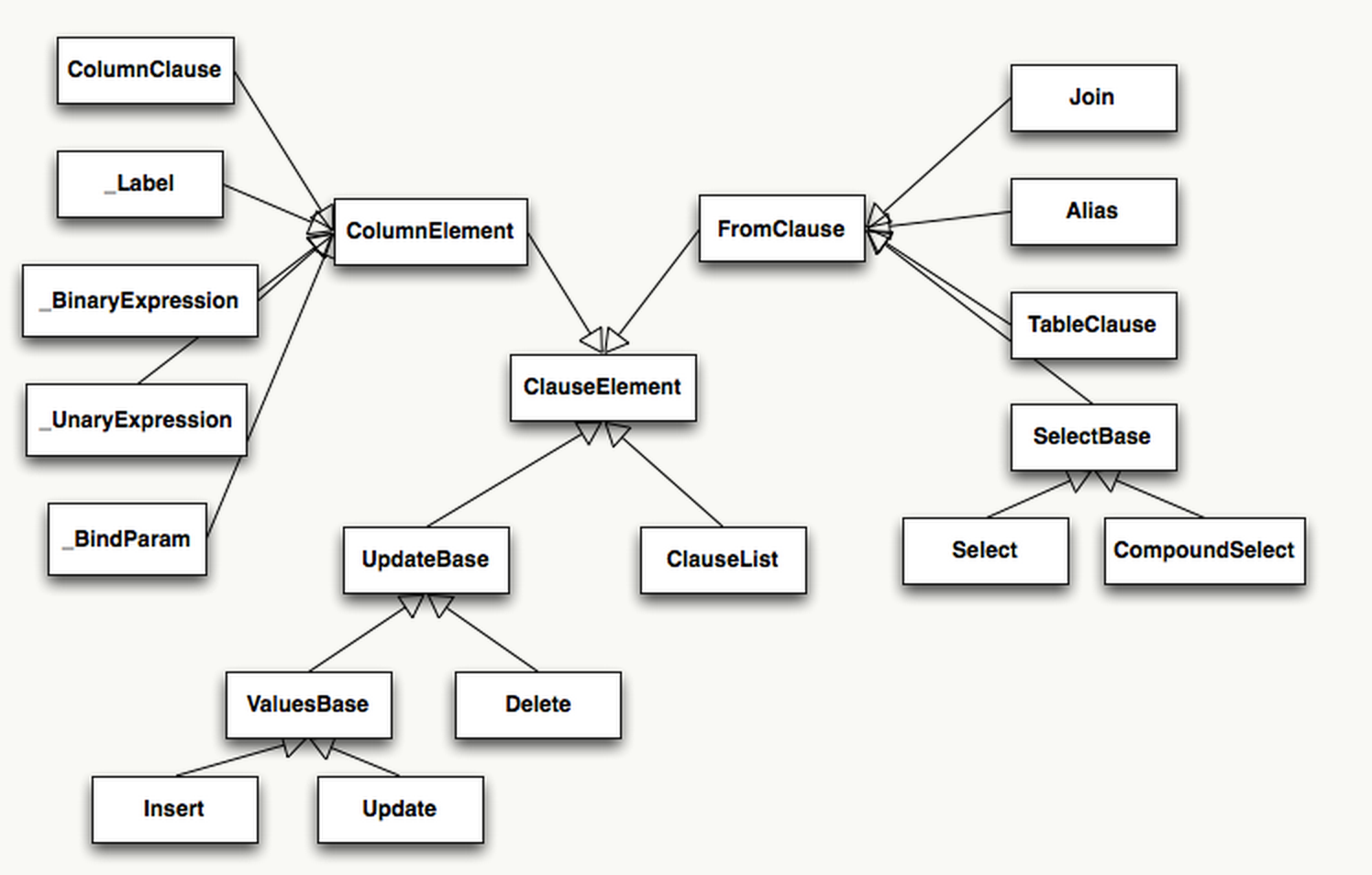
�� Python �У��������� Magic Method�����ǿ�����__eq__��__ne__��__le__��__lt__��__add__��__mul__������������������
Column Ϊ������������һ�� mixin ��ColumnOperatorsʵ�����ء�
����
���������ָ���� SQL ��䣬��Ҫ��Compiled����ɣ���������������ĵ����࣬SQLComplier��DDLCompiler��SQLComplier������SELECT��INSERT��UPDATE��DELETE��Щͳ��ΪDQL
(data query language) �� DML (data manipulation language)�IJ���������Ⱦ��DDLCompiler����CREATE��DROP��һ���Ϊ
DDL�����⣬����һ����TypeCompiler����ijЩ���ݿ���������
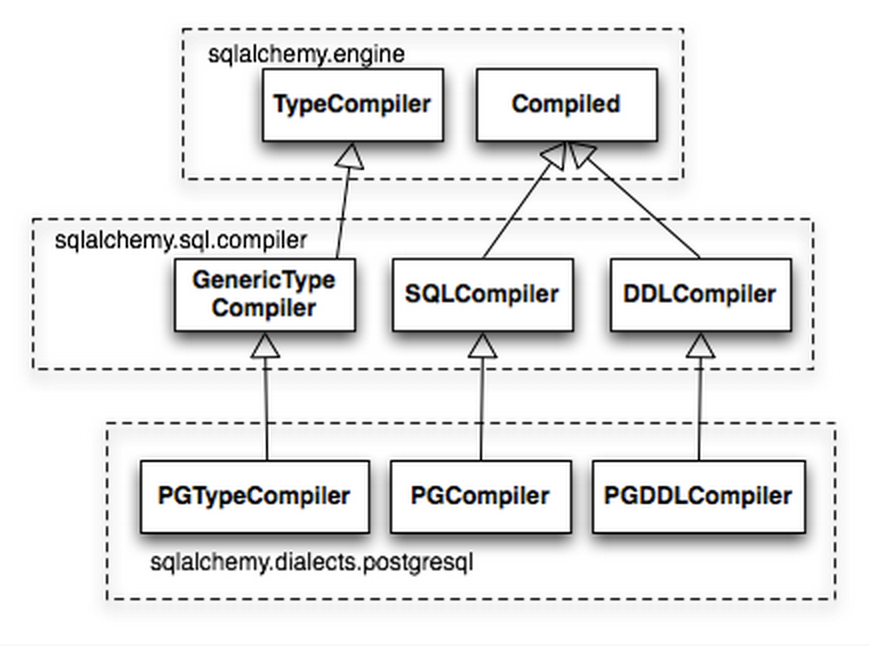
Compiled�����ඨ����һϵ�е� visit ��ͷ�ķ�����ÿһ����Դ��һ��ClauseElement���ض����ࡣȻ��Compiled����ά�����֡���ϲ������Ӳ�ѯ��������Ϊ������һ��
SQL ��ѯ��䡣
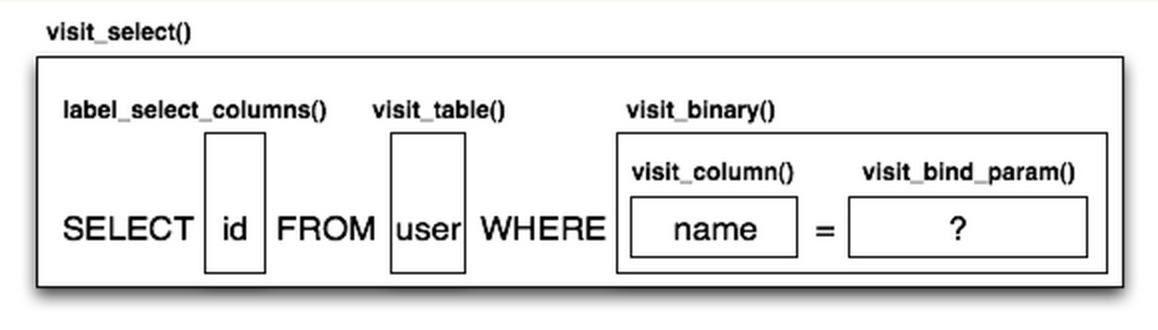
Migration
����ϣ�������������һ���������ݿ⣬������ git һ�������ݿⶨ��汾����/���������ǩ������ô���𰸾���
Alembic��
Alembic �������� SQLAlchemy ��ͬһ�ˣ�ʹ�������е����� git���� db Ŀ¼��ִ��
init���Ϳ����Զ����ɻ����ṹ�������ļ�����������ʹ�� alembic ��������һ�����ݿ�ģ�棬��Ϊ������汾����������/�����ļ���SQLAlchemy
���Զ������䡰�汾�š�����ʷ��ϵ��������Ҫ���ı�ֻ���õ��� SQLAlchemy �� Alembic �ṩ��
sa �� op �������ݿ�����ɡ�
��ͬѧ���������� SQLAlchemy ������һģһ���Ķ����ˣ��Dz����ܲ�Ҫ�����ظ��Ͷ������������Ҹ�
SQLAlchemy �����ĺ� Alembic �ܲ����Զ�����֪������Щ��Ȼ���Լ����ɰ汾�ļ��������ǿ��Եģ����ú�Ԫ������Դ��Alembic
�����èCautogenerate�Զ�������Ӧ�İ汾�ļ��� |






