|

分离+借助社区力量:
OpenStack持续交付进阶
分离+借助社区力量:OpenStack持续交付进阶
此文由在UnitedStack运维团队负责人余兴超在3月21日OpenStack Meetup活动的部分演讲整理而成。在上一篇名为《OpenStack持续交付的六大挑战与四个统一》的文章中,余兴超讲述了OpenStack在实际服务运维工作中所遇到的具体挑战,以及统一运维的具体策略。而在统一的基础之上,我们还需要以整体的角度去观察整套OpenStack持续交付系统,对于系统的运维团队而言,还有很多细化的工作要做。
【欢迎大家关注UnitedStack官方微信,我们将会在第一时间与您分享UnitedStack的工程师们工作中的经验与心得。】
一个参数引发的故障
2014年,我曾写过一篇blog,题目为《一个purge参数引发的惨案――从线上hbase数据被删事故说起》。在写下这篇文字前,我的心情是如此的忐忑,虽然早就明白运维工作如履薄冰,但没有料到这么一个细小的疏漏竟会带来如此严重的灾难。
这个Puppet参数的“坑”我也遇到过,幸运的是当时是在开发环境中。这样的一个案例引发了我很多有关运维的思考。
这个故障本可以从多个层面上去避免:
1.部署逻辑的上线,需要经开发和测试环境的验证;
2.不应盲目使用第三方模块,使用前应充分阅读源码或者README文档;
3.上线流程做好权限分离,保证有合理的审批机制。
首先有一个观念需要矫正。有些人认为部署逻辑不属于开发范畴,往往编写后不经测试就直接上线。其实只要涉及到代码的变更,无论是业务逻辑还是部署逻辑,都需要通过开发环境和测试环境的验证。那么,到底应该如何避免类似故障的发生呢?
分离与解耦
分离是关键:合理的分离可以对复杂逻辑和环境进行解耦,可以设立明晰的安全边界,可以更好地细化工作。
1.环境的分离
环境涵盖了部署逻辑与业务逻辑的环境,它们分别被划分为dev、test、production三种环境;其中,生产环境又被进一步细分为pre_production(预发布)和production(正式)环境。
2.仓库的分离
仓库分离是源自于我们在软件包管理上所经历过的血和泪的教训:
首先,根据包的类型划分为3类仓库;
其次,每个仓库也需要根据环境划分为devel、test、products三个子仓库;
最后,每个集群拥有完全独立的软件仓库;
3.部署逻辑和数据分离
我们要对配置管理工作进行划分,目的是为了解耦,并降低维护成本。具体还说我们把配置管理工作划分为三类,具体如下:
部署逻辑管理: modules 软件和服务的配置管理代码集合;
部署数据管理: hieradata 涵盖了所有集群软件和服务的定制化数据;
节点角色管理: manifests 所有被管理的服务器的角色定义集合;
4.角色的分离
角色分离是为了实现OpenStack灵活的部署架构。因为我们前面已经提到,我们可以对OpenStack的部署架构进行随意的调整。目前,我们一共涵盖了49种元角色,可以根据需要进行自由组合。比方说,Controller
= API + MySQL + MQ + MC;Comb = Compute + OSD + OVS。
5.权限分离
权限分离的目的是为了设立安全边界。
无论是部署逻辑、部署数据或变更脚本,都需要通过版本控制工具管理,其中部署数据项目只有少数员工拥有访问权限,因为其中包括了敏感的密码或者密钥信息;代码要进入仓库,必须通过项目负责人的人工审查,这与OpenStack社区的代码开发流程是相同的;要执行线上业务变更,根据变更的类型和级别,须通过相关负责人的审核;最后,我们为不同环境的集群提供统一入口,后端划分独立的配置管理服务器,每台服务器有不同的访问权限。
借助开源的力量
我们前面提到Openstack项目众多,即使我们做到了统一,做到了解耦,做到了隔离,这只能说我们把这个架子搭好了,还有那么多的模块需要投入精力去开发。而一个人的精力毕竟是有限的。我做了一个简单的统计,目前我们通过git
submodule的方式管理了:85个puppet module、67698行的puppet代码、79868行ruby代码和19371行的yaml格式数据。那么关键点在于哪?是加班吗?
当然不是!我们需要借助开源的力量。Puppet-Openstack项目是OpenStack社区推出的一系列的puppet
modules,旨在提供OpensStack各服务的配置管理。(https://wiki.openstack.org/wiki/Puppet-openstack)
stackforge/puppet-openstacklib
stackforge/puppet-openstack-specs
stackforge/puppet-openstack_extras
这些是Puppet的公共库以及Blue Print Collection项目,在Havana Desigin
Summit上,我们决定开始把一些公共的代码抽取出来,作为Puppet-Openstack基础模块的公共库,提高代码的复用率。
在这里我想强调,一个开源项目的成功与否,关键在于它的用户数和活跃度。那么我们就来看看Puppet项目的用户。Mirantis
Fuel和RedHat Packstack是目前主流的OpenStack部署工具。其中,Mirantis
Fuel 的部署逻辑使用了Puppet-Openstack 模块,当然Mirantis 进行了一些定制化的修改,主要在HA方面,同时它提供了灵活多变的部署方式。RedHat
Packstack则直接使用了upstream的Puppet-Openstack模块。
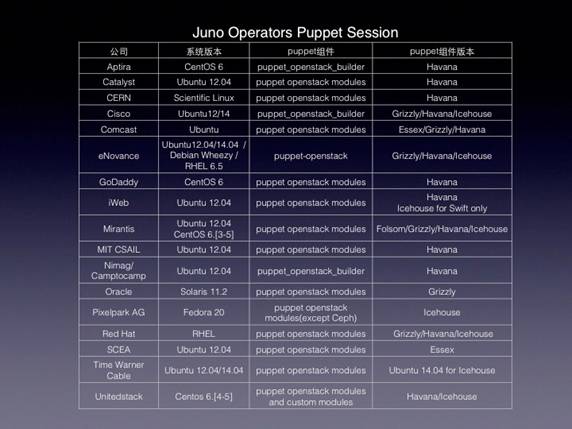
这是在Juno Operator Puppet Session上做的一个统计,我们可以看到思科、欧洲原子能、Godaddy、甲骨文、时代华纳等公司都在使用这个项目。当然,通过这张表我惊奇地发现大家更喜欢用Ubuntu。

这张图来自Openstack社区的官方用户调查,关于部署工具占有率的最新数据统计。可以看到,在所有规模的Openstack集群部署调研中,Puppet的占有率排名第一。
UnitedStack如何参与社区?
参与社区的目的是什么,每个人都会有自己的答案。我从自己的角度来回答主要有三点:首先,能够更加深入地理解源代码;第二,能够掌握项目的发展动态;第三,能够有效提升项目的代码质量。
UnitedStack在社区做了不少的工作,就拿最近一个比较重要的变更来说,是关于配置管理的改进和变迁的。事实上,社区在如何改善配置文件的管理上,持续投入了大量的精力。我们在2014年提交的数个Patch让配置参数的管理变得更加灵活。
配置文件管理的终极目标是有效、灵活和低成本。在早期,配置文件的管理是“模板统治一切”的时代。要管理nova.conf中的libvirt_type选项,首先在nova模块的templates文件夹下的nova.conf.erb文件,使用ERB语法在里面添加以下一行代码:
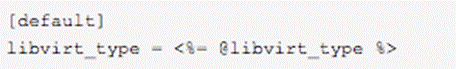
然后,在nova模块init.pp中,使用file resource来管理nova.conf配置文件。

然而,通过模板来管理配置文件是非常复杂和繁琐的,以nova.conf为例,算上注释文件,代码超过1700多行。这个庞大的模板文件是非常难于维护的。
后来,社区中出现了拼接(Concat)的方法来取代模板,它把一个模板拆分为多个子模板进行管理,然后再进行拼接。OpenStack的配置文件是标准的INI格式,每个配置文件由多个section组成。例如,在swift的proxy-server.conf中有[default]、[pipeline:main]、[app:proxy-server]等。
concat模块将配置拆分成了子模板,然后使用concat::fragment define把这些Template拼接起来。使用方式和file
resource来渲染template类似,唯一的区别就是order参数,指明这片(fragment)配置在目标配置文件中的顺序,升序排列。
事实上,拼接方法的出现只是提高了代码的可维护性,并没有带来实质的变化。
使用模板进行配置文件管理的最主要缺点就是繁琐:每次添加一个新变量,都需要修改三个不同的代码文件。
在template文件里添加上这个新变量:
<%= @new_variable %>
在class文件中添加这个变量:
$new_vairable = ‘hello’
最后在hieradata文件中对其赋值:
xxx::new_vairable:: ‘hey’
对于一个成熟的项目来说,配置变更并不频繁,使用模板是理所当然的。但是对于快速迭代、频繁变更的Openstack项目来说,模板将成为一个梦魇。PTL曾经做了一个统计,在G版前的过半提交都是和配置选项有关的。
因此,在模板之后,社区使用Ruby扩展了一种自定义的资源类型,来管理配置选项。新方式的成本是,新增一个配置选项需要修改两个配置文件。以nova为例,社区开发了nova_config
custom resource type。在管理libvirt_type = ‘kvm’选项时,无需在模板里定义,直接在class中定义:
nova_config { ‘default/libvirt_type': value => $libvirt_type;}
但是一个新的问题产生了: 新增一个配置选项 = 在两个配置文件中各添加一行代码。
懒是程序员的天性。有没有一种办法不需要事先定义,并且只需要声明一次就能添加一个配置参数的呢?比方说,某些plugin或者driver的配置选项缺失了,例如cinder的solidfire,neutron的ibm
plugin等等;还有一定自定义参数。 例如,我们针对Neutron、Nova、Ceilometer、Keystone做了定制化修改,添加了大量的自定义选项。
驱使我这样去做的动力是UnitedStack活力十足的网络组同事。这些同事每天都会在协作平台上给我分上一堆非常有趣的任务,其中和配置相关的任务我大致分成了一下三类。
a. 在测试环境中,在abc配置文件中添加参数x
b. 把参数x的值修改为y
c. 删除参数x
被折腾了两个多月后,我终于厌倦这样烦躁的重复劳动了,开始思考人生。我曾经和iweb的Mathieu(社区的一位核心开发者)对此也进行过讨论和尝试,因为他也饱受相同的痛苦。
我们在2014年6月提出了一个关于灵活管理自定义参数的BP,它的代码其实很简洁,核心在于create_resouces函数所做的迭代,类似于编程语言中的for循环。Puppet
3.5之前还不支持这种语法的迭代(虽然有trick可以做到)。create_resources接受两个参数,第一个是resource
name,第二个是带有多组键值的hash数据。
下面是一个调用的用例(不需要在Puppet代码中预先定义,直接调用即可):
nova::config class:用于管理自定义参数

nova::config的调用用例
 |






